- BigQuery 教程
- BigQuery - 首頁
- BigQuery - 概述
- BigQuery - 初始設定
- BigQuery 與本地 SQL 引擎的比較
- BigQuery - Google Cloud Console
- BigQuery - Google Cloud 層次結構
- 什麼是 Dremel?
- 什麼是 BigQuery Studio?
- BigQuery - 資料集
- BigQuery - 表
- BigQuery - 檢視
- BigQuery - 建立表
- BigQuery - 基本模式設計
- BigQuery - 修改表
- BigQuery - 複製表
- 刪除和恢復表
- BigQuery - 填充表
- 標準 SQL 與傳統 SQL
- BigQuery - 編寫第一個查詢
- BigQuery - CRUD 操作
- 分割槽和叢集
- BigQuery - 資料型別
- BigQuery - 複雜資料型別
- BigQuery - STRUCT 資料型別
- BigQuery - ARRAY 資料型別
- BigQuery - JSON 資料型別
- BigQuery - 表元資料
- BigQuery - 使用者自定義函式
- 連線到外部資料來源
- 整合計劃查詢
- 整合 BigQuery API
- BigQuery - 整合 Airflow
- 整合連線的表格
- 整合資料傳輸
- BigQuery - 物化檢視
- BigQuery - 角色和許可權
- BigQuery - 查詢最佳化
- BigQuery - BI 引擎
- 監控使用情況和效能
- BigQuery - 資料倉庫
- 挑戰和最佳實踐
- BigQuery 資源
- BigQuery - 快速指南
- BigQuery - 資源
- BigQuery - 討論
BigQuery - 資料集
BigQuery 中的資料集是什麼?
資料集是存在於專案中的實體。資料集充當 BigQuery 表以及檢視、例程和機器學習模型的容器。
表不能獨立於資料集存在,因此在 BigQuery Studio 中建立新的資料來源時,必須建立資料集。
除了人機可讀名稱等屬性外,開發人員還必須在授權建立資料集時指定一個**位置**。這些位置與全球 Google 資料中心的物理位置相對應。
指定位置時,需要指定單個區域或多區域。例如,您不必選擇芝加哥的資料中心,而是指定“us-central-1”。
將資料集建立為多區域實體可以提供額外優勢,即當特定區域的資源無法跟上當前需求時,BigQuery 會更改位置。當前的多區域位於美洲(美國)或歐盟(歐洲)。
在 BigQuery 中建立資料集的步驟
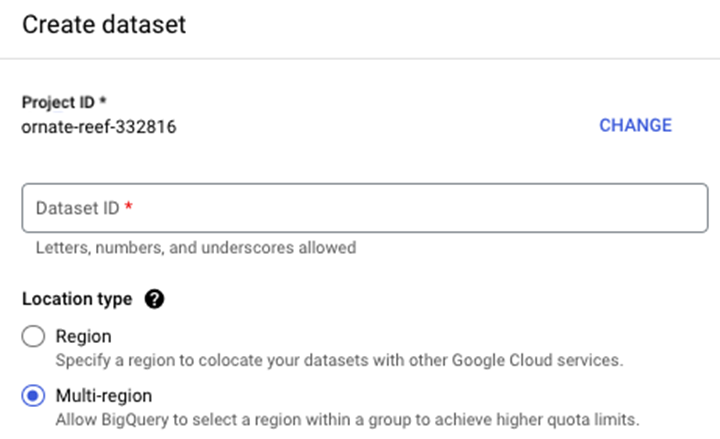
要建立資料集,請按照以下步驟操作。首先,導航到您的專案名稱並單擊三個點,這將觸發帶有**“建立資料集”**的彈出視窗 -

單擊“建立資料集”後,系統將提示您輸入 -
- dataset_id
- 位置型別(區域與多區域)。
- 預設表過期時間(表過期的天數)。
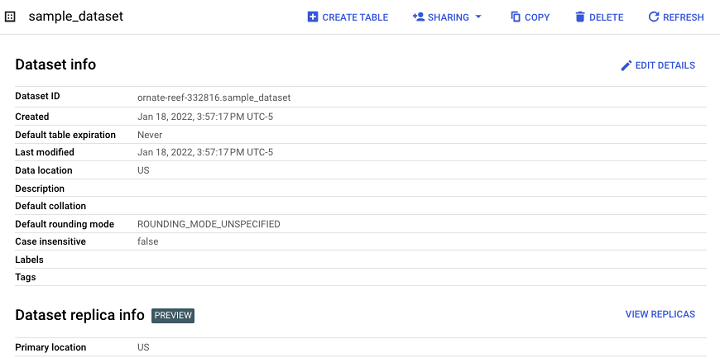
最終結果是一個數據集,它充當未來表、檢視和物化檢視的容器。
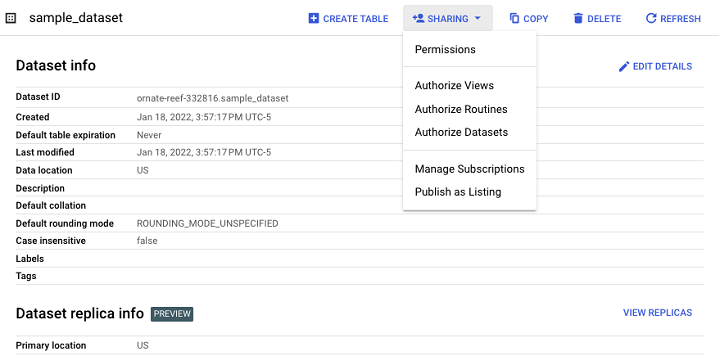
“共享”選項允許開發人員管理對資料集的訪問控制,以限制未經授權的使用者。
BigQuery:公共資料集
如果您是 BigQuery 的新手,也可能是 SQL 的新手,那麼您可能沒有生成要儲存和操作的資料。這是使用 BigQuery Studio 作為 SQL 沙箱的優勢之一。除了無伺服器基礎設施外,BigQuery 還提供數 TB 的樣本資料,供學生和專業人士學習和改進他們的 SQL 技能。
- 透過 Google Cloud 公共資料集計劃釋出,BigQuery 公共資料集儲存在其自身可公開訪問的專案中:**bigquery-public-data**。
- 根據每 TB 付費定價模式,開發人員每月最多可以免費查詢 1 TB 的資料。
- 與許多庫存資料集不同,表中包含的資料是真實的,也就是“雜亂的”,有時需要進行大量的轉換才能產生可操作的見解。
BigQuery 還提供了一些獨立於其 BigQuery 公共資料集的示例表,這些表可以在 **bigquery-public-data:samples** 表資料集中找到 -
- gsod
- github_nested
- github_timeline
- natality
- shakespeare
- trigrams
- wikipedia
訪問 BigQuery 公共資料集可能最重要的優勢在於,資料是從 BBC、Hacker News 和約翰·霍普金斯大學等真實資料來源中提取的。
廣告