
 資料結構
資料結構 網路
網路 關係資料庫管理系統(RDBMS)
關係資料庫管理系統(RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何使用TensorFlow視覺化模型結果?
應用增強和dropout方法(避免過擬合)後,可以使用'matplotlib'庫視覺化花卉資料集。這透過'plot'方法完成。
閱讀更多: 什麼是TensorFlow以及Keras如何與TensorFlow一起建立神經網路?
我們將使用Keras Sequential API,它有助於構建一個順序模型,用於處理簡單的層堆疊,其中每一層只有一個輸入張量和一個輸出張量。
包含至少一層卷積層的神經網路稱為卷積神經網路。我們可以使用卷積神經網路構建學習模型。
使用keras.Sequential模型建立影像分類器,並使用preprocessing.image_dataset_from_directory載入資料。資料高效地從磁碟載入。識別過擬合併應用技術來減輕它。這些技術包括資料增強和dropout。
共有3700張花卉影像。此資料集包含5個子目錄,每個類有一個子目錄。
它們是雛菊、蒲公英、玫瑰、向日葵和鬱金香。
我們使用Google Colaboratory執行以下程式碼。Google Colab或Colaboratory幫助在瀏覽器上執行Python程式碼,無需任何配置,並且可以免費訪問GPU(圖形處理單元)。Colaboratory構建在Jupyter Notebook之上。
當訓練樣本數量較少時,模型會從訓練樣本中的噪聲或不需要的細節中學習。這會對模型在新樣本上的效能產生負面影響。
當dropout應用於一層時,在訓練過程中會隨機丟棄該層中的多個輸出單元。這是透過將啟用函式設定為0來實現的。Dropout技術採用分數作為輸入值(例如0.1、0.2、0.4等)。這個數字0.1或0.2基本上表示應用層的10%或20%的輸出單元被隨機丟棄。
資料增強透過使用隨機變換來增強現有樣本,從而從現有樣本生成額外的訓練資料,這些變換將產生看起來可信的影像。以下是一個示例
print("Visualizing the data after performing data augmentation and dropout")
print("Accuracy is being calculated")
acc = history.history['accuracy']
print("Loss is being calculated")
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
print("The results are being visualized")
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()示例
程式碼來源 −https://www.tensorflow.org/tutorials/images/classification
Visualizing the data after performing data augmentation and dropout Accuracy is being calculated Loss is being calculated The results are being visualized
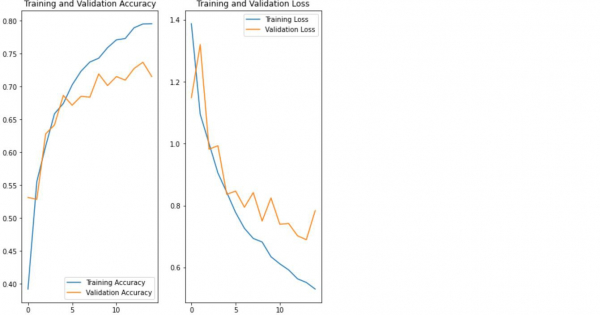
輸出
- 解釋
- 使用'matplotlib'庫視覺化資料。
- 計算與模型訓練相關的準確性和損失。

AmitDiwan
更新於:2021年2月22日

列印頁面