- SEO 教程
- SEO - 首頁
- SEO - 什麼是 SEO?
- SEO - 策略與方法
- SEO - 頁面內最佳化技巧
- SEO - 頁面外最佳化技巧
- SEO - 網站域名
- SEO - 相關檔名
- SEO - 設計與佈局
- SEO - 最佳化關鍵詞
- SEO - 長尾關鍵詞
- SEO - 標題標籤
- SEO - 元描述
- SEO - 最佳化元標籤
- SEO - 為 Google 最佳化
- SEO - robots.txt
- SEO - URL 結構
- SEO - 標題
- SEO - 重定向
- SEO - 權威性和信任度
- SEO - PDF 檔案
- SEO - 最佳化錨文字
- SEO - 最佳化圖片
- SEO - 重複內容
- SEO - Meta Robots 標籤
- SEO - Nofollow 連結
- SEO - XML 網站地圖
- SEO - 規範化 URL
- SEO - UI/UX 的作用
- SEO - 關鍵詞差距分析
- SEO - 獲取高質量反向連結
- SEO - 新增 Schema 標記
- SEO - 作者權威性
- SEO - 修復斷鏈
- SEO - 內部頁面連結
- SEO - 清理不良連結
- SEO - 獲取權威反向連結
- SEO - 核心網頁指標
- SEO - 更新舊內容
- SEO - 填補內容空白
- SEO - 連結建設
- SEO - 特色程式碼段
- SEO - 從 Google 中刪除 URL
- SEO - 內容為王
- SEO - 驗證網站
- SEO - 多媒體型別
- SEO - Google 段落排名
- SEO - 最大化社交分享
- SEO - 首次連結優先規則
- SEO - 最佳化頁面載入時間
- SEO - 聘請專家
- SEO - 學習 EAT 原則
- SEO - 移動端 SEO 技巧
- SEO - 避免負面策略
- SEO - 其他技巧
- SEO - 持續站點審計
- SEO - 總結
- SEO 有用資源
- SEO - 快速指南
- SEO - 有用資源
- SEO - 討論
SEO - robots.txt
robots.txt 檔案包含網站上搜索引擎蜘蛛可以訪問的 URL 列表。這種方法不會阻止 Google 對網站進行索引;它主要用於控制網站免受搜尋過載的影響。使用 <noindex>阻止 Google 抓取網站內容或使用密碼保護以將其隱藏。
標準 robots.txt 檔案結構

即使 robots.txt 檔案可能包含許多使用者代理和指令(例如禁止、允許、抓取延遲等)行,但這兩部分組合在一起被認為是整個 robots.txt 檔案。
這是一個真實的“robots.txt”檔案示例

什麼是使用者代理?
每個搜尋引擎都使用唯一的使用者代理來識別自己。在 robots.txt 檔案中,您可以為每個使用者代理指定特定的指令。可以使用無數的使用者代理。但是,以下幾個對 SEO 很有幫助:
| 平臺和瀏覽器 | 使用者代理示例 |
|---|---|
| Windows 10 上的 Google Chrome | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 |
| MS Windows 10 上的 Mozilla | Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/113.0 |
| 適用於 macOS 的 Mozilla | Mozilla/5.0 (Macintosh; Intel Mac OS X 13.4; rv:109.0) Gecko/20100101 Firefox/113.0 |
| 適用於 Android 的 Mozilla | Mozilla/5.0 (Android 13; Mobile; rv:109.0) Gecko/113.0 Firefox/113.0 |
| macOS 上的 Safari | Mozilla/5.0 (Macintosh; Intel Mac OS X 13_4) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.5 Safari/605.1.15 |
| Microsoft Edge | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/113.0.1774.57 |
注意
請記住,robots.txt 對所有使用者代理都非常敏感。
要將指令分配給每個使用者代理,請使用星號 (*) 萬用字元。
以下是一些最流行的使用者代理機器人的示例:
| 建立者 | 機器人 |
|---|---|
| Googlebot | |
| 微軟必應 | Bingbot |
| 雅虎 | Slurp |
| Google 圖片 | Googlebot-Image |
| 百度 | Baiduspider |
| DuckDuckGo | DuckDuckBot |
例如,假設您希望阻止除 Googlebot 之外的所有機器人分析您的網站。以下是如何操作:

指令
您希望指定的使用者的代理遵守的準則稱為指令。
支援的指令
以下是 Google 目前識別及其應用的指令:
Disallow - 此指令用於阻止搜尋引擎訪問位於特定路徑的檔案和網頁。
Allow - 此指令用於允許或許可搜尋引擎訪問位於特定路徑的檔案和網頁。
Sitemaps - 要告訴搜尋引擎網站地圖的位置,請使用此指令。網站地圖通常包含網站開發者希望搜尋引擎蜘蛛掃描和索引的內容。
不支援的指令
以下列出的 Google 指令是從未正式支援且不再可用的一些指令。
Crawl-delay - 此指令以前用於指定抓取時間間隔。例如,假設您希望 Googlebot 在每次抓取操作之間保持 10 秒的空閒狀態,那麼抓取延遲將設定為 10。Bing 繼續支援此請求,而 Google 已停止。
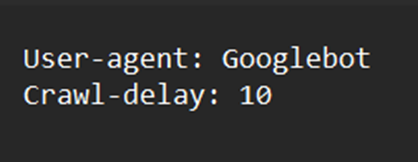
Noindex - Google 從未為此指令集提供任何正式支援。
Nofollow - Google 從未正式支援此指令。
robots.txt 檔案的最大允許大小是多少?
大約 500 千位元組。
robots.txt 檔案是必需的嗎?
大多數網站,特別是流量較小的網站,不一定需要包含 robots.txt 檔案。但是,沒有不包含它的正當理由。透過對搜尋引擎爬蟲允許訪問網站的內容擁有更大的控制權,您可以處理以下問題:
保護網站的私密區域,限制對相同資料的抓取。
限制對網頁內部搜尋結果的抓取。
防止伺服器擁塞和過載。
阻止 Google 消耗設定的抓取資源。
禁止資產檔案、影片和照片出現在 Google 搜尋結果頁面上。
儘管 Google 通常無法索引具有 robots.txt 限制的網站,但務必記住,沒有辦法透過使用 robots.txt 檔案來確保從搜尋結果中刪除。
查詢 robots.txt 檔案的方法
如果您已經設定了一個 robots.txt 檔案,則可以在“exampledomain.com/robots.txt”處找到網站的 robots.txt 指令碼。在 Web 瀏覽器中輸入那裡的 URL。當您看到類似以下內容的文字時,您就擁有了一個 robots.txt 檔案:

建立 robots.txt 檔案:說明
如果您從未建立過 robots.txt 檔案,它很簡單。只需啟動一個空白的 .txt 檔案並開始輸入指令。繼續新增您操作的指令,直到您涵蓋了所有預期欄位。將您儲存的檔案命名為“robots.txt”。
robots.txt 生成器是另一種選擇。使用此類工具的好處是它減少了語法錯誤。這是幸運的,因為單個錯誤可能會對您的網站產生災難性的 SEO 影響。缺點是靈活性方面存在一些限制。
robots.txt 檔案的位置
您的 robots.txt 檔案引用的子域名的主要目錄應包含它。例如,robots.txt 檔案必須位於“tutorialspoint.com/robots.txt”處才能控制“tutorialspoint.com”的抓取行為。
如果您希望將抓取限制為“ebooks.domain.com”等子域名,則必須能夠在“ebooks.domain.com/robots.txt”處檢視 robots.txt 檔案。
robots.txt 檔案指南
為每個指令另起一行
每個指令必須建立一行。如果它沒有建立,搜尋引擎蜘蛛將會感到困惑。
可以使用萬用字元使指令更易於訪問
在表達指令時,萬用字元 (*) 可以識別 URL 序列並在所有使用者代理中實現它們。
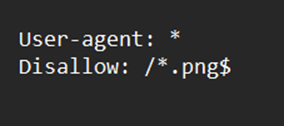
要指示 URL 的結尾,請輸入“$”。
要指示 URL 的結尾,請使用美元符號“$”。如果您希望阻止 Web 爬蟲檢視您網站上的所有 .png 檔案,則 robots.txt 檔案可能類似於以下內容:
每個使用者代理只使用一次
當您重複使用單個使用者代理時,Google 不會介意。但是,將合併和遵循來自不同宣告的所有規則,從而降低準確性,並且在某些情況下,不會計算一個方面。考慮到配置的複雜性較低,因此只需指定每個使用者代理一次是有意義的。保持井井有條和簡單可以降低您犯嚴重錯誤的風險。
編寫註釋以告知其他人有關您的 robots.txt 檔案
由於註釋的存在,開發人員(甚至您以後的自己)可以更容易地理解您的 robots.txt 檔案。應使用雜湊 (#) 開頭註釋行。
詳細說明以防止意外錯誤
設定指令而沒有具體準則可能會導致被忽視的錯誤,這些錯誤可能會嚴重損害您的 SEO 工作。
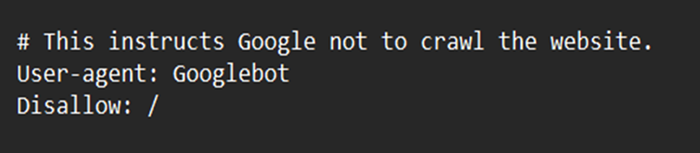
由於 robots.txt 導致的阻止問題
這表示您的網站上存在未被 Google 索引的內容,這些內容已被 robots.txt 限制。如果資料很重要並且需要被抓取和索引,請關閉 robots.txt 爬蟲限制。
結論
robots.txt 是一個簡單但有效的檔案。如果使用得當,它可以幫助您的 SEO。如果您不小心使用它,您以後會後悔的。