- MapReduce 教程
- MapReduce - 首頁
- MapReduce - 簡介
- MapReduce - 演算法
- MapReduce - 安裝
- MapReduce - API
- MapReduce - Hadoop 實現
- MapReduce - 分割槽器
- MapReduce - 組合器
- MapReduce - Hadoop 管理
- MapReduce 資源
- MapReduce 快速指南
- MapReduce - 有用資源
- MapReduce - 討論
MapReduce 快速指南
MapReduce - 簡介
MapReduce 是一種程式設計模型,用於編寫可以在多個節點上並行處理大資料的應用程式。MapReduce 提供了分析海量複雜資料的能力。
什麼是大資料?
大資料是指無法使用傳統計算技術處理的大型資料集的集合。例如,Facebook 或 YouTube 每天需要收集和管理的資料量就屬於大資料的範疇。然而,大資料不僅僅是規模和體積,它還涉及以下一個或多個方面:速度、多樣性、體積和複雜性。
為什麼選擇 MapReduce?
傳統的企業系統通常擁有一箇中心伺服器來儲存和處理資料。下圖描述了傳統企業系統的示意圖。傳統模型當然不適合處理海量可擴充套件資料,並且無法被標準資料庫伺服器容納。此外,集中式系統在同時處理多個檔案時會造成大量的瓶頸。
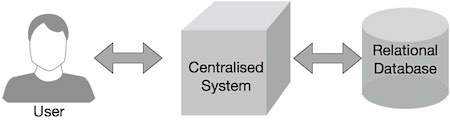
Google 使用名為 MapReduce 的演算法解決了這個瓶頸問題。MapReduce 將任務分成小部分,並將它們分配給許多計算機。之後,結果在一個地方收集並整合以形成結果資料集。

MapReduce 如何工作?
MapReduce 演算法包含兩個重要的任務,即 Map 和 Reduce。
Map 任務接收一組資料並將其轉換為另一組資料,其中各個元素被分解成元組(鍵值對)。
Reduce 任務接收 Map 的輸出作為輸入,並將這些資料元組(鍵值對)組合成更小的元組集。
Reduce 任務總是在 Map 作業之後執行。
現在讓我們仔細看看每個階段,並嘗試瞭解它們的意義。
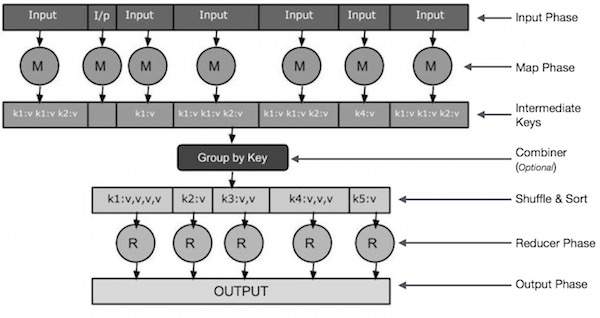
輸入階段 - 在這裡,我們有一個 Record Reader,它轉換輸入檔案中的每個記錄,並將解析後的資料以鍵值對的形式傳送到 Mapper。
Map - Map 是一個使用者定義的函式,它接收一系列鍵值對,並處理其中的每一個以生成零個或多個鍵值對。
中間鍵 - Mapper 生成的鍵值對被稱為中間鍵。
組合器 - 組合器是一種本地 Reducer,它將 Map 階段的相似資料分組到可識別的集合中。它接收來自 Mapper 的中間鍵作為輸入,並應用使用者定義的程式碼在一個 Mapper 的小範圍內聚合值。它不是 MapReduce 演算法的主要部分;它是可選的。
混洗和排序 - Reducer 任務從混洗和排序步驟開始。它將分組的鍵值對下載到本地機器,Reducer 在該機器上執行。各個鍵值對按鍵排序到一個更大的資料列表中。資料列表將等效的鍵分組在一起,以便可以輕鬆地在 Reducer 任務中迭代它們的值。
Reducer - Reducer 將分組的鍵值對資料作為輸入,並在每個鍵值對上執行 Reducer 函式。在這裡,資料可以以多種方式進行聚合、過濾和組合,並且需要廣泛的處理。執行完成後,它會向最後一步提供零個或多個鍵值對。
輸出階段 - 在輸出階段,我們有一個輸出格式化程式,它轉換 Reducer 函式的最終鍵值對,並使用記錄寫入器將它們寫入檔案。
讓我們嘗試藉助一個小圖表來了解 Map & Reduce 這兩個任務 -

MapReduce 示例
讓我們來看一個現實世界的例子,以理解 MapReduce 的強大功能。Twitter 每天接收大約 5 億條推文,即每秒近 3000 條推文。下圖顯示了 Tweeter 如何藉助 MapReduce 管理其推文。
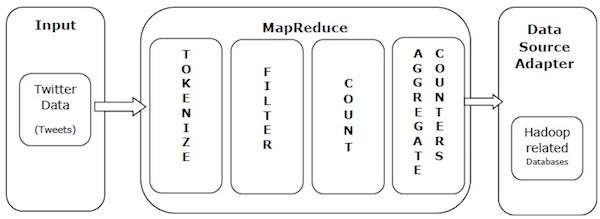
如圖所示,MapReduce 演算法執行以下操作:
標記化 - 將推文標記化為標記對映,並將它們寫為鍵值對。
過濾 - 從標記對映中過濾不需要的單詞,並將過濾後的對映寫為鍵值對。
計數 - 為每個單詞生成一個標記計數器。
聚合計數器 - 將相似的計數器值聚合為小的可管理單元。
MapReduce - 演算法
MapReduce 演算法包含兩個重要的任務,即 Map 和 Reduce。
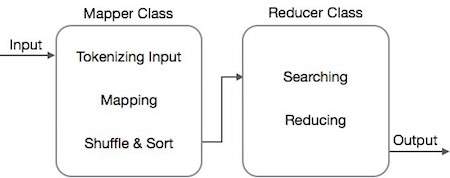
- Map 任務透過 Mapper 類完成
- Reduce 任務透過 Reducer 類完成。
Mapper 類接收輸入,對其進行標記化、對映和排序。Mapper 類的輸出被用作 Reducer 類的輸入,後者反過來搜尋匹配對並對其進行歸約。
MapReduce 實現各種數學演算法,將任務分成小部分並將其分配給多個系統。從技術角度來看,MapReduce 演算法有助於將 Map & Reduce 任務傳送到叢集中的適當伺服器。
這些數學演算法可能包括:
- 排序
- 搜尋
- 索引
- TF-IDF
排序
排序是處理和分析資料的基本 MapReduce 演算法之一。MapReduce 實現排序演算法以按其鍵自動對來自 Mapper 的輸出鍵值對進行排序。
排序方法在 Mapper 類本身中實現。
在混洗和排序階段,在對 Mapper 類中的值進行標記化後,Context 類(使用者定義類)將匹配的值鍵作為集合收集。
為了收集相似的鍵值對(中間鍵),Mapper 類藉助RawComparator 類對鍵值對進行排序。
在將給定 Reducer 的中間鍵值對集合呈現給 Reducer 之前,Hadoop 會自動對其進行排序以形成鍵值 (K2, {V2, V2, …})。
搜尋
搜尋在 MapReduce 演算法中扮演著重要的角色。它有助於組合器階段(可選)和 Reducer 階段。讓我們嘗試透過一個例子來了解搜尋是如何工作的。
示例
以下示例顯示了 MapReduce 如何使用搜索演算法在一個給定的員工資料集中找出薪水最高的員工的詳細資訊。
讓我們假設我們在四個不同的檔案中(A、B、C 和 D)擁有員工資料。讓我們還假設由於重複從所有資料庫表匯入員工資料,所有四個檔案中都有重複的員工記錄。請參見下圖。
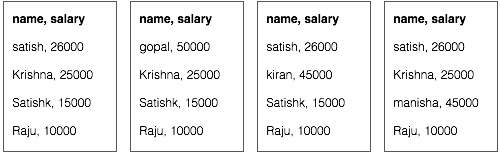
Map 階段處理每個輸入檔案,並以鍵值對的形式提供員工資料(<k, v> : <員工姓名, 工資>)。請參見下圖。

組合器階段(搜尋技術)將接收來自 Map 階段的輸入作為鍵值對,其中包含員工姓名和工資。使用搜索技術,組合器將檢查所有員工的工資,以查詢每個檔案中薪水最高的員工。請參見以下程式碼片段。
<k: employee name, v: salary>
Max= the salary of an first employee. Treated as max salary
if(v(second employee).salary > Max){
Max = v(salary);
}
else{
Continue checking;
}
預期結果如下:
|
Reducer 階段 - 從每個檔案中,你將找到薪水最高的員工。為了避免冗餘,請檢查所有 <k, v> 對並消除任何重複項。相同的演算法用於四個 <k, v> 對之間,這四個 <k, v> 對來自四個輸入檔案。最終輸出應如下所示:
<gopal, 50000>
索引
通常使用索引來指向特定資料及其地址。它對特定 Mapper 的輸入檔案執行批次索引。
MapReduce 中通常使用的索引技術稱為倒排索引。像 Google 和 Bing 這樣的搜尋引擎使用倒排索引技術。讓我們嘗試透過一個簡單的例子來了解索引是如何工作的。
示例
以下文字是倒排索引的輸入。這裡 T[0]、T[1] 和 t[2] 是檔名,它們的內容用雙引號括起來。
T[0] = "it is what it is" T[1] = "what is it" T[2] = "it is a banana"
應用索引演算法後,我們得到以下輸出:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
這裡 "a": {2} 表示術語 "a" 出現在 T[2] 檔案中。類似地,"is": {0, 1, 2} 表示術語 "is" 出現在 T[0]、T[1] 和 T[2] 檔案中。
TF-IDF
TF-IDF 是一種文字處理演算法,它是術語頻率 - 逆文件頻率的縮寫。它是常見的 Web 分析演算法之一。在這裡,“頻率”一詞指的是術語在文件中出現的次數。
詞頻 (TF)
它衡量特定術語在文件中出現的頻率。它是透過文件中單詞出現的次數除以該文件中單詞的總數來計算的。
TF(the) = (Number of times term the ‘the’ appears in a document) / (Total number of terms in the document)
逆文件頻率 (IDF)
它衡量術語的重要性。它是透過文字資料庫中的文件數量除以特定術語出現的文件數量來計算的。
在計算 TF 時,所有術語都被認為同等重要。這意味著 TF 計算正常單詞(如“is”、“a”、“what”等)的詞頻。因此,我們需要知道頻繁出現的術語,同時透過計算以下內容來擴充套件稀有術語:
IDF(the) = log_e(Total number of documents / Number of documents with term ‘the’ in it).
以下是透過一個小例子來解釋該演算法。
示例
考慮一個包含 1000 個單詞的文件,其中單詞hive 出現了 50 次。那麼hive 的 TF 為 (50 / 1000) = 0.05。
現在,假設我們有 1000 萬個文件,其中單詞hive 出現在其中的 1000 個文件中。然後,IDF 計算為 log(10,000,000 / 1,000) = 4。
TF-IDF 權重是這些數量的乘積 - 0.05 × 4 = 0.20。
MapReduce - 安裝
MapReduce 僅適用於 Linux 風格的作業系統,並且它與 Hadoop 框架內建在一起。我們需要執行以下步驟才能安裝 Hadoop 框架。
驗證 JAVA 安裝
安裝 Hadoop 之前,必須在系統上安裝 Java。 使用以下命令檢查系統上是否已安裝 Java。
$ java –version
如果系統上已安裝 Java,則會看到以下響應:
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果系統上未安裝 Java,請按照以下步驟操作。
安裝 Java
步驟 1
從以下連結下載最新版本的 Java:此連結。
下載後,您可以在“下載”資料夾中找到檔案 **jdk-7u71-linux-x64.tar.gz**。
步驟 2
使用以下命令解壓 jdk-7u71-linux-x64.gz 的內容。
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
步驟 3
要使所有使用者都能使用 Java,必須將其移動到“/usr/local/”位置。 切換到 root 使用者並輸入以下命令:
$ su password: # mv jdk1.7.0_71 /usr/local/java # exit
步驟 4
要設定 PATH 和 JAVA_HOME 變數,請將以下命令新增到 ~/.bashrc 檔案中。
export JAVA_HOME=/usr/local/java export PATH=$PATH:$JAVA_HOME/bin
將所有更改應用於當前執行的系統。
$ source ~/.bashrc
步驟 5
使用以下命令配置 Java 備選方案:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2 # alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 # alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 # alternatives --set java usr/local/java/bin/java # alternatives --set javac usr/local/java/bin/javac # alternatives --set jar usr/local/java/bin/jar
現在,使用終端中的命令 **java -version** 驗證安裝。
驗證 Hadoop 安裝
安裝 MapReduce 之前,必須在系統上安裝 Hadoop。 讓我們使用以下命令驗證 Hadoop 安裝:
$ hadoop version
如果系統上已安裝 Hadoop,則會收到以下響應:
Hadoop 2.4.1 -- Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
如果系統上未安裝 Hadoop,請繼續執行以下步驟。
下載 Hadoop
從 Apache 軟體基金會下載 Hadoop 2.4.1,並使用以下命令解壓其內容。
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
以偽分散式模式安裝 Hadoop
以下步驟用於以偽分散式模式安裝 Hadoop 2.4.1。
步驟 1 - 設定 Hadoop
您可以透過將以下命令新增到 ~/.bashrc 檔案來設定 Hadoop 環境變數。
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
將所有更改應用於當前執行的系統。
$ source ~/.bashrc
步驟 2 - Hadoop 配置
您可以在“$HADOOP_HOME/etc/hadoop”位置找到所有 Hadoop 配置檔案。 您需要根據您的 Hadoop 基礎架構對這些配置檔案進行適當的更改。
$ cd $HADOOP_HOME/etc/hadoop
為了使用 Java 開發 Hadoop 程式,您必須在 **hadoop-env.sh** 檔案中重置 Java 環境變數,方法是用系統中 Java 的位置替換 JAVA_HOME 值。
export JAVA_HOME=/usr/local/java
您必須編輯以下檔案以配置 Hadoop:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
core-site.xml 包含以下資訊:
- Hadoop 例項使用的埠號
- 為檔案系統分配的記憶體
- 儲存資料的記憶體限制
- 讀/寫緩衝區的大小
開啟 core-site.xml 並將以下屬性新增到
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://:9000 </value>
</property>
</configuration>
hdfs-site.xml
hdfs-site.xml 包含以下資訊:
- 複製資料的數值
- NameNode 路徑
- 本地檔案系統的 DataNode 路徑(您要儲存 Hadoop 基礎架構的位置)
讓我們假設以下資料。
dfs.replication (data replication value) = 1 (In the following path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
開啟此檔案,並將以下屬性新增到
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>
**注意** - 在上面的檔案中,所有屬性值都是使用者定義的,您可以根據您的 Hadoop 基礎架構進行更改。
yarn-site.xml
此檔案用於將 Yarn 配置到 Hadoop 中。 開啟 yarn-site.xml 檔案,並將以下屬性新增到
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
此檔案用於指定我們使用的 MapReduce 框架。 預設情況下,Hadoop 包含 yarn-site.xml 的模板。 首先,您需要使用以下命令將檔案從 mapred-site.xml.template 複製到 mapred-site.xml 檔案。
$ cp mapred-site.xml.template mapred-site.xml
開啟 mapred-site.xml 檔案,並將以下屬性新增到
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
驗證 Hadoop 安裝
以下步驟用於驗證 Hadoop 安裝。
步驟 1 - NameNode 設定
使用命令“hdfs namenode -format”設定 namenode,如下所示:
$ cd ~ $ hdfs namenode -format
預期結果如下:
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
步驟 2 - 驗證 Hadoop dfs
執行以下命令以啟動 Hadoop 檔案系統。
$ start-dfs.sh
預期輸出如下:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
步驟 3 - 驗證 Yarn 指令碼
以下命令用於啟動 Yarn 指令碼。 執行此命令將啟動您的 Yarn 守護程式。
$ start-yarn.sh
預期輸出如下:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting node manager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
步驟 4 - 在瀏覽器上訪問 Hadoop
訪問 Hadoop 的預設埠號為 50070。 使用以下 URL 在瀏覽器上獲取 Hadoop 服務。
https://:50070/
以下螢幕截圖顯示了 Hadoop 瀏覽器。

步驟 5 - 驗證叢集的所有應用程式
訪問叢集所有應用程式的預設埠號為 8088。 使用以下 URL 使用此服務。
https://:8088/
以下螢幕截圖顯示了 Hadoop 叢集瀏覽器。

MapReduce - API
在本章中,我們將仔細研究參與 MapReduce 程式設計操作的類及其方法。 我們將主要關注以下內容:
- JobContext 介面
- Job 類
- Mapper 類
- Reducer 類
JobContext 介面
JobContext 介面是所有類的超介面,它定義了 MapReduce 中的不同作業。 它提供作業的只讀檢視,在任務執行時提供給任務。
以下是 JobContext 介面的子介面。
| 序號 | 子介面描述 |
|---|---|
| 1. | MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
定義提供給 Mapper 的上下文。 |
| 2. | ReduceContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
定義傳遞給 Reducer 的上下文。 |
Job 類是實現 JobContext 介面的主要類。
Job 類
Job 類是 MapReduce API 中最重要的類。 它允許使用者配置作業、提交作業、控制作業執行以及查詢狀態。 set 方法僅在作業提交之前有效,之後它們將丟擲 IllegalStateException 異常。
通常,使用者建立應用程式,描述作業的各個方面,然後提交作業並監控其進度。
以下是提交作業的示例:
// Create a new Job
Job job = new Job(new Configuration());
job.setJarByClass(MyJob.class);
// Specify various job-specific parameters
job.setJobName("myjob");
job.setInputPath(new Path("in"));
job.setOutputPath(new Path("out"));
job.setMapperClass(MyJob.MyMapper.class);
job.setReducerClass(MyJob.MyReducer.class);
// Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true);
建構函式
以下是 Job 類的建構函式摘要。
| 序號 | 建構函式摘要 |
|---|---|
| 1 | Job() |
| 2 | **Job**(Configuration conf) |
| 3 | **Job**(Configuration conf, String jobName) |
方法
Job 類的一些重要方法如下:
| 序號 | 方法描述 |
|---|---|
| 1 | getJobName()
使用者指定的作業名稱。 |
| 2 | getJobState() 返回作業的當前狀態。 |
| 3 | isComplete() 檢查作業是否已完成。 |
| 4 | setInputFormatClass() 設定作業的 InputFormat。 |
| 5 | setJobName(String name) 設定使用者指定的作業名稱。 |
| 6 | setOutputFormatClass() 設定作業的 OutputFormat。 |
| 7 | setMapperClass(Class) 設定作業的 Mapper。 |
| 8 | setReducerClass(Class) 設定作業的 Reducer。 |
| 9 | setPartitionerClass(Class) 設定作業的 Partitioner。 |
| 10 | setCombinerClass(Class) 設定作業的 Combiner。 |
Mapper 類
Mapper 類定義 Map 作業。 將輸入鍵值對對映到一組中間鍵值對。 Mapper 是將輸入記錄轉換為中間記錄的單個任務。 變換後的中間記錄的型別不必與輸入記錄相同。 給定的輸入對可以對映到零個或多個輸出對。
方法
**map** 是 Mapper 類中最突出的方法。 語法定義如下:
map(KEYIN key, VALUEIN value, org.apache.hadoop.mapreduce.Mapper.Context context)
此方法針對輸入分片中的每個鍵值對呼叫一次。
Reducer 類
Reducer 類定義 MapReduce 中的 Reduce 作業。 它將共享一個鍵的一組中間值減少到較小的一組值。 Reducer 實現可以透過 JobContext.getConfiguration() 方法訪問作業的 Configuration。 Reducer 有三個主要階段:Shuffle、Sort 和 Reduce。
**Shuffle** - Reducer 使用 HTTP 透過網路複製來自每個 Mapper 的已排序輸出。
**Sort** - 框架按鍵合併排序 Reducer 輸入(因為不同的 Mapper 可能會輸出相同的鍵)。 Shuffle 和 Sort 階段同時發生,即在獲取輸出時,它們會合並。
**Reduce** - 在此階段,reduce(Object, Iterable, Context) 方法針對已排序輸入中的每個
方法
**reduce** 是 Reducer 類中最突出的方法。 語法定義如下:
reduce(KEYIN key, Iterable<VALUEIN> values, org.apache.hadoop.mapreduce.Reducer.Context context)
此方法針對鍵值對集合中的每個鍵呼叫一次。
MapReduce - Hadoop 實現
MapReduce 是一個框架,用於編寫應用程式以可靠的方式處理大型商品硬體叢集上大量資料。 本章將引導您使用 Java 在 Hadoop 框架中操作 MapReduce。
MapReduce 演算法
通常,MapReduce 範例基於將 map-reduce 程式傳送到實際資料所在的計算機。
在 MapReduce 作業期間,Hadoop 將 Map 和 Reduce 任務傳送到叢集中的相應伺服器。
框架管理所有資料傳遞細節,例如發出任務、驗證任務完成以及在節點之間複製叢集周圍的資料。
大部分計算發生在具有本地磁碟資料的節點上,從而減少了網路流量。
完成給定任務後,叢集將收集並減少資料以形成適當的結果,並將其傳送回 Hadoop 伺服器。

輸入和輸出(Java 視角)
MapReduce 框架操作鍵值對,也就是說,框架將作業的輸入視為一組鍵值對,併產生一組鍵值對作為作業的輸出,這些鍵值對可能型別不同。
鍵和值類必須由框架序列化,因此需要實現 Writable 介面。 此外,鍵類必須實現 WritableComparable 介面以方便框架排序。
MapReduce 作業的輸入和輸出格式都是鍵值對的形式:
(輸入) <k1, v1> -> map -> <k2, v2> -> reduce -> <k3, v3> (輸出)。
| 輸入 | 輸出 | |
|---|---|---|
| Map | <k1, v1> | 列表 (<k2, v2>) |
| Reduce | <k2, 列表(v2)> | 列表 (<k3, v3>) |
MapReduce 實現
下表顯示了有關組織電力消耗的資料。 該表包括連續五年的月度電力消耗和年度平均值。
| 一月 | 二月 | 三月 | 四月 | 五月 | 六月 | 七月 | 八月 | 九月 | 十月 | 十一月 | 十二月 | 平均 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
我們需要編寫應用程式來處理給定表中的輸入資料,以查詢最大使用量年份、最小使用量年份等等。對於具有有限記錄數量的程式設計師來說,此任務很容易,因為他們只需編寫邏輯以生成所需的輸出,並將資料傳遞到已編寫的應用程式。
現在讓我們提高輸入資料規模。假設我們需要分析某個州所有大型工業的電力消耗。當我們編寫應用程式來處理如此大量的資料時,
它們將花費大量時間執行。
當我們將資料從源移動到網路伺服器時,網路流量將會非常大。
為了解決這些問題,我們有MapReduce框架。
輸入資料
以上資料儲存為sample.txt檔案,並作為輸入提供。輸入檔案如下所示。
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
示例程式
以下程式使用MapReduce框架處理示例資料。
package hadoop;
import java.util.*;
import java.io.IOException;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class ProcessUnits
{
//Mapper class
public static class E_EMapper extends MapReduceBase implements
Mapper<LongWritable, /*Input key Type */
Text, /*Input value Type*/
Text, /*Output key Type*/
IntWritable> /*Output value Type*/
{
//Map function
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException
{
String line = value.toString();
String lasttoken = null;
StringTokenizer s = new StringTokenizer(line,"\t");
String year = s.nextToken();
while(s.hasMoreTokens()){
lasttoken=s.nextToken();
}
int avgprice = Integer.parseInt(lasttoken);
output.collect(new Text(year), new IntWritable(avgprice));
}
}
//Reducer class
public static class E_EReduce extends MapReduceBase implements
Reducer< Text, IntWritable, Text, IntWritable >
{
//Reduce function
public void reduce(Text key, Iterator <IntWritable> values, OutputCollector>Text, IntWritable> output, Reporter reporter) throws IOException
{
int maxavg=30;
int val=Integer.MIN_VALUE;
while (values.hasNext())
{
if((val=values.next().get())>maxavg)
{
output.collect(key, new IntWritable(val));
}
}
}
}
//Main function
public static void main(String args[])throws Exception
{
JobConf conf = new JobConf(Eleunits.class);
conf.setJobName("max_eletricityunits");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(E_EMapper.class);
conf.setCombinerClass(E_EReduce.class);
conf.setReducerClass(E_EReduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
將上述程式儲存為ProcessUnits.java。程式的編譯和執行如下所示。
ProcessUnits程式的編譯和執行
假設我們在Hadoop使用者的家目錄中(例如,/home/hadoop)。
請按照以下步驟編譯和執行上述程式。
步驟1 − 使用以下命令建立一個目錄來儲存編譯後的Java類。
$ mkdir units
步驟2 − 下載Hadoop-core-1.2.1.jar,該檔案用於編譯和執行MapReduce程式。從mvnrepository.com下載jar包。假設下載資料夾為/home/hadoop/。
步驟3 − 使用以下命令編譯ProcessUnits.java程式併為程式建立一個jar包。
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java $ jar -cvf units.jar -C units/ .
步驟4 − 使用以下命令在HDFS中建立一個輸入目錄。
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
步驟5 − 使用以下命令將名為sample.txt的輸入檔案複製到HDFS的輸入目錄中。
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dir
步驟6 − 使用以下命令驗證輸入目錄中的檔案。
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
步驟7 − 使用以下命令執行Eleunit_max應用程式,並從輸入目錄中獲取輸入檔案。
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir
等待一段時間直到檔案執行完畢。執行後,輸出包含許多輸入分片、Map任務、Reduce任務等。
INFO mapreduce.Job: Job job_1414748220717_0002 completed successfully 14/10/31 06:02:52 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=61 FILE: Number of bytes written=279400 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=546 HDFS: Number of bytes written=40 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=146137 Total time spent by all reduces in occupied slots (ms)=441 Total time spent by all map tasks (ms)=14613 Total time spent by all reduce tasks (ms)=44120 Total vcore-seconds taken by all map tasks=146137 Total vcore-seconds taken by all reduce tasks=44120 Total megabyte-seconds taken by all map tasks=149644288 Total megabyte-seconds taken by all reduce tasks=45178880 Map-Reduce Framework Map input records=5 Map output records=5 Map output bytes=45 Map output materialized bytes=67 Input split bytes=208 Combine input records=5 Combine output records=5 Reduce input groups=5 Reduce shuffle bytes=6 Reduce input records=5 Reduce output records=5 Spilled Records=10 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=948 CPU time spent (ms)=5160 Physical memory (bytes) snapshot=47749120 Virtual memory (bytes) snapshot=2899349504 Total committed heap usage (bytes)=277684224 File Output Format Counters Bytes Written=40
步驟8 − 使用以下命令驗證輸出資料夾中的結果檔案。
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
步驟9 − 使用以下命令檢視Part-00000檔案中的輸出。此檔案由HDFS生成。
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
以下是MapReduce程式生成的輸出:
| 1981 | 34 |
| 1984 | 40 |
| 1985 | 45 |
步驟10 − 使用以下命令將輸出資料夾從HDFS複製到本地檔案系統。
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs -get output_dir /home/hadoop
MapReduce - 分割槽器
分割槽器在處理輸入資料集時就像一個條件。分割槽階段發生在Map階段之後,Reduce階段之前。
分割槽器的數量等於Reducer的數量。這意味著分割槽器將根據Reducer的數量劃分資料。因此,從單個分割槽器傳遞的資料由單個Reducer處理。
分割槽器
分割槽器對中間Map輸出的鍵值對進行分割槽。它使用使用者定義的條件(類似於雜湊函式)對資料進行分割槽。分割槽的總數與作業的Reducer任務數相同。讓我們來看一個例子來理解分割槽器是如何工作的。
MapReduce分割槽器實現
為方便起見,讓我們假設我們有一個名為Employee的小表,包含以下資料。我們將使用此示例資料作為我們的輸入資料集來演示分割槽器的工作方式。
| Id | Name | Age | Gender | Salary |
|---|---|---|---|---|
| 1201 | gopal | 45 | Male | 50,000 |
| 1202 | manisha | 40 | Female | 50,000 |
| 1203 | khalil | 34 | Male | 30,000 |
| 1204 | prasanth | 30 | Male | 30,000 |
| 1205 | kiran | 20 | Male | 40,000 |
| 1206 | laxmi | 25 | Female | 35,000 |
| 1207 | bhavya | 20 | Female | 15,000 |
| 1208 | reshma | 19 | Female | 15,000 |
| 1209 | kranthi | 22 | Male | 22,000 |
| 1210 | Satish | 24 | Male | 25,000 |
| 1211 | Krishna | 25 | Male | 25,000 |
| 1212 | Arshad | 28 | Male | 20,000 |
| 1213 | lavanya | 18 | Female | 8,000 |
我們需要編寫一個應用程式來處理輸入資料集,以查詢不同年齡組(例如,20歲以下、21歲到30歲、30歲以上)中按性別劃分的最高薪員工。
輸入資料
以上資料儲存在“/home/hadoop/hadoopPartitioner”目錄下的input.txt檔案中,並作為輸入提供。
| 1201 | gopal | 45 | Male | 50000 |
| 1202 | manisha | 40 | Female | 51000 |
| 1203 | khaleel | 34 | Male | 30000 |
| 1204 | prasanth | 30 | Male | 31000 |
| 1205 | kiran | 20 | Male | 40000 |
| 1206 | laxmi | 25 | Female | 35000 |
| 1207 | bhavya | 20 | Female | 15000 |
| 1208 | reshma | 19 | Female | 14000 |
| 1209 | kranthi | 22 | Male | 22000 |
| 1210 | Satish | 24 | Male | 25000 |
| 1211 | Krishna | 25 | Male | 26000 |
| 1212 | Arshad | 28 | Male | 20000 |
| 1213 | lavanya | 18 | Female | 8000 |
基於給定的輸入,以下是程式的演算法解釋。
Map任務
Map任務接受鍵值對作為輸入,而我們有文字檔案中的文字資料。此Map任務的輸入如下:
輸入 − 鍵將是類似於“任何特殊鍵 + 檔名 + 行號”的模式(例如:key = @input1),值將是該行中的資料(例如:value = 1201 \t gopal \t 45 \t Male \t 50000)。
方法 − 此Map任務的操作如下:
讀取value(記錄資料),它作為輸入值從引數列表中的字串傳入。
使用split函式,分離性別並存儲到字串變數中。
String[] str = value.toString().split("\t", -3);
String gender=str[3];
將性別資訊和記錄資料value作為鍵值對從Map任務輸出到分割槽任務。
context.write(new Text(gender), new Text(value));
對文字檔案中的所有記錄重複以上所有步驟。
輸出 − 您將獲得性別數據和記錄資料值作為鍵值對。
分割槽器任務
分割槽器任務接受來自Map任務的鍵值對作為其輸入。分割槽意味著將資料分成多個段。根據給定的分割槽條件標準,輸入鍵值對資料可以根據年齡標準分為三部分。
輸入 − 鍵值對集合中的所有資料。
key = 記錄中的性別欄位值。
value = 該性別的整個記錄資料值。
方法 − 分割槽邏輯過程如下。
- 從輸入鍵值對中讀取年齡欄位值。
String[] str = value.toString().split("\t");
int age = Integer.parseInt(str[2]);
使用以下條件檢查年齡值。
- 年齡小於或等於20
- 年齡大於20且小於或等於30。
- 年齡大於30。
if(age<=20)
{
return 0;
}
else if(age>20 && age<=30)
{
return 1 % numReduceTasks;
}
else
{
return 2 % numReduceTasks;
}
輸出 − 鍵值對的所有資料被分成三個鍵值對集合。Reducer將分別對每個集合進行處理。
Reduce任務
分割槽器任務的數量等於Reducer任務的數量。這裡我們有三個分割槽器任務,因此我們需要執行三個Reducer任務。
輸入 − Reducer將使用不同的鍵值對集合執行三次。
key = 記錄中的性別欄位值。
value = 該性別的整個記錄資料。
方法 − 以下邏輯將應用於每個集合。
- 讀取每個記錄的薪資欄位值。
String [] str = val.toString().split("\t", -3);
Note: str[4] have the salary field value.
將薪資與max變數進行比較。如果str[4]是最高薪資,則將str[4]賦值給max,否則跳過此步驟。
if(Integer.parseInt(str[4])>max)
{
max=Integer.parseInt(str[4]);
}
對每個鍵集合(Male & Female是鍵集合)重複步驟1和2。執行這三個步驟後,您將找到Male鍵集合中的最高薪資和Female鍵集合中的最高薪資。
context.write(new Text(key), new IntWritable(max));
輸出 − 最後,您將獲得三個不同年齡組的鍵值對資料集合。它分別包含每個年齡組中Male集合和Female集合中的最高薪資。
執行Map、分割槽器和Reduce任務後,三個鍵值對資料集合將作為輸出儲存在三個不同的檔案中。
所有三個任務都被視為MapReduce作業。這些作業的以下要求和規範應在配置中指定:
- 作業名稱
- 鍵和值的輸入和輸出格式
- Map、Reduce和分割槽器任務的各個類
Configuration conf = getConf(); //Create Job Job job = new Job(conf, "topsal"); job.setJarByClass(PartitionerExample.class); // File Input and Output paths FileInputFormat.setInputPaths(job, new Path(arg[0])); FileOutputFormat.setOutputPath(job,new Path(arg[1])); //Set Mapper class and Output format for key-value pair. job.setMapperClass(MapClass.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //set partitioner statement job.setPartitionerClass(CaderPartitioner.class); //Set Reducer class and Input/Output format for key-value pair. job.setReducerClass(ReduceClass.class); //Number of Reducer tasks. job.setNumReduceTasks(3); //Input and Output format for data job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class);
示例程式
以下程式展示瞭如何在MapReduce程式中為給定條件實現分割槽器。
package partitionerexample;
import java.io.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
import org.apache.hadoop.util.*;
public class PartitionerExample extends Configured implements Tool
{
//Map class
public static class MapClass extends Mapper<LongWritable,Text,Text,Text>
{
public void map(LongWritable key, Text value, Context context)
{
try{
String[] str = value.toString().split("\t", -3);
String gender=str[3];
context.write(new Text(gender), new Text(value));
}
catch(Exception e)
{
System.out.println(e.getMessage());
}
}
}
//Reducer class
public static class ReduceClass extends Reducer<Text,Text,Text,IntWritable>
{
public int max = -1;
public void reduce(Text key, Iterable <Text> values, Context context) throws IOException, InterruptedException
{
max = -1;
for (Text val : values)
{
String [] str = val.toString().split("\t", -3);
if(Integer.parseInt(str[4])>max)
max=Integer.parseInt(str[4]);
}
context.write(new Text(key), new IntWritable(max));
}
}
//Partitioner class
public static class CaderPartitioner extends
Partitioner < Text, Text >
{
@Override
public int getPartition(Text key, Text value, int numReduceTasks)
{
String[] str = value.toString().split("\t");
int age = Integer.parseInt(str[2]);
if(numReduceTasks == 0)
{
return 0;
}
if(age<=20)
{
return 0;
}
else if(age>20 && age<=30)
{
return 1 % numReduceTasks;
}
else
{
return 2 % numReduceTasks;
}
}
}
@Override
public int run(String[] arg) throws Exception
{
Configuration conf = getConf();
Job job = new Job(conf, "topsal");
job.setJarByClass(PartitionerExample.class);
FileInputFormat.setInputPaths(job, new Path(arg[0]));
FileOutputFormat.setOutputPath(job,new Path(arg[1]));
job.setMapperClass(MapClass.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//set partitioner statement
job.setPartitionerClass(CaderPartitioner.class);
job.setReducerClass(ReduceClass.class);
job.setNumReduceTasks(3);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true)? 0 : 1);
return 0;
}
public static void main(String ar[]) throws Exception
{
int res = ToolRunner.run(new Configuration(), new PartitionerExample(),ar);
System.exit(0);
}
}
將上述程式碼儲存為PartitionerExample.java,檔案路徑為“/home/hadoop/hadoopPartitioner”。程式的編譯和執行如下所示。
編譯和執行
假設我們在Hadoop使用者的家目錄中(例如,/home/hadoop)。
請按照以下步驟編譯和執行上述程式。
步驟1 − 下載Hadoop-core-1.2.1.jar,該檔案用於編譯和執行MapReduce程式。您可以從mvnrepository.com下載jar包。
假設下載資料夾為“/home/hadoop/hadoopPartitioner”
步驟2 − 使用以下命令編譯程式PartitionerExample.java併為程式建立一個jar包。
$ javac -classpath hadoop-core-1.2.1.jar -d ProcessUnits.java $ jar -cvf PartitionerExample.jar -C .
步驟3 − 使用以下命令在HDFS中建立一個輸入目錄。
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
步驟4 − 使用以下命令將名為input.txt的輸入檔案複製到HDFS的輸入目錄中。
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/hadoopPartitioner/input.txt input_dir
步驟5 − 使用以下命令驗證輸入目錄中的檔案。
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
步驟6 − 使用以下命令執行Top salary應用程式,並從輸入目錄中獲取輸入檔案。
$HADOOP_HOME/bin/hadoop jar PartitionerExample.jar partitionerexample.PartitionerExample input_dir/input.txt output_dir
等待一段時間直到檔案執行完畢。執行後,輸出包含許多輸入分片、Map任務和Reducer任務。
15/02/04 15:19:51 INFO mapreduce.Job: Job job_1423027269044_0021 completed successfully 15/02/04 15:19:52 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=467 FILE: Number of bytes written=426777 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=480 HDFS: Number of bytes written=72 HDFS: Number of read operations=12 HDFS: Number of large read operations=0 HDFS: Number of write operations=6 Job Counters Launched map tasks=1 Launched reduce tasks=3 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=8212 Total time spent by all reduces in occupied slots (ms)=59858 Total time spent by all map tasks (ms)=8212 Total time spent by all reduce tasks (ms)=59858 Total vcore-seconds taken by all map tasks=8212 Total vcore-seconds taken by all reduce tasks=59858 Total megabyte-seconds taken by all map tasks=8409088 Total megabyte-seconds taken by all reduce tasks=61294592 Map-Reduce Framework Map input records=13 Map output records=13 Map output bytes=423 Map output materialized bytes=467 Input split bytes=119 Combine input records=0 Combine output records=0 Reduce input groups=6 Reduce shuffle bytes=467 Reduce input records=13 Reduce output records=6 Spilled Records=26 Shuffled Maps =3 Failed Shuffles=0 Merged Map outputs=3 GC time elapsed (ms)=224 CPU time spent (ms)=3690 Physical memory (bytes) snapshot=553816064 Virtual memory (bytes) snapshot=3441266688 Total committed heap usage (bytes)=334102528 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=361 File Output Format Counters Bytes Written=72
步驟7 − 使用以下命令驗證輸出資料夾中的結果檔案。
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
您將在三個檔案中找到輸出,因為您在程式中使用了三個分割槽器和三個Reducer。
步驟8 − 使用以下命令檢視Part-00000檔案中的輸出。此檔案由HDFS生成。
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
Part-00000中的輸出
Female 15000 Male 40000
使用以下命令檢視Part-00001檔案中的輸出。
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00001
Part-00001中的輸出
Female 35000 Male 31000
使用以下命令檢視Part-00002檔案中的輸出。
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00002
Part-00002中的輸出
Female 51000 Male 50000
MapReduce - 組合器
Combiner,也稱為半歸約器,是一個可選的類,它透過接受來自Map類的輸入,然後將輸出鍵值對傳遞給Reducer類來執行。
Combiner 的主要功能是彙總具有相同鍵的 Map 輸出記錄。Combiner 的輸出(鍵值對集合)將透過網路傳送到實際的 Reducer 任務作為輸入。
Combiner
Combiner 類用於 Map 類和 Reduce 類之間,以減少 Map 和 Reduce 之間的資料傳輸量。通常情況下,Map 任務的輸出量很大,傳輸到 Reduce 任務的資料量也很高。
下面的 MapReduce 任務圖顯示了 COMBINER 階段。
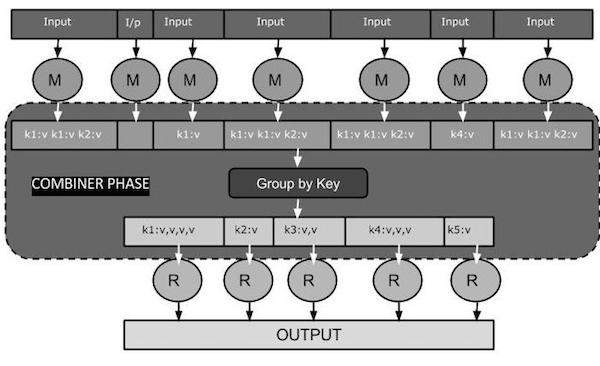
Combiner 如何工作?
以下是關於 MapReduce Combiner 如何工作的簡要總結:
Combiner 沒有預定義的介面,它必須實現 Reducer 介面的 reduce() 方法。
Combiner 對每個 Map 輸出鍵進行操作。它必須與 Reducer 類具有相同的輸出鍵值型別。
Combiner 可以從大型資料集中生成彙總資訊,因為它替換了原始的 Map 輸出。
雖然 Combiner 是可選的,但它有助於將資料分成多個組以便進行 Reduce 階段處理,從而簡化處理過程。
MapReduce Combiner 實現
下面的示例提供了一個關於 Combiner 的理論概念。讓我們假設我們有以下名為 **input.txt** 的 MapReduce 輸入文字檔案。
What do you mean by Object What do you know about Java What is Java Virtual Machine How Java enabled High Performance
下面討論了包含 Combiner 的 MapReduce 程式的重要階段。
記錄讀取器 (Record Reader)
這是 MapReduce 的第一個階段,記錄讀取器從輸入文字檔案中逐行讀取文字,並以鍵值對的形式輸出。
**輸入** - 來自輸入檔案的逐行文字。
**輸出** - 形成鍵值對。以下是預期的鍵值對集合。
<1, What do you mean by Object> <2, What do you know about Java> <3, What is Java Virtual Machine> <4, How Java enabled High Performance>
Map 階段
Map 階段從記錄讀取器接收輸入,對其進行處理,併產生另一組鍵值對作為輸出。
**輸入** - 從記錄讀取器接收到的以下鍵值對是輸入。
<1, What do you mean by Object> <2, What do you know about Java> <3, What is Java Virtual Machine> <4, How Java enabled High Performance>
Map 階段讀取每個鍵值對,使用 StringTokenizer 將值中的每個單詞分開,將每個單詞作為鍵,並將該單詞的計數作為值。以下程式碼片段顯示了 Mapper 類和 map 函式。
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
**輸出** - 預期輸出如下:
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1> <What,1> <do,1> <you,1> <know,1> <about,1> <Java,1> <What,1> <is,1> <Java,1> <Virtual,1> <Machine,1> <How,1> <Java,1> <enabled,1> <High,1> <Performance,1>
Combiner 階段
Combiner 階段接收來自 Map 階段的每個鍵值對,對其進行處理,併產生 **鍵值對集合** 作為輸出。
**輸入** - 從 Map 階段接收到的以下鍵值對是輸入。
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1> <What,1> <do,1> <you,1> <know,1> <about,1> <Java,1> <What,1> <is,1> <Java,1> <Virtual,1> <Machine,1> <How,1> <Java,1> <enabled,1> <High,1> <Performance,1>
Combiner 階段讀取每個鍵值對,將公共單詞組合為鍵,將值組合為集合。通常,Combiner 的程式碼和操作類似於 Reducer。以下是 Mapper、Combiner 和 Reducer 類宣告的程式碼片段。
job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class);
**輸出** - 預期輸出如下:
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,1,1,1> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Reducer 階段
Reducer 階段接收來自 Combiner 階段的每個鍵值對集合,對其進行處理,並將輸出作為鍵值對傳遞。請注意,Combiner 的功能與 Reducer 相同。
**輸入** - 從 Combiner 階段接收到的以下鍵值對是輸入。
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,1,1,1> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Reducer 階段讀取每個鍵值對。以下是 Combiner 的程式碼片段。
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
**輸出** - Reducer 階段的預期輸出如下:
<What,3> <do,2> <you,2> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,3> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
記錄寫入器 (Record Writer)
這是 MapReduce 的最後階段,記錄寫入器寫入 Reducer 階段的每個鍵值對,並將輸出作為文字傳送。
**輸入** - 來自 Reducer 階段的每個鍵值對以及輸出格式。
**輸出** - 它以文字格式提供鍵值對。以下是預期輸出。
What 3 do 2 you 2 mean 1 by 1 Object 1 know 1 about 1 Java 3 is 1 Virtual 1 Machine 1 How 1 enabled 1 High 1 Performance 1
示例程式
下面的程式碼塊計算程式中單詞的數量。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
將上述程式儲存為 **WordCount.java**。程式的編譯和執行如下所示。
編譯和執行
讓我們假設我們在 Hadoop 使用者的主目錄中(例如,/home/hadoop)。
請按照以下步驟編譯和執行上述程式。
步驟1 − 使用以下命令建立一個目錄來儲存編譯後的Java類。
$ mkdir units
**步驟 2** - 下載 Hadoop-core-1.2.1.jar,用於編譯和執行 MapReduce 程式。您可以從 mvnrepository.com 下載該 jar 包。
讓我們假設下載的資料夾是 /home/hadoop/。
**步驟 3** - 使用以下命令編譯 **WordCount.java** 程式併為該程式建立一個 jar 包。
$ javac -classpath hadoop-core-1.2.1.jar -d units WordCount.java $ jar -cvf units.jar -C units/ .
**步驟 4** - 使用以下命令在 HDFS 中建立一個輸入目錄。
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
**步驟 5** - 使用以下命令將名為 **input.txt** 的輸入檔案複製到 HDFS 的輸入目錄中。
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/input.txt input_dir
**步驟 6** - 使用以下命令驗證輸入目錄中的檔案。
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
**步驟 7** - 使用以下命令執行 Word count 應用程式,從輸入目錄獲取輸入檔案。
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir
等待一段時間直到檔案執行完畢。執行後,輸出包含許多輸入分片、Map 任務和 Reducer 任務。
**步驟 8** - 使用以下命令驗證輸出資料夾中的結果檔案。
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
**步驟 9** - 使用以下命令檢視 **Part-00000** 檔案中的輸出。此檔案由 HDFS 生成。
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
以下是 MapReduce 程式生成的輸出。
What 3 do 2 you 2 mean 1 by 1 Object 1 know 1 about 1 Java 3 is 1 Virtual 1 Machine 1 How 1 enabled 1 High 1 Performance 1
MapReduce - Hadoop 管理
本章解釋 Hadoop 管理,包括 HDFS 和 MapReduce 管理。
HDFS 管理包括監控 HDFS 檔案結構、位置和更新的檔案。
MapReduce 管理包括監控應用程式列表、節點配置、應用程式狀態等。
HDFS 監控
HDFS(Hadoop 分散式檔案系統)包含使用者目錄、輸入檔案和輸出檔案。使用 MapReduce 命令 **put** 和 **get** 進行儲存和檢索。
透過在“/$HADOOP_HOME/sbin”上執行命令“start-all.sh”啟動 Hadoop 框架(守護程序)後,將以下 URL 傳遞到瀏覽器“https://:50070”。您應該在瀏覽器上看到以下螢幕。
以下螢幕截圖顯示瞭如何瀏覽 HDFS。

以下螢幕截圖顯示了 HDFS 的檔案結構。它顯示了“/user/hadoop”目錄中的檔案。

以下螢幕截圖顯示了叢集中的 DataNode 資訊。在這裡您可以找到一個節點及其配置和容量。

MapReduce 作業監控
MapReduce 應用程式是作業的集合(Map 作業、Combiner、Partitioner 和 Reduce 作業)。必須監控和維護以下內容:
- 適合應用程式的 datanode 配置。
- 每個應用程式使用的 datanode 數量和資源。
為了監控所有這些內容,我們必須擁有一個使用者介面。透過在“/$HADOOP_HOME/sbin”上執行命令“start-all.sh”啟動 Hadoop 框架後,將以下 URL 傳遞到瀏覽器“https://:8080”。您應該在瀏覽器上看到以下螢幕。

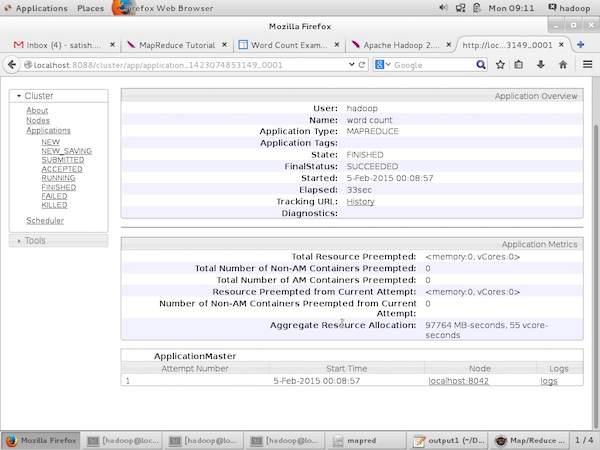
在上圖中,滑鼠指標位於應用程式 ID 上。只需單擊它即可在瀏覽器上找到以下螢幕。它描述了以下內容:
當前應用程式在哪個使用者下執行
應用程式名稱
該應用程式的型別
當前狀態、最終狀態
應用程式啟動時間、經過時間(完成時間),如果在監控時已完成
此應用程式的歷史記錄,即日誌資訊
最後,節點資訊,即參與執行應用程式的節點。
以下螢幕截圖顯示了特定應用程式的詳細資訊:
以下螢幕截圖描述了當前正在執行的節點資訊。此處,螢幕截圖僅包含一個節點。滑鼠指標顯示正在執行的節點的本地主機地址。
