Weka - 特徵選擇
當資料庫包含大量屬性時,其中一些屬性在當前分析中並不重要。因此,從資料集中刪除不需要的屬性成為開發良好機器學習模型的重要任務。
您可以直觀地檢查整個資料集並確定無關屬性。對於包含大量屬性(例如您在前面課程中看到的超市案例)的資料庫,這可能是一項巨大的任務。幸運的是,WEKA 提供了一個自動化的特徵選擇工具。
本章將在一個包含大量屬性的資料庫上演示此功能。
載入資料
在 WEKA explorer 的 **預處理** 選項卡中,選擇 **labor.arff** 檔案載入到系統中。載入資料後,您將看到以下螢幕:
請注意,共有 17 個屬性。我們的任務是透過消除與分析無關的一些屬性來建立縮減後的資料集。
特徵提取
點選 **選擇屬性** 選項卡。您將看到以下螢幕:
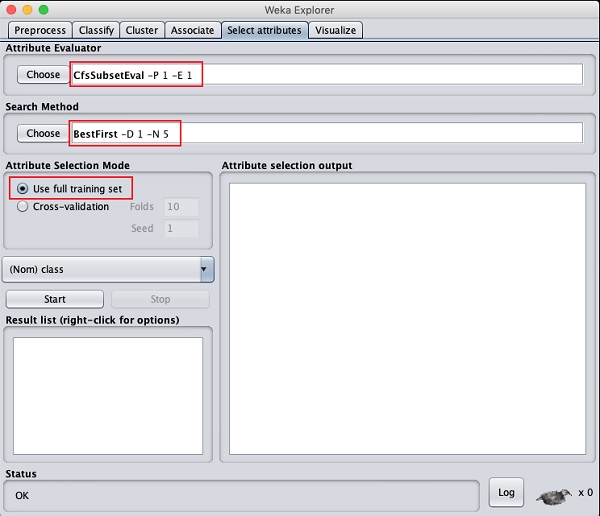
在 **屬性評估器** 和 **搜尋方法** 下,您會找到多個選項。這裡我們只使用預設設定。在 **屬性選擇模式** 中,使用完整訓練集選項。
點選“開始”按鈕處理資料集。您將看到以下輸出:
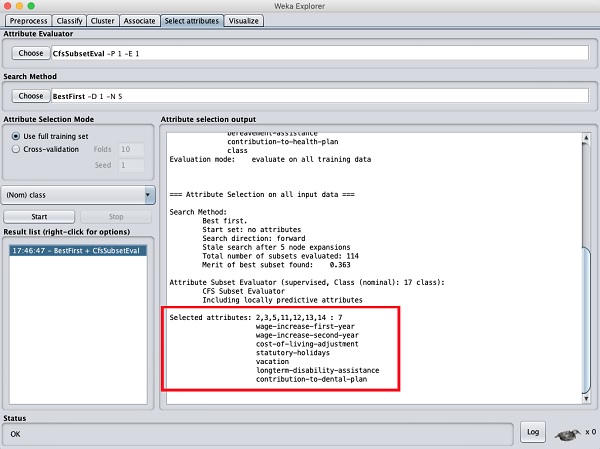
在結果視窗底部,您將獲得 **已選擇** 屬性的列表。要獲得視覺化表示,請右鍵單擊 **結果** 列表中的結果。
輸出顯示在以下螢幕截圖中:
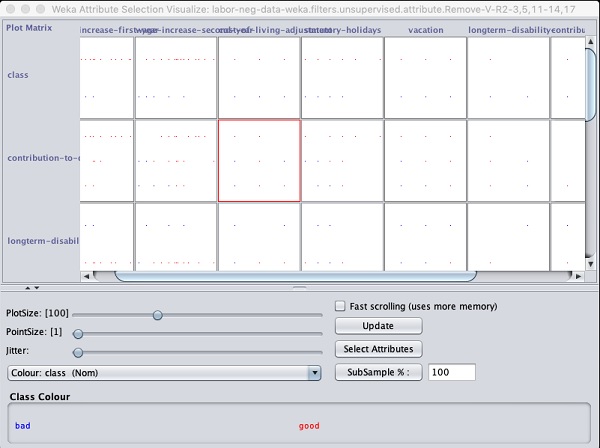
點選任意方塊將為您提供資料圖,以便您進一步分析。典型的資料圖如下所示:
這與我們在前面章節中看到的類似。嘗試使用不同的選項來分析結果。
下一步是什麼?
到目前為止,您已經看到了 WEKA 在快速開發機器學習模型方面的強大功能。我們使用的是一個名為 **Explorer** 的圖形工具來開發這些模型。WEKA 還提供命令列介面,它比 explorer 提供更強大的功能。
在 **GUI 選擇器** 應用程式中點選 **簡單 CLI** 按鈕將啟動此命令列介面,如下面的螢幕截圖所示:
在底部的輸入框中鍵入您的命令。您將能夠完成在 explorer 中完成的所有操作,以及更多操作。請參考 WEKA 文件 (https://www.cs.waikato.ac.nz/ml/weka/documentation.html) 獲取更多詳細資訊。
最後,WEKA 是用 Java 開發的,並提供對其 API 的介面。因此,如果您是 Java 開發人員並且希望在您自己的 Java 專案中包含 WEKA ML 實現,您可以輕鬆做到這一點。
結論
WEKA 是一個強大的工具,用於開發機器學習模型。它提供了對幾種最常用的 ML 演算法的實現。在將這些演算法應用於您的資料集之前,它還允許您預處理資料。支援的演算法型別分為分類、聚類、關聯和選擇屬性。處理各個階段的結果可以透過美觀且強大的視覺化表示進行視覺化。這使得資料科學家更容易快速地將各種機器學習技術應用於其資料集,比較結果併為最終用途建立最佳模型。