- Python 設計模式教程
- Python 設計模式 - 首頁
- 簡介
- Python 設計模式 - 精粹
- 模型-檢視-控制器模式
- Python 設計模式 - 單例
- Python 設計模式 - 工廠
- Python 設計模式 - 生成器
- Python 設計模式 - 原型
- Python 設計模式 - 外觀
- Python 設計模式 - 命令
- Python 設計模式 - 介面卡
- Python 設計模式 - 裝飾器
- Python 設計模式 - 代理
- 責任鏈模式
- Python 設計模式 - 觀察者
- Python 設計模式 - 狀態
- Python 設計模式 - 策略
- Python 設計模式 - 模板
- Python 設計模式 - 享元
- 抽象工廠
- 面向物件
- 面向物件概念實現
- Python 設計模式 - 迭代器
- 字典
- 列表資料結構
- Python 設計模式 - 集合
- Python 設計模式 - 佇列
- 字串和序列化
- Python 中的併發性
- Python 設計模式 - 反
- 異常處理
- Python 設計模式資源
- 快速指南
- Python 設計模式 - 資源
- 討論
Python 中的併發性
併發性通常被誤認為並行性。併發性意味著以系統的方式排程獨立的程式碼來執行。本章重點介紹使用 Python 為作業系統執行併發性。
以下程式有助於為作業系統執行併發性 −
import os
import time
import threading
import multiprocessing
NUM_WORKERS = 4
def only_sleep():
print("PID: %s, Process Name: %s, Thread Name: %s" % (
os.getpid(),
multiprocessing.current_process().name,
threading.current_thread().name)
)
time.sleep(1)
def crunch_numbers():
print("PID: %s, Process Name: %s, Thread Name: %s" % (
os.getpid(),
multiprocessing.current_process().name,
threading.current_thread().name)
)
x = 0
while x < 10000000:
x += 1
for _ in range(NUM_WORKERS):
only_sleep()
end_time = time.time()
print("Serial time=", end_time - start_time)
# Run tasks using threads
start_time = time.time()
threads = [threading.Thread(target=only_sleep) for _ in range(NUM_WORKERS)]
[thread.start() for thread in threads]
[thread.join() for thread in threads]
end_time = time.time()
print("Threads time=", end_time - start_time)
# Run tasks using processes
start_time = time.time()
processes = [multiprocessing.Process(target=only_sleep()) for _ in range(NUM_WORKERS)]
[process.start() for process in processes]
[process.join() for process in processes]
end_time = time.time()
print("Parallel time=", end_time - start_time)
輸出
以上程式生成以下輸出 −
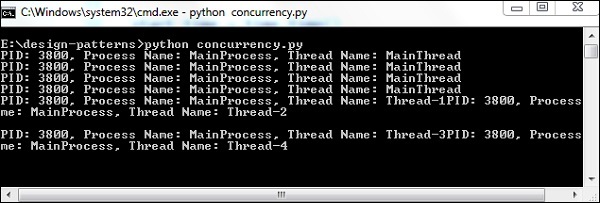
解釋
“多處理”是一個與處理模組類似的包。此包支援本地和遠端併發性。由於此模組,程式設計師可以利用在給定系統上使用多個程序。
廣告