Weka 快速指南
Weka - 簡介
任何機器學習應用程式的基礎都是資料 - 不僅僅是一點點資料,而是一大批資料,在當前術語中被稱為大資料。
為了訓練機器分析大資料,您需要對資料進行一些考慮 -
- 資料必須是乾淨的。
- 它不應該包含空值。
此外,資料表中的並非所有列都對您嘗試實現的分析型別有用。在將資料饋送到機器學習演算法之前,必須刪除不相關的列或機器學習術語中的“特徵”。
簡而言之,您的海量資料在用於機器學習之前需要大量預處理。資料準備就緒後,您將應用各種機器學習演算法(如分類、迴歸、聚類等)來解決您最終的問題。
您應用的演算法型別很大程度上取決於您的領域知識。即使在同一型別中,例如分類,也有多種演算法可用。您可能希望測試同一類別下的不同演算法以構建有效的機器學習模型。在此過程中,您會更喜歡視覺化處理後的資料,因此您還需要視覺化工具。
在接下來的章節中,您將學習 Weka,一個能夠輕鬆完成所有上述操作並讓您舒適地處理大資料的軟體。
什麼是 Weka?
WEKA - 一個開源軟體,提供資料預處理、多種機器學習演算法的實現以及視覺化工具,以便您可以開發機器學習技術並將它們應用於現實世界的資料探勘問題。WEKA 提供的功能在下面的圖表中進行了總結 -
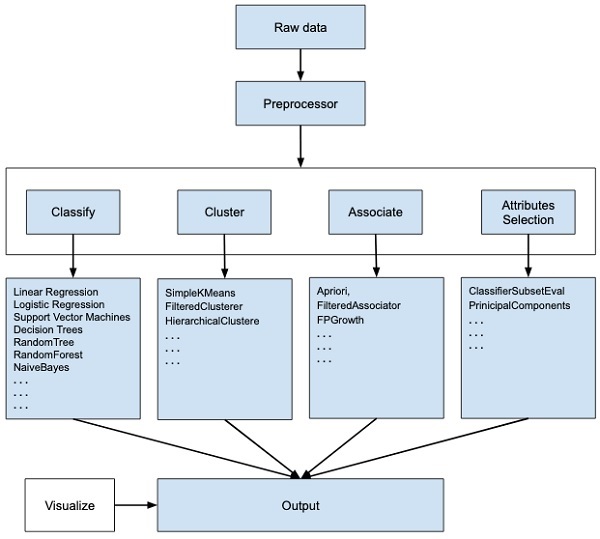
如果您觀察影像流程的開始,您就會明白,處理大資料以使其適合機器學習有很多步驟 -
首先,您將從現場收集的原始資料開始。此資料可能包含多個空值和不相關的欄位。您使用 WEKA 中提供的資料預處理工具來清理資料。
然後,您將預處理後的資料儲存到本地儲存中以應用 ML 演算法。
接下來,根據您嘗試開發的 ML 模型型別,您將選擇其中一個選項,例如分類、聚類或關聯。屬性選擇允許自動選擇特徵以建立縮減的資料集。
請注意,在每個類別下,WEKA 都提供了多種演算法的實現。您可以選擇您選擇的演算法,設定所需的引數並在資料集上執行它。
然後,WEKA 將為您提供模型處理的統計輸出。它為您提供了一個視覺化工具來檢查資料。
各種模型可以應用於相同的資料集。然後,您可以比較不同模型的輸出並選擇最符合您目的的模型。
因此,使用 WEKA 可以更快地開發整個機器學習模型。
現在我們已經瞭解了 WEKA 是什麼以及它做什麼,在下一章中,讓我們學習如何在本地計算機上安裝 WEKA。
Weka - 安裝
要在您的機器上安裝 WEKA,請訪問WEKA 的官方網站並下載安裝檔案。WEKA 支援在 Windows、Mac OS X 和 Linux 上安裝。您只需要按照此頁面上的說明為您的作業系統安裝 WEKA 即可。
在 Mac 上安裝的步驟如下 -
- 下載 Mac 安裝檔案。
- 雙擊下載的weka-3-8-3-corretto-jvm.dmg 檔案。
成功安裝後,您將看到以下螢幕。
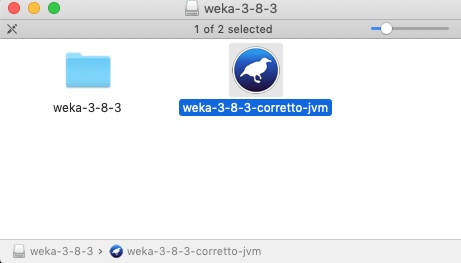
- 單擊weak-3-8-3-corretto-jvm圖示以啟動 Weka。
- 您也可以從命令列啟動它 -
java -jar weka.jar
WEKA GUI 選擇器應用程式將啟動,您將看到以下螢幕 -
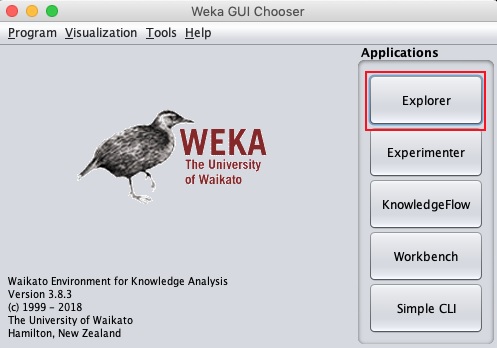
GUI 選擇器應用程式允許您執行五種不同型別的應用程式,如下所示 -
- Explorer
- Experimenter
- KnowledgeFlow
- Workbench
- Simple CLI
在本教程中,我們將使用Explorer。
Weka - 啟動 Explorer
在本章中,讓我們深入瞭解 Explorer 為處理大資料提供的各種功能。
當您單擊應用程式選擇器中的Explorer按鈕時,它將開啟以下螢幕 -
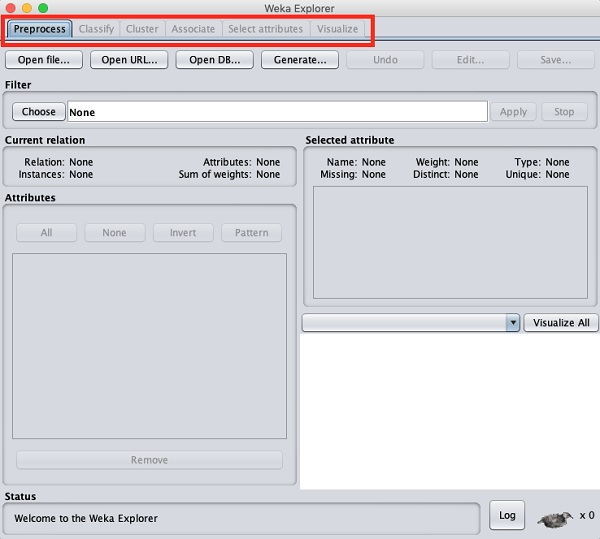
在頂部,您將看到幾個選項卡,如下所示 -
- 預處理
- 分類
- 聚類
- 關聯
- 選擇屬性
- 視覺化
在這些選項卡下,有幾個預先實現的機器學習演算法。現在讓我們詳細瞭解一下每個演算法。
預處理選項卡
最初,當您開啟 Explorer 時,只有預處理選項卡可用。機器學習的第一步是對資料進行預處理。因此,在預處理選項中,您將選擇資料檔案,對其進行處理並使其適合應用各種機器學習演算法。
分類選項卡
分類選項卡為您提供了用於對資料進行分類的多種機器學習演算法。舉幾個例子,您可以應用線性迴歸、邏輯迴歸、支援向量機、決策樹、隨機樹、隨機森林、樸素貝葉斯等演算法。該列表非常詳盡,提供了監督和無監督的機器學習演算法。
聚類選項卡
在聚類選項卡下,提供了多種聚類演算法,例如 SimpleKMeans、FilteredClusterer、HierarchicalClusterer 等。
關聯選項卡
在關聯選項卡下,您會找到 Apriori、FilteredAssociator 和 FPGrowth。
選擇屬性選項卡
選擇屬性允許您基於多種演算法(如 ClassifierSubsetEval、PrinicipalComponents 等)進行特徵選擇。
視覺化選項卡
最後,視覺化選項允許您視覺化處理後的資料以進行分析。
正如您所注意到的,WEKA 提供了多種現成的演算法來測試和構建您的機器學習應用程式。要有效地使用 WEKA,您必須具備這些演算法的紮實知識,瞭解它們的工作原理,在什麼情況下選擇哪一個,在它們的處理輸出中尋找什麼,等等。簡而言之,您必須擁有機器學習的堅實基礎才能有效地使用 WEKA 構建您的應用程式。
在接下來的章節中,您將深入研究 Explorer 中的每個選項卡。
Weka - 載入資料
在本章中,我們從第一個選項卡開始,用於預處理資料。這對於您應用於資料以構建模型的所有演算法都是通用的,並且是 WEKA 中所有後續操作的常見步驟。
為了使機器學習演算法獲得可接受的準確性,必須首先清理資料。這是因為從現場收集的原始資料可能包含空值、不相關的列等等。
在本章中,您將學習如何預處理原始資料併為進一步使用建立乾淨、有意義的資料集。
首先,您將學習如何將資料檔案載入到 WEKA Explorer 中。資料可以從以下來源載入 -
- 本地檔案系統
- 網路
- 資料庫
在本章中,我們將詳細瞭解這三種載入資料的方式。
從本地檔案系統載入資料
在上一課中學習的機器學習選項卡下方,您會找到以下三個按鈕 -
- 開啟檔案…
- 開啟 URL…
- 開啟 DB…
單擊開啟檔案…按鈕。將開啟一個目錄導航器視窗,如下面的螢幕截圖所示 -
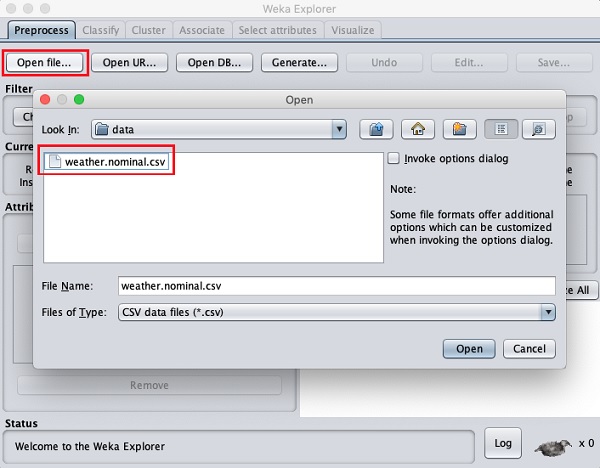
現在,導航到儲存資料檔案的資料夾。WEKA 安裝附帶了許多示例資料庫,供您進行實驗。它們位於 WEKA 安裝的data資料夾中。
為了學習目的,從該資料夾中選擇任何資料檔案。檔案內容將載入到 WEKA 環境中。我們很快就會學習如何檢查和處理這些載入的資料。在此之前,讓我們看看如何從 Web 載入資料檔案。
從 Web 載入資料
單擊開啟 URL…按鈕後,您會看到一個視窗,如下所示 -
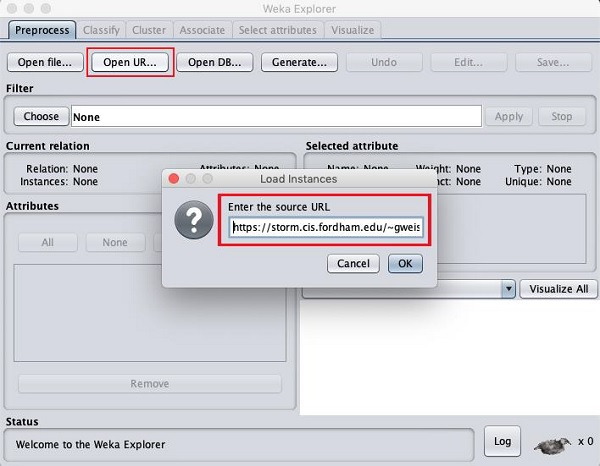
我們將從公共 URL 開啟檔案。在彈出框中輸入以下 URL -
https://storm.cis.fordham.edu/~gweiss/data-mining/weka-data/weather.nominal.arff
您可以指定儲存資料的任何其他 URL。Explorer將從遠端站點載入資料到其環境中。
從 DB 載入資料
單擊開啟 DB…按鈕後,您會看到一個視窗,如下所示 -
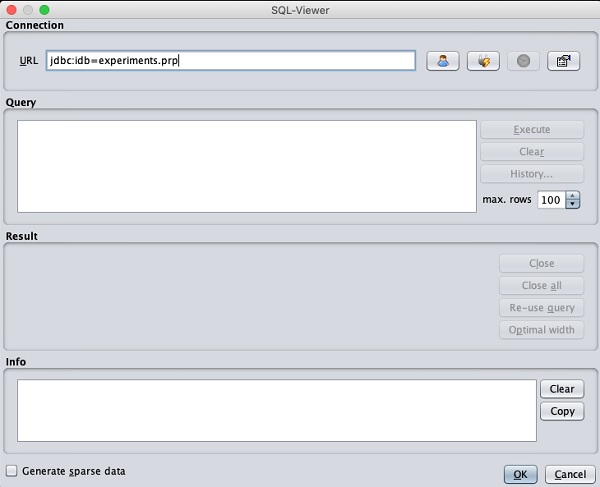
將連線字串設定為您的資料庫,設定資料選擇查詢,處理查詢並將選定的記錄載入到 WEKA 中。
Weka - 檔案格式
WEKA 支援大量資料檔案格式。以下是完整列表 -
- arff
- arff.gz
- bsi
- csv
- dat
- data
- json
- json.gz
- libsvm
- m
- names
- xrff
- xrff.gz
它支援的檔案型別列在螢幕底部的下拉列表框中。這在下面給出的螢幕截圖中顯示。
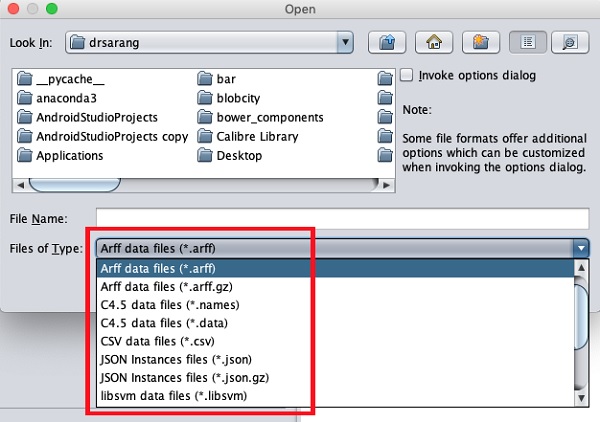
正如您所注意到的,它支援多種格式,包括 CSV 和 JSON。預設檔案型別為 Arff。
Arff 格式
Arff檔案包含兩個部分 - 標題和資料。
- 標題描述了屬性型別。
- 資料部分包含一個逗號分隔的資料列表。
作為 Arff 格式的示例,從 WEKA 示例資料庫載入的天氣資料檔案如下所示 -

從螢幕截圖中,您可以推斷出以下幾點 -
@relation 標記定義了資料庫的名稱。
@attribute 標記定義了屬性。
@data 標記開始資料行的列表,每個資料行包含逗號分隔的欄位。
屬性可以採用名義值,如這裡所示的 outlook -
@attribute outlook (sunny, overcast, rainy)
屬性可以採用實數值,在本例中 -
@attribute temperature real
您還可以設定目標或稱為 play 的類變數,如這裡所示 -
@attribute play (yes, no)
目標採用兩個名義值 yes 或 no。
其他格式
Explorer 可以載入前面提到的任何格式的資料。由於 arff 是 WEKA 中的首選格式,因此您可以從任何格式載入資料並將其儲存為 arff 格式以供以後使用。在預處理資料後,只需將其儲存為 arff 格式以供進一步分析。
既然您已經學習瞭如何將資料載入到 WEKA 中,那麼在下一章中,您將學習如何預處理資料。
Weka - 資料預處理
從現場收集的資料包含許多不需要的東西,這會導致錯誤的分析。例如,資料可能包含空欄位,可能包含與當前分析無關的列,等等。因此,必須對資料進行預處理,以滿足您正在尋求的分析型別的要求。這在預處理模組中完成。
為了演示預處理中可用的功能,我們將使用安裝中提供的Weather資料庫。
使用Preprocess標籤下的Open file ...選項選擇weather-nominal.arff檔案。
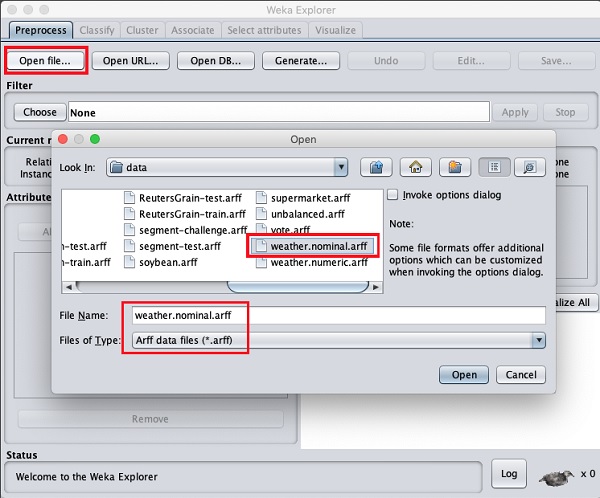
開啟檔案後,您的螢幕將如下所示:
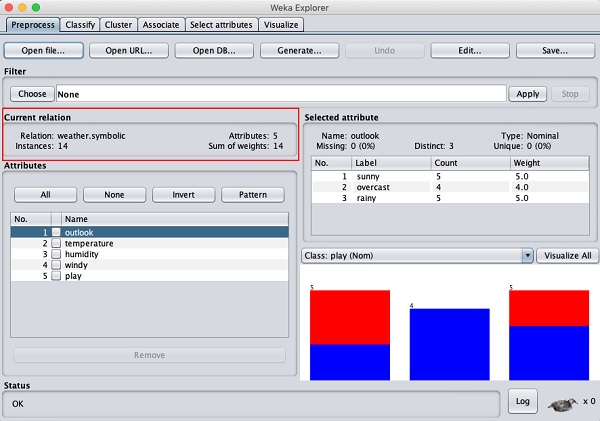
此螢幕告訴我們有關載入資料的幾件事,這些內容將在本章中進一步討論。
理解資料
讓我們首先檢視突出顯示的Current relation子視窗。它顯示當前載入的資料庫的名稱。您可以從此子視窗推斷出兩點:
有14個例項 - 表格中的行數。
該表包含5個屬性 - 欄位,將在接下來的部分中討論。
在左側,請注意Attributes子視窗,它顯示資料庫中的各個欄位。
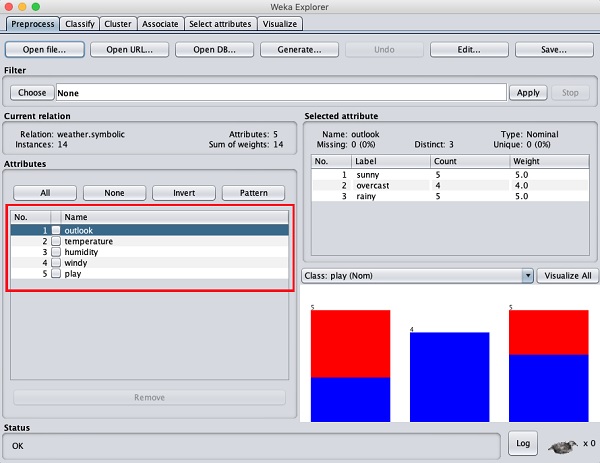
weather資料庫包含五個欄位 - outlook、temperature、humidity、windy和play。當您透過單擊從該列表中選擇一個屬性時,屬性本身的更多詳細資訊將顯示在右側。
讓我們首先選擇temperature屬性。當您單擊它時,您將看到以下螢幕:
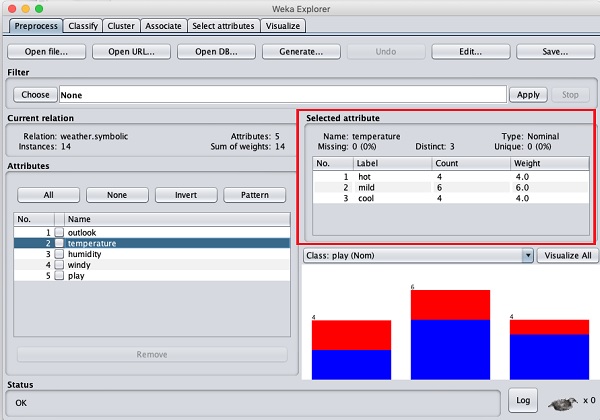
在Selected Attribute子視窗中,您可以觀察到以下內容:
顯示了屬性的名稱和型別。
temperature屬性的型別為Nominal。
Missing值的數目為零。
有三個不同的值,沒有唯一的值。
此資訊下方的表格顯示了此欄位的標稱值為hot、mild和cold。
它還顯示了每個標稱值的計數和權重(百分比)。
在視窗底部,您可以看到class值的視覺表示。
如果您單擊Visualize All按鈕,您將能夠在一個視窗中看到所有功能,如下所示:
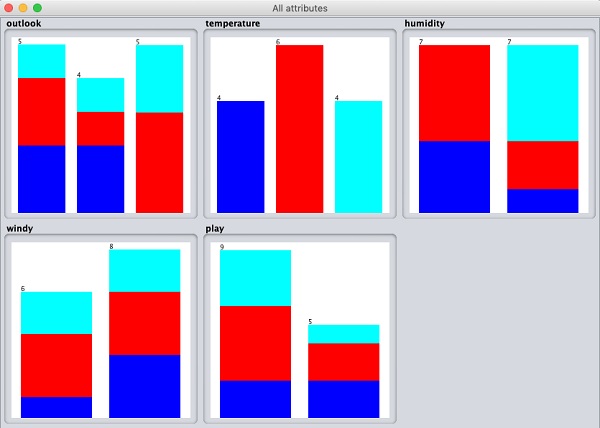
移除屬性
很多時候,您想要用於模型構建的資料會附帶許多不相關的欄位。例如,客戶資料庫可能包含他的手機號碼,這與分析他的信用評級相關。
要移除屬性,請選擇它們並單擊底部的Remove按鈕。
選定的屬性將從資料庫中移除。在您完全預處理資料後,您可以將其儲存以進行模型構建。
接下來,您將學習透過對這些資料應用過濾器來預處理資料。
應用過濾器
一些機器學習技術(如關聯規則挖掘)需要分類資料。為了說明過濾器的使用,我們將使用包含兩個numeric屬性(temperature和humidity)的weather-numeric.arff資料庫。
我們將透過對原始資料應用過濾器將其轉換為nominal。單擊Filter子視窗中的Choose按鈕,然後選擇以下過濾器:
weka→filters→supervised→attribute→Discretize
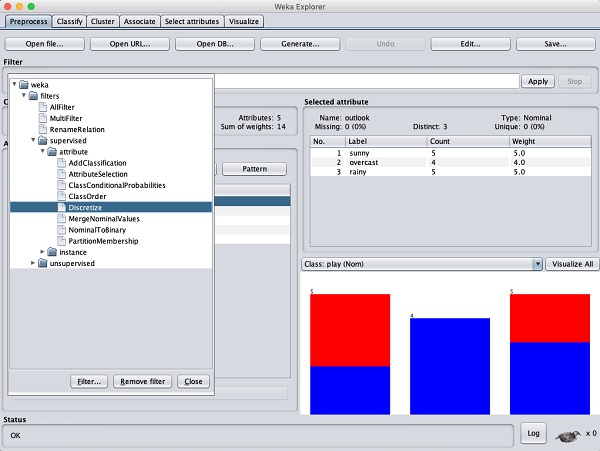
單擊Apply按鈕並檢查temperature和/或humidity屬性。您會注意到它們已從數字型別更改為標稱型別。
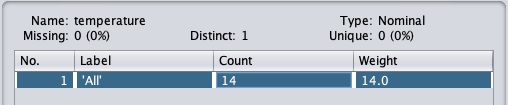
現在讓我們看看另一個過濾器。假設您想選擇決定play的最佳屬性。選擇並應用以下過濾器:
weka→filters→supervised→attribute→AttributeSelection
您會注意到它從資料庫中移除了temperature和humidity屬性。
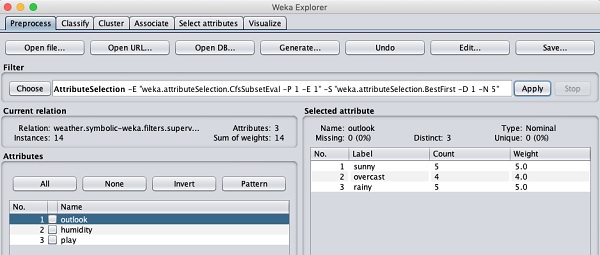
在您對資料的預處理感到滿意後,透過單擊Save ...按鈕儲存資料。您將使用此儲存的檔案進行模型構建。
在下一章中,我們將探討使用幾個預定義的ML演算法進行模型構建。
Weka - 分類器
許多機器學習應用程式都與分類相關。例如,您可能希望將腫瘤分類為惡性或良性。您可能希望根據天氣狀況決定是否進行戶外遊戲。通常,此決定取決於天氣的幾個特徵/條件。因此,您可能更喜歡使用樹分類器來決定是否玩遊戲。
在本章中,我們將學習如何在天氣資料上構建這樣的樹分類器來決定比賽條件。
設定測試資料
我們將使用上一課中預處理的天氣資料檔案。使用Preprocess選項卡下的Open file ...選項開啟儲存的檔案,單擊Classify選項卡,您將看到以下螢幕:
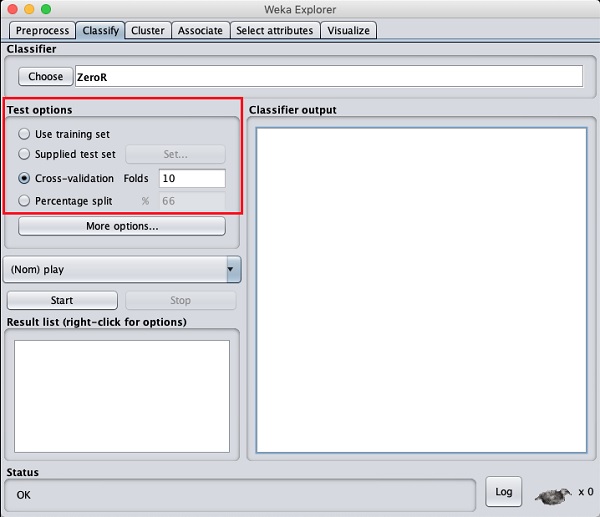
在您瞭解可用分類器之前,讓我們檢查一下測試選項。您會注意到如下所示的四個測試選項:
- 訓練集
- 提供的測試集
- 交叉驗證
- 百分比分割
除非您有自己的訓練集或客戶提供的測試集,否則您將使用交叉驗證或百分比分割選項。在交叉驗證下,您可以設定整個資料將被分割並用於每次訓練迭代的摺疊數。在百分比分割中,您將使用設定的分割百分比將資料分割為訓練和測試。
現在,將預設的play選項保留為輸出類:
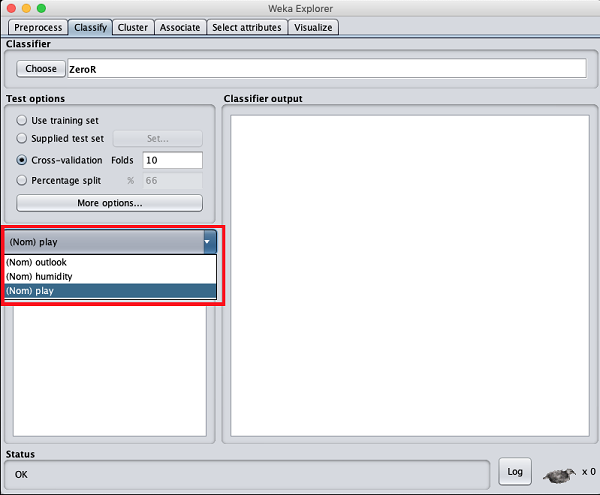
接下來,您將選擇分類器。
選擇分類器
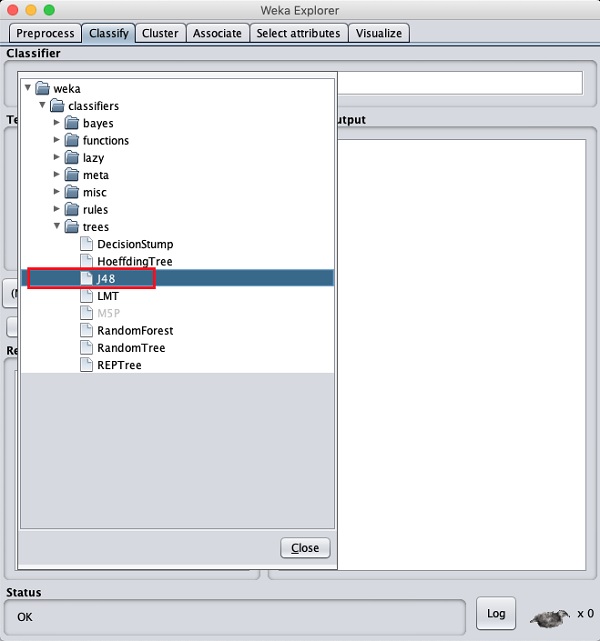
單擊Choose按鈕,然後選擇以下分類器:
weka→classifiers>trees>J48
這在下面的螢幕截圖中顯示:
單擊Start按鈕開始分類過程。一段時間後,分類結果將顯示在您的螢幕上,如下所示:
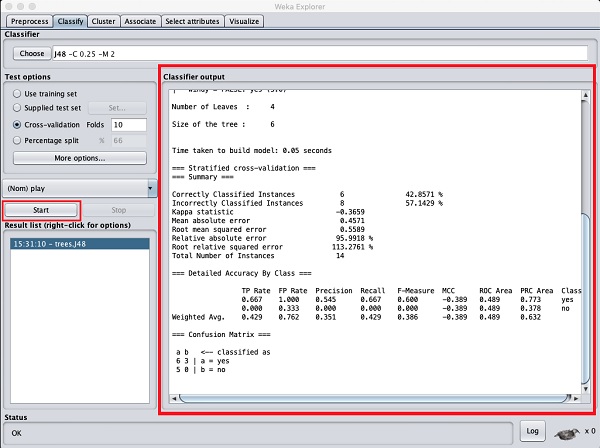
讓我們檢查一下螢幕右側顯示的輸出。
它說樹的大小為6。您很快就會看到樹的視覺化表示。在摘要中,它說正確分類的例項為2,錯誤分類的例項為3,它還說相對絕對誤差為110%。它還顯示了混淆矩陣。深入分析這些結果超出了本教程的範圍。但是,您可以很容易地從這些結果中看出分類不可接受,並且您需要更多資料進行分析,以改進您的特徵選擇,重建模型,依此類推,直到您對模型的準確性感到滿意為止。無論如何,這就是WEKA的全部意義所在。它允許您快速測試您的想法。
視覺化結果
要檢視結果的視覺化表示,請右鍵單擊Result list框中的結果。螢幕上將彈出幾個選項,如下所示:
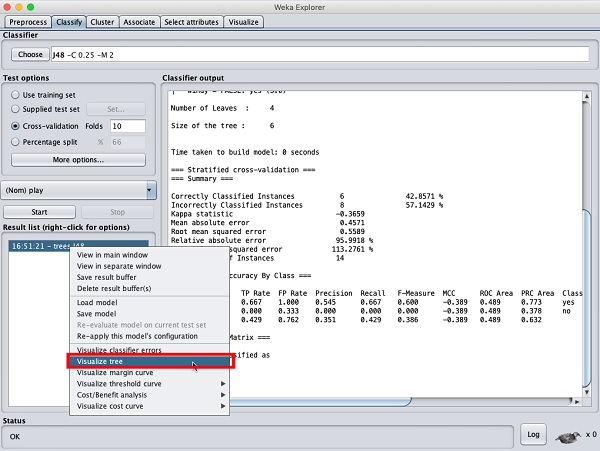
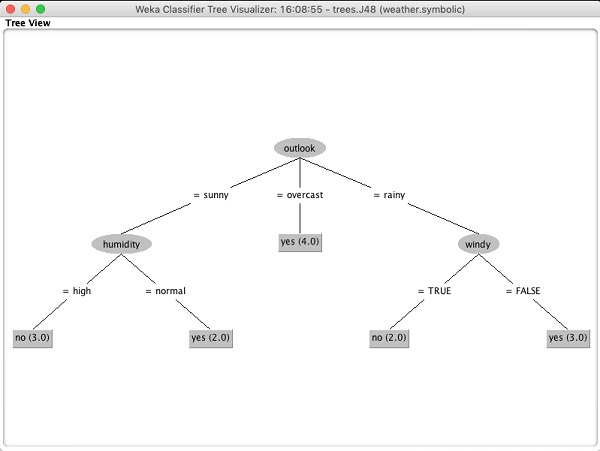
選擇Visualize tree以獲得遍歷樹的視覺化表示,如下面的螢幕截圖所示:
選擇Visualize classifier errors將繪製分類結果,如下所示:
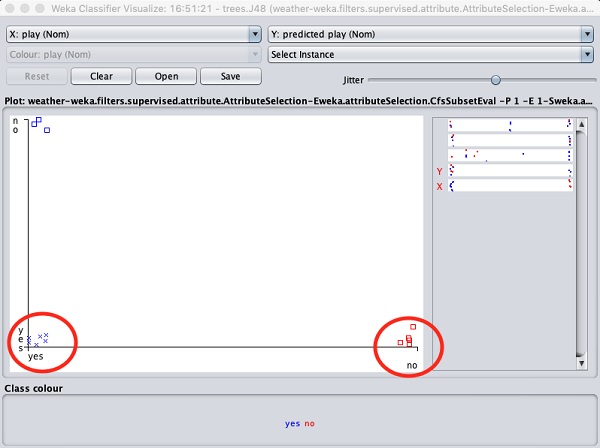
十字表示正確分類的例項,而正方形表示錯誤分類的例項。在圖的左下角,您會看到一個十字,表示如果outlook為sunny,則play遊戲。因此,這是一個正確分類的例項。要定位例項,您可以透過滑動jitter滑塊在其上引入一些抖動。
當前圖是outlook與play的關係。它們由螢幕頂部的兩個下拉列表框指示。
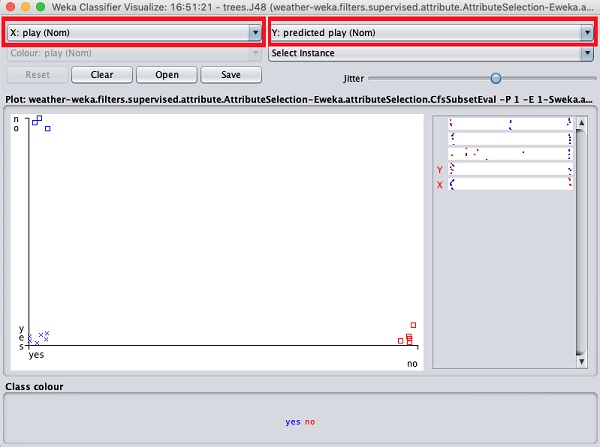
現在,嘗試在每個框中進行不同的選擇,並注意X和Y軸如何變化。可以透過使用圖右側的水平條來實現相同的效果。每個條帶代表一個屬性。左鍵單擊條帶將在X軸上設定選定的屬性,而右鍵單擊將在Y軸上設定它。
為了更深入的分析,還提供了其他幾個圖。明智地使用它們來微調您的模型。下面顯示了一個成本/收益分析圖,供您快速參考。
解釋這些圖表中的分析超出了本教程的範圍。鼓勵讀者複習他們對機器學習演算法分析的知識。
在下一章中,我們將學習下一組機器學習演算法,即聚類。
Weka - 聚類
聚類演算法在整個資料集中查詢相似例項的組。WEKA支援多種聚類演算法,例如EM、FilteredClusterer、HierarchicalClusterer、SimpleKMeans等等。您應該完全理解這些演算法,以充分利用WEKA的功能。
與分類一樣,WEKA允許您以圖形方式視覺化檢測到的聚類。為了演示聚類,我們將使用提供的iris資料庫。資料集包含三個類別,每個類別包含50個例項。每個類別都指一種鳶尾花植物。
載入資料
在WEKA資源管理器中,選擇Preprocess選項卡。單擊Open file ...選項,並在檔案選擇對話方塊中選擇iris.arff檔案。載入資料後,螢幕將如下所示:
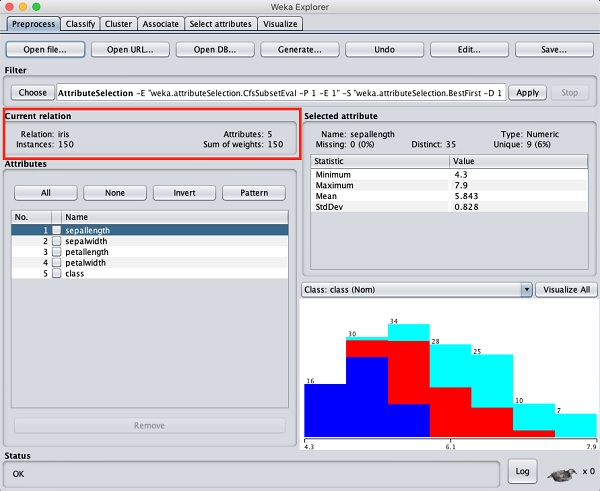
您可以觀察到有150個例項和5個屬性。屬性的名稱列為sepallength、sepalwidth、petallength、petalwidth和class。前四個屬性為數字型別,而class為標稱型別,具有3個不同的值。檢查每個屬性以瞭解資料庫的功能。我們不會對此資料進行任何預處理,而是直接進行模型構建。
聚類
單擊Cluster選項卡以將聚類演算法應用於我們載入的資料。單擊Choose按鈕。您將看到以下螢幕:
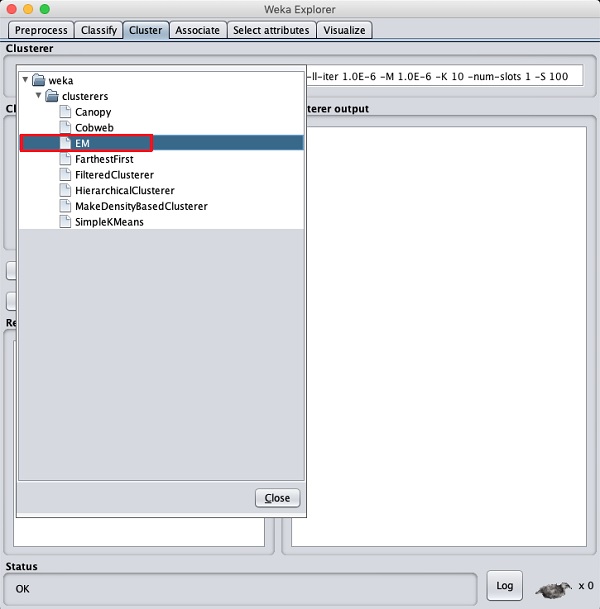
現在,選擇EM作為聚類演算法。在Cluster mode子視窗中,選擇Classes to clusters evaluation選項,如下面的螢幕截圖所示:
單擊Start按鈕處理資料。一段時間後,結果將顯示在螢幕上。
接下來,讓我們研究一下結果。
檢查輸出
資料處理的輸出顯示在下面的螢幕中:
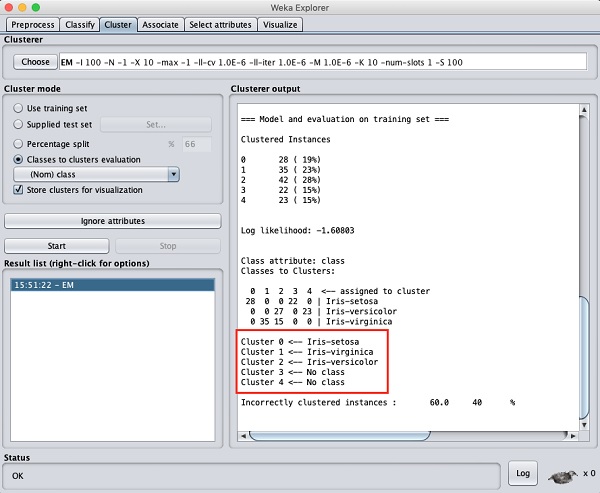
從輸出螢幕中,您可以觀察到:
在資料庫中檢測到5個聚類例項。
Cluster 0表示setosa,Cluster 1表示virginica,Cluster 2表示versicolor,而最後兩個聚類沒有任何與之關聯的類。
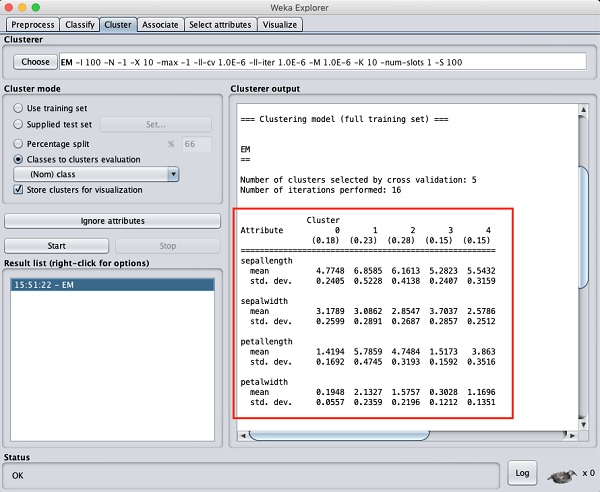
如果您向上滾動輸出視窗,您還將看到一些統計資訊,這些資訊提供了各個檢測到的聚類中每個屬性的均值和標準差。這在下面給出的螢幕截圖中顯示:
接下來,我們將檢視聚類的視覺化表示。
視覺化聚類
要視覺化聚類,請右鍵單擊Result list中的EM結果。您將看到以下選項:
選擇Visualize cluster assignments。您將看到以下輸出:
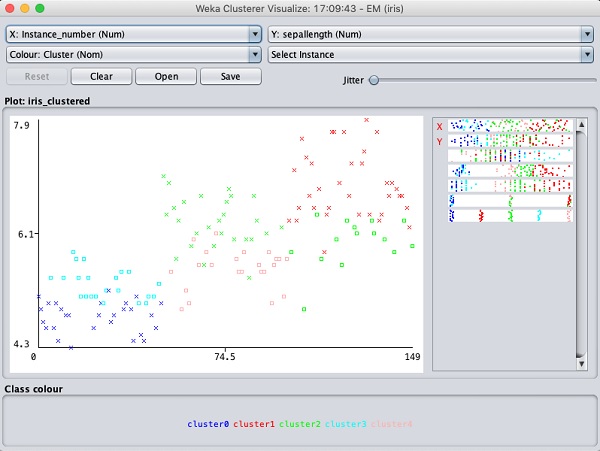
與分類的情況類似,您會注意到正確識別和錯誤識別的例項之間的區別。您可以透過更改 X 軸和 Y 軸來分析結果。您可以像分類情況下那樣使用抖動來找出正確識別例項的集中情況。視覺化圖中的操作與您在分類案例中學習的操作類似。
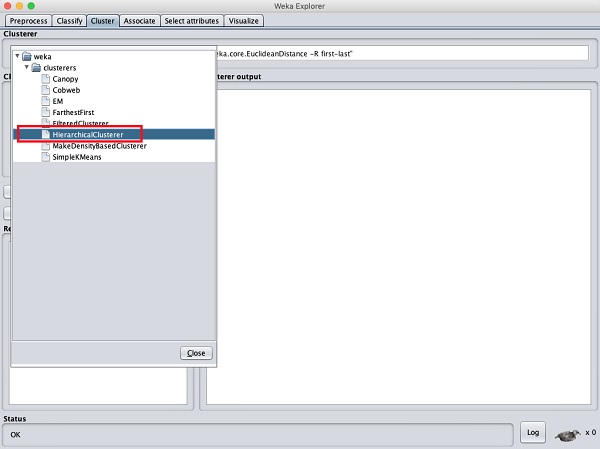
應用層次聚類
為了演示 WEKA 的強大功能,讓我們現在看看另一種聚類演算法的應用。在 WEKA 瀏覽器中,選擇HierarchicalClusterer作為您的機器學習演算法,如下面的螢幕截圖所示:
選擇聚類模式為類到聚類評估,然後單擊開始按鈕。您將看到以下輸出:
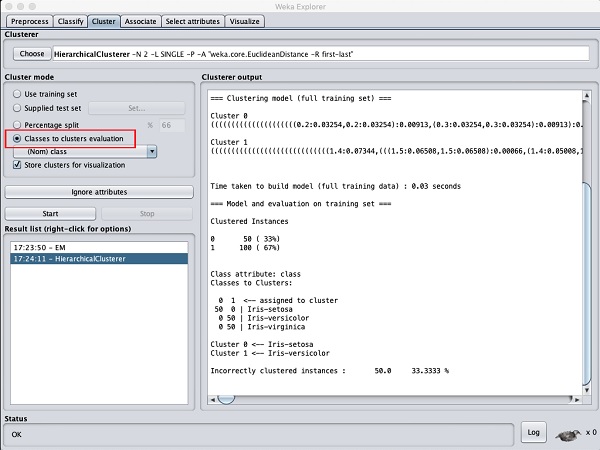
請注意,在結果列表中,列出了兩個結果:第一個是 EM 結果,第二個是當前的層次結果。同樣,您可以將多種機器學習演算法應用於相同的資料集,並快速比較其結果。
如果您檢查此演算法生成的樹,您將看到以下輸出:
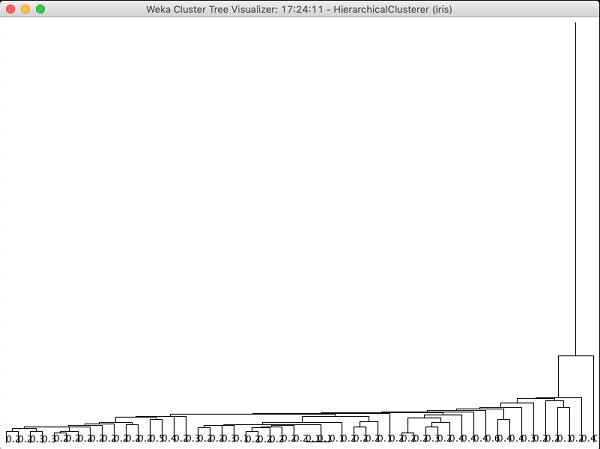
在下一章中,您將學習關聯型別的機器學習演算法。
Weka - 關聯規則
據觀察,購買啤酒的人也同時購買尿布。也就是說,在購買啤酒和尿布之間存在關聯。雖然這似乎不太令人信服,但此關聯規則是從超市的大型資料庫中挖掘出來的。類似地,花生醬和麵包之間也可能存在關聯。
發現這種關聯對於超市至關重要,因為它們會將尿布存放在啤酒旁邊,以便顧客可以輕鬆找到兩種商品,從而增加超市的銷量。
Apriori演算法就是這樣一種機器學習演算法,它可以找出可能的關聯並建立關聯規則。WEKA 提供了 Apriori 演算法的實現。在計算這些規則時,您可以定義最小支援度和可接受的置信度水平。您將把Apriori演算法應用於 WEKA 安裝中提供的超市資料。
載入資料
在 WEKA 瀏覽器中,開啟預處理選項卡,單擊開啟檔案...按鈕,並從安裝資料夾中選擇supermarket.arff資料庫。資料載入後,您將看到以下螢幕:
該資料庫包含 4627 個例項和 217 個屬性。您可以輕鬆理解檢測如此大量屬性之間的關聯有多麼困難。幸運的是,藉助 Apriori 演算法,這項任務可以自動化。
關聯器
單擊關聯選項卡,然後單擊選擇按鈕。選擇Apriori關聯,如螢幕截圖所示:
要設定 Apriori 演算法的引數,請單擊其名稱,將彈出一個視窗,如下所示,允許您設定引數:
設定引數後,單擊開始按鈕。過一段時間後,您將看到如下面的螢幕截圖所示的結果:
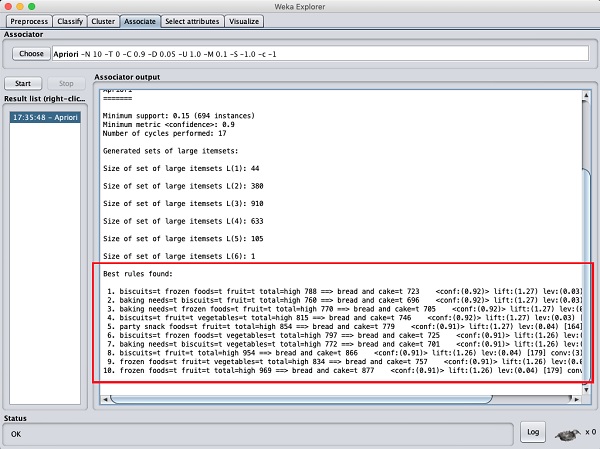
在底部,您將找到檢測到的最佳關聯規則。這將有助於超市將其產品存放在合適的貨架上。
Weka - 特徵選擇
當資料庫包含大量屬性時,將有一些屬性在您當前正在尋求的分析中變得不重要。因此,從資料集中刪除不需要的屬性成為開發良好機器學習模型的重要任務。
您可以直觀地檢查整個資料集,並確定不相關的屬性。對於包含大量屬性(例如您在上一課中看到的超市案例)的資料庫來說,這可能是一項巨大的任務。幸運的是,WEKA 提供了一個自動化的特徵選擇工具。
本章將在此資料庫上演示此功能,該資料庫包含大量屬性。
載入資料
在 WEKA 瀏覽器的預處理標籤中,選擇labor.arff檔案以載入到系統中。載入資料後,您將看到以下螢幕:
請注意,有 17 個屬性。我們的任務是透過消除與我們的分析無關的一些屬性來建立縮減後的資料集。
特徵提取
單擊選擇屬性選項卡。您將看到以下螢幕:
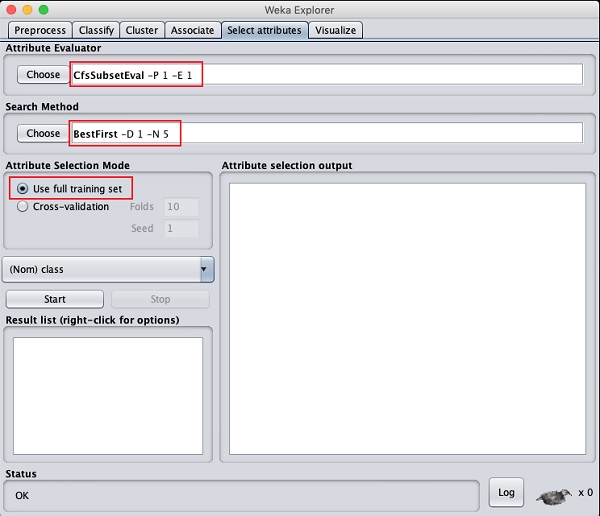
在屬性評估器和搜尋方法下,您會找到多個選項。我們在這裡只使用預設值。在屬性選擇模式中,使用完整訓練集選項。
單擊開始按鈕以處理資料集。您將看到以下輸出:
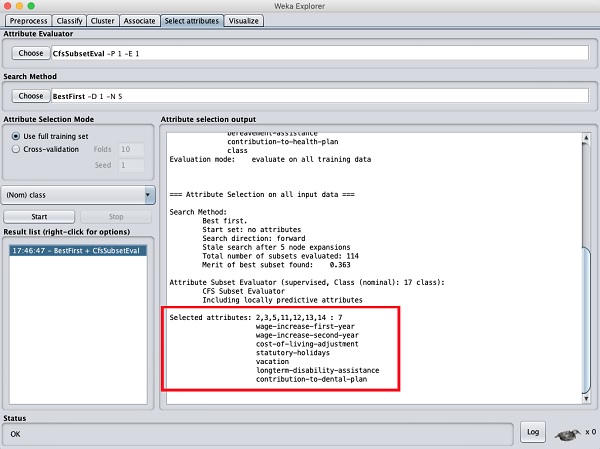
在結果視窗底部,您將獲得已選擇屬性的列表。要獲得視覺化表示,請右鍵單擊結果列表中的結果。
輸出顯示在以下螢幕截圖中:
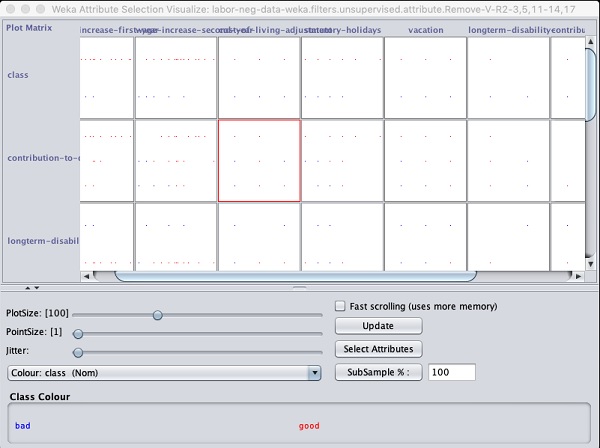
單擊任意正方形將為您提供資料圖,以供您進一步分析。一個典型的資料圖如下所示:
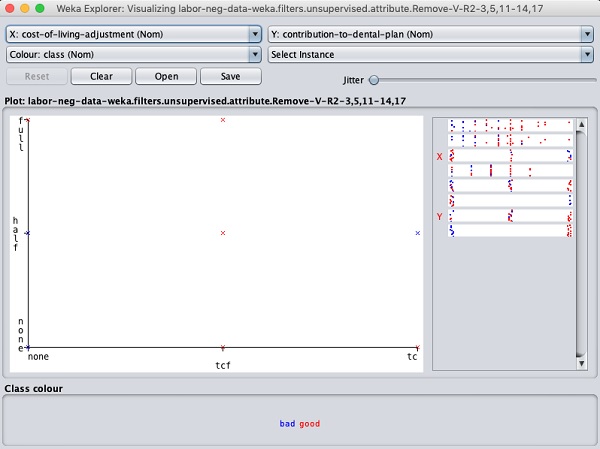
這類似於我們在前面章節中看到的那些。嘗試使用不同的可用選項來分析結果。
下一步是什麼?
到目前為止,您已經看到了 WEKA 在快速開發機器學習模型方面的強大功能。我們使用的是一個名為Explorer的圖形工具來開發這些模型。WEKA 還提供了一個命令列介面,它為您提供了比瀏覽器中提供的更多功能。
在GUI 選擇器應用程式中單擊簡單 CLI按鈕將啟動此命令列介面,如下面的螢幕截圖所示:
在底部的輸入框中鍵入您的命令。您將能夠完成到目前為止在瀏覽器中完成的所有操作,以及更多操作。有關更多詳細資訊,請參閱 WEKA 文件 (https://www.cs.waikato.ac.nz/ml/weka/documentation.html)。
最後,WEKA 是用 Java 開發的,併為其 API 提供了一個介面。因此,如果您是 Java 開發人員並且熱衷於將 WEKA 機器學習實現包含在您自己的 Java 專案中,您可以輕鬆做到這一點。
結論
WEKA 是一個用於開發機器學習模型的強大工具。它提供了多種最廣泛使用的機器學習演算法的實現。在將這些演算法應用於您的資料集之前,它還允許您預處理資料。支援的演算法型別分為分類、聚類、關聯和選擇屬性。處理各個階段的結果可以透過美觀且強大的視覺化表示來顯示。這使得資料科學家更容易在其資料集上快速應用各種機器學習技術,比較結果併為最終用途建立最佳模型。