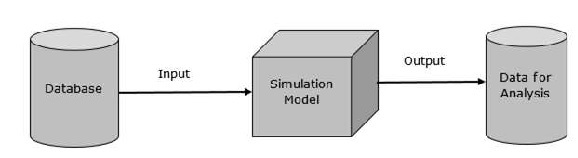
建模與模擬 - 資料庫
建模與模擬中資料庫的目標是提供資料表示及其關係,以用於分析和測試目的。第一個資料模型由 Edgar Codd 於 1980 年提出。以下是該模型的主要特徵。
資料庫是不同資料物件的集合,定義了資訊及其關係。
規則用於定義物件中資料的約束。
操作可以應用於物件以檢索資訊。
最初,資料建模基於實體與關係的概念,其中實體是資料資訊型別,關係表示實體之間的關聯。
最新的資料建模概念是面向物件的設計,其中實體表示為類,在計算機程式設計中用作模板。一個類具有其名稱、屬性、約束以及與其他類物件的關係。
其基本表示如下所示:
資料表示
事件的資料表示
模擬事件具有其屬性,例如事件名稱及其關聯的時間資訊。它表示使用與輸入檔案引數關聯的一組輸入資料執行提供的模擬,並將其結果作為一組輸出資料提供,儲存在與資料檔案關聯的多個檔案中。
輸入檔案的資料表示
每個模擬過程都需要一組不同的輸入資料及其關聯的引數值,這些值在輸入資料檔案中表示。輸入檔案與處理模擬的軟體相關聯。資料模型透過與資料檔案的關聯來表示引用的檔案。
輸出檔案的資料表示
模擬過程完成後,它會生成各種輸出檔案,每個輸出檔案都表示為一個數據檔案。每個檔案都有其名稱、描述和通用因子。資料檔案分為兩類。第一個檔案包含數值,第二個檔案包含數值檔案內容的描述資訊。
建模與模擬中的神經網路
神經網路是人工智慧的一個分支。神經網路是由許多稱為單元的處理器組成的網路,每個單元都有其小的本地儲存器。每個單元都透過稱為連線的單向通訊通道連線,這些通道攜帶數值資料。每個單元僅在其本地資料和從連線接收的輸入上工作。
歷史
模擬的歷史視角按時間順序排列如下。
第一個神經模型由 McCulloch & Pitts 於 **1940** 年開發。
在 **1949** 年,唐納德·赫布寫了一本書“行為的組織”,指出了神經元的概念。
在 **1950** 年,隨著計算機的進步,根據這些理論建立模型成為可能。這是由 IBM 研究實驗室完成的。然而,這項工作失敗了,後來的嘗試取得了成功。
在 **1959** 年,Bernard Widrow 和 Marcian Hoff 開發了名為 ADALINE 和 MADALINE 的模型。這些模型具有多個自適應線性元素。MADALINE 是第一個應用於現實世界問題的**神經網路**。
在 **1962** 年,Rosenblatt 開發了感知器模型,該模型能夠解決簡單的模式分類問題。
在 **1969** 年,Minsky & Papert 提供了感知器模型在計算方面侷限性的數學證明。據說感知器模型無法解決異或問題。這些缺點導致神經網路暫時衰落。
在 **1982** 年,加州理工學院的 John Hopfield 向美國國家科學院提交了他的論文,提出使用雙向線路建立機器。以前使用的是單向線路。
當涉及符號方法的傳統人工智慧技術失敗時,就出現了使用神經網路的必要性。神經網路具有其大規模並行技術,這提供瞭解決此類問題所需的計算能力。
應用領域
神經網路可用於語音合成機、模式識別、檢測診斷問題、機器人控制板和醫療裝置中。
建模與模擬中的模糊集
如前所述,連續模擬的每個過程都依賴於微分方程及其引數,例如 a、b、c、d > 0。通常,計算點估計並在模型中使用。但是,有時這些估計是不確定的,因此我們需要在微分方程中使用模糊數,這提供了未知引數的估計。
什麼是模糊集?
在經典集合中,一個元素要麼是集合的成員,要麼不是。模糊集根據經典集合 **X** 定義為:
A = {(x,μA(x))| x ∈ X}
**情況 1** - 函式 **μA(x)** 具有以下屬性:
∀x ∈ X μA(x) ≥ 0
sup x ∈ X {μA(x)} = 1
**情況 2** - 令模糊集 **B** 定義為 **A = {(3, 0.3), (4, 0.7), (5, 1), (6, 0.4)}**,則其標準模糊表示法寫為 **A = {0.3/3, 0.7/4, 1/5, 0.4/6}**
任何隸屬度為零的值都不會出現在集合的表示式中。
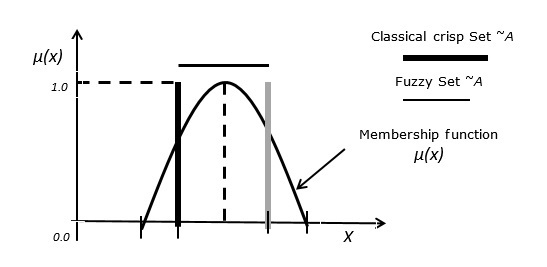
**情況 3** - 模糊集與經典清晰集之間的關係。
下圖描述了模糊集與經典清晰集之間的關係。