- Perl 基礎
- Perl - 首頁
- Perl - 簡介
- Perl - 環境
- Perl - 語法概述
- Perl - 資料型別
- Perl - 變數
- Perl - 標量
- Perl - 陣列
- Perl - 雜湊表
- Perl - IF...ELSE
- Perl - 迴圈
- Perl - 運算子
- Perl - 日期與時間
- Perl - 子程式
- Perl - 引用
- Perl - 格式
- Perl - 檔案I/O
- Perl - 目錄
- Perl - 錯誤處理
- Perl - 特殊變數
- Perl - 編碼規範
- Perl - 正則表示式
- Perl - 傳送郵件
- Perl 高階
- Perl - 套接字程式設計
- Perl - 面向物件
- Perl - 資料庫訪問
- Perl - CGI 程式設計
- Perl - 包與模組
- Perl - 程序管理
- Perl - 內嵌文件
- Perl - 函式引用
- Perl 有用資源
- Perl - 問答
- Perl 快速指南
- Perl - 有用資源
- Perl - 討論
Perl 快速指南
Perl - 簡介
Perl 是一種通用的程式語言,最初開發用於文字處理,現在用於各種任務,包括系統管理、Web 開發、網路程式設計、GUI 開發等等。
什麼是 Perl?
Perl 是一種穩定、跨平臺的程式語言。
雖然 Perl 官方並非首字母縮寫詞,但一些人將其稱為 **Practical Extraction and Report Language**(實用提取和報告語言)。
它被用於公共和私營部門的關鍵任務專案。
Perl 是一個 *開源* 軟體,其許可證為 *Artistic License* 或 *GNU General Public License (GPL)*。
Perl 由 Larry Wall 建立。
Perl 1.0 於 1987 年釋出到 usenet 的 alt.comp.sources。
在撰寫本教程時,Perl 的最新版本為 5.16.2。
Perl 被列入 *牛津英語詞典*。
《PC Magazine》宣佈 Perl 為其 1998 年開發工具類別的技術卓越獎決賽入圍者。
Perl 特性
Perl 汲取了其他語言(如 C、awk、sed、sh 和 BASIC 等)的最佳特性。
Perl 的資料庫整合介面 DBI 支援第三方資料庫,包括 Oracle、Sybase、Postgres、MySQL 等。
Perl 可與 HTML、XML 和其他標記語言一起使用。
Perl 支援 Unicode。
Perl 相容 Y2K。
Perl 支援程序式程式設計和麵向物件程式設計。
Perl 透過 XS 或 SWIG 與外部 C/C++ 庫進行介面。
Perl 可擴充套件。從 Comprehensive Perl Archive Network (CPAN) 可獲得超過 20,000 個第三方模組。
Perl 直譯器可以嵌入到其他系統中。
Perl 和 Web
由於其文字處理能力和快速開發週期,Perl 曾是最流行的 Web 程式語言。
Perl 被廣泛稱為 "網際網路的膠帶"。
Perl 可以處理加密的 Web 資料,包括電子商務交易。
Perl 可以嵌入到 Web 伺服器中,從而將處理速度提高多達 2000%。
Perl 的 mod_perl 允許 Apache Web 伺服器嵌入 Perl 直譯器。
Perl 的 DBI 包使 Web 資料庫整合變得容易。
Perl 是解釋型語言
Perl 是一種解釋型語言,這意味著您的程式碼可以按原樣執行,無需編譯階段來建立不可移植的可執行程式。
傳統的編譯器將程式轉換為機器語言。當您執行 Perl 程式時,它首先被編譯成位元組碼,然後在程式執行時轉換為機器指令。因此,它與 shell 或 Tcl(它們是**嚴格**解釋的,沒有中間表示)並不完全相同。
它也不像大多數版本的 C 或 C++,它們直接編譯成與機器相關的格式。它介於兩者之間,與 *Python*、*awk* 和 Emacs .elc 檔案類似。
Perl - 環境
在開始編寫 Perl 程式之前,讓我們瞭解如何設定 Perl 環境。Perl 可用於各種平臺:-
- Unix(Solaris、Linux、FreeBSD、AIX、HP/UX、SunOS、IRIX 等)
- Win 9x/NT/2000/
- WinCE
- Macintosh(PPC,68K)
- Solaris(x86,SPARC)
- OpenVMS
- Alpha(7.2 及更高版本)
- Symbian
- Debian GNU/kFreeBSD
- MirOS BSD
- 等等…
您的系統很可能已經安裝了 perl。只需在 $ 提示符下嘗試以下命令:-
$perl -v
如果您的機器上安裝了 perl,那麼您將收到類似以下的訊息:-
This is perl 5, version 16, subversion 2 (v5.16.2) built for i686-linux Copyright 1987-2012, Larry Wall Perl may be copied only under the terms of either the Artistic License or the GNU General Public License, which may be found in the Perl 5 source kit. Complete documentation for Perl, including FAQ lists, should be found on this system using "man perl" or "perldoc perl". If you have access to the Internet, point your browser at http://www.perl.org/, the Perl Home Page.
如果您的機器上尚未安裝 perl,則繼續下一節。
獲取 Perl 安裝程式
最新的原始碼、二進位制檔案、文件、新聞等都可以在 Perl 的官方網站上找到。
**Perl 官方網站** - https://www.perl.org/
您可以從以下網站下載 Perl 文件。
**Perl 文件網站** - https://perldoc.perl.org
安裝 Perl
Perl 發行版適用於各種平臺。您只需下載適用於您平臺的二進位制程式碼並安裝 Perl。
如果您的平臺沒有提供二進位制程式碼,則需要使用 C 編譯器手動編譯原始碼。編譯原始碼在您需要的安裝功能的選擇方面提供了更大的靈活性。
以下是關於在各種平臺上安裝 Perl 的快速概述。
Unix 和 Linux 安裝
以下是關於在 Unix/Linux 機器上安裝 Perl 的簡單步驟。
開啟 Web 瀏覽器並訪問 https://www.perl.org/get.html。
點選連結下載適用於 Unix/Linux 的壓縮原始碼。
下載 **perl-5.x.y.tar.gz** 檔案,並在 $ 提示符下執行以下命令。
$tar -xzf perl-5.x.y.tar.gz $cd perl-5.x.y $./Configure -de $make $make test $make install
**注意** - 此處的 $ 是 Unix 提示符,您可以在其中鍵入命令,因此請確保在鍵入上述命令時不要鍵入 $。
這將把 Perl 安裝到標準位置 * /usr/local/bin*,其庫安裝在 * /usr/local/lib/perlXX* 中,其中 XX 是您正在使用的 Perl 版本。
在發出 **make** 命令後,編譯原始碼需要一段時間。安裝完成後,您可以在 $ 提示符下發出 **perl -v** 命令來檢查 perl 安裝。如果一切正常,它將顯示我們上面顯示的訊息。
Windows 安裝
以下是關於在 Windows 機器上安裝 Perl 的步驟。
按照在 Windows 上安裝 Strawberry Perl 的連結操作 http://strawberryperl.com
下載 32 位或 64 位版本的安裝程式。
雙擊 Windows 資源管理器中的下載檔案執行它。這將調出 Perl 安裝嚮導,它非常易於使用。只需接受預設設定,等待安裝完成,您就可以開始使用了!
Macintosh 安裝
為了構建您自己的 Perl 版本,您需要 'make',它是通常隨 Mac OS 安裝 DVD 提供的 Apple 開發者工具的一部分。您不需要最新版本的 Xcode(現在是收費的)來安裝 make。
以下是關於在 Mac OS X 機器上安裝 Perl 的簡單步驟。
開啟 Web 瀏覽器並訪問 https://www.perl.org/get.html。
點選連結下載適用於 Mac OS X 的壓縮原始碼。
下載 **perl-5.x.y.tar.gz** 檔案,並在 $ 提示符下執行以下命令。
$tar -xzf perl-5.x.y.tar.gz $cd perl-5.x.y $./Configure -de $make $make test $make install
這將把 Perl 安裝到標準位置 * /usr/local/bin*,其庫安裝在 * /usr/local/lib/perlXX* 中,其中 XX 是您正在使用的 Perl 版本。
執行 Perl
以下是啟動 Perl 的不同方法。
互動式直譯器
您可以輸入 **perl** 並從命令列啟動它,立即在互動式直譯器中開始編碼。您可以從 Unix、DOS 或任何其他提供命令列直譯器或 shell 視窗的系統執行此操作。
$perl -e <perl code> # Unix/Linux or C:>perl -e <perl code> # Windows/DOS
以下是所有可用的命令列選項列表:-
| 序號 | 選項和說明 |
|---|---|
| 1 | -d[:debugger] 在偵錯程式下執行程式 |
| 2 | -Idirectory 指定 @INC/#include 目錄 |
| 3 | -T 啟用汙染檢查 |
| 4 | -t 啟用汙染警告 |
| 5 | -U 允許不安全操作 |
| 6 | -w 啟用許多有用的警告 |
| 7 | -W 啟用所有警告 |
| 8 | -X 停用所有警告 |
| 9 | -e program 執行作為程式傳送的 Perl 指令碼 |
| 10 | file 從給定檔案執行 Perl 指令碼 |
來自命令列的指令碼
Perl 指令碼是一個文字檔案,其中包含 perl 程式碼,可以透過在命令列上呼叫直譯器來執行您的應用程式,如下所示:-
$perl script.pl # Unix/Linux or C:>perl script.pl # Windows/DOS
整合開發環境
您也可以從圖形使用者介面 (GUI) 環境執行 Perl。您只需要系統上支援 Perl 的 GUI 應用程式即可。您可以下載 Padre,Perl IDE。如果您熟悉 Eclipse,也可以使用 Eclipse 外掛 EPIC - Perl 編輯器和 Eclipse IDE。
在繼續下一章之前,請確保您的環境已正確設定並執行良好。如果您無法正確設定環境,則可以尋求系統管理員的幫助。
後續章節中提供的所有示例都在 CentOS 版本的 Linux 上使用 v5.16.2 版本執行。
Perl - 語法概述
Perl 借鑑了許多語言的語法和概念:awk、sed、C、Bourne Shell、Smalltalk、Lisp 甚至英語。但是,這些語言之間存在一些明顯的差異。本章旨在讓您快速瞭解 Perl 中預期的語法。
Perl 程式由一系列宣告和語句組成,這些宣告和語句從上到下執行。迴圈、子程式和其他控制結構允許你在程式碼中跳轉。每個簡單語句都必須以分號 (;) 結尾。
Perl 是一種自由格式的語言:你可以根據自己的喜好來格式化和縮排程式碼。空格主要用於分隔標記,這與 Python 等語言(其中空格是語法的重要組成部分)或 Fortran 等語言(其中空格無關緊要)不同。
第一個 Perl 程式
互動模式程式設計
你可以在命令列中使用 Perl 直譯器和 -e 選項,這允許你從命令列執行 Perl 語句。讓我們在 $ 提示符下嘗試如下操作:
$perl -e 'print "Hello World\n"'
執行結果如下:
Hello, world
指令碼模式程式設計
假設你已經在 $ 提示符下,讓我們使用 vi 或 vim 編輯器開啟一個文字檔案 hello.pl,並將以下幾行程式碼放入你的檔案中。
#!/usr/bin/perl # This will print "Hello, World" print "Hello, world\n";
這裡 /usr/bin/perl 實際上是 perl 直譯器的二進位制檔案。在執行指令碼之前,務必更改指令碼檔案的模式並賦予執行許可權,通常設定為 0755 就足夠了,最後你可以按如下方式執行上述指令碼:
$chmod 0755 hello.pl $./hello.pl
執行結果如下:
Hello, world
你可以根據個人喜好為函式引數使用括號或省略括號。只有在需要澄清優先順序問題時才需要它們。以下兩個語句產生相同的結果。
print("Hello, world\n");
print "Hello, world\n";
Perl 副檔名
Perl 指令碼可以在任何普通的純文字編輯器程式中建立。每種型別的平臺都有多個可用的程式。網路上可以下載許多為程式設計師設計的程式。
按照 Perl 的約定,Perl 檔案必須儲存為 .pl 或 .PL 副檔名,才能被識別為有效的 Perl 指令碼。檔名可以包含數字、符號和字母,但不能包含空格。用下劃線 (_) 代替空格。
Perl 中的註釋
任何程式語言中的註釋都是開發人員的朋友。註釋可以使程式更易於使用,並且它們會被直譯器簡單地跳過,而不會影響程式碼的功能。例如,在上例程式中,以井號 # 開頭的行就是註釋。
簡單來說,Perl 中的註釋以井號開頭,一直延續到行尾:
# This is a comment in perl
以 = 開頭的行被解釋為嵌入式文件 (pod) 部分的開頭,編譯器會忽略所有後續行,直到下一個 =cut。以下是一個示例:
#!/usr/bin/perl # This is a single line comment print "Hello, world\n"; =begin comment This is all part of multiline comment. You can use as many lines as you like These comments will be ignored by the compiler until the next =cut is encountered. =cut
這將產生以下結果:
Hello, world
Perl 中的空格
Perl 程式不關心空格。以下程式可以完美執行:
#!/usr/bin/perl print "Hello, world\n";
但是,如果空格位於引號字串內,則會按原樣列印。例如:
#!/usr/bin/perl
# This would print with a line break in the middle
print "Hello
world\n";
這將產生以下結果:
Hello
world
所有型別的空格,例如空格、製表符、換行符等,當它們用在引號之外時,對於直譯器來說是等效的。僅包含空格(可能帶有註釋)的行稱為空行,Perl 會完全忽略它。
Perl 中的單引號和雙引號
你可以使用雙引號或單引號括起文字字串,如下所示:
#!/usr/bin/perl print "Hello, world\n"; print 'Hello, world\n';
這將產生以下結果:
Hello, world Hello, world\n$
單引號和雙引號之間有一個重要的區別。只有雙引號內插變數和特殊字元(如換行符 \n),而單引號不內插任何變數或特殊字元。請檢視下面的示例,我們使用 $a 作為變數來儲存一個值,然後列印該值:
#!/usr/bin/perl $a = 10; print "Value of a = $a\n"; print 'Value of a = $a\n';
這將產生以下結果:
Value of a = 10 Value of a = $a\n$
“Here”文件
你可以非常方便地儲存或列印多行文字。你甚至可以在“here”文件中使用變數。以下是一個簡單的語法,請仔細檢查,在 << 和識別符號之間不能有空格。
識別符號可以是裸詞或一些引用的文字,就像我們在下面使用的 EOF 一樣。如果識別符號被引用,則你使用的引號型別決定了對“here”文件內文字的處理方式,就像在常規引用中一樣。未引用的識別符號的工作方式類似於雙引號。
#!/usr/bin/perl $a = 10; $var = <<"EOF"; This is the syntax for here document and it will continue until it encounters a EOF in the first line. This is case of double quote so variable value will be interpolated. For example value of a = $a EOF print "$var\n"; $var = <<'EOF'; This is case of single quote so variable value will be interpolated. For example value of a = $a EOF print "$var\n";
這將產生以下結果:
This is the syntax for here document and it will continue until it encounters a EOF in the first line. This is case of double quote so variable value will be interpolated. For example value of a = 10 This is case of single quote so variable value will be interpolated. For example value of a = $a
跳脫字元
Perl 使用反斜槓 (\) 字元來轉義任何可能干擾我們程式碼的字元。讓我們來看一個示例,我們想要列印雙引號和 $ 符號:
#!/usr/bin/perl $result = "This is \"number\""; print "$result\n"; print "\$result\n";
這將產生以下結果:
This is "number" $result
Perl 識別符號
Perl 識別符號是用於標識變數、函式、類、模組或其他物件的名稱。Perl 變數名以 $、@ 或 % 開頭,後面可以跟零個或多個字母、下劃線和數字 (0 到 9)。
Perl 不允許在識別符號中使用 @、$ 和 % 等標點符號。Perl 是一種區分大小寫的程式語言。因此,$Manpower 和 $manpower 在 Perl 中是兩個不同的識別符號。
Perl - 資料型別
Perl 是一種弱型別語言,在程式中使用資料時不需要指定資料的型別。Perl 直譯器將根據資料的上下文字身選擇型別。
Perl 有三種基本資料型別:標量、標量陣列和標量雜湊(也稱為關聯陣列)。以下是關於這些資料型別的簡要說明。
| 序號 | 型別與說明 |
|---|---|
| 1 | 標量 標量是簡單的變數。它們前面帶有美元符號 ($) 。標量可以是數字、字串或引用。引用實際上是變數的地址,我們將在接下來的章節中看到。 |
| 2 | 陣列 陣列是有序的標量列表,你可以使用從 0 開始的數字索引訪問它們。它們前面帶有“at”符號 (@)。 |
| 3 | 雜湊 雜湊是無序的鍵/值對集合,你可以使用鍵作為下標來訪問它們。它們前面帶有百分號 (%)。 |
數值字面量
Perl 在內部將所有數字儲存為帶符號整數或雙精度浮點值。數值字面量可以採用以下任何浮點或整數格式指定:
| 型別 | 值 |
|---|---|
| 整數 | 1234 |
| 負整數 | -100 |
| 浮點數 | 2000 |
| 科學計數法 | 16.12E14 |
| 十六進位制 | 0xffff |
| 八進位制 | 0577 |
字串字面量
字串是字元序列。它們通常是字母數字值,由單引號 (') 或雙引號 (") 括起來。它們的工作方式與 UNIX shell 引號非常相似,你可以在其中使用單引號字串和雙引號字串。
雙引號字串字面量允許變數內插,而單引號字串不允許。某些字元在前面帶有反斜槓時具有特殊含義,它們用於表示換行符 (\n) 或製表符 (\t) 等。
你可以在雙引號字串中直接嵌入換行符或以下任何轉義序列:
| 轉義序列 | 含義 |
|---|---|
| \\ | 反斜槓 |
| \' | 單引號 |
| \" | 雙引號 |
| \a | 警告或鈴聲 |
| \b | 退格 |
| \f | 換頁 |
| \n | 換行 |
| \r | 回車 |
| \t | 水平製表符 |
| \v | 垂直製表符 |
| \0nn | 建立八進位制格式的數字 |
| \xnn | 建立十六進位制格式的數字 |
| \cX | 控制字元,x 可以是任何字元 |
| \u | 強制下一個字元為大寫 |
| \l | 強制下一個字元為小寫 |
| \U | 強制所有後續字元為大寫 |
| \L | 強制所有後續字元為小寫 |
| \Q | 對所有後續非字母數字字元進行反斜槓轉義 |
| \E | 結束 \U、\L 或 \Q |
示例
讓我們再次看看字串在單引號和雙引號中的行為。在這裡,我們將使用上表中提到的字串轉義符,並將使用標量變數來賦值字串。
#!/usr/bin/perl # This is case of interpolation. $str = "Welcome to \ntutorialspoint.com!"; print "$str\n"; # This is case of non-interpolation. $str = 'Welcome to \ntutorialspoint.com!'; print "$str\n"; # Only W will become upper case. $str = "\uwelcome to tutorialspoint.com!"; print "$str\n"; # Whole line will become capital. $str = "\UWelcome to tutorialspoint.com!"; print "$str\n"; # A portion of line will become capital. $str = "Welcome to \Ututorialspoint\E.com!"; print "$str\n"; # Backsalash non alpha-numeric including spaces. $str = "\QWelcome to tutorialspoint's family"; print "$str\n";
這將產生以下結果:
Welcome to tutorialspoint.com! Welcome to \ntutorialspoint.com! Welcome to tutorialspoint.com! WELCOME TO TUTORIALSPOINT.COM! Welcome to TUTORIALSPOINT.com! Welcome\ to\ tutorialspoint\'s\ family
Perl - 變數
變數是保留的記憶體位置,用於儲存值。這意味著當你建立變數時,你會保留一些記憶體空間。
根據變數的資料型別,直譯器會分配記憶體並決定可以在保留的記憶體中儲存什麼內容。因此,透過為變數分配不同的資料型別,你可以在這些變數中儲存整數、小數或字串。
我們已經瞭解到 Perl 具有以下三種基本資料型別:
- 標量
- 陣列
- 雜湊
相應地,我們將在 Perl 中使用三種類型的變數。標量變數前面將帶有美元符號 ($) ,它可以儲存數字、字串或引用。陣列變數前面將帶有 @ 符號,它將儲存有序的標量列表。最後,雜湊變數前面將帶有 % 符號,並將用於儲存鍵/值對的集合。
Perl 在單獨的名稱空間中維護每種變數型別。因此,你可以不必擔心衝突,可以為標量變數、陣列或雜湊使用相同的名稱。這意味著 $foo 和 @foo 是兩個不同的變數。
建立變數
Perl 變數不必顯式宣告即可保留記憶體空間。當你為變數賦值時,宣告會自動發生。等號 (=) 用於為變數賦值。
請注意,如果我們在程式中使用 use strict 語句,則必須在使用變數之前宣告變數。
= 運算子左側的運算元是變數的名稱,= 運算子右側的運算元是儲存在變數中的值。例如:
$age = 25; # An integer assignment $name = "John Paul"; # A string $salary = 1445.50; # A floating point
這裡 25、“John Paul”和 1445.50 分別是分配給$age、$name和$salary變數的值。我們很快就會看到如何為陣列和雜湊賦值。
標量變數
標量是單個數據單元。該資料可能是整數、浮點數、字元、字串、段落或整個網頁。簡單地說,它可以是任何東西,但只能是一件東西。
以下是用標量變數的簡單示例:
#!/usr/bin/perl $age = 25; # An integer assignment $name = "John Paul"; # A string $salary = 1445.50; # A floating point print "Age = $age\n"; print "Name = $name\n"; print "Salary = $salary\n";
這將產生以下結果:
Age = 25 Name = John Paul Salary = 1445.5
陣列變數
陣列是一個變數,它儲存有序的標量值列表。陣列變數前面帶有“at”符號 (@)。要引用陣列的單個元素,你將使用美元符號 ($) ,後跟變數名稱,然後是方括號中的元素索引。
以下是用陣列變數的簡單示例:
#!/usr/bin/perl
@ages = (25, 30, 40);
@names = ("John Paul", "Lisa", "Kumar");
print "\$ages[0] = $ages[0]\n";
print "\$ages[1] = $ages[1]\n";
print "\$ages[2] = $ages[2]\n";
print "\$names[0] = $names[0]\n";
print "\$names[1] = $names[1]\n";
print "\$names[2] = $names[2]\n";
在這裡,我們在 $ 符號之前使用了轉義符 (\),只是為了列印它。否則 Perl 會將其理解為變數並列印其值。執行後,將產生以下結果:
$ages[0] = 25 $ages[1] = 30 $ages[2] = 40 $names[0] = John Paul $names[1] = Lisa $names[2] = Kumar
雜湊變數
雜湊(Hash)是一組鍵值對。雜湊變數以百分號 (%) 開頭。要引用雜湊的單個元素,可以使用雜湊變數名稱,後跟花括號中與值關聯的“鍵”。
這是一個使用雜湊變數的簡單示例:
#!/usr/bin/perl
%data = ('John Paul', 45, 'Lisa', 30, 'Kumar', 40);
print "\$data{'John Paul'} = $data{'John Paul'}\n";
print "\$data{'Lisa'} = $data{'Lisa'}\n";
print "\$data{'Kumar'} = $data{'Kumar'}\n";
這將產生以下結果:
$data{'John Paul'} = 45
$data{'Lisa'} = 30
$data{'Kumar'} = 40
變數上下文
Perl 根據上下文(即變數使用的場景)以不同的方式處理相同的變數。讓我們檢查以下示例:
#!/usr/bin/perl
@names = ('John Paul', 'Lisa', 'Kumar');
@copy = @names;
$size = @names;
print "Given names are : @copy\n";
print "Number of names are : $size\n";
這將產生以下結果:
Given names are : John Paul Lisa Kumar Number of names are : 3
這裡 @names 是一個數組,它在兩種不同的上下文中使用。首先,我們將其複製到另一個數組(即列表),因此它返回所有元素,假設上下文是列表上下文。接下來,我們使用相同的陣列並嘗試將此陣列儲存在一個標量中,因此在這種情況下,它只返回此陣列中的元素數量,假設上下文是標量上下文。下表列出了各種上下文:
| 序號 | 上下文和描述 |
|---|---|
| 1 | 標量 賦值給標量變數會以標量上下文評估右側。 |
| 2 | 列表 (List) 賦值給陣列或雜湊會以列表上下文評估右側。 |
| 3 | 布林值 (Boolean) 布林上下文只是任何評估表示式以檢視其真假的地方。 |
| 4 | 空值 (Void) 此上下文不僅不關心返回值是什麼,甚至也不想要返回值。 |
| 5 | 插值 (Interpolative) 此上下文僅發生在引號內或類似引號的功能中。 |
Perl - 標量
標量是單個數據單元。該資料可能是整數、浮點數、字元、字串、段落或整個網頁。
以下是用標量變數的簡單示例:
#!/usr/bin/perl $age = 25; # An integer assignment $name = "John Paul"; # A string $salary = 1445.50; # A floating point print "Age = $age\n"; print "Name = $name\n"; print "Salary = $salary\n";
這將產生以下結果:
Age = 25 Name = John Paul Salary = 1445.5
數值標量 (Numeric Scalars)
標量通常是數字或字串。以下示例演示了各種型別數值標量的用法:
#!/usr/bin/perl $integer = 200; $negative = -300; $floating = 200.340; $bigfloat = -1.2E-23; # 377 octal, same as 255 decimal $octal = 0377; # FF hex, also 255 decimal $hexa = 0xff; print "integer = $integer\n"; print "negative = $negative\n"; print "floating = $floating\n"; print "bigfloat = $bigfloat\n"; print "octal = $octal\n"; print "hexa = $hexa\n";
這將產生以下結果:
integer = 200 negative = -300 floating = 200.34 bigfloat = -1.2e-23 octal = 255 hexa = 255
字串標量 (String Scalars)
以下示例演示了各種型別字串標量的用法。請注意單引號字串和雙引號字串之間的區別:
#!/usr/bin/perl $var = "This is string scalar!"; $quote = 'I m inside single quote - $var'; $double = "This is inside single quote - $var"; $escape = "This example of escape -\tHello, World!"; print "var = $var\n"; print "quote = $quote\n"; print "double = $double\n"; print "escape = $escape\n";
這將產生以下結果:
var = This is string scalar! quote = I m inside single quote - $var double = This is inside single quote - This is string scalar! escape = This example of escape - Hello, World
標量運算 (Scalar Operations)
您將在單獨的章節中看到Perl中可用各種運算子的詳細資訊,但在這裡我們將列出一些數值和字串運算。
#!/usr/bin/perl $str = "hello" . "world"; # Concatenates strings. $num = 5 + 10; # adds two numbers. $mul = 4 * 5; # multiplies two numbers. $mix = $str . $num; # concatenates string and number. print "str = $str\n"; print "num = $num\n"; print "mix = $mix\n";
這將產生以下結果:
str = helloworld num = 15 mul = 20 mix = helloworld15
多行字串 (Multiline Strings)
如果要將多行字串引入程式,可以使用標準單引號,如下所示:
#!/usr/bin/perl $string = 'This is a multiline string'; print "$string\n";
這將產生以下結果:
This is a multiline string
您也可以使用“here”文件語法來儲存或列印多行,如下所示:
#!/usr/bin/perl print <<EOF; This is a multiline string EOF
這也會產生相同的結果:
This is a multiline string
V字串 (V-Strings)
形式為 v1.20.300.4000 的字面量被解析為由具有指定序數的字元組成的字串。此形式稱為 v 字串。
v 字串提供了一種替代且更易讀的構造字串的方法,而不是使用不太易讀的插值形式“\x{1}\x{14}\x{12c}\x{fa0}”。
它們是以 v 開頭,後跟一個或多個點分隔元素的任何字面量。例如:
#!/usr/bin/perl $smile = v9786; $foo = v102.111.111; $martin = v77.97.114.116.105.110; print "smile = $smile\n"; print "foo = $foo\n"; print "martin = $martin\n";
這也會產生相同的結果:
smile = ☺ foo = foo martin = Martin Wide character in print at main.pl line 7.
特殊字面量 (Special Literals)
到目前為止,您一定對字串標量及其連線和插值操作有了一些瞭解。讓我告訴您三個特殊字面量 __FILE__、__LINE__ 和 __PACKAGE__,它們分別代表程式中該點的當前檔名、行號和包名。
它們只能用作單獨的標記,不會被插值到字串中。檢查以下示例:
#!/usr/bin/perl print "File name ". __FILE__ . "\n"; print "Line Number " . __LINE__ ."\n"; print "Package " . __PACKAGE__ ."\n"; # they can not be interpolated print "__FILE__ __LINE__ __PACKAGE__\n";
這將產生以下結果:
File name hello.pl Line Number 4 Package main __FILE__ __LINE__ __PACKAGE__
Perl - 陣列
陣列是一個變數,它儲存有序的標量值列表。陣列變數前面帶有“at”符號 (@)。要引用陣列的單個元素,你將使用美元符號 ($) ,後跟變數名稱,然後是方括號中的元素索引。
這是一個使用陣列變數的簡單示例:
#!/usr/bin/perl
@ages = (25, 30, 40);
@names = ("John Paul", "Lisa", "Kumar");
print "\$ages[0] = $ages[0]\n";
print "\$ages[1] = $ages[1]\n";
print "\$ages[2] = $ages[2]\n";
print "\$names[0] = $names[0]\n";
print "\$names[1] = $names[1]\n";
print "\$names[2] = $names[2]\n";
在這裡,我們在 $ 符號之前使用了轉義符 (\),只是為了列印它。否則Perl會將其理解為變數並列印其值。執行後,將產生以下結果:
$ages[0] = 25 $ages[1] = 30 $ages[2] = 40 $names[0] = John Paul $names[1] = Lisa $names[2] = Kumar
在Perl中,列表和陣列術語經常被互換使用。但是列表是資料,陣列是變數。
陣列建立 (Array Creation)
陣列變數以 @ 符號開頭,並使用圓括號或 qw 運算子填充。例如:
@array = (1, 2, 'Hello'); @array = qw/This is an array/;
第二行使用 qw// 運算子,它返回字串列表,用空格分隔分隔符字串。在此示例中,這導致一個四元素陣列;第一個元素是 'this',最後一個(第四個)是 'array'。這意味著您可以使用不同的行,如下所示:
@days = qw/Monday Tuesday ... Sunday/;
您還可以透過分別分配每個值來填充陣列,如下所示:
$array[0] = 'Monday'; ... $array[6] = 'Sunday';
訪問陣列元素 (Accessing Array Elements)
訪問陣列中的單個元素時,必須在變數前加上美元符號 ($) ,然後在變數名稱後方方括號內附加元素索引。例如:
#!/usr/bin/perl @days = qw/Mon Tue Wed Thu Fri Sat Sun/; print "$days[0]\n"; print "$days[1]\n"; print "$days[2]\n"; print "$days[6]\n"; print "$days[-1]\n"; print "$days[-7]\n";
這將產生以下結果:
Mon Tue Wed Sun Sun Mon
陣列索引從零開始,因此要訪問第一個元素,您需要給出 0 作為索引。您也可以給出負索引,在這種情況下,您將從陣列的末尾而不是開頭選擇元素。這意味著:
print $days[-1]; # outputs Sun print $days[-7]; # outputs Mon
連續編號陣列 (Sequential Number Arrays)
Perl 為連續數字和字母提供了快捷方式。例如,不用在計算到 100 時鍵入每個元素,我們可以執行以下操作:
#!/usr/bin/perl @var_10 = (1..10); @var_20 = (10..20); @var_abc = (a..z); print "@var_10\n"; # Prints number from 1 to 10 print "@var_20\n"; # Prints number from 10 to 20 print "@var_abc\n"; # Prints number from a to z
這裡雙點 (..) 稱為範圍運算子。這將產生以下結果:
1 2 3 4 5 6 7 8 9 10 10 11 12 13 14 15 16 17 18 19 20 a b c d e f g h i j k l m n o p q r s t u v w x y z
陣列大小 (Array Size)
可以使用陣列上的標量上下文來確定陣列的大小——返回值將是陣列中的元素個數:
@array = (1,2,3); print "Size: ",scalar @array,"\n";
返回的值始終是陣列的物理大小,而不是有效元素的數量。您可以使用此片段演示這一點以及標量 @array 和 $#array 之間的區別,如下所示:
#!/usr/bin/perl @array = (1,2,3); $array[50] = 4; $size = @array; $max_index = $#array; print "Size: $size\n"; print "Max Index: $max_index\n";
這將產生以下結果:
Size: 51 Max Index: 50
陣列中只有四個包含資訊的元素,但陣列長度為 51 個元素,最高索引為 50。
在陣列中新增和刪除元素 (Adding and Removing Elements in Array)
Perl 提供了許多有用的函式來在陣列中新增和刪除元素。您可能想知道什麼是函式?到目前為止,您已使用print函式來列印各種值。類似地,還有各種其他函式,有時稱為子例程,可用於各種其他功能。
| 序號 | 型別與說明 |
|---|---|
| 1 | push @ARRAY, LIST 將列表的值推送到陣列的末尾。 |
| 2 | pop @ARRAY 彈出並返回陣列的最後一個值。 |
| 3 | shift @ARRAY 將陣列的第一個值移出並返回它,使陣列縮短 1 並將所有內容向下移動。 |
| 4 | unshift @ARRAY, LIST 將列表新增到陣列的前面,並返回新陣列中的元素數量。 |
#!/usr/bin/perl
# create a simple array
@coins = ("Quarter","Dime","Nickel");
print "1. \@coins = @coins\n";
# add one element at the end of the array
push(@coins, "Penny");
print "2. \@coins = @coins\n";
# add one element at the beginning of the array
unshift(@coins, "Dollar");
print "3. \@coins = @coins\n";
# remove one element from the last of the array.
pop(@coins);
print "4. \@coins = @coins\n";
# remove one element from the beginning of the array.
shift(@coins);
print "5. \@coins = @coins\n";
這將產生以下結果:
1. @coins = Quarter Dime Nickel 2. @coins = Quarter Dime Nickel Penny 3. @coins = Dollar Quarter Dime Nickel Penny 4. @coins = Dollar Quarter Dime Nickel 5. @coins = Quarter Dime Nickel
切片陣列元素 (Slicing Array Elements)
您還可以從陣列中提取“切片”——也就是說,您可以按順序從陣列中選擇多個專案以產生另一個數組。
#!/usr/bin/perl @days = qw/Mon Tue Wed Thu Fri Sat Sun/; @weekdays = @days[3,4,5]; print "@weekdays\n";
這將產生以下結果:
Thu Fri Sat
切片的規範必須包含一個有效的索引列表,無論是正數還是負數,每個索引之間用逗號分隔。為了速度,您也可以使用..範圍運算子:
#!/usr/bin/perl @days = qw/Mon Tue Wed Thu Fri Sat Sun/; @weekdays = @days[3..5]; print "@weekdays\n";
這將產生以下結果:
Thu Fri Sat
替換陣列元素 (Replacing Array Elements)
現在我們將介紹另一個名為splice()的函式,其語法如下:
splice @ARRAY, OFFSET [ , LENGTH [ , LIST ] ]
此函式將刪除由 OFFSET 和 LENGTH 指定的 @ARRAY 的元素,如果指定,則用 LIST 替換它們。最後,它返回從陣列中刪除的元素。以下是一個例子:
#!/usr/bin/perl @nums = (1..20); print "Before - @nums\n"; splice(@nums, 5, 5, 21..25); print "After - @nums\n";
這將產生以下結果:
Before - 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 After - 1 2 3 4 5 21 22 23 24 25 11 12 13 14 15 16 17 18 19 20
在這裡,實際替換從第六個數開始,然後用數字 21、22、23、24 和 25 替換從 6 到 10 的五個元素。
將字串轉換為陣列 (Transform Strings to Arrays)
讓我們來看另一個名為split()的函式,其語法如下:
split [ PATTERN [ , EXPR [ , LIMIT ] ] ]
此函式將字串拆分為字串陣列,並返回它。如果指定了 LIMIT,則最多拆分為該數量的欄位。如果省略 PATTERN,則在空格處拆分。以下是一個例子:
#!/usr/bin/perl
# define Strings
$var_string = "Rain-Drops-On-Roses-And-Whiskers-On-Kittens";
$var_names = "Larry,David,Roger,Ken,Michael,Tom";
# transform above strings into arrays.
@string = split('-', $var_string);
@names = split(',', $var_names);
print "$string[3]\n"; # This will print Roses
print "$names[4]\n"; # This will print Michael
這將產生以下結果:
Roses Michael
將陣列轉換為字串 (Transform Arrays to Strings)
我們可以使用join()函式重新連線陣列元素並形成一個長的標量字串。此函式具有以下語法:
join EXPR, LIST
此函式將 LIST 的單獨字串連線成一個字串,欄位由 EXPR 的值分隔,並返回該字串。以下是一個例子:
#!/usr/bin/perl
# define Strings
$var_string = "Rain-Drops-On-Roses-And-Whiskers-On-Kittens";
$var_names = "Larry,David,Roger,Ken,Michael,Tom";
# transform above strings into arrays.
@string = split('-', $var_string);
@names = split(',', $var_names);
$string1 = join( '-', @string );
$string2 = join( ',', @names );
print "$string1\n";
print "$string2\n";
這將產生以下結果:
Rain-Drops-On-Roses-And-Whiskers-On-Kittens Larry,David,Roger,Ken,Michael,Tom
排序陣列 (Sorting Arrays)
sort()函式根據 ASCII 數字標準對陣列的每個元素進行排序。此函式具有以下語法:
sort [ SUBROUTINE ] LIST
此函式對 LIST 進行排序並返回已排序的陣列值。如果指定了 SUBROUTINE,則在排序元素時會應用 SUBTROUTINE 中的指定邏輯。
#!/usr/bin/perl # define an array @foods = qw(pizza steak chicken burgers); print "Before: @foods\n"; # sort this array @foods = sort(@foods); print "After: @foods\n";
這將產生以下結果:
Before: pizza steak chicken burgers After: burgers chicken pizza steak
請注意,排序是根據單詞的 ASCII 數字值執行的。因此,最好的方法是首先將陣列的每個元素轉換為小寫字母,然後執行排序函式。
合併陣列 (Merging Arrays)
因為陣列只是一系列用逗號分隔的值,所以您可以將它們組合在一起,如下所示:
#!/usr/bin/perl @numbers = (1,3,(4,5,6)); print "numbers = @numbers\n";
這將產生以下結果:
numbers = 1 3 4 5 6
嵌入式陣列只是成為主陣列的一部分,如下所示:
#!/usr/bin/perl @odd = (1,3,5); @even = (2, 4, 6); @numbers = (@odd, @even); print "numbers = @numbers\n";
這將產生以下結果:
numbers = 1 3 5 2 4 6
從列表中選擇元素 (Selecting Elements from Lists)
列表表示法與陣列的表示法相同。您可以透過將方括號附加到列表並提供一個或多個索引來從陣列中提取元素:
#!/usr/bin/perl $var = (5,4,3,2,1)[4]; print "value of var = $var\n"
這將產生以下結果:
value of var = 1
類似地,我們可以提取切片,但不需要前導 @ 字元:
#!/usr/bin/perl @list = (5,4,3,2,1)[1..3]; print "Value of list = @list\n";
這將產生以下結果:
Value of list = 4 3 2
Perl - 雜湊表
雜湊是一組鍵值對。雜湊變數以百分號 (%) 開頭。要引用雜湊的單個元素,可以使用雜湊變數名稱,前面加"$"符號,後跟花括號中與值關聯的“鍵”。
這是一個使用雜湊變數的簡單示例:
#!/usr/bin/perl
%data = ('John Paul', 45, 'Lisa', 30, 'Kumar', 40);
print "\$data{'John Paul'} = $data{'John Paul'}\n";
print "\$data{'Lisa'} = $data{'Lisa'}\n";
print "\$data{'Kumar'} = $data{'Kumar'}\n";
這將產生以下結果:
$data{'John Paul'} = 45
$data{'Lisa'} = 30
$data{'Kumar'} = 40
建立雜湊 (Creating Hashes)
雜湊可以透過以下兩種方式之一建立。在第一種方法中,您可以逐個將值分配給命名鍵:
$data{'John Paul'} = 45;
$data{'Lisa'} = 30;
$data{'Kumar'} = 40;
在第二種情況下,您使用列表,該列表透過從列表中獲取單個對來轉換:對的第一個元素用作鍵,第二個元素用作值。例如:
%data = ('John Paul', 45, 'Lisa', 30, 'Kumar', 40);
為清晰起見,您可以使用 => 作為 , 的別名,以指示鍵值對,如下所示:
%data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40);
這是上述形式的另一種變體,請看一看,這裡所有鍵都以連字元 (-) 開頭,並且不需要在其周圍使用引號:
%data = (-JohnPaul => 45, -Lisa => 30, -Kumar => 40);
但需要注意的是,這種形式的雜湊形成使用的是單個單詞(即沒有空格的鍵),如果您以這種方式構建雜湊,則只能使用連字元訪問鍵,如下所示。
$val = %data{-JohnPaul}
$val = %data{-Lisa}
訪問雜湊元素 (Accessing Hash Elements)
訪問雜湊中的單個元素時,必須在變數前加上美元符號 ($) ,然後在變數名稱後方括號內附加元素鍵。例如:
#!/usr/bin/perl
%data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40);
print "$data{'John Paul'}\n";
print "$data{'Lisa'}\n";
print "$data{'Kumar'}\n";
這將產生以下結果:
45 30 40
提取切片 (Extracting Slices)
您可以提取雜湊的切片,就像您可以從陣列中提取切片一樣。您需要使用 @ 字首作為變數來儲存返回值,因為它們將是值列表:
#!/uer/bin/perl
%data = (-JohnPaul => 45, -Lisa => 30, -Kumar => 40);
@array = @data{-JohnPaul, -Lisa};
print "Array : @array\n";
這將產生以下結果:
Array : 45 30
提取鍵和值 (Extracting Keys and Values)
您可以使用keys函式獲取雜湊的所有鍵的列表,該函式具有以下語法:
keys %HASH
此函式返回命名雜湊的所有鍵的陣列。以下是一個例子:
#!/usr/bin/perl
%data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40);
@names = keys %data;
print "$names[0]\n";
print "$names[1]\n";
print "$names[2]\n";
這將產生以下結果:
Lisa John Paul Kumar
類似地,您可以使用values函式獲取所有值的列表。此函式具有以下語法:
values %HASH
此函式返回一個普通陣列,其中包含命名雜湊的所有值。以下是一個例子:
#!/usr/bin/perl
%data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40);
@ages = values %data;
print "$ages[0]\n";
print "$ages[1]\n";
print "$ages[2]\n";
這將產生以下結果:
30 45 40
檢查是否存在 (Checking for Existence)
如果您嘗試從不存在的雜湊中訪問鍵值對,通常會得到未定義的值,如果您啟用了警告,則會在執行時生成警告。您可以使用exists函式來解決此問題,如果命名鍵存在,無論其值是什麼,此函式都返回 true:
#!/usr/bin/perl
%data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40);
if( exists($data{'Lisa'} ) ) {
print "Lisa is $data{'Lisa'} years old\n";
} else {
print "I don't know age of Lisa\n";
}
這裡我們介紹了 IF...ELSE 語句,我們將在單獨的章節中學習它。目前,你只需要假設只有當給定的條件為真時才會執行if( condition )部分,否則將執行else部分。因此,當我們執行上述程式時,它會產生以下結果,因為這裡給定的條件exists($data{'Lisa'}返回 true −
Lisa is 30 years old
獲取雜湊大小
你可以透過在 keys 或 values 上使用標量上下文來獲取雜湊的大小,也就是元素的數量。簡單來說,你首先需要獲取 keys 或 values 的陣列,然後就可以按照如下方式獲取陣列的大小:
#!/usr/bin/perl
%data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40);
@keys = keys %data;
$size = @keys;
print "1 - Hash size: is $size\n";
@values = values %data;
$size = @values;
print "2 - Hash size: is $size\n";
這將產生以下結果:
1 - Hash size: is 3 2 - Hash size: is 3
在雜湊中新增和刪除元素
使用簡單的賦值運算子,一行程式碼就可以新增新的鍵值對。但是要從雜湊中刪除元素,需要使用delete函式,如下例所示:
#!/usr/bin/perl
%data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40);
@keys = keys %data;
$size = @keys;
print "1 - Hash size: is $size\n";
# adding an element to the hash;
$data{'Ali'} = 55;
@keys = keys %data;
$size = @keys;
print "2 - Hash size: is $size\n";
# delete the same element from the hash;
delete $data{'Ali'};
@keys = keys %data;
$size = @keys;
print "3 - Hash size: is $size\n";
這將產生以下結果:
1 - Hash size: is 3 2 - Hash size: is 4 3 - Hash size: is 3
Perl 條件語句 - IF...ELSE
Perl 條件語句有助於決策,這需要程式設計師指定一個或多個條件由程式進行評估或測試,以及如果條件確定為真則要執行的語句,以及可選地,如果條件確定為假則要執行的其他語句。
以下是大多數程式語言中常見的典型決策結構的一般形式:

數字 0,字串 '0' 和 "",空列表 () 和 undef 在布林上下文中都為false,所有其他值都為true。使用!或not對真值取反會返回一個特殊的假值。
Perl 程式語言提供以下型別的條件語句。
| 序號 | 語句 & 說明 |
|---|---|
| 1 | if 語句
一個if 語句由一個布林表示式後跟一個或多個語句組成。 |
| 2 | if...else 語句
一個if 語句可以後跟一個可選的else 語句。 |
| 3 | if...elsif...else 語句
一個if 語句可以後跟一個可選的elsif 語句,然後是一個可選的else 語句。 |
| 4 | unless 語句
一個unless 語句由一個布林表示式後跟一個或多個語句組成。 |
| 5 | unless...else 語句
一個unless 語句可以後跟一個可選的else 語句。 |
| 6 | unless...elsif..else 語句
一個unless 語句可以後跟一個可選的elsif 語句,然後是一個可選的else 語句。 |
| 7 | switch 語句
使用最新版本的 Perl,你可以使用switch語句,它允許以簡單的方式將變數值與各種條件進行比較。 |
?: 運算子
讓我們檢查一下條件運算子 ?:,它可以用來替換if...else語句。它具有以下一般形式:
Exp1 ? Exp2 : Exp3;
其中 Exp1、Exp2 和 Exp3 是表示式。注意冒號的使用和位置。
?: 表示式的值是這樣確定的:Exp1 被評估。如果為真,則評估 Exp2 併成為整個 ?: 表示式的值。如果 Exp1 為假,則評估 Exp3,其值成為表示式的值。下面是一個使用此運算子的簡單示例:
#!/usr/local/bin/perl $name = "Ali"; $age = 10; $status = ($age > 60 )? "A senior citizen" : "Not a senior citizen"; print "$name is - $status\n";
這將產生以下結果:
Ali is - Not a senior citizen
Perl - 迴圈
你可能需要多次執行一段程式碼的情況。一般來說,語句是順序執行的:函式中的第一個語句首先執行,然後是第二個,依此類推。
程式語言提供各種控制結構,允許更復雜的執行路徑。
迴圈語句允許我們多次執行一個語句或一組語句,以下是大多數程式語言中迴圈語句的一般形式:

Perl 程式語言提供以下型別的迴圈來處理迴圈需求。
| 序號 | 迴圈型別 & 說明 |
|---|---|
| 1 | while 迴圈
當給定條件為真時,重複執行一個語句或一組語句。它在執行迴圈體之前測試條件。 |
| 2 | until 迴圈
重複執行一個語句或一組語句,直到給定條件變為真。它在執行迴圈體之前測試條件。 |
| 3 | for 迴圈
多次執行一系列語句,並縮寫管理迴圈變數的程式碼。 |
| 4 | foreach 迴圈
foreach 迴圈迭代一個普通的列表值,並將變數 VAR 設定為依次為列表中的每個元素。 |
| 5 | do...while 迴圈
類似於 while 語句,只是它在迴圈體末尾測試條件 |
| 6 | 巢狀迴圈
你可以在任何其他 while、for 或 do..while 迴圈內使用一個或多個迴圈。 |
迴圈控制語句
迴圈控制語句改變執行的正常順序。當執行離開作用域時,在該作用域中建立的所有自動物件都會被銷燬。
Perl 支援以下控制語句。點選以下連結檢視其詳細資訊。
| 序號 | 控制語句 & 說明 |
|---|---|
| 1 | next 語句
導致迴圈跳過其主體其餘部分,並在重複之前立即重新測試其條件。 |
| 2 | last 語句
終止迴圈語句並將執行轉移到迴圈後緊跟的語句。 |
| 3 | continue 語句
一個 continue 塊,它總是在條件即將再次被評估之前執行。 |
| 4 | redo 語句
redo 命令重新啟動迴圈塊,而無需再次評估條件。不會執行 continue 塊(如果有的話)。 |
| 5 | goto 語句
Perl 支援三種形式的 goto 命令:goto label、goto expr 和 goto &name。 |
無限迴圈
如果條件永遠不會變為 false,則迴圈將變成無限迴圈。for迴圈傳統上用於此目的。由於構成for迴圈的三個表示式都不需要,因此你可以透過省略條件表示式來建立一個無限迴圈。
#!/usr/local/bin/perl
for( ; ; ) {
printf "This loop will run forever.\n";
}
你可以透過按 Ctrl + C 鍵來終止上述無限迴圈。
當條件表示式不存在時,它被認為是 true。你可能有初始化和增量表達式,但作為程式設計師更常用 for (;;) 結構來表示無限迴圈。
Perl - 運算子
什麼是運算子?
可以使用表示式4 + 5 等於 9給出簡單的答案。這裡 4 和 5 稱為運算元,+ 稱為運算子。Perl 語言支援許多運算子型別,但以下是重要且最常用的運算子列表:
- 算術運算子
- 等式運算子
- 邏輯運算子
- 賦值運算子
- 位運算子
- 邏輯運算子
- 類似引號的運算子
- 其他運算子
讓我們逐一檢視所有運算子。
Perl 算術運算子
假設變數 $a 包含 10,變數 $b 包含 20,則以下是 Perl 算術運算子:
| 序號 | 運算子 & 說明 |
|---|---|
| 1 | + (加法) 將運算子兩側的值相加 示例 − $a + $b 將得到 30 |
| 2 | - (減法) 從左運算元中減去右運算元 示例 − $a - $b 將得到 -10 |
| 3 | * (乘法) 將運算子兩側的值相乘 示例 − $a * $b 將得到 200 |
| 4 | / (除法) 將左運算元除以右運算元 示例 − $b / $a 將得到 2 |
| 5 | % (模) 將左運算元除以右運算元並返回餘數 示例 − $b % $a 將得到 0 |
| 6 | ** (指數) 對運算子執行指數(冪)計算 示例 − $a**$b 將得到 10 的 20 次冪 |
Perl 等式運算子
這些也稱為關係運算符。假設變數 $a 包含 10,變數 $b 包含 20,那麼讓我們檢查以下數值等式運算子:
| 序號 | 運算子 & 說明 |
|---|---|
| 1 | == (等於) 檢查兩個運算元的值是否相等,如果相等則條件變為真。 示例 − ($a == $b) 為假。 |
| 2 | != (不等於) 檢查兩個運算元的值是否相等,如果不相等則條件變為真。 示例 − ($a != $b) 為真。 |
| 3 | <=> 檢查兩個運算元的值是否相等,並返回 -1、0 或 1,具體取決於左引數在數值上是否小於、等於或大於右引數。 示例 − ($a <=> $b) 返回 -1。 |
| 4 | > (大於) 檢查左運算元的值是否大於右運算元的值,如果大於則條件變為真。 示例 − ($a > $b) 為假。 |
| 5 | < (小於) 檢查左運算元的值是否小於右運算元的值,如果小於則條件變為真。 示例 − ($a < $b) 為真。 |
| 6 | >= (大於或等於) 檢查左運算元的值是否大於或等於右運算元的值,如果大於或等於則條件變為真。 示例 − ($a >= $b) 為假。 |
| 7 | <= (小於或等於) 檢查左運算元的值是否小於或等於右運算元的值,如果小於或等於則條件變為真。 示例 − ($a <= $b) 為真。 |
以下是等式運算子的列表。假設變數 $a 包含 "abc",變數 $b 包含 "xyz",那麼讓我們檢查以下字串等式運算子:
| 序號 | 運算子 & 說明 |
|---|---|
| 1 | lt 如果左引數在字串上小於右引數,則返回 true。 示例 − ($a lt $b) 為真。 |
| 2 | gt 如果左引數在字串上大於右引數,則返回 true。 示例 − ($a gt $b) 為假。 |
| 3 | le 如果左引數在字串上小於或等於右引數,則返回 true。 示例 − ($a le $b) 為真。 |
| 4 | ge 如果左引數在字串上大於或等於右引數,則返回 true。 示例 − ($a ge $b) 為假。 |
| 5 | eq 如果左引數在字串上等於右引數,則返回 true。 示例 − ($a eq $b) 為假。 |
| 6 | ne 如果左引數在字串上不等於右引數,則返回 true。 示例 − ($a ne $b) 為真。 |
| 7 | cmp 返回 -1、0 或 1,具體取決於左引數在字串上是否小於、等於或大於右引數。 示例 − ($a cmp $b) 為 -1。 |
Perl 賦值運算子
假設變數 $a 包含 10,變數 $b 包含 20,則以下是 Perl 中可用的賦值運算子及其用法:
| 序號 | 運算子 & 說明 |
|---|---|
| 1 | = 簡單的賦值運算子,將值從右側運算元賦值給左側運算元 示例 − $c = $a + $b 將 $a + $b 的值賦值給 $c |
| 2 | += 加法和賦值運算子,它將右運算元新增到左運算元,並將結果賦值給左運算元 示例 − $c += $a 等效於 $c = $c + $a |
| 3 | -= 減法和賦值運算子,它從左運算元中減去右運算元,並將結果賦值給左運算元 示例 − $c -= $a 等效於 $c = $c - $a |
| 4 | *= 乘法和賦值運算子,它將右運算元乘以左運算元,並將結果賦值給左運算元 示例 − $c *= $a 等效於 $c = $c * $a |
| 5 | /= 除法並賦值運算子,它將左運算元除以右運算元並將結果賦值給左運算元。 示例 − $c /= $a 等效於 $c = $c / $a |
| 6 | %= 取模並賦值運算子,它使用兩個運算元進行取模運算並將結果賦值給左運算元。 示例 − $c %= $a 等效於 $c = $c % $a |
| 7 | **= 指數並賦值運算子,對運算元執行指數(冪)計算並將結果賦值給左運算元。 示例 − $c **= $a 等效於 $c = $c ** $a |
Perl 位運算子
位運算子對位進行操作並執行逐位運算。假設 $a = 60;和 $b = 13;現在它們的二進位制格式如下:
$a = 0011 1100
$b = 0000 1101
-----------------
$a & $b = 0000 1100
$a | $b = 0011 1101
$a ^ $b = 0011 0001
~$a = 1100 0011
Perl 語言支援以下位運算子,假設 $a = 60;和 $b = 13
| 序號 | 運算子 & 說明 |
|---|---|
| 1 | & 二進位制 AND 運算子:如果位同時存在於兩個運算元中,則將其複製到結果中。 示例 − ($a & $b) 將得到 12,即 0000 1100 |
| 2 | | 二進位制 OR 運算子:如果位存在於任一運算元中,則將其複製。 示例 − ($a | $b) 將得到 61,即 0011 1101 |
| 3 | ^ 二進位制 XOR 運算子:如果位在一個運算元中設定,但在另一個運算元中未設定,則將其複製。 示例 − ($a ^ $b) 將得到 49,即 0011 0001 |
| 4 | ~ 二進位制反碼運算子:是單目運算子,具有“翻轉”位的作用。 示例 − (~$a) 將得到 -61,由於是帶符號二進位制數,因此其二進位制補碼形式為 1100 0011。 |
| 5 | << 二進位制左移運算子:左運算元的值向左移動由右運算元指定的位數。 示例 − $a << 2 將得到 240,即 1111 0000 |
| 6 | >> 二進位制右移運算子:左運算元的值向右移動由右運算元指定的位數。 示例 − $a >> 2 將得到 15,即 0000 1111 |
Perl 邏輯運算子
Perl 語言支援以下邏輯運算子。假設變數 $a 為真,變數 $b 為假,則:
| 序號 | 運算子 & 說明 |
|---|---|
| 1 | and 稱為邏輯 AND 運算子。如果兩個運算元都為真,則條件為真。 示例 − ($a and $b) 為假。 |
| 2 | && C 風格的邏輯 AND 運算子:如果位同時存在於兩個運算元中,則將其複製到結果中。 示例 − ($a && $b) 為假。 |
| 3 | or 稱為邏輯 OR 運算子。如果兩個運算元中任何一個非零,則條件為真。 示例 − ($a or $b) 為真。 |
| 4 | || C 風格的邏輯 OR 運算子:如果位存在於任一運算元中,則將其複製。 示例 − ($a || $b) 為真。 |
| 5 | not 稱為邏輯 NOT 運算子。用於反轉其運算元的邏輯狀態。如果條件為真,則邏輯 NOT 運算子將使其為假。 示例 − not($a and $b) 為真。 |
類似引號的運算子
Perl 語言支援以下類似引號的運算子。在下表中,{} 代表您選擇的任何一對定界符。
| 序號 | 運算子 & 說明 |
|---|---|
| 1 | q{ } 用單引號括起字串 示例 − q{abcd} 得到 'abcd' |
| 2 | qq{ } 用雙引號括起字串 示例 − qq{abcd} 得到 "abcd" |
| 3 | qx{ } 用反引號括起字串 示例 − qx{abcd} 得到 `abcd` |
其他運算子
Perl 語言支援以下其他運算子。假設變數 a 為 10,變數 b 為 20,則:
| 序號 | 運算子 & 說明 |
|---|---|
| 1 | . 二元點運算子 (.) 用於連線兩個字串。 示例 − 如果 $a = "abc",$b = "def",則 $a.$b 將得到 "abcdef" |
| 2 | x 重複運算子 x 返回一個字串,該字串由左運算元重複右運算元指定的次陣列成。 示例 − ('-' x 3) 將得到 ---。 |
| 3 | .. 範圍運算子 .. 返回一個值列表,這些值從左值計數(每次遞增一個)到右值。 示例 − (2..5) 將得到 (2, 3, 4, 5) |
| 4 | ++ 自動遞增運算子將整數的值增加一。 示例 − $a++ 將得到 11 |
| 5 | -- 自動遞減運算子將整數的值減少一。 示例 − $a-- 將得到 9 |
| 6 | -> 箭頭運算子主要用於從物件或類名取消引用方法或變數。 示例 − $obj->{$a} 是從物件 $obj 訪問變數 $a 的示例。 |
Perl 運算子優先順序
下表列出了所有運算子,從最高優先順序到最低優先順序。
left terms and list operators (leftward) left -> nonassoc ++ -- right ** right ! ~ \ and unary + and - left =~ !~ left * / % x left + - . left << >> nonassoc named unary operators nonassoc < > <= >= lt gt le ge nonassoc == != <=> eq ne cmp ~~ left & left | ^ left && left || // nonassoc .. ... right ?: right = += -= *= etc. left , => nonassoc list operators (rightward) right not left and left or xor
Perl - 日期和時間
本章將幫助您瞭解如何在 Perl 中處理和操作日期和時間。
當前日期和時間
讓我們從localtime()函式開始,如果未提供任何引數,則該函式將返回當前日期和時間的值。以下是localtime函式在列表上下文中使用的返回值(9 個元素的列表):
sec, # seconds of minutes from 0 to 61 min, # minutes of hour from 0 to 59 hour, # hours of day from 0 to 24 mday, # day of month from 1 to 31 mon, # month of year from 0 to 11 year, # year since 1900 wday, # days since sunday yday, # days since January 1st isdst # hours of daylight savings time
嘗試以下示例以列印 localtime() 函式返回的不同元素:
#!/usr/local/bin/perl @months = qw( Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec ); @days = qw(Sun Mon Tue Wed Thu Fri Sat Sun); ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime(); print "$mday $months[$mon] $days[$wday]\n";
執行上述程式碼時,將產生以下結果:
16 Feb Sat
如果在標量上下文中使用 localtime() 函式,則它將返回系統中設定的當前時區的日期和時間。嘗試以下示例以列印完整格式的當前日期和時間:
#!/usr/local/bin/perl $datestring = localtime(); print "Local date and time $datestring\n";
執行上述程式碼時,將產生以下結果:
Local date and time Sat Feb 16 06:50:45 2013
GMT 時間
函式gmtime()的工作方式與 localtime() 函式類似,但返回值已針對標準格林威治時間區域進行了本地化。在列表上下文中呼叫時,gmtime 返回的最後一個值 $isdst 始終為 0。GMT 沒有夏令時。
請注意,localtime() 將返回執行指令碼的計算機上的當前本地時間,而 gmtime() 將返回世界標準時間,即 GMT(或 UTC)。
嘗試以下示例以列印當前日期和時間,但以 GMT 標準顯示:
#!/usr/local/bin/perl $datestring = gmtime(); print "GMT date and time $datestring\n";
執行上述程式碼時,將產生以下結果:
GMT date and time Sat Feb 16 13:50:45 2013
格式化日期和時間
您可以使用 localtime() 函式獲取 9 個元素的列表,然後可以使用printf()函式根據您的要求格式化日期和時間,如下所示:
#!/usr/local/bin/perl
($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime();
printf("Time Format - HH:MM:SS\n");
printf("%02d:%02d:%02d", $hour, $min, $sec);
執行上述程式碼時,將產生以下結果:
Time Format - HH:MM:SS 06:58:52
紀元時間
您可以使用 time() 函式獲取紀元時間,即自給定日期以來經過的秒數,在 Unix 中是 1970 年 1 月 1 日。
#!/usr/local/bin/perl $epoc = time(); print "Number of seconds since Jan 1, 1970 - $epoc\n";
執行上述程式碼時,將產生以下結果:
Number of seconds since Jan 1, 1970 - 1361022130
您可以將給定的秒數轉換為日期和時間字串,如下所示:
#!/usr/local/bin/perl $datestring = localtime(); print "Current date and time $datestring\n"; $epoc = time(); $epoc = $epoc - 24 * 60 * 60; # one day before of current date. $datestring = localtime($epoc); print "Yesterday's date and time $datestring\n";
執行上述程式碼時,將產生以下結果:
Current date and time Tue Jun 5 05:54:43 2018 Yesterday's date and time Mon Jun 4 05:54:43 2018
POSIX 函式 strftime()
您可以使用 POSIX 函式strftime()來格式化日期和時間,方法是使用下表。請注意,用星號 (*) 標記的說明符是依賴於區域設定的。
| 說明符 | 替換為 | 示例 |
|---|---|---|
%a |
縮寫的星期幾名稱* | Thu |
%A |
完整的星期幾名稱* | Thursday |
%b |
縮寫的月份名稱* | Aug |
%B |
完整的月份名稱* | August |
%c |
日期和時間的表示* | Thu Aug 23 14:55:02 2001 |
%C |
年份除以 100 並截斷為整數 (00-99) |
20 |
%d |
月份中的天數,用零填充 (01-31) |
23 |
%D |
簡短的 MM/DD/YY 日期,相當於 %m/%d/%y |
08/23/01 |
%e |
月份中的天數,用空格填充 ( 1-31) |
23 |
%F |
簡短的 YYYY-MM-DD 日期,相當於 %Y-%m-%d |
2001-08-23 |
%g |
基於星期的年份,後兩位數字 (00-99) |
01 |
%G |
基於星期的年份 | 2001 |
%h |
縮寫的月份名稱*(與%b相同) |
Aug |
%H |
24 小時制的小時數 (00-23) |
14 |
%I |
12 小時制的小時數 (01-12) |
02 |
%j |
一年中的天數 (001-366) |
235 |
%m |
月份的十進位制數 (01-12) |
08 |
%M |
分鐘 (00-59) |
55 |
%n |
換行符 ('\n') |
|
%p |
AM 或 PM 表示 | PM |
%r |
12 小時制的時間* | 02:55:02 pm |
%R |
24 小時制 HH:MM 時間,相當於 %H:%M |
14:55 |
%S |
秒 (00-61) |
02 |
%t |
水平製表符 ('\t') |
|
%T |
ISO 8601 時間格式 (HH:MM:SS),相當於 %H:%M:%S |
14:55 |
%u |
ISO 8601 星期幾,星期一為 1 (1-7) |
4 |
%U |
星期數,以第一個星期日為第一週的第一天 (00-53) |
33 |
%V |
ISO 8601 星期數 (00-53) |
34 |
%w |
星期幾的十進位制數,星期日為 0 (0-6) |
4 |
%W |
星期數,以第一個星期一為第一週的第一天 (00-53) |
34 |
%x |
日期表示* | 08/23/01 |
%X |
時間表示* | 14:55:02 |
%y |
年份,後兩位數字 (00-99) |
01 |
%Y |
年份 | 2001 |
%z |
ISO 8601 與 UTC 的時區偏移量(1 分鐘 = 1,1 小時 = 100) 如果無法確定時區,則無字元 |
+100 |
%Z |
時區名稱或縮寫* 如果無法確定時區,則無字元 |
CDT |
%% |
% 符號 |
% |
讓我們檢查以下示例以瞭解其用法:
#!/usr/local/bin/perl
use POSIX qw(strftime);
$datestring = strftime "%a %b %e %H:%M:%S %Y", localtime;
printf("date and time - $datestring\n");
# or for GMT formatted appropriately for your locale:
$datestring = strftime "%a %b %e %H:%M:%S %Y", gmtime;
printf("date and time - $datestring\n");
執行上述程式碼時,將產生以下結果:
date and time - Sat Feb 16 07:10:23 2013 date and time - Sat Feb 16 14:10:23 2013
Perl - 子程式
Perl 子例程或函式是一組語句,這些語句一起執行一項任務。您可以將程式碼劃分為單獨的子例程。如何將程式碼劃分為不同的子例程取決於您,但從邏輯上講,劃分通常是讓每個函式執行特定任務。
Perl 互換使用子例程、方法和函式。
定義和呼叫子例程
Perl 程式語言中子例程定義的一般形式如下:
sub subroutine_name {
body of the subroutine
}
呼叫 Perl 子例程的典型方法如下:
subroutine_name( list of arguments );
在 5.0 之前的 Perl 版本中,呼叫子例程的語法略有不同,如下所示。這仍然適用於最新版本的 Perl,但不推薦,因為它繞過了子例程原型。
&subroutine_name( list of arguments );
讓我們來看以下示例,該示例定義了一個簡單的函式,然後呼叫它。因為 Perl 在執行程式之前會編譯程式,所以您宣告子例程的位置無關緊要。
#!/usr/bin/perl
# Function definition
sub Hello {
print "Hello, World!\n";
}
# Function call
Hello();
執行上述程式時,將產生以下結果:
Hello, World!
向子例程傳遞引數
您可以像在其他任何程式語言中一樣,向子程式傳遞各種引數,並且可以使用特殊的陣列 `@_` 在函式內部訪問它們。因此,函式的第一個引數在 `$_[0]` 中,第二個引數在 `$_[1]` 中,依此類推。
您可以像任何標量一樣傳遞陣列和雜湊作為引數,但是傳遞多個數組或雜湊通常會導致它們丟失各自的標識。因此,我們將使用引用(下一章將解釋)來傳遞任何陣列或雜湊。
讓我們嘗試以下示例,它接收一組數字並列印它們的平均值:
#!/usr/bin/perl
# Function definition
sub Average {
# get total number of arguments passed.
$n = scalar(@_);
$sum = 0;
foreach $item (@_) {
$sum += $item;
}
$average = $sum / $n;
print "Average for the given numbers : $average\n";
}
# Function call
Average(10, 20, 30);
執行上述程式時,將產生以下結果:
Average for the given numbers : 20
向子程式傳遞列表
因為 `@_` 變數是一個數組,所以它可以用來向子程式提供列表。但是,由於 Perl 接受和解析列表和陣列的方式,從 `@_` 中提取單個元素可能很困難。如果您必須與其他標量引數一起傳遞列表,則應將列表作為最後一個引數,如下所示:
#!/usr/bin/perl
# Function definition
sub PrintList {
my @list = @_;
print "Given list is @list\n";
}
$a = 10;
@b = (1, 2, 3, 4);
# Function call with list parameter
PrintList($a, @b);
執行上述程式時,將產生以下結果:
Given list is 10 1 2 3 4
向子程式傳遞雜湊
當您向接受列表的子程式或運算子提供雜湊時,雜湊會自動轉換為鍵/值對列表。例如:
#!/usr/bin/perl
# Function definition
sub PrintHash {
my (%hash) = @_;
foreach my $key ( keys %hash ) {
my $value = $hash{$key};
print "$key : $value\n";
}
}
%hash = ('name' => 'Tom', 'age' => 19);
# Function call with hash parameter
PrintHash(%hash);
執行上述程式時,將產生以下結果:
name : Tom age : 19
從子程式返回值
您可以像在任何其他程式語言中一樣從子程式返回值。如果您沒有從子程式返回值,則子程式中最後執行的任何計算也自動成為返回值。
您可以像任何標量一樣從子程式返回陣列和雜湊,但是返回多個數組或雜湊通常會導致它們丟失各自的標識。因此,我們將使用引用(下一章將解釋)從函式返回任何陣列或雜湊。
讓我們嘗試以下示例,它接收一組數字並返回它們的平均值:
#!/usr/bin/perl
# Function definition
sub Average {
# get total number of arguments passed.
$n = scalar(@_);
$sum = 0;
foreach $item (@_) {
$sum += $item;
}
$average = $sum / $n;
return $average;
}
# Function call
$num = Average(10, 20, 30);
print "Average for the given numbers : $num\n";
執行上述程式時,將產生以下結果:
Average for the given numbers : 20
子程式中的私有變數
預設情況下,Perl 中的所有變數都是全域性變數,這意味著可以從程式的任何位置訪問它們。但是您可以隨時使用 `my` 運算子建立稱為**詞法變數**的**私有**變數。
`my` 運算子將變數限制在可以使用和訪問它的特定程式碼區域內。在此區域之外,無法使用或訪問此變數。此區域稱為其作用域。詞法作用域通常是一塊程式碼塊,周圍有一組大括號,例如定義子程式主體的大括號,或標記 `if`、`while`、`for`、`foreach` 和 `eval` 語句的程式碼塊的大括號。
以下是一個示例,展示瞭如何使用 `my` 運算子定義單個或多個私有變數:
sub somefunc {
my $variable; # $variable is invisible outside somefunc()
my ($another, @an_array, %a_hash); # declaring many variables at once
}
讓我們檢查以下示例,以區分全域性變數和私有變數:
#!/usr/bin/perl
# Global variable
$string = "Hello, World!";
# Function definition
sub PrintHello {
# Private variable for PrintHello function
my $string;
$string = "Hello, Perl!";
print "Inside the function $string\n";
}
# Function call
PrintHello();
print "Outside the function $string\n";
執行上述程式時,將產生以下結果:
Inside the function Hello, Perl! Outside the function Hello, World!
透過 `local()` 使用臨時值
`local` 主要用於當前變數的值必須對呼叫的子程式可見的情況。`local` 只是為全域性(即包)變數提供臨時值。這被稱為 *動態作用域*。詞法作用域使用 `my` 完成,其工作方式更類似於 C 語言的 `auto` 宣告。
如果向 `local` 提供多個變數或表示式,則必須將它們放在括號中。此運算子的工作方式是將其引數列表中這些變數的當前值儲存在隱藏的堆疊上,並在退出塊、子程式或 `eval` 時將其恢復。
讓我們檢查以下示例,以區分全域性變數和區域性變數:
#!/usr/bin/perl
# Global variable
$string = "Hello, World!";
sub PrintHello {
# Private variable for PrintHello function
local $string;
$string = "Hello, Perl!";
PrintMe();
print "Inside the function PrintHello $string\n";
}
sub PrintMe {
print "Inside the function PrintMe $string\n";
}
# Function call
PrintHello();
print "Outside the function $string\n";
執行上述程式時,將產生以下結果:
Inside the function PrintMe Hello, Perl! Inside the function PrintHello Hello, Perl! Outside the function Hello, World!
透過 `state()` 使用狀態變數
還有一種詞法變數,它們類似於私有變數,但它們保持其狀態,並且在多次呼叫子程式時不會重新初始化。這些變數使用 `state` 運算子定義,並且從 Perl 5.9.4 開始可用。
讓我們檢查以下示例,以演示 `state` 變數的使用:
#!/usr/bin/perl
use feature 'state';
sub PrintCount {
state $count = 0; # initial value
print "Value of counter is $count\n";
$count++;
}
for (1..5) {
PrintCount();
}
執行上述程式時,將產生以下結果:
Value of counter is 0 Value of counter is 1 Value of counter is 2 Value of counter is 3 Value of counter is 4
在 Perl 5.10 之前,您必須這樣編寫:
#!/usr/bin/perl
{
my $count = 0; # initial value
sub PrintCount {
print "Value of counter is $count\n";
$count++;
}
}
for (1..5) {
PrintCount();
}
子程式呼叫上下文
子程式或語句的上下文定義為預期返回的型別。這允許您使用單個函式根據使用者期望接收的內容返回不同的值。例如,以下 `localtime()` 在標量上下文中呼叫時返回字串,但在列表上下文中呼叫時返回列表。
my $datestring = localtime( time );
在此示例中,`$timestr` 的值現在是一個由當前日期和時間組成的字串,例如 Thu Nov 30 15:21:33 2000。相反:
($sec,$min,$hour,$mday,$mon, $year,$wday,$yday,$isdst) = localtime(time);
現在各個變數包含 `localtime()` 子程式返回的相應值。
Perl - 引用
Perl 引用是一種標量資料型別,它儲存另一個值的地址,該值可以是標量、陣列或雜湊。由於其標量特性,引用可以在任何可以使用標量的地方使用。
您可以構造包含對其他列表的引用的列表,這些列表可以包含對雜湊的引用,依此類推。這就是 Perl 中巢狀資料結構的構建方式。
建立引用
透過在任何變數、子程式或值前面加上反斜槓,可以輕鬆地為其建立引用,如下所示:
$scalarref = \$foo; $arrayref = \@ARGV; $hashref = \%ENV; $coderef = \&handler; $globref = \*foo;
您不能使用反斜槓運算子為 I/O 控制代碼(檔案控制代碼或目錄控制代碼)建立引用,但可以使用方括號建立對匿名陣列的引用,如下所示:
$arrayref = [1, 2, ['a', 'b', 'c']];
類似地,您可以使用花括號建立對匿名雜湊的引用,如下所示:
$hashref = {
'Adam' => 'Eve',
'Clyde' => 'Bonnie',
};
可以使用不帶子程式名的 `sub` 建立對匿名子程式的引用,如下所示:
$coderef = sub { print "Boink!\n" };
取消引用
取消引用從指向該位置的引用返回該值。要取消引用,只需根據引用指向標量、陣列還是雜湊,在引用變數前面使用 `$`、`@` 或 `%` 即可。以下示例解釋了這個概念:
#!/usr/bin/perl
$var = 10;
# Now $r has reference to $var scalar.
$r = \$var;
# Print value available at the location stored in $r.
print "Value of $var is : ", $$r, "\n";
@var = (1, 2, 3);
# Now $r has reference to @var array.
$r = \@var;
# Print values available at the location stored in $r.
print "Value of @var is : ", @$r, "\n";
%var = ('key1' => 10, 'key2' => 20);
# Now $r has reference to %var hash.
$r = \%var;
# Print values available at the location stored in $r.
print "Value of %var is : ", %$r, "\n";
執行上述程式時,將產生以下結果:
Value of 10 is : 10 Value of 1 2 3 is : 123 Value of %var is : key220key110
如果您不確定變數型別,則可以使用 `ref` 輕鬆瞭解其型別,如果其引數是引用,則返回以下字串之一。否則,它返回 false:
SCALAR ARRAY HASH CODE GLOB REF
讓我們嘗試以下示例:
#!/usr/bin/perl
$var = 10;
$r = \$var;
print "Reference type in r : ", ref($r), "\n";
@var = (1, 2, 3);
$r = \@var;
print "Reference type in r : ", ref($r), "\n";
%var = ('key1' => 10, 'key2' => 20);
$r = \%var;
print "Reference type in r : ", ref($r), "\n";
執行上述程式時,將產生以下結果:
Reference type in r : SCALAR Reference type in r : ARRAY Reference type in r : HASH
迴圈引用
當兩個引用相互包含引用時,就會發生迴圈引用。建立引用時必須小心,否則迴圈引用會導致記憶體洩漏。以下是一個示例:
#!/usr/bin/perl my $foo = 100; $foo = \$foo; print "Value of foo is : ", $$foo, "\n";
執行上述程式時,將產生以下結果:
Value of foo is : REF(0x9aae38)
對函式的引用
如果您需要建立訊號處理程式,則可能會發生這種情況,您可以透過在函式名前面加上 `\&` 來生成對函式的引用,要取消引用該引用,您只需使用 `&` 字首引用變數即可。以下是一個示例:
#!/usr/bin/perl
# Function definition
sub PrintHash {
my (%hash) = @_;
foreach $item (%hash) {
print "Item : $item\n";
}
}
%hash = ('name' => 'Tom', 'age' => 19);
# Create a reference to above function.
$cref = \&PrintHash;
# Function call using reference.
&$cref(%hash);
執行上述程式時,將產生以下結果:
Item : name Item : Tom Item : age Item : 19
Perl - 格式
Perl 使用稱為“格式”的編寫模板來輸出報表。要使用 Perl 的格式功能,您必須首先定義格式,然後可以使用該格式來寫入格式化資料。
定義格式
以下是定義 Perl 格式的語法:
format FormatName = fieldline value_one, value_two, value_three fieldline value_one, value_two .
這裡 `FormatName` 代表格式的名稱。`fieldline` 是資料應如何格式化的特定方式。`values lines` 代表將輸入到 `fieldline` 中的值。您用一個句點結束格式。
下一個 `fieldline` 可以包含任何文字或欄位佔位符。欄位佔位符為稍後要放置在那裡的資料保留空間。欄位佔位符的格式為:
@<<<<
此欄位佔位符左對齊,欄位空間為 5。您必須計算 `@` 符號和 `<` 符號來了解欄位中的空格數。其他欄位佔位符包括:
@>>>> right-justified @|||| centered @####.## numeric field holder @* multiline field holder
一個示例格式將是:
format EMPLOYEE = =================================== @<<<<<<<<<<<<<<<<<<<<<< @<< $name $age @#####.## $salary =================================== .
在此示例中,`$name` 將左對齊寫入 22 個字元空間內,然後年齡將寫入兩個空間。
使用格式
為了呼叫此格式宣告,我們將使用 `write` 關鍵字:
write EMPLOYEE;
問題是格式名稱通常是開啟的檔案控制代碼的名稱,`write` 語句會將輸出傳送到此檔案控制代碼。因為我們希望資料傳送到 STDOUT,所以我們必須使用 `select()` 函式將 EMPLOYEE 與 STDOUT 檔案控制代碼關聯。但是,首先我們必須確保 STDOUT 是我們選擇的檔案控制代碼。
select(STDOUT);
然後,我們將透過使用特殊變數 `$~` 或 `$FORMAT_NAME` 設定新的格式名稱來將 EMPLOYEE 與 STDOUT 關聯,如下所示:
$~ = "EMPLOYEE";
當我們現在執行 `write()` 時,資料將傳送到 STDOUT。記住:如果您要在任何其他檔案控制代碼(而不是 STDOUT)中寫入報表,則可以使用 `select()` 函式選擇該檔案控制代碼,其餘邏輯保持不變。
讓我們來看下面的例子。這裡我們只是為了演示用法而硬編碼了值。在實際使用中,您將從檔案或資料庫讀取值以生成實際報表,並且您可能需要再次將最終報表寫入檔案。
#!/usr/bin/perl
format EMPLOYEE =
===================================
@<<<<<<<<<<<<<<<<<<<<<< @<<
$name $age
@#####.##
$salary
===================================
.
select(STDOUT);
$~ = EMPLOYEE;
@n = ("Ali", "Raza", "Jaffer");
@a = (20,30, 40);
@s = (2000.00, 2500.00, 4000.000);
$i = 0;
foreach (@n) {
$name = $_;
$age = $a[$i];
$salary = $s[$i++];
write;
}
執行後,將產生以下結果:
=================================== Ali 20 2000.00 =================================== =================================== Raza 30 2500.00 =================================== =================================== Jaffer 40 4000.00 ===================================
定義報表頁首
一切看起來都很好。但是您可能希望向報表中新增頁首。此頁首將列印在每一頁的頂部。這樣做很簡單。除了定義模板之外,您還必須定義頁首並將其分配給 `$^` 或 `$FORMAT_TOP_NAME` 變數:
#!/usr/bin/perl
format EMPLOYEE =
===================================
@<<<<<<<<<<<<<<<<<<<<<< @<<
$name $age
@#####.##
$salary
===================================
.
format EMPLOYEE_TOP =
===================================
Name Age
===================================
.
select(STDOUT);
$~ = EMPLOYEE;
$^ = EMPLOYEE_TOP;
@n = ("Ali", "Raza", "Jaffer");
@a = (20,30, 40);
@s = (2000.00, 2500.00, 4000.000);
$i = 0;
foreach (@n) {
$name = $_;
$age = $a[$i];
$salary = $s[$i++];
write;
}
現在您的報表將如下所示:
=================================== Name Age =================================== =================================== Ali 20 2000.00 =================================== =================================== Raza 30 2500.00 =================================== =================================== Jaffer 40 4000.00 ===================================
定義分頁
如果您的報表超過一頁怎麼辦?您有一個解決方案,只需使用 `$%` 或 `$FORMAT_PAGE_NUMBER` 變數以及頁首,如下所示:
format EMPLOYEE_TOP =
===================================
Name Age Page @<
$%
===================================
.
現在您的輸出將如下所示:
=================================== Name Age Page 1 =================================== =================================== Ali 20 2000.00 =================================== =================================== Raza 30 2500.00 =================================== =================================== Jaffer 40 4000.00 ===================================
每頁的行數
您可以使用特殊變數 `$=`(或 `$FORMAT_LINES_PER_PAGE`)設定每頁的行數,預設為 `$=` 為 60。
定義報表頁尾
雖然 `$^` 或 `$FORMAT_TOP_NAME` 包含當前頁首格式的名稱,但是沒有相應的機制可以自動對頁尾執行相同的操作。如果您有固定大小的頁尾,則可以在每次 `write()` 之前檢查變數 `$-` 或 `$FORMAT_LINES_LEFT` 並根據需要使用另一個定義的格式列印頁尾,如下所示:
format EMPLOYEE_BOTTOM =
End of Page @<
$%
.
有關與格式相關的完整變數集,請參閱 Perl 特殊變數 部分。
Perl - 檔案I/O
檔案處理的基礎知識很簡單:您將**檔案控制代碼**與外部實體(通常是檔案)關聯,然後使用 Perl 中的各種運算子和函式來讀取和更新與檔案控制代碼關聯的資料流中儲存的資料。
檔案控制代碼是命名的內部 Perl 結構,它將物理檔案與名稱關聯。所有檔案控制代碼都能夠進行讀/寫訪問,因此您可以讀取和更新與檔案控制代碼關聯的任何檔案或裝置。但是,當您關聯檔案控制代碼時,您可以指定開啟檔案控制代碼的模式。
三個基本檔案控制代碼是 `STDIN`、`STDOUT` 和 `STDERR`,它們分別代表標準輸入、標準輸出和標準錯誤裝置。
開啟和關閉檔案
以下有兩個具有多種形式的函式,可用於在 Perl 中開啟任何新的或現有檔案。
open FILEHANDLE, EXPR open FILEHANDLE sysopen FILEHANDLE, FILENAME, MODE, PERMS sysopen FILEHANDLE, FILENAME, MODE
此處 FILEHANDLE 是由 **open** 函式返回的檔案控制代碼,而 EXPR 是包含檔名和檔案開啟模式的表示式。
Open 函式
以下是以只讀模式開啟 **file.txt** 的語法。這裡的小於號 < 表示檔案需要以只讀模式開啟。
open(DATA, "<file.txt");
此處 DATA 是檔案控制代碼,將用於讀取檔案。以下是一個示例,它將開啟一個檔案並將內容列印到螢幕上。
#!/usr/bin/perl
open(DATA, "<file.txt") or die "Couldn't open file file.txt, $!";
while(<DATA>) {
print "$_";
}
以下是以寫入模式開啟 file.txt 的語法。這裡的大於號 > 表示檔案需要以寫入模式開啟。
open(DATA, ">file.txt") or die "Couldn't open file file.txt, $!";
此示例在開啟檔案寫入之前實際上會截斷(清空)檔案,這可能不是所需的效果。如果要開啟檔案進行讀寫,可以在 > 或 < 字元前加上加號。
例如,要開啟檔案進行更新而不截斷它:
open(DATA, "+<file.txt"); or die "Couldn't open file file.txt, $!";
要先截斷檔案:
open DATA, "+>file.txt" or die "Couldn't open file file.txt, $!";
可以以追加模式開啟檔案。在此模式下,寫入指標將設定為檔案的末尾。
open(DATA,">>file.txt") || die "Couldn't open file file.txt, $!";
雙 >> 將開啟檔案以進行追加,並將檔案指標置於末尾,以便可以立即開始追加資訊。但是,除非您還在其前面加上加號,否則無法從中讀取:
open(DATA,"+>>file.txt") || die "Couldn't open file file.txt, $!";
下表列出了不同模式的可能值
| 序號 | 實體 & 定義 |
|---|---|
| 1 | < 或 r 只讀訪問 |
| 2 | > 或 w 建立、寫入和截斷 |
| 3 | > 或 a 寫入、追加和建立 |
| 4 | +< 或 r+ 讀寫 |
| 5 | +> 或 w+ 讀取、寫入、建立和截斷 |
| 6 | +>> 或 a+ 讀取、寫入、追加和建立 |
Sysopen 函式
**sysopen** 函式類似於主要的 open 函式,不同之處在於它使用系統 **open()** 函式,並將其提供的引數用作系統函式的引數:
例如,要開啟檔案進行更新,模擬 open 的 **+<filename** 格式:
sysopen(DATA, "file.txt", O_RDWR);
或者在更新之前截斷檔案:
sysopen(DATA, "file.txt", O_RDWR|O_TRUNC );
可以使用 O_CREAT 建立新檔案,使用 O_WRONLY 開啟只寫模式的檔案,使用 O_RDONLY 開啟只讀模式的檔案。
如果必須建立 **PERMS** 引數,則指定檔案的許可權。預設情況下,它取值為 **0x666**。
下表列出了 MODE 的可能值。
| 序號 | 實體 & 定義 |
|---|---|
| 1 | O_RDWR 讀寫 |
| 2 | O_RDONLY 只讀 |
| 3 | O_WRONLY 只寫 |
| 4 | O_CREAT 建立檔案 |
| 5 | O_APPEND 追加到檔案 |
| 6 | O_TRUNC 截斷檔案 |
| 7 | O_EXCL 如果檔案已存在則停止 |
| 8 | O_NONBLOCK 非阻塞可用性 |
Close 函式
要關閉檔案控制代碼,從而取消檔案控制代碼與相應檔案的關聯,可以使用 **close** 函式。這將重新整理檔案控制代碼的緩衝區並關閉系統的檔案描述符。
close FILEHANDLE close
如果沒有指定 FILEHANDLE,則它將關閉當前選擇的檔案控制代碼。只有在成功重新整理緩衝區並關閉檔案時,它才返回 true。
close(DATA) || die "Couldn't close file properly";
讀取和寫入檔案
開啟檔案控制代碼後,需要能夠讀取和寫入資訊。有多種不同的方法可以讀取和寫入檔案中的資料。
<FILEHANDL> 運算子
從開啟的檔案控制代碼讀取資訊的主要方法是 <FILEHANDLE> 運算子。在標量上下文中,它從檔案控制代碼返回一行。例如:
#!/usr/bin/perl print "What is your name?\n"; $name = <STDIN>; print "Hello $name\n";
在列表上下文中使用 <FILEHANDLE> 運算子時,它將從指定的檔案控制代碼返回一個行列表。例如,要將檔案中的所有行匯入陣列:
#!/usr/bin/perl open(DATA,"<import.txt") or die "Can't open data"; @lines = <DATA>; close(DATA);
getc 函式
getc 函式從指定 FILEHANDLE 或 STDIN(如果未指定)返回單個字元:
getc FILEHANDLE getc
如果發生錯誤,或者檔案控制代碼位於檔案末尾,則返回 undef。
read 函式
read 函式從緩衝的檔案控制代碼讀取一段資訊:此函式用於從檔案讀取二進位制資料。
read FILEHANDLE, SCALAR, LENGTH, OFFSET read FILEHANDLE, SCALAR, LENGTH
讀取的資料長度由 LENGTH 定義,如果未指定 OFFSET,則資料將放在 SCALAR 的開頭。否則,資料將放在 SCALAR 中 OFFSET 位元組之後。該函式在成功時返回讀取的位元組數,在檔案末尾返回零,如果發生錯誤則返回 undef。
print 函式
對於所有用於從檔案控制代碼讀取資訊的不同方法,寫入資訊的主要函式是 print 函式。
print FILEHANDLE LIST print LIST print
print 函式將 LIST 的計算值列印到 FILEHANDLE 或當前輸出檔案控制代碼(預設為 STDOUT)。例如:
print "Hello World!\n";
複製檔案
以下示例開啟現有檔案 file1.txt 並逐行讀取它,然後生成另一個副本檔案 file2.txt。
#!/usr/bin/perl
# Open file to read
open(DATA1, "<file1.txt");
# Open new file to write
open(DATA2, ">file2.txt");
# Copy data from one file to another.
while(<DATA1>) {
print DATA2 $_;
}
close( DATA1 );
close( DATA2 );
重新命名檔案
以下是一個示例,它演示瞭如何將檔案 file1.txt 重新命名為 file2.txt。假設檔案位於 /usr/test 目錄中。
#!/usr/bin/perl
rename ("/usr/test/file1.txt", "/usr/test/file2.txt" );
此函式 **rename** 接受兩個引數,它只是重新命名現有檔案。
刪除現有檔案
以下是一個示例,它演示瞭如何使用 **unlink** 函式刪除檔案 file1.txt。
#!/usr/bin/perl
unlink ("/usr/test/file1.txt");
在檔案中定位
可以使用 **tell** 函式來了解檔案的當前位置,並使用 **seek** 函式來指向檔案內的特定位置。
tell 函式
第一個要求是在檔案中找到您的位置,您可以使用 tell 函式:
tell FILEHANDLE tell
如果指定了 FILEHANDLE,則返回檔案指標在 FILEHANDLE 中的位元組位置;如果沒有指定,則返回當前預設選擇的檔案控制代碼的位元組位置。
seek 函式
seek 函式將檔案指標定位到檔案中的指定位元組數:
seek FILEHANDLE, POSITION, WHENCE
該函式使用 fseek 系統函式,您可以相對三個不同的點進行定位:開頭、結尾和當前位置。您可以透過為 WHENCE 指定一個值來實現這一點。
零將定位設定為相對於檔案的開頭。例如,該行將檔案指標設定為檔案中的第 256 個位元組。
seek DATA, 256, 0;
檔案資訊
您可以使用一系列統稱為 -X 測試的測試運算子在 Perl 中快速測試某些功能。例如,要對檔案的各種許可權進行快速測試,可以使用這樣的指令碼:
#/usr/bin/perl
my $file = "/usr/test/file1.txt";
my (@description, $size);
if (-e $file) {
push @description, 'binary' if (-B _);
push @description, 'a socket' if (-S _);
push @description, 'a text file' if (-T _);
push @description, 'a block special file' if (-b _);
push @description, 'a character special file' if (-c _);
push @description, 'a directory' if (-d _);
push @description, 'executable' if (-x _);
push @description, (($size = -s _)) ? "$size bytes" : 'empty';
print "$file is ", join(', ',@description),"\n";
}
以下是您可以檢查檔案或目錄的功能列表:
| 序號 | 運算子 & 定義 |
|---|---|
| 1 | -A 指令碼啟動時間減去檔案上次訪問時間(以天為單位)。 |
| 2 | -B 它是二進位制檔案嗎? |
| 3 | -C 指令碼啟動時間減去檔案上次 inode 更改時間(以天為單位)。 |
| 3 | -M 指令碼啟動時間減去檔案修改時間(以天為單位)。 |
| 4 | -O 該檔案是否由真實使用者 ID 擁有? |
| 5 | -R 真實使用者 ID 或真實組是否可以讀取該檔案? |
| 6 | -S 該檔案是套接字嗎? |
| 7 | -T 它是文字檔案嗎? |
| 8 | -W 真實使用者 ID 或真實組是否可以寫入該檔案? |
| 9 | -X 真實使用者 ID 或真實組是否可以執行該檔案? |
| 10 | -b 它是塊特殊檔案嗎? |
| 11 | -c 它是字元特殊檔案嗎? |
| 12 | -d 該檔案是目錄嗎? |
| 13 | -e 檔案是否存在? |
| 14 | -f 它是普通檔案嗎? |
| 15 | -g 該檔案是否設定了 setgid 位? |
| 16 | -k 該檔案是否設定了粘滯位? |
| 17 | -l 該檔案是符號連結嗎? |
| 18 | -o 該檔案是否由有效使用者 ID 擁有? |
| 19 | -p 該檔案是命名管道嗎? |
| 20 | -r 有效使用者或組 ID 是否可以讀取該檔案? |
| 21 | -s 返回檔案的大小,零大小 = 空檔案。 |
| 22 | -t 檔案控制代碼是由 TTY(終端)開啟的嗎? |
| 23 | -u 該檔案是否設定了 setuid 位? |
| 24 | -w 有效使用者或組 ID 是否可以寫入該檔案? |
| 25 | -x 有效使用者或組 ID 是否可以執行該檔案? |
| 26 | -z 檔案大小是否為零? |
Perl - 目錄
以下是用於處理目錄的標準函式。
opendir DIRHANDLE, EXPR # To open a directory readdir DIRHANDLE # To read a directory rewinddir DIRHANDLE # Positioning pointer to the begining telldir DIRHANDLE # Returns current position of the dir seekdir DIRHANDLE, POS # Pointing pointer to POS inside dir closedir DIRHANDLE # Closing a directory.
顯示所有檔案
有多種方法可以列出特定目錄中所有可用的檔案。首先,讓我們使用簡單的方法來獲取並列出使用 **glob** 運算子的所有檔案:
#!/usr/bin/perl
# Display all the files in /tmp directory.
$dir = "/tmp/*";
my @files = glob( $dir );
foreach (@files ) {
print $_ . "\n";
}
# Display all the C source files in /tmp directory.
$dir = "/tmp/*.c";
@files = glob( $dir );
foreach (@files ) {
print $_ . "\n";
}
# Display all the hidden files.
$dir = "/tmp/.*";
@files = glob( $dir );
foreach (@files ) {
print $_ . "\n";
}
# Display all the files from /tmp and /home directories.
$dir = "/tmp/* /home/*";
@files = glob( $dir );
foreach (@files ) {
print $_ . "\n";
}
以下是一個示例,它開啟一個目錄並列出此目錄中所有可用的檔案。
#!/usr/bin/perl
opendir (DIR, '.') or die "Couldn't open directory, $!";
while ($file = readdir DIR) {
print "$file\n";
}
closedir DIR;
另一個列印 C 原始檔列表的示例:
#!/usr/bin/perl
opendir(DIR, '.') or die "Couldn't open directory, $!";
foreach (sort grep(/^.*\.c$/,readdir(DIR))) {
print "$_\n";
}
closedir DIR;
建立新目錄
可以使用 **mkdir** 函式建立一個新目錄。您需要具有建立目錄所需的許可權。
#!/usr/bin/perl $dir = "/tmp/perl"; # This creates perl directory in /tmp directory. mkdir( $dir ) or die "Couldn't create $dir directory, $!"; print "Directory created successfully\n";
刪除目錄
可以使用 **rmdir** 函式刪除目錄。您需要具有刪除目錄所需的許可權。此外,在嘗試刪除目錄之前,該目錄必須為空。
#!/usr/bin/perl $dir = "/tmp/perl"; # This removes perl directory from /tmp directory. rmdir( $dir ) or die "Couldn't remove $dir directory, $!"; print "Directory removed successfully\n";
更改目錄
可以使用 **chdir** 函式更改目錄並轉到新位置。您需要具有更改目錄並進入新目錄所需的許可權。
#!/usr/bin/perl $dir = "/home"; # This changes perl directory and moves you inside /home directory. chdir( $dir ) or die "Couldn't go inside $dir directory, $!"; print "Your new location is $dir\n";
Perl - 錯誤處理
執行和錯誤總是同時出現。如果您開啟一個不存在的檔案,那麼如果您沒有正確處理這種情況,那麼您的程式就被認為質量不好。
如果發生錯誤,程式將停止。因此,使用正確的錯誤處理來處理程式執行期間可能發生的各種型別的錯誤,並採取適當的措施,而不是完全停止程式。
您可以透過多種不同的方式識別和捕獲錯誤。在 Perl 中捕獲錯誤然後正確處理它們非常容易。這裡有一些可以使用的方法。
if 語句
當您需要檢查語句的返回值時,**if 語句** 是顯而易見的選擇;例如:
if(open(DATA, $file)) {
...
} else {
die "Error: Couldn't open the file - $!";
}
這裡的變數 $! 返回實際的錯誤訊息。或者,在有意義的情況下,我們可以將語句縮減為一行;例如:
open(DATA, $file) || die "Error: Couldn't open the file $!";
unless 函式
unless 函式與 if 函式邏輯相反:語句可以完全繞過成功狀態,只有在表示式返回 false 時才執行。例如:
unless(chdir("/etc")) {
die "Error: Can't change directory - $!";
}
當您只想在表示式失敗時引發錯誤或備選方案時,最好使用 unless 語句。當用於單行語句時,該語句也說得通:
die "Error: Can't change directory!: $!" unless(chdir("/etc"));
這裡只有當 chdir 操作失敗時我們才會終止程式,而且讀起來也很流暢。
三元運算子
對於非常短的測試,可以使用條件運算子 ?:
print(exists($hash{value}) ? 'There' : 'Missing',"\n");
這裡不太清楚我們試圖實現什麼,但效果與使用 if 或 unless 語句相同。當您想快速在一個表示式或語句中返回兩個值中的一個時,最好使用條件運算子。
warn 函式
warn 函式只發出警告,一條訊息將列印到 STDERR,但不會採取進一步的操作。因此,如果您只想為使用者列印警告並繼續執行其餘操作,它將更有用:
chdir('/etc') or warn "Can't change directory";
die 函式
die 函式的工作方式與 warn 函式類似,不同之處在於它還會呼叫 exit。在普通指令碼中,此函式的效果是立即終止執行。如果程式出現錯誤,繼續執行毫無意義,則應使用此函式:
chdir('/etc') or die "Can't change directory";
模組中的錯誤
我們應該能夠處理兩種不同的情況:
報告模組中的錯誤,該錯誤引用模組的檔名和行號——這在除錯模組時很有用,或者當您特別想要引發與模組相關的而不是與指令碼相關的錯誤時。
報告模組中引用的呼叫者資訊的錯誤,以便您可以除錯導致錯誤的指令碼中的行。這樣引發的錯誤對終端使用者很有用,因為它們突出了與呼叫指令碼的起始行相關的錯誤。
從模組中呼叫時,warn 和 die 函式的工作方式與您預期的略有不同。例如,簡單的模組:
package T;
require Exporter;
@ISA = qw/Exporter/;
@EXPORT = qw/function/;
use Carp;
sub function {
warn "Error in module!";
}
1;
從如下指令碼呼叫時:
use T; function();
它將產生以下結果:
Error in module! at T.pm line 9.
這或多或少是您可能期望的,但不一定是您想要的。從模組程式設計師的角度來看,該資訊很有用,因為它有助於指出模組本身中的錯誤。對於終端使用者而言,提供的資訊幾乎毫無用處,對於除經驗豐富的程式設計師以外的所有人來說,它完全毫無意義。
解決此類問題的方案是 Carp 模組,它提供了一種簡化的方法來報告模組中的錯誤,這些錯誤返回有關呼叫指令碼的資訊。Carp 模組提供四個函式:carp、cluck、croak 和 confess。下面將討論這些函式。
carp 函式
carp 函式是 warn 的基本等效項,它將訊息列印到 STDERR,而不會實際退出指令碼並列印指令碼名稱。
package T;
require Exporter;
@ISA = qw/Exporter/;
@EXPORT = qw/function/;
use Carp;
sub function {
carp "Error in module!";
}
1;
從如下指令碼呼叫時:
use T; function();
它將產生以下結果:
Error in module! at test.pl line 4
cluck 函式
cluck 函式是一種增強版的 carp,它遵循相同的基本原理,但也列印導致呼叫該函式的所有模組的堆疊跟蹤,包括原始指令碼的資訊。
package T;
require Exporter;
@ISA = qw/Exporter/;
@EXPORT = qw/function/;
use Carp qw(cluck);
sub function {
cluck "Error in module!";
}
1;
從如下指令碼呼叫時:
use T; function();
它將產生以下結果:
Error in module! at T.pm line 9 T::function() called at test.pl line 4
croak 函式
croak 函式等效於 die,不同之處在於它向上報告一個級別的呼叫者。與 die 一樣,此函式還會在將錯誤報告到 STDERR 後退出指令碼:
package T;
require Exporter;
@ISA = qw/Exporter/;
@EXPORT = qw/function/;
use Carp;
sub function {
croak "Error in module!";
}
1;
從如下指令碼呼叫時:
use T; function();
它將產生以下結果:
Error in module! at test.pl line 4
與 carp 一樣,關於根據 warn 和 die 函式包含行和檔案資訊的相同基本規則適用。
confess 函式
confess 函式類似於 cluck;它呼叫 die,然後列印一直到原始指令碼的堆疊跟蹤。
package T;
require Exporter;
@ISA = qw/Exporter/;
@EXPORT = qw/function/;
use Carp;
sub function {
confess "Error in module!";
}
1;
從如下指令碼呼叫時:
use T; function();
它將產生以下結果:
Error in module! at T.pm line 9 T::function() called at test.pl line 4
Perl - 特殊變數
Perl 中有一些變數具有預定義的特殊含義。它們是在通常的變數指示符($、@ 或 %)之後使用標點符號的變數,例如 $_(如下所述)。
大多數特殊變數都有一個類似英文的長名稱,例如,作業系統錯誤變數 $! 可以寫成 $OS_ERROR。但是,如果您要使用類似英文的名稱,則必須在程式檔案的頂部新增一行 use English;。這指導直譯器拾取變數的確切含義。
最常用的特殊變數是 $_,它包含預設的輸入和模式搜尋字串。例如,在以下幾行中:
#!/usr/bin/perl
foreach ('hickory','dickory','doc') {
print $_;
print "\n";
}
執行後,將產生以下結果:
hickory dickory doc
同樣,讓我們檢查一下不顯式使用 $_ 變數的相同示例:
#!/usr/bin/perl
foreach ('hickory','dickory','doc') {
print;
print "\n";
}
執行後,這也將產生以下結果:
hickory dickory doc
第一次執行迴圈時,列印 "hickory"。第二次列印 "dickory",第三次列印 "doc"。這是因為在每次迴圈迭代中,當前字串都放在 $_ 中,並被 print 預設使用。以下是 Perl 即使您沒有指定它也會假定 $_ 的地方:
各種一元函式,包括諸如 ord 和 int 之類的函式,以及所有檔案測試(-f、-d),除了 -t,它預設為 STDIN。
各種列表函式,如 print 和 unlink。
模式匹配操作 m//、s/// 和 tr///,當不使用 =~ 運算子時。
如果沒有提供其他變數,則在 foreach 迴圈中的預設迭代器變數。
grep 和 map 函式中的隱式迭代器變數。
當行輸入操作的結果本身作為 while 測試的唯一條件進行測試時(即,),將輸入記錄放在預設位置。請注意,在 while 測試之外,不會發生這種情況。
特殊變數型別
根據特殊變數的用法和性質,我們可以將它們分為以下幾類:
- 全域性標量特殊變數。
- 全域性陣列特殊變數。
- 全域性雜湊特殊變數。
- 全域性特殊檔案控制代碼。
- 全域性特殊常量。
- 正則表示式特殊變數。
- 檔案控制代碼特殊變數。
全域性標量特殊變數
以下是所有標量特殊變數的列表。我們列出了相應的類似英文的名稱以及符號名稱。
| $_ | 預設輸入和模式搜尋空間。 |
| $ARG | |
| $. | 最後讀取的檔案控制代碼的當前輸入行號。對檔案控制代碼的顯式關閉將重置行號。 |
| $NR | |
| $/ | 輸入記錄分隔符;預設為換行符。如果設定為空字串,則將其視為空白行作為分隔符。 |
| $RS | |
| $, | print 運算子的輸出欄位分隔符。 |
| $OFS | |
| $\ | print 運算子的輸出記錄分隔符。 |
| $ORS | |
| $" | 類似於 "$,",但它適用於插入到雙引號字串(或類似的解釋字串)中的列表值。預設為空格。 |
| $LIST_SEPARATOR | |
| $; | 用於多維陣列模擬的下標分隔符。預設為 "\034"。 |
| $SUBSCRIPT_SEPARATOR | |
| $^L | 格式輸出以執行換頁符。預設為 "\f"。 |
| $FORMAT_FORMFEED | |
| $: | 當前字元集,字串之後可以中斷以填充格式中的延續欄位(以 ^ 開頭)。預設為 "\n""。 |
| $FORMAT_LINE_BREAK_CHARACTERS | |
| $^A | 格式行的寫累加器的當前值。 |
| $ACCUMULATOR | |
| $# | 包含列印數字的輸出格式(已棄用)。 |
| $OFMT | |
| $? | 上次管道關閉、反引號 (``) 命令或系統運算子返回的狀態。 |
| $CHILD_ERROR | |
| $! | 如果在數值上下文中使用,則產生 errno 變數的當前值,標識上次系統呼叫錯誤。如果在字串上下文中使用,則產生相應的系統錯誤字串。 |
| $OS_ERROR 或 $ERRNO | |
| $@ | 來自上次 eval 命令的 Perl 語法錯誤訊息。 |
| $EVAL_ERROR | |
| $$ | 執行此指令碼的 Perl 程序的 pid。 |
| $PROCESS_ID 或 $PID | |
| $< | 此程序的真實使用者 ID (uid)。 |
| $REAL_USER_ID 或 $UID | |
| $> | 此程序的有效使用者 ID。 |
| $EFFECTIVE_USER_ID 或 $EUID | |
| $( | 此程序的真實組 ID (gid)。 |
| $REAL_GROUP_ID 或 $GID | |
| $) | 此程序的有效 gid。 |
| $EFFECTIVE_GROUP_ID 或 $EGID | |
| $0 | 包含正在執行的 Perl 指令碼的檔名。 |
| $PROGRAM_NAME | |
| $[ | 陣列中第一個元素和子字串中第一個字元的索引。預設為 0。 |
| $] | 返回版本加上補丁級別除以 1000。 |
| $PERL_VERSION | |
| $^D | 除錯標誌的當前值。 |
| $DEBUGGING | |
| $^E | 某些平臺上的擴充套件錯誤訊息。 |
| $EXTENDED_OS_ERROR | |
| $^F | 最大系統檔案描述符,通常為 2。 |
| $SYSTEM_FD_MAX | |
| $^H | 包含某些實用模組啟用的內部編譯器提示。 |
| $^I | 就地編輯擴充套件的當前值。使用 undef 停用就地編輯。 |
| $INPLACE_EDIT | |
| $^M | $M 的內容可以用作緊急記憶體池,以防 Perl 因記憶體不足錯誤而崩潰。$M 的使用需要特殊編譯的 Perl。有關更多資訊,請參閱 INSTALL 文件。 |
| $^O | 包含當前 Perl 二進位制檔案編譯的 operating system 的名稱。 |
| $OSNAME | |
| $^P | 偵錯程式清除的內部標誌,以便它不除錯自身。 |
| $PERLDB | |
| $^T | 指令碼開始執行的時間,以自紀元以來的秒數為單位。 |
| $BASETIME | |
| $^W | 警告開關的當前值,為 true 或 false。 |
| $WARNING | |
| $^X | Perl 二進位制檔案本身執行的名稱。 |
| $EXECUTABLE_NAME | |
| $ARGV | 從 <ARGV> 讀取時包含當前檔名的名稱。 |
全域性陣列特殊變數
| @ARGV | 包含針對指令碼的命令列引數的陣列。 |
| @INC | 包含要由 do、require 或 use 結構評估的 Perl 指令碼查詢位置列表的陣列。 |
| @F | 當給出 -a 命令列開關時,輸入行被分割到的陣列。 |
全域性雜湊特殊變數
| %INC | 包含已透過 do 或 require 包含的每個檔案的 filenames 條目的雜湊。 |
| %ENV | 包含當前環境的雜湊。 |
| %SIG | 用於為各種訊號設定訊號處理程式的雜湊。 |
全域性特殊檔案控制代碼
| ARGV | 特殊檔案控制代碼,迭代 @ARGV 中的命令列檔名。通常在 <> 中寫成空檔案控制代碼。 |
| STDERR | 任何包中的標準錯誤的特殊檔案控制代碼。 |
| STDIN | 任何包中的標準輸入的特殊檔案控制代碼。 |
| STDOUT | 任何包中的標準輸出的特殊檔案控制代碼。 |
| DATA | 特殊檔案控制代碼,引用包含指令碼的檔案中 __END__ 令牌之後的任何內容。或者,對於所需檔案中 __DATA__ 令牌之後的任何內容的特殊檔案控制代碼,只要您在找到 __DATA__ 的同一包中讀取資料即可。 |
| _(下劃線) | 特殊檔案控制代碼,用於快取來自上次 stat、lstat 或檔案測試運算子的資訊。 |
全域性特殊常量
| __END__ | 指示程式的邏輯結尾。任何後續文字都將被忽略,但可以透過 DATA 檔案控制代碼讀取。 |
| __FILE__ | 表示程式中使用它的點的檔名。不會被插入到字串中。 |
| __LINE__ | 表示當前行號。不會被插入到字串中。 |
| __PACKAGE__ | 表示編譯時的當前包名,如果沒有當前包,則未定義。不會被插入到字串中。 |
正則表示式特殊變數
| $digit | 包含上次匹配模式中對應括號組匹配到的文字。例如,$1 匹配上一個正則表示式中第一個括號組包含的內容。 |
| $& | 上次成功模式匹配匹配到的字串。 |
| $MATCH | |
| $` | 上次成功模式匹配之前匹配到的字串。 |
| $PREMATCH | |
| $' | 上次成功模式匹配之後匹配到的字串。 |
| $POSTMATCH | |
| $+ | 上次搜尋模式匹配到的最後一個括號。如果您不知道匹配了一組備選模式中的哪一個,這將非常有用。例如:/Version: (.*)|Revision: (.*)/ && ($rev = $+); |
| $LAST_PAREN_MATCH |
檔案控制代碼特殊變數
| $| | 如果設定為非零值,則強制在當前選擇的輸出通道上的每次寫入或列印後執行 fflush(3)。 |
| $OUTPUT_AUTOFLUSH | |
| $% | 當前選擇的輸出通道的當前頁碼。 |
| $FORMAT_PAGE_NUMBER | |
| $= | 當前選擇的輸出通道的當前頁長(可列印行數)。預設為 60。 |
| $FORMAT_LINES_PER_PAGE | |
| $- | 當前選擇的輸出通道頁面上剩餘的行數。 |
| $FORMAT_LINES_LEFT | |
| $~ | 當前選擇的輸出通道的當前報表格式的名稱。預設為檔案控制代碼的名稱。 |
| $FORMAT_NAME | |
| $^ | 當前選擇的輸出通道的當前頁首格式的名稱。預設為檔案控制代碼名稱後附加 _TOP。 |
| $FORMAT_TOP_NAME |
Perl - 編碼規範
當然,每個程式設計師都會有自己關於格式的偏好,但有一些通用的指導原則可以讓您的程式更易於閱讀、理解和維護。
最重要的是始終在 -w 標誌下執行您的程式。如果您必須這樣做,您可以透過 no warnings pragma 或 $^W 變數顯式關閉特定程式碼部分的警告。您還應該始終在 use strict 下執行,或者知道不這樣做的原因。use sigtrap 和 even use diagnostics pragma 也可能證明有用。
關於程式碼佈局的美感,Larry 唯一強烈關注的是多行塊的閉合大括號應該與啟動該結構的關鍵字對齊。除此之外,他還有其他不太強烈的偏好:
- 4 列縮排。
- 如果可能,在同一行上開啟大括號,否則對齊。
- 多行塊的左大括號前留一個空格。
- 單行塊可以放在一行上,包括大括號。
- 分號前不留空格。
- 在“短”單行塊中省略分號。
- 大多數運算子周圍留有空格。
- 複雜下標(括號內)周圍留有空格。
- 執行不同操作的程式碼塊之間留空行。
- 避免 else 語句巢狀。
- 函式名稱與其左括號之間不留空格。
- 每個逗號後留一個空格。
- 長行在運算子之後換行(except 和 and 或除外)。
- 當前行匹配的右括號後留一個空格。
- 垂直對齊對應的專案。
- 只要不影響清晰度,就省略冗餘標點符號。
以下是一些其他更重要的風格問題需要考慮:僅僅因為您可以以某種特定方式做某事並不意味著您應該那樣做。Perl 旨在為您提供多種方法來完成任何事情,因此請考慮選擇最易讀的一種。例如:
open(FOO,$foo) || die "Can't open $foo: $!";
比這更好:
die "Can't open $foo: $!" unless open(FOO,$foo);
因為第二種方法將語句的主要要點隱藏在修飾符中。另一方面,
print "Starting analysis\n" if $verbose;
比這更好:
$verbose && print "Starting analysis\n";
因為主要問題不在於使用者是否鍵入了 -v。
當 Perl 提供 last 運算子以便您可以在中間退出時,不要費力地嘗試在迴圈頂部或底部退出迴圈。只需稍微“縮排”一下,使其更清晰:
LINE:
for (;;) {
statements;
last LINE if $foo;
next LINE if /^#/;
statements;
}
讓我們看看更多重要的點:
不要害怕使用迴圈標籤——它們既可以增強可讀性,也可以允許多級迴圈中斷。參見前面的示例。
避免在空上下文中使用 grep()(或 map())或反引號,也就是說,當您只是丟棄它們的返回值時。這些函式都有返回值,因此請使用它們。否則,請改用 foreach() 迴圈或 system() 函式。
為了可移植性,當使用可能並非在每臺機器上都實現的功能時,請在 eval 中測試該構造以檢視它是否失敗。如果您知道某個特定功能是在哪個版本或補丁級別實現的,您可以測試 $](英文中的 $PERL_VERSION)以檢視它是否存在。Config 模組還可以讓您查詢 Perl 安裝時 Configure 程式確定的值。
選擇助記符識別符號。如果您不記得助記符是什麼意思,那麼您就遇到問題了。
雖然像 $gotit 這樣的短識別符號可能沒問題,但請使用下劃線分隔較長識別符號中的單詞。閱讀 $var_names_like_this 通常比 $VarNamesLikeThis 更容易,尤其對於非英語母語人士而言。這也是一個適用於 VAR_NAMES_LIKE_THIS 的簡單且一致的規則。
包名稱有時是此規則的例外。Perl 非正式地為像 integer 和 strict 這樣的“pragma”模組保留小寫模組名稱。其他模組應該以大寫字母開頭並使用混合大小寫,但可能由於原始檔案系統將模組名稱表示為必須適合少數稀疏位元組的檔案的限制而沒有下劃線。
如果您有一個非常複雜的正則表示式,請使用 /x 修飾符並新增一些空格,使其看起來不那麼像噪音。當您的正則表示式包含斜槓或反斜槓時,請不要使用斜槓作為分隔符。
始終檢查系統呼叫的返回程式碼。良好的錯誤訊息應該傳送到 STDERR,包括導致問題的程式、失敗的系統呼叫和引數是什麼,以及(非常重要)應該包含導致錯誤的標準系統錯誤訊息。這是一個簡單但足夠的示例:
opendir(D, $dir) or die "can't opendir $dir: $!";
考慮可重用性。當您可能想要再次執行類似操作時,為什麼要浪費腦力去完成一次性任務?考慮泛化您的程式碼。考慮編寫模組或物件類。考慮讓您的程式碼在使用 use strict 和 use warnings(或 -w)的情況下乾淨地執行。考慮分發您的程式碼。考慮改變你的整個世界觀。考慮……哦,別介意。
保持一致。
友善待人。
Perl - 正則表示式
正則表示式是由字元組成的字串,用於定義您正在檢視的模式或模式。Perl 中正則表示式的語法與您在其他支援正則表示式的程式(如 **sed**、**grep** 和 **awk**)中看到的非常相似。
應用正則表示式的基本方法是使用模式繫結運算子 =~ 和 **!~**。第一個運算子是測試和賦值運算子。
Perl 中有三個正則表示式運算子。
- 匹配正則表示式 - m//
- 替換正則表示式 - s///
- 轉換正則表示式 - tr///
在每種情況下,正斜槓都充當您指定的正則表示式 (regex) 的分隔符。如果您對任何其他分隔符感到滿意,那麼您可以使用它來代替正斜槓。
匹配運算子
匹配運算子 m// 用於將字串或語句與正則表示式匹配。例如,要將字元序列“foo”與標量 $bar 匹配,您可以使用這樣的語句:
#!/usr/bin/perl
$bar = "This is foo and again foo";
if ($bar =~ /foo/) {
print "First time is matching\n";
} else {
print "First time is not matching\n";
}
$bar = "foo";
if ($bar =~ /foo/) {
print "Second time is matching\n";
} else {
print "Second time is not matching\n";
}
執行上述程式時,將產生以下結果:
First time is matching Second time is matching
m// 的工作方式實際上與 q// 運算子系列相同。您可以使用任何自然匹配字元的組合來充當表示式的分隔符。例如,m{}、m() 和 m>< 都是有效的。因此,上面的例子可以改寫如下:
#!/usr/bin/perl
$bar = "This is foo and again foo";
if ($bar =~ m[foo]) {
print "First time is matching\n";
} else {
print "First time is not matching\n";
}
$bar = "foo";
if ($bar =~ m{foo}) {
print "Second time is matching\n";
} else {
print "Second time is not matching\n";
}
如果分隔符是正斜槓,則可以省略 m// 中的 m,但對於所有其他分隔符,都必須使用 m 字首。
請注意,整個匹配表示式(即 =~ 或 !~ 左側的表示式和匹配運算子)在標量上下文中返回 true(如果表示式匹配)。因此,語句:
$true = ($foo =~ m/foo/);
如果 $foo 與正則表示式匹配,則將 $true 設定為 1,如果匹配失敗則設定為 0。在列表上下文中,匹配返回任何分組表示式的內容。例如,當從時間字串中提取小時、分鐘和秒時,我們可以使用:
my ($hours, $minutes, $seconds) = ($time =~ m/(\d+):(\d+):(\d+)/);
匹配運算子修飾符
匹配運算子支援它自己的一組修飾符。/g 修飾符允許全域性匹配。/i 修飾符將使匹配不區分大小寫。以下是修飾符的完整列表:
| 序號 | 修飾符和說明 |
|---|---|
| 1 | i 使匹配不區分大小寫。 |
| 2 | m 指定如果字串包含換行符或回車符,則 ^ 和 $ 運算子現在將與換行符邊界匹配,而不是字串邊界。 |
| 3 | o 僅評估表示式一次。 |
| 4 | s 允許使用 . 來匹配換行符。 |
| 5 | x 允許您在表示式中使用空格以提高畫質晰度。 |
| 6 | g 全域性查詢所有匹配項。 |
| 7 | cg 允許搜尋即使在全域性匹配失敗後也能繼續。 |
僅匹配一次
匹配運算子還有一個更簡單的版本 - ?PATTERN? 運算子。這基本上與 m// 運算子相同,只是它在每次呼叫重置之間只匹配字串中的一次。
例如,您可以使用它來獲取列表中的第一個和最後一個元素:
#!/usr/bin/perl
@list = qw/food foosball subeo footnote terfoot canic footbrdige/;
foreach (@list) {
$first = $1 if /(foo.*?)/;
$last = $1 if /(foo.*)/;
}
print "First: $first, Last: $last\n";
執行上述程式時,將產生以下結果:
First: foo, Last: footbrdige
正則表示式變數
正則表示式變數包括 **$**,它包含上次分組匹配匹配到的內容;**$&**,它包含整個匹配字串;**$`**,它包含匹配字串之前的所有內容;以及 **$'**,它包含匹配字串之後的所有內容。下面的程式碼演示了結果:
#!/usr/bin/perl $string = "The food is in the salad bar"; $string =~ m/foo/; print "Before: $`\n"; print "Matched: $&\n"; print "After: $'\n";
執行上述程式時,將產生以下結果:
Before: The Matched: foo After: d is in the salad bar
替換運算子
替換運算子 s/// 實際上只是匹配運算子的擴充套件,允許您將匹配的文字替換為一些新文字。運算子的基本形式是:
s/PATTERN/REPLACEMENT/;
PATTERN 是我們正在尋找的文字的正則表示式。REPLACEMENT 是我們想要用來替換找到的文字的文字或正則表示式的規範。例如,我們可以使用以下正則表示式將所有出現的 **dog** 替換為 **cat**:
#/user/bin/perl $string = "The cat sat on the mat"; $string =~ s/cat/dog/; print "$string\n";
執行上述程式時,將產生以下結果:
The dog sat on the mat
替換運算子修飾符
以下是與替換運算子一起使用的所有修飾符的列表。
| 序號 | 修飾符和說明 |
|---|---|
| 1 | i 使匹配不區分大小寫。 |
| 2 | m 指定如果字串包含換行符或回車符,則 ^ 和 $ 運算子現在將與換行符邊界匹配,而不是字串邊界。 |
| 3 | o 僅評估表示式一次。 |
| 4 | s 允許使用 . 來匹配換行符。 |
| 5 | x 允許您在表示式中使用空格以提高畫質晰度。 |
| 6 | g 將所有找到的表示式的出現替換為替換文字。 |
| 7 | e 將替換作為 Perl 語句進行評估,並將其返回值用作替換文字。 |
轉換運算子
翻譯類似於,但並非完全等同於替換原則,但與替換不同的是,翻譯(或音譯)不使用正則表示式進行搜尋和替換值。翻譯運算子為:
tr/SEARCHLIST/REPLACEMENTLIST/cds y/SEARCHLIST/REPLACEMENTLIST/cds
翻譯將SEARCHLIST中所有出現的字元替換為REPLACEMENTLIST中對應的字元。例如,使用我們在本章中一直在使用的字串“The cat sat on the mat.”:
#/user/bin/perl $string = 'The cat sat on the mat'; $string =~ tr/a/o/; print "$string\n";
執行上述程式時,將產生以下結果:
The cot sot on the mot.
也可以使用標準的Perl範圍,允許您按字母或數值指定字元範圍。要更改字串的大小寫,您可以使用以下語法代替uc函式。
$string =~ tr/a-z/A-Z/;
翻譯運算子修飾符
以下是與翻譯相關的運算子列表。
| 序號 | 修飾符和說明 |
|---|---|
| 1 | c 補充SEARCHLIST。 |
| 2 | d 刪除找到但未替換的字元。 |
| 3 | s 壓縮重複的替換字元。 |
/d修飾符刪除與SEARCHLIST匹配但REPLACEMENTLIST中沒有對應條目的字元。例如:
#!/usr/bin/perl $string = 'the cat sat on the mat.'; $string =~ tr/a-z/b/d; print "$string\n";
執行上述程式時,將產生以下結果:
b b b.
最後一個修飾符/s刪除被替換的重複字元序列,因此:
#!/usr/bin/perl $string = 'food'; $string = 'food'; $string =~ tr/a-z/a-z/s; print "$string\n";
執行上述程式時,將產生以下結果:
fod
更復雜的正則表示式
您不必只匹配固定字串。事實上,透過使用更復雜的正則表示式,您可以匹配幾乎任何您能想到的東西。這是一個快速備忘單:
下表列出了Python中可用的正則表示式語法。
| 序號 | 模式與描述 |
|---|---|
| 1 | ^ 匹配行首。 |
| 2 | $ 匹配行尾。 |
| 3 | . 匹配除換行符之外的任何單個字元。使用m選項也可以匹配換行符。 |
| 4 | [...] 匹配括號中任何單個字元。 |
| 5 | [^...] 匹配括號中不存在的任何單個字元。 |
| 6 | * 匹配前面表示式的0次或多次出現。 |
| 7 | + 匹配前面表示式的1次或多次出現。 |
| 8 | ? 匹配前面表示式的0次或1次出現。 |
| 9 | { n} 匹配前面表示式恰好n次出現。 |
| 10 | { n,} 匹配前面表示式n次或多次出現。 |
| 11 | { n, m} 匹配前面表示式至少n次,至多m次出現。 |
| 12 | a| b 匹配a或b。 |
| 13 | \w 匹配單詞字元。 |
| 14 | \W 匹配非單詞字元。 |
| 15 | \s 匹配空格。等同於[\t\n\r\f]。 |
| 16 | \S 匹配非空格。 |
| 17 | \d 匹配數字。等同於[0-9]。 |
| 18 | \D 匹配非數字。 |
| 19 | \A 匹配字串開頭。 |
| 20 | \Z 匹配字串結尾。如果存在換行符,則匹配換行符之前的字元。 |
| 21 | \z 匹配字串結尾。 |
| 22 | \G 匹配上次匹配結束的位置。 |
| 23 | \b 在括號外匹配單詞邊界。在括號內匹配退格鍵 (0x08)。 |
| 24 | \B 匹配非單詞邊界。 |
| 25 | \n, \t, etc. 匹配換行符、回車符、製表符等。 |
| 26 | \1...\9 匹配第n個分組子表示式。 |
| 27 | \10 如果第n個分組子表示式已匹配,則匹配它。否則引用字元程式碼的八進位制表示。 |
| 28 | [aeiou] 匹配給定集合中的單個字元 |
| 29 | [^aeiou] 匹配給定集合之外的單個字元 |
^元字元匹配字串的開頭,$元符號匹配字串的結尾。以下是一些簡短的示例。
# nothing in the string (start and end are adjacent)
/^$/
# a three digits, each followed by a whitespace
# character (eg "3 4 5 ")
/(\d\s) {3}/
# matches a string in which every
# odd-numbered letter is a (eg "abacadaf")
/(a.)+/
# string starts with one or more digits
/^\d+/
# string that ends with one or more digits
/\d+$/
讓我們看看另一個例子。
#!/usr/bin/perl $string = "Cats go Catatonic\nWhen given Catnip"; ($start) = ($string =~ /\A(.*?) /); @lines = $string =~ /^(.*?) /gm; print "First word: $start\n","Line starts: @lines\n";
執行上述程式時,將產生以下結果:
First word: Cats Line starts: Cats When
匹配邊界
\b 匹配任何單詞邊界,由 \w 類和 \W 類之間的差異定義。因為 \w 包括單詞的字元,而 \W 包括相反的字元,所以這通常意味著單詞的終止。\B 斷言匹配任何不是單詞邊界的位置。例如:
/\bcat\b/ # Matches 'the cat sat' but not 'cat on the mat' /\Bcat\B/ # Matches 'verification' but not 'the cat on the mat' /\bcat\B/ # Matches 'catatonic' but not 'polecat' /\Bcat\b/ # Matches 'polecat' but not 'catatonic'
選擇備選方案
| 字元就像 Perl 中的標準或按位 OR 一樣。它指定正則表示式或組中的備選匹配。例如,要在表示式中匹配“cat”或“dog”,您可以使用:
if ($string =~ /cat|dog/)
您可以將表示式的各個元素組合在一起,以支援複雜的匹配。搜尋兩個人的姓名可以透過兩個單獨的測試來實現,如下所示:
if (($string =~ /Martin Brown/) || ($string =~ /Sharon Brown/)) This could be written as follows if ($string =~ /(Martin|Sharon) Brown/)
分組匹配
從正則表示式的角度來看,兩者之間沒有區別,也許除了前者稍微清晰一些。
$string =~ /(\S+)\s+(\S+)/; and $string =~ /\S+\s+\S+/;
但是,分組的好處是它允許我們從正則表示式中提取序列。分組按其在原始表示式中出現的順序返回為列表。例如,在下面的片段中,我們從字串中提取了小時、分鐘和秒。
my ($hours, $minutes, $seconds) = ($time =~ m/(\d+):(\d+):(\d+)/);
除了這種直接方法外,匹配的組也可用在特殊的$x變數中,其中x是正則表示式中組的編號。因此,我們可以將前面的示例改寫如下:
#!/usr/bin/perl $time = "12:05:30"; $time =~ m/(\d+):(\d+):(\d+)/; my ($hours, $minutes, $seconds) = ($1, $2, $3); print "Hours : $hours, Minutes: $minutes, Second: $seconds\n";
執行上述程式時,將產生以下結果:
Hours : 12, Minutes: 05, Second: 30
當在替換表示式中使用組時,$x語法可以在替換文字中使用。因此,我們可以使用以下方法重新格式化日期字串:
#!/usr/bin/perl $date = '03/26/1999'; $date =~ s#(\d+)/(\d+)/(\d+)#$3/$1/$2#; print "$date\n";
執行上述程式時,將產生以下結果:
1999/03/26
\G 斷言
\G 斷言允許您從上次匹配發生的位置繼續搜尋。例如,在下面的程式碼中,我們使用了 \G,以便我們可以搜尋到正確的位置,然後提取一些資訊,而無需建立更復雜的單個正則表示式:
#!/usr/bin/perl
$string = "The time is: 12:31:02 on 4/12/00";
$string =~ /:\s+/g;
($time) = ($string =~ /\G(\d+:\d+:\d+)/);
$string =~ /.+\s+/g;
($date) = ($string =~ m{\G(\d+/\d+/\d+)});
print "Time: $time, Date: $date\n";
執行上述程式時,將產生以下結果:
Time: 12:31:02, Date: 4/12/00
\G 斷言實際上只是 pos 函式的元符號等價物,因此在正則表示式呼叫之間,您可以繼續使用 pos,甚至可以透過使用 pos 作為 lvalue 子例程來修改 pos(因此是 \G)的值。
正則表示式示例
字面字元
| 序號 | 示例與描述 |
|---|---|
| 1 | Perl 匹配“Perl”。 |
字元類
| 序號 | 示例與描述 |
|---|---|
| 1 | [Pp]ython 匹配“Python”或“python”。 |
| 2 | rub[ye] 匹配“ruby”或“rube”。 |
| 3 | [aeiou] 匹配任何一個小寫母音。 |
| 4 | [0-9] 匹配任何數字;與 [0123456789] 相同。 |
| 5 | [a-z] 匹配任何小寫 ASCII 字母。 |
| 6 | [A-Z] 匹配任何大寫 ASCII 字母。 |
| 7 | [a-zA-Z0-9] 匹配以上任何一個。 |
| 8 | [^aeiou] 匹配任何非小寫母音。 |
| 9 | [^0-9] 匹配任何非數字。 |
特殊字元類
| 序號 | 示例與描述 |
|---|---|
| 1 | . 匹配除換行符之外的任何字元。 |
| 2 | \d 匹配數字:[0-9] |
| 3 | \D 匹配非數字:[0-9] |
| 4 | \s 匹配空格字元:[ \t\r\n\f] |
| 5 | \S 匹配非空格:[ \t\r\n\f] |
| 6 | \w 匹配單個單詞字元:[A-Za-z0-9_] |
| 7 | \W 匹配非單詞字元:[A-Za-z0-9_] |
重複情況
| 序號 | 示例與描述 |
|---|---|
| 1 | ruby? 匹配“rub”或“ruby”:y 是可選的。 |
| 2 | ruby* 匹配“rub”加上 0 個或多個 y。 |
| 3 | ruby+ 匹配“rub”加上 1 個或多個 y。 |
| 4 | \d{3} 匹配正好 3 個數字。 |
| 5 | \d{3,} 匹配 3 個或更多數字。 |
| 6. | \d{3,5} 匹配 3、4 或 5 個數字。 |
非貪婪重複
這匹配最少的重複次數:
| 序號 | 示例與描述 |
|---|---|
| 1 | <.*> 貪婪重複:匹配“<python>perl>”。 |
| 2 | <.*?> 非貪婪:在“<python>perl>”中匹配“<python>”。 |
使用括號進行分組
| 序號 | 示例與描述 |
|---|---|
| 1 | \D\d+ 無分組:+ 重複 \d。 |
| 2 | (\D\d)+ 分組:+ 重複 \D\d 對。 |
| 3 | ([Pp]ython(, )?)+ 匹配“Python”、“Python, python, python”等。 |
反向引用
這再次匹配先前匹配的組:
| 序號 | 示例與描述 |
|---|---|
| 1 | ([Pp])ython&\1ails 匹配 python&pails 或 Python&Pails。 |
| 2 | (['"])[^\1]*\1 單引號或雙引號字串。\1 匹配第一個組匹配的任何內容。\2 匹配第二個組匹配的任何內容,依此類推。 |
備選方案
| 序號 | 示例與描述 |
|---|---|
| 1 | python|perl 匹配“python”或“perl”。 |
| 2 | rub(y|le)) 匹配“ruby”或“ruble”。 |
| 3 | Python(!+|\?) “Python”後跟一個或多個 ! 或一個 ?。 |
錨點
這需要指定匹配位置。
| 序號 | 示例與描述 |
|---|---|
| 1 | ^Python 匹配字串或內部行的開頭的“Python”。 |
| 2 | Python$ 匹配字串或行結尾的“Python”。 |
| 3 | \APython 匹配字串開頭的“Python”。 |
| 4 | Python\Z 匹配字串結尾的“Python”。 |
| 5 | \bPython\b 匹配單詞邊界的“Python”。 |
| 6 | \brub\B \B是非單詞邊界:在“rube”和“ruby”中匹配“rub”,但不能單獨匹配。 |
| 7 | Python(?=!) 如果後跟感嘆號,則匹配“Python”。 |
| 8 | Python(?!!) 如果後不跟感嘆號,則匹配“Python”。 |
帶括號的特殊語法
| 序號 | 示例與描述 |
|---|---|
| 1 | R(?#comment) 匹配“R”。其餘都是註釋。 |
| 2 | R(?i)uby 匹配“uby”時不區分大小寫。 |
| 3 | R(?i:uby) 與上面相同。 |
| 4 | rub(?:y|le)) 僅分組而不建立 \1 反向引用。 |
Perl - 傳送郵件
使用sendmail實用程式
傳送純文字郵件
如果您在Linux/Unix機器上工作,那麼您可以簡單地在Perl程式中使用sendmail實用程式來發送電子郵件。這是一個可以將電子郵件傳送到給定電子郵件ID的示例指令碼。只需確保sendmail實用程式的給定路徑正確即可。對於您的Linux/Unix機器,這可能有所不同。
#!/usr/bin/perl $to = 'abcd@gmail.com'; $from = 'webmaster@yourdomain.com'; $subject = 'Test Email'; $message = 'This is test email sent by Perl Script'; open(MAIL, "|/usr/sbin/sendmail -t"); # Email Header print MAIL "To: $to\n"; print MAIL "From: $from\n"; print MAIL "Subject: $subject\n\n"; # Email Body print MAIL $message; close(MAIL); print "Email Sent Successfully\n";
實際上,上面的指令碼是一個客戶端電子郵件指令碼,它將起草電子郵件並提交到您的Linux/Unix機器上本地執行的伺服器。此指令碼不負責將電子郵件傳送到實際目的地。因此,您必須確保電子郵件伺服器已正確配置並在您的機器上執行,才能將電子郵件傳送到給定的電子郵件ID。
傳送HTML郵件
如果您想使用sendmail傳送HTML格式的電子郵件,那麼您只需要在電子郵件的標題部分新增Content-type: text/html\n,如下所示:
#!/usr/bin/perl $to = 'abcd@gmail.com'; $from = 'webmaster@yourdomain.com'; $subject = 'Test Email'; $message = '<h1>This is test email sent by Perl Script</h1>'; open(MAIL, "|/usr/sbin/sendmail -t"); # Email Header print MAIL "To: $to\n"; print MAIL "From: $from\n"; print MAIL "Subject: $subject\n\n"; print MAIL "Content-type: text/html\n"; # Email Body print MAIL $message; close(MAIL); print "Email Sent Successfully\n";
使用MIME::Lite模組
如果您在Windows機器上工作,那麼您將無法訪問sendmail實用程式。但是,您可以使用MIME:Lite perl模組編寫您自己的電子郵件客戶端作為替代。您可以從此處下載此模組 MIME-Lite-3.01.tar.gz 並將其安裝在您的Windows或Linux/Unix機器上。要安裝它,請按照以下簡單步驟操作:
$tar xvfz MIME-Lite-3.01.tar.gz $cd MIME-Lite-3.01 $perl Makefile.PL $make $make install
就是這樣,您的機器上將安裝MIME::Lite模組。現在您可以使用下面解釋的簡單指令碼來發送電子郵件了。
傳送純文字郵件
下面是一個負責向指定郵箱傳送郵件的指令碼:
#!/usr/bin/perl
use MIME::Lite;
$to = 'abcd@gmail.com';
$cc = 'efgh@mail.com';
$from = 'webmaster@yourdomain.com';
$subject = 'Test Email';
$message = 'This is test email sent by Perl Script';
$msg = MIME::Lite->new(
From => $from,
To => $to,
Cc => $cc,
Subject => $subject,
Data => $message
);
$msg->send;
print "Email Sent Successfully\n";
傳送HTML郵件
如果您想使用sendmail傳送HTML格式的郵件,只需在郵件的頭部新增Content-type: text/html\n即可。下面是傳送HTML格式郵件的指令碼:
#!/usr/bin/perl
use MIME::Lite;
$to = 'abcd@gmail.com';
$cc = 'efgh@mail.com';
$from = 'webmaster@yourdomain.com';
$subject = 'Test Email';
$message = '<h1>This is test email sent by Perl Script</h1>';
$msg = MIME::Lite->new(
From => $from,
To => $to,
Cc => $cc,
Subject => $subject,
Data => $message
);
$msg->attr("content-type" => "text/html");
$msg->send;
print "Email Sent Successfully\n";
傳送附件
如果您想傳送附件,可以使用以下指令碼:
#!/usr/bin/perl
use MIME::Lite;
$to = 'abcd@gmail.com';
$cc = 'efgh@mail.com';
$from = 'webmaster@yourdomain.com';
$subject = 'Test Email';
$message = 'This is test email sent by Perl Script';
$msg = MIME::Lite->new(
From => $from,
To => $to,
Cc => $cc,
Subject => $subject,
Type => 'multipart/mixed'
);
# Add your text message.
$msg->attach(Type => 'text',
Data => $message
);
# Specify your file as attachement.
$msg->attach(Type => 'image/gif',
Path => '/tmp/logo.gif',
Filename => 'logo.gif',
Disposition => 'attachment'
);
$msg->send;
print "Email Sent Successfully\n";
您可以使用attach()方法在郵件中新增任意數量的附件。
使用SMTP伺服器
如果您的機器沒有執行郵件伺服器,您可以使用遠端位置的任何其他郵件伺服器。但是,要使用其他郵件伺服器,您需要擁有使用者名稱、密碼、URL等資訊。一旦您擁有所有必要的資訊,只需在send()方法中提供這些資訊,如下所示:
$msg->send('smtp', "smtp.myisp.net", AuthUser=>"id", AuthPass=>"password" );
您可以聯絡您的郵件伺服器管理員獲取上述資訊,如果使用者名稱和密碼尚不存在,您的管理員可以在幾分鐘內建立它們。
Perl - 套接字程式設計
什麼是套接字?
套接字是伯克利UNIX中的一種機制,用於在不同的程序之間建立虛擬雙工連線。後來,它被移植到所有已知的作業系統上,從而實現了在執行不同作業系統軟體的不同地理位置的系統之間的通訊。如果沒有套接字,大多數系統之間的網路通訊將永遠不會發生。
更仔細地觀察一下;網路上的典型計算機系統會根據其上執行的各種應用程式的要求接收和傳送資訊。由於為其指定了唯一的IP地址,因此此資訊被路由到系統。在系統上,此資訊將被提供給相關的應用程式,這些應用程式監聽不同的埠。例如,網際網路瀏覽器監聽埠80以接收來自Web伺服器的資訊。我們還可以編寫自定義應用程式,這些應用程式可以監聽並在特定埠號上傳送/接收資訊。
現在,讓我們總結一下,套接字是一個IP地址和一個埠,可以啟用連線以透過網路傳送和接收資料。
為了解釋上述套接字概念,我們將以使用Perl的客戶端-伺服器程式設計為例。要完成客戶端伺服器架構,我們將需要執行以下步驟:
建立伺服器
使用socket呼叫建立套接字。
使用bind呼叫將套接字繫結到埠地址。
使用listen呼叫監聽埠地址上的套接字。
使用accept呼叫接受客戶端連線。
建立客戶端
使用socket呼叫建立套接字。
使用connect呼叫連線(套接字)到伺服器。
下圖顯示了客戶端和伺服器用於相互通訊的呼叫的完整序列:

伺服器端套接字呼叫
socket() 呼叫
socket()呼叫是建立網路連線的第一步,它建立了一個套接字。此呼叫的語法如下:
socket( SOCKET, DOMAIN, TYPE, PROTOCOL );
上述呼叫建立一個SOCKET,其他三個引數是整數,對於TCP/IP連線應具有以下值。
DOMAIN應為PF_INET。在您的計算機上可能是2。
TYPE對於TCP/IP連線應為SOCK_STREAM。
PROTOCOL應為(getprotobyname('tcp'))[2]。它是透過套接字使用的特定協議,例如TCP。
因此,伺服器發出的socket函式呼叫將類似於:
use Socket # This defines PF_INET and SOCK_STREAM
socket(SOCKET,PF_INET,SOCK_STREAM,(getprotobyname('tcp'))[2]);
bind() 呼叫
由socket()呼叫建立的套接字在繫結到主機名和埠號之前是無用的。伺服器使用以下bind()函式來指定它將接受客戶端連線的埠。
bind( SOCKET, ADDRESS );
這裡SOCKET是由socket()呼叫返回的描述符,ADDRESS是套接字地址(對於TCP/IP),包含三個元素:
地址族(對於TCP/IP,是AF_INET,在您的系統上可能是2)。
埠號(例如21)。
計算機的網際網路地址(例如10.12.12.168)。
由於bind()由伺服器使用,伺服器不需要知道它自己的地址,因此引數列表如下所示:
use Socket # This defines PF_INET and SOCK_STREAM $port = 12345; # The unique port used by the sever to listen requests $server_ip_address = "10.12.12.168"; bind( SOCKET, pack_sockaddr_in($port, inet_aton($server_ip_address))) or die "Can't bind to port $port! \n";
or die子句非常重要,因為如果伺服器在沒有未完成連線的情況下死亡,除非您使用setsockopt()函式使用選項SO_REUSEADDR,否則埠將不會立即可重用。這裡使用pack_sockaddr_in()函式將埠和IP地址打包成二進位制格式。
listen() 呼叫
如果這是一個伺服器程式,則需要在指定的埠上發出對listen()的呼叫以進行監聽,即等待傳入請求。此呼叫的語法如下:
listen( SOCKET, QUEUESIZE );
上述呼叫使用socket()呼叫返回的SOCKET描述符,QUEUESIZE是允許同時存在的最大未完成連線請求數。
accept() 呼叫
如果這是一個伺服器程式,則需要發出對access()函式的呼叫以接受傳入的連線。此呼叫的語法如下:
accept( NEW_SOCKET, SOCKET );
accept呼叫接收socket()函式返回的SOCKET描述符,成功完成時,將返回一個新的套接字描述符NEW_SOCKET,用於客戶端和伺服器之間的所有未來通訊。如果access()呼叫失敗,則返回我們在初始階段使用的Socket模組中定義的FLASE。
通常,accept()用於無限迴圈中。一旦一個連線到達,伺服器要麼建立一個子程序來處理它,要麼自己服務它,然後返回去監聽更多連線。
while(1) {
accept( NEW_SOCKET, SOCKT );
.......
}
現在所有與伺服器相關的呼叫都已完成,讓我們看看客戶端將需要的呼叫。
客戶端套接字呼叫
connect() 呼叫
如果您要準備客戶端程式,那麼首先您將使用socket()呼叫建立套接字,然後您必須使用connect()呼叫連線到伺服器。您已經看到了socket()呼叫的語法,它與伺服器socket()呼叫類似,但這裡是connect()呼叫的語法:
connect( SOCKET, ADDRESS );
這裡SCOKET是客戶端發出的socket()呼叫返回的套接字描述符,ADDRESS是與bind呼叫類似的套接字地址,不同之處在於它包含遠端伺服器的IP地址。
$port = 21; # For example, the ftp port $server_ip_address = "10.12.12.168"; connect( SOCKET, pack_sockaddr_in($port, inet_aton($server_ip_address))) or die "Can't connect to port $port! \n";
如果您成功連線到伺服器,則可以使用SOCKET描述符開始向伺服器傳送命令,否則您的客戶端將透過顯示錯誤訊息退出。
客戶端-伺服器示例
以下是用Perl套接字實現簡單的客戶端-伺服器程式的Perl程式碼。這裡伺服器監聽傳入請求,一旦建立連線,它就簡單地回覆Smile from the server。客戶端讀取該訊息並列印到螢幕上。讓我們看看它是如何完成的,假設我們的伺服器和客戶端在同一臺機器上。
建立伺服器的指令碼
#!/usr/bin/perl -w
# Filename : server.pl
use strict;
use Socket;
# use port 7890 as default
my $port = shift || 7890;
my $proto = getprotobyname('tcp');
my $server = "localhost"; # Host IP running the server
# create a socket, make it reusable
socket(SOCKET, PF_INET, SOCK_STREAM, $proto)
or die "Can't open socket $!\n";
setsockopt(SOCKET, SOL_SOCKET, SO_REUSEADDR, 1)
or die "Can't set socket option to SO_REUSEADDR $!\n";
# bind to a port, then listen
bind( SOCKET, pack_sockaddr_in($port, inet_aton($server)))
or die "Can't bind to port $port! \n";
listen(SOCKET, 5) or die "listen: $!";
print "SERVER started on port $port\n";
# accepting a connection
my $client_addr;
while ($client_addr = accept(NEW_SOCKET, SOCKET)) {
# send them a message, close connection
my $name = gethostbyaddr($client_addr, AF_INET );
print NEW_SOCKET "Smile from the server";
print "Connection recieved from $name\n";
close NEW_SOCKET;
}
要在後臺模式下執行伺服器,請在Unix提示符下發出以下命令:
$perl sever.pl&
建立客戶端的指令碼
!/usr/bin/perl -w
# Filename : client.pl
use strict;
use Socket;
# initialize host and port
my $host = shift || 'localhost';
my $port = shift || 7890;
my $server = "localhost"; # Host IP running the server
# create the socket, connect to the port
socket(SOCKET,PF_INET,SOCK_STREAM,(getprotobyname('tcp'))[2])
or die "Can't create a socket $!\n";
connect( SOCKET, pack_sockaddr_in($port, inet_aton($server)))
or die "Can't connect to port $port! \n";
my $line;
while ($line = <SOCKET>) {
print "$line\n";
}
close SOCKET or die "close: $!";
現在讓我們在命令提示符下啟動我們的客戶端,它將連線到伺服器並讀取伺服器傳送的訊息,並在螢幕上顯示如下:
$perl client.pl Smile from the server
注意 - 如果您使用點分十進位制表示法提供實際IP地址,則建議在客戶端和伺服器中都使用相同的格式提供IP地址,以避免任何混淆。
Perl中的面向物件程式設計
我們已經學習了Perl中的引用以及Perl匿名陣列和雜湊表。Perl中的面向物件概念很大程度上基於引用以及匿名陣列和雜湊表。讓我們開始學習Perl面向物件的其本概念。
物件基礎
從Perl如何處理物件的角度來看,有三個主要術語。這些術語是物件、類和方法。
Perl中的物件僅僅是對知道其所屬類的某種資料型別的引用。物件作為引用儲存在標量變數中。因為標量只包含對物件的引用,所以同一個標量可以在不同的類中儲存不同的物件。
Perl中的類是一個包含建立和操作物件所需相應方法的包。
Perl中的方法是一個子例程,它使用包進行定義。方法的第一個引數是物件引用或包名稱,這取決於方法是影響當前物件還是類。
Perl提供了一個bless()函式,用於返回最終成為物件的引用。
定義類
在Perl中定義類非常簡單。在最簡單的形式中,類對應於Perl包。要在Perl中建立類,我們首先構建一個包。
包是使用者定義變數和子例程的自包含單元,可以重複使用。
Perl包在Perl程式中提供一個單獨的名稱空間,它使子例程和變數獨立於與其他包中的那些變數衝突。
要在Perl中宣告名為Person的類,我們這樣做:
package Person;
包定義的作用域擴充套件到檔案的末尾,或者直到遇到另一個package關鍵字。
建立和使用物件
要建立類的例項(物件),我們需要一個物件建構函式。此建構函式是在包中定義的方法。大多數程式設計師選擇將此物件建構函式方法命名為new,但在Perl中您可以使用任何名稱。
您可以在Perl中使用任何型別的Perl變數作為物件。大多數Perl程式設計師選擇陣列或雜湊的引用。
讓我們使用Perl雜湊引用為Person類建立建構函式。建立物件時,需要提供建構函式,它是包中的一個子例程,它返回物件引用。物件引用是透過將對包類的引用進行祝福來建立的。例如:
package Person;
sub new {
my $class = shift;
my $self = {
_firstName => shift,
_lastName => shift,
_ssn => shift,
};
# Print all the values just for clarification.
print "First Name is $self->{_firstName}\n";
print "Last Name is $self->{_lastName}\n";
print "SSN is $self->{_ssn}\n";
bless $self, $class;
return $self;
}
現在讓我們看看如何建立物件。
$object = new Person( "Mohammad", "Saleem", 23234345);
如果您不想為任何類變數賦值,可以在建構函式中使用簡單的雜湊。例如:
package Person;
sub new {
my $class = shift;
my $self = {};
bless $self, $class;
return $self;
}
定義方法
其他面向物件的語言具有資料安全性的概念,以防止程式設計師直接更改物件資料,並且它們提供訪問器方法來修改物件資料。Perl沒有私有變數,但我們仍然可以使用輔助方法的概念來操作物件資料。
讓我們定義一個輔助方法來獲取人的名字:
sub getFirstName {
return $self->{_firstName};
}
另一個設定人名的輔助函式:
sub setFirstName {
my ( $self, $firstName ) = @_;
$self->{_firstName} = $firstName if defined($firstName);
return $self->{_firstName};
}
現在讓我們看看完整的示例:將Person包和輔助函式放入Person.pm檔案中。
#!/usr/bin/perl
package Person;
sub new {
my $class = shift;
my $self = {
_firstName => shift,
_lastName => shift,
_ssn => shift,
};
# Print all the values just for clarification.
print "First Name is $self->{_firstName}\n";
print "Last Name is $self->{_lastName}\n";
print "SSN is $self->{_ssn}\n";
bless $self, $class;
return $self;
}
sub setFirstName {
my ( $self, $firstName ) = @_;
$self->{_firstName} = $firstName if defined($firstName);
return $self->{_firstName};
}
sub getFirstName {
my( $self ) = @_;
return $self->{_firstName};
}
1;
現在讓我們在employee.pl檔案中使用Person物件,如下所示:
#!/usr/bin/perl use Person; $object = new Person( "Mohammad", "Saleem", 23234345); # Get first name which is set using constructor. $firstName = $object->getFirstName(); print "Before Setting First Name is : $firstName\n"; # Now Set first name using helper function. $object->setFirstName( "Mohd." ); # Now get first name set by helper function. $firstName = $object->getFirstName(); print "Before Setting First Name is : $firstName\n";
當我們執行上述程式時,它會產生以下結果:
First Name is Mohammad Last Name is Saleem SSN is 23234345 Before Setting First Name is : Mohammad Before Setting First Name is : Mohd.
繼承
面向物件程式設計有一個非常好用的概念叫做繼承。繼承簡單來說就是父類的屬性和方法將可用於子類。因此,您不必一遍遍地編寫相同的程式碼,您可以直接繼承父類。
例如,我們可以有一個Employee類,它繼承自Person類。這被稱為“isa”關係,因為員工是一個人。Perl有一個特殊的變數@ISA來幫助實現這一點。@ISA控制(方法)繼承。
使用繼承時,需要考慮以下重要事項:
Perl在指定物件的類中搜索給定的方法或屬性,即變數。
Perl搜尋在物件類的@ISA陣列中定義的類。
如果在步驟1或2中找不到方法,則Perl使用AUTOLOAD子例程(如果在@ISA樹中找到一個)。
如果仍然找不到匹配的方法,則Perl將在作為標準Perl庫一部分的UNIVERSAL類(包)中搜索該方法。
如果仍然找不到該方法,則Perl將放棄並引發執行時異常。
因此,要建立一個新的 Employee 類,繼承 Person 類的所有方法和屬性,只需編寫如下程式碼:將此程式碼儲存到 Employee.pm 檔案中。
#!/usr/bin/perl package Employee; use Person; use strict; our @ISA = qw(Person); # inherits from Person
現在 Employee 類繼承了 Person 類所有的方法和屬性,您可以按如下方式使用它們:使用 main.pl 檔案進行測試 -
#!/usr/bin/perl use Employee; $object = new Employee( "Mohammad", "Saleem", 23234345); # Get first name which is set using constructor. $firstName = $object->getFirstName(); print "Before Setting First Name is : $firstName\n"; # Now Set first name using helper function. $object->setFirstName( "Mohd." ); # Now get first name set by helper function. $firstName = $object->getFirstName(); print "After Setting First Name is : $firstName\n";
當我們執行上述程式時,它會產生以下結果:
First Name is Mohammad Last Name is Saleem SSN is 23234345 Before Setting First Name is : Mohammad Before Setting First Name is : Mohd.
方法重寫
子類 Employee 繼承了父類 Person 的所有方法。但是,如果您想在子類中重寫這些方法,可以透過提供您自己的實現來做到這一點。您可以在子類中新增額外的函式,或者新增或修改父類中現有方法的功能。操作方法如下:修改 Employee.pm 檔案。
#!/usr/bin/perl
package Employee;
use Person;
use strict;
our @ISA = qw(Person); # inherits from Person
# Override constructor
sub new {
my ($class) = @_;
# Call the constructor of the parent class, Person.
my $self = $class->SUPER::new( $_[1], $_[2], $_[3] );
# Add few more attributes
$self->{_id} = undef;
$self->{_title} = undef;
bless $self, $class;
return $self;
}
# Override helper function
sub getFirstName {
my( $self ) = @_;
# This is child class function.
print "This is child class helper function\n";
return $self->{_firstName};
}
# Add more methods
sub setLastName{
my ( $self, $lastName ) = @_;
$self->{_lastName} = $lastName if defined($lastName);
return $self->{_lastName};
}
sub getLastName {
my( $self ) = @_;
return $self->{_lastName};
}
1;
現在讓我們再次嘗試在 main.pl 檔案中使用 Employee 物件並執行它。
#!/usr/bin/perl use Employee; $object = new Employee( "Mohammad", "Saleem", 23234345); # Get first name which is set using constructor. $firstName = $object->getFirstName(); print "Before Setting First Name is : $firstName\n"; # Now Set first name using helper function. $object->setFirstName( "Mohd." ); # Now get first name set by helper function. $firstName = $object->getFirstName(); print "After Setting First Name is : $firstName\n";
當我們執行上述程式時,它會產生以下結果:
First Name is Mohammad Last Name is Saleem SSN is 23234345 This is child class helper function Before Setting First Name is : Mohammad This is child class helper function After Setting First Name is : Mohd.
預設自動載入
Perl 提供了一個在其他程式語言中找不到的功能:預設子程式。這意味著,如果您定義了一個名為 AUTOLOAD() 的函式,則對未定義子程式的任何呼叫都將自動呼叫 AUTOLOAD() 函式。丟失的子程式的名稱在此子程式中作為 $AUTOLOAD 可訪問。
預設自動載入功能對於錯誤處理非常有用。這是一個實現 AUTOLOAD 的示例,您可以根據自己的方式實現此函式。
sub AUTOLOAD {
my $self = shift;
my $type = ref ($self) || croak "$self is not an object";
my $field = $AUTOLOAD;
$field =~ s/.*://;
unless (exists $self->{$field}) {
croak "$field does not exist in object/class $type";
}
if (@_) {
return $self->($name) = shift;
} else {
return $self->($name);
}
}
解構函式和垃圾回收
如果您之前使用過面向物件的程式設計,那麼您就會意識到需要建立一個 解構函式 來釋放使用完物件後分配給物件的記憶體。Perl 會在物件超出作用域後自動執行此操作。
如果您想實現自己的解構函式,它應該負責關閉檔案或執行一些額外的處理,那麼您需要定義一個名為 DESTROY 的特殊方法。此方法將在 Perl 釋放分配給它的記憶體之前立即在物件上呼叫。在所有其他方面,DESTROY 方法與任何其他方法一樣,您可以在此方法內實現任何您想要的邏輯。
解構函式只是一個名為 DESTROY 的成員函式(子程式),它將在以下情況下自動呼叫 -
- 當物件引用的變數超出作用域時。
- 當物件引用的變數被 undef 時。
- 當指令碼終止時
- 當 Perl 直譯器終止時
例如,您可以簡單地將以下 DESTROY 方法放入您的類中 -
package MyClass;
...
sub DESTROY {
print "MyClass::DESTROY called\n";
}
面向物件 Perl 示例
這是一個很好的例子,它將幫助您理解 Perl 的面向物件概念。將此原始碼放入任何 Perl 檔案中並執行它。
#!/usr/bin/perl
# Following is the implementation of simple Class.
package MyClass;
sub new {
print "MyClass::new called\n";
my $type = shift; # The package/type name
my $self = {}; # Reference to empty hash
return bless $self, $type;
}
sub DESTROY {
print "MyClass::DESTROY called\n";
}
sub MyMethod {
print "MyClass::MyMethod called!\n";
}
# Following is the implemnetation of Inheritance.
package MySubClass;
@ISA = qw( MyClass );
sub new {
print "MySubClass::new called\n";
my $type = shift; # The package/type name
my $self = MyClass->new; # Reference to empty hash
return bless $self, $type;
}
sub DESTROY {
print "MySubClass::DESTROY called\n";
}
sub MyMethod {
my $self = shift;
$self->SUPER::MyMethod();
print " MySubClass::MyMethod called!\n";
}
# Here is the main program using above classes.
package main;
print "Invoke MyClass method\n";
$myObject = MyClass->new();
$myObject->MyMethod();
print "Invoke MySubClass method\n";
$myObject2 = MySubClass->new();
$myObject2->MyMethod();
print "Create a scoped object\n";
{
my $myObject2 = MyClass->new();
}
# Destructor is called automatically here
print "Create and undef an object\n";
$myObject3 = MyClass->new();
undef $myObject3;
print "Fall off the end of the script...\n";
# Remaining destructors are called automatically here
當我們執行上述程式時,它會產生以下結果:
Invoke MyClass method MyClass::new called MyClass::MyMethod called! Invoke MySubClass method MySubClass::new called MyClass::new called MyClass::MyMethod called! MySubClass::MyMethod called! Create a scoped object MyClass::new called MyClass::DESTROY called Create and undef an object MyClass::new called MyClass::DESTROY called Fall off the end of the script... MyClass::DESTROY called MySubClass::DESTROY called
Perl - 資料庫訪問
本章將教您如何在 Perl 指令碼中訪問資料庫。從 Perl 5 開始,使用 DBI 模組編寫資料庫應用程式變得非常容易。DBI 代表 Perl 的 資料庫獨立介面,這意味著 DBI 在 Perl 程式碼和底層資料庫之間提供了一個抽象層,允許您非常輕鬆地切換資料庫實現。
DBI 是 Perl 程式語言的資料庫訪問模組。它提供了一組方法、變數和約定,這些方法、變數和約定提供了一致的資料庫介面,獨立於正在使用的實際資料庫。
DBI 應用程式的架構
DBI 獨立於後端可用的任何資料庫。無論您使用的是 Oracle、MySQL 還是 Informix 等,都可以使用 DBI。從以下架構圖可以清楚地看出這一點。

這裡 DBI 負責透過 API(即應用程式程式設計介面)獲取所有 SQL 命令,並將它們分派給相應的驅動程式以進行實際執行。最後,DBI 負責從驅動程式獲取結果並將其返回給呼叫指令碼。
符號和約定
在本章中,將使用以下符號,建議您也遵循相同的約定。
$dsn Database source name $dbh Database handle object $sth Statement handle object $h Any of the handle types above ($dbh, $sth, or $drh) $rc General Return Code (boolean: true=ok, false=error) $rv General Return Value (typically an integer) @ary List of values returned from the database. $rows Number of rows processed (if available, else -1) $fh A filehandle undef NULL values are represented by undefined values in Perl \%attr Reference to a hash of attribute values passed to methods
資料庫連線
假設我們將使用 MySQL 資料庫。連線到資料庫之前,請確保以下事項。如果您不瞭解如何在 MySQL 資料庫中建立資料庫和表,可以參考我們的 MySQL 教程。
您已建立了一個名為 TESTDB 的資料庫。
您已在 TESTDB 中建立了一個名為 TEST_TABLE 的表。
此表具有欄位 FIRST_NAME、LAST_NAME、AGE、SEX 和 INCOME。
已設定使用者 ID“testuser”和密碼“test123”以訪問 TESTDB。
您的機器上已正確安裝 Perl 模組 DBI。
您已閱讀 MySQL 教程以瞭解 MySQL 基礎知識。
以下是連線 MySQL 資料庫“TESTDB”的示例 -
#!/usr/bin/perl use DBI use strict; my $driver = "mysql"; my $database = "TESTDB"; my $dsn = "DBI:$driver:database=$database"; my $userid = "testuser"; my $password = "test123"; my $dbh = DBI->connect($dsn, $userid, $password ) or die $DBI::errstr;
如果與資料來源建立連線,則返回資料庫控制代碼並將其儲存到 $dbh 以供進一步使用,否則 $dbh 設定為 undef 值,而 $DBI::errstr 返回錯誤字串。
INSERT 操作
當您想要在表中建立一些記錄時,需要進行 INSERT 操作。這裡我們使用 TEST_TABLE 表來建立我們的記錄。因此,一旦我們的資料庫連線建立,我們就可以準備在 TEST_TABLE 中建立記錄了。以下是建立單個記錄到 TEST_TABLE 的過程。您可以使用相同的概念建立任意數量的記錄。
記錄建立包含以下步驟 -
使用 INSERT 語句準備 SQL 語句。這將使用 prepare() API 完成。
執行 SQL 查詢以從資料庫中選擇所有結果。這將使用 execute() API 完成。
釋放語句控制代碼。這將使用 finish() API 完成。
如果一切順利,則 提交此操作,否則您可以 回滾整個事務。提交和回滾將在下一節中解釋。
my $sth = $dbh->prepare("INSERT INTO TEST_TABLE
(FIRST_NAME, LAST_NAME, SEX, AGE, INCOME )
values
('john', 'poul', 'M', 30, 13000)");
$sth->execute() or die $DBI::errstr;
$sth->finish();
$dbh->commit or die $DBI::errstr;
使用繫結值
可能存在需要輸入的值事先未給出的情況。因此,您可以使用繫結變數,這些變數將在執行時獲取所需的值。Perl DBI 模組使用問號代替實際值,然後實際值在執行時透過 execute() API 傳遞。示例如下 -
my $first_name = "john";
my $last_name = "poul";
my $sex = "M";
my $income = 13000;
my $age = 30;
my $sth = $dbh->prepare("INSERT INTO TEST_TABLE
(FIRST_NAME, LAST_NAME, SEX, AGE, INCOME )
values
(?,?,?,?)");
$sth->execute($first_name,$last_name,$sex, $age, $income)
or die $DBI::errstr;
$sth->finish();
$dbh->commit or die $DBI::errstr;
READ 操作
任何資料庫上的 READ 操作都意味著從資料庫中提取一些有用的資訊,即一個或多個表中的一條或多條記錄。因此,一旦我們的資料庫連線建立,我們就可以準備對這個資料庫進行查詢了。以下是查詢所有年齡大於 20 的記錄的過程。這將包含四個步驟 -
根據所需條件準備 SQL SELECT 查詢。這將使用 prepare() API 完成。
執行 SQL 查詢以從資料庫中選擇所有結果。這將使用 execute() API 完成。
逐一獲取所有結果並列印這些結果。這將使用 fetchrow_array() API 完成。
釋放語句控制代碼。這將使用 finish() API 完成。
my $sth = $dbh->prepare("SELECT FIRST_NAME, LAST_NAME
FROM TEST_TABLE
WHERE AGE > 20");
$sth->execute() or die $DBI::errstr;
print "Number of rows found :" + $sth->rows;
while (my @row = $sth->fetchrow_array()) {
my ($first_name, $last_name ) = @row;
print "First Name = $first_name, Last Name = $last_name\n";
}
$sth->finish();
使用繫結值
可能存在條件事先未給出的情況。因此,您可以使用繫結變數,這些變數將在執行時獲取所需的值。Perl DBI 模組使用問號代替實際值,然後實際值在執行時透過 execute() API 傳遞。示例如下 -
$age = 20;
my $sth = $dbh->prepare("SELECT FIRST_NAME, LAST_NAME
FROM TEST_TABLE
WHERE AGE > ?");
$sth->execute( $age ) or die $DBI::errstr;
print "Number of rows found :" + $sth->rows;
while (my @row = $sth->fetchrow_array()) {
my ($first_name, $last_name ) = @row;
print "First Name = $first_name, Last Name = $last_name\n";
}
$sth->finish();
UPDATE 操作
任何資料庫上的 UPDATE 操作都意味著更新資料庫表中已存在的記錄。以下是更新所有 SEX 為“M”的記錄的過程。這裡我們將所有男性的 AGE 增加一年。這將包含三個步驟 -
根據所需條件準備 SQL 查詢。這將使用 prepare() API 完成。
執行 SQL 查詢以從資料庫中選擇所有結果。這將使用 execute() API 完成。
釋放語句控制代碼。這將使用 finish() API 完成。
如果一切順利,則 提交此操作,否則您可以 回滾整個事務。有關提交和回滾 API,請參閱下一節。
my $sth = $dbh->prepare("UPDATE TEST_TABLE
SET AGE = AGE + 1
WHERE SEX = 'M'");
$sth->execute() or die $DBI::errstr;
print "Number of rows updated :" + $sth->rows;
$sth->finish();
$dbh->commit or die $DBI::errstr;
使用繫結值
可能存在條件事先未給出的情況。因此,您可以使用繫結變數,這些變數將在執行時獲取所需的值。Perl DBI 模組使用問號代替實際值,然後實際值在執行時透過 execute() API 傳遞。示例如下 -
$sex = 'M';
my $sth = $dbh->prepare("UPDATE TEST_TABLE
SET AGE = AGE + 1
WHERE SEX = ?");
$sth->execute('$sex') or die $DBI::errstr;
print "Number of rows updated :" + $sth->rows;
$sth->finish();
$dbh->commit or die $DBI::errstr;
在某些情況下,您可能希望設定一個事先未給出的值,因此您可以按如下方式使用繫結值。在此示例中,所有男性的收入將設定為 10000。
$sex = 'M';
$income = 10000;
my $sth = $dbh->prepare("UPDATE TEST_TABLE
SET INCOME = ?
WHERE SEX = ?");
$sth->execute( $income, '$sex') or die $DBI::errstr;
print "Number of rows updated :" + $sth->rows;
$sth->finish();
DELETE 操作
當您想要從資料庫中刪除某些記錄時,需要進行 DELETE 操作。以下是刪除 TEST_TABLE 中 AGE 等於 30 的所有記錄的過程。此操作將包含以下步驟。
根據所需條件準備 SQL 查詢。這將使用 prepare() API 完成。
執行 SQL 查詢以從資料庫中刪除所需記錄。這將使用 execute() API 完成。
釋放語句控制代碼。這將使用 finish() API 完成。
如果一切順利,則 提交此操作,否則您可以 回滾整個事務。
$age = 30;
my $sth = $dbh->prepare("DELETE FROM TEST_TABLE
WHERE AGE = ?");
$sth->execute( $age ) or die $DBI::errstr;
print "Number of rows deleted :" + $sth->rows;
$sth->finish();
$dbh->commit or die $DBI::errstr;
使用 do 語句
如果您要執行 UPDATE、INSERT 或 DELETE 操作,則不會從資料庫返回任何資料,因此可以使用快捷方式執行此操作。您可以使用 do 語句執行任何命令,如下所示。
$dbh->do('DELETE FROM TEST_TABLE WHERE age =30');
如果 do 成功,則返回真值;如果失敗,則返回假值。實際上,如果成功,它將返回受影響的行數。在示例中,它將返回實際刪除的行數。
COMMIT 操作
Commit 是一個向資料庫發出訊號以完成更改的操作,此操作後,任何更改都無法恢復到其原始位置。
這是一個呼叫 commit API 的簡單示例。
$dbh->commit or die $dbh->errstr;
ROLLBACK 操作
如果您對所有更改不滿意,或者在任何操作過程中遇到錯誤,您可以使用 rollback API 來恢復這些更改。
這是一個呼叫 rollback API 的簡單示例。
$dbh->rollback or die $dbh->errstr;
開始事務
許多資料庫支援事務。這意味著您可以進行許多修改資料庫的查詢,但沒有任何更改實際生效。然後,最後,您發出特殊的 SQL 查詢 COMMIT,所有更改將同時生效。或者,您可以發出查詢 ROLLBACK,在這種情況下,所有更改都將被丟棄,資料庫保持不變。
Perl DBI 模組提供了 begin_work API,它啟用事務(透過關閉 AutoCommit),直到下次呼叫 commit 或 rollback。在下一次提交或回滾後,AutoCommit 將自動再次開啟。
$rc = $dbh->begin_work or die $dbh->errstr;
AutoCommit 選項
如果您的事務很簡單,您可以避免發出大量提交的麻煩。進行連線呼叫時,您可以指定一個 AutoCommit 選項,該選項將在每次成功查詢後執行自動提交操作。如下所示 -
my $dbh = DBI->connect($dsn, $userid, $password,
{AutoCommit => 1})
or die $DBI::errstr;
這裡 AutoCommit 可以取值 1 或 0,其中 1 表示 AutoCommit 已開啟,0 表示 AutoCommit 已關閉。
自動錯誤處理
進行連線呼叫時,您可以指定一個 RaiseErrors 選項,該選項將自動為您處理錯誤。發生錯誤時,DBI 將中止您的程式,而不是返回失敗程式碼。如果您只想在發生錯誤時中止程式,這可能會很方便。如下所示 -
my $dbh = DBI->connect($dsn, $userid, $password,
{RaiseError => 1})
or die $DBI::errstr;
這裡 RaiseError 可以取值 1 或 0。
斷開資料庫連線
要斷開資料庫連線,請使用 disconnect API,如下所示 -
$rc = $dbh->disconnect or warn $dbh->errstr;
disconnect 方法的事務行為很遺憾是未定義的。某些資料庫系統(如 Oracle 和 Ingres)將自動提交任何未完成的更改,但其他系統(如 Informix)將回滾任何未完成的更改。不使用 AutoCommit 的應用程式應在呼叫 disconnect 之前顯式呼叫 commit 或 rollback。
使用 NULL 值
未定義值,或 undef,用於表示 NULL 值。您可以像插入和更新非 NULL 值一樣插入和更新具有 NULL 值的列。以下示例使用 NULL 值插入和更新 age 列:
$sth = $dbh->prepare(qq {
INSERT INTO TEST_TABLE (FIRST_NAME, AGE) VALUES (?, ?)
});
$sth->execute("Joe", undef);
這裡使用qq{}將帶引號的字串返回到prepare API。但是,在 WHERE 子句中使用 NULL 值時必須小心。請考慮:
SELECT FIRST_NAME FROM TEST_TABLE WHERE age = ?
將 undef (NULL) 繫結到佔位符不會選擇 age 為 NULL 的行!至少對於符合 SQL 標準的資料庫引擎是這樣。有關原因,請參閱您的資料庫引擎的 SQL 手冊或任何 SQL 書籍。要顯式選擇 NULL 值,您必須使用“WHERE age IS NULL”。
一個常見的問題是讓程式碼片段處理執行時可能已定義或未定義(非 NULL 或 NULL)的值。一個簡單的技術是根據需要準備相應的語句,並在非 NULL 的情況下替換佔位符:
$sql_clause = defined $age? "age = ?" : "age IS NULL";
$sth = $dbh->prepare(qq {
SELECT FIRST_NAME FROM TEST_TABLE WHERE $sql_clause
});
$sth->execute(defined $age ? $age : ());
其他一些 DBI 函式
available_drivers
@ary = DBI->available_drivers; @ary = DBI->available_drivers($quiet);
透過搜尋 @INC 中目錄下的 DBD::* 模組來返回所有可用驅動程式的列表。預設情況下,如果某些驅動程式被同一名稱的早期目錄中的其他驅動程式隱藏,則會發出警告。將 $quiet 的值傳遞為 true 將抑制警告。
installed_drivers
%drivers = DBI->installed_drivers();
返回當前程序中所有“已安裝”(已載入)驅動程式的驅動程式名稱和驅動程式控制代碼對列表。驅動程式名稱不包含“DBD::”字首。
data_sources
@ary = DBI->data_sources($driver);
返回透過指定驅動程式可用的資料來源(資料庫)列表。如果 $driver 為空或未定義,則使用 DBI_DRIVER 環境變數的值。
quote
$sql = $dbh->quote($value); $sql = $dbh->quote($value, $data_type);
為在 SQL 語句中用作文字值而引用字串文字,方法是跳脫字元串中包含的任何特殊字元(例如引號),並新增所需的外部引號型別。
$sql = sprintf "SELECT foo FROM bar WHERE baz = %s",
$dbh->quote("Don't");
對於大多數資料庫型別,quote 將返回 'Don''t'(包括外部引號)。quote() 方法返回計算結果為所需字串的 SQL 表示式是有效的。例如:
$quoted = $dbh->quote("one\ntwo\0three")
may produce results which will be equivalent to
CONCAT('one', CHAR(12), 'two', CHAR(0), 'three')
所有控制代碼通用的方法
err
$rv = $h->err; or $rv = $DBI::err or $rv = $h->err
返回上次呼叫的驅動程式方法的本機資料庫引擎錯誤程式碼。該程式碼通常是整數,但您不應假設它是整數。這等效於 $DBI::err 或 $h->err。
errstr
$str = $h->errstr; or $str = $DBI::errstr or $str = $h->errstr
返回上次呼叫的 DBI 方法的本機資料庫引擎錯誤訊息。這與上面描述的“err”方法具有相同的生命週期問題。這等效於 $DBI::errstr 或 $h->errstr。
rows
$rv = $h->rows; or $rv = $DBI::rows
這返回前一個 SQL 語句影響的行數,等效於 $DBI::rows。
trace
$h->trace($trace_settings);
DBI 具有一個非常有用的功能,可以生成其正在執行的操作的執行時跟蹤資訊,這在嘗試跟蹤 DBI 程式中奇怪問題的過程中可以節省大量時間。您可以使用不同的值來設定跟蹤級別。這些值從 0 到 4 不等。值為 0 表示停用跟蹤,值為 4 表示生成完整的跟蹤。
禁止使用內插語句
強烈建議不要使用如下所示的內插語句:
while ($first_name = <>) {
my $sth = $dbh->prepare("SELECT *
FROM TEST_TABLE
WHERE FIRST_NAME = '$first_name'");
$sth->execute();
# and so on ...
}
因此,不要使用內插語句,而是使用繫結值來準備動態 SQL 語句。
Perl - CGI 程式設計
什麼是 CGI?
公共閘道器介面 (CGI) 是一組標準,定義瞭如何在 Web 伺服器和自定義指令碼之間交換資訊。
CGI 規範目前由 NCSA 維護,NCSA 對 CGI 的定義如下:
公共閘道器介面 (CGI) 是外部閘道器程式與資訊伺服器(例如 HTTP 伺服器)介面的標準。
當前版本為 CGI/1.1,CGI/1.2 正在開發中。
網頁瀏覽
為了理解 CGI 的概念,讓我們看看當我們點選網頁上提供的超連結來瀏覽特定網頁或 URL 時會發生什麼。
您的瀏覽器使用 HTTP 協議聯絡 Web 伺服器並請求 URL,即網頁檔名。
Web 伺服器將檢查 URL 並查詢請求的檔名。如果 Web 伺服器找到該檔案,則它會將檔案傳送回瀏覽器,無需進一步執行;否則,它會發送一條錯誤訊息,指示您請求的檔案錯誤。
Web 瀏覽器接收來自 Web 伺服器的響應,並顯示接收到的檔案內容或在找不到檔案的情況下顯示錯誤訊息。
但是,可以以這樣一種方式設定 HTTP 伺服器:每當請求某個目錄中的檔案時,該檔案不會被髮送回來;相反,它作為程式執行,該程式輸出的結果將被髮送回瀏覽器以顯示。這可以透過使用 Web 伺服器中提供的特殊功能來實現,該功能稱為公共閘道器介面或 CGI,並且伺服器執行以產生最終結果的此類程式稱為 CGI 指令碼。這些 CGI 程式可以是 PERL 指令碼、Shell 指令碼、C 或 C++ 程式等。
CGI 架構圖
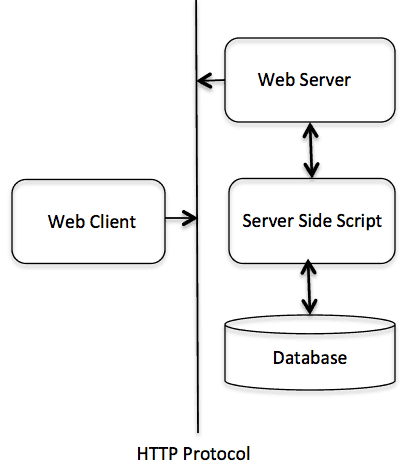
Web 伺服器支援和配置
在繼續進行 CGI 程式設計之前,請確保您的 Web 伺服器支援 CGI 功能,並且已配置為處理 CGI 程式。所有要由 Web 伺服器執行的 CGI 程式都儲存在預配置的目錄中。此目錄稱為 CGI 目錄,按照慣例,其名稱為 /cgi-bin。按照慣例,Perl CGI 檔案的副檔名為.cgi。
第一個 CGI 程式
這是一個簡單的連結,它連結到名為 hello.cgi 的 CGI 指令碼。此檔案已儲存在/cgi-bin/目錄中,其內容如下。在執行 CGI 程式之前,請確保已使用chmod 755 hello.cgi UNIX 命令更改檔案的模式。
#!/usr/bin/perl print "Content-type:text/html\r\n\r\n"; print '<html>'; print '<head>'; print '<title>Hello Word - First CGI Program</title>'; print '</head>'; print '<body>'; print '<h2>Hello Word! This is my first CGI program</h2>'; print '</body>'; print '</html>'; 1;
現在,如果您單擊hello.cgi連結,則請求將轉到 Web 伺服器,Web 伺服器在 /cgi-bin 目錄中搜索 hello.cgi,執行它,並將生成的任何結果傳送回 Web 瀏覽器,如下所示:
Hello Word! This is my first CGI program
這個 hello.cgi 指令碼是一個簡單的 Perl 指令碼,它將其輸出寫入 STDOUT 檔案(即螢幕)。有一個重要的額外功能,即要列印的第一行Content-type:text/html\r\n\r\n。此行被髮送回瀏覽器,並指定要在瀏覽器螢幕上顯示的內容型別。現在您一定已經理解了 CGI 的基本概念,您可以使用 Perl 編寫許多複雜的 CGI 程式。此指令碼還可以與任何其他外部系統互動以交換資訊,例如資料庫、Web 服務或任何其他複雜的介面。
理解 HTTP 頭
第一行Content-type:text/html\r\n\r\n是 HTTP 頭的一部分,它被髮送到瀏覽器,以便瀏覽器可以理解來自伺服器端的傳入內容。所有 HTTP 頭都將採用以下形式:
HTTP Field Name: Field Content
例如:
Content-type:text/html\r\n\r\n
還有一些其他重要的 HTTP 頭,您將在 CGI 程式設計中經常使用它們。
| 序號 | 頭 & 描述 |
|---|---|
| 1 | Content-type: 字串 定義返回內容格式的 MIME 字串。例如 Content-type:text/html |
| 2 | Expires: 日期字串 資訊變得無效的日期。瀏覽器應該使用它來決定何時需要重新整理頁面。有效的日期字串應採用 01 Jan 1998 12:00:00 GMT 格式。 |
| 3 | Location: URL 字串 應該返回的 URL,而不是請求的 URL。您可以使用此欄位將請求重定向到任何其他位置。 |
| 4 | Last-modified: 字串 檔案的上次修改日期。 |
| 5 | Content-length: 字串 返回資料的長度(以位元組為單位)。瀏覽器使用此值來報告檔案的估計下載時間。 |
| 6 | Set-Cookie: 字串 設定透過字串傳遞的 cookie |
CGI 環境變數
所有 CGI 程式都可以訪問以下環境變數。這些變數在編寫任何 CGI 程式時都起著重要作用。
| 序號 | 變數名稱 & 描述 |
|---|---|
| 1 | CONTENT_TYPE 內容的資料型別。當客戶端向伺服器傳送附加內容時使用。例如檔案上傳等。 |
| 2 | CONTENT_LENGTH 查詢資訊的長度。僅對 POST 請求可用 |
| 3 | HTTP_COOKIE 以鍵值對的形式返回設定的 cookie。 |
| 4 | HTTP_USER_AGENT User-Agent 請求頭欄位包含有關發起請求的使用者代理的資訊。這是 Web 瀏覽器的名稱。 |
| 5 | PATH_INFO CGI 指令碼的路徑。 |
| 6 | QUERY_STRING 使用 GET 方法請求傳送的 URL 編碼資訊。 |
| 7 | REMOTE_ADDR 發出請求的遠端主機的 IP 地址。這對於記錄或身份驗證目的很有用。 |
| 8 | REMOTE_HOST 發出請求的主機的完全限定名稱。如果此資訊不可用,則可以使用 REMOTE_ADDR 獲取 IR 地址。 |
| 9 | REQUEST_METHOD 用於發出請求的方法。最常用的方法是 GET 和 POST。 |
| 10 | SCRIPT_FILENAME CGI 指令碼的完整路徑。 |
| 11 | SCRIPT_NAME CGI 指令碼的名稱。 |
| 12 | SERVER_NAME 伺服器的主機名或 IP 地址。 |
| 13 | SERVER_SOFTWARE 伺服器執行的軟體的名稱和版本。 |
這是一個小的 CGI 程式,用於列出 Web 伺服器支援的所有 CGI 變數。單擊此連結檢視結果 獲取環境變數
#!/usr/bin/perl
print "Content-type: text/html\n\n";
print "<font size=+1>Environment</font>\n";
foreach (sort keys %ENV) {
print "<b>$_</b>: $ENV{$_}<br>\n";
}
1;
如何彈出“檔案下載”對話方塊?
有時您希望提供一個選項,使用者單擊連結後會彈出一個“檔案下載”對話方塊,而不是顯示實際內容。這很容易實現,並且可以透過 HTTP 頭實現。
此 HTTP 頭將與上一節中提到的頭不同。例如,如果您想使FileName檔案可從給定連結下載,則其語法如下:
#!/usr/bin/perl
# HTTP Header
print "Content-Type:application/octet-stream; name = \"FileName\"\r\n";
print "Content-Disposition: attachment; filename = \"FileName\"\r\n\n";
# Actual File Content will go hear.
open( FILE, "<FileName" );
while(read(FILE, $buffer, 100) ) {
print("$buffer");
}
GET 和 POST 方法
您肯定遇到過許多需要將資訊從瀏覽器傳遞到 Web 伺服器,最終傳遞到處理您請求的 CGI 程式的情況。瀏覽器最常用兩種方法將資訊傳遞到 Web 伺服器。這兩種方法是 **GET** 方法和 **POST** 方法。讓我們逐一檢查它們。
使用 GET 方法傳遞資訊
GET 方法將編碼後的使用者資訊附加到頁面 URL 本身。頁面和編碼後的資訊以 ? 字元分隔,如下所示:
http://www.test.com/cgi-bin/hello.cgi?key1=value1&key2=value2
GET 方法是將資訊從瀏覽器傳遞到 Web 伺服器的預設方法,它會生成一個長字串,該字串顯示在瀏覽器的“位置”框中。如果您需要將密碼或其他敏感資訊傳遞到伺服器,則絕不應使用 GET 方法。GET 方法有大小限制:請求字串中只能傳遞 1024 個字元。
此資訊使用 **QUERY_STRING** 標頭傳遞,並且可以透過 QUERY_STRING 環境變數在您的 CGI 程式中訪問,您可以解析此變數並在 CGI 程式中使用它。
您可以透過簡單地連線鍵值對以及任何 URL 來傳遞資訊,也可以使用 HTML <FORM> 標籤使用 GET 方法傳遞資訊。
簡單的 URL 示例:GET 方法
這是一個簡單的 URL,它將使用 GET 方法將兩個值傳遞給 hello_get.cgi 程式。
https://tutorialspoint.tw/cgi-bin/hello_get.cgi?first_name=ZARA&last_name=ALI以下是處理 Web 瀏覽器給出的輸入的 **hello_get.cgi** 指令碼。
#!/usr/bin/perl
local ($buffer, @pairs, $pair, $name, $value, %FORM);
# Read in text
$ENV{'REQUEST_METHOD'} =~ tr/a-z/A-Z/;
if ($ENV{'REQUEST_METHOD'} eq "GET") {
$buffer = $ENV{'QUERY_STRING'};
}
# Split information into name/value pairs
@pairs = split(/&/, $buffer);
foreach $pair (@pairs) {
($name, $value) = split(/=/, $pair);
$value =~ tr/+/ /;
$value =~ s/%(..)/pack("C", hex($1))/eg;
$FORM{$name} = $value;
}
$first_name = $FORM{first_name};
$last_name = $FORM{last_name};
print "Content-type:text/html\r\n\r\n";
print "<html>";
print "<head>";
print "<title>Hello - Second CGI Program</title>";
print "</head>";
print "<body>";
print "<h2>Hello $first_name $last_name - Second CGI Program</h2>";
print "</body>";
print "</html>";
1;
簡單的表單示例:GET 方法
這是一個簡單的示例,它使用 HTML 表單和提交按鈕傳遞兩個值。我們將使用相同的 CGI 指令碼 hello_get.cgi 來處理此輸入。
<FORM action = "/cgi-bin/hello_get.cgi" method = "GET"> First Name: <input type = "text" name = "first_name"> <br> Last Name: <input type = "text" name = "last_name"> <input type = "submit" value = "Submit"> </FORM>
這是上述表單程式碼的實際輸出。現在您可以輸入名字和姓氏,然後單擊提交按鈕檢視結果。
使用 POST 方法傳遞資訊
將資訊傳遞到 CGI 程式的一種更可靠的方法是 **POST** 方法。此方法以與 GET 方法完全相同的方式打包資訊,但它不是在 URL 中的 **?** 後將其作為文字字串傳送,而是將其作為 HTTP 標頭的一部分作為單獨的訊息傳送。Web 伺服器以標準輸入的形式將此訊息提供給 CGI 指令碼。
以下是修改後的 **hello_post.cgi** 指令碼,用於處理 Web 瀏覽器給出的輸入。此指令碼將處理 GET 和 POST 方法。
#!/usr/bin/perl
local ($buffer, @pairs, $pair, $name, $value, %FORM);
# Read in text
$ENV{'REQUEST_METHOD'} =~ tr/a-z/A-Z/;
if ($ENV{'REQUEST_METHOD'} eq "POST") {
read(STDIN, $buffer, $ENV{'CONTENT_LENGTH'});
} else {
$buffer = $ENV{'QUERY_STRING'};
}
# Split information into name/value pairs
@pairs = split(/&/, $buffer);
foreach $pair (@pairs) {
($name, $value) = split(/=/, $pair);
$value =~ tr/+/ /;
$value =~ s/%(..)/pack("C", hex($1))/eg;
$FORM{$name} = $value;
}
$first_name = $FORM{first_name};
$last_name = $FORM{last_name};
print "Content-type:text/html\r\n\r\n";
print "<html>";
print "<head>";
print "<title>Hello - Second CGI Program</title>";
print "</head>";
print "<body>";
print "<h2>Hello $first_name $last_name - Second CGI Program</h2>";
print "</body>";
print "</html>";
1;
讓我們再次採用與上述相同的示例,該示例使用 HTML 表單和提交按鈕傳遞兩個值。我們將使用 CGI 指令碼 hello_post.cgi 來處理此輸入。
<FORM action = "/cgi-bin/hello_post.cgi" method = "POST"> First Name: <input type = "text" name = "first_name"> <br> Last Name: <input type = "text" name = "last_name"> <input type = "submit" value = "Submit"> </FORM>
這是上述表單程式碼的實際輸出,您可以輸入名字和姓氏,然後單擊提交按鈕檢視結果。
將複選框資料傳遞到 CGI 程式
當需要選擇多個選項時,使用複選框。這是一個帶有兩個複選框的表單的 HTML 程式碼示例。
<form action = "/cgi-bin/checkbox.cgi" method = "POST" target = "_blank"> <input type = "checkbox" name = "maths" value = "on"> Maths <input type = "checkbox" name = "physics" value = "on"> Physics <input type = "submit" value = "Select Subject"> </form>
此程式碼的結果是以下表單:
以下是處理 Web 瀏覽器為單選按鈕提供的輸入的 **checkbox.cgi** 指令碼。
#!/usr/bin/perl
local ($buffer, @pairs, $pair, $name, $value, %FORM);
# Read in text
$ENV{'REQUEST_METHOD'} =~ tr/a-z/A-Z/;
if ($ENV{'REQUEST_METHOD'} eq "POST") {
read(STDIN, $buffer, $ENV{'CONTENT_LENGTH'});
} else {
$buffer = $ENV{'QUERY_STRING'};
}
# Split information into name/value pairs
@pairs = split(/&/, $buffer);
foreach $pair (@pairs) {
($name, $value) = split(/=/, $pair);
$value =~ tr/+/ /;
$value =~ s/%(..)/pack("C", hex($1))/eg;
$FORM{$name} = $value;
}
if( $FORM{maths} ) {
$maths_flag ="ON";
} else {
$maths_flag ="OFF";
}
if( $FORM{physics} ) {
$physics_flag ="ON";
} else {
$physics_flag ="OFF";
}
print "Content-type:text/html\r\n\r\n";
print "<html>";
print "<head>";
print "<title>Checkbox - Third CGI Program</title>";
print "</head>";
print "<body>";
print "<h2> CheckBox Maths is : $maths_flag</h2>";
print "<h2> CheckBox Physics is : $physics_flag</h2>";
print "</body>";
print "</html>";
1;
將單選按鈕資料傳遞到 CGI 程式
當只需要選擇一個選項時,使用單選按鈕。這是一個帶有兩個單選按鈕的表單的 HTML 程式碼示例:
<form action = "/cgi-bin/radiobutton.cgi" method = "POST" target = "_blank"> <input type = "radio" name = "subject" value = "maths"> Maths <input type = "radio" name = "subject" value = "physics"> Physics <input type = "submit" value = "Select Subject"> </form>
此程式碼的結果是以下表單:
以下是處理 Web 瀏覽器為單選按鈕提供的輸入的 **radiobutton.cgi** 指令碼。
#!/usr/bin/perl
local ($buffer, @pairs, $pair, $name, $value, %FORM);
# Read in text
$ENV{'REQUEST_METHOD'} =~ tr/a-z/A-Z/;
if ($ENV{'REQUEST_METHOD'} eq "POST") {
read(STDIN, $buffer, $ENV{'CONTENT_LENGTH'});
} else {
$buffer = $ENV{'QUERY_STRING'};
}
# Split information into name/value pairs
@pairs = split(/&/, $buffer);
foreach $pair (@pairs) {
($name, $value) = split(/=/, $pair);
$value =~ tr/+/ /;
$value =~ s/%(..)/pack("C", hex($1))/eg;
$FORM{$name} = $value;
}
$subject = $FORM{subject};
print "Content-type:text/html\r\n\r\n";
print "<html>";
print "<head>";
print "<title>Radio - Fourth CGI Program</title>";
print "</head>";
print "<body>";
print "<h2> Selected Subject is $subject</h2>";
print "</body>";
print "</html>";
1;
將文字區域資料傳遞到 CGI 程式
當必須將多行文字傳遞到 CGI 程式時,使用文字區域元素。這是一個帶有文字區域框的表單的 HTML 程式碼示例:
<form action = "/cgi-bin/textarea.cgi" method = "POST" target = "_blank"> <textarea name = "textcontent" cols = 40 rows = 4> Type your text here... </textarea> <input type = "submit" value = "Submit"> </form>
此程式碼的結果是以下表單:
以下是處理 Web 瀏覽器提供的輸入的 **textarea.cgi** 指令碼。
#!/usr/bin/perl
local ($buffer, @pairs, $pair, $name, $value, %FORM);
# Read in text
$ENV{'REQUEST_METHOD'} =~ tr/a-z/A-Z/;
if ($ENV{'REQUEST_METHOD'} eq "POST") {
read(STDIN, $buffer, $ENV{'CONTENT_LENGTH'});
} else {
$buffer = $ENV{'QUERY_STRING'};
}
# Split information into name/value pairs
@pairs = split(/&/, $buffer);
foreach $pair (@pairs) {
($name, $value) = split(/=/, $pair);
$value =~ tr/+/ /;
$value =~ s/%(..)/pack("C", hex($1))/eg;
$FORM{$name} = $value;
}
$text_content = $FORM{textcontent};
print "Content-type:text/html\r\n\r\n";
print "<html>";
print "<head>";
print "<title>Text Area - Fifth CGI Program</title>";
print "</head>";
print "<body>";
print "<h2> Entered Text Content is $text_content</h2>";
print "</body>";
print "</html>";
1;
將下拉框資料傳遞到 CGI 程式
當有很多選項可用但只選擇一兩個時,使用下拉框。這是一個帶有下拉框的表單的 HTML 程式碼示例
<form action = "/cgi-bin/dropdown.cgi" method = "POST" target = "_blank"> <select name = "dropdown"> <option value = "Maths" selected>Maths</option> <option value = "Physics">Physics</option> </select> <input type = "submit" value = "Submit"> </form>
此程式碼的結果是以下表單:
以下是處理 Web 瀏覽器提供的輸入的 **dropdown.cgi** 指令碼。
#!/usr/bin/perl
local ($buffer, @pairs, $pair, $name, $value, %FORM);
# Read in text
$ENV{'REQUEST_METHOD'} =~ tr/a-z/A-Z/;
if ($ENV{'REQUEST_METHOD'} eq "POST") {
read(STDIN, $buffer, $ENV{'CONTENT_LENGTH'});
} else {
$buffer = $ENV{'QUERY_STRING'};
}
# Split information into name/value pairs
@pairs = split(/&/, $buffer);
foreach $pair (@pairs) {
($name, $value) = split(/=/, $pair);
$value =~ tr/+/ /;
$value =~ s/%(..)/pack("C", hex($1))/eg;
$FORM{$name} = $value;
}
$subject = $FORM{dropdown};
print "Content-type:text/html\r\n\r\n";
print "<html>";
print "<head>";
print "<title>Dropdown Box - Sixth CGI Program</title>";
print "</head>";
print "<body>";
print "<h2> Selected Subject is $subject</h2>";
print "</body>";
print "</html>";
1;
在 CGI 中使用 Cookie
HTTP 協議是一種無狀態協議。但是對於商業網站來說,需要在不同的頁面之間維護會話資訊。例如,一個使用者註冊在跨越多個頁面的事務之後結束。但是如何跨所有網頁維護使用者的會話資訊呢?
在許多情況下,使用 Cookie 是記住和跟蹤偏好、購買、佣金以及其他需要改善訪客體驗或網站統計資訊的資訊的最有效方法。
工作原理
您的伺服器以 Cookie 的形式向訪問者的瀏覽器傳送一些資料。瀏覽器可能會接受 Cookie。如果接受,它將作為純文字記錄儲存在訪問者的硬碟驅動器上。現在,當訪問者到達您網站上的另一個頁面時,Cookie 可供檢索。檢索後,您的伺服器就知道/記住儲存的內容。
Cookie 是 5 個變長欄位的純文字資料記錄:
**Expires** - Cookie 將過期的日期。如果為空,則 Cookie 將在訪問者退出瀏覽器時過期。
**Domain** - 您網站的域名。
**Path** - 設定 Cookie 的目錄或網頁的路徑。如果您想從任何目錄或頁面檢索 Cookie,則可以留空。
**Secure** - 如果此欄位包含單詞“secure”,則只能使用安全伺服器檢索 Cookie。如果此欄位為空,則不存在此類限制。
**Name = Value** - Cookie 以鍵值對的形式設定和檢索。
設定 Cookie
向瀏覽器傳送 Cookie 非常容易。這些 Cookie 將與 HTTP 標頭一起傳送。假設您想將 UserID 和 Password 設定為 Cookie。因此,操作步驟如下:
#!/usr/bin/perl print "Set-Cookie:UserID = XYZ;\n"; print "Set-Cookie:Password = XYZ123;\n"; print "Set-Cookie:Expires = Tuesday, 31-Dec-2007 23:12:40 GMT";\n"; print "Set-Cookie:Domain = www.tutorialspoint.com;\n"; print "Set-Cookie:Path = /perl;\n"; print "Content-type:text/html\r\n\r\n"; ...........Rest of the HTML Content goes here....
我們在這裡使用 **Set-Cookie** HTTP 標頭來設定 Cookie。可選設定 Cookie 屬性,如 Expires、Domain 和 Path。重要的是要注意,Cookie 是在傳送魔法行 **"Content-type:text/html\r\n\r\n"** 之前設定的。
檢索 Cookie
檢索所有已設定的 Cookie 非常容易。Cookie 儲存在 CGI 環境變數 HTTP_COOKIE 中,它們將具有以下形式。
key1 = value1;key2 = value2;key3 = value3....
這是一個關於如何檢索 Cookie 的示例。
#!/usr/bin/perl
$rcvd_cookies = $ENV{'HTTP_COOKIE'};
@cookies = split /;/, $rcvd_cookies;
foreach $cookie ( @cookies ) {
($key, $val) = split(/=/, $cookie); # splits on the first =.
$key =~ s/^\s+//;
$val =~ s/^\s+//;
$key =~ s/\s+$//;
$val =~ s/\s+$//;
if( $key eq "UserID" ) {
$user_id = $val;
} elsif($key eq "Password") {
$password = $val;
}
}
print "User ID = $user_id\n";
print "Password = $password\n";
如果在呼叫檢索 Cookie 指令碼之前已設定上述 Cookie,則將產生以下結果。
User ID = XYZ Password = XYZ123
CGI 模組和庫
您會在網際網路上找到許多內建模組,這些模組為您提供可在 CGI 程式中直接使用的函式。以下是重要的模組。
Perl - 包和模組
什麼是包?
**package** 語句將當前命名上下文切換到指定的名稱空間(符號表)。因此:
包是存在於其自身名稱空間中的一組程式碼。
名稱空間是唯一變數名稱的命名集合(也稱為符號表)。
名稱空間可防止包之間發生變數名稱衝突。
包支援構建模組,使用這些模組時不會破壞模組自身名稱空間之外的變數和函式。
包一直有效,直到呼叫另一個 package 語句,或者直到當前塊或檔案的結尾。
您可以使用 **::** 包限定符顯式引用包中的變數。
以下示例在一個檔案中包含 main 和 Foo 包。這裡使用了特殊變數 __PACKAGE__ 來列印包名。
#!/usr/bin/perl # This is main package $i = 1; print "Package name : " , __PACKAGE__ , " $i\n"; package Foo; # This is Foo package $i = 10; print "Package name : " , __PACKAGE__ , " $i\n"; package main; # This is again main package $i = 100; print "Package name : " , __PACKAGE__ , " $i\n"; print "Package name : " , __PACKAGE__ , " $Foo::i\n"; 1;
執行上述程式碼時,會產生以下結果:
Package name : main 1 Package name : Foo 10 Package name : main 100 Package name : main 10
BEGIN 和 END 塊
您可以定義任意數量名為 BEGIN 和 END 的程式碼塊,它們分別充當建構函式和解構函式。
BEGIN { ... }
END { ... }
BEGIN { ... }
END { ... }
每個 **BEGIN** 塊在 Perl 指令碼載入和編譯後但在執行任何其他語句之前執行。
每個 END 塊在 Perl 直譯器退出之前執行。
BEGIN 和 END 塊在建立 Perl 模組時特別有用。
以下示例顯示了它的用法:
#!/usr/bin/perl
package Foo;
print "Begin and Block Demo\n";
BEGIN {
print "This is BEGIN Block\n"
}
END {
print "This is END Block\n"
}
1;
執行上述程式碼時,會產生以下結果:
This is BEGIN Block Begin and Block Demo This is END Block
什麼是 Perl 模組?
Perl 模組是在庫檔案中定義的可重用包,其名稱與包的名稱相同,副檔名為 .pm。
名為 **Foo.pm** 的 Perl 模組檔案可能包含如下語句。
#!/usr/bin/perl
package Foo;
sub bar {
print "Hello $_[0]\n"
}
sub blat {
print "World $_[0]\n"
}
1;
關於 Perl 模組的一些重要點
函式 **require** 和 **use** 將載入模組。
兩者都使用 **@INC** 中的搜尋路徑列表來查詢模組。
這兩個函式 **require** 和 **use** 都呼叫 **eval** 函式來處理程式碼。
底部的 **1;** 使 eval 的計算結果為 TRUE(因此不會失敗)。
Require 函式
可以透過呼叫 **require** 函式來載入模組,如下所示:
#!/usr/bin/perl require Foo; Foo::bar( "a" ); Foo::blat( "b" );
您可能已經注意到,必須完全限定子程式名稱才能呼叫它們。最好啟用子程式 **bar** 和 **blat** 匯入到我們自己的名稱空間中,這樣我們就不必使用 Foo:: 限定符。
Use 函式
可以透過呼叫 **use** 函式來載入模組。
#!/usr/bin/perl use Foo; bar( "a" ); blat( "b" );
請注意,我們不必完全限定包的函式名。**use** 函式將在模組中新增一些語句後,從模組匯出符號列表。
require Exporter; @ISA = qw(Exporter);
然後,透過填充名為 **@EXPORT** 的列表變數來提供符號列表(標量、列表、雜湊、子程式等):例如:
package Module;
require Exporter;
@ISA = qw(Exporter);
@EXPORT = qw(bar blat);
sub bar { print "Hello $_[0]\n" }
sub blat { print "World $_[0]\n" }
sub splat { print "Not $_[0]\n" } # Not exported!
1;
建立 Perl 模組樹
當您準備好釋出 Perl 模組時,有一種建立 Perl 模組樹的標準方法。這是使用 **h2xs** 實用程式完成的。此實用程式隨 Perl 一起提供。以下是使用 h2xs 的語法:
$h2xs -AX -n ModuleName
例如,如果您的模組位於 **Person.pm** 檔案中,則只需發出以下命令:
$h2xs -AX -n Person
這將產生以下結果:
Writing Person/lib/Person.pm Writing Person/Makefile.PL Writing Person/README Writing Person/t/Person.t Writing Person/Changes Writing Person/MANIFEST
以下是這些選項的描述:
**-A** 省略自動載入器程式碼(最適合定義大量不常用子程式的模組)。
-X 忽略 XS 元素(eXternal Subroutine,其中 eXternal 指 Perl 之外的外部程式,即 C 程式)。
-n 指定模組名稱。
因此,上述命令會在 Person 目錄內建立如下結構。實際結果如上所示。
- 變更
- Makefile.PL
- MANIFEST(包含包中所有檔案的列表)
- README
- t/(測試檔案)
- lib/(實際原始碼位於此處)
最後,您需要將此目錄結構打包成 Person.tar.gz 檔案,然後即可釋出。您需要更新 README 檔案,新增正確的安裝說明。您也可以在 t 目錄中提供一些測試示例檔案。
安裝 Perl 模組
下載 tar.gz 格式的 Perl 模組。使用以下步驟安裝任何已下載為 Person.tar.gz 檔案的 Perl 模組 Person.pm。
tar xvfz Person.tar.gz cd Person perl Makefile.PL make make install
Perl 直譯器有一個目錄列表,用於搜尋模組(全域性陣列 @INC)。
Perl - 程序管理
您可以使用 Perl 以各種方式根據您的需求建立新程序。本教程將列出建立和管理 Perl 程序的一些重要且最常用的方法。
您可以使用特殊變數 $$ 或 $PROCESS_ID 獲取當前程序 ID。
使用任何上述方法建立的每個程序,都維護其自身的虛擬環境,位於 %ENV 變數中。
exit() 函式始終只退出執行此函式的子程序,除非所有正在執行的子程序都已退出,否則主程序不會整體退出。
所有開啟的控制代碼在子程序中都會被 dup(),因此在一個程序中關閉任何控制代碼都不會影響其他程序。
反引號運算子
執行任何 Unix 命令最簡單的方法是使用反引號運算子。您只需將命令放在反引號運算子內,這將導致命令執行並返回其結果,該結果可以按如下方式儲存:
#!/usr/bin/perl
@files = `ls -l`;
foreach $file (@files) {
print $file;
}
1;
執行上述程式碼時,它將列出當前目錄中所有可用檔案和目錄。
drwxr-xr-x 3 root root 4096 Sep 14 06:46 9-14 drwxr-xr-x 4 root root 4096 Sep 13 07:54 android -rw-r--r-- 1 root root 574 Sep 17 15:16 index.htm drwxr-xr-x 3 544 401 4096 Jul 6 16:49 MIME-Lite-3.01 -rw-r--r-- 1 root root 71 Sep 17 15:16 test.pl drwx------ 2 root root 4096 Sep 17 15:11 vAtrJdy
system() 函式
您也可以使用 system() 函式執行任何 Unix 命令,其輸出將轉到 perl 指令碼的輸出。預設情況下,它是螢幕,即 STDOUT,但您可以使用重定向運算子 > 將其重定向到任何檔案:
#!/usr/bin/perl system( "ls -l") 1;
執行上述程式碼時,它將列出當前目錄中所有可用檔案和目錄。
drwxr-xr-x 3 root root 4096 Sep 14 06:46 9-14 drwxr-xr-x 4 root root 4096 Sep 13 07:54 android -rw-r--r-- 1 root root 574 Sep 17 15:16 index.htm drwxr-xr-x 3 544 401 4096 Jul 6 16:49 MIME-Lite-3.01 -rw-r--r-- 1 root root 71 Sep 17 15:16 test.pl drwx------ 2 root root 4096 Sep 17 15:11 vAtrJdy
如果您的命令包含 shell 環境變數(如 $PATH 或 $HOME),請務必小心。嘗試以下三種情況:
#!/usr/bin/perl
$PATH = "I am Perl Variable";
system('echo $PATH'); # Treats $PATH as shell variable
system("echo $PATH"); # Treats $PATH as Perl variable
system("echo \$PATH"); # Escaping $ works.
1;
執行上述程式碼時,產生的結果取決於 shell 變數 $PATH 中設定的內容。
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin I am Perl Variable /usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin
fork() 函式
Perl 提供一個 fork() 函式,它對應於同名的 Unix 系統呼叫。在大多數支援 fork() 系統呼叫的類 Unix 平臺上,Perl 的 fork() 只是簡單地呼叫它。在某些平臺(如 Windows)上,fork() 系統呼叫不可用,Perl 可以構建為在直譯器級別模擬 fork()。
fork() 函式用於克隆當前程序。此呼叫建立一個新的程序,執行相同的程式,並在同一位置執行。它將子程序 pid 返回給父程序,將 0 返回給子程序,如果 fork 不成功則返回 undef。
您可以在程序中使用 exec() 函式啟動請求的可執行檔案,該檔案將在單獨的程序區域中執行,exec() 將等待其完成,然後使用與該程序相同的退出狀態退出。
#!/usr/bin/perl
if(!defined($pid = fork())) {
# fork returned undef, so unsuccessful
die "Cannot fork a child: $!";
} elsif ($pid == 0) {
print "Printed by child process\n";
exec("date") || die "can't exec date: $!";
} else {
# fork returned 0 nor undef
# so this branch is parent
print "Printed by parent process\n";
$ret = waitpid($pid, 0);
print "Completed process id: $ret\n";
}
1;
執行上述程式碼時,會產生以下結果:
Printed by parent process Printed by child process Tue Sep 17 15:41:08 CDT 2013 Completed process id: 17777
wait() 和 waitpid() 可以作為 fork() 返回的偽程序 ID 傳遞。這些呼叫將正確等待偽程序的終止並返回其狀態。如果您使用 fork() 但從未使用 waitpid() 函式等待子程序,則會累積殭屍程序。在 Unix 系統上,您可以透過將 $SIG{CHLD} 設定為 "IGNORE" 來避免這種情況,如下所示:
#!/usr/bin/perl
local $SIG{CHLD} = "IGNORE";
if(!defined($pid = fork())) {
# fork returned undef, so unsuccessful
die "Cannot fork a child: $!";
} elsif ($pid == 0) {
print "Printed by child process\n";
exec("date") || die "can't exec date: $!";
} else {
# fork returned 0 nor undef
# so this branch is parent
print "Printed by parent process\n";
$ret = waitpid($pid, 0);
print "Completed process id: $ret\n";
}
1;
執行上述程式碼時,會產生以下結果:
Printed by parent process Printed by child process Tue Sep 17 15:44:07 CDT 2013 Completed process id: -1
kill() 函式
Perl kill('KILL', (Process List)) 函式可用於透過向其傳遞 fork() 返回的 ID 來終止偽程序。
請注意,在偽程序上使用 kill('KILL', (Process List)) 通常會導致記憶體洩漏,因為實現偽程序的執行緒沒有機會清理其資源。
您可以使用 kill() 函式向目標程序傳送任何其他訊號,例如,以下操作將向程序 ID 104 和 102 傳送 SIGINT:
#!/usr/bin/perl
kill('INT', 104, 102);
1;
Perl - 內嵌文件
您可以在 Perl 模組和指令碼中嵌入 Pod(Plain Old Documentation)文件。以下是使用 Perl 程式碼中嵌入式文件的規則:
以空行開頭,以 =head1 命令開頭,以 =cut 命令結尾。
Perl 將忽略您在程式碼中輸入的 Pod 文字。以下是使用 Perl 程式碼中嵌入式文件的簡單示例:
#!/usr/bin/perl print "Hello, World\n"; =head1 Hello, World Example This example demonstrate very basic syntax of Perl. =cut print "Hello, Universe\n";
執行上述程式碼時,會產生以下結果:
Hello, World Hello, Universe
如果您要將 Pod 放在檔案的末尾,並且正在使用 __END__ 或 __DATA__ 分隔符,請確保在第一個 Pod 命令之前新增一個空行,否則如果沒有在 =head1 之前新增空行,許多轉換器將無法識別 =head1 作為 Pod 塊的起始標記。
#!/usr/bin/perl
print "Hello, World\n";
while(<DATA>) {
print $_;
}
__END__
=head1 Hello, World Example
This example demonstrate very basic syntax of Perl.
print "Hello, Universe\n";
執行上述程式碼時,會產生以下結果:
Hello, World =head1 Hello, World Example This example demonstrate very basic syntax of Perl. print "Hello, Universe\n";
讓我們再舉一個不讀取 DATA 部分的相同程式碼的例子:
#!/usr/bin/perl print "Hello, World\n"; __END__ =head1 Hello, World Example This example demonstrate very basic syntax of Perl. print "Hello, Universe\n";
執行上述程式碼時,會產生以下結果:
Hello, World
什麼是 POD?
Pod 是一種易於使用的標記語言,用於編寫 Perl、Perl 程式和 Perl 模組的文件。有各種轉換器可用於將 Pod 轉換為各種格式,如純文字、HTML、手冊頁等等。Pod 標記由三種基本型別的段落組成:
普通段落 - 您可以在普通段落中使用格式程式碼,用於粗體、斜體、程式碼樣式、超連結等等。
逐欄位落 - 逐欄位落通常用於呈現程式碼塊或不需要任何特殊解析或格式化的其他文字,並且不應換行。
命令段落 - 命令段落用於對整塊文字進行特殊處理,通常作為標題或列表的一部分。所有命令段落都以 = 開頭,後跟一個識別符號,然後是命令可以隨意使用的任意文字。當前識別的命令是:
=pod =head1 Heading Text =head2 Heading Text =head3 Heading Text =head4 Heading Text =over indentlevel =item stuff =back =begin format =end format =for format text... =encoding type =cut
POD 示例
考慮以下 POD:
=head1 SYNOPSIS Copyright 2005 [TUTORIALSOPOINT]. =cut
您可以使用 Linux 上可用的 pod2html 實用程式將上述 POD 轉換為 HTML,因此它將產生以下結果:
版權所有 2005 [TUTORIALSOPOINT]。
接下來,考慮以下示例:
=head2 An Example List =over 4 =item * This is a bulleted list. =item * Here's another item. =back =begin html <p> Here's some embedded HTML. In this block I can include images, apply <span style="color: green"> styles</span>, or do anything else I can do with HTML. pod parsers that aren't outputting HTML will completely ignore it. </p> =end html
當您使用 pod2html 將上述 POD 轉換為 HTML 時,它將產生以下結果:
An Example List This is a bulleted list. Here's another item. Here's some embedded HTML. In this block I can include images, apply styles, or do anything else I can do with HTML. pod parsers that aren't outputting HTML will completely ignore it.
Perl - 函式引用
以下是標準 Perl 支援的所有重要函式的列表。
abs - 絕對值函式
accept - 接受傳入的套接字連線
alarm - 安排 SIGALRM
atan2 - Y/X 的反正切值,範圍為 -PI 到 PI
bind - 將地址繫結到套接字
binmode - 為 I/O 準備二進位制檔案
bless - 建立物件
caller - 獲取當前子例程呼叫的上下文
chdir - 更改當前工作目錄
chmod - 更改檔案列表的許可權
chomp - 從字串中刪除尾隨記錄分隔符
chop - 從字串中刪除最後一個字元
chown - 更改檔案列表的所有權
chr - 獲取此數字表示的字元
chroot - 使目錄成為路徑查詢的新根目錄
close - 關閉檔案(或管道或套接字)控制代碼
closedir - 關閉目錄控制代碼
connect - 連線到遠端套接字
continue - while 或 foreach 中可選的尾隨塊
cos - 餘弦函式
crypt - 單向密碼式加密
dbmclose - 斷開與繫結到 dbm 檔案的連線
dbmopen - 建立與繫結到 dbm 檔案的連線
defined - 測試值、變數或函式是否已定義
delete - 從雜湊中刪除值
die - 丟擲異常或退出
do - 將 BLOCK 轉換為 TERM
dump - 建立立即核心轉儲
each - 從雜湊中檢索下一個鍵/值對
endgrent - 完成使用組檔案
endhostent - 完成使用主機檔案
endnetent - 完成使用網路檔案
endprotoent - 完成使用協議檔案
endpwent - 完成使用 passwd 檔案
endservent - 完成使用服務檔案
eof - 測試檔案控制代碼是否已結束
eval - 捕獲異常或編譯和執行程式碼
exec - 放棄此程式以執行另一個程式
exists - 測試雜湊鍵是否存在
exit - 終止此程式
exp - 將 I
提升到冪 fcntl - 檔案控制系統呼叫
fileno - 從檔案控制代碼返回檔案描述符
flock - 使用建議鎖鎖定整個檔案
fork - 建立一個新的程序,與當前程序相同
format - 宣告一個圖片格式,供 write() 函式使用
formline - 用於格式的內部函式
getc - 從檔案控制代碼獲取下一個字元
getgrent - 獲取下一個組記錄
getgrgid - 給定組使用者 ID 獲取組記錄
getgrnam - 給定組名稱獲取組記錄
gethostbyaddr - 給定地址獲取主機記錄
gethostbyname - 給定名稱獲取主機記錄
gethostent - 獲取下一個主機記錄
getlogin - 返回在此 tty 上登入的使用者
getnetbyaddr - 給定地址獲取網路記錄
getnetbyname - 給定名稱獲取網路記錄
getnetent - 獲取下一個網路記錄
getpeername - 查詢套接字連線的另一端
getpgrp - 獲取程序組
getppid - 獲取父程序 ID
getpriority - 獲取當前的 nice 值
getprotobyname - 給定名稱獲取協議記錄
getprotobynumber - 給定數字協議獲取協議記錄
getprotoent - 獲取下一個協議記錄
getpwent - 獲取下一個 passwd 記錄
getpwnam - 給定使用者名稱獲取 passwd 記錄
getpwuid - 給定使用者 ID 獲取 passwd 記錄
getservbyname - 給定名稱獲取服務記錄
getservbyport - 給定數字埠獲取服務記錄
getservent - 獲取下一個服務記錄
getsockname - 檢索給定套接字的 sockaddr
getsockopt - 獲取給定套接字的套接字選項
glob - 使用萬用字元展開檔名
gmtime - 使用格林威治時間格式將 UNIX 時間轉換為記錄或字串。
goto - 建立義大利麵條式程式碼
grep - 在列表中查詢滿足給定條件的元素
hex - 將字串轉換為十六進位制數
import - 將模組的名稱空間匯入到自己的名稱空間中
index - 在字串中查詢子字串
int - 獲取數字的整數部分
ioctl - 系統相關的裝置控制系統呼叫
join - 使用分隔符將列表連線成字串
keys - 從雜湊中檢索索引列表
kill - 向程序或程序組傳送訊號
last - 提早退出程式碼塊
lc - 返回字串的小寫版本
lcfirst - 返回僅將第一個字母轉換為小寫的字串
length - 返回字串的位元組數
link - 在檔案系統中建立一個硬連結
listen - 將套接字註冊為伺服器
local - 為全域性變數建立臨時值(動態作用域)
localtime - 使用本地時間將UNIX時間轉換為記錄或字串
lock - 獲取變數、子程式或方法的執行緒鎖
log - 獲取數字的自然對數
lstat - 獲取符號連結的狀態資訊
m - 使用正則表示式模式匹配字串
map - 將更改應用於列表,以獲取包含更改的新列表
mkdir - 建立目錄
msgctl - SysV IPC 訊息控制操作
msgget - 獲取 SysV IPC 訊息佇列
msgrcv - 從訊息佇列接收 SysV IPC 訊息
msgsnd - 向訊息佇列傳送 SysV IPC 訊息
my - 宣告和賦值區域性變數(詞法作用域)
next - 提早迭代程式碼塊
no - 在編譯時取消匯入某些模組符號或語義
oct - 將字串轉換為八進位制數
open - 開啟檔案、管道或描述符
opendir - 開啟目錄
ord - 查詢字元的數字表示
our - 宣告和賦值包變數(詞法作用域)
pack - 將列表轉換為二進位制表示
package - 宣告單獨的全域性名稱空間
pipe - 開啟一對連線的檔案控制代碼
pop - 從陣列中移除最後一個元素並返回它
pos - 查詢或設定最後/下一個 m//g 搜尋的偏移量
print - 將列表輸出到檔案控制代碼
printf - 將格式化的列表輸出到檔案控制代碼
prototype - 獲取子程式的原型(如果有)
push - 將一個或多個元素附加到陣列
q - 單引號字串
qq - 雙引號字串
qr - 編譯模式
quotemeta - 轉義正則表示式特殊字元
qw - 引用單詞列表
qx - 反引號引用字串
rand - 獲取下一個偽隨機數
read - 從檔案控制代碼進行固定長度的緩衝輸入
readdir - 從目錄控制代碼獲取目錄項
readline - 從檔案中獲取記錄
readlink - 確定符號連結指向的位置
readpipe - 執行系統命令並收集標準輸出
recv - 透過套接字接收訊息
redo - 重新開始本次迴圈迭代
ref - 找出被引用的物件的型別
rename - 更改檔名
require - 在執行時載入庫中的外部函式
reset - 清除所有給定名稱的變數
return - 提早退出函式
reverse - 反轉字串或列表
rewinddir - 重置目錄控制代碼
rindex - 從右到左的子字串搜尋
rmdir - 刪除目錄
s - 將模式替換為字串
scalar - 強制標量上下文
seek - 為隨機訪問I/O重新定位檔案指標
seekdir - 重新定位目錄指標
select - 重置預設輸出或進行I/O多路複用
semctl - SysV 訊號量控制操作
semget - 獲取 SysV 訊號量集
semop - SysV 訊號量操作
send - 透過套接字傳送訊息
setgrent - 準備使用組檔案
sethostent - 準備使用主機檔案
setnetent - 準備使用網路檔案
setpgrp - 設定程序的程序組
setpriority - 設定程序的 nice 值
setprotoent - 準備使用協議檔案
setpwent - 準備使用 passwd 檔案
setservent - 準備使用服務檔案
setsockopt - 設定套接字選項
shift - 從陣列中移除第一個元素並返回它
shmctl - SysV 共享記憶體操作
shmget - 獲取 SysV 共享記憶體段識別符號
shmread - 讀取 SysV 共享記憶體
shmwrite - 寫入 SysV 共享記憶體
shutdown - 關閉套接字連線的一半
sin - 返回數字的正弦值
sleep - 阻塞一段時間
socket - 建立套接字
socketpair - 建立一對套接字
sort - 對值列表進行排序
splice - 在陣列中的任何位置新增或刪除元素
split - 使用正則表示式分隔符分割字串
sprintf - 將格式化的輸出寫入字串
sqrt - 平方根函式
srand - 為隨機數生成器設定種子
stat - 獲取檔案的狀態資訊
study - 最佳化輸入資料以進行重複搜尋
sub - 宣告子程式,可能匿名
substr - 獲取或更改字串的一部分
symlink - 建立指向檔案的符號連結
syscall - 執行任意系統呼叫
sysopen - 開啟檔案、管道或描述符
sysread - 從檔案控制代碼進行固定長度的無緩衝輸入
sysseek - 定位與 sysread 和 syswrite 一起使用的控制代碼上的 I/O 指標
system - 執行單獨的程式
syswrite - 向檔案控制代碼進行固定長度的無緩衝輸出
tell - 獲取檔案控制代碼上的當前查詢指標
telldir - 獲取目錄控制代碼上的當前查詢指標
tie - 將變數繫結到物件類
tied - 獲取對繫結變數底層物件的引用
time - 返回自 1970 年以來的秒數
times - 返回自身和子程序的已用時間
tr - 轉化字串
truncate - 截斷檔案
uc - 返回字串的大寫版本
ucfirst - 返回僅將第一個字母轉換為大寫的字串
umask - 設定檔案建立模式掩碼
undef - 刪除變數或函式定義
unlink - 刪除指向檔案的連結
unpack - 將二進位制結構轉換為普通的 Perl 變數
unshift - 在列表的開頭新增元素
untie - 解除與變數的繫結
use - 在編譯時載入模組
utime - 設定檔案的最後訪問和修改時間
values - 返回雜湊中值的列表
vec - 測試或設定字串中的特定位
wait - 等待任何子程序結束
waitpid - 等待特定子程序結束
wantarray - 獲取當前子程式呼叫的 void、標量或列表上下文
warn - 列印除錯資訊
write - 列印圖片記錄
-X - 檔案測試 (-r, -x 等)
y - 轉化字串