
 資料結構
資料結構 網路
網路 關係資料庫管理系統
關係資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C程式設計
C程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPPython中的統計思維
統計學是學習機器學習和人工智慧的基礎。由於 Python 是這些技術的首選語言,我們將瞭解如何編寫包含統計分析的 Python 程式。在本文中,我們將瞭解如何使用各種 Python 模組建立圖形和圖表。這些圖表有助於我們快速分析資料並以圖形方式得出見解和結論。
資料準備
我們採用包含各種種子資料的資料集。此資料集可在 kaggle 上獲得,連結顯示在下面的程式中。它有八列,將用於建立各種型別的圖表以比較不同種子的特徵。下面的程式從本地環境載入資料集並顯示樣本行。
示例
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
datainput = pd.read_csv('E:\seeds.csv')
#https://www.kaggle.com/jmcaro/wheat-seedsuci
print(datainput)輸出
執行以上程式碼將得到以下結果:
Area Perimeter Compactness ... Asymmetry.Coeff Kernel.Groove Type 0 15.26 14.84 0.8710 ... 2.221 5.220 1 1 14.88 14.57 0.8811 ... 1.018 4.956 1 2 14.29 14.09 0.9050 ... 2.699 4.825 1 3 13.84 13.94 0.8955 ... 2.259 4.805 1 4 16.14 14.99 0.9034 ... 1.355 5.175 1 .. ... ... ... ... ... ... ... 194 12.19 13.20 0.8783 ... 3.631 4.870 3 195 11.23 12.88 0.8511 ... 4.325 5.003 3 196 13.20 13.66 0.8883 ... 8.315 5.056 3 197 11.84 13.21 0.8521 ... 3.598 5.044 3 198 12.30 13.34 0.8684 ... 5.637 5.063 3 [199 rows x 8 columns]
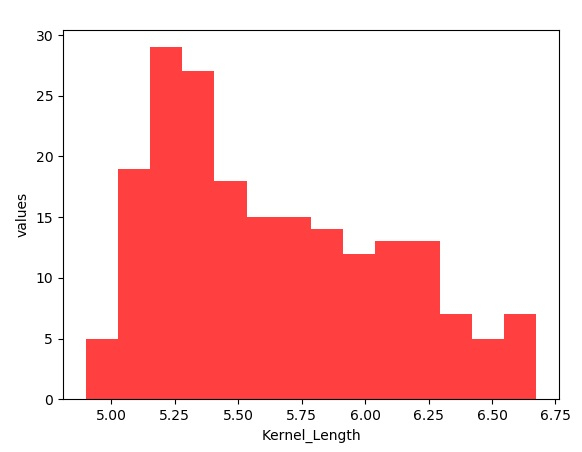
建立直方圖
要建立直方圖,我們從 csv 檔案中刪除標題行並將其作為 numpy 陣列讀取。然後我們使用 genfromtxt 模組讀取檔案。核心長度欄位位於陣列中的列索引 3。最後,我們使用 matplotlib 使用 numpy 建立的資料集繪製直方圖,並應用所需的標籤。
示例
import matplotlib.pyplot as plot
import numpy as np
from numpy import genfromtxt
seed_data = genfromtxt('E:\seeds.csv', delimiter=',')
Kernel_Length = seed_data[:, [3]]
x = len(Kernel_Length)
y = np.sqrt(x)
y = int(y)
z = plot.hist(Kernel_Length, bins=y, color='#FF4040')
z = plot.xlabel('Kernel_Length')
z = plot.ylabel('values')
plot.show()輸出
執行以上程式碼將得到以下結果:
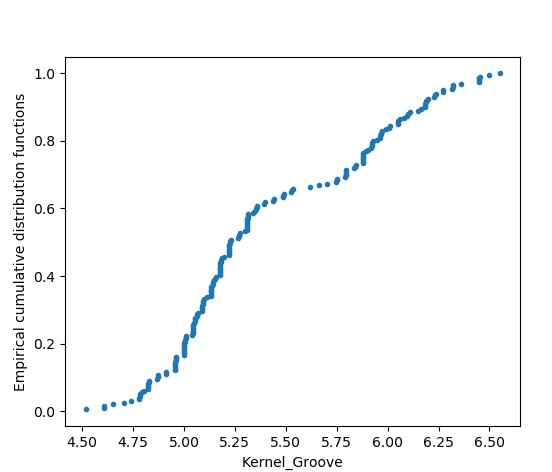
經驗累積分佈函式
此圖表顯示了資料集上分佈的核心溝槽大小的圖。它按從小到大的值排列,並顯示為分佈。
示例
import matplotlib.pyplot as plot
import numpy as np
from numpy import genfromtxt
seed_data = genfromtxt('E:\seeds.csv', delimiter=',')
Kernel_groove = seed_data[:, 6]
def ECDF(seed_data):#Empirical cumulative distribution functions
i = len(seed_data)
m = np.sort(seed_data)
n = np.arange(1, i + 1) / i
return m, n
m, n = ECDF(Kernel_groove)
plot.plot(m, n, marker='.', linestyle='none')
plot.xlabel('Kernel_Groove')
plot.ylabel('Empirical cumulative distribution functions')
plot.show()輸出
執行以上程式碼將得到以下結果:
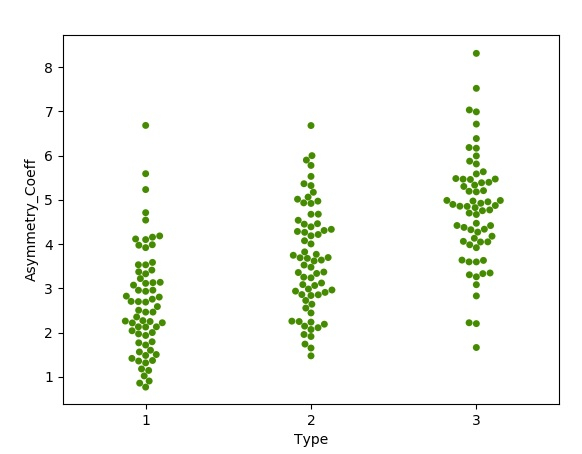
蜜蜂群圖
蜜蜂群圖透過視覺上對每個單獨的資料點進行聚類來顯示一組資料點的尺寸。我們使用 seaborn 庫來建立此圖形。我們使用資料集中的 Type 列將類似型別的種子聚類在一起。
示例
import pandas as pd
import matplotlib.pyplot as plot
import seaborn as sns
datainput = pd.read_csv('E:\seeds.csv')
sns.swarmplot(x='Type', y='Asymmetry.Coeff',data=datainput, color='#458B00')#bee swarm plot
plot.xlabel('Type')
plot.ylabel('Asymmetry_Coeff')
plot.show()輸出
執行以上程式碼將得到以下結果:

更新於:2020年2月4日
278 次檢視

廣告