- 使用Keras進行深度學習教程
- 使用Keras進行深度學習 - 首頁
- 使用Keras進行深度學習 - 簡介
- 深度學習
- 專案設定
- 匯入庫
- 建立深度學習模型
- 編譯模型
- 準備資料
- 訓練模型
- 評估模型效能
- 對測試資料進行預測
- 儲存模型
- 載入模型進行預測
- 結論
- 使用Keras進行深度學習資源
- 使用Keras進行深度學習 - 快速指南
- 使用Keras進行深度學習 - 有用資源
- 使用Keras進行深度學習 - 討論
評估模型效能
為了評估模型效能,我們呼叫evaluate方法,如下所示:
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)
為了評估模型效能,我們呼叫evaluate方法,如下所示:
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)
我們將使用以下兩條語句列印損失和準確率:
print("Test Loss", loss_and_metrics[0])
print("Test Accuracy", loss_and_metrics[1])
執行上述語句後,您將看到以下輸出:
Test Loss 0.08041584826191042 Test Accuracy 0.9837
這顯示了98%的測試準確率,這對我們來說應該是可以接受的。這意味著在2%的情況下,手寫數字將無法被正確分類。我們還將繪製準確率和損失指標,以檢視模型在測試資料上的表現。
繪製準確率指標
我們使用訓練期間記錄的history來獲取準確率指標的圖表。以下程式碼將繪製每個epoch的準確率。我們選擇訓練資料準確率(“acc”)和驗證資料準確率(“val_acc”)進行繪製。
plot.subplot(2,1,1)
plot.plot(history.history['acc'])
plot.plot(history.history['val_acc'])
plot.title('model accuracy')
plot.ylabel('accuracy')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='lower right')
輸出圖表如下所示:
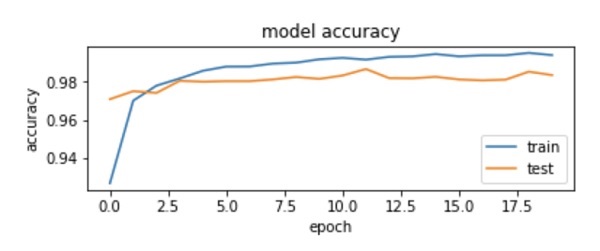
正如您在圖中看到的,準確率在前兩個epoch迅速增加,表明網路學習速度很快。之後,曲線趨於平緩,表明不需要太多epoch來進一步訓練模型。通常,如果訓練資料準確率(“acc”)持續提高,而驗證資料準確率(“val_acc”)變差,則會遇到過擬合問題。這表明模型開始記憶資料。
我們還將繪製損失指標來檢查模型的效能。
繪製損失指標
同樣,我們繪製訓練資料(“loss”)和測試資料(“val_loss”)的損失。這是使用以下程式碼完成的:
plot.subplot(2,1,2)
plot.plot(history.history['loss'])
plot.plot(history.history['val_loss'])
plot.title('model loss')
plot.ylabel('loss')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='upper right')
此程式碼的輸出如下所示:

正如您在圖中看到的,訓練集的損失在前兩個epoch迅速下降。對於測試集,損失的下降速度不如訓練集,但在多個epoch中幾乎保持不變。這意味著我們的模型能夠很好地泛化到未見資料。
現在,我們將使用訓練好的模型來預測測試資料中的數字。
廣告