Weka - 聚類
聚類演算法在整個資料集中查詢相似例項的組。WEKA 支援多種聚類演算法,例如 EM、FilteredClusterer、HierarchicalClusterer、SimpleKMeans 等。您應該完全理解這些演算法才能充分利用 WEKA 的功能。
與分類一樣,WEKA 允許您以圖形方式視覺化檢測到的叢集。為了演示聚類,我們將使用提供的 iris 資料庫。該資料集包含三個類別,每個類別包含 50 個例項。每個類別指一種鳶尾花植物。
載入資料
在 WEKA explorer 中選擇預處理選項卡。單擊開啟檔案...選項,並在檔案選擇對話方塊中選擇iris.arff檔案。載入資料後,螢幕如下所示:
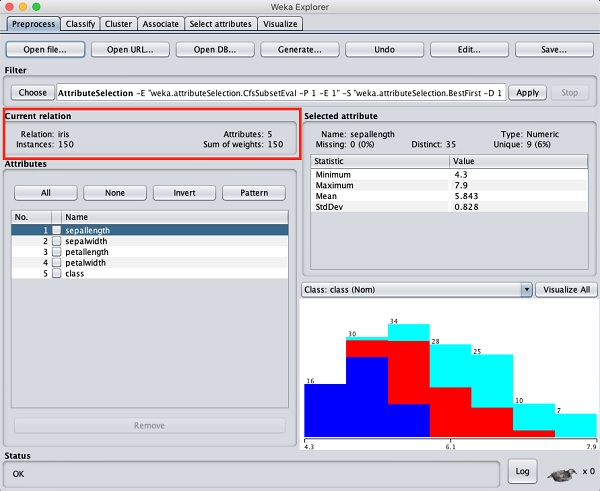
您可以看到有 150 個例項和 5 個屬性。屬性名稱列為sepallength、sepalwidth、petallength、petalwidth和class。前四個屬性為數值型,而 class 為名義型,具有 3 個不同的值。檢查每個屬性以瞭解資料庫的特徵。我們不會對這些資料進行任何預處理,而是直接進行模型構建。
聚類
單擊聚類選項卡,將聚類演算法應用於我們載入的資料。單擊選擇按鈕。您將看到以下螢幕:
現在,選擇EM作為聚類演算法。在聚類模式子視窗中,選擇類別到聚類評估選項,如下面的螢幕截圖所示:
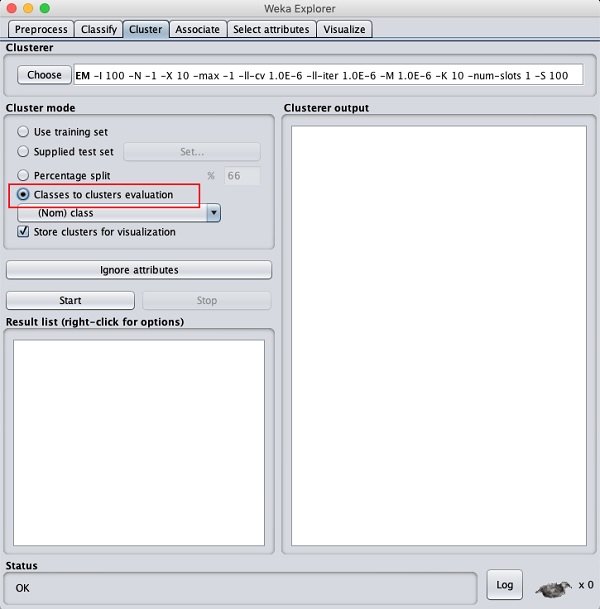
單擊開始按鈕處理資料。一段時間後,結果將顯示在螢幕上。
接下來,讓我們研究一下結果。
檢查輸出
資料處理的輸出顯示在下面的螢幕中:
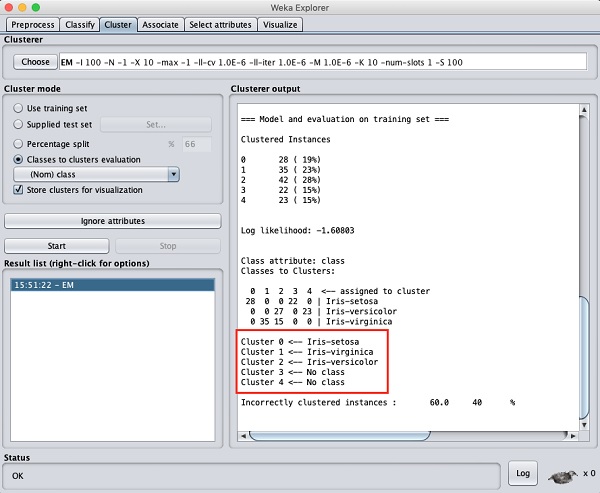
從輸出螢幕中,您可以觀察到:
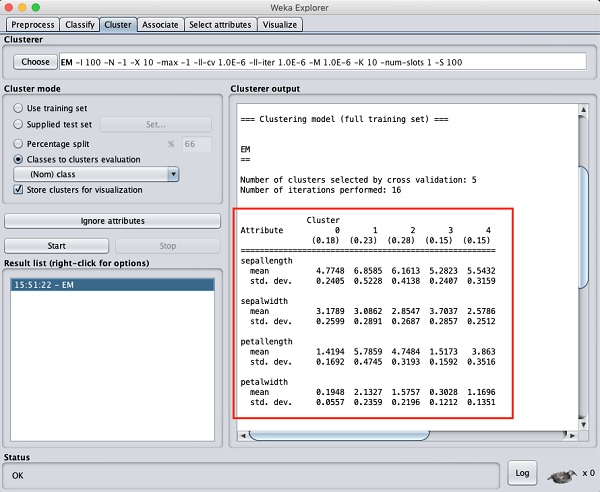
在資料庫中檢測到 5 個聚類例項。
聚類 0表示 setosa,聚類 1表示 virginica,聚類 2表示 versicolor,而最後兩個聚類沒有任何類別與之關聯。
如果您向上滾動輸出視窗,您還會看到一些統計資料,這些資料給出了各個檢測到的聚類中每個屬性的均值和標準差。這在下面給出的螢幕截圖中顯示:
接下來,我們將檢視聚類的視覺化表示。
視覺化聚類
要視覺化聚類,請右鍵單擊結果列表中的EM結果。您將看到以下選項:
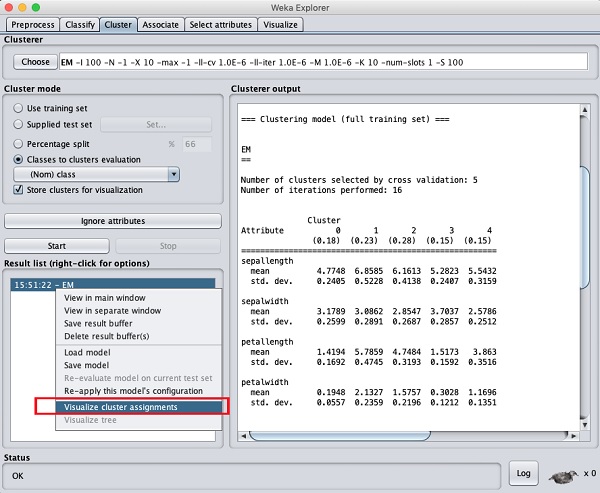
選擇視覺化聚類分配。您將看到以下輸出:
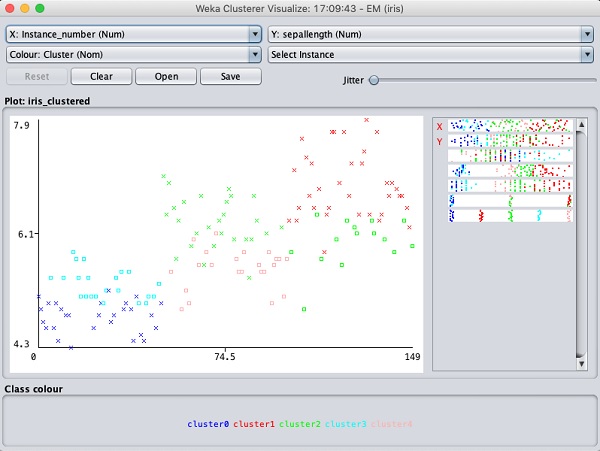
與分類一樣,您會注意到正確識別和錯誤識別例項之間的區別。您可以透過更改 X 和 Y 軸來分析結果。您可以像分類一樣使用抖動來找出正確識別例項的集中度。視覺化圖中的操作與您在分類中學習的操作相似。
應用層次聚類
為了演示 WEKA 的強大功能,讓我們現在研究另一種聚類演算法的應用。在 WEKA explorer 中,選擇HierarchicalClusterer作為您的 ML 演算法,如下面的螢幕截圖所示:
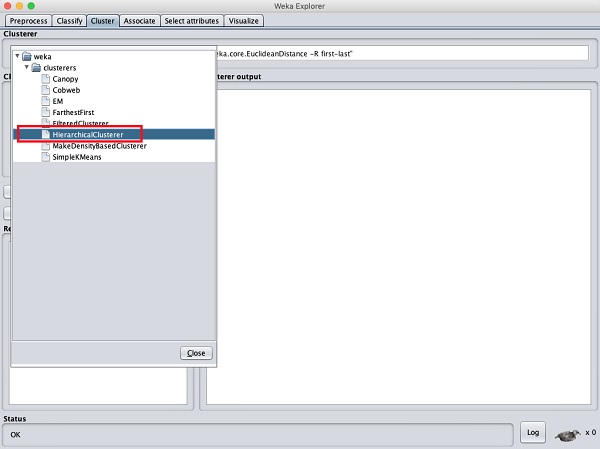
將聚類模式選擇設定為類別到聚類評估,然後單擊開始按鈕。您將看到以下輸出:
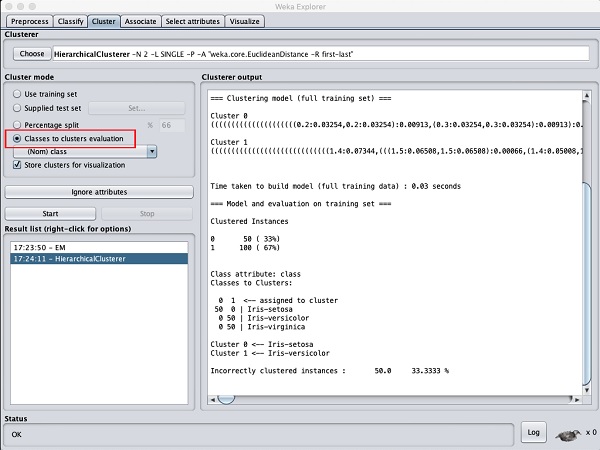
請注意,在結果列表中,列出了兩個結果:第一個是 EM 結果,第二個是當前的 Hierarchical。同樣,您可以將多個 ML 演算法應用於相同的資料集並快速比較其結果。
如果您檢查此演算法生成的樹,您將看到以下輸出:
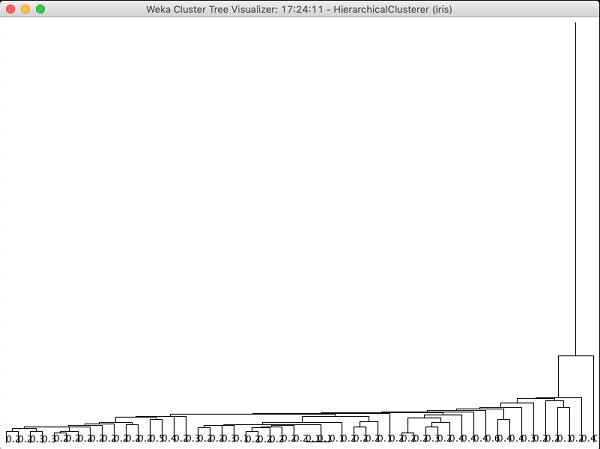
在下一章中,您將學習關聯型別的 ML 演算法。