人工智慧 - 自然語言處理
自然語言處理 (NLP) 指的是人工智慧利用自然語言(例如英語)與智慧系統進行交流的方法。
當您希望機器人等智慧系統根據您的指令執行操作時,或者當您希望從基於對話的臨床專家系統中聽到決策時,就需要進行自然語言處理。
NLP 領域涉及使計算機能夠使用人類使用的自然語言執行有用的任務。NLP 系統的輸入和輸出可以是:
- 語音
- 書面文字
NLP 的組成部分
NLP 有兩個組成部分:
自然語言理解 (NLU)
理解包括以下任務:
- 將給定的自然語言輸入對映到有用的表示形式。
- 分析語言的不同方面。
自然語言生成 (NLG)
它是從某種內部表示生成有意義的短語和句子的過程,以自然語言的形式呈現。
它包括:
文字規劃 - 它包括從知識庫中檢索相關內容。
句子規劃 - 它包括選擇所需的單詞,形成有意義的短語,設定句子的語氣。
文字實現 - 它是將句子計劃對映到句子結構。
NLU 比 NLG 更難。
NLU 的難點
自然語言具有極其豐富的形式和結構。
它非常模糊。可能存在不同級別的歧義:
詞彙歧義 - 這是在非常原始的級別,例如詞級。
例如,將單詞“board”視為名詞還是動詞?
句法級別歧義 - 一個句子可以以不同的方式解析。
例如,“He lifted the beetle with red cap.” - 他是用帽子舉起甲蟲,還是舉起了一隻戴著紅色帽子的甲蟲?
指稱歧義 - 使用代詞指代某事物。例如,麗瑪去了高麗。她說:“我累了。” - 到底是誰累了?
一個輸入可以表示不同的含義。
許多輸入可以表示相同的含義。
NLP 術語
音系學 - 它是對系統地組織聲音的研究。
形態學 - 它是對從原始有意義的單元構建單詞的研究。
語素 - 它是語言中意義的原始單位。
句法 - 它指的是排列單詞以構成句子。它還包括確定單詞在句子和短語中的結構作用。
語義學 - 它關注單詞的含義以及如何將單詞組合成有意義的短語和句子。
語用學 - 它處理在不同情況下使用和理解句子,以及句子的解釋是如何受到影響的。
語篇 - 它處理緊接的前一句如何影響下一句的解釋。
世界知識 - 它包括關於世界的常識。
NLP 的步驟
一般有五個步驟:
詞彙分析 - 它涉及識別和分析單詞的結構。一種語言的詞彙表是指該語言中單詞和短語的集合。詞彙分析是將整塊文字劃分為段落、句子和單詞。
句法分析(解析) - 它涉及分析句子中單詞的語法,並以顯示單詞之間關係的方式排列單詞。例如,“The school goes to boy”這樣的句子會被英語句法分析器拒絕。
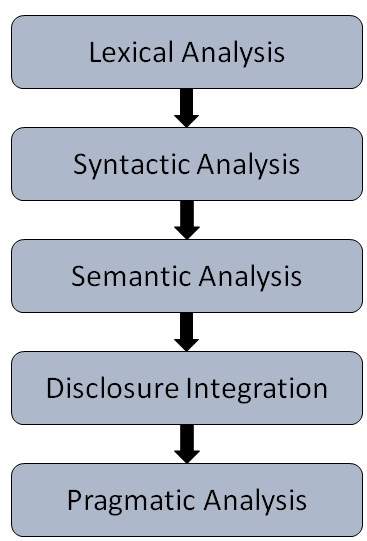
語義分析 - 它從文字中提取確切的含義或字典含義。文字的意義會被檢查。這是透過將句法結構和任務域中的物件對映來完成的。語義分析器會忽略諸如“熱的冰淇淋”之類的句子。
語篇整合 - 任何句子的含義都取決於其之前的句子的含義。此外,它還帶來了緊隨其後的句子的含義。
語用分析 - 在此過程中,所說的話會被重新解釋為其實際含義。它涉及推匯出需要現實世界知識的語言方面。
句法分析的實現方面
研究人員已經開發了許多用於句法分析的演算法,但我們只考慮以下簡單方法:
- 上下文無關文法
- 自頂向下解析器
讓我們詳細瞭解一下:
上下文無關文法
它是一種文法,其規則在重寫規則的左側只有一個符號。讓我們建立一個文法來解析句子:
“The bird pecks the grains”
冠詞 (DET) - a | an | the
名詞 - bird | birds | grain | grains
名詞短語 (NP) - 冠詞 + 名詞 | 冠詞 + 形容詞 + 名詞
= DET N | DET ADJ N
動詞 - pecks | pecking | pecked
動詞短語 (VP) - NP V | V NP
形容詞 (ADJ) - beautiful | small | chirping
解析樹將句子分解成結構化的部分,以便計算機可以輕鬆地理解和處理它。為了讓解析演算法構建這個解析樹,需要構建一組重寫規則,這些規則描述哪些樹結構是合法的。
這些規則說明樹中的某個符號可以透過其他符號的序列來展開。根據一階邏輯規則,如果有兩個字串名詞短語 (NP) 和動詞短語 (VP),則由 NP 後跟 VP 組合的字串就是一個句子。句子的重寫規則如下:
S → NP VP
NP → DET N | DET ADJ N
VP → V NP
詞彙表 -
DET → a | the
ADJ → beautiful | perching
N → bird | birds | grain | grains
V → peck | pecks | pecking
可以建立如下所示的解析樹:

現在考慮上述重寫規則。由於 V 可以被“peck”或“pecks”兩者替換,因此諸如“The bird peck the grains”之類的句子可能會被錯誤地允許。即主謂一致錯誤被認為是正確的。
優點 - 最簡單的語法風格,因此也是最常用的。
缺點:
它們不夠精確。例如,“The grains peck the bird”根據解析器在句法上是正確的,但即使它沒有意義,解析器也會將其視為正確的句子。
為了提高精度,需要準備多組語法。它可能需要為解析單數和複數變體、被動句等完全不同的規則集,這可能導致建立難以管理的大量規則集。
自頂向下解析器
在這裡,解析器從 S 符號開始,並嘗試將其重寫成與輸入句子中單詞類別匹配的終端符號序列,直到它完全由終端符號組成。
然後將其與輸入句子進行檢查以檢視是否匹配。如果不匹配,則使用不同的規則集重新啟動該過程。重複此過程,直到找到描述句子結構的特定規則。
優點 - 易於實現。
缺點:
- 它效率低下,因為如果發生錯誤,則必須重複搜尋過程。
- 工作速度慢。