Python深度學習 - 快速指南
Python深度學習 - 簡介
深度結構化學習或分層學習,簡稱深度學習,是機器學習方法家族的一部分,而機器學習本身又是人工智慧更廣泛領域的一個子集。
深度學習是一類機器學習演算法,它使用多層非線性處理單元進行特徵提取和轉換。每一層都使用前一層輸出作為輸入。
深度神經網路、深度信念網路和迴圈神經網路已被應用於計算機視覺、語音識別、自然語言處理、音訊識別、社交網路過濾、機器翻譯和生物資訊學等領域,其產生的結果與人類專家相當,在某些情況下甚至優於人類專家。
深度學習演算法和網路 -
基於對資料多級特徵或表示的無監督學習。高階特徵源自低階特徵,形成分層表示。
使用某種形式的梯度下降進行訓練。
Python深度學習 - 環境
在本章中,我們將學習Python深度學習的環境設定。為了構建深度學習演算法,我們必須安裝以下軟體。
- Python 2.7+
- 帶有Numpy的Scipy
- Matplotlib
- Theano
- Keras
- TensorFlow
強烈建議透過Anaconda發行版安裝Python、NumPy、SciPy和Matplotlib。它包含所有這些軟體包。
我們需要確保不同型別的軟體正確安裝。
讓我們轉到命令列程式並輸入以下命令 -
$ python Python 3.6.3 |Anaconda custom (32-bit)| (default, Oct 13 2017, 14:21:34) [GCC 7.2.0] on linux
接下來,我們可以匯入所需的庫並列印其版本 -
import numpy print numpy.__version__
輸出
1.14.2
Theano、TensorFlow和Keras的安裝
在我們開始安裝Theano、TensorFlow和Keras軟體包之前,我們需要確認是否安裝了pip。Anaconda中的包管理系統稱為pip。
要確認pip的安裝,請在命令列中鍵入以下內容 -
$ pip
確認pip安裝後,我們可以透過執行以下命令來安裝TensorFlow和Keras -
$pip install theano $pip install tensorflow $pip install keras
透過執行以下程式碼行確認Theano的安裝 -
$python –c “import theano: print (theano.__version__)”
輸出
1.0.1
透過執行以下程式碼行確認Tensorflow的安裝 -
$python –c “import tensorflow: print tensorflow.__version__”
輸出
1.7.0
透過執行以下程式碼行確認Keras的安裝 -
$python –c “import keras: print keras.__version__” Using TensorFlow backend
輸出
2.1.5
Python深度學習基礎機器學習
人工智慧(AI)是任何使計算機能夠模仿人類認知行為或智慧的程式碼、演算法或技術。機器學習(ML)是AI的一個子集,它使用統計方法使機器能夠從經驗中學習和改進。深度學習是機器學習的一個子集,它使多層神經網路的計算成為可能。機器學習被視為淺層學習,而深度學習被視為具有抽象性的分層學習。
機器學習涉及廣泛的概念。這些概念如下所示 -
- 監督學習
- 無監督學習
- 強化學習
- 線性迴歸
- 成本函式
- 過擬合
- 欠擬合
- 超引數等。
在監督學習中,我們學習從標記資料中預測值。一種有助於此的ML技術是分類,其中目標值是離散值;例如,貓和狗。機器學習中另一種可能提供幫助的技術是迴歸。迴歸作用於目標值。目標值是連續值;例如,可以使用迴歸分析股票市場資料。
在無監督學習中,我們從未標記或未結構化的輸入資料中進行推斷。如果我們有一百萬份醫療記錄,我們必須理解它,找到底層結構、異常值或檢測異常,我們使用聚類技術將資料劃分為廣泛的叢集。
資料集被劃分為訓練集、測試集、驗證集等。
2012年的一項突破使深度學習的概念變得突出。一種演算法使用2個GPU和大型資料等最新技術成功地將100萬張影像分類為1000個類別。
深度學習與傳統機器學習的關係
傳統機器學習模型遇到的主要挑戰之一是稱為特徵提取的過程。程式設計師需要具體說明並告訴計算機要查詢的特徵。這些特徵將有助於做出決策。
將原始資料輸入演算法很少有效,因此特徵提取是傳統機器學習工作流程的關鍵部分。
這給程式設計師帶來了巨大的責任,並且演算法的效率在很大程度上取決於程式設計師的創造力。對於諸如物件識別或手寫識別之類的複雜問題,這是一個巨大的問題。
深度學習能夠學習多層表示,是為數不多的幫助我們進行自動特徵提取的方法之一。可以假設較低層執行自動特徵提取,程式設計師幾乎不需要或不需要任何指導。
人工神經網路
人工神經網路,簡稱神經網路,並不是一個新概念。它已經存在了大約80年。
直到2011年,隨著新技術的應用、海量資料集的可用性和功能強大的計算機,深度神經網路才變得流行起來。
神經網路模仿神經元,神經元具有樹突、細胞核、軸突和軸突末梢。
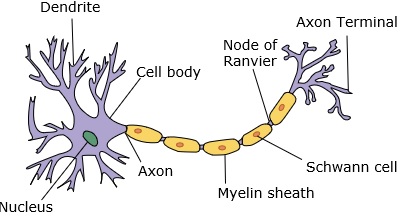
對於一個網路,我們需要兩個神經元。這些神經元透過一個神經元樹突和另一個神經元軸突末梢之間的突觸傳遞資訊。
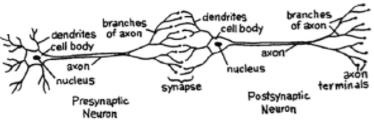
人工神經元的可能模型如下所示 -
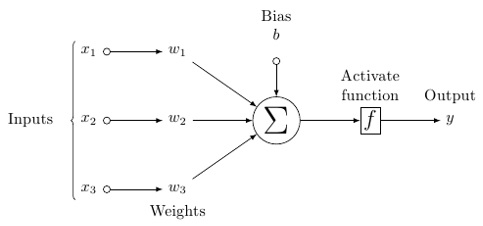
神經網路看起來如下所示 -
圓圈是神經元或節點,它們對資料執行函式,連線它們的線/邊是權重/正在傳遞的資訊。
每一列都是一層。資料的第一層是輸入層。然後,輸入層和輸出層之間的所有層都是隱藏層。
如果你有一個或幾個隱藏層,那麼你有一個淺層神經網路。如果你有很多隱藏層,那麼你有一個深度神經網路。
在這個模型中,你有輸入資料,你對其進行加權,並將其透過神經元中的稱為閾值函式或啟用函式的函式傳遞。
基本上,它是將所有值與某個值進行比較後的總和。如果你發出訊號,則結果為(1)輸出,或者沒有發出任何訊號,則為(0)。然後對其進行加權並傳遞到下一個神經元,並執行相同型別的函式。
我們可以使用S形(S形)函式作為啟用函式。
至於權重,它們最初是隨機的,並且每個輸入到節點/神經元的權重都是唯一的。
在典型的前饋神經網路(最基本型別的神經網路)中,您讓資訊直接透過您建立的網路,然後使用樣本資料將輸出與您希望的輸出進行比較。
從這裡,你需要調整權重以幫助你的輸出與你期望的輸出相匹配。
將資料直接傳送透過神經網路的過程稱為前饋神經網路。
我們的資料按順序從輸入到各層,然後到輸出。
當我們向後移動並開始調整權重以最小化損失/成本時,這稱為反向傳播。
這是一個最佳化問題。在實際的神經網路中,我們必須處理數十萬個變數,甚至數百萬個或更多。
第一個解決方案是使用隨機梯度下降作為最佳化方法。現在,有AdaGrad、Adam最佳化器等選項。無論哪種方式,這都是一個巨大的計算操作。這就是為什麼神經網路在半個多世紀以來基本上被束之高閣。直到最近,我們才擁有機器中能夠考慮執行這些操作的強大功能和架構,以及與之匹配的適當大小的資料集。
對於簡單的分類任務,神經網路的效能與其他簡單的演算法(如K最近鄰)相對接近。當我們擁有更多資料和更復雜的問題時,神經網路的真正效用就會顯現出來,這兩種情況都優於其他機器學習模型。
深度神經網路
深度神經網路(DNN)是輸入層和輸出層之間有多個隱藏層的人工神經網路。與淺層人工神經網路類似,DNN可以模擬複雜的非線性關係。
神經網路的主要目的是接收一組輸入,對其進行逐步複雜的計算,並輸出結果來解決現實世界的問題,例如分類。我們限制自己使用前饋神經網路。
在深度網路中,我們有輸入、輸出和順序資料的流。
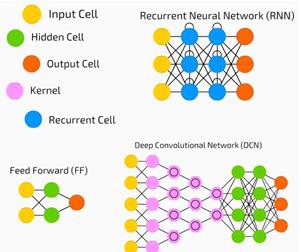
神經網路廣泛用於監督學習和強化學習問題。這些網路基於一組相互連線的層。
在深度學習中,隱藏層的數量(主要是非線性的)可能很大;例如大約1000層。
DL模型產生的結果比普通ML網路好得多。
我們主要使用梯度下降方法來最佳化網路並最小化損失函式。
我們可以使用ImageNet(一個包含數百萬張數字影像的儲存庫)將資料集分類為貓和狗等類別。除了靜態影像外,DL網路越來越多地用於動態影像以及時間序列和文字分析。
訓練資料集是深度學習模型的重要組成部分。此外,反向傳播是訓練深度學習模型的主要演算法。
深度學習處理具有複雜輸入輸出轉換的大型神經網路的訓練。
深度學習的一個例子是將照片對映到照片中人物的姓名,就像他們在社交網路上做的那樣,用短語描述圖片是深度學習的另一個最新應用。
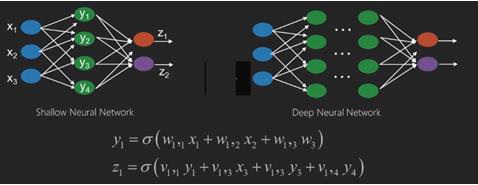
神經網路是具有輸入(如x1、x2、x3…)的函式,這些輸入被轉換為輸出(如z1、z2、z3等),在兩個(淺層網路)或多箇中間操作中,也稱為層(深層網路)。
權重和偏差在層與層之間發生變化。“w”和“v”是神經網路各層中的權重或突觸。
深度學習的最佳用例是監督學習問題。在這裡,我們有一大組資料輸入和一組所需的輸出。
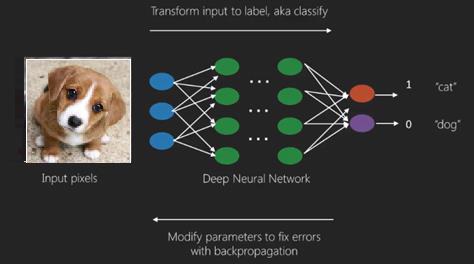
在這裡,我們應用反向傳播演算法來獲得正確的輸出預測。
深度學習最基本的資料集是MNIST,一個手寫數字資料集。
我們可以使用Keras訓練一個深度卷積神經網路,以對來自該資料集的手寫數字影像進行分類。
神經網路分類器的激發或啟用會產生一個分數。例如,要將患者分類為患病和健康,我們考慮身高、體重和體溫、血壓等引數。
高分表示患者患病,低分表示患者健康。
輸出層和隱藏層中的每個節點都有自己的分類器。輸入層接收輸入並將分數傳遞到下一個隱藏層以進行進一步啟用,依此類推,直到達到輸出。
從輸入到輸出從左到右的這個向前過程稱為**前向傳播**。
神經網路中的信用分配路徑(CAP)是從輸入到輸出的一系列轉換。CAP闡明瞭輸入和輸出之間可能存在的因果關係。
給定前饋神經網路的CAP深度或CAP深度是隱藏層的數量加上1,因為輸出層包括在內。對於迴圈神經網路,訊號可能多次透過一層,CAP深度可能無限大。
深層網路和淺層網路
沒有明確的深度閾值將淺層學習與深度學習區分開來;但大多數人認為,對於具有多個非線性層的深度學習,CAP必須大於2。
神經網路中的基本節點是一個感知器,模仿生物神經網路中的神經元。然後我們有多層感知器或MLP。每組輸入都由一組權重和偏差進行修改;每條邊都有唯一的權重,每個節點都有唯一的偏差。
神經網路的預測**準確性**取決於其**權重和偏差**。
提高神經網路準確性的過程稱為**訓練**。前向傳播網路的輸出與已知正確的輸出值進行比較。
**成本函式或損失函式**是生成輸出與實際輸出之間的差異。
訓練的目的是使數百萬個訓練樣本的訓練成本儘可能小。為此,網路會調整權重和偏差,直到預測與正確的輸出相匹配。
經過良好訓練後,神經網路每次都有可能做出準確的預測。
當模式變得複雜並且您希望計算機識別它們時,您必須使用神經網路。在如此複雜的模式場景中,神經網路優於所有其他競爭演算法。
現在有GPU可以比以往更快地訓練它們。深度神經網路已經在徹底改變人工智慧領域。
計算機已被證明擅長執行重複計算和遵循詳細的指令,但在識別複雜模式方面卻不太擅長。
如果存在識別簡單模式的問題,支援向量機(SVM)或邏輯迴歸分類器可以很好地完成這項工作,但是隨著模式複雜性的增加,別無選擇,只能轉向深度神經網路。
因此,對於像人臉這樣複雜的模式,淺層神經網路會失敗,別無選擇,只能轉向具有更多層的深度神經網路。深度網路能夠透過將複雜模式分解成更簡單的模式來完成其工作。例如,人臉;深度網路將使用邊緣來檢測嘴唇、鼻子、眼睛、耳朵等部位,然後將它們重新組合以形成人臉。
正確預測的準確性已變得如此精確,以至於最近在谷歌模式識別挑戰賽中,深度網路擊敗了人類。
這種分層感知器網路的想法已經存在一段時間了;在這個領域,深度網路模仿人腦。但其缺點之一是訓練時間很長,這是一個硬體限制。
然而,最近的高效能GPU能夠在一週內訓練出此類深度網路;而快速的CPU可能需要數週甚至數月才能完成相同的工作。
選擇深度網路
如何選擇深度網路?我們必須確定我們是構建分類器,還是試圖在資料中查詢模式,以及是否將使用無監督學習。為了從一組未標記的資料中提取模式,我們使用受限玻爾茲曼機或自動編碼器。
在選擇深度網路時,請考慮以下幾點 -
對於文字處理、情感分析、解析和命名實體識別,我們使用迴圈網路或遞迴神經張量網路或RNTN;
對於在字元級別執行的任何語言模型,我們使用迴圈網路。
對於影像識別,我們使用深度信念網路DBN或卷積網路。
對於物體識別,我們使用RNTN或卷積網路。
對於語音識別,我們使用迴圈網路。
通常,深度信念網路和具有整流線性單元或RELU的多層感知器都是分類的良好選擇。
對於時間序列分析,始終建議使用迴圈網路。
神經網路已經存在了50多年;但直到現在它們才開始嶄露頭角。原因是它們很難訓練;當我們嘗試使用一種稱為反向傳播的方法訓練它們時,我們會遇到一個稱為消失或爆炸梯度的問題。發生這種情況時,訓練需要更長的時間,準確性會受到影響。在訓練資料集時,我們不斷計算成本函式,它是預測輸出與一組標記訓練資料中的實際輸出之間的差異。然後透過調整權重和偏差值來最小化成本函式,直到獲得最低值。訓練過程使用梯度,它是成本相對於權重或偏差值變化的變化率。
受限玻爾茲曼機或自動編碼器 - RBM
2006年,在解決消失梯度問題方面取得了突破。Geoffrey Hinton設計了一種新穎的策略,導致了**受限玻爾茲曼機 - RBM**的開發,這是一種淺層兩層網路。
第一層是**可見**層,第二層是**隱藏**層。可見層中的每個節點都連線到隱藏層中的每個節點。該網路被稱為受限的,因為不允許同一層內的兩層共享連線。
自動編碼器是將輸入資料編碼為向量的網路。它們建立原始資料的隱藏或壓縮表示。這些向量可用於降維;該向量將原始資料壓縮成較少的基本維度。自動編碼器與解碼器配對,允許根據其隱藏表示重建輸入資料。
RBM是雙向翻譯器的數學等價物。前向傳遞接收輸入並將它們轉換為一組編碼輸入的數字。同時,反向傳遞接收這組數字並將它們轉換回重建的輸入。經過良好訓練的網路以高精度執行反向傳播。
在這兩個步驟中,權重和偏差都起著關鍵作用;它們幫助RBM解碼輸入之間的相互關係,並決定哪些輸入對於檢測模式至關重要。透過前向和反向傳遞,RBM經過訓練以使用不同的權重和偏差來重建輸入,直到輸入和重建儘可能接近。RBM的一個有趣的方面是資料不需要標記。這對於照片、影片、語音和感測器資料等現實世界的資料集非常重要,所有這些資料集往往都是未標記的。RBM無需人工標記資料,即可自動對資料進行排序;透過正確調整權重和偏差,RBM能夠提取重要特徵並重建輸入。RBM是特徵提取神經網路家族的一部分,這些網路旨在識別資料中固有的模式。這些也稱為自動編碼器,因為它們必須編碼自己的結構。

深度信念網路 - DBN
深度信念網路(DBN)是透過組合RBM並引入一種巧妙的訓練方法形成的。我們有一個新模型,最終解決了消失梯度問題。Geoffrey Hinton發明了RBM和深度信念網路作為反向傳播的替代方案。
DBN在結構上類似於MLP(多層感知器),但在訓練方面卻大不相同。正是訓練使DBN能夠勝過其淺層對應物。
DBN可以視覺化為RBM的堆疊,其中一個RBM的隱藏層是其上方RBM的可見層。第一個RBM經過訓練以儘可能準確地重建其輸入。
第一個RBM的隱藏層作為第二個RBM的可見層,並且第二個RBM使用第一個RBM的輸出進行訓練。此過程迭代,直到網路中的每一層都經過訓練。
在DBN中,每個RBM都學習整個輸入。DBN透過依次微調整個輸入來全域性工作,因為模型像相機鏡頭緩慢聚焦影像一樣緩慢改進。RBM的堆疊優於單個RBM,就像多層感知器MLP優於單個感知器一樣。
在這個階段,受限玻爾茲曼機(RBM)已經檢測到資料中的內在模式,但沒有任何名稱或標籤。為了完成深度信念網路(DBN)的訓練,我們必須為這些模式引入標籤,並使用監督學習對網路進行微調。
我們需要一個非常小的帶標籤樣本集,以便將特徵和模式與名稱關聯起來。這套帶有標籤的小資料集用於訓練。與原始資料集相比,這套帶標籤的資料集可以非常小。
權重和偏差會發生微小的變化,導致網路對模式的感知發生細微變化,並且通常會導致整體準確率略有提高。
透過使用GPU,訓練可以在合理的時間內完成,並且與淺層網路相比,可以獲得非常準確的結果,我們也看到了解決梯度消失問題的方案。
生成對抗網路 - GANs
生成對抗網路是深度神經網路,包含兩個相互對抗的網路,因此得名“對抗”。
GANs 於 2014 年由蒙特利爾大學的研究人員發表的一篇論文中提出。Facebook 的人工智慧專家 Yann LeCun 在談到 GANs 時,稱對抗訓練是“過去 10 年機器學習中最有趣的想法”。
GANs 的潛力巨大,因為網路可以學習模仿任何資料分佈。GANs 可以被訓練來建立與我們自身世界驚人相似的平行世界,無論是在影像、音樂、語音還是散文領域。從某種意義上說,它們是機器人藝術家,並且它們的輸出令人印象深刻。
在 GAN 中,一個神經網路被稱為生成器,它生成新的資料例項,而另一個神經網路被稱為鑑別器,它評估這些例項的真實性。
假設我們正在嘗試生成手寫數字,例如 MNIST 資料集中發現的那些數字,這些數字來自現實世界。當鑑別器看到來自真實 MNIST 資料集的例項時,它的工作就是將其識別為真實的。
現在考慮 GAN 的以下步驟 -
生成器網路以隨機數的形式接收輸入,並返回一個影像。
生成的影像與來自實際資料集的一系列影像一起作為輸入提供給鑑別器網路。
鑑別器接收真實和偽造的影像,並返回機率(0 到 1 之間的數字),其中 1 表示預測為真實,0 表示預測為偽造。
所以你有一個雙重反饋迴路 -
鑑別器與我們已知的影像的真實情況處於反饋迴路中。
生成器與鑑別器處於反饋迴路中。
迴圈神經網路 - RNNs
RNN是神經網路,其中資料可以沿任何方向流動。這些網路用於語言建模或自然語言處理 (NLP) 等應用。
RNNs 的基本概念是利用順序資訊。在普通的神經網路中,假設所有輸入和輸出彼此獨立。如果我們想預測句子中的下一個單詞,我們必須知道它前面的單詞。
RNNs 被稱為迴圈神經網路,因為它們對序列的每個元素重複相同的任務,輸出基於之前的計算。因此,可以認為 RNNs 具有“記憶”,它捕獲有關先前計算的資訊。理論上,RNNs 可以使用非常長序列中的資訊,但在現實中,它們只能回溯幾個步驟。
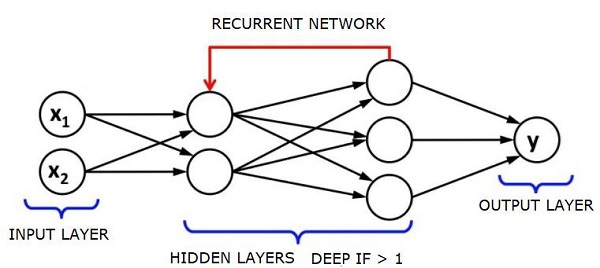
長短期記憶網路 (LSTMs) 是最常用的 RNNs。
與卷積神經網路一起,RNNs 已被用作模型的一部分,用於生成未標記影像的描述。這種方法的效果令人驚歎。
卷積深度神經網路 - CNNs
如果我們增加神經網路的層數以使其更深,則會增加網路的複雜性,並允許我們對更復雜的函式進行建模。但是,權重和偏差的數量將呈指數級增長。事實上,對於普通神經網路來說,學習此類難題可能變得不可能。這導致了一種解決方案:卷積神經網路。
CNNs 廣泛應用於計算機視覺;也已應用於聲學建模以進行自動語音識別。
卷積神經網路背後的思想是“移動濾波器”的概念,它穿過影像。這個移動濾波器或卷積應用於節點的某個鄰域,例如畫素,其中應用的濾波器為節點值的 0.5 倍 -
著名研究員 Yann LeCun 開創了卷積神經網路。Facebook 的人臉識別軟體使用了這些網路。CNN 已經成為機器視覺專案的首選解決方案。卷積網路有多個層。在 2015 年的 ImageNet 挑戰賽中,一臺機器在物體識別方面擊敗了人類。
簡而言之,卷積神經網路 (CNNs) 是多層神經網路。層數有時多達 17 層或更多,並假設輸入資料為影像。
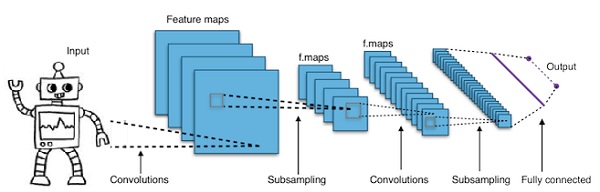
CNNs 大幅減少了需要調整的引數數量。因此,CNNs 可以有效地處理原始影像的高維度。
Python 深度學習 - 基礎
在本章中,我們將深入瞭解 Python 深度學習的基礎知識。
深度學習模型/演算法
現在讓我們學習不同的深度學習模型/演算法。
深度學習中的一些流行模型如下 -
- 卷積神經網路
- 迴圈神經網路
- 深度信念網路
- 生成對抗網路
- 自動編碼器等等
輸入和輸出表示為向量或張量。例如,神經網路的輸入可能是影像中各個畫素的 RGB 值,表示為向量。
位於輸入層和輸出層之間的神經元層稱為隱藏層。當神經網路嘗試解決問題時,大部分工作都在這裡發生。仔細觀察隱藏層可以揭示網路學習從資料中提取的許多特徵。
透過選擇將哪些神經元連線到下一層中的其他神經元來形成神經網路的不同架構。
計算輸出的虛擬碼
以下是計算前饋神經網路輸出的虛擬碼 -
- # node[] := 拓撲排序後的節點陣列
- # 從 a 到 b 的邊表示 a 在 b 的左側
- # 如果神經網路有 R 個輸入和 S 個輸出,
- # 則前 R 個節點是輸入節點,最後 S 個節點是輸出節點。
- # incoming[x] := 連線到節點 x 的節點
- # weight[x] := 連線到 x 的邊的權重
從左到右,對於每個神經元 x -
- 如果 x <= R:不做任何操作 # 它是輸入節點
- inputs[x] = [output[i] for i in incoming[x]]
- weighted_sum = dot_product(weights[x], inputs[x])
- output[x] = Activation_function(weighted_sum)
訓練神經網路
現在我們將學習如何訓練神經網路。我們還將學習反向傳播演算法和 Python 深度學習中的反向傳播過程。
我們必須找到神經網路權重的最佳值以獲得所需的輸出。為了訓練神經網路,我們使用迭代梯度下降法。我們最初以權重的隨機初始化開始。隨機初始化後,我們使用前向傳播過程對資料的一部分進行預測,計算相應的成本函式 C,並透過與 dC/dw 成比例的量更新每個權重 w,即成本函式相對於權重的導數。比例常數稱為學習率。
可以使用反向傳播演算法有效地計算梯度。反向傳播或反向傳播的關鍵觀察結果是,由於微分的鏈式法則,神經網路中每個神經元的梯度都可以使用其具有傳出邊的神經元的梯度來計算。因此,我們反向計算梯度,即首先計算輸出層的梯度,然後計算最頂層的隱藏層,然後計算前面的隱藏層,依此類推,直到輸入層。
反向傳播演算法主要使用計算圖的概念來實現,其中每個神經元都擴充套件到計算圖中的多個節點,並執行簡單的數學運算,如加法、乘法。計算圖的邊上沒有任何權重;所有權重都分配給節點,因此權重成為它們自己的節點。然後在計算圖上執行反向傳播演算法。計算完成後,只需要權重節點的梯度進行更新。其餘的梯度可以丟棄。
梯度下降最佳化技術
一個常用的最佳化函式,根據它們導致的誤差調整權重,稱為“梯度下降”。
梯度是斜率的另一個名稱,而斜率在 x-y 圖上表示兩個變數之間的關係:上升量除以執行量,距離變化量除以時間變化量等。在本例中,斜率是網路誤差與單個權重之間的比率;即,隨著權重的變化,誤差如何變化。
更準確地說,我們想要找到產生最小誤差的權重。我們想要找到正確表示輸入資料中包含的訊號並將它們轉換為正確分類的權重。
隨著神經網路的學習,它會緩慢地調整許多權重,以便它們能夠正確地將訊號對映到含義。網路誤差與每個權重之間的比率是一個導數 dE/dw,它計算權重的微小變化導致誤差的微小變化的程度。
每個權重只是涉及許多變換的深度網路中的一個因素;權重的訊號透過啟用並跨多個層求和,因此我們使用微積分的鏈式法則來回溯網路啟用和輸出。這將我們引向所討論的權重,以及它與整體誤差的關係。
假設有兩個變數,誤差(error)和權重(weight),它們由第三個變數**啟用(activation)**介導,權重透過啟用傳遞。我們可以透過首先計算啟用的變化如何影響誤差的變化,以及權重的變化如何影響啟用的變化,來計算權重的變化如何影響誤差的變化。
深度學習的基本思想不過如此:根據模型產生的誤差調整模型的權重,直到無法進一步減少誤差。
如果梯度值較小,深度網路訓練速度緩慢;如果梯度值較高,訓練速度較快。訓練過程中的任何不準確性都會導致輸出不準確。從輸出到輸入訓練網路的過程稱為反向傳播或反向傳播(back propagation 或 back prop)。我們知道前向傳播從輸入開始,向前工作。反向傳播則相反,從右到左計算梯度。
每次計算梯度時,我們都會使用之前所有計算過的梯度。
讓我們從輸出層的一個節點開始。該邊使用該節點處的梯度。當我們回到隱藏層時,它變得更加複雜。兩個介於0到1之間的數字的乘積會得到一個更小的數字。梯度值不斷減小,因此反向傳播需要大量時間來訓練,並且準確性會受到影響。
深度學習演算法的挑戰
淺層神經網路和深層神經網路都面臨著一些挑戰,例如過擬合和計算時間。DNNs容易受到過擬合的影響,因為它們使用了額外的抽象層,使它們能夠對訓練資料中的罕見依賴關係進行建模。
在訓練過程中應用**正則化(Regularization)**方法,如dropout、提前停止、資料增強、遷移學習,可以有效對抗過擬合。Dropout正則化在訓練期間隨機忽略隱藏層中的單元,這有助於避免罕見的依賴關係。DNNs會考慮多個訓練引數,例如大小(即層數和每層單元數)、學習率和初始權重。由於時間和計算資源成本高昂,找到最優引數並不總是切實可行的。一些技巧,例如批處理,可以加快計算速度。GPU強大的處理能力極大地幫助了訓練過程,因為所需的矩陣和向量計算在GPU上執行效率很高。
Dropout
Dropout是一種流行的神經網路正則化技術。深度神經網路特別容易過擬合。
現在讓我們看看什麼是Dropout以及它是如何工作的。
用深度學習先驅之一傑弗裡·辛頓(Geoffrey Hinton)的話來說,“如果你有一個深度神經網路,它沒有過擬合,那麼你可能應該使用一個更大的網路並使用Dropout”。
Dropout是一種技術,在梯度下降的每次迭代中,我們都會隨機丟棄一組選定的節點。這意味著我們會隨機忽略一些節點,就好像它們不存在一樣。
每個神經元以機率q保留,並以機率1-q隨機丟棄。神經網路中每一層的q值可能不同。對於隱藏層,q值為0.5,對於輸入層,q值為0,這種設定在各種任務中表現良好。
在評估和預測期間,不使用Dropout。每個神經元的輸出乘以q,以便下一層的輸入具有相同的期望值。
Dropout背後的想法如下:在沒有Dropout正則化的神經網路中,神經元之間會產生相互依賴關係,這會導致過擬合。
實現技巧
在TensorFlow和Pytorch等庫中,Dropout的實現是將隨機選擇的神經元的輸出保持為0。也就是說,雖然神經元存在,但其輸出被覆蓋為0。
提前停止
我們使用一種稱為梯度下降的迭代演算法來訓練神經網路。
提前停止背後的思想很簡單:當誤差開始增加時停止訓練。這裡的誤差指的是在驗證資料上測量的誤差,驗證資料是用於調整超引數的一部分訓練資料。在這種情況下,超引數是停止標準。
資料增強
我們透過使用現有資料並對其應用一些變換來增加我們擁有的資料量或增強資料。使用的確切變換取決於我們打算實現的任務。此外,有助於神經網路的變換取決於其架構。
例如,在許多計算機視覺任務(如物體分類)中,一種有效的資料增強技術是新增新的資料點,這些資料點是原始資料的裁剪或平移版本。
當計算機接受影像作為輸入時,它會接收一個畫素值陣列。假設整張影像向左移動了15個畫素。我們應用許多不同方向的不同偏移量,從而生成一個增強的資料集,其大小是原始資料集的許多倍。
遷移學習
使用預訓練模型並用我們自己的資料集“微調”模型的過程稱為遷移學習。有幾種方法可以做到這一點。下面描述了一些方法:
我們使用大型資料集訓練預訓練模型。然後,我們移除網路的最後一層,並用一個具有隨機權重的新層替換它。
然後,我們凍結所有其他層的權重,並像往常一樣訓練網路。這裡的凍結層是指在梯度下降或最佳化過程中不改變權重。
其背後的概念是,預訓練模型將充當特徵提取器,只有最後一層將在當前任務上進行訓練。
計算圖
反向傳播在Tensorflow、Torch、Theano等深度學習框架中透過使用計算圖來實現。更重要的是,理解計算圖上的反向傳播結合了多種不同的演算法及其變體,例如時間反向傳播和具有共享權重的反向傳播。一旦所有內容都被轉換為計算圖,它們仍然是相同的演算法——只是計算圖上的反向傳播。
什麼是計算圖
計算圖被定義為一個有向圖,其中節點對應於數學運算。計算圖是表達和評估數學表示式的途徑。
例如,這裡有一個簡單的數學方程式:
$$p = x+y$$
我們可以繪製上述方程式的計算圖如下所示。
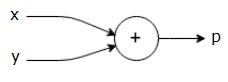
上述計算圖有一個加法節點(帶“+”號的節點),有兩個輸入變數x和y,以及一個輸出q。
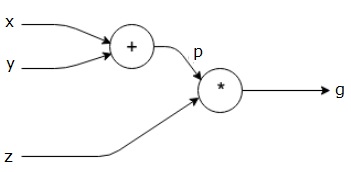
讓我們再舉一個稍微複雜一點的例子。我們有以下方程式:
$$g = \left (x+y \right ) \ast z $$
上述方程式由以下計算圖表示。
計算圖和反向傳播
計算圖和反向傳播都是深度學習中訓練神經網路的重要核心概念。
前向傳遞
前向傳遞是評估計算圖表示的數學表示式值的步驟。進行前向傳遞意味著我們正在將值從變數向前傳遞,從左側(輸入)到右側(輸出)。
讓我們考慮一個例子,為所有輸入賦予一些值。假設所有輸入都被賦予以下值:
$$x=1, y=3, z=−3$$
透過將這些值賦予輸入,我們可以執行前向傳遞,並獲得每個節點上輸出的以下值。
首先,我們使用x = 1和y = 3的值,得到p = 4。
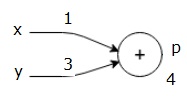
然後我們使用p = 4和z = -3得到g = -12。我們從左到右,向前進行。
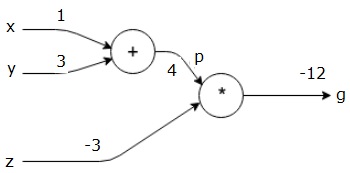
反向傳遞的目標
在反向傳遞中,我們的目的是計算每個輸入相對於最終輸出的梯度。這些梯度對於使用梯度下降訓練神經網路至關重要。
例如,我們希望得到以下梯度。
所需的梯度
$$\frac{\partial x}{\partial f}, \frac{\partial y}{\partial f}, \frac{\partial z}{\partial f}$$
反向傳遞(反向傳播)
我們從求最終輸出相對於最終輸出本身的導數開始反向傳遞!因此,它將產生恆等導數,其值等於1。
$$\frac{\partial g}{\partial g} = 1$$
我們的計算圖現在如下圖所示:
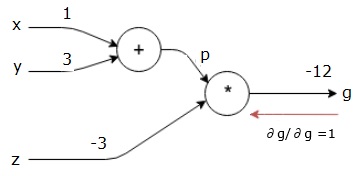
接下來,我們將透過“*”運算進行反向傳遞。我們將計算p和z處的梯度。由於g = p*z,我們知道:
$$\frac{\partial g}{\partial z} = p$$
$$\frac{\partial g}{\partial p} = z$$
我們已經從前向傳遞中知道了z和p的值。因此,我們得到:
$$\frac{\partial g}{\partial z} = p = 4$$
以及
$$\frac{\partial g}{\partial p} = z = -3$$
我們想要計算x和y處的梯度:
$$\frac{\partial g}{\partial x}, \frac{\partial g}{\partial y}$$
但是,我們希望有效地做到這一點(雖然x和g在這個圖中只有兩跳遠,想象一下它們彼此之間相距很遠)。為了有效地計算這些值,我們將使用微分的鏈式法則。根據鏈式法則,我們有:
$$\frac{\partial g}{\partial x}=\frac{\partial g}{\partial p}\ast \frac{\partial p}{\partial x}$$
$$\frac{\partial g}{\partial y}=\frac{\partial g}{\partial p}\ast \frac{\partial p}{\partial y}$$
但我們已經知道dg/dp = -3,dp/dx和dp/dy很容易計算,因為p直接依賴於x和y。我們有:
$$p=x+y\Rightarrow \frac{\partial x}{\partial p} = 1, \frac{\partial y}{\partial p} = 1$$
因此,我們得到:
$$\frac{\partial g} {\partial f} = \frac{\partial g} {\partial p}\ast \frac{\partial p} {\partial x} = \left ( -3 \right ).1 = -3$$
此外,對於輸入y:
$$\frac{\partial g} {\partial y} = \frac{\partial g} {\partial p}\ast \frac{\partial p} {\partial y} = \left ( -3 \right ).1 = -3$$
這樣向後計算的主要原因是,當我們需要計算x處的梯度時,我們只使用了已經計算過的值,以及dq/dx(節點輸出相對於同一節點輸入的導數)。我們使用區域性資訊來計算全域性值。
訓練神經網路的步驟
按照以下步驟訓練神經網路:
對於資料集中的資料點x,我們進行前向傳遞,將x作為輸入,並計算成本c作為輸出。
我們從c開始進行反向傳遞,並計算圖中所有節點的梯度。這包括表示神經網路權重的節點。
然後我們透過W = W - 學習率 * 梯度來更新權重。
我們重複此過程,直到滿足停止條件。
Python深度學習 - 應用
深度學習在一些應用中取得了良好的成果,例如計算機視覺、語言翻譯、影像字幕、音訊轉錄、分子生物學、語音識別、自然語言處理、自動駕駛汽車、腦腫瘤檢測、即時語音翻譯、音樂創作、自動遊戲玩耍等等。
深度學習是繼機器學習之後更高階的實現,是下一個重大飛躍。目前,它正朝著成為行業標準的方向發展,並有望在處理原始非結構化資料方面成為遊戲規則改變者。
深度學習目前是解決各種現實世界問題的最佳解決方案提供商之一。開發人員正在構建人工智慧程式,這些程式不是使用預先給定的規則,而是從示例中學習以解決複雜的任務。隨著許多資料科學家使用深度學習,更深層的神經網路正在提供越來越準確的結果。
其想法是透過增加每個網路的訓練層數來開發深度神經網路;機器學習更多關於資料的資訊,直到它儘可能準確。開發人員可以使用深度學習技術來實現複雜的機器學習任務,並訓練人工智慧網路具有高水平的感知識別能力。
深度學習在計算機視覺領域得到了廣泛應用。其中一項取得成功的任務是影像分類,即給定輸入影像,將其分類為貓、狗等,或者將其分類為最能描述影像的類別或標籤。我們人類在很早的時候就學會了如何執行這項任務,並具備了快速識別模式、從先驗知識中歸納以及適應不同影像環境的能力。
庫和框架
在本章中,我們將深度學習與不同的庫和框架聯絡起來。
深度學習和Theano
如果我們想開始編寫深度神經網路程式碼,最好了解Theano、TensorFlow、Keras、PyTorch等不同框架的工作原理。
Theano是一個Python庫,它提供了一組函式來構建深度網路,這些網路可以在我們的機器上快速訓練。
Theano由加拿大蒙特利爾大學在深度網路先驅Yoshua Bengio的領導下開發。
Theano允許我們定義和評估包含向量和矩陣的數學表示式,其中矩陣是數字的矩形陣列。
從技術上講,神經網路和輸入資料都可以表示為矩陣,所有標準網路操作都可以重新定義為矩陣操作。這很重要,因為計算機可以非常快速地執行矩陣運算。
我們可以並行處理多個矩陣值,如果我們使用這種底層結構構建神經網路,則可以使用帶有GPU的單臺機器在合理的時間視窗內訓練巨大的網路。
但是,如果我們使用Theano,則必須從頭開始構建深度網路。該庫沒有提供建立特定型別深度網路的完整功能。
相反,我們必須編寫深度網路的每個方面,例如模型、層、啟用函式、訓練方法以及任何用於阻止過擬合的特殊方法。
不過,好訊息是Theano允許在向量化函式之上構建我們的實現,從而為我們提供了一個高度最佳化的解決方案。
還有許多其他庫擴充套件了Theano的功能。TensorFlow和Keras可以使用Theano作為後端。
使用TensorFlow進行深度學習
Google的TensorFlow是一個Python庫。對於構建商業級深度學習應用程式來說,這是一個不錯的選擇。
TensorFlow起源於另一個庫DistBelief V2,它是Google Brain專案的一部分。該庫旨在擴充套件機器學習的可移植性,以便將研究模型應用於商業級應用程式。
與Theano庫非常相似,TensorFlow基於計算圖,其中節點表示持久資料或數學運算,邊表示節點之間的資料流,資料流是一個多維陣列或張量;因此得名TensorFlow。
來自一個操作或一組操作的輸出作為輸入饋送到下一個操作中。
儘管TensorFlow是為神經網路設計的,但它也適用於其他網路,在這些網路中,計算可以建模為資料流圖。
TensorFlow還使用了Theano的幾個特性,例如公共和子表示式消除、自動微分、共享和符號變數。
可以使用TensorFlow構建不同型別的深度網路,例如卷積網路、自動編碼器、RNTN、RNN、RBM、DBM/MLP等等。
但是,TensorFlow不支援超引數配置。對於此功能,我們可以使用Keras。
深度學習和Keras
Keras是一個功能強大、易於使用的Python庫,用於開發和評估深度學習模型。
它具有極簡主義的設計,允許我們逐層構建網路;訓練它,並執行它。
它封裝了高效的數值計算庫Theano和TensorFlow,並允許我們在幾行程式碼中定義和訓練神經網路模型。
它是一個高階神經網路API,有助於廣泛使用深度學習和人工智慧。它執行在許多低階庫之上,包括TensorFlow、Theano等等。Keras程式碼是可移植的;我們可以使用Theano或TensorFlow作為後端在Keras中實現神經網路,而無需更改程式碼。
Python深度學習 - 實現
在這個深度學習的實現中,我們的目標是預測某家銀行的客戶流失或客戶流失資料 - 哪些客戶可能離開這家銀行服務。所使用的資料集相對較小,包含10000行和14列。我們使用Anaconda發行版以及Theano、TensorFlow和Keras等框架。Keras構建在Tensorflow和Theano之上,它們充當Keras的後端。
# Artificial Neural Network # Installing Theano pip install --upgrade theano # Installing Tensorflow pip install –upgrade tensorflow # Installing Keras pip install --upgrade keras
步驟1:資料預處理
In[]:
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the database
dataset = pd.read_csv('Churn_Modelling.csv')
步驟2
我們建立資料集特徵和目標變數的矩陣,目標變數是第14列,標記為“Exited”。
資料的初始外觀如下所示:
In[]: X = dataset.iloc[:, 3:13].values Y = dataset.iloc[:, 13].values X
輸出
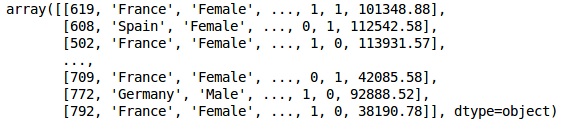
步驟3
Y
輸出
array([1, 0, 1, ..., 1, 1, 0], dtype = int64)
步驟4
我們透過對字串變數進行編碼來簡化分析。我們使用ScikitLearn函式'LabelEncoder'自動對列中的不同標籤進行編碼,其值為0到n_classes-1。
from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X_1 = LabelEncoder() X[:,1] = labelencoder_X_1.fit_transform(X[:,1]) labelencoder_X_2 = LabelEncoder() X[:, 2] = labelencoder_X_2.fit_transform(X[:, 2]) X
輸出
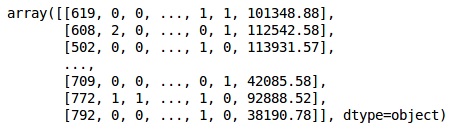
在上面的輸出中,國家名稱被替換為0、1和2;而男性和女性分別被替換為0和1。
步驟5
標籤編碼資料
我們使用相同的ScikitLearn庫和另一個稱為OneHotEncoder的函式,只需傳遞列號即可建立虛擬變數。
onehotencoder = OneHotEncoder(categorical features = [1]) X = onehotencoder.fit_transform(X).toarray() X = X[:, 1:] X
現在,前兩列表示國家,第4列表示性別。
輸出

我們總是將資料分成訓練和測試部分;我們在訓練資料上訓練我們的模型,然後我們在測試資料上檢查模型的準確性,這有助於評估模型的效率。
步驟6
我們使用ScikitLearn的train_test_split函式將我們的資料分成訓練集和測試集。我們將訓練與測試的分割比例保持為80:20。
#Splitting the dataset into the Training set and the Test Set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
有些變數的值以千計,而有些變數的值則以十或一計。我們對資料進行縮放,使其更具代表性。
步驟7
在這段程式碼中,我們使用StandardScaler函式擬合併轉換訓練資料。我們標準化我們的縮放,以便我們使用相同的擬合方法來轉換/縮放測試資料。
# Feature Scaling
fromsklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test)
輸出
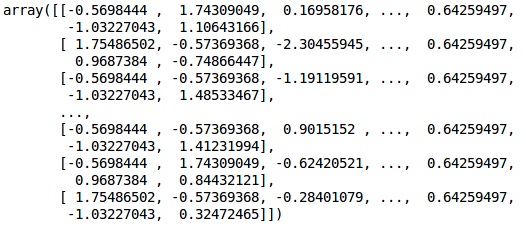
資料現在已正確縮放。最後,我們完成了資料預處理。現在,我們將開始我們的模型。
步驟8
我們在這裡匯入所需的模組。我們需要Sequential模組來初始化神經網路,以及dense模組來新增隱藏層。
# Importing the Keras libraries and packages import keras from keras.models import Sequential from keras.layers import Dense
步驟9
我們將模型命名為Classifier,因為我們的目標是分類客戶流失。然後我們使用Sequential模組進行初始化。
#Initializing Neural Network classifier = Sequential()
步驟10
我們使用dense函式逐一新增隱藏層。在下面的程式碼中,我們將看到許多引數。
我們的第一個引數是output_dim。它是我們新增到此層的節點數。init是隨機梯度下降的初始化。在神經網路中,我們為每個節點分配權重。在初始化時,權重應接近於零,我們使用uniform函式隨機初始化權重。input_dim引數僅在第一層需要,因為模型不知道我們的輸入變數的數量。這裡輸入變數的總數為11。在第二層,模型會自動從第一隱藏層知道輸入變數的數量。
執行以下程式碼行以新增輸入層和第一隱藏層:
classifier.add(Dense(units = 6, kernel_initializer = 'uniform', activation = 'relu', input_dim = 11))
執行以下程式碼行以新增第二隱藏層:
classifier.add(Dense(units = 6, kernel_initializer = 'uniform', activation = 'relu'))
執行以下程式碼行以新增輸出層:
classifier.add(Dense(units = 1, kernel_initializer = 'uniform', activation = 'sigmoid'))
步驟11
編譯ANN
到目前為止,我們已經向分類器添加了多個層。我們現在將使用compile方法編譯它們。在最終編譯中新增的引數控制了整個神經網路的完成。因此,我們必須謹慎地執行此步驟。
以下是引數的簡要說明。
第一個引數是Optimizer。這是一種用於找到最佳權重集的演算法。該演算法稱為隨機梯度下降(SGD)。這裡我們使用幾種型別中的一種,稱為“Adam最佳化器”。SGD依賴於損失,因此我們的第二個引數是損失。如果我們的因變數是二元的,我們使用稱為'binary_crossentropy'的對數損失函式,如果我們的因變數在輸出中有多於兩個類別,則我們使用'categorical_crossentropy'。我們希望根據accuracy提高神經網路的效能,因此我們將metrics新增為準確性。
# Compiling Neural Network classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
步驟12
此步驟需要執行多行程式碼。
將ANN擬合到訓練集
我們現在在訓練資料上訓練我們的模型。我們使用fit方法來擬合我們的模型。我們還最佳化權重以提高模型效率。為此,我們必須更新權重。Batch size是在更新權重後觀察到的次數。Epoch是迭代的總數。批大小和時期的值是透過試錯法選擇的。
classifier.fit(X_train, y_train, batch_size = 10, epochs = 50)
做出預測並評估模型
# Predicting the Test set results y_pred = classifier.predict(X_test) y_pred = (y_pred > 0.5)
預測單個新的觀察結果
# Predicting a single new observation """Our goal is to predict if the customer with the following data will leave the bank: Geography: Spain Credit Score: 500 Gender: Female Age: 40 Tenure: 3 Balance: 50000 Number of Products: 2 Has Credit Card: Yes Is Active Member: Yes
步驟13
預測測試集結果
預測結果將為您提供客戶離開公司的機率。我們將該機率轉換為二進位制0和1。
# Predicting the Test set results y_pred = classifier.predict(X_test) y_pred = (y_pred > 0.5)
new_prediction = classifier.predict(sc.transform (np.array([[0.0, 0, 500, 1, 40, 3, 50000, 2, 1, 1, 40000]]))) new_prediction = (new_prediction > 0.5)
步驟14
這是我們評估模型效能的最後一步。我們已經有了原始結果,因此我們可以構建混淆矩陣來檢查模型的準確性。
建立混淆矩陣
from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred) print (cm)
輸出
loss: 0.3384 acc: 0.8605 [ [1541 54] [230 175] ]
從混淆矩陣中,可以計算出模型的準確率為:
Accuracy = 1541+175/2000=0.858
我們實現了85.8%的準確率,這是一個不錯的結果。
前向傳播演算法
在本節中,我們將學習如何編寫程式碼以對簡單神經網路進行前向傳播(預測):
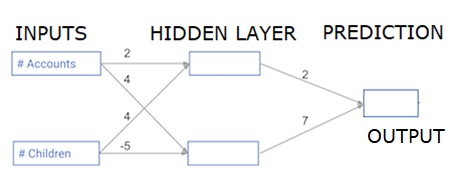
每個資料點都是一個客戶。第一個輸入是他們有多少個賬戶,第二個輸入是他們有多少個孩子。該模型將預測使用者明年將進行多少次交易。
輸入資料預先載入為 input_data,權重儲存在一個名為 weights 的字典中。隱藏層第一個節點的權重陣列位於 weights['node_0'] 中,隱藏層第二個節點的權重陣列位於 weights['node_1'] 中。
輸出節點的輸入權重可在 weights 中獲取。
修正線性啟用函式
“啟用函式”是每個節點都會執行的一個函式。它將節點的輸入轉換為某種輸出。
修正線性啟用函式(稱為ReLU)廣泛應用於高效能網路中。此函式接收一個數字作為輸入,如果輸入為負數則返回 0,如果輸入為正數則返回輸入值作為輸出。
以下是一些示例:
- relu(4) = 4
- relu(-2) = 0
我們填寫 relu() 函式的定義:
- 我們使用 max() 函式計算 relu() 輸出的值。
- 我們將 relu() 函式應用於 node_0_input 以計算 node_0_output。
- 我們將 relu() 函式應用於 node_1_input 以計算 node_1_output。
import numpy as np
input_data = np.array([-1, 2])
weights = {
'node_0': np.array([3, 3]),
'node_1': np.array([1, 5]),
'output': np.array([2, -1])
}
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = np.tanh(node_0_input)
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = np.tanh(node_1_input)
hidden_layer_output = np.array(node_0_output, node_1_output)
output =(hidden_layer_output * weights['output']).sum()
print(output)
def relu(input):
'''Define your relu activation function here'''
# Calculate the value for the output of the relu function: output
output = max(input,0)
# Return the value just calculated
return(output)
# Calculate node 0 value: node_0_output
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 value: node_1_output
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# Calculate model output (do not apply relu)
odel_output = (hidden_layer_outputs * weights['output']).sum()
print(model_output)# Print model output
輸出
0.9950547536867305 -3
將網路應用於多個觀測值/資料行
在本節中,我們將學習如何定義一個名為 predict_with_network() 的函式。此函式將根據上述網路作為輸入的 input_data 生成多個數據觀測值的預測。將使用上述網路中給出的權重。也將使用 relu() 函式的定義。
讓我們定義一個名為 predict_with_network() 的函式,它接受兩個引數 - input_data_row 和 weights - 並返回網路的預測作為輸出。
我們計算每個節點的輸入和輸出值,並將其儲存為:node_0_input、node_0_output、node_1_input 和 node_1_output。
為了計算節點的輸入值,我們將相關的陣列相乘並計算它們的和。
為了計算節點的輸出值,我們將 relu() 函式應用於節點的輸入值。我們使用“for 迴圈”迭代 input_data:
我們還使用我們的 predict_with_network() 為 input_data 的每一行 - input_data_row 生成預測。我們還將每個預測追加到 results 中。
# Define predict_with_network() def predict_with_network(input_data_row, weights): # Calculate node 0 value node_0_input = (input_data_row * weights['node_0']).sum() node_0_output = relu(node_0_input) # Calculate node 1 value node_1_input = (input_data_row * weights['node_1']).sum() node_1_output = relu(node_1_input) # Put node values into array: hidden_layer_outputs hidden_layer_outputs = np.array([node_0_output, node_1_output]) # Calculate model output input_to_final_layer = (hidden_layer_outputs*weights['output']).sum() model_output = relu(input_to_final_layer) # Return model output return(model_output) # Create empty list to store prediction results results = [] for input_data_row in input_data: # Append prediction to results results.append(predict_with_network(input_data_row, weights)) print(results)# Print results
輸出
[0, 12]
在這裡,我們使用了 relu 函式,其中 relu(26) = 26,relu(-13) = 0,依此類推。
深度多層神經網路
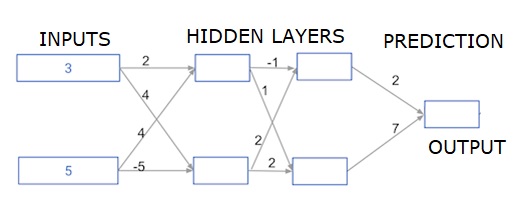
在這裡,我們正在編寫程式碼來對具有兩個隱藏層的神經網路進行前向傳播。每個隱藏層有兩個節點。輸入資料已預先載入為input_data。第一個隱藏層中的節點稱為 node_0_0 和 node_0_1。
它們的權重分別預先載入為 weights['node_0_0'] 和 weights['node_0_1']。
第二個隱藏層中的節點稱為node_1_0 和 node_1_1。它們的權重分別預先載入為weights['node_1_0'] 和weights['node_1_1']。
然後,我們使用預先載入為weights['output'] 的權重從隱藏節點建立模型輸出。
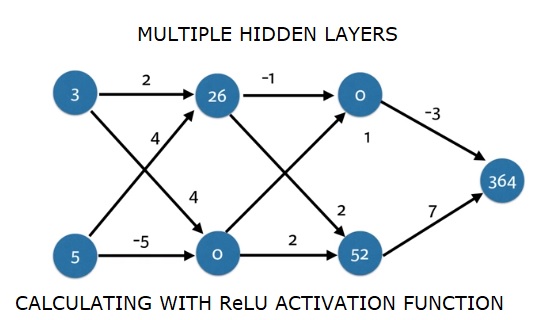
我們使用其權重 weights['node_0_0'] 和給定的 input_data 計算 node_0_0_input。然後應用 relu() 函式以獲取 node_0_0_output。
我們對 node_0_1_input 執行與上述相同的操作以獲取 node_0_1_output。
我們使用其權重 weights['node_1_0'] 和第一隱藏層的輸出 - hidden_0_outputs 計算 node_1_0_input。然後應用 relu() 函式以獲取 node_1_0_output。
我們對 node_1_1_input 執行與上述相同的操作以獲取 node_1_1_output。
我們使用 weights['output'] 和第二隱藏層 hidden_1_outputs 陣列的輸出計算 model_output。我們不將 relu() 函式應用於此輸出。
import numpy as np
input_data = np.array([3, 5])
weights = {
'node_0_0': np.array([2, 4]),
'node_0_1': np.array([4, -5]),
'node_1_0': np.array([-1, 1]),
'node_1_1': np.array([2, 2]),
'output': np.array([2, 7])
}
def predict_with_network(input_data):
# Calculate node 0 in the first hidden layer
node_0_0_input = (input_data * weights['node_0_0']).sum()
node_0_0_output = relu(node_0_0_input)
# Calculate node 1 in the first hidden layer
node_0_1_input = (input_data*weights['node_0_1']).sum()
node_0_1_output = relu(node_0_1_input)
# Put node values into array: hidden_0_outputs
hidden_0_outputs = np.array([node_0_0_output, node_0_1_output])
# Calculate node 0 in the second hidden layer
node_1_0_input = (hidden_0_outputs*weights['node_1_0']).sum()
node_1_0_output = relu(node_1_0_input)
# Calculate node 1 in the second hidden layer
node_1_1_input = (hidden_0_outputs*weights['node_1_1']).sum()
node_1_1_output = relu(node_1_1_input)
# Put node values into array: hidden_1_outputs
hidden_1_outputs = np.array([node_1_0_output, node_1_1_output])
# Calculate model output: model_output
model_output = (hidden_1_outputs*weights['output']).sum()
# Return model_output
return(model_output)
output = predict_with_network(input_data)
print(output)
輸出
364