面向物件Python - 物件序列化
在資料儲存的上下文中,序列化是指將資料結構或物件狀態轉換為可儲存(例如,儲存在檔案或記憶體緩衝區中)或傳輸並在以後重建的格式的過程。
在序列化中,物件被轉換為可儲存的格式,以便能夠在以後反序列化它並從序列化格式中重新建立原始物件。
Pickle
Pickling是一個將Python物件層次結構轉換為位元組流(通常不可人為閱讀)以便寫入檔案的過程,這也被稱為序列化。Unpickling是相反的操作,它將位元組流轉換回可工作的Python物件層次結構。
Pickle是儲存物件的執行時最簡單的方法。Python Pickle模組是一種面向物件的方法,可以直接以特殊的儲存格式儲存物件。
它能做什麼?
- Pickle可以非常輕鬆地儲存和複製字典和列表。
- 儲存物件屬性並將它們恢復到相同的狀態。
Pickle不能做什麼?
- 它不儲存物件的程式碼。只儲存它的屬性值。
- 它不能儲存檔案控制代碼或連線套接字。
簡而言之,pickling是一種將資料變數儲存到檔案和從檔案中檢索資料變數的方法,其中變數可以是列表、類等。
要Pickle某些東西,你必須:
- import pickle
- 將變數寫入檔案,例如
pickle.dump(mystring, outfile, protocol),
其中第3個引數protocol是可選的。要unpickling某些東西,你必須:
Import pickle
將變數寫入檔案,例如
myString = pickle.load(inputfile)
方法
pickle介面提供四種不同的方法。
dump() − dump()方法序列化到一個開啟的檔案(類檔案物件)。
dumps() − 序列化到一個字串
load() − 從類檔案物件反序列化。
loads() − 從字串反序列化。
基於上述過程,以下是“pickling”的一個示例。
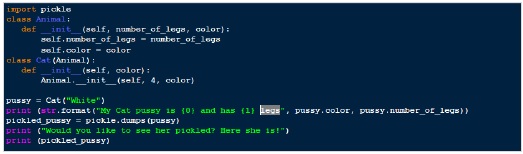
輸出
My Cat pussy is White and has 4 legs Would you like to see her pickled? Here she is! b'\x80\x03c__main__\nCat\nq\x00)\x81q\x01}q\x02(X\x0e\x00\x00\x00number_of_legsq\x03K\x04X\x05\x00\x00\x00colorq\x04X\x05\x00\x00\x00Whiteq\x05ub.'
因此,在上面的例子中,我們建立了一個Cat類的例項,然後我們對其進行了pickling,將我們的“Cat”例項轉換為一個簡單的位元組陣列。
這樣,我們可以輕鬆地將位元組陣列儲存在二進位制檔案或資料庫欄位中,並在以後從我們的儲存支援中將其恢復到原始形式。
此外,如果你想建立一個包含pickled物件的 檔案,你可以使用dump()方法(而不是dumps*()*方法),同時傳遞一個開啟的二進位制檔案,pickling結果將自動儲存在檔案中。
[….] binary_file = open(my_pickled_Pussy.bin', mode='wb') my_pickled_Pussy = pickle.dump(Pussy, binary_file) binary_file.close()
Unpickling
將二進位制陣列轉換為物件層次結構的過程稱為unpickling。
unpickling過程是透過使用pickle模組的load()函式完成的,它從一個簡單的位元組陣列返回一個完整的物件層次結構。
讓我們在之前的例子中使用load函式。

輸出
MeOw is black Pussy is white
JSON
JSON(JavaScript物件表示法)是Python標準庫的一部分,是一種輕量級的資料交換格式。它易於人類閱讀和編寫。它易於解析和生成。
由於其簡單性,JSON是一種我們儲存和交換資料的方式,這是透過其JSON語法實現的,並且在許多Web應用程式中使用。由於它是人類可讀的格式,這可能是它用於資料傳輸的原因之一,此外,在使用API時,它的效率很高。
JSON格式資料的示例如下:
{"EmployID": 40203, "Name": "Zack", "Age":54, "isEmployed": True}
Python使使用Json檔案變得簡單。用於此目的的模組是JSON模組。此模組應包含在你的Python安裝中(內建)。
那麼讓我們看看如何將Python字典轉換為JSON並將其寫入文字檔案。
JSON到Python
讀取JSON意味著將JSON轉換為Python值(物件)。json庫將JSON解析為Python中的字典或列表。為此,我們使用loads()函式(從字串載入),如下所示:

輸出

下面是一個示例json檔案:
data1.json
{"menu": {
"id": "file",
"value": "File",
"popup": {
"menuitem": [
{"value": "New", "onclick": "CreateNewDoc()"},
{"value": "Open", "onclick": "OpenDoc()"},
{"value": "Close", "onclick": "CloseDoc()"}
]
}
}}
以上內容(Data1.json)看起來像一個常規的字典。我們可以使用pickle來儲存此檔案,但它的輸出不是人類可讀的格式。
JSON(Java Script物件通知)是一種非常簡單的格式,這就是它流行的原因之一。現在讓我們透過以下程式檢視json輸出。
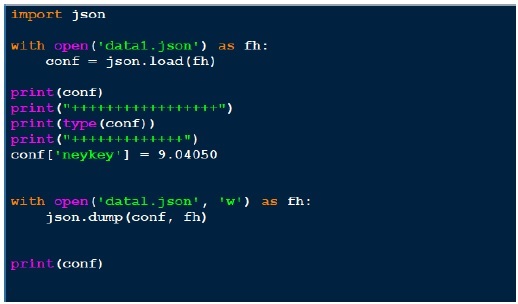
輸出
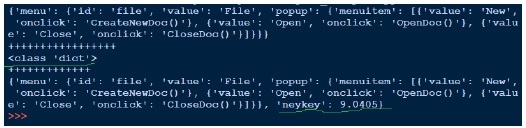
在上面,我們開啟json檔案(data1.json)進行讀取,獲取檔案控制代碼並傳遞給json.load,並獲取物件。當我們嘗試列印物件的輸出時,它與json檔案相同。雖然物件的型別是字典,但它顯示為Python物件。寫入json就像我們看到的pickle一樣簡單。在上面,我們載入json檔案,新增另一個鍵值對並將其寫回同一個json檔案。現在如果我們看到我們的data1.json,它看起來不同,即與我們之前看到的格式不同。
為了使我們的輸出看起來相同(人類可讀格式),在我們的程式的最後一行中新增幾個引數:
json.dump(conf, fh, indent = 4, separators = (‘,’, ‘: ‘))
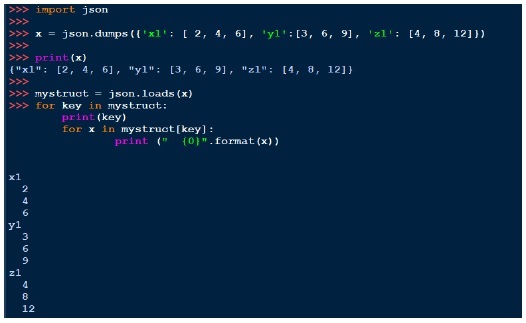
與pickle類似,我們可以使用dumps列印字串,使用loads載入。以下是一個例子:
YAML
YAML可能是所有程式語言中最人性化的資料序列化標準。
Python yaml模組稱為pyaml
YAML是JSON的替代方案:
人類可讀程式碼 − YAML是最人類可讀的格式,以至於即使它的首頁內容也以YAML顯示來強調這一點。
緊湊程式碼 − 在YAML中,我們使用空格縮排來表示結構,而不是括號。
關係資料的語法 − 對於內部引用,我們使用錨點(&)和別名(*)。
它廣泛用於檢視/編輯資料結構的一個領域 − 例如配置檔案、除錯期間的轉儲和文件標題。
安裝YAML
由於yaml不是內建模組,我們需要手動安裝它。在Windows機器上安裝yaml的最佳方法是透過pip。在你的Windows終端上執行以下命令以安裝yaml:
pip install pyaml (Windows machine) sudo pip install pyaml (*nix and Mac)
執行上述命令後,螢幕將顯示類似以下內容,具體取決於當前的最新版本。
Collecting pyaml Using cached pyaml-17.12.1-py2.py3-none-any.whl Collecting PyYAML (from pyaml) Using cached PyYAML-3.12.tar.gz Installing collected packages: PyYAML, pyaml Running setup.py install for PyYAML ... done Successfully installed PyYAML-3.12 pyaml-17.12.1
要測試它,請轉到Python shell並匯入yaml模組,匯入yaml,如果沒有發現錯誤,那麼我們可以說安裝成功。
安裝pyaml後,讓我們看看下面的程式碼:
script_yaml1.py

在上面,我們建立了三種不同的資料結構:字典、列表和元組。在每個結構上,我們都執行yaml.dump。重要的是螢幕上顯示的輸出方式。
輸出
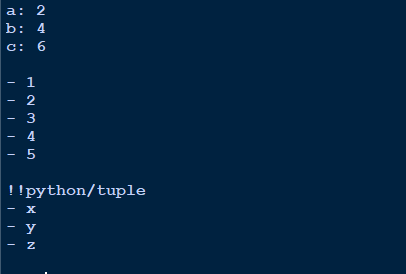
字典輸出看起來很乾淨,即鍵:值。
使用空格分隔不同的物件。
列表用破折號(-)表示。
元組首先用!!Python/tuple表示,然後以與列表相同的格式表示。
載入yaml檔案
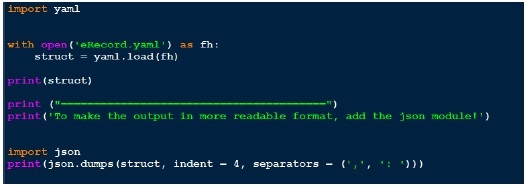
假設我有一個yaml檔案,其中包含:
--- # An employee record name: Raagvendra Joshi job: Developer skill: Oracle employed: True foods: - Apple - Orange - Strawberry - Mango languages: Oracle: Elite power_builder: Elite Full Stack Developer: Lame education: 4 GCSEs 3 A-Levels MCA in something called com
現在讓我們編寫一個程式碼,透過yaml.load函式載入此yaml檔案。以下是相同的程式碼。
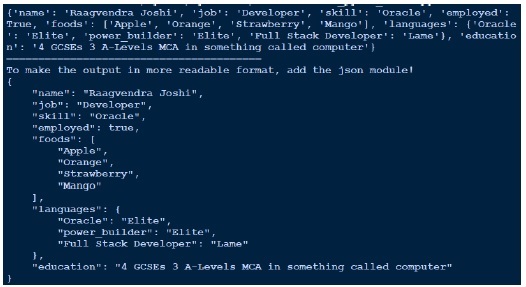
由於輸出看起來不太可讀,我最終使用json對其進行了美化。比較我們得到的輸出和我們實際擁有的yaml檔案。
輸出
軟體開發最重要的方面之一是除錯。在本節中,我們將看到使用內建偵錯程式或第三方偵錯程式的不同Python除錯方法。
PDB – Python偵錯程式
PDB模組支援設定斷點。斷點是程式的故意暫停,你可以在其中獲得更多關於程式狀態的資訊。
要設定斷點,請插入以下行:
pdb.set_trace()
示例
pdb_example1.py import pdb x = 9 y = 7 pdb.set_trace() total = x + y pdb.set_trace()
我們在這個程式中插入了一些斷點。程式將在每個斷點處暫停(pdb.set_trace())。要檢視變數的內容,只需鍵入變數名即可。
c:\Python\Python361>Python pdb_example1.py > c:\Python\Python361\pdb_example1.py(8)<module>() -> total = x + y (Pdb) x 9 (Pdb) y 7 (Pdb) total *** NameError: name 'total' is not defined (Pdb)
按c或continue繼續程式執行,直到下一個斷點。
(Pdb) c --Return-- > c:\Python\Python361\pdb_example1.py(8)<module>()->None -> total = x + y (Pdb) total 16
最終,你需要除錯更大的程式——使用子例程的程式。有時,你試圖查詢的問題會出現在子例程中。考慮以下程式:
import pdb def squar(x, y): out_squared = x^2 + y^2 return out_squared if __name__ == "__main__": #pdb.set_trace() print (squar(4, 5))
現在執行上述程式:
c:\Python\Python361>Python pdb_example2.py > c:\Python\Python361\pdb_example2.py(10)<module>() -> print (squar(4, 5)) (Pdb)
我們可以使用?來獲取幫助,但箭頭表示即將執行的行。此時,點選s進入s進入該行很有幫助。
(Pdb) s --Call-- >c:\Python\Python361\pdb_example2.py(3)squar() -> def squar(x, y):
這是一個對函式的呼叫。如果你想了解你程式碼中所在位置的概述,請嘗試l:
(Pdb) l 1 import pdb 2 3 def squar(x, y): 4 -> out_squared = x^2 + y^2 5 6 return out_squared 7 8 if __name__ == "__main__": 9 pdb.set_trace() 10 print (squar(4, 5)) [EOF] (Pdb)
你可以點選n前進到下一行。此時,你位於out_squared方法內部,並且可以訪問函式內部宣告的變數,即x和y。
(Pdb) x 4 (Pdb) y 5 (Pdb) x^2 6 (Pdb) y^2 7 (Pdb) x**2 16 (Pdb) y**2 25 (Pdb)
所以我們可以看到^運算子不是我們想要的,相反,我們需要使用**運算子來進行平方。
這樣我們就可以在函式/方法內部除錯程式了。
日誌記錄
日誌記錄模組自Python 2.3版本以來一直是Python標準庫的一部分。由於它是一個內建模組,所有Python模組都可以參與日誌記錄,因此我們的應用程式日誌可以包含你自己的訊息以及來自第三方模組的訊息。它提供了很多靈活性和功能。
日誌記錄的好處
診斷日誌記錄 − 它記錄與應用程式操作相關的事件。
審計日誌記錄 − 它記錄事件以進行業務分析。
訊息按“嚴重性”級別寫入並記錄&minu
DEBUG (debug()) − 開發診斷訊息。
INFO (info()) − 標準“進度”訊息。
WARNING (warning()) − 檢測到非嚴重問題。
ERROR (error()) − 遇到錯誤,可能嚴重。
CRITICAL (critical()) − 通常是致命錯誤(程式停止)。
讓我們看看下面的簡單程式:
import logging
logging.basicConfig(level=logging.INFO)
logging.debug('this message will be ignored') # This will not print
logging.info('This should be logged') # it'll print
logging.warning('And this, too') # It'll print
我們在上面按嚴重性級別記錄訊息。首先,我們匯入模組,呼叫basicConfig並設定日誌級別。我們上面設定的級別是INFO。然後,我們有三個不同的語句:debug語句、info語句和warning語句。
logging1.py 的輸出
INFO:root:This should be logged WARNING:root:And this, too
由於info語句在debug語句之後,我們無法看到debug訊息。要在輸出終端中也獲得debug訊息,我們只需要更改basicConfig級別。
logging.basicConfig(level = logging.DEBUG)
在輸出中,我們可以看到:
DEBUG:root:this message will be ignored INFO:root:This should be logged WARNING:root:And this, too
而且,預設行為意味著如果我們不設定任何日誌級別,則為警告。只需註釋掉上面程式中的第二行並執行程式碼。
#logging.basicConfig(level = logging.DEBUG)
輸出
WARNING:root:And this, too
Python內建的日誌級別實際上是整數。
>>> import logging >>> >>> logging.DEBUG 10 >>> logging.CRITICAL 50 >>> logging.WARNING 30 >>> logging.INFO 20 >>> logging.ERROR 40 >>>
我們還可以將日誌訊息儲存到檔案中。
logging.basicConfig(level = logging.DEBUG, filename = 'logging.log')
現在所有日誌訊息都將寫入當前工作目錄中的檔案 (logging.log),而不是螢幕。這是一種更好的方法,因為它允許我們對收到的訊息進行後期分析。
我們還可以設定日誌訊息的日期戳。
logging.basicConfig(level=logging.DEBUG, format = '%(asctime)s %(levelname)s:%(message)s')
輸出將類似於:
2018-03-08 19:30:00,066 DEBUG:this message will be ignored 2018-03-08 19:30:00,176 INFO:This should be logged 2018-03-08 19:30:00,201 WARNING:And this, too
基準測試
基準測試或效能分析基本上是為了測試程式碼的執行速度以及瓶頸在哪裡?這樣做的主要原因是為了最佳化。
timeit
Python自帶一個名為timeit的內建模組。您可以使用它來計時小的程式碼片段。timeit模組使用特定於平臺的時間函式,以便您可以獲得儘可能準確的計時。
因此,它允許我們比較兩種程式碼的執行時間,然後最佳化指令碼以獲得更好的效能。
timeit模組具有命令列介面,但也可以匯入。
有兩種方法可以呼叫指令碼。讓我們首先使用指令碼,為此,執行以下程式碼並檢視輸出。
import timeit
print ( 'by index: ', timeit.timeit(stmt = "mydict['c']", setup = "mydict = {'a':5, 'b':10, 'c':15}", number = 1000000))
print ( 'by get: ', timeit.timeit(stmt = 'mydict.get("c")', setup = 'mydict = {"a":5, "b":10, "c":15}', number = 1000000))
輸出
by index: 0.1809192126703489 by get: 0.6088525265034692
我們在上面使用了兩種不同的方法,即透過下標和get來訪問字典鍵值。我們執行語句100萬次,因為對於非常小的資料,它的執行速度太快了。現在我們可以看到索引訪問比get快得多。我們可以多次執行程式碼,執行時間會有細微的變化,以便更好地理解。
另一種方法是在命令列中執行上述測試。讓我們來做吧:
c:\Python\Python361>Python -m timeit -n 1000000 -s "mydict = {'a': 5, 'b':10, 'c':15}" "mydict['c']"
1000000 loops, best of 3: 0.187 usec per loop
c:\Python\Python361>Python -m timeit -n 1000000 -s "mydict = {'a': 5, 'b':10, 'c':15}" "mydict.get('c')"
1000000 loops, best of 3: 0.659 usec per loop
以上輸出可能因您的系統硬體以及當前在系統中執行的所有應用程式而異。
如果我們想呼叫函式,我們可以在下面使用timeit模組。因為我們可以在函式中新增多個語句進行測試。
import timeit
def testme(this_dict, key):
return this_dict[key]
print (timeit.timeit("testme(mydict, key)", setup = "from __main__ import testme; mydict = {'a':9, 'b':18, 'c':27}; key = 'c'", number = 1000000))
輸出
0.7713474590139164