- MapReduce 教程
- MapReduce - 首頁
- MapReduce - 簡介
- MapReduce - 演算法
- MapReduce - 安裝
- MapReduce - API
- MapReduce - Hadoop 實現
- MapReduce - 分割槽器
- MapReduce - 合併器
- MapReduce - Hadoop 管理
- MapReduce 資源
- MapReduce - 快速指南
- MapReduce - 有用資源
- MapReduce - 討論
MapReduce - 演算法
MapReduce 演算法包含兩個重要的任務,即 Map 和 Reduce。
- map 任務透過 Mapper 類完成
- reduce 任務透過 Reducer 類完成。
Mapper 類接收輸入,對其進行標記化、對映和排序。Mapper 類的輸出被用作 Reducer 類的輸入,後者依次搜尋匹配的鍵值對並對其進行歸約。
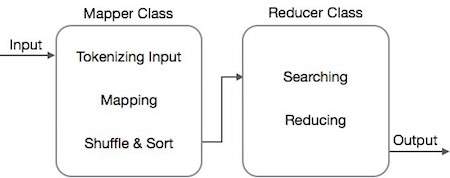
MapReduce 使用各種數學演算法將任務分解成小部分並將其分配給多個系統。從技術角度講,MapReduce 演算法有助於將 Map 和 Reduce 任務傳送到叢集中相應的伺服器。
這些數學演算法可能包括以下內容 -
- 排序
- 搜尋
- 索引
- TF-IDF
排序
排序是處理和分析資料的基本 MapReduce 演算法之一。MapReduce 實現排序演算法以根據其鍵自動對來自對映器的輸出鍵值對進行排序。
排序方法在對映器類本身中實現。
在 Shuffle 和 Sort 階段,在對對映器類中的值進行標記化後,Context 類(使用者定義類)將匹配的值鍵作為集合收集。
為了收集類似的鍵值對(中間鍵),Mapper 類藉助 RawComparator 類對鍵值對進行排序。
給定 Reducer 的中間鍵值對集合由 Hadoop 自動排序,以形成鍵值(K2,{V2,V2,…}),然後將其呈現給 Reducer。
搜尋
搜尋在 MapReduce 演算法中起著重要作用。它有助於合併器階段(可選)和 Reducer 階段。讓我們嘗試透過一個例子來了解搜尋是如何工作的。
示例
以下示例顯示了 MapReduce 如何使用搜索演算法查詢給定員工資料集裡薪資最高的員工的詳細資訊。
假設我們在四個不同的檔案中擁有員工資料 - A、B、C 和 D。還假設由於從所有資料庫表重複匯入員工資料,因此所有四個檔案中都存在重複的員工記錄。請參閱以下插圖。
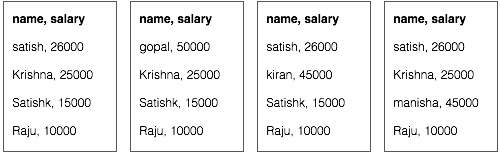
Map 階段處理每個輸入檔案,並以鍵值對(<k, v> : <員工姓名, 薪資>)的形式提供員工資料。請參閱以下插圖。

合併器階段(搜尋技術)將接收來自 Map 階段的輸入,作為帶有員工姓名和薪資的鍵值對。使用搜索技術,合併器將檢查所有員工的薪資,以查詢每個檔案中薪資最高的員工。請參閱以下程式碼片段。
<k: employee name, v: salary>
Max= the salary of an first employee. Treated as max salary
if(v(second employee).salary > Max){
Max = v(salary);
}
else{
Continue checking;
}
預期結果如下 -
|
Reducer 階段 - 從每個檔案中,您將找到薪資最高的員工。為了避免冗餘,請檢查所有 <k, v> 對並消除任何重複項。在來自四個輸入檔案的四個 <k, v> 對之間使用相同的演算法。最終輸出應如下 -
<gopal, 50000>
索引
通常使用索引來指向特定資料及其地址。它對特定對映器的輸入檔案執行批次索引。
MapReduce 中通常使用的索引技術稱為倒排索引。像 Google 和 Bing 這樣的搜尋引擎使用倒排索引技術。讓我們嘗試透過一個簡單的例子來了解索引是如何工作的。
示例
以下文字是倒排索引的輸入。這裡 T[0]、T[1] 和 t[2] 是檔名,它們的內容用雙引號括起來。
T[0] = "it is what it is" T[1] = "what is it" T[2] = "it is a banana"
應用索引演算法後,我們得到以下輸出 -
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
這裡 "a": {2} 表示術語 "a" 出現在 T[2] 檔案中。類似地,"is": {0, 1, 2} 表示術語 "is" 出現在 T[0]、T[1] 和 T[2] 檔案中。
TF-IDF
TF-IDF 是一種文字處理演算法,它是術語頻率 - 逆文件頻率的縮寫。它是常見的 Web 分析演算法之一。這裡,“頻率”一詞是指某個術語在一個文件中出現的次數。
詞頻 (TF)
它衡量特定術語在一個文件中出現的頻率。它是透過一個單詞在一個文件中出現的次數除以該文件中的總單詞數來計算的。
TF(the) = (Number of times term the ‘the’ appears in a document) / (Total number of terms in the document)
逆文件頻率 (IDF)
它衡量術語的重要性。它是透過文字資料庫中的文件總數除以特定術語出現的文件數來計算的。
在計算 TF 時,所有術語都被認為同等重要。這意味著,TF 計算像“is”、“a”、“what”等普通詞的詞頻。因此,我們需要在按比例放大稀有詞的同時瞭解常用詞,方法是計算以下內容 -
IDF(the) = log_e(Total number of documents / Number of documents with term ‘the’ in it).
以下將透過一個小型示例來解釋該演算法。
示例
考慮一個包含 1000 個單詞的文件,其中單詞 hive 出現了 50 次。那麼 hive 的 TF 為 (50 / 1000) = 0.05。
現在,假設我們有 1000 萬個文件,並且單詞 hive 出現在其中的 1000 個文件中。然後,IDF 計算為 log(10,000,000 / 1,000) = 4。
TF-IDF 權重是這些量的乘積 - 0.05 × 4 = 0.20。