- Keras深度學習教程
- Keras深度學習 - 首頁
- Keras深度學習 - 簡介
- 深度學習
- 專案設定
- 匯入庫
- 建立深度學習模型
- 編譯模型
- 資料準備
- 訓練模型
- 評估模型效能
- 對測試資料進行預測
- 儲存模型
- 載入模型進行預測
- 結論
- Keras深度學習資源
- Keras深度學習 - 快速指南
- Keras深度學習 - 有用資源
- Keras深度學習 - 討論
Keras深度學習 - 資料準備
在將資料饋送到網路之前,必須將其轉換為網路所需的格式。這稱為為網路準備資料。它通常包括將多維輸入轉換為單維向量並對資料點進行歸一化。
重塑輸入向量
我們資料集中的影像由 28 x 28 畫素組成。這必須轉換為大小為 28 * 28 = 784 的單維向量,以便將其饋送到我們的網路中。我們透過對向量呼叫reshape方法來做到這一點。
X_train = X_train.reshape(60000, 784) X_test = X_test.reshape(10000, 784)
現在,我們的訓練向量將包含 60000 個數據點,每個資料點都包含一個大小為 784 的單維向量。類似地,我們的測試向量將包含 10000 個大小為 784 的單維向量資料點。
資料歸一化
輸入向量當前包含的資料具有介於 0 和 255 之間的離散值 - 灰度等級。將這些畫素值歸一化到 0 到 1 之間有助於加快訓練速度。由於我們將使用隨機梯度下降,因此歸一化資料還有助於減少陷入區域性最優解的可能性。
為了歸一化資料,我們將它表示為浮點型別並將其除以 255,如下面的程式碼片段所示:
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
現在讓我們看看歸一化後的資料是什麼樣的。
檢查歸一化資料
要檢視歸一化後的資料,我們將呼叫直方圖函式,如下所示:
plot.hist(X_train[0])
plot.title("Digit: {}".format(y_train[0]))
在這裡,我們繪製了X_train向量的第一個元素的直方圖。我們還列印了此資料點表示的數字。執行上述程式碼的輸出如下所示:
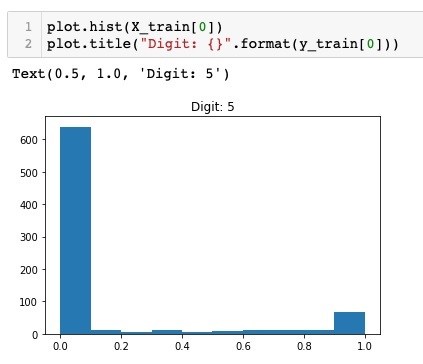
你會注意到,值接近零的點的密度很大。這些是影像中的黑色點,顯然是影像的主要部分。其餘接近白色的灰度點表示數字。您可以檢視另一個數字的畫素分佈。下面的程式碼列印訓練資料集中索引為 2 的數字的直方圖。
plot.hist(X_train[2])
plot.title("Digit: {}".format(y_train[2])
執行上述程式碼的輸出如下所示:

比較以上兩圖,你會注意到兩幅影像中白色畫素的分佈不同,表明表示不同的數字——上面兩幅圖中的“5”和“4”。
接下來,我們將檢查我們完整訓練資料集中資料的分佈。
檢查資料分佈
在我們使用資料集訓練機器學習模型之前,我們應該瞭解資料集中唯一數字的分佈。我們的影像表示從 0 到 9 的 10 個不同數字。我們想知道資料集中數字 0、1 等的數量。我們可以使用 NumPy 的unique方法獲取此資訊。
使用以下命令列印唯一值的個數以及每個值的出現次數:
print(np.unique(y_train, return_counts=True))
執行上述命令時,你會看到以下輸出:
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([5923, 6742, 5958, 6131, 5842, 5421, 5918, 6265, 5851, 5949]))
它顯示有 10 個不同的值——0 到 9。數字 0 出現 5923 次,數字 1 出現 6742 次,依此類推。輸出的螢幕截圖如下所示:

作為資料準備的最後一步,我們需要對資料進行編碼。
資料編碼
我們的資料集中有十個類別。因此,我們將使用獨熱編碼將我們的輸出編碼到這十個類別中。我們使用 NumPy 實用程式的 to_categorical 方法進行編碼。輸出資料編碼後,每個資料點將轉換為大小為 10 的單維向量。例如,數字 5 現在將表示為 [0,0,0,0,0,1,0,0,0,0]。
使用以下程式碼段對資料進行編碼:
n_classes = 10 Y_train = np_utils.to_categorical(y_train, n_classes)
您可以透過列印分類後的 Y_train 向量的前 5 個元素來檢視編碼的結果。
使用以下程式碼列印前 5 個向量:
for i in range(5): print (Y_train[i])
你會看到以下輸出:
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] [1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
第一個元素表示數字 5,第二個元素表示數字 0,依此類推。
最後,你還必須對測試資料進行分類,這可以使用以下語句完成:
Y_test = np_utils.to_categorical(y_test, n_classes)
在這個階段,你的資料已完全準備好饋送到網路中。
接下來是最重要的部分,那就是訓練我們的網路模型。