建模與模擬 - 快速指南
建模與模擬 - 引言
建模是表示模型的過程,包括模型的構建和運作。該模型類似於真實系統,幫助分析師預測系統變化的影響。換句話說,建模就是建立代表系統及其屬性的模型。這是一個構建模型的行為。
模擬是對系統在時間或空間上的操作,有助於分析現有或擬議系統的效能。換句話說,模擬就是使用模型來研究系統性能的過程。這是一個使用模型進行模擬的行為。
模擬的歷史
模擬的歷史視角按時間順序排列如下。
1940年 - 一種名為“蒙特卡洛”的方法由參與曼哈頓計劃的研究人員(約翰·馮·諾依曼、斯坦尼斯瓦夫·烏蘭、愛德華·泰勒、赫爾曼·卡恩)和物理學家開發,用於研究中子散射。
1960年 - 開發了第一批專用模擬語言,例如蘭德公司Harry Markowitz開發的SIMSCRIPT。
1970年 - 在此期間,開始了對模擬數學基礎的研究。
1980年 - 在此期間,開發了基於PC的模擬軟體、圖形使用者介面和麵向物件的程式設計。
1990年 - 在此期間,開發了基於Web的模擬、精美動畫圖形、基於模擬的最佳化、馬爾可夫鏈蒙特卡洛方法。
開發模擬模型
模擬模型由以下元件組成:系統實體、輸入變數、效能指標和功能關係。以下是開發模擬模型的步驟。
步驟1 - 識別現有系統的問題或提出系統需求。
步驟2 - 在考慮現有系統因素和限制的情況下設計問題。
步驟3 - 收集並開始處理系統資料,觀察其效能和結果。
步驟4 - 使用網路圖開發模型,並使用各種驗證技術對其進行驗證。
步驟5 - 透過比較其在各種條件下的效能與真實系統來驗證模型。
步驟6 - 為將來使用建立模型文件,其中包括詳細的目標、假設、輸入變數和效能。
步驟7 - 根據要求選擇合適的實驗設計。
步驟8 - 對模型施加實驗條件並觀察結果。
進行模擬分析
以下是進行模擬分析的步驟。
步驟1 - 準備問題陳述。
步驟2 - 選擇輸入變數併為模擬過程建立實體。變數有兩種型別:決策變數和不可控變數。決策變數由程式設計師控制,而不可控變數是隨機變數。
步驟3 - 透過將決策變數分配給模擬過程來建立約束。
步驟4 - 確定輸出變數。
步驟5 - 從真實系統收集資料輸入到模擬中。
步驟6 - 建立一個流程圖,顯示模擬過程的進度。
步驟7 - 選擇合適的模擬軟體來執行模型。
步驟8 - 透過將其結果與即時系統進行比較來驗證模擬模型。
步驟9 - 透過更改變數值對模型進行實驗以找到最佳解決方案。
步驟10 - 最後,將這些結果應用到即時系統中。
建模與模擬 ─ 優點
以下是使用建模與模擬的優點:
易於理解 - 允許理解系統如何真正執行,而無需在即時系統上工作。
易於測試 - 允許對系統進行更改以及對其輸出的影響,而無需在即時系統上工作。
易於升級 - 允許透過應用不同的配置來確定系統需求。
易於識別約束 - 允許執行瓶頸分析,找出導致工作流程、資訊等延遲的原因。
易於診斷問題 - 某些系統非常複雜,難以同時理解其相互作用。但是,建模與模擬允許理解所有相互作用並分析其影響。此外,可以探索新的策略、操作和程式,而不會影響真實系統。
建模與模擬 ─ 缺點
以下是使用建模與模擬的缺點:
設計模型是一門藝術,需要領域知識、培訓和經驗。
使用隨機數對系統進行操作,因此難以預測結果。
模擬需要人力,是一個耗時的過程。
模擬結果難以翻譯,需要專家理解。
模擬過程成本高昂。
建模與模擬 ─ 應用領域
建模與模擬可以應用於以下領域:軍事應用、培訓與支援、半導體設計、電信、土木工程設計與演示以及電子商務模型。
此外,它還用於研究複雜系統的內部結構,例如生物系統。它用於最佳化系統設計,例如路由演算法、裝配線等。它用於測試新設計和策略。它用於驗證分析解決方案。
概念與分類
本章將討論建模的各種概念和分類。
模型與事件
以下是建模與模擬的基本概念。
物件是真實世界中存在的實體,用於研究模型的行為。
基礎模型是對物件屬性及其行為的假設性解釋,在整個模型中有效。
系統是在特定條件下清晰表達的物件,存在於現實世界中。
實驗框架用於在現實世界中研究系統,例如實驗條件、方面、目標等。基本實驗框架由兩組變數組成:框架輸入變數和框架輸出變數,它們與系統或模型端子匹配。框架輸入變數負責匹配應用於系統或模型的輸入。框架輸出變數負責將輸出值與系統或模型匹配。
集總模型是對遵循給定實驗框架指定條件的系統的精確解釋。
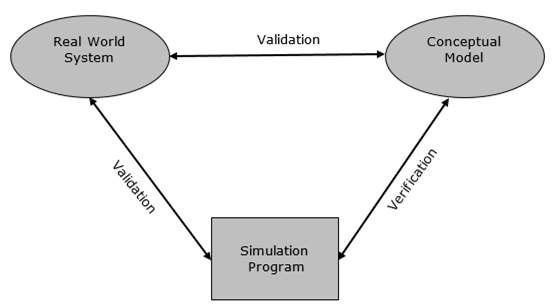
驗證是比較兩個或多個專案以確保其準確性的過程。在建模與模擬中,可以透過比較模擬程式和集總模型的一致性來確保其效能。有各種方法可以執行驗證過程,我們將在單獨的章節中介紹。
確認是比較兩個結果的過程。在建模與模擬中,確認是透過在實驗框架的上下文中比較實驗測量值與模擬結果來執行的。如果結果不匹配,則模型無效。有各種方法可以執行確認過程,我們將在單獨的章節中介紹。
系統狀態變數
系統狀態變數是一組資料,需要在給定時間點定義系統內的內部過程。
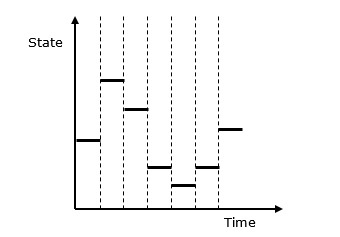
在離散事件模型中,系統狀態變數在一段時間內保持不變,其值在稱為事件時間的定義點發生變化。
在連續事件模型中,系統狀態變數由微分方程結果定義,其值隨時間連續變化。
以下是一些系統狀態變數:
實體與屬性 - 實體表示一個物件,其值可以是靜態的或動態的,這取決於與其他實體的過程。屬性是實體使用的區域性值。
資源 - 資源是一個實體,一次可以為一個或多個動態實體提供服務。動態實體可以請求一個或多個資源單元;如果接受,則實體可以使用資源並在完成時釋放。如果被拒絕,實體可以加入佇列。
列表 - 列表用於表示實體和資源使用的佇列。根據過程的不同,佇列有各種可能性,例如LIFO、FIFO等。
延遲 - 這是由某些系統條件組合引起的無限期持續時間。
模型分類
系統可以分為以下幾類。
離散事件模擬模型 - 在此模型中,狀態變數值僅在事件發生的一些離散時間點發生變化。事件只會在定義的活動時間和延遲時發生。
隨機系統與確定性系統 - 隨機系統不受隨機性影響,其輸出不是隨機變數,而確定性系統受隨機性影響,其輸出是隨機變數。
靜態模擬與動態模擬 - 靜態模擬包括不受時間影響的模型。例如:蒙特卡洛模型。動態模擬包括受時間影響的模型。
離散系統與連續系統 - 離散系統受狀態變數在離散時間點發生變化的影響。其行為在下面的圖形表示中描述。
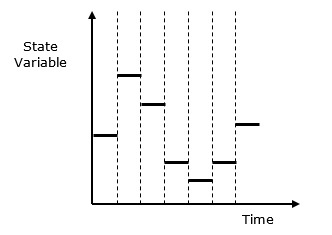
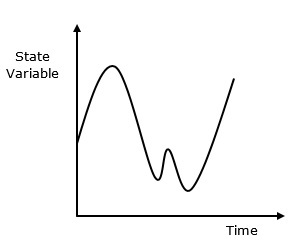
連續系統受狀態變數的影響,狀態變數作為時間的函式而連續變化。其行為在下面的圖形表示中描述。
建模過程
建模過程包括以下步驟。
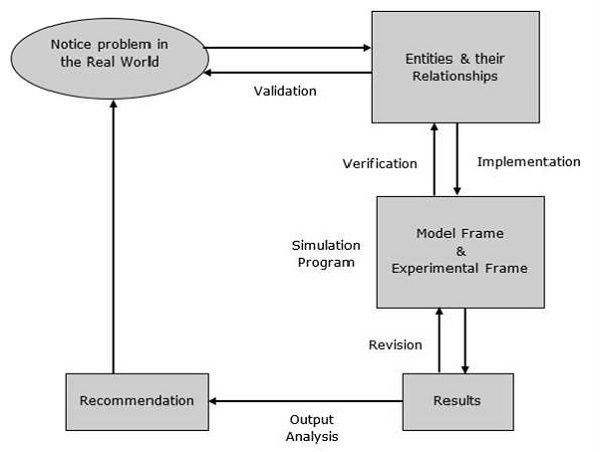
步驟1 - 檢查問題。在此階段,我們必須理解問題並相應地選擇其分類,例如確定性或隨機性。
步驟2 - 設計模型。在此階段,我們必須執行以下簡單的任務,這些任務有助於我們設計模型:
根據系統行為和未來需求收集資料。
分析系統特性、其假設以及為使模型成功而需要採取的必要措施。
確定模型中使用的變數名稱、函式、單位、關係及其應用。
使用合適的技術求解模型,並使用驗證方法驗證結果。接下來,驗證結果。
準備一份報告,其中包括結果、解釋、結論和建議。
步驟3 - 完成與模型相關的整個過程後,提供建議。包括投資、資源、演算法、技術等。
驗證與確認
模擬分析人員面臨的實際問題之一是驗證模型。只有當模型是實際系統的準確表示時,模擬模型才有效,否則無效。
驗證和確認是任何模擬專案中驗證模型的兩個步驟。
確認是比較兩個結果的過程。在這個過程中,我們需要將概念模型的表示與真實系統進行比較。如果比較結果為真,則有效,否則無效。
驗證是比較兩個或多個結果以確保其準確性的過程。在這個過程中,我們必須將模型的實現及其相關資料與開發人員的概念描述和規範進行比較。
驗證與確認技術
模擬模型的驗證與確認有多種技術。以下是幾種常用的技術:
模擬模型驗證技術
以下是執行模擬模型驗證的方法:
利用程式設計技能編寫和除錯子程式中的程式。
使用“結構化走查”策略,其中有多個人閱讀程式。
跟蹤中間結果並將其與觀察到的結果進行比較。
使用各種輸入組合檢查模擬模型輸出。
將最終模擬結果與分析結果進行比較。
模擬模型確認技術
步驟1 - 設計一個具有高有效性的模型。這可以透過以下步驟實現:
- 設計過程中必須與系統專家討論模型。
- 模型必須在整個過程中與客戶互動。
- 輸出必須由系統專家監督。
步驟2 - 測試模型的假設資料。這可以透過將假設資料應用到模型中並進行定量測試來實現。還可以進行敏感性分析,以觀察當輸入資料發生重大變化時結果變化的影響。
步驟3 - 確定模擬模型的代表性輸出。這可以透過以下步驟實現:
確定模擬輸出與實際系統輸出的接近程度。
可以使用圖靈測試進行比較。它以系統格式呈現資料,只有專家才能解釋。
可以使用統計方法將模型輸出與實際系統輸出進行比較。
模型資料與實際資料的比較
模型開發完成後,我們必須將其輸出資料與實際系統資料進行比較。以下是執行此比較的兩種方法。
驗證現有系統
在這種方法中,我們使用模型的真實世界輸入,將其輸出與真實系統的真實世界輸入進行比較。這個驗證過程很簡單,但是,在執行時可能會遇到一些困難,例如,如果輸出要與平均長度、等待時間、空閒時間等進行比較,可以使用統計檢驗和假設檢驗進行比較。一些統計檢驗包括卡方檢驗、Kolmogorov-Smirnov檢驗、Cramer-von Mises檢驗和矩檢驗。
驗證首次建模
假設我們必須描述一個目前不存在也從未存在過的擬議系統。因此,沒有可用於與其效能進行比較的歷史資料。因此,我們必須使用基於假設的假設系統。以下有用的提示將有助於提高效率。
子系統有效性 - 模型本身可能沒有任何現有的系統可以與其進行比較,但它可能包含已知的子系統。每個有效性都可以單獨測試。
內部有效性 - 具有高度內部方差的模型將被拒絕,因為由於其內部過程而具有高度方差的隨機系統將隱藏由於輸入變化而導致的輸出變化。
敏感性分析 - 它提供有關係統中敏感引數的資訊,我們需要對此給予更多關注。
表面有效性 - 當模型在相反的邏輯上執行時,即使它的行為像真實系統一樣,也應該被拒絕。
離散系統模擬
在離散系統中,系統狀態的變化是不連續的,系統狀態的每一次變化都稱為一個事件。離散系統模擬中使用的模型有一組數字來表示系統狀態,稱為狀態描述符。在本章中,我們還將學習排隊模擬,這是離散事件模擬以及時間共享系統模擬的一個非常重要的方面。
以下是離散系統模擬行為的圖形表示。(此處應插入圖形)
離散事件模擬——關鍵特徵
離散事件模擬通常由用高階程式語言(如Pascal、C++或任何專門的模擬語言)設計的軟體執行。以下是五個關鍵特徵:
實體 - 這些是真實元素(例如機器部件)的表示。
關係 - 意思是將實體連線在一起。
模擬執行器 - 它負責控制時間推進和執行離散事件。
隨機數生成器 - 它有助於模擬進入模擬模型的不同資料。
結果與統計 - 它驗證模型並提供其效能指標。
時間圖表示
每個系統都依賴於時間引數。在圖形表示中,它被稱為時鐘時間或時間計數器,最初設定為零。時間根據以下兩個因素更新:
時間切片 - 這是模型為每個事件定義的時間,直到沒有事件出現。
下一個事件 - 這是模型為下一個要執行的事件定義的事件,而不是時間間隔。它比時間切片更有效。
排隊系統的模擬
佇列是系統中所有正在服務的實體以及那些等待輪到的實體的組合。
引數
以下是排隊系統中使用的引數列表。
| 符號 | 描述 |
|---|---|
| λ | 表示到達率,即每秒到達的數量 |
| Ts | 表示每次到達的平均服務時間,不包括在佇列中的等待時間 |
| σTs | 表示服務時間的標準差 |
| ρ | 表示伺服器時間利用率,包括空閒和繁忙時 |
| u | 表示流量強度 |
| r | 表示系統中專案的平均數量 |
| R | 表示系統中專案的總數 |
| Tr | 表示系統中專案的平均時間 |
| TR | 表示系統中專案的總時間 |
| σr | 表示r的標準差 |
| σTr | 表示Tr的標準差 |
| w | 表示佇列中等待專案的平均數量 |
| σw | 表示w的標準差 |
| Tw | 表示所有專案的平均等待時間 |
| Td | 表示佇列中等待專案的平均等待時間 |
| N | 表示系統中的伺服器數量 |
| mx(y) | 表示第y個百分位數,這意味著x值小於y百分比時間的y值 |
單伺服器佇列
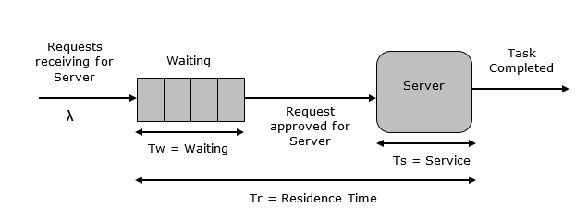
這是最簡單的排隊系統,如下圖所示。系統的核心元素是一個伺服器,它為連線的裝置或專案提供服務。專案請求系統進行服務,如果伺服器空閒,則立即服務,否則加入等待佇列。伺服器完成任務後,專案離開。
多伺服器佇列
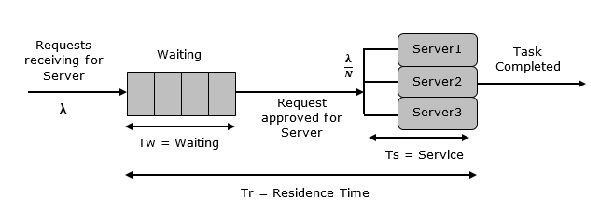
顧名思義,該系統由多個伺服器和所有專案的公共佇列組成。當任何專案請求伺服器時,如果至少有一個伺服器可用,則會分配給它。否則,佇列開始啟動,直到伺服器空閒。在這個系統中,我們假設所有伺服器都是相同的,即選擇的伺服器與哪個專案無關。
利用率有一個例外。令N為相同的伺服器,則ρ為每個伺服器的利用率。考慮Nρ為整個系統的利用率;則最大利用率為N*100%,最大輸入率為:
$λmax = \frac{\text{N}}{\text{T}s}$
排隊關係
下表顯示了一些基本的排隊關係。
| 一般術語 | 單伺服器 | 多伺服器 |
|---|---|---|
| r = λTr Little公式 | ρ = λTs | ρ = λTs/N |
| w = λTw Little公式 | r = w + ρ | u = λTs = ρN |
| Tr = Tw + Ts | r = w + Nρ |
時間共享系統的模擬
時間共享系統的設計方式是,每個使用者使用在系統上共享的一小部分時間,這導致多個使用者同時共享系統。每個使用者的切換速度如此之快,以至於每個使用者都感覺像是在使用自己的系統一樣。它基於CPU排程和多程式設計的概念,在該概念中,可以透過在系統上同時執行多個作業來有效地利用多個資源。
示例 - SimOS模擬系統。
它由斯坦福大學設計,用於研究複雜的計算機硬體設計,分析應用程式效能以及研究作業系統。SimOS包含現代計算機系統所有硬體元件的軟體模擬,即處理器、記憶體管理單元(MMU)、快取等。
建模與模擬 - 連續
連續系統是指系統的重要活動平穩完成而沒有任何延遲的系統,即沒有事件佇列,沒有時間模擬排序等。當連續系統用數學建模時,表示屬性的變數由連續函式控制。
什麼是連續模擬?
連續模擬是一種模擬型別,其中狀態變數相對於時間連續變化。以下是其行為的圖形表示。(此處應插入圖形)
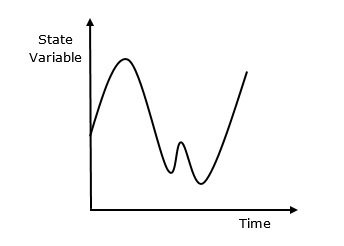
為什麼要使用連續模擬?
我們必須使用連續模擬,因為它取決於與系統相關的各種引數的微分方程及其已知的估計結果。
應用領域
連續模擬用於以下行業:土木工程中的水壩堤壩和隧道建設;軍事應用中的導彈彈道模擬、戰鬥機飛行訓練模擬以及水下航行器智慧控制器的設計與測試。
物流中的收費站設計、機場航站樓的旅客流量分析以及主動航班時刻表評估;業務發展中的產品開發規劃、員工管理規劃和市場研究分析。
蒙特卡洛模擬
蒙特卡羅模擬是一種計算機數學技術,用於基於某些已知分佈生成隨機樣本資料以進行數值實驗。此方法應用於風險定量分析和決策問題。此方法由各種領域的專業人士使用,例如金融、專案管理、能源、製造、工程、研發、保險、石油和天然氣、運輸等。
這種方法最早由1940年參與原子彈研發的科學家使用。在需要進行估計和不確定性決策的情況下,例如天氣預報,可以使用此方法。
蒙特卡洛模擬——重要特性
以下是蒙特卡洛方法的三個重要特性:
- 其輸出必須生成隨機樣本。
- 其輸入分佈必須已知。
- 進行實驗時,其結果必須已知。
蒙特卡洛模擬——優點
- 易於實現。
- 利用計算機為數值實驗提供統計抽樣。
- 為數學問題提供近似解。
- 可用於隨機問題和確定性問題。
蒙特卡洛模擬——缺點
耗時,因為需要生成大量的樣本才能獲得期望的輸出。
此方法的結果只是真實值的近似值,而非精確值。
蒙特卡洛模擬方法——流程圖
下圖顯示了蒙特卡洛模擬的通用流程圖。(此處應插入流程圖)
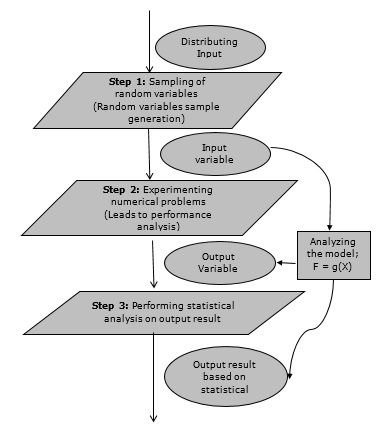
建模與模擬 - 資料庫
建模與模擬中資料庫的目標是提供資料表示及其關係,用於分析和測試目的。第一個資料模型由Edgar Codd於1980年提出。該模型的主要特點如下。
資料庫是定義資訊及其關係的不同資料物件的集合。
規則用於定義物件中資料的約束。
可以對物件應用操作以檢索資訊。
最初,資料建模基於實體與關係的概念,其中實體是資料資訊的型別,關係表示實體之間的關聯。
最新的資料建模概念是面向物件設計,其中實體表示為類,在計算機程式設計中用作模板。一個類具有其名稱、屬性、約束以及與其他類的物件的關係。
其基本表示如下:
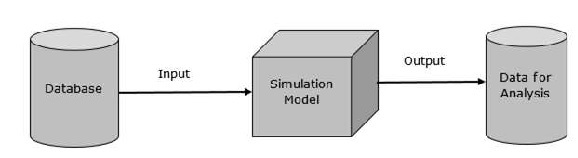
資料表示
事件的資料表示
模擬事件具有其屬性,例如事件名稱及其關聯的時間資訊。它表示使用與輸入檔案引數相關的一組輸入資料執行提供的模擬,並將其結果作為一組輸出資料提供,儲存在與資料檔案關聯的多個檔案中。
輸入檔案的資料表示
每個模擬過程都需要一組不同的輸入資料及其關聯的引數值,這些值在輸入資料檔案中表示。輸入檔案與處理模擬的軟體相關聯。資料模型透過與資料檔案的關聯來表示引用的檔案。
輸出檔案的資料表示
模擬過程完成後,它會生成各種輸出檔案,每個輸出檔案都表示為一個數據檔案。每個檔案都有其名稱、描述和一個通用因子。資料檔案分為兩個檔案。第一個檔案包含數值,第二個檔案包含數值檔案內容的描述資訊。
建模與模擬中的神經網路
神經網路是人工智慧的一個分支。神經網路是由許多稱為單元的處理器組成的網路,每個單元都有其小的區域性儲存器。每個單元都透過稱為連線的單向通訊通道連線,這些通道攜帶數值資料。每個單元只處理其區域性資料和從連線接收到的輸入。
歷史
模擬的歷史視角按時間順序排列如下。
第一個神經模型是由1940年McCulloch & Pitts開發的。
1949年,Donald Hebb撰寫了一本名為“行為的組織”的書,指出了神經元的概念。
1950年,隨著計算機技術的進步,根據這些理論建立模型成為可能。這是由IBM研究實驗室完成的。然而,這項努力失敗了,後來的嘗試才成功。
1959年,Bernard Widrow和Marcian Hoff開發了名為ADALINE和MADALINE的模型。這些模型具有多個自適應線性元件。MADALINE是第一個應用於實際問題的神經網路。
1962年,Rosenblatt開發了感知器模型,該模型能夠解決簡單的模式分類問題。
1969年,Minsky & Papert提供了感知器模型在計算方面的侷限性的數學證明。據說感知器模型無法解決異或問題。這些缺點導致神經網路暫時衰落。
1982年,加州理工學院的John Hopfield向美國國家科學院提交了他的論文,提出利用雙向線路建立機器。之前使用的是單向線路。
當涉及符號方法的傳統人工智慧技術失敗時,就產生了使用神經網路的需要。神經網路具有其大規模並行技術,這提供瞭解決此類問題所需的計算能力。
應用領域
神經網路可用於語音合成機、模式識別、檢測診斷問題、機器人控制板和醫療裝置。
建模與模擬中的模糊集
如前所述,連續模擬的每個過程都依賴於微分方程及其引數,例如a、b、c、d > 0。通常,計算點估計並將其用於模型。然而,有時這些估計是不確定的,因此我們需要在微分方程中使用模糊數,這可以提供未知引數的估計。
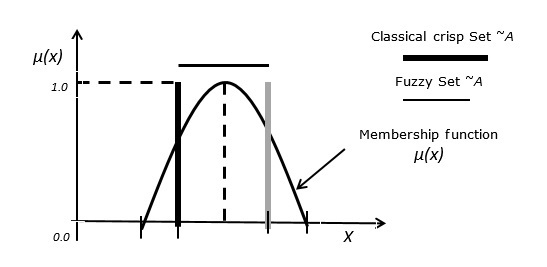
什麼是模糊集?
在經典集合中,一個元素要麼是集合的成員,要麼不是。模糊集是用經典集合X來定義的:
A = {(x,μA(x))| x ∈ X}
情況1 - 函式μA(x)具有以下屬性:
∀x ∈ X μA(x) ≥ 0
sup x ∈ X {μA(x)} = 1
情況2 - 令模糊集B定義為A = {(3, 0.3), (4, 0.7), (5, 1), (6, 0.4)},則其標準模糊表示法寫為A = {0.3/3, 0.7/4, 1/5, 0.4/6}
任何隸屬度為零的值都不會出現在集合的表示式中。
情況3 - 模糊集與經典清晰集之間的關係。
下圖描述了模糊集和經典清晰集之間的關係。(此處應插入圖表)