面向物件Python速成指南
面向物件Python - 簡介
程式語言不斷湧現,不同的方法論也是如此。面向物件程式設計就是這樣一種方法論,在過去幾年中變得非常流行。
本章討論Python程式語言的特性,這些特性使其成為一種面向物件程式語言。
語言程式設計分類方案
Python可以歸類於面向物件程式設計方法論。下圖顯示了各種程式語言的特性。觀察使Python面向物件的特性。
| 語言類別 | 類別 | 語言 |
|---|---|---|
| 程式設計正規化 | 過程式 | C, C++, C#, Objective-C, Java, Go |
| 指令碼式 | CoffeeScript, JavaScript, Python, Perl, PHP, Ruby | |
| 函式式 | Clojure, Erlang, Haskell, Scala | |
| 編譯類別 | 靜態 | C, C++, C#, Objective-C, Java, Go, Haskell, Scala |
| 動態 | CoffeeScript, JavaScript, Python, Perl, PHP, Ruby, Clojure, Erlang | |
| 型別類別 | 強型別 | C#, Java, Go, Python, Ruby, Clojure, Erlang, Haskell, Scala |
| 弱型別 | C, C++, C#, Objective-C, CoffeeScript, JavaScript, Perl, PHP | |
| 記憶體類別 | 託管 | 其他 |
| 非託管 | C, C++, C#, Objective-C |
什麼是面向物件程式設計?
面向物件意味著面向物件。換句話說,這意味著功能上傾向於對物件建模。這是用於透過描述物件的集合及其資料和行為來建模複雜系統的一種技術。
Python,一種面向物件程式設計(OOP)語言,是一種程式設計方法,它專注於使用物件和類來設計和構建應用程式。面向物件程式設計(OOP)的主要支柱是繼承、多型、抽象和封裝。
面向物件分析(OOA)是對問題、系統或任務進行檢查,並識別物件及其之間互動的過程。
為什麼要選擇面向物件程式設計?
Python的設計採用了面向物件的方法。OOP提供以下優點:
提供清晰的程式結構,使之易於對映現實世界的問題及其解決方案。
方便維護和修改現有程式碼。
增強程式模組化,因為每個物件獨立存在,可以輕鬆新增新功能而不會影響現有功能。
為程式碼庫提供了一個良好的框架,程式設計師可以輕鬆地適應和修改提供的元件。
提高程式碼可重用性
程序式程式設計與面向物件程式設計
程序式程式設計源於基於函式/過程/例程概念的結構化程式設計。在程序式程式設計中,易於訪問和更改資料。另一方面,面向物件程式設計(OOP)允許將問題分解成許多稱為物件的單元,然後圍繞這些物件構建資料和函式。它比過程或函式更強調資料。此外,在OOP中,資料是隱藏的,外部過程無法訪問。
下圖中的表格顯示了POP和OOP方法的主要區別。
過程式面向物件程式設計(POP)與面向物件程式設計(OOP)的區別。
| 過程式面向物件程式設計 | 面向物件程式設計 | |
|---|---|---|
| 基於 | 在POP中,整個重點在於資料和函式 | OOP基於現實世界場景。整個程式被分成稱為物件的小部分 |
| 可重用性 | 程式碼重用有限 | 程式碼重用 |
| 方法 | 自頂向下方法 | 面向物件設計 |
| 訪問說明符 | 沒有 | 公共、私有和保護 |
| 資料移動 | 資料可以在系統中從一個函式自由地移動到另一個函式 | 在OOP中,資料可以透過成員函式相互移動和通訊 |
| 資料訪問 | 在POP中,大多數函式使用全域性資料共享,可以從系統中的一個函式自由地訪問另一個函式 | 在OOP中,資料不能從一個方法自由地移動到另一個方法,它可以儲存在公共或私有中,因此我們可以控制資料的訪問 |
| 資料隱藏 | 在POP中,沒有特定的方法來隱藏資料,因此安全性較低 | 它提供資料隱藏,因此更安全 |
| 過載 | 不可能 | 函式和運算子過載 |
| 示例語言 | C, VB, Fortran, Pascal | C++, Python, Java, C# |
| 抽象 | 在過程級別使用抽象 | 在類和物件級別使用抽象 |
面向物件程式設計的原則
面向物件程式設計(OOP)基於物件而不是動作,資料而不是邏輯的概念。為了使程式語言面向物件,它應該具有啟用使用類和物件以及實現和使用基本面向物件原則和概念(即繼承、抽象、封裝和多型)的機制。
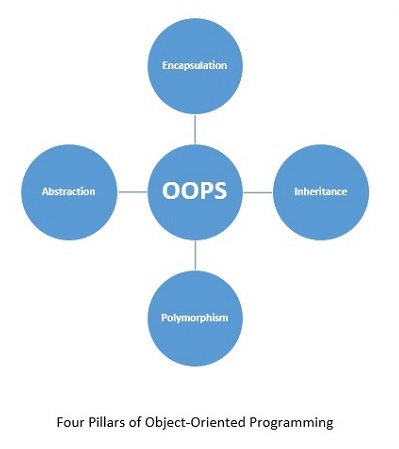
讓我們簡要了解面向物件程式設計的每個支柱:
封裝
此屬性隱藏不必要的細節,並使程式結構更容易管理。每個物件的實現和狀態都隱藏在定義良好的邊界後面,這為使用它們提供了一個簡潔明瞭的介面。實現此目的的一種方法是將資料設為私有。
繼承
繼承,也稱為泛化,允許我們捕獲類和物件之間的層次關係。例如,“水果”是“橙子”的泛化。從程式碼重用的角度來看,繼承非常有用。
抽象
此屬性允許我們隱藏細節,並僅公開概念或物件的必要特徵。例如,駕駛踏板車的人知道按下喇叭會發出聲音,但他不知道按下喇叭時聲音是如何產生的。
多型
多型意味著多種形式。也就是說,事物或行為以不同的形式或方式存在。多型的一個很好的例子是類中的建構函式過載。
面向物件的Python
Python程式設計的核心是物件和OOP,但是您不必將自己限制在透過將程式碼組織成類來使用OOP。OOP補充了Python的整體設計理念,並鼓勵一種簡潔實用的程式設計方式。OOP還有助於編寫更大更復雜的程式。
模組與類和物件
模組就像“字典”
使用模組時,請注意以下幾點:
Python模組是一個封裝可重用程式碼的包。
模組位於包含__init__.py檔案的資料夾中。
模組包含函式和類。
使用import關鍵字匯入模組。
回想一下,字典是鍵值對。這意味著如果您有一個鍵為EmployeID的字典,並且想要檢索它,那麼您必須使用以下幾行程式碼:
employee = {“EmployeID”: “Employee Unique Identity!”}
print (employee [‘EmployeID])
您必須按照以下過程處理模組:
模組是一個包含一些函式或變數的Python檔案。
匯入您需要的檔案。
現在,您可以使用“.”(點)運算子訪問該模組中的函式或變數。
考慮一個名為employee.py的模組,其中包含一個名為employee的函式。該函式的程式碼如下所示:
# this goes in employee.py def EmployeID(): print (“Employee Unique Identity!”)
現在匯入模組,然後訪問函式EmployeID:
import employee employee. EmployeID()
您可以在其中插入一個名為Age的變數,如下所示:
def EmployeID(): print (“Employee Unique Identity!”) # just a variable Age = “Employee age is **”
現在,以以下方式訪問該變數:
import employee employee.EmployeID() print(employee.Age)
現在,讓我們將其與字典進行比較:
Employee[‘EmployeID’] # get EmployeID from employee Employee.employeID() # get employeID from the module Employee.Age # get access to variable
請注意,Python中存在共同模式:
採用鍵=值樣式的容器
透過鍵的名稱從中獲取某些內容
將模組與字典進行比較時,兩者都相似,但以下幾點除外:
在字典的情況下,鍵是字串,語法為[key]。
在模組的情況下,鍵是識別符號,語法為.key。
類就像模組
模組是一個特殊的字典,可以儲存Python程式碼,以便您可以使用“.”運算子訪問它。類是一種將函式和資料的組合放入容器中以便您可以使用“.”運算子訪問它們的方法。
如果您必須建立一個類似於employee模組的類,您可以使用以下程式碼:
class employee(object):
def __init__(self):
self. Age = “Employee Age is ##”
def EmployeID(self):
print (“This is just employee unique identity”)
注意 - 首選類而不是模組,因為您可以原樣重用它們而不會造成太多幹擾。而對於模組,您只有一個用於整個程式。
物件就像迷你匯入
類就像一個迷你模組,您可以使用稱為例項化的概念以與類類似的方式匯入它。請注意,當您例項化一個類時,您會得到一個物件。
您可以例項化一個物件,類似於將類像函式一樣呼叫,如下所示:
this_obj = employee() # Instantiatethis_obj.EmployeID() # get EmployeId from the class print(this_obj.Age) # get variable Age
您可以透過以下三種方式中的任何一種來執行此操作:
# dictionary style Employee[‘EmployeID’] # module style Employee.EmployeID() Print(employee.Age) # Class style this_obj = employee() this_obj.employeID() Print(this_obj.Age)
面向物件Python - 環境設定
本章將詳細解釋如何在本地計算機上設定Python環境。
先決條件和工具包
在繼續學習Python之前,我們建議您檢查是否滿足以下先決條件:
您的計算機上安裝了最新版本的Python
安裝了IDE或文字編輯器
您具備使用Python進行編寫和除錯的基本知識,也就是說,您可以在Python中執行以下操作:
能夠編寫和執行Python程式。
除錯程式並診斷錯誤。
使用基本資料型別。
編寫for迴圈、while迴圈和if語句
編寫函式
如果您沒有任何程式語言經驗,您可以在以下網站找到許多Python入門教程:
https://www.tutorialpoints.com/安裝Python
以下步驟詳細介紹瞭如何在本地計算機上安裝Python:
步驟1 - 前往Python官方網站 https://python.club.tw/,點選下載選單,選擇最新版本或任何您選擇的穩定版本。
步驟2 - 儲存您下載的Python安裝程式exe檔案,下載完成後開啟它。單擊執行,預設情況下選擇下一步選項,然後完成安裝。
步驟3 - 安裝完成後,您應該會看到如下所示的Python選單。透過選擇IDLE(Python GUI)啟動程式。
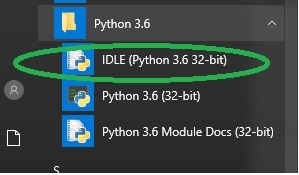
這將啟動Python shell。輸入簡單的命令來檢查安裝。

選擇IDE
整合開發環境 (IDE) 是一種面向軟體開發的文字編輯器。您需要安裝一個IDE來控制程式設計流程,並在使用Python時將專案組合在一起。以下是一些可線上使用的IDE。您可以根據自己的方便選擇一個。
- Pycharm IDE
- Komodo IDE
- Eric Python IDE
注意 - Eclipse IDE主要用於Java,但它有一個Python外掛。
Pycharm

Pycharm是一個跨平臺IDE,是目前最流行的IDE之一。它提供程式碼輔助和分析,包括程式碼補全、專案和程式碼導航、整合單元測試、版本控制整合、除錯等等。
下載連結
https://www.jetbrains.com/pycharm/download/#section=windows支援的語言 - Python、HTML、CSS、JavaScript、CoffeeScript、TypeScript、Cython、AngularJS、Node.js、模板語言。
截圖

為什麼選擇PyCharm?
PyCharm為使用者提供以下功能和優勢:
- 跨平臺IDE,相容Windows、Linux和Mac OS
- 包含Django IDE,以及CSS和JavaScript支援
- 包含數千個外掛、整合終端和版本控制
- 與Git、SVN和Mercurial整合
- 為Python提供智慧編輯工具
- 易於與Virtualenv、Docker和Vagrant整合
- 簡單的導航和搜尋功能
- 程式碼分析和重構
- 可配置的注入
- 支援大量的Python庫
- 包含模板和JavaScript偵錯程式
- 包含Python/Django偵錯程式
- 可與Google App Engine、其他框架和庫一起使用。
- 具有可自定義的UI,提供VIM模擬。
Komodo IDE

這是一個多語言IDE,支援100多種語言,基本上用於Python、PHP和Ruby等動態語言。這是一個商業IDE,提供21天的免費試用,功能齊全。ActiveState是管理Komodo IDE開發的軟體公司。它還提供Komodo的精簡版,稱為Komodo Edit,用於簡單的程式設計任務。
此IDE包含從最基本到高階的所有功能。如果您是學生或自由職業者,則可以以幾乎一半的實際價格購買它。但是,對於來自認可機構和大學的教師和教授來說,它是完全免費的。
它擁有您進行Web和移動開發所需的所有功能,包括對所有語言和框架的支援。
下載連結
Komodo Edit(免費版)和Komodo IDE(付費版)的下載連結如下:
Komodo Edit (免費)
https://www.activestate.com/komodo-editKomodo IDE (付費)
https://www.activestate.com/komodo-ide/downloads/ide截圖
為什麼選擇PyCharm?
- 功能強大的IDE,支援Perl、PHP、Python、Ruby以及更多語言。
- 跨平臺IDE。
它包括基本功能,例如整合偵錯程式支援、自動完成、文件物件模型 (DOM) 檢視器、程式碼瀏覽器、互動式shell、斷點配置、程式碼分析、整合單元測試。簡而言之,它是一個具有許多提高生產率功能的專業IDE。
Eric Python IDE

這是一個用於Python和Ruby的開源IDE。Eric是一個功能齊全的編輯器和IDE,用Python編寫。它基於跨平臺Qt GUI工具包,集成了高度靈活的Scintilla編輯器控制元件。IDE非常可配置,可以選擇使用哪些功能,哪些不使用。您可以從以下連結下載Eric IDE:
https://eric-ide.python-projects.org/eric-download.html為什麼選擇Eric?
- 出色的縮排,錯誤高亮。
- 程式碼輔助
- 程式碼補全
- 使用PyLint進行程式碼清理
- 快速搜尋
- 整合的Python偵錯程式。
截圖

選擇文字編輯器
您可能並不總是需要IDE。對於學習使用Python或Arduino進行編碼的任務,或者在shell指令碼中編寫快速指令碼以幫助您自動化某些任務時,簡單輕便的程式碼中心文字編輯器就足夠了。此外,許多文字編輯器還提供語法高亮顯示和程式內指令碼執行等功能,類似於IDE。以下是一些文字編輯器:
- Atom
- Sublime Text
- Notepad++
Atom文字編輯器

Atom是由GitHub團隊構建的可修改文字編輯器。它是一個免費且開源的文字和程式碼編輯器,這意味著所有程式碼都可以供您閱讀、修改以供自己使用,甚至可以貢獻改進。它是一個跨平臺文字編輯器,相容macOS、Linux和Microsoft Windows,支援用Node.js編寫的外掛和嵌入式Git Control。
下載連結
https://atom.io/截圖

支援的語言
C/C++、C#、CSS、CoffeeScript、HTML、JavaScript、Java、JSON、Julia、Objective-C、PHP、Perl、Python、Ruby on Rails、Ruby、Shell指令碼、Scala、SQL、XML、YAML等等。
Sublime Text編輯器

Sublime Text是一個專有軟體,它提供免費試用版供您在購買前測試。根據stackoverflow.com,它是第四大最流行的開發環境。
它提供的一些優勢包括其令人難以置信的速度、易用性和社群支援。它還支援許多程式語言和標記語言,使用者可以使用外掛新增功能,這些外掛通常由社群構建和維護,並根據自由軟體許可證進行管理。
截圖
支援的語言
- Python、Ruby、JavaScript等。
為什麼選擇PyCharm?
自定義鍵繫結、選單、程式碼片段、宏、補全等等。
自動完成功能
- 使用程式碼片段、欄位標記和佔位符快速插入文字和程式碼。
快速開啟
跨平臺支援Mac、Linux和Windows。
將游標跳轉到您想要的位置
選擇多行、單詞和列
Notepad ++

這是一個免費的原始碼編輯器和Notepad替代品,支援從彙編到XML以及包括Python在內的多種語言。它在MS Windows環境下執行,其使用受GPL許可證管轄。除了語法高亮顯示外,Notepad++還具有一些對編碼人員特別有用的功能。
截圖
主要功能
- 語法高亮顯示和語法摺疊
- PCRE(Perl相容正則表示式)搜尋/替換
- 完全可自定義的GUI
- 自動完成
- 選項卡式編輯
- 多檢視
- 多語言環境
- 可以使用不同的引數啟動
支援的語言
- 幾乎所有語言(60多種語言),如Python、C、C++、C#、Java等。
面向物件的Python - 資料結構
從語法的角度來看,Python資料結構非常直觀,它們提供了大量的操作選擇。您需要根據資料涉及的內容、是否需要修改資料、資料是否是固定資料以及需要什麼型別的訪問(例如開頭/結尾/隨機等)來選擇Python資料結構。
列表
列表表示Python中最通用的資料結構型別。列表是一個容器,它在方括號之間儲存用逗號分隔的值(專案或元素)。當我們想要處理多個相關值時,列表非常有用。由於列表將資料儲存在一起,因此我們可以對多個值同時執行相同的方法和操作。列表索引從零開始,與字串不同,列表是可變的。
資料結構 - 列表
>>> >>> # Any Empty List >>> empty_list = [] >>> >>> # A list of String >>> str_list = ['Life', 'Is', 'Beautiful'] >>> # A list of Integers >>> int_list = [1, 4, 5, 9, 18] >>> >>> #Mixed items list >>> mixed_list = ['This', 9, 'is', 18, 45.9, 'a', 54, 'mixed', 99, 'list'] >>> # To print the list >>> >>> print(empty_list) [] >>> print(str_list) ['Life', 'Is', 'Beautiful'] >>> print(type(str_list)) <class 'list'> >>> print(int_list) [1, 4, 5, 9, 18] >>> print(mixed_list) ['This', 9, 'is', 18, 45.9, 'a', 54, 'mixed', 99, 'list']
訪問Python列表中的專案
列表的每個專案都分配了一個數字——這就是該數字的索引或位置。索引始終從零開始,第二個索引為一,依此類推。要訪問列表中的專案,我們可以在方括號內使用這些索引號。例如,請觀察以下程式碼:
>>> mixed_list = ['This', 9, 'is', 18, 45.9, 'a', 54, 'mixed', 99, 'list'] >>> >>> # To access the First Item of the list >>> mixed_list[0] 'This' >>> # To access the 4th item >>> mixed_list[3] 18 >>> # To access the last item of the list >>> mixed_list[-1] 'list'
空物件
空物件是最簡單、最基本的Python內建型別。我們在不知不覺中多次使用它們,並將其擴充套件到我們建立的每個類。編寫空類的主要目的是暫時阻止某些東西,然後擴充套件並向其新增行為。
向類新增行為意味著用物件替換資料結構並更改對它的所有引用。因此,在建立任何內容之前,檢查資料(是否是偽裝的物件)非常重要。觀察以下程式碼以更好地理解
>>> #Empty objects >>> >>> obj = object() >>> obj.x = 9 Traceback (most recent call last): File "<pyshell#3>", line 1, in <module> obj.x = 9 AttributeError: 'object' object has no attribute 'x'
因此,從上面我們可以看到,不可能直接在例項化的物件上設定任何屬性。當Python允許物件具有任意屬性時,它需要一定的系統記憶體來跟蹤每個物件具有哪些屬性,用於儲存屬性名稱及其值。即使不儲存任何屬性,也會為潛在的新屬性分配一定的記憶體。
因此,預設情況下,Python停用物件和幾個其他內建物件的任意屬性。
>>> # Empty Objects
>>>
>>> class EmpObject:
pass
>>> obj = EmpObject()
>>> obj.x = 'Hello, World!'
>>> obj.x
'Hello, World!'
因此,如果我們想將屬性組合在一起,我們可以像上面程式碼中所示的那樣將它們儲存在空物件中。但是,這種方法並不總是建議的。請記住,只有當您想要同時指定資料和行為時,才應使用類和物件。
元組
元組類似於列表,可以儲存元素。但是,它們是不可變的,因此我們無法新增、刪除或替換物件。元組由於其不可變性而提供的首要好處是,我們可以將它們用作字典中的鍵,或者在物件需要雜湊值的其他位置。
元組用於儲存資料,而不是行為。如果您需要行為來操作元組,則需要將元組傳遞給執行該操作的函式(或另一個物件上的方法)。
由於元組可以充當字典鍵,因此儲存的值彼此不同。我們可以透過逗號分隔值來建立一個元組。元組用括號括起來,但並非強制性。以下程式碼顯示了兩個相同的賦值。
>>> stock1 = 'MSFT', 95.00, 97.45, 92.45
>>> stock2 = ('MSFT', 95.00, 97.45, 92.45)
>>> type (stock1)
<class 'tuple'>
>>> type(stock2)
<class 'tuple'>
>>> stock1 == stock2
True
>>>
定義元組
元組與列表非常相似,只是所有元素都用括號括起來,而不是方括號。
就像切片列表時得到一個新列表一樣,切片元組時也會得到一個新的元組。
>>> tupl = ('Tuple','is', 'an','IMMUTABLE', 'list')
>>> tupl
('Tuple', 'is', 'an', 'IMMUTABLE', 'list')
>>> tupl[0]
'Tuple'
>>> tupl[-1]
'list'
>>> tupl[1:3]
('is', 'an')
Python元組方法
以下程式碼顯示了Python元組中的方法:
>>> tupl
('Tuple', 'is', 'an', 'IMMUTABLE', 'list')
>>> tupl.append('new')
Traceback (most recent call last):
File "<pyshell#148>", line 1, in <module>
tupl.append('new')
AttributeError: 'tuple' object has no attribute 'append'
>>> tupl.remove('is')
Traceback (most recent call last):
File "<pyshell#149>", line 1, in <module>
tupl.remove('is')
AttributeError: 'tuple' object has no attribute 'remove'
>>> tupl.index('list')
4
>>> tupl.index('new')
Traceback (most recent call last):
File "<pyshell#151>", line 1, in <module>
tupl.index('new')
ValueError: tuple.index(x): x not in tuple
>>> "is" in tupl
True
>>> tupl.count('is')
1
從上面顯示的程式碼中,我們可以理解元組是不可變的,因此:
您不能向元組新增元素。
您不能追加或擴充套件方法。
您不能從元組中刪除元素。
元組沒有remove或pop方法。
元組中可用的方法包括計數和索引。
字典
字典是Python的內建資料型別之一,它定義了鍵和值之間的一對一關係。
定義字典
觀察以下程式碼,瞭解如何定義字典:
>>> # empty dictionary
>>> my_dict = {}
>>>
>>> # dictionary with integer keys
>>> my_dict = { 1:'msft', 2: 'IT'}
>>>
>>> # dictionary with mixed keys
>>> my_dict = {'name': 'Aarav', 1: [ 2, 4, 10]}
>>>
>>> # using built-in function dict()
>>> my_dict = dict({1:'msft', 2:'IT'})
>>>
>>> # From sequence having each item as a pair
>>> my_dict = dict([(1,'msft'), (2,'IT')])
>>>
>>> # Accessing elements of a dictionary
>>> my_dict[1]
'msft'
>>> my_dict[2]
'IT'
>>> my_dict['IT']
Traceback (most recent call last):
File "<pyshell#177>", line 1, in <module>
my_dict['IT']
KeyError: 'IT'
>>>
從上面的程式碼我們可以看出
首先,我們建立一個包含兩個元素的字典,並將其賦值給變數my_dict。每個元素都是一個鍵值對,整個元素集合用花括號括起來。
數字1是鍵,msft是其值。類似地,2是鍵,IT是其值。
您可以透過鍵獲取值,但反之則不行。因此,當我們嘗試使用my_dict['IT']時,它會引發異常,因為IT不是鍵。
修改字典
觀察以下程式碼,瞭解如何修改字典:
>>> # Modifying a Dictionary
>>>
>>> my_dict
{1: 'msft', 2: 'IT'}
>>> my_dict[2] = 'Software'
>>> my_dict
{1: 'msft', 2: 'Software'}
>>>
>>> my_dict[3] = 'Microsoft Technologies'
>>> my_dict
{1: 'msft', 2: 'Software', 3: 'Microsoft Technologies'}
從上面的程式碼我們可以看出:
字典中不能有重複的鍵。更改現有鍵的值將刪除舊值。
您可以隨時新增新的鍵值對。
字典沒有元素之間順序的概念。它們只是簡單的無序集合。
在字典中混合資料型別
觀察以下程式碼,瞭解如何在字典中混合資料型別:
>>> # Mixing Data Types in a Dictionary
>>>
>>> my_dict
{1: 'msft', 2: 'Software', 3: 'Microsoft Technologies'}
>>> my_dict[4] = 'Operating System'
>>> my_dict
{1: 'msft', 2: 'Software', 3: 'Microsoft Technologies', 4: 'Operating System'}
>>> my_dict['Bill Gates'] = 'Owner'
>>> my_dict
{1: 'msft', 2: 'Software', 3: 'Microsoft Technologies', 4: 'Operating System',
'Bill Gates': 'Owner'}
從上面的程式碼我們可以看出:
字典值不僅可以是字串,還可以是任何資料型別,包括字串、整數,甚至字典本身。
與字典值不同,字典鍵的限制更多,但可以是任何型別,例如字串、整數或其他任何型別。
從字典中刪除專案
觀察以下程式碼,瞭解如何從字典中刪除專案:
>>> # Deleting Items from a Dictionary
>>>
>>> my_dict
{1: 'msft', 2: 'Software', 3: 'Microsoft Technologies', 4: 'Operating System',
'Bill Gates': 'Owner'}
>>>
>>> del my_dict['Bill Gates']
>>> my_dict
{1: 'msft', 2: 'Software', 3: 'Microsoft Technologies', 4: 'Operating System'}
>>>
>>> my_dict.clear()
>>> my_dict
{}
從上面的程式碼我們可以看出:
del - 允許您透過鍵從字典中刪除單個專案。
clear - 刪除字典中的所有專案。
集合
Set() 是一個無序集合,沒有重複的元素。雖然單個專案是不可變的,但集合本身是可變的,也就是說我們可以向集合中新增或刪除元素/專案。我們可以對集合執行並集、交集等數學運算。
雖然集合通常可以使用樹來實現,但Python中的集合可以使用雜湊表來實現。這使得它成為一種高度最佳化的檢查特定元素是否包含在集合中的方法。
建立集合
集合是透過將所有專案(元素)放在花括號{}內,用逗號分隔,或者使用內建函式set()來建立的。觀察以下程式碼:
>>> #set of integers
>>> my_set = {1,2,4,8}
>>> print(my_set)
{8, 1, 2, 4}
>>>
>>> #set of mixed datatypes
>>> my_set = {1.0, "Hello World!", (2, 4, 6)}
>>> print(my_set)
{1.0, (2, 4, 6), 'Hello World!'}
>>>
集合的方法
觀察以下程式碼,瞭解集合的方法:
>>> >>> #METHODS FOR SETS
>>>
>>> #add(x) Method
>>> topics = {'Python', 'Java', 'C#'}
>>> topics.add('C++')
>>> topics
{'C#', 'C++', 'Java', 'Python'}
>>>
>>> #union(s) Method, returns a union of two set.
>>> topics
{'C#', 'C++', 'Java', 'Python'}
>>> team = {'Developer', 'Content Writer', 'Editor','Tester'}
>>> group = topics.union(team)
>>> group
{'Tester', 'C#', 'Python', 'Editor', 'Developer', 'C++', 'Java', 'Content
Writer'}
>>> # intersets(s) method, returns an intersection of two sets
>>> inters = topics.intersection(team)
>>> inters
set()
>>>
>>> # difference(s) Method, returns a set containing all the elements of
invoking set but not of the second set.
>>>
>>> safe = topics.difference(team)
>>> safe
{'Python', 'C++', 'Java', 'C#'}
>>>
>>> diff = topics.difference(group)
>>> diff
set()
>>> #clear() Method, Empties the whole set.
>>> group.clear()
>>> group
set()
>>>
集合的運算子
觀察以下程式碼,瞭解集合的運算子:
>>> # PYTHON SET OPERATIONS
>>>
>>> #Creating two sets
>>> set1 = set()
>>> set2 = set()
>>>
>>> # Adding elements to set
>>> for i in range(1,5):
set1.add(i)
>>> for j in range(4,9):
set2.add(j)
>>> set1
{1, 2, 3, 4}
>>> set2
{4, 5, 6, 7, 8}
>>>
>>> #Union of set1 and set2
>>> set3 = set1 | set2 # same as set1.union(set2)
>>> print('Union of set1 & set2: set3 = ', set3)
Union of set1 & set2: set3 = {1, 2, 3, 4, 5, 6, 7, 8}
>>>
>>> #Intersection of set1 & set2
>>> set4 = set1 & set2 # same as set1.intersection(set2)
>>> print('Intersection of set1 and set2: set4 = ', set4)
Intersection of set1 and set2: set4 = {4}
>>>
>>> # Checking relation between set3 and set4
>>> if set3 > set4: # set3.issuperset(set4)
print('Set3 is superset of set4')
elif set3 < set4: #set3.issubset(set4)
print('Set3 is subset of set4')
else: #set3 == set4
print('Set 3 is same as set4')
Set3 is superset of set4
>>>
>>> # Difference between set3 and set4
>>> set5 = set3 - set4
>>> print('Elements in set3 and not in set4: set5 = ', set5)
Elements in set3 and not in set4: set5 = {1, 2, 3, 5, 6, 7, 8}
>>>
>>> # Check if set4 and set5 are disjoint sets
>>> if set4.isdisjoint(set5):
print('Set4 and set5 have nothing in common\n')
Set4 and set5 have nothing in common
>>> # Removing all the values of set5
>>> set5.clear()
>>> set5 set()
面向物件Python - 構建塊
在本章中,我們將詳細討論面向物件的術語和程式設計概念。類只是一個例項的工廠。這個工廠包含藍圖,描述瞭如何製作例項。例項或物件是由類構造的。在大多數情況下,我們可以擁有一個類的一個以上例項。每個例項都有一組屬性,這些屬性在類中定義,因此特定類的每個例項都應該具有相同的屬性。
類捆綁:行為和狀態
類允許您將物件的行為和狀態捆綁在一起。觀察下圖以更好地理解:
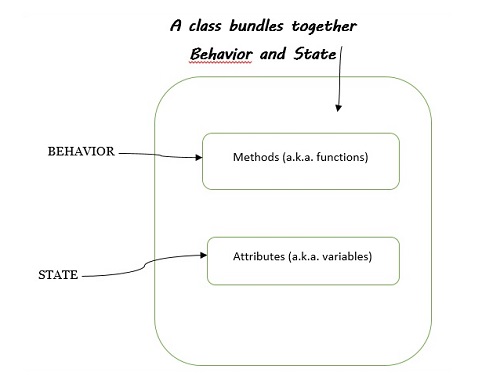
討論類捆綁時,以下幾點值得注意:
單詞行為與函式相同 - 它是一段執行某些操作(或實現行為)的程式碼。
單詞狀態與變數相同 - 它是儲存類中值的地方。
當我們將類的行為和狀態一起斷言時,這意味著一個類打包了函式和變數。
類具有方法和屬性
在Python中,建立方法定義了類的行為。方法這個詞是在類中定義的函式的OOP名稱。總結一下:
類函式 - 是方法的同義詞
類變數 - 是名稱屬性的同義詞。
類 - 具有精確行為的例項的藍圖。
物件 - 類的一個例項,執行在類中定義的功能。
型別 - 指示例項所屬的類
屬性 - 任何物件值:object.attribute
方法 - 在類中定義的“可呼叫屬性”
觀察以下程式碼示例:
var = “Hello, John” print( type (var)) # < type ‘str’> or <class 'str'> print(var.upper()) # upper() method is called, HELLO, JOHN
建立和例項化
以下程式碼顯示瞭如何建立我們的第一個類以及它的例項。
class MyClass(object): pass # Create first instance of MyClass this_obj = MyClass() print(this_obj) # Another instance of MyClass that_obj = MyClass() print (that_obj)
在這裡,我們建立了一個名為MyClass的類,它不執行任何任務。MyClass類中的引數object涉及類繼承,將在後面的章節中討論。上面程式碼中的pass表示此塊為空,即它是一個空的類定義。
讓我們建立一個MyClass()類的例項this_obj並列印它,如下所示:
<__main__.MyClass object at 0x03B08E10> <__main__.MyClass object at 0x0369D390>
在這裡,我們建立了一個MyClass的例項。十六進位制程式碼指的是物件儲存的地址。另一個例項指向另一個地址。
現在讓我們在MyClass()類中定義一個變數,並從該類的例項中獲取該變數,如下面的程式碼所示:
class MyClass(object): var = 9 # Create first instance of MyClass this_obj = MyClass() print(this_obj.var) # Another instance of MyClass that_obj = MyClass() print (that_obj.var)
輸出
執行上面給出的程式碼時,您可以觀察到以下輸出:
9 9
由於例項知道它是從哪個類例項化的,因此當請求從例項獲取屬性時,例項會查詢屬性和類。這稱為屬性查詢。
例項方法
在類中定義的函式稱為方法。例項方法需要一個例項才能呼叫它,並且不需要裝飾器。建立例項方法時,第一個引數始終是self。雖然我們可以用任何其他名稱來呼叫它 (self),但建議使用 self,因為它是一種命名約定。
class MyClass(object):
var = 9
def firstM(self):
print("hello, World")
obj = MyClass()
print(obj.var)
obj.firstM()
輸出
執行上面給出的程式碼時,您可以觀察到以下輸出:
9 hello, World
請注意,在上例程式中,我們定義了一個帶有 self 作為引數的方法。但是我們不能呼叫該方法,因為我們沒有宣告任何引數。
class MyClass(object):
def firstM(self):
print("hello, World")
print(self)
obj = MyClass()
obj.firstM()
print(obj)
輸出
執行上面給出的程式碼時,您可以觀察到以下輸出:
hello, World <__main__.MyClass object at 0x036A8E10> <__main__.MyClass object at 0x036A8E10>
封裝
封裝是OOP的基本原理之一。OOP使我們能夠隱藏物件內部工作機制的複雜性,這對開發人員有以下好處:
簡化並易於理解如何使用物件,而無需瞭解內部結構。
任何更改都易於管理。
面向物件程式設計嚴重依賴封裝。封裝和抽象(也稱為資料隱藏)這兩個術語經常互換使用。它們幾乎是同義詞,因為抽象是透過封裝實現的。
封裝為我們提供了一種限制對某些物件元件訪問的機制,這意味著物件內部表示無法從物件定義外部看到。對這些資料的訪問通常是透過特殊方法實現的 - Getter 和 Setter。
這些資料儲存在例項屬性中,可以從類外部的任何地方進行操作。為了保護它,這些資料應該只使用例項方法訪問。不應允許直接訪問。
class MyClass(object):
def setAge(self, num):
self.age = num
def getAge(self):
return self.age
zack = MyClass()
zack.setAge(45)
print(zack.getAge())
zack.setAge("Fourty Five")
print(zack.getAge())
輸出
執行上面給出的程式碼時,您可以觀察到以下輸出:
45 Fourty Five
資料應僅在正確和有效的情況下儲存,使用異常處理結構。正如我們上面看到的,對 setAge() 方法的使用者輸入沒有限制。它可以是字串、數字或列表。因此,我們需要檢查上面的程式碼以確保儲存的正確性。
class MyClass(object):
def setAge(self, num):
self.age = num
def getAge(self):
return self.age
zack = MyClass()
zack.setAge(45)
print(zack.getAge())
zack.setAge("Fourty Five")
print(zack.getAge())
Init 建構函式
__init__ 方法會在類的物件例項化後立即隱式呼叫。這將初始化物件。
x = MyClass()
上面顯示的程式碼行將建立一個新例項並將此物件分配給區域性變數 x。
例項化操作,即呼叫類物件,會建立一個空物件。許多類都喜歡建立具有自定義為特定初始狀態的例項的物件。因此,類可以定義一個名為“__init__()”的特殊方法,如下所示:
def __init__(self): self.data = []
Python 在例項化期間呼叫 __init__ 以定義一個附加屬性,該屬性應在例項化類時發生,這可能是為該物件設定一些起始值或執行例項化時所需例程。因此,在這個例子中,可以透過以下方式獲得一個新的、已初始化的例項:
x = MyClass()
__init__() 方法可以具有單個或多個引數,以獲得更大的靈活性。init 代表初始化,因為它初始化例項的屬性。它被稱為類的建構函式。
class myclass(object):
def __init__(self,aaa, bbb):
self.a = aaa
self.b = bbb
x = myclass(4.5, 3)
print(x.a, x.b)
輸出
4.5 3
類屬性
在類中定義的屬性稱為“類屬性”,在函式中定義的屬性稱為“例項屬性”。定義時,這些屬性前面不加 self,因為這些是類的屬性,而不是特定例項的屬性。
類屬性既可以被類本身 (className.attributeName) 訪問,也可以被類的例項 (inst.attributeName) 訪問。因此,例項可以訪問例項屬性和類屬性。
>>> class myclass(): age = 21 >>> myclass.age 21 >>> x = myclass() >>> x.age 21 >>>
類屬性可以在例項中被覆蓋,即使這不是破壞封裝的好方法。
Python 中有一個屬性查詢路徑。首先是在類中定義的方法,然後是上面的類。
>>> class myclass(object): classy = 'class value' >>> dd = myclass() >>> print (dd.classy) # This should return the string 'class value' class value >>> >>> dd.classy = "Instance Value" >>> print(dd.classy) # Return the string "Instance Value" Instance Value >>> >>> # This will delete the value set for 'dd.classy' in the instance. >>> del dd.classy >>> >>> # Since the overriding attribute was deleted, this will print 'class value'. >>> print(dd.classy) class value >>>
我們在例項 dd 中覆蓋了“classy”類屬性。當它被覆蓋時,Python 直譯器讀取覆蓋的值。但是一旦新的值用“del”刪除,例項中不再存在覆蓋的值,因此查詢向上移動一級並從類中獲取它。
使用類和例項資料
在本節中,讓我們瞭解類資料如何與例項資料相關。我們可以將資料儲存在類中或例項中。當我們設計一個類時,我們決定哪些資料屬於例項,哪些資料應該儲存到整個類中。
例項可以訪問類資料。如果我們建立多個例項,則這些例項可以訪問它們各自的屬性值以及整個類資料。
因此,類資料是在所有例項之間共享的資料。觀察下面的程式碼以更好地理解:
class InstanceCounter(object):
count = 0 # class attribute, will be accessible to all instances
def __init__(self, val):
self.val = val
InstanceCounter.count +=1 # Increment the value of class attribute, accessible through class name
# In above line, class ('InstanceCounter') act as an object
def set_val(self, newval):
self.val = newval
def get_val(self):
return self.val
def get_count(self):
return InstanceCounter.count
a = InstanceCounter(9)
b = InstanceCounter(18)
c = InstanceCounter(27)
for obj in (a, b, c):
print ('val of obj: %s' %(obj.get_val())) # Initialized value ( 9, 18, 27)
print ('count: %s' %(obj.get_count())) # always 3
輸出
val of obj: 9 count: 3 val of obj: 18 count: 3 val of obj: 27 count: 3
簡而言之,類屬性對於類的所有例項都是相同的,而例項屬性對於每個例項都是特定的。對於兩個不同的例項,我們將擁有兩個不同的例項屬性。
class myClass:
class_attribute = 99
def class_method(self):
self.instance_attribute = 'I am instance attribute'
print (myClass.__dict__)
輸出
執行上面給出的程式碼時,您可以觀察到以下輸出:
{'__module__': '__main__', 'class_attribute': 99, 'class_method': <function myClass.class_method at 0x04128D68>, '__dict__': <attribute '__dict__' of 'myClass' objects>, '__weakref__': <attribute '__weakref__' of 'myClass' objects>, '__doc__': None}
例項屬性**myClass.__dict__** 如下所示:
>>> a = myClass()
>>> a.class_method()
>>> print(a.__dict__)
{'instance_attribute': 'I am instance attribute'}
面向物件快捷方式
本章詳細介紹了Python中的各種內建函式、檔案I/O操作和過載概念。
Python內建函式
Python直譯器有一些稱為內建函式的函式,可以隨時使用。在最新版本中,Python包含68個內建函式,如下表所示:
| 內建函式 | ||||
|---|---|---|---|---|
| abs() | dict() | help() | min() | setattr() |
| all() | dir() | hex() | next() | slice() |
| any() | divmod() | id() | object() | sorted() |
| ascii() | enumerate() | input() | oct() | staticmethod() |
| bin() | eval() | int() | open() | str() |
| bool() | exec() | isinstance() | ord() | sum() |
| bytearray() | filter() | issubclass() | pow() | super() |
| bytes() | float() | iter() | print() | tuple() |
| callable() | format() | len() | property() | type() |
| chr() | frozenset() | list() | range() | vars() |
| classmethod() | getattr() | locals() | repr() | zip() |
| compile() | globals() | map() | reversed() | __import__() |
| complex() | hasattr() | max() | round() | |
| delattr() | hash() | memoryview() | set() | |
本節簡要討論一些重要的函式:
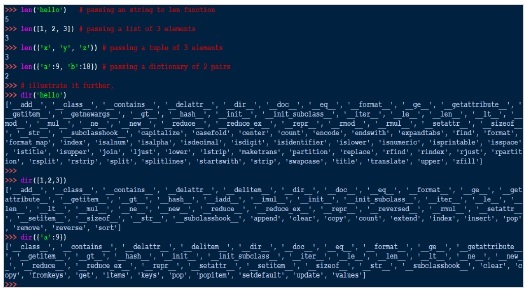
len() 函式
len() 函式獲取字串、列表或集合的長度。它返回物件的長度或專案數,其中物件可以是字串、列表或集合。
>>> len(['hello', 9 , 45.0, 24]) 4
len() 函式內部的工作方式類似於**list.__len__()** 或 **tuple.__len__()**。因此,請注意,len() 僅適用於具有 __len__() 方法的物件。
>>> set1
{1, 2, 3, 4}
>>> set1.__len__()
4
但是,在實踐中,我們更傾向於使用 **len()** 而不是 **__len__()** 函式,原因如下:
它更高效。並且不必編寫特定方法來拒絕訪問諸如 __len__ 之類的特殊方法。
易於維護。
它支援向後相容性。
reversed(seq)
它返回反向迭代器。seq 必須是一個具有 __reversed__() 方法或支援序列協議(__len__() 方法和 __getitem__() 方法)的物件。當我們想要從後往前迴圈遍歷專案時,它通常用於 **for** 迴圈。
>>> normal_list = [2, 4, 5, 7, 9]
>>>
>>> class CustomSequence():
def __len__(self):
return 5
def __getitem__(self,index):
return "x{0}".format(index)
>>> class funkyback():
def __reversed__(self):
return 'backwards!'
>>> for seq in normal_list, CustomSequence(), funkyback():
print('\n{}: '.format(seq.__class__.__name__), end="")
for item in reversed(seq):
print(item, end=", ")
最後的 for 迴圈列印普通列表的反向列表以及兩個自定義序列的例項。輸出顯示 **reversed()** 對所有三個都起作用,但在我們定義 **__reversed__** 時結果大相徑庭。
輸出
執行上面給出的程式碼時,您可以觀察到以下輸出:
list: 9, 7, 5, 4, 2, CustomSequence: x4, x3, x2, x1, x0, funkyback: b, a, c, k, w, a, r, d, s, !,
enumerate
**enumerate()** 方法為可迭代物件新增計數器並返回 enumerate 物件。
enumerate() 的語法為:
enumerate(iterable, start = 0)
這裡第二個引數 **start** 是可選的,預設情況下索引從零 (0) 開始。
>>> # Enumerate >>> names = ['Rajesh', 'Rahul', 'Aarav', 'Sahil', 'Trevor'] >>> enumerate(names) <enumerate object at 0x031D9F80> >>> list(enumerate(names)) [(0, 'Rajesh'), (1, 'Rahul'), (2, 'Aarav'), (3, 'Sahil'), (4, 'Trevor')] >>>
因此,**enumerate()** 返回一個迭代器,該迭代器產生一個元組,該元組對傳遞的序列中的元素進行計數。由於返回值是迭代器,因此直接訪問它並沒有多大用處。enumerate() 的更好方法是在 for 迴圈中進行計數。
>>> for i, n in enumerate(names):
print('Names number: ' + str(i))
print(n)
Names number: 0
Rajesh
Names number: 1
Rahul
Names number: 2
Aarav
Names number: 3
Sahil
Names number: 4
Trevor
標準庫中還有許多其他函式,這裡還有另一個更廣泛使用的函式列表:
**hasattr、getattr、setattr** 和 **delattr**,允許透過其字串名稱來操作物件的屬性。
**all** 和 **any**,它們接受一個可迭代物件,如果所有或任何專案計算結果為真,則返回 **True**。
**zip**,它接受兩個或多個序列並返回一個新的元組序列,其中每個元組包含每個序列中的單個值。
檔案 I/O
檔案的概念與面向物件程式設計術語相關。Python 已將作業系統提供的介面封裝在允許我們使用檔案物件的抽象中。
**open()** 內建函式用於開啟檔案並返回檔案物件。它是兩個引數中最常用的函式:
open(filename, mode)
open() 函式呼叫兩個引數,第一個是檔名,第二個是模式。這裡的模式可以是 'r'(只讀模式)、'w'(只寫,同名現有檔案將被擦除)和 'a'(開啟檔案進行追加,寫入檔案的所有資料都會自動新增到結尾)。'r+' 開啟檔案進行讀寫。預設模式是隻讀。
在 Windows 上,附加到模式的 'b' 將以二進位制模式開啟檔案,因此還有 'rb'、'wb' 和 'r+b' 等模式。
>>> text = 'This is the first line'
>>> file = open('datawork','w')
>>> file.write(text)
22
>>> file.close()
在某些情況下,我們只想追加到現有檔案而不是覆蓋它,為此我們可以提供 'a' 值作為模式引數,以追加到檔案末尾,而不是完全覆蓋現有檔案內容。
>>> f = open('datawork','a')
>>> text1 = ' This is second line'
>>> f.write(text1)
20
>>> f.close()
一旦開啟檔案進行讀取,我們可以呼叫 read、readline 或 readlines 方法來獲取檔案的內容。read 方法將檔案的全部內容作為 str 或 bytes 物件返回,具體取決於第二個引數是否為 'b'。
為了可讀性,並避免一次讀取大型檔案,最好直接在檔案物件上使用 for 迴圈。對於文字檔案,它將一次讀取一行,我們可以在迴圈體中處理它。但是,對於二進位制檔案,最好使用 read() 方法讀取固定大小的資料塊,並傳遞一個引數來指定要讀取的最大位元組數。
>>> f = open('fileone','r+')
>>> f.readline()
'This is the first line. \n'
>>> f.readline()
'This is the second line. \n'
寫入檔案,透過檔案物件的 write 方法將字串(二進位制資料的位元組)物件寫入檔案。writelines 方法接受一系列字串並將每個迭代值寫入檔案。writelines 方法不會在序列中的每個專案後追加換行符。
最後,當我們完成檔案讀取或寫入時,應該呼叫 close() 方法,以確保將任何緩衝寫入寫入磁碟,檔案已正確清理,並且與檔案繫結的所有資源都已釋放回作業系統。呼叫 close() 方法是一種更好的方法,但在技術上,這會在指令碼退出時自動發生。
方法過載的替代方法
方法過載是指擁有多個同名但接受不同引數集的方法。
對於單個方法或函式,我們可以自己指定引數的數量。根據函式定義,它可以呼叫零個、一個、兩個或多個引數。
class Human:
def sayHello(self, name = None):
if name is not None:
print('Hello ' + name)
else:
print('Hello ')
#Create Instance
obj = Human()
#Call the method, else part will be executed
obj.sayHello()
#Call the method with a parameter, if part will be executed
obj.sayHello('Rahul')
輸出
Hello Hello Rahul
預設引數
函式也是物件
可呼叫物件是可以接受某些引數並可能返回物件的 物件。函式是 Python 中最簡單的可呼叫物件,但還有其他物件,例如類或某些類例項。
Python 中的每個函式都是一個物件。物件可以包含方法或函式,但物件不一定是函式。
def my_func():
print('My function was called')
my_func.description = 'A silly function'
def second_func():
print('Second function was called')
second_func.description = 'One more sillier function'
def another_func(func):
print("The description:", end=" ")
print(func.description)
print('The name: ', end=' ')
print(func.__name__)
print('The class:', end=' ')
print(func.__class__)
print("Now I'll call the function passed in")
func()
another_func(my_func)
another_func(second_func)
在上面的程式碼中,我們能夠將兩個不同的函式作為引數傳遞到我們的第三個函式中,併為每個函式獲得不同的輸出:
The description: A silly function The name: my_func The class:Now I'll call the function passed in My function was called The description: One more sillier function The name: second_func The class: Now I'll call the function passed in Second function was called
可呼叫物件
正如函式是可以設定屬性的物件一樣,也可以建立一個可以像函式一樣呼叫的物件。
在 Python 中,任何具有 __call__() 方法的物件都可以使用函式呼叫語法進行呼叫。
繼承和多型性
繼承和多型性——這是 Python 中一個非常重要的概念。如果你想學習,必須更好地理解它。
繼承
面向物件程式設計的主要優勢之一是重用。繼承是實現相同目標的一種機制。繼承允許程式設計師首先建立一個通用類或基類,然後將其擴充套件到更專業的類。它允許程式設計師編寫更好的程式碼。
使用繼承,您可以使用或繼承基類中可用的所有資料欄位和方法。稍後您可以新增您自己的方法和資料欄位,因此繼承提供了一種組織程式碼的方法,而不是從頭開始重寫程式碼。
在面向物件的術語中,當類 X 擴充套件類 Y 時,Y 被稱為超類/父類/基類,X 被稱為子類/子類/派生類。這裡需要注意的一點是,只有非私有的資料欄位和方法才能被子類訪問。私有資料欄位和方法只能在類內部訪問。
建立派生類的語法為:
class BaseClass: Body of base class class DerivedClass(BaseClass): Body of derived class
繼承屬性
現在看看下面的例子:
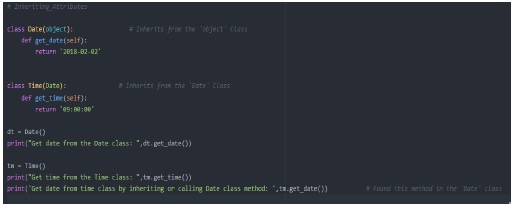
輸出

我們首先建立了一個名為 Date 的類並將物件作為引數傳遞,這裡物件是 Python 提供的內建類。稍後我們建立了另一個名為 time 的類並呼叫 Date 類作為引數。透過此呼叫,我們可以訪問 Time 類中 Date 類中的所有資料和屬性。正因為如此,當我們嘗試從我們之前建立的 Time 類物件 tm 獲取 get_date 方法時是可能的。
物件.屬性查詢層次結構
- 例項
- 類
- 此類繼承的任何類
繼承示例
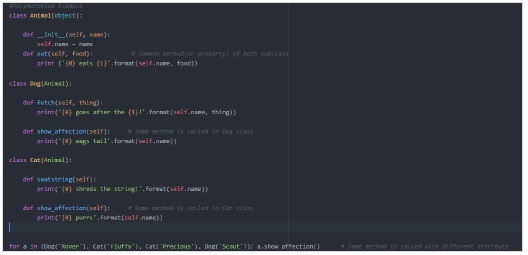
讓我們仔細看看繼承示例:

讓我們建立幾個類來參與示例:
- Animal——模擬動物的類
- Cat——Animal 的子類
- Dog——Animal 的子類
在 Python 中,類的建構函式用於建立物件(例項)併為屬性賦值。
子類的建構函式總是呼叫父類的建構函式來初始化父類中屬性的值,然後它開始為其屬性賦值。
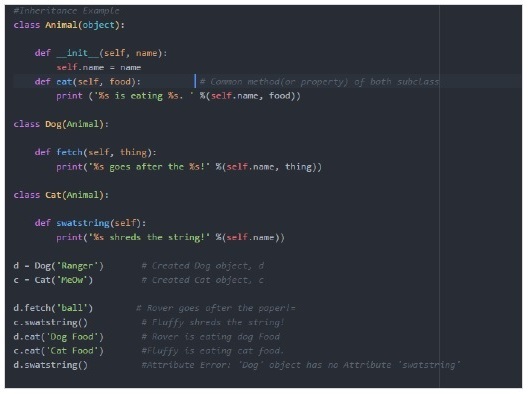
輸出
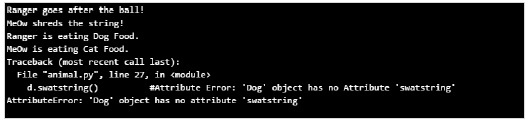
在上面的例子中,我們看到了在父類中放置的命令屬性或方法,以便所有子類或子類都將從父類繼承該屬性。
如果子類嘗試從另一個子類繼承方法或資料,那麼它將引發錯誤,正如我們看到 Dog 類嘗試從 cat 類呼叫 swatstring() 方法時一樣,它會引發錯誤(在我們的例子中是 AttributeError)。
多型性(“多種形態”)
多型性是 Python 中類定義的一個重要特性,當您在類或子類中具有常用命名的方 法時,就會使用它。這允許函式在不同時間使用不同型別的實體。因此,它提供了靈活性和鬆散耦合,以便程式碼可以隨著時間的推移而擴充套件和輕鬆維護。
這允許函式使用任何這些多型類的物件,而無需瞭解類之間的區別。
多型可以透過繼承來實現,子類利用基類方法或覆蓋它們。
讓我們用之前的繼承示例來理解多型的概念,並在兩個子類中新增一個名為show_affection的公共方法:
從這個例子我們可以看出,它指的是一種設計,其中不同型別的物件可以以相同的方式處理,或者更具體地說,兩個或多個類具有相同名稱的方法或公共介面,因為相同的方法(以下示例中的show_affection)可以使用任何型別的物件呼叫。
輸出

所以,所有動物都會表達感情(show_affection),但它們表達的方式不同。“show_affection”行為因此是多型的,因為它根據動物的不同而表現不同。因此,“動物”這個抽象概念實際上並沒有“表達感情”,但具體的動物(如狗和貓)對“表達感情”這個動作有具體的實現。
Python本身就有一些多型的類。例如,len()函式可以用於多個物件,並且所有物件都根據輸入引數返回正確的輸出。
方法覆蓋
在Python中,當子類包含一個覆蓋超類方法的方法時,你也可以透過呼叫超類方法來呼叫
Super(Subclass, self).method而不是self.method。
示例
class Thought(object):
def __init__(self):
pass
def message(self):
print("Thought, always come and go")
class Advice(Thought):
def __init__(self):
super(Advice, self).__init__()
def message(self):
print('Warning: Risk is always involved when you are dealing with market!')
繼承建構函式
如果我們從之前的繼承示例來看,`__init__`位於父類中,因為子類dog或cat在其內部沒有`__init__`方法。Python使用繼承屬性查詢在animal類中查詢`__init__`。當我們建立子類時,它首先會在dog類中查詢`__init__`方法,如果沒有找到,則會查詢父類Animal,並在那裡找到並呼叫它。因此,隨著我們類設計的複雜化,我們可能希望首先透過父類建構函式處理例項,然後透過子類建構函式處理例項。
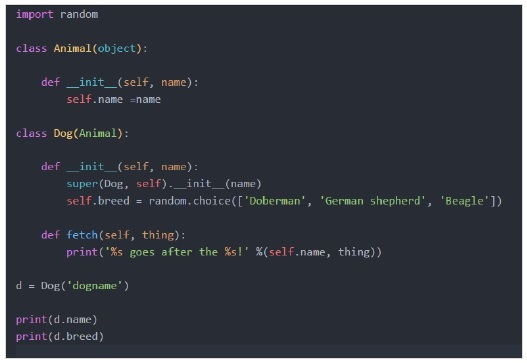
輸出

在上例中,所有動物都有一個名字,所有狗都有一個特定的品種。我們用super呼叫了父類建構函式。所以狗有它自己的`__init__`,但是首先發生的事情是我們呼叫super。Super是一個內建函式,它被設計用來將一個類與其超類或父類關聯起來。
在這種情況下,我們說的是獲取狗的超類,並將狗例項傳遞給這裡所說的任何方法,即建構函式`__init__`。換句話說,我們用狗物件呼叫父類Animal的`__init__`。你可能會問,為什麼我們不直接用狗例項來呼叫Animal `__init__`,我們可以這樣做,但是如果動物類的名稱將來發生變化會怎樣?如果我們想重新排列類層次結構,讓狗繼承自另一個類呢?在這種情況下使用super允許我們保持事物模組化,易於更改和維護。
所以在本例中,我們能夠將一般的`__init__`功能與更具體的函式結合起來。這給了我們一個機會,可以將公共功能與特定功能分開,從而消除程式碼重複,並以反映系統整體設計的方式將類關聯起來。
結論
`__init__`就像任何其他方法一樣;它可以被繼承。
如果一個類沒有`__init__`建構函式,Python將檢查其父類以檢視是否可以找到一個。
一旦找到一個,Python就會呼叫它並停止查詢。
我們可以使用super()函式呼叫父類中的方法。
我們可能希望在父類以及我們自己的類中進行初始化。
多重繼承和查詢樹
顧名思義,Python中的多重繼承是指一個類繼承自多個類。
例如,一個孩子繼承了父母雙方的性格特徵(母親和父親)。
Python多重繼承語法
要使一個類繼承自多個父類,我們在定義派生類時將這些類的名稱寫在派生類的括號內。我們將這些名稱用逗號分隔。
以下是一個例子:
>>> class Mother: pass >>> class Father: pass >>> class Child(Mother, Father): pass >>> issubclass(Child, Mother) and issubclass(Child, Father) True
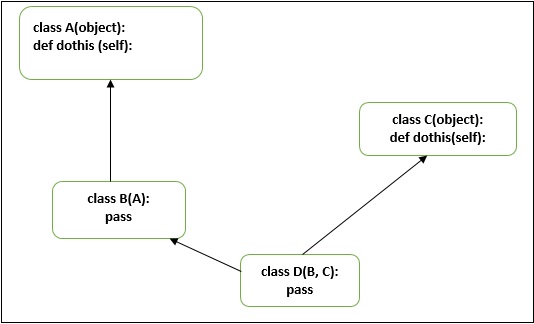
多重繼承是指繼承自兩個或多個類。當子類繼承自父類,而父類又繼承自祖先類時,複雜性就出現了。Python會遍歷繼承樹,查詢從物件讀取的請求屬性。它將檢查例項、類本身、父類,最後是祖先類。現在問題出現了,將按什麼順序搜尋類——廣度優先還是深度優先?預設情況下,Python使用深度優先。
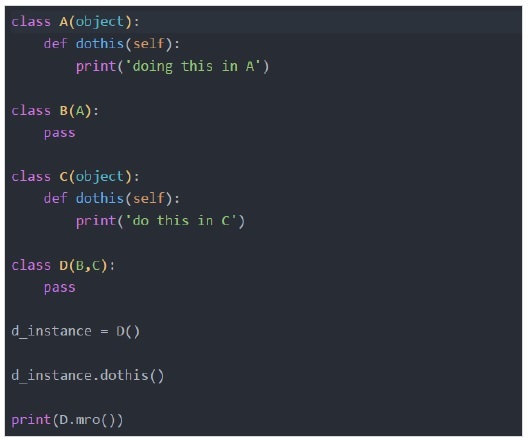
這就是為什麼在下圖中,Python首先在A類中搜索dothis()方法。所以以下示例中的方法解析順序將是
MRO:D→B→A→C
請看下面的多重繼承圖:
讓我們來看一個例子來理解Python的“mro”特性。
輸出
示例3
讓我們再來看一個“菱形”多重繼承的例子。
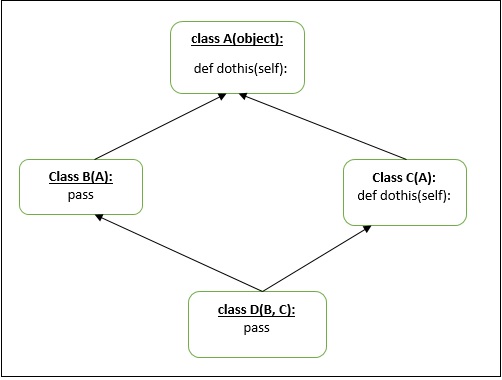
上圖將被認為是模稜兩可的。根據我們之前的例子理解“方法解析順序”,即mro將是D→B→A→C→A,但事實並非如此。在從C獲取第二個A時,Python將忽略之前的A。所以在這種情況下,mro將是D→B→C→A。
讓我們根據上圖建立一個示例:
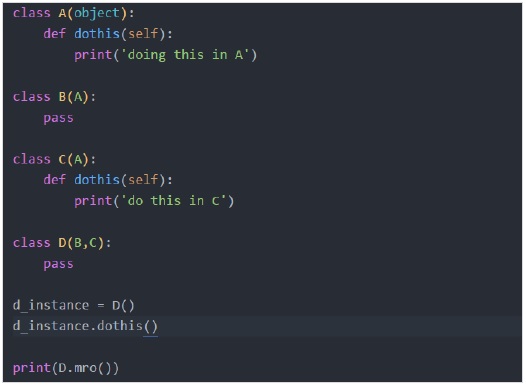
輸出

理解上述輸出的簡單規則是:如果同一個類出現在方法解析順序中,則該類的早期出現將從方法解析順序中刪除。
總之:
任何類都可以繼承自多個類。
Python通常在搜尋繼承類時使用“深度優先”順序。
但是當兩個類繼承自同一個類時,Python會從mro中刪除該類的第一次出現。
裝飾器、靜態方法和類方法
函式(或方法)由def語句建立。
儘管方法的工作方式與函式完全相同,只有一點不同,即方法的第一個引數是例項物件。
我們可以根據它們的行為對方法進行分類,例如
簡單方法 - 在類外部定義。此函式可以透過提供例項引數來訪問類屬性。
def outside_func(():
例項方法 -
def func(self,)
類方法 - 如果我們需要使用類屬性。
@classmethod def cfunc(cls,)
靜態方法 - 沒有關於類的任何資訊。
@staticmethod def sfoo()
到目前為止,我們已經看到了例項方法,現在是時候深入瞭解其他兩種方法了:
類方法
@classmethod 裝飾器是一個內建函式裝飾器,它將呼叫它的類或呼叫它的例項的類作為第一個引數傳遞。該評估的結果會覆蓋你的函式定義。
語法
class C(object):
@classmethod
def fun(cls, arg1, arg2, ...):
....
fun: function that needs to be converted into a class method
returns: a class method for function
它們可以訪問這個cls引數,但不能修改物件例項狀態。這需要訪問self。
它繫結到類,而不是類的物件。
類方法仍然可以修改適用於類的所有例項的類狀態。
靜態方法
靜態方法既不接受self引數也不接受cls(類)引數,但它可以自由地接受任意數量的其他引數。
語法
class C(object): @staticmethod def fun(arg1, arg2, ...): ... returns: a static method for function funself.
- 靜態方法既不能修改物件狀態也不能修改類狀態。
- 它們在可以訪問的資料方面受到限制。
何時使用什麼
我們通常使用類方法來建立工廠方法。工廠方法為不同的用例返回類物件(類似於建構函式)。
我們通常使用靜態方法來建立實用程式函式。
Python設計模式
概述
現代軟體開發需要解決複雜的業務需求。它還需要考慮諸如未來的可擴充套件性和可維護性等因素。良好的軟體系統設計對於實現這些目標至關重要。設計模式在這樣的系統中扮演著重要的角色。
為了理解設計模式,讓我們考慮下面的例子:
每輛車的設計都遵循一個基本的設計模式,四個輪子、方向盤、核心驅動系統(如油門-剎車-離合器)等。
所以,所有重複建造/生產的東西,在其設計中不可避免地遵循某種模式……無論是汽車、腳踏車、比薩餅、自動取款機,還是任何東西……甚至你的沙發床。
在軟體中對某些邏輯/機制/技術進行編碼幾乎已經成為標準方式的設計,因此被稱為或被研究為軟體設計模式。
為什麼設計模式很重要?
使用設計模式的好處是:
透過經過驗證的方法幫助你解決常見的設計問題。
由於它們有良好的文件記錄,因此理解上沒有歧義。
減少整體開發時間。
幫助你比其他方法更容易地處理未來的擴充套件和修改。
由於它們是針對常見問題的經過驗證的解決方案,因此可以減少系統中的錯誤。
設計模式的分類
GoF(四人幫)設計模式分為三類:建立型、結構型和行為型。
建立型模式
建立型設計模式將物件建立邏輯與系統的其餘部分分離。建立型模式會為你建立物件,而不是你建立物件。建立型模式包括抽象工廠、生成器、工廠方法、原型和單例。
由於語言的動態特性,建立型模式在Python中並不常用。而且語言本身也提供了我們建立足夠優雅方式所需的所有靈活性,我們很少需要在其之上實現任何東西,例如單例或工廠。
此外,這些模式提供了一種建立物件的方式,同時隱藏建立邏輯,而不是直接使用new運算子例項化物件。
結構型模式
有時,你不需要從頭開始,而是需要使用一組現有的類來構建更大的結構。這就是結構型類模式使用繼承來構建新結構的地方。結構型物件模式使用組合/聚合來獲得新的功能。介面卡、橋接器、組合、裝飾器、外觀、享元和代理是結構型模式。它們提供了組織類層次結構的最佳方法。
行為型模式
行為型模式提供了處理物件之間通訊的最佳方法。屬於此類別的模式有:訪問者、責任鏈、命令、直譯器、迭代器、中介者、備忘錄、觀察者、狀態、策略和模板方法是行為型模式。
因為它們代表系統的行為,所以它們通常用來描述軟體系統的功能。
常用的設計模式
單例模式
這是所有設計模式中最具爭議和最著名的模式之一。它用於過度面向物件的語言,並且是傳統面向物件程式設計的重要組成部分。
單例模式用於:
需要實現日誌記錄時。日誌記錄器例項由系統的所有元件共享。
配置檔案使用它,因為需要維護資訊快取並由系統中的所有各種元件共享。
管理資料庫連線。
以下是 UML 圖:

class Logger(object):
def __new__(cls, *args, **kwargs):
if not hasattr(cls, '_logger'):
cls._logger = super(Logger, cls).__new__(cls, *args, **kwargs)
return cls._logger
在此示例中,Logger 是一個單例。
呼叫 `__new__` 時,它通常會構造該類的新的例項。當我們重寫它時,我們首先檢查我們的單例例項是否已被建立。如果沒有,我們使用 super 呼叫來建立它。因此,無論何時我們在 Logger 上呼叫建構函式,我們總是獲得完全相同的例項。
>>> >>> obj1 = Logger() >>> obj2 = Logger() >>> obj1 == obj2 True >>> >>> obj1 <__main__.Logger object at 0x03224090> >>> obj2 <__main__.Logger object at 0x03224090>
面向物件 Python - 高階特性
在本節中,我們將瞭解 Python 提供的一些高階特性。
類設計中的核心語法
在本節中,我們將瞭解 Python 如何允許我們在類中利用運算子。Python 很大程度上是物件和物件上的方法呼叫,即使它被一些方便的語法隱藏,這也是如此。
>>> var1 = 'Hello' >>> var2 = ' World!' >>> var1 + var2 'Hello World!' >>> >>> var1.__add__(var2) 'Hello World!' >>> num1 = 45 >>> num2 = 60 >>> num1.__add__(num2) 105 >>> var3 = ['a', 'b'] >>> var4 = ['hello', ' John'] >>> var3.__add__(var4) ['a', 'b', 'hello', ' John']
因此,如果我們必須將魔術方法 `__add__` 新增到我們自己的類中,我們也可以這樣做嗎?讓我們嘗試一下。
我們有一個名為 Sumlist 的類,它有一個建構函式 `__init__`,它將列表作為名為 my_list 的引數。
class SumList(object):
def __init__(self, my_list):
self.mylist = my_list
def __add__(self, other):
new_list = [ x + y for x, y in zip(self.mylist, other.mylist)]
return SumList(new_list)
def __repr__(self):
return str(self.mylist)
aa = SumList([3,6, 9, 12, 15])
bb = SumList([100, 200, 300, 400, 500])
cc = aa + bb # aa.__add__(bb)
print(cc) # should gives us a list ([103, 206, 309, 412, 515])
輸出
[103, 206, 309, 412, 515]
但是,許多方法是由其他魔術方法內部管理的。以下是一些方法:
'abc' in var # var.__contains__('abc')
var == 'abc' # var.__eq__('abc')
var[1] # var.__getitem__(1)
var[1:3] # var.__getslice__(1, 3)
len(var) # var.__len__()
print(var) # var.__repr__()
繼承內建型別
類也可以繼承自內建型別,這意味著繼承自任何內建型別並利用在那裡找到的所有功能。
在下面的示例中,我們繼承自字典,但隨後我們實現了它的一個方法 `__setitem__`。當我們在字典中設定鍵值對時,會呼叫此 (setitem)。由於這是一個魔術方法,因此會隱式呼叫它。
class MyDict(dict):
def __setitem__(self, key, val):
print('setting a key and value!')
dict.__setitem__(self, key, val)
dd = MyDict()
dd['a'] = 10
dd['b'] = 20
for key in dd.keys():
print('{0} = {1}'.format(key, dd[key]))
輸出
setting a key and value! setting a key and value! a = 10 b = 20
讓我們擴充套件之前的示例,下面我們呼叫了兩個魔術方法 `__getitem__` 和 `__setitem__`,在處理列表索引時最好呼叫它們。
# Mylist inherits from 'list' object but indexes from 1 instead for 0!
class Mylist(list): # inherits from list
def __getitem__(self, index):
if index == 0:
raise IndexError
if index > 0:
index = index - 1
return list.__getitem__(self, index) # this method is called when
# we access a value with subscript like x[1]
def __setitem__(self, index, value):
if index == 0:
raise IndexError
if index > 0:
index = index - 1
list.__setitem__(self, index, value)
x = Mylist(['a', 'b', 'c']) # __init__() inherited from builtin list
print(x) # __repr__() inherited from builtin list
x.append('HELLO'); # append() inherited from builtin list
print(x[1]) # 'a' (Mylist.__getitem__ cutomizes list superclass
# method. index is 1, but reflects 0!
print (x[4]) # 'HELLO' (index is 4 but reflects 3!
輸出
['a', 'b', 'c'] a HELLO
在上面的示例中,我們在 Mylist 中設定了一個包含三個專案的列表,並隱式呼叫 `__init__` 方法,當我們列印元素 x 時,我們得到包含三個專案的列表(['a','b','c'])。然後我們將另一個元素新增到此列表中。稍後我們請求索引 1 和索引 4。但是如果你看到輸出,我們得到的是我們請求的 (index-1) 元素。我們知道列表索引從 0 開始,但這裡的索引從 1 開始(這就是為什麼我們得到列表的第一個專案的原因)。
命名約定
在本節中,我們將瞭解我們將用於變數(尤其是私有變數)的名稱以及全球 Python 程式設計師使用的約定。雖然變數被指定為私有變數,但在 Python 中不存在隱私,這是設計使然。像任何其他有良好文件記錄的語言一樣,Python 具有它提倡的命名和樣式約定,儘管它不強制執行它們。Python 的創始人 Guido van Rossum 編寫了一份樣式指南,其中描述了最佳實踐和名稱的使用,稱為 PEP8。以下是此指南的連結:https://python.club.tw/dev/peps/pep-0008/
PEP 代表 Python 增強提案,是一系列在 Python 社群中分發的文件,用於討論提出的更改。例如,建議所有:
- 模組名稱 - all_lower_case
- 類名和異常名 - CamelCase
- 全域性名稱和區域性名稱 - all_lower_case
- 函式和方法名稱 - all_lower_case
- 常量 - ALL_UPPER_CASE
這些只是建議,如果願意,你可以有所不同。但是由於大多數開發人員遵循這些建議,因此你的程式碼的可讀性可能會降低。
為什麼要遵守約定?
我們可以遵循 PEP 建議,因為它允許我們獲得:
- 對絕大多數開發人員來說更熟悉
- 對大多數閱讀你程式碼的人來說更清晰
- 將與在同一程式碼庫上工作的其他貢獻者的風格相匹配
- 專業軟體開發人員的標誌
- 每個人都會接受你。
變數命名 - “公共”和“私有”
在 Python 中,當我們處理模組和類時,我們將某些變數或屬性指定為私有。在 Python 中,不存在“私有”例項變數,除非在物件內部,否則無法訪問它。私有隻是意味著它們並非旨在被程式碼使用者使用,而是旨在在內部使用。通常,大多數 Python 開發人員都遵循一種約定,即以下劃線為字首的名稱,例如 _attrval(下面的示例)應被視為 API 或任何 Python 程式碼(無論是函式、方法還是資料成員)的非公共部分。以下是我們遵循的命名約定:
公共屬性或變數(旨在被此模組的匯入者或此類的使用者使用) - regular_lower_case
私有屬性或變數(模組或類內部使用) - _single_leading_underscore
不應進行子類化的私有屬性 - __double_leading_underscore
魔術屬性 - __double_underscores__(使用它們,不要建立它們)
class GetSet(object):
instance_count = 0 # public
__mangled_name = 'no privacy!' # special variable
def __init__(self, value):
self._attrval = value # _attrval is for internal use only
GetSet.instance_count += 1
@property
def var(self):
print('Getting the "var" attribute')
return self._attrval
@var.setter
def var(self, value):
print('setting the "var" attribute')
self._attrval = value
@var.deleter
def var(self):
print('deleting the "var" attribute')
self._attrval = None
cc = GetSet(5)
cc.var = 10 # public name
print(cc._attrval)
print(cc._GetSet__mangled_name)
輸出
setting the "var" attribute 10 no privacy!
面向物件 Python - 檔案和字串
字串
字串是在每種程式語言中最常用的資料型別。為什麼?因為我們比數字更瞭解文字,所以在寫作和談話中我們使用文字和單詞,同樣在程式設計中我們也使用字串。在字串中,我們解析文字,分析文字語義,並進行資料探勘——所有這些資料都是人類使用的文字。Python 中的字串是不可變的。
字串操作
在 Python 中,字串可以用多種方式標記,可以使用單引號(')、雙引號(")甚至三引號('''),如果是多行字串。
>>> # String Examples
>>> a = "hello"
>>> b = ''' A Multi line string,
Simple!'''
>>> e = ('Multiple' 'strings' 'togethers')
字串操作非常有用,並且在每種語言中都廣泛使用。程式設計師經常需要分解字串並仔細檢查它們。
可以迭代字串(逐字元)、切片或連線。語法與列表相同。
str 類在其上有很多方法,使操作字串更容易。dir 和 help 命令在 Python 直譯器中提供了關於如何使用它們的指導。
以下是一些我們常用的字串方法。
| 序號 | 方法和描述 |
|---|---|
| 1 | isalpha() 檢查所有字元是否都是字母 |
| 2 | isdigit() 檢查數字字元 |
| 3 | isdecimal() 檢查十進位制字元 |
| 4 | isnumeric() 檢查數字字元 |
| 5 | find() 返回子字串的最高索引 |
| 6 | istitle() 檢查標題大小寫的字串 |
| 7 | join() 返回連線的字串 |
| 8 | lower() 返回小寫字串 |
| 9 | upper() 返回大寫字串 |
| 10 | partition() 返回一個元組 |
| 11 | bytearray() 返回給定位元組大小的陣列 |
| 12 | enumerate() 返回一個列舉物件 |
| 13 | isprintable() 檢查可列印字元 |
讓我們嘗試執行幾個字串方法:
>>> str1 = 'Hello World!'
>>> str1.startswith('h')
False
>>> str1.startswith('H')
True
>>> str1.endswith('d')
False
>>> str1.endswith('d!')
True
>>> str1.find('o')
4
>>> #Above returns the index of the first occurence of the character/substring.
>>> str1.find('lo')
3
>>> str1.upper()
'HELLO WORLD!'
>>> str1.lower()
'hello world!'
>>> str1.index('b')
Traceback (most recent call last):
File "<pyshell#19>", line 1, in <module>
str1.index('b')
ValueError: substring not found
>>> s = ('hello How Are You')
>>> s.split(' ')
['hello', 'How', 'Are', 'You']
>>> s1 = s.split(' ')
>>> '*'.join(s1)
'hello*How*Are*You'
>>> s.partition(' ')
('hello', ' ', 'How Are You')
>>>
字串格式化
在 Python 3.x 中,字串的格式化方式發生了變化,現在它更合乎邏輯並且更靈活。可以使用 format() 方法或 % 符號(舊樣式)在格式字串中進行格式化。
字串可以包含文字文字或由大括號 {} 分隔的替換欄位,每個替換欄位可以包含位置引數的數字索引或關鍵字引數的名稱。
語法
str.format(*args, **kwargs)
基本格式化
>>> '{} {}'.format('Example', 'One')
'Example One'
>>> '{} {}'.format('pie', '3.1415926')
'pie 3.1415926'
下面的示例允許重新排列顯示順序,而無需更改引數。
>>> '{1} {0}'.format('pie', '3.1415926')
'3.1415926 pie'
填充和對齊字串
可以將值填充到特定長度。
>>> #Padding Character, can be space or special character
>>> '{:12}'.format('PYTHON')
'PYTHON '
>>> '{:>12}'.format('PYTHON')
' PYTHON'
>>> '{:<{}s}'.format('PYTHON',12)
'PYTHON '
>>> '{:*<12}'.format('PYTHON')
'PYTHON******'
>>> '{:*^12}'.format('PYTHON')
'***PYTHON***'
>>> '{:.15}'.format('PYTHON OBJECT ORIENTED PROGRAMMING')
'PYTHON OBJECT O'
>>> #Above, truncated 15 characters from the left side of a specified string
>>> '{:.{}}'.format('PYTHON OBJECT ORIENTED',15)
'PYTHON OBJECT O'
>>> #Named Placeholders
>>> data = {'Name':'Raghu', 'Place':'Bangalore'}
>>> '{Name} {Place}'.format(**data)
'Raghu Bangalore'
>>> #Datetime
>>> from datetime import datetime
>>> '{:%Y/%m/%d.%H:%M}'.format(datetime(2018,3,26,9,57))
'2018/03/26.09:57'
字串是 Unicode
作為不可變 Unicode 字元集合的字串。Unicode 字串提供了建立可在任何地方執行的軟體或程式的機會,因為 Unicode 字串可以表示任何可能的字元,而不僅僅是 ASCII 字元。
許多 IO 操作只知道如何處理位元組,即使位元組物件指的是文字資料。因此,瞭解如何在位元組和 Unicode 之間進行交換非常重要。
將文字轉換為位元組
將字串轉換為位元組物件稱為編碼。有許多編碼形式,最常見的是:PNG;JPEG、MP3、WAV、ASCII、UTF-8 等。此外,這(編碼)是一種以位元組表示音訊、影像、文字等的格式。
此轉換可以透過 encode() 完成。它以編碼技術作為引數。預設情況下,我們使用 'UTF-8' 技術。
>>> # Python Code to demonstrate string encoding
>>>
>>> # Initialising a String
>>> x = 'TutorialsPoint'
>>>
>>> #Initialising a byte object
>>> y = b'TutorialsPoint'
>>>
>>> # Using encode() to encode the String >>> # encoded version of x is stored in z using ASCII mapping
>>> z = x.encode('ASCII')
>>>
>>> # Check if x is converted to bytes or not
>>>
>>> if(z==y):
print('Encoding Successful!')
else:
print('Encoding Unsuccessful!')
Encoding Successful!
將位元組轉換為文字
將位元組轉換為文字稱為解碼。這是透過 decode() 實現的。如果我們知道用於對其進行編碼的編碼,則可以將位元組字串轉換為字元字串。
因此,編碼和解碼是相反的過程。
>>>
>>> # Python code to demonstrate Byte Decoding
>>>
>>> #Initialise a String
>>> x = 'TutorialsPoint'
>>>
>>> #Initialising a byte object
>>> y = b'TutorialsPoint'
>>>
>>> #using decode() to decode the Byte object
>>> # decoded version of y is stored in z using ASCII mapping
>>> z = y.decode('ASCII')
>>> #Check if y is converted to String or not
>>> if (z == x):
print('Decoding Successful!')
else:
print('Decoding Unsuccessful!') Decoding Successful!
>>>
檔案 I/O
作業系統將檔案表示為位元組序列,而不是文字。
檔案是磁碟上用於儲存相關資訊的命名位置。它用於永久儲存磁碟中的資料。
在 Python 中,檔案操作按以下順序進行。
- 開啟檔案
- 讀取或寫入檔案(操作)。開啟檔案
- 關閉檔案。
Python 使用適當的 decode(或 encode)呼叫包裝傳入(或傳出)的位元組流,因此我們可以直接處理 str 物件。
開啟檔案
Python 有一個內建函式 open() 用於開啟檔案。這將生成一個檔案物件,也稱為控制代碼,因為它用於相應地讀取或修改檔案。
>>> f = open(r'c:\users\rajesh\Desktop\index.webm','rb') >>> f <_io.BufferedReader name='c:\\users\\rajesh\\Desktop\\index.webm'> >>> f.mode 'rb' >>> f.name 'c:\\users\\rajesh\\Desktop\\index.webm'
要從檔案讀取文字,我們只需要將檔名傳遞給函式。檔案將被開啟以進行讀取,並且位元組將使用平臺預設編碼轉換為文字。
異常和異常類
通常,異常是任何異常情況。異常通常表示錯誤,但有時它們有意地放入程式中,例如提前終止過程或從資源短缺中恢復。有許多內建異常,它們指示諸如讀取檔案末尾之後或除以零之類的條件。我們可以定義我們自己的異常,稱為自定義異常。
異常處理使您可以優雅地處理錯誤並對錯誤執行有意義的操作。異常處理有兩個組成部分:“丟擲”和“捕獲”。
識別異常(錯誤)
Python 中發生的每個錯誤都會導致異常,這將是其錯誤型別標識的錯誤條件。
>>> #Exception
>>> 1/0
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
1/0
ZeroDivisionError: division by zero
>>>
>>> var = 20
>>> print(ver)
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
print(ver)
NameError: name 'ver' is not defined
>>> #Above as we have misspelled a variable name so we get an NameError.
>>>
>>> print('hello)
SyntaxError: EOL while scanning string literal
>>> #Above we have not closed the quote in a string, so we get SyntaxError.
>>>
>>> #Below we are asking for a key, that doen't exists.
>>> mydict = {}
>>> mydict['x']
Traceback (most recent call last):
File "<pyshell#15>", line 1, in <module>
mydict['x']
KeyError: 'x'
>>> #Above keyError
>>>
>>> #Below asking for a index that didn't exist in a list.
>>> mylist = [1,2,3,4]
>>> mylist[5]
Traceback (most recent call last):
File "<pyshell#20>", line 1, in <module>
mylist[5]
IndexError: list index out of range
>>> #Above, index out of range, raised IndexError.
捕獲/捕獲異常
當程式中發生異常情況並且你希望使用異常機制來處理它時,你“丟擲異常”。try 和 except 關鍵字用於捕獲異常。每當 try 塊中發生錯誤時,Python 都會查詢匹配的 except 塊來處理它。如果存在,執行將跳轉到那裡。
語法
try: #write some code #that might throw some exception except <ExceptionType>: # Exception handler, alert the user
try 子句中的程式碼將逐條語句執行。
如果發生異常,則將跳過 try 塊的其餘部分,並將執行 except 子句。
try: some statement here except: exception handling
讓我們編寫一些程式碼來檢視在程式中不使用任何錯誤處理機制時會發生什麼。
number = int(input('Please enter the number between 1 & 10: '))
print('You have entered number',number)
只要使用者輸入數字,上述程式就會正常工作,但是如果使用者嘗試輸入其他資料型別(例如字串或列表)會發生什麼?
Please enter the number between 1 > 10: 'Hi'
Traceback (most recent call last):
File "C:/Python/Python361/exception2.py", line 1, in <module>
number = int(input('Please enter the number between 1 & 10: '))
ValueError: invalid literal for int() with base 10: "'Hi'"
現在,ValueError 是一個異常型別。讓我們嘗試使用異常處理重寫上面的程式碼。
import sys
print('Previous code with exception handling')
try:
number = int(input('Enter number between 1 > 10: '))
except(ValueError):
print('Error..numbers only')
sys.exit()
print('You have entered number: ',number)
如果我們執行程式並輸入字串(而不是數字),我們可以看到得到不同的結果。
Previous code with exception handling Enter number between 1 > 10: 'Hi' Error..numbers only
引發異常
要從你自己的方法中引發異常,你需要使用像這樣的 raise 關鍵字
raise ExceptionClass(‘Some Text Here’)
讓我們來看一個例子
def enterAge(age):
if age<0:
raise ValueError('Only positive integers are allowed')
if age % 2 ==0:
print('Entered Age is even')
else:
print('Entered Age is odd')
try:
num = int(input('Enter your age: '))
enterAge(num)
except ValueError:
print('Only positive integers are allowed')
執行程式並輸入正整數。
預期輸出
Enter your age: 12 Entered Age is even
但是當我們嘗試輸入負數時,我們會得到:
預期輸出
Enter your age: -2 Only positive integers are allowed
建立自定義異常類
你可以透過擴充套件 BaseException 類或 BaseException 的子類來建立一個自定義異常類。

從上圖我們可以看到,Python 中的大多數異常類都擴充套件自 BaseException 類。你可以從 BaseException 類或其子類派生你自己的異常類。
建立一個名為 NegativeNumberException.py 的新檔案並編寫以下程式碼。
class NegativeNumberException(RuntimeError):
def __init__(self, age):
super().__init__()
self.age = age
上面的程式碼建立了一個名為 NegativeNumberException 的新異常類,它只包含一個建構函式,該建構函式使用 super().__init__() 呼叫父類建構函式並設定年齡。
現在,要建立你自己的自定義異常類,我們將編寫一些程式碼並匯入新的異常類。
from NegativeNumberException import NegativeNumberException
def enterage(age):
if age < 0:
raise NegativeNumberException('Only positive integers are allowed')
if age % 2 == 0:
print('Age is Even')
else:
print('Age is Odd')
try:
num = int(input('Enter your age: '))
enterage(num)
except NegativeNumberException:
print('Only positive integers are allowed')
except:
print('Something is wrong')
輸出
Enter your age: -2 Only positive integers are allowed
另一種建立自定義異常類的方法。
class customException(Exception):
def __init__(self, value):
self.parameter = value
def __str__(self):
return repr(self.parameter)
try:
raise customException('My Useful Error Message!')
except customException as instance:
print('Caught: ' + instance.parameter)
輸出
Caught: My Useful Error Message!
異常層次結構
內建異常的類層次結構為:
+-- SystemExit +-- KeyboardInterrupt +-- GeneratorExit +-- Exception +-- StopIteration +-- StopAsyncIteration +-- ArithmeticError | +-- FloatingPointError | +-- OverflowError | +-- ZeroDivisionError +-- AssertionError +-- AttributeError +-- BufferError +-- EOFError +-- ImportError +-- LookupError | +-- IndexError | +-- KeyError +-- MemoryError +-- NameError | +-- UnboundLocalError +-- OSError | +-- BlockingIOError | +-- ChildProcessError | +-- ConnectionError | | +-- BrokenPipeError | | +-- ConnectionAbortedError | | +-- ConnectionRefusedError | | +-- ConnectionResetError | +-- FileExistsError | +-- FileNotFoundError | +-- InterruptedError | +-- IsADirectoryError | +-- NotADirectoryError | +-- PermissionError | +-- ProcessLookupError | +-- TimeoutError +-- ReferenceError +-- RuntimeError | +-- NotImplementedError | +-- RecursionError +-- SyntaxError | +-- IndentationError | +-- TabError +-- SystemError +-- TypeError +-- ValueError | +-- UnicodeError | +-- UnicodeDecodeError | +-- UnicodeEncodeError | +-- UnicodeTranslateError +-- Warning +-- DeprecationWarning +-- PendingDeprecationWarning +-- RuntimeWarning +-- SyntaxWarning +-- UserWarning +-- FutureWarning +-- ImportWarning +-- UnicodeWarning +-- BytesWarning +-- ResourceWarning
面向物件 Python - 物件序列化
在資料儲存的上下文中,序列化是將資料結構或物件狀態轉換為可以儲存(例如,在檔案或記憶體緩衝區中)或傳輸並在以後重建的格式的過程。
在序列化中,物件被轉換為可以儲存的格式,以便以後能夠反序列化它並從序列化格式中重新建立原始物件。
Pickle
Pickling 是將 Python 物件層次結構轉換為位元組流(通常不可讀)以寫入檔案的過程,這也被稱為序列化。Unpickling 是反向操作,其中位元組流被轉換回可工作的 Python 物件層次結構。
Pickle 是儲存物件的執行時最簡單的方法。Python Pickle 模組是一種面向物件的方法,可以直接以特殊的儲存格式儲存物件。
它能做什麼?
- Pickle 可以非常輕鬆地儲存和複製字典和列表。
- 儲存物件屬性並將它們恢復到相同的狀態。
Pickle 不能做什麼?
- 它不儲存物件的程式碼。只有它的屬性值。
- 它不能儲存檔案控制代碼或連線套接字。
簡而言之,我們可以說,pickling 是一種將資料變數儲存到檔案和從檔案中檢索資料變數的方法,其中變數可以是列表、類等。
要進行 Pickle 操作,你必須:
- 匯入 pickle
- 將變數寫入檔案,例如
pickle.dump(mystring, outfile, protocol),
其中第 3 個引數 protocol 是可選的。要進行 unpickling 操作,你必須:
匯入 pickle
將變數寫入檔案,例如
myString = pickle.load(inputfile)
方法
pickle 介面提供四種不同的方法。
dump() − dump() 方法序列化到開啟的檔案(類檔案物件)。
dumps() − 序列化到字串
load() − 從類檔案物件反序列化。
loads() − 從字串反序列化。
基於上述過程,以下是“pickling”的示例。
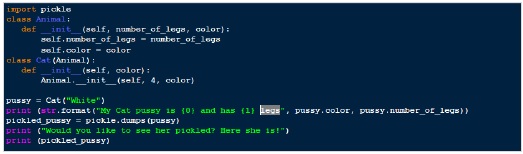
輸出
My Cat pussy is White and has 4 legs Would you like to see her pickled? Here she is! b'\x80\x03c__main__\nCat\nq\x00)\x81q\x01}q\x02(X\x0e\x00\x00\x00number_of_legsq\x03K\x04X\x05\x00\x00\x00colorq\x04X\x05\x00\x00\x00Whiteq\x05ub.'
因此,在上例中,我們建立了一個 Cat 類的例項,然後我們對其進行了 pickling,將我們的“Cat”例項轉換為簡單的位元組陣列。
這樣,我們可以輕鬆地將位元組陣列儲存在二進位制檔案或資料庫欄位中,並在以後的時間從我們的儲存支援中將其恢復到原始形式。
此外,如果你想建立一個包含 pickled 物件的檔案,可以使用 dump() 方法(而不是 dumps() 方法),同時傳遞一個開啟的二進位制檔案,pickling 結果將自動儲存在檔案中。
[….] binary_file = open(my_pickled_Pussy.bin', mode='wb') my_pickled_Pussy = pickle.dump(Pussy, binary_file) binary_file.close()
Unpickling
將二進位制陣列轉換為物件層次結構的過程稱為 unpickling。
unpickling 過程是透過使用 pickle 模組的 load() 函式完成的,它從簡單的位元組陣列返回完整的物件層次結構。
讓我們在上一個示例中使用 load 函式。

輸出
MeOw is black Pussy is white
JSON
JSON(JavaScript 物件表示法)是 Python 標準庫的一部分,是一種輕量級的資料交換格式。它易於人類閱讀和編寫。它易於解析和生成。
由於其簡單性,JSON 是一種儲存和交換資料的方法,這是透過其 JSON 語法實現的,並用於許多 Web 應用程式中。由於它是人類可讀的格式,這可能是它在資料傳輸中使用的原因之一,此外它在處理 API 時也很有效。
JSON 格式化資料的示例如下:
{"EmployID": 40203, "Name": "Zack", "Age":54, "isEmployed": True}
Python 使得使用 Json 檔案變得簡單。為此目的使用的模組是 JSON 模組。此模組應包含在你的 Python 安裝中(內建)。
讓我們看看如何將 Python 字典轉換為 JSON 並將其寫入文字檔案。
JSON 到 Python
讀取 JSON 表示將 JSON 轉換為 Python 值(物件)。json 庫將 JSON 解析為 Python 中的字典或列表。為此,我們使用 loads() 函式(從字串載入),如下所示:

輸出

下面是一個示例 json 檔案:
data1.json
{"menu": {
"id": "file",
"value": "File",
"popup": {
"menuitem": [
{"value": "New", "onclick": "CreateNewDoc()"},
{"value": "Open", "onclick": "OpenDoc()"},
{"value": "Close", "onclick": "CloseDoc()"}
]
}
}}
上面的內容(Data1.json)看起來像一個常規字典。我們可以使用 pickle 儲存此檔案,但其輸出不是人類可讀的格式。
JSON(Java Script 物件通知)是一種非常簡單的格式,這就是它流行的原因之一。現在讓我們透過下面的程式來看一下 json 輸出。
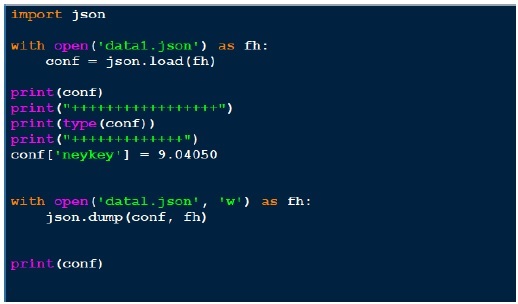
輸出
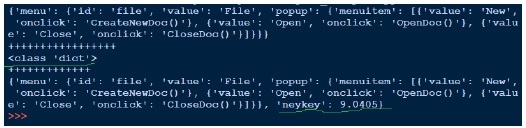
在上面,我們開啟 json 檔案 (data1.json) 進行讀取,獲取檔案控制代碼並傳遞給 json.load 並獲取物件。當我們嘗試列印物件的輸出時,它與 json 檔案相同。儘管物件的型別是字典,但它顯示為 Python 物件。寫入 json 與我們看到的 pickle 一樣簡單。我們在上面載入 json 檔案,新增另一個鍵值對並將其寫回同一個 json 檔案。現在如果我們檢視 data1.json,它看起來不同,即與我們之前看到的格式不同。
為了使我們的輸出看起來相同(人類可讀的格式),在程式的最後一行新增幾個引數:
json.dump(conf, fh, indent = 4, separators = (‘,’, ‘: ‘))
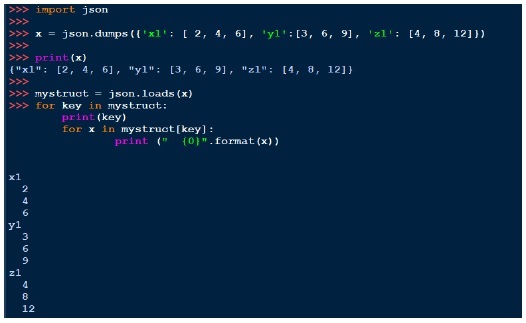
與 pickle 類似,我們可以使用 dumps 列印字串,使用 loads 載入字串。下面是一個例子:
YAML
YAML 可能是所有程式語言中最友好的資料序列化標準。
Python yaml 模組稱為 pyaml
YAML 是 JSON 的替代方案:
人類可讀的程式碼 − YAML 是最容易讓人閱讀的格式,以至於甚至它的首頁內容也以 YAML 顯示來強調這一點。
緊湊的程式碼 − 在 YAML 中,我們使用空格縮排表示結構,而不是括號。
關係資料的語法 − 對於內部引用,我們使用錨點 (&) 和別名 (*)。
它廣泛用於檢視/編輯資料結構的一個領域 − 例如配置檔案、除錯期間的轉儲和文件標題。
安裝 YAML
由於 yaml 不是內建模組,我們需要手動安裝它。在 Windows 機器上安裝 yaml 的最佳方法是透過 pip。在你的 Windows 終端上執行以下命令來安裝 yaml:
pip install pyaml (Windows machine) sudo pip install pyaml (*nix and Mac)
執行上述命令後,螢幕將顯示類似下面的內容,具體取決於當前的最新版本。
Collecting pyaml Using cached pyaml-17.12.1-py2.py3-none-any.whl Collecting PyYAML (from pyaml) Using cached PyYAML-3.12.tar.gz Installing collected packages: PyYAML, pyaml Running setup.py install for PyYAML ... done Successfully installed PyYAML-3.12 pyaml-17.12.1
要測試它,請轉到 Python shell 並匯入 yaml 模組,匯入 yaml,如果沒有發現錯誤,那麼我們可以說安裝成功。
安裝 pyaml 後,讓我們看看下面的程式碼:
script_yaml1.py

在上面,我們建立了三種不同的資料結構:字典、列表和元組。在每個結構上,我們都執行 yaml.dump。重要的是螢幕上如何顯示輸出。
輸出
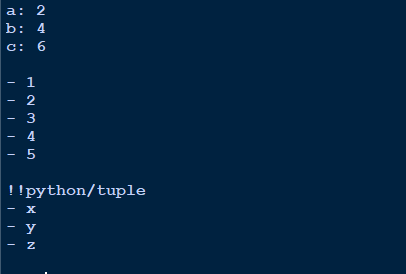
字典輸出看起來很清晰,即鍵:值。
空格用於分隔不同的物件。
列表用破折號 (-) 表示。
元組首先用 !!Python/tuple 表示,然後與列表的格式相同。
載入 yaml 檔案
假設我有一個 yaml 檔案,其中包含:
--- # An employee record name: Raagvendra Joshi job: Developer skill: Oracle employed: True foods: - Apple - Orange - Strawberry - Mango languages: Oracle: Elite power_builder: Elite Full Stack Developer: Lame education: 4 GCSEs 3 A-Levels MCA in something called com
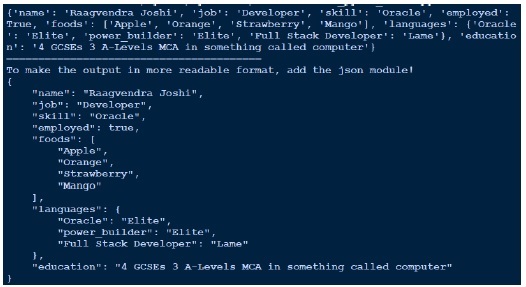
現在讓我們編寫一個程式碼,透過 yaml.load 函式載入此 yaml 檔案。以下是相同的程式碼。
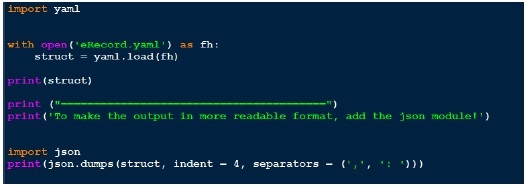
由於輸出看起來不太可讀,我最終使用了 json 來美化它。比較我們獲得的輸出和我們擁有的實際 yaml 檔案。
輸出
軟體開發最重要的方面之一是除錯。在本節中,我們將看到使用內建偵錯程式或第三方偵錯程式的不同 Python 除錯方法。
PDB – Python 偵錯程式
PDB 模組支援設定斷點。斷點是程式的有意暫停,你可以在其中獲取有關程式狀態的更多資訊。
要設定斷點,請插入以下行:
pdb.set_trace()
示例
pdb_example1.py import pdb x = 9 y = 7 pdb.set_trace() total = x + y pdb.set_trace()
我們在這個程式中插入了一些斷點。程式將在每個斷點 (pdb.set_trace()) 處暫停。要檢視變數的內容,只需鍵入變數名。
c:\Python\Python361>Python pdb_example1.py > c:\Python\Python361\pdb_example1.py(8)<module>() -> total = x + y (Pdb) x 9 (Pdb) y 7 (Pdb) total *** NameError: name 'total' is not defined (Pdb)
按 c 或 continue 繼續程式執行,直到下一個斷點。
(Pdb) c --Return-- > c:\Python\Python361\pdb_example1.py(8)<module>()->None -> total = x + y (Pdb) total 16
最終,你將需要除錯更大的程式——使用子例程的程式。有時,你試圖查詢的問題可能位於子例程內。考慮以下程式。
import pdb def squar(x, y): out_squared = x^2 + y^2 return out_squared if __name__ == "__main__": #pdb.set_trace() print (squar(4, 5))
現在執行上面的程式:
c:\Python\Python361>Python pdb_example2.py > c:\Python\Python361\pdb_example2.py(10)<module>() -> print (squar(4, 5)) (Pdb)
我們可以使用 ? 獲取幫助,但箭頭指示即將執行的行。此時,點選 s 以 s 進入該行很有幫助。
(Pdb) s --Call-- >c:\Python\Python361\pdb_example2.py(3)squar() -> def squar(x, y):
這是一個對函式的呼叫。如果你想概述你在程式碼中的位置,請嘗試 l:
(Pdb) l 1 import pdb 2 3 def squar(x, y): 4 -> out_squared = x^2 + y^2 5 6 return out_squared 7 8 if __name__ == "__main__": 9 pdb.set_trace() 10 print (squar(4, 5)) [EOF] (Pdb)
您可以按 n 鍵跳轉到下一行。此時您位於 out_squared 方法內部,並且可以訪問在函式內宣告的變數,例如 x 和 y。
(Pdb) x 4 (Pdb) y 5 (Pdb) x^2 6 (Pdb) y^2 7 (Pdb) x**2 16 (Pdb) y**2 25 (Pdb)
因此我們可以看到 ^ 運算子不是我們想要的,我們需要使用 ** 運算子來進行平方運算。
這樣我們就可以在函式/方法內部除錯程式了。
日誌記錄
日誌記錄模組自 Python 2.3 版本以來一直是 Python 標準庫的一部分。因為它是一個內建模組,所以所有 Python 模組都可以參與日誌記錄,這樣我們的應用程式日誌可以包含您自己的訊息以及來自第三方模組的訊息。它提供了很大的靈活性和功能。
日誌記錄的優勢
診斷日誌記錄 − 它記錄與應用程式操作相關的事件。
審計日誌記錄 − 它記錄用於業務分析的事件。
訊息按“嚴重性”級別寫入和記錄 &minu
DEBUG (debug()) − 開發診斷訊息。
INFO (info()) − 標準“進度”訊息。
WARNING (warning()) − 檢測到非嚴重問題。
ERROR (error()) − 遇到錯誤,可能很嚴重。
CRITICAL (critical()) − 通常是致命錯誤(程式停止)。
讓我們看看下面的簡單程式:
import logging
logging.basicConfig(level=logging.INFO)
logging.debug('this message will be ignored') # This will not print
logging.info('This should be logged') # it'll print
logging.warning('And this, too') # It'll print
我們在上面按嚴重性級別記錄訊息。首先我們匯入模組,呼叫 basicConfig 並設定日誌級別。我們上面設定的級別是 INFO。然後我們有三個不同的語句:debug 語句、info 語句和 warning 語句。
logging1.py 的輸出
INFO:root:This should be logged WARNING:root:And this, too
由於 info 語句在 debug 語句下面,我們無法看到 debug 訊息。要在輸出終端中也獲得 debug 語句,我們只需要更改 basicConfig 級別。
logging.basicConfig(level = logging.DEBUG)
在輸出中我們可以看到:
DEBUG:root:this message will be ignored INFO:root:This should be logged WARNING:root:And this, too
而且預設行為意味著如果我們不設定任何日誌級別,則為 warning。只需註釋掉上面程式中的第二行並執行程式碼。
#logging.basicConfig(level = logging.DEBUG)
輸出
WARNING:root:And this, too
Python 內建的日誌級別實際上是整數。
>>> import logging >>> >>> logging.DEBUG 10 >>> logging.CRITICAL 50 >>> logging.WARNING 30 >>> logging.INFO 20 >>> logging.ERROR 40 >>>
我們還可以將日誌訊息儲存到檔案中。
logging.basicConfig(level = logging.DEBUG, filename = 'logging.log')
現在所有日誌訊息都將寫入當前工作目錄中的檔案 (logging.log),而不是螢幕。這是一種更好的方法,因為它允許我們對收到的訊息進行後期分析。
我們還可以設定日誌訊息的時間戳。
logging.basicConfig(level=logging.DEBUG, format = '%(asctime)s %(levelname)s:%(message)s')
輸出將類似於:
2018-03-08 19:30:00,066 DEBUG:this message will be ignored 2018-03-08 19:30:00,176 INFO:This should be logged 2018-03-08 19:30:00,201 WARNING:And this, too
基準測試
基準測試或效能分析基本上是為了測試程式碼的執行速度以及瓶頸在哪裡?這樣做的主要原因是為了最佳化。
timeit
Python 自帶一個名為 timeit 的內建模組。您可以使用它來計時小的程式碼片段。timeit 模組使用特定於平臺的時間函式,以便您可以獲得儘可能準確的計時結果。
因此,它允許我們比較兩種程式碼的執行時間,然後最佳化指令碼以獲得更好的效能。
timeit 模組具有命令列介面,但也可以匯入。
有兩種方法可以呼叫指令碼。讓我們先使用指令碼,為此執行以下程式碼並檢視輸出。
import timeit
print ( 'by index: ', timeit.timeit(stmt = "mydict['c']", setup = "mydict = {'a':5, 'b':10, 'c':15}", number = 1000000))
print ( 'by get: ', timeit.timeit(stmt = 'mydict.get("c")', setup = 'mydict = {"a":5, "b":10, "c":15}', number = 1000000))
輸出
by index: 0.1809192126703489 by get: 0.6088525265034692
我們在上面使用了兩種不同的方法,即透過下標和 get 來訪問字典鍵值。我們執行語句 100 萬次,因為對於非常小的資料,它的執行速度太快了。現在我們可以看到索引訪問比 get 快得多。我們可以多次執行程式碼,並且時間執行會略有變化,以便更好地理解。
另一種方法是在命令列中執行上述測試。讓我們來做吧:
c:\Python\Python361>Python -m timeit -n 1000000 -s "mydict = {'a': 5, 'b':10, 'c':15}" "mydict['c']"
1000000 loops, best of 3: 0.187 usec per loop
c:\Python\Python361>Python -m timeit -n 1000000 -s "mydict = {'a': 5, 'b':10, 'c':15}" "mydict.get('c')"
1000000 loops, best of 3: 0.659 usec per loop
上述輸出可能因您的系統硬體以及當前在您的系統中執行的所有應用程式而異。
如果我們想呼叫函式,可以在下面使用 timeit 模組。因為我們可以在函式中新增多個語句進行測試。
import timeit
def testme(this_dict, key):
return this_dict[key]
print (timeit.timeit("testme(mydict, key)", setup = "from __main__ import testme; mydict = {'a':9, 'b':18, 'c':27}; key = 'c'", number = 1000000))
輸出
0.7713474590139164
面向物件 Python - 庫
Requests − Python Requests 模組
Requests 是一個 Python 模組,它是一個優雅而簡單的 Python HTTP 庫。有了它,您可以傳送各種 HTTP 請求。使用此庫,我們可以新增標頭、表單資料、多部分檔案和引數,並訪問響應資料。
由於 Requests 不是內建模組,因此我們需要先安裝它。
您可以透過在終端中執行以下命令來安裝它:
pip install requests
安裝模組後,您可以透過在 Python shell 中鍵入以下命令來驗證安裝是否成功。
import requests
如果安裝成功,您將不會看到任何錯誤訊息。
發出 GET 請求
作為一個例子,我們將使用“pokeapi”。
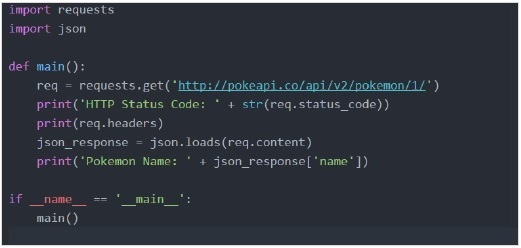
輸出:

發出 POST 請求
requests 庫方法適用於當前使用的所有 HTTP 動詞。如果您想向 API 端點發出簡單的 POST 請求,您可以這樣做:
req = requests.post(‘http://api/user’, data = None, json = None)
這將與我們之前的 GET 請求完全一樣,但是它有兩個額外的關鍵字引數:
data 可以用字典、檔案或位元組填充,這些資料將傳遞到 POST 請求的 HTTP 主體中。
json 可以用 json 物件填充,該物件也將傳遞到 HTTP 請求的主體中。
Pandas:Python 庫 Pandas
Pandas 是一個開源 Python 庫,它使用其強大的資料結構提供高效能的資料操作和分析工具。Pandas 是資料科學中最廣泛使用的 Python 庫之一。它主要用於資料整理,並且有充分的理由:強大的和靈活的功能組。
構建在 Numpy 包之上,關鍵資料結構稱為 DataFrame。這些資料框允許我們以觀測行和變數列的形式儲存和操作表格資料。
有幾種方法可以建立 DataFrame。一種方法是使用字典。例如:
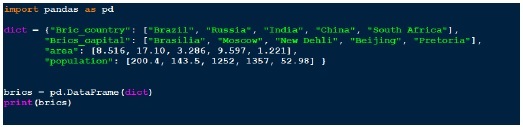
輸出
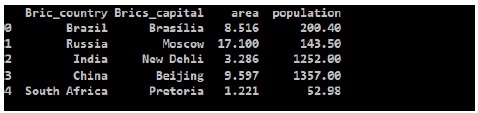
從輸出中我們可以看到新的 brics DataFrame,Pandas 為每個國家/地區分配了一個鍵作為數值 0 到 4。
如果我們不想使用從 0 到 4 的索引值,而是想要不同的索引值,例如兩位字母的國家程式碼,你也可以很容易地做到這一點:
在上面的程式碼中新增以下一行,得到
brics.index = ['BR', 'RU', 'IN', 'CH', 'SA']
輸出

索引 DataFrames
輸出
Pygame
Pygame 是一個開源的跨平臺庫,用於製作多媒體應用程式,包括遊戲。它包含旨在與 Python 程式語言一起使用的計算機圖形和聲音庫。您可以使用 Pygame 開發許多很酷的遊戲。
概述
Pygame 由多個模組組成,每個模組處理一組特定的任務。例如,display 模組處理顯示視窗和螢幕,draw 模組提供繪製形狀的函式,key 模組與鍵盤配合使用。這些只是該庫的一些模組。
Pygame 庫的主頁位於 https://www.pygame.org/news
要製作 Pygame 應用程式,請按照以下步驟操作:
匯入 Pygame 庫
import pygame
初始化 Pygame 庫
pygame.init()
建立視窗。
screen = Pygame.display.set_mode((560,480)) Pygame.display.set_caption(‘First Pygame Game’)
初始化遊戲物件
在此步驟中,我們載入影像、載入聲音、進行物件定位、設定一些狀態變數等。
啟動遊戲迴圈。
它只是一個迴圈,我們不斷處理事件、檢查輸入、移動物件並繪製它們。迴圈的每次迭代都稱為一幀。
讓我們將上述所有邏輯放在下面的一個程式中:
Pygame_script.py

輸出

Beautiful Soup:使用 Beautiful Soup 進行網頁抓取
網頁抓取背後的基本思想是從網站上獲取資料,並將其轉換為可用於分析的某種格式。
它是一個 Python 庫,用於從 HTML 或 XML 檔案中提取資料。使用您最喜歡的解析器,它提供以慣用方式導航、搜尋和修改解析樹的方法。
由於 BeautifulSoup 不是內建庫,因此我們需要在嘗試使用它之前安裝它。要安裝 BeautifulSoup,請執行以下命令
$ apt-get install Python-bs4 # For Linux and Python2 $ apt-get install Python3-bs4 # for Linux based system and Python3. $ easy_install beautifulsoup4 # For windows machine, Or $ pip instal beatifulsoup4 # For window machine
安裝完成後,我們就可以執行一些示例並詳細探索 Beautifulsoup 了:

輸出
以下是一些導航該資料結構的簡單方法:
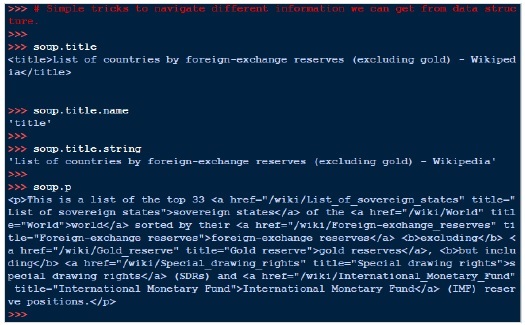
一個常見的任務是提取頁面 <a> 標記中找到的所有 URL:

另一個常見的任務是從頁面中提取所有文字: