- BigQuery 教程
- BigQuery - 首頁
- BigQuery - 概述
- BigQuery - 初始設定
- BigQuery 與本地 SQL 引擎
- BigQuery - Google Cloud Console
- BigQuery - Google Cloud 層級結構
- 什麼是 Dremel?
- 什麼是 BigQuery Studio?
- BigQuery - 資料集
- BigQuery - 表
- BigQuery - 檢視
- BigQuery - 建立表
- BigQuery - 基本 Schema 設計
- BigQuery - 修改表
- BigQuery - 複製表
- 刪除和恢復表
- BigQuery - 填充表
- 標準 SQL 與傳統 SQL
- BigQuery - 編寫第一個查詢
- BigQuery - CRUD 操作
- 分割槽和聚類
- BigQuery - 資料型別
- BigQuery - 複雜資料型別
- BigQuery - STRUCT 資料型別
- BigQuery - ARRAY 資料型別
- BigQuery - JSON 資料型別
- BigQuery - 表元資料
- BigQuery - 使用者定義函式
- 連線外部資料來源
- 整合計劃查詢
- 整合 BigQuery API
- BigQuery - 整合 Airflow
- 整合連線表格
- 整合資料傳輸
- BigQuery - 物化檢視
- BigQuery - 角色和許可權
- BigQuery - 查詢最佳化
- BigQuery - BI 引擎
- 監控使用情況和效能
- BigQuery - 資料倉庫
- 挑戰與最佳實踐
- BigQuery 資源
- BigQuery 快速指南
- BigQuery - 資源
- BigQuery - 討論
BigQuery 快速指南
BigQuery - 概述
BigQuery 是 Google Cloud Platform (GCP) 的結構化查詢語言 (SQL) 引擎。BigQuery 允許使用者使用無伺服器雲基礎設施即時查詢、建立和操作資料集。因此,學生、專業人士和組織能夠以幾乎無限的規模儲存和分析資料。
與其他一些 Google 計劃一樣,BigQuery 最初是 Google 開發人員內部用於處理和分析大型資料集的工具。自 2006 年以來,Google 員工一直在使用 BigQuery 及其前身 **Dremel**。在 Google 內部取得成功後,GCP 於 2010 年首次釋出了 BigQuery 的 Beta 版,然後在 2011 年將其廣泛可用。
BigQuery 如何勝過競爭對手?
雖然在 BigQuery 釋出時市場上有很多 **SQL** 引擎和整合開發環境 (IDE),但 BigQuery 利用了幾個競爭優勢,其中包括:
- 率先採用基於槽的查詢系統,該系統可以根據使用者需求自動分配計算能力或“槽”
- 提供與各種程式語言(從 **Python** 到 **JavaScript**)的 API 整合
- 為使用者提供使用 SQL 編寫的機器學習模型的訓練、執行和部署能力
- 與 Google Data Studio(已棄用)和 Looker 等視覺化平臺無縫整合
- 能夠儲存和查詢 ARRAY 和 STRUCT 型別,這兩種都是複雜的 SQL 資料型別
為了幫助學生和專業人士,BigQuery 提供了有關函式、公共資料集和可用整合的可靠文件。
Google BigQuery 使用案例
如果使用得當,Google BigQuery 可以用作個人或組織的 **資料倉庫**。但是,由於 BigQuery 面向 SQL,因此最適合與具有結構化資料(而不是非結構化資料)的源一起使用。
Google 的雲架構促進了可靠的儲存並實現了幾乎無限的可擴充套件性。這使得 BigQuery 成為企業流行的選擇,尤其是在生成或攝取大量資料的組織中。
要真正理解 BigQuery 的強大功能,瞭解不同資料團隊角色之間的用例差異非常有幫助。
- 資料分析師 - 將 BigQuery 與 Tableau 或 Looker 等資料視覺化工具結合使用,為組織領導層建立頂級報告。
- 資料科學家 - 利用 BigQuery 的機器學習功能 Big ML 建立和實施機器學習模型。
- 資料工程師 - 使用 BigQuery 作為資料倉庫,並構建檢視和使用者定義函式等工具,使終端使用者能夠在清理後的預處理資料集中發現見解。
當結合使用時,BigQuery 提供了一個最佳化儲存並生成細緻入微的見解以提高增長和收入的機會。
在 BigQuery 中載入資料
在 BigQuery 中載入資料非常簡單直觀,雲開發人員可以使用多種選項。BigQuery 可以以多種形式攝取資料,包括:
- CSV
- JSON
- Parquet
BigQuery 還可以與 Google Sheets 等 Google 整合同步以建立即時連線的表。並且 BigQuery 可以載入儲存在 Google Cloud Storage 等雲端儲存儲存庫中的檔案。
開發人員還可以利用以下方法將資料乾淨地載入到 BigQuery 中:
- BigQuery 資料傳輸,一種無需程式碼的資料管道,可與 Google Analytics 等 GCP 資料整合。
- 包含 CRUD 語句以建立、刪除或刪除表的基於 SQL 的管道。
- 利用 **BigQuery API** 執行批處理或流式載入作業的管道。
- 提供 BigQuery 連線的第三方管道,例如 Fivetran。
定期從上述來源載入資料使下游利益相關者能夠可靠地訪問及時、準確的資料。
BigQuery 查詢基礎
瞭解 BigQuery 用例和如何正確載入資料很有幫助,但學習 BigQuery 的初學者很可能從查詢層開始。
BigQuery 中的表引用約定
在編寫第一個 SELECT 語句之前,瞭解 BigQuery 中的表引用約定很有幫助。
BigQuery **語法**與其他 SQL 方言不同,因為正確的 BigQuery SQL 要求開發人員將表引用括在單引號中,如下所示:**' '**。
**表引用**涉及三個元素:
- 專案
- 資料集
- 表
放在一起,當在 SQL 查詢或指令碼中引用 BigQuery 表時,它看起來像這樣:
'my_project.dataset.table'
一個基本的 BigQuery 查詢如下所示:
SELECT * FROM 'my_project.dataset.table.'
傳統 SQL 和標準 SQL
BigQuery SQL 與其他型別的 SQL 之間的一個重要區別是,BigQuery 支援兩種 SQL 分類:**傳統**和**標準**。
- 傳統 SQL 使使用者能夠使用舊的、可能已棄用的 SQL 函式。
- 標準 SQL 代表了 SQL 的更新解釋。
出於我們的目的,我們將使用標準 SQL 指定。
在 BigQuery 中編寫查詢時需要注意的事項
與其他 SQL 環境不同,當您在 BigQuery 中編寫查詢時,UI 會自動告訴您您的查詢是否會執行以及它將處理多少資料。請注意,處理的資料量與預計的執行時間之間幾乎沒有明確的相關性。
- 執行後,您的查詢將返回 **在 UI 中可見的結果**,這類似於檢視電子表格或 Pandas 資料框。
- 您還可以選擇將結果 **下載**為 CSV 或 JSON 檔案,這兩種檔案都提供了一種簡單的方法來儲存資料以供以後使用。
- 如果您需要儲存查詢文字以供以後執行或編輯,BigQuery 還提供了一個選項來 **儲存查詢**並進行 **版本控制**以幫助跟蹤更改。
在企業級執行 BigQuery
在具有多個 BigQuery 使用者的組織中執行查詢時,務必牢記幾個因素,以確保您的查詢能夠在不中斷或不導致其他使用者擁塞的情況下執行:
- 避免在高峰使用時間執行查詢。
- 儘可能使用 WHERE 子句來縮小處理的資料量。
- 對於大型表,建立使用者可以更輕鬆、更有效地查詢的檢視。
從學習 BigQuery 到在企業級執行查詢需要時間來了解特定於您組織的變數,例如槽使用情況和計算資源消耗。
但是,首先有必要更深入地瞭解在 BigQuery 中構建和最佳化查詢。
BigQuery - 初始設定
要嘗試以下一些概念,需要建立一個 Google Cloud Platform 帳戶。透過建立 GCP 帳戶,您將能夠訪問 Google 的雲應用程式套件,包括 BigQuery。
為了向廣大受眾公開 GCP 產品,Google 為其許多旗艦產品(包括 BigQuery)添加了 **免費使用層**。BigQuery 使用者,無論定價計劃如何,每月都可以免費查詢最多 1 TB(TB)的資料和儲存最多 10 GB(GB)的資料。
但是,為了避免必須將信用卡附加到您的帳戶併產生任何意外費用,新使用者可以註冊 90 天的免費試用期。免費試用期提供 300 美元的 GCP 積分。老實說,除非使用者正在執行計算密集型流程(如虛擬機器)或部署機器學習模型,否則這綽綽有餘。
根據 Google 的說法,如果使用者滿足以下條件,則有資格參加該計劃:
- 從未成為 Google Cloud 或關聯產品的付費客戶
- 以前從未註冊過 Google Cloud Platform 免費試用版
要註冊 BigQuery 的 90 天試用版,請執行以下步驟:導航到 cloud.google.com/free 您應該會看到此頁面。
點選“免費開始”(頁面中央)
登入您的 Google 帳戶 -
完成註冊流程後,您將可以訪問 Google Cloud Platform。

每次登入時,您都會看到 GCP 徽標以及“歡迎”字樣。在“歡迎”頁面底部,您將看到指向您常用的 GCP 應用程式的“快速訪問”連結。

此外,您還將能夠訪問本教程將重點介紹和探索的 BigQuery 的所有功能。
BigQuery 與本地 SQL 引擎
由於 **SQL** 已經存在 40 多年了,因此 BigQuery 並不是第一個 SQL 環境。在 BigQuery 釋出之前,SQL 開發人員主要使用本地或“本地”資料庫。
允許開發人員管理和互動資料庫的系統稱為資料庫管理系統 (DBMS)。
在 **“雲工程師”** 或 **“資料工程師”** 職位名稱流行和廣泛使用之前,那些使用 **DBMS** 工具的人擁有“架構師”等職位。通常,這個職位名稱是字面意思,因為那些使用資料庫的人維護著物理和數字基礎設施。
資料建模
隨著資料庫技術的不斷發展,架構師的職責主要涉及一項名為 **資料建模**的任務。
雖然像 INSERT() 這樣的函式可以讓從源獲取資料並將其新增到資料庫中看起來很容易,但在採用資料建模的組織中,如何儲存和塑造資料需要大量的思考。
流行的資料建模概念包括諸如“星型模式”或“規範化”和“正規化”之類的短語。
BigQuery 與任何傳統 DBMS 有何不同?
雖然在建立 BigQuery 表時仍然建議遵循最佳實踐,但 BigQuery 比傳統的 DBMS 介面更具開箱即用性。
BigQuery 在以下方面與更 **“傳統”** 的 DBMS 不同:
- 可擴充套件性 - 由於 Google 資料中心提供的驚人數量的雲端儲存,BigQuery 可以擴充套件以滿足幾乎任何儲存或查詢需求。
- API 整合 - BigQuery 的 SQL 引擎可以透過程式設計方式利用,而像 Postgre 這樣的 DBMS 只能執行本機 SQL 查詢。
- ML/AI 功能,與 Vertex AI 整合。
- 可用於長期儲存的更多 **特定資料型別**。
- 一種 Google 專屬的 SQL 方言,即 **Google 查詢語言** (GQL),它包含比傳統 SQL 方言更多更專業的函式。
從使用者的角度來看,BigQuery 還提供了更多關於執行統計資訊和使用者活動的可見性 -
- 允許使用者在執行相應的 SQL 之前檢視查詢是否可接受
- 提供執行計劃和查詢血緣關係
- 擴充套件元資料儲存,以深入瞭解查詢使用情況、儲存和成本
BigQuery 確實是雲端 SQL 查詢的標準,它始於 Google Cloud Console。
BigQuery - Google Cloud Console
由於 BigQuery 是一個基於雲的 **資料倉庫** 和查詢工具,因此可以透過 **Google Cloud Console** 在任何地方訪問它。與本地資料庫(例如 **PostgreSQL** 或 **MySQL**)不同,Google 沒有為 BigQuery 建立應用程式。相反,BigQuery 存在於 Google Cloud Console 中的“雲端”。
Google Cloud Console:所有 GCP 應用程式的主頁
如果您已建立 Google 帳戶並關聯了 GCP 專案,您將能夠訪問 Google Cloud Console。
要導航到 BigQuery,您可以在搜尋欄中鍵入 **“BigQuery”** 或從 Google Cloud Console 左側的彈出選單中選擇它,您可以在“分析”類別下找到它。
為了確保在本教程中始終能夠訪問,建議您將其固定,以將“BigQuery”指定為您的環境中固定產品。
透過控制檯,您將能夠訪問 BigQuery 的所有方面,包括 -
- BigQuery Studio
- BigQuery API
- 與 BigQuery 相關的日誌和錯誤
- BigQuery 時段使用量的計費
就像您設定 IDE 以滿足您的舒適度和效率標準一樣,強烈建議您花時間自定義您的 Google Cloud Console 體驗,以便能夠快速可靠地訪問相關的 BigQuery 資源。
BigQuery - Google Cloud 層級結構
在繼續之前,瞭解與 BigQuery 及其相關流程相關的基本概念和詞彙非常重要。
首先,重要的是要理解,即使雲計算提供了幾乎無限的處理能力,如果 BigQuery 使用者需要執行以下活動,他們也會遇到問題 -
- 執行計算量大的 SQL 操作,例如交叉連線或笛卡爾積連線。
- 嘗試執行大型查詢而未指定目標表。
- 在使用高峰時段執行大型查詢(如果將 BigQuery 用作企業使用者)。
- 按需或 **“臨時”** 查詢可能並且會造成死鎖,尤其是在與計劃流程爭奪執行時段時。
Google Cloud 層次結構
如果您預計要在 BigQuery 中建立和填充資料來源,請務必注意 Google Cloud 層次結構 -
- 組織
- 專案
- 資料集
- 表
1. 組織層
除非您是帳戶所有者、高管或決策者,否則您不太可能需要擔心組織層。將其視為包含您在導航 BigQuery Studio 和在 SQL 環境中編寫 SQL 查詢時遇到的其他元素的實體。
2. Google Cloud 組織中的多個專案
任何 Google Cloud 組織都可以有多個專案。有時,公司或企業使用者(為了避免混淆,我們將有意避免使用“組織”一詞)建立不同的專案以分離暫存和生產環境。
其他時候,這些高階使用者建立不同的專案以更好地控制可能敏感的資料,例如個人身份資訊 (PII) 和機密收入資訊。
無論哪種情況,當您開始使用 BigQuery 時,您將建立或接收許可權以訪問 BigQuery,作為具有特定許可權和角色範圍的使用者。
3. 專案中的資料集和表
在專案中,最重要的是要記住資料集和表。為了澄清,**資料集包含一個表**或**多個表**。為了在技術討論中保持準確性,請儘量避免互換使用這些術語。
您將在資料集中看到的其他元素包括 -
- 例程
- 模型
- 檢視
這些其他資料元素將在後續章節中更詳細地討論。
什麼是 Dremel?
BigQuery 不是一個無限的工具。事實上,最好避免將 BigQuery 視為一個諺語中的黑盒。為了加深您的理解,有必要“深入瞭解”並檢查 BigQuery 引擎的一些內部工作原理。
Google 的 Dremel:一個分散式計算框架
BigQuery 基於一個名為 **Dremel** 的分散式計算框架,Google 在 2010 年的白皮書“Dremel:Web 規模資料集的互動式分析”中更詳細地解釋了這一點。
該白皮書描述了定義現代 BigQuery 的許多核心特徵的願景,例如臨時查詢系統、幾乎無限的計算能力以及強調處理大資料(TB 和 PB)。
Dremel 如何工作?
由於 Dremel 最初是內部產品(自 2006 年以來在 Google 內部使用),因此它結合了搜尋和並行資料庫管理系統的各個方面。
為了執行查詢,Dremel 使用了一種“樹狀”結構,其中查詢的每個階段都按順序執行,並且可以並行執行多個查詢。Dremel 將 SQL 查詢轉換為執行樹。
時段:BigQuery 執行的基本單元
在 **“查詢執行”** 標題下,作者描述了 BigQuery 執行的基本單元:**時段**。
- 時段是表示可用處理單元的抽象。
- 時段是有限的,這就是為什麼專案中的任何阻塞通常是由於時段可用性不足造成的。
- 由於時段的使用會根據許多因素(如處理的資料量和一天中的時間)而變化,因此可以想象,在一天早些時候快速執行的查詢現在可能需要幾分鐘。
**時段的抽象**可能是 Dremel 論文中表達的最適用的概念;其他資訊有助於瞭解,但主要描述了 BigQuery 產品的早期迭代。
BigQuery:定價和使用模型
無論您是練習第一個 BigQuery 查詢的學生還是高層決策者,瞭解定價對於定義您可以在 BigQuery 中儲存、訪問和操作內容的限制至關重要。
要徹底瞭解 BigQuery 定價,最好將成本分為兩個部分 -
- 使用情況(BigQuery 的文件將其稱為“計算”)
- 儲存
使用情況涵蓋了您可以想到的幾乎所有 SQL 活動,從執行簡單的 SELECT 查詢到部署機器學習模型或編寫複雜的自定義函式。
對於任何與使用相關的活動,BigQuery 提供以下選擇 -
- 按使用付費或“按需”模型。
- 批次時段或“容量”模型,其中客戶按時段付費。
哪個定價模型最適合您?
在決定使用哪種定價模型時,務必考慮以下因素 -
- 查詢的資料量
- 產生的使用者流量
“按需”模型按 TB 定價,這意味著對於擁有許多大型(多個 TB)表的使用者來說,這可能是一種直觀且方便的跟蹤費用的方式。
**“容量”** 或時段模型對於正在發展其資料基礎設施的組織或個人很有幫助,他們可能沒有固定數量的資料來幫助他們計算可靠的每月費率。與其擔心每個資源生成多少資料,不如將問題轉移到改進最佳實踐,以便將查詢時間分配給計劃流程和個人臨時查詢。
從本質上講,時段模型遵循 Dremel 專案建立的框架,其中時段(伺服器)被預留並相應定價。
什麼是 BigQuery Studio?
在建立了基本的產品知識和理論之後,是時候返回到 **Google Cloud Console** 並進入 BigQuery Studio 了。BigQuery Studio 曾經被稱為“SQL 工作區”,使用者不僅可以在其中執行 BigQuery 查詢,還可以執行一系列其他資料和 **AI** 工作流。
BigQuery 的目標是提供一個類似於 GitHub 的空間,它使使用者能夠編寫和部署 SQL、**Spark** 甚至 **Python** 程式碼,同時維護版本歷史記錄並促進資料團隊之間的協作。
SQL 查詢、Python 筆記本、資料畫布
第一次開啟 BigQuery Studio 讓人聯想到任何其他 **SQL** IDE。但是,與本地 SQL IDE 不同,當 BigQuery 開啟時,您有三種操作選擇 -
- SQL 查詢
- Python 筆記本
- 資料畫布
單擊 SQL 查詢應該會開啟一個空白頁面,您可以在其中編寫和執行查詢。因此,SQL 查詢和 Python 筆記本選項應該是不言自明的。資料畫布是 AI 整合,在本教程中不會介紹。
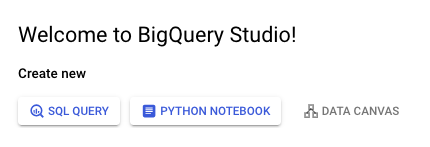
假設您已建立或有權訪問 BigQuery 專案,在左側選單中,您將看到一個專案名稱的下拉列表,以及該專案範圍內的任何資料集。
單擊任何這些資料集,您將看到在該資料集中建立的表。

在底部,您將看到與您執行的 SQL 作業相關的資訊。這些作業分為“個人”或由您的個人資料建立和執行的查詢,或“專案”,這使您能夠檢視在專案中執行的所有作業的元資料。
在 BigQuery Studio 中儲存工作可以透過兩種方式實現:一種是無版本歷史記錄的“經典”儲存查詢,另一種是有版本歷史記錄的儲存查詢。儲存功能還便於輕鬆建立檢視,這將在後面的章節中更詳細地介紹。
BigQuery - 資料集
資料集是存在於專案中的實體。資料集充當 BigQuery 表以及檢視、例程和機器學習模型的容器。
表不能獨立於資料集存在,因此在 BigQuery Studio 中建立新的資料來源時,必須建立一個數據集。
除了可讀名稱等屬性外,開發人員還必須在授權建立資料集時指定一個 **位置**。這些位置對應於全球 Google 資料中心的物理位置。
指定位置時,您需要指定單個區域或多區域。例如,您不會選擇芝加哥的資料中心,而是指定“us-central-1”。
將資料集設定為多區域實體可以提供額外的優勢,即當特定區域沒有資源來滿足當前需求時,BigQuery 會轉移位置。當前的多區域位於美洲(美國)或歐盟(歐洲)。
在 BigQuery 中建立資料集的步驟
要建立資料集,請按照以下步驟操作。首先,導航到您的專案名稱,然後單擊三個點,這將觸發一個包含“建立資料集”的彈出視窗 -

單擊“建立資料集”後,系統將提示您輸入 -
- 資料集 ID
- 位置型別(區域與多區域)。
- 預設表格過期時間(表格過期前的天數)。
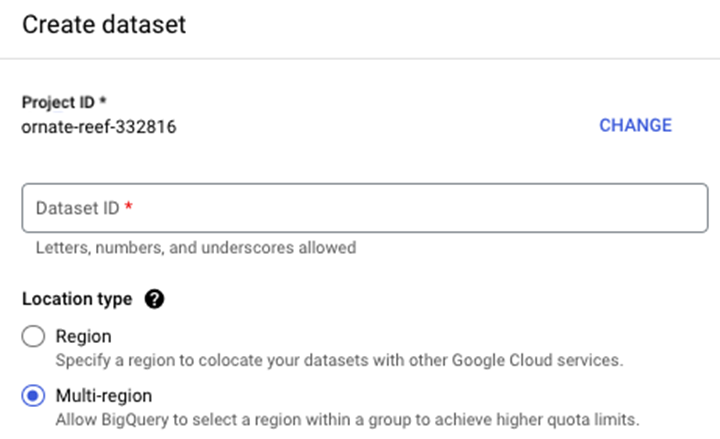
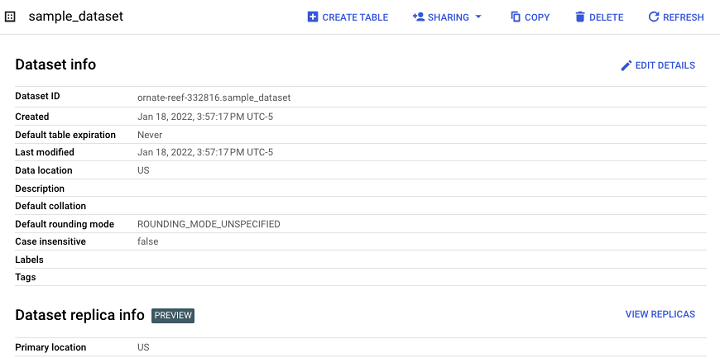
最終結果是一個數據集,它充當未來表格、檢視和物化檢視的容器。
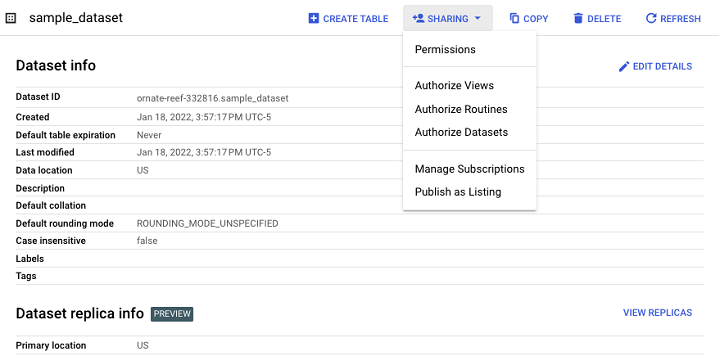
“共享”選項允許開發人員管理對資料集的訪問控制,以限制未經授權的使用者。
BigQuery:公共資料集
如果您是 BigQuery 的新手,並且可能也是 SQL 的新手,那麼您可能還沒有生成要儲存和操作的資料。這是使用 BigQuery Studio 作為 SQL 沙箱的優勢之一。除了無伺服器基礎設施之外,BigQuery 還提供了數 TB 的示例資料,學生和專業人士可以使用這些資料來學習和改進他們的 SQL 技能。
- 透過 Google Cloud 公共資料集計劃釋出,BigQuery 公共資料集儲存在它們自己的通用訪問專案中:bigquery-public-data。
- 根據每 TB 付費定價模型,開發人員每月可以免費查詢最多 1 TB 的資料。
- 與許多庫存資料集不同,表格中包含的資料是真實的,即“雜亂的”,並且有時需要進行大量轉換才能產生可操作的見解。
BigQuery 還提供了一些獨立於其 BigQuery 公共資料集的示例表格,這些表格可以在bigquery-public-data:samples表格資料集中找到 -
- gsod
- github_nested
- github_timeline
- natality
- shakespeare
- trigrams
- wikipedia
也許訪問 BigQuery 公共資料集最重要的優勢在於,資料是從 BBC、Hacker News 和約翰霍普金斯大學等真實資料來源中提取的。
BigQuery - 表
表格是 BigQuery 的基礎資料來源。BigQuery 是一個SQL資料儲存,因此資料以結構化(而不是非結構化或 NoSQL)的方式儲存。BigQuery SQL 表是列式的,其結構類似於電子表格,屬性或欄位對映到列,記錄填充行。
與資料集不同,建立表格時,使用者無需指定位置。
BigQuery 中的表格型別
BigQuery 中有兩種重要的表格型別 -
- 標準表格(如任何面向 SQL 的表格)。
- 檢視(一個可以像標準表格一樣查詢的半永久性表格)。
表格示例
表格建立將在後面的章節中介紹。但是,在此期間,識別和識別上面討論的表格型別很有幫助。
這是一個標準表格的示例 -

值得注意的是,使用者可以看到一個元資料屬性“描述”,該屬性立即向開發人員和使用者告知表格包含哪些資料。
檢視示例
建立或訪問表格使開發人員能夠基於此資料來源構建後續資源。您一定會遇到並使用的表格型別之一是檢視。
這是檢視在 BigQuery 中的顯示方式。

它的模式和在 UI 中的顯示幾乎與標準表格相同。
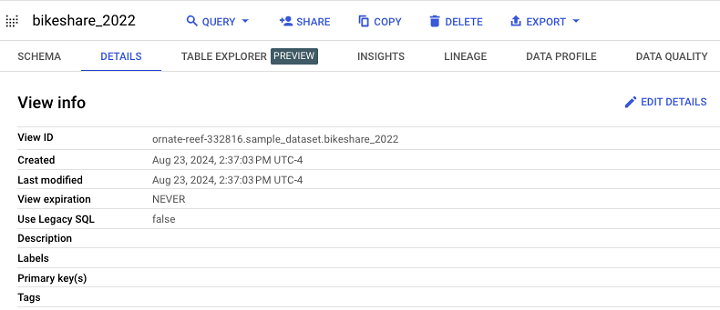
最後,檢視是使用檢視定義建立的,它實際上只是一個物化查詢。

BigQuery - 檢視
SQL 中的檢視是什麼?
在SQL中,檢視是一個虛擬化表格,它不包含像 CSV 檔案這樣的資料來源的輸出,而是包含一個預執行的查詢,該查詢會在新資料可用時更新。
由於檢視僅包含預過濾資料,因此它們是減少處理資料量範圍的常用方法,並且還可以縮短某些資料來源的執行時間。
- 表格是資料來源的全部,而視圖表示由儲存的查詢生成的資料片段。
- 查詢可能從給定表格中選擇所有內容,而檢視可能僅包含最近一天的資料。
建立 BigQuery 檢視
BigQuery 檢視可以透過資料操作語言 (DML) 語句建立 -
CREATE OR REPLACE VIEW project.dataset.view
這是一個建立檢視定義的示例,該定義僅包含 2022 年的奧斯汀腳踏車共享站資料(來自同名的 BigQuery 公共資料集)。
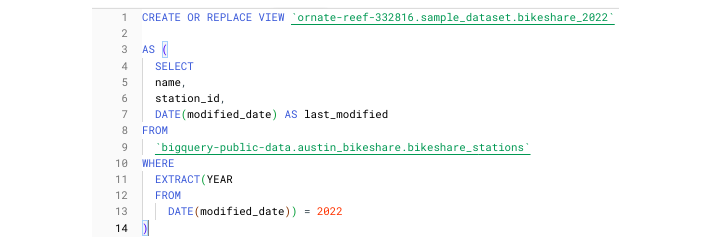
或者,BigQuery 使用者可以在 BigQuery 使用者介面 (UI) 中建立檢視。單擊資料集後,只需選擇“建立檢視”,而不是選擇“建立表格”。BigQuery 提供了單獨的圖示來區分標準表格和檢視,以便開發人員可以一目瞭然地看出區別。
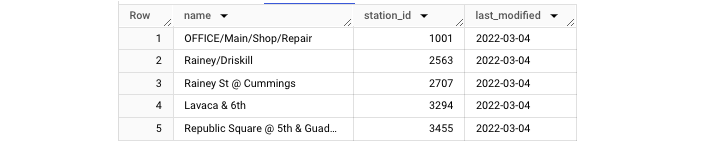
要訪問我們上面建立的檢視,只需執行 SELECT 語句,就像您用於訪問在標準表格中生成的資料一樣。

使用此查詢,您將獲得如下所示的輸出表格 -
物化檢視
除了標準檢視之外,BigQuery 使用者還可以建立物化檢視。物化檢視位於檢視和標準表格之間。
BigQuery 文件將物化檢視定義為:“ [P] 定期快取檢視查詢結果的預計算檢視。快取的結果儲存在 BigQuery 儲存中。”
需要注意的是,標準檢視不會無限期地儲存資料,因此不會產生長期儲存費用。
BigQuery - 建立表
要開始利用 BigQuery 的強大功能,有必要建立一個表格。在本章中,我們將演示如何在 BigQuery 中建立表格。
建立 BigQuery 表格的要求
建立 BigQuery 表格的要求為 -
- 表格來源(“從…建立表格”)
- 專案
- 資料集
- 表格名稱
- 表格型別
示例:建立 BigQuery 表格
回到奧斯汀腳踏車共享資料集,我們可以執行此 CREATE TABLE 語句。
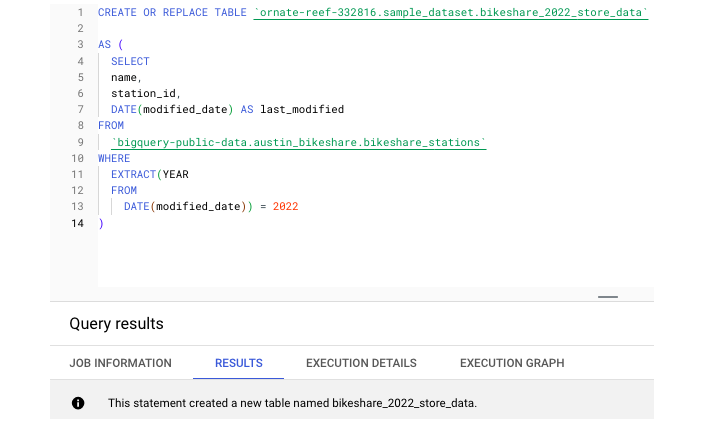
此語句建立了一個名為 bikeshare_2022_store_data 的新表格。接下來,讓我們執行一個查詢以從這個新建立的表格中提取一些資料 -
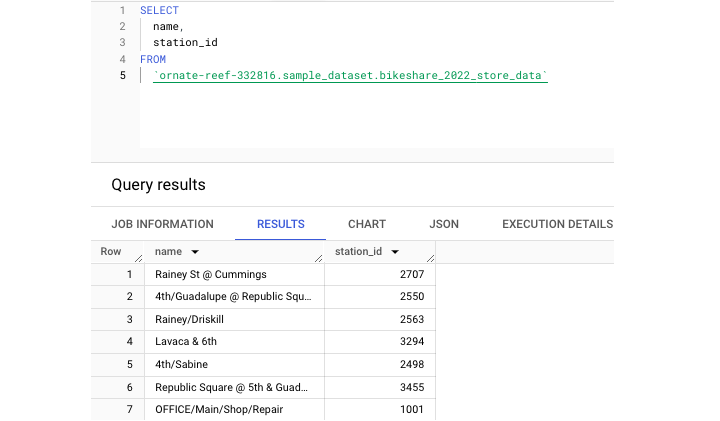
此外,表格可以進行分割槽和聚類,這兩種儲存方法都可以幫助提高表格儲存和查詢的效率。
最後,表格會生成幷包含有用的元資料,讓開發人員知道其內容上次更改的時間(上次修改欄位),提供表格用途的簡要說明,甚至規定表格資料過期之前的時間(分割槽過期天數)。
BigQuery - 基本 Schema 設計
與Excel電子表格不同,SQL表格不會自動接受呈現的資料。資料來源和表格必須就資料的範圍和型別達成一致,然後才能成功攝取。型別必須一致且採用 BigQuery 可以解析並在BigQuery Studio中提供的格式。
什麼是模式?
為此,開發人員必須提供一個模式。本質上,模式是有序的屬性列表和它們對應的型別。
在 BigQuery 中,列順序和列數很重要,因此任何提供的模式都必須與源表格的模式匹配。
指定模式的三種方法
在 BigQuery 中,有三種方法可以指定模式 -
- 在“建立表格”步驟期間在 UI 中建立模式。
- 將模式作為 JSON 文字檔案編寫或上傳。
- 告訴 BigQuery 自動推斷模式。
自動推斷模式
雖然自動推斷模式對於開發人員來說工作量最小,但這也會給資料管道帶來最大的風險。
即使資料型別在一個執行中保持一致,它們也可能會意外更改。如果沒有固定的模式,BigQuery 必須“確定”要接受哪種資料型別,這可能導致模式不匹配錯誤。
建立模式的 UI 方法
由於建立模式的 UI 方法相當直觀,因此下一部分將重點介紹如何將模式建立為 JSON 檔案。
將模式建立為 JSON 檔案
JSON 模式格式是列表“[ ]”內的字典“{ }”。每個欄位可以有三個屬性 -
- 欄位名稱
- 列型別
- 列模式
預設列模式為“NULLABLE”,這意味著列接受 NULL 值。其他列模式將在巢狀資料型別的討論中介紹。
JSON 模式的一行示例如下 -
{"name": "id", "type": "STRING", "mode": "NULLABLE"}
如果您只是新增一列或更改現有列的型別,您可以使用此查詢生成現有表格的模式 -
[Generate schema query]
只需確保將結果設定為“JSON”即可複製/下載生成的 JSON 檔案。
GCP Cloud Shell:建立表格
Cloud Shell 是 Google Cloud Platform 的命令列介面 (CLI) 工具,允許使用者直接從終端視窗與資料來源互動。就像可以使用 GCP Console 中的 BigQuery UI 建立表格一樣,也可以透過 CLI 使用類似 Linux 的語法快速建立表格。
與在本地機器上配置 CLI 不同,只要您登入到 Google 帳戶,您就會自動登入到 Cloud Shell,因此可以在終端中與 BigQuery 資源互動。也可以(但更復雜)在本地 IDE 中配置 gcloud CLI。
“bq”命令列
無論哪種情況,BigQuery Cloud Shell 整合都依賴於一個命令:bq。bq 命令列是一個基於 Python 的命令列工具,與 Cloud Shell 相容。
要建立表格,有必要將“bq”與“mk”結合使用 -
--bq mk
此語法與“–table”或“-t”標誌結合使用。還可以像在 BigQuery UI 中建立表格時一樣指定多個引數。
可用的引數包括 -
- 過期規則(以秒為單位的過期時間)
- 描述
- 標籤
- 新增標籤(策略標籤)
- 專案 ID
- 資料集 ID
- 表格名稱
- 模式
這是一個示例 -
注意 - 提供了一個內聯模式。
Bq mk -t sample_dataset.bikeshare_table_cli name:STRING,station_id:STRING,modified_date:TIMESTAMP
成功執行後,您將獲得如下輸出 -

選擇 Cloud Shell 而不是 UI 不會帶來效能優勢;這僅僅取決於使用者偏好。但是,以這種方式建立表格在建立重複或自動流程時非常有用。
BigQuery - 修改表
在 SQL 開發過程中,幾乎肯定會需要以某種形式編輯您已完成的工作。這可能意味著更新查詢或細化檢視。但是,通常這意味著更改**SQL 表格**以滿足新的需求或促進新資料的傳輸。
ALTER 命令的使用場景
為了更改現有表格,BigQuery 提供了一個ALTER關鍵字,它允許對錶格結構和元資料進行強大的操作。
在 SQL 環境中更改任何表格的語法為“ALTER TABLE”。ALTER 命令的使用場景包括:
- 新增列
- 刪除列
- 重命名錶格
- 新增表格描述
- 新增分割槽過期天數
現在讓我們逐一介紹這些情況。
新增列
以下是修改前原始表格架構。
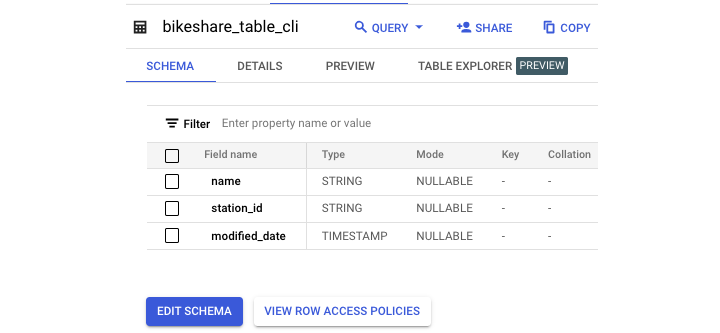
這是用於新增列的SQL 語句:
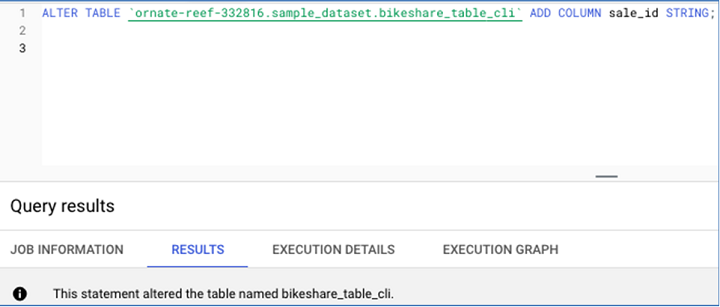
以下是新增新列後的表格架構。
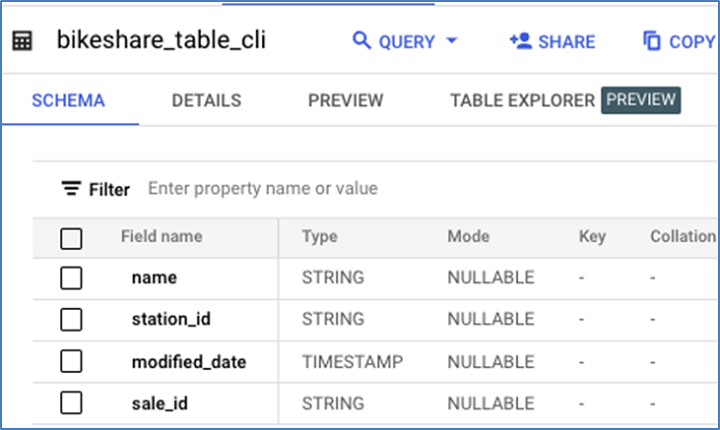
刪除列
這是現有表格的架構,在刪除sale_id之前。
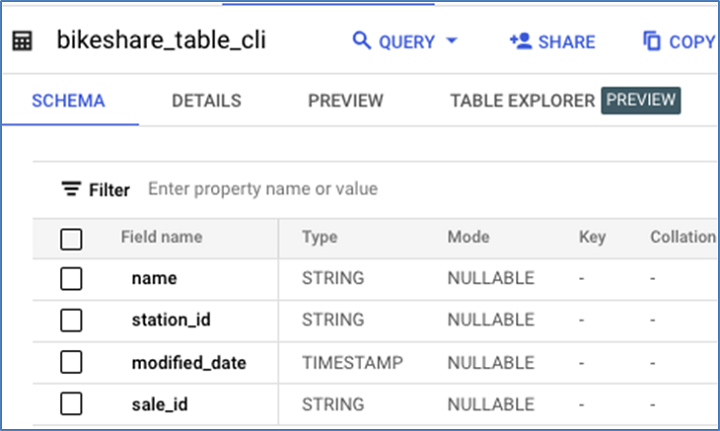
這是用於刪除sale_id的DML:
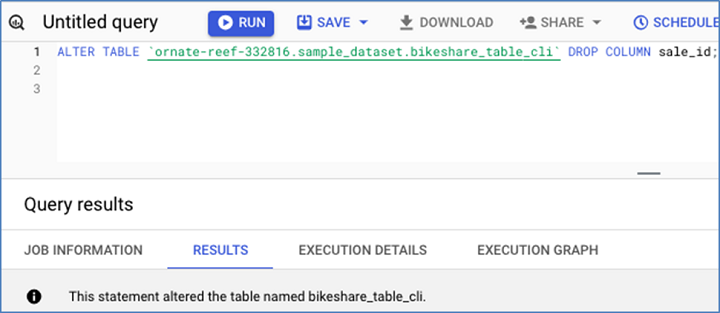
以下是結果架構:
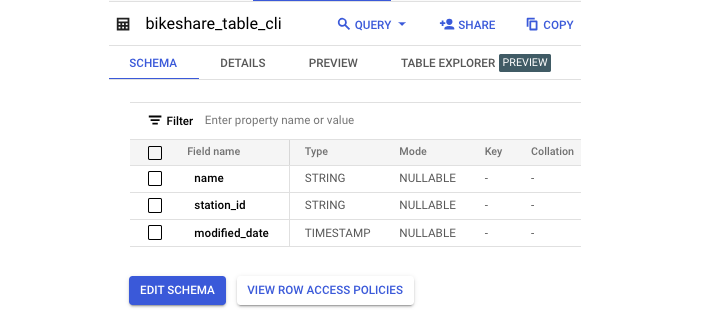
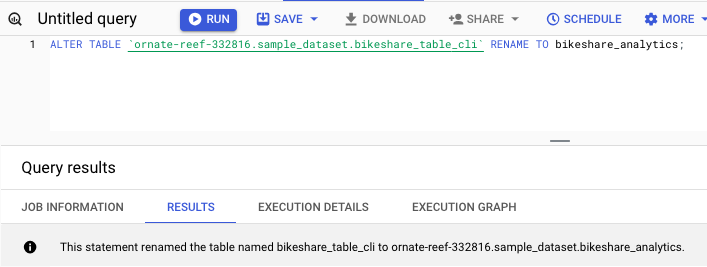
重命名錶格
您可以使用以下命令重命名錶格:
新增表格描述
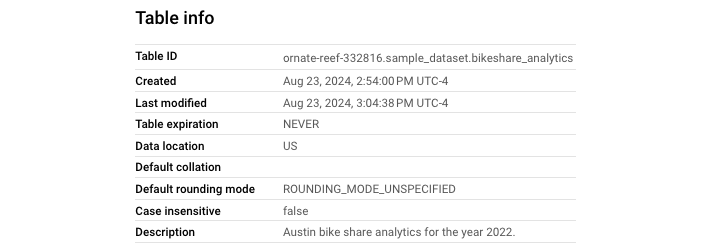
使用以下查詢新增表格描述:
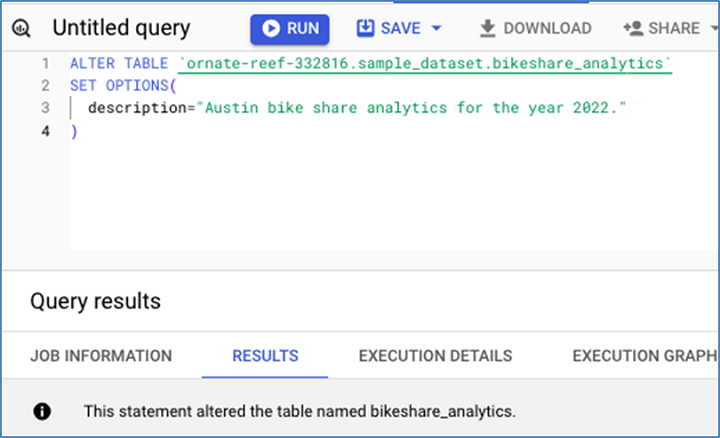
您可以在以下螢幕截圖中看到,此語句成功地向表格添加了描述。
新增分割槽過期天數
使用以下查詢新增分割槽過期天數:
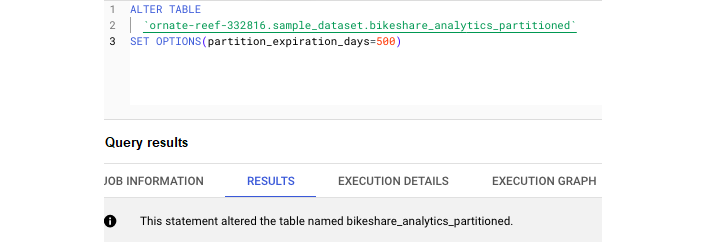
與 SELECT 語句不同,任何以 ALTER 開頭的 SQL 程式碼都將從根本上改變給定表格的結構或元資料。
注意:您應該謹慎使用這些查詢。
BigQuery - 複製表
SQL 表格可以像桌面上的檔案一樣根據需要複製或刪除。
複製表格可以採取兩種形式:
- 複製/重新建立表格
- 克隆表格
讓我們瞭解一下克隆表格與複製表格的區別。
在 BigQuery 中克隆表格
在 BigQuery 中建立現有表格的完美副本稱為克隆表格。此任務可以透過**BigQuery Studio** UI 或透過 SQL 複製過程來完成。
無論哪種情況,重要的是要記住,任何建立的新表格,即使是克隆的表格,仍然會產生長期儲存和使用費用。
在 BigQuery 中複製表格
複製表格會保留其所有當前屬性,包括:
- 儲存的所有資料
- 分割槽規範
- 聚類規範
- 元資料(如描述)
- 敏感資料保護策略標籤
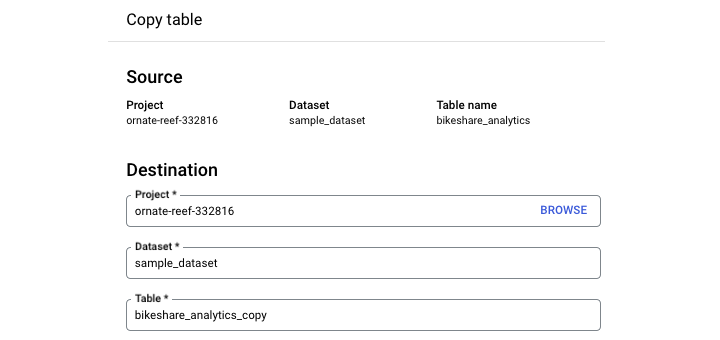
要在 BigQuery Studio UI 中複製表格,請導航到查詢環境。點選您要複製的表格。選擇“複製”。

需要注意的是,此複製過程不是自動的。當您點選“複製”時,您需要指定要將新表格複製到的資料集,並提供一個新的表格名稱。
注意:GCP 的預設命名約定是在原始表格名稱的末尾附加“_copy”。
BigQuery 不支援“SQL COPY”命令。相反,開發人員可以使用幾種不同的方法複製表格。
建立或替換表格
CREATE OR REPLACE TABLE 通常被認為是 BigQuery 中的預設建立表格語句,它可以充當事實上的 COPY。
CREATE OR REPLACE TABLE project.dataset.table
它需要使用 AS 關鍵字提供某種查詢:
CREATE OR REPLACE TABLE project.dataset.table AS ( )
要執行復制,您可以簡單地“SELECT * from”現有表格。

為了建立完美的克隆,開發人員可以使用“CREATE TABLE CLONE”關鍵字。此命令建立現有表格的完美副本,無需提供查詢。
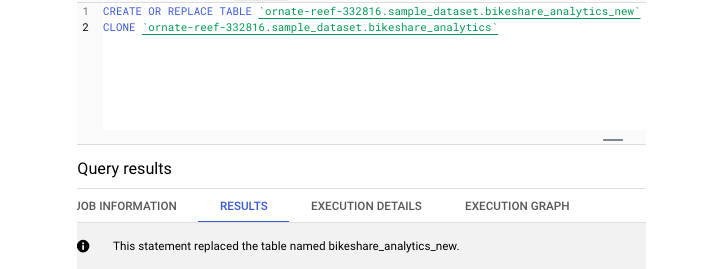
透過 UI 和支援的 SQL 語法,BigQuery 提供了與複製和克隆表格相關的靈活性。
BigQuery - 刪除和恢復表格
刪除表格提供了相同的兩個選項:UI 和SQL 語法。要在 UI 中刪除表格,只需選擇要刪除的表格並選擇“刪除表格”即可。由於這是一個永久性操作,因此在刪除之前系統會提示您鍵入表格名稱。
注意:您也可以在 SQL 環境中 DROP 表格。
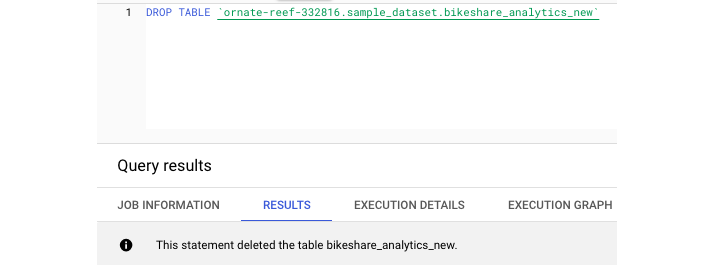
要僅刪除表格的內容並保留其中的資料,可以使用 DELETE 命令,該命令需要 WHERE 子句。
要在沒有任何引數的情況下刪除任何內容,可以使用以下查詢:
DELETE FROM project.dataset.table WHERE 1=1
注意:請謹慎使用此查詢。
在 BigQuery 中恢復表格
儘管採用了分兩步的刪除過程,但仍然很可能意外地 DROP 或刪除表格。因此,BigQuery 的建立者意識到可能需要為使用者提供一種方法來恢復過早刪除的表格。
BigQuery 表格快照
在 SQL 環境中建立和使用表格時,這一點並不明顯,但在後臺,BigQuery 正在自動儲存您的工作——在一定程度上。
BigQuery 使用“快照”定期儲存表格,作為提供即時備份的一種方式,以備不時之需。需要注意的是,如果使用者從快照中恢復表格,他們實際上並沒有恢復其原始表格——他們只是恢復到表格的快照或副本。
此工具並非沒有限制。BigQuery 表格快照僅保留 7 天。因此,只能在初始刪除後的 7 天內恢復已刪除的表格。
兩種恢復表格的方法
BigQuery 提供了兩種恢復表格的方法。順便說一句,它們都沒有使用 BigQuery SQL。它們需要透過gcloud 命令列或透過訪問 API以程式設計方式訪問 BigQuery。任一語句都將依賴於選擇要恢復到的快照的正確時間戳。
1. Gcloud 命令
在此,命令“bq cp”為“bq copy”。“No-clobber”是一個引數,如果目標表格不存在,則會指示命令失敗。
bq cp \ – restore \ – no-clobber \ –snapshot_project_id.snapshot_dataset_id.snapshot_table_id \ –target_project_id.target_dataset_id.target_table_id
2. Python 函式
理想情況下,開發人員將實施預防措施以避免需要恢復。但是,如果發生最壞的情況,BigQuery 提供了此故障保護。
BigQuery - 填充表
在初學 BigQuery 時,立即使用其功能和編寫SQL 查詢的最快速方法之一是提供現有的資料來源。最容易上傳和開始使用的其中一個數據源是靜態檔案。
BigQuery 接受的檔案型別
BigQuery 將任何從檔案建立的表格視為外部表格。
BigQuery 接受來自 GCP 的 Google Cloud Storage 中的本地上傳或雲端儲存的檔案輸入。
接受的檔案型別包括:
- CSV(逗號分隔值)
- JSONL(換行符分隔的 JSON)
- Parquet
- Avro
- ORC
就像建立空表格一樣,要填充資料,需要指定架構。提醒一下,架構可以是推斷的(自動生成的),也可以在 UI 中或作為 JSON 檔案提供。
檢查 BigQuery 是否支援資料型別
使用外部檔案(尤其是 CSV)時面臨的挑戰之一是,BigQuery 對某些資料型別有特殊要求。
在上傳檔案之前,最好檢查 BigQuery 是否支援資料型別並相應地調整輸入。例如,BigQuery 對其攝取時間戳資料的方式非常挑剔,即使對於縮寫日期,也更喜歡每個值有兩個整數而不是一個。
BigQuery 如何避免檔案上傳錯誤?
開發人員在將檔案載入到任何 SQL 表格時遇到的另一個挑戰是特殊字元的存在,例如換行符“\n”。雖然始終建議以程式設計方式刪除這些字元並充分清理資料,但 BigQuery 提供了過濾掉或完全忽略可能導致檔案上傳錯誤的行的方法。
- 首先,BigQuery 允許開發人員指定一個整數,表示允許出現多少個錯誤。如果有一行特定的錯誤行不包含任何有意義的資料,這將很有幫助。
- 此外,BigQuery 提供了一個引數用於跳過標題行,包括帶引號的換行符,並允許參差不齊或格式錯誤的行。
不幸的是,即使使用這些選項,確定檔案是否可以上傳的唯一方法是進行一些試用、錯誤和迭代。
BigQuery Studio:從 SQL 語句填充表格
根據具體情況,有兩種方法可以從“頭開始”(即簡單的 SQL 語句)填充表格。
1. CREATE OR REPLACE 命令
第一個 CREATE OR REPLACE 已經介紹過了。在這種情況下,開發人員正在建立一個全新的表格,並且必須定義表格架構以及表格內容。通常,當聚合或擴充套件 SQL 表格中已存在的資料時,最好使用 CREATE OR REPLACE。
2. INSERT 命令
如果您發現自己擁有一個表格的“外殼”,包括定義良好的架構但尚未新增任何資料,並且您沒有外部檔案或 API 有效負載之類的源,那麼新增資料的方式就是透過 INSERT 命令。
在這種情況下,要正確使用 INSERT,不僅需要定義列、型別和模式,還需要提供要插入的資料。
在 SQL 的限制範圍內定義資料涉及提供值和列別名。例如:

3. UNION 命令
要新增多行,請使用 UNION 命令。對於不熟悉 UNION 的人來說,它類似於 Pandas 的concat,並且本質上是將行條目“堆疊”在彼此之上,而不是根據公共鍵進行連線。
UNION 有兩種型別:
- UNION ALL
- UNION DISTINCT

為了確保您的資料使用 UNION 正確插入,有必要確保資料型別彼此一致。例如,由於我為 station_id 提供了 STRING 值,因此我無法將後續行的型別更改為 INTEGER。

在專業環境中,INSERT 不用於一次插入一行。相反,INSERT 通常用於插入資料分割槽,通常按日期(即最近一天的資料)進行分割槽。
從連線的電子表格填充表格
如您現在所見,BigQuery 中的查詢與在本地環境中編寫 SQL 不同,部分原因在於開發人員能夠將 BigQuery 資料與 GCP 的雲端工具同步。其中一個功能強大且直觀的整合是將 BigQuery 與 Google Sheets 結合使用。
展開外部表源的下拉選單,您會發現“Sheets”作為開發人員可用於使用資料填充表的源。

Google Sheet 作為主要資料來源
使用 Google Sheet 作為主要資料來源非常有用,因為與靜態 CSV 檔案不同,Sheet 是動態實體。這意味著對連線的 Sheet 中的行所做的任何更改都將即時反映在關聯的 BigQuery 表中。
要將 Google Sheet 連線到 BigQuery 表,請按照原始的建立表流程操作。您需要選擇**“驅動器”**作為源,而不是從上傳中選擇建立表。即使 Google Sheet 是在 Sheets UI 中建立的,它們也位於 Google Drive 中。
與 CSV 檔案類似,連線的 Sheet 必須具有定義的標題。但是,與 CSV 檔案不同,開發人員可以指定要包含和省略的列。
其**語法**類似於建立和執行 Excel 公式。只需編寫列字母和行號即可。要選擇給定行之後的全部行,請在列前加上感嘆號。
Like: !A2:M
使用相同的語法,您甚至可以選擇提供的 Sheet 中的不同選項卡。例如 -
"Sheet2 !A2:M"
與使用 CSV 檔案一樣,您可以指定要忽略哪些行和標題,以及是否允許帶引號的新行或參差不齊的行。
重要說明
DML 語句(如 INSERT 或 DROP)不適用於連線的 Sheet。要省略列,您需要在 Sheet 中隱藏它或在初始配置中指定它。
BigQuery 標準 SQL 與傳統 SQL
雖然SQL 沒有像Python(或任何其他指令碼語言)那樣的底層依賴項,但您選擇的 BigQuery SQL 版本之間存在差異。
由於 Google Cloud Platform 認識到開發人員熟悉不同的 SQL 方言,因此他們為那些習慣於使用更傳統或“傳統”SQL 版本的開發人員提供了選項。
標準 SQL 與傳統 SQL 之間的區別
標準 SQL 和傳統 SQL 之間的主要區別在於**型別的對映**。傳統 SQL 支援更接近於通用資料型別的型別,而標準 SQL 型別則更特定於 BigQuery。例如,BigQuery 標準 SQL 支援的時間戳值的範圍要窄得多。
其他區別包括 -
- 使用反引號而不是方括號來轉義特殊字元。
- 表引用使用冒號而不是點。
- 不支援萬用字元運算子。
在 BigQuery SQL 環境中切換標準 SQL 和傳統 SQL 非常簡單。在編寫和執行 SQL 查詢之前,只需在第 1 行添加註釋:“#legacy”。
BigQuery 的標準 SQL 優勢
與派生的傳統 SQL 方言相比,標準 SQL 使 SQL 開發人員能夠更靈活、更高效地編寫查詢。標準 SQL 透過提供在處理專業環境中遇到的“雜亂”資料時有用的函式和框架,提供了更多“現實世界”的實用程式。
標準 SQL 促進了以下功能 -
- 更靈活的 WITH 子句,使使用者能夠在指令碼中多次重複使用子查詢和 CTE。
- 可以用 SQL 或 JavaScript 編寫的使用者定義函式。
- SELECT 子句中的子查詢。
- 相關子查詢。
- 複雜資料型別(ARRAY 和 STRUCT 型別)。
標準 SQL 與傳統 SQL 之間的相容性問題
通常,標準 SQL 和傳統 SQL 操作之間的不相容性不會導致很多問題。但是,有一種情況適用於**AirFlow** 使用者。
如果使用**BigQueryExecuteQuery** 運算子,則可以指定是否使用傳統 SQL。要使用標準 SQL,請設定**"use_legacy_sql = FALSE"**。
但是,如果開發人員沒有這樣做並使用了僅與標準 SQL 相容的函式,例如**TIMESTAMP_MILLIS()**(一個時間戳轉換函式),則整個查詢可能會失敗。
BigQuery - 編寫第一個查詢
可以在查詢編輯器中開啟一個空白頁面,但是最好直接從表選擇步驟編寫第一個查詢,以避免語法錯誤。
要以這種方式編寫第一個查詢,請首先導航到包含要查詢的表的dataset。單擊“查看錶”。在上面面板中,選擇“查詢”。此過程將開啟一個新視窗,其中表名已填充,以及建立者新增的任何限制。
例如,表可能需要 WHERE 子句,或者建議的查詢可能會將使用者限制為例如 1000 行。為了**遵循最佳實踐**,請將“*”替換為您要查詢的列的名稱。

- 如果向**SELECT**新增任何聚合,請注意包含**GROUP BY**子句。
- 如果您想格外注意語法錯誤,還可以透過單擊提供的架構中的列名來選擇列名。
如果您按照這些步驟操作,則無需編寫表名。但是,為了養成構建正確表引用的習慣,請記住公式為:**project.dataset.table**。這些元素都用**反引號**(而不是引號)括起來。
BigQuery Studio 的一個獨特之處在於,IDE 會告訴您查詢是否會執行。這將由一個綠色複選標記指示。

確認所有內容看起來都正確後,點選**執行**。在查詢執行時,您將看到執行指標,例如處理的資料量、查詢執行所需的時間以及所需的步驟數。如果您檢視底部面板,您還將看到執行所需的插槽數量。

在 Cloud Shell 終端編寫您的第一個查詢
與在 UI 中查詢類似,在 Cloud Shell 終端中查詢遵循類似的結構,並允許使用者使用 SQL 語法訪問和操作資料。
“bq”查詢及其常用標誌
使用命令**bq** query 在 Cloud Shell 中編寫和執行查詢非常簡單。在同一行中,使用者可以提供標誌來指示執行的某些方面。
**bq** query 命令的一些更**常用標誌**包括 -
- –allow-large-results(不會因結果過大而取消作業)
- –batch = {true | false}
- –clustering-fields = [ ]
- –destination-table = table_name
您可能會注意到,所有這些引數都對應於在 UI 中建立表或執行查詢時出現的下拉選單。
要在 Cloud Shell 中執行查詢 -
- 登入 GCP
- 進入 Cloud Shell 終端
- 進行身份驗證(自動完成)
- 編寫並執行查詢
看起來像 -
(ornate-reaf-332816)$ bq query --use_legacy_sql=false \ 'SELECT * FROM ornate-reef-332816.sample_dataset.bikeshare_2022_stsore_date';
**結果**顯示為終端輸出。雖然結果沒有像 BigQuery UI 結果那樣呈現,但輸出仍然整潔易懂。

BigQuery - CRUD 操作
CRUD 代表建立、替換、更新和刪除,是一個基礎的 SQL 概念。與僅在臨時表中返回資料的常規查詢不同,執行 CRUD 操作後,表的結構和架構會發生根本性變化。
CREATE OR REPLACE 查詢
BigQuery 將 CRUD 的 C 和 R 與其語句**CREATE** OR **REPLACE** 結合起來。
CREATE OR REPLACE 可用於 BigQuery 的各種實體,例如 -
- 表
- 檢視
- 使用者定義函式 (UDF)
使用 CREATE OR REPLACE 命令的**語法**為 -
CREATE OR REPLACE project.dataset.table
建立操作將建立一個全新的實體,而 UPDATE 語句將在行(而不是表)級別更改記錄。
UPDATE 查詢
與 CREATE OR REPLACE 不同,UPDATE 使用了另一個語法片段 SET。最後,UPDATE 必須與 WHERE 子句一起使用,以便 UPDATE 知道要更改哪些記錄。
組合在一起,它看起來像這樣 -

以上查詢更新了表,但僅影響日期等於當前日期的行。如果是這種情況,它將把日期更改為昨天。
DELETE 命令
與 UPDATE 類似,DELETE 也需要 WHERE 子句。DELTE 查詢的語法很簡單 -
DELETE FROM project.dataset.table WHERE condition = TRUE

ALTER 命令
除了 CRUD 語句之外,BigQuery 還具有之前介紹過的 ALTER 語句。提醒一下,ALTER 用於 -
- 新增列
- 刪除列
- 重命名錶
謹慎使用這些功能中的每一個,尤其是在處理生產資料時。
BigQuery - 分割槽和聚類
由於本教程中已經使用了**“分割槽”**和**“聚類”**這兩個術語,因此提供更多上下文很有幫助。
什麼是分割槽和聚類?
這兩個術語用於描述最佳化資料儲存和處理的兩種方法。
分割槽是指開發人員如何分割資料,通常(但不總是)按日期元素(如年、月或日)進行分割。聚類描述瞭如何在指定分割槽內對資料進行排序。
要使用任何一種儲存方法,您必須定義所需的欄位。只能為分割槽使用一個欄位,但可以為聚類使用多個欄位。
需要注意的是,要應用分割槽或聚類,必須在構建的“建立表”階段執行此操作。否則,您將需要刪除/重新建立具有更新的分割槽/聚類規範的表。
如何將分割槽或聚類應用於表
要在建立表時應用分割槽和/或聚類,請執行以下命令 -
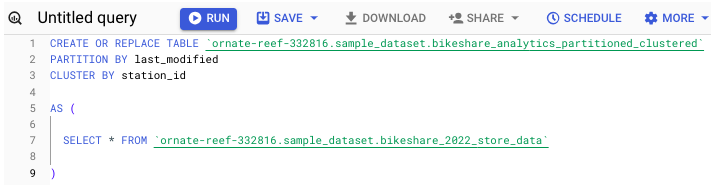
您也可以在 UI 中指定這些方向。在點選“建立表”之前,請花點時間填寫架構建立框正下方找到的欄位。
如果您正確應用了分割槽/聚類,它可以顯著降低長期儲存成本和處理時間,尤其是在查詢大型表時。
BigQuery - 資料型別
在載入和查詢資料時,瞭解 BigQuery 對資料型別的使用和解釋至關重要。如架構章節所示,載入到 BigQuery 中的每一列都必須具有定義的、可接受的型別。
BigQuery 接受其他 SQL 方言使用的許多資料型別,並且還提供 BigQuery 獨有的資料型別。
跨 SQL 方言的常用資料型別
跨 SQL 方言通用的資料型別包括 -
- STRING
- INTEGER
- FLOAT
- BOOLEAN
BigQuery 還支援特殊資料型別,例如 JSON 陣列,這將在後面的章節中討論。
**注意** - 如果在載入過程中未提供架構或未指定型別,BigQuery 將推斷型別。但是,對於依賴於不可預測的上游資料的整合,這並非一定是積極的結果。
與分割槽和聚類列一樣,必須在建立表時指定型別。
使用 CAST() 函式更改型別
可以在查詢中(臨時或永久)更改資料型別。為此,請使用 CAST() 函式。CAST 使用以下語法:
CAST(column_name AS column_type)
例如:
CAST(id AS STRING)
類似於指定錯誤的型別,嘗試強制將不相容的型別 CAST 為其他型別可能會令人沮喪,並導致基礎架構中斷。
為了更可靠地轉換資料型別,請使用 **SAFE_CAST()**,它會對不相容的行返回 NULL,而不是完全中斷:
SAFE_CAST(id AS STRING)
深入瞭解 BigQuery 如何解釋給定輸入的型別對於建立健壯的 SQL 查詢至關重要。
BigQuery 資料型別 STRING
在 SQL 開發人員使用的大多數常見資料型別中,BigQuery 中的 STRING 型別通常易於識別。但是,字串的操作或解釋偶爾會出現一些特殊情況。
通常,字串型別由字母數字字元組成。雖然字串型別可以包含類似整數的數字和符號,但如果指定了 STRING 型別,則這些資訊將像常規字串一樣儲存。
新開發人員遇到的一個棘手的情況是處理包含整數或浮點數以及符號的行,例如貨幣情況。
雖然可能認為 $5.00 由於小數點而是一個 FLOAT,但美元符號使它成為一個字串。因此,在載入包含美元符號的行時,BigQuery 會期望在架構中將其定義為 STRING 型別。
DATE 資料型別
DATE 資料型別是 STRING 型別的一個子集。
- 即使 BigQuery 有自己的日期值表示法,但預設情況下,日期值本身也以字串形式表示。
- 對於使用 Python 中的 Pandas 的使用者來說,這類似於日期欄位如何在資料框中表示為物件。
- 有多種函式專門用於解析 STRING 資料。
STRING 函式
值得注意的 STRING 函式包括:
- **LOWER()** - 將字串中的所有內容轉換為小寫
- **UPPER()** - LOWER 的反向操作;將值轉換為大寫
- **INITCAP()** - 將每個句子的第一個字母大寫;即句子大小寫
- **CONCAT()** - 組合字串元素
重要的是,BigQuery 中的資料型別預設為 STRING。除了傳統的字串元素之外,這也包括開發人員未指定 REPEATED 模式列表。
INTEGER & FLOAT
如果您在企業(商業)規模上使用 BigQuery,則很可能需要處理涉及數字的資料。這可能是任何資料,從出席資料到營業收入。
無論如何,STRING 資料型別對於這些用例都沒有意義。這不僅是因為這些數字沒有像美元符號或歐元這樣的貨幣符號,還因為為了生成有用的見解,需要利用特定於數值資料的函式。
**注意** INTEGER 和 FLOAT 之間的區別很簡單:**"."**
在許多 SQL 方言中,當指定數值時,開發人員需要告訴 SQL 引擎期望多少位數字。這就是傳統 SQL 獲取像 **BIGINT** 這樣的指定的來源。
**BigQuery 將 FLOAT 型別編碼為 64 位實體**。因此,當您將列 CAST() 為 FLOAT 型別時,您會這樣操作:
CAST(column_name AS FLOAT64)
值得注意的 INTEGER 和 FLOAT 函式
其他值得注意的 INTEGER 和 FLOAT 函式包括:
- ROUND()
- AVG()
- MAX()
- MIN()
注意事項
FLOAT 型別的 **一個重要注意事項** 是,除了指定由句點分隔的數字外,FLOAT 型別也是 NULL 的預設型別。
如果使用 **SAFE_CAST()**,最好包含其他邏輯將從 FLOAT 返回的任何 NULL 值轉換為所需的型別。
BigQuery - 複雜資料型別
BigQuery 除了支援 STRING、INTEGER 和 BOOLEAN 等“常規”資料型別外,還提供對所謂的 **複雜資料** 的支援。通常,這也稱為 **巢狀資料**,因為資料不適合傳統的扁平表,並且必須位於列的子集中。
複雜資料結構很常見
對巢狀架構的支援允許更簡化的載入過程。儘管 Google Cloud 列出了關於以下資料型別的各種教程為“高階”,但巢狀資料非常常見。
瞭解如何展平並使用這些資料型別是任何面向 SQL 的開發人員的一項有價值的技能。
這些資料結構常見的原因是源資料(例如 API 的 JSON 輸出)通常以這種格式返回資料:
[{data: "id": '125467", "name": "Acme Inc.", "locations":
{"store_no": 4, "employee_count": 15}}]
- 請注意,“id”和“name”如何處於相同的引用級別。可以使用“data”作為鍵訪問它們。
- 但是,要獲取諸如“store_no”和“employee_count”之類的欄位,就需要不僅訪問 data 鍵,還需要展平“locations”陣列。
這就是 BigQuery 的複雜資料型別支援有幫助的地方。資料工程師無需編寫一個指令碼遍歷並展開“locations”,而是可以原樣將這些資料載入到 BigQuery 表中。
BigQuery 中的複雜資料結構
BigQuery 支援以下三種類型的複雜或巢狀資料:
- STRUCT
- ARRAY
- JSON
處理這些型別的策略將在接下來的章節中解釋。
BigQuery - STRUCT 資料型別
STRUCT 和 ARRAY 是開發人員在 BigQuery 的列式結構中儲存巢狀資料的方式。
什麼是 Struct?
STRUCT 是一個欄位集合,具有指定的型別(必需)和欄位名稱(可選)。值得注意的是,與 ARRAY 不同,STRUCT 型別可以包含混合的資料型別。
為了更好地理解 STRUCT 型別,請再次檢視上一章中的示例,現在進行了一些更改。
"locations": [
{"store_no": 4, "employee_count": 15, "store_name": "New York 5th Ave"},
{"store_no": 5, "employee_count": 30, "store_name": "New York Lower Manh"}
]
之前“locations”是相同型別的 **dict**(用 JSON 表示),現在它包含兩個 STRUCT,其型別為 **<INTEGER, INTEGER, STRING>**。
- 儘管支援 STRUCT 型別,但在表建立階段,BigQuery 沒有提供可用的顯式標籤 STRUCT。
- 相反,STRUCT 被表示為具有 NULLABLE 模式的 RECORD。
**注意** - 將 STRUCT 視為容器而不是專用資料型別。
在架構中定義時,STRUCT 內部的元素將使用“.”表示和選擇。此處,**架構**將是:
{"locations", "RECORD", "NULLABLE"},
{"locations.store_no", "INTEGER", "NULLABLE},
{"locations.employee_count", "INTEGER", "NULLABLE"},
{"locations.store_name", "STRING", "NULLABLE"}
點表示法
要選擇 STRUCT 元素,需要在 FROM 子句中使用 **點表示法**:

查詢執行後,您可能會得到如下所示的 **輸出**:
BigQuery - ARRAY 資料型別
與允許包含不同型別資料的 STRUCT 型別不同,ARRAY 資料型別必須包含相同型別的元素。
- 在像 Python 這樣的程式語言中,ARRAY(也稱為列表)用方括號表示:**[ ]**。
- STRUCT 型別可以包含其他 STRUCT(以建立非常巢狀的資料),ARRAY 不能包含另一個 ARRAY。
- 但是,ARRAY 可以包含 STRUCT,因此開發人員可能會遇到一個 ARRAY,其中嵌入了多個 STRUCT。
BigQuery 不會將列標記為顯式的 ARRAY 型別。相反,它以不同的模式表示。雖然常規 STRING 型別具有“NULLABLE”模式,但 ARRAY 型別具有“REPEATED”模式。

可以使用點選擇 STRUCT 型別,但是 ARRAY 型別在表面級操作方面受到更多限制。
可以將 ARRAY 作為分組元素進行選擇

但是,使用點或任何其他方法選擇陣列的元素是不可能的,因此這將不起作用:

UNNEST() 函式
要訪問 store_information 中的名稱,需要執行一個額外的步驟:**UNNEST()**,這是一個函式,它將展平資料,使其更易於訪問。
UNNEST() 函式在 FROM 子句中與逗號一起使用。作為上下文:逗號表示隱式 CROSS JOIN。
要正確訪問此 ARRAY,請使用以下查詢:
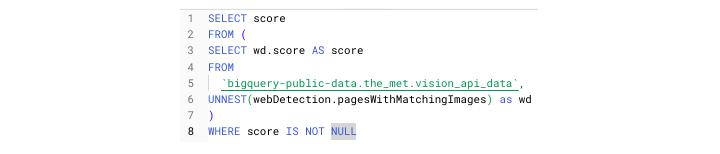
它將為您獲取如下所示的 **輸出** 表:
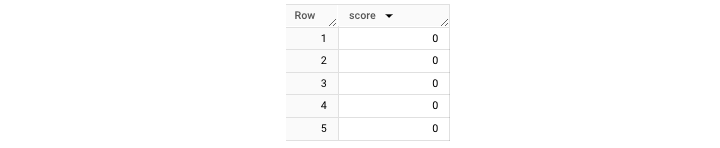
除了使用 UNNEST() 之外,還可以為記錄設定別名。然後,生成的別名 **“wd”** 可用於訪問展開的資料。
BigQuery - JSON 資料型別
JSON 是 BigQuery 支援的最新資料型別。與 STRUCT 和 ARRAY 型別不同,JSON 相對容易識別。
對於使用指令碼語言處理過資料或解析過 API 響應的開發人員來說,JSON 資料將很熟悉。
JSON 資料由花括號表示:{ },就像 Python 字典一樣。
**注意** - 在 BigQuery 引入對 JSON 型別的支援之前,JSON 物件需要表示為具有 NULLABLE 模式的 STRING。
開發人員可以在 UI 和基於文字的架構定義中指定 JSON:
不將 JSON 資料儲存為 JSON 型別不一定導致載入失敗,因為 BigQuery 可以支援 JSON 資料的 STRING 型別。
但是,不正確地儲存 JSON 資料意味著開發人員將無法訪問強大的 JSON 特定函式。
強大的 JSON 函式
藉助內建函式,在 BigQuery 中使用 JSON 資料的開發人員無需編寫指令碼來展平 JSON 資料。相反,他們可以使用 JSON_EXTRACT 提取 JSON 物件的內容,然後允許處理和操作生成的資料。
其他強大的 JSON 函式包括:
- JSON_EXTRACT_ARRAY()
- PARSE_JSON()
- TO_JSON()
能夠在 BigQuery 中準確直觀地查詢 JSON 資料,使開發人員無需使用複雜的 CASE 邏輯或編寫自定義函式來提取有價值的資料。
BigQuery - 表元資料
能夠分析和理解組織資料的範圍和內容固然重要,但對於 SQL 開發人員來說,瞭解使用 BigQuery 的效能和儲存成本方面也很重要。
這時,查詢 BigQuery 表元資料對於開發人員很有用,對於尋求充分利用 SQL 引擎的組織來說也至關重要。
對於那些沒有廣泛使用元資料的人來說:元資料顧名思義,是關於資料的資料。這通常與圍繞資源效能或監控等內容的統計資料相關。
BigQuery 提供了 **多個元資料儲存**,使用者可以查詢這些儲存以更好地瞭解他們的專案如何消耗資源,其中一些包括:
- INFORMATION_SCHEMA
- __TABLES__ 檢視
- BigQuery 審計日誌
每個表都可以像儲存資料一樣進行查詢。
對於 INFORMATION_SCHEMA 和 __TABLES__,需要注意的是,表引用的語法有所不同。
而不是遵循典型的:**project.dataset.table** 表示法,INFORMATION_SCHEMA 和 __TABLES__ 的元素是在結束反引號後引用的。
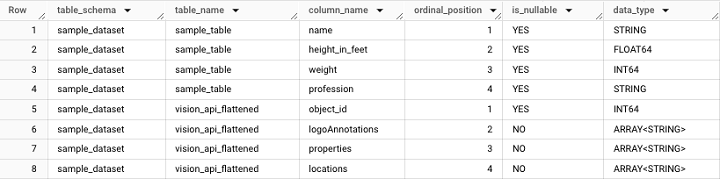
INFORMATION_SCHEMA 是一個數據源,它有幾個分支資源,如 COLUMNS 或 JOBS_BY_PROJECT
例如,引用 INFORMATION_SCHEMA 如下所示:

它將獲取以下 **輸出**:
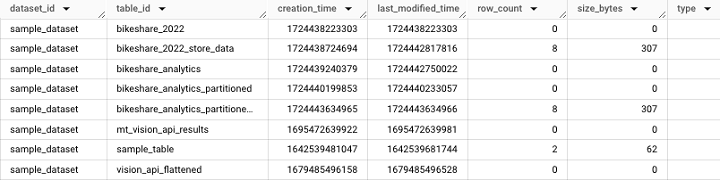
TABLES 檢視
TABLES 檢視提供表級別的資訊,例如表建立時間和上次訪問表的使用者。需要注意的是,TABLES 檢視可以在資料集級別訪問。

它將獲取以下 **輸出**:
基於現有表建立架構
INFORMATION_SCHEMA.COLUMNS 的一個有用的用例是能夠使用此查詢基於現有表建立架構:

BigQuery - 使用者定義函式
BigQuery 的優勢之一是能夠建立自定義邏輯來操作資料。在像**Python**這樣的程式語言中,開發者可以輕鬆地編寫和定義函式,這些函式可以在指令碼中的多個位置使用。
BigQuery 中的持久化使用者自定義函式
許多**SQL**方言,包括 BigQuery,都支援這些函式。BigQuery 將它們稱為持久化使用者自定義函式。簡稱為 UDF(使用者自定義函式)或 PUDF(持久化使用者自定義函式)。
使用者自定義函式的本質可以分解成兩個步驟:
- 定義函式邏輯
- 在指令碼中使用函式
定義使用者自定義函式
定義使用者自定義函式從一個熟悉的 CRUD 語句開始:CREATE OR REPLACE。
這裡,不需要使用 CREATE OR REPLACE TABLE,而是需要使用 CREATE OR REPLACE FUNCTION,後面跟著AS()命令。
與可以在 BigQuery 中編寫的其他 SQL 查詢不同,在建立 UDF 時,需要指定輸入欄位和型別。
這些輸入的定義方式類似於 Python 函式:
(column_name, type)
為了看到這些步驟組合在一起,我建立了一個簡單的臨時 UDF,由 TEMP FUNCTION 指定,它根據使用者輸入解析各種 URL。
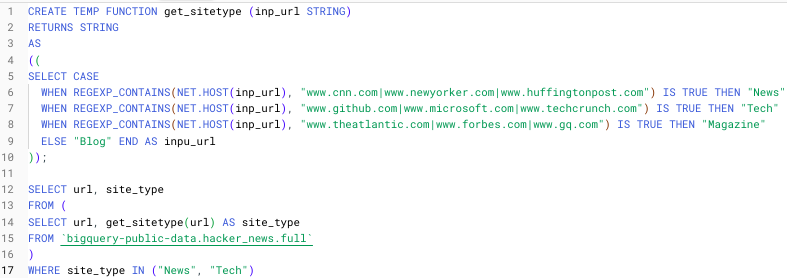
建立上述臨時函式的步驟如下:
- CREATE TEMP FUNCTION
- 指定函式名稱 (get_sitetype)
- 指定函式輸入和型別 (inp_url, STRING)
- 告訴函式返回哪種型別 (STRING)
REGEXP_CONTAINS() 函式搜尋包含提供的 URL 字串的字串中的匹配項。NET.HOST() 函式從輸入 URL 字串中提取主機域名。
將其應用於 hacker news 資料集(BigQuery 公共資料集),我們可以生成一個輸出,將儲存的 URL 分類到不同的媒體類別中:
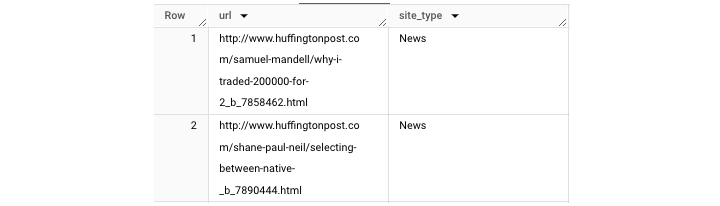
注意:臨時函式必須緊跟在查詢後面。
BigQuery - 連線外部資料來源
雖然到目前為止,本教程的大部分內容都涉及 UI 和雲終端,但現在是時候探索透過外部資料來源連線到 BigQuery 了。
在 UI 中編寫查詢的侷限性
即使在 BigQuery Studio 中編寫查詢可能很方便,但事實是,這隻能滿足有限範圍的目的:
- 最初開發 SQL 查詢或指令碼
- 除錯查詢
- 進行抽查或質量保證
僅僅在 UI 中編寫和執行查詢並不能幫助交付自動化的資料解決方案。這意味著在 BigQuery SQL 環境中,您無法:
- 訪問 BigQuery API
- 與 Airflow 整合
- 建立 ETL 管道
外部 BigQuery 整合
在接下來的章節中,我們將探討如何將 BigQuery 與以下內容整合:
- BigQuery 計劃查詢
- BigQuery API (Python)
- Cloud Composer / Airflow
- Google Sheets
- BigQuery 資料傳輸
外部 BigQuery 整合使開發人員能夠利用 SQL 的強大功能來執行以下任務:
- 建立自動化的提取載入 (EL)
- 提取轉換載入 (ETL)
- 提取載入轉換 (ELT) 作業
BigQuery - 整合計劃查詢
計劃查詢除了是與 BigQuery 整合的最直觀的外部整合(外部是因為該機制依賴於 BigQuery 資料傳輸服務)之外,還可以從**BigQuery Studio**中進行計劃。
如果您願意,也可以導航到側邊欄上的“計劃查詢”。但是,即使此頁面也會提示您“建立查詢”,這將帶您返回到 UI。因此,最好透過以下方式在 UI 中建立和計劃您的查詢:
- 在**SQL**工作區中編寫查詢。
- 驗證並執行查詢(只有有效的查詢才能執行或計劃)。
- 選擇“計劃查詢”,這將開啟一個下拉選單。
進入“計劃查詢”選單後,您必須填寫:
- 查詢名稱
- 計劃頻率
- 開始時間
- 結束時間
如果您不填寫結束時間,則查詢將永久按照其分配的計劃執行。
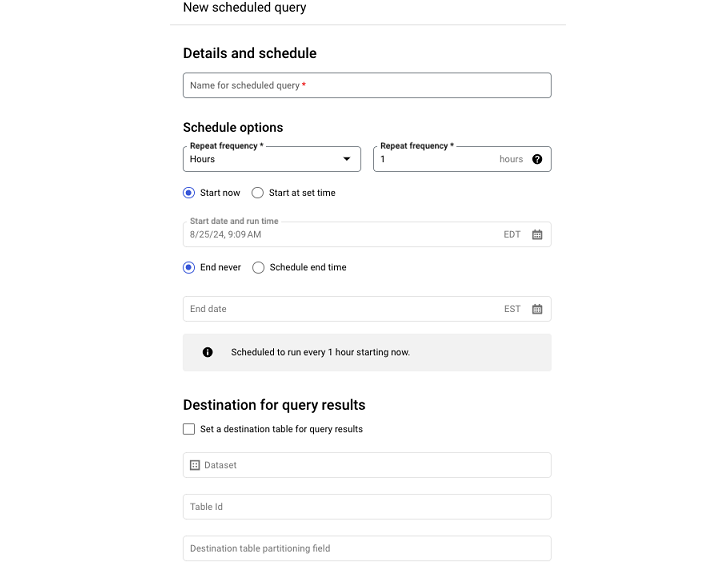
注意:關於計劃查詢的一個注意事項是,一旦它們被計劃,查詢執行引數的某些方面(例如與查詢關聯的使用者)就無法在 UI 中更改。
為此,需要透過**BigQuery API**或命令列訪問計劃查詢。
整合 BigQuery API
BigQuery API 允許開發人員利用 BigQuery 的處理能力和 Google SQL 資料操作功能來執行重複性任務。
BigQuery API 是一個 REST API,支援以下語言:
由於 Python 是資料科學和資料分析中最流行的語言之一,本章將探討 Python 上下文中的 BigQuery API。
BigQuery API 部署選項
就像開發人員無法直接從 BigQuery Studio 部署 SQL 一樣,對於生產工作流,訪問 BigQuery API 的程式碼必須透過相關的 GCP 產品進行部署。
部署選項包括:
- Cloud Run
- Cloud Functions
- 虛擬機器
- Cloud Composer (Airflow)
BigQuery API 需要身份驗證
使用 BigQuery API 需要身份驗證:
- 如果在本地執行指令碼,可以下載與執行 BigQuery 的服務帳戶關聯的憑據檔案,然後將其設定為環境變數。
- 如果在連線到雲的上下文中執行 BigQuery,例如在 Vertex AI 筆記本中,則會自動進行身份驗證。
為了避免下載檔案,GCP 還為大多數應用程式支援Oauth2 身份驗證流程。
一旦經過身份驗證,典型的 BigQuery API 用例包括:
- 執行包含給定表的 CRUD 操作的 SQL 指令碼。
- 檢索專案或資料集元資料以建立監控框架。
- 執行 SQL 查詢以使用來自另一個數據源的資料合成或豐富 BigQuery 資料。
".query()" 方法
毫無疑問,最流行的 BigQuery API 方法之一是".query() 方法"。當與 Pandas 的.to_dataframe()結合使用時,它為以可讀形式查詢和顯示資料提供了一個強大的選項。
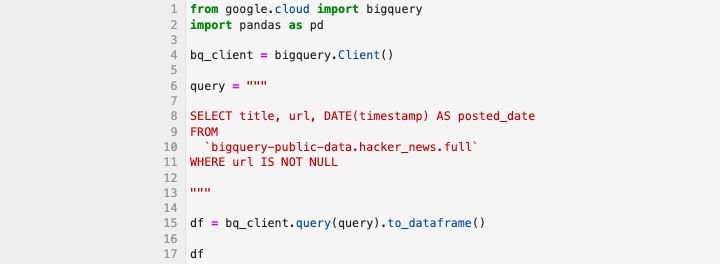
此查詢應獲取以下輸出:
BigQuery API 不是黑盒。除了日誌記錄(使用 Google Cloud Logging 客戶端)之外,開發人員還可以檢視 UI 中個人使用者和專案級別上的即時作業資訊細分。對於任何失敗的作業進行故障排除,這應該是您的首選步驟。
BigQuery - 整合 Airflow
執行**Python**指令碼載入 BigQuery 表格對於單個作業可能很有幫助。但是,當開發人員需要建立多個順序任務時,孤立的解決方案並非最佳選擇。因此,有必要超越簡單的執行。需要編排。
BigQuery 可以與一些流行的編排解決方案整合,例如Airflow和DBT。但是,本教程將重點介紹 Airflow。
有向無環圖 (DAG)
Apache Airflow 允許開發人員建立稱為有向無環圖 (DAG) 的執行塊。每個 DAG 由許多工組成。
每個任務都需要一個運算子。有兩個重要的 BigQuery 相容運算子:
- BigQueryCheck 運算子
- BigQueryExecuteQuery 運算子
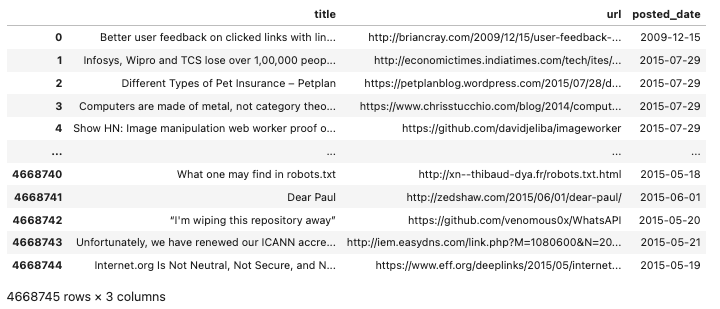
BigQueryCheck 運算子
BigQueryCheck 運算子允許開發人員進行上游檢查以確定資料是否已更新當天。
如果表在架構中不包含上傳時間戳,則可以查詢元資料(如前所述)。
開發人員可以透過執行此查詢的版本來確定上次更新表的日期:

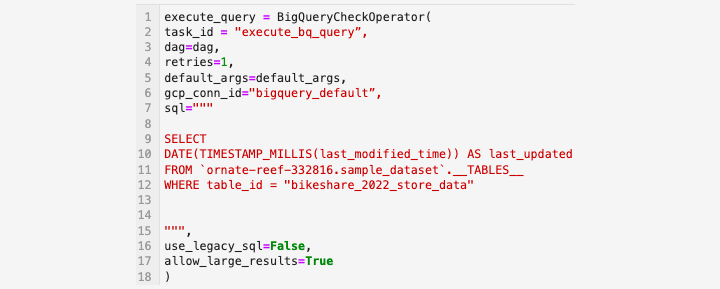
BigQueryExecuteQuery 運算子
要執行依賴於上游資料的**SQL**指令碼,SQL 開發人員可以使用BigQueryExecuteQuery 運算子來建立載入作業。
Airflow 的更深入解釋超出了本教程的範圍,但 GCP 為想要了解更多資訊的人員提供了廣泛的文件。
BigQuery - 整合連線的 Sheets
對於選擇使用 BigQuery 等雲服務作為**資料倉庫**的使用者,通常的目標是從電子表格遷移資料到資料庫。因此,將資料倉庫和電子表格配對可能顯得多餘。
但是,將 Google Sheet 連線到 BigQuery 允許無縫重複“重新整理”電子表格資料,因為源是 BigQuery 中的檢視或表。
Google Sheets 透過兩種方式支援 BigQuery 整合:
- 直接連線到表。
- 連線到自定義查詢的結果。
與 BigQuery 中可用的外部資料來源以下拉選單形式顯示不同,在 Google Sheets 中查詢資料來源需要一些挖掘。
將 BigQuery 資源連線到 Google Sheets
要將 BigQuery 資源連線到 Google Sheets,請按照以下步驟操作:
- 開啟一個新的 Google Sheet
- 點選“資料”選項卡
- 在資料下,導航到資料連線
- 選擇現有資料集
- 找到所需的表
- 或者,編寫自定義查詢
- 點選連線
該表單應從標準電子表格更改為類似於電子表格和 SQL 表混合的 UI。
如何確保同步並計劃重新整理?
雖然按照這些步驟可以確保連線處於活動狀態,但就此停止將無法確保未來的同步。
- 要隨著其關聯資源的更新自動更新表單,您必須計劃重新整理。
- 您可以透過導航到“連線設定”來計劃重新整理。
- 與配置計劃查詢一樣,計劃重新整理也很簡單。選擇您的重新整理間隔、開始時間和結束時間。
配置完成後,表單現在將按照該計劃更新,假設 BigQuery 表格中有可用資料。
BigQuery - 整合資料傳輸
BigQuery 資料傳輸促進來自 Google 關聯產品的同步,並將生成的資料有效載荷匯入 BigQuery。由於這些資料傳輸是在 Google 產品之間進行的,因此它們基於現成的報表。
在配置期間,使用者可以選擇他們想要匯入的報表。不幸的是,這意味著沒有空間進行上游自定義。
雖然擔心給定報表缺少特定欄位可能很直觀,但情況往往相反。Google 的報表通常包含如此多的資料,因此需要構建檢視以僅提取與您的用例相關的相關資訊。
資料傳輸需要身份驗證
與其他 BigQuery 整合一樣,資料傳輸需要身份驗證。
- 幸運的是,由於傳輸最初是在 UI 中配置的,因此這是一個簡單的身份驗證流程。
- 使用 Oauth2,設定 BigQuery 傳輸的使用者需要登入並驗證連線到 Google Cloud Platform 的帳戶。
- 經過身份驗證後,開發人員可以從 Google 產品和報表型別的下拉列表中進行選擇。
為了便於使用生成的資料,該過程中最重要的方面之一是為生成表的尾綴提供一個難忘的名稱。
注意:某些報表(如計費報表)不允許使用者更改匯入表的名稱。
報表示例
可以作為資料傳輸計劃的報表示例包括:
- DFP
- Google Ad Manager
- YouTube 頻道報表
這些現成的報表可以消除某些 BigQuery 相容資料資源的開發負擔。
BigQuery - 物化檢視
除了建立表和檢視之外,BigQuery 還支援建立物化檢視。
什麼是物化檢視?
物化檢視類似於表,因為它也是資料的“快照”。但是,物化檢視的不同之處在於,真正的物化檢視會動態更新——無需執行查詢即可。
物化檢視的型別
從廣義上講,有兩種型別的物化檢視:
- 已儲存為表的檢視,並將定期從外部源更新。
- 在 BigQuery Studio 中建立的“真正”的物化檢視。
以下是第一種檢視的示例架構:
- SQL 查詢現有檢視
- 在 Python 指令碼中,該檢視被轉換為資料框
- 資料框上傳到 BigQuery
- 物化檢視被追加或覆蓋
由於以上概述了一個多步驟過程,因此 BigQuery 簡化了物化檢視的建立和維護。
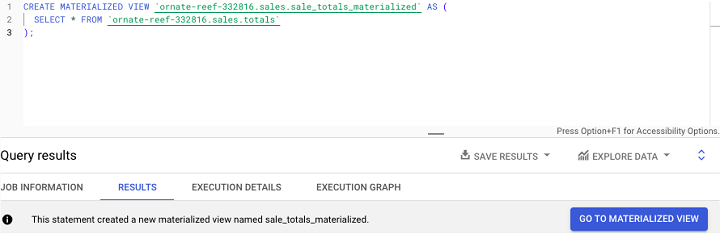
建立 BigQuery 物化檢視
使用者可以透過執行CREATE MATERIALIZED VIEW SQL 語句,後跟以下內容來建立 BigQuery 物化檢視:
- 專案
- 資料集
- 新的 mv 名稱
- SQL 語句
示例
這是一個示例,其中物化了包含假設銷售資料的現有表:
根據 BigQuery 文件,請注意以下限制:
- 每個表在一個數據集內最多有 20 個物化檢視
- 一個專案中最多隻能有 100 個物化檢視
- 一個組織中最多隻能有 500 個物化檢視
在 BigQuery 中編寫簡單的 SQL 指令碼
現在將所有內容整合在一起,是時候編寫一個簡單的指令碼,該指令碼將:
- 利用動態變數
- 刪除昨天的資料
- 將新資料插入表中
- 使用查詢選擇/載入資料
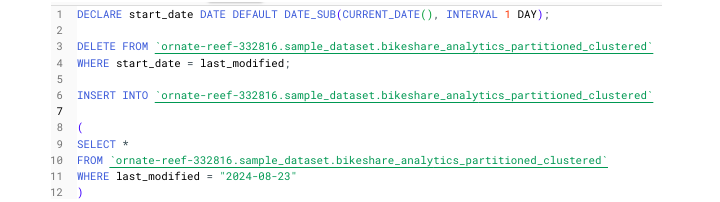
到目前為止,尚未介紹如何在 SQL 指令碼中定義和使用變數。
在 BigQuery 中,變數語法如下:
DECLARE variable_name TYPE DEFAULT function used to create dynamic variable
例如:
DECLARE yesterday DATE DEFAULT DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
我們將以此作為以下指令碼的開頭,該指令碼將刪除奧斯汀共享單車分割槽表中的先前資料,並僅插入最新資料。
在 BigQuery 中執行此指令碼時,由於分號的存在,SQL 引擎將分階段執行它。可以透過點選“檢視結果”檢視最終結果。
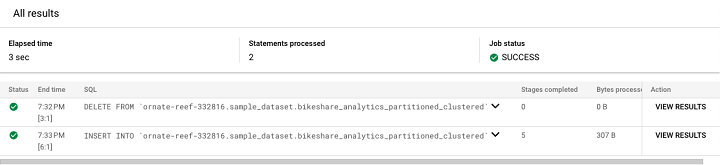
點選“檢視結果”將生成此輸出。

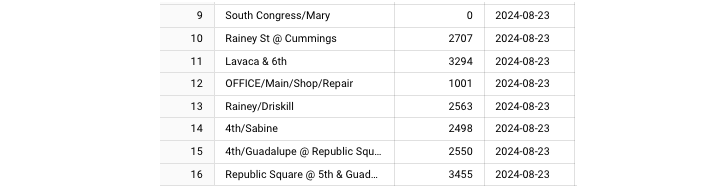
最後,我們可以看到新增到表中的新行。
BigQuery - 角色和許可權
在 BigQuery Studio UI 中執行查詢看似非常簡單。由於開發人員已登入其 Google Cloud Platform 帳戶,因此無需進行身份驗證。但是,在幕後,某些限制和防護措施確保開發人員只能在專案中執行某些操作。
身份訪問和管理 (IAM) 角色
這些限制或指定稱為角色和許可權。在 GCP 中,這些稱為身份訪問和管理 (IAM) 角色。
從廣義上講,這些角色分為 3 個層級:
- BigQuery 管理員
- BigQuery 資料編輯器
- BigQuery 使用者
1. BigQuery 管理員
BigQuery 管理員可以在專案中執行任何操作,例如建立或刪除表以及啟動和停止作業的執行——即使是由其他使用者啟動的作業。
2. BigQuery 資料編輯器
BigQuery 資料編輯器的許可權略少。雖然他們可以讀取、更新和刪除表或檢視,但他們缺乏專案級別的控制和許可權,並且無法控制其他使用者的作業。
3. BigQuery 使用者
BigQuery 使用者是 BigQuery IAM 角色的最低層級。在訪問和操作資源方面,他們的許可權非常有限。他們有限的能力包括:列出表和訪問元資料。
自己使用 BigQuery 無需瞭解任何這些角色或許可權。但是,當您使用企業級資料時,瞭解角色和許可權可以幫助加快解決訪問問題或在配置服務帳戶時派上用場。
BigQuery:策略標籤和 PII
就像 BigQuery 管理員可以授予許可權並影響擁有較低級別訪問許可權的使用者一樣,他們還可以控制個人可以檢視和互動的資料。這可以透過使用策略標籤來實現。
什麼是策略標籤?
策略標籤本質上是組織資料的審查欄。管理員可以應用此標籤來阻止組織內的使用者訪問敏感資料。雖然確定構成敏感資料的部分內容是主觀的,但也存在客觀定義。
什麼是個人身份資訊 (PII)?
在資料治理中,敏感資料稱為個人身份資訊 (PII)。PII 包括任何可用於立即和密切識別特定個人的屬性。它包括以下資訊:
- 電話號碼
- 生物識別資訊
- 電子郵件
- 社會安全號碼(美國)
- 信用卡號碼
以上任何資訊都被視為極其敏感的資訊,必須小心保管。為了指導保護,GCP 在其資料治理產品 Data Loss Prevention 的文件中識別了 150 多個 PII 屬性。
可以配置策略標籤
策略標籤也可以用於保護組織免受不應訪問業務關鍵資訊(如收入資料)的內部使用者的侵害。
可以透過以下方式配置策略標籤,然後在 BigQuery 中應用:
- 選擇一個表
- 點選“編輯架構”
- 選擇所有可能包含敏感資訊的列
- 應用已配置的策略標籤
開發人員可以知道何時應用了此類標籤,因為它將在表架構中欄位名稱旁邊顯示為灰色框。

BigQuery - 查詢最佳化
BigQuery 由雲計算提供支援,但這並不意味著計算能力是無限的。這也不意味著每個查詢都會在相同的時間內執行,無論一天中的時間或有多少程序在爭奪插槽。
什麼是查詢最佳化?
最佳化是一個經常被資料工程和其他程式設計學科的人員使用的流行詞。
使用SQL,最佳化有兩種形式:
- 基於程式碼的最佳化
- 基於平臺的最佳化
基於程式碼的最佳化概念化和執行起來很複雜。因此,它超出了本教程的範圍。相反,我們將重點介紹 BigQuery 中允許使用者準確跟蹤和主動抑制過度使用的工具。
透過提高可見性和創造性的插槽分配,可以維護一個具有多個使用者的 BigQuery 專案,併為所有使用者提供足夠的儲存空間和插槽空間。這可以透過以下方式實現:
- 透過執行圖和資料血緣工具跟蹤使用情況。
- 以不同的模式執行查詢以減少在給定時間處理的資料量。
- 利用 BI Engine 等工具對重複違規者(表)進行細分,以主動限制在高流量時段處理的資料範圍。
批處理與互動式模式
在 BigQuery Studio SQL 環境中編寫了前幾個查詢後,您可能會覺得所有查詢都以相同的方式執行。從某種意義上說,您是正確的。所有查詢在執行期間都會使用一定數量的插槽,以插槽小時表示。但是,實際上有兩種不同的方法可以執行 BigQuery 查詢以節省處理和成本。
大多數 BigQuery 查詢是在所謂的互動式模式下執行的。事實上,這是 BigQuery 查詢的預設執行狀態。並且 UI 沒有使更改模式的能力可見或明顯。要檢視或更改查詢的執行模式,需要導航到查詢設定。
在該檢視中,您可以配置下一個查詢執行。除了選擇查詢模式外,開發人員還可以選擇如何儲存查詢的結果,可以選擇從臨時表、新的 BigQuery 表或覆蓋現有表的內容等選項。在這些選項下方是選擇批處理與互動式的選單。
雖然互動式模式會立即執行查詢,但批處理模式允許使用者:
- 排隊所需的 BigQuery 作業。
- 執行較低優先順序的查詢,而不會影響較高優先順序的作業(這些作業可能會消耗更多資源)。
執行批處理模式作業可以幫助使用者規避 BigQuery 查詢執行限制:使用者最多可以同時執行 20 個查詢。
如果批處理作業與正在進行的互動式作業爭奪插槽,則批處理作業將被掛起或“排隊”,直到有可用空間。這有助於節省資源並避免達到對互動式查詢施加的硬性速率限制。
BigQuery - BI 引擎
除了 BigQuery 中的最佳化設定外,BigQuery 還提供了一個併發服務BI Engine,其目的是掃描和最佳化 BigQuery 查詢效能。
- BI Engine 是一種記憶體中服務,用於分析正在執行的作業範圍與執行時可用的插槽和計算資源的數量。
- BI Engine 不僅分析查詢資源,而且在分配可用資源後主動加速其執行(因此稱為“引擎”)。
- BI Engine 是可配置和可自定義的,這意味著開發人員可以選擇將其範圍內的表和檢視。
- BI Engine 是 BigQuery 中的一個產品。要訪問 BI 著陸頁,只需在 Cloud Console 搜尋欄中搜索“BI Engine”即可。
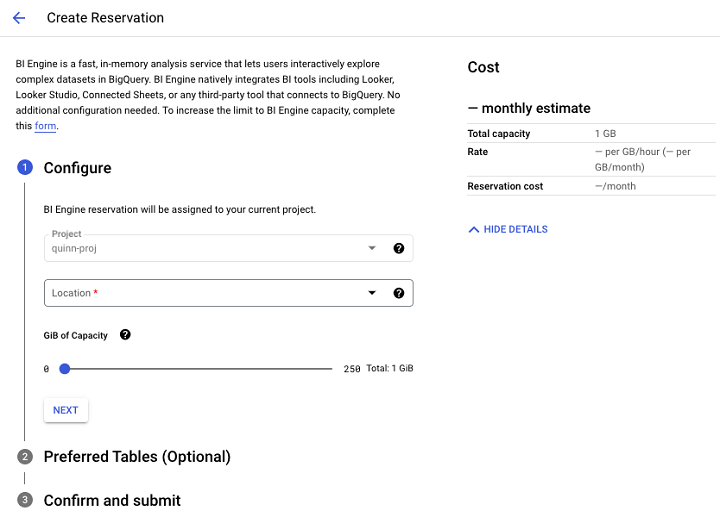
BI Engine 頁面將提示您建立預留。
點選“建立預留”後,您將能夠配置要在 BI Engine 範圍內設定多少千兆位元組,並新增要在 BI Engine 的效能最佳化功能範圍內包含的表。
BI Engine 的查詢加速
此外,BI Engine 與 BigQuery API 同步,為從自動化流程載入、更新或修改的表提供查詢加速優勢。
BI Engine 最大的成就就是向量化執行時,它允許它利用雲 CPU 並能夠壓縮資料以實現無縫執行。
BI Engine 的真正強大之處在於它能夠與 BigQuery 相關平臺和應用程式整合。例如,基於 BigQuery 查詢建立資料的 Looker 儀表板將有資格獲得BI Engine 加速。
BI Engine 的用例
對於具有經常查詢的大量資料表的使用者,BI Engine 將最受益。
BI Engine 的用例包括:
- 由 BigQuery 提供支援的資源密集型視覺化。
- 您有一些特定的大型且經常被查詢的表格。
- 多個使用者在相似的時間查詢資源,導致效能瓶頸。
無論如何,BI 引擎仍然是任何尋求提高流程效率並降低計算密集度的使用者強大的最佳化策略。
BigQuery - 監控使用情況和效能
瞭解使用情況和效能限制至關重要,尤其是在組織內部工作的人員。持續關注使用不成比例的插槽時間的使用者和資料來源,可以幫助 BigQuery 管理員做出明智的決策,限制對資源的訪問,並在執行資源密集型作業的團隊之間引發富有成效的對話。
效能儀表板
為了實現更透明的即時監控,BigQuery 在 BigQuery Studio UI 的監控選項卡中提供了效能儀表板。
注意 - 每次執行查詢時都會繪製效能圖表。
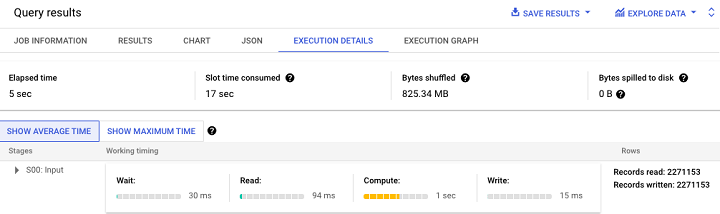
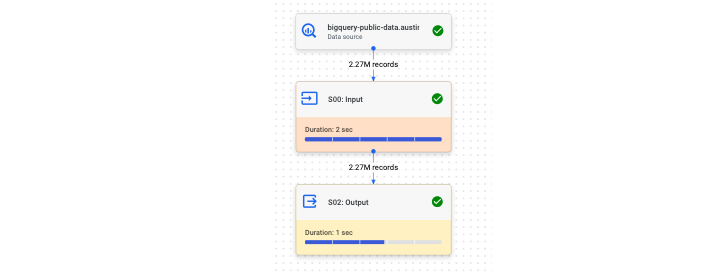
此外,BigQuery 還提供了一個執行圖,以便更直觀地解釋查詢效能。
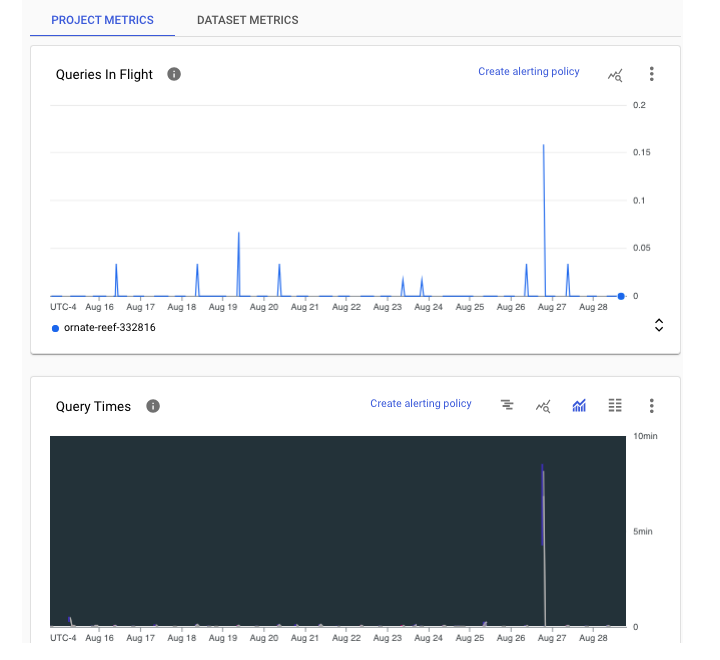
在專案級別,管理員可以在“監控”儀表板中檢視 BigQuery 資料。監控可在專案級別和資料集級別使用。
專案級監控
專案級別顯示當前正在執行或“進行中”的查詢數量。
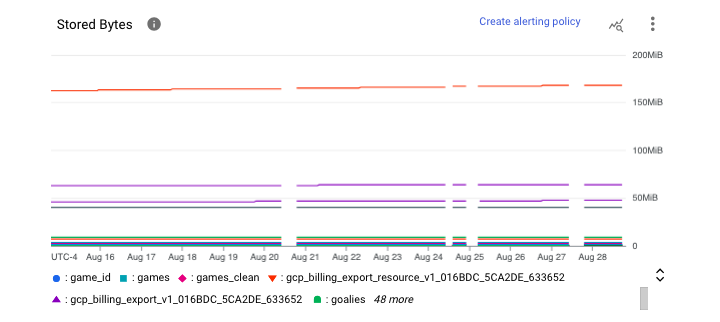
資料集級監控
在資料集級別,我們可以看到每個表的儲存位元組數。
要訪問和操作這些圖表,請按照以下步驟操作 -
- 導航到 BigQuery
- 選擇管理
- 點選監控
- 如果需要:切換即時資料
在此 UI 中,使用者還可以訪問執行狀況,它以兩種不同的檢視提供資訊:摘要檢視和更詳細的檢視。
管理員和使用者都會發現操作執行狀況摘要表中的一些主要指標很有幫助,包括 -
- 插槽使用情況
- 混洗(預留重新分配)使用情況
- 併發性(同時作業)
- 處理的位元組數
- 作業持續時間
- 總儲存量
注意 - 使用單位為位元組(如有必要,可以轉換為千兆位元組或太位元組)。
要獲得更細粒度的檢視,使用者可以使用本教程前面部分的元資料查詢技術查詢 INFORMATION_SCHEMA 檢視。
BigQuery 的常見錯誤
儘管掌握了有關 BigQuery 功能的教育和資訊,但與任何開發過程一樣,錯誤是可能的,事實上,錯誤是不可避免的。鑑於新使用者缺乏對平臺的經驗,他們特別容易受到 BigQuery 錯誤的影響。
BigQuery 錯誤型別
BigQuery 錯誤分為兩類 -
- 基於程式碼的錯誤
- 基於平臺的錯誤
雖然 BigQuery 的 SQL 方言(Google SQL)旨在得到普遍理解並讓人想起其他 SQL 方言,但語法錯誤可能會發生,坦率地說,這可能會令人非常沮喪。
BigQuery 語法錯誤
這是一個 BigQuery 語法錯誤的非詳盡列表 -
- 使用撇號而不是反引號。
- 在 FROM 子句中省略資料集或表格。
- 錯誤地使用 UNNEST()(在 STRUCT 而不是 ARRAY 上)。
- 在使用 AVG() 等聚合函式時忘記 GROUP BY 子句。
- 在列名之間忘記逗號。
基於平臺的錯誤
基於平臺的錯誤源於對 BigQuery 執行約束的誤解,可能包括 -
- 執行超過 20 個併發查詢。
- 未將大型查詢的結果寫入表中,導致“結果過大”錯誤。
- 未將大型查詢作為批處理作業執行。
- 覆蓋或截斷表而不是追加結果。
不幸的是,不可能標記新 BigQuery SQL 開發人員將遇到的幾乎所有錯誤。但是,以上代表了您可能遇到的各種問題。
BigQuery - 資料倉庫
對於許多組織而言,BigQuery 是資料倉庫的自然選擇。資料倉庫是一個業務系統和中央儲存庫,用於儲存資料以進行分析,然後進行下游報告。
注意 通常,儲存在資料倉庫中的資料是結構化的或半結構化的,而不是資料湖,後者儲存非結構化資料。
BigQuery 連線到Looker或Tableau等視覺化平臺的能力使其成為為企業儀表板和臨時報告提供支援的理想引擎。應用分割槽和聚類等儲存最佳化功能意味著資料團隊可以自信且高效地儲存資料數年或數十年,而無需擔心效能下降。能夠與 Python 和 JavaScript 等指令碼語言整合,允許軟體工程師、資料架構師和資料工程師等專業人員建立自動化的定期載入作業。
將 BigQuery 與 Google Sheets 等其他應用程式整合,使儲存在 BigQuery 中的資料對可能更喜歡或專門使用電子表格的非技術利益相關者更可見且更易訪問。
利用BigQuery API,開發人員可以將 BigQuery SQL與程式邏輯相結合以生成自定義見解。
能夠按需新增插槽、升級儲存和加速查詢,例如使用BI引擎,對於最初構建或擴充套件其資料基礎設施的組織來說是一個有吸引力的建議。
這些功能的缺點是成本。但是,透過固定和按使用付費的定價模式,業務使用者和決策者可能會發現使用面向 BigQuery 的資料倉庫的成本效益是值得的。
下圖由 Google Cloud 提供,說明了如何構建和實現面向基本資料倉庫的解決方案。
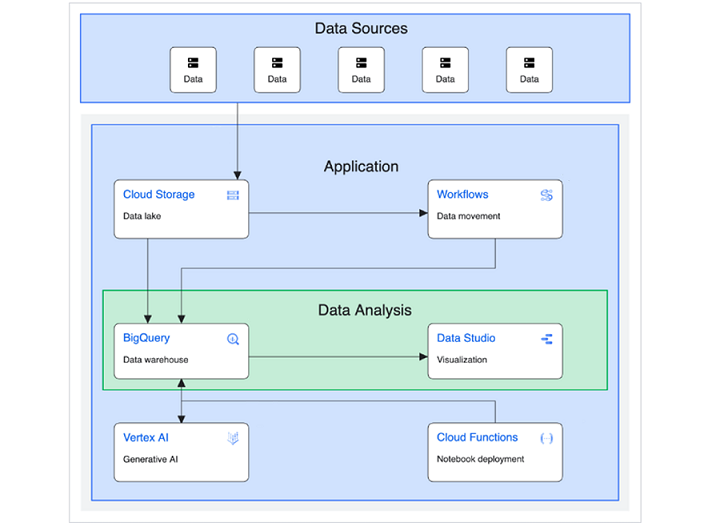
(來源:https://cloud.google.com/architecture/big-data-analytics/data-warehouse)
除了資料來源、應用程式和資料分析之外,此圖還可以細分為更具體的類別並解釋為 -
- 上游源(第三方 API 或外部資料來源)。
- 中間/暫存儲存(Cloud Storage 儲存桶)。
- 永久/長期儲存(BigQuery)。
- ML/AI 應用程式(Vertex AI、Cloud Functions 和 Compute Engine 虛擬機器)。
- 下游使用者:透過 Looker 等視覺化平臺訪問模型和查詢輸出的業務使用者。
在任何一種解釋中,BigQuery 都是包含資料在生成下游使用者業務價值之前的資料的中央儲存庫或“資料倉庫”。
BigQuery - 挑戰與最佳實踐
作為一種雲計算工具,BigQuery 也並非沒有挑戰。在本簡短章節中,我們試圖突出 BigQuery 面臨的一些顯著挑戰。
從業務角度看 BigQuery
從業務角度來看,關於 BigQuery 的最大障礙之一是確保領導層同意測試、調整或擴充套件平臺以滿足特定組織的需求。
- 許多企業滿足於依賴本地資料儲存,並且不考慮雲端儲存選項。
- 或者,更糟糕的是,企業甚至可能不認為任何形式的資料倉庫都是其大資料儲存的可行解決方案。
- 業務領導者可能會將 BigQuery 的可變成本視為潛在的資源消耗,尤其是在其組織中有許多開發人員、工程師、架構師和終端使用者依賴儲存在 BigQuery 中並從中查詢的資料時。
從使用者角度看 BigQuery
從使用者的角度來看,BigQuery 存在一定的學習曲線。
- 可用的兩種 SQL 版本,標準 SQL和傳統 SQL,意味著那些使用過其他 SQL 方言的人可能會對需要啟用哪種模式來執行給定查詢或使用特定函式感到困惑。
- 當嘗試將基於 BigQuery 的資料倉庫與外部連線(如 Google Sheet 或 BigQuery API)整合時,使用 BigQuery 進行開發可能會具有挑戰性。
- 儘管在執行時間前後提供了對所消耗資源和其他效能指標的可見性,但 BigQuery 的錯誤日誌可能很模糊,這在進行故障排除時會導致沮喪——尤其對於較新的開發人員而言。
BigQuery 最佳實踐
為了避免或克服這些挑戰,有必要了解和實施 BigQuery 最佳實踐。充分利用 BigQuery 需要了解 Google Cloud Platform、雲計算和一般的 SQL。
為了減少收到意外的高昂月度賬單的可能性,請啟用監控並經常檢視過濾在 BigQuery 上的計費和使用情況儀表板。
與其不斷地臨時增加插槽,不如迫使開發人員考慮並在程式碼級別實施最佳實踐。這可能包括 -
- 透過避免像“SELECT *”這樣的廣泛查詢來減少處理的資料範圍
- 選擇高效的 SQL 查詢設計模式以最佳化查詢操作
- 避免計算密集型查詢,例如那些使用萬用字元引用和過度元資料讀取的查詢
- 使用BigQuery 的 BI 引擎等可用工具來識別有問題的操作,並在必要時提供更高的效能提升
- 透過僅允許使用者使用 WHERE 子句進行查詢來為大型表格指定查詢限制
掌握平臺和 SQL 知識的使用者將是構建、擴充套件和推廣平臺的人,將 BigQuery 的強大功能新增到他們的個人技能和組織技術棧中。