- 表特定語句
- Impala - 建立表語句
- Impala - 插入語句
- Impala - 選擇語句
- Impala - 描述語句
- Impala - 修改表
- Impala - 刪除表
- Impala - 清空表
- Impala - 顯示錶
- Impala - 建立檢視
- Impala - 修改檢視
- Impala - 刪除檢視
- Impala - 子句
- Impala - ORDER BY 子句
- Impala - GROUP BY 子句
- Impala - HAVING 子句
- Impala - LIMIT 子句
- Impala - OFFSET 子句
- Impala - UNION 子句
- Impala - WITH 子句
- Impala - DISTINCT 運算子
- Impala 有用資源
- Impala 快速指南
- Impala - 有用資源
- Impala - 討論
Impala 快速指南
Impala - 簡介
什麼是 Impala?
Impala 是一個用於處理儲存在 Hadoop 叢集中大量資料的 MPP(大規模並行處理)SQL 查詢引擎。它是一個用 C++ 和 Java 編寫的開源軟體。與其他 Hadoop SQL 引擎相比,它提供更高的效能和更低的延遲。
換句話說,Impala 是效能最高的 SQL 引擎(提供類似 RDBMS 的體驗),它提供訪問儲存在 Hadoop 分散式檔案系統中的資料的最快方式。
為什麼選擇 Impala?
Impala 透過利用 HDFS、HBase、元資料儲存、YARN 和 Sentry 等標準組件,將傳統分析資料庫的 SQL 支援和多使用者效能與 Apache Hadoop 的可擴充套件性和靈活性結合在一起。
使用 Impala,使用者可以使用 SQL 查詢以比 Hive 等其他 SQL 引擎更快的速度與 HDFS 或 HBase 通訊。
Impala 可以讀取 Hadoop 使用的幾乎所有檔案格式,例如 Parquet、Avro 和 RCFile。
Impala 使用與 Apache Hive 相同的元資料、SQL 語法(Hive SQL)、ODBC 驅動程式和使用者介面(Hue Beeswax),為面向批處理或即時的查詢提供了一個熟悉且統一的平臺。
與 Apache Hive 不同,**Impala 不是基於 MapReduce 演算法的**。它實現了一個基於**守護程序**的分散式架構,這些守護程序負責在同一臺機器上執行的查詢執行的所有方面。
因此,它減少了使用 MapReduce 的延遲,這使得 Impala 比 Apache Hive 更快。
Impala 的優勢
以下是 Cloudera Impala 的一些顯著優勢。
使用 Impala,您可以使用傳統的 SQL 知識以閃電般的速度處理儲存在 HDFS 中的資料。
由於資料處理是在資料駐留的位置(Hadoop 叢集)進行的,因此在使用 Impala 時,無需對儲存在 Hadoop 上的資料進行資料轉換和資料移動。
使用 Impala,您可以訪問儲存在 HDFS、HBase 和 Amazon S3 中的資料,而無需瞭解 Java(MapReduce 作業)。您可以透過對 SQL 查詢的基本瞭解來訪問它們。
要在業務工具中編寫查詢,資料必須經過複雜的提取-轉換-載入 (ETL) 迴圈。但是,使用 Impala,此過程得到了簡化。使用**探索性資料分析和資料發現**等新技術克服了耗時的載入和重組階段,從而加快了流程。
Impala 是 Parquet 檔案格式的先驅,這是一種列式儲存佈局,針對資料倉庫場景中常見的大規模查詢進行了最佳化。
Impala 的特性
以下是 Cloudera Impala 的特性:
Impala 可在 Apache 許可下免費作為開源軟體使用。
Impala 支援記憶體資料處理,即它在無需資料移動的情況下訪問/分析儲存在 Hadoop 資料節點上的資料。
您可以使用類似 SQL 的查詢透過 Impala 訪問資料。
與其他 SQL 引擎相比,Impala 提供對 HDFS 中資料的更快訪問。
使用 Impala,您可以將資料儲存在 HDFS、Apache HBase 和 Amazon S3 等儲存系統中。
您可以將 Impala 與 Tableau、Pentaho、Micro Strategy 和 Zoomdata 等商業智慧工具整合。
Impala 支援多種檔案格式,例如 LZO、Sequence File、Avro、RCFile 和 Parquet。
Impala 使用來自 Apache Hive 的元資料、ODBC 驅動程式和 SQL 語法。
關係資料庫和 Impala
Impala 使用類似於 SQL 和 HiveQL 的查詢語言。下表描述了 SQL 和 Impala 查詢語言之間的一些關鍵區別。
| Impala | 關係資料庫 |
|---|---|
| Impala 使用類似於 HiveQL 的 SQL 查詢語言。 | 關係資料庫使用 SQL 語言。 |
| 在 Impala 中,您無法更新或刪除單個記錄。 | 在關係資料庫中,可以更新或刪除單個記錄。 |
| Impala 不支援事務。 | 關係資料庫支援事務。 |
| Impala 不支援索引。 | 關係資料庫支援索引。 |
| Impala 儲存和管理大量資料(PB 級)。 | 與 Impala 相比,關係資料庫處理的資料量較小(TB 級)。 |
Hive、HBase 和 Impala
儘管 Cloudera Impala 使用與 Hive 相同的查詢語言、元資料儲存和使用者介面,但在某些方面它與 Hive 和 HBase 不同。下表對 HBase、Hive 和 Impala 進行了比較分析。
| HBase | Hive | Impala |
|---|---|---|
| HBase 是基於 Apache Hadoop 的寬列儲存資料庫。它使用 BigTable 的概念。 | Hive 是一種資料倉庫軟體。使用它,我們可以訪問和管理構建在 Hadoop 之上的大型分散式資料集。 | Impala 是一種用於管理和分析儲存在 Hadoop 上的資料的工具。 |
| HBase 的資料模型是寬列儲存。 | Hive 遵循關係模型。 | Impala 遵循關係模型。 |
| HBase 使用 Java 語言開發。 | Hive 使用 Java 語言開發。 | Impala 使用 C++ 開發。 |
| HBase 的資料模型是無模式的。 | Hive 的資料模型是基於模式的。 | Impala 的資料模型是基於模式的。 |
| HBase 提供 Java、RESTful 和 Thrift API。 | Hive 提供 JDBC、ODBC、Thrift API。 | Impala 提供 JDBC 和 ODBC API。 |
| 支援 C、C#、C++、Groovy、Java、PHP、Python 和 Scala 等程式語言。 | 支援 C++、Java、PHP 和 Python 等程式語言。 | Impala 支援所有支援 JDBC/ODBC 的語言。 |
| HBase 支援觸發器。 | Hive 不支援觸發器。 | Impala 不支援觸發器。 |
所有這三個資料庫:
都是 NoSQL 資料庫。
作為開源軟體提供。
支援伺服器端指令碼。
遵循 ACID 屬性,如永續性和併發性。
使用**分片**進行**分割槽**。
Impala 的缺點
使用 Impala 的一些缺點如下:
- Impala 不支援序列化和反序列化。
- Impala 只能讀取文字檔案,不能讀取自定義二進位制檔案。
- 每當將新記錄/檔案新增到 HDFS 中的資料目錄時,都需要重新整理表。
Impala - 環境
本章介紹安裝 Impala 的先決條件,如何在系統中下載、安裝和設定**Impala**。
與 Hadoop 及其生態系統軟體類似,我們需要在 Linux 作業系統上安裝 Impala。由於 Cloudera 釋出了 Impala,因此它與**Cloudera Quick Start VM**一起提供。
本章介紹如何下載**Cloudera Quick Start VM**並啟動 Impala。
下載 Cloudera Quick Start VM
按照以下步驟下載最新版本的**Cloudera QuickStartVM**。
步驟 1
開啟 Cloudera 網站的主頁 http://www.cloudera.com/。您將看到如下所示的頁面。
步驟 2
單擊 Cloudera 主頁上的**登入**連結,這將跳轉到如下所示的登入頁面。

如果您尚未註冊,請單擊**立即註冊**連結,這將顯示**帳戶註冊**表單。在那裡註冊並登入 Cloudera 帳戶。
步驟 3
登入後,透過單擊以下快照中突出顯示的**下載**連結,開啟 Cloudera 網站的下載頁面。
步驟 4 - 下載 QuickStartVM
透過單擊以下快照中突出顯示的**立即下載**按鈕,下載 Cloudera **QuickStartVM**
這將跳轉到**QuickStart VM**的下載頁面。
單擊**立即獲取一個**按鈕,接受許可協議,然後單擊提交按鈕,如下所示。
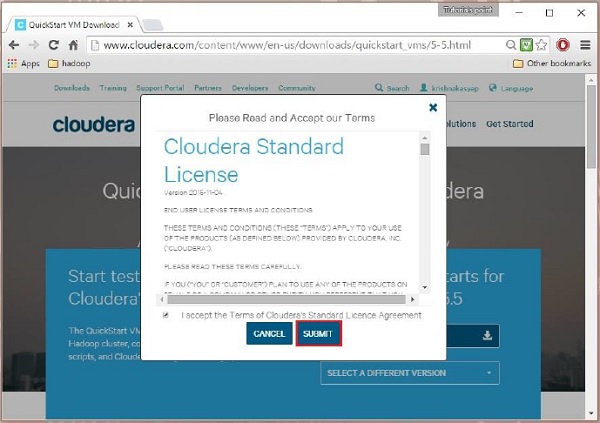
Cloudera 提供與其 VM 相容的 VMware、KVM 和 VIRTUALBOX。選擇所需版本。在本教程中,我們演示了使用 VirtualBox 設定**Cloudera QuickStartVM**,因此請單擊**VIRTUALBOX 下載**按鈕,如下所示。
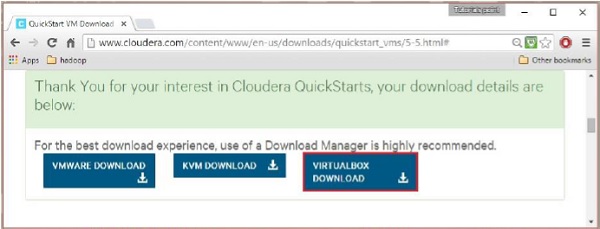
這將開始下載名為**cloudera-quickstart-vm-5.5.0-0-virtualbox.ovf**的檔案,這是一個 VirtualBox 映像檔案。
匯入 Cloudera QuickStartVM
下載**cloudera-quickstart-vm-5.5.0-0-virtualbox.ovf**檔案後,我們需要使用 VirtualBox 匯入它。為此,首先需要在系統中安裝 VirtualBox。按照以下步驟匯入下載的映像檔案。
步驟 1
從以下連結下載 VirtualBox 並安裝它 https://www.virtualbox.org/
步驟 2
開啟 VirtualBox 軟體。單擊**檔案**並選擇**匯入裝置**,如下所示。
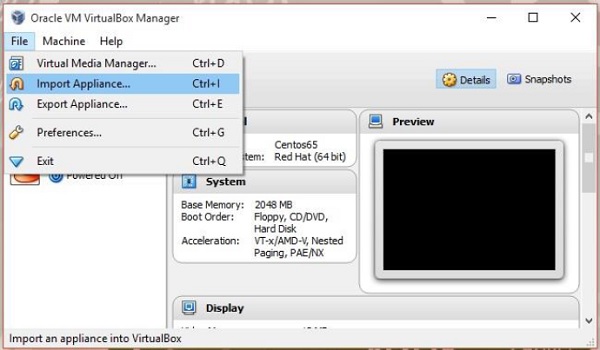
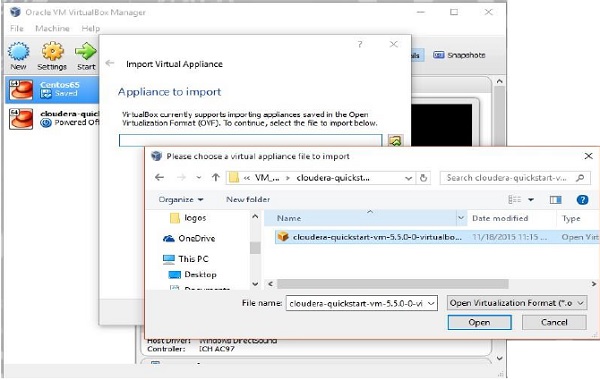
步驟 3
單擊**匯入裝置**後,您將看到“匯入虛擬裝置”視窗。選擇下載的映像檔案的位置,如下所示。
匯入**Cloudera QuickStartVM**映像後,啟動虛擬機器。此虛擬機器已安裝 Hadoop、Cloudera Impala 和所有必需的軟體。VM 的快照如下所示。
啟動 Impala Shell
要啟動 Impala,請開啟終端並執行以下命令。
[cloudera@quickstart ~] $ impala-shell
這將啟動 Impala Shell,並顯示以下訊息。
Starting Impala Shell without Kerberos authentication Connected to quickstart.cloudera:21000 Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build 0c891d79aa38f297d244855a32f1e17280e2129b) ******************************************************************************** Welcome to the Impala shell. Copyright (c) 2015 Cloudera, Inc. All rights reserved. (Impala Shell v2.3.0-cdh5.5.0 (0c891d7) built on Mon Nov 9 12:18:12 PST 2015) Press TAB twice to see a list of available commands. ******************************************************************************** [quickstart.cloudera:21000] >
**注意** - 我們將在後面的章節中討論所有 impala-shell 命令。
Impala 查詢編輯器
除了**Impala shell**之外,您還可以使用 Hue 瀏覽器與 Impala 通訊。安裝 CDH5 並啟動 Impala 後,如果您開啟瀏覽器,您將看到如下所示的 Cloudera 主頁。

現在,單擊書籤**Hue**以開啟 Hue 瀏覽器。單擊後,您可以看到 Hue 瀏覽器的登入頁面,使用憑據 cloudera 和 cloudera 登入。
登入 Hue 瀏覽器後,您將看到 Hue 瀏覽器的快速入門嚮導,如下所示。
單擊**查詢編輯器**下拉選單,您將看到 Impala 支援的編輯器列表,如下面的螢幕截圖所示。

在下拉選單中單擊**Impala**,您將看到如下所示的 Impala 查詢編輯器。
Impala - 架構
Impala 是一個 MPP(大規模並行處理)查詢執行引擎,它執行在 Hadoop 叢集中的許多系統上。與傳統的儲存系統不同,Impala 與其儲存引擎分離。它具有三個主要元件,即 Impala 守護程式(Impalad)、Impala 狀態儲存和 Impala 元資料或元資料儲存。
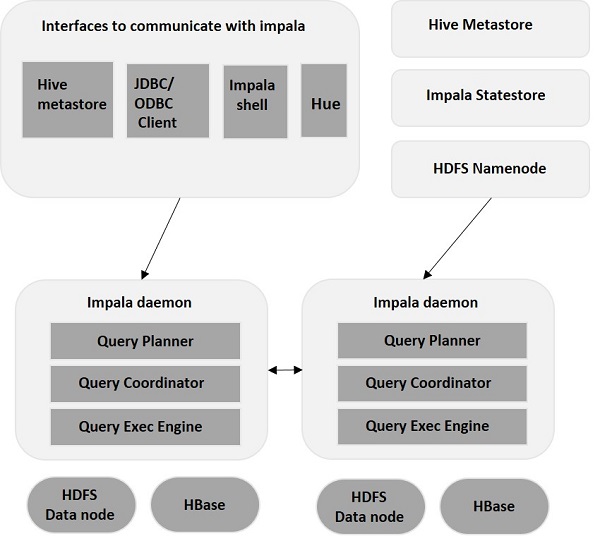
Impala 守護程式(Impalad)
Impala守護程序(也稱為impalad)執行在安裝了Impala的每個節點上。它接收來自各種介面(例如Impala shell、Hue瀏覽器等)的查詢並處理它們。
每當向特定節點上的impalad提交查詢時,該節點將作為該查詢的“協調器節點”。多個查詢也由執行在其他節點上的Impalad處理。Impalad接受查詢後,會讀取和寫入資料檔案,並透過將工作分配給Impala叢集中的其他Impala節點來並行化查詢。當查詢在各個Impalad例項上處理時,所有例項都會將結果返回到中央協調節點。
根據需求,可以將查詢提交到專用的Impalad,也可以以負載均衡的方式提交到叢集中的另一個Impalad。
Impala狀態儲存
Impala還有一個重要的元件稱為Impala狀態儲存,它負責檢查每個Impalad的執行狀況,然後定期將每個Impala守護程序的執行狀況轉發給其他守護程序。它可以在執行Impala伺服器的同一節點或叢集中的其他節點上執行。
Impala狀態儲存守護程序的名稱為State stored。Impalad將其執行狀況狀態報告給Impala狀態儲存守護程序,即State stored。
如果由於任何原因發生節點故障,Statestore會將此故障更新到所有其他節點,並且一旦其他impalad收到此通知,就不會有其他Impala守護程序將任何其他查詢分配給受影響的節點。
Impala元資料和元儲存
Impala元資料和元儲存是另一個重要元件。Impala使用傳統的MySQL或PostgreSQL資料庫來儲存表定義。諸如表和列資訊以及表定義之類的重要詳細資訊儲存在稱為元儲存的集中式資料庫中。
每個Impala節點都在本地快取所有元資料。在處理海量資料和/或許多分割槽時,獲取特定於表的元資料可能需要大量時間。因此,本地儲存的元資料快取有助於即時提供此類資訊。
當表定義或表資料更新時,其他Impala守護程序必須透過檢索最新的元資料來更新其元資料快取,然後才能針對相關表發出新的查詢。
查詢處理介面
為了處理查詢,Impala提供了以下三個介面。
Impala-shell − 使用Cloudera VM設定Impala後,您可以在編輯器中鍵入命令impala-shell來啟動Impala shell。我們將在接下來的章節中詳細討論Impala shell。
Hue介面 − 您也可以使用Hue瀏覽器處理Impala查詢。在Hue瀏覽器中,您可以使用Impala查詢編輯器鍵入和執行Impala查詢。要訪問此編輯器,首先需要登入Hue瀏覽器。
ODBC/JDBC驅動程式 − 與其他資料庫一樣,Impala也提供ODBC/JDBC驅動程式。使用這些驅動程式,您可以透過支援這些驅動程式的程式語言連線到Impala,並構建使用這些程式語言在Impala中處理查詢的應用程式。
查詢執行過程
每當使用者使用任何提供的介面傳遞查詢時,叢集中的一個Impalad都會接受該查詢。此Impalad將被視為該特定查詢的協調器。
接收查詢後,查詢協調器會使用Hive元儲存中的表模式驗證查詢是否合適。之後,它從HDFS名稱節點收集執行查詢所需的資料位置資訊,並將此資訊傳送給其他impalad以執行查詢。
所有其他Impala守護程序讀取指定的資料塊並處理查詢。一旦所有守護程序完成其任務,查詢協調器就會收集結果並將其交付給使用者。
Impala - Shell
在前面的章節中,我們已經瞭解了使用Cloudera安裝Impala及其架構。
- Impala shell(命令提示符)
- Hue(使用者介面)
- ODBC和JDBC(第三方庫)
本章介紹如何啟動Impala Shell以及shell的各種選項。
Impala Shell命令參考
Impala shell的命令分為常規命令、特定於查詢的選項和特定於表和資料庫的選項,如下所述。
常規命令
- help
- version
- history
- shell (或) !
- connect
- exit | quit
特定於查詢的選項
- Set/unset
- Profile
- Explain
特定於表和資料庫的選項
- Alter
- describe
- drop
- insert
- select
- show
- use
啟動 Impala Shell
開啟Cloudera終端,以超級使用者身份登入,並鍵入cloudera作為密碼,如下所示。
[cloudera@quickstart ~]$ su Password: cloudera [root@quickstart cloudera]#
鍵入以下命令啟動Impala shell:
[root@quickstart cloudera] # impala-shell Starting Impala Shell without Kerberos authentication Connected to quickstart.cloudera:21000 Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build 0c891d79aa38f297d244855a32f1e17280e2129b) ********************************************************************* Welcome to the Impala shell. Copyright (c) 2015 Cloudera, Inc. All rights reserved. (Impala Shell v2.3.0-cdh5.5.0 (0c891d7) built on Mon Nov 9 12:18:12 PST 2015) Want to know what version of Impala you're connected to? Run the VERSION command to find out! ********************************************************************* [quickstart.cloudera:21000] >
Impala – 通用命令
以下是Impala的通用命令的說明:
help命令
Impala shell的help命令會顯示Impala中可用命令的列表。
[quickstart.cloudera:21000] > help; Documented commands (type help <topic>): ======================================================== compute describe insert set unset with version connect explain quit show values use exit history profile select shell tip Undocumented commands: ========================================= alter create desc drop help load summary
version命令
version命令顯示當前的Impala版本,如下所示。
[quickstart.cloudera:21000] > version; Shell version: Impala Shell v2.3.0-cdh5.5.0 (0c891d7) built on Mon Nov 9 12:18:12 PST 2015 Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build 0c891d79aa38f297d244855a32f1e17280e2129b)
history命令
Impala的history命令顯示shell中執行的最後10個命令。以下是history命令的示例。在這裡,我們執行了5個命令,分別是version、help、show、use和history。
[quickstart.cloudera:21000] > history; [1]:version; [2]:help; [3]:show databases; [4]:use my_db; [5]:history;
quit/exit命令
您可以使用quit或exit命令退出Impala shell,如下所示。
[quickstart.cloudera:21000] > exit; Goodbye cloudera
connect命令
connect命令用於連線到給定的Impala例項。如果您未指定任何例項,則它將連線到預設埠21000,如下所示。
[quickstart.cloudera:21000] > connect; Connected to quickstart.cloudera:21000 Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build 0c891d79aa38f297d244855a32f1e17280e2129b)
Impala特定於查詢的選項
Impala的特定於查詢的命令接受查詢。以下是它們的說明:
Explain
explain命令返回給定查詢的執行計劃。
[quickstart.cloudera:21000] > explain select * from sample; Query: explain select * from sample +------------------------------------------------------------------------------------+ | Explain String | +------------------------------------------------------------------------------------+ | Estimated Per-Host Requirements: Memory = 48.00MB VCores = 1 | | WARNING: The following tables are missing relevant table and/or column statistics. | | my_db.customers | | 01:EXCHANGE [UNPARTITIONED] | | 00:SCAN HDFS [my_db.customers] | | partitions = 1/1 files = 6 size = 148B | +------------------------------------------------------------------------------------+ Fetched 7 row(s) in 0.17s
Profile
profile命令顯示有關最近查詢的低級別資訊。此命令用於診斷和效能調整查詢。以下是profile命令的示例。在這種情況下,profile命令返回explain查詢的低級別資訊。
[quickstart.cloudera:21000] > profile;
Query Runtime Profile:
Query (id=164b1294a1049189:a67598a6699e3ab6):
Summary:
Session ID: e74927207cd752b5:65ca61e630ad3ad
Session Type: BEESWAX
Start Time: 2016-04-17 23:49:26.08148000 End Time: 2016-04-17 23:49:26.2404000
Query Type: EXPLAIN
Query State: FINISHED
Query Status: OK
Impala Version: impalad version 2.3.0-cdh5.5.0 RELEASE (build 0c891d77280e2129b)
User: cloudera
Connected User: cloudera
Delegated User:
Network Address:10.0.2.15:43870
Default Db: my_db
Sql Statement: explain select * from sample
Coordinator: quickstart.cloudera:22000
: 0ns
Query Timeline: 167.304ms
- Start execution: 41.292us (41.292us) - Planning finished: 56.42ms (56.386ms)
- Rows available: 58.247ms (1.819ms)
- First row fetched: 160.72ms (101.824ms)
- Unregister query: 166.325ms (6.253ms)
ImpalaServer:
- ClientFetchWaitTimer: 107.969ms
- RowMaterializationTimer: 0ns
特定於表和資料庫的選項
下表列出了Impala中特定於表和資料的選項。
| 序號 | 命令和說明 |
|---|---|
| 1 |
Alter alter命令用於更改Impala中表的結構和名稱。 |
| 2 |
Describe Impala的describe命令提供表的元資料。它包含列及其資料型別的資訊。describe命令的快捷方式為desc。 |
| 3 |
Drop drop命令用於從Impala中刪除構造,其中構造可以是表、檢視或資料庫函式。 |
| 4 |
insert Impala的insert命令用於:
|
| 5 |
select select語句用於對特定資料集執行所需的操作。它指定要完成某些操作的資料集。您可以列印或儲存(在檔案中)select語句的結果。 |
| 6 |
show Impala的show語句用於顯示各種構造(例如表、資料庫和表)的元儲存。 |
| 7 |
use Impala的use語句用於將當前上下文更改為所需的資料庫。 |
Impala - 查詢語言基礎
Impala資料型別
下表描述了Impala資料型別。
| 序號 | 資料型別和說明 |
|---|---|
| 1 |
BIGINT 此資料型別儲存數值,其範圍為-9223372036854775808到9223372036854775807。此資料型別用於create table和alter table語句。 |
| 2 |
BOOLEAN 此資料型別僅儲存true或false值,它用於create table語句的列定義中。 |
| 3 |
CHAR 此資料型別是固定長度儲存,用空格填充,您可以儲存最多255的最大長度。 |
| 4 |
DECIMAL 此資料型別用於儲存十進位制值,它用於create table和alter table語句。 |
| 5 |
DOUBLE 此資料型別用於儲存範圍為正或負4.94065645841246544e-324d到-1.79769313486231570e+308的浮點值。 |
| 6 |
FLOAT 此資料型別用於儲存範圍為正或負1.40129846432481707e-45到3.40282346638528860e+38的單精度浮點值資料型別。 |
| 7 |
INT 此資料型別用於儲存4位元組整數,範圍為-2147483648到2147483647。 |
| 8 |
SMALLINT 此資料型別用於儲存2位元組整數,範圍為-32768到32767。 |
| 9 |
STRING 此資料型別用於儲存字串值。 |
| 10 |
TIMESTAMP 此資料型別用於表示時間點。 |
| 11 |
TINYINT 此資料型別用於儲存1位元組整數值,範圍為-128到127。 |
| 12 |
VARCHAR 此資料型別用於儲存最大長度為65,535的可變長度字元。 |
| 13 |
ARRAY 這是一個複雜的資料型別,用於儲存可變數量的有序元素。 |
| 14 |
Map 這是一個複雜的資料型別,用於儲存可變數量的鍵值對。 |
| 15 |
Struct 這是一個複雜的資料型別,用於表示單個專案的多個欄位。 |
Impala中的註釋
Impala中的註釋類似於SQL中的註釋。通常,程式語言中有兩種型別的註釋:單行註釋和多行註釋。
單行註釋 − 以“—”結尾的每一行都被視為Impala中的註釋。以下是Impala中單行註釋的示例。
-- Hello welcome to tutorials point.
多行註釋 − /*和*/之間的所有行都被視為Impala中的多行註釋。以下是Impala中多行註釋的示例。
/* Hi this is an example Of multiline comments in Impala */
Impala中的運算子類似於SQL中的運算子。點選以下連結參考我們的SQL教程 sql-operators。
Impala - 建立資料庫
在 Impala 中,資料庫是一個構造,它在其名稱空間內儲存相關的表、檢視和函式。它在 HDFS 中表示為目錄樹;它包含表分割槽和資料檔案。本章解釋如何在 Impala 中建立資料庫。
CREATE DATABASE 語句
CREATE DATABASE 語句用於在 Impala 中建立一個新的資料庫。
語法
以下是CREATE DATABASE語句的語法。
CREATE DATABASE IF NOT EXISTS database_name;
這裡,IF NOT EXISTS是一個可選子句。如果使用此子句,只有在不存在具有相同名稱的資料庫時,才會建立具有給定名稱的資料庫。
示例
以下是create database 語句的示例。在此示例中,我們建立了一個名為my_database的資料庫。
[quickstart.cloudera:21000] > CREATE DATABASE IF NOT EXISTS my_database;
在cloudera impala-shell中執行上述查詢後,您將獲得以下輸出。
Query: create DATABASE my_database Fetched 0 row(s) in 0.21s
驗證
SHOW DATABASES查詢提供 Impala 中資料庫的列表,因此您可以使用SHOW DATABASES語句驗證是否已建立資料庫。在這裡,您可以觀察到列表中新建立的資料庫my_db。
[quickstart.cloudera:21000] > show databases; Query: show databases +-----------------------------------------------+ | name | +-----------------------------------------------+ | _impala_builtins | | default | | my_db | +-----------------------------------------------+ Fetched 3 row(s) in 0.20s [quickstart.cloudera:21000] >
Hdfs 路徑
為了在 HDFS 檔案系統中建立資料庫,您需要指定資料庫的建立位置。
CREATE DATABASE IF NOT EXISTS database_name LOCATION hdfs_path;
使用 Hue 瀏覽器建立資料庫
開啟 Impala 查詢編輯器並在其中鍵入CREATE DATABASE語句。然後,單擊執行按鈕,如下面的螢幕截圖所示。
執行查詢後,輕輕將游標移動到下拉選單的頂部,您將找到一個重新整理符號。如果單擊重新整理符號,資料庫列表將重新整理,並應用最新的更改。

驗證
單擊編輯器左側“DATABASE”標題下的下拉框。您可以在其中看到系統中資料庫的列表。在這裡,您可以看到如下所示新建立的資料庫my_db。
如果您仔細觀察,您會發現列表中只有一個數據庫,即my_db以及預設資料庫。
Impala - 刪除資料庫
Impala 的DROP DATABASE 語句用於從 Impala 中刪除資料庫。在刪除資料庫之前,建議先從中刪除所有表。
語法
以下是DROP DATABASE語句的語法。
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT | CASCADE] [LOCATION hdfs_path];
這裡,IF EXISTS是一個可選子句。如果在存在具有給定名稱的資料庫時使用此子句,則將其刪除。如果不存在具有給定名稱的資料庫,則不執行任何操作。
示例
以下是DROP DATABASE語句的示例。假設您在 Impala 中有一個名為sample_database的資料庫。
而且,如果您使用SHOW DATABASES語句驗證資料庫列表,您將在其中看到其名稱。
[quickstart.cloudera:21000] > SHOW DATABASES; Query: show DATABASES +-----------------------+ | name | +-----------------------+ | _impala_builtins | | default | | my_db | | sample_database | +-----------------------+ Fetched 4 row(s) in 0.11s
現在,您可以使用如下所示的DROP DATABASE 語句刪除此資料庫。
< DROP DATABASE IF EXISTS sample_database;
這將刪除指定的資料庫併為您提供以下輸出。
Query: drop DATABASE IF EXISTS sample_database;
驗證
您可以使用SHOW DATABASES語句驗證給定的資料庫是否已刪除。在這裡,您可以看到名為sample_database的資料庫已從資料庫列表中刪除。
[quickstart.cloudera:21000] > SHOW DATABASES; Query: show DATABASES +----------------------+ | name | +----------------------+ | _impala_builtins | | default | | my_db | +----------------------+ Fetched 3 row(s) in 0.10s [quickstart.cloudera:21000] >
級聯
通常,要刪除資料庫,您需要手動刪除其中的所有表。如果您使用級聯,Impala 會在刪除資料庫之前刪除指定資料庫中的表。
示例
假設 Impala 中有一個名為sample的資料庫,它包含兩個表,即student和test。如果您嘗試直接刪除此資料庫,您將收到如下所示的錯誤。
[quickstart.cloudera:21000] > DROP database sample; Query: drop database sample ERROR: ImpalaRuntimeException: Error making 'dropDatabase' RPC to Hive Metastore: CAUSED BY: InvalidOperationException: Database sample is not empty. One or more tables exist.
使用cascade,您可以直接刪除此資料庫(無需手動刪除其內容),如下所示。
[quickstart.cloudera:21000] > DROP database sample cascade; Query: drop database sample cascade
注意 - 您不能刪除 Impala 中的“當前資料庫”。因此,在刪除資料庫之前,您需要確保當前上下文設定為除要刪除的資料庫以外的其他資料庫。
使用 Hue 瀏覽器刪除資料庫
開啟 Impala 查詢編輯器並在其中鍵入DELETE DATABASE語句,然後單擊執行按鈕,如下所示。假設有三個資料庫,即my_db、my_database和sample_database以及預設資料庫。這裡我們刪除名為 my_database 的資料庫。

執行查詢後,輕輕將游標移動到下拉選單的頂部。然後,您將找到如下面的螢幕截圖所示的重新整理符號。如果單擊重新整理符號,資料庫列表將重新整理,並應用所做的最新更改。
驗證
單擊編輯器左側“DATABASE”標題下的下拉選單。在那裡,您可以看到系統中資料庫的列表。在這裡,您可以看到如下所示新建立的資料庫my_db。
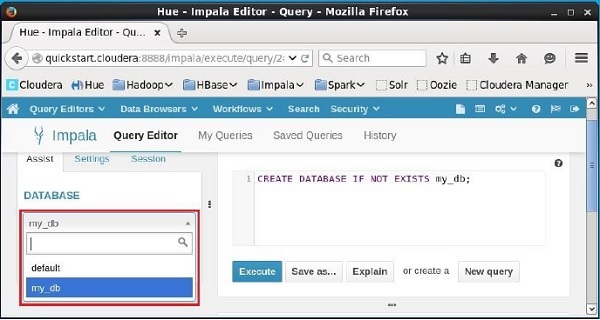
如果您仔細觀察,您會發現列表中只有一個數據庫,即my_db以及預設資料庫。
Impala - 選擇資料庫
連線到 Impala 後,需要在可用的資料庫中選擇一個。Impala 的USE DATABASE 語句用於將當前會話切換到另一個數據庫。
語法
以下是USE語句的語法。
USE db_name;
示例
以下是USE 語句的示例。首先,讓我們建立一個名為sample_database的資料庫,如下所示。
> CREATE DATABASE IF NOT EXISTS sample_database;
這將建立一個新的資料庫併為您提供以下輸出。
Query: create DATABASE IF NOT EXISTS my_db2 Fetched 0 row(s) in 2.73s
如果您使用SHOW DATABASES語句驗證資料庫列表,您可以在其中看到新建立的資料庫的名稱。
> SHOW DATABASES; Query: show DATABASES +-----------------------+ | name | +-----------------------+ | _impala_builtins | | default | | my_db | | sample_database | +-----------------------+ Fetched 4 row(s) in 0.11s
現在,讓我們使用如下所示的USE語句將會話切換到新建立的資料庫 (sample_database)。
> USE sample_database;
這將更改當前上下文到 sample_database 並顯示如下所示的訊息。
Query: use sample_database
使用 Hue 瀏覽器選擇資料庫
在 Impala 的查詢編輯器左側,您將找到如下面的螢幕截圖所示的下拉選單。
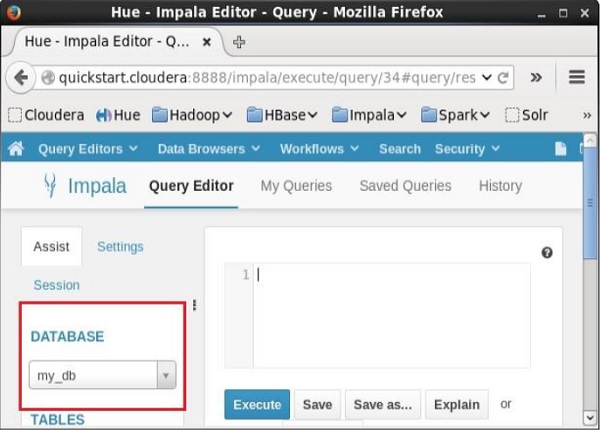
如果您單擊下拉選單,您將找到 Impala 中所有資料庫的列表,如下所示。

只需選擇您需要更改當前上下文的資料庫。
Impala - 建立表語句
CREATE TABLE語句用於在 Impala 的所需資料庫中建立新表。建立基本表包括命名錶和定義其列以及每列的資料型別。
語法
以下是CREATE TABLE語句的語法。這裡,IF NOT EXISTS是一個可選子句。如果使用此子句,只有在指定的資料庫中不存在具有相同名稱的表時,才會建立具有給定名稱的表。
create table IF NOT EXISTS database_name.table_name ( column1 data_type, column2 data_type, column3 data_type, ……… columnN data_type );
CREATE TABLE 是指示資料庫系統建立新表的關鍵字。表的唯一名稱或識別符號位於 CREATE TABLE 語句之後。您可以選擇性地指定database_name以及table_name。
示例
以下是 create table 語句的示例。在此示例中,我們在資料庫my_db中建立了一個名為student的表。
[quickstart.cloudera:21000] > CREATE TABLE IF NOT EXISTS my_db.student (name STRING, age INT, contact INT );
執行上述語句後,將建立一個具有指定名稱的表,並顯示以下輸出。
Query: create table student (name STRING, age INT, phone INT) Fetched 0 row(s) in 0.48s
驗證
show Tables查詢提供 Impala 中當前資料庫中表的列表。因此,您可以使用Show Tables語句驗證是否已建立表。
首先,您需要將上下文切換到存在所需表的資料庫,如下所示。
[quickstart.cloudera:21000] > use my_db; Query: use my_db
然後,如果您使用show tables查詢獲取表的列表,您可以在其中看到名為student的表,如下所示。
[quickstart.cloudera:21000] > show tables; Query: show tables +-----------+ | name | +-----------+ | student | +-----------+ Fetched 1 row(s) in 0.10s
HDFS 路徑
為了在 HDFS 檔案系統中建立資料庫,您需要指定資料庫的建立位置,如下所示。
CREATE DATABASE IF NOT EXISTS database_name LOCATION hdfs_path;
使用 Hue 瀏覽器建立資料庫
開啟 impala 查詢編輯器並在其中鍵入CREATE Table語句。然後單擊執行按鈕,如下面的螢幕截圖所示。

執行查詢後,輕輕將游標移動到下拉選單的頂部,您將找到一個重新整理符號。如果單擊重新整理符號,資料庫列表將重新整理,並應用所做的最新更改。

驗證
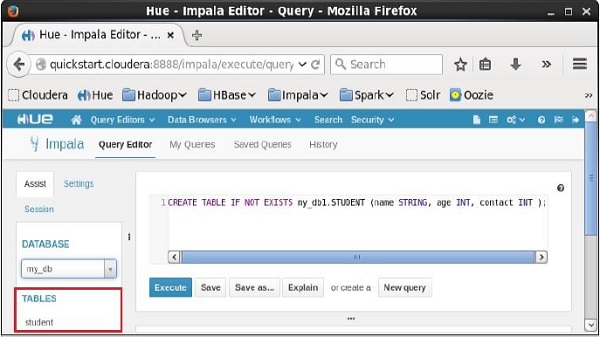
單擊編輯器左側“DATABASE”標題下的下拉選單。您可以在其中看到資料庫列表。選擇資料庫my_db,如下所示。

選擇資料庫my_db後,您可以看到其中的表列表,如下所示。在這裡,您可以找到新建立的表student,如下所示。
Impala - 插入語句
Impala 的INSERT語句有兩個子句 - into和overwrite。帶有into子句的 insert 語句用於將新記錄新增到資料庫中現有表中。
語法
INSERT語句有兩個基本語法,如下所示:
insert into table_name (column1, column2, column3,...columnN) values (value1, value2, value3,...valueN);
這裡,column1、column2…columnN 是您要向其中插入資料的表的列名。
您也可以在不指定列名的情況下新增值,但是,為此您需要確保值的順序與表中的列順序相同,如下所示。
Insert into table_name values (value1, value2, value2);
CREATE TABLE 是告訴資料庫系統建立新表的關鍵字。表的唯一名稱或識別符號位於 CREATE TABLE 語句之後。您可以選擇性地指定database_name以及table_name。
示例
假設我們在 Impala 中建立了一個名為student的表,如下所示。
create table employee (Id INT, name STRING, age INT,address STRING, salary BIGINT);
以下是建立名為employee的表中記錄的示例。
[quickstart.cloudera:21000] > insert into employee (ID,NAME,AGE,ADDRESS,SALARY)VALUES (1, 'Ramesh', 32, 'Ahmedabad', 20000 );
執行上述語句後,將向名為employee的表中插入一條記錄,並顯示以下訊息。
Query: insert into employee (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Ramesh', 32, 'Ahmedabad', 20000 ) Inserted 1 row(s) in 1.32s
您可以不指定列名地插入另一條記錄,如下所示。
[quickstart.cloudera:21000] > insert into employee values (2, 'Khilan', 25, 'Delhi', 15000 );
執行上述語句後,將向名為employee的表中插入一條記錄,並顯示以下訊息。
Query: insert into employee values (2, 'Khilan', 25, 'Delhi', 15000 ) Inserted 1 row(s) in 0.31s
您可以在 employee 表中插入更多記錄,如下所示。
Insert into employee values (3, 'kaushik', 23, 'Kota', 30000 ); Insert into employee values (4, 'Chaitali', 25, 'Mumbai', 35000 ); Insert into employee values (5, 'Hardik', 27, 'Bhopal', 40000 ); Insert into employee values (6, 'Komal', 22, 'MP', 32000 );
插入值後,Impala 中的employee表將如下所示。
+----+----------+-----+-----------+--------+ | id | name | age | address | salary | +----+----------+-----+-----------+--------+ | 1 | Ramesh | 32 | Ahmedabad | 20000 | | 2 | Khilan | 25 | Delhi | 15000 | | 5 | Hardik | 27 | Bhopal | 40000 | | 4 | Chaitali | 25 | Mumbai | 35000 | | 3 | kaushik | 23 | Kota | 30000 | | 6 | Komal | 22 | MP | 32000 | +----+----------+-----+-----------+--------+
覆蓋表中的資料
我們可以使用 overwrite 子句覆蓋表的記錄。被覆蓋的記錄將從表中永久刪除。以下是使用 overwrite 子句的語法。
Insert overwrite table_name values (value1, value2, value2);
示例
以下是使用overwrite子句的示例。
[quickstart.cloudera:21000] > Insert overwrite employee values (1, 'Ram', 26, 'Vishakhapatnam', 37000 );
執行上述查詢後,這將使用指定的記錄覆蓋表資料,並顯示以下訊息。
Query: insert overwrite employee values (1, 'Ram', 26, 'Vishakhapatnam', 37000 ) Inserted 1 row(s) in 0.31s
驗證表後,您可以看到表employee的所有記錄都被新記錄覆蓋,如下所示。
+----+------+-----+---------------+--------+ | id | name | age | address | salary | +----+------+-----+---------------+--------+ | 1 | Ram | 26 | Vishakhapatnam| 37000 | +----+------+-----+---------------+--------+
使用 Hue 瀏覽器插入資料
開啟 Impala 查詢編輯器並在其中鍵入insert語句。然後單擊執行按鈕,如下面的螢幕截圖所示。
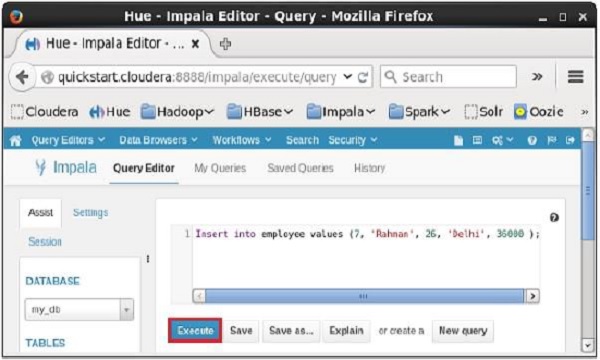
執行查詢/語句後,此記錄將新增到表中。
Impala - 選擇語句
Impala 的SELECT語句用於從資料庫中的一個或多個表中獲取資料。此查詢以表的格式返回資料。
語法
以下是 Impala select語句的語法。
SELECT column1, column2, columnN from table_name;
這裡,column1、column2…是您要獲取其值的表的欄位。如果要獲取欄位中所有可用的欄位,則可以使用以下語法:
SELECT * FROM table_name;
示例
假設我們在 Impala 中有一個名為customers的表,其中包含以下資料:
ID NAME AGE ADDRESS SALARY --- ------- --- ---------- ------- 1 Ramesh 32 Ahmedabad 20000 2 Khilan 25 Delhi 15000 3 Hardik 27 Bhopal 40000 4 Chaitali 25 Mumbai 35000 5 kaushik 23 Kota 30000 6 Komal 22 Mp 32000
您可以使用select語句獲取customers表所有記錄的id、name和age,如下所示:
[quickstart.cloudera:21000] > select id, name, age from customers;
執行上述查詢後,Impala 將獲取指定表中所有記錄的 id、name、age 並將其顯示如下。
Query: select id,name,age from customers +----+----------+-----+ | id | name | age | | 1 | Ramesh | 32 | | 2 | Khilan | 25 | | 3 | Hardik | 27 | | 4 | Chaitali | 25 | | 5 | kaushik | 23 | | 6 | Komal | 22 | +----+----------+-----+ Fetched 6 row(s) in 0.66s
您還可以使用select查詢獲取customers表中的所有記錄,如下所示。
[quickstart.cloudera:21000] > select name, age from customers; Query: select * from customers
執行上述查詢後,Impala 將獲取並顯示指定表中的所有記錄,如下所示。
+----+----------+-----+-----------+--------+ | id | name | age | address | salary | +----+----------+-----+-----------+--------+ | 1 | Ramesh | 32 | Ahmedabad | 20000 | | 2 | Khilan | 25 | Delhi | 15000 | | 3 | Hardik | 27 | Bhopal | 40000 | | 4 | Chaitali | 25 | Mumbai | 35000 | | 5 | kaushik | 23 | Kota | 30000 | | 6 | Komal | 22 | MP | 32000 | +----+----------+-----+-----------+--------+ Fetched 6 row(s) in 0.66s
使用 Hue 獲取記錄
開啟 Impala 查詢編輯器,在其中鍵入**select**語句,然後單擊執行按鈕,如下面的螢幕截圖所示。
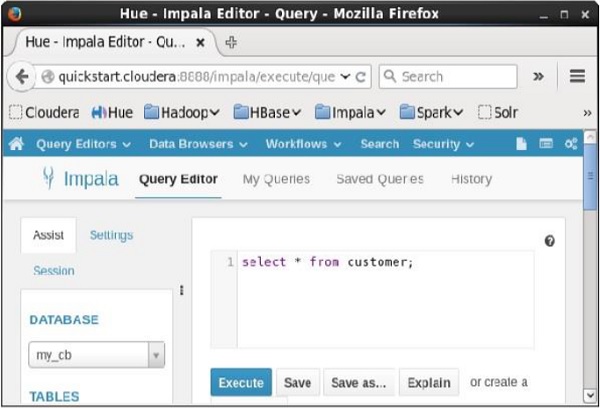
執行查詢後,如果向下滾動並選擇**結果**選項卡,您將看到指定表的記錄列表,如下所示。
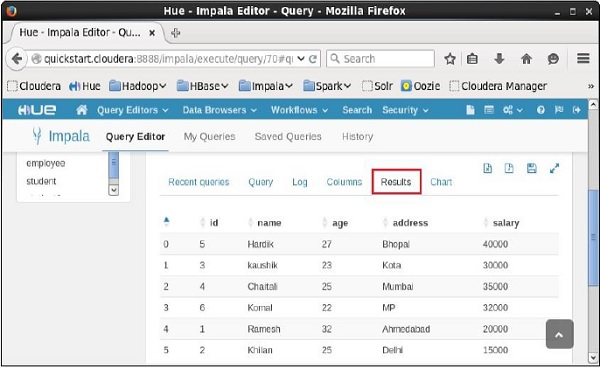
Impala - 描述語句
Impala 中的**describe**語句用於給出表的描述。此語句的結果包含有關表的資訊,例如列名及其資料型別。
語法
以下是 Impala **describe** 語句的語法。
Describe table_name;
示例
例如,假設我們在 Impala 中有一個名為**customer**的表,資料如下:
ID NAME AGE ADDRESS SALARY --- --------- ----- ----------- ----------- 1 Ramesh 32 Ahmedabad 20000 2 Khilan 25 Delhi 15000 3 Hardik 27 Bhopal 40000 4 Chaitali 25 Mumbai 35000 5 kaushik 23 Kota 30000 6 Komal 22 Mp 32000
您可以使用如下所示的**describe**語句獲取**customer**表的描述:
[quickstart.cloudera:21000] > describe customer;
執行上述查詢後,Impala 將獲取指定表的**元資料**並顯示它,如下所示。
Query: describe customer +---------+--------+---------+ | name | type | comment | +---------+--------+---------+ | id | int | | | name | string | | | age | int | | | address | string | | | salary | bigint | | +---------+--------+---------+ Fetched 5 row(s) in 0.51s
使用 Hue 描述記錄
開啟 Impala 查詢編輯器,在其中鍵入**describe**語句,然後單擊執行按鈕,如下面的螢幕截圖所示。
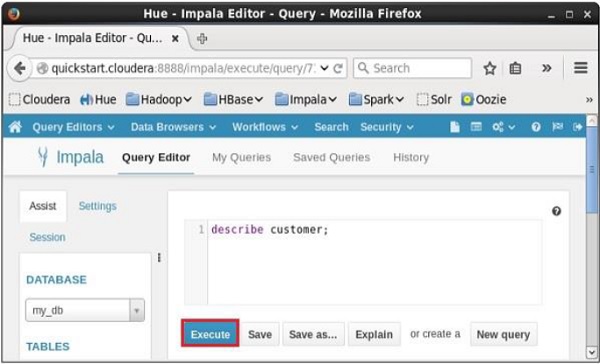
執行查詢後,如果向下滾動並選擇**結果**選項卡,您將看到表的元資料,如下所示。

Impala - 修改表
Impala 中的 Alter table 語句用於對給定表執行更改。使用此語句,我們可以新增、刪除或修改現有表中的列,也可以重新命名它。
本章解釋了各種型別的 alter 語句,包括語法和示例。首先,假設我們在 Impala 的**my_db**資料庫中有一個名為**customers**的表,資料如下:
ID NAME AGE ADDRESS SALARY --- --------- ----- ----------- -------- 1 Ramesh 32 Ahmedabad 20000 2 Khilan 25 Delhi 15000 3 Hardik 27 Bhopal 40000 4 Chaitali 25 Mumbai 35000 5 kaushik 23 Kota 30000 6 Komal 22 Mp 32000
並且,如果您獲取**my_db**資料庫中的表列表,您可以在其中找到**customers**表,如下所示。
[quickstart.cloudera:21000] > show tables; Query: show tables +-----------+ | name | +-----------+ | customers | | employee | | student | | student1 | +-----------+
更改表名
語法
重新命名現有表的**ALTER TABLE**的基本語法如下:
ALTER TABLE [old_db_name.]old_table_name RENAME TO [new_db_name.]new_table_name
示例
以下是使用**alter**語句更改表名的示例。這裡我們將表**customers**的名稱更改為 users。
[quickstart.cloudera:21000] > ALTER TABLE my_db.customers RENAME TO my_db.users;
執行上述查詢後,Impala 將根據需要更改表名,並顯示以下訊息。
Query: alter TABLE my_db.customers RENAME TO my_db.users
您可以使用**show tables**語句驗證當前資料庫中的表列表。您可以找到名為**users**而不是**customers**的表。
Query: show tables +----------+ | name | +----------+ | employee | | student | | student1 | | users | +----------+ Fetched 4 row(s) in 0.10s
向表中新增列
語法
向現有表新增列的**ALTER TABLE**基本語法如下:
ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...])
示例
以下查詢是一個演示如何向現有表新增列的示例。這裡我們將兩列 account_no 和 phone_number(都是 bigint 資料型別)新增到**users**表。
[quickstart.cloudera:21000] > ALTER TABLE users ADD COLUMNS (account_no BIGINT, phone_no BIGINT);
執行上述查詢後,它將向名為**student**的表新增指定的列,並顯示以下訊息。
Query: alter TABLE users ADD COLUMNS (account_no BIGINT, phone_no BIGINT)
如果您驗證**users**表的模式,您可以在其中找到新新增的列,如下所示。
quickstart.cloudera:21000] > describe users; Query: describe users +------------+--------+---------+ | name | type | comment | +------------+--------+---------+ | id | int | | | name | string | | | age | int | | | address | string | | | salary | bigint | | | account_no | bigint | | | phone_no | bigint | | +------------+--------+---------+ Fetched 7 row(s) in 0.20s
從表中刪除列
語法
在現有表中**DROP COLUMN**的 ALTER TABLE 基本語法如下:
ALTER TABLE name DROP [COLUMN] column_name
示例
以下查詢是從現有表中刪除列的示例。這裡我們刪除名為**account_no**的列。
[quickstart.cloudera:21000] > ALTER TABLE users DROP account_no;
執行上述查詢後,Impala 將刪除名為 account_no 的列,並顯示以下訊息。
Query: alter TABLE users DROP account_no
如果您驗證**users**表的模式,您將找不到名為**account_no**的列,因為它已被刪除。
[quickstart.cloudera:21000] > describe users; Query: describe users +----------+--------+---------+ | name | type | comment | +----------+--------+---------+ | id | int | | | name | string | | | age | int | | | address | string | | | salary | bigint | | | phone_no | bigint | | +----------+--------+---------+ Fetched 6 row(s) in 0.11s
更改列的名稱和型別
語法
在現有表中**更改列的名稱和資料型別**的 ALTER TABLE 基本語法如下:
ALTER TABLE name CHANGE column_name new_name new_type
示例
以下是使用 alter 語句更改列的名稱和資料型別的示例。這裡我們將列**phone_no**的名稱更改為**email**,其資料型別更改為**string**。
[quickstart.cloudera:21000] > ALTER TABLE users CHANGE phone_no e_mail string;
執行上述查詢後,Impala 將進行指定的更改,並顯示以下訊息。
Query: alter TABLE users CHANGE phone_no e_mail string
您可以使用**describe**語句驗證 users 表的元資料。您可以觀察到 Impala 已對指定的列進行了必要的更改。
[quickstart.cloudera:21000] > describe users; Query: describe users +----------+--------+---------+ | name | type | comment | +----------+--------+---------+ | id | int | | | name | string | | | age | int | | | address | string | | | salary | bigint | | | phone_no | bigint | | +----------+--------+---------+ Fetched 6 row(s) in 0.11s
使用 Hue 更改表
開啟 Impala 查詢編輯器,在其中鍵入**alter**語句,然後單擊執行按鈕,如下面的螢幕截圖所示。
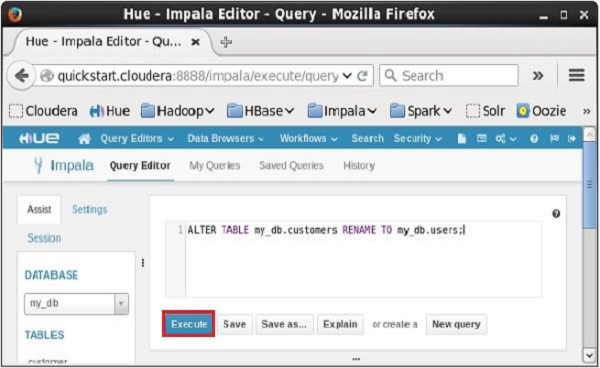
執行上述查詢後,它將把表**customers**的名稱更改為**users**。同樣,我們可以執行所有**alter**查詢。
Impala - 刪除表
Impala 的**drop table**語句用於刪除 Impala 中的現有表。此語句還將刪除內部表的底層 HDFS 檔案
**注意** - 使用此命令時必須小心,因為一旦表被刪除,表中所有可用資訊也將永遠丟失。
語法
以下是**DROP TABLE**語句的語法。這裡,**IF EXISTS**是一個可選子句。如果我們使用此子句,則只有在存在給定名稱的表時才刪除該表。否則,將不執行任何操作。
DROP table database_name.table_name;
如果您嘗試刪除不存在的表而不使用 IF EXISTS 子句,則會生成錯誤。您可以選擇性地與**table_name**一起指定**database_name**。
示例
讓我們首先驗證**my_db**資料庫中的表列表,如下所示。
[quickstart.cloudera:21000] > show tables; Query: show tables +------------+ | name | +------------+ | customers | | employee | | student | +------------+ Fetched 3 row(s) in 0.11s
從上述結果可以看出,**my_db**資料庫包含 3 個表。
以下是**drop table 語句**的示例。在此示例中,我們正在從**my_db**資料庫中刪除名為**student**的表。
[quickstart.cloudera:21000] > drop table if exists my_db.student;
執行上述查詢後,將刪除具有指定名稱的表,並顯示以下輸出。
Query: drop table if exists student
驗證
**show Tables**查詢提供 Impala 當前資料庫中表的列表。因此,您可以使用**Show Tables**語句驗證表是否已刪除。
首先,您需要將上下文切換到存在所需表的資料庫,如下所示。
[quickstart.cloudera:21000] > use my_db; Query: use my_db
然後,如果您使用**show tables**查詢獲取表列表,您可以觀察到名為**student**的表不在列表中。
[quickstart.cloudera:21000] > show tables; Query: show tables +-----------+ | name | +-----------+ | customers | | employee | | student | +-----------+ Fetched 3 row(s) in 0.11s
使用 Hue 瀏覽器建立資料庫
開啟 Impala 查詢編輯器,在其中鍵入**drop Table**語句,然後單擊執行按鈕,如下面的螢幕截圖所示。
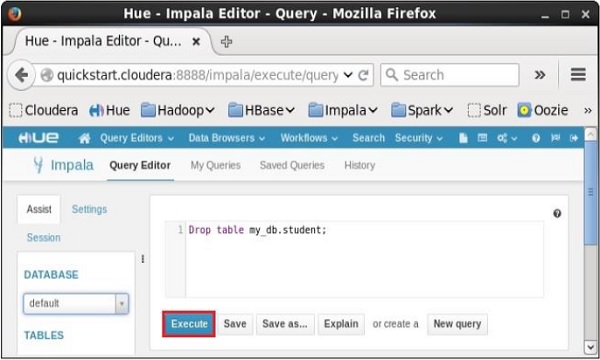
執行查詢後,輕輕將游標移動到下拉選單的頂部,您將找到一個重新整理符號。如果單擊重新整理符號,資料庫列表將重新整理,並應用所做的最新更改。

驗證
單擊編輯器左側**DATABASE**標題下的**下拉選單**。在那裡您可以看到資料庫列表;選擇資料庫**my_db**,如下所示。

選擇資料庫**my_db**後,您可以看到其中的表列表,如下所示。在這裡,您找不到已刪除的表**student**,如下所示。

Impala - 清空表
Impala 的**Truncate Table**語句用於刪除現有表中的所有記錄。
您還可以使用 DROP TABLE 命令刪除整個表,但這將從資料庫中刪除整個表結構,如果您希望儲存一些資料,則需要重新建立此表。
語法
以下是 truncate table 語句的語法。
truncate table_name;
示例
假設我們在 Impala 中有一個名為**customers**的表,如果您驗證其內容,您將得到以下結果。這意味著 customers 表包含 6 條記錄。
[quickstart.cloudera:21000] > select * from customers; Query: select * from customers +----+----------+-----+-----------+--------+--------+ | id | name | age | address | salary | e_mail | +----+----------+-----+-----------+--------+--------+ | 1 | Ramesh | 32 | Ahmedabad | 20000 | NULL | | 2 | Khilan | 25 | Delhi | 15000 | NULL | | 3 | kaushik | 23 | Kota | 30000 | NULL | | 4 | Chaitali | 25 | Mumbai | 35000 | NULL | | 5 | Hardik | 27 | Bhopal | 40000 | NULL | | 6 | Komal | 22 | MP | 32000 | NULL | +----+----------+-----+-----------+--------+--------+
以下是使用**truncate 語句**截斷 Impala 中表的示例。這裡我們刪除名為**customers**的表的所有記錄。
[quickstart.cloudera:21000] > truncate customers;
執行上述語句後,Impala 將刪除指定表的所有記錄,並顯示以下訊息。
Query: truncate customers Fetched 0 row(s) in 0.37s
驗證
如果您使用**select**語句驗證刪除操作後 customers 表的內容,您將得到一個空行,如下所示。
[quickstart.cloudera:21000] > select * from customers; Query: select * from customers Fetched 0 row(s) in 0.12s
使用 Hue 瀏覽器截斷表
開啟 Impala 查詢編輯器,在其中鍵入**truncate**語句,然後單擊執行按鈕,如下面的螢幕截圖所示。
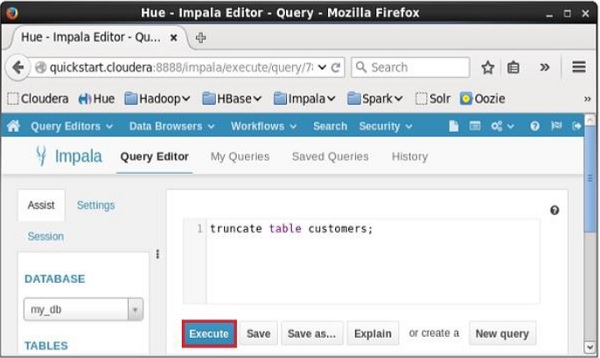
執行查詢/語句後,表中的所有記錄都將被刪除。
Impala - 顯示錶
Impala 中的**show tables**語句用於獲取當前資料庫中所有現有表的列表。
示例
以下是**show tables**語句的示例。如果您想獲取特定資料庫中的表列表,首先將上下文更改為所需的資料庫,然後使用**show tables**語句獲取其中的表列表,如下所示。
[quickstart.cloudera:21000] > use my_db; Query: use my_db [quickstart.cloudera:21000] > show tables;
執行上述查詢後,Impala 將獲取指定資料庫中的所有表列表並顯示它,如下所示。
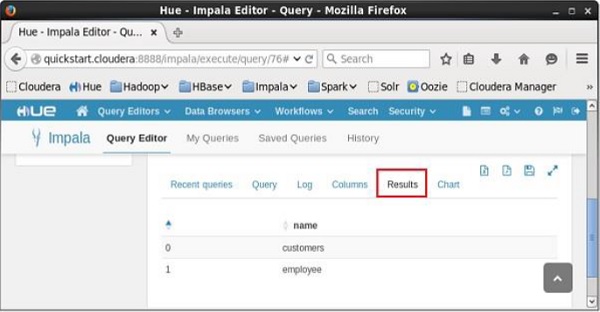
Query: show tables +-----------+ | name | +-----------+ | customers | | employee | +-----------+ Fetched 2 row(s) in 0.10s
使用 Hue 列出表
開啟 Impala 查詢編輯器,選擇上下文為**my_db**,在其中鍵入**show tables**語句,然後單擊執行按鈕,如下面的螢幕截圖所示。
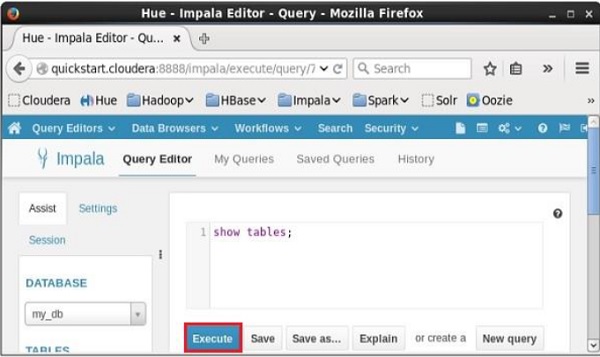
執行查詢後,如果向下滾動並選擇**結果**選項卡,您將看到表列表,如下所示。
Impala - 建立檢視
檢視只不過是儲存在資料庫中並具有關聯名稱的 Impala 查詢語言語句。它是以預定義 SQL 查詢的形式組合的表。
檢視可以包含表的所有行或選定行。檢視可以從一個或多個表建立。檢視允許使用者:
以使用者或使用者類別認為自然或直觀的方式組織資料。
限制對資料的訪問,以便使用者只能看到(有時)修改他們需要的內容,而不會更多。
彙總來自各種表的,可用於生成報告的資料。
您可以使用 Impala 的**Create View**語句建立檢視。
語法
以下是 create view 語句的語法。**IF NOT EXISTS**是一個可選子句。如果我們使用此子句,則只有在指定的資料庫中不存在具有相同名稱的現有表時,才建立具有給定名稱的表。
Create View IF NOT EXISTS view_name as Select statement
示例
例如,假設我們在 Impala 的**my_db**資料庫中有一個名為**customers**的表,資料如下。
ID NAME AGE ADDRESS SALARY --- --------- ----- ----------- -------- 1 Ramesh 32 Ahmedabad 20000 2 Khilan 25 Delhi 15000 3 Hardik 27 Bhopal 40000 4 Chaitali 25 Mumbai 35000 5 kaushik 23 Kota 30000 6 Komal 22 MP 32000
以下是**Create View 語句**的示例。在此示例中,我們正在建立一個名為**customers**表的檢視,其中包含 name 和 age 列。
[quickstart.cloudera:21000] > CREATE VIEW IF NOT EXISTS customers_view AS select name, age from customers;
執行上述查詢後,將建立一個具有所需列的檢視,並顯示以下訊息。
Query: create VIEW IF NOT EXISTS sample AS select * from customers Fetched 0 row(s) in 0.33s
驗證
您可以使用如下所示的**select**語句驗證剛剛建立的檢視的內容。
[quickstart.cloudera:21000] > select * from customers_view;
這將產生以下結果。
Query: select * from customers_view +----------+-----+ | name | age | +----------+-----+ | Komal | 22 | | Khilan | 25 | | Ramesh | 32 | | Hardik | 27 | | Chaitali | 25 | | kaushik | 23 | +----------+-----+ Fetched 6 row(s) in 4.80s
使用 Hue 建立檢視
開啟 Impala 查詢編輯器,選擇上下文為**my_db**,在其中鍵入**Create View**語句,然後單擊執行按鈕,如下面的螢幕截圖所示。

執行查詢後,如果向下滾動,您將在表列表中看到名為**sample**的**檢視**,如下所示。

Impala - 修改檢視
Impala 的**Alter View**語句用於更改檢視。使用此語句,您可以更改檢視的名稱、資料庫以及與其關聯的查詢。
由於**檢視**是一個邏輯結構,因此**修改檢視**查詢不會影響任何物理資料。
語法
以下是**修改檢視**語句的語法
ALTER VIEW database_name.view_name as Select statement
示例
例如,假設我們在Impala的**my_db**資料庫中有一個名為**customers_view**的檢視,其內容如下。
+----------+-----+ | name | age | +----------+-----+ | Komal | 22 | | Khilan | 25 | | Ramesh | 32 | | Hardik | 27 | | Chaitali | 25 | | kaushik | 23 | +----------+-----+
以下是一個**修改檢視語句**的示例。在這個例子中,我們將列id、name和salary新增到**customers_view**中,而不是name和age。
[quickstart.cloudera:21000] > Alter view customers_view as select id, name, salary from customers;
執行上述查詢後,Impala會對**customers_view**進行指定的更改,並顯示以下訊息。
Query: alter view customers_view as select id, name, salary from customers
驗證
您可以使用如下所示的**select**語句驗證名為**customers_view**的**檢視**的內容。
[quickstart.cloudera:21000] > select * from customers_view; Query: select * from customers_view
這將產生以下結果。
+----+----------+--------+ | id | name | salary | +----+----------+--------+ | 3 | kaushik | 30000 | | 2 | Khilan | 15000 | | 5 | Hardik | 40000 | | 6 | Komal | 32000 | | 1 | Ramesh | 20000 | | 4 | Chaitali | 35000 | +----+----------+--------+ Fetched 6 row(s) in 0.69s
使用Hue修改檢視
開啟Impala查詢編輯器,選擇上下文為**my_db**,在其中鍵入**修改檢視**語句,然後單擊執行按鈕,如下圖所示。
執行查詢後,名為**sample**的**檢視**將相應地被修改。
Impala - 刪除檢視
Impala的**刪除檢視**查詢用於刪除現有檢視。由於**檢視**是一個邏輯結構,因此**刪除檢視**查詢不會影響任何物理資料。
語法
以下是刪除檢視語句的語法。
DROP VIEW database_name.view_name;
示例
例如,假設我們在Impala的**my_db**資料庫中有一個名為**customers_view**的檢視,其內容如下。
+----------+-----+ | name | age | +----------+-----+ | Komal | 22 | | Khilan | 25 | | Ramesh | 32 | | Hardik | 27 | | Chaitali | 25 | | kaushik | 23 | +----------+-----+
以下是一個**刪除檢視語句**的示例。在這個例子中,我們嘗試使用**drop view**查詢刪除名為**customers_view**的**檢視**。
[quickstart.cloudera:21000] > Drop view customers_view;
執行上述查詢後,Impala會刪除指定的檢視,並顯示以下訊息。
Query: drop view customers_view
驗證
如果您使用**show tables**語句驗證表列表,您可以看到名為**customers_view**的**檢視**已被刪除。
[quickstart.cloudera:21000] > show tables;
這將產生以下結果。
Query: show tables +-----------+ | name | +-----------+ | customers | | employee | | sample | +-----------+ Fetched 3 row(s) in 0.10s
使用Hue刪除檢視
開啟Impala查詢編輯器,選擇上下文為**my_db**,在其中鍵入**刪除檢視**語句,然後單擊執行按鈕,如下圖所示。
執行查詢後,如果向下滾動,您可以看到一個名為**TABLES**的列表。此列表包含當前資料庫中的所有**表**和**檢視**。在此列表中,您可以找到指定的**檢視**已被刪除。
Impala - ORDER BY 子句
Impala的**ORDER BY**子句用於根據一列或多列對資料進行升序或降序排序。某些資料庫預設按升序對查詢結果進行排序。
語法
以下是ORDER BY子句的語法。
select * from table_name ORDER BY col_name [ASC|DESC] [NULLS FIRST|NULLS LAST]
您可以分別使用關鍵字**ASC**或**DESC**將表中的資料排列為升序或降序。
同樣,如果我們使用NULLS FIRST,則表中的所有空值都將排列在頂部行;如果我們使用NULLS LAST,則包含空值的行將排列在最後。
示例
假設我們在**my_db**資料庫中有一個名為**customers**的表,其內容如下:
[quickstart.cloudera:21000] > select * from customers; Query: select * from customers +----+----------+-----+-----------+--------+ | id | name | age | address | salary | +----+----------+-----+-----------+--------+ | 3 | kaushik | 23 | Kota | 30000 | | 1 | Ramesh | 32 | Ahmedabad | 20000 | | 2 | Khilan | 25 | Delhi | 15000 | | 6 | Komal | 22 | MP | 32000 | | 4 | Chaitali | 25 | Mumbai | 35000 | | 5 | Hardik | 27 | Bhopal | 40000 | +----+----------+-----+-----------+--------+ Fetched 6 row(s) in 0.51s
以下是如何使用**order by**子句按**id**的升序排列**customers**表中的資料的示例。
[quickstart.cloudera:21000] > Select * from customers ORDER BY id asc;
執行後,上述查詢將產生以下輸出。
Query: select * from customers ORDER BY id asc +----+----------+-----+-----------+--------+ | id | name | age | address | salary | +----+----------+-----+-----------+--------+ | 1 | Ramesh | 32 | Ahmedabad | 20000 | | 2 | Khilan | 25 | Delhi | 15000 | | 3 | kaushik | 23 | Kota | 30000 | | 4 | Chaitali | 25 | Mumbai | 35000 | | 5 | Hardik | 27 | Bhopal | 40000 | | 6 | Komal | 22 | MP | 32000 | +----+----------+-----+-----------+--------+ Fetched 6 row(s) in 0.56s
同樣,您可以使用如下所示的**order by**子句將**customers**表中的資料按降序排列。
[quickstart.cloudera:21000] > Select * from customers ORDER BY id desc;
執行後,上述查詢將產生以下輸出。
Query: select * from customers ORDER BY id desc +----+----------+-----+-----------+--------+ | id | name | age | address | salary | +----+----------+-----+-----------+--------+ | 6 | Komal | 22 | MP | 32000 | | 5 | Hardik | 27 | Bhopal | 40000 | | 4 | Chaitali | 25 | Mumbai | 35000 | | 3 | kaushik | 23 | Kota | 30000 | | 2 | Khilan | 25 | Delhi | 15000 | | 1 | Ramesh | 32 | Ahmedabad | 20000 | +----+----------+-----+-----------+--------+ Fetched 6 row(s) in 0.54s
Impala - GROUP BY 子句
Impala的**GROUP BY**子句與SELECT語句一起使用,用於將相同的資料排列到組中。
語法
以下是GROUP BY子句的語法。
select data from table_name Group BY col_name;
示例
假設我們在**my_db**資料庫中有一個名為**customers**的表,其內容如下:
[quickstart.cloudera:21000] > select * from customers; Query: select * from customers +----+----------+-----+-----------+--------+ | id | name | age | address | salary | +----+----------+-----+-----------+--------+ | 1 | Ramesh | 32 | Ahmedabad | 20000 | | 2 | Khilan | 25 | Delhi | 15000 | | 3 | kaushik | 23 | Kota | 30000 | | 4 | Chaitali | 25 | Mumbai | 35000 | | 5 | Hardik | 27 | Bhopal | 40000 | | 6 | Komal | 22 | MP | 32000 | +----+----------+-----+-----------+--------+ Fetched 6 row(s) in 0.51s
您可以使用GROUP BY查詢獲取每個客戶的總薪資,如下所示。
[quickstart.cloudera:21000] > Select name, sum(salary) from customers Group BY name;
執行後,上述查詢將給出以下輸出。
Query: select name, sum(salary) from customers Group BY name +----------+-------------+ | name | sum(salary) | +----------+-------------+ | Ramesh | 20000 | | Komal | 32000 | | Hardik | 40000 | | Khilan | 15000 | | Chaitali | 35000 | | kaushik | 30000 | +----------+-------------+ Fetched 6 row(s) in 1.75s
假設此表有多條記錄,如下所示。
+----+----------+-----+-----------+--------+ | id | name | age | address | salary | +----+----------+-----+-----------+--------+ | 1 | Ramesh | 32 | Ahmedabad | 20000 | | 2 | Ramesh | 32 | Ahmedabad | 1000| | | 3 | Khilan | 25 | Delhi | 15000 | | 4 | kaushik | 23 | Kota | 30000 | | 5 | Chaitali | 25 | Mumbai | 35000 | | 6 | Chaitali | 25 | Mumbai | 2000 | | 7 | Hardik | 27 | Bhopal | 40000 | | 8 | Komal | 22 | MP | 32000 | +----+----------+-----+-----------+--------+
現在,您可以再次使用**Group By**子句獲取員工的總薪資,其中考慮了重複的記錄條目,如下所示。
Select name, sum(salary) from customers Group BY name;
執行後,上述查詢將給出以下輸出。
Query: select name, sum(salary) from customers Group BY name +----------+-------------+ | name | sum(salary) | +----------+-------------+ | Ramesh | 21000 | | Komal | 32000 | | Hardik | 40000 | | Khilan | 15000 | | Chaitali | 37000 | | kaushik | 30000 | +----------+-------------+ Fetched 6 row(s) in 1.75s
Impala - HAVING 子句
Impala中的**Having**子句允許您指定條件來篩選最終結果中顯示的組結果。
通常,**Having**子句與**group by**子句一起使用;它對GROUP BY子句建立的組設定條件。
語法
以下是**Having**子句的語法。
select * from table_name ORDER BY col_name [ASC|DESC] [NULLS FIRST|NULLS LAST]
示例
假設我們在**my_db**資料庫中有一個名為**customers**的表,其內容如下:
[quickstart.cloudera:21000] > select * from customers; Query: select * from customers +----+----------+-----+-------------+--------+ | id | name | age | address | salary | +----+----------+-----+-------------+--------+ | 1 | Ramesh | 32 | Ahmedabad | 20000 | | 2 | Khilan | 25 | Delhi | 15000 | | 3 | kaushik | 23 | Kota | 30000 | | 4 | Chaitali | 25 | Mumbai | 35000 | | 5 | Hardik | 27 | Bhopal | 40000 | | 6 | Komal | 22 | MP | 32000 | | 7 | ram | 25 | chennai | 23000 | | 8 | rahim | 22 | vizag | 31000 | | 9 | robert | 23 | banglore | 28000 | +----+----------+-----+-----------+--------+ Fetched 9 row(s) in 0.51s
以下是如何在Impala中使用**Having**子句的示例:
[quickstart.cloudera:21000] > select max(salary) from customers group by age having max(salary) > 20000;
此查詢首先按年齡對錶進行分組,並選擇每個組的最大薪資,並顯示那些大於20000的薪資,如下所示。
20000 +-------------+ | max(salary) | +-------------+ | 30000 | | 35000 | | 40000 | | 32000 | +-------------+ Fetched 4 row(s) in 1.30s
Impala - LIMIT 子句
Impala中的**limit**子句用於將結果集的行數限制為所需數量,即查詢的結果集不包含超過指定限制的記錄。
語法
以下是Impala中**Limit**子句的語法。
select * from table_name order by id limit numerical_expression;
示例
假設我們在**my_db**資料庫中有一個名為**customers**的表,其內容如下:
[quickstart.cloudera:21000] > select * from customers; Query: select * from customers +----+----------+-----+-----------+--------+ | id | name | age | address | salary | +----+----------+-----+-----------+--------+ | 3 | kaushik | 23 | Kota | 30000 | | 6 | Komal | 22 | MP | 32000 | | 1 | Ramesh | 32 | Ahmedabad | 20000 | | 5 | Hardik | 27 | Bhopal | 40000 | | 2 | Khilan | 25 | Delhi | 15000 | | 8 | ram | 22 | vizag | 31000 | | 9 | robert | 23 | banglore | 28000 | | 7 | ram | 25 | chennai | 23000 | | 4 | Chaitali | 25 | Mumbai | 35000 | +----+----------+-----+-----------+--------+ Fetched 9 row(s) in 0.51s
您可以使用**order by**子句按id的升序排列表中的記錄,如下所示。
[quickstart.cloudera:21000] > select * from customers order by id; Query: select * from customers order by id +----+----------+-----+-----------+--------+ | id | name | age | address | salary | +----+----------+-----+-----------+--------+ | 1 | Ramesh | 32 | Ahmedabad | 20000 | | 2 | Khilan | 25 | Delhi | 15000 | | 3 | kaushik | 23 | Kota | 30000 | | 4 | Chaitali | 25 | Mumbai | 35000 | | 5 | Hardik | 27 | Bhopal | 40000 | | 6 | Komal | 22 | MP | 32000 | | 7 | ram | 25 | chennai | 23000 | | 8 | ram | 22 | vizag | 31000 | | 9 | robert | 23 | banglore | 28000 | +----+----------+-----+-----------+--------+ Fetched 9 row(s) in 0.54s
現在,使用**limit**子句,您可以使用**limit**子句將輸出的記錄數限制為4,如下所示。
[quickstart.cloudera:21000] > select * from customers order by id limit 4;
執行後,上述查詢將給出以下輸出。
Query: select * from customers order by id limit 4 +----+----------+-----+-----------+--------+ | id | name | age | address | salary | +----+----------+-----+-----------+--------+ | 1 | Ramesh | 32 | Ahmedabad | 20000 | | 2 | Khilan | 25 | Delhi | 15000 | | 3 | kaushik | 23 | Kota | 30000 | | 4 | Chaitali | 25 | Mumbai | 35000 | +----+----------+-----+-----------+--------+ Fetched 4 row(s) in 0.64s
Impala - OFFSET 子句
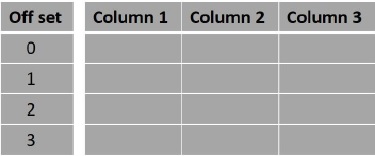
通常,**select**查詢結果集中的行從0開始。使用**offset**子句,我們可以決定從哪裡開始考慮輸出。例如,如果我們將偏移量選擇為0,則結果將與往常一樣,如果我們將偏移量選擇為5,則結果將從第五行開始。
語法
以下是Impala中**offset**子句的語法。
select data from table_name Group BY col_name;
示例
假設我們在**my_db**資料庫中有一個名為**customers**的表,其內容如下:
[quickstart.cloudera:21000] > select * from customers; Query: select * from customers +----+----------+-----+-----------+--------+ | id | name | age | address | salary | +----+----------+-----+-----------+--------+ | 3 | kaushik | 23 | Kota | 30000 | | 6 | Komal | 22 | MP | 32000 | | 1 | Ramesh | 32 | Ahmedabad | 20000 | | 5 | Hardik | 27 | Bhopal | 40000 | | 2 | Khilan | 25 | Delhi | 15000 | | 8 | ram | 22 | vizag | 31000 | | 9 | robert | 23 | banglore | 28000 | | 7 | ram | 25 | chennai | 23000 | | 4 | Chaitali | 25 | Mumbai | 35000 | +----+----------+-----+-----------+--------+ Fetched 9 row(s) in 0.51s
您可以使用**limit**和**order by**子句按id的升序排列表中的記錄並將記錄數限制為4,如下所示。
Query: select * from customers order by id limit 4 +----+----------+-----+-----------+--------+ | id | name | age | address | salary | +----+----------+-----+-----------+--------+ | 1 | Ramesh | 32 | Ahmedabad | 20000 | | 2 | Khilan | 25 | Delhi | 15000 | | 3 | kaushik | 23 | Kota | 30000 | | 4 | Chaitali | 25 | Mumbai | 35000 | +----+----------+-----+-----------+--------+ Fetched 4 row(s) in 0.64s
以下是一個**offset**子句的示例。在這裡,我們按id的順序獲取**customers**表中的記錄,並列印從第0行開始的前四行。
[quickstart.cloudera:21000] > select * from customers order by id limit 4 offset 0;
執行後,上述查詢將給出以下結果。
Query: select * from customers order by id limit 4 offset 0 +----+----------+-----+-----------+--------+ | id | name | age | address | salary | +----+----------+-----+-----------+--------+ | 1 | Ramesh | 32 | Ahmedabad | 20000 | | 2 | Khilan | 25 | Delhi | 15000 | | 3 | kaushik | 23 | Kota | 30000 | | 4 | Chaitali | 25 | Mumbai | 35000 | +----+----------+-----+-----------+--------+ Fetched 4 row(s) in 0.62s
同樣,您可以從偏移量為5的行開始獲取**customers**表中的四條記錄,如下所示。
[quickstart.cloudera:21000] > select * from customers order by id limit 4 offset 5; Query: select * from customers order by id limit 4 offset 5 +----+--------+-----+----------+--------+ | id | name | age | address | salary | +----+--------+-----+----------+--------+ | 6 | Komal | 22 | MP | 32000 | | 7 | ram | 25 | chennai | 23000 | | 8 | ram | 22 | vizag | 31000 | | 9 | robert | 23 | banglore | 28000 | +----+--------+-----+----------+--------+ Fetched 4 row(s) in 0.52s
Impala - UNION 子句
您可以使用Impala的**Union**子句組合兩個查詢的結果。
語法
以下是Impala中**Union**子句的語法。
query1 union query2;
示例
假設我們在**my_db**資料庫中有一個名為**customers**的表,其內容如下:
[quickstart.cloudera:21000] > select * from customers; Query: select * from customers +----+----------+-----+-----------+--------+ | id | name | age | address | salary | +----+----------+-----+-----------+--------+ | 1 | Ramesh | 32 | Ahmedabad | 20000 | | 9 | robert | 23 | banglore | 28000 | | 2 | Khilan | 25 | Delhi | 15000 | | 4 | Chaitali | 25 | Mumbai | 35000 | | 7 | ram | 25 | chennai | 23000 | | 6 | Komal | 22 | MP | 32000 | | 8 | ram | 22 | vizag | 31000 | | 5 | Hardik | 27 | Bhopal | 40000 | | 3 | kaushik | 23 | Kota | 30000 | +----+----------+-----+-----------+--------+ Fetched 9 row(s) in 0.59s
同樣,假設我們有另一個名為**employee**的表,其內容如下:
[quickstart.cloudera:21000] > select * from employee; Query: select * from employee +----+---------+-----+---------+--------+ | id | name | age | address | salary | +----+---------+-----+---------+--------+ | 3 | mahesh | 54 | Chennai | 55000 | | 2 | ramesh | 44 | Chennai | 50000 | | 4 | Rupesh | 64 | Delhi | 60000 | | 1 | subhash | 34 | Delhi | 40000 | +----+---------+-----+---------+--------+ Fetched 4 row(s) in 0.59s
以下是如何在Impala中使用**union**子句的示例。在這個例子中,我們使用兩個單獨的查詢按id的順序排列兩個表中的記錄,並將它們的數目限制為3,並使用**UNION**子句連線這些查詢。
[quickstart.cloudera:21000] > select * from customers order by id limit 3 union select * from employee order by id limit 3;
執行後,上述查詢將給出以下輸出。
Query: select * from customers order by id limit 3 union select * from employee order by id limit 3 +----+---------+-----+-----------+--------+ | id | name | age | address | salary | +----+---------+-----+-----------+--------+ | 2 | Khilan | 25 | Delhi | 15000 | | 3 | mahesh | 54 | Chennai | 55000 | | 1 | subhash | 34 | Delhi | 40000 | | 2 | ramesh | 44 | Chennai | 50000 | | 3 | kaushik | 23 | Kota | 30000 | | 1 | Ramesh | 32 | Ahmedabad | 20000 | +----+---------+-----+-----------+--------+ Fetched 6 row(s) in 3.11s
Impala - WITH 子句
如果查詢過於複雜,我們可以為複雜部分定義**別名**,並使用Impala的**with**子句將它們包含在查詢中。
語法
以下是Impala中**with**子句的語法。
with x as (select 1), y as (select 2) (select * from x union y);
示例
假設我們在**my_db**資料庫中有一個名為**customers**的表,其內容如下:
[quickstart.cloudera:21000] > select * from customers; Query: select * from customers +----+----------+-----+-----------+--------+ | id | name | age | address | salary | +----+----------+-----+-----------+--------+ | 1 | Ramesh | 32 | Ahmedabad | 20000 | | 9 | robert | 23 | banglore | 28000 | | 2 | Khilan | 25 | Delhi | 15000 | | 4 | Chaitali | 25 | Mumbai | 35000 | | 7 | ram | 25 | chennai | 23000 | | 6 | Komal | 22 | MP | 32000 | | 8 | ram | 22 | vizag | 31000 | | 5 | Hardik | 27 | Bhopal | 40000 | | 3 | kaushik | 23 | Kota | 30000 | +----+----------+-----+-----------+--------+ Fetched 9 row(s) in 0.59s
同樣,假設我們有另一個名為**employee**的表,其內容如下:
[quickstart.cloudera:21000] > select * from employee; Query: select * from employee +----+---------+-----+---------+--------+ | id | name | age | address | salary | +----+---------+-----+---------+--------+ | 3 | mahesh | 54 | Chennai | 55000 | | 2 | ramesh | 44 | Chennai | 50000 | | 4 | Rupesh | 64 | Delhi | 60000 | | 1 | subhash | 34 | Delhi | 40000 | +----+---------+-----+---------+--------+ Fetched 4 row(s) in 0.59s
以下是如何在Impala中使用**with**子句的示例。在這個例子中,我們使用**with**子句顯示年齡大於25的**employee**和**customers**中的記錄。
[quickstart.cloudera:21000] > with t1 as (select * from customers where age>25), t2 as (select * from employee where age>25) (select * from t1 union select * from t2);
執行後,上述查詢將給出以下輸出。
Query: with t1 as (select * from customers where age>25), t2 as (select * from employee where age>25) (select * from t1 union select * from t2) +----+---------+-----+-----------+--------+ | id | name | age | address | salary | +----+---------+-----+-----------+--------+ | 3 | mahesh | 54 | Chennai | 55000 | | 1 | subhash | 34 | Delhi | 40000 | | 2 | ramesh | 44 | Chennai | 50000 | | 5 | Hardik | 27 | Bhopal | 40000 | | 4 | Rupesh | 64 | Delhi | 60000 | | 1 | Ramesh | 32 | Ahmedabad | 20000 | +----+---------+-----+-----------+--------+ Fetched 6 row(s) in 1.73s
Impala - DISTINCT 運算子
Impala中的**distinct**運算子用於透過刪除重複項來獲取唯一值。
語法
以下是**distinct**運算子的語法。
select distinct columns… from table_name;
示例
假設我們在Impala中有一個名為**customers**的表,其內容如下:
[quickstart.cloudera:21000] > select distinct id, name, age, salary from customers; Query: select distinct id, name, age, salary from customers
在這裡,您可以看到客戶Ramesh和Chaitali的薪水輸入了兩次,使用**distinct**運算子,我們可以選擇唯一值,如下所示。
[quickstart.cloudera:21000] > select distinct name, age, address from customers;
執行後,上述查詢將給出以下輸出。
Query: select distinct id, name from customers +----------+-----+-----------+ | name | age | address | +----------+-----+-----------+ | Ramesh | 32 | Ahmedabad | | Khilan | 25 | Delhi | | kaushik | 23 | Kota | | Chaitali | 25 | Mumbai | | Hardik | 27 | Bhopal | | Komal | 22 | MP | +----------+-----+-----------+ Fetched 9 row(s) in 1.46s