- PyTorch 教程
- PyTorch - 首頁
- PyTorch - 簡介
- PyTorch - 安裝
- 神經網路的數學基礎
- PyTorch - 神經網路基礎
- 機器學習的通用工作流程
- 機器學習與深度學習
- 實現第一個神經網路
- 神經網路到功能模組
- PyTorch - 術語
- PyTorch - 載入資料
- PyTorch - 線性迴歸
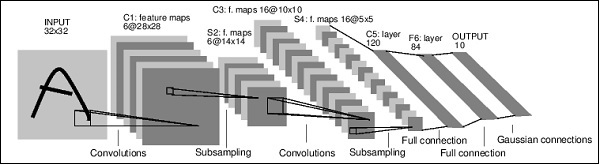
- PyTorch - 卷積神經網路
- PyTorch - 迴圈神經網路
- PyTorch - 資料集
- PyTorch - 卷積神經網路簡介
- 從零開始訓練卷積神經網路
- PyTorch - 卷積神經網路中的特徵提取
- PyTorch - 卷積神經網路的視覺化
- 使用卷積神經網路進行序列處理
- PyTorch - 詞嵌入
- PyTorch - 遞迴神經網路
- PyTorch 有用資源
- PyTorch 快速指南
- PyTorch - 有用資源
- PyTorch - 討論
PyTorch 快速指南
PyTorch - 簡介
PyTorch 定義為一個用於 Python 的開源機器學習庫。它用於自然語言處理等應用程式。它最初由 Facebook 人工智慧研究小組開發,Uber 的機率程式設計軟體 Pyro 也基於它構建。
最初,PyTorch 由 Hugh Perkins 開發,作為基於 Torch 框架的 LusJIT 的 Python 包裝器。PyTorch 有兩個變體。
PyTorch 使用 Python 重設計和實現了 Torch,同時共享相同的核心 C 庫作為後端程式碼。PyTorch 開發人員調整了這個後端程式碼以高效地執行 Python。他們還保留了基於 GPU 的硬體加速以及使基於 Lua 的 Torch 成為可能的擴充套件功能。
特性
PyTorch 的主要特性如下:
簡單的介面 - PyTorch 提供易於使用的 API;因此它被認為非常易於操作,並且在 Python 上執行。在這個框架中的程式碼執行非常容易。
Python 使用 - 這個庫被認為是 Pythonic 的,它與 Python 資料科學棧無縫整合。因此,它可以利用 Python 環境提供的所有服務和功能。
計算圖 - PyTorch 提供了一個優秀的平臺,它提供動態計算圖。因此使用者可以在執行時更改它們。當開發人員不知道建立神經網路模型需要多少記憶體時,這非常有用。
PyTorch 以具有以下三個抽象級別而聞名:
張量 - 在 GPU 上執行的命令式 n 維陣列。
變數 - 計算圖中的節點。它儲存資料和梯度。
模組 - 神經網路層,它將儲存狀態或可學習的權重。
PyTorch 的優勢
以下是 PyTorch 的優勢:
易於除錯和理解程式碼。
它包含許多與 Torch 相同的層。
它包含許多損失函式。
它可以被認為是 NumPy 對 GPU 的擴充套件。
它允許構建其結構依賴於計算本身的網路。
TensorFlow 與 PyTorch
我們將看看 TensorFlow 和 PyTorch 之間的主要區別:
| PyTorch | TensorFlow |
|---|---|
PyTorch 與在 Facebook 中積極使用的基於 lua 的 Torch 框架密切相關。 |
TensorFlow 由 Google Brain 開發,並在 Google 積極使用。 |
與其他競爭技術相比,PyTorch 相對較新。 |
TensorFlow 並不新,被許多研究人員和行業專業人士視為首選工具。 |
PyTorch 以命令式和動態的方式包含所有內容。 |
TensorFlow 將靜態圖和動態圖結合在一起。 |
PyTorch 中的計算圖在執行時定義。 |
TensorFlow 不包含任何執行時選項。 |
PyTorch 包含用於移動和嵌入式框架的部署功能。 |
TensorFlow 更適用於嵌入式框架。 |
PyTorch - 安裝
PyTorch 是一個流行的深度學習框架。在本教程中,我們將“Windows 10”作為我們的作業系統。成功環境設定的步驟如下:
步驟 1
以下連結包含一個軟體包列表,其中包含適用於 PyTorch 的合適的軟體包。
https://drive.google.com/drive/folders/0B-X0-FlSGfCYdTNldW02UGl4MXM您需要做的就是下載相應的軟體包並按照以下螢幕截圖所示安裝它:

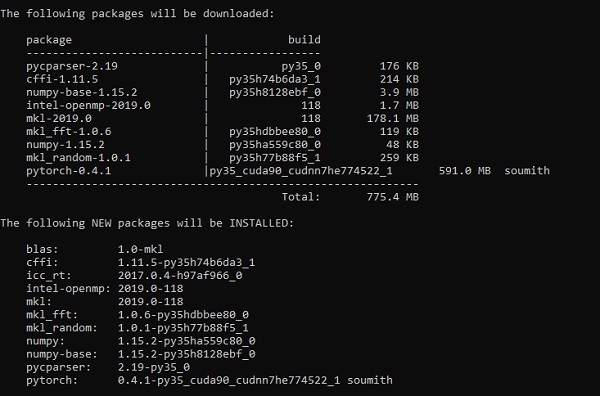
步驟 2
它涉及使用 Anaconda 框架驗證 PyTorch 框架的安裝。
使用以下命令驗證:
conda list

“Conda list” 顯示已安裝的框架列表。
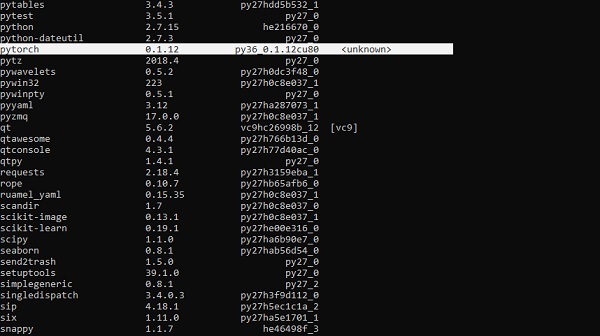
突出顯示的部分表明 PyTorch 已成功安裝到我們的系統中。
神經網路的數學基礎
數學在任何機器學習演算法中都至關重要,它包含各種核心數學概念,以設計出特定方式的正確演算法。
以下是數學主題對機器學習和資料科學的重要性:

現在,讓我們關注機器學習中重要的數學概念,這些概念對於自然語言處理來說很重要:
向量
向量被認為是數字陣列,可以是連續的或離散的,包含向量的空間稱為向量空間。向量的空間維度可以是有限的或無限的,但據觀察,機器學習和資料科學問題處理的是固定長度的向量。
向量表示如下所示:
temp = torch.FloatTensor([23,24,24.5,26,27.2,23.0]) temp.size() Output - torch.Size([6])
在機器學習中,我們處理多維資料。因此,向量變得非常重要,並被認為是任何預測問題陳述的輸入特徵。
標量
標量被定義為只有零維且只包含一個值的量。在 PyTorch 中,它不包含一個特殊的零維張量;因此,宣告將如下進行:
x = torch.rand(10) x.size() Output - torch.Size([10])
矩陣
大多數結構化資料通常以表格或特定矩陣的形式表示。我們將使用一個名為波士頓房價的資料集,它在 Python scikit-learn 機器學習庫中很容易獲得。
boston_tensor = torch.from_numpy(boston.data) boston_tensor.size() Output: torch.Size([506, 13]) boston_tensor[:2] Output: Columns 0 to 7 0.0063 18.0000 2.3100 0.0000 0.5380 6.5750 65.2000 4.0900 0.0273 0.0000 7.0700 0.0000 0.4690 6.4210 78.9000 4.9671 Columns 8 to 12 1.0000 296.0000 15.3000 396.9000 4.9800 2.0000 242.0000 17.8000 396.9000 9.1400
PyTorch - 神經網路基礎
神經網路的主要原理包括一系列基本元素,即人工神經元或感知器。它包括幾個基本輸入,例如 x1、x2……xn,如果總和大於啟用電位,則產生二進位制輸出。
示例神經元的示意圖如下所示:
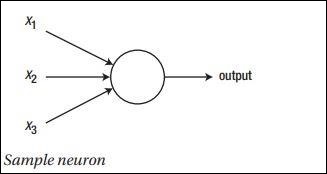
生成的輸出可以被認為是帶啟用電位或偏差的加權和。
$$Output=\sum_jw_jx_j+Bias$$
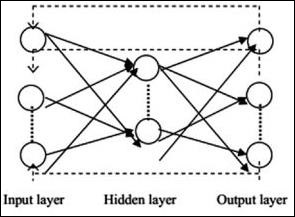
典型的神經網路架構如下所示:

輸入和輸出之間的層稱為隱藏層,層之間連線的密度和型別是配置。例如,全連線配置具有連線到 L+1 層的所有 L 層神經元。對於更明顯的區域性化,我們可以只連線區域性鄰域,例如九個神經元,到下一層。圖 1-9 說明了具有密集連線的兩個隱藏層。
各種型別的神經網路如下:
前饋神經網路
前饋神經網路包括神經網路家族的基本單元。這種型別的神經網路中的資料移動是從輸入層到輸出層,透過存在的隱藏層。一層的一個輸出作為輸入層,限制了網路架構中任何型別的迴圈。

迴圈神經網路
當資料模式隨時間連續變化時,就是迴圈神經網路。在 RNN 中,相同的層用於接受輸入引數並在指定的神經網路中顯示輸出引數。
可以使用 torch.nn 包構建神經網路。
這是一個簡單的前饋網路。它接收輸入,將其依次饋送到多層,然後最終給出輸出。
藉助 PyTorch,我們可以使用以下步驟進行神經網路的典型訓練過程:
- 定義具有某些可學習引數(或權重)的神經網路。
- 迭代輸入資料集。
- 透過網路處理輸入。
- 計算損失(輸出與正確結果的距離)。
- 將梯度反向傳播到網路的引數中。
- 更新網路的權重,通常使用如下所示的簡單更新
rule: weight = weight -learning_rate * gradient
機器學習的通用工作流程
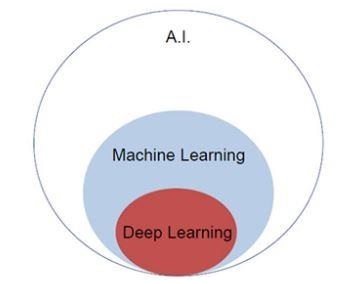
人工智慧如今正日益流行。機器學習和深度學習構成了人工智慧。下面的維恩圖解釋了機器學習和深度學習之間的關係。
機器學習
機器學習是一門允許計算機根據設計和程式設計的演算法執行的科學藝術。許多研究人員認為機器學習是朝著人類水平人工智慧取得進展的最佳途徑。它包括各種型別的模式,例如:
- 監督學習模式
- 無監督學習模式
深度學習
深度學習是機器學習的一個子領域,其中所關注的演算法的靈感來自大腦的結構和功能,稱為人工神經網路。
深度學習透過監督學習或從標記資料和演算法中學習而獲得了極大的重視。深度學習中的每個演算法都經歷相同的過程。它包括輸入的分層非線性變換,並用於建立統計模型作為輸出。
機器學習過程使用以下步驟定義:
- 識別相關資料集併為分析準備它們。
- 選擇要使用的演算法型別。
- 基於所使用的演算法構建分析模型。
- 在測試資料集上訓練模型,根據需要進行修改。
- 執行模型以生成測試分數。
PyTorch - 機器學習與深度學習
在本章中,我們將討論機器學習和深度學習概念之間的主要區別。
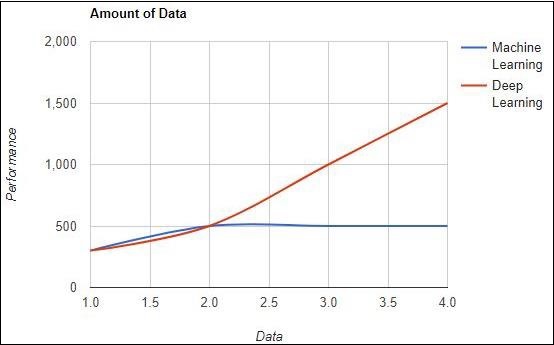
資料量
機器學習使用不同數量的資料,主要用於少量資料。另一方面,深度學習如果資料量迅速增加,則可以高效地工作。下圖描述了機器學習和深度學習關於資料量的執行情況:
硬體依賴性
深度學習演算法的設計嚴重依賴於高階機器,這與傳統的機器學習演算法相反。深度學習演算法執行大量的矩陣乘法運算,這需要巨大的硬體支援。
特徵工程
特徵工程是將領域知識放入特定特徵以降低資料複雜性並使學習演算法可見的模式的過程。
例如,傳統的機器學習模式側重於畫素和其他特徵工程過程所需的屬性。深度學習演算法側重於來自資料的高階特徵。它減少了為每個新問題開發新的特徵提取器的任務。
PyTorch - 實現第一個神經網路
PyTorch 包含建立和實現神經網路的特殊功能。在本章中,我們將建立一個具有一個隱藏層並開發單個輸出單元的簡單神經網路。
我們將使用以下步驟來使用 PyTorch 實現第一個神經網路:
步驟 1
首先,我們需要使用以下命令匯入 PyTorch 庫:
import torch import torch.nn as nn
步驟 2
定義所有層和批次大小以開始執行神經網路,如下所示:
# Defining input size, hidden layer size, output size and batch size respectively n_in, n_h, n_out, batch_size = 10, 5, 1, 10
步驟 3
由於神經網路包括輸入資料的組合以獲得相應的輸出資料,我們將遵循以下相同步驟:
# Create dummy input and target tensors (data) x = torch.randn(batch_size, n_in) y = torch.tensor([[1.0], [0.0], [0.0], [1.0], [1.0], [1.0], [0.0], [0.0], [1.0], [1.0]])
步驟 4
使用內建函式建立一個順序模型。使用下面的程式碼行建立一個順序模型:
# Create a model model = nn.Sequential(nn.Linear(n_in, n_h), nn.ReLU(), nn.Linear(n_h, n_out), nn.Sigmoid())
步驟 5
使用梯度下降最佳化器構建損失函式,如下所示:
Construct the loss function criterion = torch.nn.MSELoss() # Construct the optimizer (Stochastic Gradient Descent in this case) optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
步驟 6
使用給定的程式碼行實現帶有迭代迴圈的梯度下降模型:
# Gradient Descent
for epoch in range(50):
# Forward pass: Compute predicted y by passing x to the model
y_pred = model(x)
# Compute and print loss
loss = criterion(y_pred, y)
print('epoch: ', epoch,' loss: ', loss.item())
# Zero gradients, perform a backward pass, and update the weights.
optimizer.zero_grad()
# perform a backward pass (backpropagation)
loss.backward()
# Update the parameters
optimizer.step()
步驟 7
生成的輸出如下:
epoch: 0 loss: 0.2545787990093231 epoch: 1 loss: 0.2545052170753479 epoch: 2 loss: 0.254431813955307 epoch: 3 loss: 0.25435858964920044 epoch: 4 loss: 0.2542854845523834 epoch: 5 loss: 0.25421255826950073 epoch: 6 loss: 0.25413978099823 epoch: 7 loss: 0.25406715273857117 epoch: 8 loss: 0.2539947032928467 epoch: 9 loss: 0.25392240285873413 epoch: 10 loss: 0.25385022163391113 epoch: 11 loss: 0.25377824902534485 epoch: 12 loss: 0.2537063956260681 epoch: 13 loss: 0.2536346912384033 epoch: 14 loss: 0.25356316566467285 epoch: 15 loss: 0.25349172949790955 epoch: 16 loss: 0.25342053174972534 epoch: 17 loss: 0.2533493936061859 epoch: 18 loss: 0.2532784342765808 epoch: 19 loss: 0.25320762395858765 epoch: 20 loss: 0.2531369626522064 epoch: 21 loss: 0.25306645035743713 epoch: 22 loss: 0.252996027469635 epoch: 23 loss: 0.2529257833957672 epoch: 24 loss: 0.25285571813583374 epoch: 25 loss: 0.25278574228286743 epoch: 26 loss: 0.25271597504615784 epoch: 27 loss: 0.25264623761177063 epoch: 28 loss: 0.25257670879364014 epoch: 29 loss: 0.2525072991847992 epoch: 30 loss: 0.2524380087852478 epoch: 31 loss: 0.2523689270019531 epoch: 32 loss: 0.25229987502098083 epoch: 33 loss: 0.25223103165626526 epoch: 34 loss: 0.25216227769851685 epoch: 35 loss: 0.252093642950058 epoch: 36 loss: 0.25202515721321106 epoch: 37 loss: 0.2519568204879761 epoch: 38 loss: 0.251888632774353 epoch: 39 loss: 0.25182053446769714 epoch: 40 loss: 0.2517525553703308 epoch: 41 loss: 0.2516847252845764 epoch: 42 loss: 0.2516169846057892 epoch: 43 loss: 0.2515493929386139 epoch: 44 loss: 0.25148195028305054 epoch: 45 loss: 0.25141456723213196 epoch: 46 loss: 0.2513473629951477 epoch: 47 loss: 0.2512802183628082 epoch: 48 loss: 0.2512132525444031 epoch: 49 loss: 0.2511464059352875
PyTorch - 神經網路到功能塊
訓練深度學習演算法包括以下步驟:
- 構建資料管道
- 構建網路架構
- 使用損失函式評估架構
- 使用最佳化演算法最佳化網路架構權重
訓練特定的深度學習演算法正是將神經網路轉換為功能塊的具體要求,如下所示:
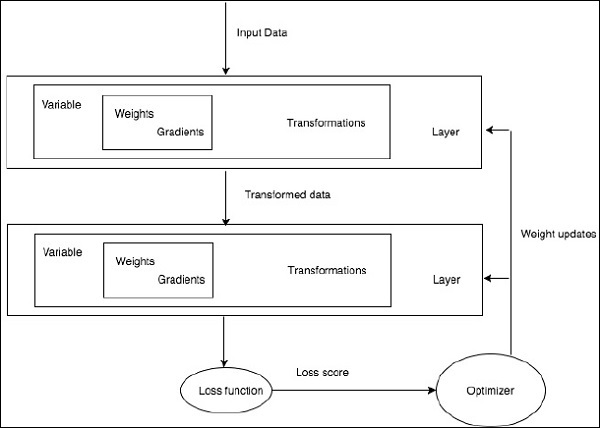
根據上圖,任何深度學習演算法都涉及獲取輸入資料,構建相應的架構,其中包含嵌入其中的許多層。
如果您觀察上圖,則使用損失函式根據神經網路權重的最佳化來評估準確性。
PyTorch - 術語
在本章中,我們將討論 PyTorch 中一些最常用的術語。
PyTorch NumPy
PyTorch 張量與 NumPy 陣列相同。張量是 n 維陣列,對於 PyTorch 而言,它提供了許多用於操作這些張量的函式。
PyTorch 張量通常利用 GPU 來加速其數值計算。這些在 PyTorch 中建立的張量可用於將兩層網路擬合到隨機資料。使用者可以手動實現網路的正向和反向傳遞。
變數和自動梯度
使用 autograd 時,網路的正向傳遞將定義一個計算圖 - 圖中的節點將是張量,邊將是根據輸入張量生成輸出張量的函式。
PyTorch 張量可以建立為變數物件,其中變量表示計算圖中的節點。
動態圖
靜態圖很好,因為使用者可以預先最佳化圖。如果程式設計師反覆重用相同的圖,那麼這種潛在的代價高昂的預先最佳化可以保持不變,因為相同的圖會被反覆執行。
它們的主要區別在於 TensorFlow 的計算圖是靜態的,而 PyTorch 使用動態計算圖。
Optim 包
PyTorch 中的 optim 包抽象了以多種方式實現的最佳化演算法的概念,並提供了常用最佳化演算法的示例。這可以在 import 語句中呼叫。
多程序
多程序支援相同的操作,以便所有張量都在多個處理器上工作。佇列將把它們的資料移入共享記憶體,並且只會向另一個程序傳送控制代碼。
PyTorch - 載入資料
PyTorch 包含一個名為 torchvision 的包,用於載入和準備資料集。它包括兩個基本函式,即 Dataset 和 DataLoader,它們有助於資料集的轉換和載入。
資料集
Dataset 用於從給定資料集中讀取和轉換資料點。實現的基本語法如下所示:
trainset = torchvision.datasets.CIFAR10(root = './data', train = True, download = True, transform = transform)
DataLoader 用於打亂和批次處理資料。它可以用來使用多程序工作程式並行載入資料。
trainloader = torch.utils.data.DataLoader(trainset, batch_size = 4, shuffle = True, num_workers = 2)
示例:載入 CSV 檔案
我們使用 Python 包 Panda 來載入 csv 檔案。原始檔案具有以下格式:(影像名稱,68 個地標 - 每個地標都有 x,y 座標)。
landmarks_frame = pd.read_csv('faces/face_landmarks.csv')
n = 65
img_name = landmarks_frame.iloc[n, 0]
landmarks = landmarks_frame.iloc[n, 1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1, 2)
PyTorch - 線性迴歸
在本章中,我們將重點介紹使用 TensorFlow 實現線性迴歸的基本示例。邏輯迴歸或線性迴歸是一種監督機器學習方法,用於對有序離散類別進行分類。本章的目標是構建一個模型,使用者可以透過該模型預測預測變數和一個或多個自變數之間的關係。
這兩個變數之間的關係被認為是線性的,即,如果 y 是因變數,x 被認為是自變數,那麼這兩個變數的線性迴歸關係將如下所示:
Y = Ax+b
接下來,我們將設計一個線性迴歸演算法,使我們能夠理解下面給出的兩個重要概念:
- 成本函式
- 梯度下降演算法
線性迴歸的示意圖如下所示
解釋結果
$$Y=ax+b$$
a 的值是斜率。
b 的值是y 截距。
r 是相關係數。
r2 是相關係數。
線性迴歸方程的圖形檢視如下所示:

使用 PyTorch 實現線性迴歸使用以下步驟:
步驟 1
使用以下程式碼匯入建立 PyTorch 中的線性迴歸所需的包:
import numpy as np import matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation import seaborn as sns import pandas as pd %matplotlib inline sns.set_style(style = 'whitegrid') plt.rcParams["patch.force_edgecolor"] = True
步驟 2
使用可用的資料集建立一個單一的訓練集,如下所示:
m = 2 # slope c = 3 # interceptm = 2 # slope c = 3 # intercept x = np.random.rand(256) noise = np.random.randn(256) / 4 y = x * m + c + noise df = pd.DataFrame() df['x'] = x df['y'] = y sns.lmplot(x ='x', y ='y', data = df)

步驟 3
使用下面提到的 PyTorch 庫實現線性迴歸:
import torch
import torch.nn as nn
from torch.autograd import Variable
x_train = x.reshape(-1, 1).astype('float32')
y_train = y.reshape(-1, 1).astype('float32')
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
input_dim = x_train.shape[1]
output_dim = y_train.shape[1]
input_dim, output_dim(1, 1)
model = LinearRegressionModel(input_dim, output_dim)
criterion = nn.MSELoss()
[w, b] = model.parameters()
def get_param_values():
return w.data[0][0], b.data[0]
def plot_current_fit(title = ""):
plt.figure(figsize = (12,4))
plt.title(title)
plt.scatter(x, y, s = 8)
w1 = w.data[0][0]
b1 = b.data[0]
x1 = np.array([0., 1.])
y1 = x1 * w1 + b1
plt.plot(x1, y1, 'r', label = 'Current Fit ({:.3f}, {:.3f})'.format(w1, b1))
plt.xlabel('x (input)')
plt.ylabel('y (target)')
plt.legend()
plt.show()
plot_current_fit('Before training')
生成的繪圖如下所示:

PyTorch - 卷積神經網路
深度學習是機器學習的一個分支,被認為是近幾十年來研究人員採取的關鍵步驟。深度學習實現的例子包括影像識別和語音識別等應用。
下面給出兩種重要的深度神經網路型別:
- 卷積神經網路
- 迴圈神經網路。
在本章中,我們將重點介紹第一種型別,即卷積神經網路 (CNN)。
卷積神經網路
卷積神經網路旨在透過多層陣列處理資料。這種型別的神經網路用於影像識別或人臉識別等應用。
CNN 與任何其他普通神經網路的主要區別在於,CNN 將輸入作為二維陣列,並直接對影像進行操作,而不是關注其他神經網路關注的特徵提取。
CNN 的主要方法包括解決識別問題。谷歌和 Facebook 等頂級公司已投資識別專案的研發專案,以更快地完成活動。
每個卷積神經網路都包含三個基本思想:
- 區域性感受野
- 卷積
- 池化
讓我們詳細瞭解這些術語。
區域性感受野
CNN 利用輸入資料中存在的空間相關性。神經網路的併發層中的每一個都連線一些輸入神經元。這個特定區域稱為區域性感受野。它只關注隱藏神經元。隱藏神經元將處理所述欄位內的輸入資料,而不會意識到特定邊界之外的變化。
生成區域性感受野的圖表表示如下:

卷積
在上圖中,我們觀察到每個連線學習隱藏神經元與從一層移動到另一層的相關連線的權重。在這裡,單個神經元會不時進行移位。此過程稱為“卷積”。
從輸入層到隱藏特徵圖的連線對映定義為“共享權重”,包含的偏差稱為“共享偏差”。
池化
卷積神經網路使用池化層,這些層位於 CNN 宣告之後。它將使用者的輸入作為從卷積網路輸出的特徵圖,並準備一個壓縮的特徵圖。池化層有助於建立具有前一層神經元的層。
PyTorch 的實現
使用以下步驟建立使用 PyTorch 的卷積神經網路。
步驟 1
匯入建立簡單神經網路所需的包。
from torch.autograd import Variable import torch.nn.functional as F
步驟 2
建立一個具有卷積神經網路批量表示的類。我們的輸入 x 批次形狀的維度為 (3, 32, 32)。
class SimpleCNN(torch.nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
#Input channels = 3, output channels = 18
self.conv1 = torch.nn.Conv2d(3, 18, kernel_size = 3, stride = 1, padding = 1)
self.pool = torch.nn.MaxPool2d(kernel_size = 2, stride = 2, padding = 0)
#4608 input features, 64 output features (see sizing flow below)
self.fc1 = torch.nn.Linear(18 * 16 * 16, 64)
#64 input features, 10 output features for our 10 defined classes
self.fc2 = torch.nn.Linear(64, 10)
步驟 3
計算第一個卷積的啟用大小,從 (3, 32, 32) 變為 (18, 32, 32)。
維度大小從 (18, 32, 32) 變為 (18, 16, 16)。由於神經網路輸入層的維度重塑,大小從 (18, 16, 16) 變為 (1, 4608)。
回想一下,-1 從其他給定的維度推斷出這個維度。
def forward(self, x): x = F.relu(self.conv1(x)) x = self.pool(x) x = x.view(-1, 18 * 16 *16) x = F.relu(self.fc1(x)) #Computes the second fully connected layer (activation applied later) #Size changes from (1, 64) to (1, 10) x = self.fc2(x) return(x)
PyTorch - 迴圈神經網路
迴圈神經網路是一種面向深度學習的演算法,它採用順序方法。在神經網路中,我們總是假設每個輸入和輸出都獨立於所有其他層。這些型別的神經網路被稱為迴圈神經網路,因為它們以順序方式執行數學計算,一個接一個地完成任務。
下圖指定了迴圈神經網路的完整方法和工作原理:

在上圖中,c1、c2、c3 和 x1 被認為是輸入,其中包括一些隱藏輸入值,即 h1、h2 和 h3,它們提供相應的輸出 o1。我們現在將重點介紹使用 PyTorch 來建立正弦波。
在訓練期間,我們將對我們的模型採用一次一個資料點的訓練方法。輸入序列 x 包含 20 個數據點,目標序列被認為與輸入序列相同。
步驟 1
使用以下程式碼匯入實現迴圈神經網路所需的包:
import torch from torch.autograd import Variable import numpy as np import pylab as pl import torch.nn.init as init
步驟 2
我們將設定模型超引數,輸入層的大小設定為 7。將有 6 個上下文神經元和 1 個輸入神經元來建立目標序列。
dtype = torch.FloatTensor input_size, hidden_size, output_size = 7, 6, 1 epochs = 300 seq_length = 20 lr = 0.1 data_time_steps = np.linspace(2, 10, seq_length + 1) data = np.sin(data_time_steps) data.resize((seq_length + 1, 1)) x = Variable(torch.Tensor(data[:-1]).type(dtype), requires_grad=False) y = Variable(torch.Tensor(data[1:]).type(dtype), requires_grad=False)
我們將生成訓練資料,其中 x 是輸入資料序列,y 是所需的目標序列。
步驟 3
迴圈神經網路中的權重使用具有零均值的正態分佈進行初始化。W1 將表示接受輸入變數,w2 將表示生成的輸出,如下所示:
w1 = torch.FloatTensor(input_size, hidden_size).type(dtype) init.normal(w1, 0.0, 0.4) w1 = Variable(w1, requires_grad = True) w2 = torch.FloatTensor(hidden_size, output_size).type(dtype) init.normal(w2, 0.0, 0.3) w2 = Variable(w2, requires_grad = True)
步驟 4
現在,重要的是為前饋建立唯一定義神經網路的函式。
def forward(input, context_state, w1, w2): xh = torch.cat((input, context_state), 1) context_state = torch.tanh(xh.mm(w1)) out = context_state.mm(w2) return (out, context_state)
步驟 5
下一步是開始迴圈神經網路的正弦波實現的訓練過程。外迴圈迭代每個迴圈,內迴圈迭代序列的元素。在這裡,我們還將計算均方誤差 (MSE),這有助於預測連續變數。
for i in range(epochs):
total_loss = 0
context_state = Variable(torch.zeros((1, hidden_size)).type(dtype), requires_grad = True)
for j in range(x.size(0)):
input = x[j:(j+1)]
target = y[j:(j+1)]
(pred, context_state) = forward(input, context_state, w1, w2)
loss = (pred - target).pow(2).sum()/2
total_loss += loss
loss.backward()
w1.data -= lr * w1.grad.data
w2.data -= lr * w2.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
context_state = Variable(context_state.data)
if i % 10 == 0:
print("Epoch: {} loss {}".format(i, total_loss.data[0]))
context_state = Variable(torch.zeros((1, hidden_size)).type(dtype), requires_grad = False)
predictions = []
for i in range(x.size(0)):
input = x[i:i+1]
(pred, context_state) = forward(input, context_state, w1, w2)
context_state = context_state
predictions.append(pred.data.numpy().ravel()[0])
步驟 6
現在,是時候繪製正弦波了。
pl.scatter(data_time_steps[:-1], x.data.numpy(), s = 90, label = "Actual") pl.scatter(data_time_steps[1:], predictions, label = "Predicted") pl.legend() pl.show()
輸出
上述過程的輸出如下:

PyTorch - 資料集
在本章中,我們將更多地關注torchvision.datasets及其各種型別。PyTorch 包含以下資料集載入器:
- MNIST
- COCO(影像標題生成和目標檢測)
資料集主要包含以下兩種型別的函式:
Transform − 一個函式,它接收影像作為輸入,並返回一個修改後的標準化版本。這些變換函式可以組合在一起。
Target_transform − 一個函式,它接收目標並對其進行變換。例如,接收標題字串作為輸入,並返回一個單詞索引張量。
MNIST
以下是MNIST資料集的示例程式碼:
dset.MNIST(root, train = TRUE, transform = NONE, target_transform = None, download = FALSE)
引數如下:
root − 資料集的根目錄,其中包含已處理的資料。
train − True = 訓練集,False = 測試集
download − True = 從網際網路下載資料集並將其放入根目錄。
COCO
這需要安裝COCO API。以下示例演示了使用PyTorch實現COCO資料集:
import torchvision.dataset as dset import torchvision.transforms as transforms cap = dset.CocoCaptions(root = ‘ dir where images are’, annFile = ’json annotation file’, transform = transforms.ToTensor()) print(‘Number of samples: ‘, len(cap)) print(target)
取得的輸出如下:
Number of samples: 82783 Image Size: (3L, 427L, 640L)
PyTorch - 卷積神經網路簡介
卷積神經網路(Convnets)是關於從零開始構建CNN模型的。網路架構將包含以下步驟的組合:
- Conv2d (二維卷積)
- MaxPool2d (最大池化)
- 修正線性單元 (ReLU)
- View (檢視變換)
- 線性層
模型訓練
模型訓練過程與影像分類問題相同。以下程式碼片段完成了在提供的資料集上訓練模型的過程:
def fit(epoch,model,data_loader,phase
= 'training',volatile = False):
if phase == 'training':
model.train()
if phase == 'training':
model.train()
if phase == 'validation':
model.eval()
volatile=True
running_loss = 0.0
running_correct = 0
for batch_idx , (data,target) in enumerate(data_loader):
if is_cuda:
data,target = data.cuda(),target.cuda()
data , target = Variable(data,volatile),Variable(target)
if phase == 'training':
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output,target)
running_loss + =
F.nll_loss(output,target,size_average =
False).data[0]
preds = output.data.max(dim = 1,keepdim = True)[1]
running_correct + =
preds.eq(target.data.view_as(preds)).cpu().sum()
if phase == 'training':
loss.backward()
optimizer.step()
loss = running_loss/len(data_loader.dataset)
accuracy = 100. * running_correct/len(data_loader.dataset)
print(f'{phase} loss is {loss:{5}.{2}} and {phase} accuracy is {running_correct}/{len(data_loader.dataset)}{accuracy:{return loss,accuracy}})
該方法包含用於訓練和驗證的不同邏輯。使用不同模式有兩個主要原因:
在訓練模式下,dropout會移除一定比例的值,這在驗證或測試階段不應該發生。
在訓練模式下,我們計算梯度並更改模型的引數值,但在測試或驗證階段不需要反向傳播。
PyTorch - 從零開始訓練卷積神經網路
在本章中,我們將重點介紹從零開始建立卷積神經網路。這意味著使用torch建立相應的卷積神經網路或示例神經網路。
步驟 1
建立一個具有相應引數的必要類。引數包括具有隨機值的權重。
class Neural_Network(nn.Module):
def __init__(self, ):
super(Neural_Network, self).__init__()
self.inputSize = 2
self.outputSize = 1
self.hiddenSize = 3
# weights
self.W1 = torch.randn(self.inputSize,
self.hiddenSize) # 3 X 2 tensor
self.W2 = torch.randn(self.hiddenSize, self.outputSize) # 3 X 1 tensor
步驟 2
建立一個具有sigmoid函式的前饋模式函式。
def forward(self, X):
self.z = torch.matmul(X, self.W1) # 3 X 3 ".dot"
does not broadcast in PyTorch
self.z2 = self.sigmoid(self.z) # activation function
self.z3 = torch.matmul(self.z2, self.W2)
o = self.sigmoid(self.z3) # final activation
function
return o
def sigmoid(self, s):
return 1 / (1 + torch.exp(-s))
def sigmoidPrime(self, s):
# derivative of sigmoid
return s * (1 - s)
def backward(self, X, y, o):
self.o_error = y - o # error in output
self.o_delta = self.o_error * self.sigmoidPrime(o) # derivative of sig to error
self.z2_error = torch.matmul(self.o_delta, torch.t(self.W2))
self.z2_delta = self.z2_error * self.sigmoidPrime(self.z2)
self.W1 + = torch.matmul(torch.t(X), self.z2_delta)
self.W2 + = torch.matmul(torch.t(self.z2), self.o_delta)
步驟 3
建立如下所示的訓練和預測模型:
def train(self, X, y):
# forward + backward pass for training
o = self.forward(X)
self.backward(X, y, o)
def saveWeights(self, model):
# Implement PyTorch internal storage functions
torch.save(model, "NN")
# you can reload model with all the weights and so forth with:
# torch.load("NN")
def predict(self):
print ("Predicted data based on trained weights: ")
print ("Input (scaled): \n" + str(xPredicted))
print ("Output: \n" + str(self.forward(xPredicted)))
PyTorch - 卷積神經網路中的特徵提取
卷積神經網路包含一個主要特徵:特徵提取。使用以下步驟實現卷積神經網路的特徵提取。
步驟 1
匯入相應的模型,使用“PyTorch”建立特徵提取模型。
import torch import torch.nn as nn from torchvision import models
步驟 2
建立一個特徵提取器類,可以在需要時呼叫。
class Feature_extractor(nn.module):
def forward(self, input):
self.feature = input.clone()
return input
new_net = nn.Sequential().cuda() # the new network
target_layers = [conv_1, conv_2, conv_4] # layers you want to extract`
i = 1
for layer in list(cnn):
if isinstance(layer,nn.Conv2d):
name = "conv_"+str(i)
art_net.add_module(name,layer)
if name in target_layers:
new_net.add_module("extractor_"+str(i),Feature_extractor())
i+=1
if isinstance(layer,nn.ReLU):
name = "relu_"+str(i)
new_net.add_module(name,layer)
if isinstance(layer,nn.MaxPool2d):
name = "pool_"+str(i)
new_net.add_module(name,layer)
new_net.forward(your_image)
print (new_net.extractor_3.feature)
PyTorch - 卷積神經網路的視覺化
在本章中,我們將重點介紹藉助卷積神經網路進行資料視覺化模型。要獲得卷積神經網路視覺化的完美影像,需要執行以下步驟。
步驟 1
匯入對卷積神經網路視覺化很重要的必要模組。
import os import numpy as np import pandas as pd from scipy.misc import imread from sklearn.metrics import accuracy_score import keras from keras.models import Sequential, Model from keras.layers import Dense, Dropout, Flatten, Activation, Input from keras.layers import Conv2D, MaxPooling2D import torch
步驟 2
為了避免訓練和測試資料中的潛在隨機性,請呼叫如下程式碼中給出的相應資料集:
seed = 128
rng = np.random.RandomState(seed)
data_dir = "../../datasets/MNIST"
train = pd.read_csv('../../datasets/MNIST/train.csv')
test = pd.read_csv('../../datasets/MNIST/Test_fCbTej3.csv')
img_name = rng.choice(train.filename)
filepath = os.path.join(data_dir, 'train', img_name)
img = imread(filepath, flatten=True)
步驟 3
使用以下程式碼繪製必要的影像,以完美的方式定義訓練和測試資料:
pylab.imshow(img, cmap ='gray')
pylab.axis('off')
pylab.show()
輸出如下所示:

PyTorch - 使用卷積神經網路進行序列處理
在本章中,我們提出了一種替代方法,它依賴於在兩個序列上使用單個二維卷積神經網路。我們網路的每一層都基於迄今為止生成的輸出序列重新編碼源標記。因此,注意力特性在整個網路中普遍存在。
在這裡,我們將重點介紹建立具有特定池化的順序網路,這些池化來自資料集中包含的值。此過程也最適用於“影像識別模組”。
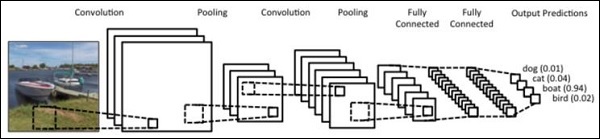
使用以下步驟使用PyTorch建立使用卷積神經網路的序列處理模型:
步驟 1
匯入使用卷積神經網路進行序列處理所需的模組。
import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D import numpy as np
步驟 2
執行必要的操作,使用以下程式碼在相應序列中建立模式:
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000,28,28,1)
x_test = x_test.reshape(10000,28,28,1)
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
步驟 3
編譯模型並將模式擬合到提到的卷積神經網路模型中,如下所示:
model.compile(loss =
keras.losses.categorical_crossentropy,
optimizer = keras.optimizers.Adadelta(), metrics =
['accuracy'])
model.fit(x_train, y_train,
batch_size = batch_size, epochs = epochs,
verbose = 1, validation_data = (x_test, y_test))
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
生成的輸出如下:
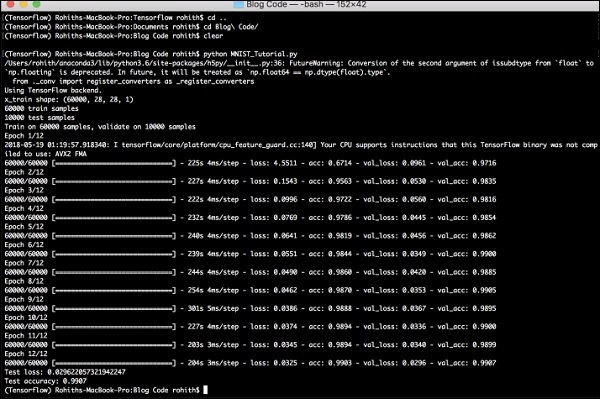
PyTorch - 詞嵌入
在本章中,我們將瞭解著名的詞嵌入模型——word2vec。word2vec模型用於藉助一組相關模型生成詞嵌入。word2vec模型使用純C程式碼實現,梯度是手動計算的。
在PyTorch中實現word2vec模型的步驟如下:
步驟 1
如下所示實現詞嵌入中的庫:
import torch from torch.autograd import Variable import torch.nn as nn import torch.nn.functional as F
步驟 2
使用名為word2vec的類實現詞嵌入的Skip Gram模型。它包括emb_size、emb_dimension、u_embedding、v_embedding型別的屬性。
class SkipGramModel(nn.Module):
def __init__(self, emb_size, emb_dimension):
super(SkipGramModel, self).__init__()
self.emb_size = emb_size
self.emb_dimension = emb_dimension
self.u_embeddings = nn.Embedding(emb_size, emb_dimension, sparse=True)
self.v_embeddings = nn.Embedding(emb_size, emb_dimension, sparse = True)
self.init_emb()
def init_emb(self):
initrange = 0.5 / self.emb_dimension
self.u_embeddings.weight.data.uniform_(-initrange, initrange)
self.v_embeddings.weight.data.uniform_(-0, 0)
def forward(self, pos_u, pos_v, neg_v):
emb_u = self.u_embeddings(pos_u)
emb_v = self.v_embeddings(pos_v)
score = torch.mul(emb_u, emb_v).squeeze()
score = torch.sum(score, dim = 1)
score = F.logsigmoid(score)
neg_emb_v = self.v_embeddings(neg_v)
neg_score = torch.bmm(neg_emb_v, emb_u.unsqueeze(2)).squeeze()
neg_score = F.logsigmoid(-1 * neg_score)
return -1 * (torch.sum(score)+torch.sum(neg_score))
def save_embedding(self, id2word, file_name, use_cuda):
if use_cuda:
embedding = self.u_embeddings.weight.cpu().data.numpy()
else:
embedding = self.u_embeddings.weight.data.numpy()
fout = open(file_name, 'w')
fout.write('%d %d\n' % (len(id2word), self.emb_dimension))
for wid, w in id2word.items():
e = embedding[wid]
e = ' '.join(map(lambda x: str(x), e))
fout.write('%s %s\n' % (w, e))
def test():
model = SkipGramModel(100, 100)
id2word = dict()
for i in range(100):
id2word[i] = str(i)
model.save_embedding(id2word)
步驟 3
實現主方法以正確顯示詞嵌入模型。
if __name__ == '__main__': test()
PyTorch - 遞迴神經網路
深度神經網路具有獨有的功能,可以促進機器學習的突破,從而理解自然語言處理的過程。據觀察,大多數這些模型將語言視為單詞或字元的扁平序列,並使用一種稱為迴圈神經網路或RNN的模型。
許多研究人員得出結論,最好根據短語的分層樹來理解語言。這種型別包含在遞迴神經網路中,它考慮了特定的結構。
PyTorch具有一項特定功能,可以使這些複雜的自然語言處理模型變得更容易。它是一個功能齊全的深度學習框架,對計算機視覺有強大的支援。
遞迴神經網路的特性
遞迴神經網路的建立方式是:它包括對具有不同圖狀結構的相同權重集進行應用。
以拓撲順序遍歷節點。
這種型別的網路透過反向模式自動微分進行訓練。
自然語言處理包含遞迴神經網路的一個特例。
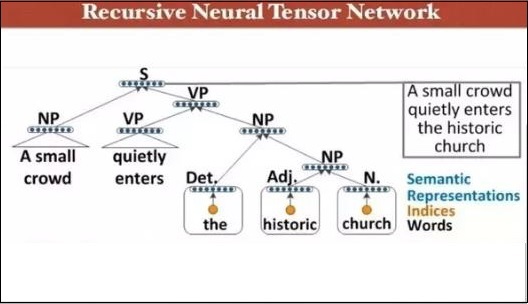
這個遞迴神經張量網路在樹中包含各種組合函式節點。
遞迴神經網路的示例如下所示: