- MapReduce 教程
- MapReduce - 首頁
- MapReduce - 簡介
- MapReduce - 演算法
- MapReduce - 安裝
- MapReduce - API
- MapReduce - Hadoop 實現
- MapReduce - 分割槽器
- MapReduce - 組合器
- MapReduce - Hadoop 管理
- MapReduce 資源
- MapReduce - 快速指南
- MapReduce - 有用資源
- MapReduce - 討論
MapReduce - 簡介
MapReduce 是一種程式設計模型,用於編寫可以在多個節點上並行處理大資料的應用程式。MapReduce 提供了分析海量複雜資料的能力。
什麼是大資料?
大資料是指無法使用傳統計算技術處理的大型資料集的集合。例如,Facebook 或 Youtube 每天需要收集和管理的資料量就屬於大資料範疇。然而,大資料不僅僅是規模和體積,它還涉及以下一個或多個方面:速度、多樣性、體積和複雜性。
為什麼要使用 MapReduce?
傳統的企業系統通常使用集中式伺服器來儲存和處理資料。下圖描述了傳統企業系統的示意圖。傳統模型顯然不適合處理海量可擴充套件的資料,並且無法由標準資料庫伺服器容納。此外,集中式系統在同時處理多個檔案時會造成嚴重的瓶頸。
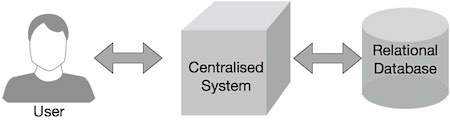
Google 使用名為 MapReduce 的演算法解決了這個瓶頸問題。MapReduce 將任務劃分為小的部分,並將它們分配給許多計算機。之後,結果將收集到一個地方並整合以形成結果資料集。

MapReduce 如何工作?
MapReduce 演算法包含兩個重要的任務,即 Map 和 Reduce。
Map 任務接收一組資料並將其轉換為另一組資料,其中各個元素被分解成元組(鍵值對)。
Reduce 任務接收 Map 的輸出作為輸入,並將這些資料元組(鍵值對)組合成更小的元組集。
Reduce 任務總是在 Map 作業之後執行。
現在讓我們仔細看看每個階段,並嘗試理解它們的意義。
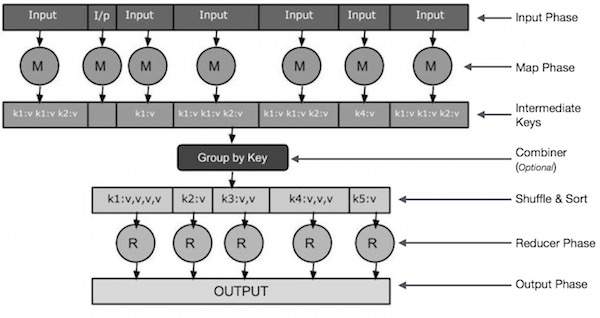
輸入階段 - 在這裡,我們有一個 Record Reader,它轉換輸入檔案中的每個記錄,並將解析後的資料以鍵值對的形式傳送到 Mapper。
Map - Map 是一個使用者定義的函式,它接收一系列鍵值對,並處理每個鍵值對以生成零個或多個鍵值對。
中間鍵 - Mapper 生成的鍵值對稱為中間鍵。
組合器 - 組合器是一種本地 Reducer,它將 Map 階段中的相似資料分組到可識別的集合中。它接收來自 Mapper 的中間鍵作為輸入,並應用使用者定義的程式碼來在一個 Mapper 的小範圍內聚合值。它不是 MapReduce 演算法的主要部分;它是可選的。
混洗和排序 - Reducer 任務從混洗和排序步驟開始。它將分組的鍵值對下載到本地機器上,Reducer 在該機器上執行。各個鍵值對按鍵排序成更大的資料列表。資料列表將等效的鍵分組在一起,以便可以輕鬆地在 Reducer 任務中迭代它們的值。
Reducer - Reducer 將分組的鍵值對資料作為輸入,並在每個鍵值對上執行 Reducer 函式。在這裡,資料可以以多種方式進行聚合、過濾和組合,並且需要廣泛的處理。執行完成後,它會向最後一步提供零個或多個鍵值對。
輸出階段 - 在輸出階段,我們有一個輸出格式化程式,它轉換來自 Reducer 函式的最終鍵值對,並使用記錄寫入器將它們寫入檔案。
讓我們嘗試藉助一個小圖表來理解 Map 和 Reduce 這兩個任務:

MapReduce 示例
讓我們以一個現實世界的例子來理解 MapReduce 的強大功能。Twitter 每天接收大約 5 億條推文,大約每秒 3000 條推文。下圖顯示了 Tweeter 如何藉助 MapReduce 來管理其推文。
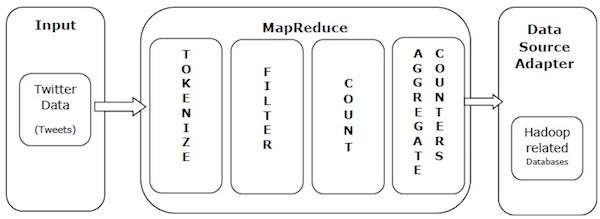
如下圖所示,MapReduce 演算法執行以下操作:
標記化 - 將推文標記化為標記對映,並將它們寫為鍵值對。
過濾 - 從標記對映中過濾不需要的詞,並將過濾後的對映寫為鍵值對。
計數 - 為每個詞生成一個標記計數器。
聚合計數器 - 將類似的計數器值聚合為小的易於管理的單元。