- 亞馬遜網路服務教程
- AWS - 首頁
- 亞馬遜網路服務基礎
- AWS - 雲計算
- AWS - 基本架構
- AWS - 管理控制檯
- AWS - 控制檯移動應用
- AWS - 賬戶
- 亞馬遜計算機服務
- AWS - 彈性計算雲
- AWS - 自動擴充套件
- AWS - 工作空間
- AWS - Lambda
- 亞馬遜資料庫服務
- AWS - 關係資料庫服務
- AWS - DynamoDB
- AWS - Redshift
- 亞馬遜應用服務
- AWS - 簡單工作流服務
- AWS - WorkMail
- 亞馬遜網路服務資源
- AWS - 快速指南
- AWS - 有用資源
- AWS - 討論
亞馬遜網路服務 - 彈性 MapReduce
Amazon Elastic MapReduce (EMR) 是一種網路服務,它提供了一個託管框架,可以輕鬆、經濟高效且安全地執行資料處理框架,例如 Apache Hadoop、Apache Spark 和 Presto。
它用於資料分析、網路索引、資料倉庫、財務分析、科學模擬等。
如何設定 Amazon EMR?
按照以下步驟設定 Amazon EMR:
步驟 1 - 登入 AWS 賬戶並在管理控制檯中選擇 Amazon EMR。
步驟 2 - 為叢集日誌和輸出資料建立 Amazon S3 儲存桶。(Amazon S3 部分詳細介紹了此過程)
步驟 3 - 啟動 Amazon EMR 叢集。
以下是建立叢集並將其啟動到 EMR 的步驟。
使用此連結開啟 Amazon EMR 控制檯:https://console.aws.amazon.com/elasticmapreduce/home
選擇建立叢集並在“叢集配置”頁面提供所需詳細資訊。

將“標籤”部分選項保留為預設值並繼續。
在“軟體配置”部分,將選項保留為預設值。
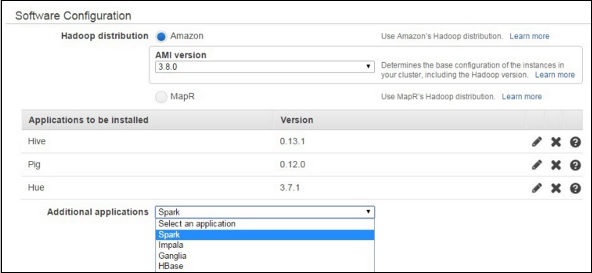
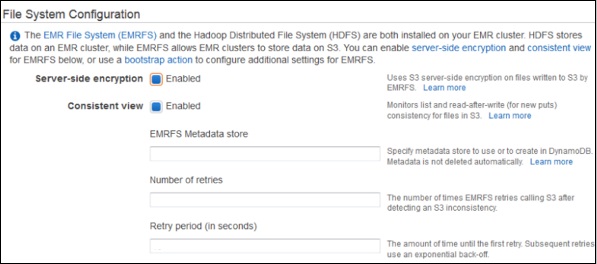
在“檔案系統配置”部分,將 EMRFS 的選項保留為預設設定。EMRFS 是 HDFS 的一種實現,它允許 Amazon EMR 叢集將資料儲存在 Amazon S3 上。
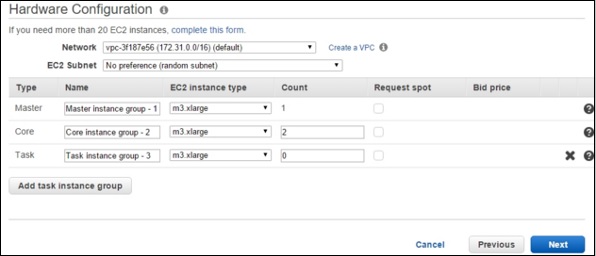
在“硬體配置”部分,在 EC2 例項型別欄位中選擇 m3.xlarge,並將其他設定保留為預設值。單擊“下一步”按鈕。
在“安全和訪問”部分,對於 EC2 金鑰對,從 EC2 金鑰對欄位中的列表中選擇該對,並將其他設定保留為預設值。
在“引導操作”部分,將欄位保留為預設設定,然後單擊“新增”按鈕。引導操作是在每個叢集節點上啟動 Hadoop 之前的設定期間執行的指令碼。
在“步驟”部分,將設定保留為預設值並繼續。
單擊“建立叢集”按鈕,將開啟“叢集詳細資訊”頁面。在這裡,我們應該執行 Hive 指令碼作為叢集步驟,並使用 Hue Web 介面查詢資料。
步驟 4 - 使用以下步驟執行 Hive 指令碼。
開啟 Amazon EMR 控制檯並選擇所需的叢集。
移動到“步驟”部分並展開它。然後單擊“新增步驟”按鈕。
將開啟“新增步驟”對話方塊。填寫所需欄位,然後單擊“新增”按鈕。

要檢視 Hive 指令碼的輸出,請使用以下步驟:
開啟 Amazon S3 控制檯並選擇用於輸出資料的 S3 儲存桶。
選擇輸出資料夾。
查詢將結果寫入一個單獨的資料夾中。選擇os_requests。
輸出儲存在文字檔案中。可以下載此檔案。
Amazon EMR 的優勢
以下是 Amazon EMR 的優勢:
易於使用 - Amazon EMR 易於使用,即易於設定叢集、Hadoop 配置、節點預置等。
可靠 - 從可靠性方面來說,它會重試失敗的任務並自動替換效能不佳的例項。
彈性 - Amazon EMR 允許計算大量例項以按任何規模處理資料。它可以輕鬆增加或減少例項數量。
安全 - 它會自動配置 Amazon EC2 防火牆設定、控制對例項的網路訪問、在 Amazon VPC 中啟動叢集等。
靈活 - 它允許完全控制叢集並訪問每個例項的根訪問許可權。它還允許安裝其他應用程式並根據需要自定義叢集。
經濟高效 - 其定價易於估算。它按小時對使用的每個例項收費。