- SQL 教程
- SQL - 首頁
- SQL - 概述
- SQL - RDBMS 概念
- SQL - 資料庫
- SQL - 語法
- SQL - 資料型別
- SQL - 運算子
- SQL - 表示式
- SQL 資料庫
- SQL - 建立資料庫
- SQL - 刪除資料庫
- SQL - 選擇資料庫
- SQL - 重新命名資料庫
- SQL - 顯示資料庫
- SQL - 備份資料庫
- SQL 表
- SQL - 建立表
- SQL - 顯示錶
- SQL - 重命名錶
- SQL - 截斷表
- SQL - 克隆表
- SQL - 臨時表
- SQL - 修改表
- SQL - 刪除表
- SQL - 刪除表資料
- SQL - 約束
- SQL 查詢
- SQL - 插入查詢
- SQL - 選擇查詢
- SQL - Select Into
- SQL - Insert Into Select
- SQL - 更新查詢
- SQL - 刪除查詢
- SQL - 排序結果
- SQL 檢視
- SQL - 建立檢視
- SQL - 更新檢視
- SQL - 刪除檢視
- SQL - 重新命名檢視
- SQL 運算子和子句
- SQL - Where 子句
- SQL - Top 子句
- SQL - Distinct 子句
- SQL - Order By 子句
- SQL - Group By 子句
- SQL - Having 子句
- SQL - AND & OR
- SQL - BOOLEAN (BIT) 運算子
- SQL - LIKE 運算子
- SQL - IN 運算子
- SQL - ANY, ALL 運算子
- SQL - EXISTS 運算子
- SQL - CASE
- SQL - NOT 運算子
- SQL - 不等於
- SQL - IS NULL
- SQL - IS NOT NULL
- SQL - NOT NULL
- SQL - BETWEEN 運算子
- SQL - UNION 運算子
- SQL - UNION vs UNION ALL
- SQL - INTERSECT 運算子
- SQL - EXCEPT 運算子
- SQL - 別名
- SQL 連線
- SQL - 使用連線
- SQL - 內連線
- SQL - 左連線
- SQL - 右連線
- SQL - 交叉連線
- SQL - 全連線
- SQL - 自連線
- SQL - 刪除連線
- SQL - 更新連線
- SQL - 左連線 vs 右連線
- SQL - Union vs Join
- SQL 鍵
- SQL - 唯一鍵
- SQL - 主鍵
- SQL - 外部索引鍵
- SQL - 組合鍵
- SQL - 候選鍵
- SQL 索引
- SQL - 索引
- SQL - 建立索引
- SQL - 刪除索引
- SQL - 顯示索引
- SQL - 唯一索引
- SQL - 聚集索引
- SQL - 非聚集索引
- 高階 SQL
- SQL - 萬用字元
- SQL - 註釋
- SQL - 注入
- SQL - 託管
- SQL - Min & Max
- SQL - 空值函式
- SQL - 檢查約束
- SQL - 預設約束
- SQL - 儲存過程
- SQL - NULL 值
- SQL - 事務
- SQL - 子查詢
- SQL - 處理重複資料
- SQL - 使用序列
- SQL - 自動遞增
- SQL - 日期和時間
- SQL - 遊標
- SQL - 公共表表達式
- SQL - Group By vs Order By
- SQL - IN vs EXISTS
- SQL - 資料庫調優
- SQL 函式參考
- SQL - 日期函式
- SQL - 字串函式
- SQL - 聚合函式
- SQL - 數值函式
- SQL - 文字和影像函式
- SQL - 統計函式
- SQL - 邏輯函式
- SQL - 遊標函式
- SQL - JSON 函式
- SQL - 轉換函式
- SQL - 資料型別函式
- SQL 有用資源
- SQL - 問答
- SQL - 快速指南
- SQL - 有用函式
- SQL - 有用資源
- SQL - 討論
SQL - 非聚集索引

SQL 非聚集索引
SQL **非聚集** 索引類似於聚集索引。當在某列上定義時,它會建立一個特殊的表,該表包含索引列的副本以及指向表中實際資料位置的指標。但是,與聚集索引不同,非聚集索引無法物理排序索引列。
以下是 SQL 中非聚集索引的一些關鍵點:
- 非聚集索引是一種用於資料庫的索引型別,用於加快資料庫查詢的執行時間。
- 這些索引需要的儲存空間比聚集索引少,因為它們不儲存實際的資料行。
- 我們可以在單個表上建立多個非聚集索引。
MySQL 沒有非聚集索引的概念。PRIMARY KEY(如果存在)和第一個 NOT NULL UNIQUE KEY(如果不存在 PRIMARY KEY)在 MySQL 中被視為聚集索引;所有其他索引都被稱為二級索引,並且是隱式定義的。
為了更好地理解,請檢視以下說明非聚集索引工作原理的圖:
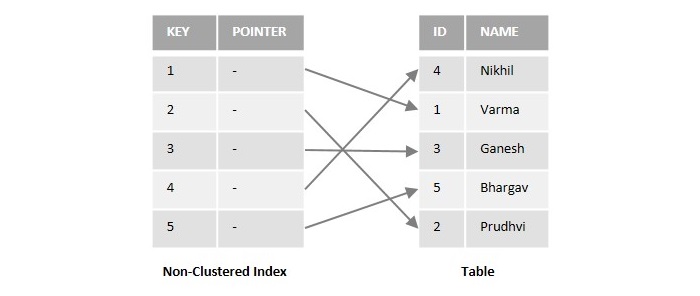
假設我們有一個示例資料庫表,其中包含兩列,名為 **ID** 和 **NAME**。如果我們在上述表中名為 **ID** 的列上建立非聚集索引,它將儲存 ID 列的副本以及指向表中實際資料特定位置的指標。
語法
以下是 SQL Server 中建立 **非聚集** 索引的語法:
CREATE NONCLUSTERED INDEX index_name ON table_name (column_name)
這裡,
- **index_name**:儲存非聚集索引的名稱。
- **table_name**:儲存要建立非聚集索引的表的名稱。
- **column_name**:儲存要為其定義非聚集索引的列的名稱。
示例
讓我們使用以下查詢建立一個名為 **CUSTOMERS** 的表:
CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (20, 2), );
讓我們使用以下查詢將一些值插入到上面建立的表中:
INSERT INTO CUSTOMERS VALUES (7, 'Muffy', '24', 'Indore', 5500), (1, 'Ramesh', '32', 'Ahmedabad', 2000), (6, 'Komal', '22', 'Hyderabad', 9000), (2, 'Khilan', '25', 'Delhi', 1500), (4, 'Chaitali', '25', 'Mumbai', 6500), (5, 'Hardik','27', 'Bhopal', 8500), (3, 'Kaushik', '23', 'Kota', 2000);
該表已成功在 SQL 資料庫中建立。
| ID | NAME | AGE | ADDRESS | SALARY |
|---|---|---|---|---|
| 7 | Muffy | 24 | Indore | 5500.00 |
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 6 | Komal | 22 | Hyderabad | 9000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 3 | Kaushik | 23 | Kota | 2500.00 |
現在,讓我們使用以下查詢在名為 **ID** 的 **單個列** 上建立非聚集索引:
CREATE NONCLUSTERED INDEX NON_CLU_ID ON customers (ID ASC);
輸出
執行上述查詢後,輸出將顯示如下:
Commands Completed Successfully.
驗證
讓我們使用以下查詢檢索在 CUSTOMERS 表上建立的所有索引:
EXEC sys.sp_helpindex @objname = N'CUSTOMERS';
正如我們觀察到的,我們可以在索引列表中找到名為 ID 的列。
| index_name | index_description | index_keys | |
|---|---|---|---|
| 1 | NON_CLU_ID | 位於 PRIMARY 上的非聚集索引 | ID |
現在,使用以下查詢再次檢索 CUSTOMERS 表以檢查表是否已排序:
SELECT * FROM CUSTOMERS;
正如我們觀察到的,非聚集索引不會物理排序行,而是從表資料建立單獨的鍵值結構。
| ID | NAME | AGE | ADDRESS | SALARY |
|---|---|---|---|---|
| 7 | Muffy | 24 | Indore | 5500.00 |
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 6 | Komal | 22 | Hyderabad | 9000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 3 | Kaushik | 23 | Kota | 2500.00 |
在多列上建立非聚集索引
不用建立新表,讓我們考慮之前建立的 CUSTOMERS 表。現在,嘗試使用以下查詢在表的 **多個列**(例如 ID、AGE 和 SALARY)上建立非聚集索引:
CREATE NONCLUSTERED INDEX NON_CLUSTERED_ID ON CUSTOMERS (ID, AGE, SALARY);
輸出
以下查詢將為 ID、AGE 和 SALARY 建立三個單獨的非聚集索引。
Commands Completed Successfully.
驗證
讓我們使用以下查詢檢索在 CUSTOMERS 表上建立的所有索引:
EXEC sys.sp_helpindex @objname = N'CUSTOMERS';
正如我們觀察到的,我們可以在索引列表中找到列名 ID、AGE 和 SALARY 列。
| index_name | index_description | index_keys | |
|---|---|---|---|
| 1 | NON_CLU_ID | 位於 PRIMARY 上的非聚集索引 | ID、AGE、SALARY |
廣告