- PyTorch 教程
- PyTorch——主頁
- PyTorch——簡介
- PyTorch——安裝
- 神經網路的數學構件
- PyTorch——神經網路基礎
- 機器學習的通用工作流
- 機器學習與深度學習
- 實現第一個神經網路
- 神經網路到功能模組
- PyTorch——術語
- PyTorch——載入資料
- PyTorch——線性迴歸
- PyTorch——卷積神經網路
- PyTorch——迴圈神經網路
- PyTorch——資料集
- PyTorch——卷積簡介
- 從頭開始訓練一個卷積
- PyTorch——卷積中的特徵提取
- PyTorch——卷積的視覺化
- 使用卷積進行序列處理
- PyTorch——詞嵌入
- PyTorch——遞迴神經網路
- PyTorch 有用資源
- PyTorch——快速指南
- PyTorch——有用資源
- PyTorch——討論
PyTorch——使用卷積進行序列處理
在本章中,我們提出一種替代方法,而這種方法依賴於同時在兩個序列間的一個二維卷積神經網路。我們網路的每一層都根據迄今為止產生的輸出序列重新編碼源標記。因此,類注意力屬性貫穿整個網路。
這裡,我們重點是利用資料集中的值從特定池中建立順序網路。此過程也最適用於“影像識別模組”。
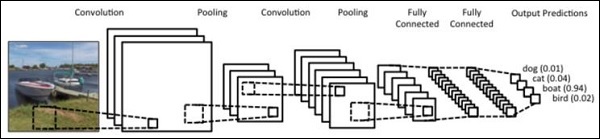
使用 PyTorch 使用卷積建立序列處理模型的步驟如下——
步驟 1
匯入使用卷積進行序列處理所需的模組。
import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D import numpy as np
步驟 2
執行必要的操作以使用以下程式碼在相應序列中建立模式——
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000,28,28,1)
x_test = x_test.reshape(10000,28,28,1)
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
步驟 3
編譯模型並按照展示在下面——提到的常規神經網路模型中適應模式−
model.compile(loss =
keras.losses.categorical_crossentropy,
optimizer = keras.optimizers.Adadelta(), metrics =
['accuracy'])
model.fit(x_train, y_train,
batch_size = batch_size, epochs = epochs,
verbose = 1, validation_data = (x_test, y_test))
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
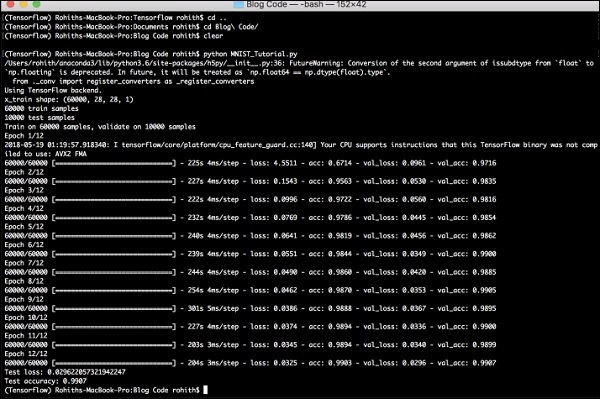
生成的輸出如下——
廣告