- MapReduce 教程
- MapReduce - 首頁
- MapReduce - 簡介
- MapReduce - 演算法
- MapReduce - 安裝
- MapReduce - API
- MapReduce - Hadoop 實現
- MapReduce - 分割槽器
- MapReduce - 組合器
- MapReduce - Hadoop 管理
- MapReduce 資源
- MapReduce - 快速指南
- MapReduce - 有用資源
- MapReduce - 討論
MapReduce - 組合器
組合器,也稱為**半歸約器**,是一個可選的類,它透過接受來自 Map 類的輸入,然後將輸出鍵值對傳遞給 Reducer 類來執行。
組合器的主要功能是彙總具有相同鍵的 map 輸出記錄。組合器的輸出(鍵值集合)將作為輸入透過網路傳送到實際的 Reducer 任務。
組合器
組合器類用於 Map 類和 Reduce 類之間,以減少 Map 和 Reduce 之間的資料傳輸量。通常,map 任務的輸出很大,傳輸到 reduce 任務的資料量很大。
下面的 MapReduce 任務圖顯示了組合器階段。
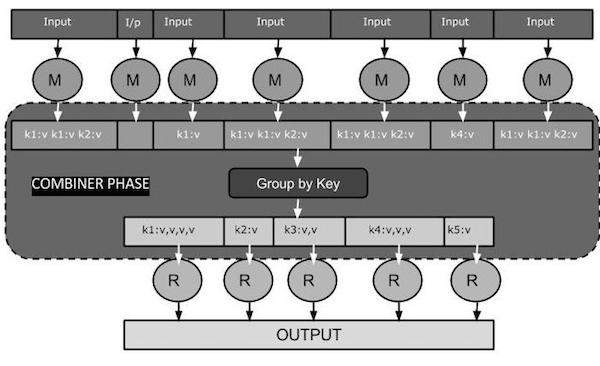
組合器如何工作?
以下是關於 MapReduce 組合器如何工作的簡要總結:
組合器沒有預定義的介面,它必須實現 Reducer 介面的 reduce() 方法。
組合器對每個 map 輸出鍵進行操作。它必須與 Reducer 類具有相同的輸出鍵值型別。
組合器可以從大型資料集中生成摘要資訊,因為它替換了原始的 Map 輸出。
雖然組合器是可選的,但它有助於將資料分成多個組以用於 Reduce 階段,這使得處理更容易。
MapReduce 組合器實現
以下示例提供了關於組合器的理論概念。讓我們假設我們有以下名為**input.txt** 的輸入文字檔案用於 MapReduce。
What do you mean by Object What do you know about Java What is Java Virtual Machine How Java enabled High Performance
下面討論了帶有組合器的 MapReduce 程式的重要階段。
記錄讀取器
這是 MapReduce 的第一階段,其中記錄讀取器逐行讀取輸入文字檔案中的文字,併產生鍵值對作為輸出。
**輸入** - 來自輸入檔案的逐行文字。
**輸出** - 形成鍵值對。以下是預期的鍵值對集。
<1, What do you mean by Object> <2, What do you know about Java> <3, What is Java Virtual Machine> <4, How Java enabled High Performance>
Map 階段
Map 階段從記錄讀取器接收輸入,對其進行處理,併產生另一組鍵值對作為輸出。
**輸入** - 來自記錄讀取器的以下鍵值對是輸入。
<1, What do you mean by Object> <2, What do you know about Java> <3, What is Java Virtual Machine> <4, How Java enabled High Performance>
Map 階段讀取每個鍵值對,使用 StringTokenizer 將值中的每個單詞分開,將每個單詞視為鍵,並將該單詞的計數作為值。以下程式碼片段顯示了 Mapper 類和 map 函式。
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
**輸出** - 預期輸出如下:
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1> <What,1> <do,1> <you,1> <know,1> <about,1> <Java,1> <What,1> <is,1> <Java,1> <Virtual,1> <Machine,1> <How,1> <Java,1> <enabled,1> <High,1> <Performance,1>
組合器階段
組合器階段接收來自 Map 階段的每個鍵值對,對其進行處理,併產生**鍵值集合**對作為輸出。
**輸入** - 來自 Map 階段的以下鍵值對是輸入。
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1> <What,1> <do,1> <you,1> <know,1> <about,1> <Java,1> <What,1> <is,1> <Java,1> <Virtual,1> <Machine,1> <How,1> <Java,1> <enabled,1> <High,1> <Performance,1>
組合器階段讀取每個鍵值對,將公共單詞組合為鍵,將值組合為集合。通常,組合器的程式碼和操作與 Reducer 的程式碼和操作類似。以下是 Mapper、Combiner 和 Reducer 類宣告的程式碼片段。
job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class);
**輸出** - 預期輸出如下:
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,1,1,1> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Reducer 階段
Reducer 階段接收來自組合器階段的每個鍵值集合對,對其進行處理,並將輸出作為鍵值對傳遞。請注意,組合器的功能與 Reducer 相同。
**輸入** - 來自組合器階段的以下鍵值對是輸入。
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,1,1,1> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Reducer 階段讀取每個鍵值對。以下是組合器的程式碼片段。
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
**輸出** - Reducer 階段的預期輸出如下:
<What,3> <do,2> <you,2> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,3> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
記錄寫入器
這是 MapReduce 的最後階段,其中記錄寫入器寫入 Reducer 階段的每個鍵值對,並將輸出作為文字傳送。
**輸入** - 來自 Reducer 階段的每個鍵值對以及輸出格式。
**輸出** - 它以文字格式提供鍵值對。以下是預期輸出。
What 3 do 2 you 2 mean 1 by 1 Object 1 know 1 about 1 Java 3 is 1 Virtual 1 Machine 1 How 1 enabled 1 High 1 Performance 1
示例程式
以下程式碼塊計算程式中的單詞數。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
將上述程式儲存為**WordCount.java**。程式的編譯和執行如下所示。
編譯和執行
讓我們假設我們位於 Hadoop 使用者的主目錄(例如,/home/hadoop)。
按照以下步驟編譯和執行上述程式。
**步驟 1** - 使用以下命令建立一個目錄來儲存已編譯的 Java 類。
$ mkdir units
**步驟 2** - 下載 Hadoop-core-1.2.1.jar,用於編譯和執行 MapReduce 程式。您可以從mvnrepository.com下載該 jar 包。
讓我們假設下載的資料夾是 /home/hadoop/。
**步驟 3** - 使用以下命令編譯**WordCount.java**程式併為程式建立一個 jar 包。
$ javac -classpath hadoop-core-1.2.1.jar -d units WordCount.java $ jar -cvf units.jar -C units/ .
**步驟 4** - 使用以下命令在 HDFS 中建立一個輸入目錄。
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
**步驟 5** - 使用以下命令將名為**input.txt** 的輸入檔案複製到 HDFS 的輸入目錄中。
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/input.txt input_dir
**步驟 6** - 使用以下命令驗證輸入目錄中的檔案。
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
**步驟 7** - 使用以下命令執行 Word count 應用程式,並從輸入目錄中獲取輸入檔案。
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir
等待一段時間直到檔案執行完畢。執行後,輸出包含許多輸入拆分、Map 任務和 Reducer 任務。
**步驟 8** - 使用以下命令驗證輸出資料夾中的結果檔案。
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
**步驟 9** - 使用以下命令檢視**Part-00000**檔案中的輸出。此檔案由 HDFS 生成。
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
以下是 MapReduce 程式生成的輸出。
What 3 do 2 you 2 mean 1 by 1 Object 1 know 1 about 1 Java 3 is 1 Virtual 1 Machine 1 How 1 enabled 1 High 1 Performance 1