Weka - 資料預處理
從現場收集的資料包含許多不需要的東西,這些東西會導致錯誤的分析。例如,資料可能包含空欄位,可能包含與當前分析無關的列,等等。因此,必須預處理資料以滿足您正在尋求的分析型別的要求。這在預處理模組中完成。
為了演示預處理中可用的功能,我們將使用安裝中提供的Weather資料庫。
使用預處理選項卡下的開啟檔案…選項,選擇weather-nominal.arff檔案。
開啟檔案後,螢幕將如下所示:
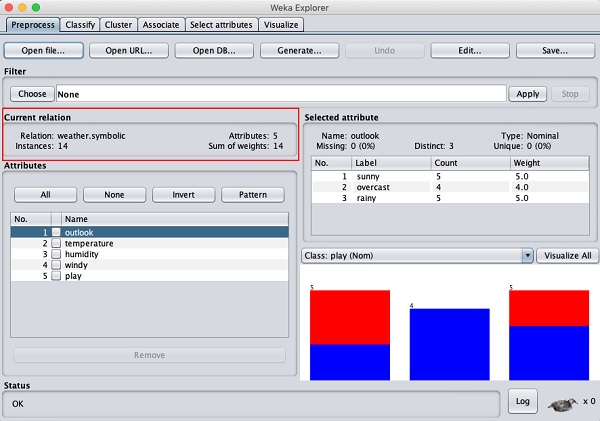
此螢幕告訴我們有關載入資料的幾件事,這些將在本章中進一步討論。
理解資料
讓我們首先看看突出顯示的當前關係子視窗。它顯示當前載入的資料庫的名稱。您可以從此子視窗推斷出兩點:
共有 14 個例項 - 表中的行數。
表包含 5 個屬性 - 欄位,這些將在接下來的部分中討論。
在左側,請注意屬性子視窗,它顯示資料庫中的各個欄位。
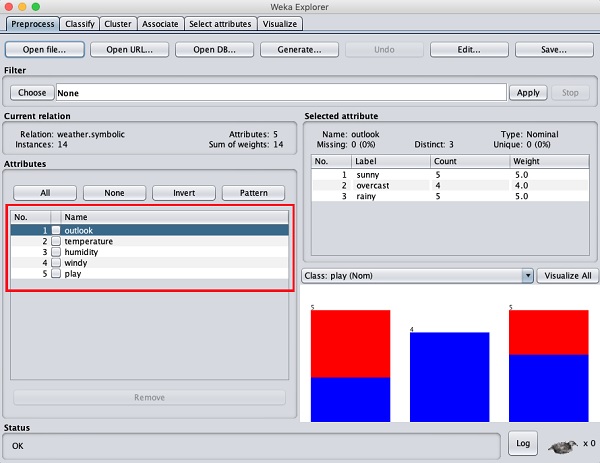
weather資料庫包含五個欄位 - outlook(天氣),temperature(溫度),humidity(溼度),windy(有風)和 play(玩耍)。當您透過單擊選擇此列表中的屬性時,屬性本身的更多詳細資訊將顯示在右側。
讓我們首先選擇temperature(溫度)屬性。單擊它後,您將看到以下螢幕:
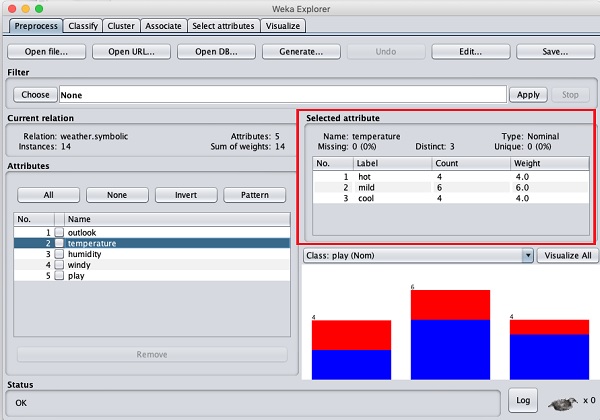
在選定屬性子視窗中,您可以觀察到以下內容:
顯示屬性的名稱和型別。
temperature(溫度)屬性的型別為Nominal(名義)。
缺失值的個數為零。
有三個不同的值,沒有唯一值。
此資訊下方的表格顯示此欄位的名義值為 hot(熱),mild(溫和)和 cold(冷)。
它還顯示每個名義值的計數和權重(百分比)。
在視窗底部,您可以看到類別值的直觀表示。
如果您單擊視覺化全部按鈕,您將能夠在一個視窗中看到所有特徵,如下所示:
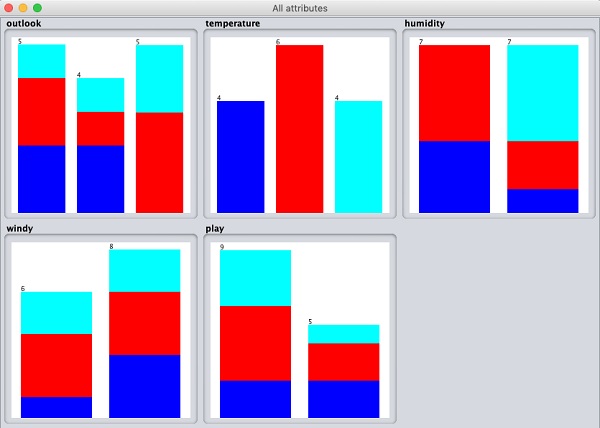
刪除屬性
很多時候,您想要用於模型構建的資料包含許多不相關的欄位。例如,客戶資料庫可能包含他的手機號碼,這與分析他的信用評級無關。
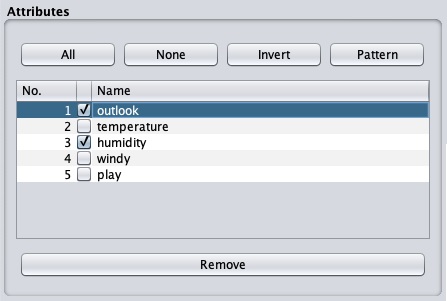
要刪除屬性,請選擇它們並單擊底部的刪除按鈕。
選定的屬性將從資料庫中刪除。完全預處理資料後,您可以將其儲存以進行模型構建。
接下來,您將學習如何透過對資料應用過濾器來預處理資料。
應用過濾器
一些機器學習技術,例如關聯規則挖掘,需要分類資料。為了說明過濾器的使用,我們將使用包含兩個數值屬性 - temperature(溫度)和humidity(溼度)的weather-numeric.arff資料庫。
我們將透過對原始資料應用過濾器將其轉換為名義資料。單擊過濾器子視窗中的選擇按鈕,然後選擇以下過濾器:
weka→filters→supervised→attribute→Discretize
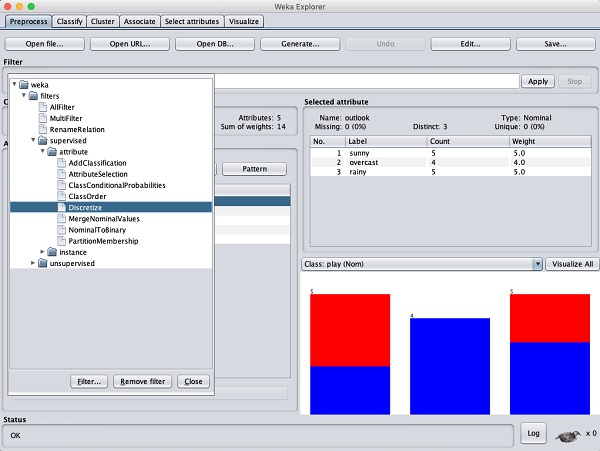
單擊應用按鈕並檢查temperature(溫度)和/或humidity(溼度)屬性。您會注意到它們已從數值型別更改為名義型別。
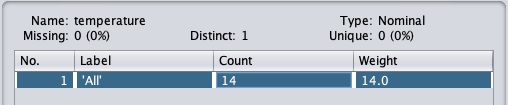
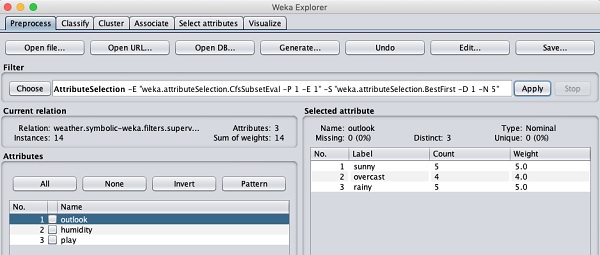
現在讓我們來看另一個過濾器。假設您想選擇決定play(玩耍)的最佳屬性。選擇並應用以下過濾器:
weka→filters→supervised→attribute→AttributeSelection
您會注意到它從資料庫中刪除了 temperature(溫度)和 humidity(溼度)屬性。
對資料預處理滿意後,請單擊儲存…按鈕儲存資料。您將使用此儲存的檔案進行模型構建。
在下一章中,我們將探索使用幾種預定義的 ML 演算法進行模型構建。