設定專案
在本章中,我們將詳細瞭解在 Python 中執行邏輯迴歸所涉及的設定專案流程。
安裝 Jupyter
我們將使用 Jupyter,這是機器學習領域使用最廣泛的平臺之一。如果你沒有在自己的機器上安裝 Jupyter,可以從 此處 下載。關於安裝,你可以按照網站上的說明安裝該平臺。正如網站建議的那樣,你可能更願意使用隨 Python 和許多常用的 Python 科學計算和資料科學軟體包一起提供的Anaconda Distribution。這將避免單獨安裝這些軟體包的需要。
在成功安裝 Jupyter 之後,啟動一個新專案,此階段的螢幕將顯示如下,準備接受你的程式碼。

現在,透過單擊標題名稱並對其進行編輯,將專案名稱從Untitled1 更改為“Logistic Regression”。
首先,我們將匯入程式碼中需要的幾個 Python 軟體包。
匯入 Python 軟體包
為此,在程式碼編輯器中輸入或剪下並貼上以下程式碼 −
In [1]: # import statements import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn import preprocessing from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split
此時,你的筆記本應如下所示 −
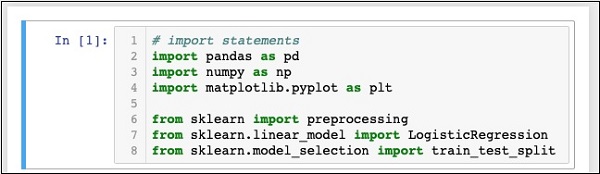
透過單擊執行按鈕執行該程式碼。如果沒有產生任何錯誤,則表示你已成功安裝 Jupyter,現已準備好進行其餘的開發。
前三個匯入語句在我們的專案中匯入了 pandas、numpy 和 matplotlib.pyplot 軟體包。接下來的三個語句從 sklearn 匯入了指定的模組。
我們的下一個任務是下載專案所需的資料。我們將在下一章中學習這一點。
廣告