- MongoDB 教程
- MongoDB - 首頁
- MongoDB - 概述
- MongoDB - 優點
- MongoDB - 環境
- MongoDB - 資料建模
- MongoDB - 建立資料庫
- MongoDB - 刪除資料庫
- MongoDB - 建立集合
- MongoDB - 刪除集合
- MongoDB - 資料型別
- MongoDB - 插入文件
- MongoDB - 查詢文件
- MongoDB - 更新文件
- MongoDB - 刪除文件
- MongoDB - 投影
- MongoDB - 限制記錄
- MongoDB - 排序記錄
- MongoDB - 索引
- MongoDB - 聚合
- MongoDB - 複製
- MongoDB - 分片
- MongoDB - 建立備份
- MongoDB - 部署
- MongoDB - Java
- MongoDB - PHP
- 高階 MongoDB
- MongoDB - 關係
- MongoDB - 資料庫引用
- MongoDB - 覆蓋查詢
- MongoDB - 分析查詢
- MongoDB - 原子操作
- MongoDB - 高階索引
- MongoDB - 索引限制
- MongoDB - ObjectId
- MongoDB - Map Reduce
- MongoDB - 文字搜尋
- MongoDB - 正則表示式
- 使用 Rockmongo
- MongoDB - GridFS
- MongoDB - 有界集合
- 自動遞增序列
- MongoDB 有用資源
- MongoDB - 問題和解答
- MongoDB - 快速指南
- MongoDB - 有用資源
- MongoDB - 討論
MongoDB - 快速指南
MongoDB - 概述
MongoDB 是一個跨平臺的、面向文件的資料庫,它提供高效能、高可用性和易擴充套件性。MongoDB 基於集合和文件的概念。
資料庫
資料庫是集合的物理容器。每個資料庫在檔案系統上都有自己的一組檔案。單個 MongoDB 伺服器通常包含多個數據庫。
集合
集合是一組 MongoDB 文件。它相當於 RDBMS 表格。集合存在於單個數據庫中。集合不強制執行模式。集合中的文件可以具有不同的欄位。通常,集合中的所有文件都具有相同或相關的用途。
文件
文件是一組鍵值對。文件具有動態模式。動態模式意味著同一集合中的文件不需要具有相同的欄位集或結構,並且集合中文件的公共欄位可能儲存不同型別的資料。
下表顯示了 RDBMS 術語與 MongoDB 的關係。
| RDBMS | MongoDB |
|---|---|
| 資料庫 | 資料庫 |
| 表 | 集合 |
| 元組/行 | 文件 |
| 列 | 欄位 |
| 表連線 | 嵌入式文件 |
| 主鍵 | 主鍵(MongoDB 本身提供的預設鍵 _id) |
| 資料庫伺服器和客戶端 | |
| Mysqld/Oracle | mongod |
| mysql/sqlplus | mongo |
示例文件
以下示例顯示了部落格網站的文件結構,它只是一個逗號分隔的鍵值對。
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'https://tutorialspoint.tw',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2011,1,20,2,15),
like: 0
},
{
user:'user2',
message: 'My second comments',
dateCreated: new Date(2011,1,25,7,45),
like: 5
}
]
}
_id 是一個 12 位元組的十六進位制數字,它確保每個文件的唯一性。您可以在插入文件時提供 _id。如果您不提供,則 MongoDB 會為每個文件提供一個唯一的 ID。這 12 個位元組中,前 4 個位元組用於當前時間戳,接下來的 3 個位元組用於機器 ID,接下來的 2 個位元組用於 MongoDB 伺服器的程序 ID,其餘 3 個位元組是簡單的增量值。
MongoDB - 優點
任何關係資料庫都具有典型的模式設計,該設計顯示了表數以及這些表之間的關係。而在 MongoDB 中,沒有關係的概念。
MongoDB 相對於 RDBMS 的優勢
無模式 - MongoDB 是一個文件資料庫,其中一個集合包含不同的文件。文件的欄位數、內容和大小可能彼此不同。
單個物件的結構清晰。
沒有複雜的連線。
強大的查詢能力。MongoDB 支援使用基於文件的查詢語言對文件進行動態查詢,該語言幾乎與 SQL 一樣強大。
調整。
易於擴充套件 - MongoDB 易於擴充套件。
無需將應用程式物件轉換為資料庫物件。
使用內部記憶體儲存(視窗化)工作集,從而能夠更快地訪問資料。
為什麼要使用 MongoDB?
面向文件的儲存 - 資料以 JSON 樣式文件的形式儲存。
對任何屬性進行索引
複製和高可用性
自動分片
豐富的查詢
快速就地更新
MongoDB 提供專業支援
在哪裡使用 MongoDB?
- 大資料
- 內容管理和交付
- 移動和社交基礎設施
- 使用者資料管理
- 資料中心
MongoDB - 環境
現在讓我們看看如何在 Windows 上安裝 MongoDB。
在 Windows 上安裝 MongoDB
要在 Windows 上安裝 MongoDB,首先從https://www.mongodb.org/downloads下載最新版本的 MongoDB。請確保根據您的 Windows 版本獲取正確的 MongoDB 版本。要獲取您的 Windows 版本,請開啟命令提示符並執行以下命令。
C:\>wmic os get osarchitecture OSArchitecture 64-bit C:\>
32 位版本的 MongoDB 僅支援小於 2GB 的資料庫,僅適用於測試和評估目的。
現在將下載的檔案解壓縮到 c:\ 驅動器或任何其他位置。確保解壓縮資料夾的名稱為 mongodb-win32-i386-[version] 或 mongodb-win32-x86_64-[version]。此處 [version] 是 MongoDB 下載的版本。
接下來,開啟命令提示符並執行以下命令。
C:\>move mongodb-win64-* mongodb 1 dir(s) moved. C:\>
如果您在不同位置解壓縮了 MongoDB,則使用命令 cd FOLDER/DIR 轉到該路徑,然後執行上述過程。
MongoDB 需要一個數據資料夾來儲存其檔案。MongoDB 資料目錄的預設位置是 c:\data\db。因此,您需要使用命令提示符建立此資料夾。執行以下命令序列。
C:\>md data C:\md data\db
如果您必須在不同位置安裝 MongoDB,則需要透過在 mongod.exe 中設定路徑 dbpath 來指定 \data\db 的備用路徑。為此,請發出以下命令。
在命令提示符中,導航到 MongoDB 安裝資料夾中的 bin 目錄。假設我的安裝資料夾是 D:\set up\mongodb
C:\Users\XYZ>d: D:\>cd "set up" D:\set up>cd mongodb D:\set up\mongodb>cd bin D:\set up\mongodb\bin>mongod.exe --dbpath "d:\set up\mongodb\data"
這將在控制檯輸出上顯示 等待連線 訊息,這表示 mongod.exe 程序已成功執行。
現在要執行 MongoDB,您需要開啟另一個命令提示符併發出以下命令。
D:\set up\mongodb\bin>mongo.exe
MongoDB shell version: 2.4.6
connecting to: test
>db.test.save( { a: 1 } )
>db.test.find()
{ "_id" : ObjectId(5879b0f65a56a454), "a" : 1 }
>
這將顯示 MongoDB 已成功安裝和執行。下次執行 MongoDB 時,您只需要發出命令即可。
D:\set up\mongodb\bin>mongod.exe --dbpath "d:\set up\mongodb\data" D:\set up\mongodb\bin>mongo.exe
在 Ubuntu 上安裝 MongoDB
執行以下命令以匯入 MongoDB 公共 GPG 金鑰 -
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10
使用以下命令建立 /etc/apt/sources.list.d/mongodb.list 檔案。
echo 'deb http://downloads-distro.mongodb.org/repo/ubuntu-upstart dist 10gen' | sudo tee /etc/apt/sources.list.d/mongodb.list
現在發出以下命令以更新儲存庫 -
sudo apt-get update
接下來,使用以下命令安裝 MongoDB -
apt-get install mongodb-10gen = 2.2.3
在上述安裝中,2.2.3 是當前釋出的 MongoDB 版本。請務必始終安裝最新版本。現在 MongoDB 已成功安裝。
啟動 MongoDB
sudo service mongodb start
停止 MongoDB
sudo service mongodb stop
重新啟動 MongoDB
sudo service mongodb restart
要使用 MongoDB,請執行以下命令。
mongo
這將連線到正在執行的 MongoDB 例項。
MongoDB 幫助
要獲取命令列表,請在 MongoDB 客戶端中鍵入 db.help()。這將為您提供如下面的螢幕截圖所示的命令列表。
MongoDB 統計資訊
要獲取有關 MongoDB 伺服器的統計資訊,請在 MongoDB 客戶端中鍵入命令 db.stats()。這將顯示資料庫名稱、資料庫中的集合數和文件數。該命令的輸出顯示在下面的螢幕截圖中。

MongoDB - 資料建模
MongoDB 中的資料具有靈活的模式。同一集合中的文件。它們不需要具有相同的欄位集或結構,並且集合中文件的公共欄位可能儲存不同型別的資料。
在 MongoDB 中設計模式時的一些注意事項
根據使用者需求設計模式。
如果要將物件一起使用,則將其組合到一個文件中。否則將它們分開(但要確保不需要連線)。
複製資料(但要有限制),因為與計算時間相比,磁碟空間便宜。
在寫入時執行連線,而不是在讀取時執行連線。
針對最頻繁的使用案例最佳化模式。
在模式中進行復雜的聚合。
示例
假設客戶需要一個用於其部落格/網站的資料庫設計,並檢視 RDBMS 和 MongoDB 模式設計之間的差異。網站具有以下要求。
- 每個帖子都有唯一的標題、描述和 URL。
- 每個帖子可以有一個或多個標籤。
- 每個帖子都有其釋出者的姓名和點贊總數。
- 每個帖子都有使用者提供的評論,以及他們的姓名、訊息、日期時間和點贊。
- 每個帖子可以有零個或多個評論。
在 RDBMS 模式中,上述要求的設計將至少包含三個表。

而在 MongoDB 模式中,設計將包含一個集合 post 以及以下結構 -
{
_id: POST_ID
title: TITLE_OF_POST,
description: POST_DESCRIPTION,
by: POST_BY,
url: URL_OF_POST,
tags: [TAG1, TAG2, TAG3],
likes: TOTAL_LIKES,
comments: [
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
},
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
}
]
}
因此,在顯示資料時,在 RDBMS 中,您需要連線三個表,而在 MongoDB 中,資料將僅從一個集合中顯示。
MongoDB - 建立資料庫
在本章中,我們將瞭解如何在 MongoDB 中建立資料庫。
use 命令
MongoDB 的 use DATABASE_NAME 用於建立資料庫。如果資料庫不存在,則該命令將建立一個新資料庫,否則它將返回現有資料庫。
語法
use DATABASE 語句的基本語法如下 -
use DATABASE_NAME
示例
如果您要使用名為 <mydb> 的資料庫,則 use DATABASE 語句將如下所示 -
>use mydb switched to db mydb
要檢查您當前選擇的資料庫,請使用命令 db
>db mydb
如果您要檢查資料庫列表,請使用命令 show dbs。
>show dbs local 0.78125GB test 0.23012GB
您建立的資料庫(mydb)不在列表中。要顯示資料庫,您需要向其中插入至少一個文件。
>db.movie.insert({"name":"tutorials point"})
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GB
在 MongoDB 中,預設資料庫是 test。如果您沒有建立任何資料庫,則集合將儲存在 test 資料庫中。
MongoDB - 刪除資料庫
在本章中,我們將瞭解如何使用 MongoDB 命令刪除資料庫。
dropDatabase() 方法
MongoDB 的 db.dropDatabase() 命令用於刪除現有資料庫。
語法
dropDatabase() 命令的基本語法如下 -
db.dropDatabase()
這將刪除選定的資料庫。如果您沒有選擇任何資料庫,則它將刪除預設的“test”資料庫。
示例
首先,使用命令 show dbs 檢查可用資料庫的列表。
>show dbs local 0.78125GB mydb 0.23012GB test 0.23012GB >
如果您要刪除新資料庫 <mydb>,則 dropDatabase() 命令將如下所示 -
>use mydb
switched to db mydb
>db.dropDatabase()
>{ "dropped" : "mydb", "ok" : 1 }
>
現在檢查資料庫列表。
>show dbs local 0.78125GB test 0.23012GB >
MongoDB - 建立集合
在本章中,我們將瞭解如何在 MongoDB 中建立集合。
createCollection() 方法
MongoDB 的 db.createCollection(name, options) 用於建立集合。
語法
createCollection() 命令的基本語法如下 -
db.createCollection(name, options)
在命令中,name 是要建立的集合的名稱。Options 是一個文件,用於指定集合的配置。
| 引數 | 型別 | 描述 |
|---|---|---|
| Name | String | 要建立的集合的名稱 |
| Options | 文件 | (可選) 指定關於記憶體大小和索引的選項 |
Options 引數是可選的,因此您只需要指定集合的名稱。以下是您可以使用的選項列表 -
| 欄位 | 型別 | 描述 |
|---|---|---|
| capped | 布林型 | (可選) 如果為 true,則啟用固定大小集合。固定大小集合是一個固定大小的集合,當它達到最大大小時會自動覆蓋其最舊的條目。如果您指定 true,則也需要指定 size 引數。 |
| autoIndexId | 布林型 | (可選) 如果為 true,則自動在 _id 欄位上建立索引。預設值為 false。 |
| size | 數字 | (可選) 為固定大小集合指定最大大小(以位元組為單位)。如果 capped 為 true,則也需要指定此欄位。 |
| max | 數字 | (可選) 指定固定大小集合中允許的最大文件數。 |
插入文件時,MongoDB 首先檢查固定大小集合的 size 欄位,然後檢查 max 欄位。
示例
不帶選項的createCollection()方法的基本語法如下所示 -
>use test
switched to db test
>db.createCollection("mycollection")
{ "ok" : 1 }
>
您可以使用show collections命令檢查已建立的集合。
>show collections mycollection system.indexes
以下示例顯示了帶有一些重要選項的createCollection()方法的語法 -
>db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
{ "ok" : 1 }
>
在 MongoDB 中,您不需要建立集合。當您插入一些文件時,MongoDB 會自動建立集合。
>db.tutorialspoint.insert({"name" : "tutorialspoint"})
>show collections
mycol
mycollection
system.indexes
tutorialspoint
>
MongoDB - 刪除集合
在本章中,我們將瞭解如何使用 MongoDB 刪除集合。
drop() 方法
MongoDB 的db.collection.drop()用於從資料庫中刪除集合。
語法
drop()命令的基本語法如下所示 -
db.COLLECTION_NAME.drop()
示例
首先,檢查資料庫mydb中可用的集合。
>use mydb switched to db mydb >show collections mycol mycollection system.indexes tutorialspoint >
現在刪除名為mycollection的集合。
>db.mycollection.drop() true >
再次檢查資料庫中的集合列表。
>show collections mycol system.indexes tutorialspoint >
如果成功刪除選定的集合,則drop()方法將返回 true,否則將返回 false。
MongoDB - 資料型別
MongoDB 支援多種資料型別。其中一些是 -
字串 - 這是用於儲存資料的最常用的資料型別。MongoDB 中的字串必須是 UTF-8 有效的。
整數 - 此型別用於儲存數值。整數可以是 32 位或 64 位,具體取決於您的伺服器。
布林型 - 此型別用於儲存布林(true/false)值。
雙精度浮點數 - 此型別用於儲存浮點值。
最小/最大鍵 - 此型別用於將值與最低和最高的 BSON 元素進行比較。
陣列 - 此型別用於將陣列或列表或多個值儲存到一個鍵中。
時間戳 - ctimestamp。這對於記錄文件何時被修改或新增非常有用。
物件 - 此資料型別用於嵌入文件。
空值 - 此型別用於儲存空值。
符號 - 此資料型別與字串的使用方式相同;但是,它通常保留給使用特定符號型別的語言。
日期 - 此資料型別用於以 UNIX 時間格式儲存當前日期或時間。您可以透過建立 Date 物件並將日期、月份、年份傳遞給它來指定您自己的日期時間。
物件 ID - 此資料型別用於儲存文件的 ID。
二進位制資料 - 此資料型別用於儲存二進位制資料。
程式碼 - 此資料型別用於將 JavaScript 程式碼儲存到文件中。
正則表示式 - 此資料型別用於儲存正則表示式。
MongoDB - 插入文件
在本章中,我們將學習如何在 MongoDB 集合中插入文件。
insert() 方法
要將資料插入 MongoDB 集合,您需要使用 MongoDB 的insert()或save()方法。
語法
insert()命令的基本語法如下所示 -
>db.COLLECTION_NAME.insert(document)
示例
>db.mycol.insert({
_id: ObjectId(7df78ad8902c),
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'https://tutorialspoint.tw',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
這裡mycol是我們的集合名稱,如上一章所建立。如果資料庫中不存在該集合,則 MongoDB 將建立此集合,然後向其中插入一個文件。
在插入的文件中,如果我們不指定 _id 引數,則 MongoDB 會為該文件分配一個唯一的 ObjectId。
_id 是 12 個位元組的十六進位制數字,對於集合中的每個文件都是唯一的。12 個位元組的劃分如下所示 -
_id: ObjectId(4 bytes timestamp, 3 bytes machine id, 2 bytes process id, 3 bytes incrementer)
要在單個查詢中插入多個文件,可以在 insert() 命令中傳遞一個文件陣列。
示例
>db.post.insert([
{
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'https://tutorialspoint.tw',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
title: 'NoSQL Database',
description: "NoSQL database doesn't have tables",
by: 'tutorials point',
url: 'https://tutorialspoint.tw',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 20,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2013,11,10,2,35),
like: 0
}
]
}
])
要插入文件,您也可以使用db.post.save(document)。如果您沒有在文件中指定_id,則save()方法的工作方式與insert()方法相同。如果您指定了 _id,則它將替換包含在 save() 方法中指定的 _id 的文件的全部資料。
MongoDB - 查詢文件
在本章中,我們將學習如何從 MongoDB 集合中查詢文件。
find() 方法
要從 MongoDB 集合中查詢資料,您需要使用 MongoDB 的find()方法。
語法
find()方法的基本語法如下所示 -
>db.COLLECTION_NAME.find()
find()方法將以非結構化的方式顯示所有文件。
pretty() 方法
要以格式化的方式顯示結果,可以使用pretty()方法。
語法
>db.mycol.find().pretty()
示例
>db.mycol.find().pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "https://tutorialspoint.tw",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>
除了 find() 方法之外,還有一個findOne()方法,它只返回一個文件。
RDBMS 中 Where 子句等效項在 MongoDB 中
要根據某些條件查詢文件,您可以使用以下操作。
| 操作 | 語法 | 示例 | RDBMS 等效項 |
|---|---|---|---|
| 等於 | {<key>:<value>} | db.mycol.find({"by":"tutorials point"}).pretty() | where by = 'tutorials point' |
| 小於 | {<key>:{$lt:<value>}} | db.mycol.find({"likes":{$lt:50}}).pretty() | where likes < 50 |
| 小於等於 | {<key>:{$lte:<value>}} | db.mycol.find({"likes":{$lte:50}}).pretty() | where likes <= 50 |
| 大於 | {<key>:{$gt:<value>}} | db.mycol.find({"likes":{$gt:50}}).pretty() | where likes > 50 |
| 大於等於 | {<key>:{$gte:<value>}} | db.mycol.find({"likes":{$gte:50}}).pretty() | where likes >= 50 |
| 不等於 | {<key>:{$ne:<value>}} | db.mycol.find({"likes":{$ne:50}}).pretty() | where likes != 50 |
MongoDB 中的 AND
語法
在find()方法中,如果您透過用 ',' 分隔多個鍵來傳遞它們,則 MongoDB 會將其視為AND條件。以下是AND的基本語法 -
>db.mycol.find(
{
$and: [
{key1: value1}, {key2:value2}
]
}
).pretty()
示例
以下示例將顯示由“tutorials point”編寫且標題為“MongoDB 概述”的所有教程。
>db.mycol.find({$and:[{"by":"tutorials point"},{"title": "MongoDB Overview"}]}).pretty() {
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "https://tutorialspoint.tw",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
對於上面給出的示例,等效的 where 子句將為' where by = 'tutorials point' AND title = 'MongoDB Overview' '。您可以在 find 子句中傳遞任意數量的鍵值對。
MongoDB 中的 OR
語法
要根據 OR 條件查詢文件,您需要使用$or關鍵字。以下是OR的基本語法 -
>db.mycol.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
示例
以下示例將顯示由“tutorials point”編寫或標題為“MongoDB 概述”的所有教程。
>db.mycol.find({$or:[{"by":"tutorials point"},{"title": "MongoDB Overview"}]}).pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "https://tutorialspoint.tw",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>
一起使用 AND 和 OR
示例
以下示例將顯示點贊數大於 10 且標題為“MongoDB 概述”或作者為“tutorials point”的文件。等效的 SQL where 子句為'where likes>10 AND (by = 'tutorials point' OR title = 'MongoDB Overview')'
>db.mycol.find({"likes": {$gt:10}, $or: [{"by": "tutorials point"},
{"title": "MongoDB Overview"}]}).pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "https://tutorialspoint.tw",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>
MongoDB - 更新文件
MongoDB 的update()和save()方法用於更新集合中的文件。update() 方法更新現有文件中的值,而 save() 方法用 save() 方法中傳遞的文件替換現有文件。
MongoDB Update() 方法
update() 方法更新現有文件中的值。
語法
update()方法的基本語法如下所示 -
>db.COLLECTION_NAME.update(SELECTION_CRITERIA, UPDATED_DATA)
示例
假設 mycol 集合具有以下資料。
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
以下示例將為標題為“MongoDB 概述”的文件設定新的標題“新的 MongoDB 教程”。
>db.mycol.update({'title':'MongoDB Overview'},{$set:{'title':'New MongoDB Tutorial'}})
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"New MongoDB Tutorial"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>
預設情況下,MongoDB 只會更新單個文件。要更新多個文件,您需要將引數“multi”設定為 true。
>db.mycol.update({'title':'MongoDB Overview'},
{$set:{'title':'New MongoDB Tutorial'}},{multi:true})
MongoDB Save() 方法
save()方法用 save() 方法中傳遞的新文件替換現有文件。
語法
MongoDB save()方法的基本語法如下所示 -
>db.COLLECTION_NAME.save({_id:ObjectId(),NEW_DATA})
示例
以下示例將替換 _id 為“5983548781331adf45ec5”的文件。
>db.mycol.save(
{
"_id" : ObjectId(5983548781331adf45ec5), "title":"Tutorials Point New Topic",
"by":"Tutorials Point"
}
)
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"Tutorials Point New Topic",
"by":"Tutorials Point"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>
MongoDB - 刪除文件
在本章中,我們將學習如何使用 MongoDB 刪除文件。
remove() 方法
MongoDB 的remove()方法用於從集合中刪除文件。remove() 方法接受兩個引數。一個是刪除條件,第二個是 justOne 標誌。
刪除條件 - (可選)根據文件將刪除的刪除條件。
justOne - (可選)如果設定為 true 或 1,則僅刪除一個文件。
語法
remove()方法的基本語法如下所示 -
>db.COLLECTION_NAME.remove(DELLETION_CRITTERIA)
示例
假設 mycol 集合具有以下資料。
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
以下示例將刪除標題為“MongoDB 概述”的所有文件。
>db.mycol.remove({'title':'MongoDB Overview'})
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>
僅刪除一個
如果有多條記錄並且您只想刪除第一條記錄,則在remove()方法中設定justOne引數。
>db.COLLECTION_NAME.remove(DELETION_CRITERIA,1)
刪除所有文件
如果您不指定刪除條件,則 MongoDB 將刪除集合中的所有文件。這相當於 SQL 的截斷命令。
>db.mycol.remove({})
>db.mycol.find()
>
MongoDB - 投影
在 MongoDB 中,投影意味著選擇僅必要的資料,而不是選擇文件的全部資料。如果一個文件有 5 個欄位,而您只需要顯示 3 個,則只選擇其中的 3 個欄位。
find() 方法
在MongoDB 查詢文件中解釋的 MongoDB 的find()方法接受第二個可選引數,即您要檢索的欄位列表。在 MongoDB 中,當您執行find()方法時,它會顯示文件的所有欄位。要限制此操作,您需要設定一個值為 1 或 0 的欄位列表。1 用於顯示欄位,而 0 用於隱藏欄位。
語法
帶投影的find()方法的基本語法如下所示 -
>db.COLLECTION_NAME.find({},{KEY:1})
示例
假設集合 mycol 具有以下資料 -
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
以下示例將在查詢文件時顯示文件的標題。
>db.mycol.find({},{"title":1,_id:0})
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
{"title":"Tutorials Point Overview"}
>
請注意,在執行find()方法時,始終顯示_id欄位,如果您不希望此欄位,則需要將其設定為 0。
MongoDB - 限制記錄
在本章中,我們將學習如何使用 MongoDB 限制記錄。
Limit() 方法
要限制 MongoDB 中的記錄,您需要使用limit()方法。該方法接受一個數字型別引數,即您希望顯示的文件數量。
語法
limit()方法的基本語法如下所示 -
>db.COLLECTION_NAME.find().limit(NUMBER)
示例
假設集合 myycol 具有以下資料。
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
以下示例在查詢文件時只會顯示兩個文件。
>db.mycol.find({},{"title":1,_id:0}).limit(2)
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
>
如果您沒有在limit()方法中指定數字引數,則它將顯示集合中的所有文件。
MongoDB Skip() 方法
除了 `limit()` 方法外,還有一個方法 `skip()` 也接受數字型別的引數,用於跳過指定數量的文件。
語法
`skip()` 方法的基本語法如下所示:
>db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
示例
下面的示例將只顯示第二個文件。
>db.mycol.find({},{"title":1,_id:0}).limit(1).skip(1)
{"title":"NoSQL Overview"}
>
請注意,`skip()` 方法的預設值為 0。
MongoDB - 排序記錄
在本章中,我們將學習如何在 MongoDB 中排序記錄。
`sort()` 方法
要對 MongoDB 中的文件進行排序,需要使用 `sort()` 方法。該方法接受一個包含欄位列表及其排序順序的文件。要指定排序順序,使用 1 和 -1。1 用於升序,-1 用於降序。
語法
`sort()` 方法的基本語法如下所示:
>db.COLLECTION_NAME.find().sort({KEY:1})
示例
假設集合 myycol 具有以下資料。
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
下面的示例將按標題降序顯示文件。
>db.mycol.find({},{"title":1,_id:0}).sort({"title":-1})
{"title":"Tutorials Point Overview"}
{"title":"NoSQL Overview"}
{"title":"MongoDB Overview"}
>
請注意,如果不指定排序順序,則 `sort()` 方法將按升序顯示文件。
MongoDB - 索引
索引支援高效地解決查詢。如果沒有索引,MongoDB 必須掃描集合中的每個文件以選擇與查詢語句匹配的文件。此掃描效率極低,並且需要 MongoDB 處理大量資料。
索引是特殊的資料結構,以易於遍歷的形式儲存資料集的一小部分資料。索引儲存特定欄位或欄位集的值,並按索引中指定的欄位值排序。
`createIndex()` 方法
要建立索引,需要使用 MongoDB 的 `createIndex()` 方法。
語法
`createIndex()` 方法的基本語法如下所示。
>db.COLLECTION_NAME.createIndex({KEY:1})
這裡 `key` 是要建立索引的欄位的名稱,1 表示升序。要建立降序索引,需要使用 -1。
示例
>db.mycol.createIndex({"title":1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
>
在 `createIndex()` 方法中,可以傳遞多個欄位,以在多個欄位上建立索引。
>db.mycol.createIndex({"title":1,"description":-1})
>
此方法還接受選項列表(可選)。以下是列表:
| 引數 | 型別 | 描述 |
|---|---|---|
| `background` | 布林型 | 在後臺構建索引,以便構建索引不會阻塞其他資料庫活動。指定 `true` 以在後臺構建。預設值為 `false` 。 |
| `unique` | 布林型 | 建立唯一索引,以便集合不會接受插入索引鍵或鍵與索引中現有值匹配的文件。指定 `true` 以建立唯一索引。預設值為 `false` 。 |
| `name` | `string` | 索引的名稱。如果未指定,MongoDB 會透過連線已索引欄位的名稱和排序順序來生成索引名稱。 |
| `sparse` | 布林型 | 如果為 `true` ,則索引僅引用具有指定欄位的文件。這些索引使用的空間更少,但在某些情況下(尤其是排序)的行為有所不同。預設值為 `false` 。 |
| `expireAfterSeconds` | `integer` | 以秒為單位指定一個值作為 TTL,以控制 MongoDB 在此集合中保留文件的時間。 |
| `weights` | `document` | 權重是 1 到 99,999 之間的數字,表示欄位相對於其他已索引欄位在分數方面的意義。 |
| `default_language` | `string` | 對於文字索引,確定停用詞列表以及詞幹分析器和分詞器的規則的語言。預設值為 `English` 。 |
| `language_override` | `string` | 對於文字索引,指定文件中包含用於覆蓋預設語言的語言的欄位的名稱。預設值為 `language` 。 |
`dropIndex()` 方法
可以使用 MongoDB 的 `dropIndex()` 方法刪除特定索引。
語法
`DropIndex()` 方法的基本語法如下所示。
>db.COLLECTION_NAME.dropIndex({KEY:1})
這裡,"key" 是要刪除現有索引的檔案的名稱。除了索引規範文件(上述語法)之外,還可以直接指定索引的名稱,如下所示
dropIndex("name_of_the_index")
示例
> db.mycol.dropIndex({"title":1})
{
"ok" : 0,
"errmsg" : "can't find index with key: { title: 1.0 }",
"code" : 27,
"codeName" : "IndexNotFound"
}
`dropIndexes()` 方法
此方法刪除集合上的多個(指定的)索引。
語法
`DropIndexes()` 方法的基本語法如下所示:
>db.COLLECTION_NAME.dropIndexes()
示例
假設我們在名為 mycol 的集合中建立了 2 個索引,如下所示:
> db.mycol.createIndex({"title":1,"description":-1})
以下示例刪除上面建立的 mycol 的索引:
>db.mycol.dropIndexes({"title":1,"description":-1})
{ "nIndexesWas" : 2, "ok" : 1 }
>
`getIndexes()` 方法
此方法返回集合中所有索引的描述。
語法
以下是 `getIndexes()` 方法的基本語法:
db.COLLECTION_NAME.getIndexes()
示例
假設我們在名為 mycol 的集合中建立了 2 個索引,如下所示:
> db.mycol.createIndex({"title":1,"description":-1})
以下示例檢索集合 mycol 中的所有索引:
> db.mycol.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.mycol"
},
{
"v" : 2,
"key" : {
"title" : 1,
"description" : -1
},
"name" : "title_1_description_-1",
"ns" : "test.mycol"
}
]
>
MongoDB - 聚合
聚合操作處理資料記錄並返回計算結果。聚合操作將來自多個文件的值組合在一起,並且可以在組合資料上執行各種操作以返回單個結果。在 SQL 中,`count(*)` 和 `group by` 等價於 mongodb 聚合。
`aggregate()` 方法
對於 MongoDB 中的聚合,應使用 `aggregate()` 方法。
語法
`aggregate()` 方法的基本語法如下所示:
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
示例
在集合中,您有以下資料:
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'tutorials point',
url: 'https://tutorialspoint.tw',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'tutorials point',
url: 'https://tutorialspoint.tw',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Neo4j',
url: 'http://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
},
現在,從上面的集合中,如果要顯示一個列表,說明每個使用者編寫了多少個教程,則將使用以下 `aggregate()` 方法:
> db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
{
"result" : [
{
"_id" : "tutorials point",
"num_tutorial" : 2
},
{
"_id" : "Neo4j",
"num_tutorial" : 1
}
],
"ok" : 1
}
>
上述用例的等效 SQL 查詢將為 `select by_user, count(*) from mycol group by by_user` 。
在上面的示例中,我們已按欄位 `by_user` 對文件進行分組,並且在 `by_user` 的每次出現時,都會遞增 `sum` 的先前值。以下是可用聚合表示式的列表。
| 表示式 | 描述 | 示例 |
|---|---|---|
| `$sum` | 將集合中所有文件中定義的值加起來。 | `db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}])` |
| `$avg` | 計算集合中所有文件中所有給定值的平均值。 | `db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}])` |
| `$min` | 獲取集合中所有文件中相應值的最小值。 | `db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}])` |
| `$max` | 獲取集合中所有文件中相應值的最大值。 | `db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}])` |
| `$push` | 將值插入到結果文件中的陣列中。 | `db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}])` |
| `$addToSet` | 將值插入到結果文件中的陣列中,但不建立重複項。 | `db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}])` |
| `$first` | 根據分組從源文件中獲取第一個文件。通常,這隻有與之前應用的某些“$sort”階段一起使用才有意義。 | `db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}])` |
| `$last` | 根據分組從源文件中獲取最後一個文件。通常,這隻有與之前應用的某些“$sort”階段一起使用才有意義。 | `db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}])` |
管道概念
在 UNIX 命令中,shell 管道意味著可以在某些輸入上執行操作並將輸出用作下一個命令的輸入,依此類推。MongoDB 在聚合框架中也支援相同的概念。有一組可能的階段,每個階段都被視為一組文件作為輸入,併產生一組結果文件(或管道末尾的最終結果 JSON 文件)。然後,這可以依次用於下一個階段,依此類推。
以下是聚合框架中可能的階段:
`$project` - 用於從集合中選擇一些特定欄位。
`$match` - 這是一個過濾操作,因此這可以減少作為輸入傳遞給下一階段的文件數量。
`$group` - 如上所述,這將執行實際的聚合。
`$sort` - 對文件進行排序。
`$skip` - 透過此操作,可以向前跳過給定數量的文件列表。
`$limit` - 這將限制要檢視的文件數量,從當前位置開始的給定數量。
`$unwind` - 這用於展開使用陣列的文件。使用陣列時,資料會某種程度上預先連線,此操作將透過此操作撤消,以便再次獲得單個文件。因此,透過此階段,我們將增加下一階段的文件數量。
MongoDB - 複製
複製是跨多個伺服器同步資料的過程。複製提供冗餘並透過在不同資料庫伺服器上覆制資料來提高資料可用性。複製保護資料庫免受單個伺服器丟失的影響。複製還允許您從硬體故障和服務中斷中恢復。使用資料的其他副本,您可以將一個副本專門用於災難恢復、報告或備份。
為什麼要複製?
- 為了確保您的資料安全
- 資料的高(24*7)可用性
- 災難恢復
- 維護(如備份、索引重建、壓縮)期間無停機時間
- 讀取擴充套件(額外的副本可供讀取)
- 副本集對應用程式是透明的
MongoDB 中的複製工作原理
MongoDB 透過使用副本集來實現複製。副本集是一組承載相同資料集的 `mongod` 例項。在一個副本中,一個節點是主節點,它接收所有寫操作。所有其他例項(例如輔助節點)都應用來自主節點的操作,以便它們具有相同的資料集。副本集只能有一個主節點。
副本集是由兩個或多個節點組成的一組(通常至少需要 3 個節點)。
在一個副本集中,一個節點是主節點,其餘節點是輔助節點。
所有資料都從主節點複製到輔助節點。
在自動故障轉移或維護時,將為主要節點進行選舉,並選舉新的主節點。
在故障節點恢復後,它將再次加入副本集並充當輔助節點。
MongoDB 複製的典型示意圖顯示,客戶端應用程式始終與主節點互動,然後主節點將資料複製到輔助節點。

副本集功能
- 一個由 N 個節點組成的叢集
- 任何一個節點都可以是主節點
- 所有寫操作都轉到主節點
- 自動故障轉移
- 自動恢復
- 主節點的一致性選舉
設定副本集
在本教程中,我們將把獨立的 MongoDB 例項轉換為副本集。要轉換為副本集,請執行以下步驟:
關閉已執行的 MongoDB 伺服器。
透過指定 `--replSet` 選項啟動 MongoDB 伺服器。以下是 `--replSet` 的基本語法:
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"
示例
mongod --port 27017 --dbpath "D:\set up\mongodb\data" --replSet rs0
它將在埠 27017 上啟動一個名為 rs0 的 mongod 例項。
現在啟動命令提示符並連線到此 mongod 例項。
在 Mongo 客戶端中,發出命令rs.initiate()以初始化一個新的副本集。
要檢查副本集配置,請發出命令rs.conf()。要檢查副本集的狀態,請發出命令rs.status()。
向副本集新增成員
要向副本集新增成員,請在多臺機器上啟動 mongod 例項。現在啟動一個 mongo 客戶端併發出命令rs.add()。
語法
rs.add()命令的基本語法如下所示:
>rs.add(HOST_NAME:PORT)
示例
假設您的 mongod 例項名稱為mongod1.net,並且它在埠27017上執行。要將此例項新增到副本集,請在 Mongo 客戶端中發出命令rs.add()。
>rs.add("mongod1.net:27017")
>
只有在連線到主節點時,才能將 mongod 例項新增到副本集。要檢查是否已連線到主節點,請在 mongo 客戶端中發出命令db.isMaster()。
MongoDB - 分片
分片是將資料記錄儲存在多臺機器上的過程,它是 MongoDB 滿足資料增長需求的方法。隨著資料大小的增加,單臺機器可能不足以儲存資料,也無法提供可接受的讀寫吞吐量。分片透過水平擴充套件解決了這個問題。使用分片,您可以新增更多機器來支援資料增長以及讀寫操作的需求。
為什麼要分片?
- 在複製中,所有寫入都轉到主節點
- 延遲敏感查詢仍然轉到主節點
- 單個副本集最多隻能有 12 個節點
- 當活動資料集很大時,記憶體可能不夠大
- 本地磁碟不夠大
- 垂直擴充套件成本過高
MongoDB 中的分片
下圖顯示了使用分片叢集在 MongoDB 中進行分片。
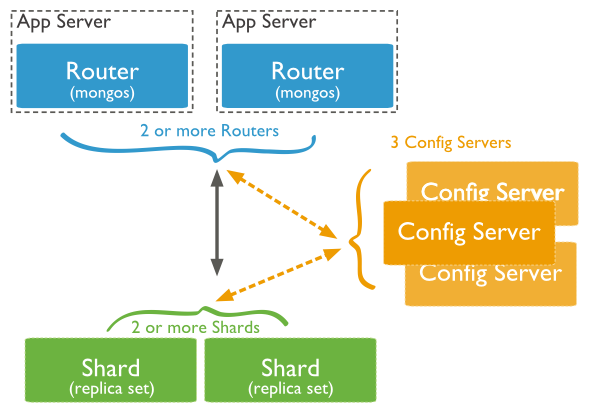
在下圖中,有三個主要元件:
分片 - 分片用於儲存資料。它們提供高可用性和資料一致性。在生產環境中,每個分片都是一個單獨的副本集。
配置伺服器 - 配置伺服器儲存叢集的元資料。此資料包含叢集資料集到分片的對映。查詢路由器使用此元資料將操作定位到特定分片。在生產環境中,分片叢集正好有 3 個配置伺服器。
查詢路由器 - 查詢路由器基本上是 mongo 例項,與客戶端應用程式互動並將操作引導到相應的分片。查詢路由器處理並將操作定位到分片,然後將結果返回給客戶端。分片叢集可以包含多個查詢路由器來劃分客戶端請求負載。客戶端將請求傳送到一個查詢路由器。通常,分片叢集有很多查詢路由器。
MongoDB - 建立備份
在本章中,我們將瞭解如何在 MongoDB 中建立備份。
轉儲 MongoDB 資料
要建立 MongoDB 中資料庫的備份,您應該使用mongodump命令。此命令會將伺服器的全部資料轉儲到轉儲目錄中。有許多選項可用於限制資料量或建立遠端伺服器的備份。
語法
mongodump命令的基本語法如下所示:
>mongodump
示例
啟動您的 mongod 伺服器。假設您的 mongod 伺服器在 localhost 和埠 27017 上執行,請開啟命令提示符並轉到 mongodb 例項的 bin 目錄,然後鍵入命令mongodump
假設 mycol 集合具有以下資料。
>mongodump
該命令將連線到在127.0.0.1和埠27017上執行的伺服器,並將伺服器的所有資料備份到目錄/bin/dump/。以下是命令的輸出:

以下是可與mongodump命令一起使用的可用選項列表。
| 語法 | 描述 | 示例 |
|---|---|---|
| mongodump --host HOST_NAME --port PORT_NUMBER | 此命令將備份指定 mongod 例項的所有資料庫。 | mongodump --host tutorialspoint.com --port 27017 |
| mongodump --dbpath DB_PATH --out BACKUP_DIRECTORY | 此命令將僅備份指定路徑下的指定資料庫。 | mongodump --dbpath /data/db/ --out /data/backup/ |
| mongodump --collection COLLECTION --db DB_NAME | 此命令將僅備份指定資料庫的指定集合。 | mongodump --collection mycol --db test |
恢復資料
要恢復備份資料,可以使用 MongoDB 的mongorestore命令。此命令會從備份目錄恢復所有資料。
語法
mongorestore命令的基本語法如下所示:
>mongorestore
以下是命令的輸出:
MongoDB - 部署
在準備 MongoDB 部署時,您應該嘗試瞭解您的應用程式如何在生產環境中執行。最好制定一種一致且可重複的方法來管理您的部署環境,以便最大程度地減少在生產環境中出現任何意外情況。
最佳方法包括對您的設定進行原型設計、進行負載測試、監控關鍵指標,並利用這些資訊來擴充套件您的設定。該方法的關鍵部分是主動監控您的整個系統 - 這將幫助您瞭解您的生產系統在部署之前將如何執行,並確定您需要在何處增加容量。例如,深入瞭解記憶體使用情況的潛在峰值可能有助於在寫入鎖故障發生之前將其撲滅。
為了監控您的部署,MongoDB 提供了一些以下命令:
mongostat
此命令檢查所有正在執行的 mongod 例項的狀態,並返回資料庫操作的計數器。這些計數器包括插入、查詢、更新、刪除和遊標。命令還顯示何時遇到頁面錯誤,並顯示您的鎖定百分比。這意味著您的記憶體不足、寫入容量不足或存在某些效能問題。
要執行該命令,請啟動您的 mongod 例項。在另一個命令提示符中,轉到 mongodb 安裝的bin目錄,然後鍵入mongostat。
D:\set up\mongodb\bin>mongostat
以下是命令的輸出:

mongotop
此命令跟蹤並報告 MongoDB 例項在集合基礎上的讀寫活動。預設情況下,mongotop每秒返回資訊,您可以相應地更改它。您應該檢查此讀寫活動是否與您的應用程式意圖相匹配,並且您沒有一次向資料庫寫入太多資料、過於頻繁地從磁碟讀取資料或超過您的工作集大小。
要執行該命令,請啟動您的 mongod 例項。在另一個命令提示符中,轉到 mongodb 安裝的bin目錄,然後鍵入mongotop。
D:\set up\mongodb\bin>mongotop
以下是命令的輸出:
要更改mongotop命令以較不頻繁地返回資訊,請在 mongotop 命令後指定一個特定數字。
D:\set up\mongodb\bin>mongotop 30
以上示例將每 30 秒返回一次值。
除了 MongoDB 工具之外,10gen 還提供了一個免費的託管監控服務 MongoDB Management Service (MMS),該服務提供了一個儀表板,併為您提供整個叢集的指標檢視。
MongoDB - Java
在本章中,我們將學習如何設定 MongoDB JDBC 驅動程式。
安裝
在開始在 Java 程式中使用 MongoDB 之前,您需要確保機器上已安裝 MongoDB JDBC 驅動程式和 Java。您可以檢視 Java 教程以瞭解如何在您的機器上安裝 Java。現在,讓我們檢查如何設定 MongoDB JDBC 驅動程式。
您需要從路徑下載 mongo.jar下載 jar 檔案。確保下載其最新版本。
您需要將 mongo.jar 包含到您的類路徑中。
連線到資料庫
要連線資料庫,您需要指定資料庫名稱,如果資料庫不存在,則 MongoDB 會自動建立它。
以下是連線到資料庫的程式碼片段:
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class ConnectToDB {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
System.out.println("Credentials ::"+ credential);
}
}
現在,讓我們編譯並執行上述程式以建立我們的資料庫 myDb,如下所示。
$javac ConnectToDB.java $java ConnectToDB
執行後,上述程式將為您提供以下輸出。
Connected to the database successfully
Credentials ::MongoCredential{
mechanism = null,
userName = 'sampleUser',
source = 'myDb',
password = <hidden>,
mechanismProperties = {}
}
建立集合
要建立集合,可以使用com.mongodb.client.MongoDatabase類的createCollection()方法。
以下是建立集合的程式碼片段:
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class CreatingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
//Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
//Creating a collection
database.createCollection("sampleCollection");
System.out.println("Collection created successfully");
}
}
編譯後,上述程式將為您提供以下結果:
Connected to the database successfully Collection created successfully
獲取/選擇集合
要從資料庫中獲取/選擇集合,可以使用com.mongodb.client.MongoDatabase類的getCollection()方法。
以下是獲取/選擇集合的程式:
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class selectingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Creating a collection
System.out.println("Collection created successfully");
// Retieving a collection
MongoCollection<Document> collection = database.getCollection("myCollection");
System.out.println("Collection myCollection selected successfully");
}
}
編譯後,上述程式將為您提供以下結果:
Connected to the database successfully Collection created successfully Collection myCollection selected successfully
插入文件
要將文件插入 MongoDB,可以使用com.mongodb.client.MongoCollection類的insert()方法。
以下是插入文件的程式碼片段:
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class InsertingDocument {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
Document document = new Document("title", "MongoDB")
.append("id", 1)
.append("description", "database")
.append("likes", 100)
.append("url", "https://tutorialspoint.tw/mongodb/")
.append("by", "tutorials point");
collection.insertOne(document);
System.out.println("Document inserted successfully");
}
}
編譯後,上述程式將為您提供以下結果:
Connected to the database successfully Collection sampleCollection selected successfully Document inserted successfully
檢索所有文件
要從集合中選擇所有文件,可以使用com.mongodb.client.MongoCollection類的find()方法。此方法返回一個遊標,因此您需要迭代此遊標。
以下是選擇所有文件的程式:
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class RetrievingAllDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println(it.next());
i++;
}
}
}
編譯後,上述程式將為您提供以下結果:
Document{{
_id = 5967745223993a32646baab8,
title = MongoDB,
id = 1,
description = database,
likes = 100,
url = https://tutorialspoint.tw/mongodb/, by = tutorials point
}}
Document{{
_id = 7452239959673a32646baab8,
title = RethinkDB,
id = 2,
description = database,
likes = 200,
url = https://tutorialspoint.tw/rethinkdb/, by = tutorials point
}}
更新文件
要更新集合中的文件,可以使用com.mongodb.client.MongoCollection類的updateOne()方法。
以下是選擇第一個文件的程式:
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.model.Filters;
import com.mongodb.client.model.Updates;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class UpdatingDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection myCollection selected successfully");
collection.updateOne(Filters.eq("id", 1), Updates.set("likes", 150));
System.out.println("Document update successfully...");
// Retrieving the documents after updation
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println(it.next());
i++;
}
}
}
編譯後,上述程式將為您提供以下結果:
Document update successfully...
Document {{
_id = 5967745223993a32646baab8,
title = MongoDB,
id = 1,
description = database,
likes = 150,
url = https://tutorialspoint.tw/mongodb/, by = tutorials point
}}
刪除文件
要從集合中刪除文件,您需要使用com.mongodb.client.MongoCollection類的deleteOne()方法。
以下是刪除文件的程式:
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.model.Filters;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class DeletingDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
// Deleting the documents
collection.deleteOne(Filters.eq("id", 1));
System.out.println("Document deleted successfully...");
// Retrieving the documents after updation
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println("Inserted Document: "+i);
System.out.println(it.next());
i++;
}
}
}
編譯後,上述程式將為您提供以下結果:
Connected to the database successfully Collection sampleCollection selected successfully Document deleted successfully...
刪除集合
要從資料庫中刪除集合,您需要使用com.mongodb.client.MongoCollection類的drop()方法。
以下是刪除集合的程式:
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class DropingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Creating a collection
System.out.println("Collections created successfully");
// Retieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
// Dropping a Collection
collection.drop();
System.out.println("Collection dropped successfully");
}
}
編譯後,上述程式將為您提供以下結果:
Connected to the database successfully Collection sampleCollection selected successfully Collection dropped successfully
列出所有集合
要列出資料庫中的所有集合,您需要使用com.mongodb.client.MongoDatabase類的listCollectionNames()方法。
以下是列出資料庫所有集合的程式:
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class ListOfCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
System.out.println("Collection created successfully");
for (String name : database.listCollectionNames()) {
System.out.println(name);
}
}
}
編譯後,上述程式將為您提供以下結果:
Connected to the database successfully Collection created successfully myCollection myCollection1 myCollection5
其餘的 MongoDB 方法save()、limit()、skip()、sort()等的工作方式與後續教程中解釋的相同。
MongoDB - PHP
要將 MongoDB 與 PHP 一起使用,您需要使用 MongoDB PHP 驅動程式。從網址下載 PHP 驅動程式下載驅動程式。確保下載其最新版本。現在解壓縮存檔並將 php_mongo.dll 放入您的 PHP 擴充套件目錄(預設為“ext”),然後將以下行新增到您的 php.ini 檔案中:
extension = php_mongo.dll
建立連線並選擇資料庫
要建立連線,您需要指定資料庫名稱,如果資料庫不存在,則 MongoDB 會自動建立它。
以下是連線到資料庫的程式碼片段:
<?php // connect to mongodb $m = new MongoClient(); echo "Connection to database successfully"; // select a database $db = $m->mydb; echo "Database mydb selected"; ?>
程式執行後,將產生以下結果:
Connection to database successfully Database mydb selected
建立集合
以下是建立集合的程式碼片段:
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->createCollection("mycol");
echo "Collection created succsessfully";
?>
程式執行後,將產生以下結果:
Connection to database successfully Database mydb selected Collection created succsessfully
插入文件
要將文件插入 MongoDB,可以使用insert()方法。
以下是插入文件的程式碼片段:
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
$document = array(
"title" => "MongoDB",
"description" => "database",
"likes" => 100,
"url" => "https://tutorialspoint.tw/mongodb/",
"by" => "tutorials point"
);
$collection->insert($document);
echo "Document inserted successfully";
?>
程式執行後,將產生以下結果:
Connection to database successfully Database mydb selected Collection selected succsessfully Document inserted successfully
查詢所有文件
要從集合中選擇所有文件,可以使用 find() 方法。
以下是選擇所有文件的程式碼片段:
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
$cursor = $collection->find();
// iterate cursor to display title of documents
foreach ($cursor as $document) {
echo $document["title"] . "\n";
}
?>
程式執行後,將產生以下結果:
Connection to database successfully
Database mydb selected
Collection selected succsessfully {
"title": "MongoDB"
}
更新文件
要更新文件,您需要使用 update() 方法。
在以下示例中,我們將插入文件的標題更新為MongoDB 教程。以下是更新文件的程式碼片段:
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
// now update the document
$collection->update(array("title"=>"MongoDB"),
array('$set'=>array("title"=>"MongoDB Tutorial")));
echo "Document updated successfully";
// now display the updated document
$cursor = $collection->find();
// iterate cursor to display title of documents
echo "Updated document";
foreach ($cursor as $document) {
echo $document["title"] . "\n";
}
?>
程式執行後,將產生以下結果:
Connection to database successfully
Database mydb selected
Collection selected succsessfully
Document updated successfully
Updated document {
"title": "MongoDB Tutorial"
}
刪除文件
要刪除文件,您需要使用 remove() 方法。
在以下示例中,我們將刪除標題為MongoDB 教程的文件。以下是刪除文件的程式碼片段:
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
// now remove the document
$collection->remove(array("title"=>"MongoDB Tutorial"),false);
echo "Documents deleted successfully";
// now display the available documents
$cursor = $collection->find();
// iterate cursor to display title of documents
echo "Updated document";
foreach ($cursor as $document) {
echo $document["title"] . "\n";
}
?>
程式執行後,將產生以下結果:
Connection to database successfully Database mydb selected Collection selected succsessfully Documents deleted successfully
在以上示例中,第二個引數是布林型別,用於remove()方法的justOne欄位。
其餘的 MongoDB 方法findOne()、save()、limit()、skip()、sort()等的工作方式與上述解釋相同。
MongoDB - 關係
MongoDB 中的關係表示各種文件在邏輯上如何相互關聯。關係可以透過嵌入和引用方法建模。此類關係可以是 1:1、1:N、N:1 或 N:N。
讓我們考慮為使用者儲存地址的情況。因此,一個使用者可以有多個地址,這使得它成為 1:N 關係。
以下是使用者文件的示例文件結構:
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"name": "Tom Hanks",
"contact": "987654321",
"dob": "01-01-1991"
}
以下是地址文件的示例文件結構:
{
"_id":ObjectId("52ffc4a5d85242602e000000"),
"building": "22 A, Indiana Apt",
"pincode": 123456,
"city": "Los Angeles",
"state": "California"
}
建模嵌入關係
在嵌入方法中,我們將地址文件嵌入到使用者文件中。
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address": [
{
"building": "22 A, Indiana Apt",
"pincode": 123456,
"city": "Los Angeles",
"state": "California"
},
{
"building": "170 A, Acropolis Apt",
"pincode": 456789,
"city": "Chicago",
"state": "Illinois"
}
]
}
此方法將所有相關資料儲存在單個文件中,這使得它易於檢索和維護。整個文件可以在單個查詢中檢索,例如:
>db.users.findOne({"name":"Tom Benzamin"},{"address":1})
請注意,在上面的查詢中,db和users分別是資料庫和集合。
缺點是,如果嵌入文件的大小不斷增長,則會影響讀寫效能。
建模引用關係
這是設計規範化關係的方法。在這種方法中,使用者和地址文件將分別維護,但使用者文件將包含一個欄位,該欄位將引用地址文件的id欄位。
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address_ids": [
ObjectId("52ffc4a5d85242602e000000"),
ObjectId("52ffc4a5d85242602e000001")
]
}
如上所示,使用者文件包含陣列欄位address_ids,其中包含相應地址的ObjectId。使用這些ObjectId,我們可以查詢地址文件並從中獲取地址詳細資訊。透過這種方法,我們需要兩個查詢:第一個是從user文件中獲取address_ids欄位,第二個是從address集合中獲取這些地址。
>var result = db.users.findOne({"name":"Tom Benzamin"},{"address_ids":1})
>var addresses = db.address.find({"_id":{"$in":result["address_ids"]}})
MongoDB - 資料庫引用
如MongoDB關係最後一章所述,要在MongoDB中實現規範化的資料庫結構,我們使用引用關係的概念,也稱為手動引用,其中我們手動將引用文件的id儲存在其他文件中。但是,在文件包含來自不同集合的引用的情況下,我們可以使用MongoDB DBRefs。
DBRefs與手動引用
例如,在使用DBRefs而不是手動引用的場景中,考慮一個數據庫,我們將在不同的集合(address_home、address_office、address_mailing等)中儲存不同型別的地址(家庭、辦公室、郵寄等)。現在,當user集合的文件引用地址時,它還需要根據地址型別指定要查詢哪個集合。在這種情況下,文件引用來自多個集合的文件,我們應該使用DBRefs。
使用DBRefs
DBRefs中有三個欄位:
$ref - 此欄位指定引用文件的集合
$id - 此欄位指定引用文件的_id欄位
$db - 這是一個可選欄位,包含引用文件所在的資料庫名稱
考慮一個示例使用者文件,其中包含DBRef欄位address,如程式碼片段所示:
{
"_id":ObjectId("53402597d852426020000002"),
"address": {
"$ref": "address_home",
"$id": ObjectId("534009e4d852427820000002"),
"$db": "tutorialspoint"},
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin"
}
此處的address DBRef欄位指定引用地址文件位於tutorialspoint資料庫的address_home集合中,並且id為534009e4d852427820000002。
以下程式碼動態地在由$ref引數(在本例中為address_home)指定的集合中查詢id與DBRef中的$id引數指定的id相同的文件。
>var user = db.users.findOne({"name":"Tom Benzamin"})
>var dbRef = user.address
>db[dbRef.$ref].findOne({"_id":(dbRef.$id)})
以上程式碼返回存在於address_home集合中的以下地址文件:
{
"_id" : ObjectId("534009e4d852427820000002"),
"building" : "22 A, Indiana Apt",
"pincode" : 123456,
"city" : "Los Angeles",
"state" : "California"
}
MongoDB - 覆蓋查詢
在本節中,我們將學習覆蓋查詢。
什麼是覆蓋查詢?
根據MongoDB官方文件,覆蓋查詢是指:
- 查詢中的所有欄位都是索引的一部分。
- 查詢中返回的所有欄位都在同一個索引中。
由於查詢中存在的所有欄位都是索引的一部分,因此MongoDB使用同一個索引匹配查詢條件並返回結果,而無需實際檢視文件內部。由於索引存在於RAM中,因此與透過掃描文件獲取資料相比,從索引中獲取資料要快得多。
使用覆蓋查詢
要測試覆蓋查詢,請考慮users集合中的以下文件:
{
"_id": ObjectId("53402597d852426020000002"),
"contact": "987654321",
"dob": "01-01-1991",
"gender": "M",
"name": "Tom Benzamin",
"user_name": "tombenzamin"
}
我們將首先使用以下查詢為users集合中的gender和user_name欄位建立一個複合索引:
>db.users.ensureIndex({gender:1,user_name:1})
現在,此索引將覆蓋以下查詢:
>db.users.find({gender:"M"},{user_name:1,_id:0})
也就是說,對於上述查詢,MongoDB不會去資料庫文件中查詢。相反,它會從索引資料中獲取所需的資料,這非常快。
由於我們的索引不包含_id欄位,因此我們已將其顯式地從查詢的結果集中排除,因為MongoDB預設在每個查詢中都返回_id欄位。因此,以下查詢將不會被上面建立的索引覆蓋:
>db.users.find({gender:"M"},{user_name:1})
最後,請記住,如果以下情況,索引無法覆蓋查詢:
- 任何索引欄位都是陣列
- 任何索引欄位都是子文件
MongoDB - 分析查詢
分析查詢是衡量資料庫和索引設計有效性的一個非常重要的方面。我們將學習常用的$explain和$hint查詢。
使用$explain
$explain運算子提供有關查詢、查詢中使用的索引和其他統計資訊的資訊。在分析索引的最佳化程度時,它非常有用。
在上一節中,我們已經使用以下查詢為users集合中的gender和user_name欄位建立了一個索引:
>db.users.ensureIndex({gender:1,user_name:1})
我們現在將在以下查詢上使用$explain:
>db.users.find({gender:"M"},{user_name:1,_id:0}).explain()
上述explain()查詢返回以下分析結果:
{
"cursor" : "BtreeCursor gender_1_user_name_1",
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 0,
"nscanned" : 1,
"nscannedObjectsAllPlans" : 0,
"nscannedAllPlans" : 1,
"scanAndOrder" : false,
"indexOnly" : true,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"gender" : [
[
"M",
"M"
]
],
"user_name" : [
[
{
"$minElement" : 1
},
{
"$maxElement" : 1
}
]
]
}
}
我們現在將檢視此結果集中的欄位:
indexOnly的true值表示此查詢已使用索引。
cursor欄位指定使用的遊標型別。BTreeCursor型別表示使用了索引,並且還給出了使用的索引的名稱。BasicCursor表示在沒有使用任何索引的情況下進行了完整掃描。
n表示返回的匹配文件的數量。
nscannedObjects表示掃描的文件總數。
nscanned表示掃描的文件或索引條目的總數。
使用$hint
$hint運算子強制查詢最佳化器使用指定的索引來執行查詢。當您想要測試使用不同索引的查詢的效能時,這尤其有用。例如,以下查詢指定要用於此查詢的gender和user_name欄位上的索引:
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1})
要使用$explain分析上述查詢:
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1}).explain()
MongoDB - 原子操作
原子操作的模型資料
維護原子性的推薦方法是使用嵌入文件將所有相關的、經常一起更新的資訊儲存在單個文件中。這將確保單個文件的所有更新都是原子的。
考慮以下產品文件:
{
"_id":1,
"product_name": "Samsung S3",
"category": "mobiles",
"product_total": 5,
"product_available": 3,
"product_bought_by": [
{
"customer": "john",
"date": "7-Jan-2014"
},
{
"customer": "mark",
"date": "8-Jan-2014"
}
]
}
在此文件中,我們已將購買產品的客戶的資訊嵌入到product_bought_by欄位中。現在,每當新客戶購買產品時,我們首先會使用product_available欄位檢查產品是否仍然可用。如果可用,我們將減少product_available欄位的值,並將新客戶的嵌入文件插入product_bought_by欄位。我們將使用findAndModify命令來實現此功能,因為它可以同時搜尋和更新文件。
>db.products.findAndModify({
query:{_id:2,product_available:{$gt:0}},
update:{
$inc:{product_available:-1},
$push:{product_bought_by:{customer:"rob",date:"9-Jan-2014"}}
}
})
我們使用嵌入文件和findAndModify查詢的方法確保僅當產品可用時才會更新產品購買資訊。並且整個事務都在同一個查詢中,是原子的。
與此相反,考慮我們可能將產品可用性和誰購買了產品的資訊分開儲存的場景。在這種情況下,我們首先將使用第一個查詢檢查產品是否可用。然後在第二個查詢中,我們將更新購買資訊。但是,在執行這兩個查詢之間,其他使用者可能已購買了產品,並且該產品不再可用。在不知道這一點的情況下,我們的第二個查詢將根據第一個查詢的結果更新購買資訊。這將使資料庫不一致,因為我們已經銷售了不可用的產品。
MongoDB - 高階索引
考慮users集合的以下文件:
{
"address": {
"city": "Los Angeles",
"state": "California",
"pincode": "123"
},
"tags": [
"music",
"cricket",
"blogs"
],
"name": "Tom Benzamin"
}
以上文件包含一個address子文件和一個tags陣列。
索引陣列欄位
假設我們想根據使用者的標籤搜尋使用者文件。為此,我們將在集合中的tags陣列上建立索引。
為陣列建立索引會為其每個欄位建立單獨的索引條目。因此,在我們的例子中,當我們在tags陣列上建立索引時,將為其值music、cricket和blogs建立單獨的索引。
要在tags陣列上建立索引,請使用以下程式碼:
>db.users.ensureIndex({"tags":1})
建立索引後,我們可以像這樣搜尋集合的tags欄位:
>db.users.find({tags:"cricket"})
要驗證是否使用了正確的索引,請使用以下explain命令:
>db.users.find({tags:"cricket"}).explain()
上述命令導致"cursor" : "BtreeCursor tags_1",這確認使用了正確的索引。
索引子文件欄位
假設我們想根據city、state和pincode欄位搜尋文件。由於所有這些欄位都是address子文件欄位的一部分,因此我們將在子文件的所有欄位上建立索引。
要為子文件的所有三個欄位建立索引,請使用以下程式碼:
>db.users.ensureIndex({"address.city":1,"address.state":1,"address.pincode":1})
建立索引後,我們可以利用此索引搜尋任何子文件欄位,如下所示:
>db.users.find({"address.city":"Los Angeles"})
請記住,查詢表示式必須遵循指定的索引順序。因此,上面建立的索引將支援以下查詢:
>db.users.find({"address.city":"Los Angeles","address.state":"California"})
它還將支援以下查詢:
>db.users.find({"address.city":"LosAngeles","address.state":"California",
"address.pincode":"123"})
MongoDB - 索引限制
在本節中,我們將學習索引限制及其其他元件。
額外開銷
每個索引都會佔用一些空間,並且在每次插入、更新和刪除時都會造成開銷。因此,如果您很少將集合用於讀取操作,則沒有必要使用索引。
RAM使用情況
由於索引儲存在RAM中,因此您應該確保索引的總大小不超過RAM限制。如果總大小超過RAM大小,它將開始刪除一些索引,從而導致效能下降。
查詢限制
索引不能用於使用以下內容的查詢:
- 正則表示式或否定運算子,如$nin、$not等。
- 算術運算子,如$mod等。
- $where子句
因此,始終建議檢查查詢的索引使用情況。
索引鍵限制
從2.6版本開始,如果現有索引欄位的值超過索引鍵限制,MongoDB將不會建立索引。
插入超過索引鍵限制的文件
如果文件的索引欄位值超過索引鍵限制,MongoDB將不會將任何文件插入到索引集合中。mongorestore和mongoimport實用程式也是如此。
最大範圍
- 一個集合最多隻能有64個索引。
- 索引名稱的長度不能超過125個字元。
- 複合索引最多可以有31個索引欄位。
MongoDB - ObjectId
在之前的所有章節中,我們一直在使用MongoDB ObjectId。在本節中,我們將瞭解ObjectId的結構。
ObjectId是一個12位元組的BSON型別,具有以下結構:
- 前4個位元組表示自Unix紀元以來的秒數
- 接下來的3個位元組是機器識別符號
- 接下來的2個位元組包含程序ID
- 最後3個位元組是隨機計數器值
MongoDB 使用 ObjectId 作為每個文件的_id 欄位的預設值,該值在建立任何文件時生成。ObjectId 的複雜組合使得所有 _id 欄位都唯一。
建立新的 ObjectId
要生成一個新的 ObjectId,使用以下程式碼:
>newObjectId = ObjectId()
以上語句返回以下唯一生成的 ID:
ObjectId("5349b4ddd2781d08c09890f3")
除了由 MongoDB 生成 ObjectId 之外,您還可以提供一個 12 位元組的 ID:
>myObjectId = ObjectId("5349b4ddd2781d08c09890f4")
建立文件的時間戳
由於預設情況下 _id ObjectId 儲存 4 位元組的時間戳,因此在大多數情況下,您不需要儲存任何文件的建立時間。您可以使用 getTimestamp 方法獲取文件的建立時間:
>ObjectId("5349b4ddd2781d08c09890f4").getTimestamp()
這將以 ISO 日期格式返回此文件的建立時間:
ISODate("2014-04-12T21:49:17Z")
將 ObjectId 轉換為字串
在某些情況下,您可能需要 ObjectId 的字串格式的值。要將 ObjectId 轉換為字串,請使用以下程式碼:
>newObjectId.str
以上程式碼將返回 Guid 的字串格式:
5349b4ddd2781d08c09890f3
MongoDB - Map Reduce
根據 MongoDB 文件,Map-Reduce 是一種資料處理正規化,用於將大量資料壓縮成有用的聚合結果。MongoDB 使用mapReduce 命令進行 Map-Reduce 操作。MapReduce 通常用於處理大型資料集。
MapReduce 命令
以下是基本 mapReduce 命令的語法:
>db.collection.mapReduce(
function() {emit(key,value);}, //map function
function(key,values) {return reduceFunction}, { //reduce function
out: collection,
query: document,
sort: document,
limit: number
}
)
map-reduce 函式首先查詢集合,然後將結果文件對映到發出鍵值對,然後根據具有多個值的鍵進行歸約。
在以上語法中:
map 是一個 JavaScript 函式,它將值與鍵對映併發出鍵值對
reduce 是一個 JavaScript 函式,它減少或組合所有具有相同鍵的文件
out 指定 map-reduce 查詢結果的位置
query 指定用於選擇文件的可選選擇條件
sort 指定可選的排序條件
limit 指定要返回的可選最大文件數
使用 MapReduce
考慮以下儲存使用者帖子的文件結構。該文件儲存使用者的 user_name 和帖子的狀態。
{
"post_text": "tutorialspoint is an awesome website for tutorials",
"user_name": "mark",
"status":"active"
}
現在,我們將對我們的posts 集合使用 mapReduce 函式來選擇所有活躍的帖子,根據 user_name 對其進行分組,然後使用以下程式碼計算每個使用者的帖子數量:
>db.posts.mapReduce(
function() { emit(this.user_id,1); },
function(key, values) {return Array.sum(values)}, {
query:{status:"active"},
out:"post_total"
}
)
以上 MapReduce 查詢輸出以下結果:
{
"result" : "post_total",
"timeMillis" : 9,
"counts" : {
"input" : 4,
"emit" : 4,
"reduce" : 2,
"output" : 2
},
"ok" : 1,
}
結果顯示共有 4 個文件匹配查詢 (status:"active"),map 函式發出了 4 個帶有鍵值對的文件,最後 reduce 函式將具有相同鍵的對映文件分組為 2 個。
要檢視此 mapReduce 查詢的結果,請使用 find 運算子:
>db.posts.mapReduce(
function() { emit(this.user_id,1); },
function(key, values) {return Array.sum(values)}, {
query:{status:"active"},
out:"post_total"
}
).find()
以上查詢給出以下結果,表明tom 和mark 這兩個使用者都各有 2 篇帖子處於活躍狀態:
{ "_id" : "tom", "value" : 2 }
{ "_id" : "mark", "value" : 2 }
以類似的方式,MapReduce 查詢可用於構建大型複雜的聚合查詢。自定義 JavaScript 函式的使用使 MapReduce 的使用非常靈活和強大。
MongoDB - 文字搜尋
從 2.4 版開始,MongoDB 開始支援文字索引以在字串內容內進行搜尋。文字搜尋 使用詞幹提取技術透過刪除諸如a、an、the 等詞幹停止詞來查詢字串欄位中的指定單詞。目前,MongoDB 支援大約 15 種語言。
啟用文字搜尋
最初,文字搜尋是一個實驗性功能,但從 2.6 版開始,預設情況下啟用該配置。但是,如果您使用的是 MongoDB 的早期版本,則必須使用以下程式碼啟用文字搜尋:
>db.adminCommand({setParameter:true,textSearchEnabled:true})
建立文字索引
考慮posts 集合下包含帖子文字及其標籤的以下文件:
{
"post_text": "enjoy the mongodb articles on tutorialspoint",
"tags": [
"mongodb",
"tutorialspoint"
]
}
我們將對 post_text 欄位建立文字索引,以便我們可以在帖子文字中進行搜尋:
>db.posts.ensureIndex({post_text:"text"})
使用文字索引
現在我們已在 post_text 欄位上建立了文字索引,我們將搜尋所有在其文字中包含單詞tutorialspoint 的帖子。
>db.posts.find({$text:{$search:"tutorialspoint"}})
以上命令返回以下在帖子文字中包含單詞tutorialspoint 的結果文件:
{
"_id" : ObjectId("53493d14d852429c10000002"),
"post_text" : "enjoy the mongodb articles on tutorialspoint",
"tags" : [ "mongodb", "tutorialspoint" ]
}
{
"_id" : ObjectId("53493d1fd852429c10000003"),
"post_text" : "writing tutorials on mongodb",
"tags" : [ "mongodb", "tutorial" ]
}
如果您使用的是舊版本的 MongoDB,則必須使用以下命令:
>db.posts.runCommand("text",{search:" tutorialspoint "})
與普通搜尋相比,使用文字搜尋極大地提高了搜尋效率。
刪除文字索引
要刪除現有的文字索引,首先使用以下查詢查詢索引的名稱:
>db.posts.getIndexes()
從以上查詢獲取索引名稱後,執行以下命令。此處,post_text_text 是索引的名稱。
>db.posts.dropIndex("post_text_text")
MongoDB - 正則表示式
正則表示式在所有語言中都經常用於在任何字串中搜索模式或單詞。MongoDB 還提供正則表示式的功能,使用$regex 運算子進行字串模式匹配。MongoDB 使用 PCRE(Perl 相容正則表示式)作為正則表示式語言。
與文字搜尋不同,我們不需要進行任何配置或命令來使用正則表示式。
考慮posts 集合下包含帖子文字及其標籤的以下文件結構:
{
"post_text": "enjoy the mongodb articles on tutorialspoint",
"tags": [
"mongodb",
"tutorialspoint"
]
}
使用正則表示式
以下正則表示式查詢搜尋所有包含字串tutorialspoint 的帖子:
>db.posts.find({post_text:{$regex:"tutorialspoint"}})
相同的查詢也可以寫成:
>db.posts.find({post_text:/tutorialspoint/})
使用不區分大小寫的正則表示式
要使搜尋不區分大小寫,我們使用$options 引數,其值為$i。以下命令將查詢包含單詞tutorialspoint 的字串,無論大小寫如何:
>db.posts.find({post_text:{$regex:"tutorialspoint",$options:"$i"}})
此查詢返回的結果之一是以下文件,其中包含不同大小寫的單詞tutorialspoint:
{
"_id" : ObjectId("53493d37d852429c10000004"),
"post_text" : "hey! this is my post on TutorialsPoint",
"tags" : [ "tutorialspoint" ]
}
對陣列元素使用正則表示式
我們也可以對陣列欄位使用正則表示式的概念。當我們實現標籤的功能時,這尤其重要。因此,如果您想搜尋所有以單詞 tutorial 開頭的標籤(tutorial 或 tutorials 或 tutorialpoint 或 tutorialphp)的帖子,您可以使用以下程式碼:
>db.posts.find({tags:{$regex:"tutorial"}})
最佳化正則表示式查詢
如果文件欄位已索引,則查詢將使用索引值來匹配正則表示式。這使得搜尋速度比正則表示式掃描整個集合快得多。
如果正則表示式是字首表示式,則所有匹配項都必須以某些字串字元開頭。例如,如果正則表示式為^tut,則查詢必須僅搜尋以tut 開頭的字串。
使用 RockMongo
RockMongo 是一種 MongoDB 管理工具,您可以使用它來管理伺服器、資料庫、集合、文件、索引等等。它提供了一種非常使用者友好的方式來讀取、寫入和建立文件。它類似於 PHP 和 MySQL 的 PHPMyAdmin 工具。
下載 RockMongo
您可以從此處下載最新版本的 RockMongo:https://github.com/iwind/rockmongo
安裝 RockMongo
下載完成後,您可以將軟體包解壓縮到伺服器根資料夾中,並將解壓縮的資料夾重新命名為rockmongo。開啟任何 Web 瀏覽器並訪問資料夾 rockmongo 中的index.php 頁面。分別輸入 admin/admin 作為使用者名稱/密碼。
使用 RockMongo
我們現在將瞭解您可以使用 RockMongo 執行的一些基本操作。
建立新資料庫
要建立新資料庫,請單擊資料庫選項卡。單擊建立新資料庫。在下一個螢幕上,提供新資料庫的名稱,然後單擊建立。您將看到左側面板中添加了一個新資料庫。
建立新集合
要在資料庫中建立新集合,請從左側面板中單擊該資料庫。單擊頂部的新集合連結。提供所需的集合名稱。不必擔心 Is Capped、Size 和 Max 的其他欄位。單擊建立。將建立一個新集合,您將能夠在左側面板中看到它。
建立新文件
要建立新文件,請單擊要在其下新增文件的集合。當您單擊集合時,您將能夠看到列出在該集合中的所有文件。要建立新文件,請單擊頂部的插入連結。您可以以 JSON 或陣列格式輸入文件資料,然後單擊儲存。
匯出/匯入資料
要匯入/匯出任何集合的資料,請單擊該集合,然後單擊頂部面板上的匯出/匯入連結。按照後續說明將資料匯出為 zip 格式,然後匯入相同的 zip 檔案以匯入資料。
MongoDB - GridFS
GridFS 是 MongoDB 用於儲存和檢索大型檔案(如影像、音訊檔案、影片檔案等)的規範。它是一種用於儲存檔案的某種檔案系統,但其資料儲存在 MongoDB 集合中。GridFS 能夠儲存檔案,即使檔案大小超過其 16MB 的文件大小限制。
GridFS 將檔案分成塊,並將每個資料塊儲存在單獨的文件中,每個文件的最大大小為 255k。
GridFS 預設使用兩個集合fs.files 和fs.chunks 來儲存檔案的元資料和塊。每個塊都由其唯一的 _id ObjectId 欄位標識。fs.files 充當父文件。fs.chunks 文件中的files_id 欄位將塊連結到其父級。
以下是 fs.files 集合的示例文件:
{
"filename": "test.txt",
"chunkSize": NumberInt(261120),
"uploadDate": ISODate("2014-04-13T11:32:33.557Z"),
"md5": "7b762939321e146569b07f72c62cca4f",
"length": NumberInt(646)
}
該文件指定檔名、塊大小、上傳日期和長度。
以下是 fs.chunks 文件的示例文件:
{
"files_id": ObjectId("534a75d19f54bfec8a2fe44b"),
"n": NumberInt(0),
"data": "Mongo Binary Data"
}
將檔案新增到 GridFS
現在,我們將使用 GridFS 使用put 命令儲存一個 mp3 檔案。為此,我們將使用 MongoDB 安裝資料夾的 bin 資料夾中提供的mongofiles.exe 實用程式。
開啟命令提示符,導航到 MongoDB 安裝資料夾的 bin 資料夾中的 mongofiles.exe,然後鍵入以下程式碼:
>mongofiles.exe -d gridfs put song.mp3
此處,gridfs 是將儲存檔案的資料庫的名稱。如果資料庫不存在,MongoDB 將自動動態建立一個新文件。Song.mp3 是上傳的檔案的名稱。要檢視資料庫中的檔案文件,您可以使用 find 查詢:
>db.fs.files.find()
以上命令返回以下文件:
{
_id: ObjectId('534a811bf8b4aa4d33fdf94d'),
filename: "song.mp3",
chunkSize: 261120,
uploadDate: new Date(1397391643474), md5: "e4f53379c909f7bed2e9d631e15c1c41",
length: 10401959
}
我們還可以使用以下程式碼檢視與儲存的檔案相關的 fs.chunks 集合中存在的所有塊,使用上一個查詢中返回的文件 ID:
>db.fs.chunks.find({files_id:ObjectId('534a811bf8b4aa4d33fdf94d')})
在我的情況下,查詢返回了 40 個文件,這意味著整個 mp3 文件被分成了 40 個數據塊。
MongoDB - 有界集合
有限集合(Capped Collections)是固定大小的迴圈集合,按照插入順序儲存資料,從而支援高效的建立、讀取和刪除操作。迴圈是指,當分配給集合的固定大小用盡時,它將開始刪除集合中最舊的文件,而無需任何顯式命令。
有限集合限制對文件的更新,如果更新導致文件大小增加。由於有限集合按磁碟儲存順序儲存文件,因此可以確保文件大小不會增加磁碟上分配的大小。有限集合最適合儲存日誌資訊、快取資料或任何其他大量資料。
建立有限集合
要建立有限集合,我們使用正常的 createCollection 命令,但將 capped 選項設定為 true,並以位元組為單位指定集合的最大大小。
>db.createCollection("cappedLogCollection",{capped:true,size:10000})
除了集合大小外,我們還可以使用 max 引數限制集合中的文件數量 -
>db.createCollection("cappedLogCollection",{capped:true,size:10000,max:1000})
如果要檢查集合是否為有限集合,請使用以下 isCapped 命令 -
>db.cappedLogCollection.isCapped()
如果您有一個現有的集合,計劃將其轉換為有限集合,您可以使用以下程式碼 -
>db.runCommand({"convertToCapped":"posts",size:10000})
此程式碼會將我們現有的集合 posts 轉換為有限集合。
查詢有限集合
預設情況下,對有限集合的 find 查詢將按插入順序顯示結果。但是,如果希望以相反的順序檢索文件,請使用以下程式碼所示的 sort 命令 -
>db.cappedLogCollection.find().sort({$natural:-1})
關於有限集合,還有一些其他重要的要點值得了解 -
我們無法從有限集合中刪除文件。
有限集合中沒有預設索引,即使在 _id 欄位上也沒有。
在插入新文件時,MongoDB 不必實際查詢磁碟上容納新文件的位置。它可以盲目地將新文件插入到集合的尾部。這使得有限集合中的插入操作非常快。
類似地,在讀取文件時,MongoDB 以與磁碟上相同的順序返回文件。這使得讀取操作非常快。
MongoDB - 自動遞增序列
MongoDB 沒有開箱即用的自動遞增功能,如 SQL 資料庫。預設情況下,它使用 12 位元組的 ObjectId 作為 _id 欄位的主鍵,以唯一地標識文件。但是,在某些情況下,我們可能希望 _id 欄位具有除 ObjectId 之外的某些自動遞增值。
由於這不是 MongoDB 的預設功能,因此我們將透過使用 MongoDB 文件建議的 counters 集合以程式設計方式實現此功能。
使用計數器集合
考慮以下 products 文件。我們希望 _id 欄位為從 1、2、3、4 到 n 開始的 自動遞增整數序列。
{
"_id":1,
"product_name": "Apple iPhone",
"category": "mobiles"
}
為此,建立一個 counters 集合,它將跟蹤所有序列欄位的最後一個序列值。
>db.createCollection("counters")
現在,我們將以下文件插入 counters 集合中,其中 productid 為其鍵 -
{
"_id":"productid",
"sequence_value": 0
}
欄位 sequence_value 跟蹤序列的最後一個值。
使用以下程式碼將此序列文件插入 counters 集合中 -
>db.counters.insert({_id:"productid",sequence_value:0})
建立 Javascript 函式
現在,我們將建立一個函式 getNextSequenceValue,它將序列名稱作為輸入,將序列號遞增 1 並返回更新的序列號。在我們的例子中,序列名稱為 productid。
>function getNextSequenceValue(sequenceName){
var sequenceDocument = db.counters.findAndModify({
query:{_id: sequenceName },
update: {$inc:{sequence_value:1}},
new:true
});
return sequenceDocument.sequence_value;
}
使用 Javascript 函式
現在,我們將在建立新文件時使用 getNextSequenceValue 函式,並將返回的序列值作為文件的 _id 欄位。
使用以下程式碼插入兩個示例文件 -
>db.products.insert({
"_id":getNextSequenceValue("productid"),
"product_name":"Apple iPhone",
"category":"mobiles"
})
>db.products.insert({
"_id":getNextSequenceValue("productid"),
"product_name":"Samsung S3",
"category":"mobiles"
})
如您所見,我們已使用 getNextSequenceValue 函式為 _id 欄位設定值。
為了驗證功能,讓我們使用 find 命令獲取文件 -
>db.products.find()
上述查詢返回了以下具有自動遞增 _id 欄位的文件 -
{ "_id" : 1, "product_name" : "Apple iPhone", "category" : "mobiles"}
{ "_id" : 2, "product_name" : "Samsung S3", "category" : "mobiles" }