人工神經網路
人工神經網路,簡稱神經網路,並不是一個新概念。它已經存在大約80年了。
直到2011年,隨著新技術的應用、海量資料集的可用性和強大計算機的出現,深度神經網路才開始流行。
神經網路模仿神經元,神經元具有樹突、細胞核、軸突和軸突末梢。
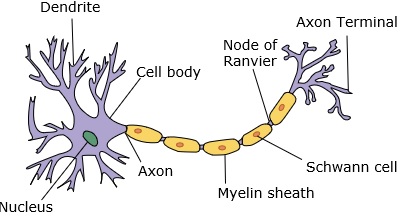
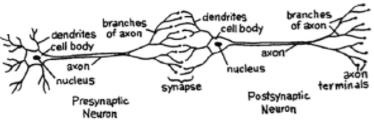
對於一個網路,我們需要兩個神經元。這些神經元透過一個神經元樹突和另一個神經元軸突末梢之間的突觸傳遞資訊。
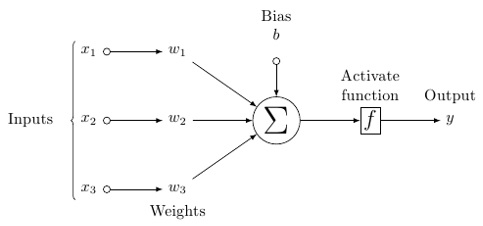
人工神經元的可能模型如下所示:
神經網路看起來如下所示:
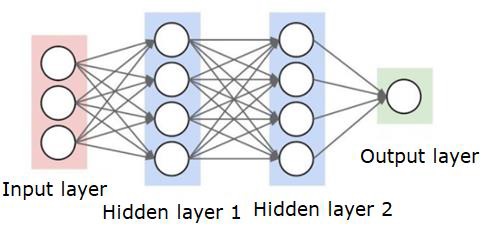
圓圈是神經元或節點,它們對資料執行函式,連線它們的線/邊是傳遞的資訊/權重。
每一列都是一層。你的資料的第一個層是輸入層。然後,輸入層和輸出層之間的所有層都是隱藏層。
如果你有一個或幾個隱藏層,那麼你有一個淺層神經網路。如果你有很多隱藏層,那麼你有一個深度神經網路。
在這個模型中,你擁有輸入資料,對其進行加權,並將其透過神經元中的函式,該函式稱為閾值函式或啟用函式。
基本上,它是將所有值與某個特定值進行比較後的總和。如果你發出訊號,則結果為(1)輸出,或者沒有發出任何訊號,則為(0)。然後對其進行加權並傳遞到下一個神經元,並執行相同型別的函式。
我們可以使用sigmoid(S形)函式作為啟用函式。
至於權重,它們最初是隨機的,並且對於每個輸入到節點/神經元的權重都是唯一的。
在典型的“前饋”中,這是最基本型別的神經網路,你的資訊直接透過你建立的網路傳遞,你使用樣本資料將輸出與你希望的輸出進行比較。
從這裡,你需要調整權重以幫助你使輸出與你的期望輸出相匹配。
將資料直接傳送透過神經網路的行為稱為**前饋神經網路**。
我們的資料按順序從輸入到各層,然後到輸出。
當我們向後開始調整權重以最小化損失/成本時,這稱為**反向傳播**。
這是一個**最佳化問題**。在實際應用中,神經網路必須處理數十萬個變數,甚至數百萬個或更多。
第一個解決方案是使用隨機梯度下降作為最佳化方法。現在,還有AdaGrad、Adam最佳化器等選項。無論哪種方式,這都是一個巨大的計算操作。這就是為什麼神經網路在半個多世紀裡基本上被束之高閣。直到最近,我們的機器才擁有執行這些操作的能力和架構,以及與之匹配的適當大小的資料集。
對於簡單的分類任務,神經網路的效能與其他簡單的演算法(如K最近鄰)相對接近。當我們擁有更多資料和更復雜的問題時,神經網路的真正效用就體現出來了,這兩種情況都優於其他機器學習模型。