
- SAP HANA 教程
- SAP HANA - 首頁
- SAP HANA 簡介
- SAP HANA - 概述
- 記憶體計算引擎 (In-Memory Computing Engine)
- SAP HANA - Studio
- Studio 管理檢視
- SAP HANA - 系統監控
- SAP HANA - 資訊建模器
- SAP HANA - 核心架構
- SAP HANA 建模
- SAP HANA - 建模
- SAP HANA - 資料倉庫
- SAP HANA - 表
- SAP HANA - 包
- SAP HANA - 屬性檢視
- SAP HANA - 分析檢視
- SAP HANA - 計算檢視
- SAP HANA - 分析許可權
- SAP HANA - 資訊組合器
- SAP HANA - 匯出和匯入
- SAP HANA 安全性
- SAP HANA - 安全性概述
- 使用者管理與維護
- SAP HANA - 身份驗證
- SAP HANA - 授權方法
- SAP HANA - 許可證管理
- SAP HANA - 審計
- SAP HANA 資料複製
- SAP HANA - 資料複製概述
- SAP HANA - 基於 ETL 的複製
- SAP HANA - 基於日誌的複製
- SAP HANA - DXC 方法
- SAP HANA - CTL 方法
- SAP HANA - MDX 提供程式
- SAP HANA SQL
- SAP HANA - SQL 概述
- SAP HANA - 資料型別
- SAP HANA - SQL 運算子
- SAP HANA - SQL 函式
- SAP HANA - SQL 表示式
- SAP HANA - SQL 儲存過程
- SAP HANA - SQL 序列
- SAP HANA - SQL 觸發器
- SAP HANA - SQL 同義詞
- SAP HANA - SQL 執行計劃
- SAP HANA - SQL 資料分析
- SAP HANA - SQL 指令碼
- SAP HANA 有用資源
- SAP HANA - 問答
- SAP HANA 快速指南
- SAP HANA - 有用資源
- SAP HANA - 討論
SAP HANA 快速指南
SAP HANA - 概述
SAP HANA 集成了 HANA 資料庫、資料建模、HANA 管理和資料供應在一個單一的套件中。在 SAP HANA 中,HANA 代表高效能分析裝置 (High-Performance Analytic Appliance)。
據前 SAP 高管 Vishal Sikka 博士介紹,HANA 代表 Hasso 的新架構 (Hasso’s New Architecture)。HANA 在 2011 年中期引起了人們的興趣,此後,許多財富 500 強公司開始將其視為滿足業務倉庫需求的一種選擇。
SAP HANA 的特性
SAP HANA 的主要特性如下:
SAP HANA 結合了軟體和硬體創新,可以處理海量即時資料。
基於分散式系統環境中的多核架構。
基於資料庫中行和列型別的資料儲存。
廣泛應用於記憶體計算引擎 (IMCE) 中,用於處理和分析海量即時資料。
它降低了擁有成本,提高了應用程式效能,使以前不可能在即時環境中執行的新應用程式得以執行。
它是用 C++ 編寫的,僅支援並在 Suse Linux Enterprise Server 11 SP1/2 作業系統上執行。
SAP HANA 的需求
如今,大多數成功的公司都能快速響應市場變化和新機遇。關鍵在於分析師和管理人員有效且高效地利用資料和資訊。
HANA 克服了以下限制:
由於“資料量”的增加,公司難以提供對即時資料進行分析和業務使用的訪問。
對於 IT 公司來說,儲存和維護大量資料會產生高昂的維護成本。
由於即時資料不可用,分析和處理結果會延遲。
SAP HANA 供應商
SAP 已與 IBM、Dell、Cisco 等領先的 IT 硬體供應商建立了合作伙伴關係,並將 SAP 許可服務和技術與之結合,以銷售 SAP HANA 平臺。
共有 11 家供應商生產 HANA 裝置,並提供 HANA 系統安裝和配置的現場支援。
主要的幾家供應商包括:
- IBM
- Dell
- HP
- Cisco
- 富士通
- 聯想(中國)
- NEC
- 華為
根據 SAP 提供的統計資料,IBM 是 SAP HANA 硬體裝置的主要供應商之一,市場份額為 50-52%,但根據 HANA 客戶進行的另一項市場調查,IBM 的市場佔有率高達 70%。
SAP HANA 安裝
HANA 硬體供應商提供預配置的硬體、作業系統和 SAP 軟體產品裝置。
供應商透過 HANA 元件的現場設定和配置完成安裝。現場訪問包括在資料中心部署 HANA 系統、連線到組織網路、SAP 系統 ID 適配、來自 Solution Manager 的更新、SAP 路由器連線、SSL 啟用和其他系統配置。
客戶開始連線資料來源系統和 BI 客戶端。HANA Studio 安裝在本地系統上完成,並新增 HANA 系統以執行資料建模和管理。
SAP HANA - 記憶體計算引擎 (In-Memory Computing Engine)
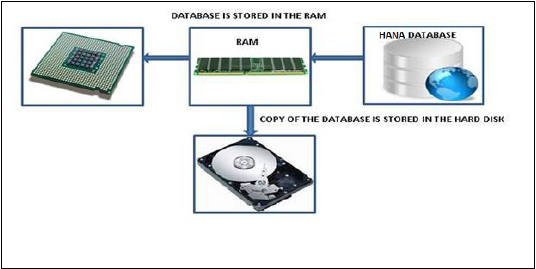
記憶體資料庫意味著來自源系統的所有資料都儲存在 RAM 記憶體中。在傳統的資料庫系統中,所有資料都儲存在硬碟中。SAP HANA 記憶體資料庫無需花費時間將資料從硬碟載入到 RAM。它為多核 CPU 提供更快的資料訪問,用於資訊處理和分析。
記憶體資料庫的特性
SAP HANA 記憶體資料庫的主要特性:
SAP HANA 是混合記憶體資料庫。
它結合了基於行、基於列和基於物件的技術。
它使用多核 CPU 架構進行並行處理。
傳統資料庫讀取記憶體資料需要 5 毫秒。SAP HANA 記憶體資料庫讀取資料需要 5 納秒。
這意味著 HANA 資料庫中的記憶體讀取速度比傳統資料庫硬碟記憶體讀取速度快 100 萬倍。
分析師希望立即即時檢視當前資料,而不希望等到資料載入到 SAP BW 系統後再檢視。SAP HANA 記憶體處理允許使用各種資料供應技術載入即時資料。
記憶體資料庫的優勢
HANA 資料庫利用記憶體處理來提供最快的資料檢索速度,這對於難以處理大規模線上交易或及時預測和規劃的公司來說非常誘人。
基於磁碟的儲存仍然是企業標準,RAM 的價格一直在穩步下降,因此記憶體密集型架構最終將取代緩慢的機械旋轉磁碟,並將降低資料儲存成本。
基於列的記憶體儲存可將資料壓縮高達 11 倍,從而減少大量資料的儲存空間。
RAM 儲存系統提供的速度優勢透過在分散式環境中使用多核 CPU、每個節點的多個 CPU 和每個伺服器的多個節點得到進一步增強。
SAP HANA - Studio
SAP HANA Studio 是一個基於 Eclipse 的工具。SAP HANA Studio 既是 HANA 系統的中央開發環境,也是主要的管理工具。其他功能包括:
它是一個客戶端工具,可用於訪問本地或遠端 HANA 系統。
它為 HANA 管理、HANA 資訊建模和 HANA 資料庫中的資料供應提供了一個環境。
SAP HANA Studio 可在以下平臺上使用:
Microsoft Windows 32 位和 64 位版本:Windows XP、Windows Vista、Windows 7
SUSE Linux Enterprise Server SLES11:x86 64 位
Mac OS,HANA Studio 客戶端不可用
根據 HANA Studio 的安裝情況,並非所有功能都可用。在 Studio 安裝時,請根據角色指定要安裝的功能。要使用最新版本的 HANA Studio,可以使用軟體生命週期管理器更新客戶端。
SAP HANA Studio 透檢視/功能
SAP HANA Studio 提供了用於處理以下 HANA 功能的透檢視。您可以從以下選項中選擇 HANA Studio 中的透檢視:
Sap Hana Studio → 視窗 → 開啟透檢視 → 其他
SAP HANA Studio 管理
用於各種管理任務的工具集,不包括可傳輸的設計時儲存庫物件。還包括諸如跟蹤、目錄瀏覽器和 SQL 控制檯之類的常規故障排除工具。
SAP HANA Studio 資料庫開發
它提供內容開發工具集。它尤其解決了 DataMarts 和 ABAP on SAP HANA 場景,其中不包括 SAP HANA 原生應用程式開發 (XS)。
SAP HANA Studio 應用程式開發
SAP HANA 系統包含一個小型 Web 伺服器,可用於託管小型應用程式。它提供用於開發 SAP HANA 原生應用程式的工具集,例如用 Java 和 HTML 編寫的應用程式程式碼。
預設情況下,所有功能都已安裝。
SAP HANA - Studio 管理檢視
要執行 HANA 資料庫管理和監控功能,可以使用 SAP HANA 管理控制檯透檢視。
管理員編輯器可以透過多種方式訪問:
從系統檢視工具欄 - 選擇“開啟管理”預設按鈕
在系統檢視中 - 雙擊 HANA 系統或開啟透檢視

HANA Studio:管理員編輯器
在管理檢視中:HANA Studio 提供多個選項卡來檢查 HANA 系統的配置和執行狀況。概述選項卡顯示常規資訊,例如操作狀態、第一次和最後一次啟動服務的啟動時間、版本、構建日期和時間、平臺、硬體製造商等。
將 HANA 系統新增到 Studio
可以將一個或多個系統新增到 HANA Studio 以進行管理和資訊建模。要新增新的 HANA 系統,需要主機名、例項號以及資料庫使用者名稱和密碼。
- 應開啟埠 3615 以連線到資料庫
- 埠 31015 例項號 10
- 埠 30015 例項號 00
- 還應開啟 SSh 埠
將系統新增到 Hana Studio
要將系統新增到 HANA Studio,請按照以下步驟操作。
右鍵單擊導航器空間,然後單擊“新增系統”。輸入 HANA 系統詳細資訊,即主機名和例項號,然後單擊下一步。
輸入資料庫使用者名稱和密碼以連線到 SAP HANA 資料庫。單擊下一步,然後單擊完成。

單擊完成後,HANA 系統將新增到系統檢視中,用於管理和建模。每個 HANA 系統都有兩個主要的子節點,即目錄和內容。

目錄和內容
目錄
它包含所有可用的模式,即所有資料結構、表和資料、列檢視、可在內容選項卡中使用的過程。
內容
內容選項卡包含設計時儲存庫,其中包含使用 HANA Modeler 建立的所有資料模型的資訊。這些模型按包組織。內容節點提供對相同物理資料的不同檢視。
SAP HANA - 系統監控
HANA Studio 中的系統監控器提供所有 HANA 系統的概覽。從系統監控器中,您可以深入瞭解管理編輯器中單個系統的詳細資訊。它顯示有關資料磁碟、日誌磁碟、跟蹤磁碟以及資源使用情況(按優先順序排序)的警報。
系統監控器中提供以下資訊:

SAP HANA - 資訊建模器
SAP HANA 資訊建模器;也稱為 HANA 資料建模器是 HANA 系統的核心。它能夠在資料庫表之上建立建模檢視,並實現業務邏輯以建立有意義的分析報告。
資訊建模器的功能
提供儲存在 HANA 資料庫物理表中的事務資料的多種檢視,用於分析和業務邏輯目的。
資訊建模器僅適用於基於列的儲存表。
資訊建模檢視由基於 Java 或 HTML 的應用程式或 SAP 工具(如 SAP Lumira 或 Analysis Office)用於報告目的。
也可以使用第三方工具(如 MS Excel)連線到 HANA 並建立報表。
SAP HANA 建模檢視充分利用了 SAP HANA 的強大功能。
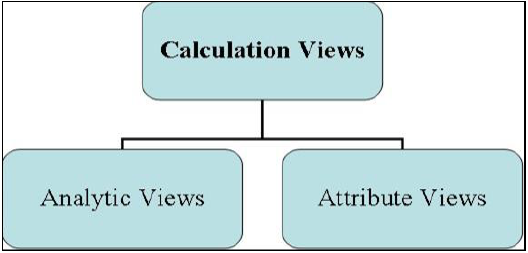
資訊檢視有三種類型,定義如下:
- 屬性檢視
- 分析檢視
- 計算檢視
行儲存與列儲存
SAP HANA 建模檢視只能在基於列的表之上建立。將資料儲存在列表中並非什麼新鮮事。早些時候,人們認為將資料儲存在基於列的結構中會佔用更多記憶體,並且效能未經最佳化。

隨著 SAP HANA 的發展,HANA 在資訊檢視中使用了基於列的資料儲存,並展示了列表相對於行表的真正優勢。
列儲存
在列儲存表中,資料垂直儲存。因此,類似的資料型別組合在一起,如上例所示。它藉助記憶體計算引擎提供更快的記憶體讀寫操作。
在傳統的資料庫中,資料以基於行的結構(即水平)儲存。SAP HANA 以基於行和基於列的結構儲存資料。這在 HANA 資料庫中提供了效能最佳化、靈活性和資料壓縮。
在基於列的表中儲存資料具有以下優點:
資料壓縮
與傳統的基於行的儲存相比,表讀寫訪問速度更快
靈活性和並行處理
以更高的速度執行聚合和計算
有多種方法和演算法可以將資料儲存在基於列的結構中——字典壓縮、遊程長度壓縮等等。
在字典壓縮中,單元格以數字的形式儲存在表中,數字單元格始終比字元具有更好的效能。
在遊程長度壓縮中,它以數字格式儲存單元格值的乘數,乘數顯示錶中重複的值。

功能差異 - 行儲存與列儲存
如果 SQL 語句需要執行聚合函式和計算,則始終建議使用基於列的儲存。在執行 Sum、Count、Max、Min 等聚合函式時,基於列的表始終表現更好。
如果輸出必須返回完整行,則首選基於行儲存。以下示例使理解變得更容易。
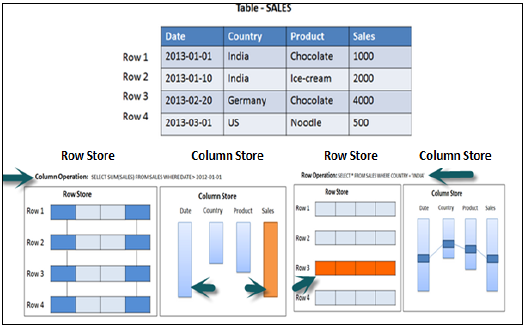
在上面的示例中,在使用 Where 子句執行 sales 列中的聚合函式 (Sum) 時,它只使用 Date 和 Sales 列執行 SQL 查詢,因此,如果它是基於列的儲存表,則它將是效能最佳化的,速度更快,因為只需要來自兩列的資料。
在執行簡單的 Select 查詢時,必須在輸出中列印完整行,因此在這種情況下建議將表儲存為基於行的表。
資訊建模檢視
屬性檢視
屬性是資料庫表中不可度量的元素。它們表示主資料,類似於 BW 的特徵。屬性檢視是資料庫中的維度,或者用於在建模中連線維度或其他屬性檢視。
重要功能包括:
- 屬性檢視用於分析檢視和計算檢視。
- 屬性視圖表示主資料。
- 用於過濾分析檢視和計算檢視中維度表的大小。
分析檢視
分析檢視利用 SAP HANA 的強大功能對資料庫中的表執行計算和聚合函式。它至少有一個包含度量和維度表主鍵的事實表,並且周圍的維度表包含主資料。
重要功能包括:
分析檢視旨在執行星型模式查詢。
分析檢視至少包含一個事實表和多個包含主資料的維度表,並執行計算和聚合。
它們類似於 SAP BW 中的 InfoCube 和 Info 物件。
分析檢視可以建立在屬性檢視和事實表之上,並執行計算,例如銷售數量、總價格等。
計算檢視
計算檢視用於在分析檢視和屬性檢視之上執行復雜的計算,這些計算是分析檢視無法實現的。計算檢視是基本列表、屬性檢視和分析檢視的組合,用於提供業務邏輯。
重要功能包括:
計算檢視可以使用 HANA 建模功能以圖形方式定義,也可以使用 SQL 編寫指令碼。
它的建立是為了執行復雜的計算,而這些計算是 SAP HANA 建模器的其他檢視(屬性檢視和分析檢視)無法實現的。
藉助內建函式(如 Projects、Union、Join、Rank),計算檢視會使用一個或多個屬性檢視和分析檢視。
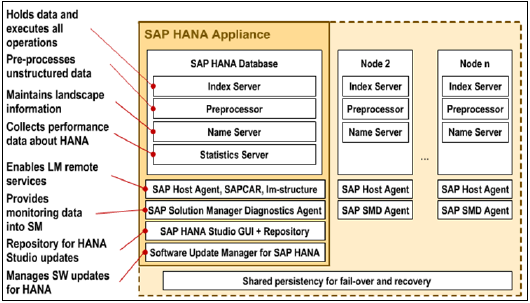
SAP HANA - 核心架構
SAP HANA 最初是用 Java 和 C++ 開發的,並且設計為僅執行 Suse Linux Enterprise Server 11 作業系統。SAP HANA 系統包含多個元件,這些元件負責強調 HANA 系統的計算能力。
SAP HANA 系統最重要的元件是索引伺服器,它包含 SQL/MDX 處理器,用於處理資料庫的查詢語句。
HANA 系統包含名稱伺服器、預處理器伺服器、統計伺服器和 XS 引擎,用於通訊和託管小型 Web 應用程式以及各種其他元件。
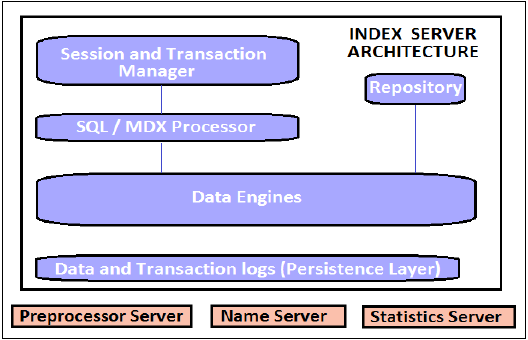
索引伺服器
索引伺服器是 SAP HANA 資料庫系統的核心。它包含實際資料和處理該資料的引擎。當為 SAP HANA 系統觸發 SQL 或 MDX 時,索引伺服器會處理所有這些請求並對其進行處理。所有 HANA 處理都在索引伺服器中進行。
索引伺服器包含資料引擎,用於處理進入 HANA 資料庫系統的所有 SQL/MDX 語句。它還具有永續性層,負責 HANA 系統的永續性,並確保在系統故障或重新啟動時將 HANA 系統恢復到最新狀態。
索引伺服器還具有會話和事務管理器,用於管理事務並跟蹤所有正在執行和已關閉的事務。
索引伺服器 - 架構
SQL/MDX 處理器
它負責使用負責執行查詢的資料引擎處理 SQL/MDX 事務。它分割所有查詢請求並將它們定向到正確的引擎以進行效能最佳化。
它還確保所有 SQL/MDX 請求都已授權,並提供錯誤處理以有效處理這些語句。它包含用於查詢執行的多個引擎和處理器:
MDX(多維表示式)是 OLAP 系統的查詢語言,就像 SQL 用於關係資料庫一樣。MDX 引擎負責處理查詢並操作儲存在 OLAP 多維資料集中多維資料。
規劃引擎負責在 SAP HANA 資料庫中執行規劃操作。
計算引擎將資料轉換為計算模型,以建立邏輯執行計劃以支援語句的並行處理。
儲存過程處理器執行過程呼叫以進行最佳化的處理;它將 OLAP 多維資料集轉換為 HANA 最佳化的多維資料集。
事務和會話管理
它負責協調所有資料庫事務並跟蹤所有正在執行和已關閉的事務。
當事務執行或失敗時,事務管理器會通知相關資料引擎採取必要的措施。
會話管理元件負責使用預定義的會話引數初始化和管理 SAP HANA 系統的會話和連線。
永續性層
它負責 HANA 系統中事務的永續性和原子性。永續性層為 HANA 資料庫提供內建的災難恢復系統。
它確保資料庫恢復到最新狀態,並確保在系統故障或重新啟動時完成或撤消所有事務。
它還負責管理資料和事務日誌,還包含 HANA 系統的資料備份、日誌備份和配置備份。備份作為儲存點儲存在資料卷中,透過儲存點協調器,通常設定為每 5-10 分鐘儲存一次備份。
預處理器伺服器
SAP HANA 系統中的預處理器伺服器用於文字資料分析。
當使用文字搜尋功能時,索引伺服器使用預處理器伺服器分析文字資料並從文字資料中提取資訊。
名稱伺服器
名稱伺服器包含 HANA 系統的系統環境資訊。在分散式環境中,有多個節點,每個節點有多個 CPU,名稱伺服器儲存 HANA 系統的拓撲結構,幷包含有關所有正在執行的元件的資訊,這些資訊分佈在所有元件上。
這裡記錄了 SAP HANA 系統的拓撲結構。
它減少了重新索引的時間,因為它儲存了分散式環境中哪些資料位於哪個伺服器上。
統計伺服器
此伺服器檢查並分析 HANA 系統中所有元件的執行狀況。統計伺服器負責收集與系統資源、資源分配和使用以及 HANA 系統整體效能相關的資料。
它還提供與系統性能相關的歷史資料,用於分析目的,以檢查和修復 HANA 系統中的效能相關問題。
XS 引擎
XS 引擎幫助外部基於 Java 和 HTML 的應用程式透過 XS 客戶端訪問 HANA 系統。由於 SAP HANA 系統包含一個 Web 伺服器,該伺服器可用於託管小型基於 JAVA/HTML 的應用程式。
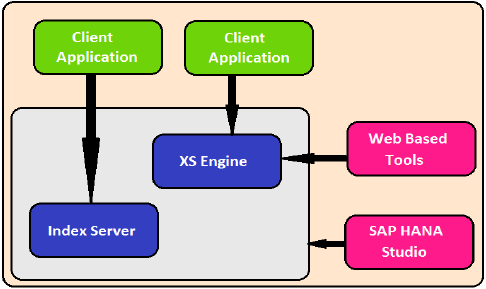
XS 引擎將儲存在資料庫中的永續性模型轉換為透過 HTTP/HTTPS 公開的客戶端的消費模型。
SAP 主機代理
應在屬於 SAP HANA 系統環境的所有計算機上安裝 SAP 主機代理。軟體更新管理器 SUM 使用 SAP 主機代理在分散式環境中將自動更新安裝到 HANA 系統的所有元件。
LM 結構
SAP HANA 系統的 LM 結構包含有關當前安裝詳細資訊的資訊。軟體更新管理器使用此資訊在 HANA 系統元件上安裝自動更新。
SAP Solution Manager (SAP SOLMAN) 診斷代理
此診斷代理向 SAP Solution Manager 提供所有資料以監控 SAP HANA 系統。此代理提供有關 HANA 資料庫的所有資訊,包括資料庫當前狀態和常規資訊。
當 SAP SOLMAN 與 SAP HANA 系統整合時,它提供 HANA 系統的配置詳細資訊。
SAP HANA Studio 資源庫
SAP HANA Studio 倉庫幫助 HANA 開發人員將當前版本的 HANA Studio 更新到最新版本。Studio 倉庫儲存執行此更新的程式碼。
SAP HANA 軟體更新管理器
SAP Market Place 用於安裝 SAP 系統的更新。HANA 系統的軟體更新管理器有助於從 SAP Market Place 更新 HANA 系統。
它用於軟體下載、客戶訊息、SAP Notes 和請求 HANA 系統的許可證金鑰。它還用於將 HANA Studio 分發到終端使用者的系統。
SAP HANA - 建模
SAP HANA Modeler 選項用於在 HANA 資料庫的模式 → 表之上建立資訊檢視。這些檢視由基於 JAVA/HTML 的應用程式或 SAP 應用程式(如 SAP Lumira、Office Analysis)或第三方軟體(如 MS Excel)用於報告目的,以滿足業務邏輯並執行分析和資訊提取。
HANA 建模是在 HANA Studio 中“模式”下的“目錄”選項卡中提供的表之上完成的,所有檢視都儲存在“包”下的“內容”表中。
您可以在 HANA Studio 的“內容”選項卡下,右鍵單擊“內容”並選擇“新建”來建立新的包。
在一個包內建立的所有建模檢視都位於 HANA Studio 中的同一個包下,並按檢視型別進行分類。
每個檢視對於維度表和事實表都有不同的結構。維度表定義了主資料,事實表包含維度表的主鍵和度量,例如銷售單位數量、平均延遲時間、總價等。
事實表和維度表
事實表包含維度表的主鍵和度量。它們在 HANA 檢視中與維度表連線以滿足業務邏輯。
度量示例 - 銷售單位數量、總價、平均延遲時間等。
維度表包含主資料,並與一個或多個事實表連線以實現某些業務邏輯。維度表用於建立具有事實表的模式,並且可以被規範化。
維度表示例 - 客戶、產品等。
假設一家公司向客戶銷售產品。每次銷售都是公司內發生的事實,事實表用於記錄這些事實。
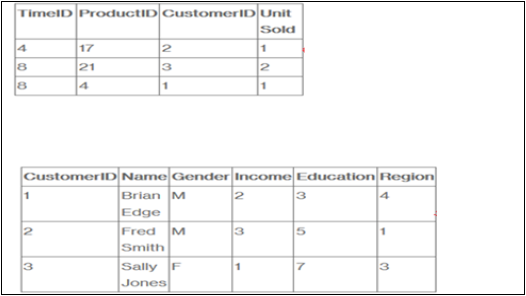
例如,事實表中的第 3 行記錄了客戶 1(Brian)在第 4 天購買了一件商品的事實。在一個完整的示例中,我們還將擁有產品表和時間表,以便我們知道她購買了什麼以及確切的時間。
事實表列出了我們公司中發生的事情(或至少是我們想要分析的事件——銷售單位數量、利潤率和銷售收入)。維度表列出了我們想要據此分析資料的因素(客戶、時間和產品)。
SAP HANA - 資料倉庫中的模式
模式是對資料倉庫中表的邏輯描述。模式是透過連線多個事實表和維度表來滿足某些業務邏輯而建立的。
資料庫使用關係模型來儲存資料。但是,資料倉庫使用連線維度表和事實表以滿足業務邏輯的模式。資料倉庫中使用三種類型的模式:
- 星型模式
- 雪花模式
- 星系模式
星型模式
在星型模式中,每個維度都連線到一個事實表。每個維度僅由一個維度表示,並且不會進一步規範化。
維度表包含用於分析資料的屬性集。
示例 - 在下面的示例中,我們有一個事實表 FactSales,它包含所有維度表的主鍵以及度量 units_sold 和 dollars_sold 用於分析。
我們有四個維度表:DimTime、DimItem、DimBranch、DimLocation。
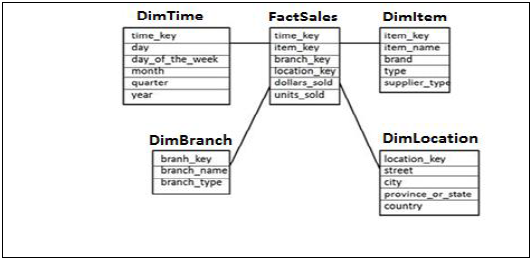
每個維度表都連線到事實表,因為事實表包含每個維度表的主鍵,用於連線兩個表。
事實表中的事實/度量與維度表中的屬性一起用於分析目的。
雪花模式
在雪花模式中,某些維度表被進一步規範化,並且維度表連線到單個事實表。規範化用於組織資料庫的屬性和表,以最大限度地減少資料冗餘。
規範化包括將表分解成冗餘較少的較小表,而不會丟失任何資訊,並且較小表連線到維度表。
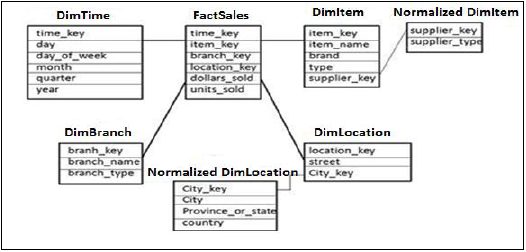
在上面的示例中,DimItem 和 DimLocation 維度表在不丟失任何資訊的情況下被規範化。這稱為雪花模式,其中維度表被進一步規範化為較小表。
星系模式
在星系模式中,存在多個事實表和維度表。每個事實表儲存一些維度表的主鍵以及度量/事實以進行分析。

在上面的示例中,有兩個事實表 FactSales、FactShipping 和多個連線到事實表的維度表。每個事實表都包含連線的維度表的主鍵以及度量/事實以執行分析。
SAP HANA - 表
可以從 HANA Studio 中“模式”下的“目錄”選項卡訪問 HANA 資料庫中的表。可以使用以下兩種方法建立新表:
- 使用 SQL 編輯器
- 使用 GUI 選項
HANA Studio 中的 SQL 編輯器
可以透過選擇要使用系統檢視 SQL 編輯器選項建立新表的模式名稱,或右鍵單擊模式名稱(如下所示)來開啟 SQL 控制檯:

開啟 SQL 編輯器後,可以從 SQL 編輯器頂部顯示的名稱確認模式名稱。可以使用 SQL Create Table 語句建立新表:
Create column Table Test1 ( ID INTEGER, NAME VARCHAR(10), PRIMARY KEY (ID) );
在此 SQL 語句中,我們建立了一個列表“Test1”,定義了表的資料庫型別和主鍵。
編寫 Create table SQL 查詢後,單擊 SQL 編輯器右側頂部的“執行”選項。語句執行後,我們將收到如下快照所示的確認訊息:
語句“Create column Table Test1 (ID INTEGER,NAME VARCHAR(10), PRIMARY KEY (ID))”
已在 13 毫秒 761 微秒內成功執行(伺服器處理時間:12 毫秒 979 微秒) - 受影響的行數:0
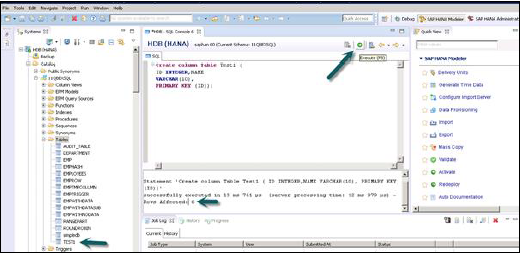
執行語句還說明了執行語句所花費的時間。語句成功執行後,右鍵單擊系統檢視中模式名稱下的“表”選項卡並重新整理。新表將反映在模式名稱下的表列表中。
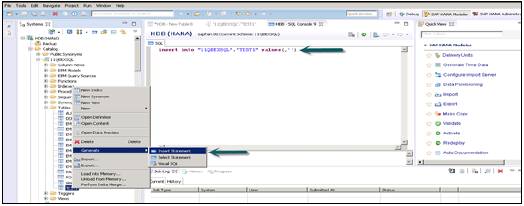
Insert 語句用於使用 SQL 編輯器將資料輸入表中。
Insert into TEST1 Values (1,'ABCD') Insert into TEST1 Values (2,'EFGH');
單擊“執行”。
您可以右鍵單擊表名並使用“開啟資料定義”查看錶的資料庫型別。使用“開啟資料預覽/開啟內容”查看錶內容。
使用 GUI 選項建立表
在 HANA 資料庫中建立表的另一種方法是使用 HANA Studio 中的 GUI 選項。
右鍵單擊模式下的“表”選項卡 → 選擇“新建表”選項,如下面的快照所示。
單擊“新建表”後,將開啟一個視窗以輸入表名,從下拉列表中選擇模式名稱,從下拉列表中定義表型別:列儲存或行儲存。
定義如下所示的資料庫型別。可以透過單擊“+”號新增列,可以透過單擊列名前主鍵單元格選擇主鍵,“非空”預設情況下處於活動狀態。
新增列後,單擊“執行”。

執行 (F8) 後,右鍵單擊“表”選項卡 → 重新整理。新表將反映在所選模式下的表列表中。下面的“插入”選項可用於將資料插入表中。“選擇”語句用於查看錶的內容。
在 HANA Studio 中使用 GUI 將資料插入表中
您可以右鍵單擊表名並使用“開啟資料定義”查看錶的資料庫型別。使用“開啟資料預覽/開啟內容”查看錶內容。
要使用一個模式中的表建立檢視,我們應該向在 HANA 建模中執行所有檢視的預設使用者提供對該模式的訪問許可權。這可以透過轉到 SQL 編輯器並執行以下查詢來完成:
GRANT SELECT ON SCHEMA "<SCHEMA_NAME>" TO _SYS_REPO WITH GRANT OPTION
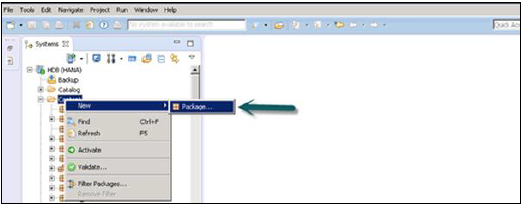
SAP HANA - 包
SAP HANA 包顯示在 HANA Studio 的“內容”選項卡下。所有 HANA 建模都儲存在包中。
您可以透過右鍵單擊“內容”選項卡 → 新建 → 包來建立新包。
您還可以透過右鍵單擊包名稱在包下建立子包。當我們右鍵單擊包時,我們會得到 7 個選項:我們可以在包下建立 HANA 檢視屬性檢視、分析檢視和計算檢視。
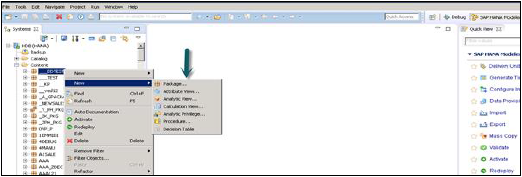
您還可以建立決策表、定義分析許可權並在包中建立過程。
右鍵單擊包並單擊“新建”時,您還可以建立包中的子包。建立包時,您必須輸入包名稱和描述。
SAP HANA - 屬性檢視
SAP HANA 建模中的屬性檢視是在維度表之上建立的。它們用於連線維度表或其他屬性檢視。您還可以從其他包中已存在的屬性檢視複製新的屬性檢視,但這不允許您更改檢視屬性。
屬性檢視的特性
HANA 中的屬性檢視用於連線維度表或其他屬性檢視。
屬性檢視用於分析檢視和計算檢視中進行分析以傳遞主資料。
它們類似於 BM 中的特徵,幷包含主資料。
屬性檢視用於大型維度表的效能最佳化,您可以限制屬性檢視中進一步用於報告和分析目的的屬性數量。
屬性檢視用於建模主資料以提供一些上下文。
如何建立屬性檢視?
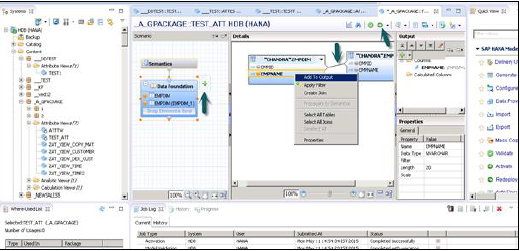
選擇要在其下建立屬性檢視的包名稱。右鍵單擊包 → 轉到新建 → 屬性檢視

單擊“屬性檢視”後,將開啟一個新視窗。輸入屬性檢視名稱和描述。從下拉列表中選擇檢視型別和子型別。在子型別中,有三種類型的屬性檢視:標準、時間和派生。
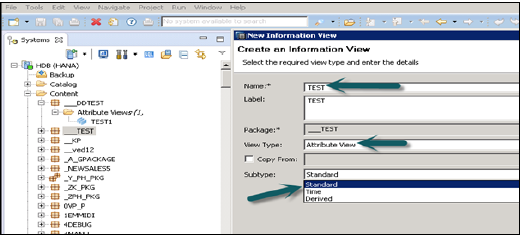
時間子型別屬性檢視是一種特殊型別的屬性檢視,它向資料基礎新增時間維度。輸入屬性名稱、型別和子型別並單擊“完成”後,它將開啟三個工作窗格:
具有資料基礎和語義層的場景窗格。
詳細資訊窗格顯示新增到資料基礎的所有表的屬性以及它們之間的連線。
輸出面板,我們可以在這裡新增來自詳細資訊面板的屬性來過濾報表。
您可以透過點選資料基礎旁邊的“+”號來向資料基礎新增物件。您可以在方案面板中新增多個維度表和屬性檢視,並使用主鍵將它們連線起來。
當您點選資料基礎中的“新增物件”時,將會出現一個搜尋欄,您可以從中將維度表和屬性檢視新增到方案面板。一旦表或屬性檢視新增到資料基礎,就可以在詳細資訊面板中使用主鍵將它們連線起來,如下所示。

連線完成後,在詳細資訊面板中選擇多個屬性,右鍵單擊並選擇“新增到輸出”。所有列都將新增到輸出面板。現在點選“啟用”選項,您將在作業日誌中收到確認訊息。
現在您可以右鍵單擊屬性檢視並進行資料預覽。
注意 - 當檢視未啟用時,上面會有菱形標記。但是,一旦您啟用它,菱形標記就會消失,這確認檢視已成功啟用。
單擊“資料預覽”後,它將顯示已新增到輸出面板的“可用物件”下的所有屬性。
這些物件可以透過右鍵單擊並新增或透過拖動物件新增到標籤和值軸,如下所示:

SAP HANA - 分析檢視
分析檢視採用星型模式,其中我們將一個事實表連線到多個維度表。分析檢視利用SAP HANA的強大功能,透過以星型模式連線表並執行星型模式查詢來執行復雜的計算和聚合函式。
分析檢視的特點
以下是SAP HANA分析檢視的屬性:
分析檢視用於執行復雜的計算和聚合函式,例如Sum、Count、Min、Max等。
分析檢視設計用於執行星型模式查詢。
每個分析檢視都有一個事實表,周圍環繞著多個維度表。事實表包含每個維度表的primaryKey和度量。
分析檢視類似於SAP BW的資訊物件和資訊集。
如何建立分析檢視?
選擇要在其下建立分析檢視的包名稱。右鍵單擊包→轉到新建→分析檢視。當您單擊分析檢視時,將開啟一個新視窗。輸入檢視名稱和描述,然後從下拉列表中選擇檢視型別並單擊“完成”。

單擊“完成”後,您可以看到一個帶有資料基礎和星型連線選項的分析檢視。
單擊“資料基礎”以新增維度表和事實表。單擊“星型連線”以新增屬性檢視。
使用“+”號將維度表和事實表新增到資料基礎。在下面給出的示例中,已新增3個維度表:DIM_CUSTOMER、DIM_PRODUCT、DIM_REGION和1個事實表FCT_SALES到詳細資訊面板。使用儲存在事實表中的主鍵將維度表連線到事實表。

選擇要新增到輸出面板的維度表和事實表的屬性,如上圖所示。現在將事實表的資料型別從事實表更改為度量。
單擊語義層,選擇事實,然後單擊如下所示的度量符號以將資料型別更改為度量並激活檢視。

啟用檢視並單擊“資料預覽”後,所有屬性和度量都將新增到“可用物件”列表中。將屬性新增到標籤軸,將度量新增到值軸以進行分析。
可以選擇不同型別的圖表。

SAP HANA - 計算檢視
計算檢視用於使用其他分析檢視、屬性檢視和其他計算檢視以及基本列表。它們用於執行其他型別的檢視無法執行的複雜計算。
計算檢視的特點
以下是計算檢視的一些特點:
計算檢視用於使用分析檢視、屬性檢視和其他計算檢視。
它們用於執行其他檢視無法執行的複雜計算。
建立計算檢視有兩種方法:SQL編輯器或圖形編輯器。
內建的Union、Join、Projection和Aggregation節點。
如何建立一個計算檢視?
選擇要在其下建立計算檢視的包名稱。右鍵單擊包→轉到新建→計算檢視。當您單擊計算檢視時,將開啟一個新視窗。

輸入檢視名稱、描述並選擇檢視型別為計算檢視,子型別為標準或時間(這是一種特殊的檢視,它新增時間維度)。您可以使用兩種型別的計算檢視:圖形和SQL指令碼。
圖形計算檢視
它具有預設節點,如聚合、投影、連線和聯合。它用於使用其他屬性檢視、分析檢視和其他計算檢視。
基於SQL指令碼的計算檢視
它使用基於SQL命令或HANA定義函式的SQL指令碼編寫。
資料類別
Cube,在此預設節點中為聚合。您可以選擇具有Cube維度的星型連線。
Dimension,在此預設節點中為投影。

具有星型連線的計算檢視
它不允許在資料基礎中新增基本列表、屬性檢視或分析檢視。所有維度表都必須更改為維度計算檢視才能在星型連線中使用。所有事實表都可以新增,並且可以使用計算檢視中的預設節點。
示例
以下示例顯示瞭如何使用具有星型連線的計算檢視:
您有四個表,兩個維度表和兩個事實表。您需要查詢所有員工及其入職日期、員工姓名、員工ID、工資和獎金的列表。
將下面的指令碼複製並貼上到SQL編輯器中並執行。
維度表 - Empdim和Empdate
Create column table Empdim (empId nvarchar(3),Empname nvarchar(100));
Insert into Empdim values('AA1','John');
Insert into Empdim values('BB1','Anand');
Insert into Empdim values('CC1','Jason');
Create column table Empdate (caldate date, CALMONTH nvarchar(4) ,CALYEAR nvarchar(4));
Insert into Empdate values('20100101','04','2010');
Insert into Empdate values('20110101','05','2011');
Insert into Empdate values('20120101','06','2012');
事實表 - Empfact1、Empfact2
Create column table Empfact1 (empId nvarchar(3), Empdate date, Sal integer );
Insert into Empfact1 values('AA1','20100101',5000);
Insert into Empfact1 values('BB1','20110101',10000);
Insert into Empfact1 values('CC1','20120101',12000);
Create column table Empfact2 (empId nvarchar(3), deptName nvarchar(20), Bonus integer );
Insert into Empfact2 values ('AA1','SAP', 2000);
Insert into Empfact2 values ('BB1','Oracle', 2500);
Insert into Empfact2 values ('CC1','JAVA', 1500);
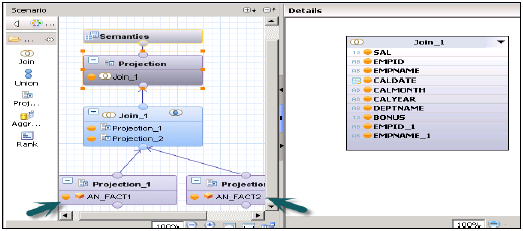
現在我們必須實現具有星型連線的計算檢視。首先將兩個維度表都更改為維度計算檢視。
建立一個具有星型連線的計算檢視。在圖形面板中,為兩個事實表新增2個投影。將兩個事實表都新增到兩個投影中,並將這些投影的屬性新增到輸出面板。

從預設節點新增一個連線,並將兩個事實表連線起來。將事實連線的引數新增到輸出面板。

在星型連線中,新增兩個維度計算檢視,並將事實連線新增到星型連線,如下所示。選擇輸出面板中的引數並激活檢視。

SAP HANA計算檢視 - 星型連線
成功啟用檢視後,右鍵單擊檢視名稱並單擊“資料預覽”。將屬性和度量新增到值軸和標籤軸並進行分析。
使用星型連線的優點
它簡化了設計過程。您無需建立分析檢視和屬性檢視,可以直接將事實表用作投影。
星型連線允許3NF。
沒有星型連線的計算檢視
在兩個維度表上建立2個屬性檢視 - 新增輸出並激活這兩個檢視。
在事實表上建立2個分析檢視→在分析檢視的資料基礎中新增兩個屬性檢視和Fact1/Fact2。
現在建立一個計算檢視→維度(投影)。建立兩個分析檢視的投影並連線它們。將此連線的屬性新增到輸出面板。現在連線到投影並再次新增輸出。
成功啟用檢視並轉到資料預覽進行分析。
SAP HANA - 分析許可權
分析許可權用於限制對HANA資訊檢視的訪問。您可以在分析許可權中為不同使用者的檢視的不同元件分配不同型別的許可權。
有時,需要將同一檢視中的資料對沒有相關需求的其他使用者不可訪問。
示例
假設您有一個包含公司員工詳細資訊的分析檢視EmpDetails:員工姓名、員工ID、部門、工資、入職日期、員工登入名等。如果您不想讓報表開發人員檢視所有員工的工資詳細資訊或員工登入詳細資訊,您可以使用分析許可權選項將其隱藏。
分析許可權僅應用於資訊檢視中的屬性。我們不能新增度量來限制分析許可權中的訪問。
分析許可權用於控制對SAP HANA資訊檢視的讀取訪問。
因此,我們可以按員工姓名、員工ID、員工登入名或部門來限制資料,而不能按數值(如工資、獎金)來限制。
建立分析許可權
右鍵單擊包名稱,然後轉到新建分析許可權,或者您可以使用HANA建模器快速啟動開啟。

輸入分析許可權的名稱和描述→完成。將開啟一個新視窗。
您可以在單擊“完成”之前單擊“下一步”按鈕,在此視窗中新增建模檢視。還有一個選項可以複製現有的分析許可權包。
單擊“新增”按鈕後,它將顯示“內容”選項卡下的所有檢視。

選擇要新增到分析許可權包的檢視,然後單擊“確定”。選定的檢視將新增到引用模型下。
現在要新增選定檢視下的屬性到分析許可權,請單擊帶有關聯屬性限制視窗的“新增”按鈕。

從選擇物件選項中新增要新增到分析許可權的物件,然後單擊“確定”。
在“分配限制”選項中,它允許您新增要從特定使用者處隱藏的建模檢視中的值。您可以新增在建模檢視的資料預覽中不會反映的物件值。

我們現在必須透過單擊頂部的綠色圓形圖示來啟用分析許可權。狀態訊息 - 成功完成確認成功啟用,然後我們現在可以透過新增到角色來使用此檢視。
現在要將此角色新增到使用者,請轉到安全選項卡→使用者→選擇要應用這些分析許可權的使用者。

搜尋要應用的分析許可權(使用名稱),然後單擊“確定”。該檢視將新增到分析許可權下的使用者角色中。
要從特定使用者中刪除分析許可權,請選擇選項卡下的檢視,然後使用紅色的刪除選項。使用部署(頂部的箭頭標記或F8)將其應用於使用者配置檔案。
SAP HANA - 資訊組合器
SAP HANA資訊組合器是一個自助建模環境,供終端使用者分析資料集。它允許您將資料從工作簿格式(.xls、.csv)匯入到HANA資料庫中,並建立用於分析的建模檢視。
資訊組合器與HANA建模器非常不同,兩者都旨在面向不同的使用者組。技術嫻熟且在資料建模方面擁有豐富經驗的人員使用HANA建模器。沒有技術知識的業務使用者使用資訊組合器。它提供簡單易用的功能和介面。
資訊組合器的功能
資料提取 - 資訊組合器有助於提取資料、清理資料、預覽資料並自動化在HANA資料庫中建立物理表的過程。
資料操作 - 它幫助我們將兩個物件(物理表、分析檢視、屬性檢視和計算檢視)組合起來,並建立一個資訊檢視,該檢視可以被SAP BO工具(如SAP Business Objects Analysis、SAP Business Objects Explorer)和其他工具(如MS Excel)使用。
它以URL的形式提供集中的IT服務,可以從任何地方訪問。
如何使用資訊組合器上傳資料?
它允許我們上傳大量資料(最多500萬個單元格)。訪問資訊組合器的連結:
http://<server>:<port>/IC
登入SAP HANA資訊組合器。您可以使用此工具執行資料載入或操作。
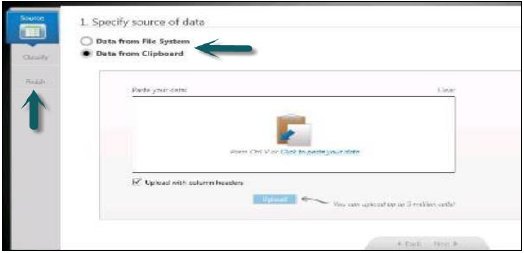
上傳資料可以透過兩種方式完成:
- 直接將.xls、.csv檔案上傳到HANA資料庫
- 另一種方法是將資料複製到剪貼簿,然後從剪貼簿複製到HANA資料庫。
- 它允許載入包含標題的資料。
在資訊組合器的左側,您有三個選項:
選擇資料來源 → 分類資料 → 釋出
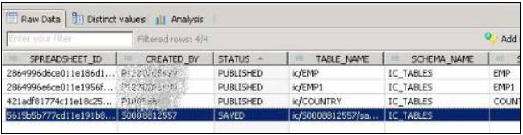
一旦資料釋出到HANA資料庫,就不能重命名錶。在這種情況下,您必須從HANA資料庫的模式中刪除該表。
“SAP_IC”模式,其中存在IC_MODELS、IC_SPREADSHEETS等表。可以在這些表下找到使用IC建立的表的詳細資訊。
使用剪貼簿
在IC中上傳資料的另一種方法是使用剪貼簿。將資料複製到剪貼簿,並藉助資訊組合器將其上傳。資訊組合器還允許您檢視資料的預覽,甚至在臨時儲存中提供資料的摘要。它具有內建的資料清洗功能,用於消除資料中的任何不一致性。
資料清洗完成後,需要對資料進行分類,判斷其是否為屬性資料。IC具有內建功能來檢查上傳資料的型別。
最後一步是將資料釋出到HANA資料庫中的物理表。提供表的技術名稱和描述,這將載入到IC_Tables模式中。
使用資訊組合器釋出的資料的使用者角色
可以定義兩組使用者來使用從IC釋出的資料。
IC_MODELER用於建立物理表、上傳資料和建立資訊檢視。
IC_PUBLIC允許使用者檢視其他使用者建立的資訊檢視。此角色不允許使用者使用IC上傳或建立任何資訊檢視。
資訊組合器的系統要求
伺服器要求:
至少需要2GB可用RAM。
必須在伺服器上安裝Java 6(64位)。
資訊組合器伺服器必須物理地位於HANA伺服器旁邊。
客戶端要求:
- 已安裝Silverlight 4的Internet Explorer。
SAP HANA - 匯出和匯入
HANA匯出和匯入選項允許將表、資訊模型和環境移動到不同的或現有的系統。您無需重新建立所有表和資訊模型,因為您可以簡單地將其匯出到新系統或匯入到現有的目標系統以減少工作量。
此選項可以透過頂部的“檔案”選單訪問,也可以透過右鍵單擊HANA Studio中的任何表或資訊模型來訪問。
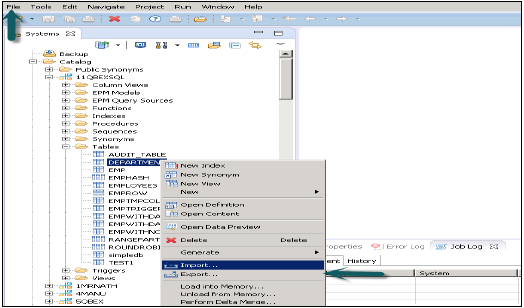
在HANA Studio中匯出表/資訊模型
轉到檔案選單→匯出→您將看到如下所示的選項:
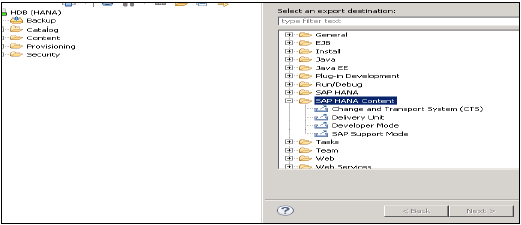
SAP HANA內容下的匯出選項
交付單元
交付單元是一個單一單元,可以對映到多個包,並且可以作為一個單一實體匯出,以便分配給交付單元的所有包都可以作為一個單元處理。
使用者可以使用此選項將構成交付單元的所有包及其包含的相關物件匯出到HANA伺服器或本地客戶端位置。
使用者應在使用交付單元之前建立它。
這可以透過HANA建模器→交付單元→選擇系統和下一步→建立→填寫名稱、版本等詳細資訊→確定→將包新增到交付單元→完成來實現。
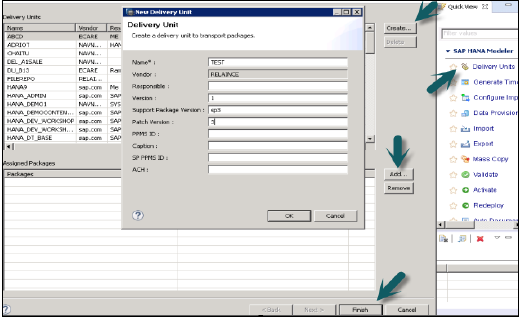
建立交付單元並將包分配給它後,使用者可以使用匯出選項檢視包列表:
轉到檔案→匯出→交付單元→選擇交付單元。
您可以看到分配給交付單元的所有包的列表。它提供了一個選擇匯出位置的選項:
- 匯出到伺服器
- 匯出到客戶端
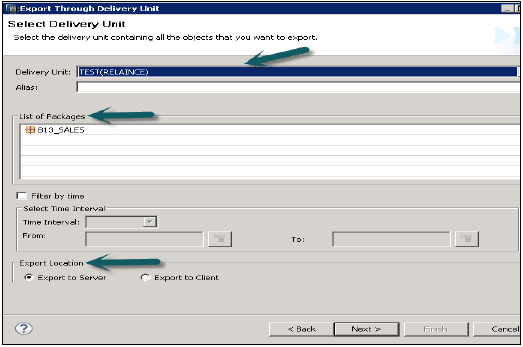
您可以將交付單元匯出到HANA伺服器位置或客戶端位置,如圖所示。
使用者可以透過“按時間篩選”來限制匯出,這意味著只有在指定時間間隔內更新的資訊檢視才會被匯出。
選擇交付單元和匯出位置,然後單擊下一步→完成。這將把選定的交付單元匯出到指定位置。
開發人員模式
此選項可用於將單個物件匯出到本地系統中的位置。使用者可以選擇單個資訊檢視或檢視和包組,並選擇本地客戶端位置進行匯出並完成。
這在下面的快照中顯示。
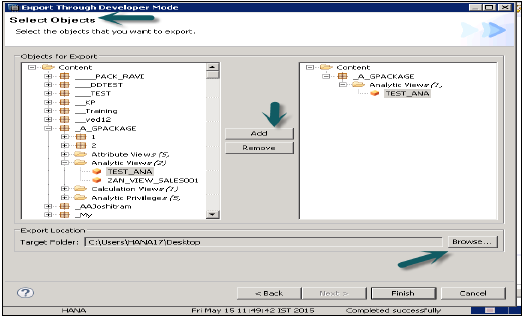
支援模式
這可用於將物件及其資料一起匯出,用於SAP支援目的。僅在請求時使用。
示例:使用者建立一個資訊檢視,該檢視引發錯誤,並且他無法解決。在這種情況下,他可以使用此選項匯出檢視及其資料,並將其與SAP共享以進行除錯。
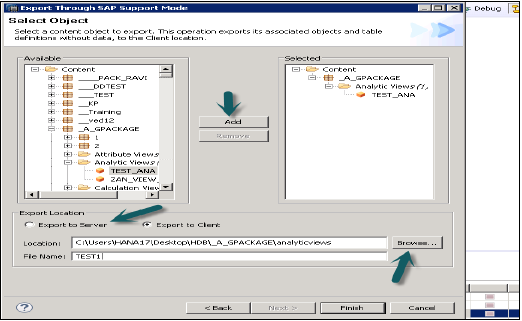
SAP HANA Studio下的匯出選項:
環境:將環境從一個系統匯出到另一個系統。
表:此選項可用於匯出表及其內容。
SAP HANA內容下的匯入選項
轉到檔案→匯入,您將在匯入下看到如下所示的所有選項。
來自本地檔案的資料
這用於從平面檔案(如.xls或.csv檔案)匯入資料。
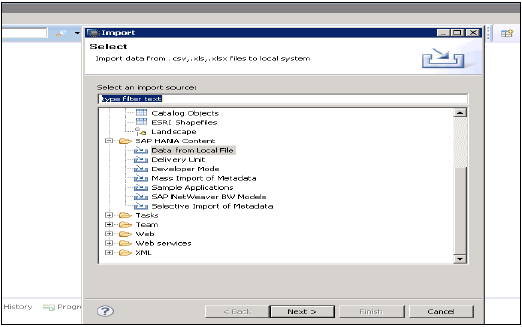
單擊下一步→選擇目標系統→定義匯入屬性
透過瀏覽本地系統選擇原始檔。如果您想保留標題行,它也會提供一個選項。它還提供了一個選項,即您是否要在現有模式下建立新表,或者您是否要將資料從檔案匯入到現有表。
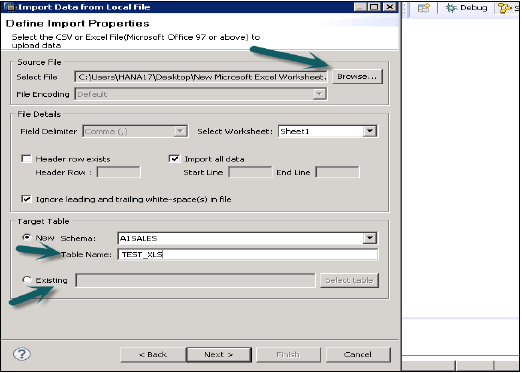
單擊下一步時,它提供了一個選項來定義主鍵、更改列的資料型別、定義表的儲存型別,並且還允許您更改表的建議結構。
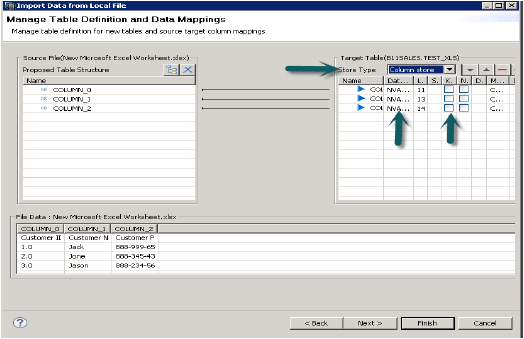
單擊完成時,該表將在所述模式的表列表下填充。您可以進行資料預覽並檢查表的資料定義,它將與.xls檔案相同。
交付單元
轉到檔案→匯入→交付單元選擇交付單元。您可以從伺服器或本地客戶端選擇。
您可以選擇“覆蓋非活動版本”,這允許您覆蓋存在的任何非活動版本的物件。如果使用者選擇“啟用物件”,則匯入後,所有匯入的物件都將預設啟用。使用者無需手動觸發匯入檢視的啟用。
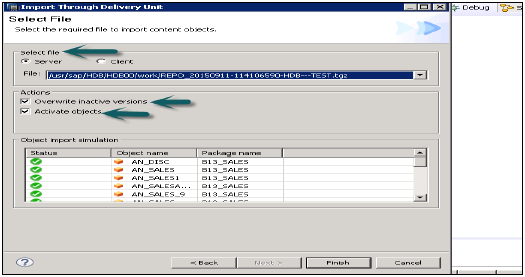
單擊完成,一旦成功完成,它將填充到目標系統。
開發人員模式
瀏覽匯出檢視的本地客戶端位置並選擇要匯入的檢視,使用者可以選擇單個檢視或檢視和包組,然後單擊完成。
元資料的批次匯入
轉到檔案→匯入→元資料的批次匯入→下一步並選擇源系統和目標系統。
配置用於批次匯入的系統,然後單擊完成。
元資料的選擇性匯入
它允許您選擇表和目標模式以從SAP應用程式匯入元資料。
轉到檔案→匯入→元資料的選擇性匯入→下一步
選擇型別為“SAP應用程式”的源連線。請記住,型別為SAP應用程式的資料儲存應該已經建立→單擊下一步
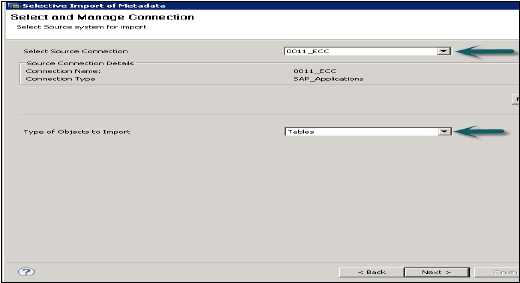
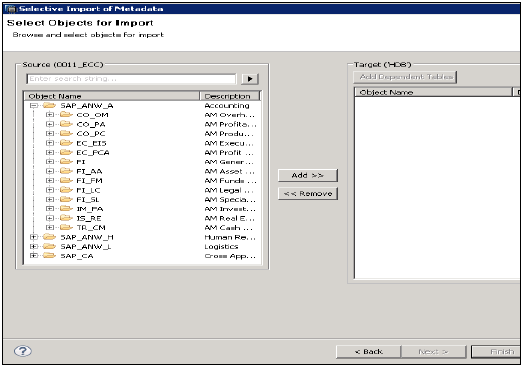
選擇要匯入的表,並在需要時驗證資料。之後單擊完成。
SAP HANA - 報表檢視
我們知道,透過使用SAP HANA中的資訊建模功能,我們可以建立不同的資訊檢視、屬性檢視、分析檢視和計算檢視。這些檢視可以被不同的報表工具使用,例如SAP Business Object、SAP Lumira、Design Studio、Office Analysis,甚至第三方工具,如MS Excel。
這些報表工具使業務經理、分析師、銷售經理和高階管理人員能夠分析歷史資訊,以建立業務場景並決定公司的業務戰略。
這就需要不同的報表工具使用HANA建模檢視,並生成終端使用者易於理解的報表和儀表板。
在大多數已實施SAP的公司中,HANA上的報表是使用BI平臺工具完成的,這些工具藉助關係和OLAP連線使用SQL和MDX查詢。有各種各樣的BI工具,例如:Web Intelligence、Crystal Reports、Dashboard、Explorer、Office Analysis等等。
BI 4.0連線到Hana檢視
報表工具
Web Intelligence和Crystal Reports是最常用的報表工具。WebI使用稱為Universe的語義層來連線到資料來源,這些Universe用於在工具中進行報表。這些Universe是藉助Universe設計工具UDT或資訊設計工具IDT設計的。IDT支援多源啟用資料來源。但是,UDT僅支援單一資料來源。
用於設計互動式儀表板的主要工具是Design Studio和Dashboard Designer。Design Studio是用於設計儀表板的未來工具,它透過BI消費者服務BICS連線使用HANA檢視。儀表板設計(xcelsius)使用IDT透過關係或OLAP連線使用HANA資料庫中的模式。
SAP Lumira具有直接連線或從HANA資料庫載入資料的內建功能。HANA檢視可以直接在Lumira中使用,用於視覺化和建立故事。
Office Analysis使用OLAP連線連線到HANA資訊檢視。此OLAP連線可以在CMC或IDT中建立。
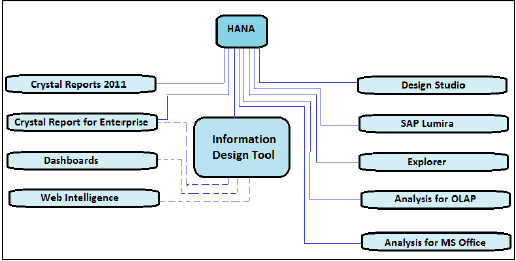
上圖顯示了所有BI工具,它們可以使用實線直接連線和整合到SAP HANA中,並使用OLAP連線。它還描述了需要使用IDT建立關係連線到HANA的工具,這些工具用虛線表示。
關係連線與OLAP連線
基本思想是,如果您需要訪問表或傳統資料庫中的資料,則您的連線應該是關係連線;但如果您的源是應用程式,並且資料儲存在多維資料儲存區(例如Info cubes、資訊模型)中,則應使用OLAP連線。
- 關係連線只能在IDT/UDT中建立。
- OLAP連線可以在IDT和CMC中建立。
需要注意的另一點是,關係連線總是產生要從報表中觸發的SQL語句,而OLAP連線通常會建立MDX語句。
資訊設計工具
在資訊設計工具(IDT)中,您可以使用JDBC或ODBC驅動程式建立到SAP HANA檢視或表的連線,並使用此連線構建Universe,以便為客戶端工具(如儀表板和Web Intelligence)提供訪問許可權,如上圖所示。
您可以使用JDBC或ODBC驅動程式建立到SAP HANA的直接連線。
SAP HANA - Crystal Reports
企業版Crystal Reports
在企業版Crystal Reports中,您可以使用資訊設計工具建立的現有關係連線訪問SAP HANA資料。
您還可以使用資訊設計工具或CMC建立的OLAP連線連線到SAP HANA。
Design Studio
Design Studio可以使用資訊設計工具或CMC中建立的現有OLAP連線訪問SAP HANA資料,這與Office Analysis類似。
儀表板
儀表板只能透過關係Universe連線到SAP HANA。在SAP HANA之上使用儀表板的客戶應認真考慮使用Design Studio構建新的儀表板。
Web Intelligence
Web Intelligence只能透過關係Universe連線到SAP HANA。
SAP Lumira
Lumira可以直連SAP HANA分析和計算檢視。它也可以透過SAP BI平臺使用關係型Universe連線SAP HANA。
Office Analysis OLAP版
在Office Analysis OLAP版中,您可以使用在中央管理控制檯 (CMC) 或資訊設計工具中定義的OLAP連線來連線SAP HANA。
Explorer
您可以使用JDBC驅動程式基於SAP HANA檢視建立資訊空間。
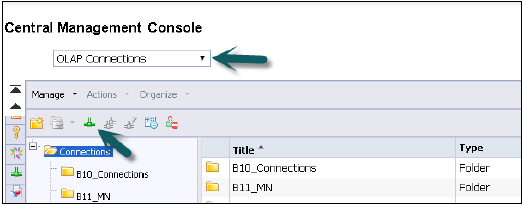
在CMC中建立OLAP連線
我們可以為所有想要在HANA檢視之上使用的BI工具建立OLAP連線,例如用於分析的OLAP、用於企業的Crystal Reports和Design Studio。透過IDT的關係連線用於將Web Intelligence和Dashboard連線到HANA資料庫。
這些連線可以使用IDT和CMC建立,並且兩個連線都儲存在BO Repository中。
使用使用者名稱和密碼登入CMC。
從連線的下拉列表中,選擇一個OLAP連線。它還會顯示在CMC中已建立的連線。要建立新連線,請點選綠色圖示。
輸入OLAP連線的名稱和描述。多人可以使用此連線在不同的BI平臺工具中連線到HANA檢視。
提供程式 - SAP HANA
伺服器 - 輸入HANA伺服器名稱
例項 - 例項編號
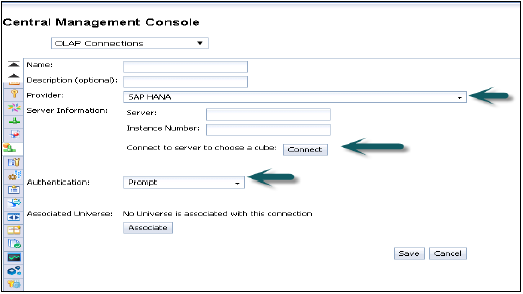
它還提供連線到單個多維資料集(您也可以選擇連線到單個分析或計算檢視)或連線到完整HANA系統的選項。
單擊“連線”並透過輸入使用者名稱和密碼選擇建模檢視。
身份驗證型別 - 在CMC中建立OLAP連線時,可以使用三種身份驗證型別。
預定義 - 使用此連線時,不會再次詢問使用者名稱和密碼。
提示 - 每次都會詢問使用者名稱和密碼
SSO - 使用者特定
輸入使用者 - 輸入HANA系統的使用者名稱和密碼,儲存後,新的連線將新增到現有的連線列表中。
現在開啟BI Launchpad以開啟所有用於報告的BI平臺工具,例如Office Analysis for OLAP,它將要求選擇連線。預設情況下,如果在建立此連線時指定了資訊檢視,它將顯示資訊檢視;否則,單擊“下一步”,然後轉到資料夾→選擇檢視(分析檢視或計算檢視)。
SAP Lumira與HANA系統的連線
從“開始”程式開啟SAP Lumira,單擊檔案選單→新建→新增新資料集→連線到SAP HANA→下一步

連線到SAP HANA和從SAP HANA下載之間的區別在於,它會將資料從HANA系統下載到BO Repository,並且資料重新整理不會隨著HANA系統中的更改而發生。輸入HANA伺服器名稱和例項編號。輸入使用者名稱和密碼→單擊“連線”。

它將顯示所有檢視。您可以使用檢視名稱進行搜尋→選擇檢視→下一步。它將顯示所有度量和維度。您可以根據需要從這些屬性中選擇→單擊建立選項。
SAP Lumira內部有四個選項卡:
準備 - 您可以檢視資料並進行任何自定義計算。
視覺化 - 您可以新增圖表。單擊X軸和Y軸的加號以新增屬性。
組合 - 此選項可用於建立視覺化序列(故事)→單擊“面板”以新增多個面板→建立→它將在左側顯示所有視覺化效果。拖動第一個視覺化效果,然後新增頁面,再新增第二個視覺化效果。
共享 - 如果它構建在SAP HANA上,我們只能釋出到SAP Lumira伺服器。否則,您還可以將故事從SAP Lumira釋出到SAP社群網路SCN或BI平臺。
儲存檔案以便以後使用→轉到檔案-儲存→選擇本地→儲存
在IDT中建立關係連線以在WebI和Dashboard中使用HANA檢視 -
開啟資訊設計工具→轉到BI平臺客戶端工具。單擊“新建”→“專案”輸入專案名稱→“完成”。
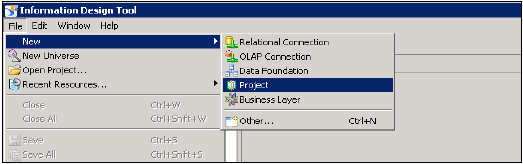
右鍵單擊專案名稱→轉到“新建”→選擇“關係連線”→輸入連線/資源名稱→下一步→從列表中選擇SAP以連線到HANA系統→SAP HANA→選擇JDBC/ODBC驅動程式→單擊下一步→輸入HANA系統詳細資訊→單擊下一步和完成。
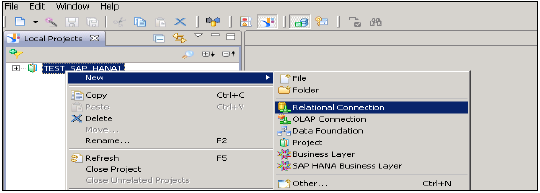
您還可以透過單擊“測試連線”選項來測試此連線。
測試連線→成功。下一步是將此連線釋出到Repository,使其可供使用。
右鍵單擊連線名稱→單擊“將連線釋出到Repository”→輸入BO Repository名稱和密碼→單擊“連線”→下一步→完成→是。
它將建立一個具有.cns副檔名的新的關係連線。
.cns - 連線型別表示安全的Repository連線,應將其用於建立資料基礎。
.cnx - 表示本地非安全連線。如果在建立和釋出Universe時使用此連線,則不允許您將其釋出到Repository。
選擇.cns連線型別→右鍵單擊此連線→單擊“新建資料基礎”→輸入資料基礎的名稱→下一步→單一源/多源→單擊下一步→完成。

它將在中間窗格中顯示HANA資料庫中的所有表以及模式名稱。
將HANA資料庫中的所有表匯入到主窗格以建立Universe。使用Dim表中的主鍵連線Dim表和Fact表以建立模式。

雙擊連線並檢測基數→檢測→確定→儲存頂部所有內容。現在,我們必須在資料基礎上建立一個新的業務層,該層將由BI應用程式工具使用。
右鍵單擊.dfx並選擇“新建業務層”→輸入名稱→完成→。它將自動顯示主窗格下所有物件→。將維度更改為度量(根據需要更改型別-度量投影)→全部儲存。
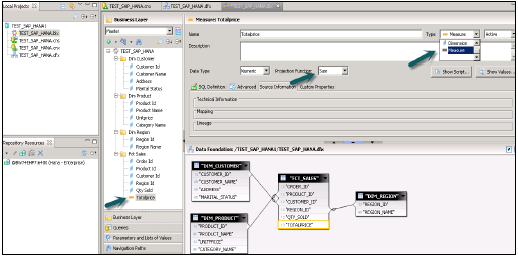
右鍵單擊.bfx檔案→單擊“釋出”→到Repository→單擊“下一步”→“完成”→Universe釋出成功。
現在從BI Launchpad開啟WebI報表或從BI平臺客戶端工具開啟Webi富客戶端→新建→選擇Universe→TEST_SAP_HANA→確定。
所有物件都將新增到查詢面板。您可以從左窗格中選擇屬性和度量,並將它們新增到結果物件。“執行查詢”將執行SQL查詢,並在WebI中以報表形式生成輸出,如下所示。
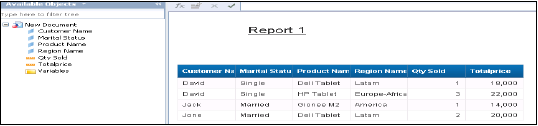
SAP HANA - Excel 整合
許多組織認為Microsoft Excel是最常見的BI報表和分析工具。業務經理和分析師可以將其連線到HANA資料庫,以繪製用於分析的透視表和圖表。
將MS Excel連線到HANA
開啟Excel,然後轉到“資料”選項卡→從其他來源→單擊“資料連線嚮導”→其他/高階,然後單擊“下一步”→將開啟“資料鏈接屬性”。
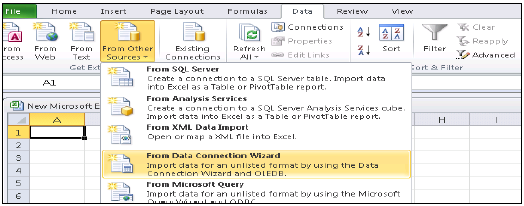

從列表中選擇SAP HANA MDX提供程式以連線到任何MDX資料來源→輸入HANA系統詳細資訊(伺服器名稱、例項、使用者名稱和密碼)→單擊“測試連線”→連線成功→確定。
它將在下拉列表中為您提供HANA系統中可用的所有包的列表。您可以選擇一個資訊檢視→單擊“下一步”→選擇透視表/其他→確定。

資訊檢視中的所有屬性都將新增到MS Excel。您可以選擇不同的屬性和度量進行報告,如所示,您可以從頂部的設計選項中選擇不同的圖表,如餅圖和條形圖。
SAP HANA - 安全性概述
安全意味著保護公司關鍵資料免受未經授權的訪問和使用,並確保根據公司政策滿足合規性和標準。SAP HANA使客戶能夠實施不同的安全策略和程式,並滿足公司的合規性要求。
SAP HANA在一個HANA系統中支援多個數據庫,這稱為多租戶資料庫容器。HANA系統還可以包含多個多租戶資料庫容器。多容器系統始終只有一個系統資料庫和任意數量的多租戶資料庫容器。在此環境中安裝的SAP HANA系統由單個系統ID (SID) 標識。HANA系統中的資料庫容器由SID和資料庫名稱標識。稱為HANA Studio的SAP HANA客戶端連線到特定的資料庫。
SAP HANA提供所有與安全相關的功能,例如身份驗證、授權、加密和審計,以及一些其他多租戶資料庫不支援的附加功能。

以下是SAP HANA提供的與安全相關的功能列表:
- 使用者和角色管理
- 身份驗證和SSO
- 授權
- 網路中資料通訊的加密
- 持久層中資料的加密
多租戶HANA資料庫中的附加功能:
資料庫隔離 - 它涉及透過作業系統機制防止跨租戶攻擊
配置更改黑名單 - 它涉及阻止租戶資料庫管理員更改某些系統屬性
受限功能 - 它涉及停用某些資料庫功能,這些功能提供對檔案系統、網路或其他資源的直接訪問。
SAP HANA使用者和角色管理
SAP HANA使用者和角色管理配置取決於HANA系統的架構。
如果SAP HANA與BI平臺工具整合並充當報表資料庫,則終端使用者和角色在應用程式伺服器中管理。
如果終端使用者直接連線到SAP HANA資料庫,則HANA系統資料庫層中的使用者和角色對於終端使用者和管理員都是必需的。
每個想要使用HANA資料庫的使用者都必須具有具有必要許可權的資料庫使用者。訪問HANA系統的使用者可以是技術使用者或終端使用者,具體取決於訪問要求。成功登入系統後,將驗證使用者執行所需操作的授權。執行該操作取決於已授予使用者的許可權。可以使用HANA Security中的角色授予這些許可權。HANA Studio是管理HANA資料庫系統使用者和角色的強大工具之一。
使用者型別
使用者型別根據安全策略和分配給使用者配置檔案的不同許可權而有所不同。使用者型別可以是技術資料庫使用者,也可以是終端使用者,他們需要訪問HANA系統以進行報告或資料處理。
標準使用者
標準使用者可以在自己的模式中建立物件,並具有系統資訊模型的讀取許可權。讀取許可權由 PUBLIC 角色提供,該角色分配給每個標準使用者。

受限使用者
受限使用者是指使用某些應用程式訪問 HANA 系統且不具有 HANA 系統 SQL 許可權的使用者。建立這些使用者時,他們最初沒有任何訪問許可權。
如果我們將受限使用者與標準使用者進行比較:
受限使用者無法在 HANA 資料庫或其自己的模式中建立物件。
他們無法檢視資料庫中的任何資料,因為他們沒有像標準使用者那樣在配置檔案中新增通用的 PUBLIC 角色。
他們只能使用 HTTP/HTTPS 連線到 HANA 資料庫。
使用者管理和角色管理
技術資料庫使用者僅用於管理目的,例如在資料庫中建立新物件、向其他使用者分配許可權、以及對包和應用程式等進行操作。
SAP HANA 使用者管理活動
根據業務需求和 HANA 系統的配置,可以使用使用者管理工具(如 HANA Studio)執行不同的使用者活動。
最常見的活動包括:
- 建立使用者
- 向用戶授予角色
- 定義和建立角色
- 刪除使用者
- 重置使用者密碼
- 在多次登入失敗後重新啟用使用者
- 在需要時停用使用者
如何在 HANA Studio 中建立使用者?
只有具有系統許可權 ROLE ADMIN 的資料庫使用者才能在 HANA Studio 中建立使用者和角色。要在 HANA Studio 中建立使用者和角色,請轉到 HANA 管理控制檯。您將在“系統”檢視中看到“安全”選項卡:
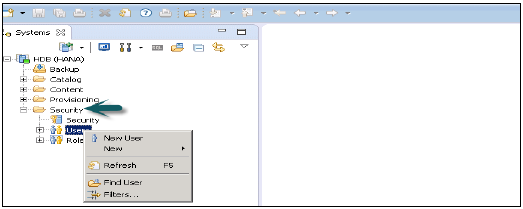
展開“安全”選項卡後,會顯示“使用者”和“角色”選項。要建立新使用者,請右鍵單擊“使用者”,然後轉到“新建使用者”。將開啟一個新視窗,您可以在其中定義使用者和使用者引數。
輸入使用者名稱(必填),並在“身份驗證”欄位中輸入密碼。儲存新使用者的密碼時,密碼將被應用。您也可以選擇建立受限使用者。
指定的使用者名稱不能與現有使用者或角色的名稱相同。密碼規則包括最短密碼長度以及必須包含哪些字元型別(小寫、大寫、數字、特殊字元)的定義。
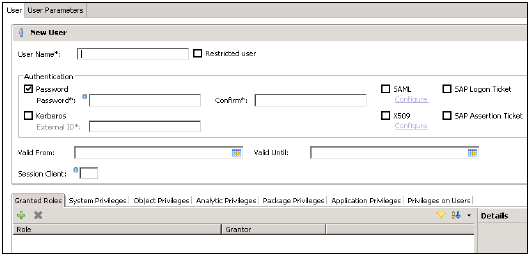
可以配置不同的授權方法,例如 SAML、X509 證書、SAP Logon ticket 等。資料庫中的使用者可以透過不同的機制進行身份驗證:
使用密碼的內部身份驗證機制。
外部機制,例如 Kerberos、SAML、SAP Logon Ticket、SAP Assertion Ticket 或 X.509。
一個使用者可以同時透過多種機制進行身份驗證。但是,任何時候只能有一個密碼和一個 Kerberos 主體名稱有效。必須指定一種身份驗證機制,才能允許使用者連線並使用資料庫例項。
它還提供定義使用者有效性的選項,您可以透過選擇日期來指定有效期。有效期規範是一個可選的使用者引數。
SAP HANA 資料庫預設情況下提供的一些使用者包括:SYS、SYSTEM、_SYS_REPO、_SYS_STATISTICS。
完成此操作後,下一步是為使用者配置檔案定義許可權。可以向用戶配置檔案新增不同型別的許可權。
向用戶授予角色
這用於向用戶配置檔案新增內建的 SAP HANA 角色或新增在“角色”選項卡下建立的自定義角色。自定義角色允許您根據訪問需求定義角色,您可以直接將這些角色新增到使用者配置檔案。這樣無需每次為不同的訪問型別記住並向用戶配置檔案新增物件。
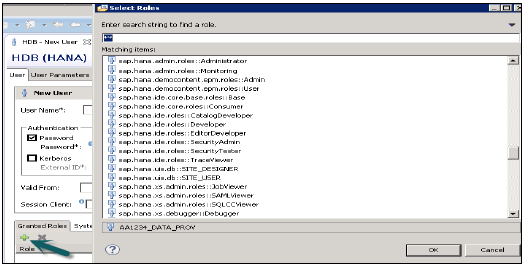
PUBLIC - 這是一個通用角色,預設情況下分配給所有資料庫使用者。此角色包含對系統檢視的只讀訪問許可權以及某些過程的執行許可權。這些角色無法撤銷。

建模
它包含在 SAP HANA Studio 中使用資訊建模器所需的所有許可權。
系統許可權
可以向用戶配置檔案新增不同型別的系統許可權。要向用戶配置檔案新增系統許可權,請單擊“+”號。
系統許可權用於備份/還原、使用者管理、例項啟動和停止等。
內容管理員
它包含與 MODELING 角色中類似的許可權,但除此之外,此角色還允許將這些許可權授予其他使用者。它還包含用於處理匯入物件的儲存庫許可權。
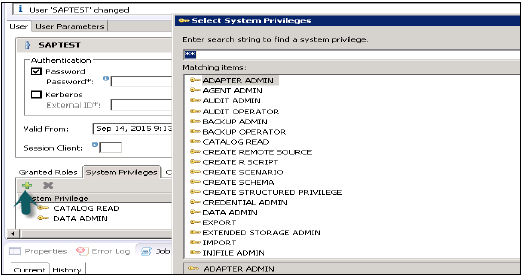
資料管理員
這是一種許可權型別,需要將資料從物件新增到使用者配置檔案。
以下是常見的受支援系統許可權:
附加偵錯程式
它授權除錯由不同使用者呼叫的過程呼叫。此外,還需要對應過程的 DEBUG 許可權。
審計管理員
控制以下與審計相關的命令的執行:CREATE AUDIT POLICY、DROP AUDIT POLICY 和 ALTER AUDIT POLICY 以及審計配置的更改。還允許訪問 AUDIT_LOG 系統檢視。
審計操作員
它授權執行以下命令:ALTER SYSTEM CLEAR AUDIT LOG。還允許訪問 AUDIT_LOG 系統檢視。
備份管理員
它授權 BACKUP 和 RECOVERY 命令,用於定義和啟動備份和恢復過程。
備份操作員
它授權 BACKUP 命令啟動備份過程。
目錄讀取
它授權使用者對所有系統檢視具有無過濾的只讀訪問許可權。通常情況下,這些檢視的內容會根據訪問使用者的許可權進行過濾。
建立模式
它授權使用 CREATE SCHEMA 命令建立資料庫模式。預設情況下,每個使用者擁有一個模式,擁有此許可權的使用者可以建立其他模式。
建立結構化許可權
它授權建立結構化許可權(分析許可權)。只有分析許可權的所有者才能進一步向其他使用者或角色授予或撤銷該許可權。
憑據管理員
它授權憑據命令:CREATE/ALTER/DROP CREDENTIAL。
資料管理員
它授權讀取系統檢視中的所有資料。它還能夠在 SAP HANA 資料庫中執行任何資料定義語言 (DDL) 命令。
擁有此許可權的使用者無法選擇或更改他們沒有訪問許可權的儲存表中的資料,但他們可以刪除表或修改表定義。
資料庫管理員
它授權與多資料庫中的資料庫相關的所有命令,例如 CREATE、DROP、ALTER、RENAME、BACKUP、RECOVERY。
匯出
它透過 EXPORT TABLE 命令授權資料庫中的匯出活動。
請注意,除了此許可權之外,使用者還需要對要匯出的源表具有 SELECT 許可權。
匯入
它使用 IMPORT 命令授權資料庫中的匯入活動。
請注意,除了此許可權之外,使用者還需要對要匯入的目標表具有 INSERT 許可權。
Inifile 管理員
它授權更改系統設定。
許可證管理員
它授權 SET SYSTEM LICENSE 命令安裝新許可證。
日誌管理員
它授權 ALTER SYSTEM LOGGING [ON|OFF] 命令啟用或停用日誌重新整理機制。
監控管理員
它授權用於 EVENT 的 ALTER SYSTEM 命令。
最佳化器管理員
它授權與 SQL PLAN CACHE 相關的 ALTER SYSTEM 命令和 ALTER SYSTEM UPDATE STATISTICS 命令,這些命令會影響查詢最佳化器的行為。
資源管理員
此許可權授權與系統資源相關的命令。例如,ALTER SYSTEM RECLAIM DATAVOLUME 和 ALTER SYSTEM RESET MONITORING VIEW。它還授權管理控制檯中可用的許多命令。
角色管理員
此許可權授權使用 CREATE ROLE 和 DROP ROLE 命令建立和刪除角色。它還授權使用 GRANT 和 REVOKE 命令授予和撤銷角色。
已啟用的角色(即建立者是預定義使用者 _SYS_REPO 的角色)既不能授予其他角色或使用者,也不能直接刪除。即使擁有 ROLE ADMIN 許可權的使用者也無法這樣做。請檢視有關啟用物件的文件。
儲存點管理員
它授權使用 ALTER SYSTEM SAVEPOINT 命令執行儲存點過程。
SAP HANA 資料庫的元件可以建立新的系統許可權。這些許可權使用元件名稱作為系統許可權的第一個識別符號,使用元件許可權名稱作為第二個識別符號。
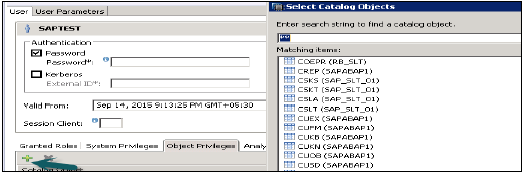
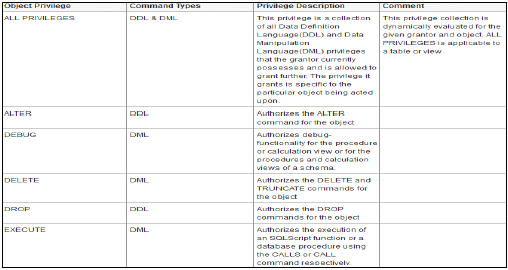
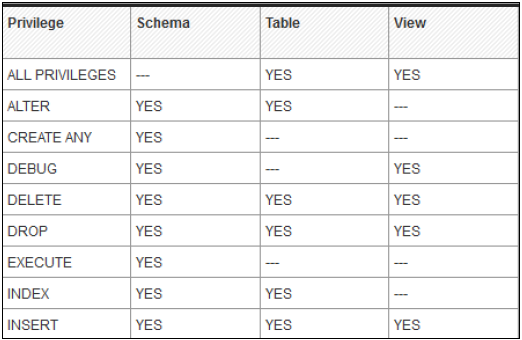
物件/SQL 許可權
物件許可權也稱為 SQL 許可權。這些許可權用於允許訪問物件,例如表、檢視或模式的選擇、插入、更新和刪除。
以下是可能的 Object 許可權型別:
僅在執行時存在的資料庫物件的 Object 許可權
在儲存庫中建立的啟用物件(如計算檢視)上的 Object 許可權
包含在儲存庫中建立的啟用物件的模式上的 Object 許可權
Object/SQL 許可權是資料庫物件上所有 DDL 和 DML 許可權的集合。
以下是常見的受支援物件許可權:
HANA 資料庫中有多個數據庫物件,因此並非所有許可權都適用於所有型別的資料庫物件。
物件許可權及其對資料庫物件的適用性:
分析許可權
有時,需要確保同一檢視中的資料對於沒有相關需求的其他使用者不可訪問。
分析許可權用於限制對 HANA 資訊檢視的物件級訪問。我們可以在分析許可權中應用行級和列級安全性。
分析許可權用於:
- 為特定值範圍分配行級和列級安全性。
- 為建模檢視分配行級和列級安全性。
包許可權
在 SAP HANA 儲存庫中,您可以為特定使用者或角色設定包授權。包許可權用於允許訪問資料模型(分析檢視或計算檢視)或儲存庫物件。分配給儲存庫包的所有許可權也分配給所有子包。您還可以指定是否可以將分配的使用者授權傳遞給其他使用者。
將包許可權新增到使用者配置檔案的步驟:
在 HANA Studio 的使用者建立下單擊“包許可權”選項卡→ 選擇“+”以新增一個或多個包。使用 Ctrl 鍵選擇多個包。
在“選擇儲存庫包”對話方塊中,使用包名稱的全部或部分來查詢要授權訪問的儲存庫包。
選擇一個或多個要授權訪問的儲存庫包,選定的包將顯示在“包許可權”選項卡中。
以下是用於授權使用者修改物件的儲存庫包上的授予許可權:
REPO.READ - 讀取選定包和設計時物件(本地和匯入的)的訪問許可權
REPO.EDIT_NATIVE_OBJECTS - 授權修改包中的物件。
可授予他人 - 如果為此選擇“是”,則允許將分配的使用者授權傳遞給其他使用者。
應用程式許可權
使用者配置檔案中的應用程式許可權用於定義對 HANA XS 應用程式的訪問授權。這可以分配給單個使用者或使用者組。應用程式許可權還可以用於為同一應用程式提供不同級別的訪問許可權,例如為資料庫管理員提供高階功能,為普通使用者提供只讀訪問許可權。
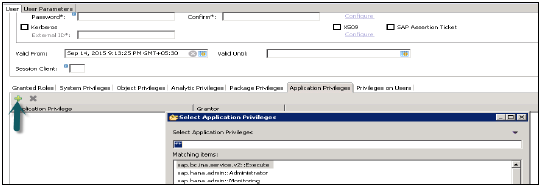
要在使用者配置檔案中定義特定於應用程式的許可權或新增使用者組,應使用以下許可權:
- 應用程式許可權檔案 (.xsprivileges)
- 應用程式訪問檔案 (.xsaccess)
- 角色定義檔案 (<RoleName>.hdbrole)
SAP HANA - 身份驗證
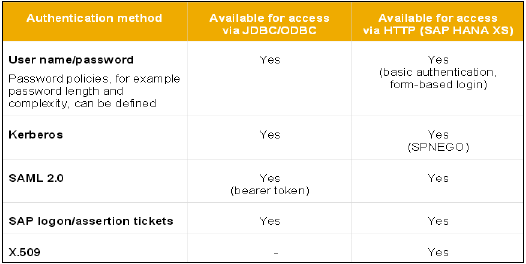
所有具有 HANA 資料庫訪問許可權的 SAP HANA 使用者都將透過不同的身份驗證方法進行驗證。SAP HANA 系統支援各種型別的身份驗證方法,所有這些登入方法都在建立配置檔案時進行配置。
以下是 SAP HANA 支援的身份驗證方法列表:
- 使用者名稱/密碼
- Kerberos
- SAML 2.0
- SAP Logon Ticket
- X.509
使用者名稱/密碼
此方法需要HANA使用者輸入使用者名稱和密碼才能登入資料庫。此使用者配置檔案是在HANA Studio中使用者管理→安全選項卡下建立的。
密碼應符合密碼策略,即密碼長度、複雜性、大小寫字母等。
您可以根據組織的安全標準更改密碼策略。請注意,密碼策略無法停用。
Kerberos
所有使用外部身份驗證方法連線到HANA資料庫系統的使用者也應該擁有一個數據庫使用者。需要將外部登入對映到內部資料庫使用者。
此方法允許使用者透過網路或使用SAP Business Objects中的前端應用程式,使用JDBC/ODBC驅動程式直接對HANA系統進行身份驗證。
它還允許在使用HANA XS引擎的HANA擴充套件服務中進行HTTP訪問。它使用SPENGO機制進行Kerberos身份驗證。
SAML
SAML代表安全斷言標記語言,可用於對直接從ODBC/JDBC客戶端訪問HANA系統的使用者進行身份驗證。它也可用於透過HANA XS引擎透過HTTP訪問HANA系統的使用者身份驗證。
SAML僅用於身份驗證目的,不用於授權。
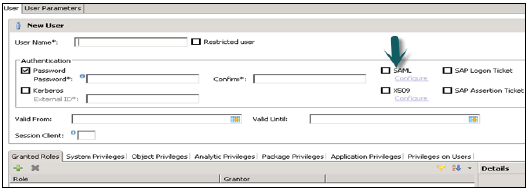
SAP Logon和斷言Ticket
SAP Logon/斷言Ticket可用於對HANA系統中的使用者進行身份驗證。這些Ticket在使用者登入到配置為發出此類Ticket的SAP系統(例如SAP Portal等)時發放給使用者。SAP Logon Ticket中指定的使用者應在HANA系統中建立,因為它不支援使用者對映。
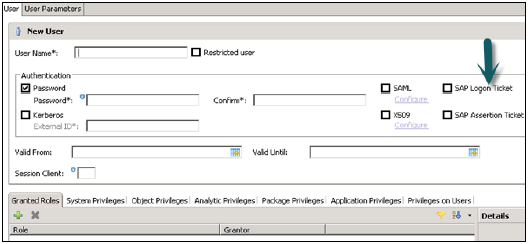
X.509客戶端證書
X.509證書也可用於透過HANA XS引擎的HTTP訪問請求登入HANA系統。使用者透過從受信任的證書頒發機構簽名的證書進行身份驗證,該證書儲存在HANA XS系統中。
受信任證書中的使用者應存在於HANA系統中,因為不支援使用者對映。
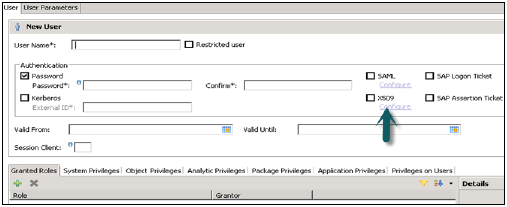
HANA系統中的單點登入
可以在HANA系統中配置單點登入,允許使用者在客戶端進行初始身份驗證後登入HANA系統。使用者使用不同的身份驗證方法在客戶端應用程式中登入,而SSO允許使用者直接訪問HANA系統。
SSO可以在以下配置方法中配置:
- SAML
- Kerberos
- 來自HANA XS引擎的HTTP訪問的X.509客戶端證書
- SAP Logon/斷言Ticket
SAP HANA - 授權方法
當用戶嘗試連線到HANA資料庫並執行一些資料庫操作時,將檢查授權。當用戶透過JDBC/ODBC或透過HTTP使用客戶端工具連線到HANA資料庫以對資料庫物件執行某些操作時,相應的操作將由授予使用者的訪問許可權確定。
授予使用者的許可權由分配給使用者配置檔案或已授予使用者的角色的物件許可權確定。授權是兩種訪問許可權的組合。當用戶嘗試對HANA資料庫執行某些操作時,系統將執行授權檢查。當找到所有必需的許可權時,系統將停止此檢查並授予請求的訪問許可權。
SAP HANA中使用了不同型別的許可權,如下面的使用者角色和管理中所述:
系統許可權
它們適用於使用者的系統和資料庫授權以及控制系統活動。它們用於管理任務,例如建立模式、資料備份、建立使用者和角色等等。系統許可權也用於執行儲存庫操作。
物件許可權
它們適用於資料庫操作,並應用於資料庫物件,如表、模式等。它們用於管理資料庫物件,如表和檢視。可以根據資料庫物件定義不同的操作,如選擇、執行、更改、刪除、刪除。
它們還用於控制透過SMART資料訪問連線到SAP HANA的遠端資料物件。
分析許可權
它們適用於HANA儲存庫中建立的所有包內部的資料。它們用於控制在包內建立的建模檢視,如屬性檢視、分析檢視和計算檢視。它們將行和列級安全性應用於在HANA包中的建模檢視中定義的屬性。
包許可權
它們適用於允許訪問和使用在HANA資料庫儲存庫中建立的包。包包含不同的建模檢視,如屬性檢視、分析檢視和計算檢視,以及在HANA儲存庫資料庫中定義的分析許可權。
應用程式許可權
它們適用於透過HTTP請求訪問HANA資料庫的HANA XS應用程式。它們用於控制對使用HANA XS引擎建立的應用程式的訪問。
可以使用HANA Studio直接將應用程式許可權應用於使用者/角色,但最好是在設計時將它們應用於在儲存庫中建立的角色。
SAP HANA資料庫中的儲存庫授權
_SYS_REPO使用者擁有HANA儲存庫中的所有物件。此使用者應在HANA系統中對建模儲存庫物件的外部物件進行授權。_SYS_REPO是所有物件的擁有者,因此它只能用於授予對這些物件的訪問許可權,其他使用者無法以_SYS_REPO使用者身份登入。
GRANT SELECT ON SCHEMA "<SCHEMA_NAME>" TO _SYS_REPO WITH GRANT OPTION
SAP HANA - 許可證管理
需要SAP HANA許可證管理和金鑰才能使用HANA資料庫。您可以使用HANA Studio安裝或刪除HANA許可證金鑰。
許可證金鑰型別
SAP HANA系統支援兩種型別的許可證金鑰:
臨時許可證金鑰 - 安裝HANA資料庫時會自動安裝臨時許可證金鑰。這些金鑰僅有效90天,您應在安裝後90天期限到期前從SAP市場請求永久許可證金鑰。
永久許可證金鑰 - 永久許可證金鑰僅在預定義的到期日期之前有效。許可證金鑰指定許可給目標HANA安裝的記憶體量。它們可以從SAP市場“金鑰和請求”選項卡下安裝。當永久許可證金鑰過期時,將發放一個臨時許可證金鑰,該金鑰僅有效28天。在此期間,您必須再次安裝永久許可證金鑰。
HANA系統有兩種型別的永久許可證金鑰:
非強制 - 如果安裝了非強制許可證金鑰,並且HANA系統的消耗超過許可的記憶體量,則在這種情況下,SAP HANA的操作不會受到影響。
強制 - 如果安裝了強制許可證金鑰,並且HANA系統的消耗超過許可的記憶體量,則HANA系統將被鎖定。如果發生這種情況,則必須重新啟動HANA系統或請求並安裝新的許可證金鑰。
HANA系統可以使用不同的許可證方案,具體取決於系統的環境(獨立式、HANA Cloud、BW on HANA等),並非所有這些模型都基於HANA系統安裝的記憶體。
如何檢查HANA的許可證屬性
右鍵單擊HANA系統→屬性→許可證

它說明了許可證型別、開始日期和到期日期、記憶體分配以及透過SAP市場請求新許可證所需的資訊(硬體金鑰、系統ID)。
安裝許可證金鑰→瀏覽→輸入路徑,用於安裝新的許可證金鑰,刪除選項用於刪除任何舊的過期金鑰。
“許可證”下的“所有許可證”選項卡顯示產品名稱、說明、硬體金鑰、首次安裝時間等。
SAP HANA - 審計
SAP HANA審計策略說明了要審計的操作,以及必須執行操作才能與審計相關的條件。審計策略定義了在HANA系統中執行了哪些活動,以及誰在何時執行了這些活動。
SAP HANA資料庫審計功能允許監控在HANA系統中執行的操作。必須在HANA系統上啟用SAP HANA審計策略才能使用它。執行操作時,策略將觸發審計事件以寫入審計跟蹤。您也可以刪除審計跟蹤中的審計條目。
在分散式環境中,如果您有多個數據庫,則可以在每個單獨的系統上啟用審計策略。對於系統資料庫,審計策略在nameserver.ini檔案中定義,對於租戶資料庫,它在global.ini檔案中定義。
啟用審計策略
要在HANA系統中定義審計策略,您應該擁有系統許可權 - 審計管理員。
轉到HANA系統中的安全選項→審計

在全域性設定下→將審計狀態設定為啟用。
您還可以選擇審計跟蹤目標。可能的審計跟蹤目標如下:
Syslog(預設) - Linux作業系統的日誌記錄系統。
資料庫表 - 內部資料庫表,擁有審計管理員或審計操作員系統許可權的使用者只能對該表執行選擇操作。
CSV文字 - 此型別的審計跟蹤僅用於非生產環境中的測試目的。

您還可以在審計策略區域建立新的審計策略→選擇建立新策略。輸入要審計的策略名稱和操作。
使用部署按鈕儲存新策略。滿足操作條件時,新策略會自動啟用,審計條目將建立在審計跟蹤表中。您可以透過將狀態更改為停用來停用策略,也可以刪除策略。
SAP HANA - 資料複製概述
SAP HANA複製允許將資料從源系統遷移到SAP HANA資料庫。使用各種資料複製技術,將資料從現有SAP系統移動到HANA的一種簡單方法。
可以透過命令列或使用HANA Studio在控制檯上設定系統複製。在此過程中,主要的ECC或事務系統可以保持線上狀態。HANA系統中有三種類型的資料複製方法:
- SAP LT複製方法
- ETL工具SAP Business Objects Data Services (BODS)方法
- 直接提取器連線方法 (DXC)
SAP LT複製方法
SAP Landscape Transformation複製是HANA系統中基於觸發器的資料複製方法。它是從SAP和非SAP源複製即時資料或基於計劃的複製的完美解決方案。它具有SAP LT複製伺服器,負責處理所有觸發器請求。複製伺服器可以作為獨立伺服器安裝,也可以在任何具有SAP NW 7.02或更高版本的SAP系統上執行。
HANA DB和ECC事務系統之間存在受信任的RFC連線,這使得HANA系統環境中基於觸發器的複製成為可能。

SLT複製的優勢
SLT複製方法允許將資料從多個源系統複製到一個HANA系統,以及從一個源系統複製到多個HANA系統。
SAP LT採用觸發器機制。它對源系統的效能沒有可衡量的影響。
它還在載入到HANA資料庫之前提供資料轉換和過濾功能。
它允許即時資料複製,僅將相關資料從SAP和非SAP源系統複製到HANA。
它與HANA系統和HANA studio完全整合。
在ECC系統中建立受信任的RFC連線
在您的源SAP系統AA1上,您想設定一個指向目標系統BB1的受信任RFC。完成後,這意味著當您登入到AA1並且您的使用者在BB1中擁有足夠的授權時,您可以使用RFC連線並登入到BB1,而無需重新輸入使用者名稱和密碼。
使用兩個SAP系統之間的RFC信任/可信關係,來自受信任系統到可信系統的RFC,登入到可信系統不需要密碼。
使用SAP登入開啟SAP ECC系統。輸入事務程式碼sm59 → 這是建立新的受信任RFC連線的事務程式碼 → 點選第3個圖示開啟新的連線嚮導 → 點選建立,將開啟一個新視窗。

RFC目標ECCHANA(輸入RFC目標的名稱)連線型別 - 3(對於ABAP系統)
轉到技術設定
輸入目標主機 - ECC系統名稱、IP並輸入系統編號。

轉到“登入和安全”選項卡,輸入語言、客戶端、ECC系統使用者名稱和密碼。

點選頂部的“儲存”選項。

點選“測試連線”,它將成功測試連線。

配置RFC連線
執行事務 - ltr(配置RFC連線)→ 將開啟新的瀏覽器 → 輸入ECC系統使用者名稱和密碼並登入。

點選“新建”→ 將開啟新視窗 → 輸入配置名稱 → 點選“下一步” → 輸入RFC目標(之前建立的連線名稱),使用搜索選項,選擇名稱並點選“下一步”。

在“指定目標系統”中,輸入HANA系統管理員使用者名稱和密碼、主機名、例項號並點選“下一步”。輸入資料傳輸作業數,例如007(不能為000)→ 下一步 → 建立配置。
現在轉到HANA Studio使用此連線 -
轉到HANA Studio → 點選“資料供應”→ 選擇HANA系統

選擇源系統(受信任RFC連線的名稱)和要載入ECC系統表的目標模式名稱。選擇要移動到HANA資料庫的表 → 新增 → 完成。
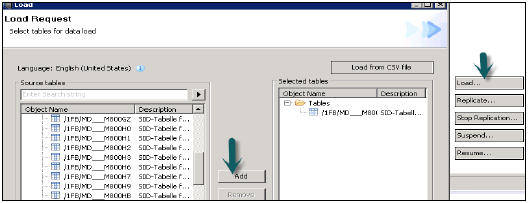
選定的表將移動到HANA資料庫下的選定模式。
SAP HANA - 基於 ETL 的複製
基於SAP HANA ETL的複製使用SAP Data Services將資料從SAP或非SAP源系統遷移到目標HANA資料庫。BODS系統是一個ETL工具,用於將資料從源系統提取、轉換和載入到目標系統。
它能夠在應用程式層讀取業務資料。您需要在Data Services中定義資料流,安排複製作業並在Data Services設計器中的資料儲存中定義源系統和目標系統。
如何使用基於SAP HANA Data Services ETL的複製?
登入Data Services Designer(選擇資源庫)→ 建立資料儲存
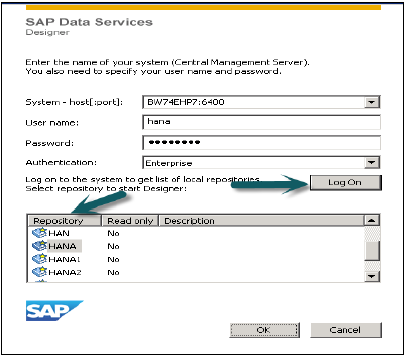
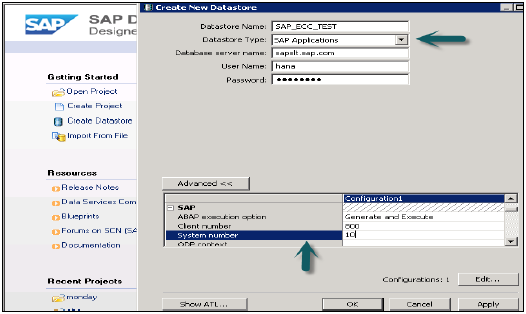
對於SAP ECC系統,選擇資料庫為SAP應用程式,輸入ECC伺服器名稱、ECC系統的使用者名稱和密碼,“高階”選項卡選擇詳細資訊,如例項號、客戶端號等,然後應用。
此資料儲存將位於本地物件庫下,如果展開此庫,則其中不包含任何表。
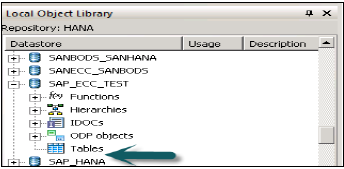
右鍵單擊“表”→ “按名稱匯入”→ 輸入要從ECC系統匯入的ECC表(MARA是ECC系統中的預設表)→ “匯入”→ 現在展開“表”→ MARA → 右鍵單擊“檢視資料”。如果顯示資料,則資料儲存連線正常。
現在,要選擇目標系統為HANA資料庫,請建立一個新的資料儲存。建立資料儲存 → 資料儲存名稱SAP_HANA_TEST → 資料儲存型別(資料庫)→ 資料庫型別SAP HANA → 資料庫版本HANA 1.x。
輸入HANA伺服器名稱、HANA系統的使用者名稱和密碼,然後單擊“確定”。
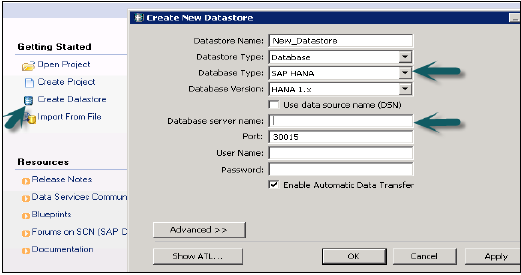
此資料儲存將新增到本地物件庫。如果要將資料從源表移動到HANA資料庫中的特定表,則可以新增表。請注意,目標表的資料型別應與源表相似。
建立複製作業
建立一個新專案 → 輸入專案名稱 → 右鍵單擊專案名稱 → 新批處理作業 → 輸入作業名稱。
從右側選項卡中,選擇工作流 → 輸入工作流名稱 → 雙擊將其新增到批處理作業下 → 輸入資料流 → 輸入資料流名稱 → 雙擊將其新增到專案區域中的批處理作業下,點選頂部的“儲存全部”選項。

將表從第一個資料儲存ECC(MARA)拖到工作區。選擇它並右鍵單擊 → 新增新 → 模板表,以在HANA DB中建立具有類似資料型別的新表 → 輸入表名、資料儲存ECC_HANA_TEST2 → 所有者名稱(模式名稱)→ 確定
將表拖到前面並連線兩個表 → 儲存全部。現在轉到批處理作業 → 右鍵單擊 → 執行 → 是 → 確定
執行復製作業後,您將收到作業已成功完成的確認。
轉到HANA studio → 展開模式 → 表 → 驗證資料。這是批處理作業的手動執行。
批處理作業的排程
您還可以透過轉到Data Services Management控制檯來排程批處理作業。登入Data Services Management控制檯。
從左側選擇資源庫 → 導航到“批處理作業配置”選項卡,您將在其中看到作業列表 → 在要排程的作業上 → 點選“新增排程” → 輸入“排程名稱”並設定引數(時間、日期、重複等)適當,然後點選“應用”。
SAP HANA - 基於日誌的複製
這在HANA系統中也稱為Sybase複製。此複製方法的主要元件是Sybase複製代理(它是SAP源應用程式系統的一部分)、複製代理和要在SAP HANA系統中實現的Sybase複製伺服器。

Sybase複製方法中的初始載入由載入控制器啟動,並由SAP HANA中的管理員觸發。它通知R3載入將初始載入傳輸到HANA資料庫。源系統上的R3載入匯出源系統中所選表的數,並將此資料傳輸到HANA系統中的R3載入元件。目標系統上的R3載入將資料匯入SAP HANA資料庫。
SAP主機代理管理源系統和目標系統之間的身份驗證,它是源系統的一部分。Sybase複製代理在初始載入時檢測任何資料更改,並確保完成每個更改。當源系統中表的條目發生更改、更新和刪除時,會建立一個表日誌。此表日誌將資料從源系統移動到HANA資料庫。
初始載入後的增量複製
一旦初始載入和複製完成,增量複製就會即時捕獲源系統中的資料更改。使用上述方法,源系統中的所有進一步更改都將被捕獲並從源系統複製到HANA資料庫。
此方法是SAP HANA複製的初始產品的一部分,但由於許可問題和複雜性,不再定位/支援,SLT也提供相同的功能。
注意 - 此方法僅支援SAP ERP系統作為資料來源和DB2作為資料庫。
SAP HANA - DXC 方法
直接提取器連線資料複製透過與SAP HANA的簡單HTTP(S)連線,重用透過SAP Business Suite系統內建的現有提取、轉換和載入機制。它是一種批處理驅動的資料複製技術。它被認為是具有有限資料提取能力的提取、轉換和載入方法。
DXC是一個批處理驅動的過程,在許多情況下,以特定間隔使用DXC進行資料提取就足夠了。您可以設定批處理作業執行的間隔,例如:每20分鐘,在大多數情況下,以特定時間間隔使用這些批處理作業提取資料就足夠了。
DXC資料複製的優點
此方法不需要在SAP HANA系統環境中新增額外的伺服器或應用程式。
DXC方法簡化了SAP HANA中的資料建模,因為資料在應用源系統中的所有業務提取器邏輯後傳送到HANA。
它加快了SAP HANA實施專案的時間表
它為SAP HANA提供了來自SAP Business Suite的語義豐富的的資料
它透過與SAP HANA的簡單HTTP(S)連線,重用SAP Business Suite系統中內建的現有專有提取、轉換和載入機制。
DXC資料複製的侷限性
資料來源必須具有預定義的提取、轉換和載入機制,如果沒有,我們需要定義一個。
它需要基於Net Weaver 7.0或更高版本的Business Suite系統,至少具有以下SP:Release 700 SAPKW70021(SP堆疊19,2008年11月起)。
配置DXC資料複製
在HANA Studio的“配置”選項卡中啟用XS Engine服務 - 轉到系統HANA studio的“管理員”選項卡。轉到“配置”→ xsengine.ini並將例項值設定為1。
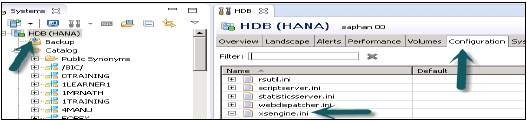
在HANA Studio中啟用ICM Web Dispatcher服務 - 轉到“配置”→ webdispatcher.ini並將例項值設定為1。
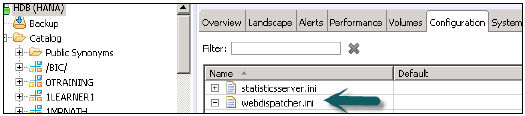
它在HANA系統中啟用ICM Web Dispatcher服務。Web Dispatcher使用ICM方法在HANA系統中讀取和載入資料。
設定SAP HANA直接提取器連線 - 將DXC交付單元下載到SAP HANA。您可以在/usr/sap/HDB/SYS/global/hdb/content位置匯入單元。
使用SAP HANA內容節點中的“匯入對話方塊”匯入單元 → 配置XS應用程式伺服器以利用DXC → 將application_container值更改為libxsdxc
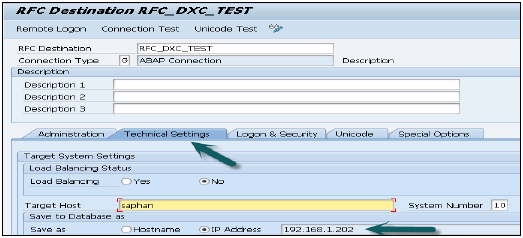
在SAP BW中建立HTTP連線 - 現在我們需要使用事務程式碼SM59在SAP BW中建立http連線。
輸入引數 - 輸入RFC連線的名稱、HANA主機名和<例項號>
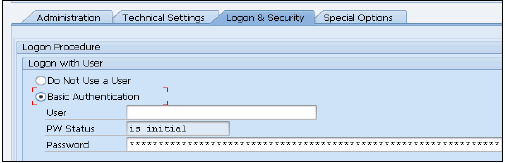
在“登入安全”選項卡中,使用基本身份驗證方法輸入在HANA studio中建立的DXC使用者 -
設定HANA的BW引數 - 需要使用事務SE 38設定BW中的以下引數。引數列表 -
PSA_TO_HDB_DESTINATION - 我們需要提到我們需要將傳入資料移動到哪裡(使用SM 59建立的連線名稱)
PSA_TO_HDB_SCHEMA - 將複製的資料需要分配到的模式
PSA_TO_HDB - GLOBAL將所有資料來源複製到HANA。SYSTEM – 指定要使用DXC的客戶端。DATASOURCE – 僅使用指定的Data Source
PSA_TO_HDB_DATASOURCETABLE - 需要提供包含用於DXC的資料來源列表的表名。
資料來源複製
使用RSA5在ECC中安裝資料來源。
使用指定的應用程式元件複製元資料(資料來源版本需要為7.0,如果我們有3.5版本的資料來源,我們需要遷移它。在SAP BW中啟用資料來源。一旦資料來源在SAP BW中被啟用,它將在定義的模式下建立以下表 -
/BIC/A<資料來源>00 – IMDSO活動表
/BIC/A<資料來源>40 –IMDSO啟用佇列
/BIC/A<資料來源>70 – 記錄模式處理表
/BIC/A<資料來源>80 – 請求和資料包ID資訊表
/BIC/A<資料來源>A0 – 請求時間戳表
RSODSO_IMOLOG - 與IMDSO相關的表。儲存與DXC相關的所有資料來源的資訊。
現在資料已成功載入到表/BIC/A0FI_AA_2000中(一旦啟用)。
SAP HANA - CTL 方法
開啟SAP HANA Studio → 在“目錄”選項卡下建立模式。<從這裡開始>
準備資料並將其儲存為csv格式。現在建立一個副檔名為“ctl”的檔案,語法如下:
--------------------------------------- import data into table Schema."Table name" from 'file.csv' records delimited by '\n' fields delimited by ',' Optionally enclosed by '"' error log 'table.err' -----------------------------------------
將此“ctl”檔案傳輸到FTP並執行此檔案以匯入資料:
從 ‘table.ctl’ 匯入
透過以下路徑檢查表中的資料:HANA Studio → 目錄 → 模式 → 表格 → 檢視內容
SAP HANA - MDX 提供程式
MDX Provider 用於連線 MS Excel 到 SAP HANA 資料庫系統。它提供驅動程式以連線 HANA 系統到 Excel,並進一步用於資料建模。您可以使用 Microsoft Office Excel 2010/2013 來連線 32 位和 64 位 Windows 系統下的 HANA。
SAP HANA 支援兩種查詢語言:SQL 和 MDX。兩種語言都可以使用:JDBC 和 ODBC 用於 SQL,ODBO 用於 MDX 處理。Excel 資料透視表使用 MDX 作為查詢語言來讀取 SAP HANA 系統中的資料。MDX 定義為 Microsoft 的 ODBO (OLE DB for OLAP) 規範的一部分,用於資料選擇、計算和佈局。MDX 支援多維資料模型,並支援報表和分析需求。
MDX 提供程式允許 SAP 和非 SAP 報表工具使用在 HANA studio 中定義的資訊檢視。現有的物理表和模式構成了資訊模型的資料基礎。
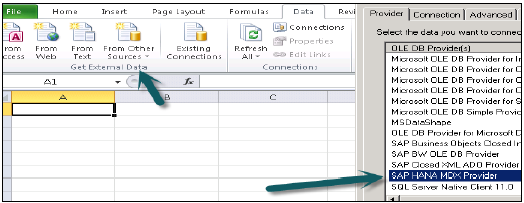
一旦您從要連線的資料來源列表中選擇 SAP HANA MDX 提供程式,請傳入 HANA 系統詳細資訊,例如主機名、例項編號、使用者名稱和密碼。

連線成功後,您可以選擇包名稱 → HANA 建模檢視來生成資料透視表。

MDX 與 HANA 資料庫緊密整合。HANA 資料庫的連線和會話管理處理由 HANA 執行的語句。當執行這些語句時,它們由 MDX 介面解析,併為每個 MDX 語句生成一個計算模型。此計算模型建立一個執行計劃,該計劃生成 MDX 的標準結果。這些結果直接由 OLAP 客戶端使用。
要與 HANA 資料庫建立 MDX 連線,需要 HANA 客戶端工具。您可以從 SAP 市場下載此客戶端工具。安裝 HANA 客戶端後,您將在 MS Excel 的資料來源列表中看到 SAP HANA MDX 提供程式選項。
SAP HANA - 監控與警報
SAP HANA 警報監控用於監控 HANA 系統中執行的系統資源和服務的執行狀況。警報監控用於處理關鍵警報,例如 CPU 使用率、磁碟已滿、檔案系統達到閾值等。HANA 系統的監控元件持續收集有關 HANA 資料庫所有元件的健康狀況、使用情況和效能的資訊。當任何元件超過設定的閾值時,它會發出警報。
HANA 系統中發出的警報優先順序指示問題的嚴重性,它取決於對元件執行的檢查。例如:如果 CPU 使用率為 80%,則會發出低優先順序警報。但是,如果它達到 96%,系統將發出高優先順序警報。
系統監控器是監控 HANA 系統和驗證所有 SAP HANA 系統元件可用性的最常用方法。系統監控器用於檢查 HANA 系統的所有關鍵元件和服務。

您還可以深入瞭解管理編輯器中單個系統的詳細資訊。它顯示有關資料磁碟、日誌磁碟、跟蹤磁碟以及資源使用情況的警報(及其優先順序)的資訊。
管理員編輯器中的“警報”選項卡用於檢查 HANA 系統中當前和所有警報。
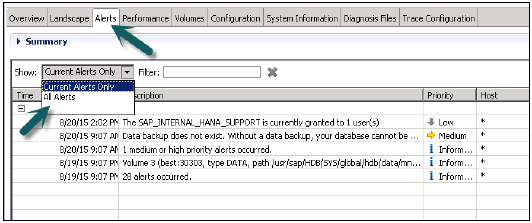
它還顯示警報發出時間、警報描述、警報優先順序等。
SAP HANA 監控儀表板顯示系統健康狀況和配置的關鍵方面:

- 高優先順序和中優先順序警報。
- 記憶體和 CPU 使用率
- 資料備份
SAP HANA - 持久層
SAP HANA 資料庫持久層負責管理所有事務的日誌,以提供標準資料備份和系統恢復功能。
它確保資料庫可以在重新啟動或系統崩潰後恢復到最近提交的狀態,並且事務已完全執行或完全撤消。SAP HANA 持久層是索引伺服器的一部分,它具有 HANA 系統的資料和事務日誌卷,並且記憶體中的資料會定期儲存到這些卷中。HANA 系統中有一些服務具有自己的永續性。它還為自上次儲存點以來的所有資料庫事務提供儲存點和日誌。
為什麼 SAP HANA 資料庫需要持久層?
主記憶體是易失性的,因此在重新啟動或斷電期間資料會丟失。
資料需要儲存在持久介質中。
提供備份和恢復功能。
它確保資料庫在重新啟動後恢復到最近提交的狀態,並且事務要麼完全執行,要麼完全撤消。
資料和事務日誌卷
資料庫始終可以恢復到其最新狀態,以確保定期將對資料庫中資料的這些更改複製到磁碟。包含資料更改和某些事務事件的日誌檔案也定期儲存到磁碟。系統的日誌和資料儲存在日誌卷中。
資料卷儲存 SQL 資料和撤消日誌資訊,以及 SAP HANA 資訊建模資料。這些資訊儲存在資料頁中,稱為塊。這些塊會定期寫入資料卷,這稱為儲存點。
日誌卷儲存有關資料更改的資訊。在兩個日誌點之間進行的更改將寫入日誌卷,並稱為日誌條目。事務提交時,它們將儲存到日誌緩衝區。
儲存點
在 SAP HANA 資料庫中,更改的資料會自動從記憶體儲存到磁碟。這些定期間隔稱為儲存點,預設情況下,它們設定為每五分鐘發生一次。SAP HANA 資料庫中的持久層定期執行這些儲存點操作。在此操作期間,更改的資料將寫入磁碟,重做日誌也將儲存到磁碟。
屬於儲存點的資料指示磁碟上資料的穩定狀態,並且保留在那裡,直到下一個儲存點操作完成。重做日誌條目將為對持久資料的全部更改寫入日誌卷。如果資料庫重新啟動,則可以從資料卷讀取上次完成的儲存點的資料,並從日誌卷寫入重做日誌條目。
儲存點的頻率可以透過 global.ini 檔案配置。儲存點可以由其他操作啟動,例如資料庫關閉或系統重新啟動。您還可以透過執行以下命令來執行儲存點:
ALTER System SAVEPOINT
要將資料和重做日誌儲存到日誌卷,您應確保有足夠的磁碟空間來捕獲這些資料,否則系統將發出磁碟已滿事件,資料庫將停止工作。
在 HANA 系統安裝期間,以下預設目錄將建立為資料和日誌卷的儲存位置:
- /usr/sap/
/SYS/global/hdb/data - /usr/sap/
/SYS/global/hdb/log
這些目錄在 global.ini 檔案中定義,可以在以後更改。
請注意,儲存點不會影響在 HANA 系統中執行的事務的效能。在儲存點操作期間,事務將繼續正常執行。如果 HANA 系統在合適的硬體上執行,則儲存點對系統性能的影響可以忽略不計。
SAP HANA - 備份與恢復
SAP HANA 備份和恢復用於執行 HANA 系統備份以及在任何資料庫故障的情況下恢復系統。
概述選項卡
它顯示當前正在執行的資料備份和上次成功的資料備份的狀態。

“立即備份”選項可用於執行資料備份嚮導。
配置選項卡
它顯示備份間隔設定、基於檔案的資料庫備份設定和基於日誌的資料庫備份設定。

備份間隔設定
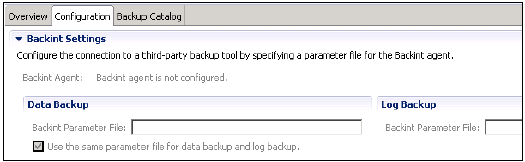
Backint 設定提供了一個選項,可以使用第三方工具進行資料和日誌備份,並配置備份代理。
透過為 Backint 代理指定引數檔案來配置與第三方備份工具的連線。
基於檔案和日誌的資料備份設定
基於檔案的資料庫備份設定顯示要在 HANA 系統上儲存資料備份的資料夾。您可以更改備份資料夾。
您還可以限制資料備份檔案的大小。如果系統資料備份超過此設定的檔案大小,它將拆分為多個檔案。
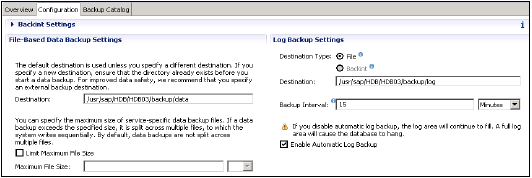
日誌備份設定顯示要在外部伺服器上儲存日誌備份的目標資料夾。您可以為日誌備份選擇目標型別
檔案 - 確保系統中有足夠的儲存空間來儲存備份
Backint - 是檔案系統上存在的特殊命名管道,但不需要磁碟空間。
您可以從下拉選單中選擇備份間隔。它表示在寫入新的日誌備份之前可以經過的最長時間。備份間隔:可以是秒、分鐘或小時。
啟用自動日誌備份選項:這有助於保持日誌區域為空。如果您停用此功能,日誌區域將繼續填充,這可能導致資料庫掛起。
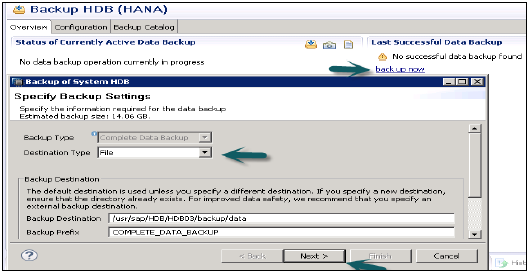
開啟備份嚮導 - 以執行系統備份。
備份嚮導用於指定備份設定。它顯示備份型別、目標型別、備份目標資料夾、備份字首、備份大小等。
單擊下一步 → 檢視備份設定 → 完成
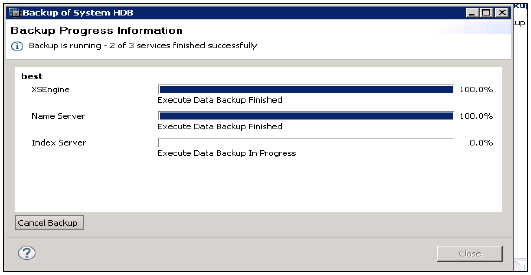
它執行系統備份,並顯示每個伺服器完成備份所需的時間。
HANA 系統恢復
要恢復 SAP HANA 資料庫,需要關閉資料庫。因此,在恢復期間,終端使用者或 SAP 應用程式無法訪問資料庫。
在以下情況下需要恢復 SAP HANA 資料庫:
資料區域中的磁碟不可用,或者日誌區域中的磁碟不可用。
由於邏輯錯誤,需要將資料庫重置到特定時間點上的狀態。
您想要建立資料庫的副本。
如何恢復 HANA 系統?
選擇 HANA 系統 → 右鍵單擊 → 備份和恢復 → 恢復系統

HANA 系統中的恢復型別
最新狀態 - 用於將資料庫恢復到儘可能接近當前時間的時刻。對於此恢復,自上次資料備份以來必須提供資料備份和日誌備份,並且需要日誌區域來執行上述型別的恢復。
特定時間點 - 用於將資料庫恢復到特定時間點。對於此恢復,自上次資料備份以來必須提供資料備份和日誌備份,並且需要日誌區域來執行上述型別的恢復
特定資料備份 − 用於將資料庫恢復到指定的資料備份。此類恢復選項需要特定資料備份。
特定日誌位置 − 此恢復型別是高階選項,可在之前的恢復失敗的特殊情況下使用。
注意 − 要執行恢復嚮導,您必須擁有 HANA 系統的管理員許可權。
SAP HANA - 高可用性
SAP HANA 提供用於應對系統故障和軟體錯誤的業務連續性和災難恢復機制。HANA 系統中的高可用性定義了一套實踐,有助於在災難情況下(例如資料中心的電源故障、火災、洪水等自然災害或任何硬體故障)實現業務連續性。
SAP HANA 高可用性提供容錯能力,使系統能夠在中斷後恢復系統操作,並將業務損失降至最低。
下圖顯示了 HANA 系統中高可用性的階段 −
第一階段是為故障做好準備。故障可以自動檢測到,也可以透過管理操作檢測到。資料備份完畢後,備用系統接管操作。恢復過程包括修復故障系統和將原始系統恢復到之前的配置。

為了在 HANA 系統中實現高可用性,關鍵在於包含額外的元件,這些元件在其他元件發生故障時並非必需的功能和使用。它包括硬體冗餘、網路冗餘和資料中心冗餘。SAP HANA 提供以下幾個級別的硬體和軟體冗餘 −
HANA 系統硬體冗餘
SAP HANA 裝置供應商提供多層冗餘硬體、軟體和網路元件,例如冗餘電源和風扇、糾錯記憶體、完全冗餘的網路交換機和路由器以及不間斷電源 (UPS)。磁碟儲存系統保證即使在電源故障的情況下也能寫入資料,並使用條帶化和映象功能來提供冗餘,以便從磁碟故障中自動恢復。
SAP HANA 軟體冗餘
SAP HANA 基於 SUSE Linux Enterprise 11 for SAP,幷包含安全預配置。
SAP HANA 系統軟體包括看門狗功能,該功能可在檢測到停止(被終止或崩潰)的情況下自動重啟已配置的服務(索引伺服器、名稱伺服器等)。
SAP HANA 永續性冗餘
SAP HANA 提供事務日誌、儲存點和快照的永續性,以支援系統重啟和從故障中恢復,同時最大限度地減少延遲且不會丟失資料。
HANA 系統備用和故障轉移
SAP HANA 系統包含單獨的備用主機,用於在主系統發生故障時進行故障轉移。這透過減少中斷後的恢復時間來提高 HANA 系統的可用性。
SAP HANA - 日誌配置
SAP HANA 系統將所有更改應用程式資料或資料庫目錄的事務記錄到日誌條目中,並將它們儲存在日誌區域中。它使用日誌區域中的這些日誌條目來回滾或重複 SQL 語句。日誌檔案位於 HANA 系統中,可以透過 HANA studio 在管理員編輯器下的“診斷檔案”頁面訪問。
在日誌備份過程中,只有日誌段的實際資料才會從日誌區域寫入特定於服務的日誌備份檔案或第三方備份工具。
系統故障後,您可能需要從日誌備份中重做日誌條目,以將資料庫恢復到所需狀態。
如果具有永續性的資料庫服務停止,務必確保將其重新啟動,否則只能恢復到服務停止之前的某個點。
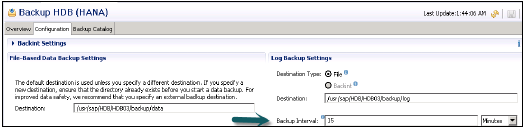
配置日誌備份超時
如果在此間隔內發生了提交,則日誌備份超時將確定備份日誌段的間隔。您可以使用 SAP HANA studio 中的備份控制檯配置日誌備份超時 −
您也可以在 global.ini 配置檔案中配置 log_backup_timeout_s 間隔。
安裝 SAP HANA 系統後,“檔案”日誌備份和“NORMAL”備份模式是自動日誌備份功能的預設設定。只有執行了至少一個完整的資料備份後,自動日誌備份才有效。
執行第一次完整資料備份後,自動日誌備份功能處於活動狀態。可以使用 SAP HANA studio 啟用/停用自動日誌備份功能。建議保持啟用自動日誌備份,否則日誌區域將繼續填充。日誌區域已滿會導致 HANA 系統資料庫凍結。
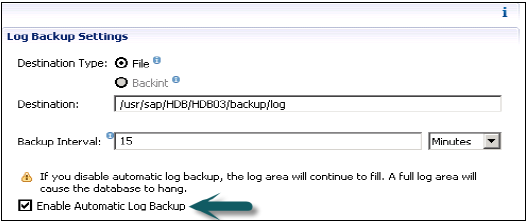
您也可以更改 global.ini 配置檔案 persistence 部分中的 enable_auto_log_backup 引數。
SAP HANA - SQL 概述
SQL 代表結構化查詢語言。
它是一種與資料庫通訊的標準化語言。SQL 用於檢索、儲存或操作資料庫中的資料。
SQL 語句執行以下功能 −
- 資料定義和操作
- 系統管理
- 會話管理
- 事務管理
- 模式定義和操作
允許開發人員將資料推入資料庫的 SQL 擴充套件集稱為SQL 指令碼。
資料操縱語言 (DML)
DML 語句用於管理模式物件中的資料。一些示例 −
SELECT − 從資料庫中檢索資料
INSERT − 將資料插入表中
UPDATE − 更新表中現有資料
資料定義語言 (DDL)
DDL 語句用於定義資料庫結構或模式。一些示例 −
CREATE − 在資料庫中建立物件
ALTER − 更改資料庫的結構
DROP − 從資料庫中刪除物件
資料控制語言 (DCL)
DCL 語句的一些示例是 −
GRANT − 向用戶授予對資料庫的訪問許可權
REVOKE − 撤銷使用 GRANT 命令授予的訪問許可權
為什麼我們需要 SQL?
當我們在 SAP HANA Modeler 中建立資訊檢視時,我們是在某些 OLTP 應用程式之上建立的。所有這些後端都在 SQL 上執行。資料庫只理解這種語言。
要測試我們的報告是否滿足業務需求,如果輸出符合需求,我們必須在資料庫中執行 SQL 語句。
HANA 計算檢視可以透過兩種方式建立 - 圖形方式或使用 SQL 指令碼。當我們建立更復雜的計算檢視時,我們可能需要使用直接 SQL 指令碼。
如何在 HANA Studio 中開啟 SQL 控制檯?
選擇 HANA 系統,然後單擊系統檢視中的 SQL 控制檯選項。您也可以透過右鍵單擊“目錄”選項卡或任何模式名稱來開啟 SQL 控制檯。
SAP HANA 可以同時充當關係資料庫和 OLAP 資料庫。當我們在 HANA 上使用 BW 時,我們在 BW 和 HANA 中建立多維資料集,它們充當關係資料庫並始終生成 SQL 語句。但是,當我們使用 OLAP 連線直接訪問 HANA 檢視時,它將充當 OLAP 資料庫,並將生成 MDX。
SAP HANA - 資料型別
您可以使用 create table 選項在 SAP HANA 中建立行儲存表或列儲存表。可以透過執行資料定義 create table 語句或使用 HANA studio 中的圖形選項來建立表。
建立表時,還需要在其中定義屬性。
在 HANA Studio SQL 控制檯中建立表的 SQL 語句 −
Create column Table TEST ( ID INTEGER, NAME VARCHAR(10), PRIMARY KEY (ID) );
使用 GUI 選項在 HANA studio 中建立表 −
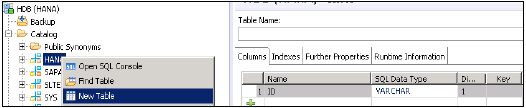
建立表時,需要定義列的名稱和 SQL 資料型別。“維度”欄位指示值的長度,“鍵”選項用於將其定義為主鍵。
SAP HANA 支援表中的以下資料型別 −
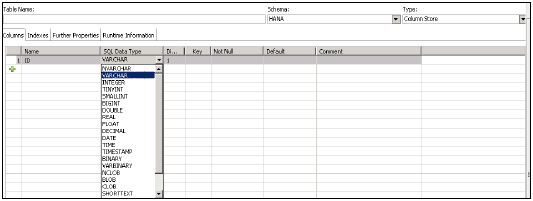
SAP HANA 支援 7 類 SQL 資料型別,這取決於您必須在列中儲存的資料型別。
- 數值型
- 字元/字串
- 布林型
- 日期時間型
- 二進位制型
- 大型物件
- 多值型
下表列出了每類資料型別 −

日期時間型
這些資料型別用於在 HANA 資料庫中的表中儲存日期和時間。
DATE − 資料型別包含年份、月份和日期資訊,用於表示列中的日期值。日期資料型別的預設格式為 YYYY-MM-DD。
TIME − 資料型別包含 HANA 資料庫中表中的小時、分鐘和秒值。時間資料型別的預設格式為 HH:MI:SS。
SECONDDATE − 資料型別包含 HANA 資料庫中表中的年份、月份、日期、小時、分鐘、秒值。SECONDDATE 資料型別的預設格式為 YYYY-MM-DD HH:MM:SS。
TIMESTAMP − 資料型別包含 HANA 資料庫中表中的日期和時間資訊。TIMESTAMP 資料型別的預設格式為 YYYY-MM-DD HH:MM:SS:FFn,其中 FFn 表示秒的分數。
數值型
TinyINT − 儲存 8 位無符號整數。最小值:0,最大值:255
SMALLINT − 儲存 16 位有符號整數。最小值:-32,768,最大值:32,767
Integer − 儲存 32 位有符號整數。最小值:-2,147,483,648,最大值:2,147,483,648
BIGINT − 儲存 64 位有符號整數。最小值:-9,223,372,036,854,775,808,最大值:9,223,372,036,854,775,808
SMALL − DECIMAL 和 DECIMAL:最小值:-10^38 +1,最大值:10^38 -1
REAL − 最小值:-3.40E + 38,最大值:3.40E + 38
DOUBLE − 儲存 64 位浮點數。最小值:-1.7976931348623157E308,最大值:1.7976931348623157E308
布林型
布林資料型別儲存布林值,即 TRUE、FALSE
字元型
Varchar − 最大 8000 個字元。
Nvarchar − 最大長度為 4000 個字元
ALPHANUM − 儲存字母數字字元。整數的值介於 1 到 127 之間。
SHORTTEXT − 儲存可變長度的字元字串,支援文字搜尋功能和字串搜尋功能。
二進位制型
二進位制型別用於儲存二進位制資料的位元組。
VARBINARY − 以位元組為單位儲存二進位制資料。最大整數長度介於 1 和 5000 之間。
大型物件
LARGEOBJECTS 用於儲存大量資料,例如文字文件和影像。
NCLOB − 儲存大型 UNICODE 字元物件。
BLOB − 儲存大量二進位制資料。
CLOB − 儲存大量 ASCII 字元資料。
TEXT − 它啟用文字搜尋功能。此資料型別只能為列表定義,不能為行儲存表定義。
BINTEXT − 支援文字搜尋功能,但也可以插入二進位制資料。
多值
多值資料型別用於儲存具有相同資料型別的多個值的集合。
陣列
陣列儲存具有相同資料型別的多個值的集合。它們也可以包含空值。
SAP HANA - SQL 運算子
運算子是特殊字元,主要用於 SQL 語句的 WHERE 子句中執行操作,例如比較和算術運算。它們用於在 SQL 查詢中傳遞條件。
HANA 中 SQL 語句可以使用以下運算子型別:
- 算術運算子
- 比較/關係運算符
- 邏輯運算子
- 集合運算子
算術運算子
算術運算子用於執行簡單的計算函式,例如加法、減法、乘法、除法和百分比。
| 運算子 | 描述 |
|---|---|
| + | 加法 − 將運算子兩側的值相加 |
| - | 減法 − 從左運算元中減去右運算元 |
| * | 乘法 − 將運算子兩側的值相乘 |
| / | 除法 − 將左運算元除以右運算元 |
| % | 模數 − 將左運算元除以右運算元並返回餘數 |
比較運算子
比較運算子用於比較 SQL 語句中的值。
| 運算子 | 描述 |
|---|---|
| = | 檢查兩個運算元的值是否相等,如果相等,則條件為真。 |
| != | 檢查兩個運算元的值是否不相等,如果不相等,則條件為真。 |
| <> | 檢查兩個運算元的值是否不相等,如果不相等,則條件為真。 |
| > | 檢查左運算元的值是否大於右運算元的值,如果是,則條件為真。 |
| < | 檢查左運算元的值是否小於右運算元的值,如果是,則條件為真。 |
| >= | 檢查左運算元的值是否大於或等於右運算元的值,如果是,則條件為真。 |
| <= | 檢查左運算元的值是否小於或等於右運算元的值,如果是,則條件為真。 |
| !< | 檢查左運算元的值是否不小於右運算元的值,如果是,則條件為真。 |
| !> | 檢查左運算元的值是否不大於右運算元的值,如果是,則條件為真。 |
邏輯運算子
邏輯運算子用於在 SQL 語句中傳遞多個條件,或用於操作條件的結果。
| 運算子 | 描述 |
|---|---|
| ALL | ALL 運算子用於將值與另一個值集中的所有值進行比較。 |
| AND | AND 運算子允許 SQL 語句的 WHERE 子句中存在多個條件。 |
| ANY | ANY 運算子用於根據條件將值與列表中任何適用的值進行比較。 |
| BETWEEN | BETWEEN 運算子用於搜尋在給定最小值和最大值的一組值內的值。 |
| EXISTS | EXISTS 運算子用於搜尋指定表中是否存在滿足特定條件的行。 |
| IN | IN 運算子用於將值與已指定的文字值列表進行比較。 |
| LIKE | LIKE 運算子用於使用萬用字元運算子將值與類似的值進行比較。 |
| NOT | NOT 運算子反轉與其一起使用的邏輯運算子的含義。例如:NOT EXISTS、NOT BETWEEN、NOT IN 等。這是一個否定運算子。 |
| OR | OR 運算子用於比較 SQL 語句 WHERE 子句中的多個條件。 |
| IS NULL | NULL 運算子用於將值與 NULL 值進行比較。 |
| UNIQUE | UNIQUE 運算子搜尋指定表中每一行的唯一性(無重複)。 |
集合運算子
集合運算子用於將兩個查詢的結果組合成一個結果。兩個表的的資料型別應該相同。
UNION − 它組合兩個或多個 Select 語句的結果。但是它會消除重複的行。
UNION ALL − 此運算子類似於 Union,但它也顯示重複的行。
INTERSECT − 交集運算用於組合兩個 SELECT 語句,並返回兩個 SELECT 語句中都存在的記錄。對於 Intersect,兩個表中的列數和資料型別必須相同。
MINUS − 減法運算組合兩個 SELECT 語句的結果,並且只返回屬於第一組結果的結果,並從第一個結果的輸出中消除第二個語句中的行。
SAP HANA - SQL 函式
SAP HANA 資料庫提供了各種 SQL 函式:
- 數值函式
- 字串函式
- 全文函式
- 日期時間函式
- 聚合函式
- 資料型別轉換函式
- 視窗函式
- 序列資料函式
- 雜項函式
數值函式
這些是 SQL 中的內建數值函式,用於指令碼編寫。它接受數值或包含數字字元的字串,並返回數值。
ABS − 它返回數值引數的絕對值。
Example − SELECT ABS (-1) "abs" FROM TEST; abs 1
ACOS、ASIN、ATAN、ATAN2(這些函式返回引數的三角函式值)
BINTOHEX − 它將二進位制值轉換為十六進位制值。
BITAND − 它對傳入引數的位執行 AND 運算。
BITCOUNT − 它計算引數中已設定位的數量。
BITNOT − 它對引數的位執行按位 NOT 運算。
BITOR − 它對傳入引數的位執行 OR 運算。
BITSET − 用於從 <start_bit> 位置設定 <target_num> 中的位為 1。
BITUNSET − 用於從 <start_bit> 位置設定 <target_num> 中的位為 0。
BITXOR − 它對傳入引數的位執行 XOR 運算。
CEIL − 它返回大於或等於傳入值的首個整數。
COS、COSH、COT(這些函式返回引數的三角函式值)
EXP − 它返回自然對數 e 的底數提升到傳入值的冪的結果。
FLOOR − 它返回不大於數值引數的最大整數。
HEXTOBIN − 它將十六進位制值轉換為二進位制值。
LN − 它返回引數的自然對數。
LOG − 它返回傳入正值的演算法值。底數和對數值都應為正數。
還可以使用各種其他數值函式:MOD、POWER、RAND、ROUND、SIGN、SIN、SINH、SQRT、TAN、TANH、UMINUS
字串函式
HANA 中可以使用各種 SQL 字串函式以及 SQL 指令碼。最常見的字串函式包括:
ASCII − 它返回傳入字串的整數 ASCII 值。
CHAR − 它返回與傳入 ASCII 值關聯的字元。
CONCAT − 它是連線運算子,返回組合的傳入字串。
LCASE − 它將字串的所有字元轉換為小寫。
LEFT − 它根據提到的值返回傳入字串的第一個字元。
LENGTH − 它返回傳入字串中的字元數。
LOCATE − 它返回子字串在傳入字串中的位置。
LOWER − 它將字串中的所有字元轉換為小寫。
NCHAR − 它返回具有傳入整數值的 Unicode 字元。
REPLACE − 它在傳入的原始字串中搜索搜尋字串的所有出現,並用替換字串替換它們。
RIGHT − 它返回提到字串的最右邊的傳入值字元。
UPPER − 它將傳入字串中的所有字元轉換為大寫。
UCASE − 它與 UPPER 函式相同。它將傳入字串中的所有字元轉換為大寫。
其他可使用的字串函式包括:LPAD、LTRIM、RTRIM、STRTOBIN、SUBSTR_AFTER、SUBSTR_BEFORE、SUBSTRING、TRIM、UNICODE、RPAD、BINTOSTR
日期時間函式
HANA 中的 SQL 指令碼可以使用各種日期時間函式。最常見的日期時間函式包括:
CURRENT_DATE − 它返回當前本地系統日期。
CURRENT_TIME − 它返回當前本地系統時間。
CURRENT_TIMESTAMP − 它返回當前本地系統時間戳詳細資訊 (YYYY-MM-DD HH:MM:SS:FF)。
CURRENT_UTCDATE − 它返回當前 UTC(格林威治平均日期)日期。
CURRENT_UTCTIME − 它返回當前 UTC(格林威治標準時間)時間。
CURRENT_UTCTIMESTAMP
DAYOFMONTH − 它返回引數中傳入日期的月份中的整數天數。
HOUR − 它返回引數中傳入時間的小時整數。
YEAR − 它返回傳入日期的年份值。
其他日期時間函式包括:DAYOFYEAR、DAYNAME、DAYS_BETWEEN、EXTRACT、NANO100_BETWEEN、NEXT_DAY、NOW、QUARTER、SECOND、SECONDS_BETWEEN、UTCTOLOCAL、WEEK、WEEKDAY、WORKDAYS_BETWEEN、ISOWEEK、LAST_DAY、LOCALTOUTC、MINUTE、MONTH、MONTHNAME、ADD_DAYS、ADD_MONTHS、ADD_SECONDS、ADD_WORKDAYS
資料型別轉換函式
這些函式用於將一種資料型別轉換為另一種資料型別,或用於檢查轉換是否可行。
HANA 中 SQL 指令碼中最常用的資料型別轉換函式:
CAST − 它返回已轉換為提供的 資料型別的表示式的值。
TO_ALPHANUM − 它將傳入的值轉換為 ALPHANUM 資料型別
TO_REAL − 它將值轉換為 REAL 資料型別。
TO_TIME − 它將傳入的時間字串轉換為 TIME 資料型別。
TO_CLOB − 它將值轉換為 CLOB 資料型別。
其他類似的資料型別轉換函式包括:TO_BIGINT、TO_BINARY、TO_BLOB、TO_DATE、TO_DATS、TO_DECIMAL、TO_DOUBLE、TO_FIXEDCHAR、TO_INT、TO_INTEGER、TO_NCLOB、TO_NVARCHAR、TO_TIMESTAMP、TO_TINYINT、TO_VARCHAR、TO_SECONDDATE、TO_SMALLDECIMAL、TO_SMALLINT
HANA SQL 指令碼中還可以使用各種視窗和其他雜項函式。
Current_Schema − 它返回包含當前模式名稱的字串。
Session_User − 它返回當前會話的使用者名稱
SAP HANA - SQL 表示式
表示式用於計算子句以返回值。HANA 中可以使用不同的 SQL 表示式:
- Case 表示式
- 函式表示式
- 聚合表示式
- 表示式中的子查詢
Case 表示式
這用於在 SQL 表示式中傳遞多個條件。它允許在 SQL 語句中使用 IF-ELSE-THEN 邏輯而無需使用過程。
示例
SELECT COUNT( CASE WHEN sal < 2000 THEN 1 ELSE NULL END ) count1, COUNT( CASE WHEN sal BETWEEN 2001 AND 4000 THEN 1 ELSE NULL END ) count2, COUNT( CASE WHEN sal > 4000 THEN 1 ELSE NULL END ) count3 FROM emp;
此語句將根據傳入的條件返回具有整數值的 count1、count2、count3。
函式表示式
函式表示式涉及在表示式中使用的 SQL 內建函式。
聚合表示式
聚合函式用於執行復雜的計算,例如求和、百分比、最小值、最大值、計數、眾數、中位數等。聚合表示式使用聚合函式從多個值計算單個值。
聚合函式 − 求和、計數、最小值、最大值。這些應用於度量值(事實),並且始終與維度相關聯。
常見的聚合函式包括:
- 平均值 ()
- 計數 ()
- 最大值 ()
- 中位數 ()
- 最小值 ()
- 眾數 ()
- 求和 ()
表示式中的子查詢
作為表示式的子查詢是一個 Select 語句。當它用在表示式中時,它返回零個或單個值。
子查詢用於返回將在主查詢中用作條件的資料,以進一步限制要檢索的資料。
子查詢可與 SELECT、INSERT、UPDATE 和 DELETE 語句以及 =、<、>、>=、<=、IN、BETWEEN 等運算子一起使用。
子查詢必須遵循一些規則:
子查詢必須用括號括起來。
除非子查詢的主查詢有多個列用於比較子查詢選擇的列,否則子查詢的SELECT語句中只能有一列。
子查詢中不能使用ORDER BY,雖然主查詢可以使用ORDER BY。可以使用GROUP BY 來實現子查詢中ORDER BY的功能。
返回多行的子查詢只能與多值運算子一起使用,例如IN運算子。
SELECT 列表中不能包含任何引用BLOB、ARRAY、CLOB或NCLOB值的表示式。
子查詢不能直接包含在集合函式中。
BETWEEN運算子不能與子查詢一起使用;但是,BETWEEN運算子可以在子查詢中使用。
帶有SELECT語句的子查詢
子查詢最常與SELECT語句一起使用。基本語法如下:
示例
SELECT * FROM CUSTOMERS WHERE ID IN (SELECT ID FROM CUSTOMERS WHERE SALARY > 4500) ;
+----+----------+-----+---------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+---------+----------+ | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+---------+----------+
SAP HANA - SQL 儲存過程
過程允許您將SQL語句分組到單個塊中。儲存過程用於跨應用程式實現某些結果。用於執行某些特定任務的一組SQL語句和邏輯儲存在SQL儲存過程中。這些儲存過程由應用程式執行以執行該任務。
儲存過程可以以輸出引數(整數或字元)或遊標變數的形式返回資料。它還可以生成一組SELECT語句,這些語句由其他儲存過程使用。
儲存過程也用於效能最佳化,因為它包含一系列SQL語句,並且一組語句的結果決定了要執行的下一組語句。儲存過程防止使用者檢視資料庫中表的複雜性和細節。由於儲存過程包含某些業務邏輯,因此使用者需要執行或呼叫過程名稱。
無需重複發出單個語句,而可以直接引用資料庫過程。
建立過程的示例語句
Create procedure prc_name (in inp integer, out opt "EFASION"."ARTICLE_LOOKUP") as begin opt = select * from "EFASION"."ARTICLE_LOOKUP" where article_id = :inp ; end;
SAP HANA - SQL 序列
序列是一組按需生成的整數1、2、3…序列在資料庫中經常使用,因為許多應用程式要求表中的每一行都包含唯一值,而序列提供了一種簡單的方法來生成它們。
使用AUTO_INCREMENT列
在MySQL中使用序列最簡單的方法是將列定義為AUTO_INCREMENT,並將其餘的事情交給MySQL處理。
示例
嘗試以下示例。這將建立表,然後在此表中插入幾行,其中不需要提供記錄ID,因為它由MySQL自動遞增。
mysql> CREATE TABLE INSECT -> ( -> id INT UNSIGNED NOT NULL AUTO_INCREMENT, -> PRIMARY KEY (id), -> name VARCHAR(30) NOT NULL, # type of insect -> date DATE NOT NULL, # date collected -> origin VARCHAR(30) NOT NULL # where collected ); Query OK, 0 rows affected (0.02 sec) mysql> INSERT INTO INSECT (id,name,date,origin) VALUES -> (NULL,'housefly','2001-09-10','kitchen'), -> (NULL,'millipede','2001-09-10','driveway'), -> (NULL,'grasshopper','2001-09-10','front yard'); Query OK, 3 rows affected (0.02 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> SELECT * FROM INSECT ORDER BY id;
+----+-------------+------------+------------+ | id | name | date | origin | +----+-------------+------------+------------+ | 1 | housefly | 2001-09-10 | kitchen | | 2 | millipede | 2001-09-10 | driveway | | 3 | grasshopper | 2001-09-10 | front yard | +----+-------------+------------+------------+ 3 rows in set (0.00 sec)
獲取AUTO_INCREMENT值
LAST_INSERT_ID()是一個SQL函式,因此您可以從任何瞭解如何發出SQL語句的客戶端中使用它。否則,PERL和PHP指令碼提供專用函式來檢索最後一條記錄的自動遞增值。
PERL示例
使用mysql_insertid屬性獲取查詢生成的AUTO_INCREMENT值。此屬性可以透過資料庫控制代碼或語句控制代碼訪問,具體取決於您發出查詢的方式。以下示例透過資料庫控制代碼引用它:
$dbh->do ("INSERT INTO INSECT (name,date,origin)
VALUES('moth','2001-09-14','windowsill')");
my $seq = $dbh->{mysql_insertid};
PHP示例
發出生成AUTO_INCREMENT值的查詢後,透過呼叫mysql_insert_id()檢索該值:
mysql_query ("INSERT INTO INSECT (name,date,origin)
VALUES('moth','2001-09-14','windowsill')", $conn_id);
$seq = mysql_insert_id ($conn_id);
重新編號現有序列
可能有一種情況,您已從表中刪除了許多記錄,並且想要重新排序所有記錄。這可以透過使用一個簡單的技巧來完成,但是如果您的表與其他表具有連線,則應非常小心地執行此操作。
如果您確定必須重新排序AUTO_INCREMENT列,則執行此操作的方法是從表中刪除該列,然後再次新增它。以下示例顯示瞭如何使用此技術重新編號insect表中的id值:
mysql> ALTER TABLE INSECT DROP id; mysql> ALTER TABLE insect -> ADD id INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST, -> ADD PRIMARY KEY (id);
從特定值開始序列
預設情況下,MySQL將從1開始序列,但您也可以在建立表時指定其他任何數字。以下是在MySQL中將序列從100開始的示例。
mysql> CREATE TABLE INSECT -> ( -> id INT UNSIGNED NOT NULL AUTO_INCREMENT = 100, -> PRIMARY KEY (id), -> name VARCHAR(30) NOT NULL, # type of insect -> date DATE NOT NULL, # date collected -> origin VARCHAR(30) NOT NULL # where collected );
或者,您可以建立表,然後使用ALTER TABLE設定初始序列值。
SAP HANA - SQL 觸發器
觸發器是儲存程式,當某些事件發生時會自動執行或觸發。實際上,觸發器是編寫為響應以下任何事件而執行的:
資料庫操作(DML)語句(DELETE、INSERT或UPDATE)。
資料庫定義(DDL)語句(CREATE、ALTER或DROP)。
資料庫操作(SERVERERROR、LOGON、LOGOFF、STARTUP或SHUTDOWN)。
觸發器可以在與事件關聯的表、檢視、模式或資料庫上定義。
觸發器的優點
觸發器可以用於以下目的:
- 自動生成一些派生列值
- 強制參照完整性
- 事件日誌記錄和儲存有關表訪問的資訊
- 審計
- 表的同步複製
- 強制安全授權
- 防止無效事務
SAP HANA - SQL 同義詞
SQL同義詞是資料庫中表或模式物件的別名。它們用於保護客戶端應用程式免受對物件名稱或位置的更改的影響。
同義詞允許應用程式獨立於擁有該表的使用者以及哪個資料庫儲存該表或物件而執行。
Create Synonym語句用於為表、檢視、包、過程、物件等建立同義詞。
示例
有一個位於Server1上的efashion的Customer表。要從Server2訪問它,客戶端應用程式必須使用Server1.efashion.Customer作為名稱。現在我們更改Customer表的位置,客戶端應用程式必須修改以反映此更改。
為了解決這些問題,我們可以在Server2上為Server1上的表建立Customer表的同義詞Cust_Table。現在,客戶端應用程式必須使用單部分名稱Cust_Table來引用此表。現在,如果此表的位置發生更改,您必須修改同義詞以指向該表的新位置。
由於沒有ALTER SYNONYM語句,因此您必須刪除同義詞Cust_Table,然後使用相同的名稱重新建立同義詞,並將同義詞指向Customer表的新位置。
公共同義詞
公共同義詞由資料庫中的PUBLIC模式擁有。所有資料庫使用者都可以引用公共同義詞。它們由應用程式所有者為表和其他物件(如過程和包)建立,以便應用程式使用者可以看到這些物件。
語法
CREATE PUBLIC SYNONYM Cust_table for efashion.Customer;
要建立公共同義詞,您必須使用關鍵字PUBLIC,如下所示。
私有同義詞
私有同義詞用於資料庫模式中以隱藏表、過程、檢視或任何其他資料庫物件的真實名稱。
只有擁有該表或物件的模式才能引用私有同義詞。
語法
CREATE SYNONYM Cust_table FOR efashion.Customer;
刪除同義詞
可以使用DROP Synonym命令刪除同義詞。如果要刪除公共同義詞,則必須在drop語句中使用關鍵字public。
語法
DROP PUBLIC Synonym Cust_table; DROP Synonym Cust_table;
SAP HANA - SQL 執行計劃
SQL解釋計劃用於生成SQL語句的詳細解釋。它們用於評估SAP HANA資料庫為執行SQL語句而遵循的執行計劃。
解釋計劃的結果儲存在EXPLAIN_PLAN_TABLE中以進行評估。要使用解釋計劃,傳入的SQL查詢必須是資料操作語言(DML)。
常見的DML語句
SELECT - 從資料庫中檢索資料
INSERT − 將資料插入表中
UPDATE − 更新表中現有資料
SQL解釋計劃不能與DDL和DCL SQL語句一起使用。
資料庫中的EXPLAIN PLAN TABLE
資料庫中的EXPLAIN PLAN_TABLE包含多個列。一些常見的列名:OPERATOR_NAME、OPERATOR_ID、PARENT_OPERATOR_ID、LEVEL和POSITION等。
COLUMN SEARCH值指示列引擎運算子的起始位置。
ROW SEARCH值指示行引擎運算子的起始位置。
為SQL查詢建立EXPLAIN PLAN語句
EXPLAIN PLAN SET STATEMENT_NAME = ‘statement_name’ FOR <SQL DML statement>
檢視EXPLAIN PLAN TABLE中的值
SELECT Operator_Name, Operator_ID FROM explain_plan_table WHERE statement_name = 'statement_name';
刪除EXPLAIN PLAN TABLE中的語句
DELETE FROM explain_plan_table WHERE statement_name = 'TPC-H Q10';
SAP HANA - SQL 資料分析
SQL資料分析任務用於理解和分析來自多個數據源的資料。它用於刪除不正確、不完整的資料,並在將資料載入到資料倉庫之前防止資料質量問題。
以下是SQL資料分析任務的優點:
它有助於更有效地分析源資料。
它有助於更好地理解源資料。
它刪除不正確、不完整的資料,並在將其載入到資料倉庫之前提高資料質量。
它與提取、轉換和載入任務一起使用。
資料分析任務檢查配置檔案,這有助於理解資料來源並識別資料中需要修復的問題。
您可以在Integration Services包中使用資料分析任務來分析儲存在SQL Server中的資料,並識別資料質量的潛在問題。
注意 - 資料分析任務僅適用於SQL Server資料來源,不支援任何其他基於檔案或第三方的資料來源。
訪問要求
要執行包含資料分析任務的包,使用者帳戶必須對tempdb資料庫具有讀取/寫入許可權和CREATE TABLE許可權。
資料分析器檢視器
資料分析器檢視器用於檢視分析器輸出。資料分析器檢視器還支援鑽取功能,可幫助您理解在分析輸出中標識的資料質量問題。此鑽取功能會向原始資料來源傳送即時查詢。
資料分析任務設定和檢視
設定資料分析任務
這涉及執行包含資料分析任務的包以計算概要檔案。該任務將輸出以XML格式儲存到檔案或包變數中。
檢視概要檔案
要檢視資料概要檔案,請將輸出傳送到檔案,然後使用資料分析器檢視器。此檢視器是一個獨立實用程式,可以以摘要和詳細資訊格式顯示概要檔案輸出,並具有可選的鑽取功能。
資料分析 - 配置選項
資料分析任務具有以下方便的配置選項:
萬用字元列
在配置概要請求時,任務接受使用“*”萬用字元來代替列名。這簡化了配置,並使發現不熟悉資料的特性更容易。當任務執行時,任務會分析每個具有適當資料型別的列。
快速概要
您可以選擇“快速概要”來快速配置任務。“快速概要”使用所有預設概要和設定來分析表或檢視。
資料概要任務可以計算八種不同的資料概要。其中五種概要可以檢查單個列,其餘三種分析多個列或列之間的關係。
資料概要 - 任務輸出
資料概要任務將選定的概要輸出為類似於DataProfile.xsd模式的XML格式。
您可以儲存模式的本地副本,並在Microsoft Visual Studio或其他模式編輯器、XML編輯器或文字編輯器(如記事本)中檢視模式的本地副本。
SAP HANA - SQL 指令碼
用於HANA資料庫的一組SQL語句,允許開發者將複雜的邏輯傳遞到資料庫中,稱為SQL指令碼。SQL指令碼被稱為SQL擴充套件的集合。這些擴充套件包括資料擴充套件、函式擴充套件和過程擴充套件。
SQL指令碼支援儲存的函式和過程,這允許將應用程式邏輯的複雜部分推送到資料庫。
使用SQL指令碼的主要好處是允許在SAP HANA資料庫中執行復雜的計算。使用SQL指令碼代替單個查詢使函式能夠返回多個值。複雜的SQL函式可以進一步分解成更小的函式。SQL指令碼提供了單一SQL語句中不可用的控制邏輯。
SQL指令碼用於透過在資料庫層執行指令碼來實現HANA的效能最佳化:
透過在資料庫層執行SQL指令碼,消除了將大量資料從資料庫傳輸到應用程式的需要。
計算在資料庫層執行,以獲得HANA資料庫的優勢,例如列操作、查詢的並行處理等。
與資訊建模器的整合
在資訊建模器中使用SQL指令碼時,以下內容應用於過程:
- 輸入引數可以是標量型別或表型別。
- 輸出引數必須是表型別。
- 簽名所需的表型別會自動生成。
帶有計算檢視的SQL指令碼
SQL指令碼用於建立基於指令碼的計算檢視。針對現有的原始表或列儲存編寫SQL語句。定義輸出結構,檢視的啟用會根據結構建立表型別。
如何使用SQL指令碼建立計算檢視?
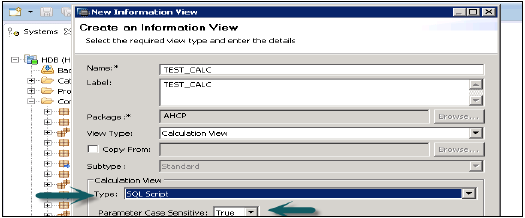
**啟動SAP HANA Studio**。展開內容節點→選擇要建立新的計算檢視的包。右鍵單擊→新建計算檢視 →提供名稱和描述。
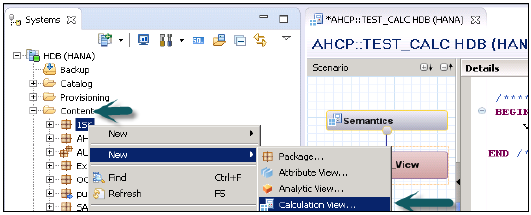
**選擇計算檢視型別**→從“型別”下拉列表中,選擇“SQL指令碼”→根據您需要的計算檢視輸出引數的命名約定,將“引數區分大小寫”設定為“真”或“假”→選擇“完成”。
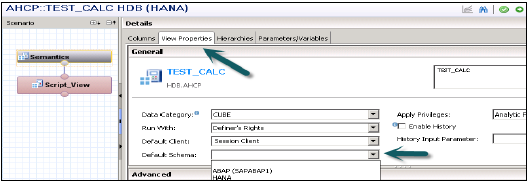
**選擇預設模式** - 選擇“語義”節點→選擇“檢視屬性”選項卡→在“預設模式”下拉列表中,選擇預設模式。
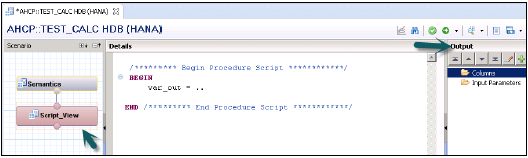
**在“語義”節點中選擇“SQL指令碼”節點**→定義輸出結構。在輸出窗格中,選擇“建立目標”。新增所需的輸出引數並指定其長度和型別。
要將作為現有資訊檢視或目錄表或表函式一部分的多個列新增到基於指令碼的計算檢視的輸出結構中:
在輸出窗格中,選擇“開始導航路徑 新建 下一步導航步驟 新增來自 結束導航路徑”→包含要新增到輸出的列的物件的名稱→從下拉列表中選擇一個或多個物件→選擇“下一步”。
在“源”窗格中,選擇要新增到輸出的列→要將選擇的列新增到輸出,請選擇這些列並選擇“新增”。要將物件的所有列新增到輸出,請選擇該物件並選擇“新增”→“完成”。
**啟用基於指令碼的計算檢視** - 在SAP HANA建模器透檢視中 - 儲存並激活 - 啟用當前檢視,如果受影響物件的活動版本存在,則重新部署受影響的物件。否則,只啟用當前檢視。
**儲存並激活所有** - 啟用當前檢視以及所需的和受影響的物件。
**在SAP HANA開發透檢視中** - 在“專案資源管理器”檢視中,選擇所需的物件。在上下文選單中,選擇“開始導航路徑 團隊 下一步導航步驟 啟用 結束導航路徑”。
HANA資訊建模器中的SQL指令碼用於建立複雜的計算檢視,這些檢視無法使用GUI選項建立。