- 人工智慧教程
- AI - 首頁
- AI - 概述
- AI - 智慧系統
- AI - 研究領域
- AI - 智慧體與環境
- AI - 常用搜索演算法
- AI - 模糊邏輯系統
- AI - 自然語言處理
- AI - 專家系統
- AI - 機器人技術
- AI - 神經網路
- AI - 問題
- AI - 術語
- 人工智慧資源
- 人工智慧快速指南
- 人工智慧 - 面試問題與解答
- AI - 有用資源
- 人工智慧 - 討論
人工智慧快速指南
人工智慧 - 概述
自從計算機或機器發明以來,它們執行各種任務的能力呈指數級增長。人類在計算機系統的各種工作領域、不斷提高的速度以及隨著時間的推移而減小的尺寸方面,都提高了計算機系統的能力。
一個名為人工智慧的計算機科學分支致力於創造與人類一樣聰明的計算機或機器。
什麼是人工智慧?
根據人工智慧之父約翰·麥卡錫的說法,它是“製造智慧機器,特別是智慧計算機程式的科學和工程”。
人工智慧是一種使計算機、計算機控制的機器人或軟體能夠像聰明的人類一樣思考的方法。
人工智慧是透過研究人腦如何思考,以及人類如何學習、決策和工作來解決問題,然後將這項研究的結果作為開發智慧軟體和系統的基礎來實現的。
人工智慧的哲學
在利用計算機系統能力的同時,人類的好奇心促使人們思考:“機器能否像人類一樣思考和行動?”
因此,人工智慧的發展始於在機器中創造類似於我們在人類身上發現和高度重視的智慧的意圖。
人工智慧的目標
建立專家系統——展示智慧行為、學習、演示、解釋和為使用者提供建議的系統。
在機器中實現人類智慧——建立能夠理解、思考、學習和像人類一樣行動的系統。
什麼促成了人工智慧?
人工智慧是一門基於計算機科學、生物學、心理學、語言學、數學和工程等學科的科學和技術。人工智慧的一個主要推動力是開發與人類智慧相關的計算機功能,例如推理、學習和解決問題。
在以下領域中,一個或多個領域可以有助於構建智慧系統。
有無AI的程式設計
有無AI的程式設計在以下方面有所不同:
| 無AI程式設計 | 有AI程式設計 |
|---|---|
| 沒有AI的計算機程式可以回答其旨在解決的特定問題。 | 帶有AI的計算機程式可以回答其旨在解決的通用問題。 |
| 程式的修改會導致其結構發生變化。 | AI程式可以透過將高度獨立的資訊片段組合在一起來吸收新的修改。因此,您可以修改程式的甚至很小一部分資訊,而不會影響其結構。 |
| 修改並不迅速和容易。它可能會對程式產生不利影響。 | 快速簡單的程式修改。 |
什麼是AI技術?
在現實世界中,知識具有一些不受歡迎的特性:
- 其數量巨大,難以想象。
- 它組織不完善或格式不規範。
- 它不斷變化。
AI技術是一種有效組織和使用知識的方式,其方式如下:
- 它應該被提供它的人理解。
- 它應該易於修改以糾正錯誤。
- 即使不完整或不準確,它也應該在許多情況下有用。
AI技術提高了其配備的複雜程式的執行速度。
AI的應用
AI在各個領域都佔據主導地位,例如:
遊戲——AI在國際象棋、撲克、井字棋等策略遊戲中發揮著至關重要的作用,機器可以根據啟發式知識思考大量可能的位置。
自然語言處理——可以與理解人類所說的自然語言的計算機進行互動。
專家系統——有些應用程式集成了機器、軟體和特殊資訊以提供推理和建議。它們為使用者提供解釋和建議。
視覺系統——這些系統理解、解釋和理解計算機上的視覺輸入。例如:
間諜飛機拍攝照片,這些照片用於找出區域的空間資訊或地圖。
醫生使用臨床專家系統來診斷病人。
警方使用可以識別罪犯面部與法醫藝術家製作的儲存肖像相匹配的計算機軟體。
語音識別——一些智慧系統能夠聽到和理解人類說話時的句子及其含義。它可以處理不同的口音、俚語、背景噪音、因感冒而導致的人聲變化等。
手寫識別——手寫識別軟體讀取用筆寫在紙上或用觸控筆寫在螢幕上的文字。它可以識別字母的形狀並將其轉換為可編輯文字。
智慧機器人——機器人能夠執行人類賦予的任務。它們具有感測器,可以檢測來自現實世界的物理資料,例如光、熱、溫度、運動、聲音、碰撞和壓力。它們擁有高效的處理器、多個感測器和巨大的記憶體,以展現智慧。此外,它們能夠從錯誤中學習,並且能夠適應新的環境。
AI的歷史
以下是20世紀人工智慧的歷史:
| 年份 | 里程碑/創新 |
|---|---|
| 1923 | 卡雷爾·恰佩克的戲劇《羅素姆萬能機器人》(RUR)在倫敦上演,這是“機器人”一詞首次在英語中使用。 |
| 1943 | 神經網路的基礎奠定。 |
| 1945 | 哥倫比亞大學校友艾薩克·阿西莫夫創造了機器人技術一詞。 |
| 1950 | 艾倫·圖靈介紹了用於評估智慧的圖靈測試,並發表了《計算機器與智慧》。克勞德·夏農發表了《國際象棋博弈的詳細分析》作為一種搜尋方法。 |
| 1956 | 約翰·麥卡錫創造了人工智慧一詞。卡內基梅隆大學展示了第一個執行的AI程式。 |
| 1958 | 約翰·麥卡錫發明了用於AI的LISP程式語言。 |
| 1964 | 丹尼·鮑勃羅在麻省理工學院的論文表明,計算機能夠足夠好地理解自然語言,以正確解決代數文字題。 |
| 1965 | 麻省理工學院的約瑟夫·魏澤鮑姆構建了ELIZA,一個能夠用英語進行對話的互動式程式。 |
| 1969 | 斯坦福研究院的科學家開發了Shakey,一個配備了運動、感知和解決問題能力的機器人。 |
| 1973 | 愛丁堡大學的裝配機器人小組建造了Freddy,這個著名的蘇格蘭機器人能夠利用視覺來定位和組裝模型。 |
| 1979 | 第一輛計算機控制的自主車輛斯坦福車問世。 |
| 1985 | 哈羅德·科恩建立並演示了繪圖程式Aaron。 |
| 1990 | 人工智慧所有領域取得重大進展:
|
| 1997 | 深藍國際象棋程式擊敗了當時的國際象棋世界冠軍加里·卡斯帕羅夫。 |
| 2000 | 互動式機器人寵物開始商業化。麻省理工學院展示了Kismet,一個面部可以表達情感的機器人。Nomad機器人探索南極洲的偏遠地區並尋找隕石。 |
人工智慧 - 智慧系統
在學習人工智慧時,你需要了解什麼是智慧。本章涵蓋了智慧的概念、型別和組成部分。
什麼是智慧?
系統計算、推理、感知關係和類比、從經驗中學習、從記憶中儲存和檢索資訊、解決問題、理解複雜思想、流利地使用自然語言、分類、概括和適應新情況的能力。
智慧型別
正如美國發展心理學家霍華德·加德納所描述的那樣,智力是多方面的:
| 智力 | 描述 | 例子 |
|---|---|---|
| 語言智慧 | 說話、識別和使用語音(語音)、語法(語法)和語義(意義)機制的能力。 | 敘述者、演說家 |
| 音樂智慧 | 創造、交流和理解由聲音構成的意義的能力,理解音調、節奏。 | 音樂家、歌手、作曲家 |
| 邏輯-數學智慧 | 在沒有行動或物體的情況下使用和理解關係的能力。理解複雜和抽象的思想。 | 數學家、科學家 |
| 空間智慧 | 感知視覺或空間資訊、改變它以及在不參考物體的情況下重新建立視覺影像的能力,構建3D影像以及移動和旋轉它們。 | 地圖閱讀者、宇航員、物理學家 |
| 身體-動覺智慧 | 使用全部或部分身體來解決問題或製作產品的能力,對精細和粗略運動技能的控制以及操縱物體。 | 運動員、舞蹈家 |
| 內省智慧 | 區分自身感受、意圖和動機的能力。 | 喬達摩·悉達多 |
| 人際智慧 | 識別和區分他人感受、信念和意圖的能力。 | 大眾傳播者、採訪者 |
當機器或系統至少具備一種,最多具備所有智慧時,你可以說它是人工智慧的。
智慧由什麼組成?
智慧是無形的。它由以下部分組成:
- 推理
- 學習
- 解決問題
- 感知
- 語言智慧
讓我們簡要了解所有組成部分:
推理——這是一組使我們能夠為判斷、決策和預測提供依據的過程。主要分為兩種:
| 歸納推理 | 演繹推理 |
|---|---|
| 它進行具體的觀察以做出廣泛的概括性陳述。 | 它從一個一般的陳述開始,並檢查各種可能性以得出具體的、合乎邏輯的結論。 |
| 即使陳述中所有前提都是正確的,歸納推理也允許結論是錯誤的。 | 如果某事物普遍適用於某一類事物,則它也適用於該類的所有成員。 |
| 例如:“尼塔是一位老師。尼塔很勤奮。因此,所有老師都很勤奮。” | 例如:“所有60歲以上的女人都是祖母。莎麗妮65歲。因此,莎麗妮是祖母。” |
學習——透過學習、練習、被教導或體驗某事物來獲得知識或技能的活動。學習增強了對學習主題的認識。
人類、一些動物和啟用AI的系統都擁有學習能力。學習分為:
聽覺學習——透過聆聽和聽到來學習。例如,學生收聽錄製的音訊講座。
情景學習——透過記住自己見證或經歷的事件序列來學習。這是線性的和有序的。
動作學習——透過精確的肌肉運動來學習。例如,拾取物體、書寫等。
觀察學習——透過觀察和模仿他人來學習。例如,孩子試圖透過模仿父母來學習。
感知學習 (gǎnzhī xuéxí) − 它指的是學習識別之前見過的刺激。例如,識別和分類物體和情境。
關係學習 (guānxi xuéxí) − 它涉及基於關係屬性而非絕對屬性來區分各種刺激。例如,上次煮土豆太鹹了(加了一湯匙鹽),這次煮土豆時就少加一點鹽。
空間學習 (kōngjiān xuéxí) − 它指的是透過視覺刺激(如影像、顏色、地圖等)進行學習。例如,一個人可以在實際走路線之前在腦海中建立路線圖。
刺激-反應學習 (cìjī-fǎnyìng xuéxí) − 它指的是學習在出現某種刺激時執行特定行為。例如,狗聽到門鈴聲會豎起耳朵。
問題解決 (wèntí jiějué) − 它是一個過程,在這個過程中,人們感知並試圖透過某種路徑從當前情境中得出期望的解決方案,而這條路徑可能被已知或未知的障礙所阻礙。
問題解決還包括決策 (juécè),它是從多個可用的替代方案中選擇最佳方案以達到期望目標的過程。
感知 (gǎnzhī) − 它是一個獲取、解釋、選擇和組織感覺資訊的過程。
感知預設了感覺 (gǎnjué)。在人類中,感知藉助感覺器官。在人工智慧領域,感知機制以有意義的方式將感測器獲取的資料組合在一起。
語言智慧 (yǔyán zhìnéng) − 指的是一個人使用、理解、說和寫口頭和書面語言的能力。這在人際交往中非常重要。
人類智慧與機器智慧的差異
人類透過模式感知,而機器透過規則和資料集合感知。
人類透過模式儲存和回憶資訊,機器透過搜尋演算法來實現。例如,數字 40404040 很容易記住、儲存和回憶,因為它的模式很簡單。
即使某些部分缺失或變形,人類也能弄清楚完整的物體;而機器卻做不到。
人工智慧 - 研究領域
人工智慧領域範圍很廣。在接下來的討論中,我們將考慮人工智慧領域中廣泛且蓬勃發展的一些研究領域:

語音識別和聲紋識別
這兩個術語在機器人技術、專家系統和自然語言處理中很常見。雖然這兩個術語可以互換使用,但它們的目標不同。
| 語音識別 | 聲紋識別 |
|---|---|
| 語音識別的目標是理解和領會說了什麼 (shuōle shénme)。 | 聲紋識別的目標是識別說話者是誰 (shuōhuà zhě shì shuí)。 |
| 它用於擴音計算、地圖或選單導航。 | 它透過分析說話人的音調、音高和口音等來識別一個人。 |
| 語音識別不需要機器進行訓練,因為它不依賴於說話者。 | 這種識別系統需要訓練,因為它面向特定人員。 |
| 開發獨立於說話者的語音識別系統非常困難。 | 與之相比,開發依賴於說話者的語音識別系統相對容易。 |
語音識別和聲紋識別系統的運作方式
使用者在麥克風上說的話會傳到系統的音效卡。轉換器將模擬訊號轉換為等效的數字訊號,用於語音處理。資料庫用於比較聲音模式以識別單詞。最後,會向資料庫提供反向反饋。
源語言文字成為翻譯引擎的輸入,翻譯引擎將其轉換為目標語言文字。它們支援互動式圖形使用者介面、大型詞彙資料庫等。
研究領域的現實應用
人工智慧在人們日常生活中有很多應用:
| 序號 | 研究領域 | 現實應用 |
|---|---|---|
| 1 | 專家系統 例如:航班追蹤系統、臨床系統。 |
 |
| 2 | 自然語言處理 例如:Google Now 功能、語音識別、自動語音輸出。 |
 |
| 3 | 神經網路 例如:模式識別系統,如人臉識別、字元識別、手寫識別。 |
 |
| 4 | 機器人技術 例如:用於移動、噴塗、繪畫、精密檢查、鑽孔、清潔、塗層、雕刻等的工業機器人。 |
 |
| 5 | 模糊邏輯系統 例如:消費電子產品、汽車等。 |
 |
人工智慧的任務分類
人工智慧領域分為形式化任務 (xíngshì huà rènwu)、日常任務 (rìcháng rènwu)和專家任務 (zhuānjiā rènwu)。
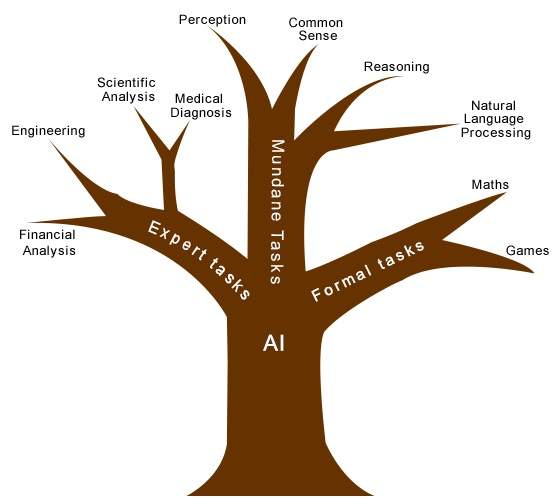
| 人工智慧的任務領域 | ||
|---|---|---|
| 日常任務 | 形式化任務 | 專家任務 |
感知
|
|
|
自然語言處理
|
遊戲
|
科學分析 |
| 常識 | 驗證 | 財務分析 |
| 推理 | 定理證明 | 醫學診斷 |
| 規劃 | 創造力 | |
機器人技術
|
||
人類從出生起就學習日常任務。他們透過感知、說話、使用語言和運動來學習。他們後來按順序學習形式化任務和專家任務。
對於人類來說,日常任務最容易學習。在嘗試將日常任務應用於機器之前,人們也認為這是正確的。早期,人工智慧的所有工作都集中在日常任務領域。
後來,事實證明,機器需要更多的知識、複雜 的知識表示和複雜的演算法來處理日常任務。這就是為什麼人工智慧工作現在在專家任務領域發展得更好的原因,因為專家任務領域需要專家知識而不需要常識,這更容易表示和處理。
人工智慧 - 智慧體和環境
一個 AI 系統由一個智慧體及其環境組成。智慧體在其環境中行動。環境可能包含其他智慧體。
什麼是智慧體和環境?
智慧體 (zhìnéng tǐ) 是任何能夠透過感測器 (chuǎncè qì)感知其環境並透過效應器 (xiàoyìng qì)作用於該環境的事物。
人類智慧體具有與感測器平行的感覺器官,如眼睛、耳朵、鼻子、舌頭和皮膚,以及作為效應器的其他器官,如手、腳、嘴。
機器人智慧體用攝像頭和紅外測距儀代替感測器,用各種電機和執行器代替效應器。
軟體智慧體將其程式和操作編碼為位字串。

智慧體術語
智慧體效能度量 (zhìnéng tǐ xìngnéng dùliáng) − 它是確定智慧體成功程度的標準。
智慧體的行為 (zhìnéng tǐ de xíngwéi) − 它是智慧體在任何給定的感知序列後執行的動作。
感知 (gǎnzhī) − 它是在給定時刻智慧體的感知輸入。
感知序列 (gǎnzhī xuélìè) − 它是一個智慧體迄今為止感知到的所有內容的歷史記錄。
智慧體函式 (zhìnéng tǐ hánshù) − 它是一個從感知序列到動作的對映。
理性
理性只不過是合理、明智和具有良好判斷力的狀態。
理性與預期行為和結果有關,這取決於智慧體感知了什麼。以獲取有用資訊為目標執行操作是理性中的重要部分。
什麼是理想理性智慧體?
理想理性智慧體能夠根據以下條件執行預期操作以最大化其效能度量:
- 其感知序列
- 其內建的知識庫
智慧體的理性取決於以下因素:
效能度量,它決定成功的程度。
智慧體迄今為止的感知序列。
智慧體對環境的先驗知識。
智慧體可以執行的動作。
理性智慧體總是執行正確的動作,其中正確的動作是指導致智慧體在給定的感知序列中最成功的動作。智慧體解決的問題的特徵在於效能度量、環境、執行器和感測器 (PEAS)。
智慧體的結構
智慧體的結構可以看作:
- 智慧體 = 體系結構 + 智慧體程式
- 體系結構 = 智慧體在其上執行的機制。
- 智慧體程式 = 智慧體函式的實現。
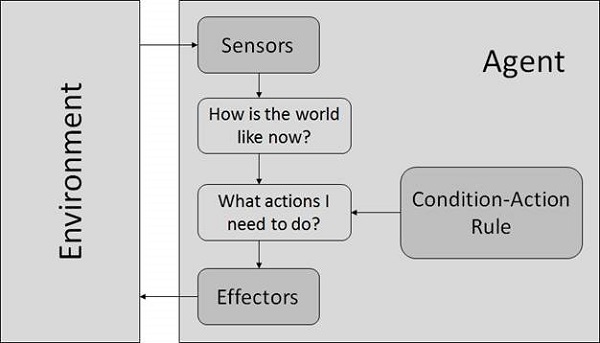
簡單的反射智慧體
- 它們僅根據當前感知選擇動作。
- 只有在僅根據當前感知做出正確決策的情況下,它們才是理性的。
- 它們的環境是完全可觀察的。
條件-動作規則 (tiáojiàn-dòngzuò guīzé) − 它是一個將狀態(條件)對映到動作的規則。
基於模型的反射智慧體
它們使用世界模型來選擇其動作。它們保持內部狀態。
模型 (móxíng) − 關於“事物如何在世界上發生”的知識。
內部狀態 (nèibù zhuàngtài) − 它是一個根據感知歷史對當前狀態的未觀察到的方面的表示。
更新狀態需要以下資訊:
- 世界如何演變。
- 智慧體的行為如何影響世界。
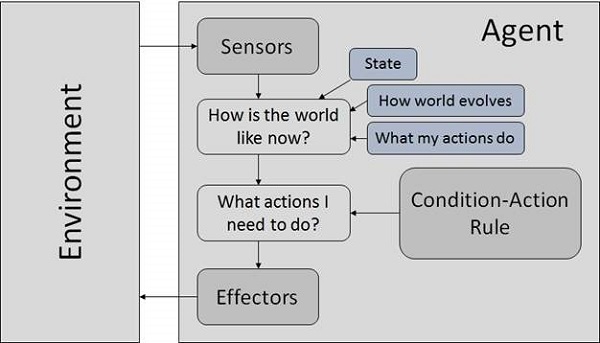
基於目標的智慧體
它們選擇動作是為了實現目標。基於目標的方法比反射智慧體更靈活,因為支援決策的知識是顯式建模的,從而允許進行修改。
目標 (mùbiāo) − 它是理想情況的描述。
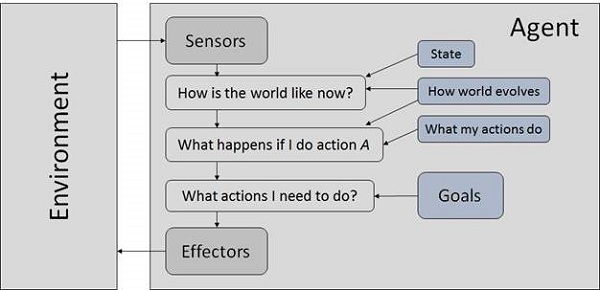
基於效用的智慧體
它們根據對每個狀態的偏好(效用)來選擇動作。
當以下情況發生時,目標是不夠的:
存在衝突的目標,其中只能實現少數目標。
目標實現存在一定的不確定性,需要權衡成功的可能性與目標的重要性。
環境的性質
某些程式完全在人工環境 (rén gōng huánjìng)中執行,該環境僅限於鍵盤輸入、資料庫、計算機檔案系統和螢幕上的字元輸出。
相反,一些軟體代理(軟體機器人或軟機器人)存在於豐富、無限的軟機器人領域。模擬器具有非常詳細、複雜的環境。軟體代理需要即時地從一系列動作中進行選擇。設計用於掃描客戶線上偏好並向客戶展示有趣商品的軟機器人,既可在真實環境中工作,也可在人工環境中工作。
最著名的人工環境是圖靈測試環境,其中一個真實代理和另一個人工代理在同等條件下進行測試。這是一個非常具有挑戰性的環境,因為對於軟體代理來說,要像人類一樣表現出色非常困難。
圖靈測試
可以使用圖靈測試來衡量系統智慧行為的成功程度。
測試中包括兩個人和一臺待評估的機器。兩人中一人擔任測試員。他們分別坐在不同的房間裡。測試員不知道誰是機器,誰是人。他透過輸入問題並將其傳送給兩個智慧體來進行提問,並接收他們的文字回覆。
此測試旨在迷惑測試員。如果測試員無法區分機器的回應和人類的回應,則認為該機器具有智慧。
環境特性
環境具有多種特性:
離散/連續 - 如果環境只有有限數量的不同、明確定義的狀態,則該環境是離散的(例如,國際象棋);否則它是連續的(例如,駕駛)。
可觀察/部分可觀察 - 如果能夠根據感知結果確定每個時間點的環境完整狀態,則它是可觀察的;否則,它只是部分可觀察的。
靜態/動態 - 如果在代理採取行動時環境沒有變化,則它是靜態的;否則它是動態的。
單代理/多代理 - 環境可能包含其他代理,這些代理可能與該代理相同或不同。
可訪問/不可訪問 - 如果代理的感知裝置可以訪問環境的完整狀態,則該環境對於該代理是可訪問的。
確定性/非確定性 - 如果環境的下一個狀態完全由當前狀態和代理的動作決定,則該環境是確定性的;否則是非確定性的。
情景式/非情景式 - 在情景式環境中,每個情景都包括代理感知然後採取行動。其行動的質量僅取決於情景本身。後續情景不依賴於先前情景中的行動。情景式環境要簡單得多,因為代理不需要提前考慮。
AI - 常用搜索演算法
搜尋是人工智慧中解決問題的通用技術。有一些單人遊戲,例如拼圖遊戲、數獨、填字遊戲等。搜尋演算法可以幫助您在這些遊戲中搜索特定位置。
單代理尋路問題
像 3X3 八塊拼圖、4X4 十五塊拼圖和 5X5 二十四塊拼圖這樣的遊戲都是單代理尋路挑戰。它們由帶有空白塊的矩陣組成。玩家需要透過垂直或水平地將一個塊滑入空白處來排列這些塊,目的是實現某個目標。
單代理尋路問題的其他例子包括旅行商問題、魔方和定理證明。
搜尋術語
問題空間 - 搜尋發生的環境。(一組狀態和一組改變這些狀態的運算子)
問題例項 - 初始狀態 + 目標狀態。
問題空間圖 - 它表示問題狀態。狀態用節點表示,運算子用邊表示。
問題的深度 - 從初始狀態到目標狀態的最短路徑或最短運算子序列的長度。
空間複雜度 - 儲存在記憶體中的最大節點數。
時間複雜度 - 建立的最大節點數。
可採納性 - 演算法始終找到最優解的特性。
分支因子 - 問題空間圖中子節點的平均數量。
深度 - 從初始狀態到目標狀態的最短路徑的長度。
蠻力搜尋策略
它們是最簡單的,因為它們不需要任何特定領域的知識。它們在可能狀態數量較少的情況下效果很好。
要求:
- 狀態描述
- 一組有效的運算子
- 初始狀態
- 目標狀態描述
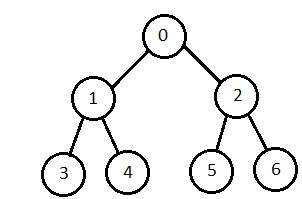
廣度優先搜尋
它從根節點開始,首先探索相鄰節點,然後移向下一層鄰居。它一次生成一棵樹,直到找到解決方案。它可以使用 FIFO 佇列資料結構來實現。此方法提供到解決方案的最短路徑。
如果分支因子(給定節點的子節點平均數量)= b,深度 = d,則 d 層的節點數 = bd。
最壞情況下建立的節點總數為 b + b2 + b3 + … + bd。
缺點 - 由於為了建立下一個節點而儲存每一層節點,因此它會消耗大量記憶體空間。儲存節點的空間需求是指數級的。
其複雜度取決於節點數。它可以檢查重複節點。
深度優先搜尋
它使用 LIFO 堆疊資料結構以遞迴方式實現。它建立與廣度優先方法相同的節點集,只是順序不同。
由於在每次迭代中從根節點到葉節點儲存單路徑上的節點,因此儲存節點的空間需求是線性的。分支因子為 *b*,深度為 *m*,儲存空間為 *bm*。
缺點 - 此演算法可能不會終止,並可能在一條路徑上無限期地進行下去。解決這個問題的方法是選擇一個截止深度。如果理想的截止深度為 *d*,而選擇的截止深度小於 *d*,則此演算法可能會失敗。如果選擇的截止深度大於 *d*,則執行時間會增加。
其複雜度取決於路徑數。它無法檢查重複節點。

雙向搜尋
它從初始狀態向前搜尋,從目標狀態向後搜尋,直到兩者相遇以識別公共狀態。
初始狀態的路徑與目標狀態的反向路徑連線在一起。每次搜尋僅進行到總路徑的一半。
一致代價搜尋
按到達節點的路徑成本遞增排序。它總是擴充套件成本最低的節點。如果每個轉換的成本相同,則它與廣度優先搜尋相同。
它按成本遞增的順序探索路徑。
缺點 - 可能有多條成本 ≤ C* 的長路徑。一致代價搜尋必須全部探索它們。
迭代加深深度優先搜尋
它執行到 1 層的深度優先搜尋,然後重新開始,執行到 2 層的完整深度優先搜尋,以此類推,直到找到解決方案。
在生成所有較低節點之前,它永遠不會建立節點。它只儲存一個節點堆疊。當它在深度 *d* 找到解決方案時,演算法結束。深度 *d* 處建立的節點數為 bd,深度 *d-1* 處為 bd-1。
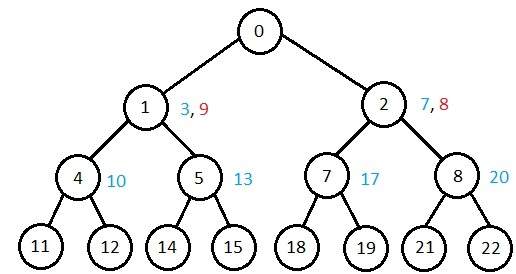
各種演算法複雜度的比較
讓我們根據各種標準檢視演算法的效能:
| 標準 | 廣度優先 | 深度優先 | 雙向 | 一致代價 | 迭代加深 |
|---|---|---|---|---|---|
| 時間 | bd | bm | bd/2 | bd | bd |
| 空間 | bd | bm | bd/2 | bd | bd |
| 最優性 | 是 | 否 | 是 | 是 | 是 |
| 完整性 | 是 | 否 | 是 | 是 | 是 |
啟發式(啟發式)搜尋策略
為了解決具有大量可能狀態的大型問題,需要新增特定於問題的知識以提高搜尋演算法的效率。
啟發式評估函式
它們計算兩個狀態之間最優路徑的成本。滑動塊遊戲的啟發式函式是透過計算每個塊與其目標狀態之間的移動次數,並將所有塊的這些移動次數相加來計算的。
純啟發式搜尋
它按照啟發式值的順序擴充套件節點。它建立兩個列表,一個用於已擴充套件節點的封閉列表和一個用於已建立但未擴充套件節點的開放列表。
在每次迭代中,擴充套件具有最小啟發式值的節點,建立其所有子節點並將其放入封閉列表中。然後,將啟發式函式應用於子節點,並根據其啟發式值將其放入開放列表中。儲存較短的路徑,並丟棄較長的路徑。
A*搜尋
它是最佳優先搜尋最著名的形式。它避免擴充套件已經很昂貴的路徑,但首先擴充套件最有希望的路徑。
f(n) = g(n) + h(n),其中
- g(n) 到達節點的成本(迄今為止)
- h(n) 從節點到目標的估計成本
- f(n) 透過 n 到目標的路徑的估計總成本。它使用優先順序佇列按 f(n) 遞增的方式實現。
貪婪最佳優先搜尋
它擴充套件估計最接近目標的節點。它基於 f(n) = h(n) 擴充套件節點。它使用優先順序佇列實現。
缺點 - 它可能會陷入迴圈。它不是最優的。
區域性搜尋演算法
它們從一個可能的解決方案開始,然後移動到一個相鄰的解決方案。即使在它們結束之前任何時候中斷,它們也可以返回一個有效的解決方案。
爬山搜尋
這是一個迭代演算法,它從問題的任意解開始,並嘗試透過增量更改解的單個元素來找到更好的解。如果更改產生更好的解,則將增量更改作為新的解。重複此過程,直到沒有進一步的改進。
函式爬山(問題),返回區域性最大值的狀態。
inputs: problem, a problem
local variables: current, a node
neighbor, a node
current <-Make_Node(Initial-State[problem])
loop
do neighbor <- a highest_valued successor of current
if Value[neighbor] ≤ Value[current] then
return State[current]
current <- neighbor
end
缺點 - 此演算法既不完整,也不最優。
區域性束搜尋
在此演算法中,它在任何給定時間都儲存 k 個狀態。一開始,這些狀態是隨機生成的。藉助目標函式計算這些 k 個狀態的後繼狀態。如果這些後繼狀態中的任何一個是目標函式的最大值,則演算法停止。
否則,將(初始 k 個狀態和 k 個狀態的後繼狀態 = 2k)狀態放入池中。然後對池進行數值排序。選擇最高的 k 個狀態作為新的初始狀態。這個過程持續到達到最大值。
函式束搜尋( 問題,k),返回一個解決方案狀態。
start with k randomly generated states loop generate all successors of all k states if any of the states = solution, then return the state else select the k best successors end
模擬退火
退火是加熱和冷卻金屬以改變其內部結構從而改變其物理性質的過程。當金屬冷卻時,它的新結構被固定,金屬保留其新獲得的性質。在模擬退火過程中,溫度保持可變。
我們最初將溫度設定得很高,然後隨著演算法的進行,使其緩慢“冷卻”。當溫度高時,演算法允許高頻地接受較差的解決方案。
開始
- 初始化 k = 0;L = 整數個變數;
- 從 i → j,搜尋效能差異 Δ。
- 如果 Δ <= 0 則接受,否則如果 exp(-Δ/T(k)) > random(0,1) 則接受;
- 重複步驟 1 和 2,進行 L(k) 步。
- k = k + 1;
重複步驟 1 到 4,直到滿足條件。
結束
旅行商問題
在這個演算法中,目標是找到一條低成本的路線,從一個城市開始,沿途精確訪問所有城市,最後回到同一個起始城市。
Start Find out all (n -1)! Possible solutions, where n is the total number of cities. Determine the minimum cost by finding out the cost of each of these (n -1)! solutions. Finally, keep the one with the minimum cost. end
人工智慧 - 模糊邏輯系統
模糊邏輯系統 (FLS) 對不完整、模糊、扭曲或不準確(模糊)的輸入產生可接受但確定的輸出。
什麼是模糊邏輯?
模糊邏輯 (FL) 是一種類似於人類推理的推理方法。FL 的方法模仿了人類決策的方式,其中包括數字值 YES 和 NO 之間的全部中間可能性。
計算機可以理解的常規邏輯塊採用精確的輸入併產生確定的輸出 TRUE 或 FALSE,這相當於人類的 YES 或 NO。
模糊邏輯的發明者 Lotfi Zadeh 觀察到,與計算機不同,人類的決策包括 YES 和 NO 之間的一系列可能性,例如:
| 肯定的 YES |
| 可能的 YES |
| 無法確定 |
| 可能的 NO |
| 肯定的 NO |
模糊邏輯基於輸入的可能性級別來實現確定的輸出。
實現
它可以實現於各種規模和能力的系統中,從小型微控制器到大型聯網的工作站控制系統。
它可以以硬體、軟體或兩者的結合方式實現。
為什麼選擇模糊邏輯?
模糊邏輯對於商業和實際用途非常有用。
- 它可以控制機器和消費產品。
- 它可能不會給出精確的推理,但會給出可接受的推理。
- 模糊邏輯有助於處理工程中的不確定性。
模糊邏輯系統架構
它有四個主要部分,如下所示:
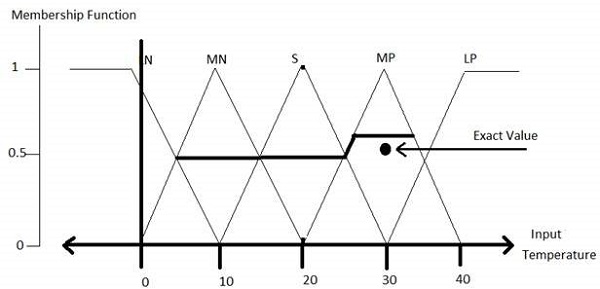
模糊化模組 - 它將系統的輸入(即清晰的數字)轉換為模糊集。它將輸入訊號分成五個步驟,例如:
| LP | x 為大正數 |
| MP | x 為中等正數 |
| S | x 為小數 |
| MN | x 為中等負數 |
| LN | x 為大負數 |
知識庫 - 它儲存專家提供的 IF-THEN 規則。
推理引擎 - 透過對輸入和 IF-THEN 規則進行模糊推理,它模擬人類的推理過程。
反模糊化模組 - 它將推理引擎獲得的模糊集轉換為清晰的值。

隸屬函式作用於變數的模糊集。
隸屬函式
隸屬函式允許你量化語言術語並以圖形方式表示模糊集。模糊集 *A* 在論域 X 上的隸屬函式定義為 μA:X → [0,1]。
在這裡,X 的每個元素都對映到 0 到 1 之間的值。它被稱為隸屬值或隸屬度。它量化了 X 中元素對模糊集 *A* 的隸屬度。
- x 軸表示論域。
- y 軸表示 [0, 1] 區間內的隸屬度。
可以有多個隸屬函式適用於將數值模糊化。使用簡單的隸屬函式,因為使用複雜的函式不會提高輸出的精度。
LP、MP、S、MN 和 LN 的所有隸屬函式如下所示:
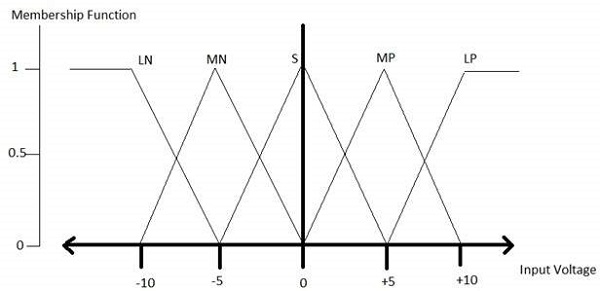
三角形隸屬函式形狀在各種其他隸屬函式形狀(如梯形、單例和高斯)中最常見。
這裡,5 級模糊器的輸入範圍為 -10 伏特到 +10 伏特。因此,相應的輸出也會發生變化。
模糊邏輯系統示例
讓我們考慮一個具有 5 級模糊邏輯系統的空調系統。該系統透過比較房間溫度和目標溫度值來調整空調的溫度。

演算法
- 定義語言變數和術語(開始)
- 為它們構建隸屬函式。(開始)
- 構建規則的知識庫(開始)
- 使用隸屬函式將清晰資料轉換為模糊資料集。(模糊化)
- 評估規則庫中的規則。(推理引擎)
- 組合每個規則的結果。(推理引擎)
- 將輸出資料轉換為非模糊值。(反模糊化)
開發
步驟 1 - 定義語言變數和術語
語言變數是以簡單詞語或句子的形式出現的輸入和輸出變數。對於室溫,冷、暖、熱等是語言術語。
溫度 (t) = {非常冷、冷、暖、非常暖、熱}
該集合的每個成員都是一個語言術語,它可以覆蓋一部分整體溫度值。
步驟 2 - 為它們構建隸屬函式
溫度變數的隸屬函式如下所示:
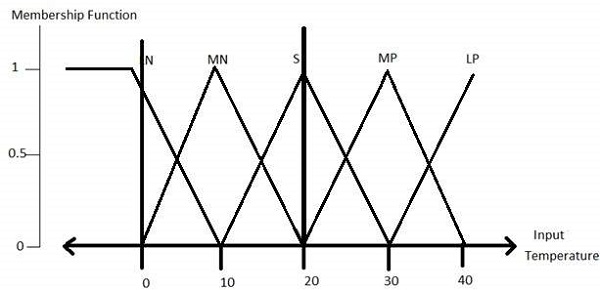
步驟 3 - 構建知識庫規則
建立一個房間溫度值與空調系統預期提供的目標溫度值的矩陣。
| RoomTemp./Target | 非常冷 | 冷 | 暖 | 熱 | 非常熱 |
|---|---|---|---|---|---|
| 非常冷 | 不變 | 加熱 | 加熱 | 加熱 | 加熱 |
| 冷 | 冷卻 | 不變 | 加熱 | 加熱 | 加熱 |
| 暖 | 冷卻 | 冷卻 | 不變 | 加熱 | 加熱 |
| 熱 | 冷卻 | 冷卻 | 冷卻 | 不變 | 加熱 |
| 非常熱 | 冷卻 | 冷卻 | 冷卻 | 冷卻 | 不變 |
將一組規則以 IF-THEN-ELSE 結構的形式構建到知識庫中。
| 序號 | 條件 | 動作 |
|---|---|---|
| 1 | 如果溫度 =(冷或非常冷)並且目標 = 暖則 | 加熱 |
| 2 | 如果溫度 =(熱或非常熱)並且目標 = 暖則 | 冷卻 |
| 3 | 如果(溫度 = 暖)並且(目標 = 暖)則 | 不變 |
步驟 4 - 獲取模糊值
模糊集運算執行規則評估。用於 OR 和 AND 的運算分別是 Max 和 Min。組合所有評估結果以形成最終結果。此結果是一個模糊值。
步驟 5 - 執行反模糊化
然後根據輸出變數的隸屬函式執行反模糊化。
模糊邏輯的應用領域
模糊邏輯的主要應用領域如下所示:
汽車系統
- 自動變速箱
- 四輪轉向
- 車輛環境控制
消費電子產品
- 高保真音響系統
- 影印機
- 靜態和攝像機
- 電視
家用電器
- 微波爐
- 冰箱
- 烤麵包機
- 真空吸塵器
- 洗衣機
環境控制
- 空調/乾燥機/加熱器
- 加溼器
FLS 的優點
模糊推理中的數學概念非常簡單。
由於模糊邏輯的靈活性,你可以透過新增或刪除規則來修改 FLS。
模糊邏輯系統可以接受不精確、扭曲、嘈雜的輸入資訊。
FLS 易於構建和理解。
模糊邏輯是解決包括醫學在內的所有領域複雜問題的解決方案,因為它類似於人類的推理和決策。
FLS 的缺點
- 沒有系統的方法來設計模糊系統。
- 只有簡單的時候才容易理解。
- 它們適用於不需要高精度的難題。
AI - 自然語言處理
自然語言處理 (NLP) 指的是使用英語等自然語言與智慧系統進行通訊的 AI 方法。
當你希望機器人等智慧系統根據你的指示執行操作時,當你希望從基於對話的臨床專家系統聽到決策時,需要自然語言處理等。
NLP 領域涉及使計算機能夠使用人類使用的自然語言執行有用的任務。NLP 系統的輸入和輸出可以是:
- 語音
- 書面文字
NLP 的組成部分
NLP 有兩個組成部分,如下所示:
自然語言理解 (NLU)
理解涉及以下任務:
- 將給定的自然語言輸入對映到有用的表示中。
- 分析語言的不同方面。
自然語言生成 (NLG)
它是根據某種內部表示,生成有意義的短語和句子的過程,以自然語言的形式呈現。
它包括:
文字規劃 - 它包括從知識庫中檢索相關內容。
句子規劃 - 它包括選擇所需的詞語、形成有意義的短語、設定句子的語氣。
文字實現 - 它將句子計劃對映到句子結構。
NLU 比 NLG 更難。
NLU 的難點
NL 具有極其豐富的形式和結構。
它非常模糊。可能存在不同級別的模糊性:
詞彙歧義 - 它處於非常原始的級別,例如詞級別。
例如,將單詞“board”作為名詞還是動詞處理?
句法級別歧義 - 一個句子可以以不同的方式解析。
例如,“他用紅色的帽子舉起了甲殼蟲。” - 他是用帽子舉起甲殼蟲,還是舉起了一隻戴著紅色帽子的甲殼蟲?
指稱歧義 - 使用代詞指代某事物。例如,麗瑪去看高麗。她說,“我累了。” - 到底是誰累了?
一個輸入可以有多種含義。
許多輸入可以表示相同的含義。
NLP 術語
音系學 - 它是有系統地組織聲音的研究。
形態學 - 它是由原始有意義的單位構成單詞的研究。
語素 - 它是語言中意義的原始單位。
句法 - 它指的是排列單詞以構成句子。它還涉及確定單詞在句子和短語中的結構作用。
語義學 - 它關注單詞的含義以及如何將單詞組合成有意義的短語和句子。
語用學 - 它處理在不同情況下使用和理解句子,以及如何影響句子的解釋。
語篇 - 它處理緊接在前的句子如何影響下一句子的解釋。
世界知識 - 它包括關於世界的常識。
NLP 的步驟
一般有五個步驟:
詞法分析 - 它涉及識別和分析單詞的結構。語言的詞典是指語言中單詞和短語的集合。詞法分析是將整塊文字分成段落、句子和單詞。
句法分析(解析) - 它涉及分析句子中單詞的語法並以顯示單詞之間關係的方式排列單詞。“學校去男孩”之類的句子會被英語句法分析器拒絕。
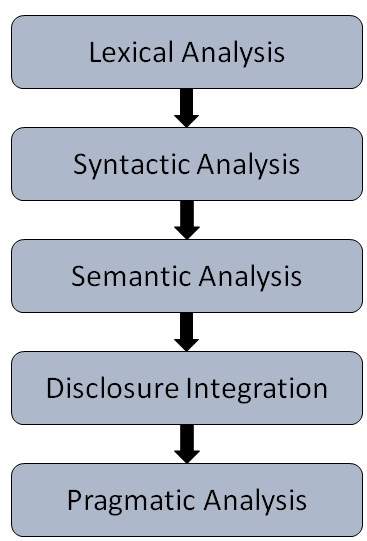
語義分析 − 它從文字中提取確切的含義或字典含義。文字被檢查其是否有意義。這是透過將句法結構和物件對映到任務域來完成的。語義分析器會忽略諸如“熱冰淇淋”之類的句子。
語篇整合 − 任何句子的含義都取決於其前面句子的含義。此外,它還會帶來緊隨其後的句子的含義。
語用分析 − 在此過程中,所說的話會被重新解釋為其實際含義。它涉及推匯出需要現實世界知識的語言方面。
句法分析的實現方面
研究人員已經開發了許多用於句法分析的演算法,但我們只考慮以下簡單方法:
- 上下文無關文法
- 自頂向下分析器
讓我們詳細瞭解一下:
上下文無關文法
它是一種文法,其規則在重寫規則的左側只有一個符號。讓我們建立一個文法來解析一個句子:
“鳥啄穀粒”
冠詞 (DET) − a | an | the
名詞 − bird | birds | grain | grains
名詞短語 (NP) − 冠詞 + 名詞 | 冠詞 + 形容詞 + 名詞
= DET N | DET ADJ N
動詞 − pecks | pecking | pecked
動詞短語 (VP) − NP V | V NP
形容詞 (ADJ) − beautiful | small | chirping
句法樹將句子分解成結構化的部分,以便計算機能夠輕鬆地理解和處理它。為了使解析演算法能夠構建此句法樹,需要構建一組重寫規則,這些規則描述哪些樹結構是合法的。
這些規則說明,某個符號可以透過其他符號的序列在樹中展開。根據一階邏輯規則,如果存在兩個字串名詞短語 (NP) 和動詞短語 (VP),那麼由 NP 後跟 VP 組合而成的字串就是一個句子。句子的重寫規則如下:
S → NP VP
NP → DET N | DET ADJ N
VP → V NP
詞典 −
DET → a | the
ADJ → beautiful | perching
N → bird | birds | grain | grains
V → peck | pecks | pecking
可以建立如下所示的句法樹:

現在考慮上述重寫規則。由於 V 可以被“peck”或“pecks”替換,因此諸如“The bird peck the grains”之類的句子可能會被錯誤地允許。即,主謂一致錯誤被認為是正確的。
優點 − 最簡單的文法型別,因此被廣泛使用。
缺點 −
它們不夠精確。例如,“穀粒啄鳥”根據解析器在句法上是正確的,但即使它沒有意義,解析器也將其視為正確的句子。
為了提高精度,需要準備多組文法。它可能需要為解析單數和複數變體、被動句等準備完全不同的規則集,這可能導致建立難以管理的大量規則集。
自頂向下分析器
在這裡,解析器從 S 符號開始,並嘗試將其重寫為與輸入句子中單詞類別匹配的終端符號序列,直到它完全由終端符號組成。
然後將這些與輸入句子進行檢查以檢視是否匹配。如果沒有匹配,則使用不同的規則集重新開始該過程。重複此過程,直到找到描述句子結構的特定規則。
優點 − 易於實現。
缺點 −
- 它效率低下,因為如果發生錯誤,則必須重複搜尋過程。
- 工作速度慢。
人工智慧 - 專家系統
專家系統 (ES) 是人工智慧的一個重要研究領域。它是由斯坦福大學計算機科學系的研究人員提出的。
什麼是專家系統?
專家系統是開發的計算機應用程式,用於解決特定領域中的複雜問題,達到非凡的人類智慧和專業知識水平。
專家系統的特點
- 高效能
- 易於理解
- 可靠
- 高度響應
專家系統的功能
專家系統能夠:
- 提供建議
- 指導和協助人類決策
- 演示
- 得出解決方案
- 診斷
- 解釋
- 解釋輸入
- 預測結果
- 論證結論
- 為問題提出替代方案
它們不能:
- 取代人類決策者
- 擁有人的能力
- 為知識庫不足的情況產生準確的輸出
- 完善自身的知識
專家系統的組成部分
ES 的組成部分包括:
- 知識庫
- 推理引擎
- 使用者介面
讓我們簡要地逐一瞭解一下:
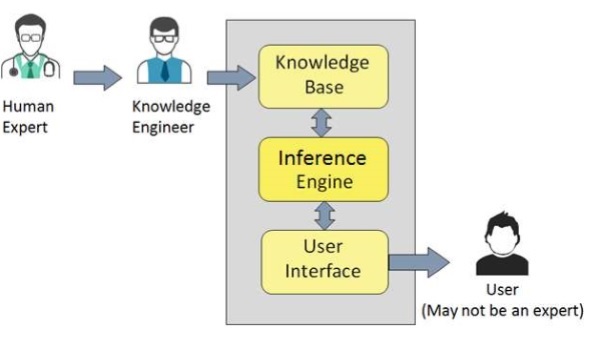
知識庫
它包含特定領域和高質量的知識。
知識是展現智慧所必需的。任何 ES 的成功都主要取決於高度準確和精確的知識的收集。
什麼是知識?
資料是事實的集合。資訊被組織成關於任務域的資料和事實。資料、資訊和過去的經驗組合在一起被稱為知識。
知識庫的組成部分
ES 的知識庫既儲存事實性知識,也儲存啟發式知識。
事實性知識 − 這是任務領域中的知識工程師和學者廣泛接受的資訊。
啟發式知識 − 關於實踐、準確的判斷、評估能力和猜測。
知識表示
它是用於組織和形式化知識庫中知識的方法。它是 IF-THEN-ELSE 規則的形式。
知識獲取
任何專家系統的成功都主要取決於儲存在知識庫中的資訊的質量、完整性和準確性。
知識庫是透過閱讀各種專家、學者和知識工程師的資料形成的。知識工程師是一個具有同理心、快速學習和案例分析能力的人。
他透過記錄、採訪和觀察專家在工作中的情況等方式從主題專家那裡獲取資訊。然後,他以有意義的方式對資訊進行分類和組織,以 IF-THEN-ELSE 規則的形式,供干預機器使用。知識工程師還監控 ES 的開發。
推理引擎
推理引擎使用高效的過程和規則對於推匯出正確、無瑕疵的解決方案至關重要。
對於基於知識的 ES,推理引擎從知識庫中獲取和操作知識以得出特定解決方案。
對於基於規則的 ES,它:
重複將規則應用於從早期規則應用中獲得的事實。
根據需要向知識庫中新增新知識。
當多個規則適用於特定情況時,解決規則衝突。
為了推薦解決方案,推理引擎使用以下策略:
- 正向連結
- 反向連結
正向連結
這是專家系統回答問題“接下來會發生什麼?”的一種策略。
在這裡,推理引擎遵循條件和推導鏈,最終推匯出結果。它考慮所有事實和規則,並在得出解決方案之前對它們進行排序。
此策略用於處理結論、結果或影響。例如,預測利率變化對股市狀況的影響。

反向連結
使用此策略,專家系統可以找到答案:“為什麼會發生這種情況?”
根據已經發生的事情,推理引擎試圖找出過去可能發生過哪些條件導致了這個結果。此策略用於找出原因或理由。例如,人類血液癌症的診斷。

使用者介面
使用者介面提供 ES 使用者和 ES 本身之間的互動。它通常是自然語言處理,以便那些精通任務領域的使用者可以使用。ES 的使用者不必一定是人工智慧專家。
它解釋了 ES 如何得出特定建議。解釋可能以以下形式出現:
- 顯示在螢幕上的自然語言。
- 自然語言的口頭敘述。
- 顯示在螢幕上的規則編號列表。
使用者介面使追蹤推論的可信度變得容易。
高效 ES 使用者介面的要求
它應該幫助使用者以最短的時間完成他們的目標。
它應該被設計用於使用者現有的或期望的工作實踐。
其技術應該適應使用者的需求;反之則不然。
它應該有效地利用使用者輸入。
專家系統的侷限性
沒有任何技術可以提供輕鬆和完整的解決方案。大型系統成本高昂,需要大量的開發時間和計算機資源。ES 有其侷限性,包括:
- 技術的侷限性
- 知識獲取困難
- ES 難以維護
- 高昂的開發成本
專家系統的應用
下表顯示了 ES 的應用領域。
| 應用 | 描述 |
|---|---|
| 設計領域 | 相機鏡頭設計、汽車設計。 |
| 醫療領域 | 診斷系統,根據觀察到的資料推斷疾病的原因,對人類進行醫療手術。 |
| 監控系統 | 將資料與觀察到的系統或規定的行為(例如長輸油管道中的洩漏監控)持續進行比較。 |
| 過程控制系統 | 基於監控控制物理過程。 |
| 知識領域 | 找出車輛、計算機的故障。 |
| 金融/商業 | 檢測可能的欺詐、可疑交易、股票市場交易、航空公司排程、貨物排程。 |
專家系統技術
有多種級別的 ES 技術可用。專家系統技術包括:
專家系統開發環境 − ES 開發環境包括硬體和工具。它們是:
工作站、小型計算機、大型機。
高階符號程式語言,例如LISt Programming (LISP) 和PROgrammation en LOGique (PROLOG)。
大型資料庫。
工具 − 它們在很大程度上減少了開發專家系統的努力和成本。
具有多視窗功能的強大的編輯器和除錯工具。
它們提供快速原型設計
具有模型、知識表示和推理設計的內建定義。
外殼 − 外殼只不過是沒有知識庫的專家系統。外殼為開發人員提供了知識獲取、推理引擎、使用者介面和解釋功能。例如,以下是一些外殼:
Java 專家系統外殼 (JESS),它提供完全開發的 Java API 用於建立專家系統。
Vidwan是1993年在孟買國家軟體技術中心開發的一種shell。它能夠以IF-THEN規則的形式進行知識編碼。
專家系統開發:一般步驟
專家系統(ES)的開發過程是迭代的。開發ES的步驟包括:
確定問題領域
- 問題必須適合由專家系統解決。
- 為ES專案找到任務領域的專家。
- 確定系統的成本效益。
系統設計
確定ES技術
瞭解並確定與其他系統和資料庫的整合程度。
瞭解如何最好地表示領域知識的概念。
開發原型
從知識庫:知識工程師的工作包括:
- 從專家那裡獲取領域知識。
- 將其表示為If-THEN-ELSE規則。
測試和改進原型
知識工程師使用示例案例來測試原型在效能方面的任何缺陷。
終端使用者測試ES的原型。
開發並完成ES
測試並確保ES與其環境的所有元素(包括終端使用者、資料庫和其他資訊系統)的互動。
做好ES專案的文件工作。
培訓使用者使用ES。
系統維護
透過定期審查和更新,保持知識庫的最新狀態。
隨著這些系統的演變,滿足與其他資訊系統的新介面的需求。
專家系統的優點
可用性——由於軟體的大規模生產,它們很容易獲得。
生產成本低——生產成本合理。這使得它們負擔得起。
速度——它們速度很快。它們減少了個人投入的工作量。
錯誤率低——與人為錯誤相比,錯誤率較低。
降低風險——它們可以在對人類危險的環境中工作。
響應穩定——它們穩定地工作,不會情緒化、緊張或疲勞。
人工智慧 - 機器人技術
機器人技術是人工智慧領域的一個分支,它涉及研究創造智慧高效的機器人。
什麼是機器人?
機器人是在真實世界環境中行動的智慧代理。
目標
機器人的目標是透過感知、拾取、移動、修改物體的物理屬性、破壞物體或產生某種效果來操縱物體,從而將人力從重複性功能中解放出來,而不會感到厭倦、分心或筋疲力盡。
什麼是機器人技術?
機器人技術是人工智慧的一個分支,它由電氣工程、機械工程和計算機科學組成,用於機器人的設計、建造和應用。
機器人技術的各個方面
機器人具有機械結構、形狀或形式,旨在完成特定任務。
它們具有電氣元件,為機械提供動力和控制。
它們包含一定程度的計算機程式,決定機器人做什麼、何時做以及如何做。
機器人系統與其他AI程式的區別
以下是兩者之間的區別:
| AI程式 | 機器人 |
|---|---|
| 它們通常在計算機模擬的世界中執行。 | 它們在真實的物理世界中執行 |
| AI程式的輸入是符號和規則。 | 機器人的輸入是語音波形或影像形式的模擬訊號 |
| 它們需要通用計算機來執行。 | 它們需要帶有感測器和效應器的專用硬體。 |
機器人運動
運動是使機器人能夠在其環境中移動的機制。有各種型別的運動:
- 腿式
- 輪式
- 腿式和輪式運動的組合
- 履帶式滑動/滑行
腿式運動
這種型別的運動在行走、跳躍、慢跑、跳躍、爬上或爬下等過程中消耗更多能量。
它需要更多的電機來完成運動。它適用於崎嶇不平的地形以及光滑的地形,在不規則或過於光滑的表面上,輪式運動會消耗更多能量。由於穩定性問題,它很難實現。
它有多種型別,包括一足、二足、四足和六足機器人。如果機器人有多條腿,則需要腿部協調才能進行運動。
機器人可以移動的步態(每條腿的提升和釋放事件的週期性序列)總數取決於其腿的數量。
如果機器人有k條腿,則可能的事件數N = (2k-1)!。
對於雙足機器人(k=2),可能的事件數為N = (2k-1)! = (2*2-1)! = 3! = 6。
因此,共有六個可能的不同事件:
- 抬起左腿
- 放下左腿
- 抬起右腿
- 放下右腿
- 同時抬起雙腿
- 同時放下雙腿
對於k=6條腿,共有39916800個可能的事件。因此,機器人的複雜度與其腿的數量成正比。

輪式運動
它需要較少的電機來完成運動。它比較容易實現,因為在輪子數量較多的情況下,穩定性問題較少。與腿式運動相比,它更節能。
標準輪——繞車輪軸和接觸點旋轉
萬向輪——繞車輪軸和偏置轉向關節旋轉。
瑞典45o和瑞典90o輪——全向輪,繞接觸點、車輪軸和滾輪旋轉。
球形輪——全向輪,技術上難以實現。

滑動/滑行運動
在這種型別中,車輛使用履帶,就像坦克一樣。透過以相同或相反的方向以不同速度移動履帶來轉向機器人。由於履帶與地面的接觸面積大,因此具有穩定性。

機器人的組成部分
機器人由以下部分構成:
電源——機器人由電池、太陽能、液壓或氣動電源供電。
執行器——它們將能量轉換為運動。
電動機(交流/直流)——它們需要進行旋轉運動。
氣動人工肌肉——當空氣被吸入其中時,它們會收縮近40%。
形狀記憶合金絲——當電流透過時,它們會收縮5%。
壓電電機和超聲波電機——最適合工業機器人。
感測器——它們提供有關任務環境即時資訊的知識。機器人配備了視覺感測器,可以計算環境中的深度。觸覺感測器模仿人手指觸覺感受器的機械特性。
計算機視覺
這是一項人工智慧技術,機器人可以用它來“看”。計算機視覺在安全、安保、健康、訪問和娛樂領域發揮著至關重要的作用。
計算機視覺自動從單個影像或一系列影像中提取、分析和理解有用的資訊。此過程涉及開發演算法以實現自動視覺理解。
計算機視覺系統的硬體
這包括:
- 電源
- 影像採集裝置,如攝像機
- 處理器
- 軟體
- 用於監控系統的顯示裝置
- 附件,如攝像機支架、電纜和聯結器
計算機視覺的任務
OCR——在計算機領域,光學字元識別器 (OCR) 是一種將掃描文件轉換為可編輯文字的軟體,它與掃描器一起使用。
人臉檢測——許多最先進的攝像機都具有此功能,它能夠讀取人臉並拍攝具有完美表情的照片。它用於在正確匹配時讓使用者訪問軟體。
物體識別——它們安裝在超市、攝像機、寶馬、通用汽車和沃爾沃等高階汽車中。
位置估計——它是在攝像機方面估計物體的位置,例如人體腫瘤的位置。
計算機視覺的應用領域
- 農業
- 自動駕駛車輛
- 生物識別
- 字元識別
- 法醫、安全和監控
- 工業質量檢驗
- 人臉識別
- 手勢分析
- 地球科學
- 醫學影像
- 汙染監測
- 過程控制
- 遙感
- 機器人技術
- 交通運輸
機器人技術的應用
機器人技術在各個領域發揮了重要作用,例如:
工業——機器人用於處理材料、切割、焊接、塗色、鑽孔、拋光等。
軍事——自主機器人可以在戰爭期間到達無法進入和危險區域。國防研究與發展組織 (DRDO) 開發的名為Daksh的機器人正在發揮作用,以安全地摧毀危及生命的物體。
醫學——機器人能夠同時進行數百項臨床測試,康復永久性殘疾人士,並進行復雜的手術,例如腦腫瘤手術。
勘探——用於太空探索的機器人攀巖者、用於海洋探索的水下無人機,僅舉幾例。
娛樂——迪士尼的工程師為電影製作創造了數百個機器人。
人工智慧 - 神經網路
人工智慧的另一個研究領域,神經網路,是受人類神經系統自然神經網路的啟發。
什麼是人工神經網路 (ANN)?
第一臺神經計算機的發明者羅伯特·赫克特-尼爾森博士將神經網路定義為:
“...一種由許多簡單、高度互連的處理單元組成的計算系統,它透過對外部輸入的動態狀態響應來處理資訊。”
人工神經網路的基本結構
人工神經網路的思想是基於這樣的信念:透過建立正確的連線,人類大腦的工作可以利用矽和電線來模仿活的神經元和樹突。
人腦由860億個稱為神經元的神經細胞組成。它們透過軸突與其他數千個細胞相連。來自外部環境的刺激或來自感覺器官的輸入被樹突接受。這些輸入產生電脈衝,這些脈衝迅速穿過神經網路。然後,神經元可以向其他神經元傳送訊息來處理問題,或者不將其轉發。

人工神經網路由多個節點組成,這些節點模擬人腦的生物神經元。神經元透過連結連線,它們相互作用。節點可以接收輸入資料並對資料執行簡單的運算。這些運算的結果傳遞給其他神經元。每個節點的輸出稱為其啟用或節點值。
每個連結都與權重相關聯。人工神經網路能夠學習,學習是透過改變權重值來實現的。下圖顯示了一個簡單的人工神經網路:
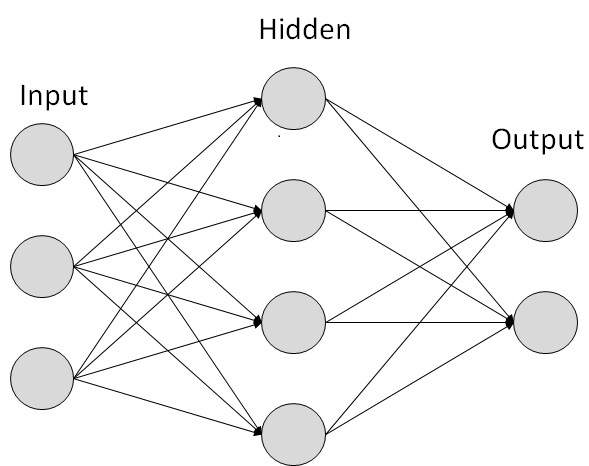
人工神經網路的型別
有兩種人工神經網路拓撲結構:前饋和反饋。
前饋人工神經網路
在這種人工神經網路中,資訊流是單向的。一個單元向另一個單元傳送資訊,而它不從該單元接收任何資訊。沒有反饋迴圈。它們用於模式生成/識別/分類。它們具有固定的輸入和輸出。

反饋人工神經網路
在這裡,允許反饋迴圈。它們用於內容定址儲存器。
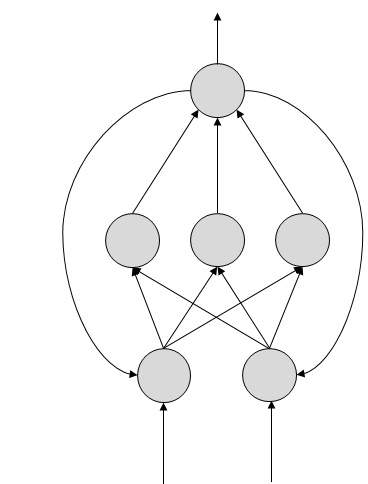
人工神經網路的工作原理
在上圖所示的拓撲圖中,每個箭頭表示兩個神經元之間的連線,並指示資訊流的路徑。每個連線都有一個權重,這是一個控制兩個神經元之間訊號的整數。
如果網路生成“良好或期望的”輸出,則無需調整權重。但是,如果網路生成“不良或非期望的”輸出或錯誤,則系統會改變權重以改進後續結果。
人工神經網路中的機器學習
人工神經網路 (ANN) 能夠學習,並且需要進行訓練。有幾種學習策略:
監督學習 − 它涉及一位比 ANN 本身更有知識的“老師”。例如,老師會提供一些示例資料,而老師已經知道這些資料的答案。
例如,模式識別。ANN 在識別過程中會做出猜測。然後,老師會向 ANN 提供答案。網路隨後會將它的猜測與老師的“正確”答案進行比較,並根據錯誤進行調整。
無監督學習 − 當沒有帶有已知答案的示例資料集時,就需要這種學習。例如,搜尋隱藏模式。在這種情況下,聚類(即根據某些未知模式將一組元素分成幾組)是基於現有資料集進行的。
強化學習 − 此策略建立在觀察的基礎上。ANN 透過觀察其環境來做出決策。如果觀察結果為負面,則網路會調整其權重,以便下次能夠做出不同的所需決策。
反向傳播演算法
這是一種訓練或學習演算法。它透過示例學習。如果您向演算法提交您希望網路執行的操作示例,它會更改網路的權重,以便在完成訓練後能夠針對特定輸入產生所需的輸出。
反向傳播網路非常適合簡單的模式識別和對映任務。
貝葉斯網路 (BN)
這些是用於表示一組隨機變數之間機率關係的圖形結構。貝葉斯網路也稱為信念網路或貝葉斯網。BN 用於推斷不確定領域。
在這些網路中,每個節點代表一個具有特定命題的隨機變數。例如,在醫學診斷領域中,節點“癌症”表示患者患有癌症的命題。
連線節點的邊表示這些隨機變數之間的機率依賴關係。如果兩個節點中的一個影響另一個,則它們必須直接連線在影響的方向上。變數之間關係的強度由與每個節點相關的機率來量化。
BN 中的弧只有一個約束條件,即您不能簡單地透過跟隨有向弧返回到一個節點。因此,BN 稱為有向無環圖 (DAG)。
BN 能夠同時處理多值變數。BN 變數由兩個維度組成:
- 命題範圍
- 分配給每個命題的機率。
考慮一個有限集 X = {X1, X2, …,Xn} 的離散隨機變數,其中每個變數 Xi 可以取自一個有限集的值,記為 Val(Xi)。如果從變數 Xi 到變數 Xj 有一個有向連結,則變數 Xi 將是變數 Xj 的父節點,表示變數之間的直接依賴關係。
BN 的結構非常適合結合先驗知識和觀察資料。BN 可用於學習因果關係,理解各種問題領域,並預測未來事件,即使在資料缺失的情況下也是如此。
構建貝葉斯網路
知識工程師可以構建貝葉斯網路。知識工程師在構建過程中需要採取許多步驟。
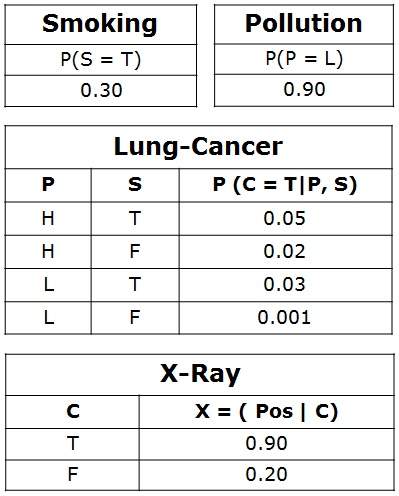
示例問題 − 肺癌。一位病人一直呼吸困難。他去看醫生,懷疑自己患有肺癌。醫生知道,除了肺癌外,病人還可能患有其他各種疾病,例如結核病和支氣管炎。
收集相關問題資訊
- 病人是吸菸者嗎?如果是,則患癌症和支氣管炎的可能性很高。
- 病人是否接觸過空氣汙染?如果是,是什麼型別的空氣汙染?
- 進行 X 光檢查,陽性的 X 光檢查表明可能是結核病或肺癌。
識別有趣的變數
知識工程師嘗試回答以下問題:
- 要表示哪些節點?
- 它們可以取哪些值?它們可以處於什麼狀態?
現在讓我們考慮只有離散值的節點。變數必須一次只取這些值中的一個。
常見的離散節點型別包括:
布林節點 − 它們表示命題,取二元值 TRUE (T) 和 FALSE (F)。
有序值 − 節點 汙染可以表示並取自 {低,中,高} 的值,描述患者接觸汙染的程度。
整數值 − 一個名為 年齡 的節點可以表示患者的年齡,其可能值範圍為 1 到 120。即使在這個早期階段,建模選擇也在進行中。
肺癌示例的可能節點和值:
| 節點名稱 | 型別 | 值 | 節點建立 |
|---|---|---|---|
| 汙染 | 二元 | {低,高,中} |  |
| 吸菸者 | 布林 | {真,假} | |
| 肺癌 | 布林 | {真,假} | |
| X 光 | 二元 | {陽性,陰性} |
建立節點之間的弧
網路的拓撲結構應捕捉變數之間的定性關係。
例如,是什麼導致病人患肺癌?- 汙染和吸菸。然後從節點 汙染 和節點 吸菸者 新增弧到節點 肺癌。
同樣,如果病人患有肺癌,則 X 光檢查結果將為陽性。然後從節點 肺癌 新增弧到節點 X 光。

指定拓撲結構
通常,BN 的佈局方式是從上到下指向弧。節點 X 的父節點集由 Parents(X) 給出。
肺癌 節點有兩個父節點(原因):汙染 和 吸菸者,而節點 吸菸者 是節點 X 光 的祖先。同樣,X 光 是節點 肺癌 的子節點(結果或影響)和節點 吸菸者 和 汙染 的後代。
條件機率
現在量化連線節點之間的關係:這是透過為每個節點指定條件機率分佈來完成的。由於這裡只考慮離散變數,因此它採用條件機率表 (CPT) 的形式。
首先,對於每個節點,我們需要檢視其所有父節點值的可能組合。每個這樣的組合稱為父節點集的一個例項。對於父節點值的每個不同例項,我們需要指定子節點將取的值的機率。
例如,肺癌 節點的父節點是 汙染 和 吸菸。它們取可能的值 = {(H,T), (H,F), (L,T), (L,F)}。CPT 分別指定每種情況下癌症的機率為 <0.05, 0.02, 0.03, 0.001>。
每個節點將具有如下關聯的條件機率:
神經網路的應用
它們可以執行對人類來說很容易但對機器來說很難的任務:
航空航天 − 自動駕駛飛機,飛機故障檢測。
汽車 − 汽車導航系統。
軍事 − 武器定向和轉向,目標跟蹤,目標識別,面部識別,訊號/影像識別。
電子 − 程式碼序列預測,IC 晶片佈局,晶片故障分析,機器視覺,語音合成。
金融 − 房地產估價,貸款顧問,抵押貸款篩選,公司債券評級,投資組合交易程式,公司財務分析,貨幣價值預測,文件閱讀器,信用申請評估器。
工業 − 製造過程控制,產品設計和分析,質量檢驗系統,焊接質量分析,紙張質量預測,化工產品設計分析,化工過程系統的動態建模,機器維護分析,專案投標,規劃和管理。
醫學 − 癌細胞分析,腦電圖和心電圖分析,假體設計,移植時間最佳化器。
語音 − 語音識別,語音分類,文字到語音轉換。
電信 − 影像和資料壓縮,自動化資訊服務,即時口語翻譯。
交通運輸 − 卡車制動系統診斷,車輛排程,路線系統。
軟體 − 面部識別、光學字元識別等中的模式識別。
時間序列預測 − ANN 用於預測股票和自然災害。
訊號處理 − 可以訓練神經網路來處理音訊訊號並在助聽器中對其進行適當濾波。
控制 − ANN 常用於對物理車輛進行轉向決策。
異常檢測 − 由於 ANN 擅長識別模式,因此也可以對其進行訓練以在發生不符合模式的異常情況時生成輸出。
人工智慧 - 問題
人工智慧發展速度如此之快,有時似乎很神奇。研究人員和開發人員認為,人工智慧可能會變得如此強大,以至於人類難以控制。
人類透過向人工智慧系統中引入他們所能想到的一切可能的智慧來開發人工智慧系統,而人類自己現在似乎受到了威脅。
對隱私的威脅
理論上,能夠識別語音並理解自然語言的人工智慧程式能夠理解電子郵件和電話上的每一次對話。
對人類尊嚴的威脅
人工智慧系統已經開始在一些行業取代人類。它不應取代那些從事與倫理相關的尊嚴職位的人,例如護士、外科醫生、法官、警官等。
對安全的威脅
自我改進的人工智慧系統可能會變得比人類強大得多,以至於很難阻止它們實現目標,這可能會導致意想不到的後果。
人工智慧 - 術語
以下是人工智慧領域中常用術語的列表:
| 序號 | 術語及含義 |
|---|---|
| 1 | 智慧體 智慧體是能夠自主、有目的且推理導向一個或多個目標的系統或軟體程式。它們也稱為助手、經紀人、機器人、機器人、智慧體和軟體智慧體。 |
| 2 | 自主機器人 擺脫外部控制或影響並能夠獨立控制自身的機器人。 |
| 3 | 反向連結 用於解決問題的原因/起因的反向工作策略。 |
| 4 | 黑板 這是計算機內部的記憶體,用於協同專家系統之間的通訊。 |
| 5 | 環境 這是代理所處的真實世界或計算世界的一部分。 |
| 6 | 正向連結 一種用於得出問題結論/解決方案的前向工作策略。 |
| 7 | 啟發式 這是基於試錯、評估和實驗的知識。 |
| 8 | 知識工程 從人類專家和其他資源獲取知識。 |
| 9 | 感知 這是代理獲取有關環境資訊的格式。 |
| 10 | 剪枝 在人工智慧系統中忽略不必要和不相關的考慮因素。 |
| 11 | 規則 這是專家系統中表示知識庫的一種格式。它採用IF-THEN-ELSE的形式。 |
| 12 | 殼 (Shell) 殼是一個軟體,有助於設計專家系統的推理引擎、知識庫和使用者介面。 |
| 13 | 任務 這是代理試圖完成的目標。 |
| 14 | 圖靈測試 阿蘭·圖靈設計的一個測試,用於測試機器的智慧與人類智慧的比較。 |