Python中的邏輯迴歸 - 快速指南
Python中的邏輯迴歸 - 介紹
邏輯迴歸是一種對物體進行分類的統計方法。本章將透過一些例子介紹邏輯迴歸。
分類
要理解邏輯迴歸,你應該知道分類是什麼意思。讓我們考慮以下例子來更好地理解這一點:
- 醫生將腫瘤分類為惡性或良性。
- 銀行交易可能是欺詐性的或真實的。
多年來,人類一直在執行這些任務——儘管它們容易出錯。問題是我們能否訓練機器來為我們完成這些任務,並獲得更高的準確率?
機器進行分類的一個例子是你機器上的郵件**客戶端**,它將每封傳入郵件分類為“垃圾郵件”或“非垃圾郵件”,並且它能夠以相當高的準確率完成這項工作。邏輯迴歸的統計技術已成功應用於郵件客戶端。在這種情況下,我們已經訓練了我們的機器來解決一個分類問題。
邏輯迴歸只是機器學習中用於解決這種二元分類問題的一部分。已經有幾種其他的機器學習技術被開發出來,並用於解決其他型別的問題。
如果你已經注意到,在所有上述例子中,預測的結果只有兩個值——是或否。我們將這些稱為類別——也就是說,我們說我們的分類器將物件分類為兩類。從技術角度來說,我們可以說結果或目標變數本質上是二分的。
還有其他分類問題,其輸出可能被分類為兩類以上。例如,給定一個裝滿水果的籃子,你被要求將不同種類的水果分開。現在,籃子裡可能包含橙子、蘋果、芒果等等。因此,當你將水果分開時,你會將它們分成兩類以上。這是一個多元分類問題。
Python中的邏輯迴歸 - 案例研究
假設一家銀行找到你,要求你開發一個機器學習應用程式,幫助他們識別可能在他們那裡開定期存款(一些銀行也稱之為定期存款)的潛在客戶。銀行定期透過電話或網路表格進行調查,以收集有關潛在客戶的資訊。調查的性質比較普遍,面向非常廣泛的受眾,其中許多人可能根本不願意與這家銀行打交道。在剩下的客戶中,只有一小部分可能對開定期存款感興趣。其他人可能對銀行提供的其他服務感興趣。因此,調查並非一定是為了識別開定期存款的客戶。你的任務是從銀行將與你分享的海量調查資料中,識別所有那些有很高機率開定期存款的客戶。
幸運的是,對於那些渴望開發機器學習模型的人來說,有一種這樣的資料是公開可用的。這些資料是由加州大學歐文分校的一些學生在外部資金的支援下準備的。該資料庫作為**UCI機器學習資源庫**的一部分提供,並被世界各地的學生、教育工作者和研究人員廣泛使用。資料可以從這裡下載。
在接下來的章節中,讓我們使用相同的資料來執行應用程式開發。
專案設定
在本章中,我們將詳細瞭解在Python中進行邏輯迴歸的專案設定過程。
安裝Jupyter
我們將使用Jupyter——最廣泛使用的機器學習平臺之一。如果你的機器上沒有安裝Jupyter,請從這裡下載。對於安裝,你可以按照網站上的說明安裝平臺。正如網站所建議的,你可能更喜歡使用**Anaconda Distribution**,它包含Python和許多常用的用於科學計算和資料科學的Python包。這將避免單獨安裝這些包的需要。
Jupyter成功安裝後,啟動一個新專案,此時你的螢幕將如下所示,準備接受你的程式碼。

現在,透過單擊標題名稱並進行編輯,將專案名稱從**Untitled1更改為“Logistic Regression”**。
首先,我們將匯入程式碼中需要的幾個Python包。
匯入Python包
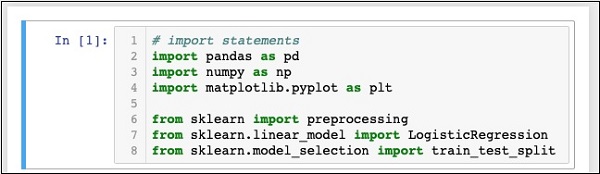
為此,請在程式碼編輯器中鍵入或複製貼上以下程式碼:
In [1]: # import statements import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn import preprocessing from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split
在此階段,你的**Notebook**應該如下所示:
透過單擊**執行**按鈕執行程式碼。如果沒有生成錯誤,則表示你已成功安裝Jupyter,並且現在可以進行其餘的開發。
前三個import語句將pandas、numpy和matplotlib.pyplot包匯入到我們的專案中。接下來的三個語句從sklearn匯入指定的模組。
我們的下一個任務是下載專案所需的資料。我們將在下一章學習這一點。
Python中的邏輯迴歸 - 獲取資料
本章詳細討論了在Python中進行邏輯迴歸的資料獲取步驟。
下載資料集
如果你還沒有下載前面提到的UCI資料集,請現在從這裡下載。單擊“Data Folder”。你將看到以下螢幕:

透過單擊給定的連結下載bank.zip檔案。zip檔案包含以下檔案:

我們將使用bank.csv檔案進行模型開發。bank-names.txt檔案包含你稍後需要使用的資料庫描述。bank-full.csv包含一個更大的資料集,你可以將其用於更高階的開發。
在這裡,我們在可下載的原始碼zip檔案中包含了bank.csv檔案。此檔案包含逗號分隔的欄位。我們還對檔案進行了一些修改。建議你使用專案原始碼zip檔案中包含的檔案進行學習。
載入資料
要載入剛剛複製的csv檔案中的資料,請鍵入以下語句並執行程式碼。
In [2]: df = pd.read_csv('bank.csv', header=0)
你還可以透過執行以下程式碼語句來檢查載入的資料:
IN [3]: df.head()
一旦命令執行,你將看到以下輸出:
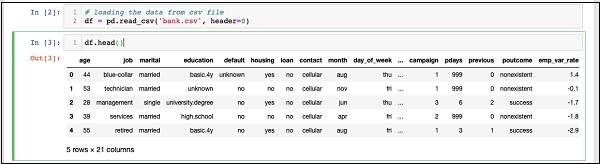
基本上,它列印了載入資料的頭五行。檢查存在的21列。我們將僅使用其中幾列進行模型開發。
接下來,我們需要清理資料。資料可能包含一些包含**NaN**的行。要消除這些行,請使用以下命令:
IN [4]: df = df.dropna()
幸運的是,bank.csv不包含任何包含NaN的行,因此在我們的案例中,此步驟實際上並非必需。但是,通常很難在一個巨大的資料庫中發現這樣的行。因此,執行上述語句來清理資料始終是比較安全的。
**注意**——你可以隨時使用以下語句輕鬆檢查資料大小:
IN [5]: print (df.shape) (41188, 21)
行數和列數將如上面的第二行所示列印在輸出中。
接下來要做的就是檢查每一列對我們試圖構建的模型的適用性。
Python中的邏輯迴歸 - 資料重構
每當任何組織進行調查時,他們都會嘗試從客戶那裡收集儘可能多的資訊,其想法是這些資訊將在以後以某種方式對組織有用。為了解決當前問題,我們必須挑選與我們問題直接相關的資訊。
顯示所有欄位
現在,讓我們看看如何選擇對我們有用的資料欄位。在程式碼編輯器中執行以下語句。
In [6]: print(list(df.columns))
你將看到以下輸出:
['age', 'job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'day_of_week', 'duration', 'campaign', 'pdays', 'previous', 'poutcome', 'emp_var_rate', 'cons_price_idx', 'cons_conf_idx', 'euribor3m', 'nr_employed', 'y']
輸出顯示資料庫中所有列的名稱。最後一列“y”是一個布林值,指示該客戶是否在銀行擁有定期存款。此欄位的值為“y”或“n”。你可以在作為資料一部分下載的banks-name.txt檔案中閱讀每一列的描述和用途。
消除不需要的欄位
檢查列名,你將知道某些欄位與當前問題無關。例如,諸如**月份、星期幾**、活動等欄位對我們沒有用處。我們將從我們的資料庫中刪除這些欄位。要刪除列,我們使用如下所示的drop命令:
In [8]: #drop columns which are not needed. df.drop(df.columns[[0, 3, 7, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19]], axis = 1, inplace = True)
該命令表示刪除列號0、3、7、8等等。為了確保正確選擇索引,請使用以下語句:
In [7]: df.columns[9] Out[7]: 'day_of_week'
這將列印給定索引的列名。
刪除不需要的列後,使用head語句檢查資料。螢幕輸出如下所示:
In [9]: df.head()
Out[9]:
job marital default housing loan poutcome y
0 blue-collar married unknown yes no nonexistent 0
1 technician married no no no nonexistent 0
2 management single no yes no success 1
3 services married no no no nonexistent 0
4 retired married no yes no success 1
現在,我們只有我們認為對我們的資料分析和預測很重要的欄位。**資料科學家**的重要性在此步驟中體現出來。資料科學家必須選擇合適的列來構建模型。
例如,雖然工作型別乍一看可能無法說服所有人將其納入資料庫,但它將是一個非常有用的欄位。並非所有型別的客戶都會開設定期存款。低收入人群可能不會開設定期存款,而高收入人群通常會將多餘的錢存入定期存款。因此,在這種情況下,工作型別變得非常重要。同樣,仔細選擇您認為與您的分析相關的列。
在下一章中,我們將準備資料以構建模型。
Python中的邏輯迴歸 - 資料準備
為了建立分類器,我們必須以分類器構建模組所需的形式準備資料。我們透過進行獨熱編碼來準備資料。
資料編碼
我們將簡要討論資料編碼的含義。首先,讓我們執行程式碼。在程式碼視窗中執行以下命令。
In [10]: # creating one hot encoding of the categorical columns. data = pd.get_dummies(df, columns =['job', 'marital', 'default', 'housing', 'loan', 'poutcome'])
如註釋所示,上述語句將建立資料的獨熱編碼。讓我們看看它建立了什麼?透過列印資料庫中的頭部記錄來檢查名為“data”的已建立資料。
In [11]: data.head()
你將看到以下輸出:

為了理解上述資料,我們將透過執行data.columns命令列出列名,如下所示:
In [12]: data.columns Out[12]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur', 'job_housemaid', 'job_management', 'job_retired', 'job_self-employed', 'job_services', 'job_student', 'job_technician', 'job_unemployed', 'job_unknown', 'marital_divorced', 'marital_married', 'marital_single', 'marital_unknown', 'default_no', 'default_unknown', 'default_yes', 'housing_no', 'housing_unknown', 'housing_yes', 'loan_no', 'loan_unknown', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'], dtype='object')
現在,我們將解釋get_dummies命令如何進行獨熱編碼。新生成的資料庫中的第一列是“y”欄位,它指示該客戶是否訂閱了定期存款。現在,讓我們看看經過編碼的列。第一列編碼列是“job”。在資料庫中,您會發現“job”列有很多可能的值,例如“admin”、“blue-collar”、“entrepreneur”等等。對於每個可能的值,我們在資料庫中建立一個新列,並將列名作為字首附加。
因此,我們有名為“job_admin”、“job_blue-collar”等等的列。對於我們原始資料庫中的每個編碼欄位,您會發現已在建立的資料庫中添加了一系列列,其中包含該列在原始資料庫中採用所有可能的值。仔細檢查列列表以瞭解資料如何對映到新資料庫。
理解資料對映
為了理解生成的資料,讓我們使用data命令打印出所有資料。執行命令後的部分輸出如下所示。
In [13]: data
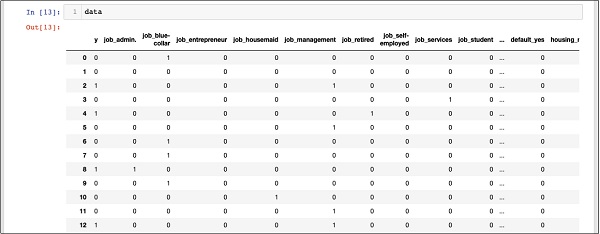
上面的螢幕顯示了前十二行。如果您向下滾動,您會看到所有行的對映都已完成。
為了方便參考,此處顯示資料庫中更下方的部分螢幕輸出。
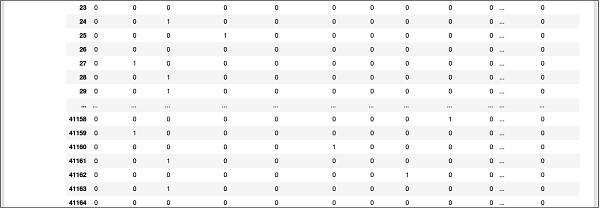
為了理解對映的資料,讓我們檢查第一行。

它表示此客戶未訂閱定期存款,如“y”欄位中的值所示。它還表明此客戶是“藍領”客戶。水平向下滾動,它會告訴您他擁有“住房”並且沒有貸款。
在此獨熱編碼之後,我們需要更多的資料處理才能開始構建我們的模型。
刪除“unknown”
如果我們檢查對映資料庫中的列,您會發現存在一些以“unknown”結尾的列。例如,使用螢幕截圖中顯示的以下命令檢查索引為 12 的列:
In [14]: data.columns[12] Out[14]: 'job_unknown'
這表明指定客戶的工作未知。顯然,在我們的分析和模型構建中包含此類列毫無意義。因此,應刪除所有具有“unknown”值的列。這是透過以下命令完成的:
In [15]: data.drop(data.columns[[12, 16, 18, 21, 24]], axis=1, inplace=True)
確保您指定了正確的列號。如有疑問,您可以隨時透過在columns命令中指定其索引來檢查列名,如前所述。
刪除不需要的列後,您可以檢查最終的列列表,如下面的輸出所示:
In [16]: data.columns Out[16]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur', 'job_housemaid', 'job_management', 'job_retired', 'job_self-employed', 'job_services', 'job_student', 'job_technician', 'job_unemployed', 'marital_divorced', 'marital_married', 'marital_single', 'default_no', 'default_yes', 'housing_no', 'housing_yes', 'loan_no', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'], dtype='object')
此時,我們的資料已準備好進行模型構建。
Python中的邏輯迴歸 - 資料分割
我們大約有四萬多條記錄。如果我們使用所有資料進行模型構建,我們將沒有任何資料用於測試。因此,通常我們將整個資料集分成兩部分,例如 70/30 的比例。我們使用 70% 的資料進行模型構建,其餘資料用於測試我們建立的模型的預測準確性。您可以根據需要使用不同的分割比例。
建立特徵陣列
在分割資料之前,我們將資料分成兩個陣列 X 和 Y。X 陣列包含我們要分析的所有特徵(資料列),而 Y 陣列是一個一維布林值陣列,它是預測的輸出。為了理解這一點,讓我們執行一些程式碼。
首先,執行以下 Python 語句以建立 X 陣列:
In [17]: X = data.iloc[:,1:]
要檢查X的內容,請使用head列印一些初始記錄。以下螢幕顯示了 X 陣列的內容。
In [18]: X.head ()
該陣列有多行和 23 列。
接下來,我們將建立一個包含“y”值的輸出陣列。
建立輸出陣列
要為預測值列建立一個數組,請使用以下 Python 語句:
In [19]: Y = data.iloc[:,0]
透過呼叫head檢查其內容。下面的螢幕輸出顯示了結果:
In [20]: Y.head() Out[20]: 0 0 1 0 2 1 3 0 4 1 Name: y, dtype: int64
現在,使用以下命令分割資料:
In [21]: X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)
這將建立四個名為X_train、Y_train、X_test 和 Y_test的陣列。和以前一樣,您可以使用 head 命令檢查這些陣列的內容。我們將使用 X_train 和 Y_train 陣列來訓練我們的模型,使用 X_test 和 Y_test 陣列來進行測試和驗證。
現在,我們準備構建我們的分類器。我們將在下一章中對此進行探討。
Python中的邏輯迴歸 - 構建分類器
不需要您必須從頭開始構建分類器。構建分類器很複雜,需要掌握統計學、機率論、最佳化技術等多個領域的知識。市場上有多個預構建的庫,這些庫具有經過充分測試且非常高效的這些分類器的實現。我們將使用sklearn中的一個這樣的預構建模型。
sklearn 分類器
從sklearn工具包建立邏輯迴歸分類器很簡單,只需一個程式語句即可完成,如下所示:
In [22]: classifier = LogisticRegression(solver='lbfgs',random_state=0)
建立分類器後,您將把訓練資料饋送到分類器中,以便它可以調整其內部引數並準備好對未來的資料進行預測。為了調整分類器,我們執行以下語句:
In [23]: classifier.fit(X_train, Y_train)
分類器現在已準備好進行測試。以下程式碼是上述兩個語句執行的輸出:
Out[23]: LogisticRegression(C = 1.0, class_weight = None, dual = False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='warn', n_jobs=None, penalty='l2', random_state=0, solver='lbfgs', tol=0.0001, verbose=0, warm_start=False))
現在,我們準備測試建立的分類器。我們將在下一章中處理這個問題。
Python中的邏輯迴歸 - 測試
在我們投入生產使用之前,我們需要測試上述建立的分類器。如果測試表明模型未達到所需的精度,我們將不得不回到上述流程中,選擇另一組特徵(資料欄位),重新構建模型並進行測試。這將是一個迭代步驟,直到分類器滿足您所需的精度要求。因此,讓我們測試我們的分類器。
預測測試資料
為了測試分類器,我們使用在早期階段生成的測試資料。我們在建立的物件上呼叫predict方法,並將測試資料的X陣列作為引數傳遞,如下面的命令所示:
In [24]: predicted_y = classifier.predict(X_test)
這將為整個訓練資料集生成一個一維陣列,給出 X 陣列中每一行的預測。您可以使用以下命令檢查此陣列:
In [25]: predicted_y
執行上述兩個命令後的輸出如下:
Out[25]: array([0, 0, 0, ..., 0, 0, 0])
輸出表明,前三位和最後三位客戶並非定期存款的潛在候選人。您可以檢查整個陣列以篩選出潛在客戶。為此,請使用以下 Python 程式碼片段:
In [26]: for x in range(len(predicted_y)):
if (predicted_y[x] == 1):
print(x, end="\t")
執行上述程式碼的輸出如下所示:

輸出顯示了所有可能訂閱定期存款的客戶的行索引。您現在可以將此輸出提供給銀行的營銷團隊,他們將收集所選行中每個客戶的聯絡資訊並繼續他們的工作。
在我們使此模型投入生產之前,我們需要驗證預測的準確性。
驗證準確性
要測試模型的準確性,請在分類器上使用 score 方法,如下所示:
In [27]: print('Accuracy: {:.2f}'.format(classifier.score(X_test, Y_test)))
執行此命令的螢幕輸出如下所示:
Accuracy: 0.90
它表明我們模型的準確率為 90%,這在大多數應用程式中都被認為非常好。因此,無需進一步調整。現在,我們的客戶已準備好啟動下一輪營銷活動,獲取潛在客戶列表並促使他們開設定期存款,並可能獲得較高的成功率。
Python中的邏輯迴歸 - 限制
正如您從上面的示例中看到的,將邏輯迴歸應用於機器學習並非一項困難的任務。但是,它也有其自身的侷限性。邏輯迴歸將無法處理大量分類特徵。在我們迄今為止討論的示例中,我們已經將特徵的數量大大減少了。
但是,如果這些特徵在我們預測中很重要,我們將被迫包含它們,但隨後邏輯迴歸將無法給我們提供良好的準確性。邏輯迴歸也容易過度擬合。它不能應用於非線性問題。對於與目標不相關且彼此相關的自變數,它的效能會很差。因此,您必須仔細評估邏輯迴歸對您嘗試解決的問題的適用性。
機器學習的許多領域都指定了其他技術。僅舉幾例,我們有 k 近鄰 (kNN)、線性迴歸、支援向量機 (SVM)、決策樹、樸素貝葉斯等演算法。在確定特定模型之前,您必須評估這些各種技術對我們試圖解決的問題的適用性。
Python中的邏輯迴歸 - 總結
邏輯迴歸是一種二元分類的統計技術。在本教程中,您學習瞭如何訓練機器使用邏輯迴歸。建立機器學習模型,最重要的要求是資料的可用性。如果沒有充分且相關的資料,您就無法簡單地讓機器學習。
擁有資料後,你的下一個主要任務是資料清洗,消除不需要的行和欄位,併為你的模型開發選擇合適的欄位。完成此操作後,你需要將資料對映到分類器訓練所需的格式。因此,資料準備是任何機器學習應用程式中的一個主要任務。準備好資料後,你可以選擇特定型別的分類器。
在本教程中,你學習瞭如何使用sklearn庫中提供的邏輯迴歸分類器。為了訓練分類器,我們使用大約70%的資料來訓練模型。我們使用其餘的資料進行測試。我們測試模型的準確性。如果精度不在可接受的範圍內,我們將返回選擇新的特徵集。
再次重複整個過程:準備資料、訓練模型並測試它,直到你對它的準確性滿意為止。在開始任何機器學習專案之前,你必須學習並接觸到迄今為止已經開發出來並在業界成功應用的各種技術。