- ArangoDB 教程
- ArangoDB - 首頁
- 多模型首選資料庫
- ArangoDB – 優勢
- 基本概念和術語
- ArangoDB – 系統要求
- ArangoDB – 命令列
- ArangoDB - Web介面
- ArangoDB - 示例案例
- 資料模型和建模
- ArangoDB - 資料庫方法
- ArangoDB - CRUD操作
- 使用Web介面進行CRUD操作
- 使用AQL查詢資料
- ArangoDB - AQL 示例查詢
- ArangoDB – 如何部署
- ArangoDB 有用資源
- ArangoDB - 快速指南
- ArangoDB - 有用資源
- ArangoDB - 討論
ArangoDB - AQL 示例查詢
本章我們將考慮一些在演員和電影資料庫上的AQL示例查詢。這些查詢基於圖。
問題
給定一個演員集合和一個電影集合,以及一個actIn邊集合(帶有一個year屬性)來連線頂點,如下所示:
[演員] <- act in -> [電影]
我們如何獲取:
- 所有在“movie1”或“movie2”中演出的演員?
- 所有同時在“movie1”和“movie2”中演出的演員?
- “actor1”和“actor2”之間所有共同出演的電影?
- 所有出演3部或以上電影的演員?
- 所有隻有6名演員出演的電影?
- 按電影計算的演員數量?
- 按演員計算的電影數量?
- 演員在2005年到2010年間出演的電影數量?
解決方案
在解決並獲得上述查詢答案的過程中,我們將使用Arangosh建立資料集並在其上執行查詢。所有AQL查詢都是字串,可以簡單地複製到您喜歡的驅動程式中,而不是Arangosh。
讓我們從在Arangosh中建立一個測試資料集開始。首先,下載此檔案:
# wget -O dataset.js https://drive.google.com/file/d/0B4WLtBDZu_QWMWZYZ3pYMEdqajA/view?usp=sharing
輸出
... HTTP request sent, awaiting response... 200 OK Length: unspecified [text/html] Saving to: ‘dataset.js’ dataset.js [ <=> ] 115.14K --.-KB/s in 0.01s 2017-09-17 14:19:12 (11.1 MB/s) - ‘dataset.js’ saved [117907]
您可以在上面的輸出中看到,我們已經下載了一個JavaScript檔案dataset.js。此檔案包含在資料庫中建立資料集的Arangosh命令。我們不會逐一複製貼上命令,而是將使用Arangosh上的--javascript.execute選項非互動式地執行多個命令。這可是個救命命令!
現在在shell上執行以下命令:
$ arangosh --javascript.execute dataset.js
出現提示時提供密碼,如上面的螢幕截圖所示。現在我們已經儲存了資料,我們將構造AQL查詢來回答本章開頭提出的具體問題。
第一個問題
讓我們來看第一個問題:所有在“movie1”或“movie2”中演出的演員。假設,我們想找到所有在“The Matrix”或“The Devil's Advocate”中演出的演員的姓名:
我們將一次處理一部電影來獲取演員的姓名:
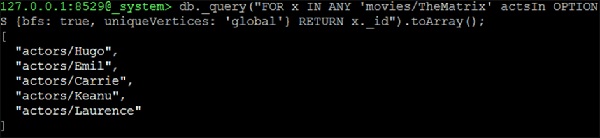
127.0.0.1:8529@_system> db._query("FOR x IN ANY 'movies/TheMatrix' actsIn
OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN x._id").toArray();
輸出
我們將收到以下輸出:
[ "actors/Hugo", "actors/Emil", "actors/Carrie", "actors/Keanu", "actors/Laurence" ]
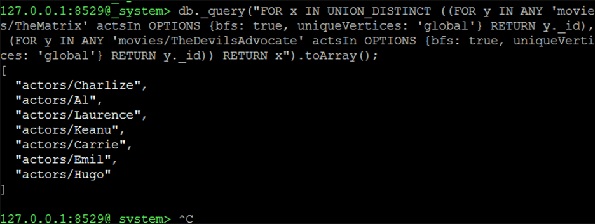
現在我們繼續形成兩個NEIGHBORS查詢的UNION_DISTINCT,這將是解決方案:
127.0.0.1:8529@_system> db._query("FOR x IN UNION_DISTINCT ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();
輸出
[ "actors/Charlize", "actors/Al", "actors/Laurence", "actors/Keanu", "actors/Carrie", "actors/Emil", "actors/Hugo" ]
第二個問題
現在讓我們考慮第二個問題:所有同時在“movie1”和“movie2”中演出的演員。這與上面的問題幾乎相同。但是這次我們對UNION不感興趣,而對INTERSECTION感興趣:
127.0.0.1:8529@_system> db._query("FOR x IN INTERSECTION ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();
輸出
我們將收到以下輸出:
[ "actors/Keanu" ]

第三個問題
現在讓我們考慮第三個問題:“actor1”和“actor2”之間所有共同出演的電影。這實際上與關於movie1和movie2中共同演員的問題相同。我們只需要更改起始頂點。例如,讓我們找到雨果·維文(“Hugo”)和基努·裡維斯共同出演的所有電影:
127.0.0.1:8529@_system> db._query(
"FOR x IN INTERSECTION (
(
FOR y IN ANY 'actors/Hugo' actsIn OPTIONS
{bfs: true, uniqueVertices: 'global'}
RETURN y._id
),
(
FOR y IN ANY 'actors/Keanu' actsIn OPTIONS
{bfs: true, uniqueVertices:'global'} RETURN y._id
)
)
RETURN x").toArray();
輸出
我們將收到以下輸出:
[ "movies/TheMatrixReloaded", "movies/TheMatrixRevolutions", "movies/TheMatrix" ]

第四個問題
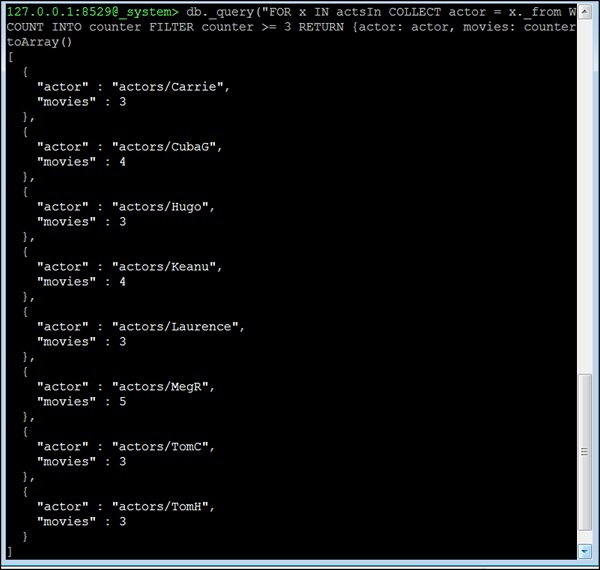
現在讓我們考慮第四個問題。所有出演3部或以上電影的演員。這個問題不同;我們不能在這裡使用neighbors函式。相反,我們將使用AQL的edge-index和COLLECT語句進行分組。基本思想是按其startVertex(在這個資料集中始終是演員)對所有邊進行分組。然後,我們將刪除所有出演少於3部電影的演員,因為這裡我們包含了演員出演的電影數量:
127.0.0.1:8529@_system> db._query("FOR x IN actsIn COLLECT actor = x._from WITH
COUNT INTO counter FILTER counter >= 3 RETURN {actor: actor, movies:
counter}"). toArray()
輸出
[
{
"actor" : "actors/Carrie",
"movies" : 3
},
{
"actor" : "actors/CubaG",
"movies" : 4
},
{
"actor" : "actors/Hugo",
"movies" : 3
},
{
"actor" : "actors/Keanu",
"movies" : 4
},
{
"actor" : "actors/Laurence",
"movies" : 3
},
{
"actor" : "actors/MegR",
"movies" : 5
},
{
"actor" : "actors/TomC",
"movies" : 3
},
{
"actor" : "actors/TomH",
"movies" : 3
}
]
對於其餘的問題,我們將討論查詢的形成,並且只提供查詢。讀者應該在Arangosh終端上自己執行查詢。
第五個問題
現在讓我們考慮第五個問題:所有隻有6名演員出演的電影。與之前的查詢相同的思路,但帶有等式過濾器。但是,現在我們需要電影而不是演員,所以我們返回_to屬性:
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter FILTER
counter == 6 RETURN movie").toArray()
按電影計算的演員數量?
我們記得在我們的資料集中,邊上的_to對應於電影,所以我們計算相同的_to出現的次數。這就是演員的數量。查詢與之前的查詢幾乎相同,但COLLECT之後沒有FILTER:
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter RETURN
{movie: movie, actors: counter}").toArray()
第六個問題
現在讓我們考慮第六個問題:按演員計算的電影數量。
我們找到上述查詢解決方案的方法也將幫助您找到此查詢的解決方案。
db._query("FOR x IN actsIn COLLECT actor = x._from WITH COUNT INTO counter
RETURN {actor: actor, movies: counter}").toArray()