Python 中的邏輯迴歸 - 分割資料
我們有大約四萬一千條奇數記錄。如果我們使用全部資料構建模型,我們將沒有資料進行測試。所以一般來說,我們將整個資料集分為兩部分,比如 70/30 的百分比。我們使用 70% 的資料構建模型,剩下的用於測試我們建立的模型在預測中的準確性。你可以根據要求使用不同的分割比例。
建立特徵陣列
在分割資料之前,我們將資料分成兩個陣列 X 和 Y。X 陣列包含我們要分析的所有特徵(資料列),Y 陣列是布林值的單維陣列,是預測的輸出。為了理解這一點,讓我們執行一些程式碼。
首先,執行以下 Python 語句來建立 X 陣列 −
In [17]: X = data.iloc[:,1:]
要檢查 X 的內容,可以使用 head 列印一些初始記錄。以下螢幕顯示了 X 陣列的內容。
In [18]: X.head ()
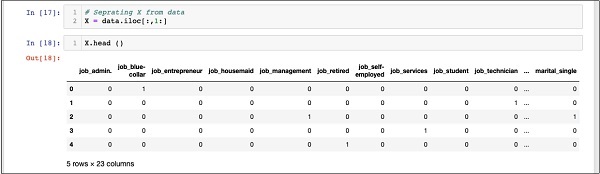
該陣列有幾行和 23 列。
接下來,我們將建立包含“y”值的輸出陣列。
建立輸出陣列
要建立預測值列的陣列,請使用以下 Python 語句 −
In [19]: Y = data.iloc[:,0]
透過呼叫 head 檢查其內容。下面的螢幕輸出顯示了結果 −
In [20]: Y.head() Out[20]: 0 0 1 0 2 1 3 0 4 1 Name: y, dtype: int64
現在,使用以下命令分割資料 −
In [21]: X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)
這將建立四個陣列,稱為 X_train、Y_train、X_test 和 Y_test。和之前一樣,你可以使用 head 命令檢查這些陣列的內容。我們將使用 X_train 和 Y_train 陣列訓練我們的模型,使用 X_test 和 Y_test 陣列進行測試和驗證。
現在,我們準備構建我們的分類器。我們將在下一章中瞭解它。
廣告