Python中的邏輯迴歸 - 獲取資料
本章詳細討論了在Python中執行邏輯迴歸所需的資料獲取步驟。
下載資料集
如果您尚未下載前面提到的UCI資料集,請現在從此處下載:此處。點選“Data Folder”。您將看到以下螢幕:

點選給定的連結下載bank.zip檔案。zip檔案包含以下檔案:

我們將使用bank.csv檔案進行模型開發。bank-names.txt檔案包含資料庫的描述,您稍後會需要。bank-full.csv包含更大的資料集,您可以將其用於更高階的開發。
這裡我們已將bank.csv檔案包含在可下載的原始碼zip檔案中。此檔案包含逗號分隔的欄位。我們也對檔案進行了一些修改。建議您使用專案原始碼zip檔案中包含的檔案進行學習。
載入資料
要載入您剛剛複製的csv檔案中的資料,請鍵入以下語句並執行程式碼。
In [2]: df = pd.read_csv('bank.csv', header=0)
您還可以透過執行以下程式碼語句來檢查載入的資料:
IN [3]: df.head()
命令執行後,您將看到以下輸出:
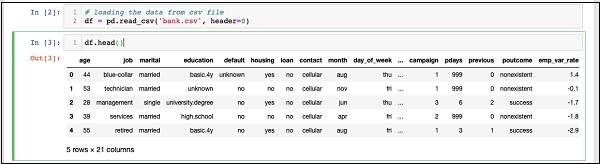
基本上,它列印了載入資料的頭五行。檢查存在的21列。我們只使用其中幾列進行模型開發。
接下來,我們需要清理資料。資料可能包含一些帶有NaN的行。要消除此類行,請使用以下命令:
IN [4]: df = df.dropna()
幸運的是,bank.csv不包含任何帶有NaN的行,因此此步驟在我們的案例中並非真正必需。但是,通常很難在一個巨大的資料庫中發現此類行。因此,執行上述語句來清理資料始終更安全。
注意 - 您可以隨時使用以下語句輕鬆檢查資料大小:
IN [5]: print (df.shape) (41188, 21)
行數和列數將如上面的第二行所示列印在輸出中。
接下來要做的就是檢查每一列對於我們試圖構建的模型的適用性。
廣告