人工智慧 - 神經網路
神經網路是 AI 中另一個研究領域,其靈感來自於人類神經系統的自然神經網路。
什麼是人工神經網路 (ANN)?
第一臺神經計算機的發明者羅伯特·赫克特-尼爾森博士將神經網路定義為:
“......一種由許多簡單、高度互連的處理單元組成的計算系統,這些單元透過對外部輸入的動態狀態響應來處理資訊。”
ANN 的基本結構
ANN 的思想基於這樣的信念:人腦透過建立正確的連線來工作,可以使用矽和導線來模仿活的神經元和樹突。
人腦由 860 億個稱為神經元的神經細胞組成。它們透過軸突與其他數千個細胞連線。來自外部環境或感覺器官的輸入刺激被樹突接收。這些輸入產生電脈衝,這些電脈衝迅速穿過神經網路。然後,神經元可以將資訊傳送給其他神經元來處理問題,或者不將其轉發。

ANN 由多個節點組成,這些節點模仿人腦的生物神經元。神經元透過連結連線,它們相互作用。節點可以接收輸入資料並在資料上執行簡單的操作。這些操作的結果傳遞給其他神經元。每個節點的輸出稱為其啟用或節點值。
每個連結都與權重相關聯。ANN 能夠學習,學習是透過改變權重值來實現的。下圖顯示了一個簡單的 ANN:
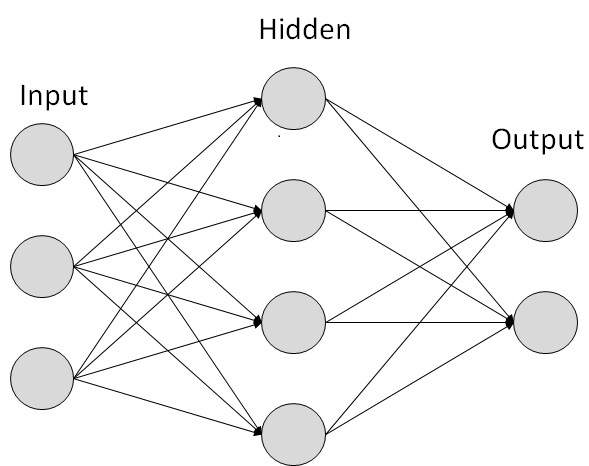
人工神經網路的型別
人工神經網路有兩種拓撲結構:前饋和反饋。
前饋 ANN
在這種 ANN 中,資訊流是單向的。一個單元將資訊傳送到另一個單元,而它不會從該單元接收任何資訊。沒有反饋迴路。它們用於模式生成/識別/分類。它們具有固定的輸入和輸出。

反饋 ANN
在這裡,允許反饋迴路。它們用於內容定址儲存器。
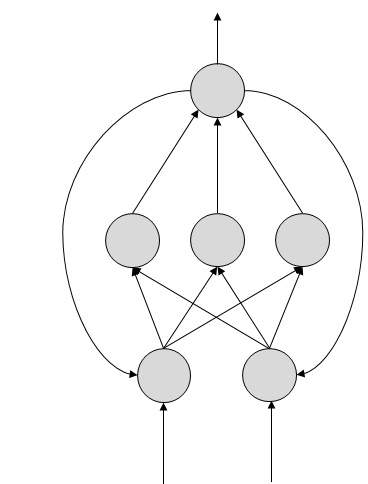
ANN 的工作原理
在所示的拓撲圖中,每個箭頭表示兩個神經元之間的連線,並指示資訊流的路徑。每個連線都有一個權重,一個控制兩個神經元之間訊號的整數。
如果網路生成“良好或期望的”輸出,則無需調整權重。但是,如果網路生成“差或不期望的”輸出或錯誤,則系統會更改權重以改進後續結果。
ANN 中的機器學習
ANN 能夠學習,並且需要進行訓練。有幾種學習策略:
監督學習 - 它涉及一位比 ANN 本身更博學的教師。例如,教師提供一些示例資料,教師已經知道這些資料的答案。
例如,模式識別。ANN 在識別時會提出猜測。然後,教師會向 ANN 提供答案。然後,網路將其猜測與教師的“正確”答案進行比較,並根據錯誤進行調整。
無監督學習 - 當沒有帶有已知答案的示例資料集時需要這種學習。例如,搜尋隱藏模式。在這種情況下,聚類,即根據現有資料集中的一些未知模式將一組元素劃分為組,是基於現有的資料集進行的。
強化學習 - 這種策略建立在觀察的基礎上。ANN 透過觀察其環境做出決策。如果觀察結果為負,則網路會調整其權重,以便下次能夠做出不同的所需決策。
反向傳播演算法
它是訓練或學習演算法。它透過示例學習。如果您向演算法提交您希望網路執行的操作的示例,它會更改網路的權重,以便它在完成訓練後可以為特定輸入生成所需的輸出。
反向傳播網路非常適合簡單的模式識別和對映任務。
貝葉斯網路 (BN)
這些是用於表示一組隨機變數之間機率關係的圖形結構。貝葉斯網路也稱為信念網路或貝葉斯網。BN 推理不確定域。
在這些網路中,每個節點都表示具有特定命題的隨機變數。例如,在醫學診斷領域,節點 Cancer 表示患者患有癌症的命題。
連線節點的邊表示這些隨機變數之間的機率依賴關係。如果兩個節點中的一個影響另一個,那麼它們必須在影響的方向上直接連線。變數之間關係的強度由與每個節點相關的機率來量化。
BN 中的弧線只有一個約束,即您不能簡單地沿著有向弧線返回到一個節點。因此,BN 被稱為有向無環圖 (DAG)。
BN 能夠同時處理多值變數。BN 變數由兩個維度組成:
- 命題的範圍
- 分配給每個命題的機率。
考慮一個有限集 X = {X1, X2, …,Xn} 的離散隨機變數,其中每個變數Xi可以取自一個有限集的值,表示為Val(Xi)。如果從變數Xi到變數Xj有一條有向連結,則變數Xi將是變數Xj的父節點,顯示變數之間的直接依賴關係。
BN 的結構非常適合結合先驗知識和觀察資料。BN 可用於學習因果關係並理解各種問題域,以及預測未來事件,即使在資料缺失的情況下也是如此。
構建貝葉斯網路
知識工程師可以構建貝葉斯網路。知識工程師在構建它時需要採取許多步驟。
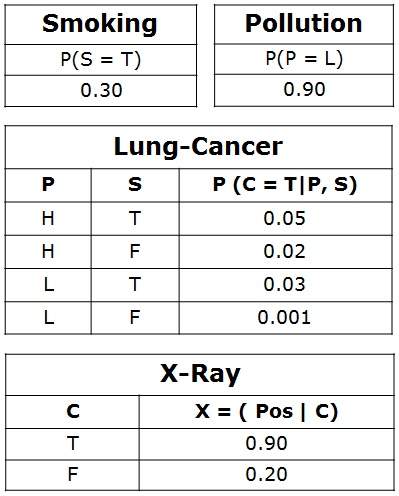
示例問題 - 肺癌。一位患者一直患有呼吸困難。他去看醫生,懷疑自己患有肺癌。醫生知道,除了肺癌外,患者還可能患有其他各種疾病,例如結核病和支氣管炎。
收集問題相關資訊
- 患者是否吸菸?如果是,則患癌症和支氣管炎的可能性很高。
- 患者是否接觸過空氣汙染?如果是,是什麼樣的空氣汙染?
- 進行 X 光檢查陽性 X 光檢查表明結核病或肺癌。
識別有趣的變數
知識工程師嘗試回答以下問題:
- 表示哪些節點?
- 它們可以取什麼值?它們可以處於什麼狀態?
現在讓我們考慮只有離散值的節點。變數必須每次恰好取這些值中的一個。
常見的離散節點型別有:
布林節點 - 它們表示命題,取二元值 TRUE (T) 和 FALSE (F)。
有序值 - 節點Pollution可以表示並取自{low, medium, high}的值,描述患者接觸汙染的程度。
整數值 - 一個名為Age的節點可以表示患者的年齡,可能的值範圍為 1 到 120。即使在這麼早的階段,建模選擇也在進行。
肺癌示例中可能的節點和值:
| 節點名稱 | 型別 | 值 | 節點建立 |
|---|---|---|---|
| 汙染 | 二進位制 | {LOW, HIGH, MEDIUM} |  |
| 吸菸者 | 布林值 | {TRUE, FASLE} | |
| 肺癌 | 布林值 | {TRUE, FASLE} | |
| X 射線 | 二進位制 | {陽性,陰性} |
建立節點之間的弧線
網路的拓撲結構應捕捉變數之間的定性關係。
例如,是什麼導致患者患肺癌?- 汙染和吸菸。然後從節點Pollution和節點Smoker新增弧線到節點Lung-Cancer。
同樣,如果患者患有肺癌,則 X 光檢查結果將為陽性。然後從節點Lung-Cancer新增弧線到節點X-Ray。

指定拓撲結構
按照慣例,BN 的佈局方式是弧線從上到下指向。節點 X 的父節點集由 Parents(X) 給出。
Lung-Cancer節點有兩個父節點(原因):Pollution和Smoker,而節點Smoker是節點X-Ray的祖先。類似地,X-Ray是節點Lung-Cancer的子節點(結果或影響)和節點Smoker和Pollution的後繼。
條件機率
現在量化連線節點之間的關係:這是透過為每個節點指定條件機率分佈來完成的。由於這裡只考慮離散變數,因此它採用條件機率表 (CPT)的形式。
首先,對於每個節點,我們需要檢視這些父節點的所有可能的值組合。每個這樣的組合稱為父集的例項化。對於父節點值的每個不同的例項化,我們需要指定子節點將取的值的機率。
例如,Lung-Cancer節點的父節點是Pollution和Smoking。它們取可能的值 = {(H,T), ( H,F), (L,T), (L,F)}。CPT 分別指定了每種情況下癌症的機率為<0.05, 0.02, 0.03, 0.001>。
每個節點將具有如下關聯的條件機率:
神經網路的應用
它們可以執行對人類來說很容易但對機器來說很困難的任務:
航空航天 - 自動駕駛飛機,飛機故障檢測。
汽車 - 汽車導航系統。
軍事 - 武器定位和轉向,目標跟蹤,目標識別,面部識別,訊號/影像識別。
電子 - 程式碼序列預測,IC 晶片佈局,晶片故障分析,機器視覺,語音合成。
金融 - 房地產估價、貸款顧問、抵押貸款篩選、公司債券評級、投資組合交易程式、公司財務分析、貨幣價值預測、檔案閱讀器、信用申請評估員。
工業 - 製造過程控制、產品設計與分析、質量檢驗系統、焊接質量分析、紙張質量預測、化學產品設計分析、化學過程系統的動態建模、機器維護分析、專案投標、計劃和管理。
醫療 - 癌細胞分析、腦電圖和心電圖分析、假肢設計、移植時間最佳化器。
語音 - 語音識別、語音分類、文字到語音轉換。
電信 - 影像和資料壓縮、自動化資訊服務、即時口語翻譯。
交通 - 卡車制動系統診斷、車輛排程、路線系統。
軟體 - 人臉識別、光學字元識別等中的模式識別。
時間序列預測 - 人工神經網路用於預測股票和自然災害。
訊號處理 - 神經網路可以被訓練來處理音訊訊號並在助聽器中對其進行適當的過濾。
控制 - 人工神經網路通常用於做出物理車輛的轉向決策。
異常檢測 - 由於人工神經網路擅長識別模式,因此它們也可以被訓練在發生與模式不符的異常情況時生成輸出。