
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP受限玻爾茲曼機是什麼?
介紹
受限玻爾茲曼機 (Restricted Boltzmann Machine, RBM) 由 Geoffrey Hinton 於 1985 年提出,它是一個對稱互聯的網路系統,其功能類似於神經元,並進行隨機決策。在 Netflix 競賽中,RBM 作為一種無監督的機器學習模型,被用作資訊檢索策略來預測電影的評分和評論,並超越了大多數競爭對手,從而獲得了廣泛關注。它對協同過濾、特徵學習、降維、迴歸、分類和特徵學習非常有用。
讓我們深入瞭解受限玻爾茲曼機。
受限玻爾茲曼機
受限玻爾茲曼機具有隨機的兩層神經網路,可以透過重構輸入來自動識別資料中的潛在模式。它們是基於能量模型的一個子集。它們有兩層,其中一層是隱藏層。隱藏層由節點組成,這些節點建立可見層並從資料中收集特徵資訊。它們沒有任何輸出節點,這可能看起來很奇怪,並且它們沒有典型的二元輸出,這使得學習模式成為可能。它們有所不同,因為如果沒有這種能力,學習就無法進行。我們不關心隱藏節點;我們只關心輸入節點。
RBM 用於許多即時商業用例,包括:
由於難以理解手寫文字或隨機模式,因此 RBM 用於模式識別應用中的特徵提取。
推薦引擎:RBM 經常用於資訊檢索方法中,以預測應該向客戶提出的推薦,以便客戶能夠享受使用特定應用程式或平臺。例如,書籍和電影都推薦。
雷達目標識別:在這種情況下,RBM 用於在具有高噪聲水平和極低信噪比的雷達系統中定位脈衝內資訊。
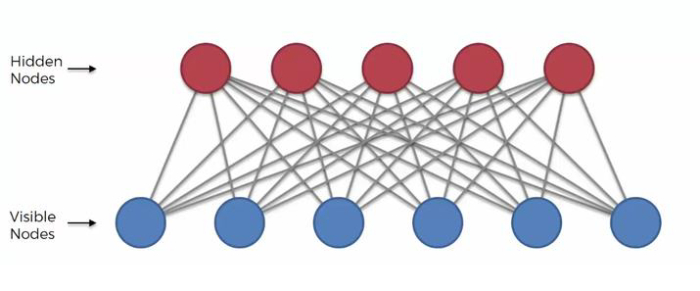
受限玻爾茲曼機的特點
玻爾茲曼機的一些關鍵特徵是:
它們採用對稱和迴圈結構。
RBM 的學習過程旨在將低能量狀態與最高機率狀態連線起來,反之亦然。
層之間沒有連線。
它使用缺乏標記響應的輸入資料來生成推斷;這使其成為一種無監督學習演算法。
在本節中,我們將對比玻爾茲曼機和受限玻爾茲曼機。每種演算法都有兩層:可見層和隱藏層。玻爾茲曼機連線每一層的每個神經元,以及可見層中的每個神經元到隱藏層中的每個神經元。但是,RBM 與玻爾茲曼機的先前示例不同,因為層中的神經元沒有連線。即,沒有層內通訊,使彼此獨立,更容易實現,因為條件獨立性意味著研究人員只需要確定微不足道的機率,這更容易計算。
RBM 的運作
如前所述,無監督學習方法受限玻爾茲曼機如何在不需要任何輸出資料的情況下學習?隱藏層神經元向從可見層神經元接收到的輸入資料新增偏差值,將結果乘以一些權重,然後產生輸出。然後,隱藏層神經元的輸出值成為新的輸入,它乘以相同的權重,並新增可見層的偏差以建立新的輸入。重構或反向傳播是此過程的兩個名稱。然後將原始輸入和新生成的輸入進行比較,以檢視它們是否匹配。
RBM 的訓練
使用吉布斯取樣和對比散度來訓練 RBM。
如果輸入由 v 表示,隱藏值由 h 表示,則預測為 p(h|v)。當已知隱藏值時,P(v|h) 用於預測再生輸入資料。讓我們想象一下,在該過程執行 k 次後,在 k 輪結束時從輸入值 v0 獲得 vk。
對比散度是一種粗略的最大似然學習策略,用於逼近梯度,梯度是網路權重與其誤差之間關係的圖形斜率。當我們無法直接評估函式以及機率集,並且需要逼近演算法的學習斜率並確定前進方向時,使用對比散度。
RBM 的應用
例如,罪證、工作場所計算機化、支票驗證和資料輸入等現代應用都需要手寫字元識別,這在當今是一個常見問題。其他問題包括不一致的書寫風格、大小和形狀變化,以及改變數字拓撲的影像噪聲。在這裡,混合 RBM-CNN 技術用於數字識別。首先,使用 RBM 深度學習技術提取特徵。然後將為分類獲得的特徵傳送到 CNN 深度學習系統。
結論
簡而言之,受限玻爾茲曼機是兩層無監督神經模型,它們從輸入分佈中學習。RBM 及其用於學習和最佳化的演算法已經過多次修改和改進。使用對比散度來訓練它們,訓練後,它們可以從訓練資料集中生成新樣本。無限 RBM 和模糊 RBM 是對原始 RBM 進行的改進,以提高其有效性和表示能力的兩個示例。

530 次瀏覽
