- Fortran 教程
- Fortran - 首頁
- Fortran - 概述
- Fortran - 環境設定
- Fortran - 基本語法
- Fortran - 資料型別
- Fortran - 變數
- Fortran - 常量
- Fortran - 運算子
- Fortran - 決策
- Fortran - 迴圈
- Fortran - 數字
- Fortran - 字元
- Fortran - 字串
- Fortran - 陣列
- Fortran - 動態陣列
- Fortran - 派生資料型別
- Fortran - 指標
- Fortran - 基本輸入輸出
- Fortran - 檔案輸入輸出
- Fortran - 過程
- Fortran - 模組
- Fortran - 內在函式
- Fortran - 數值精度
- Fortran - 程式庫
- Fortran - 程式設計風格
- Fortran - 程式除錯
- Fortran 資源
- Fortran 快速指南
- Fortran - 有用資源
- Fortran - 討論
Fortran 快速指南
Fortran - 概述
Fortran,源自公式翻譯系統 (Formula Translating System),是一種通用的指令式程式設計語言。它用於數值和科學計算。
Fortran 最初由 IBM 在 20 世紀 50 年代開發,用於科學和工程應用。長期以來,Fortran 一直統治著這個程式設計領域,並因其高效能計算能力而變得非常流行,因為:
它支援:
- 數值分析和科學計算
- 結構化程式設計
- 陣列程式設計
- 模組化程式設計
- 泛型程式設計
- 超級計算機上的高效能計算
- 面向物件程式設計
- 併發程式設計
- 計算機系統之間具有合理的可移植性
關於 Fortran 的事實
Fortran 由 John Backus 領導的團隊於 1957 年在 IBM 建立。
最初名稱全部大寫,但當前標準和實現只需要首字母大寫。
Fortran 代表 FORmula TRANslator(公式翻譯器)。
最初開發用於科學計算,對字元字串和其他通用程式設計所需的結構的支援非常有限。
後來的擴充套件和發展使其成為具有良好可移植性的高階程式語言。
Fortran I、II 和 III 原版現已過時。
仍在使用的最古老版本是 Fortran IV 和 Fortran 66。
當今最常用的版本是:Fortran 77、Fortran 90 和 Fortran 95。
Fortran 77 添加了字串作為一種不同的型別。
Fortran 90 添加了各種執行緒和直接陣列處理。
Fortran - 環境設定
在 Windows 中設定 Fortran
G95 是 GNU Fortran 多架構編譯器,用於在 Windows 中設定 Fortran。Windows 版本使用 Windows 下的 MingW 模擬 Unix 環境。安裝程式會處理此問題並自動將 g95 新增到 Windows PATH 變數中。

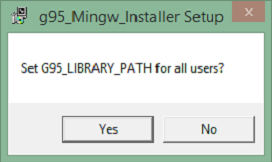
如何使用 G95
安裝過程中,如果您選擇“推薦”選項,則會自動將 **g95** 新增到您的 PATH 變數中。這意味著您可以簡單地開啟一個新的命令提示符視窗並鍵入“g95”以啟動編譯器。以下是一些基本命令,可幫助您入門。
| 序號 | 命令和說明 |
|---|---|
| 1 | g95 –c hello.f90 將 hello.f90 編譯成名為 hello.o 的目標檔案 |
| 2 | g95 hello.f90 編譯 hello.f90 並連結它以生成可執行檔案 a.out |
| 3 | g95 -c h1.f90 h2.f90 h3.f90 編譯多個原始檔。如果一切順利,將建立目標檔案 h1.o、h2.o 和 h3.o |
| 4 | g95 -o hello h1.f90 h2.f90 h3.f90 編譯多個原始檔並將它們連結到名為“hello”的可執行檔案中 |
G95 的命令列選項
-c Compile only, do not run the linker. -o Specify the name of the output file, either an object file or the executable.
可以一次指定多個原始檔和目標檔案。Fortran 檔案由以“.f”、“.F”、“.for”、“.FOR”、“.f90”、“.F90”、“.f95”、“.F95”、“.f03”和“.F03”結尾的名稱指示。可以指定多個原始檔。也可以指定目標檔案,並將它們連結以形成可執行檔案。
Fortran - 基本語法
Fortran 程式由程式單元的集合組成,例如主程式、模組和外部子程式或過程。
每個程式包含一個主程式,並且可以包含或不包含其他程式單元。主程式的語法如下:
program program_name implicit none ! type declaration statements ! executable statements end program program_name
Fortran 中的一個簡單程式
讓我們編寫一個程式來新增兩個數字並列印結果:
program addNumbers ! This simple program adds two numbers implicit none ! Type declarations real :: a, b, result ! Executable statements a = 12.0 b = 15.0 result = a + b print *, 'The total is ', result end program addNumbers
編譯並執行上述程式後,將產生以下結果:
The total is 27.0000000
請注意:
所有 Fortran 程式都以關鍵字 **program** 開頭,並以關鍵字 **end program,** 後跟程式名稱結尾。
**implicit none** 語句允許編譯器檢查所有變數型別是否已正確宣告。您必須始終在每個程式的開頭使用 **implicit none**。
Fortran 中的註釋以感嘆號 (!) 開頭,因為感嘆號之後的所有字元(字元字串除外)都被編譯器忽略。
**print *** 命令在螢幕上顯示資料。
程式碼行的縮排是保持程式可讀性的良好習慣。
Fortran 允許使用大寫和小寫字母。Fortran 不區分大小寫,但字串文字除外。
基礎知識
Fortran 的 **基本字元集** 包含:
- 字母 A ... Z 和 a ... z
- 數字 0 ... 9
- 下劃線 (_) 字元
- 特殊字元 = : + 空格 - * / ( ) [ ] , . $ ' ! " % & ; < > ?
**標記** 由基本字元集中的字元組成。標記可以是關鍵字、識別符號、常量、字串文字或符號。
程式語句由標記組成。
識別符號
識別符號是用於標識變數、過程或任何其他使用者定義項的名稱。Fortran 中的名稱必須遵循以下規則:
長度不能超過 31 個字元。
必須由字母數字字元(所有字母和數字 0 到 9)和下劃線 (_) 組成。
名稱的第一個字元必須是字母。
名稱不區分大小寫
關鍵字
關鍵字是為語言保留的特殊單詞。這些保留字不能用作識別符號或名稱。
下表列出了 Fortran 關鍵字:
| 非 I/O 關鍵字 | ||||
|---|---|---|---|---|
| allocatable | allocate | assign | assignment | block data |
| call | case | character | common | complex |
| contains | continue | cycle | data | deallocate |
| default | do | double precision | else | else if |
| elsewhere | end block data | end do | end function | end if |
| end interface | end module | end program | end select | end subroutine |
| end type | end where | entry | equivalence | exit |
| external | function | go to | if | implicit |
| in | inout | integer | intent | interface |
| intrinsic | kind | len | logical | module |
| namelist | nullify | only | operator | optional |
| out | parameter | pause | pointer | private |
| program | public | real | recursive | result |
| return | save | select case | stop | subroutine |
| target | then | type | type() | use |
| Where | While | |||
| I/O 相關關鍵字 | ||||
| backspace | close | endfile | format | inquire |
| open | read | rewind | Write | |
Fortran - 資料型別
Fortran 提供五種內在資料型別,但是,您也可以派生自己的資料型別。五種內在型別是:
- 整數型別
- 實數型別
- 複數型別
- 邏輯型別
- 字元型別
整數型別
整數型別只能儲存整數值。以下示例提取通常的四位元組整數中可以儲存的最大值:
program testingInt implicit none integer :: largeval print *, huge(largeval) end program testingInt
編譯並執行上述程式後,將產生以下結果:
2147483647
請注意,**huge()** 函式給出特定整數資料型別可以儲存的最大數字。您還可以使用 **kind** 說明符指定位元組數。以下示例演示了這一點:
program testingInt
implicit none
!two byte integer
integer(kind = 2) :: shortval
!four byte integer
integer(kind = 4) :: longval
!eight byte integer
integer(kind = 8) :: verylongval
!sixteen byte integer
integer(kind = 16) :: veryverylongval
!default integer
integer :: defval
print *, huge(shortval)
print *, huge(longval)
print *, huge(verylongval)
print *, huge(veryverylongval)
print *, huge(defval)
end program testingInt
編譯並執行上述程式後,將產生以下結果:
32767 2147483647 9223372036854775807 170141183460469231731687303715884105727 2147483647
實數型別
它儲存浮點數,例如 2.0、3.1415、-100.876 等。
傳統上,有兩種不同的實數型別,預設的 **real** 型別和 **double precision** 型別。
但是,Fortran 90/95 透過 **kind** 說明符提供了對實數和整數資料型別精度的更多控制,我們將在“數字”一章中學習。
以下示例顯示了實數資料型別的用法:
program division implicit none ! Define real variables real :: p, q, realRes ! Define integer variables integer :: i, j, intRes ! Assigning values p = 2.0 q = 3.0 i = 2 j = 3 ! floating point division realRes = p/q intRes = i/j print *, realRes print *, intRes end program division
編譯並執行上述程式後,將產生以下結果:
0.666666687 0
複數型別
這用於儲存複數。複數有兩個部分,實部和虛部。兩個連續的數值儲存單元儲存這兩個部分。
例如,複數 (3.0, -5.0) 等於 3.0 – 5.0i
我們將在“數字”一章中更詳細地討論複數型別。
邏輯型別
只有兩個邏輯值:**.true.** 和 **.false.**
字元型別
字元型別儲存字元和字串。字串的長度可以透過 len 說明符指定。如果未指定長度,則為 1。
例如:
character (len = 40) :: name name = “Zara Ali”
表示式 **name(1:4)** 將給出子字串“Zara”。
隱式型別
舊版本的 Fortran 允許一種稱為隱式型別的功能,即您不必在使用前宣告變數。如果未宣告變數,則其名稱的首字母將確定其型別。
以 i、j、k、l、m 或 n 開頭的變數名被認為是整數變數,其他變數是實數變數。但是,您必須宣告所有變數,因為這是良好的程式設計實踐。為此,您可以使用以下語句開始程式:
implicit none
此語句關閉隱式型別。
Fortran - 變數
變數只不過是賦予程式可以操作的儲存區域的名稱。每個變數都應該具有特定的型別,這決定了變數記憶體的大小和佈局;可以儲存在該記憶體中的值的範圍;以及可以應用於變數的操作集。
變數的名稱可以由字母、數字和下劃線字元組成。Fortran 中的名稱必須遵循以下規則:
長度不能超過 31 個字元。
必須由字母數字字元(所有字母和數字 0 到 9)和下劃線 (_) 組成。
名稱的第一個字元必須是字母。
名稱不區分大小寫。
基於上一章中解釋的基本型別,以下是變數型別:
| 序號 | 型別和說明 |
|---|---|
| 1 | 整數 它只能儲存整數值。 |
| 2 | 實數 它儲存浮點數。 |
| 3 | 複數 它用於儲存複數。 |
| 4 | 邏輯 它儲存邏輯布林值。 |
| 5 | 字元 它儲存字元或字串。 |
變數宣告
變數在程式(或子程式)開頭的型別宣告語句中宣告。
變數宣告的語法如下:
type-specifier :: variable_name
例如
integer :: total real :: average complex :: cx logical :: done character(len = 80) :: message ! a string of 80 characters
稍後您可以為這些變數賦值,例如:
total = 20000 average = 1666.67 done = .true. message = “A big Hello from Tutorials Point” cx = (3.0, 5.0) ! cx = 3.0 + 5.0i
您還可以使用內在函式 **cmplx** 為複數變數賦值:
cx = cmplx (1.0/2.0, -7.0) ! cx = 0.5 – 7.0i cx = cmplx (x, y) ! cx = x + yi
示例
下面的例子演示了變數的宣告、賦值和螢幕顯示。
program variableTesting implicit none ! declaring variables integer :: total real :: average complex :: cx logical :: done character(len=80) :: message ! a string of 80 characters !assigning values total = 20000 average = 1666.67 done = .true. message = "A big Hello from Tutorials Point" cx = (3.0, 5.0) ! cx = 3.0 + 5.0i Print *, total Print *, average Print *, cx Print *, done Print *, message end program variableTesting
當上述程式碼編譯並執行時,它會產生以下結果:
20000 1666.67004 (3.00000000, 5.00000000 ) T A big Hello from Tutorials Point
Fortran - 常量
常量是指程式在其執行過程中無法更改的固定值。這些固定值也稱為字面量。
常量可以是任何基本資料型別,例如整數常量、浮點常量、字元常量、複數常量或字串字面量。只有兩個邏輯常量:.true. 和 .false.
常量的處理方式與普通變數相同,只是它們的 值在定義後不能修改。
命名常量和字面量
常量有兩種型別:
- 字面常量
- 命名常量
字面常量有值,但沒有名稱。
例如,以下是字面常量:
| 型別 | 示例 |
|---|---|
| 整數常量 | 0 1 -1 300 123456789 |
| 實數常量 | 0.0 1.0 -1.0 123.456 7.1E+10 -52.715E-30 |
| 複數常量 | (0.0, 0.0) (-123.456E+30, 987.654E-29) |
| 邏輯常量 | .true. .false. |
| 字元常量 |
"PQR" "a" "123'abc$%#@!" " a quote "" " 'PQR' 'a' '123"abc$%#@!' ' an apostrophe '' ' |
命名常量既有值也有名稱。
命名常量應該在程式或過程的開頭宣告,就像變數型別宣告一樣,指明其名稱和型別。命名常量用引數屬性宣告。例如:
real, parameter :: pi = 3.1415927
示例
下面的程式計算重力作用下垂直運動的位移。
program gravitationalDisp ! this program calculates vertical motion under gravity implicit none ! gravitational acceleration real, parameter :: g = 9.81 ! variable declaration real :: s ! displacement real :: t ! time real :: u ! initial speed ! assigning values t = 5.0 u = 50 ! displacement s = u * t - g * (t**2) / 2 ! output print *, "Time = ", t print *, 'Displacement = ',s end program gravitationalDisp
當上述程式碼編譯並執行時,它會產生以下結果:
Time = 5.00000000 Displacement = 127.374992
Fortran - 運算子
運算子是一個符號,它告訴編譯器執行特定的數學或邏輯運算。Fortran 提供以下型別的運算子:
- 算術運算子
- 關係運算符
- 邏輯運算子
讓我們逐一看看這些型別的運算子。
算術運算子
下表顯示了 Fortran 支援的所有算術運算子。假設變數A為 5,變數B為 3,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| + | 加法運算子,將兩個運算元相加。 | A + B 將得到 8 |
| - | 減法運算子,從第一個運算元中減去第二個運算元。 | A - B 將得到 2 |
| * | 乘法運算子,將兩個運算元相乘。 | A * B 將得到 15 |
| / | 除法運算子,將分子除以分母。 | A / B 將得到 1 |
| ** | 冪運算子,將一個運算元提高到另一個運算元的冪。 | A ** B 將得到 125 |
關係運算符
下表顯示了 Fortran 支援的所有關係運算符。假設變數A為 10,變數B為 20,則:
| 運算子 | 等效 | 描述 | 示例 |
|---|---|---|---|
| == | .eq. | 檢查兩個運算元的值是否相等,如果相等,則條件變為真。 | (A == B) 為假。 |
| /= | .ne. | 檢查兩個運算元的值是否相等,如果不相等,則條件變為真。 | (A != B) 為真。 |
| > | .gt. | 檢查左邊運算元的值是否大於右邊運算元的值,如果是,則條件變為真。 | (A > B) 為假。 |
| < | .lt. | 檢查左邊運算元的值是否小於右邊運算元的值,如果是,則條件變為真。 | (A < B) 為真。 |
| >= | .ge. | 檢查左邊運算元的值是否大於或等於右邊運算元的值,如果是,則條件變為真。 | (A >= B) 為假。 |
| <= | .le. | 檢查左邊運算元的值是否小於或等於右邊運算元的值,如果是,則條件變為真。 | (A <= B) 為真。 |
邏輯運算子
Fortran 中的邏輯運算子僅適用於邏輯值 .true. 和 .false.
下表顯示了 Fortran 支援的所有邏輯運算子。假設變數 A 為 .true.,變數 B 為 .false.,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| .and. | 稱為邏輯與運算子。如果兩個運算元都不為零,則條件變為真。 | (A .and. B) 為假。 |
| .or. | 稱為邏輯或運算子。如果兩個運算元中的任何一個不為零,則條件變為真。 | (A .or. B) 為真。 |
| .not. | 稱為邏輯非運算子。用於反轉其運算元的邏輯狀態。如果條件為真,則邏輯非運算子將使其為假。 | !(A .and. B) 為真。 |
| .eqv. | 稱為邏輯等價運算子。用於檢查兩個邏輯值的等價性。 | (A .eqv. B) 為假。 |
| .neqv. | 稱為邏輯非等價運算子。用於檢查兩個邏輯值的非等價性。 | (A .neqv. B) 為真。 |
Fortran 中的運算子優先順序
運算子優先順序決定了表示式中項的組合方式。這會影響表示式的計算方式。某些運算子的優先順序高於其他運算子;例如,乘法運算子的優先順序高於加法運算子。
例如,x = 7 + 3 * 2;這裡,x 被賦值為 13,而不是 20,因為運算子 * 的優先順序高於 +,所以它首先與 3*2 相乘,然後加到 7 中。
這裡,優先順序最高的運算子出現在表的最上面,優先順序最低的出現在表的最下面。在一個表示式中,優先順序較高的運算子將首先被計算。
| 類別 | 運算子 | 結合性 |
|---|---|---|
| 邏輯非和負號 | .not. (-) | 從左到右 |
| 冪運算 | ** | 從左到右 |
| 乘法 | * / | 從左到右 |
| 加法 | + - | 從左到右 |
| 關係 | < <= > >= | 從左到右 |
| 相等 | == /= | 從左到右 |
| 邏輯與 | .and. | 從左到右 |
| 邏輯或 | .or. | 從左到右 |
| 賦值 | = | 從右到左 |
Fortran - 決策
決策結構要求程式設計師指定一個或多個條件供程式評估或測試,以及如果確定條件為真則要執行的語句(或語句組),以及可選地,如果條件確定為假則要執行的其他語句。
以下是大多數程式語言中常見的決策結構的一般形式:

Fortran 提供以下型別的決策結構。
| 序號 | 語句和描述 |
|---|---|
| 1 | If… then 結構
一個if… then… end if 語句由一個邏輯表示式和一個或多個語句組成。 |
| 2 | If… then...else 結構
一個if… then 語句可以後跟一個可選的else 語句,當邏輯表示式為假時執行。 |
| 3 | if...else if...else 語句
一個if 語句結構可以有一個或多個可選的else-if 結構。當if 條件失敗時,將執行緊跟其後的else-if。當else-if 也失敗時,將執行其後繼的else-if 語句(如果有),依此類推。 |
| 4 | 巢狀 if 結構
你可以在另一個if 或else if 語句中使用一個if 或else if 語句。 |
| 5 | select case 結構
一個select case 語句允許測試變數與值的列表是否相等。 |
| 6 | 巢狀 select case 結構
你可以在另一個select case 語句中使用一個select case 語句。 |
Fortran - 迴圈
可能存在這樣一種情況,你需要多次執行一段程式碼。一般來說,語句是順序執行的:函式中的第一個語句首先執行,然後是第二個語句,依此類推。
程式語言提供了各種控制結構,允許更復雜的執行路徑。
迴圈語句允許我們多次執行語句或語句組,以下是大多數程式語言中迴圈語句的一般形式:
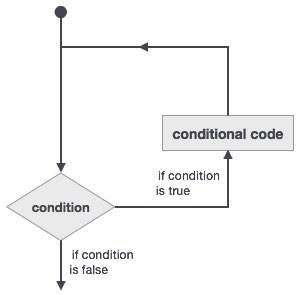
Fortran 提供以下型別的迴圈結構來處理迴圈需求。點選以下連結檢視其詳細資訊。
| 序號 | 迴圈型別和描述 |
|---|---|
| 1 | do 迴圈
此結構允許迭代地執行語句或一系列語句,同時給定的條件為真。 |
| 2 | do while 迴圈
在給定條件為真的情況下重複執行語句或語句組。它在執行迴圈體之前測試條件。 |
| 3 | 巢狀迴圈
你可以在任何其他迴圈結構中使用一個或多個迴圈結構。 |
迴圈控制語句
迴圈控制語句會改變執行的正常順序。當執行離開作用域時,在該作用域中建立的所有自動物件都會被銷燬。
Fortran 支援以下控制語句。點選以下連結檢視其詳細資訊。
| 序號 | 控制語句和描述 |
|---|---|
| 1 | exit
如果執行 exit 語句,則迴圈將退出,程式的執行將從 end do 語句後的第一個可執行語句繼續。 |
| 2 | cycle
如果執行 cycle 語句,程式將從下一次迭代的開始處繼續。 |
| 3 | stop
如果你希望程式的執行停止,可以插入 stop 語句。 |
Fortran - 數字
Fortran 中的數字由三種內在資料型別表示:
- 整數型別
- 實數型別
- 複數型別
整數型別
整數型別只能儲存整數值。下面的例子提取了通常的四位元組整數中可以儲存的最大值:
program testingInt implicit none integer :: largeval print *, huge(largeval) end program testingInt
編譯並執行上述程式後,將產生以下結果:
2147483647
請注意,huge() 函式給出特定整數資料型別可以容納的最大數字。你也可以使用kind 說明符指定位元組數。下面的例子演示了這一點:
program testingInt
implicit none
!two byte integer
integer(kind = 2) :: shortval
!four byte integer
integer(kind = 4) :: longval
!eight byte integer
integer(kind = 8) :: verylongval
!sixteen byte integer
integer(kind = 16) :: veryverylongval
!default integer
integer :: defval
print *, huge(shortval)
print *, huge(longval)
print *, huge(verylongval)
print *, huge(veryverylongval)
print *, huge(defval)
end program testingInt
編譯並執行上述程式後,將產生以下結果:
32767 2147483647 9223372036854775807 170141183460469231731687303715884105727 2147483647
實數型別
它儲存浮點數,例如 2.0、3.1415、-100.876 等。
傳統上,有兩種不同的實數型別:預設實數型別和雙精度型別。
但是,Fortran 90/95 透過kind 說明符提供了對實數和整數資料型別精度的更多控制,我們稍後將學習。
以下示例顯示了實數資料型別的用法:
program division implicit none ! Define real variables real :: p, q, realRes ! Define integer variables integer :: i, j, intRes ! Assigning values p = 2.0 q = 3.0 i = 2 j = 3 ! floating point division realRes = p/q intRes = i/j print *, realRes print *, intRes end program division
編譯並執行上述程式後,將產生以下結果:
0.666666687 0
複數型別
這用於儲存複數。複數有兩個部分:實部和虛部。兩個連續的數值儲存單元儲存這兩個部分。
例如,複數 (3.0, -5.0) 等於 3.0 – 5.0i
通用函式cmplx() 建立一個複數。它產生的結果的實部和虛部都是單精度,與輸入引數的型別無關。
program createComplex implicit none integer :: i = 10 real :: x = 5.17 print *, cmplx(i, x) end program createComplex
編譯並執行上述程式後,將產生以下結果:
(10.0000000, 5.17000008)
下面的程式演示了複數運算:
program ComplexArithmatic implicit none complex, parameter :: i = (0, 1) ! sqrt(-1) complex :: x, y, z x = (7, 8); y = (5, -7) write(*,*) i * x * y z = x + y print *, "z = x + y = ", z z = x - y print *, "z = x - y = ", z z = x * y print *, "z = x * y = ", z z = x / y print *, "z = x / y = ", z end program ComplexArithmatic
編譯並執行上述程式後,將產生以下結果:
(9.00000000, 91.0000000) z = x + y = (12.0000000, 1.00000000) z = x - y = (2.00000000, 15.0000000) z = x * y = (91.0000000, -9.00000000) z = x / y = (-0.283783793, 1.20270276)
數字的範圍、精度和大小
整數的範圍、浮點數的精度和大小取決於分配給特定資料型別的位數。
下表顯示了整數的位數和範圍:
| 位數 | 最大值 | 原因 |
|---|---|---|
| 64 | 9,223,372,036,854,774,807 | (2**63)–1 |
| 32 | 2,147,483,647 | (2**31)–1 |
下表顯示了實數的位數、最小值、最大值和精度。
| 位數 | 最大值 | 最小值 | 精度 |
|---|---|---|---|
| 64 | 0.8E+308 | 0.5E–308 | 15–18 |
| 32 | 1.7E+38 | 0.3E–38 | 6-9 |
下面的例子演示了這一點:
program rangePrecision implicit none real:: x, y, z x = 1.5e+40 y = 3.73e+40 z = x * y print *, z end program rangePrecision
編譯並執行上述程式後,將產生以下結果:
x = 1.5e+40
1
Error : Real constant overflows its kind at (1)
main.f95:5.12:
y = 3.73e+40
1
Error : Real constant overflows its kind at (1)
現在讓我們使用一個較小的數字:
program rangePrecision implicit none real:: x, y, z x = 1.5e+20 y = 3.73e+20 z = x * y print *, z z = x/y print *, z end program rangePrecision
編譯並執行上述程式後,將產生以下結果:
Infinity 0.402144760
現在讓我們看看下溢:
program rangePrecision implicit none real:: x, y, z x = 1.5e-30 y = 3.73e-60 z = x * y print *, z z = x/y print *, z end program rangePrecision
編譯並執行上述程式後,將產生以下結果:
y = 3.73e-60
1
Warning : Real constant underflows its kind at (1)
Executing the program....
$demo
0.00000000E+00
Infinity
Kind 說明符
在科學程式設計中,人們通常需要知道正在進行工作的硬體平臺的資料的範圍和精度。
內在函式kind() 允許你在執行程式之前查詢硬體資料表示的詳細資訊。
program kindCheck implicit none integer :: i real :: r complex :: cp print *,' Integer ', kind(i) print *,' Real ', kind(r) print *,' Complex ', kind(cp) end program kindCheck
編譯並執行上述程式後,將產生以下結果:
Integer 4 Real 4 Complex 4
你還可以檢查所有資料型別的 kind:
program checkKind implicit none integer :: i real :: r character :: c logical :: lg complex :: cp print *,' Integer ', kind(i) print *,' Real ', kind(r) print *,' Complex ', kind(cp) print *,' Character ', kind(c) print *,' Logical ', kind(lg) end program checkKind
編譯並執行上述程式後,將產生以下結果:
Integer 4 Real 4 Complex 4 Character 1 Logical 4
Fortran - 字元
Fortran 語言可以將字元視為單個字元或連續字串。
字元可以是來自基本字元集的任何符號,即來自字母、十進位制數字、下劃線和 21 個特殊字元。
字元常量是一個固定值的字元字串。
內在資料型別character儲存字元和字串。字串的長度可以透過len說明符指定。如果未指定長度,則為1。您可以透過位置引用字串中的單個字元;最左邊的字元位於位置1。
字元宣告
宣告字元型別資料與其他變數相同:
type-specifier :: variable_name
例如:
character :: reply, sex
您可以賦值,例如:
reply = ‘N’ sex = ‘F’
以下示例演示了字元資料型別的宣告和使用:
program hello implicit none character(len = 15) :: surname, firstname character(len = 6) :: title character(len = 25)::greetings title = 'Mr. ' firstname = 'Rowan ' surname = 'Atkinson' greetings = 'A big hello from Mr. Bean' print *, 'Here is ', title, firstname, surname print *, greetings end program hello
編譯並執行上述程式後,將產生以下結果:
Here is Mr. Rowan Atkinson A big hello from Mr. Bean
字元連線
連線運算子 // 連線字元。
以下示例演示了這一點:
program hello implicit none character(len = 15) :: surname, firstname character(len = 6) :: title character(len = 40):: name character(len = 25)::greetings title = 'Mr. ' firstname = 'Rowan ' surname = 'Atkinson' name = title//firstname//surname greetings = 'A big hello from Mr. Bean' print *, 'Here is ', name print *, greetings end program hello
編譯並執行上述程式後,將產生以下結果:
Here is Mr.Rowan Atkinson A big hello from Mr.Bean
一些字元函式
下表顯示了一些常用的字元函式及其描述:
| 序號 | 函式及描述 |
|---|---|
| 1 | len(string) 它返回字元字串的長度。 |
| 2 | index(string,substring) 它查詢子字串在另一個字串中的位置,如果未找到則返回 0。 |
| 3 | achar(int) 它將整數轉換為字元。 |
| 4 | iachar(c) 它將字元轉換為整數。 |
| 5 | trim(string) 它返回刪除了尾隨空格的字串。 |
| 6 | scan(string, chars) 它從左到右搜尋“string”(除非 back=.true.)以查詢“chars”中包含的任何字元的第一次出現。它返回一個整數,給出該字元的位置,如果未找到“chars”中的任何字元,則返回零。 |
| 7 | verify(string, chars) 它從左到右掃描“string”(除非 back=.true.)以查詢“chars”中不包含的任何字元的第一次出現。它返回一個整數,給出該字元的位置,如果只找到“chars”中的字元,則返回零。 |
| 8 | adjustl(string) 它左對齊“string”中包含的字元。 |
| 9 | adjustr(string) 它右對齊“string”中包含的字元。 |
| 10 | len_trim(string) 它返回一個整數,等於“string”的長度 (len(string)) 減去尾隨空格的數量。 |
| 11 | repeat(string,ncopy) 它返回一個字串,其長度等於“string”長度的“ncopy”倍,並且包含“ncopy”個連線的“string”副本。 |
示例 1
此示例顯示了index函式的使用:
program testingChars
implicit none
character (80) :: text
integer :: i
text = 'The intrinsic data type character stores characters and strings.'
i=index(text,'character')
if (i /= 0) then
print *, ' The word character found at position ',i
print *, ' in text: ', text
end if
end program testingChars
編譯並執行上述程式後,將產生以下結果:
The word character found at position 25 in text : The intrinsic data type character stores characters and strings.
示例 2
此示例演示了trim函式的使用:
program hello implicit none character(len = 15) :: surname, firstname character(len = 6) :: title character(len = 25)::greetings title = 'Mr.' firstname = 'Rowan' surname = 'Atkinson' print *, 'Here is', title, firstname, surname print *, 'Here is', trim(title),' ',trim(firstname),' ', trim(surname) end program hello
編譯並執行上述程式後,將產生以下結果:
Here isMr. Rowan Atkinson Here isMr. Rowan Atkinson
示例 3
此示例演示了achar函式的使用:
program testingChars
implicit none
character:: ch
integer:: i
do i = 65, 90
ch = achar(i)
print*, i, ' ', ch
end do
end program testingChars
編譯並執行上述程式後,將產生以下結果:
65 A 66 B 67 C 68 D 69 E 70 F 71 G 72 H 73 I 74 J 75 K 76 L 77 M 78 N 79 O 80 P 81 Q 82 R 83 S 84 T 85 U 86 V 87 W 88 X 89 Y 90 Z
檢查字元的詞法順序
以下函式確定字元的詞法順序:
| 序號 | 函式及描述 |
|---|---|
| 1 | lle(char, char) 比較第一個字元是否在詞法上小於或等於第二個字元。 |
| 2 | lge(char, char) 比較第一個字元是否在詞法上大於或等於第二個字元。 |
| 3 | lgt(char, char) 比較第一個字元是否在詞法上大於第二個字元。 |
| 4 | llt(char, char) 比較第一個字元是否在詞法上小於第二個字元。 |
示例 4
以下函式演示了其用法:
program testingChars
implicit none
character:: a, b, c
a = 'A'
b = 'a'
c = 'B'
if(lgt(a,b)) then
print *, 'A is lexically greater than a'
else
print *, 'a is lexically greater than A'
end if
if(lgt(a,c)) then
print *, 'A is lexically greater than B'
else
print *, 'B is lexically greater than A'
end if
if(llt(a,b)) then
print *, 'A is lexically less than a'
end if
if(llt(a,c)) then
print *, 'A is lexically less than B'
end if
end program testingChars
編譯並執行上述程式後,將產生以下結果:
a is lexically greater than A B is lexically greater than A A is lexically less than a A is lexically less than B
Fortran - 字串
Fortran 語言可以將字元視為單個字元或連續字串。
字元字串的長度可能只有一個字元,甚至可能是零長度。在 Fortran 中,字元常量用一對雙引號或單引號括起來。
內在資料型別character儲存字元和字串。字串的長度可以透過len 說明符指定。如果未指定長度,則為1。您可以透過位置引用字串中的單個字元;最左邊的字元位於位置1。
字串宣告
宣告字串與其他變數相同:
type-specifier :: variable_name
例如:
Character(len = 20) :: firstname, surname
您可以賦值,例如:
character (len = 40) :: name name = “Zara Ali”
以下示例演示了字元資料型別的宣告和使用:
program hello implicit none character(len = 15) :: surname, firstname character(len = 6) :: title character(len = 25)::greetings title = 'Mr.' firstname = 'Rowan' surname = 'Atkinson' greetings = 'A big hello from Mr. Beans' print *, 'Here is', title, firstname, surname print *, greetings end program hello
編譯並執行上述程式後,將產生以下結果:
Here isMr. Rowan Atkinson A big hello from Mr. Bean
字串連線
連線運算子 // 連線字串。
以下示例演示了這一點:
program hello implicit none character(len = 15) :: surname, firstname character(len = 6) :: title character(len = 40):: name character(len = 25)::greetings title = 'Mr.' firstname = 'Rowan' surname = 'Atkinson' name = title//firstname//surname greetings = 'A big hello from Mr. Beans' print *, 'Here is', name print *, greetings end program hello
編譯並執行上述程式後,將產生以下結果:
Here is Mr. Rowan Atkinson A big hello from Mr. Bean
提取子字串
在 Fortran 中,您可以透過對字串進行索引來從字串中提取子字串,在一對括號中給出子字串的起始和結束索引。這稱為範圍說明符。
以下示例演示如何從字串“hello world”中提取子字串“world”:
program subString character(len = 11)::hello hello = "Hello World" print*, hello(7:11) end program subString
編譯並執行上述程式後,將產生以下結果:
World
示例
以下示例使用date_and_time函式來給出日期和時間字串。我們使用範圍說明符分別提取年份、日期、月份、小時、分鐘和秒資訊。
program datetime implicit none character(len = 8) :: dateinfo ! ccyymmdd character(len = 4) :: year, month*2, day*2 character(len = 10) :: timeinfo ! hhmmss.sss character(len = 2) :: hour, minute, second*6 call date_and_time(dateinfo, timeinfo) ! let’s break dateinfo into year, month and day. ! dateinfo has a form of ccyymmdd, where cc = century, yy = year ! mm = month and dd = day year = dateinfo(1:4) month = dateinfo(5:6) day = dateinfo(7:8) print*, 'Date String:', dateinfo print*, 'Year:', year print *,'Month:', month print *,'Day:', day ! let’s break timeinfo into hour, minute and second. ! timeinfo has a form of hhmmss.sss, where h = hour, m = minute ! and s = second hour = timeinfo(1:2) minute = timeinfo(3:4) second = timeinfo(5:10) print*, 'Time String:', timeinfo print*, 'Hour:', hour print*, 'Minute:', minute print*, 'Second:', second end program datetime
編譯並執行上述程式時,它會提供詳細的日期和時間資訊:
Date String: 20140803 Year: 2014 Month: 08 Day: 03 Time String: 075835.466 Hour: 07 Minute: 58 Second: 35.466
修剪字串
trim函式接受一個字串,並在刪除所有尾隨空格後返回輸入字串。
示例
program trimString implicit none character (len = *), parameter :: fname="Susanne", sname="Rizwan" character (len = 20) :: fullname fullname = fname//" "//sname !concatenating the strings print*,fullname,", the beautiful dancer from the east!" print*,trim(fullname),", the beautiful dancer from the east!" end program trimString
編譯並執行上述程式後,將產生以下結果:
Susanne Rizwan , the beautiful dancer from the east! Susanne Rizwan, the beautiful dancer from the east!
字串的左對齊和右對齊
函式adjustl接受一個字串,並透過刪除前導空格並將它們附加為尾隨空格來返回它。
函式adjustr接受一個字串,並透過刪除尾隨空格並將它們附加為前導空格來返回它。
示例
program hello implicit none character(len = 15) :: surname, firstname character(len = 6) :: title character(len = 40):: name character(len = 25):: greetings title = 'Mr. ' firstname = 'Rowan' surname = 'Atkinson' greetings = 'A big hello from Mr. Beans' name = adjustl(title)//adjustl(firstname)//adjustl(surname) print *, 'Here is', name print *, greetings name = adjustr(title)//adjustr(firstname)//adjustr(surname) print *, 'Here is', name print *, greetings name = trim(title)//trim(firstname)//trim(surname) print *, 'Here is', name print *, greetings end program hello
編譯並執行上述程式後,將產生以下結果:
Here is Mr. Rowan Atkinson A big hello from Mr. Bean Here is Mr. Rowan Atkinson A big hello from Mr. Bean Here is Mr.RowanAtkinson A big hello from Mr. Bean
在字串中搜索子字串
index 函式接受兩個字串,並檢查第二個字串是否是第一個字串的子字串。如果第二個引數是第一個引數的子字串,則它返回一個整數,該整數是第二個字串在第一個字串中的起始索引,否則返回零。
示例
program hello
implicit none
character(len=30) :: myString
character(len=10) :: testString
myString = 'This is a test'
testString = 'test'
if(index(myString, testString) == 0)then
print *, 'test is not found'
else
print *, 'test is found at index: ', index(myString, testString)
end if
end program hello
編譯並執行上述程式後,將產生以下結果:
test is found at index: 11
Fortran - 陣列
陣列可以儲存相同型別元素的固定大小的順序集合。陣列用於儲存資料集合,但通常將陣列視為相同型別變數的集合更有用。
所有陣列都由連續的記憶體位置組成。最低地址對應於第一個元素,最高地址對應於最後一個元素。
| Numbers(1) | Numbers(2) | Numbers(3) | Numbers(4) | … |
陣列可以是一維的(如向量),二維的(如矩陣),Fortran 允許您建立最多 7 維的陣列。
宣告陣列
使用dimension屬性宣告陣列。
例如,要宣告一個名為 number 的一維陣列,其中包含 5 個實數元素,您可以這樣寫:
real, dimension(5) :: numbers
透過指定其下標來引用陣列的各個元素。陣列的第一個元素的下標為 1。陣列 numbers 包含五個實數變數——numbers(1)、numbers(2)、numbers(3)、numbers(4) 和 numbers(5)。
要建立一個名為 matrix 的 5 x 5 二維整數陣列,您可以這樣寫:
integer, dimension (5,5) :: matrix
您還可以宣告具有某些顯式下界的陣列,例如:
real, dimension(2:6) :: numbers integer, dimension (-3:2,0:4) :: matrix
賦值
您可以為各個成員賦值,例如:
numbers(1) = 2.0
或者,您可以使用迴圈:
do i =1,5 numbers(i) = i * 2.0 end do
可以使用簡寫符號(稱為陣列構造器)直接為一維陣列元素賦值,例如:
numbers = (/1.5, 3.2,4.5,0.9,7.2 /)
請注意,'(' 和 '/'之間不允許有空格。
示例
以下示例演示了上述概念。
program arrayProg
real :: numbers(5) !one dimensional integer array
integer :: matrix(3,3), i , j !two dimensional real array
!assigning some values to the array numbers
do i=1,5
numbers(i) = i * 2.0
end do
!display the values
do i = 1, 5
Print *, numbers(i)
end do
!assigning some values to the array matrix
do i=1,3
do j = 1, 3
matrix(i, j) = i+j
end do
end do
!display the values
do i=1,3
do j = 1, 3
Print *, matrix(i,j)
end do
end do
!short hand assignment
numbers = (/1.5, 3.2,4.5,0.9,7.2 /)
!display the values
do i = 1, 5
Print *, numbers(i)
end do
end program arrayProg
當上述程式碼編譯並執行時,它會產生以下結果:
2.00000000
4.00000000
6.00000000
8.00000000
10.0000000
2
3
4
3
4
5
4
5
6
1.50000000
3.20000005
4.50000000
0.899999976
7.19999981
一些與陣列相關的術語
下表給出了一些與陣列相關的術語:
| 術語 | 含義 |
|---|---|
| 秩 | 它是陣列的維度數。例如,對於名為 matrix 的陣列,秩為 2,對於名為 numbers 的陣列,秩為 1。 |
| 範圍 | 它是沿一個維度上的元素數。例如,陣列 numbers 的範圍為 5,名為 matrix 的陣列在兩個維度上的範圍均為 3。 |
| 形狀 | 陣列的形狀是一個一維整數陣列,包含每個維度中的元素數(範圍)。例如,對於陣列 matrix,形狀為 (3, 3),對於陣列 numbers,形狀為 (5)。 |
| 大小 | 它是陣列包含的元素數。對於陣列 matrix,它為 9,對於陣列 numbers,它為 5。 |
將陣列傳遞給過程
您可以將陣列作為引數傳遞給過程。以下示例演示了該概念:
program arrayToProcedure
implicit none
integer, dimension (5) :: myArray
integer :: i
call fillArray (myArray)
call printArray(myArray)
end program arrayToProcedure
subroutine fillArray (a)
implicit none
integer, dimension (5), intent (out) :: a
! local variables
integer :: i
do i = 1, 5
a(i) = i
end do
end subroutine fillArray
subroutine printArray(a)
integer, dimension (5) :: a
integer::i
do i = 1, 5
Print *, a(i)
end do
end subroutine printArray
當上述程式碼編譯並執行時,它會產生以下結果:
1 2 3 4 5
在上面的示例中,子程式 fillArray 和 printArray 只能用於維度為 5 的陣列。但是,要編寫可用於任何大小陣列的子程式,您可以使用以下技術重寫它:
program arrayToProcedure
implicit none
integer, dimension (10) :: myArray
integer :: i
interface
subroutine fillArray (a)
integer, dimension(:), intent (out) :: a
integer :: i
end subroutine fillArray
subroutine printArray (a)
integer, dimension(:) :: a
integer :: i
end subroutine printArray
end interface
call fillArray (myArray)
call printArray(myArray)
end program arrayToProcedure
subroutine fillArray (a)
implicit none
integer,dimension (:), intent (out) :: a
! local variables
integer :: i, arraySize
arraySize = size(a)
do i = 1, arraySize
a(i) = i
end do
end subroutine fillArray
subroutine printArray(a)
implicit none
integer,dimension (:) :: a
integer::i, arraySize
arraySize = size(a)
do i = 1, arraySize
Print *, a(i)
end do
end subroutine printArray
請注意,程式使用size函式來獲取陣列的大小。
當上述程式碼編譯並執行時,它會產生以下結果:
1 2 3 4 5 6 7 8 9 10
陣列節
到目前為止,我們已經引用了整個陣列,Fortran 提供了一種簡單的方法來使用單個語句引用多個元素或陣列的一部分。
要訪問陣列節,您需要為所有維度提供節的上下界以及步幅(增量)。此表示法稱為下標三元組:
array ([lower]:[upper][:stride], ...)
當未提及上下界時,它預設為您宣告的範圍,步幅值預設為 1。
以下示例演示了該概念:
program arraySubsection
real, dimension(10) :: a, b
integer:: i, asize, bsize
a(1:7) = 5.0 ! a(1) to a(7) assigned 5.0
a(8:) = 0.0 ! rest are 0.0
b(2:10:2) = 3.9
b(1:9:2) = 2.5
!display
asize = size(a)
bsize = size(b)
do i = 1, asize
Print *, a(i)
end do
do i = 1, bsize
Print *, b(i)
end do
end program arraySubsection
當上述程式碼編譯並執行時,它會產生以下結果:
5.00000000 5.00000000 5.00000000 5.00000000 5.00000000 5.00000000 5.00000000 0.00000000E+00 0.00000000E+00 0.00000000E+00 2.50000000 3.90000010 2.50000000 3.90000010 2.50000000 3.90000010 2.50000000 3.90000010 2.50000000 3.90000010
陣列內在函式
Fortran 90/95 提供了幾個內在過程。它們可以分為 7 類。
Fortran - 動態陣列
動態陣列是一個數組,其大小在編譯時未知,但在執行時將已知。
動態陣列用屬性allocatable宣告。
例如:
real, dimension (:,:), allocatable :: darray
必須提到陣列的秩,即維度,但是要為這樣的陣列分配記憶體,您使用allocate函式。
allocate ( darray(s1,s2) )
在程式中使用陣列後,應使用deallocate函式釋放建立的記憶體。
deallocate (darray)
示例
以下示例演示了上述概念。
program dynamic_array
implicit none
!rank is 2, but size not known
real, dimension (:,:), allocatable :: darray
integer :: s1, s2
integer :: i, j
print*, "Enter the size of the array:"
read*, s1, s2
! allocate memory
allocate ( darray(s1,s2) )
do i = 1, s1
do j = 1, s2
darray(i,j) = i*j
print*, "darray(",i,",",j,") = ", darray(i,j)
end do
end do
deallocate (darray)
end program dynamic_array
當上述程式碼編譯並執行時,它會產生以下結果:
Enter the size of the array: 3,4 darray( 1 , 1 ) = 1.00000000 darray( 1 , 2 ) = 2.00000000 darray( 1 , 3 ) = 3.00000000 darray( 1 , 4 ) = 4.00000000 darray( 2 , 1 ) = 2.00000000 darray( 2 , 2 ) = 4.00000000 darray( 2 , 3 ) = 6.00000000 darray( 2 , 4 ) = 8.00000000 darray( 3 , 1 ) = 3.00000000 darray( 3 , 2 ) = 6.00000000 darray( 3 , 3 ) = 9.00000000 darray( 3 , 4 ) = 12.0000000
資料語句的使用
data語句可用於初始化多個數組或用於陣列節初始化。
data 語句的語法如下:
data variable / list / ...
示例
以下示例演示了該概念:
program dataStatement
implicit none
integer :: a(5), b(3,3), c(10),i, j
data a /7,8,9,10,11/
data b(1,:) /1,1,1/
data b(2,:)/2,2,2/
data b(3,:)/3,3,3/
data (c(i),i = 1,10,2) /4,5,6,7,8/
data (c(i),i = 2,10,2)/5*2/
Print *, 'The A array:'
do j = 1, 5
print*, a(j)
end do
Print *, 'The B array:'
do i = lbound(b,1), ubound(b,1)
write(*,*) (b(i,j), j = lbound(b,2), ubound(b,2))
end do
Print *, 'The C array:'
do j = 1, 10
print*, c(j)
end do
end program dataStatement
當上述程式碼編譯並執行時,它會產生以下結果:
The A array:
7
8
9
10
11
The B array:
1 1 1
2 2 2
3 3 3
The C array:
4
2
5
2
6
2
7
2
8
2
Where語句的使用
where語句允許您根據某些邏輯條件的結果在表示式中使用陣列的某些元素。如果給定條件為真,則允許在元素上執行表示式。
示例
以下示例演示了該概念:
program whereStatement
implicit none
integer :: a(3,5), i , j
do i = 1,3
do j = 1, 5
a(i,j) = j-i
end do
end do
Print *, 'The A array:'
do i = lbound(a,1), ubound(a,1)
write(*,*) (a(i,j), j = lbound(a,2), ubound(a,2))
end do
where( a<0 )
a = 1
elsewhere
a = 5
end where
Print *, 'The A array:'
do i = lbound(a,1), ubound(a,1)
write(*,*) (a(i,j), j = lbound(a,2), ubound(a,2))
end do
end program whereStatement
當上述程式碼編譯並執行時,它會產生以下結果:
The A array:
0 1 2 3 4
-1 0 1 2 3
-2 -1 0 1 2
The A array:
5 5 5 5 5
1 5 5 5 5
1 1 5 5 5
Fortran - 派生資料型別
Fortran 允許您定義派生資料型別。派生資料型別也稱為結構,它可以由不同型別的資料物件組成。
派生資料型別用於表示記錄。例如,如果您想跟蹤圖書館中書籍的資訊,您可能想跟蹤每本書的以下屬性:
- 標題
- 作者
- 主題
- 圖書 ID
定義派生資料型別
要定義派生型別,使用 type 和end type語句。。type 語句定義一個新的資料型別,為您的程式提供多個成員。type 語句的格式如下:
type type_name declarations end type
以下是您宣告 Book 結構的方式:
type Books character(len = 50) :: title character(len = 50) :: author character(len = 150) :: subject integer :: book_id end type Books
訪問結構成員
派生資料型別的一個物件被稱為結構體。
可以在型別宣告語句中建立一個 Books 型別的結構體,例如:
type(Books) :: book1
可以使用元件選擇符字元 (%) 來訪問結構體的元件。
book1%title = "C Programming" book1%author = "Nuha Ali" book1%subject = "C Programming Tutorial" book1%book_id = 6495407
請注意,% 符號前後沒有空格。
示例
下面的程式演示了上述概念:
program deriveDataType
!type declaration
type Books
character(len = 50) :: title
character(len = 50) :: author
character(len = 150) :: subject
integer :: book_id
end type Books
!declaring type variables
type(Books) :: book1
type(Books) :: book2
!accessing the components of the structure
book1%title = "C Programming"
book1%author = "Nuha Ali"
book1%subject = "C Programming Tutorial"
book1%book_id = 6495407
book2%title = "Telecom Billing"
book2%author = "Zara Ali"
book2%subject = "Telecom Billing Tutorial"
book2%book_id = 6495700
!display book info
Print *, book1%title
Print *, book1%author
Print *, book1%subject
Print *, book1%book_id
Print *, book2%title
Print *, book2%author
Print *, book2%subject
Print *, book2%book_id
end program deriveDataType
當上述程式碼編譯並執行時,它會產生以下結果:
C Programming Nuha Ali C Programming Tutorial 6495407 Telecom Billing Zara Ali Telecom Billing Tutorial 6495700
結構體陣列
您還可以建立派生型別的陣列:
type(Books), dimension(2) :: list
可以按如下方式訪問陣列的各個元素:
list(1)%title = "C Programming" list(1)%author = "Nuha Ali" list(1)%subject = "C Programming Tutorial" list(1)%book_id = 6495407
下面的程式演示了這個概念:
program deriveDataType
!type declaration
type Books
character(len = 50) :: title
character(len = 50) :: author
character(len = 150) :: subject
integer :: book_id
end type Books
!declaring array of books
type(Books), dimension(2) :: list
!accessing the components of the structure
list(1)%title = "C Programming"
list(1)%author = "Nuha Ali"
list(1)%subject = "C Programming Tutorial"
list(1)%book_id = 6495407
list(2)%title = "Telecom Billing"
list(2)%author = "Zara Ali"
list(2)%subject = "Telecom Billing Tutorial"
list(2)%book_id = 6495700
!display book info
Print *, list(1)%title
Print *, list(1)%author
Print *, list(1)%subject
Print *, list(1)%book_id
Print *, list(1)%title
Print *, list(2)%author
Print *, list(2)%subject
Print *, list(2)%book_id
end program deriveDataType
當上述程式碼編譯並執行時,它會產生以下結果:
C Programming Nuha Ali C Programming Tutorial 6495407 C Programming Zara Ali Telecom Billing Tutorial 6495700
Fortran - 指標
在大多數程式語言中,指標變數儲存物件的記憶體地址。但是,在 Fortran 中,指標是一個數據物件,其功能不僅僅是儲存記憶體地址。它包含有關特定物件的更多資訊,例如型別、秩、範圍和記憶體地址。
指標透過分配或指標賦值與目標關聯。
宣告指標變數
指標變數是用指標屬性宣告的。
以下示例顯示了指標變數的宣告:
integer, pointer :: p1 ! pointer to integer real, pointer, dimension (:) :: pra ! pointer to 1-dim real array real, pointer, dimension (:,:) :: pra2 ! pointer to 2-dim real array
指標可以指向:
動態分配的記憶體區域。
與指標型別相同的具有 **target** 屬性的資料物件。
為指標分配空間
**allocate** 語句允許您為指標物件分配空間。例如:
program pointerExample implicit none integer, pointer :: p1 allocate(p1) p1 = 1 Print *, p1 p1 = p1 + 4 Print *, p1 end program pointerExample
當上述程式碼編譯並執行時,它會產生以下結果:
1 5
當不再需要分配的儲存空間時,應使用 **deallocate** 語句將其清空,避免積累未使用的和不可用的記憶體空間。
目標和關聯
目標是另一個普通變數,為此變數預留了空間。目標變數必須用 **target** 屬性宣告。
您可以使用關聯運算子 (=>) 將指標變數與目標變數關聯。
讓我們重寫前面的示例,以演示此概念:
program pointerExample implicit none integer, pointer :: p1 integer, target :: t1 p1=>t1 p1 = 1 Print *, p1 Print *, t1 p1 = p1 + 4 Print *, p1 Print *, t1 t1 = 8 Print *, p1 Print *, t1 end program pointerExample
當上述程式碼編譯並執行時,它會產生以下結果:
1 1 5 5 8 8
指標可以:
- 未定義
- 已關聯
- 已解除關聯
在上面的程式中,我們使用 => 運算子將指標 p1 與目標 t1 關聯。associated 函式測試指標的關聯狀態。
**nullify** 語句將指標與目標解除關聯。
nullify 不會清空目標,因為可能有多個指標指向同一個目標。但是,清空指標也意味著取消關聯。
示例 1
以下示例演示了這些概念:
program pointerExample implicit none integer, pointer :: p1 integer, target :: t1 integer, target :: t2 p1=>t1 p1 = 1 Print *, p1 Print *, t1 p1 = p1 + 4 Print *, p1 Print *, t1 t1 = 8 Print *, p1 Print *, t1 nullify(p1) Print *, t1 p1=>t2 Print *, associated(p1) Print*, associated(p1, t1) Print*, associated(p1, t2) !what is the value of p1 at present Print *, p1 Print *, t2 p1 = 10 Print *, p1 Print *, t2 end program pointerExample
當上述程式碼編譯並執行時,它會產生以下結果:
1 1 5 5 8 8 8 T F T 952754640 952754640 10 10
請注意,每次執行程式碼時,記憶體地址都會不同。
示例 2
program pointerExample implicit none integer, pointer :: a, b integer, target :: t integer :: n t = 1 a => t t = 2 b => t n = a + b Print *, a, b, t, n end program pointerExample
當上述程式碼編譯並執行時,它會產生以下結果:
2 2 2 4
Fortran - 基本輸入輸出
到目前為止,我們已經看到可以使用 **read *** 語句從鍵盤讀取資料,並分別使用 **print *** 語句將輸出顯示到螢幕上。這種形式的輸入輸出是 **自由格式** I/O,稱為 **列表定向** 輸入輸出。
自由格式簡單 I/O 的形式為:
read(*,*) item1, item2, item3... print *, item1, item2, item3 write(*,*) item1, item2, item3...
但是,格式化 I/O 為您提供了更多關於資料傳輸的靈活性。
格式化輸入輸出
格式化輸入輸出的語法如下:
read fmt, variable_list print fmt, variable_list write fmt, variable_list
其中:
fmt 是格式說明
變數列表是從鍵盤讀取或寫入螢幕的變數列表
格式說明定義了格式化資料顯示的方式。它由一個字串組成,該字串包含括號中的一系列 **編輯描述符**。
**編輯描述符** 指定精確的格式,例如寬度、小數點後的位數等,字元和數字以這種格式顯示。
例如
Print "(f6.3)", pi
下表描述了描述符:
| 描述符 | 描述 | 示例 |
|---|---|---|
| I | 用於整數輸出。其形式為“rIw.m”,其中 r、w 和 m 的含義在下表中給出。整數在其欄位中右對齊。如果欄位寬度不足以容納整數,則欄位將填充星號。 |
print "(3i5)", i, j, k |
| F | 用於實數輸出。其形式為“rFw.d”,其中 r、w 和 d 的含義在下表中給出。實數值在其欄位中右對齊。如果欄位寬度不足以容納實數,則欄位將填充星號。 |
print "(f12.3)",pi |
| E | 用於以指數表示法進行實數輸出。“E”描述符語句的形式為“rEw.d”,其中 r、w 和 d 的含義在下表中給出。實數值在其欄位中右對齊。如果欄位寬度不足以容納實數,則欄位將填充星號。 請注意,要打印出具有三位小數的實數,至少需要十位欄位寬度。一位用於尾數的符號,兩位用於零,四位用於尾數,兩位用於指數本身。一般來說,w ≥ d + 7。 |
print "(e10.3)",123456.0 gives ‘0.123e+06’ |
| ES | 用於實數輸出(科學計數法)。其形式為“rESw.d”,其中 r、w 和 d 的含義在下表中給出。“E”描述符與上面描述的傳統且眾所周知的“科學計數法”略有不同。科學計數法的尾數範圍為 1.0 到 10.0,而 E 描述符的尾數範圍為 0.1 到 1.0。實數值在其欄位中右對齊。如果欄位寬度不足以容納實數,則欄位將填充星號。這裡也必須滿足表示式 w ≥ d + 7。 |
print "(es10.3)",123456.0 gives ‘1.235e+05’ |
| A | 用於字元輸出。其形式為“rAw”,其中 r 和 w 的含義在下表中給出。字元型別在其欄位中右對齊。如果欄位寬度不足以容納字串,則欄位將填充字串的前“w”個字元。 |
print "(a10)", str |
| X | 用於空格輸出。其形式為“nX”,其中“n”是所需空格數。 |
print "(5x, a10)", str |
| / | 斜槓描述符 - 用於插入空行。其形式為“/”,並強制將下一個資料輸出放在新行上。 |
print "(/,5x, a10)", str |
以下符號用於格式描述符:
| 序號 | 符號 & 描述 |
|---|---|
| 1 | c 列號 |
| 2 | d 實數輸入或輸出小數點右邊的位數 |
| 3 | m 要顯示的最小位數 |
| 4 | n 要跳過的空格數 |
| 5 | r 重複計數 - 使用描述符或描述符組的次數 |
| 6 | w 欄位寬度 - 用於輸入或輸出的字元數 |
示例 1
program printPi pi = 3.141592653589793238 Print "(f6.3)", pi Print "(f10.7)", pi Print "(f20.15)", pi Print "(e16.4)", pi/100 end program printPi
當上述程式碼編譯並執行時,它會產生以下結果:
3.142 3.1415927 3.141592741012573 0.3142E-01
示例 2
program printName implicit none character (len = 15) :: first_name print *,' Enter your first name.' print *,' Up to 20 characters, please' read *,first_name print "(1x,a)",first_name end program printName
編譯並執行上述程式碼時,將產生以下結果:(假設使用者輸入名稱 Zara)
Enter your first name. Up to 20 characters, please Zara
示例 3
program formattedPrint implicit none real :: c = 1.2786456e-9, d = 0.1234567e3 integer :: n = 300789, k = 45, i = 2 character (len=15) :: str="Tutorials Point" print "(i6)", k print "(i6.3)", k print "(3i10)", n, k, i print "(i10,i3,i5)", n, k, i print "(a15)",str print "(f12.3)", d print "(e12.4)", c print '(/,3x,"n = ",i6, 3x, "d = ",f7.4)', n, d end program formattedPrint
當上述程式碼編譯並執行時,它會產生以下結果:
45 045 300789 45 2 300789 45 2 Tutorials Point 123.457 0.1279E-08 n = 300789 d = *******
格式語句
格式語句允許您在一個語句中混合和匹配字元、整數和實數輸出。以下示例演示了這一點:
program productDetails implicit none character (len = 15) :: name integer :: id real :: weight name = 'Ardupilot' id = 1 weight = 0.08 print *,' The product details are' print 100 100 format (7x,'Name:', 7x, 'Id:', 1x, 'Weight:') print 200, name, id, weight 200 format(1x, a, 2x, i3, 2x, f5.2) end program productDetails
當上述程式碼編譯並執行時,它會產生以下結果:
The product details are Name: Id: Weight: Ardupilot 1 0.08
Fortran - 檔案輸入輸出
Fortran 允許您從檔案讀取資料並將資料寫入檔案。
在上一章中,您已經瞭解瞭如何從終端讀取資料以及如何將資料寫入終端。在本章中,您將學習 Fortran 提供的檔案輸入和輸出功能。
您可以讀取和寫入一個或多個檔案。OPEN、WRITE、READ 和 CLOSE 語句允許您實現此目的。
開啟和關閉檔案
在使用檔案之前,必須先開啟檔案。**open** 命令用於開啟用於讀取或寫入的檔案。該命令的最簡單形式為:
open (unit = number, file = "name").
但是,open 語句可能具有通用形式:
open (list-of-specifiers)
下表描述了最常用的說明符:
| 序號 | 說明符 & 描述 |
|---|---|
| 1 | [UNIT=] u 單元號 u 可以是 9-99 範圍內的任何數字,它指示檔案,您可以選擇任何數字,但程式中每個開啟的檔案都必須具有唯一的數字 |
| 2 | IOSTAT= ios 它是 I/O 狀態識別符號,應該是整數變數。如果 open 語句成功,則返回的 ios 值為零,否則為非零值。 |
| 3 | ERR = err 這是一個標籤,在發生任何錯誤時,控制權將跳轉到該標籤。 |
| 4 | FILE = fname 檔名,一個字元字串。 |
| 5 | STATUS = sta 它顯示檔案的先前狀態。一個字元字串,可以具有三個值之一:NEW、OLD 或 SCRATCH。臨時檔案在關閉或程式結束時建立和刪除。 |
| 6 | ACCESS = acc 它是檔案訪問模式。可以具有兩個值之一:SEQUENTIAL 或 DIRECT。預設為 SEQUENTIAL。 |
| 7 | FORM = frm 它給出檔案的格式狀態。可以具有兩個值之一:FORMATTED 或 UNFORMATTED。預設為 UNFORMATTED |
| 8 | RECL = rl 它指定直接訪問檔案中每個記錄的長度。 |
開啟檔案後,可以透過 read 和 write 語句訪問它。完成後,應使用 **close** 語句將其關閉。
close 語句的語法如下:
close ([UNIT = ]u[,IOSTAT = ios,ERR = err,STATUS = sta])
請注意,括號中的引數是可選的。
示例
此示例演示了開啟一個新檔案以將一些資料寫入檔案。
program outputdata
implicit none
real, dimension(100) :: x, y
real, dimension(100) :: p, q
integer :: i
! data
do i=1,100
x(i) = i * 0.1
y(i) = sin(x(i)) * (1-cos(x(i)/3.0))
end do
! output data into a file
open(1, file = 'data1.dat', status = 'new')
do i=1,100
write(1,*) x(i), y(i)
end do
close(1)
end program outputdata
編譯並執行上述程式碼時,它將建立檔案 data1.dat 並將 x 和 y 陣列值寫入其中。然後關閉檔案。
從檔案讀取和寫入檔案
read 和 write 語句分別用於從檔案讀取和寫入檔案。
它們的語法如下:
read ([UNIT = ]u, [FMT = ]fmt, IOSTAT = ios, ERR = err, END = s) write([UNIT = ]u, [FMT = ]fmt, IOSTAT = ios, ERR = err, END = s)
上表中已經討論了大多數說明符。
END = s 說明符是一個語句標籤,當程式到達檔案結尾時,程式將跳轉到該標籤。
示例
此示例演示了從檔案讀取和寫入檔案。
本程式讀取我們在上一例中建立的檔案 data1.dat,並在螢幕上顯示其內容。
program outputdata
implicit none
real, dimension(100) :: x, y
real, dimension(100) :: p, q
integer :: i
! data
do i = 1,100
x(i) = i * 0.1
y(i) = sin(x(i)) * (1-cos(x(i)/3.0))
end do
! output data into a file
open(1, file = 'data1.dat', status='new')
do i = 1,100
write(1,*) x(i), y(i)
end do
close(1)
! opening the file for reading
open (2, file = 'data1.dat', status = 'old')
do i = 1,100
read(2,*) p(i), q(i)
end do
close(2)
do i = 1,100
write(*,*) p(i), q(i)
end do
end program outputdata
當上述程式碼編譯並執行時,它會產生以下結果:
0.100000001 5.54589933E-05 0.200000003 4.41325130E-04 0.300000012 1.47636665E-03 0.400000006 3.45637114E-03 0.500000000 6.64328877E-03 0.600000024 1.12552457E-02 0.699999988 1.74576249E-02 0.800000012 2.53552198E-02 0.900000036 3.49861123E-02 1.00000000 4.63171229E-02 1.10000002 5.92407547E-02 1.20000005 7.35742599E-02 1.30000007 8.90605897E-02 1.39999998 0.105371222 1.50000000 0.122110792 1.60000002 0.138823599 1.70000005 0.155002072 1.80000007 0.170096487 1.89999998 0.183526158 2.00000000 0.194692180 2.10000014 0.202990443 2.20000005 0.207826138 2.29999995 0.208628103 2.40000010 0.204863414 2.50000000 0.196052119 2.60000014 0.181780845 2.70000005 0.161716297 2.79999995 0.135617107 2.90000010 0.103344671 3.00000000 6.48725405E-02 3.10000014 2.02930309E-02 3.20000005 -3.01767997E-02 3.29999995 -8.61928314E-02 3.40000010 -0.147283033 3.50000000 -0.212848678 3.60000014 -0.282169819 3.70000005 -0.354410470 3.79999995 -0.428629100 3.90000010 -0.503789663 4.00000000 -0.578774154 4.09999990 -0.652400017 4.20000029 -0.723436713 4.30000019 -0.790623367 4.40000010 -0.852691114 4.50000000 -0.908382416 4.59999990 -0.956472993 4.70000029 -0.995793998 4.80000019 -1.02525222 4.90000010 -1.04385209 5.00000000 -1.05071592 5.09999990 -1.04510069 5.20000029 -1.02641726 5.30000019 -0.994243503 5.40000010 -0.948338211 5.50000000 -0.888650239 5.59999990 -0.815326691 5.70000029 -0.728716135 5.80000019 -0.629372001 5.90000010 -0.518047631 6.00000000 -0.395693362 6.09999990 -0.263447165 6.20000029 -0.122622721 6.30000019 2.53026206E-02 6.40000010 0.178709000 6.50000000 0.335851669 6.59999990 0.494883657 6.70000029 0.653881252 6.80000019 0.810866773 6.90000010 0.963840425 7.00000000 1.11080539 7.09999990 1.24979746 7.20000029 1.37891412 7.30000019 1.49633956 7.40000010 1.60037732 7.50000000 1.68947268 7.59999990 1.76223695 7.70000029 1.81747139 7.80000019 1.85418403 7.90000010 1.87160957 8.00000000 1.86922085 8.10000038 1.84674001 8.19999981 1.80414569 8.30000019 1.74167395 8.40000057 1.65982044 8.50000000 1.55933595 8.60000038 1.44121361 8.69999981 1.30668485 8.80000019 1.15719533 8.90000057 0.994394958 9.00000000 0.820112705 9.10000038 0.636327863 9.19999981 0.445154816 9.30000019 0.248800844 9.40000057 4.95488606E-02 9.50000000 -0.150278628 9.60000038 -0.348357052 9.69999981 -0.542378068 9.80000019 -0.730095863 9.90000057 -0.909344316 10.0000000 -1.07807255
Fortran - 過程
過程(procedure)是一組執行特定任務的語句,可以從程式中呼叫。資訊(或資料)作為引數傳遞給呼叫程式。
過程有兩種型別:
- 函式 (Functions)
- 子程式 (Subroutines)
函式 (Function)
函式是一個返回單個值的程式。函式不應修改其引數。
返回的值稱為函式值 (function value),用函式名錶示。
語法 (Syntax)
函式的語法如下:
function name(arg1, arg2, ....) [declarations, including those for the arguments] [executable statements] end function [name]
以下示例演示了一個名為 area_of_circle 的函式。它計算半徑為 r 的圓的面積。
program calling_func real :: a a = area_of_circle(2.0) Print *, "The area of a circle with radius 2.0 is" Print *, a end program calling_func ! this function computes the area of a circle with radius r function area_of_circle (r) ! function result implicit none ! dummy arguments real :: area_of_circle ! local variables real :: r real :: pi pi = 4 * atan (1.0) area_of_circle = pi * r**2 end function area_of_circle
編譯並執行上述程式後,將產生以下結果:
The area of a circle with radius 2.0 is 12.5663710
請注意:
您必須在主程式和過程中都指定implicit none。
被呼叫函式中的引數 r 稱為啞元引數 (dummy argument)。
結果選項 (The result Option)
如果您希望將返回值儲存在函式名以外的其他名稱中,可以使用result選項。
您可以指定返回變數名如下:
function name(arg1, arg2, ....) result (return_var_name) [declarations, including those for the arguments] [executable statements] end function [name]
子程式 (Subroutine)
子程式不返回值,但可以修改其引數。
語法 (Syntax)
subroutine name(arg1, arg2, ....) [declarations, including those for the arguments] [executable statements] end subroutine [name]
呼叫子程式 (Calling a Subroutine)
您需要使用call語句呼叫子程式。
以下示例演示了子程式 swap 的定義和使用,它更改其引數的值。
program calling_func implicit none real :: a, b a = 2.0 b = 3.0 Print *, "Before calling swap" Print *, "a = ", a Print *, "b = ", b call swap(a, b) Print *, "After calling swap" Print *, "a = ", a Print *, "b = ", b end program calling_func subroutine swap(x, y) implicit none real :: x, y, temp temp = x x = y y = temp end subroutine swap
編譯並執行上述程式後,將產生以下結果:
Before calling swap a = 2.00000000 b = 3.00000000 After calling swap a = 3.00000000 b = 2.00000000
指定引數的意圖 (Specifying the Intent of the Arguments)
intent 屬性允許您指定在過程中使用引數的意圖。下表提供了 intent 屬性的值:
| 值 (Value) | 用作 (Used as) | 解釋 (Explanation) |
|---|---|---|
| in | intent(in) | 用作輸入值,函式中不會更改 |
| out | intent(out) | 用作輸出值,會被覆蓋 |
| inout | intent(inout) | 引數既被使用又被覆蓋 |
以下示例演示了該概念:
program calling_func implicit none real :: x, y, z, disc x = 1.0 y = 5.0 z = 2.0 call intent_example(x, y, z, disc) Print *, "The value of the discriminant is" Print *, disc end program calling_func subroutine intent_example (a, b, c, d) implicit none ! dummy arguments real, intent (in) :: a real, intent (in) :: b real, intent (in) :: c real, intent (out) :: d d = b * b - 4.0 * a * c end subroutine intent_example
編譯並執行上述程式後,將產生以下結果:
The value of the discriminant is 17.0000000
遞迴過程 (Recursive Procedures)
當程式語言允許您在同一函式內呼叫函式時,就會發生遞迴。這稱為函式的遞迴呼叫。
當一個過程直接或間接地呼叫自身時,稱為遞迴過程。您應該透過在其宣告前加上recursive關鍵字來宣告此類過程。
當函式遞迴使用時,必須使用result選項。
以下是一個示例,它使用遞迴過程計算給定數字的階乘:
program calling_func
implicit none
integer :: i, f
i = 15
Print *, "The value of factorial 15 is"
f = myfactorial(15)
Print *, f
end program calling_func
! computes the factorial of n (n!)
recursive function myfactorial (n) result (fac)
! function result
implicit none
! dummy arguments
integer :: fac
integer, intent (in) :: n
select case (n)
case (0:1)
fac = 1
case default
fac = n * myfactorial (n-1)
end select
end function myfactorial
內部過程 (Internal Procedures)
當過程包含在程式中時,稱為程式的內部過程。包含內部過程的語法如下:
program program_name implicit none ! type declaration statements ! executable statements . . . contains ! internal procedures . . . end program program_name
以下示例演示了該概念:
program mainprog
implicit none
real :: a, b
a = 2.0
b = 3.0
Print *, "Before calling swap"
Print *, "a = ", a
Print *, "b = ", b
call swap(a, b)
Print *, "After calling swap"
Print *, "a = ", a
Print *, "b = ", b
contains
subroutine swap(x, y)
real :: x, y, temp
temp = x
x = y
y = temp
end subroutine swap
end program mainprog
編譯並執行上述程式後,將產生以下結果:
Before calling swap a = 2.00000000 b = 3.00000000 After calling swap a = 3.00000000 b = 2.00000000
Fortran - 模組
模組就像一個包,您可以將函式和子程式儲存在其中,如果您正在編寫一個非常大的程式,或者您的函式或子程式可以在多個程式中使用。
模組提供了一種在多個檔案之間分割程式的方法。
模組用於:
打包子程式、資料和介面塊。
定義可被多個例程使用的全域性資料。
宣告可以在您選擇的任何例程中使用的變數。
匯入整個模組以在另一個程式或子程式中使用。
模組的語法 (Syntax of a Module)
模組由兩部分組成:
- 宣告語句的說明部分
- 包含子程式和函式定義的部分
模組的一般形式如下:
module name [statement declarations] [contains [subroutine and function definitions] ] end module [name]
在程式中使用模組 (Using a Module into your Program)
您可以透過 use 語句將模組包含到程式或子程式中:
use name
請注意
您可以根據需要新增多個模組,每個模組都將儲存在單獨的檔案中並單獨編譯。
一個模組可以在不同的程式中使用。
一個模組可以在同一個程式中多次使用。
在模組說明部分宣告的變數對於該模組是全域性的。
在模組中宣告的變數成為使用該模組的任何程式或例程中的全域性變數。
use 語句可以出現在主程式或任何其他使用在特定模組中宣告的例程或變數的子程式或模組中。
示例
以下示例演示了該概念:
module constants
implicit none
real, parameter :: pi = 3.1415926536
real, parameter :: e = 2.7182818285
contains
subroutine show_consts()
print*, "Pi = ", pi
print*, "e = ", e
end subroutine show_consts
end module constants
program module_example
use constants
implicit none
real :: x, ePowerx, area, radius
x = 2.0
radius = 7.0
ePowerx = e ** x
area = pi * radius**2
call show_consts()
print*, "e raised to the power of 2.0 = ", ePowerx
print*, "Area of a circle with radius 7.0 = ", area
end program module_example
編譯並執行上述程式後,將產生以下結果:
Pi = 3.14159274 e = 2.71828175 e raised to the power of 2.0 = 7.38905573 Area of a circle with radius 7.0 = 153.938049
模組中變數和子程式的可訪問性 (Accessibility of Variables and Subroutines in a Module)
預設情況下,use語句使模組中的所有變數和子程式都可用於使用模組程式碼的程式。
但是,您可以使用private和public屬性來控制模組程式碼的可訪問性。當您將某些變數或子程式宣告為 private 時,它在模組外部不可用。
示例
以下示例說明了這個概念:
在前面的示例中,我們有兩個模組變數e和pi。讓我們將它們設為 private 並觀察輸出:
module constants
implicit none
real, parameter,private :: pi = 3.1415926536
real, parameter, private :: e = 2.7182818285
contains
subroutine show_consts()
print*, "Pi = ", pi
print*, "e = ", e
end subroutine show_consts
end module constants
program module_example
use constants
implicit none
real :: x, ePowerx, area, radius
x = 2.0
radius = 7.0
ePowerx = e ** x
area = pi * radius**2
call show_consts()
print*, "e raised to the power of 2.0 = ", ePowerx
print*, "Area of a circle with radius 7.0 = ", area
end program module_example
編譯並執行上述程式時,會顯示以下錯誤訊息:
ePowerx = e ** x 1 Error: Symbol 'e' at (1) has no IMPLICIT type main.f95:19.13: area = pi * radius**2 1 Error: Symbol 'pi' at (1) has no IMPLICIT type
由於e和pi都被宣告為 private,程式 module_example 無法再訪問這些變數。
但是,其他模組子程式可以訪問它們:
module constants
implicit none
real, parameter,private :: pi = 3.1415926536
real, parameter, private :: e = 2.7182818285
contains
subroutine show_consts()
print*, "Pi = ", pi
print*, "e = ", e
end subroutine show_consts
function ePowerx(x)result(ePx)
implicit none
real::x
real::ePx
ePx = e ** x
end function ePowerx
function areaCircle(r)result(a)
implicit none
real::r
real::a
a = pi * r**2
end function areaCircle
end module constants
program module_example
use constants
implicit none
call show_consts()
Print*, "e raised to the power of 2.0 = ", ePowerx(2.0)
print*, "Area of a circle with radius 7.0 = ", areaCircle(7.0)
end program module_example
編譯並執行上述程式後,將產生以下結果:
Pi = 3.14159274 e = 2.71828175 e raised to the power of 2.0 = 7.38905573 Area of a circle with radius 7.0 = 153.938049
Fortran - 內在函式
內在函式是一些常用且重要的函式,作為 Fortran 語言的一部分提供。我們已經在陣列、字元和字串章節中討論了其中一些函式。
內在函式可以分為:
- 數值函式 (Numeric Functions)
- 數學函式 (Mathematical Functions)
- 數值查詢函式 (Numeric Inquiry Functions)
- 浮點運算函式 (Floating-Point Manipulation Functions)
- 位操作函式 (Bit Manipulation Functions)
- 字元函式 (Character Functions)
- 型別函式 (Kind Functions)
- 邏輯函式 (Logical Functions)
- 陣列函式 (Array Functions)。
我們在陣列章節中討論了陣列函式。在下一節中,我們將簡要介紹其他類別中的所有這些函式。
在函式名列中:
- A 代表任何型別的數值變數
- R 代表實數或整數變數
- X 和 Y 代表實數變數
- Z 代表複數變數
- W 代表實數或複數變數
數值函式 (Numeric Functions)
| 序號 | 函式及描述 |
|---|---|
| 1 | ABS (A) 返回 A 的絕對值 |
| 2 | AIMAG (Z) 返回複數 Z 的虛部 |
| 3 | AINT (A [, KIND]) 將 A 的小數部分向零截斷,返回一個實數整數。 |
| 4 | ANINT (A [, KIND]) 返回一個實數值,最接近的整數。 |
| 5 | CEILING (A [, KIND]) 返回大於或等於數字 A 的最小整數。 |
| 6 | CMPLX (X [, Y, KIND]) 將實數變數 X 和 Y 轉換為複數 X+iY;如果 Y 缺失,則使用 0。 |
| 7 | CONJG (Z) 返回任何複數 Z 的共軛複數。 |
| 8 | DBLE (A) 將 A 轉換為雙精度實數。 |
| 9 | DIM (X, Y) 返回 X 和 Y 的正差。 |
| 10 | DPROD (X, Y) 返回 X 和 Y 的雙精度實數乘積。 |
| 11 | FLOOR (A [, KIND]) 返回小於或等於數字 A 的最大整數。 |
| 12 | INT (A [, KIND]) 將數字(實數或整數)轉換為整數,將實數部分向零截斷。 |
| 13 | MAX (A1, A2 [, A3,...]) 返回引數中的最大值,所有引數型別相同。 |
| 14 | MIN (A1, A2 [, A3,...]) 返回引數中的最小值,所有引數型別相同。 |
| 15 | MOD (A, P) 返回 A 除以 P 的餘數,兩個引數型別相同 (A-INT(A/P)*P) |
| 16 | MODULO (A, P) 返回 A 模 P:(A-FLOOR(A/P)*P) |
| 17 | NINT (A [, KIND]) 返回數字 A 的最接近整數 |
| 18 | REAL (A [, KIND]) 轉換為實數型別 |
| 19 | SIGN (A, B) 返回 A 的絕對值乘以 P 的符號。基本上它將 B 的符號轉移到 A。 |
示例
program numericFunctions
implicit none
! define constants
! define variables
real :: a, b
complex :: z
! values for a, b
a = 15.2345
b = -20.7689
write(*,*) 'abs(a): ',abs(a),' abs(b): ',abs(b)
write(*,*) 'aint(a): ',aint(a),' aint(b): ',aint(b)
write(*,*) 'ceiling(a): ',ceiling(a),' ceiling(b): ',ceiling(b)
write(*,*) 'floor(a): ',floor(a),' floor(b): ',floor(b)
z = cmplx(a, b)
write(*,*) 'z: ',z
end program numericFunctions
編譯並執行上述程式後,將產生以下結果:
abs(a): 15.2344999 abs(b): 20.7688999 aint(a): 15.0000000 aint(b): -20.0000000 ceiling(a): 16 ceiling(b): -20 floor(a): 15 floor(b): -21 z: (15.2344999, -20.7688999)
數學函式 (Mathematical Functions)
| 序號 | 函式及描述 |
|---|---|
| 1 | ACOS (X) 返回範圍 (0, π) 內的反餘弦值,以弧度表示。 |
| 2 | ASIN (X) 返回範圍 (-π/2, π/2) 內的反正弦值,以弧度表示。 |
| 3 | ATAN (X) 返回範圍 (-π/2, π/2) 內的反正切值,以弧度表示。 |
| 4 | ATAN2 (Y, X) 返回範圍 (-π, π) 內的反正切值,以弧度表示。 |
| 5 | COS (X) 返回以弧度表示的自變數的餘弦值。 |
| 6 | COSH (X) 返回以弧度表示的自變數的雙曲餘弦值。 |
| 7 | EXP (X) 返回 X 的指數值。 |
| 8 | LOG (X) 返回 X 的自然對數值。 |
| 9 | LOG10 (X) 返回 X 的常用對數值(以 10 為底)。 |
| 10 | SIN (X) 返回以弧度表示的自變數的正弦值。 |
| 11 | SINH (X) 返回以弧度表示的自變數的雙曲正弦值。 |
| 12 | SQRT (X) 返回 X 的平方根。 |
| 13 | TAN (X) 返回以弧度表示的自變數的正切值。 |
| 14 | TANH (X) 返回以弧度表示的自變數的雙曲正切值。 |
示例
下面的程式計算彈丸在時間 t 後的水平位置 x 和垂直位置 y:
其中,x = u t cos a 和 y = u t sin a - g t2 / 2
program projectileMotion implicit none ! define constants real, parameter :: g = 9.8 real, parameter :: pi = 3.1415927 !define variables real :: a, t, u, x, y !values for a, t, and u a = 45.0 t = 20.0 u = 10.0 ! convert angle to radians a = a * pi / 180.0 x = u * cos(a) * t y = u * sin(a) * t - 0.5 * g * t * t write(*,*) 'x: ',x,' y: ',y end program projectileMotion
編譯並執行上述程式後,將產生以下結果:
x: 141.421356 y: -1818.57861
數值查詢函式 (Numeric Inquiry Functions)
這些函式使用某種整數和浮點運算模型。函式返回與變數 X 型別相同的數字屬性,X 可以是實數,在某些情況下是整數。
| 序號 | 函式及描述 |
|---|---|
| 1 | DIGITS (X) 返回模型的有效數字位數。 |
| 2 | EPSILON (X) 返回與 1 相比幾乎可以忽略不計的數字。換句話說,它返回最小的值,使得 REAL( 1.0, KIND(X)) + EPSILON(X) 不等於 REAL( 1.0, KIND(X))。 |
| 3 | HUGE (X) 返回模型的最大數。 |
| 4 | MAXEXPONENT (X) 返回模型的最大指數。 |
| 5 | MINEXPONENT (X) 返回模型的最小指數。 |
| 6 | PRECISION (X) 返回十進位制精度。 |
| 7 | RADIX (X) 返回模型的基數。 |
| 8 | RANGE (X) 返回十進位制指數範圍。 |
| 9 | TINY (X) 返回模型中最小的正數。 |
浮點運算函式 (Floating-Point Manipulation Functions)
| 序號 | 函式及描述 |
|---|---|
| 1 | EXPONENT (X) 返回模型數的指數部分。 |
| 2 | FRACTION (X) 返回數字的小數部分。 |
| 3 | NEAREST (X, S) 返回給定方向上最接近的不同處理器數字。 |
| 4 | RRSPACING (X) 返回給定數字附近模型數字的相對間距的倒數。 |
| 5 | SCALE (X, I) 將實數乘以其基數的整數次冪。 |
| 6 | SET_EXPONENT (X, I) 返回數字的指數部分。 |
| 7 | SPACING (X) 返回給定數字附近模型數字的絕對間距。 |
位操作函式 (Bit Manipulation Functions)
| 序號 | 函式及描述 |
|---|---|
| 1 | BIT_SIZE (I) 返回模型的位數。 |
| 2 | BTEST (I, POS) 位測試 |
| 3 | IAND (I, J) 邏輯與 |
| 4 | IBCLR (I, POS) 清除位 |
| 5 | IBITS (I, POS, LEN) 位提取 |
| 6 | IBSET (I, POS) 設定位 |
| 7 | IEOR (I, J) 異或 |
| 8 | IOR (I, J) 或 |
| 9 | ISHFT (I, SHIFT) 邏輯移位 |
| 10 | ISHFTC (I, SHIFT [, SIZE]) 迴圈移位 |
| 11 | NOT (I) 邏輯非 |
字元函式 (Character Functions)
| 序號 | 函式及描述 |
|---|---|
| 1 | ACHAR (I) 返回 ASCII 排序序列中的第 I 個字元。 |
| 2 | ADJUSTL (STRING) 透過刪除所有前導空格並插入尾隨空格來左對齊字串。 |
| 3 | ADJUSTR (STRING) 透過刪除尾隨空格並插入前導空格來右對齊字串。 |
| 4 | CHAR (I [, KIND]) 返回機器特定的排序序列中的第 I 個字元。 |
| 5 | IACHAR (C) 返回字元在 ASCII 排序序列中的位置。 |
| 6 | ICHAR (C) 它返回字元在機器(處理器)特定排序順序中的位置。 |
| 7 | INDEX (STRING, SUBSTRING [, BACK]) 它返回 SUBSTRING 在 STRING 中最左邊(如果 BACK 為 .TRUE.,則為最右邊)的起始位置。 |
| 8 | LEN (STRING) 它返回字串的長度。 |
| 9 | LEN_TRIM (STRING) 它返回字串的長度,不包括尾隨的空格字元。 |
| 10 | LGE (STRING_A, STRING_B) 字典序大於或等於 |
| 11 | LGT (STRING_A, STRING_B) 字典序大於 |
| 12 | LLE (STRING_A, STRING_B) 字典序小於或等於 |
| 13 | LLT (STRING_A, STRING_B) 字典序小於 |
| 14 | REPEAT (STRING, NCOPIES) 重複連線 |
| 15 | SCAN (STRING, SET [, BACK]) 它返回 STRING 中屬於 SET 的最左邊(如果 BACK 為 .TRUE.,則為最右邊)字元的索引,如果都不屬於則返回 0。 |
| 16 | TRIM (STRING) 刪除尾隨空格字元 |
| 17 | VERIFY (STRING, SET [, BACK]) 驗證字串中的一組字元 |
型別函式 (Kind Functions)
| 序號 | 函式及描述 |
|---|---|
| 1 | KIND (X) 它返回型別引數值。 |
| 2 | SELECTED_INT_KIND (R) 它返回指定指數範圍的型別引數。 |
| 3 | SELECTED_REAL_KIND ([P, R]) 給定精度和範圍的實數型別引數值 |
邏輯函式
| 序號 | 函式及描述 |
|---|---|
| 1 | LOGICAL (L [, KIND]) 在具有不同型別引數的邏輯型別物件之間轉換 |
Fortran - 數值精度
我們已經討論過,在較舊版本的 Fortran 中,有兩種**實數**型別:預設實數型別和**雙精度**型別。
然而,Fortran 90/95 透過**kind**說明符提供了對實數和整數資料型別精度的更多控制。
Kind 屬性
不同型別的數字在計算機中的儲存方式不同。**kind**屬性允許您指定數字在內部的儲存方式。例如,
real, kind = 2 :: a, b, c real, kind = 4 :: e, f, g integer, kind = 2 :: i, j, k integer, kind = 3 :: l, m, n
在上面的宣告中,實數變數 e、f 和 g 比實數變數 a、b 和 c 具有更高的精度。整數變數 l、m 和 n 可以儲存更大的值,並且比整數變數 i、j 和 k 具有更多的儲存位數。儘管這取決於機器。
示例
program kindSpecifier implicit none real(kind = 4) :: a, b, c real(kind = 8) :: e, f, g integer(kind = 2) :: i, j, k integer(kind = 4) :: l, m, n integer :: kind_a, kind_i, kind_e, kind_l kind_a = kind(a) kind_i = kind(i) kind_e = kind(e) kind_l = kind(l) print *,'default kind for real is', kind_a print *,'default kind for int is', kind_i print *,'extended kind for real is', kind_e print *,'default kind for int is', kind_l end program kindSpecifier
編譯並執行上述程式後,將產生以下結果:
default kind for real is 4 default kind for int is 2 extended kind for real is 8 default kind for int is 4
查詢變數的大小
有一些內在函式允許您查詢數字的大小。
例如,**bit_size(i)** 內在函式指定用於儲存的位數。對於實數,**precision(x)** 內在函式返回十進位制精度的位數,而 **range(x)** 內在函式返回指數的十進位制範圍。
示例
program getSize implicit none real (kind = 4) :: a real (kind = 8) :: b integer (kind = 2) :: i integer (kind = 4) :: j print *,'precision of real(4) =', precision(a) print *,'precision of real(8) =', precision(b) print *,'range of real(4) =', range(a) print *,'range of real(8) =', range(b) print *,'maximum exponent of real(4) =' , maxexponent(a) print *,'maximum exponent of real(8) =' , maxexponent(b) print *,'minimum exponent of real(4) =' , minexponent(a) print *,'minimum exponent of real(8) =' , minexponent(b) print *,'bits in integer(2) =' , bit_size(i) print *,'bits in integer(4) =' , bit_size(j) end program getSize
編譯並執行上述程式後,將產生以下結果:
precision of real(4) = 6 precision of real(8) = 15 range of real(4) = 37 range of real(8) = 307 maximum exponent of real(4) = 128 maximum exponent of real(8) = 1024 minimum exponent of real(4) = -125 minimum exponent of real(8) = -1021 bits in integer(2) = 16 bits in integer(4) = 32
獲取 Kind 值
Fortran 提供了另外兩個內在函式來獲取所需整數和實數精度的 kind 值:
- selected_int_kind (r)
- selected_real_kind ([p, r])
selected_real_kind 函式返回一個整數,該整數是給定十進位制精度 p 和十進位制指數範圍 r 所需的 kind 型別引數值。十進位制精度是有效數字的位數,十進位制指數範圍指定可表示的最小和最大數字。因此,範圍是從 10-r 到 10+r。
例如,selected_real_kind (p = 10, r = 99) 返回實現 10 位十進位制精度和至少 10-99 到 10+99 範圍所需的 kind 值。
示例
program getKind implicit none integer:: i i = selected_real_kind (p = 10, r = 99) print *,'selected_real_kind (p = 10, r = 99)', i end program getKind
編譯並執行上述程式後,將產生以下結果:
selected_real_kind (p = 10, r = 99) 8
Fortran - 程式庫
有各種 Fortran 工具和庫。有些是免費的,有些是付費服務。
以下是一些免費庫:
- RANDLIB,隨機數和統計分佈生成器
- BLAS
- EISPACK
- GAMS–NIST 可用數學軟體指南
- NIST 的一些統計和其他例程
- LAPACK
- LINPACK
- MINPACK
- MUDPACK
- NCAR 數學庫
- Netlib 數學軟體、論文和資料庫集合。
- ODEPACK
- ODERPACK,一組用於排序和排列的例程。
- Expokit 用於計算矩陣指數
- SLATEC
- SPECFUN
- STARPAC
- StatLib 統計庫
- TOMS
- 字串排序和合並
以下庫不是免費的:
- NAG Fortran 數值庫
- Visual Numerics IMSL 庫
- 數值方法
Fortran - 程式設計風格
程式設計風格是關於在開發程式時遵循某些規則。這些良好的實踐賦予程式可讀性和清晰性。
一個好的程式應該具有以下特點:
- 可讀性
- 正確的邏輯結構
- 自解釋的註釋
例如,如果您新增如下注釋,它不會有太大幫助:
! loop from 1 to 10 do i = 1,10
但是,如果您正在計算二項式係數,並且需要此迴圈用於 nCr,那麼這樣的註釋將很有幫助:
! loop to calculate nCr do i = 1,10
縮排的程式碼塊,使不同級別的程式碼清晰易懂。
自檢程式碼,以確保不會出現數值錯誤,例如除以零、負實數的平方根或負實數的對數。
包含確保變數不會取非法值或超出範圍值的程式碼,即輸入驗證。
不要在不必要的地方新增檢查,這會降低執行速度。例如:
real :: x x = sin(y) + 1.0 if (x >= 0.0) then z = sqrt(x) end if
- 使用合適的演算法編寫清晰的程式碼。
- 使用續行符“&”分割長表示式。
- 使用有意義的變數名。
Fortran - 程式除錯
除錯工具用於查詢程式中的錯誤。
除錯程式逐步執行程式碼,並允許您在程式執行期間檢查變數和其他資料物件的值。
它載入原始碼,您應該在偵錯程式中執行程式。偵錯程式透過以下方式除錯程式:
- 設定斷點
- 單步執行原始碼
- 設定監視點。
斷點指定程式應該停止的位置,具體是在一段關鍵程式碼之後。在檢查斷點處的變數後,程式執行。
除錯程式也逐行檢查原始碼。
監視點是在需要檢查某些變數的值的點,尤其是在讀寫操作之後。
gdb 偵錯程式
gdb 偵錯程式(GNU 偵錯程式)隨 Linux 作業系統一起提供。對於 X 視窗系統,gdb 帶有圖形介面,程式名為 xxgdb。
下表提供了一些 gdb 命令:
| 命令 | 用途 |
|---|---|
| break | 設定斷點 |
| run | 開始執行 |
| cont | 繼續執行 |
| next | 僅執行下一行原始碼,不進入任何函式呼叫 |
| step | 執行下一行原始碼,如果發生函式呼叫則進入函式。 |
dbx 偵錯程式
還有一個偵錯程式,dbx 偵錯程式,用於 Linux。
下表提供了一些 dbx 命令:
| 命令 | 用途 |
|---|---|
| stop[var] | 當變數 var 的值發生變化時設定斷點。 |
| stop in [proc] | 進入過程 proc 時停止執行 |
| stop at [line] | 在指定行設定斷點。 |
| run | 開始執行。 |
| cont | 繼續執行。 |
| next | 僅執行下一行原始碼,不進入任何函式呼叫。 |
| step | 執行下一行原始碼,如果發生函式呼叫則進入函式。 |