- PostgreSQL 教程
- PostgreSQL - 首頁
- PostgreSQL - 概述
- PostgreSQL - 環境設定
- PostgreSQL - 語法
- PostgreSQL - 資料型別
- PostgreSQL - 建立資料庫
- PostgreSQL - 選擇資料庫
- PostgreSQL - 刪除資料庫
- PostgreSQL - 建立表
- PostgreSQL - 刪除表
- PostgreSQL - 模式
- PostgreSQL - 插入查詢
- PostgreSQL - 選擇查詢
- PostgreSQL - 運算子
- PostgreSQL - 表示式
- PostgreSQL - WHERE 子句
- PostgreSQL - AND & OR 子句
- PostgreSQL - 更新查詢
- PostgreSQL - 刪除查詢
- PostgreSQL - LIKE 子句
- PostgreSQL - LIMIT 子句
- PostgreSQL - ORDER BY 子句
- PostgreSQL - GROUP BY
- PostgreSQL - WITH 子句
- PostgreSQL - HAVING 子句
- PostgreSQL - DISTINCT 關鍵字
- 高階 PostgreSQL
- PostgreSQL - 約束
- PostgreSQL - 連線
- PostgreSQL - UNION 子句
- PostgreSQL - NULL 值
- PostgreSQL - 別名語法
- PostgreSQL - 觸發器
- PostgreSQL - 索引
- PostgreSQL - ALTER TABLE 命令
- TRUNCATE TABLE 命令
- PostgreSQL - 檢視
- PostgreSQL - 事務
- PostgreSQL - 鎖
- PostgreSQL - 子查詢
- PostgreSQL - 自動遞增
- PostgreSQL - 許可權
- 日期/時間函式和運算子
- PostgreSQL - 函式
- PostgreSQL - 常用函式
- PostgreSQL 介面
- PostgreSQL - C/C++
- PostgreSQL - Java
- PostgreSQL - PHP
- PostgreSQL - Perl
- PostgreSQL - Python
- PostgreSQL 資源
- PostgreSQL 快速指南
- PostgreSQL - 資源
- PostgreSQL - 討論
PostgreSQL 快速指南
PostgreSQL - 概述
PostgreSQL 是一個功能強大的開源物件關係資料庫系統。它擁有超過 15 年的活躍開發階段和久經考驗的架構,因其可靠性、資料完整性和正確性而享有盛譽。
本教程將幫助您快速入門 PostgreSQL,並使您能夠輕鬆進行 PostgreSQL 程式設計。
什麼是 PostgreSQL?
PostgreSQL(發音為 **post-gress-Q-L**)是由全球志願者團隊開發的開源關係資料庫管理系統 (DBMS)。PostgreSQL 不受任何公司或其他私人實體控制,其原始碼可免費獲得。
PostgreSQL 簡史
PostgreSQL 最初名為 Postgres,由加州大學伯克利分校 (UCB) 的計算機科學教授 Michael Stonebraker 建立。Stonebraker 於 1986 年開始開發 Postgres,作為其前身 Ingres(現為 Computer Associates 所有)的後續專案。
**1977-1985** − 開發了一個名為 INGRES 的專案。
關係資料庫的概念驗證
1980 年成立 Ingres 公司
1994 年被 Computer Associates 收購
**1986-1994** − POSTGRES
在 INGRES 的概念基礎上進行開發,重點關注面向物件和查詢語言 - Quel
INGRES 的程式碼庫未用作 POSTGRES 的基礎
商業化為 Illustra(被 Informix 收購,後被 IBM 收購)
**1994-1995** − Postgres95
1994 年增加了對 SQL 的支援
1995 年釋出為 Postgres95
1996 年重新發布為 PostgreSQL 6.0
成立 PostgreSQL 全球開發團隊
PostgreSQL 的主要特性
PostgreSQL 執行在所有主要的 作業系統上,包括 Linux、UNIX(AIX、BSD、HP-UX、SGI IRIX、Mac OS X、Solaris、Tru64)和 Windows。它支援文字、影像、聲音和影片,幷包括用於 C/C++、Java、Perl、Python、Ruby、Tcl 和開放資料庫連線 (ODBC) 的程式設計介面。
PostgreSQL 支援大部分 SQL 標準,並提供許多現代特性,包括以下內容:
- 複雜的 SQL 查詢
- SQL 子查詢
- 外部索引鍵
- 觸發器
- 檢視
- 事務
- 多版本併發控制 (MVCC)
- 流複製(從 9.0 版本開始)
- 熱備用(從 9.0 版本開始)
您可以檢視 PostgreSQL 的官方文件以瞭解上述特性。PostgreSQL 可以透過多種方式由使用者擴充套件。例如,透過新增新的:
- 資料型別
- 函式
- 運算子
- 聚合函式
- 索引方法
過程語言支援
PostgreSQL 支援四種標準的過程語言,允許使用者使用任何一種語言編寫自己的程式碼,並由 PostgreSQL 資料庫伺服器執行。這些過程語言包括 - PL/pgSQL、PL/Tcl、PL/Perl 和 PL/Python。此外,還支援其他非標準的過程語言,如 PL/PHP、PL/V8、PL/Ruby、PL/Java 等。
PostgreSQL - 環境設定
要開始理解 PostgreSQL 的基礎知識,首先讓我們安裝 PostgreSQL。本章介紹如何在 Linux、Windows 和 Mac OS 平臺上安裝 PostgreSQL。
在 Linux/Unix 上安裝 PostgreSQL
按照以下步驟在您的 Linux 機器上安裝 PostgreSQL。在繼續安裝之前,請確保您已以 **root** 使用者身份登入。
從 EnterpriseDB 選擇您想要的 PostgreSQL 版本號和儘可能精確的平臺。
我為我的 64 位 CentOS-6 機器下載了 **postgresql-9.2.4-1-linux-x64.run**。現在,讓我們按如下方式執行它:
[root@host]# chmod +x postgresql-9.2.4-1-linux-x64.run [root@host]# ./postgresql-9.2.4-1-linux-x64.run ------------------------------------------------------------------------ Welcome to the PostgreSQL Setup Wizard. ------------------------------------------------------------------------ Please specify the directory where PostgreSQL will be installed. Installation Directory [/opt/PostgreSQL/9.2]:
啟動安裝程式後,它會詢問您一些基本問題,例如安裝位置、將使用資料庫的使用者密碼、埠號等。因此,請將所有這些值保留為預設值,除了密碼,您可以根據自己的選擇提供密碼。它將在您的 Linux 機器上安裝 PostgreSQL,並顯示以下訊息:
Please wait while Setup installs PostgreSQL on your computer. Installing 0% ______________ 50% ______________ 100% ######################################### ----------------------------------------------------------------------- Setup has finished installing PostgreSQL on your computer.
按照以下安裝後步驟建立您的資料庫:
[root@host]# su - postgres Password: bash-4.1$ createdb testdb bash-4.1$ psql testdb psql (8.4.13, server 9.2.4) test=#
如果 postgres 伺服器未執行,您可以使用以下命令啟動/重啟它:
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
如果您的安裝正確,您將看到 PotsgreSQL 提示符 **test=#**,如上所示。
在 Windows 上安裝 PostgreSQL
按照以下步驟在您的 Windows 機器上安裝 PostgreSQL。安裝期間請確保已關閉第三方防毒軟體。
從 EnterpriseDB 選擇您想要的 PostgreSQL 版本號和儘可能精確的平臺。
我為我的在 32 位模式下執行的 Windows PC 下載了 postgresql-9.2.4-1-windows.exe,因此讓我們以管理員身份執行 **postgresql-9.2.4-1-windows.exe** 來安裝 PostgreSQL。選擇您想要安裝它的位置。預設情況下,它安裝在 Program Files 資料夾中。
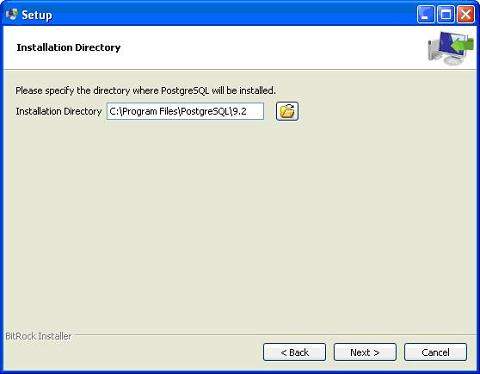
安裝過程的下一步是選擇儲存資料的目錄。預設情況下,它儲存在“data”目錄下。
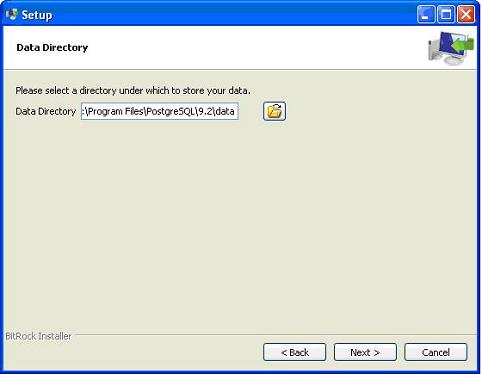
接下來,安裝程式會要求輸入密碼,您可以使用您喜歡的密碼。
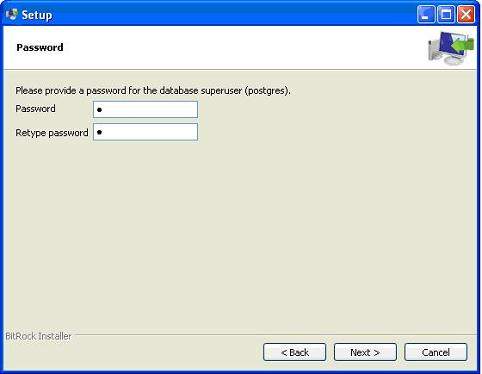
下一步;將埠保留為預設值。
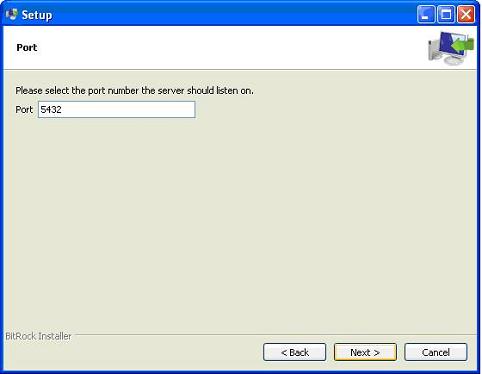
在下一步中,當詢問“區域設定”時,我選擇了“English, United States”。
在您的系統上安裝 PostgreSQL 需要一些時間。安裝過程完成後,您將看到以下螢幕。取消選中複選框並單擊“完成”按鈕。
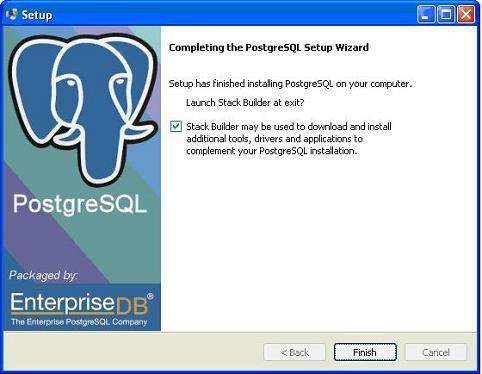
安裝過程完成後,您可以從您的程式選單下的 PostgreSQL 9.2 訪問 pgAdmin III、StackBuilder 和 PostgreSQL shell。
在 Mac 上安裝 PostgreSQL
按照以下步驟在您的 Mac 機器上安裝 PostgreSQL。在繼續安裝之前,請確保您已以 **管理員** 身份登入。
從 EnterpriseDB 選擇適用於 Mac OS 的最新 PostgreSQL 版本號。
我為我的執行 OS X 10.8.3 版本的 Mac OS 下載了 **postgresql-9.2.4-1-osx.dmg**。現在,讓我們在訪達中開啟 dmg 映象並雙擊它,這將在以下視窗中為您提供 PostgreSQL 安裝程式:
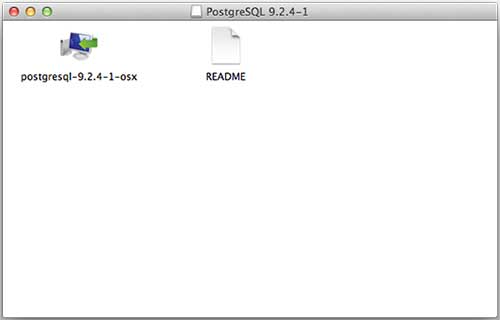
接下來,單擊 **postgres-9.2.4-1-osx** 圖示,這將顯示一條警告訊息。接受警告並繼續進行安裝。它將要求輸入管理員密碼,如下面的視窗所示:
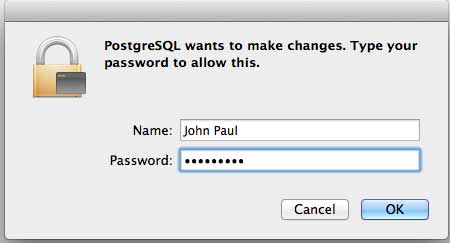
輸入密碼,繼續安裝,此步驟之後,重新啟動您的 Mac 機器。如果您沒有看到以下視窗,請再次啟動安裝。

啟動安裝程式後,它會詢問您一些基本問題,例如安裝位置、將使用資料庫的使用者密碼、埠號等。因此,請將所有這些值保留為預設值,除了密碼,您可以根據自己的選擇提供密碼。它將在您的 Mac 機器上的應用程式資料夾中安裝 PostgreSQL,您可以檢查:
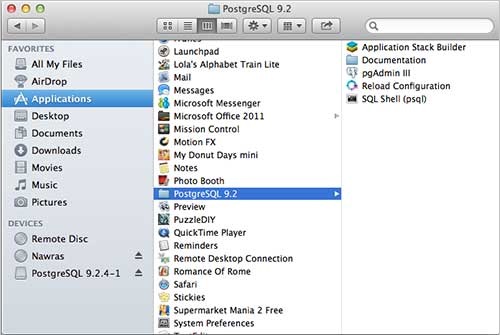
現在,您可以啟動任何程式來開始使用。讓我們從 SQL Shell 開始。啟動 SQL Shell 時,只需使用它顯示的所有預設值,除了輸入您在安裝時選擇的密碼。如果一切順利,那麼您將進入 postgres 資料庫,並將顯示 **postgress#** 提示符,如下所示:
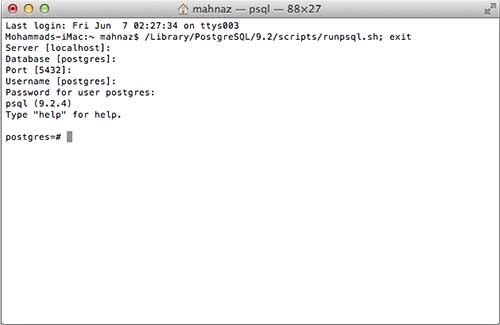
恭喜!現在您的環境已準備好開始 PostgreSQL 資料庫程式設計。
PostgreSQL - 語法
本章提供 PostgreSQL SQL 命令列表,以及每個命令的精確語法規則。這組命令取自 psql 命令列工具。現在您已經安裝了 Postgres,開啟 psql 如下:
Program Files → PostgreSQL 9.2 → SQL Shell(psql)。
使用 psql,您可以使用 \help 命令生成完整的命令列表。對於特定命令的語法,請使用以下命令:
postgres-# \help <command_name>
SQL 語句
SQL 語句由標記組成,每個標記可以表示關鍵字、識別符號、帶引號的識別符號、常量或特殊字元符號。下表使用簡單的 SELECT 語句來說明一個基本的完整 SQL 語句及其組成部分。
| SELECT | id, name | FROM | states | |
|---|---|---|---|---|
| 標記型別 | 關鍵字 | 識別符號 | 關鍵字 | 識別符號 |
| 描述 | 命令 | id 和 name 列 | 子句 | 表名 |
PostgreSQL SQL 命令
ABORT
中止當前事務。
ABORT [ WORK | TRANSACTION ]
ALTER AGGREGATE
更改聚合函式的定義。
ALTER AGGREGATE name ( type ) RENAME TO new_name ALTER AGGREGATE name ( type ) OWNER TO new_owner
ALTER CONVERSION
更改轉換的定義。
ALTER CONVERSION name RENAME TO new_name ALTER CONVERSION name OWNER TO new_owner
ALTER DATABASE
更改資料庫特定引數。
ALTER DATABASE name SET parameter { TO | = } { value | DEFAULT }
ALTER DATABASE name RESET parameter
ALTER DATABASE name RENAME TO new_name
ALTER DATABASE name OWNER TO new_owner
ALTER DOMAIN
更改域特定引數的定義。
ALTER DOMAIN name { SET DEFAULT expression | DROP DEFAULT }
ALTER DOMAIN name { SET | DROP } NOT NULL
ALTER DOMAIN name ADD domain_constraint
ALTER DOMAIN name DROP CONSTRAINT constraint_name [ RESTRICT | CASCADE ]
ALTER DOMAIN name OWNER TO new_owner
ALTER FUNCTION
更改函式的定義。
ALTER FUNCTION name ( [ type [, ...] ] ) RENAME TO new_name ALTER FUNCTION name ( [ type [, ...] ] ) OWNER TO new_owner
ALTER GROUP
更改使用者組。
ALTER GROUP groupname ADD USER username [, ... ] ALTER GROUP groupname DROP USER username [, ... ] ALTER GROUP groupname RENAME TO new_name
ALTER INDEX
更改索引的定義。
ALTER INDEX name OWNER TO new_owner ALTER INDEX name SET TABLESPACE indexspace_name ALTER INDEX name RENAME TO new_name
ALTER LANGUAGE
更改過程語言的定義。
ALTER LANGUAGE name RENAME TO new_name
ALTER OPERATOR
更改運算子的定義。
ALTER OPERATOR name ( { lefttype | NONE }, { righttype | NONE } )
OWNER TO new_owner
ALTER OPERATOR CLASS
更改運算子類的定義。
ALTER OPERATOR CLASS name USING index_method RENAME TO new_name ALTER OPERATOR CLASS name USING index_method OWNER TO new_owner
ALTER SCHEMA
更改模式的定義。
ALTER SCHEMA name RENAME TO new_name ALTER SCHEMA name OWNER TO new_owner
ALTER SEQUENCE
更改序列生成器的定義。
ALTER SEQUENCE name [ INCREMENT [ BY ] increment ] [ MINVALUE minvalue | NO MINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE ] [ RESTART [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]
ALTER TABLE
更改表的定義。
ALTER TABLE [ ONLY ] name [ * ] action [, ... ] ALTER TABLE [ ONLY ] name [ * ] RENAME [ COLUMN ] column TO new_column ALTER TABLE name RENAME TO new_name
其中 *action* 是以下行之一:
ADD [ COLUMN ] column_type [ column_constraint [ ... ] ]
DROP [ COLUMN ] column [ RESTRICT | CASCADE ]
ALTER [ COLUMN ] column TYPE type [ USING expression ]
ALTER [ COLUMN ] column SET DEFAULT expression
ALTER [ COLUMN ] column DROP DEFAULT
ALTER [ COLUMN ] column { SET | DROP } NOT NULL
ALTER [ COLUMN ] column SET STATISTICS integer
ALTER [ COLUMN ] column SET STORAGE { PLAIN | EXTERNAL | EXTENDED | MAIN }
ADD table_constraint
DROP CONSTRAINT constraint_name [ RESTRICT | CASCADE ]
CLUSTER ON index_name
SET WITHOUT CLUSTER
SET WITHOUT OIDS
OWNER TO new_owner
SET TABLESPACE tablespace_name
ALTER TABLESPACE
更改表空間的定義。
ALTER TABLESPACE name RENAME TO new_name ALTER TABLESPACE name OWNER TO new_owner
ALTER TRIGGER
更改觸發器的定義。
ALTER TRIGGER name ON table RENAME TO new_name
ALTER TYPE
更改型別的定義。
ALTER TYPE name OWNER TO new_owner
ALTER USER
更改資料庫使用者帳戶。
ALTER USER name [ [ WITH ] option [ ... ] ]
ALTER USER name RENAME TO new_name
ALTER USER name SET parameter { TO | = } { value | DEFAULT }
ALTER USER name RESET parameter
其中option可以是:
[ ENCRYPTED | UNENCRYPTED ] PASSWORD 'password' | CREATEDB | NOCREATEDB | CREATEUSER | NOCREATEUSER | VALID UNTIL 'abstime'
ANALYZE
收集關於資料庫的統計資訊。
ANALYZE [ VERBOSE ] [ table [ (column [, ...] ) ] ]
BEGIN
開始事務塊。
BEGIN [ WORK | TRANSACTION ] [ transaction_mode [, ...] ]
其中transaction_mode 是:
ISOLATION LEVEL {
SERIALIZABLE | REPEATABLE READ | READ COMMITTED
| READ UNCOMMITTED
}
READ WRITE | READ ONLY
CHECKPOINT
強制事務日誌檢查點。
CHECKPOINT
CLOSE
關閉遊標。
CLOSE name
CLUSTER
根據索引對錶進行聚類。
CLUSTER index_name ON table_name CLUSTER table_name CLUSTER
COMMENT
定義或更改物件的註釋。
COMMENT ON {
TABLE object_name |
COLUMN table_name.column_name |
AGGREGATE agg_name (agg_type) |
CAST (source_type AS target_type) |
CONSTRAINT constraint_name ON table_name |
CONVERSION object_name |
DATABASE object_name |
DOMAIN object_name |
FUNCTION func_name (arg1_type, arg2_type, ...) |
INDEX object_name |
LARGE OBJECT large_object_oid |
OPERATOR op (left_operand_type, right_operand_type) |
OPERATOR CLASS object_name USING index_method |
[ PROCEDURAL ] LANGUAGE object_name |
RULE rule_name ON table_name |
SCHEMA object_name |
SEQUENCE object_name |
TRIGGER trigger_name ON table_name |
TYPE object_name |
VIEW object_name
}
IS 'text'
COMMIT
提交當前事務。
COMMIT [ WORK | TRANSACTION ]
COPY
在檔案和表之間複製資料。
COPY table_name [ ( column [, ...] ) ]
FROM { 'filename' | STDIN }
[ WITH ]
[ BINARY ]
[ OIDS ]
[ DELIMITER [ AS ] 'delimiter' ]
[ NULL [ AS ] 'null string' ]
[ CSV [ QUOTE [ AS ] 'quote' ]
[ ESCAPE [ AS ] 'escape' ]
[ FORCE NOT NULL column [, ...] ]
COPY table_name [ ( column [, ...] ) ]
TO { 'filename' | STDOUT }
[ [ WITH ]
[ BINARY ]
[ OIDS ]
[ DELIMITER [ AS ] 'delimiter' ]
[ NULL [ AS ] 'null string' ]
[ CSV [ QUOTE [ AS ] 'quote' ]
[ ESCAPE [ AS ] 'escape' ]
[ FORCE QUOTE column [, ...] ]
CREATE AGGREGATE
定義新的聚合函式。
CREATE AGGREGATE name ( BASETYPE = input_data_type, SFUNC = sfunc, STYPE = state_data_type [, FINALFUNC = ffunc ] [, INITCOND = initial_condition ] )
CREATE CAST
定義新的轉換。
CREATE CAST (source_type AS target_type) WITH FUNCTION func_name (arg_types) [ AS ASSIGNMENT | AS IMPLICIT ] CREATE CAST (source_type AS target_type) WITHOUT FUNCTION [ AS ASSIGNMENT | AS IMPLICIT ]
CREATE CONSTRAINT TRIGGER
定義新的約束觸發器。
CREATE CONSTRAINT TRIGGER name AFTER events ON table_name constraint attributes FOR EACH ROW EXECUTE PROCEDURE func_name ( args )
CREATE CONVERSION
定義新的轉換。
CREATE [DEFAULT] CONVERSION name FOR source_encoding TO dest_encoding FROM func_name
CREATE DATABASE
建立一個新的資料庫。
CREATE DATABASE name [ [ WITH ] [ OWNER [=] db_owner ] [ TEMPLATE [=] template ] [ ENCODING [=] encoding ] [ TABLESPACE [=] tablespace ] ]
CREATE DOMAIN
定義新的域。
CREATE DOMAIN name [AS] data_type [ DEFAULT expression ] [ constraint [ ... ] ]
其中constraint是:
[ CONSTRAINT constraint_name ]
{ NOT NULL | NULL | CHECK (expression) }
CREATE FUNCTION
定義新的函式。
CREATE [ OR REPLACE ] FUNCTION name ( [ [ arg_name ] arg_type [, ...] ] )
RETURNS ret_type
{ LANGUAGE lang_name
| IMMUTABLE | STABLE | VOLATILE
| CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT
| [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER
| AS 'definition'
| AS 'obj_file', 'link_symbol'
} ...
[ WITH ( attribute [, ...] ) ]
CREATE GROUP
定義新的使用者組。
CREATE GROUP name [ [ WITH ] option [ ... ] ] Where option can be: SYSID gid | USER username [, ...]
CREATE INDEX
定義新的索引。
CREATE [ UNIQUE ] INDEX name ON table [ USING method ]
( { column | ( expression ) } [ opclass ] [, ...] )
[ TABLESPACE tablespace ]
[ WHERE predicate ]
CREATE LANGUAGE
定義新的過程語言。
CREATE [ TRUSTED ] [ PROCEDURAL ] LANGUAGE name HANDLER call_handler [ VALIDATOR val_function ]
CREATE OPERATOR
定義新的運算子。
CREATE OPERATOR name ( PROCEDURE = func_name [, LEFTARG = left_type ] [, RIGHTARG = right_type ] [, COMMUTATOR = com_op ] [, NEGATOR = neg_op ] [, RESTRICT = res_proc ] [, JOIN = join_proc ] [, HASHES ] [, MERGES ] [, SORT1 = left_sort_op ] [, SORT2 = right_sort_op ] [, LTCMP = less_than_op ] [, GTCMP = greater_than_op ] )
CREATE OPERATOR CLASS
定義新的運算子類。
CREATE OPERATOR CLASS name [ DEFAULT ] FOR TYPE data_type
USING index_method AS
{ OPERATOR strategy_number operator_name [ ( op_type, op_type ) ] [ RECHECK ]
| FUNCTION support_number func_name ( argument_type [, ...] )
| STORAGE storage_type
} [, ... ]
CREATE RULE
定義新的重寫規則。
CREATE [ OR REPLACE ] RULE name AS ON event
TO table [ WHERE condition ]
DO [ ALSO | INSTEAD ] { NOTHING | command | ( command ; command ... ) }
CREATE SCHEMA
定義新的模式。
CREATE SCHEMA schema_name [ AUTHORIZATION username ] [ schema_element [ ... ] ] CREATE SCHEMA AUTHORIZATION username [ schema_element [ ... ] ]
CREATE SEQUENCE
定義新的序列生成器。
CREATE [ TEMPORARY | TEMP ] SEQUENCE name [ INCREMENT [ BY ] increment ] [ MINVALUE minvalue | NO MINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE ] [ START [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]
CREATE TABLE
定義新的表。
CREATE [ [ GLOBAL | LOCAL ] {
TEMPORARY | TEMP } ] TABLE table_name ( {
column_name data_type [ DEFAULT default_expr ] [ column_constraint [ ... ] ]
| table_constraint
| LIKE parent_table [ { INCLUDING | EXCLUDING } DEFAULTS ]
} [, ... ]
)
[ INHERITS ( parent_table [, ... ] ) ]
[ WITH OIDS | WITHOUT OIDS ]
[ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ]
[ TABLESPACE tablespace ]
其中column_constraint是:
[ CONSTRAINT constraint_name ] {
NOT NULL |
NULL |
UNIQUE [ USING INDEX TABLESPACE tablespace ] |
PRIMARY KEY [ USING INDEX TABLESPACE tablespace ] |
CHECK (expression) |
REFERENCES ref_table [ ( ref_column ) ]
[ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ]
[ ON DELETE action ] [ ON UPDATE action ]
}
[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
而table_constraint是:
[ CONSTRAINT constraint_name ]
{ UNIQUE ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] |
PRIMARY KEY ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] |
CHECK ( expression ) |
FOREIGN KEY ( column_name [, ... ] )
REFERENCES ref_table [ ( ref_column [, ... ] ) ]
[ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ]
[ ON DELETE action ] [ ON UPDATE action ] }
[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
CREATE TABLE AS
根據查詢結果定義新的表。
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } ] TABLE table_name
[ (column_name [, ...] ) ] [ [ WITH | WITHOUT ] OIDS ]
AS query
CREATE TABLESPACE
定義新的表空間。
CREATE TABLESPACE tablespace_name [ OWNER username ] LOCATION 'directory'
CREATE TRIGGER
定義新的觸發器。
CREATE TRIGGER name { BEFORE | AFTER } { event [ OR ... ] }
ON table [ FOR [ EACH ] { ROW | STATEMENT } ]
EXECUTE PROCEDURE func_name ( arguments )
CREATE TYPE
定義新的資料型別。
CREATE TYPE name AS
( attribute_name data_type [, ... ] )
CREATE TYPE name (
INPUT = input_function,
OUTPUT = output_function
[, RECEIVE = receive_function ]
[, SEND = send_function ]
[, ANALYZE = analyze_function ]
[, INTERNALLENGTH = { internal_length | VARIABLE } ]
[, PASSEDBYVALUE ]
[, ALIGNMENT = alignment ]
[, STORAGE = storage ]
[, DEFAULT = default ]
[, ELEMENT = element ]
[, DELIMITER = delimiter ]
)
CREATE USER
定義新的資料庫使用者帳戶。
CREATE USER name [ [ WITH ] option [ ... ] ]
其中option可以是:
SYSID uid | [ ENCRYPTED | UNENCRYPTED ] PASSWORD 'password' | CREATEDB | NOCREATEDB | CREATEUSER | NOCREATEUSER | IN GROUP group_name [, ...] | VALID UNTIL 'abs_time'
CREATE VIEW
定義新的檢視。
CREATE [ OR REPLACE ] VIEW name [ ( column_name [, ...] ) ] AS query
DEALLOCATE
釋放預處理語句。
DEALLOCATE [ PREPARE ] plan_name
DECLARE
定義遊標。
DECLARE name [ BINARY ] [ INSENSITIVE ] [ [ NO ] SCROLL ]
CURSOR [ { WITH | WITHOUT } HOLD ] FOR query
[ FOR { READ ONLY | UPDATE [ OF column [, ...] ] } ]
DELETE
刪除表中的行。
DELETE FROM [ ONLY ] table [ WHERE condition ]
DROP AGGREGATE
刪除聚合函式。
DROP AGGREGATE name ( type ) [ CASCADE | RESTRICT ]
DROP CAST
刪除轉換。
DROP CAST (source_type AS target_type) [ CASCADE | RESTRICT ]
DROP CONVERSION
刪除轉換。
DROP CONVERSION name [ CASCADE | RESTRICT ]
DROP DATABASE
刪除資料庫。
DROP DATABASE name
DROP DOMAIN
刪除域。
DROP DOMAIN name [, ...] [ CASCADE | RESTRICT ]
DROP FUNCTION
刪除函式。
DROP FUNCTION name ( [ type [, ...] ] ) [ CASCADE | RESTRICT ]
DROP GROUP
刪除使用者組。
DROP GROUP name
DROP INDEX
刪除索引。
DROP INDEX name [, ...] [ CASCADE | RESTRICT ]
DROP LANGUAGE
刪除過程語言。
DROP [ PROCEDURAL ] LANGUAGE name [ CASCADE | RESTRICT ]
DROP OPERATOR
刪除運算子。
DROP OPERATOR name ( { left_type | NONE }, { right_type | NONE } )
[ CASCADE | RESTRICT ]
DROP OPERATOR CLASS
刪除運算子類。
DROP OPERATOR CLASS name USING index_method [ CASCADE | RESTRICT ]
DROP RULE
刪除重寫規則。
DROP RULE name ON relation [ CASCADE | RESTRICT ]
DROP SCHEMA
刪除模式。
DROP SCHEMA name [, ...] [ CASCADE | RESTRICT ]
DROP SEQUENCE
刪除序列。
DROP SEQUENCE name [, ...] [ CASCADE | RESTRICT ]
DROP TABLE
刪除表。
DROP TABLE name [, ...] [ CASCADE | RESTRICT ]
DROP TABLESPACE
刪除表空間。
DROP TABLESPACE tablespace_name
DROP TRIGGER
刪除觸發器。
DROP TRIGGER name ON table [ CASCADE | RESTRICT ]
DROP TYPE
刪除資料型別。
DROP TYPE name [, ...] [ CASCADE | RESTRICT ]
DROP USER
刪除資料庫使用者帳戶。
DROP USER name
DROP VIEW
刪除檢視。
DROP VIEW name [, ...] [ CASCADE | RESTRICT ]
END
提交當前事務。
END [ WORK | TRANSACTION ]
EXECUTE
執行預處理語句。
EXECUTE plan_name [ (parameter [, ...] ) ]
EXPLAIN
顯示語句的執行計劃。
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
FETCH
使用遊標從查詢中檢索行。
FETCH [ direction { FROM | IN } ] cursor_name
其中direction可以為空或:
NEXT PRIOR FIRST LAST ABSOLUTE count RELATIVE count count ALL FORWARD FORWARD count FORWARD ALL BACKWARD BACKWARD count BACKWARD ALL
GRANT
定義訪問許可權。
GRANT { { SELECT | INSERT | UPDATE | DELETE | RULE | REFERENCES | TRIGGER }
[,...] | ALL [ PRIVILEGES ] }
ON [ TABLE ] table_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { { CREATE | TEMPORARY | TEMP } [,...] | ALL [ PRIVILEGES ] }
ON DATABASE db_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { CREATE | ALL [ PRIVILEGES ] }
ON TABLESPACE tablespace_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { EXECUTE | ALL [ PRIVILEGES ] }
ON FUNCTION func_name ([type, ...]) [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { USAGE | ALL [ PRIVILEGES ] }
ON LANGUAGE lang_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
GRANT { { CREATE | USAGE } [,...] | ALL [ PRIVILEGES ] }
ON SCHEMA schema_name [, ...]
TO { username | GROUP group_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]
INSERT
在表中建立新行。
INSERT INTO table [ ( column [, ...] ) ]
{ DEFAULT VALUES | VALUES ( { expression | DEFAULT } [, ...] ) | query }
LISTEN
監聽通知。
LISTEN name
LOAD
載入或重新載入共享庫檔案。
LOAD 'filename'
LOCK
鎖定表。
LOCK [ TABLE ] name [, ...] [ IN lock_mode MODE ] [ NOWAIT ]
其中lock_mode是:
ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE | SHARE UPDATE EXCLUSIVE | SHARE | SHARE ROW EXCLUSIVE | EXCLUSIVE | ACCESS EXCLUSIVE
MOVE
定位遊標。
MOVE [ direction { FROM | IN } ] cursor_name
NOTIFY
生成通知。
NOTIFY name
PREPARE
準備執行語句。
PREPARE plan_name [ (data_type [, ...] ) ] AS statement
REINDEX
重建索引。
REINDEX { DATABASE | TABLE | INDEX } name [ FORCE ]
RELEASE SAVEPOINT
銷燬先前定義的儲存點。
RELEASE [ SAVEPOINT ] savepoint_name
RESET
將執行時引數的值恢復為預設值。
RESET name RESET ALL
REVOKE
刪除訪問許可權。
REVOKE [ GRANT OPTION FOR ]
{ { SELECT | INSERT | UPDATE | DELETE | RULE | REFERENCES | TRIGGER }
[,...] | ALL [ PRIVILEGES ] }
ON [ TABLE ] table_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ { CREATE | TEMPORARY | TEMP } [,...] | ALL [ PRIVILEGES ] }
ON DATABASE db_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ CREATE | ALL [ PRIVILEGES ] }
ON TABLESPACE tablespace_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ EXECUTE | ALL [ PRIVILEGES ] }
ON FUNCTION func_name ([type, ...]) [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ USAGE | ALL [ PRIVILEGES ] }
ON LANGUAGE lang_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
REVOKE [ GRANT OPTION FOR ]
{ { CREATE | USAGE } [,...] | ALL [ PRIVILEGES ] }
ON SCHEMA schema_name [, ...]
FROM { username | GROUP group_name | PUBLIC } [, ...]
[ CASCADE | RESTRICT ]
ROLLBACK
中止當前事務。
ROLLBACK [ WORK | TRANSACTION ]
ROLLBACK TO SAVEPOINT
回滾到儲存點。
ROLLBACK [ WORK | TRANSACTION ] TO [ SAVEPOINT ] savepoint_name
SAVEPOINT
在當前事務中定義新的儲存點。
SAVEPOINT savepoint_name
SELECT
從表或檢視中檢索行。
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
* | expression [ AS output_name ] [, ...]
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition [, ...] ]
[ { UNION | INTERSECT | EXCEPT } [ ALL ] select ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ]
[ LIMIT { count | ALL } ]
[ OFFSET start ]
[ FOR UPDATE [ OF table_name [, ...] ] ]
其中from_item可以是:[ ONLY ] table_name [ * ] [ [ AS ] alias [ ( column_alias [, ...] ) ] ] ( select ) [ AS ] alias [ ( column_alias [, ...] ) ] function_name ( [ argument [, ...] ] ) [ AS ] alias [ ( column_alias [, ...] | column_definition [, ...] ) ] function_name ( [ argument [, ...] ] ) AS ( column_definition [, ...] ) from_item [ NATURAL ] join_type from_item [ ON join_condition | USING ( join_column [, ...] ) ]
SELECT INTO
根據查詢結果定義新的表。
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
* | expression [ AS output_name ] [, ...]
INTO [ TEMPORARY | TEMP ] [ TABLE ] new_table
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition [, ...] ]
[ { UNION | INTERSECT | EXCEPT } [ ALL ] select ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ]
[ LIMIT { count | ALL } ]
[ OFFSET start ]
[ FOR UPDATE [ OF table_name [, ...] ] ]
SET
更改執行時引數。
SET [ SESSION | LOCAL ] name { TO | = } { value | 'value' | DEFAULT }
SET [ SESSION | LOCAL ] TIME ZONE { time_zone | LOCAL | DEFAULT }
SET CONSTRAINTS
設定當前事務的約束檢查模式。
SET CONSTRAINTS { ALL | name [, ...] } { DEFERRED | IMMEDIATE }
SET SESSION AUTHORIZATION
設定當前會話的會話使用者識別符號和當前使用者識別符號。
SET [ SESSION | LOCAL ] SESSION AUTHORIZATION username SET [ SESSION | LOCAL ] SESSION AUTHORIZATION DEFAULT RESET SESSION AUTHORIZATION
SET TRANSACTION
設定當前事務的特性。
SET TRANSACTION transaction_mode [, ...] SET SESSION CHARACTERISTICS AS TRANSACTION transaction_mode [, ...]
其中transaction_mode 是:
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED
| READ UNCOMMITTED }
READ WRITE | READ ONLY
SHOW
顯示執行時引數的值。
SHOW name SHOW ALL
START TRANSACTION
開始事務塊。
START TRANSACTION [ transaction_mode [, ...] ]
其中transaction_mode 是:
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED
| READ UNCOMMITTED }
READ WRITE | READ ONLY
TRUNCATE
清空表。
TRUNCATE [ TABLE ] name
UNLISTEN
停止監聽通知。
UNLISTEN { name | * }
UPDATE
更新表中的行。
UPDATE [ ONLY ] table SET column = { expression | DEFAULT } [, ...]
[ FROM from_list ]
[ WHERE condition ]
VACUUM
垃圾回收並可選地分析資料庫。
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ table ] VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] ANALYZE [ table [ (column [, ...] ) ] ]
PostgreSQL - 資料型別
本章將討論PostgreSQL中使用的資料型別。建立表時,為每一列指定資料型別,即要儲存在表字段中的資料型別。
這帶來了諸多好處:
一致性 - 對相同資料型別的列進行的操作會產生一致的結果,並且通常速度最快。
驗證 - 正確使用資料型別意味著對資料的格式進行驗證,並拒絕超出資料類型範圍的資料。
緊湊性 - 由於列可以儲存單一型別的值,因此以緊湊的方式儲存。
效能 - 正確使用資料型別可以最有效地儲存資料。儲存的值可以快速處理,從而提高效能。
PostgreSQL 支援廣泛的資料型別。此外,使用者可以使用CREATE TYPE SQL 命令建立自己的自定義資料型別。PostgreSQL 中有不同型別的資料型別類別。如下所述。
數值型別
數值型別包括兩位元組、四位元組和八位元組整數、四位元組和八位元組浮點數以及可選精度小數。下表列出了可用的型別。
| 名稱 | 儲存大小 | 描述 | 範圍 |
|---|---|---|---|
| smallint | 2 位元組 | 小範圍整數 | -32768 到 +32767 |
| integer | 4 位元組 | 整數的典型選擇 | -2147483648 到 +2147483647 |
| bigint | 8 位元組 | 大範圍整數 | -9223372036854775808 到 9223372036854775807 |
| decimal | 可變 | 使用者指定的精度,精確 | 小數點前最多 131072 位;小數點後最多 16383 位 |
| numeric | 可變 | 使用者指定的精度,精確 | 小數點前最多 131072 位;小數點後最多 16383 位 |
| real | 4 位元組 | 可變精度,不精確 | 6 位小數精度 |
| double precision | 8 位元組 | 可變精度,不精確 | 15 位小數精度 |
| smallserial | 2 位元組 | 小的自動遞增整數 | 1 到 32767 |
| serial | 4 位元組 | 自動遞增整數 | 1 到 2147483647 |
| bigserial | 8 位元組 | 大的自動遞增整數 | 1 到 9223372036854775807 |
貨幣型別
money型別儲存具有固定小數精度的貨幣金額。可以將numeric、int 和 bigint資料型別的賦值轉換為money。由於可能出現舍入誤差,因此不建議使用浮點數處理貨幣。
| 名稱 | 儲存大小 | 描述 | 範圍 |
|---|---|---|---|
| money | 8 位元組 | 貨幣金額 | -92233720368547758.08 到 +92233720368547758.07 |
字元型別
下表列出了PostgreSQL中可用的通用字元型別。
| 序號 | 名稱和描述 |
|---|---|
| 1 | character varying(n), varchar(n) 帶限制的可變長度 |
| 2 | character(n), char(n) 固定長度,用空格填充 |
| 3 | text 無限可變長度 |
二進位制資料型別
bytea資料型別允許像下表一樣儲存二進位制字串。
| 名稱 | 儲存大小 | 描述 |
|---|---|---|
| bytea | 1 或 4 位元組加上實際的二進位制字串 | 可變長度二進位制字串 |
日期/時間型別
PostgreSQL 支援完整的 SQL 日期和時間型別集,如下表所示。日期是根據格里高利曆計算的。這裡,所有型別的解析度均為1 微秒/14 位,除了date型別,其解析度為天。
| 名稱 | 儲存大小 | 描述 | 最小值 | 最大值 |
|---|---|---|---|---|
| timestamp [(p)] [without time zone ] | 8 位元組 | 日期和時間(無時區) | 公元前 4713 年 | 公元 294276 年 |
| TIMESTAMPTZ | 8 位元組 | 日期和時間,帶時區 | 公元前 4713 年 | 公元 294276 年 |
| date | 4 位元組 | 日期(沒有一天中的時間) | 公元前 4713 年 | 公元 5874897 年 |
| time [ (p)] [ without time zone ] | 8 位元組 | 一天中的時間(無日期) | 00:00:00 | 24:00:00 |
| time [ (p)] with time zone | 12 位元組 | 僅一天中的時間,帶時區 | 00:00:00+1459 | 24:00:00-1459 |
| interval [fields ] [(p) ] | 12 位元組 | 時間間隔 | -178000000 年 | 178000000 年 |
布林型別
PostgreSQL 提供標準 SQL 型別布林值。布林資料型別可以具有true、false和第三種狀態unknown,後者由 SQL 空值表示。
| 名稱 | 儲存大小 | 描述 |
|---|---|---|
| boolean | 1 位元組 | true 或 false 狀態 |
列舉型別
列舉型別是由靜態、有序的值集組成的資料型別。它們等效於許多程式語言中支援的列舉型別。
與其他型別不同,列舉型別需要使用 CREATE TYPE 命令建立。此型別用於儲存靜態、有序的值集。例如,指南針方向,即北、南、東和西,或一週中的日子,如下所示:
CREATE TYPE week AS ENUM ('Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun');
建立後,列舉型別可以像其他任何型別一樣使用。
幾何型別
幾何資料型別表示二維空間物件。最基本的型別(點)構成所有其他型別的基礎。
| 名稱 | 儲存大小 | 表示 | 描述 |
|---|---|---|---|
| point | 16 位元組 | 平面上的點 | (x,y) |
| line | 32 位元組 | 無限線(未完全實現) | ((x1,y1),(x2,y2)) |
| 線段 | 32 位元組 | 有限線段 | ((x1,y1),(x2,y2)) |
| 矩形框 | 32 位元組 | 矩形框 | ((x1,y1),(x2,y2)) |
| 路徑 | 16+16n 位元組 | 閉合路徑(類似於多邊形) | ((x1,y1),...) |
| 路徑 | 16+16n 位元組 | 開放路徑 | [(x1,y1),...] |
| 多邊形 | 40+16n | 多邊形(類似於閉合路徑) | ((x1,y1),...) |
| 圓形 | 24 位元組 | 圓形 | <(x,y),r>(中心點和半徑) |
網路地址型別
PostgreSQL 提供資料型別來儲存 IPv4、IPv6 和 MAC 地址。最好使用這些型別而不是純文字型別來儲存網路地址,因為這些型別提供輸入錯誤檢查和專門的運算子和函式。
| 名稱 | 儲存大小 | 描述 |
|---|---|---|
| cidr | 7 或 19 位元組 | IPv4 和 IPv6 網路 |
| inet | 7 或 19 位元組 | IPv4 和 IPv6 主機和網路 |
| macaddr | 6 位元組 | MAC 地址 |
位串型別
位串型別用於儲存位掩碼。它們是 0 或 1。有兩種 SQL 位型別:bit(n) 和 bit varying(n),其中 n 是一個正整數。
文字搜尋型別
此型別支援全文搜尋,即搜尋自然語言文件集合以找到最匹配查詢的文件的活動。為此,有兩種資料型別:
| 序號 | 名稱和描述 |
|---|---|
| 1 | tsvector 這是一個已排序的唯一單詞列表,這些單詞已規範化以合併同一單詞的不同變體,稱為“詞素”。 |
| 2 | tsquery 這儲存要搜尋的詞素,並結合它們來遵守布林運算子 &(AND)、|(OR)和!(NOT)。可以使用括號來強制執行運算子的分組。 |
UUID 型別
UUID(通用唯一識別符號)寫為一系列小寫十六進位制數字,分成幾組,用連字元分隔,具體來說是一組八位數字,後跟三組四位數字,然後是一組十二位數字,總共 32 位數字代表 128 位。
UUID 示例:- 550e8400-e29b-41d4-a716-446655440000
XML 型別
XML 資料型別可用於儲存 XML 資料。要儲存 XML 資料,首先必須使用以下函式 xmlparse 建立 XML 值:
XMLPARSE (DOCUMENT '<?xml version="1.0"?> <tutorial> <title>PostgreSQL Tutorial </title> <topics>...</topics> </tutorial>') XMLPARSE (CONTENT 'xyz<foo>bar</foo><bar>foo</bar>')
JSON 型別
json 資料型別可用於儲存 JSON(JavaScript 物件表示法)資料。此類資料也可以儲存為 text,但 json 資料型別具有檢查每個儲存值是否為有效 JSON 值的優勢。還有一些相關的支援函式可用,可以直接用於處理 JSON 資料型別,如下所示。
| 示例 | 示例結果 |
|---|---|
| array_to_json('{{1,5},{99,100}}'::int[]) | [[1,5],[99,100]] |
| row_to_json(row(1,'foo')) | {"f1":1,"f2":"foo"} |
陣列型別
PostgreSQL 提供了將表列定義為可變長度多維陣列的機會。可以建立任何內建或使用者定義的基本型別、列舉型別或複合型別的陣列。
陣列宣告
陣列型別可以宣告為
CREATE TABLE monthly_savings ( name text, saving_per_quarter integer[], scheme text[][] );
或使用關鍵字“ARRAY”作為
CREATE TABLE monthly_savings ( name text, saving_per_quarter integer ARRAY[4], scheme text[][] );
插入值
陣列值可以作為字面常量插入,將元素值用大括號括起來,並用逗號分隔。下面顯示一個示例:
INSERT INTO monthly_savings
VALUES (‘Manisha’,
‘{20000, 14600, 23500, 13250}’,
‘{{“FD”, “MF”}, {“FD”, “Property”}}’);
訪問陣列
下面顯示了訪問陣列的示例。以下命令將選擇儲蓄在第二季度比第四季度多的個人。
SELECT name FROM monhly_savings WHERE saving_per_quarter[2] > saving_per_quarter[4];
修改陣列
修改陣列的示例如下所示。
UPDATE monthly_savings SET saving_per_quarter = '{25000,25000,27000,27000}'
WHERE name = 'Manisha';
或使用 ARRAY 表示式語法:
UPDATE monthly_savings SET saving_per_quarter = ARRAY[25000,25000,27000,27000] WHERE name = 'Manisha';
搜尋陣列
搜尋陣列的示例如下所示。
SELECT * FROM monthly_savings WHERE saving_per_quarter[1] = 10000 OR saving_per_quarter[2] = 10000 OR saving_per_quarter[3] = 10000 OR saving_per_quarter[4] = 10000;
如果已知陣列的大小,則可以使用上述搜尋方法。否則,以下示例顯示如何在大小未知時進行搜尋。
SELECT * FROM monthly_savings WHERE 10000 = ANY (saving_per_quarter);
複合型別
此型別表示欄位名稱及其資料型別的列表,即錶行或記錄的結構。
複合型別的宣告
以下示例顯示如何聲明覆合型別
CREATE TYPE inventory_item AS ( name text, supplier_id integer, price numeric );
此資料型別可用於建立表,如下所示:
CREATE TABLE on_hand ( item inventory_item, count integer );
複合值輸入
複合值可以作為字面常量插入,將欄位值用括號括起來,並用逗號分隔。下面顯示一個示例:
INSERT INTO on_hand VALUES (ROW('fuzzy dice', 42, 1.99), 1000);
這對於上面定義的 inventory_item 有效。只要表示式中有多個欄位,ROW 關鍵字實際上就是可選的。
訪問複合型別
要訪問複合列的欄位,請使用句點後跟欄位名稱,這與從表名稱中選擇欄位非常相似。例如,要從我們的 on_hand 示例表中選擇一些子欄位,查詢將如下所示:
SELECT (item).name FROM on_hand WHERE (item).price > 9.99;
您甚至可以使用表名(例如在多表查詢中),如下所示:
SELECT (on_hand.item).name FROM on_hand WHERE (on_hand.item).price > 9.99;
範圍型別
範圍型別表示使用資料範圍的資料型別。範圍型別可以是離散範圍(例如,從 1 到 10 的所有整數值)或連續範圍(例如,上午 10:00 到上午 11:00 之間的任何時間點)。
可用的內建範圍型別包括以下範圍:
int4range - 整數範圍
int8range - bigint 範圍
numrange - 數值範圍
tsrange - 無時區時間戳範圍
tstzrange - 有時區時間戳範圍
daterange - 日期範圍
可以建立自定義範圍型別以使新的範圍型別可用,例如使用 inet 型別作為基類的 IP 地址範圍,或使用 float 資料型別作為基類的浮點範圍。
範圍型別分別使用 [ ] 和 ( ) 字元支援包含和排除範圍邊界。例如,“[4,9)”表示從 4 開始(包括 4)到 9(不包括 9)的所有整數。
物件識別符號型別
物件識別符號 (OID) 由 PostgreSQL 內部用作各種系統表的主鍵。如果指定了 WITH OIDS 或啟用了 default_with_oids 配置變數,則在這種情況下,OID 將新增到使用者建立的表中。下表列出了幾個別名型別。OID 別名型別除了專門的輸入和輸出例程之外,沒有自己的操作。
| 名稱 | 參考文獻 | 描述 | 值示例 |
|---|---|---|---|
| oid | any | 數值物件識別符號 | 564182 |
| regproc | pg_proc | 函式名 | sum |
| regprocedure | pg_proc | 帶有引數型別的函式 | sum(int4) |
| regoper | pg_operator | 運算子名稱 | + |
| regoperator | pg_operator | 帶有引數型別的運算子 | *(integer,integer) 或 -(NONE,integer) |
| regclass | pg_class | 關係名 | pg_type |
| regtype | pg_type | 資料型別名稱 | integer |
| regconfig | pg_ts_config | 文字搜尋配置 | English |
| regdictionary | pg_ts_dict | 文字搜尋字典 | simple |
偽型別
PostgreSQL 型別系統包含許多特殊用途的條目,統稱為偽型別。偽型別不能用作列資料型別,但可以用作函式的引數或結果型別。
下表列出了現有的偽型別。
| 序號 | 名稱和描述 |
|---|---|
| 1 | any 指示函式接受任何輸入資料型別。 |
| 2 | anyelement 指示函式接受任何資料型別。 |
| 3 | anyarray 指示函式接受任何陣列資料型別。 |
| 4 | anynonarray 指示函式接受任何非陣列資料型別。 |
| 5 | anyenum 指示函式接受任何列舉資料型別。 |
| 6 | anyrange 指示函式接受任何範圍資料型別。 |
| 7 | cstring 指示函式接受或返回以 null 結尾的 C 字串。 |
| 8 | internal 指示函式接受或返回伺服器內部資料型別。 |
| 9 | language_handler 過程語言呼叫處理程式宣告為返回 language_handler。 |
| 10 | fdw_handler 外部資料包裝器處理程式宣告為返回 fdw_handler。 |
| 11 | record 標識返回未指定行型別的函式。 |
| 12 | trigger 觸發器函式宣告為返回 trigger。 |
| 13 | void 指示函式不返回值。 |
PostgreSQL - 建立資料庫
本章討論如何在 PostgreSQL 中建立新的資料庫。PostgreSQL 提供兩種建立新資料庫的方法:
- 使用 CREATE DATABASE,這是一個 SQL 命令。
- 使用 createdb,這是一個命令列可執行檔案。
使用 CREATE DATABASE
此命令將在 PostgreSQL shell 提示符下建立資料庫,但您應該具有建立資料庫的適當許可權。預設情況下,新資料庫將透過克隆標準系統資料庫 template1 來建立。
語法
CREATE DATABASE 語句的基本語法如下:
CREATE DATABASE dbname;
其中 dbname 是要建立的資料庫的名稱。
示例
以下是一個簡單的示例,它將在您的 PostgreSQL 模式中建立 testdb
postgres=# CREATE DATABASE testdb; postgres-#
使用 createdb 命令
PostgreSQL 命令列可執行檔案 createdb 是 SQL 命令 CREATE DATABASE 的包裝器。此命令與 SQL 命令 CREATE DATABASE 之間的唯一區別在於,前者可以直接從命令列執行,並且它允許將註釋新增到資料庫中,所有這些都可以在一個命令中完成。
語法
createdb 的語法如下所示:
createdb [option...] [dbname [description]]
引數
下表列出了引數及其說明。
| 序號 | 引數和說明 |
|---|---|
| 1 | dbname 要建立的資料庫的名稱。 |
| 2 | description 指定要與新建立的資料庫關聯的註釋。 |
| 3 | options createdb 接受的命令列引數。 |
選項
下表列出了 createdb 接受的命令列引數:
| 序號 | 選項和說明 |
|---|---|
| 1 | -D tablespace 指定資料庫的預設表空間。 |
| 2 | -e 回顯 createdb 生成併發送到伺服器的命令。 |
| 3 | -E encoding 指定在此資料庫中使用的字元編碼方案。 |
| 4 | -l locale 指定在此資料庫中使用的區域設定。 |
| 5 | -T template 指定用於構建此資料庫的模板資料庫。 |
| 6 | --help 顯示關於 createdb 命令列引數的幫助資訊,然後退出。 |
| 7 | -h host 指定伺服器執行所在的機器的主機名。 |
| 8 | -p port 指定伺服器監聽連線的 TCP 埠或本地 Unix 域套接字副檔名。 |
| 9 | -U username 連線使用的使用者名稱。 |
| 10 | -w 從不提示輸入密碼。 |
| 11 | -W 強制 createdb 在連線到資料庫之前提示輸入密碼。 |
開啟命令提示符並轉到安裝 PostgreSQL 的目錄。轉到 bin 目錄並執行以下命令以建立資料庫。
createdb -h localhost -p 5432 -U postgres testdb password ******
上述命令將提示您輸入 PostgreSQL 管理員使用者的密碼,預設為 **postgres**。因此,請提供密碼並繼續建立您的新資料庫。
使用上述任何一種方法建立資料庫後,您可以使用 **\l**(即反斜槓 el 命令)在資料庫列表中檢查它,如下所示:
postgres-# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+---------+-------+-----------------------
postgres | postgres | UTF8 | C | C |
template0 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
testdb | postgres | UTF8 | C | C |
(4 rows)
postgres-#
PostgreSQL - 選擇資料庫
本章解釋了訪問資料庫的各種方法。假設我們已在上一章中建立了一個數據庫。您可以使用以下任一方法選擇資料庫:
- 資料庫 SQL 提示符
- 作業系統命令提示符
資料庫 SQL 提示符
假設您已經啟動了 PostgreSQL 客戶端,並且您已到達以下 SQL 提示符:
postgres=#
您可以使用 **\l**(即反斜槓 el 命令)檢查可用的資料庫列表,如下所示:
postgres-# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+---------+-------+-----------------------
postgres | postgres | UTF8 | C | C |
template0 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
testdb | postgres | UTF8 | C | C |
(4 rows)
postgres-#
現在,鍵入以下命令來連線/選擇所需的資料庫;這裡,我們將連線到 *testdb* 資料庫。
postgres=# \c testdb; psql (9.2.4) Type "help" for help. You are now connected to database "testdb" as user "postgres". testdb=#
作業系統命令提示符
您可以在登入資料庫時,直接在命令提示符處選擇您的資料庫。以下是一個簡單的示例:
psql -h localhost -p 5432 -U postgress testdb Password for user postgress: **** psql (9.2.4) Type "help" for help. You are now connected to database "testdb" as user "postgres". testdb=#
您現在已登入到 PostgreSQL testdb 並準備好執行 testdb 中的命令。要退出資料庫,可以使用命令 \q。
PostgreSQL - 刪除資料庫
本章將討論如何在 PostgreSQL 中刪除資料庫。刪除資料庫有兩種方法:
- 使用 DROP DATABASE,這是一個 SQL 命令。
- 使用 *dropdb*,一個命令列可執行檔案。
在使用此操作之前請務必小心,因為刪除現有資料庫會導致資料庫中儲存的完整資訊丟失。
使用 DROP DATABASE
此命令刪除資料庫。它刪除資料庫的目錄條目並刪除包含資料的目錄。只有資料庫所有者才能執行此命令。當您或其他任何人連線到目標資料庫時,無法執行此命令(連線到 postgres 或任何其他資料庫來發出此命令)。
語法
DROP DATABASE 的語法如下:
DROP DATABASE [ IF EXISTS ] name
引數
此表列出了引數及其說明。
| 序號 | 引數和說明 |
|---|---|
| 1 | IF EXISTS 如果資料庫不存在,則不丟擲錯誤。在這種情況下會發出通知。 |
| 2 | name 要刪除的資料庫的名稱。 |
我們無法刪除有任何開啟連線的資料庫,包括我們自己從 *psql* 或 *pgAdmin III* 的連線。如果我們要刪除當前連線的資料庫,則必須切換到另一個數據庫或 *template1*。因此,使用程式 *dropdb* 可能更方便,它是一個圍繞此命令的包裝器。
示例
以下是一個簡單的示例,它將從您的 PostgreSQL 模式中刪除 **testdb**:
postgres=# DROP DATABASE testdb; postgres-#
使用 dropdb 命令
PostgresSQL 命令列可執行檔案 **dropdb** 是 SQL 命令 *DROP DATABASE* 的命令列包裝器。透過此實用程式刪除資料庫與透過其他訪問伺服器的方法之間沒有有效區別。dropdb 會銷燬現有的 PostgreSQL 資料庫。執行此命令的使用者必須是資料庫超級使用者或資料庫所有者。
語法
*dropdb* 的語法如下:
dropdb [option...] dbname
引數
下表列出了引數及其說明。
| 序號 | 引數和說明 |
|---|---|
| 1 | dbname 要刪除的資料庫的名稱。 |
| 2 | option dropdb 接受的命令列引數。 |
選項
下表列出了 dropdb 接受的命令列引數:
| 序號 | 選項和說明 |
|---|---|
| 1 | -e 顯示傳送到伺服器的命令。 |
| 2 | -i 在執行任何破壞性操作之前發出驗證提示。 |
| 3 | -V 列印 dropdb 版本並退出。 |
| 4 | --if-exists 如果資料庫不存在,則不丟擲錯誤。在這種情況下會發出通知。 |
| 5 | --help 顯示關於 dropdb 命令列引數的幫助資訊,然後退出。 |
| 6 | -h host 指定伺服器執行所在的機器的主機名。 |
| 7 | -p port 指定伺服器監聽連線的 TCP 埠或本地 UNIX 域套接字副檔名。 |
| 8 | -U username 連線使用的使用者名稱。 |
| 9 | -w 從不提示輸入密碼。 |
| 10 | -W 強制 dropdb 在連線到資料庫之前提示輸入密碼。 |
| 11 |
--maintenance-db=dbname 指定要連線到的資料庫的名稱,以便刪除目標資料庫。 |
示例
以下示例演示了從作業系統命令提示符刪除資料庫:
dropdb -h localhost -p 5432 -U postgress testdb Password for user postgress: ****
上述命令刪除資料庫 **testdb**。在這裡,我使用了 **postgres**(位於 template1 的 pg_roles 下)使用者名稱來刪除資料庫。
PostgreSQL - 建立表
PostgreSQL CREATE TABLE 語句用於在任何給定的資料庫中建立一個新表。
語法
CREATE TABLE 語句的基本語法如下:
CREATE TABLE table_name( column1 datatype, column2 datatype, column3 datatype, ..... columnN datatype, PRIMARY KEY( one or more columns ) );
CREATE TABLE 是一個關鍵字,告訴資料庫系統建立一個新表。表的唯一名稱或識別符號位於 CREATE TABLE 語句之後。最初,當前資料庫中的空表由發出命令的使用者擁有。
然後,在括號中,列出定義表中每一列及其資料型別的列表。下面的示例將使語法更加清晰。
示例
以下是一個示例,它建立一個 COMPANY 表,其中 ID 為主鍵,NOT NULL 是約束條件,表示在建立此表中的記錄時這些欄位不能為 NULL:
CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
讓我們再建立一個表,我們將在後續章節的練習中使用它:
CREATE TABLE DEPARTMENT( ID INT PRIMARY KEY NOT NULL, DEPT CHAR(50) NOT NULL, EMP_ID INT NOT NULL );
您可以使用 **\d** 命令驗證您的表是否已成功建立,此命令將用於列出附加資料庫中的所有表。
testdb-# \d
上述 PostgreSQL 語句將產生以下結果:
List of relations Schema | Name | Type | Owner --------+------------+-------+---------- public | company | table | postgres public | department | table | postgres (2 rows)
使用 **\d *tablename*** 來描述每個表,如下所示:
testdb-# \d company
上述 PostgreSQL 語句將產生以下結果:
Table "public.company"
Column | Type | Modifiers
-----------+---------------+-----------
id | integer | not null
name | text | not null
age | integer | not null
address | character(50) |
salary | real |
join_date | date |
Indexes:
"company_pkey" PRIMARY KEY, btree (id)
PostgreSQL - 刪除表
PostgreSQL DROP TABLE 語句用於刪除表定義以及與該表關聯的所有資料、索引、規則、觸發器和約束。
使用此命令時必須小心,因為一旦刪除表,表中所有資訊也將永遠丟失。
語法
DROP TABLE 語句的基本語法如下:
DROP TABLE table_name;
示例
我們在上一章中建立了 DEPARTMENT 和 COMPANY 表。首先,驗證這些表(使用 **\d** 列出表):
testdb-# \d
這將產生以下結果:
List of relations Schema | Name | Type | Owner --------+------------+-------+---------- public | company | table | postgres public | department | table | postgres (2 rows)
這意味著 DEPARTMENT 和 COMPANY 表存在。所以讓我們刪除它們,如下所示:
testdb=# drop table department, company;
這將產生以下結果:
DROP TABLE testdb=# \d relations found. testdb=#
返回的訊息 DROP TABLE 指示刪除命令已成功執行。
PostgreSQL - 模式
**模式**是表的命名集合。模式還可以包含檢視、索引、序列、資料型別、運算子和函式。模式類似於作業系統級別的目錄,只是模式不能巢狀。PostgreSQL 語句 CREATE SCHEMA 建立一個模式。
語法
CREATE SCHEMA 的基本語法如下:
CREATE SCHEMA name;
其中 *name* 是模式的名稱。
在模式中建立表的語法
在模式中建立表的語法如下:
CREATE TABLE myschema.mytable ( ... );
示例
讓我們來看一個建立模式的例子。連線到資料庫 *testdb* 並建立一個模式 *myschema*,如下所示:
testdb=# create schema myschema; CREATE SCHEMA
訊息“CREATE SCHEMA”表示模式已成功建立。
現在,讓我們在上述模式中建立一個表,如下所示:
testdb=# create table myschema.company( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
這將建立一個空表。您可以使用以下命令驗證建立的表:
testdb=# select * from myschema.company;
這將產生以下結果:
id | name | age | address | salary ----+------+-----+---------+-------- (0 rows)
刪除模式的語法
要刪除空模式(其中的所有物件都已刪除),請使用以下命令:
DROP SCHEMA myschema;
要刪除模式及其包含的所有物件,請使用以下命令:
DROP SCHEMA myschema CASCADE;
使用模式的優點
它允許許多使用者使用一個數據庫而不會相互干擾。
它將資料庫物件組織成邏輯組,使它們更易於管理。
可以將第三方應用程式放入單獨的模式中,這樣它們就不會與其他物件的名稱衝突。
PostgreSQL - INSERT 查詢
PostgreSQL **INSERT INTO** 語句允許使用者將新行插入表中。可以一次插入一行,也可以作為查詢結果插入多行。
語法
INSERT INTO 語句的基本語法如下:
INSERT INTO TABLE_NAME (column1, column2, column3,...columnN) VALUES (value1, value2, value3,...valueN);
這裡,column1, column2,...columnN 是要向其中插入資料的表的列名。
目標列名可以按任何順序列出。VALUES 子句或查詢提供的值是從左到右與顯式或隱式列列表關聯的。
如果要為表的所有列新增值,則可能不需要在 SQL 查詢中指定列名。但是,請確保值的順序與表中的列順序相同。SQL INSERT INTO 語法如下:
INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN);
輸出
下表總結了輸出訊息及其含義:
| 序號 | 輸出訊息和說明 |
|---|---|
| 1 | INSERT oid 1 如果只插入一行,則返回此訊息。oid 是插入行的數字 OID。 |
| 2 | INSERT 0 # 如果插入多行,則返回此訊息。# 是插入的行數。 |
示例
讓我們在 **testdb** 中建立 COMPANY 表,如下所示:
CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL, JOIN_DATE DATE );
以下示例將一行插入 COMPANY 表:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (1, 'Paul', 32, 'California', 20000.00,'2001-07-13');
以下示例是插入一行;這裡省略了 *salary* 列,因此它將具有預設值:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,JOIN_DATE) VALUES (2, 'Allen', 25, 'Texas', '2007-12-13');
以下示例對 JOIN_DATE 列使用 DEFAULT 子句,而不是指定值:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (3, 'Teddy', 23, 'Norway', 20000.00, DEFAULT );
以下示例使用多行 VALUES 語法插入多行:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY,JOIN_DATE) VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00, '2007-12-13' ), (5, 'David', 27, 'Texas', 85000.00, '2007-12-13');
所有上述語句都將在 COMPANY 表中建立以下記錄。下一章將教你如何從表中顯示所有這些記錄。
ID NAME AGE ADDRESS SALARY JOIN_DATE ---- ---------- ----- ---------- ------- -------- 1 Paul 32 California 20000.0 2001-07-13 2 Allen 25 Texas 2007-12-13 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 2007-12-13 5 David 27 Texas 85000.0 2007-12-13
PostgreSQL - SELECT 查詢
PostgreSQL **SELECT** 語句用於從資料庫表中提取資料,它以結果表的形式返回資料。這些結果表稱為結果集。
語法
SELECT 語句的基本語法如下:
SELECT column1, column2, columnN FROM table_name;
這裡,column1, column2...是表的欄位,您想提取其值。如果要提取欄位中所有可用的欄位,則可以使用以下語法:
SELECT * FROM table_name;
示例
考慮表 COMPANY,其記錄如下:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一個示例,它將提取 CUSTOMERS 表中可用的客戶的 ID、Name 和 Salary 欄位:
testdb=# SELECT ID, NAME, SALARY FROM COMPANY ;
這將產生以下結果:
id | name | salary ----+-------+-------- 1 | Paul | 20000 2 | Allen | 15000 3 | Teddy | 20000 4 | Mark | 65000 5 | David | 85000 6 | Kim | 45000 7 | James | 10000 (7 rows)
如果要提取 CUSTOMERS 表的所有欄位,則使用以下查詢:
testdb=# SELECT * FROM COMPANY;
這將產生以下結果:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
PostgreSQL - 運算子
什麼是 PostgreSQL 中的運算子?
運算子是 PostgreSQL 語句中,主要用於 WHERE 子句中執行操作(例如比較和算術運算)的保留字或字元。
運算子用於指定 PostgreSQL 語句中的條件,並作為語句中多個條件的連線詞。
- 算術運算子
- 比較運算子
- 邏輯運算子
- 位運算子
PostgreSQL 算術運算子
假設變數a的值為 2,變數b的值為 3,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| + | 加法 - 將運算子兩側的值相加 | a + b 的結果為 5 |
| - | 減法 - 從左運算元中減去右運算元 | a - b 的結果為 -1 |
| * | 乘法 - 將運算子兩側的值相乘 | a * b 的結果為 6 |
| / | 除法 - 將左運算元除以右運算元 | b / a 的結果為 1 |
| % | 取模 - 將左運算元除以右運算元並返回餘數 | b % a 的結果為 1 |
| ^ | 指數 - 返回右運算元的指數值 | a ^ b 的結果為 8 |
| |/ | 平方根 | |/ 25.0 的結果為 5 |
| ||/ | 立方根 | ||/ 27.0 的結果為 3 |
| ! | 階乘 | 5 ! 的結果為 120 |
| !! | 階乘(字首運算子) | !! 5 的結果為 120 |
PostgreSQL 比較運算子
假設變數 a 的值為 10,變數 b 的值為 20,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| = | 檢查兩個運算元的值是否相等,如果相等則條件為真。 | (a = b) 為假。 |
| != | 檢查兩個運算元的值是否不相等,如果不相等則條件為真。 | (a != b) 為真。 |
| <> | 檢查兩個運算元的值是否不相等,如果不相等則條件為真。 | (a <> b) 為真。 |
| > | 檢查左運算元的值是否大於右運算元的值,如果是則條件為真。 | (a > b) 為假。 |
| < | 檢查左運算元的值是否小於右運算元的值,如果是則條件為真。 | (a < b) 為真。 |
| >= | 檢查左運算元的值是否大於或等於右運算元的值,如果是則條件為真。 | (a >= b) 為假。 |
| <= | 檢查左運算元的值是否小於或等於右運算元的值,如果是則條件為真。 | (a <= b) 為真。 |
PostgreSQL 邏輯運算子
以下是 PostgreSQL 中所有可用邏輯運算子的列表。
| 序號 | 運算子和說明 |
|---|---|
| 1 | AND AND 運算子允許在 PostgreSQL 語句的 WHERE 子句中存在多個條件。 |
| 2 | NOT NOT 運算子反轉與其一起使用的邏輯運算子的含義。例如 NOT EXISTS、NOT BETWEEN、NOT IN 等。這是否定運算子。 |
| 3 | OR OR 運算子用於組合 PostgreSQL 語句 WHERE 子句中的多個條件。 |
PostgreSQL 位串運算子
位運算子對位進行操作,並執行逐位運算。& 和 | 的真值表如下:
| p | q | p & q | p | q |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 0 | 1 |
假設 A = 60;B = 13;現在它們的二進位制格式如下:
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A|B = 0011 1101
~A = 1100 0011
PostgreSQL 支援的位運算子列在下面的表中:
| 運算子 | 描述 | 示例 |
|---|---|---|
| & | 二進位制 AND 運算子如果位同時存在於兩個運算元中,則將其複製到結果中。 | (A & B) 的結果為 12,即 0000 1100 |
| | | 二進位制 OR 運算子如果位存在於任一運算元中,則將其複製。 | (A | B) 的結果為 61,即 0011 1101 |
| ~ | 二進位制反碼運算子是一元運算子,其作用是“反轉”位。 | (~A ) 的結果為 -61,由於是有符號二進位制數,因此其二進位制補碼形式為 1100 0011。 |
| << | 二進位制左移運算子。左運算元的值向左移動由右運算元指定的位數。 | A << 2 的結果為 240,即 1111 0000 |
| >> | 二進位制右移運算子。左運算元的值向右移動由右運算元指定的位數。 | A >> 2 的結果為 15,即 0000 1111 |
| # | 按位異或。 | A # B 的結果為 49,即 00110001 |
PostgreSQL - 表示式
表示式是由一個或多個值、運算子和 PostgreSQL 函式組合而成,並計算出一個值的組合。
PostgreSQL 表示式類似於公式,它們是用查詢語言編寫的。你也可以用它來查詢資料庫中的特定資料集。
語法
考慮 SELECT 語句的基本語法如下:
SELECT column1, column2, columnN FROM table_name WHERE [CONDITION | EXPRESSION];
PostgreSQL 表示式有不同型別,如下所述:
PostgreSQL - 布林表示式
PostgreSQL 布林表示式根據匹配單個值來獲取資料。語法如下:
SELECT column1, column2, columnN FROM table_name WHERE SINGLE VALUE MATCHTING EXPRESSION;
考慮表 COMPANY,其記錄如下:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
這是一個顯示 PostgreSQL 布林表示式用法的簡單示例:
testdb=# SELECT * FROM COMPANY WHERE SALARY = 10000;
上述 PostgreSQL 語句將產生以下結果:
id | name | age | address | salary ----+-------+-----+----------+-------- 7 | James | 24 | Houston | 10000 (1 row)
PostgreSQL - 數值表示式
這些表示式用於在任何查詢中執行任何數學運算。語法如下:
SELECT numerical_expression as OPERATION_NAME [FROM table_name WHERE CONDITION] ;
這裡 numerical_expression 用於數學表示式或任何公式。以下是一個顯示 SQL 數值表示式用法的簡單示例:
testdb=# SELECT (15 + 6) AS ADDITION ;
上述 PostgreSQL 語句將產生以下結果:
addition
----------
21
(1 row)
有一些內建函式,如 avg()、sum()、count(),用於對錶或特定表列執行所謂的聚合資料計算。
testdb=# SELECT COUNT(*) AS "RECORDS" FROM COMPANY;
上述 PostgreSQL 語句將產生以下結果:
RECORDS
---------
7
(1 row)
PostgreSQL - 日期表示式
日期表示式返回當前系統的日期和時間值,這些表示式用於各種資料操作。
testdb=# SELECT CURRENT_TIMESTAMP;
上述 PostgreSQL 語句將產生以下結果:
now ------------------------------- 2013-05-06 14:38:28.078+05:30 (1 row)
PostgreSQL - WHERE 子句
PostgreSQL WHERE 子句用於在從單個表獲取資料或與多個表連線時指定條件。
只有在滿足給定條件時,它才會返回表中的特定值。您可以使用 WHERE 子句過濾掉結果集中不需要包含的行。
WHERE 子句不僅用於 SELECT 語句,還用於 UPDATE、DELETE 語句等,我們將在後續章節中進行檢查。
語法
包含 WHERE 子句的 SELECT 語句的基本語法如下:
SELECT column1, column2, columnN FROM table_name WHERE [search_condition]
您可以使用比較或邏輯運算子(如 >、<、=、LIKE、NOT 等)來指定search_condition。以下示例將使這個概念更清晰。
示例
考慮表 COMPANY,其記錄如下:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一些顯示 PostgreSQL 邏輯運算子用法的簡單示例。以下 SELECT 語句將列出所有 AGE 大於或等於 25 AND 薪水大於或等於 65000.00 的記錄:
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 65000;
上述 PostgreSQL 語句將產生以下結果:
id | name | age | address | salary ----+-------+-----+------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (2 rows)
以下 SELECT 語句列出所有 AGE 大於或等於 25 OR 薪水大於或等於 65000.00 的記錄:
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 OR SALARY >= 65000;
上述 PostgreSQL 語句將產生以下結果:
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (4 rows)
以下 SELECT 語句列出所有 AGE 不為 NULL 的記錄,這意味著所有記錄,因為沒有記錄的 AGE 等於 NULL:
testdb=# SELECT * FROM COMPANY WHERE AGE IS NOT NULL;
上述 PostgreSQL 語句將產生以下結果:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下 SELECT 語句列出所有 NAME 以 'Pa' 開頭的記錄,之後的內容無關緊要。
testdb=# SELECT * FROM COMPANY WHERE NAME LIKE 'Pa%';
上述 PostgreSQL 語句將產生以下結果:
id | name | age |address | salary ----+------+-----+-----------+-------- 1 | Paul | 32 | California| 20000
以下 SELECT 語句列出 AGE 值為 25 或 27 的所有記錄:
testdb=# SELECT * FROM COMPANY WHERE AGE IN ( 25, 27 );
上述 PostgreSQL 語句將產生以下結果:
id | name | age | address | salary ----+-------+-----+------------+-------- 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (3 rows)
以下 SELECT 語句列出 AGE 值既不是 25 也不是 27 的所有記錄:
testdb=# SELECT * FROM COMPANY WHERE AGE NOT IN ( 25, 27 );
上述 PostgreSQL 語句將產生以下結果:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 3 | Teddy | 23 | Norway | 20000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (4 rows)
以下 SELECT 語句列出 AGE 值在 25 和 27 之間的記錄:
testdb=# SELECT * FROM COMPANY WHERE AGE BETWEEN 25 AND 27;
上述 PostgreSQL 語句將產生以下結果:
id | name | age | address | salary ----+-------+-----+------------+-------- 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (3 rows)
以下 SELECT 語句使用 SQL 子查詢,子查詢查詢 AGE 欄位的 SALARY > 65000 的所有記錄,然後 WHERE 子句與 EXISTS 運算子一起使用,列出外部查詢的 AGE 存在於子查詢返回的結果中的所有記錄:
testdb=# SELECT AGE FROM COMPANY
WHERE EXISTS (SELECT AGE FROM COMPANY WHERE SALARY > 65000);
上述 PostgreSQL 語句將產生以下結果:
age ----- 32 25 23 25 27 22 24 (7 rows)
以下 SELECT 語句使用 SQL 子查詢,子查詢查詢 AGE 欄位的 SALARY > 65000 的所有記錄,然後 WHERE 子句與 > 運算子一起使用,列出外部查詢的 AGE 大於子查詢返回的結果中 AGE 的所有記錄:
testdb=# SELECT * FROM COMPANY
WHERE AGE > (SELECT AGE FROM COMPANY WHERE SALARY > 65000);
上述 PostgreSQL 語句將產生以下結果:
id | name | age | address | salary ----+------+-----+------------+-------- 1 | Paul | 32 | California | 20000
AND 和 OR 連線運算子
PostgreSQL 的AND 和OR 運算子用於組合多個條件,以縮小 PostgreSQL 語句中選擇的資料範圍。這兩個運算子稱為連線運算子。
這些運算子提供了一種方法,可以在同一個 PostgreSQL 語句中使用不同的運算子進行多次比較。
AND 運算子
AND 運算子允許在 PostgreSQL 語句的 WHERE 子句中存在多個條件。使用 AND 運算子時,只有當所有條件都為真時,整個條件才被認為是真。例如 [condition1] AND [condition2] 只有在 condition1 和 condition2 都為真時才為真。
語法
帶有 WHERE 子句的 AND 運算子的基本語法如下:
SELECT column1, column2, columnN FROM table_name WHERE [condition1] AND [condition2]...AND [conditionN];
您可以使用 AND 運算子組合 N 個條件。對於 PostgreSQL 語句要執行的操作(無論是事務還是查詢),所有由 AND 分隔的條件都必須為 TRUE。
示例
考慮表 COMPANY,其記錄如下:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下 SELECT 語句列出所有 AGE 大於或等於 25 AND 薪水大於或等於 65000.00 的記錄:
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 65000;
上述 PostgreSQL 語句將產生以下結果:
id | name | age | address | salary ----+-------+-----+------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (2 rows)
OR 運算子
OR 運算子也用於組合 PostgreSQL 語句 WHERE 子句中的多個條件。使用 OR 運算子時,只要任何一個條件為真,整個條件就都被認為是真。例如 [condition1] OR [condition2] 如果 condition1 或 condition2 為真,則為真。
語法
帶有 WHERE 子句的 OR 運算子的基本語法如下:
SELECT column1, column2, columnN FROM table_name WHERE [condition1] OR [condition2]...OR [conditionN]
您可以使用 OR 運算子組合 N 個條件。對於 PostgreSQL 語句要執行的操作(無論是事務還是查詢),只有任何一個由 OR 分隔的條件必須為 TRUE。
示例
考慮COMPANY表,它具有以下記錄:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下 SELECT 語句列出所有 AGE 大於或等於 25 OR 薪水大於或等於 65000.00 的記錄:
testdb=# SELECT * FROM COMPANY WHERE AGE >= 25 OR SALARY >= 65000;
上述 PostgreSQL 語句將產生以下結果:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (4 rows)
PostgreSQL - UPDATE 查詢
PostgreSQL 的UPDATE 查詢用於修改表中現有記錄。您可以將 WHERE 子句與 UPDATE 查詢一起使用以更新選定的行。否則,所有行都將被更新。
語法
帶有 WHERE 子句的 UPDATE 查詢的基本語法如下:
UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition];
您可以使用 AND 或 OR 運算子組合 N 個條件。
示例
考慮表COMPANY,它具有以下記錄:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一個示例,它將更新 ID 為 6 的客戶的 ADDRESS:
testdb=# UPDATE COMPANY SET SALARY = 15000 WHERE ID = 3;
現在,COMPANY 表將具有以下記錄:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 3 | Teddy | 23 | Norway | 15000 (7 rows)
如果要修改COMPANY表中所有ADDRESS和SALARY列的值,則無需使用WHERE子句,UPDATE查詢如下所示:
testdb=# UPDATE COMPANY SET ADDRESS = 'Texas', SALARY=20000;
現在,COMPANY表將包含以下記錄:
id | name | age | address | salary ----+-------+-----+---------+-------- 1 | Paul | 32 | Texas | 20000 2 | Allen | 25 | Texas | 20000 4 | Mark | 25 | Texas | 20000 5 | David | 27 | Texas | 20000 6 | Kim | 22 | Texas | 20000 7 | James | 24 | Texas | 20000 3 | Teddy | 23 | Texas | 20000 (7 rows)
PostgreSQL - DELETE 查詢
PostgreSQL 的DELETE查詢用於刪除表中已存在的記錄。可以使用WHERE子句與DELETE查詢一起刪除選定的行。否則,所有記錄都將被刪除。
語法
帶有WHERE子句的DELETE查詢的基本語法如下:
DELETE FROM table_name WHERE [condition];
您可以使用 AND 或 OR 運算子組合 N 個條件。
示例
考慮表COMPANY,它具有以下記錄:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一個示例,它將刪除ID為7的客戶:
testdb=# DELETE FROM COMPANY WHERE ID = 2;
現在,COMPANY表將包含以下記錄:
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (6 rows)
如果要從COMPANY表中刪除所有記錄,則無需在DELETE查詢中使用WHERE子句,方法如下:
testdb=# DELETE FROM COMPANY;
現在,COMPANY表沒有任何記錄,因為所有記錄都已被DELETE語句刪除。
PostgreSQL - LIKE 子句
PostgreSQL 的LIKE運算子用於使用萬用字元將文字值與模式匹配。如果搜尋表示式可以與模式表示式匹配,則LIKE運算子將返回true,即1。
與LIKE運算子一起使用的兩個萬用字元是:
- 百分號 (%)
- 下劃線 (_)
百分號代表零個、一個或多個數字或字元。下劃線代表單個數字或字元。這些符號可以組合使用。
如果這兩個符號中的任何一個都沒有與LIKE子句一起使用,則LIKE的作用類似於等於運算子。
語法
% 和 _ 的基本語法如下:
SELECT FROM table_name WHERE column LIKE 'XXXX%' or SELECT FROM table_name WHERE column LIKE '%XXXX%' or SELECT FROM table_name WHERE column LIKE 'XXXX_' or SELECT FROM table_name WHERE column LIKE '_XXXX' or SELECT FROM table_name WHERE column LIKE '_XXXX_'
可以使用AND或OR運算子組合N個條件。此處XXXX可以是任何數值或字串值。
示例
以下是一些示例,這些示例顯示了具有不同LIKE子句以及'%'和'_'運算子的WHERE部分:
| 序號 | 語句 & 說明 |
|---|---|
| 1 | WHERE SALARY::text LIKE '200%' 查詢以200開頭的任何值 |
| 2 | WHERE SALARY::text LIKE '%200%' 查詢任何位置包含200的任何值 |
| 3 | WHERE SALARY::text LIKE '_00%' 查詢在第二位和第三位具有00的任何值 |
| 4 | WHERE SALARY::text LIKE '2_%_%' 查詢以2開頭且至少3個字元長的任何值 |
| 5 | WHERE SALARY::text LIKE '%2' 查詢以2結尾的任何值 |
| 6 | WHERE SALARY::text LIKE '_2%3' 查詢第二位為2且以3結尾的任何值 |
| 7 | WHERE SALARY::text LIKE '2___3' 查詢五位數中以2開頭並以3結尾的任何值 |
Postgres LIKE 僅進行字串比較。因此,我們需要像上面的示例一樣顯式地將整數列轉換為字串。
讓我們來看一個真實的例子,考慮表COMPANY,其記錄如下:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一個示例,它將顯示COMPANY表中AGE以2開頭的所有記錄:
testdb=# SELECT * FROM COMPANY WHERE AGE::text LIKE '2%';
這將產生以下結果:
id | name | age | address | salary ----+-------+-----+-------------+-------- 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 (7 rows)
以下是一個示例,它將顯示COMPANY表中ADDRESS文字內包含連字元(-)的所有記錄:
testdb=# SELECT * FROM COMPANY WHERE ADDRESS LIKE '%-%';
這將產生以下結果:
id | name | age | address | salary ----+------+-----+-------------------------------------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 (2 rows)
PostgreSQL - LIMIT 子句
PostgreSQL 的LIMIT子句用於限制SELECT語句返回的資料量。
語法
帶有LIMIT子句的SELECT語句的基本語法如下:
SELECT column1, column2, columnN FROM table_name LIMIT [no of rows]
當LIMIT子句與OFFSET子句一起使用時的語法如下:
SELECT column1, column2, columnN FROM table_name LIMIT [no of rows] OFFSET [row num]
LIMIT和OFFSET允許您僅檢索由查詢其餘部分生成的行的部分。
示例
考慮表 COMPANY,其記錄如下:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一個示例,它根據要從表中提取的行數限制表中的行:
testdb=# SELECT * FROM COMPANY LIMIT 4;
這將產生以下結果:
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 (4 rows)
但是,在某些情況下,您可能需要從特定偏移量處提取一組記錄。這是一個示例,它從第三個位置開始提取三條記錄:
testdb=# SELECT * FROM COMPANY LIMIT 3 OFFSET 2;
這將產生以下結果:
id | name | age | address | salary ----+-------+-----+-----------+-------- 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (3 rows)
PostgreSQL - ORDER BY 子句
PostgreSQL 的ORDER BY子句用於根據一個或多個列對資料進行升序或降序排序。
語法
ORDER BY子句的基本語法如下:
SELECT column-list FROM table_name [WHERE condition] [ORDER BY column1, column2, .. columnN] [ASC | DESC];
可以在ORDER BY子句中使用多個列。確保用於排序的任何列都應在列列表中可用。
示例
考慮表 COMPANY,其記錄如下:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一個示例,它將根據SALARY按升序排序結果:
testdb=# SELECT * FROM COMPANY ORDER BY AGE ASC;
這將產生以下結果:
id | name | age | address | salary ----+-------+-----+------------+-------- 6 | Kim | 22 | South-Hall | 45000 3 | Teddy | 23 | Norway | 20000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 4 | Mark | 25 | Rich-Mond | 65000 2 | Allen | 25 | Texas | 15000 5 | David | 27 | Texas | 85000 1 | Paul | 32 | California | 20000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 (10 rows)
以下是一個示例,它將根據NAME和SALARY按升序排序結果:
testdb=# SELECT * FROM COMPANY ORDER BY NAME, SALARY ASC;
這將產生以下結果:
id | name | age | address | salary ----+-------+-----+--------------+-------- 2 | Allen | 25 | Texas | 15000 5 | David | 27 | Texas | 85000 10 | James | 45 | Texas | 5000 9 | James | 44 | Norway | 5000 7 | James | 24 | Houston | 10000 6 | Kim | 22 | South-Hall | 45000 4 | Mark | 25 | Rich-Mond | 65000 1 | Paul | 32 | California | 20000 8 | Paul | 24 | Houston | 20000 3 | Teddy | 23 | Norway | 20000 (10 rows)
以下是一個示例,它將根據NAME按降序排序結果:
testdb=# SELECT * FROM COMPANY ORDER BY NAME DESC;
這將產生以下結果:
id | name | age | address | salary ----+-------+-----+------------+-------- 3 | Teddy | 23 | Norway | 20000 1 | Paul | 32 | California | 20000 8 | Paul | 24 | Houston | 20000 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 5 | David | 27 | Texas | 85000 2 | Allen | 25 | Texas | 15000 (10 rows)
PostgreSQL - GROUP BY
PostgreSQL 的GROUP BY子句與SELECT語句一起使用,用於將表中具有相同資料的那些行組合在一起。這樣做是為了消除輸出中的冗餘和/或計算應用於這些組的聚合。
GROUP BY子句位於SELECT語句中的WHERE子句之後,位於ORDER BY子句之前。
語法
GROUP BY子句的基本語法如下所示。GROUP BY子句必須位於WHERE子句中的條件之後,如果使用了ORDER BY子句,則必須位於ORDER BY子句之前。
SELECT column-list FROM table_name WHERE [ conditions ] GROUP BY column1, column2....columnN ORDER BY column1, column2....columnN
可以在GROUP BY子句中使用多個列。確保用於分組的任何列都應在列列表中可用。
示例
考慮表 COMPANY,其記錄如下:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
如果要了解每個客戶的工資總額,則GROUP BY查詢如下所示:
testdb=# SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME;
這將產生以下結果:
name | sum -------+------- Teddy | 20000 Paul | 20000 Mark | 65000 David | 85000 Allen | 15000 Kim | 45000 James | 10000 (7 rows)
現在,讓我們使用以下INSERT語句在COMPANY表中建立三個更多記錄:
INSERT INTO COMPANY VALUES (8, 'Paul', 24, 'Houston', 20000.00); INSERT INTO COMPANY VALUES (9, 'James', 44, 'Norway', 5000.00); INSERT INTO COMPANY VALUES (10, 'James', 45, 'Texas', 5000.00);
現在,我們的表具有以下具有重複名稱的記錄:
id | name | age | address | salary ----+-------+-----+--------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 (10 rows)
再次,讓我們使用相同的語句按NAME列對所有記錄進行分組,如下所示:
testdb=# SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME ORDER BY NAME;
這將產生以下結果:
name | sum -------+------- Allen | 15000 David | 85000 James | 20000 Kim | 45000 Mark | 65000 Paul | 40000 Teddy | 20000 (7 rows)
讓我們將ORDER BY子句與GROUP BY子句一起使用,如下所示:
testdb=# SELECT NAME, SUM(SALARY)
FROM COMPANY GROUP BY NAME ORDER BY NAME DESC;
這將產生以下結果:
name | sum -------+------- Teddy | 20000 Paul | 40000 Mark | 65000 Kim | 45000 James | 20000 David | 85000 Allen | 15000 (7 rows)
PostgreSQL - WITH 子句
在PostgreSQL中,WITH查詢提供了一種編寫輔助語句以用於更大查詢的方法。它有助於將複雜的大型查詢分解成更簡單的形式,這些形式更易於閱讀。這些語句通常稱為公用表表達式或CTE,可以認為是僅為一個查詢存在的臨時表的定義。
WITH查詢作為CTE查詢,在子查詢多次執行時特別有用。它在臨時表中同樣有用。它只計算一次聚合,並允許我們在查詢中透過其名稱(可能多次)引用它。
WITH子句必須在查詢中使用之前定義。
語法
WITH查詢的基本語法如下:
WITH
name_for_summary_data AS (
SELECT Statement)
SELECT columns
FROM name_for_summary_data
WHERE conditions <=> (
SELECT column
FROM name_for_summary_data)
[ORDER BY columns]
其中name_for_summary_data是賦予WITH子句的名稱。name_for_summary_data可以與現有的表名相同,並且將優先使用。
可以在WITH中使用資料修改語句(INSERT、UPDATE或DELETE)。這允許您在同一個查詢中執行多個不同的操作。
遞迴WITH
遞迴WITH或分層查詢是一種CTE的形式,其中CTE可以引用自身,即WITH查詢可以引用其自身的輸出,因此稱為遞迴。示例
考慮表 COMPANY,其記錄如下:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
現在,讓我們使用WITH子句編寫一個查詢來從上表中選擇記錄,如下所示:
With CTE AS (Select ID , NAME , AGE , ADDRESS , SALARY FROM COMPANY ) Select * From CTE;
上述 PostgreSQL 語句將產生以下結果:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
現在,讓我們使用RECURSIVE關鍵字以及WITH子句編寫一個查詢,以查詢小於20000的工資總和,如下所示:
WITH RECURSIVE t(n) AS ( VALUES (0) UNION ALL SELECT SALARY FROM COMPANY WHERE SALARY < 20000 ) SELECT sum(n) FROM t;
上述 PostgreSQL 語句將產生以下結果:
sum ------- 25000 (1 row)
讓我們使用資料修改語句以及WITH子句編寫一個查詢,如下所示。
首先,建立一個與COMPANY表類似的COMPANY1表。示例中的查詢有效地將行從COMPANY移動到COMPANY1。WITH中的DELETE刪除COMPANY中指定的行,透過其RETURNING子句返回其內容;然後主查詢讀取該輸出並將其插入到COMPANY1表中:
CREATE TABLE COMPANY1(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
WITH moved_rows AS (
DELETE FROM COMPANY
WHERE
SALARY >= 30000
RETURNING *
)
INSERT INTO COMPANY1 (SELECT * FROM moved_rows);
上述 PostgreSQL 語句將產生以下結果:
INSERT 0 3
現在,COMPANY和COMPANY1表中的記錄如下:
testdb=# SELECT * FROM COMPANY; id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 7 | James | 24 | Houston | 10000 (4 rows) testdb=# SELECT * FROM COMPANY1; id | name | age | address | salary ----+-------+-----+-------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 (3 rows)
PostgreSQL - HAVING 子句
HAVING子句允許我們挑選出函式結果滿足某些條件的特定行。
WHERE子句對選定的列設定條件,而HAVING子句對GROUP BY子句建立的組設定條件。
語法
HAVING子句在SELECT查詢中的位置如下:
SELECT FROM WHERE GROUP BY HAVING ORDER BY
HAVING子句必須位於查詢中的GROUP BY子句之後,如果使用了ORDER BY子句,則也必須位於ORDER BY子句之前。以下是包含HAVING子句的SELECT語句的語法:
SELECT column1, column2 FROM table1, table2 WHERE [ conditions ] GROUP BY column1, column2 HAVING [ conditions ] ORDER BY column1, column2
示例
考慮表 COMPANY,其記錄如下:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是一個示例,它將顯示名稱計數小於2的記錄:
testdb-# SELECT NAME FROM COMPANY GROUP BY name HAVING count(name) < 2;
這將產生以下結果:
name ------- Teddy Paul Mark David Allen Kim James (7 rows)
現在,讓我們使用以下INSERT語句在COMPANY表中建立三個更多記錄:
INSERT INTO COMPANY VALUES (8, 'Paul', 24, 'Houston', 20000.00); INSERT INTO COMPANY VALUES (9, 'James', 44, 'Norway', 5000.00); INSERT INTO COMPANY VALUES (10, 'James', 45, 'Texas', 5000.00);
現在,我們的表具有以下具有重複名稱的記錄:
id | name | age | address | salary ----+-------+-----+--------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 24 | Houston | 20000 9 | James | 44 | Norway | 5000 10 | James | 45 | Texas | 5000 (10 rows)
以下是一個示例,它將顯示名稱計數大於1的記錄:
testdb-# SELECT NAME FROM COMPANY GROUP BY name HAVING count(name) > 1;
這將產生以下結果:
name ------- Paul James (2 rows)
PostgreSQL - DISTINCT 關鍵字
PostgreSQL 的DISTINCT關鍵字與SELECT語句一起使用,以消除所有重複記錄並僅獲取唯一記錄。
表中可能存在多個重複記錄的情況。在獲取此類記錄時,獲取唯一記錄比獲取重複記錄更有意義。
語法
消除重複記錄的DISTINCT關鍵字的基本語法如下:
SELECT DISTINCT column1, column2,.....columnN FROM table_name WHERE [condition]
示例
考慮表 COMPANY,其記錄如下:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
讓我們向此表新增兩條更多記錄,如下所示:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (8, 'Paul', 32, 'California', 20000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (9, 'Allen', 25, 'Texas', 15000.00 );
現在,COMPANY表中的記錄將是:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 32 | California | 20000 9 | Allen | 25 | Texas | 15000 (9 rows)
首先,讓我們看看以下SELECT查詢如何返回重複的工資記錄:
testdb=# SELECT name FROM COMPANY;
這將產生以下結果:
name ------- Paul Allen Teddy Mark David Kim James Paul Allen (9 rows)
現在,讓我們在上面的SELECT查詢中使用DISTINCT關鍵字並檢視結果:
testdb=# SELECT DISTINCT name FROM COMPANY;
這將產生以下結果,其中我們沒有任何重複條目:
name ------- Teddy Paul Mark David Allen Kim James (7 rows)
PostgreSQL - 約束
約束是表上資料列上強制執行的規則。這些用於防止將無效資料輸入到資料庫中。這確保了資料庫中資料的準確性和可靠性。
約束可以是列級或表級。列級約束僅應用於一列,而表級約束應用於整個表。為列定義資料型別本身就是一個約束。例如,型別為DATE的列將列約束為有效日期。
以下是PostgreSQL中常用的約束。
NOT NULL 約束 - 確保列不能具有NULL值。
UNIQUE 約束 - 確保列中的所有值都不同。
主鍵 - 唯一標識資料庫表中的每一行/記錄。
外部索引鍵 - 基於其他表中的列約束資料。
CHECK 約束 - CHECK約束確保列中的所有值都滿足某些條件。
排他約束 (EXCLUSION Constraint) − 排他約束確保,如果使用指定的運算子比較指定列或表示式上的任意兩行,則並非所有這些比較都將返回 TRUE。
非空約束 (NOT NULL Constraint)
預設情況下,列可以儲存 NULL 值。如果您不希望列具有 NULL 值,則需要在此列上定義此約束,指定該列不允許 NULL 值。NOT NULL 約束始終被寫為列約束。
NULL 不等於無資料;相反,它表示未知資料。
示例
例如,以下 PostgreSQL 語句建立一個名為 COMPANY1 的新表,並新增五列,其中三列 ID、NAME 和 AGE 指定不接受 NULL 值 −
CREATE TABLE COMPANY1( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
唯一約束 (UNIQUE Constraint)
唯一約束防止兩條記錄在特定列中具有相同的值。例如,在 COMPANY 表中,您可能希望防止兩個或更多人具有相同的年齡。
示例
例如,以下 PostgreSQL 語句建立一個名為 COMPANY3 的新表,並新增五列。這裡,AGE 列設定為 UNIQUE,因此您不能有兩條具有相同年齡的記錄 −
CREATE TABLE COMPANY3( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL UNIQUE, ADDRESS CHAR(50), SALARY REAL DEFAULT 50000.00 );
主鍵約束 (PRIMARY KEY Constraint)
主鍵約束唯一標識資料庫表中的每條記錄。可以有多個 UNIQUE 列,但表中只有一個主鍵。設計資料庫表時,主鍵非常重要。主鍵是唯一的 ID。
我們使用它們來引用錶行。在建立表之間的關係時,主鍵成為其他表中的外部索引鍵。由於“長期存在的編碼疏忽”,主鍵可以在 SQLite 中為 NULL。其他資料庫並非如此。
主鍵是表中的一個欄位,它唯一標識資料庫表中的每一行/記錄。主鍵必須包含唯一值。主鍵列不能具有 NULL 值。
一個表只能有一個主鍵,它可以由單個或多個欄位組成。當多個欄位用作主鍵時,它們被稱為組合鍵 (composite key)。
如果表在任何欄位上定義了主鍵,則您不能有兩條記錄具有該欄位的相同值。
示例
您已經在上面的各種示例中看到了我們使用 ID 作為主鍵建立 COMAPNY4 表的情況 −
CREATE TABLE COMPANY4( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
外部索引鍵約束 (FOREIGN KEY Constraint)
外部索引鍵約束指定列(或一組列)中的值必須與另一個表某一行的值匹配。我們說這保持了兩個相關表之間的參照完整性。它們被稱為外部索引鍵,因為約束是外部的;也就是說,在表之外。外部索引鍵有時也稱為引用鍵。
示例
例如,以下 PostgreSQL 語句建立一個名為 COMPANY5 的新表,並新增五列。
CREATE TABLE COMPANY6( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
例如,以下 PostgreSQL 語句建立一個名為 DEPARTMENT1 的新表,並新增三列。EMP_ID 列是外部索引鍵,並引用 COMPANY6 表的 ID 欄位。
CREATE TABLE DEPARTMENT1( ID INT PRIMARY KEY NOT NULL, DEPT CHAR(50) NOT NULL, EMP_ID INT references COMPANY6(ID) );
檢查約束 (CHECK Constraint)
檢查約束允許使用條件來檢查輸入記錄的值。如果條件計算結果為 false,則記錄違反約束,不會被輸入到表中。
示例
例如,以下 PostgreSQL 語句建立一個名為 COMPANY5 的新表,並新增五列。這裡,我們使用 SALARY 列新增一個 CHECK,這樣您就不能有任何 SALARY 為零。
CREATE TABLE COMPANY5( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL CHECK(SALARY > 0) );
排他約束 (EXCLUSION Constraint)
排他約束確保,如果使用指定的運算子比較指定列或表示式上的任意兩行,則這些運算子比較中至少有一個將返回 false 或 null。
示例
例如,以下 PostgreSQL 語句建立一個名為 COMPANY7 的新表,並新增五列。這裡,我們添加了一個 EXCLUDE 約束 −
CREATE TABLE COMPANY7( ID INT PRIMARY KEY NOT NULL, NAME TEXT, AGE INT , ADDRESS CHAR(50), SALARY REAL, EXCLUDE USING gist (NAME WITH =, AGE WITH <>) );
這裡,USING gist 是要構建和用於強制執行的索引型別。
您需要每個資料庫執行一次命令 CREATE EXTENSION btree_gist。這將安裝 btree_gist 擴充套件,該擴充套件在普通標量資料型別上定義排他約束。
由於我們強制執行年齡必須相同,讓我們透過將記錄插入表中來看一下 −
INSERT INTO COMPANY7 VALUES(1, 'Paul', 32, 'California', 20000.00 ); INSERT INTO COMPANY7 VALUES(2, 'Paul', 32, 'Texas', 20000.00 ); INSERT INTO COMPANY7 VALUES(3, 'Paul', 42, 'California', 20000.00 );
對於前兩個 INSERT 語句,記錄被新增到 COMPANY7 表中。對於第三個 INSERT 語句,將顯示以下錯誤 −
ERROR: conflicting key value violates exclusion constraint "company7_name_age_excl" DETAIL: Key (name, age)=(Paul, 42) conflicts with existing key (name, age)=(Paul, 32).
刪除約束 (Dropping Constraints)
要刪除約束,您需要知道它的名稱。如果知道名稱,則很容易刪除。否則,您需要找出系統生成的名稱。psql 命令 \d 表名在這裡可能會有所幫助。通用語法如下 −
ALTER TABLE table_name DROP CONSTRAINT some_name;
PostgreSQL - 連線 (JOINS)
PostgreSQL 的連線 (Joins) 子句用於組合資料庫中兩個或多個表中的記錄。連線是一種透過使用每個表共有的值來組合兩個表中的欄位的方法。
PostgreSQL 中的連線型別如下 −
- 交叉連線 (CROSS JOIN)
- 內部連線 (INNER JOIN)
- 左外部連線 (LEFT OUTER JOIN)
- 右外部連線 (RIGHT OUTER JOIN)
- 全外部連線 (FULL OUTER JOIN)
在我們繼續之前,讓我們考慮兩個表,COMPANY 和 DEPARTMENT。我們已經看到用於填充 COMPANY 表的 INSERT 語句。所以讓我們假設 COMPANY 表中存在以下記錄 −
id | name | age | address | salary | join_date ----+-------+-----+-----------+--------+----------- 1 | Paul | 32 | California| 20000 | 2001-07-13 3 | Teddy | 23 | Norway | 20000 | 4 | Mark | 25 | Rich-Mond | 65000 | 2007-12-13 5 | David | 27 | Texas | 85000 | 2007-12-13 2 | Allen | 25 | Texas | | 2007-12-13 8 | Paul | 24 | Houston | 20000 | 2005-07-13 9 | James | 44 | Norway | 5000 | 2005-07-13 10 | James | 45 | Texas | 5000 | 2005-07-13
另一個表是 DEPARTMENT,具有以下定義 −
CREATE TABLE DEPARTMENT( ID INT PRIMARY KEY NOT NULL, DEPT CHAR(50) NOT NULL, EMP_ID INT NOT NULL );
以下是用於填充 DEPARTMENT 表的 INSERT 語句列表 −
INSERT INTO DEPARTMENT (ID, DEPT, EMP_ID) VALUES (1, 'IT Billing', 1 ); INSERT INTO DEPARTMENT (ID, DEPT, EMP_ID) VALUES (2, 'Engineering', 2 ); INSERT INTO DEPARTMENT (ID, DEPT, EMP_ID) VALUES (3, 'Finance', 7 );
最後,DEPARTMENT 表中存在以下記錄列表 −
id | dept | emp_id ----+-------------+-------- 1 | IT Billing | 1 2 | Engineering | 2 3 | Finance | 7
交叉連線 (CROSS JOIN)
交叉連線將第一個表的每一行與第二個表的每一行匹配。如果輸入表分別具有 x 和 y 列,則結果表將具有 x+y 列。由於 CROSS JOIN 有可能生成非常大的表,因此必須注意僅在適當的時候使用它們。
以下是 CROSS JOIN 的語法 −
SELECT ... FROM table1 CROSS JOIN table2 ...
基於上述表格,我們可以編寫一個 CROSS JOIN 如下 −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY CROSS JOIN DEPARTMENT;
上述查詢將產生以下結果 −
emp_id| name | dept
------|-------|--------------
1 | Paul | IT Billing
1 | Teddy | IT Billing
1 | Mark | IT Billing
1 | David | IT Billing
1 | Allen | IT Billing
1 | Paul | IT Billing
1 | James | IT Billing
1 | James | IT Billing
2 | Paul | Engineering
2 | Teddy | Engineering
2 | Mark | Engineering
2 | David | Engineering
2 | Allen | Engineering
2 | Paul | Engineering
2 | James | Engineering
2 | James | Engineering
7 | Paul | Finance
7 | Teddy | Finance
7 | Mark | Finance
7 | David | Finance
7 | Allen | Finance
7 | Paul | Finance
7 | James | Finance
7 | James | Finance
內部連線 (INNER JOIN)
內部連線透過基於連線謂詞組合兩個表(table1 和 table2)的列值來建立一個新的結果表。查詢比較 table1 的每一行與 table2 的每一行,以查詢滿足連線謂詞的所有行對。當滿足連線謂詞時,table1 和 table2 的每一對匹配行的列值將組合到結果行中。
內部連線是最常見的連線型別,也是預設的連線型別。您可以選擇使用 INNER 關鍵字。
以下是 INNER JOIN 的語法 −
SELECT table1.column1, table2.column2... FROM table1 INNER JOIN table2 ON table1.common_filed = table2.common_field;
基於上述表格,我們可以編寫一個 INNER JOIN 如下 −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID;
上述查詢將產生以下結果 −
emp_id | name | dept
--------+-------+------------
1 | Paul | IT Billing
2 | Allen | Engineering
左外部連線 (LEFT OUTER JOIN)
外部連線是內部連線的擴充套件。SQL 標準定義了三種類型的外部連線:LEFT、RIGHT 和 FULL,PostgreSQL 支援所有這些型別。
對於左外部連線,首先執行內部連線。然後,對於 T1 中不滿足與 T2 中任何行連線條件的每一行,將新增一個連線行,其中 T2 的列中包含 null 值。因此,連線表始終至少包含 T1 中每一行的一行。
以下是 LEFT OUTER JOIN 的語法 −
SELECT ... FROM table1 LEFT OUTER JOIN table2 ON conditional_expression ...
基於上述表格,我們可以編寫一個內部連線如下 −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID;
上述查詢將產生以下結果 −
emp_id | name | dept
--------+-------+------------
1 | Paul | IT Billing
2 | Allen | Engineering
| James |
| David |
| Paul |
| Mark |
| Teddy |
| James |
右外部連線 (RIGHT OUTER JOIN)
首先,執行內部連線。然後,對於 T2 中不滿足與 T1 中任何行連線條件的每一行,將新增一個連線行,其中 T1 的列中包含 null 值。這是左連線的反向;結果表將始終包含 T2 中每一行的一行。
以下是 RIGHT OUTER JOIN 的語法 −
SELECT ... FROM table1 RIGHT OUTER JOIN table2 ON conditional_expression ...
基於上述表格,我們可以編寫一個內部連線如下 −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY RIGHT OUTER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID;
上述查詢將產生以下結果 −
emp_id | name | dept
--------+-------+--------
1 | Paul | IT Billing
2 | Allen | Engineering
7 | | Finance
全外部連線 (FULL OUTER JOIN)
首先,執行內部連線。然後,對於 T1 中不滿足與 T2 中任何行連線條件的每一行,將新增一個連線行,其中 T2 的列中包含 null 值。此外,對於 T2 中不滿足與 T1 中任何行連線條件的每一行,將新增一個在 T1 的列中包含 null 值的連線行。
以下是 FULL OUTER JOIN 的語法 −
SELECT ... FROM table1 FULL OUTER JOIN table2 ON conditional_expression ...
基於上述表格,我們可以編寫一個內部連線如下 −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY FULL OUTER JOIN DEPARTMENT ON COMPANY.ID = DEPARTMENT.EMP_ID;
上述查詢將產生以下結果 −
emp_id | name | dept
--------+-------+---------------
1 | Paul | IT Billing
2 | Allen | Engineering
7 | | Finance
| James |
| David |
| Paul |
| Mark |
| Teddy |
| James |
PostgreSQL - UNION 子句
PostgreSQL 的UNION 子句/運算子用於組合兩個或多個 SELECT 語句的結果,而不返回任何重複的行。
要使用 UNION,每個 SELECT 必須選擇相同數量的列,具有相同數量的列表達式,相同的資料型別,並且順序相同,但長度不必相同。
語法
UNION 的基本語法如下 −
SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition] UNION SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition]
這裡,給定的條件可以是基於您需求的任何給定表示式。
示例
考慮以下兩個表,(a) COMPANY 表如下 −
testdb=# SELECT * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
(b) 另一個表是 DEPARTMENT 表,如下所示 −
testdb=# SELECT * from DEPARTMENT; id | dept | emp_id ----+-------------+-------- 1 | IT Billing | 1 2 | Engineering | 2 3 | Finance | 7 4 | Engineering | 3 5 | Finance | 4 6 | Engineering | 5 7 | Finance | 6 (7 rows)
現在讓我們使用 SELECT 語句以及 UNION 子句將這兩個表連線起來,如下所示 −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID
UNION
SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID;
這將產生以下結果:
emp_id | name | dept
--------+-------+--------------
5 | David | Engineering
6 | Kim | Finance
2 | Allen | Engineering
3 | Teddy | Engineering
4 | Mark | Finance
1 | Paul | IT Billing
7 | James | Finance
(7 rows)
UNION ALL 子句
UNION ALL 運算子用於組合兩個 SELECT 語句的結果,包括重複的行。適用於 UNION 的相同規則也適用於 UNION ALL 運算子。
語法
UNION ALL 的基本語法如下 −
SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition] UNION ALL SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition]
這裡,給定的條件可以是基於您需求的任何給定表示式。
示例
現在,讓我們在 SELECT 語句中連線上述兩個表,如下所示 −
testdb=# SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID
UNION ALL
SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID;
這將產生以下結果:
emp_id | name | dept
--------+-------+--------------
1 | Paul | IT Billing
2 | Allen | Engineering
7 | James | Finance
3 | Teddy | Engineering
4 | Mark | Finance
5 | David | Engineering
6 | Kim | Finance
1 | Paul | IT Billing
2 | Allen | Engineering
7 | James | Finance
3 | Teddy | Engineering
4 | Mark | Finance
5 | David | Engineering
6 | Kim | Finance
(14 rows)
PostgreSQL - NULL 值
PostgreSQL 中的NULL 用於表示缺失值。表中的 NULL 值是欄位中看起來為空的值。
具有 NULL 值的欄位是沒有值的欄位。理解 NULL 值不同於零值或包含空格的欄位非常重要。
語法
在建立表時使用NULL 的基本語法如下 −
CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
這裡,NOT NULL 表示列應始終接受給定資料型別的顯式值。有兩列我們沒有使用 NOT NULL。因此,這意味著這些列可以為 NULL。
具有 NULL 值的欄位是在記錄建立期間留空的一個欄位。
示例
選擇資料時,NULL 值可能會導致問題,因為當將未知值與任何其他值進行比較時,結果始終是未知的,並且不包含在最終結果中。考慮以下表,COMPANY 表包含以下記錄 −
ID NAME AGE ADDRESS SALARY ---------- ---------- ---------- ---------- ---------- 1 Paul 32 California 20000.0 2 Allen 25 Texas 15000.0 3 Teddy 23 Norway 20000.0 4 Mark 25 Rich-Mond 65000.0 5 David 27 Texas 85000.0 6 Kim 22 South-Hall 45000.0 7 James 24 Houston 10000.0
讓我們使用 UPDATE 語句將一些可為空的值設定為 NULL,如下所示 −
testdb=# UPDATE COMPANY SET ADDRESS = NULL, SALARY = NULL where ID IN(6,7);
現在,COMPANY 表應該包含以下記錄 −
id | name | age | address | salary ----+-------+-----+-------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | | 7 | James | 24 | | (7 rows)
接下來,讓我們看看IS NOT NULL 運算子的使用,以列出 SALARY 不為 NULL 的所有記錄 −
testdb=# SELECT ID, NAME, AGE, ADDRESS, SALARY FROM COMPANY WHERE SALARY IS NOT NULL;
上述 PostgreSQL 語句將產生以下結果:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (5 rows)
以下是IS NULL 運算子的使用,它將列出 SALARY 為 NULL 的所有記錄 −
testdb=# SELECT ID, NAME, AGE, ADDRESS, SALARY
FROM COMPANY
WHERE SALARY IS NULL;
上述 PostgreSQL 語句將產生以下結果:
id | name | age | address | salary ----+-------+-----+---------+-------- 6 | Kim | 22 | | 7 | James | 24 | | (2 rows)
PostgreSQL - 別名語法 (ALIAS Syntax)
您可以透過賦予另一個名稱來臨時重命名錶或列,這稱為別名 (ALIAS)。使用表別名意味著在特定的 PostgreSQL 語句中重命名錶。重新命名是臨時的更改,實際的表名不會在資料庫中更改。
列別名用於為了特定 PostgreSQL 查詢的目的而重命名錶的列。
語法
表 (table) 別名的基本語法如下 −
SELECT column1, column2.... FROM table_name AS alias_name WHERE [condition];
列 (column) 別名的基本語法如下 −
SELECT column_name AS alias_name FROM table_name WHERE [condition];
示例
考慮以下兩個表,(a) COMPANY 表如下 −
testdb=# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
(b) 另一個表是 DEPARTMENT 表,如下所示 −
id | dept | emp_id ----+--------------+-------- 1 | IT Billing | 1 2 | Engineering | 2 3 | Finance | 7 4 | Engineering | 3 5 | Finance | 4 6 | Engineering | 5 7 | Finance | 6 (7 rows)
現在,以下是表別名 (TABLE ALIAS) 的用法,我們分別使用 C 和 D 作為 COMPANY 和 DEPARTMENT 表的別名 −
testdb=# SELECT C.ID, C.NAME, C.AGE, D.DEPT FROM COMPANY AS C, DEPARTMENT AS D WHERE C.ID = D.EMP_ID;
上述 PostgreSQL 語句將產生以下結果:
id | name | age | dept ----+-------+-----+------------ 1 | Paul | 32 | IT Billing 2 | Allen | 25 | Engineering 7 | James | 24 | Finance 3 | Teddy | 23 | Engineering 4 | Mark | 25 | Finance 5 | David | 27 | Engineering 6 | Kim | 22 | Finance (7 rows)
讓我們看看列別名 (COLUMN ALIAS) 的用法示例,其中 COMPANY_ID 是 ID 列的別名,COMPANY_NAME 是 name 列的別名 −
testdb=# SELECT C.ID AS COMPANY_ID, C.NAME AS COMPANY_NAME, C.AGE, D.DEPT FROM COMPANY AS C, DEPARTMENT AS D WHERE C.ID = D.EMP_ID;
上述 PostgreSQL 語句將產生以下結果:
company_id | company_name | age | dept
------------+--------------+-----+------------
1 | Paul | 32 | IT Billing
2 | Allen | 25 | Engineering
7 | James | 24 | Finance
3 | Teddy | 23 | Engineering
4 | Mark | 25 | Finance
5 | David | 27 | Engineering
6 | Kim | 22 | Finance
(7 rows)
PostgreSQL - 觸發器 (TRIGGERS)
PostgreSQL 的觸發器 (Triggers) 是資料庫回撥函式,當發生指定的資料庫事件時,它們會自動執行/呼叫。
以下是關於 PostgreSQL 觸發器的重要幾點 −
可以指定 PostgreSQL 觸發器來觸發
在對行進行操作之前(在檢查約束並嘗試 INSERT、UPDATE 或 DELETE 之前)
操作完成後(在檢查約束並完成 INSERT、UPDATE 或 DELETE 之後)
代替操作(在檢視上進行插入、更新或刪除的情況下)
標記為 FOR EACH ROW 的觸發器會為操作修改的每一行呼叫一次。相反,標記為 FOR EACH STATEMENT 的觸發器對於任何給定操作只執行一次,無論它修改多少行。
WHEN 子句和觸發器動作都可以使用 NEW.column-name 和 OLD.column-name 形式的引用訪問正在插入、刪除或更新的行元素,其中 column-name 是觸發器關聯的表的列名。
如果提供了 WHEN 子句,則只有當 WHEN 子句為真時,才會執行指定的 PostgreSQL 語句。如果沒有提供 WHEN 子句,則會對所有行執行 PostgreSQL 語句。
如果為同一事件定義了多個相同型別的觸發器,則它們將按名稱的字母順序觸發。
BEFORE、AFTER 或 INSTEAD OF 關鍵字決定觸發器動作相對於關聯行的插入、修改或刪除的執行時間。
當與觸發器關聯的表被刪除時,觸發器會自動刪除。
要修改的表必須與附加觸發器的表或檢視位於同一資料庫中,並且必須只使用 tablename,而不是 database.tablename。
指定 CONSTRAINT 選項時,會建立一個 *約束觸發器*。這與常規觸發器相同,只是可以使用 SET CONSTRAINTS 調整觸發器觸發的時機。當約束觸發器實現的約束被違反時,預計會引發異常。
語法
建立觸發器的基本語法如下:
CREATE TRIGGER trigger_name [BEFORE|AFTER|INSTEAD OF] event_name ON table_name [ -- Trigger logic goes here.... ];
這裡,event_name 可以是提到的表 table_name 上的 *INSERT、DELETE、UPDATE* 和 *TRUNCATE* 資料庫操作。您可以在表名之後選擇性地指定 FOR EACH ROW。
以下是建立在表的指定的列之一或多列上進行 UPDATE 操作的觸發器的語法:
CREATE TRIGGER trigger_name [BEFORE|AFTER] UPDATE OF column_name ON table_name [ -- Trigger logic goes here.... ];
示例
讓我們考慮一個案例,我們想要為 COMPANY 表中插入的每條記錄保留審計跟蹤,我們將新建該表如下(如果您已經擁有 COMPANY 表,請將其刪除)。
testdb=# CREATE TABLE COMPANY( ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
為了保留審計跟蹤,我們將建立一個名為 AUDIT 的新表,每當在 COMPANY 表中為新記錄新增條目時,日誌訊息都會插入到該表中:
testdb=# CREATE TABLE AUDIT( EMP_ID INT NOT NULL, ENTRY_DATE TEXT NOT NULL );
這裡,ID 是 AUDIT 記錄 ID,EMP_ID 是 ID(將來自 COMPANY 表),DATE 將保留在 COMPANY 表中建立記錄的時間戳。現在,讓我們在 COMPANY 表上建立一個觸發器,如下所示:
testdb=# CREATE TRIGGER example_trigger AFTER INSERT ON COMPANY FOR EACH ROW EXECUTE PROCEDURE auditlogfunc();
其中 auditlogfunc() 是一個 PostgreSQL 過程,其定義如下:
CREATE OR REPLACE FUNCTION auditlogfunc() RETURNS TRIGGER AS $example_table$
BEGIN
INSERT INTO AUDIT(EMP_ID, ENTRY_DATE) VALUES (new.ID, current_timestamp);
RETURN NEW;
END;
$example_table$ LANGUAGE plpgsql;
現在,我們將開始實際工作。讓我們開始在 COMPANY 表中插入記錄,這應該會導致在 AUDIT 表中建立審計日誌記錄。讓我們在 COMPANY 表中建立一條記錄,如下所示:
testdb=# INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Paul', 32, 'California', 20000.00 );
這將在 COMPANY 表中建立一條記錄,如下所示:
id | name | age | address | salary ----+------+-----+--------------+-------- 1 | Paul | 32 | California | 20000
同時,將在 AUDIT 表中建立一條記錄。此記錄是我們為 COMPANY 表上的 INSERT 操作建立的觸發器的結果。類似地,您可以根據您的需求在 UPDATE 和 DELETE 操作上建立觸發器。
emp_id | entry_date
--------+-------------------------------
1 | 2013-05-05 15:49:59.968+05:30
(1 row)
列出觸發器
您可以使用以下方法從 pg_trigger 表中列出當前資料庫中的所有觸發器:
testdb=# SELECT * FROM pg_trigger;
上面給出的 PostgreSQL 語句將列出所有觸發器。
如果您想列出特定表上的觸發器,則使用 AND 子句和表名,如下所示:
testdb=# SELECT tgname FROM pg_trigger, pg_class WHERE tgrelid=pg_class.oid AND relname='company';
上面給出的 PostgreSQL 語句也將只列出一條條目,如下所示:
tgname ----------------- example_trigger (1 row)
刪除觸發器
以下是 DROP 命令,可用於刪除現有觸發器:
testdb=# DROP TRIGGER trigger_name;
PostgreSQL - 索引
索引是資料庫搜尋引擎可以用來加快資料檢索速度的特殊查詢表。簡單地說,索引是指向表中資料的指標。資料庫中的索引與書後面的索引非常相似。
例如,如果您想引用書中討論某個主題的所有頁面,您必須首先參考索引,索引按字母順序列出所有主題,然後參考一個或多個具體的頁碼。
索引有助於加快 SELECT 查詢和 WHERE 子句的速度;但是,它會減慢資料輸入、UPDATE 和 INSERT 語句的速度。建立或刪除索引不會影響資料。
建立索引涉及 CREATE INDEX 語句,該語句允許您命名索引,指定表以及要索引的列或列,並指示索引是升序還是降序。
索引也可以是唯一的,類似於 UNIQUE 約束,因為它可以防止在有索引的列或列組合中插入重複條目。
CREATE INDEX 命令
CREATE INDEX 的基本語法如下:
CREATE INDEX index_name ON table_name;
索引型別
PostgreSQL 提供了幾種索引型別:B 樹、雜湊、GiST、SP-GiST 和 GIN。每種索引型別都使用不同的演算法,最適合不同型別的查詢。預設情況下,CREATE INDEX 命令建立 B 樹索引,這適合最常見的情況。
單列索引
單列索引是僅基於一個表列建立的索引。基本語法如下:
CREATE INDEX index_name ON table_name (column_name);
多列索引
多列索引是在表的多個列上定義的。基本語法如下:
CREATE INDEX index_name ON table_name (column1_name, column2_name);
無論建立單列索引還是多列索引,都要考慮在查詢的 WHERE 子句中經常用作篩選條件的列。
如果只有一個列被使用,則單列索引應該是最佳選擇。如果在 WHERE 子句中經常有兩個或多個列用作篩選器,則多列索引將是最佳選擇。
唯一索引
唯一索引不僅用於效能,還用於資料完整性。唯一索引不允許將任何重複值插入到表中。基本語法如下:
CREATE UNIQUE INDEX index_name on table_name (column_name);
部分索引
部分索引是在表的子集上構建的索引;子集由條件表示式(稱為部分索引的謂詞)定義。索引僅包含滿足謂詞的那些錶行的條目。基本語法如下:
CREATE INDEX index_name on table_name (conditional_expression);
隱式索引
隱式索引是在建立物件時由資料庫伺服器自動建立的索引。主鍵約束和唯一約束會自動建立索引。
示例
以下是一個示例,我們將為 COMPANY 表的 salary 列建立索引:
# CREATE INDEX salary_index ON COMPANY (salary);
現在,讓我們使用 \d company 命令列出 COMPANY 表上可用的所有索引。
# \d company
這將產生以下結果,其中 *company_pkey* 是在建立表時建立的隱式索引。
Table "public.company"
Column | Type | Modifiers
---------+---------------+-----------
id | integer | not null
name | text | not null
age | integer | not null
address | character(50) |
salary | real |
Indexes:
"company_pkey" PRIMARY KEY, btree (id)
"salary_index" btree (salary)
您可以使用 \di 命令列出整個資料庫的索引:
DROP INDEX 命令
可以使用 PostgreSQL DROP 命令刪除索引。刪除索引時應謹慎,因為效能可能會變慢或變快。
基本語法如下:
DROP INDEX index_name;
您可以使用以下語句刪除以前建立的索引:
# DROP INDEX salary_index;
何時應避免使用索引?
儘管索引旨在增強資料庫的效能,但在某些情況下應避免使用索引。以下指南指示何時應重新考慮使用索引:
不應在小型表上使用索引。
具有頻繁、大量批次更新或插入操作的表。
不應在包含大量 NULL 值的列上使用索引。
不應為經常被操作的列建立索引。
PostgreSQL - ALTER TABLE 命令
PostgreSQL ALTER TABLE 命令用於在現有表中新增、刪除或修改列。
您還可以使用 ALTER TABLE 命令在現有表上新增和刪除各種約束。
語法
在現有表中新增新列的 ALTER TABLE 的基本語法如下:
ALTER TABLE table_name ADD column_name datatype;
在現有表中刪除列的 ALTER TABLE 的基本語法如下:
ALTER TABLE table_name DROP COLUMN column_name;
更改表中列的資料型別的 ALTER TABLE 的基本語法如下:
ALTER TABLE table_name ALTER COLUMN column_name TYPE datatype;
在表中向列新增NOT NULL 約束的 ALTER TABLE 的基本語法如下:
ALTER TABLE table_name MODIFY column_name datatype NOT NULL;
在表中新增UNIQUE CONSTRAINT 的 ALTER TABLE 的基本語法如下:
ALTER TABLE table_name ADD CONSTRAINT MyUniqueConstraint UNIQUE(column1, column2...);
在表中新增CHECK CONSTRAINT 的 ALTER TABLE 的基本語法如下:
ALTER TABLE table_name ADD CONSTRAINT MyUniqueConstraint CHECK (CONDITION);
在表中新增PRIMARY KEY 約束的 ALTER TABLE 的基本語法如下:
ALTER TABLE table_name ADD CONSTRAINT MyPrimaryKey PRIMARY KEY (column1, column2...);
從表中刪除約束的 ALTER TABLE 的基本語法如下:
ALTER TABLE table_name DROP CONSTRAINT MyUniqueConstraint;
如果您使用的是 MySQL,則程式碼如下:
ALTER TABLE table_name DROP INDEX MyUniqueConstraint;
從表中刪除 PRIMARY KEY 約束的 ALTER TABLE 的基本語法如下:
ALTER TABLE table_name DROP CONSTRAINT MyPrimaryKey;
如果您使用的是 MySQL,則程式碼如下:
ALTER TABLE table_name DROP PRIMARY KEY;
示例
假設我們的 COMPANY 表包含以下記錄:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
以下是向現有表中新增新列的示例:
testdb=# ALTER TABLE COMPANY ADD GENDER char(1);
現在,COMPANY 表已更改,SELECT 語句的輸出如下:
id | name | age | address | salary | gender ----+-------+-----+-------------+--------+-------- 1 | Paul | 32 | California | 20000 | 2 | Allen | 25 | Texas | 15000 | 3 | Teddy | 23 | Norway | 20000 | 4 | Mark | 25 | Rich-Mond | 65000 | 5 | David | 27 | Texas | 85000 | 6 | Kim | 22 | South-Hall | 45000 | 7 | James | 24 | Houston | 10000 | (7 rows)
以下是從現有表中刪除 gender 列的示例:
testdb=# ALTER TABLE COMPANY DROP GENDER;
現在,COMPANY 表已更改,SELECT 語句的輸出如下:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
PostgreSQL - TRUNCATE TABLE 命令
PostgreSQL TRUNCATE TABLE 命令用於刪除現有表中的所有資料。您還可以使用 DROP TABLE 命令刪除整個表,但這會從資料庫中刪除整個表結構,如果您希望儲存一些資料,則需要重新建立該表。
它對每個表具有與 DELETE 相同的效果,但因為它實際上並沒有掃描表,所以速度更快。此外,它會立即回收磁碟空間,而不需要後續的 VACUUM 操作。這對於大型表最有用。
語法
TRUNCATE TABLE 的基本語法如下:
TRUNCATE TABLE table_name;
示例
假設 COMPANY 表包含以下記錄:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下是截斷的示例:
testdb=# TRUNCATE TABLE COMPANY;
現在,COMPANY 表已截斷,SELECT 語句的輸出如下:
testdb=# SELECT * FROM CUSTOMERS; id | name | age | address | salary ----+------+-----+---------+-------- (0 rows)
PostgreSQL - 檢視
檢視是偽表。也就是說,它們不是真實的表;然而,它們對 SELECT 看起來像普通的表。檢視可以表示真實表的一個子集,從普通表中選擇某些列或某些行。檢視甚至可以表示連線的表。由於檢視被分配了單獨的許可權,因此您可以使用它們來限制表訪問,以便使用者只能看到表的特定行或列。
檢視可以包含表的所有行或一個或多個表中選定的行。檢視可以從一個或多個表建立,這取決於用於建立檢視的已編寫 PostgreSQL 查詢。
檢視是一種虛擬表,允許使用者執行以下操作:
以使用者或使用者類發現自然或直觀的方式來組織資料。
限制對資料的訪問,以便使用者只能看到有限的資料而不是完整的表。
彙總來自各個表的資料,可用於生成報表。
由於檢視不是普通的表,因此您可能無法對檢視執行 DELETE、INSERT 或 UPDATE 語句。但是,您可以建立一個規則來糾正這個問題,以便在檢視上使用 DELETE、INSERT 或 UPDATE。
建立檢視
PostgreSQL 檢視使用 **CREATE VIEW** 語句建立。PostgreSQL 檢視可以從單個表、多個表或另一個檢視建立。
基本的 CREATE VIEW 語法如下:
CREATE [TEMP | TEMPORARY] VIEW view_name AS SELECT column1, column2..... FROM table_name WHERE [condition];
您可以在 SELECT 語句中包含多個表,方法與在普通的 PostgreSQL SELECT 查詢中使用它們的方式非常相似。如果存在可選的 TEMP 或 TEMPORARY 關鍵字,則檢視將在臨時空間中建立。臨時檢視會在當前會話結束時自動刪除。
示例
假設 COMPANY 表具有以下記錄:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000
現在,以下是如何從 COMPANY 表建立檢視的示例。此檢視將僅包含 COMPANY 表中的幾列:
testdb=# CREATE VIEW COMPANY_VIEW AS SELECT ID, NAME, AGE FROM COMPANY;
現在,您可以像查詢實際表一樣查詢 COMPANY_VIEW。以下是一個示例:
testdb=# SELECT * FROM COMPANY_VIEW;
這將產生以下結果:
id | name | age ----+-------+----- 1 | Paul | 32 2 | Allen | 25 3 | Teddy | 23 4 | Mark | 25 5 | David | 27 6 | Kim | 22 7 | James | 24 (7 rows)
刪除檢視
要刪除檢視,只需使用帶有 **view_name** 的 DROP VIEW 語句即可。基本的 DROP VIEW 語法如下:
testdb=# DROP VIEW view_name;
以下命令將刪除我們在上一節中建立的 COMPANY_VIEW 檢視:
testdb=# DROP VIEW COMPANY_VIEW;
PostgreSQL - 事務
事務是對資料庫執行的工作單元。事務是按邏輯順序完成的工作單元或序列,無論是由使用者手動執行,還是由某種資料庫程式自動執行。
事務是對資料庫傳播一個或多個更改。例如,如果您正在建立記錄、更新記錄或從表中刪除記錄,那麼您正在對錶執行事務。控制事務以確保資料完整性和處理資料庫錯誤非常重要。
實際上,您會將許多 PostgreSQL 查詢組合成一個組,並將它們一起作為事務的一部分執行。
事務的屬性
事務具有以下四個標準屬性,通常用首字母縮略詞 ACID 來表示:
**原子性** - 確保工作單元中的所有操作都成功完成;否則,事務將在故障點中止,之前的操作將回滾到其以前的狀態。
**一致性** - 確保資料庫在成功提交的事務後正確更改狀態。
**隔離性** - 使事務能夠獨立於彼此並對彼此透明地執行。
**永續性** - 確保已提交事務的結果或效果在系統故障的情況下仍然存在。
事務控制
以下命令用於控制事務:
**BEGIN TRANSACTION** - 開始事務。
**COMMIT** - 儲存更改,或者您可以使用 **END TRANSACTION** 命令。
**ROLLBACK** - 回滾更改。
事務控制命令僅與 DML 命令 INSERT、UPDATE 和 DELETE 一起使用。在建立表或刪除表時不能使用它們,因為這些操作會在資料庫中自動提交。
BEGIN TRANSACTION 命令
可以使用 BEGIN TRANSACTION 或簡單的 BEGIN 命令啟動事務。此類事務通常持續到遇到下一個 COMMIT 或 ROLLBACK 命令為止。但是,如果資料庫關閉或發生錯誤,事務也會回滾。
以下是啟動事務的簡單語法:
BEGIN; or BEGIN TRANSACTION;
COMMIT 命令
COMMIT 命令是用於將事務呼叫的更改儲存到資料庫的事務命令。
COMMIT 命令將自上次 COMMIT 或 ROLLBACK 命令以來所有事務儲存到資料庫。
COMMIT 命令的語法如下:
COMMIT; or END TRANSACTION;
ROLLBACK 命令
ROLLBACK 命令是用於撤消尚未儲存到資料庫的事務的事務命令。
ROLLBACK 命令只能用於撤消自發出上次 COMMIT 或 ROLLBACK 命令以來的事務。
ROLLBACK 命令的語法如下:
ROLLBACK;
示例
假設 COMPANY 表具有以下記錄:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
現在,讓我們開始一個事務並刪除表中 age = 25 的記錄,最後我們使用 ROLLBACK 命令撤消所有更改。
testdb=# BEGIN; DELETE FROM COMPANY WHERE AGE = 25; ROLLBACK;
如果您檢查 COMPANY 表,它仍然具有以下記錄:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000
現在,讓我們開始另一個事務並刪除表中 age = 25 的記錄,最後我們使用 COMMIT 命令提交所有更改。
testdb=# BEGIN; DELETE FROM COMPANY WHERE AGE = 25; COMMIT;
如果您檢查 COMPANY 表,它仍然具有以下記錄:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 3 | Teddy | 23 | Norway | 20000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 (5 rows)
PostgreSQL - 鎖
鎖或排他鎖或寫鎖阻止使用者修改行或整個表。UPDATE 和 DELETE 修改的行將自動在事務持續時間內被排他鎖定。這將防止其他使用者更改該行,直到事務提交或回滾。
使用者必須等待其他使用者的情況只發生在他們試圖修改同一行時。如果他們修改不同的行,則無需等待。SELECT 查詢永遠不需要等待。
資料庫自動執行鎖定。但是,在某些情況下,必須手動控制鎖定。可以使用 LOCK 命令進行手動鎖定。它允許指定事務的鎖型別和範圍。
LOCK 命令的語法
LOCK 命令的基本語法如下:
LOCK [ TABLE ] name IN lock_mode
**name** - 要鎖定的現有表的名稱(可選地限定模式)。如果在表名前指定 ONLY,則只鎖定該表。如果未指定 ONLY,則鎖定該表及其所有子表(如果有)。
**lock_mode** - 鎖模式指定此鎖與哪些鎖衝突。如果沒有指定鎖模式,則使用 ACCESS EXCLUSIVE(最嚴格的模式)。可能的值為:ACCESS SHARE、ROW SHARE、ROW EXCLUSIVE、SHARE UPDATE EXCLUSIVE、SHARE、SHARE ROW EXCLUSIVE、EXCLUSIVE、ACCESS EXCLUSIVE。
一旦獲得,鎖將在當前事務的剩餘時間內保持。沒有 UNLOCK TABLE 命令;鎖總是在事務結束時釋放。
死鎖
當兩個事務都在等待對方完成其操作時,可能會發生死鎖。雖然 PostgreSQL 可以檢測到它們並使用 ROLLBACK 結束它們,但死鎖仍然可能帶來不便。為了防止您的應用程式遇到此問題,請確保以這樣一種方式設計它們,即它們將以相同的順序鎖定物件。
建議鎖
PostgreSQL 提供了建立具有應用程式定義含義的鎖的方法。這些稱為建議鎖。由於系統不強制執行其使用,因此應用程式應正確使用它們。建議鎖可用於對 MVCC 模型不合適的鎖定策略。
例如,建議鎖的常見用途是模擬所謂的“平面檔案”資料管理系統中典型的悲觀鎖定策略。雖然儲存在表中的標誌可以用於相同的目的,但建議鎖更快,避免表膨脹,並且在會話結束時由伺服器自動清除。
示例
考慮表 COMPANY,其記錄如下:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
以下示例以 ACCESS EXCLUSIVE 模式鎖定 testdb 資料庫中的 COMPANY 表。LOCK 語句僅在事務模式下有效:
testdb=#BEGIN; LOCK TABLE company1 IN ACCESS EXCLUSIVE MODE;
上述 PostgreSQL 語句將產生以下結果:
LOCK TABLE
以上訊息表明表已鎖定,直到事務結束,要結束事務,您必須回滾或提交事務。
PostgreSQL - 子查詢
子查詢或內部查詢或巢狀查詢是另一個 PostgreSQL 查詢中的查詢,並嵌入在 WHERE 子句中。
子查詢用於返回將在主查詢中用作條件的資料,以進一步限制要檢索的資料。
子查詢可以與 SELECT、INSERT、UPDATE 和 DELETE 語句以及 =、<、>、>=、<=、IN 等運算子一起使用。
子查詢必須遵循以下一些規則:
子查詢必須用括號括起來。
除非子查詢的多個列用於主查詢比較其選擇的列,否則子查詢的 SELECT 子句中只能有一列。
雖然主查詢可以使用 ORDER BY,但在子查詢中不能使用 ORDER BY。GROUP BY 可用於執行與子查詢中的 ORDER BY 相同的功能。
返回多行的子查詢只能與多值運算子一起使用,例如 IN、EXISTS、NOT IN、ANY/SOME、ALL 運算子。
BETWEEN 運算子不能與子查詢一起使用;但是,BETWEEN 可在子查詢中使用。
帶有 SELECT 語句的子查詢
子查詢最常與 SELECT 語句一起使用。基本語法如下:
SELECT column_name [, column_name ]
FROM table1 [, table2 ]
WHERE column_name OPERATOR
(SELECT column_name [, column_name ]
FROM table1 [, table2 ]
[WHERE])
示例
假設 COMPANY 表具有以下記錄:
id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
現在,讓我們檢查帶有 SELECT 語句的以下子查詢:
testdb=# SELECT *
FROM COMPANY
WHERE ID IN (SELECT ID
FROM COMPANY
WHERE SALARY > 45000) ;
這將產生以下結果:
id | name | age | address | salary ----+-------+-----+-------------+-------- 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 (2 rows)
帶有 INSERT 語句的子查詢
子查詢也可以與 INSERT 語句一起使用。INSERT 語句使用子查詢返回的資料插入另一個表。子查詢中的選定資料可以使用任何字元、日期或數字函式進行修改。
基本語法如下:
INSERT INTO table_name [ (column1 [, column2 ]) ] SELECT [ *|column1 [, column2 ] ] FROM table1 [, table2 ] [ WHERE VALUE OPERATOR ]
示例
考慮一個表 COMPANY_BKP,其結構與 COMPANY 表類似,可以使用相同的 CREATE TABLE 語句建立,使用 COMPANY_BKP 作為表名。現在,要將完整的 COMPANY 表複製到 COMPANY_BKP,語法如下:
testdb=# INSERT INTO COMPANY_BKP
SELECT * FROM COMPANY
WHERE ID IN (SELECT ID
FROM COMPANY) ;
帶有 UPDATE 語句的子查詢
子查詢可以與 UPDATE 語句一起使用。使用子查詢與 UPDATE 語句時,可以更新表中的單個列或多個列。
基本語法如下:
UPDATE table SET column_name = new_value [ WHERE OPERATOR [ VALUE ] (SELECT COLUMN_NAME FROM TABLE_NAME) [ WHERE) ]
示例
假設我們有 COMPANY_BKP 表可用,它是 COMPANY 表的備份。
以下示例將 COMPANY 表中所有年齡大於或等於 27 的客戶的 SALARY 更新為 0.50 倍:
testdb=# UPDATE COMPANY
SET SALARY = SALARY * 0.50
WHERE AGE IN (SELECT AGE FROM COMPANY_BKP
WHERE AGE >= 27 );
這將影響兩行,最後 COMPANY 表將具有以下記錄:
id | name | age | address | salary ----+-------+-----+-------------+-------- 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 1 | Paul | 32 | California | 10000 5 | David | 27 | Texas | 42500 (7 rows)
帶有 DELETE 語句的子查詢
子查詢可以與 DELETE 語句一起使用,就像上面提到的任何其他語句一樣。
基本語法如下:
DELETE FROM TABLE_NAME [ WHERE OPERATOR [ VALUE ] (SELECT COLUMN_NAME FROM TABLE_NAME) [ WHERE) ]
示例
假設我們有 COMPANY_BKP 表可用,它是 COMPANY 表的備份。
以下示例刪除 COMPANY 表中所有年齡大於或等於 27 的客戶的記錄:
testdb=# DELETE FROM COMPANY
WHERE AGE IN (SELECT AGE FROM COMPANY_BKP
WHERE AGE > 27 );
這將影響兩行,最後 COMPANY 表將具有以下記錄:
id | name | age | address | salary ----+-------+-----+-------------+-------- 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 5 | David | 27 | Texas | 42500 (6 rows)
PostgreSQL - 自動遞增
PostgreSQL 具有資料型別smallserial、serial 和bigserial;這些不是真正的型別,而只是建立唯一識別符號列的符號約定。它們類似於其他一些資料庫支援的 AUTO_INCREMENT 屬性。
如果您希望serial列具有唯一約束或主鍵,則現在必須像任何其他資料型別一樣指定它。
型別名稱serial建立integer型別的列。型別名稱bigserial建立一個bigint型別的列。如果預計表在其生命週期內將使用超過231個識別符號,則應使用bigserial。型別名稱smallserial建立一個smallint型別的列。
語法
SERIAL 資料型別的基本用法如下:
CREATE TABLE tablename ( colname SERIAL );
示例
假設要建立名為COMPANY的表,如下所示:
testdb=# CREATE TABLE COMPANY( ID SERIAL PRIMARY KEY, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL );
現在,將以下記錄插入COMPANY表中:
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'Paul', 32, 'California', 20000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ('Allen', 25, 'Texas', 15000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ('Teddy', 23, 'Norway', 20000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'Mark', 25, 'Rich-Mond ', 65000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'David', 27, 'Texas', 85000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'Kim', 22, 'South-Hall', 45000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'James', 24, 'Houston', 10000.00 );
這將向COMPANY表插入七個元組,COMPANY表將包含以下記錄:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000
PostgreSQL - 許可權
在資料庫中建立物件時,會為其分配一個所有者。所有者通常是執行建立語句的人。對於大多數型別的物件,初始狀態是隻有所有者(或超級使用者)才能修改或刪除該物件。要允許其他角色或使用者使用它,必須授予許可權或許可。
PostgreSQL 中的不同型別的許可權包括:
- SELECT(選擇)
- INSERT(插入)
- UPDATE(更新)
- DELETE(刪除)
- TRUNCATE(截斷)
- REFERENCES(引用)
- TRIGGER(觸發器)
- CREATE(建立)
- CONNECT(連線)
- TEMPORARY(臨時)
- EXECUTE(執行) 和
- USAGE(使用)
根據物件的型別(表、函式等),許可權將應用於該物件。要為使用者分配許可權,可以使用GRANT命令。
GRANT 語法
GRANT命令的基本語法如下:
GRANT privilege [, ...]
ON object [, ...]
TO { PUBLIC | GROUP group | username }
privilege - 值可以是:SELECT、INSERT、UPDATE、DELETE、RULE、ALL。
object - 要授予訪問許可權的物件的名稱。可能的物件包括:表、檢視、序列。
PUBLIC - 代表所有使用者的簡寫形式。
GROUP group - 要授予許可權的組。
username - 要授予許可權的使用者名稱稱。PUBLIC是代表所有使用者的簡寫形式。
可以使用REVOKE命令撤銷許可權。
REVOKE 語法
REVOKE命令的基本語法如下:
REVOKE privilege [, ...]
ON object [, ...]
FROM { PUBLIC | GROUP groupname | username }
privilege - 值可以是:SELECT、INSERT、UPDATE、DELETE、RULE、ALL。
object - 要授予訪問許可權的物件的名稱。可能的物件包括:表、檢視、序列。
PUBLIC - 代表所有使用者的簡寫形式。
GROUP group - 要授予許可權的組。
username - 要授予許可權的使用者名稱稱。PUBLIC是代表所有使用者的簡寫形式。
示例
為了理解許可權,讓我們首先建立一個使用者,如下所示:
testdb=# CREATE USER manisha WITH PASSWORD 'password'; CREATE ROLE
訊息CREATE ROLE表示已建立使用者“manisha”。
考慮表 COMPANY,其記錄如下:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
接下來,讓我們向用戶“manisha”授予COMPANY表的所有許可權,如下所示:
testdb=# GRANT ALL ON COMPANY TO manisha; GRANT
訊息GRANT表示所有許可權都已分配給使用者。
接下來,讓我們從使用者“manisha”撤銷許可權,如下所示:
testdb=# REVOKE ALL ON COMPANY FROM manisha; REVOKE
訊息REVOKE表示所有許可權都已從使用者撤銷。
您甚至可以刪除使用者,如下所示:
testdb=# DROP USER manisha; DROP ROLE
訊息DROP ROLE表示使用者“Manisha”已從資料庫中刪除。
PostgreSQL - 日期/時間函式和運算子
我們在資料型別章節中討論了日期/時間資料型別。現在,讓我們看看日期/時間運算子和函式。
下表列出了基本算術運算子的行為:
| 運算子 | 示例 | 結果 |
|---|---|---|
| + | date '2001-09-28' + integer '7' | date '2001-10-05' |
| + | date '2001-09-28' + interval '1 hour' | timestamp '2001-09-28 01:00:00' |
| + | date '2001-09-28' + time '03:00' | timestamp '2001-09-28 03:00:00' |
| + | interval '1 day' + interval '1 hour' | interval '1 day 01:00:00' |
| + | timestamp '2001-09-28 01:00' + interval '23 hours' | timestamp '2001-09-29 00:00:00' |
| + | time '01:00' + interval '3 hours' | time '04:00:00' |
| - | - interval '23 hours' | interval '-23:00:00' |
| - | date '2001-10-01' - date '2001-09-28' | integer '3'(天) |
| - | date '2001-10-01' - integer '7' | date '2001-09-24' |
| - | date '2001-09-28' - interval '1 hour' | timestamp '2001-09-27 23:00:00' |
| - | time '05:00' - time '03:00' | interval '02:00:00' |
| - | time '05:00' - interval '2 hours' | time '03:00:00' |
| - | timestamp '2001-09-28 23:00' - interval '23 hours' | timestamp '2001-09-28 00:00:00' |
| - | interval '1 day' - interval '1 hour' | interval '1 day -01:00:00' |
| - | timestamp '2001-09-29 03:00' - timestamp '2001-09-27 12:00' | interval '1 day 15:00:00' |
| * | 900 * interval '1 second' | interval '00:15:00' |
| * | 21 * interval '1 day' | interval '21 days' |
| * | double precision '3.5' * interval '1 hour' | interval '03:30:00' |
| / | interval '1 hour' / double precision '1.5' | interval '00:40:00' |
以下是所有重要的日期和時間相關函式列表。
| 序號 | 函式和說明 |
|---|---|
| 1 | AGE()
相減 |
| 2 | CURRENT_DATE/TIME()
當前日期和時間 |
| 3 | DATE_PART()
獲取子欄位(等效於extract) |
| 4 | EXTRACT()
獲取子欄位 |
| 5 | ISFINITE()
測試有限的日期、時間和區間(不是 +/-infinity) |
| 6 | JUSTIFY
調整區間 |
AGE(timestamp, timestamp), AGE(timestamp)
| 序號 | 函式和說明 |
|---|---|
| 1 | AGE(timestamp, timestamp) 當使用TIMESTAMP形式的第二個引數呼叫時,AGE()會相減,產生一個使用年和月的“符號”結果,型別為INTERVAL。 |
| 2 | AGE(timestamp) 當只使用TIMESTAMP作為引數呼叫時,AGE()會從current_date(午夜)相減。 |
函式AGE(timestamp, timestamp)的示例:
testdb=# SELECT AGE(timestamp '2001-04-10', timestamp '1957-06-13');
上述 PostgreSQL 語句將產生以下結果:
age ------------------------- 43 years 9 mons 27 days
函式AGE(timestamp)的示例:
testdb=# select age(timestamp '1957-06-13');
上述 PostgreSQL 語句將產生以下結果:
age -------------------------- 55 years 10 mons 22 days
CURRENT_DATE/TIME()
PostgreSQL提供許多函式,這些函式返回與當前日期和時間相關的數值。以下是一些函式:
| 序號 | 函式和說明 |
|---|---|
| 1 | CURRENT_DATE 返回當前日期。 |
| 2 | CURRENT_TIME 返回帶時區的數值。 |
| 3 | CURRENT_TIMESTAMP 返回帶時區的數值。 |
| 4 | CURRENT_TIME(precision) 可以選擇一個精度引數,這將導致結果四捨五入到秒欄位中的那麼多小數位。 |
| 5 | CURRENT_TIMESTAMP(precision) 可以選擇一個精度引數,這將導致結果四捨五入到秒欄位中的那麼多小數位。 |
| 6 | LOCALTIME 返回不帶時區的數值。 |
| 7 | LOCALTIMESTAMP 返回不帶時區的數值。 |
| 8 | LOCALTIME(precision) 可以選擇一個精度引數,這將導致結果四捨五入到秒欄位中的那麼多小數位。 |
| 9 | LOCALTIMESTAMP(precision) 可以選擇一個精度引數,這將導致結果四捨五入到秒欄位中的那麼多小數位。 |
使用上表中函式的示例:
testdb=# SELECT CURRENT_TIME;
timetz
--------------------
08:01:34.656+05:30
(1 row)
testdb=# SELECT CURRENT_DATE;
date
------------
2013-05-05
(1 row)
testdb=# SELECT CURRENT_TIMESTAMP;
now
-------------------------------
2013-05-05 08:01:45.375+05:30
(1 row)
testdb=# SELECT CURRENT_TIMESTAMP(2);
timestamptz
------------------------------
2013-05-05 08:01:50.89+05:30
(1 row)
testdb=# SELECT LOCALTIMESTAMP;
timestamp
------------------------
2013-05-05 08:01:55.75
(1 row)
PostgreSQL還提供返回當前語句的開始時間以及函式呼叫時實際當前時間的函式。這些函式包括:
| 序號 | 函式和說明 |
|---|---|
| 1 | transaction_timestamp() 它等效於CURRENT_TIMESTAMP,但名稱清楚地反映了它返回的內容。 |
| 2 | statement_timestamp() 它返回當前語句的開始時間。 |
| 3 | clock_timestamp() 它返回實際的當前時間,因此其值即使在單個SQL命令內也會發生變化。 |
| 4 | timeofday() 它返回實際的當前時間,但作為格式化的文字字串而不是帶有時區的timestamp值。 |
| 5 | now() 它是transaction_timestamp()的傳統PostgreSQL等效項。 |
DATE_PART(text, timestamp), DATE_PART(text, interval), DATE_TRUNC(text, timestamp)
| 序號 | 函式和說明 |
|---|---|
| 1 | DATE_PART('field', source) 這些函式獲取子欄位。field引數需要是一個字串值,而不是名稱。 有效的欄位名稱包括:century, day, decade, dow, doy, epoch, hour, isodow, isoyear, microseconds, millennium, milliseconds, minute, month, quarter, second, timezone, timezone_hour, timezone_minute, week, year。 |
| 2 | DATE_TRUNC('field', source) 此函式在概念上類似於數字的trunc函式。source是型別為timestamp或interval的值表示式。field選擇將輸入值截斷到哪個精度。返回值的型別為timestamp或interval。 field的有效值包括:microseconds, milliseconds, second, minute, hour, day, week, month, quarter, year, decade, century, millennium |
以下是DATE_PART('field', source)函式的示例:
testdb=# SELECT date_part('day', TIMESTAMP '2001-02-16 20:38:40');
date_part
-----------
16
(1 row)
testdb=# SELECT date_part('hour', INTERVAL '4 hours 3 minutes');
date_part
-----------
4
(1 row)
以下是DATE_TRUNC('field', source)函式的示例:
testdb=# SELECT date_trunc('hour', TIMESTAMP '2001-02-16 20:38:40');
date_trunc
---------------------
2001-02-16 20:00:00
(1 row)
testdb=# SELECT date_trunc('year', TIMESTAMP '2001-02-16 20:38:40');
date_trunc
---------------------
2001-01-01 00:00:00
(1 row)
EXTRACT(field from timestamp), EXTRACT(field from interval)
EXTRACT(field FROM source)函式從日期/時間值中檢索子欄位,例如年份或小時。source必須是型別為timestamp、time或interval的值表示式。field是識別符號或字串,用於選擇從源值中提取哪個欄位。EXTRACT函式返回型別為double precision的值。
以下是有效的欄位名稱(類似於DATE_PART函式欄位名稱):century, day, decade, dow, doy, epoch, hour, isodow, isoyear, microseconds, millennium, milliseconds, minute, month, quarter, second, timezone, timezone_hour, timezone_minute, week, year。
以下是EXTRACT('field', source)函式的示例:
testdb=# SELECT EXTRACT(CENTURY FROM TIMESTAMP '2000-12-16 12:21:13');
date_part
-----------
20
(1 row)
testdb=# SELECT EXTRACT(DAY FROM TIMESTAMP '2001-02-16 20:38:40');
date_part
-----------
16
(1 row)
ISFINITE(date), ISFINITE(timestamp), ISFINITE(interval)
| 序號 | 函式和說明 |
|---|---|
| 1 | ISFINITE(date) 測試有限日期。 |
| 2 | ISFINITE(timestamp) 測試有限時間戳。 |
| 3 | ISFINITE(interval) 測試有限區間。 |
以下是ISFINITE()函式的示例:
testdb=# SELECT isfinite(date '2001-02-16'); isfinite ---------- t (1 row) testdb=# SELECT isfinite(timestamp '2001-02-16 21:28:30'); isfinite ---------- t (1 row) testdb=# SELECT isfinite(interval '4 hours'); isfinite ---------- t (1 row)
JUSTIFY_DAYS(interval), JUSTIFY_HOURS(interval), JUSTIFY_INTERVAL(interval)
| 序號 | 函式和說明 |
|---|---|
| 1 | JUSTIFY_DAYS(interval) 調整區間,使30天的時間段表示為月份。返回interval型別 |
| 2 | JUSTIFY_HOURS(interval) 調整區間,使24小時的時間段表示為天。返回interval型別 |
| 3 | JUSTIFY_INTERVAL(interval) 使用JUSTIFY_DAYS和JUSTIFY_HOURS調整區間,並進行額外的符號調整。返回interval型別 |
以下是ISFINITE()函式的示例:
testdb=# SELECT justify_days(interval '35 days'); justify_days -------------- 1 mon 5 days (1 row) testdb=# SELECT justify_hours(interval '27 hours'); justify_hours ---------------- 1 day 03:00:00 (1 row) testdb=# SELECT justify_interval(interval '1 mon -1 hour'); justify_interval ------------------ 29 days 23:00:00 (1 row)
PostgreSQL - 函式
PostgreSQL函式,也稱為儲存過程,允許您在一個數據庫內的單個函式中執行通常需要多個查詢和往返操作的操作。函式允許資料庫重用,因為其他應用程式可以直接與您的儲存過程互動,而不是中間層或重複程式碼。
函式可以用您選擇的語言建立,例如SQL、PL/pgSQL、C、Python等。
語法
建立函式的基本語法如下:
CREATE [OR REPLACE] FUNCTION function_name (arguments)
RETURNS return_datatype AS $variable_name$
DECLARE
declaration;
[...]
BEGIN
< function_body >
[...]
RETURN { variable_name | value }
END; LANGUAGE plpgsql;
其中:
function-name 指定函式的名稱。
[OR REPLACE]選項允許修改現有函式。
函式必須包含return語句。
RETURN子句指定您將從函式返回的資料型別。return_datatype可以是基本型別、複合型別或域型別,也可以引用表列的型別。
function-body包含可執行部分。
AS關鍵字用於建立獨立函式。
plpgsql是實現函式的語言的名稱。在這裡,我們為PostgreSQL使用此選項,它可以是SQL、C、內部或使用者定義的過程語言的名稱。為了向後相容性,名稱可以用單引號括起來。
示例
以下示例說明了建立和呼叫獨立函式。此函式返回COMPANY表中的記錄總數。我們將使用COMPANY表,該表包含以下記錄:
testdb# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
函式totalRecords()如下:
CREATE OR REPLACE FUNCTION totalRecords () RETURNS integer AS $total$ declare total integer; BEGIN SELECT count(*) into total FROM COMPANY; RETURN total; END; $total$ LANGUAGE plpgsql;
執行上述查詢後,結果將是:
testdb# CREATE FUNCTION
現在,讓我們執行對該函式的呼叫並檢查COMPANY表中的記錄
testdb=# select totalRecords();
執行上述查詢後,結果將是:
totalrecords
--------------
7
(1 row)
PostgreSQL - 常用函式
PostgreSQL內建函式,也稱為聚合函式,用於對字串或數值資料進行處理。
以下是所有 PostgreSQL 通用內建函式的列表:
PostgreSQL COUNT 函式 − PostgreSQL COUNT 聚合函式用於計算資料庫表中的行數。
PostgreSQL MAX 函式 − PostgreSQL MAX 聚合函式允許我們選擇特定列的最高(最大)值。
PostgreSQL MIN 函式 − PostgreSQL MIN 聚合函式允許我們選擇特定列的最低(最小)值。
PostgreSQL AVG 函式 − PostgreSQL AVG 聚合函式選擇特定表列的平均值。
PostgreSQL SUM 函式 − PostgreSQL SUM 聚合函式允許選擇數值列的總和。
PostgreSQL 陣列函式 − PostgreSQL 陣列聚合函式將輸入值(包括空值)連線到一個數組中。
PostgreSQL 數值函式 − 在 SQL 中運算元字所需 PostgreSQL 函式的完整列表。
PostgreSQL 字串函式 − 在 PostgreSQL 中操作字串所需 PostgreSQL 函式的完整列表。
PostgreSQL - C/C++ 介面
本教程將使用libpqxx庫,它是 PostgreSQL 的官方 C++ 客戶端 API。libpqxx 的原始碼可在 BSD 許可下獲得,因此您可以自由下載、傳遞給他人、更改、出售、將其包含在您自己的程式碼中,以及與您選擇的任何人共享您的更改。
安裝
libpqxx 的最新版本可從以下連結下載 下載 Libpqxx。下載最新版本並按照以下步驟操作:
wget http://pqxx.org/download/software/libpqxx/libpqxx-4.0.tar.gz tar xvfz libpqxx-4.0.tar.gz cd libpqxx-4.0 ./configure make make install
在開始使用 C/C++ PostgreSQL 介面之前,請在您的 PostgreSQL 安裝目錄中找到pg_hba.conf檔案並新增以下行:
# IPv4 local connections: host all all 127.0.0.1/32 md5
如果 postgres 伺服器未執行,您可以使用以下命令啟動/重啟它:
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
C/C++ 介面 API
以下是重要的介面例程,可以滿足您從 C/C++ 程式與 PostgreSQL 資料庫互動的需求。如果您正在尋找更復雜的應用程式,您可以檢視 libpqxx 官方文件,或者可以使用商業 API。
| 序號 | API 和描述 |
|---|---|
| 1 | pqxx::connection C( const std::string & dbstring ) 這是一個 typedef,用於連線到資料庫。在這裡,dbstring 提供連線到資料庫所需的引數,例如 dbname = testdb user = postgres password=pass123 hostaddr=127.0.0.1 port=5432。 如果連線成功設定,則它將建立具有連線物件的 C,該物件提供各種有用的公共函式。 |
| 2 | C.is_open() is_open() 方法是連線物件的公共方法,並返回布林值。如果連線處於活動狀態,則此方法返回 true,否則返回 false。 |
| 3 | C.disconnect() 此方法用於斷開開啟的資料庫連線。 |
| 4 | pqxx::work W( C ) 這是一個 typedef,用於使用連線 C 建立事務物件,最終用於以事務模式執行 SQL 語句。 如果事務物件建立成功,則將其分配給變數 W,該變數將用於訪問與事務物件相關的公共方法。 |
| 5 |
W.exec(const std::string & sql) 事務物件的此公共方法將用於執行 SQL 語句。 |
| 6 |
W.commit() 事務物件的此公共方法將用於提交事務。 |
| 7 |
W.abort() 事務物件的此公共方法將用於回滾事務。 |
| 8 | pqxx::nontransaction N( C ) 這是一個 typedef,用於使用連線 C 建立非事務物件,最終用於以非事務模式執行 SQL 語句。 如果事務物件建立成功,則將其分配給變數 N,該變數將用於訪問與非事務物件相關的公共方法。 |
| 9 | N.exec(const std::string & sql) 非事務物件的此公共方法將用於執行 SQL 語句並返回結果物件,該物件實際上是一個持有所有返回記錄的迭代器。 |
連線到資料庫
以下 C 程式碼段顯示如何連線到在本地機器的埠 5432 上執行的現有資料庫。在這裡,我使用反斜槓 \ 來進行續行。
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
try {
connection C("dbname = testdb user = postgres password = cohondob \
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
}
現在,讓我們編譯並執行上述程式以連線到我們的資料庫testdb,該資料庫已存在於您的模式中,並且可以使用使用者postgres和密碼pass123訪問。
您可以根據您的資料庫設定使用使用者 ID 和密碼。請記住按順序保留 -lpqxx 和 -lpq!否則,連結器將抱怨缺少名稱以“PQ.”開頭的函式。
$g++ test.cpp -lpqxx -lpq $./a.out Opened database successfully: testdb
建立表
以下 C 程式碼段將用於在先前建立的資料庫中建立表:
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
char * sql;
try {
connection C("dbname = testdb user = postgres password = cohondob \
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create SQL statement */
sql = "CREATE TABLE COMPANY(" \
"ID INT PRIMARY KEY NOT NULL," \
"NAME TEXT NOT NULL," \
"AGE INT NOT NULL," \
"ADDRESS CHAR(50)," \
"SALARY REAL );";
/* Create a transactional object. */
work W(C);
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Table created successfully" << endl;
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
編譯並執行上述程式後,它將在您的 testdb 資料庫中建立 COMPANY 表,並顯示以下語句:
Opened database successfully: testdb Table created successfully
INSERT 操作
以下 C 程式碼段顯示瞭如何在上面示例中建立的 COMPANY 表中建立記錄:
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
char * sql;
try {
connection C("dbname = testdb user = postgres password = cohondob \
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create SQL statement */
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " \
"VALUES (1, 'Paul', 32, 'California', 20000.00 ); " \
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " \
"VALUES (2, 'Allen', 25, 'Texas', 15000.00 ); " \
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)" \
"VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );" \
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)" \
"VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );";
/* Create a transactional object. */
work W(C);
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Records created successfully" << endl;
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
編譯並執行上述程式後,它將在 COMPANY 表中建立給定的記錄,並顯示以下兩行:
Opened database successfully: testdb Records created successfully
SELECT 操作
以下 C 程式碼段顯示瞭如何獲取和顯示上面示例中建立的 COMPANY 表中的記錄:
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
char * sql;
try {
connection C("dbname = testdb user = postgres password = cohondob \
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create SQL statement */
sql = "SELECT * from COMPANY";
/* Create a non-transactional object. */
nontransaction N(C);
/* Execute SQL query */
result R( N.exec( sql ));
/* List down all the records */
for (result::const_iterator c = R.begin(); c != R.end(); ++c) {
cout << "ID = " << c[0].as<int>() << endl;
cout << "Name = " << c[1].as<string>() << endl;
cout << "Age = " << c[2].as<int>() << endl;
cout << "Address = " << c[3].as<string>() << endl;
cout << "Salary = " << c[4].as<float>() << endl;
}
cout << "Operation done successfully" << endl;
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
編譯並執行上述程式後,將產生以下結果:
Opened database successfully: testdb ID = 1 Name = Paul Age = 32 Address = California Salary = 20000 ID = 2 Name = Allen Age = 25 Address = Texas Salary = 15000 ID = 3 Name = Teddy Age = 23 Address = Norway Salary = 20000 ID = 4 Name = Mark Age = 25 Address = Rich-Mond Salary = 65000 Operation done successfully
UPDATE 操作
以下 C 程式碼段顯示瞭如何使用 UPDATE 語句更新任何記錄,然後獲取和顯示 COMPANY 表中更新的記錄:
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
char * sql;
try {
connection C("dbname = testdb user = postgres password = cohondob \
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create a transactional object. */
work W(C);
/* Create SQL UPDATE statement */
sql = "UPDATE COMPANY set SALARY = 25000.00 where ID=1";
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Records updated successfully" << endl;
/* Create SQL SELECT statement */
sql = "SELECT * from COMPANY";
/* Create a non-transactional object. */
nontransaction N(C);
/* Execute SQL query */
result R( N.exec( sql ));
/* List down all the records */
for (result::const_iterator c = R.begin(); c != R.end(); ++c) {
cout << "ID = " << c[0].as<int>() << endl;
cout << "Name = " << c[1].as<string>() << endl;
cout << "Age = " << c[2].as<int>() << endl;
cout << "Address = " << c[3].as<string>() << endl;
cout << "Salary = " << c[4].as<float>() << endl;
}
cout << "Operation done successfully" << endl;
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
編譯並執行上述程式後,將產生以下結果:
Opened database successfully: testdb Records updated successfully ID = 2 Name = Allen Age = 25 Address = Texas Salary = 15000 ID = 3 Name = Teddy Age = 23 Address = Norway Salary = 20000 ID = 4 Name = Mark Age = 25 Address = Rich-Mond Salary = 65000 ID = 1 Name = Paul Age = 32 Address = California Salary = 25000 Operation done successfully
DELETE 操作
以下 C 程式碼段顯示瞭如何使用 DELETE 語句刪除任何記錄,然後獲取和顯示 COMPANY 表中剩餘的記錄:
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[]) {
char * sql;
try {
connection C("dbname = testdb user = postgres password = cohondob \
hostaddr = 127.0.0.1 port = 5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create a transactional object. */
work W(C);
/* Create SQL DELETE statement */
sql = "DELETE from COMPANY where ID = 2";
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Records deleted successfully" << endl;
/* Create SQL SELECT statement */
sql = "SELECT * from COMPANY";
/* Create a non-transactional object. */
nontransaction N(C);
/* Execute SQL query */
result R( N.exec( sql ));
/* List down all the records */
for (result::const_iterator c = R.begin(); c != R.end(); ++c) {
cout << "ID = " << c[0].as<int>() << endl;
cout << "Name = " << c[1].as<string>() << endl;
cout << "Age = " << c[2].as<int>() << endl;
cout << "Address = " << c[3].as<string>() << endl;
cout << "Salary = " << c[4].as<float>() << endl;
}
cout << "Operation done successfully" << endl;
C.disconnect ();
} catch (const std::exception &e) {
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
編譯並執行上述程式後,將產生以下結果:
Opened database successfully: testdb Records deleted successfully ID = 3 Name = Teddy Age = 23 Address = Norway Salary = 20000 ID = 4 Name = Mark Age = 25 Address = Rich-Mond Salary = 65000 ID = 1 Name = Paul Age = 32 Address = California Salary = 25000 Operation done successfully
PostgreSQL - JAVA 介面
安裝
在我們的 Java 程式中開始使用 PostgreSQL 之前,我們需要確保機器上已設定 PostgreSQL JDBC 和 Java。您可以檢視 Java 教程,瞭解如何在您的機器上安裝 Java。現在讓我們檢查如何設定 PostgreSQL JDBC 驅動程式。
從 postgresql-jdbc 儲存庫下載最新版本的postgresql-(VERSION).jdbc.jar。
將下載的 jar 檔案postgresql-(VERSION).jdbc.jar新增到您的類路徑中,或者您可以將其與 -classpath 選項一起使用,如下面的示例中所述。
以下部分假設您對 Java JDBC 概念略知一二。如果您沒有,建議您花半小時時間學習 JDBC 教程,以便熟悉下面解釋的概念。
連線到資料庫
以下 Java 程式碼顯示瞭如何連線到現有資料庫。如果資料庫不存在,則會建立它,最後返回資料庫物件。
import java.sql.Connection;
import java.sql.DriverManager;
public class PostgreSQLJDBC {
public static void main(String args[]) {
Connection c = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://:5432/testdb",
"postgres", "123");
} catch (Exception e) {
e.printStackTrace();
System.err.println(e.getClass().getName()+": "+e.getMessage());
System.exit(0);
}
System.out.println("Opened database successfully");
}
}
在編譯和執行上述程式之前,請在您的 PostgreSQL 安裝目錄中找到pg_hba.conf檔案並新增以下行:
# IPv4 local connections: host all all 127.0.0.1/32 md5
如果 postgres 伺服器未執行,您可以使用以下命令啟動/重新啟動它:
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
現在,讓我們編譯並執行上述程式以連線到 testdb。在這裡,我們使用postgres作為使用者 ID,使用123作為密碼來訪問資料庫。您可以根據您的資料庫配置和設定更改此設定。我們還假設當前版本的 JDBC 驅動程式postgresql-9.2-1002.jdbc3.jar在當前路徑中可用。
C:\JavaPostgresIntegration>javac PostgreSQLJDBC.java C:\JavaPostgresIntegration>java -cp c:\tools\postgresql-9.2-1002.jdbc3.jar;C:\JavaPostgresIntegration PostgreSQLJDBC Open database successfully
建立表
以下 Java 程式將用於在先前開啟的資料庫中建立表。確保您的目標資料庫中不存在此表。
import java.sql.*;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main( String args[] ) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://:5432/testdb",
"manisha", "123");
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "CREATE TABLE COMPANY " +
"(ID INT PRIMARY KEY NOT NULL," +
" NAME TEXT NOT NULL, " +
" AGE INT NOT NULL, " +
" ADDRESS CHAR(50), " +
" SALARY REAL)";
stmt.executeUpdate(sql);
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Table created successfully");
}
}
編譯並執行程式後,它將在testdb資料庫中建立 COMPANY 表,並顯示以下兩行:
Opened database successfully Table created successfully
INSERT 操作
以下 Java 程式顯示瞭如何在上面示例中建立的 COMPANY 表中建立記錄:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main(String args[]) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (1, 'Paul', 32, 'California', 20000.00 );";
stmt.executeUpdate(sql);
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (2, 'Allen', 25, 'Texas', 15000.00 );";
stmt.executeUpdate(sql);
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );";
stmt.executeUpdate(sql);
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );";
stmt.executeUpdate(sql);
stmt.close();
c.commit();
c.close();
} catch (Exception e) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Records created successfully");
}
}
編譯並執行上述程式後,它將在 COMPANY 表中建立給定的記錄,並顯示以下兩行:
Opened database successfully Records created successfully
SELECT 操作
以下 Java 程式顯示瞭如何獲取和顯示上面示例中建立的 COMPANY 表中的記錄:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main( String args[] ) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
ResultSet rs = stmt.executeQuery( "SELECT * FROM COMPANY;" );
while ( rs.next() ) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
String address = rs.getString("address");
float salary = rs.getFloat("salary");
System.out.println( "ID = " + id );
System.out.println( "NAME = " + name );
System.out.println( "AGE = " + age );
System.out.println( "ADDRESS = " + address );
System.out.println( "SALARY = " + salary );
System.out.println();
}
rs.close();
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Operation done successfully");
}
}
編譯並執行程式後,將產生以下結果:
Opened database successfully ID = 1 NAME = Paul AGE = 32 ADDRESS = California SALARY = 20000.0 ID = 2 NAME = Allen AGE = 25 ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy AGE = 23 ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark AGE = 25 ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
UPDATE 操作
以下 Java 程式碼顯示瞭如何使用 UPDATE 語句更新任何記錄,然後獲取和顯示 COMPANY 表中更新的記錄:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main( String args[] ) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "UPDATE COMPANY set SALARY = 25000.00 where ID=1;";
stmt.executeUpdate(sql);
c.commit();
ResultSet rs = stmt.executeQuery( "SELECT * FROM COMPANY;" );
while ( rs.next() ) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
String address = rs.getString("address");
float salary = rs.getFloat("salary");
System.out.println( "ID = " + id );
System.out.println( "NAME = " + name );
System.out.println( "AGE = " + age );
System.out.println( "ADDRESS = " + address );
System.out.println( "SALARY = " + salary );
System.out.println();
}
rs.close();
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Operation done successfully");
}
}
編譯並執行程式後,將產生以下結果:
Opened database successfully ID = 2 NAME = Allen AGE = 25 ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy AGE = 23 ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark AGE = 25 ADDRESS = Rich-Mond SALARY = 65000.0 ID = 1 NAME = Paul AGE = 32 ADDRESS = California SALARY = 25000.0 Operation done successfully
DELETE 操作
以下 Java 程式碼顯示瞭如何使用 DELETE 語句刪除任何記錄,然後獲取和顯示 COMPANY 表中剩餘的記錄:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class PostgreSQLJDBC6 {
public static void main( String args[] ) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "DELETE from COMPANY where ID = 2;";
stmt.executeUpdate(sql);
c.commit();
ResultSet rs = stmt.executeQuery( "SELECT * FROM COMPANY;" );
while ( rs.next() ) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
String address = rs.getString("address");
float salary = rs.getFloat("salary");
System.out.println( "ID = " + id );
System.out.println( "NAME = " + name );
System.out.println( "AGE = " + age );
System.out.println( "ADDRESS = " + address );
System.out.println( "SALARY = " + salary );
System.out.println();
}
rs.close();
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Operation done successfully");
}
}
編譯並執行程式後,將產生以下結果:
Opened database successfully ID = 3 NAME = Teddy AGE = 23 ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark AGE = 25 ADDRESS = Rich-Mond SALARY = 65000.0 ID = 1 NAME = Paul AGE = 32 ADDRESS = California SALARY = 25000.0 Operation done successfully
PostgreSQL - PHP 介面
安裝
PostgreSQL 擴充套件在最新版本的 PHP 5.3.x 中預設啟用。可以使用--without-pgsql在編譯時停用它。您仍然可以使用 yum 命令安裝 PHP -PostgreSQL 介面:
yum install php-pgsql
在開始使用 PHP PostgreSQL 介面之前,請在您的 PostgreSQL 安裝目錄中找到pg_hba.conf檔案並新增以下行:
# IPv4 local connections: host all all 127.0.0.1/32 md5
如果 postgres 伺服器未執行,您可以使用以下命令啟動/重新啟動它:
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
Windows 使用者必須啟用 php_pgsql.dll 才能使用此擴充套件。此 DLL 包含在最新版本的 PHP 5.3.x 的 Windows 發行版中。
有關詳細的安裝說明,請檢視我們的 PHP 教程及其官方網站。
PHP 介面 API
以下是重要的 PHP 例程,可以滿足您從 PHP 程式與 PostgreSQL 資料庫互動的需求。如果您正在尋找更復雜的應用程式,您可以檢視 PHP 官方文件。
| 序號 | API 和描述 |
|---|---|
| 1 | resource pg_connect ( string $connection_string [, int $connect_type ] ) 這將開啟到由 connection_string 指定的 PostgreSQL 資料庫的連線。 如果將 PGSQL_CONNECT_FORCE_NEW 作為 connect_type 傳遞,則即使 connection_string 與現有連線相同,在第二次呼叫 pg_connect() 時也會建立一個新連線。 |
| 2 | bool pg_connection_reset ( resource $connection ) 此例程重置連線。它對錯誤恢復很有用。成功時返回 TRUE,失敗時返回 FALSE。 |
| 3 | int pg_connection_status ( resource $connection ) 此例程返回指定連線的狀態。返回 PGSQL_CONNECTION_OK 或 PGSQL_CONNECTION_BAD。 |
| 4 | string pg_dbname ([ resource $connection ] ) 此函式返回給定 PostgreSQL 連線資源所連線的資料庫名稱。 |
| 5 | resource pg_prepare ([ resource $connection ], string $stmtname, string $query ) 此函式提交建立預處理語句的請求,並等待其完成。 |
| 6 | resource pg_execute ([ resource $connection ], string $stmtname, array $params ) 此函式傳送執行帶有給定引數的預處理語句的請求,並等待結果。 |
| 7 | resource pg_query ([ resource $connection ], string $query ) 此函式在指定的資料庫連線上執行查詢。 |
| 8 | array pg_fetch_row ( resource $result [, int $row ] ) 此函式從與指定結果資源關聯的結果集中獲取一行資料。 |
| 9 | array pg_fetch_all ( resource $result ) 此函式返回一個數組,其中包含結果資源中的所有行(記錄)。 |
| 10 | int pg_affected_rows ( resource $result ) 此函式返回 INSERT、UPDATE 和 DELETE 查詢影響的行數。 |
| 11 | int pg_num_rows ( resource $result ) 此函式返回 PostgreSQL 結果資源中的行數,例如 SELECT 語句返回的行數。 |
| 12 | bool pg_close ([ resource $connection ] ) 此函式關閉與給定連線資源關聯的非永續性 PostgreSQL 資料庫連線。 |
| 13 | string pg_last_error ([ resource $connection ] ) 此函式返回給定連線的最後一條錯誤訊息。 |
| 14 | string pg_escape_literal ([ resource $connection ], string $data ) 此函式轉義字面量,以便將其插入文字欄位。 |
| 15 | string pg_escape_string ([ resource $connection ], string $data ) 此函式跳脫字元串,以便用於資料庫查詢。 |
連線資料庫
以下 PHP 程式碼演示瞭如何連線到本地機器上的現有資料庫,最終將返回一個數據庫連線物件。
<?php
$host = "host = 127.0.0.1";
$port = "port = 5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
?>
現在,讓我們執行上述程式開啟我們的資料庫 **testdb**: 如果資料庫成功開啟,則會顯示以下訊息:
Opened database successfully
建立表
以下 PHP 程式將用於在先前建立的資料庫中建立表:
<?php
$host = "host = 127.0.0.1";
$port = "port = 5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
$sql =<<<EOF
CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
} else {
echo "Table created successfully\n";
}
pg_close($db);
?>
執行上述程式後,它將在您的 **testdb** 中建立 COMPANY 表,並顯示以下訊息:
Opened database successfully Table created successfully
INSERT 操作
以下 PHP 程式演示瞭如何在我們上面示例中建立的 COMPANY 表中建立記錄:
<?php
$host = "host=127.0.0.1";
$port = "port=5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
$sql =<<<EOF
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Paul', 32, 'California', 20000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Allen', 25, 'Texas', 15000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
} else {
echo "Records created successfully\n";
}
pg_close($db);
?>
執行上述程式後,它將在 COMPANY 表中建立給定的記錄,並顯示以下兩行:
Opened database successfully Records created successfully
SELECT 操作
以下 PHP 程式演示瞭如何從我們上面示例中建立的 COMPANY 表中獲取和顯示記錄:
<?php
$host = "host = 127.0.0.1";
$port = "port = 5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
$sql =<<<EOF
SELECT * from COMPANY;
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
exit;
}
while($row = pg_fetch_row($ret)) {
echo "ID = ". $row[0] . "\n";
echo "NAME = ". $row[1] ."\n";
echo "ADDRESS = ". $row[2] ."\n";
echo "SALARY = ".$row[4] ."\n\n";
}
echo "Operation done successfully\n";
pg_close($db);
?>
執行上述程式後,將產生以下結果。請注意,欄位按建立表時使用的順序返回。
Opened database successfully ID = 1 NAME = Paul ADDRESS = California SALARY = 20000 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
UPDATE 操作
以下 PHP 程式碼演示瞭如何使用 UPDATE 語句更新任何記錄,然後從我們的 COMPANY 表中獲取和顯示更新後的記錄:
<?php
$host = "host=127.0.0.1";
$port = "port=5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
$sql =<<<EOF
UPDATE COMPANY set SALARY = 25000.00 where ID=1;
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
exit;
} else {
echo "Record updated successfully\n";
}
$sql =<<<EOF
SELECT * from COMPANY;
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
exit;
}
while($row = pg_fetch_row($ret)) {
echo "ID = ". $row[0] . "\n";
echo "NAME = ". $row[1] ."\n";
echo "ADDRESS = ". $row[2] ."\n";
echo "SALARY = ".$row[4] ."\n\n";
}
echo "Operation done successfully\n";
pg_close($db);
?>
執行上述程式後,將產生以下結果:
Opened database successfully Record updated successfully ID = 2 NAME = Allen ADDRESS = 25 SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = 23 SALARY = 20000 ID = 4 NAME = Mark ADDRESS = 25 SALARY = 65000 ID = 1 NAME = Paul ADDRESS = 32 SALARY = 25000 Operation done successfully
DELETE 操作
以下 PHP 程式碼演示瞭如何使用 DELETE 語句刪除任何記錄,然後從我們的 COMPANY 表中獲取和顯示剩餘的記錄:
<?php
$host = "host = 127.0.0.1";
$port = "port = 5432";
$dbname = "dbname = testdb";
$credentials = "user = postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db) {
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
$sql =<<<EOF
DELETE from COMPANY where ID=2;
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
exit;
} else {
echo "Record deleted successfully\n";
}
$sql =<<<EOF
SELECT * from COMPANY;
EOF;
$ret = pg_query($db, $sql);
if(!$ret) {
echo pg_last_error($db);
exit;
}
while($row = pg_fetch_row($ret)) {
echo "ID = ". $row[0] . "\n";
echo "NAME = ". $row[1] ."\n";
echo "ADDRESS = ". $row[2] ."\n";
echo "SALARY = ".$row[4] ."\n\n";
}
echo "Operation done successfully\n";
pg_close($db);
?>
執行上述程式後,將產生以下結果:
Opened database successfully Record deleted successfully ID = 3 NAME = Teddy ADDRESS = 23 SALARY = 20000 ID = 4 NAME = Mark ADDRESS = 25 SALARY = 65000 ID = 1 NAME = Paul ADDRESS = 32 SALARY = 25000 Operation done successfully
PostgreSQL - Perl 介面
安裝
PostgreSQL 可以使用 Perl DBI 模組與 Perl 整合,這是一個用於 Perl 程式語言的資料庫訪問模組。它定義了一組方法、變數和約定,這些方法、變數和約定提供了一個標準的資料庫介面。
以下是您在 Linux/Unix 機器上安裝 DBI 模組的簡單步驟:
$ wget http://search.cpan.org/CPAN/authors/id/T/TI/TIMB/DBI-1.625.tar.gz $ tar xvfz DBI-1.625.tar.gz $ cd DBI-1.625 $ perl Makefile.PL $ make $ make install
如果您需要為 DBI 安裝 SQLite 驅動程式,則可以按如下方式安裝:
$ wget http://search.cpan.org/CPAN/authors/id/T/TU/TURNSTEP/DBD-Pg-2.19.3.tar.gz $ tar xvfz DBD-Pg-2.19.3.tar.gz $ cd DBD-Pg-2.19.3 $ perl Makefile.PL $ make $ make install
在開始使用 Perl PostgreSQL 介面之前,請在您的 PostgreSQL 安裝目錄中找到 **pg_hba.conf** 檔案並新增以下行:
# IPv4 local connections: host all all 127.0.0.1/32 md5
如果 postgres 伺服器未執行,您可以使用以下命令啟動/重新啟動它:
[root@host]# service postgresql restart Stopping postgresql service: [ OK ] Starting postgresql service: [ OK ]
DBI 介面 API
以下是重要的 DBI 函式,這些函式足以滿足您從 Perl 程式使用 SQLite 資料庫的要求。如果您正在尋找更復雜的應用程式,則可以查閱 Perl DBI 官方文件。
| 序號 | API 和描述 |
|---|---|
| 1 | DBI→connect($data_source, "userid", "password", \%attr) 建立到請求的 $data_source 的資料庫連線或會話。如果連線成功,則返回資料庫控制代碼物件。 資料來源具有如下形式:**DBI:Pg:dbname=$database;host=127.0.0.1;port=5432** Pg 是 PostgreSQL 驅動程式名稱,testdb 是資料庫名稱。 |
| 2 | $dbh→do($sql) 此函式準備並執行單個 SQL 語句。返回受影響的行數,或在出錯時返回 undef。返回值 -1 表示行數未知、不適用或不可用。這裡 $dbh 是 DBI→connect() 呼叫返回的控制代碼。 |
| 3 | $dbh→prepare($sql) 此函式準備稍後由資料庫引擎執行的語句,並返回對語句控制代碼物件的引用。 |
| 4 | $sth→execute() 此函式執行執行準備好的語句所需的任何處理。如果發生錯誤,則返回 undef。成功的執行始終返回 true,無論受影響的行數是多少。這裡 $sth 是 $dbh→prepare($sql) 呼叫返回的語句控制代碼。 |
| 5 | $sth→fetchrow_array() 此函式獲取下一行資料,並將其作為包含欄位值的列表返回。空欄位在列表中返回為 undef 值。 |
| 6 | $DBI::err 這等效於 $h→err,其中 $h 是任何控制代碼型別,例如 $dbh、$sth 或 $drh。這將返回上次呼叫的驅動程式方法的本機資料庫引擎錯誤程式碼。 |
| 7 | $DBI::errstr 這等效於 $h→errstr,其中 $h 是任何控制代碼型別,例如 $dbh、$sth 或 $drh。這將返回上次呼叫的 DBI 方法的本機資料庫引擎錯誤訊息。 |
| 8 | $dbh->disconnect() 此函式關閉先前由 DBI→connect() 呼叫開啟的資料庫連線。 |
連線資料庫
以下 Perl 程式碼演示瞭如何連線到現有資料庫。如果資料庫不存在,則會建立它,最終將返回一個數據庫物件。
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
現在,讓我們執行上述程式開啟我們的資料庫 **testdb**;如果資料庫成功開啟,則會顯示以下訊息:
Open database successfully
建立表
以下 Perl 程式將用於在先前建立的資料庫中建立表:
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname=$database;host=127.0.0.1;port=5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
my $stmt = qq(CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL););
my $rv = $dbh->do($stmt);
if($rv < 0) {
print $DBI::errstr;
} else {
print "Table created successfully\n";
}
$dbh->disconnect();
執行上述程式後,它將在您的 **testdb** 中建立 COMPANY 表,並顯示以下訊息:
Opened database successfully Table created successfully
INSERT 操作
以下 Perl 程式演示瞭如何在我們上面示例中建立的 COMPANY 表中建立記錄:
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
my $stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Paul', 32, 'California', 20000.00 ));
my $rv = $dbh->do($stmt) or die $DBI::errstr;
$stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Allen', 25, 'Texas', 15000.00 ));
$rv = $dbh->do($stmt) or die $DBI::errstr;
$stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 ));
$rv = $dbh->do($stmt) or die $DBI::errstr;
$stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 ););
$rv = $dbh->do($stmt) or die $DBI::errstr;
print "Records created successfully\n";
$dbh->disconnect();
執行上述程式後,它將在 COMPANY 表中建立給定的記錄,並顯示以下兩行:
Opened database successfully Records created successfully
SELECT 操作
以下 Perl 程式演示瞭如何從我們上面示例中建立的 COMPANY 表中獲取和顯示記錄:
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
my $stmt = qq(SELECT id, name, address, salary from COMPANY;);
my $sth = $dbh->prepare( $stmt );
my $rv = $sth->execute() or die $DBI::errstr;
if($rv < 0) {
print $DBI::errstr;
}
while(my @row = $sth->fetchrow_array()) {
print "ID = ". $row[0] . "\n";
print "NAME = ". $row[1] ."\n";
print "ADDRESS = ". $row[2] ."\n";
print "SALARY = ". $row[3] ."\n\n";
}
print "Operation done successfully\n";
$dbh->disconnect();
執行上述程式後,將產生以下結果:
Opened database successfully ID = 1 NAME = Paul ADDRESS = California SALARY = 20000 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
UPDATE 操作
以下 Perl 程式碼演示瞭如何使用 UPDATE 語句更新任何記錄,然後從我們的 COMPANY 表中獲取和顯示更新後的記錄:
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
my $stmt = qq(UPDATE COMPANY set SALARY = 25000.00 where ID=1;);
my $rv = $dbh->do($stmt) or die $DBI::errstr;
if( $rv < 0 ) {
print $DBI::errstr;
}else{
print "Total number of rows updated : $rv\n";
}
$stmt = qq(SELECT id, name, address, salary from COMPANY;);
my $sth = $dbh->prepare( $stmt );
$rv = $sth->execute() or die $DBI::errstr;
if($rv < 0) {
print $DBI::errstr;
}
while(my @row = $sth->fetchrow_array()) {
print "ID = ". $row[0] . "\n";
print "NAME = ". $row[1] ."\n";
print "ADDRESS = ". $row[2] ."\n";
print "SALARY = ". $row[3] ."\n\n";
}
print "Operation done successfully\n";
$dbh->disconnect();
執行上述程式後,將產生以下結果:
Opened database successfully Total number of rows updated : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 25000 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
DELETE 操作
以下 Perl 程式碼演示瞭如何使用 DELETE 語句刪除任何記錄,然後從我們的 COMPANY 表中獲取和顯示剩餘的記錄:
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname = $database;host = 127.0.0.1;port = 5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
my $stmt = qq(DELETE from COMPANY where ID=2;);
my $rv = $dbh->do($stmt) or die $DBI::errstr;
if( $rv < 0 ) {
print $DBI::errstr;
} else{
print "Total number of rows deleted : $rv\n";
}
$stmt = qq(SELECT id, name, address, salary from COMPANY;);
my $sth = $dbh->prepare( $stmt );
$rv = $sth->execute() or die $DBI::errstr;
if($rv < 0) {
print $DBI::errstr;
}
while(my @row = $sth->fetchrow_array()) {
print "ID = ". $row[0] . "\n";
print "NAME = ". $row[1] ."\n";
print "ADDRESS = ". $row[2] ."\n";
print "SALARY = ". $row[3] ."\n\n";
}
print "Operation done successfully\n";
$dbh->disconnect();
執行上述程式後,將產生以下結果:
Opened database successfully Total number of rows deleted : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 25000 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000 Operation done successfully
PostgreSQL - Python 介面
安裝
PostgreSQL 可以使用 psycopg2 模組與 Python 整合。psycopg2 是 Python 程式語言的 PostgreSQL 資料庫介面卡。psycopg2 的編寫目標是體積小、速度快且穩定可靠。您不需要單獨安裝此模組,因為它預設情況下與 Python 2.5.x 及更高版本一起提供。
如果您的機器上沒有安裝它,則可以使用 yum 命令按如下方式安裝:
$yum install python-psycopg2
要使用 psycopg2 模組,您必須首先建立一個表示資料庫的 Connection 物件,然後您可以選擇建立一個 cursor 物件,這將幫助您執行所有 SQL 語句。
Python psycopg2 模組 API
以下是重要的 psycopg2 模組函式,這些函式足以滿足您從 Python 程式使用 PostgreSQL 資料庫的要求。如果您正在尋找更復雜的應用程式,則可以查閱 Python psycopg2 模組的官方文件。
| 序號 | API 和描述 |
|---|---|
| 1 | psycopg2.connect(database="testdb", user="postgres", password="cohondob", host="127.0.0.1", port="5432") 此 API 開啟到 PostgreSQL 資料庫的連線。如果資料庫成功開啟,則返回一個連線物件。 |
| 2 | connection.cursor() 此函式建立一個 **遊標**,它將在您使用 Python 進行資料庫程式設計的整個過程中使用。 |
| 3 | cursor.execute(sql [, 可選引數]) 此函式執行 SQL 語句。SQL 語句可以是引數化的(即,使用佔位符而不是 SQL 字面量)。psycopg2 模組使用 %s 符號支援佔位符。 例如:cursor.execute("insert into people values (%s, %s)", (who, age)) |
| 4 | cursor.executemany(sql, seq_of_parameters) 此函式針對在序列 sql 中找到的所有引數序列或對映執行 SQL 命令。 |
| 5 | cursor.callproc(procname[, parameters]) 此函式執行具有給定名稱的儲存資料庫過程。引數序列必須包含過程期望的每個引數的一個條目。 |
| 6 | cursor.rowcount 此只讀屬性返回上次 last execute*() 修改、插入或刪除的資料庫行總數。 |
| 7 | connection.commit() 此方法提交當前事務。如果您不呼叫此方法,則自上次呼叫 commit() 以來所做的任何操作都無法從其他資料庫連線中看到。 |
| 8 | connection.rollback() 此方法回滾自上次呼叫 commit() 以來對資料庫的任何更改。 |
| 9 | connection.close() 此方法關閉資料庫連線。請注意,這不會自動呼叫 commit()。如果您在先呼叫 commit() 之前關閉資料庫連線,則您的更改將會丟失! |
| 10 | cursor.fetchone() 此方法獲取查詢結果集的下一行,返回單個序列,或者當沒有更多資料可用時返回 None。 |
| 11 | cursor.fetchmany([size=cursor.arraysize]) 此函式獲取查詢結果的下一組行,返回一個列表。當沒有更多行可用時,將返回一個空列表。此方法嘗試獲取與 size 引數指示的相同數量的行。 |
| 12 | cursor.fetchall() 此函式獲取查詢結果的所有(剩餘)行,返回一個列表。當沒有行可用時,將返回一個空列表。 |
連線資料庫
以下 Python 程式碼演示瞭如何連線到現有資料庫。如果資料庫不存在,則會建立它,最終將返回一個數據庫物件。
#!/usr/bin/python import psycopg2 conn = psycopg2.connect(database="testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432") print "Opened database successfully"
在這裡,您還可以提供資料庫 **testdb** 作為名稱,如果資料庫成功開啟,則會顯示以下訊息:
Open database successfully
建立表
以下 Python 程式將用於在先前建立的資料庫中建立表:
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute('''CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);''')
print "Table created successfully"
conn.commit()
conn.close()
執行上述程式後,它將在您的 **test.db** 中建立 COMPANY 表,並顯示以下訊息:
Opened database successfully Table created successfully
INSERT 操作
以下 Python 程式演示瞭如何在我們上面示例中建立的 COMPANY 表中建立記錄:
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (1, 'Paul', 32, 'California', 20000.00 )");
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (2, 'Allen', 25, 'Texas', 15000.00 )");
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 )");
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 )");
conn.commit()
print "Records created successfully";
conn.close()
執行上述程式後,它將在 COMPANY 表中建立給定的記錄,並顯示以下兩行:
Opened database successfully Records created successfully
SELECT 操作
以下Python程式展示瞭如何從我們在上面示例中建立的COMPANY表中獲取和顯示記錄:
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("SELECT id, name, address, salary from COMPANY")
rows = cur.fetchall()
for row in rows:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully";
conn.close()
執行上述程式後,將產生以下結果:
Opened database successfully ID = 1 NAME = Paul ADDRESS = California SALARY = 20000.0 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
UPDATE 操作
以下Python程式碼展示瞭如何使用UPDATE語句更新任何記錄,然後從我們的COMPANY表中獲取和顯示更新後的記錄:
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("UPDATE COMPANY set SALARY = 25000.00 where ID = 1")
conn.commit()
print "Total number of rows updated :", cur.rowcount
cur.execute("SELECT id, name, address, salary from COMPANY")
rows = cur.fetchall()
for row in rows:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully";
conn.close()
執行上述程式後,將產生以下結果:
Opened database successfully Total number of rows updated : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 25000.0 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
DELETE 操作
以下Python程式碼展示瞭如何使用DELETE語句刪除任何記錄,然後從我們的COMPANY表中獲取和顯示剩餘的記錄:
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database = "testdb", user = "postgres", password = "pass123", host = "127.0.0.1", port = "5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("DELETE from COMPANY where ID=2;")
conn.commit()
print "Total number of rows deleted :", cur.rowcount
cur.execute("SELECT id, name, address, salary from COMPANY")
rows = cur.fetchall()
for row in rows:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully";
conn.close()
執行上述程式後,將產生以下結果:
Opened database successfully Total number of rows deleted : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 20000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully