- 並行演算法有用資源
- 並行演算法 - 快速指南
- 並行演算法 - 有用資源
- 並行演算法 - 討論
並行演算法 - 排序
排序是將一組元素按照特定順序排列的過程,例如升序、降序、字母順序等。在這裡,我們將討論以下內容:
- 列舉排序
- 奇偶換位排序
- 並行歸併排序
- 超快速排序
對元素列表進行排序是一個非常常見的操作。當需要排序大量資料時,順序排序演算法可能效率不夠高。因此,排序中使用並行演算法。
列舉排序
列舉排序是一種透過查詢每個元素在已排序列表中的最終位置來排列列表中所有元素的方法。它是透過將每個元素與所有其他元素進行比較並找到具有較小值的元素的數量來完成的。
因此,對於任意兩個元素 ai 和 aj,以下情況之一必須為真:
- ai < aj
- ai > aj
- ai = aj
演算法
procedure ENUM_SORTING (n)
begin
for each process P1,j do
C[j] := 0;
for each process Pi, j do
if (A[i] < A[j]) or A[i] = A[j] and i < j) then
C[j] := 1;
else
C[j] := 0;
for each process P1, j do
A[C[j]] := A[j];
end ENUM_SORTING
奇偶換位排序
奇偶換位排序基於氣泡排序技術。它比較兩個相鄰的數字,如果第一個數字大於第二個數字,則交換它們以獲得升序列表。對於降序序列,則適用相反的情況。奇偶換位排序分兩個階段進行:奇數階段和偶數階段。在這兩個階段中,程序都會將其數字與右側相鄰的數字交換。
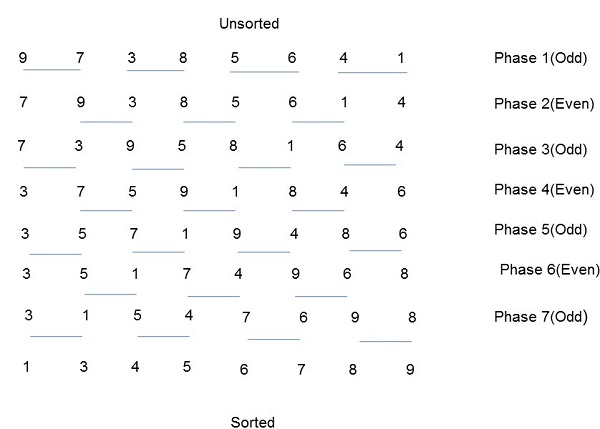
演算法
procedure ODD-EVEN_PAR (n)
begin
id := process's label
for i := 1 to n do
begin
if i is odd and id is odd then
compare-exchange_min(id + 1);
else
compare-exchange_max(id - 1);
if i is even and id is even then
compare-exchange_min(id + 1);
else
compare-exchange_max(id - 1);
end for
end ODD-EVEN_PAR
並行歸併排序
歸併排序首先將未排序的列表劃分為儘可能小的子列表,將其與相鄰列表進行比較,並按排序順序將其合併。它透過遵循分治演算法很好地實現了並行性。
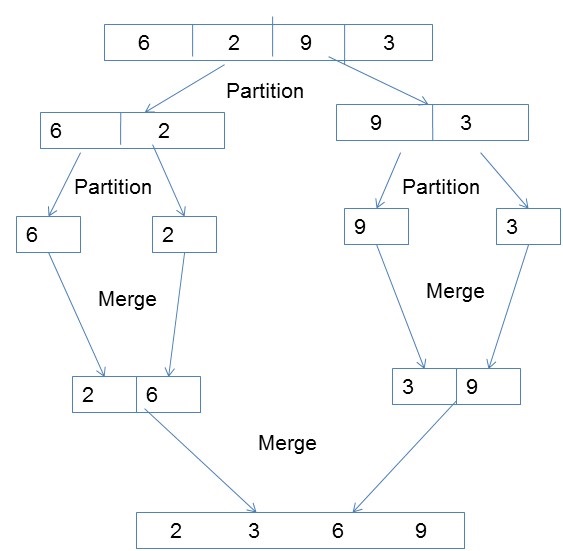
演算法
procedureparallelmergesort(id, n, data, newdata)
begin
data = sequentialmergesort(data)
for dim = 1 to n
data = parallelmerge(id, dim, data)
endfor
newdata = data
end
超快速排序
超快速排序是在超立方體上實現快速排序。其步驟如下:
- 將未排序的列表分配到每個節點。
- 在本地對每個節點進行排序。
- 從節點 0 廣播中位數。
- 在本地拆分每個列表,然後跨最高維度交換一半。
- 並行重複步驟 3 和 4,直到維度達到 0。
演算法
procedure HYPERQUICKSORT (B, n)
begin
id := process’s label;
for i := 1 to d do
begin
x := pivot;
partition B into B1 and B2 such that B1 ≤ x < B2;
if ith bit is 0 then
begin
send B2 to the process along the ith communication link;
C := subsequence received along the ith communication link;
B := B1 U C;
endif
else
send B1 to the process along the ith communication link;
C := subsequence received along the ith communication link;
B := B2 U C;
end else
end for
sort B using sequential quicksort;
end HYPERQUICKSORT
廣告