- DocumentDB SQL 教程
- DocumentDB SQL - 首頁
- DocumentDB SQL - 概述
- DocumentDB SQL - SELECT 語句
- DocumentDB SQL - FROM 語句
- DocumentDB SQL - WHERE 語句
- DocumentDB SQL - 運算子
- DocumentDB - BETWEEN 關鍵字
- DocumentDB SQL - IN 關鍵字
- DocumentDB SQL - VALUE 關鍵字
- DocumentDB SQL - ORDER BY 語句
- DocumentDB SQL - 迭代
- DocumentDB SQL - 連線
- DocumentDB SQL - 別名
- DocumentDB SQL - 陣列建立
- DocumentDB - 標量表達式
- DocumentDB SQL - 引數化
- DocumentDB SQL - 內建函式
- LINQ to SQL 轉換
- JavaScript 整合
- 使用者自定義函式
- 複合 SQL 查詢
- DocumentDB SQL 有用資源
- DocumentDB SQL - 快速指南
- DocumentDB SQL - 有用資源
- DocumentDB SQL - 討論
DocumentDB SQL - 快速指南
DocumentDB SQL - 概述
DocumentDB 是微軟最新的 NoSQL 文件資料庫平臺,執行在 Azure 上。在本教程中,我們將學習有關使用 DocumentDB 支援的 SQL 特殊版本查詢文件的所有內容。
NoSQL 文件資料庫
DocumentDB 是微軟最新的 NoSQL 文件資料庫,但是,當我們說 NoSQL 文件資料庫時,我們究竟指的是 NoSQL 和文件資料庫?
SQL 代表結構化查詢語言,它是關係資料庫的傳統查詢語言。SQL 通常等同於關係資料庫。
將 NoSQL 資料庫視為非關係資料庫更有幫助,因此 NoSQL 實際上意味著非關係型。
NoSQL 資料庫有不同的型別,包括鍵值儲存,例如 -
- Azure 表儲存
- 基於列的儲存,例如 Cassandra
- 圖形資料庫,例如 NEO4
- 文件資料庫,例如 MongoDB 和 Azure DocumentDB
為什麼使用 SQL 語法?
這乍一看可能很奇怪,但在 DocumentDB(一個 NoSQL 資料庫)中,我們使用 SQL 進行查詢。如上所述,這是基於 JSON 和 JavaScript 語義的 SQL 的特殊版本。
SQL 僅僅是一種語言,但它也是一種非常流行的語言,功能豐富且表達力強。因此,使用某種 SQL 方言而不是想出一種全新的查詢表達方式似乎是一個好主意,如果要從資料庫中獲取文件,則需要學習這種新方式。
SQL 是為關係資料庫設計的,而 DocumentDB 是非關係型文件資料庫。DocumentDB 團隊實際上已經為文件資料庫的非關係型世界改編了 SQL 語法,這就是將 SQL 根植於 JSON 和 JavaScript 的含義。
該語言的讀取方式仍然與熟悉的 SQL 相似,但語義都基於無模式的 JSON 文件,而不是關係表。在 DocumentDB 中,我們將使用 JavaScript 資料型別而不是 SQL 資料型別。我們將熟悉 SELECT、FROM、WHERE 等,但使用 JavaScript 型別,這些型別僅限於數字和字串、物件、陣列、布林值和 null,比 SQL 資料型別的廣泛範圍少得多。
類似地,表示式將作為 JavaScript 表示式而不是某種形式的 T-SQL 進行計算。例如,在非規範化資料的世界中,我們不處理行和列,而是處理包含巢狀陣列和物件的層次結構的無模式文件。
SQL 是如何工作的?
DocumentDB 團隊已經以多種創新方式回答了這個問題。其中一些列出如下 -
首先,假設您沒有更改預設行為以自動為文件中的每個屬性建立索引,您可以在查詢中使用點表示法來導航到任何屬性的路徑,無論它在文件中巢狀多深。
您還可以執行文件內聯接,其中巢狀陣列元素與其父元素在文件內聯接,方式與在關係世界中兩個表之間執行聯接的方式非常相似。
您的查詢可以按原樣從資料庫中返回文件,或者您可以根據您想要的部分或全部文件資料投射任何自定義 JSON 形狀。
DocumentDB 中的 SQL 支援許多常用運算子,包括 -
算術和位運算
AND 和 OR 邏輯
相等和範圍比較
字串連線
查詢語言還支援大量內建函式。
DocumentDB SQL - SELECT 語句
Azure 門戶有一個查詢資源管理器,允許我們對 DocumentDB 資料庫執行任何 SQL 查詢。我們將使用查詢資源管理器來演示查詢語言的許多不同功能和特性,從最簡單的查詢開始。
步驟 1 - 開啟 Azure 門戶,並在資料庫刀片中,單擊查詢資源管理器刀片。

請記住,查詢在集合的範圍內執行,因此查詢資源管理器允許我們在此下拉列表中選擇集合。我們將保持其設定為我們的 Families 集合,其中包含三個文件。讓我們在此示例中考慮這三個文件。
以下是 AndersenFamily 文件。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是 SmithFamily 文件。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是 WakefieldFamily 文件。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
查詢資源管理器以這個簡單的查詢 SELECT * FROM c 開啟,它只是從集合中檢索所有文件。雖然它很簡單,但它仍然與關係資料庫中的等效查詢大不相同。
步驟 2 - 在關係資料庫中,SELECT * 表示返回所有列,而在 DocumentDB 中。這意味著您希望結果中的每個文件都按其在資料庫中的儲存方式返回。
但是,當您選擇特定的屬性和表示式而不是簡單地發出 SELECT * 時,您就會為結果中的每個文件投射一個新的形狀。
步驟 3 - 單擊“執行”以執行查詢並開啟結果刀片。

可以看到檢索了 WakefieldFamily、SmithFamily 和 AndersonFamily。
以下是作為 SELECT * FROM c 查詢結果檢索到的三個文件。
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "SmithFamily",
"parents": [
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{
"givenName": "Tweetie",
"type": "Bird"
}
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEDAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEDAAAAAAAAAA==/",
"_etag": "\"00000600-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
"givenName": "Fluffy",
"type": "Rabbit"
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]
但是,這些結果還包括以下劃線字元為字首的所有系統生成的屬性。
DocumentDB SQL - FROM 語句
在本章中,我們將介紹 FROM 語句,它的工作原理與常規 SQL 中的標準 FROM 語句完全不同。
查詢始終在特定集合的上下文中執行,並且不能跨集合中的文件進行聯接,這讓我們想知道為什麼我們需要 FROM 語句。事實上,我們不需要,但如果我們不包含它,那麼我們將無法查詢集合中的文件。
此語句的目的是指定查詢必須在其上執行的資料來源。通常整個集合都是源,但可以指定集合的子集。除非源在查詢的後面被過濾或投影,否則 FROM <from_specification> 語句是可選的。
讓我們再看一下同一個例子。以下是 AndersenFamily 文件。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是 SmithFamily 文件。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是 WakefieldFamily 文件。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}

在上面的查詢中,“SELECT * FROM c”表示整個 Families 集合是列舉的源。
子文件
源也可以縮減到較小的子集。當我們只想檢索每個文件中的一個子樹時,子根可以成為源,如下例所示。

當我們執行以下查詢時 -
SELECT * FROM Families.parents
將檢索以下子文件。
[
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
[
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
[
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
]
]
由於此查詢的結果,我們可以看到只檢索了 parents 子文件。
DocumentDB SQL - WHERE 語句
在本章中,我們將介紹 WHERE 語句,它與 FROM 語句一樣是可選的。它用於在檢索源提供的 JSON 文件形式的資料時指定條件。任何 JSON 文件都必須評估指定的條件為“true”才能被視為結果。如果滿足給定的條件,則僅返回 JSON 文件形式的特定資料。我們可以使用 WHERE 語句過濾記錄並僅獲取必要的記錄。
我們將在本例中考慮相同的三個文件。以下是 AndersenFamily 文件。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是 SmithFamily 文件。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是 WakefieldFamily 文件。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
讓我們看一個使用 WHERE 語句的簡單示例。

在此查詢中,在 WHERE 語句中,指定了 (WHERE f.id = "WakefieldFamily") 條件。
SELECT * FROM f WHERE f.id = "WakefieldFamily"
執行上述查詢時,它將返回 WakefieldFamily 的完整 JSON 文件,如以下輸出所示。
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
}
]
DocumentDB SQL - 運算子
運算子是主要用於 SQL WHERE 語句中執行操作(例如比較和算術運算)的保留字或字元。DocumentDB SQL 也支援各種標量表達式。最常用的表示式是二元和一元表示式。
目前支援以下 SQL 運算子,可用於查詢。
SQL 比較運算子
以下是 DocumentDB SQL 語法中所有可用比較運算子的列表。
| 序號 | 運算子和描述 |
|---|---|
| 1 | = 檢查兩個運算元的值是否相等。如果是,則條件變為真。 |
| 2 | != 檢查兩個運算元的值是否相等。如果值不相等,則條件變為真。 |
| 3 | <> 檢查兩個運算元的值是否相等。如果值不相等,則條件變為真。 |
| 4 | > 檢查左運算元的值是否大於右運算元的值。如果是,則條件變為真。 |
| 5 | < 檢查左運算元的值是否小於右運算元的值。如果是,則條件變為真。 |
| 6 | >= 檢查左運算元的值是否大於或等於右運算元的值。如果是,則條件變為真。 |
| 7 | <= 檢查左運算元的值是否小於或等於右運算元的值。如果是,則條件變為真。 |
SQL 邏輯運算子
以下是 DocumentDB SQL 語法中所有可用邏輯運算子的列表。
| 序號 | 運算子和描述 |
|---|---|
| 1 | AND AND 運算子允許 SQL 語句的 WHERE 子句中存在多個條件。 |
| 2 | BETWEEN BETWEEN 運算子用於搜尋位於給定最小值和最大值的一組值內的值。 |
| 3 | IN IN 運算子用於將值與已指定的文字值列表進行比較。 |
| 4 | OR OR 運算子用於組合 SQL 語句的 WHERE 子句中的多個條件。 |
| 5 | NOT NOT 運算子反轉與其一起使用的邏輯運算子的含義。例如,NOT EXISTS、NOT BETWEEN、NOT IN 等。這是一個否定運算子。 |
SQL 算術運算子
以下是 DocumentDB SQL 語法中所有可用算術運算子的列表。
| 序號 | 運算子和描述 |
|---|---|
| 1 | + 加法 - 將運算子兩側的值相加。 |
| 2 | - 減法 - 從左運算元中減去右運算元。 |
| 3 | * 乘法 - 將運算子兩側的值相乘。 |
| 4 | / 除法 - 將左運算元除以右運算元。 |
| 5 | % 模數 - 將左運算元除以右運算元並返回餘數。 |
我們也將在本例中考慮相同的文件。以下是 AndersenFamily 文件。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是 SmithFamily 文件。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是 WakefieldFamily 文件。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
讓我們看一個在 WHERE 子句中使用比較運算子的簡單示例。

在此查詢中,在 WHERE 子句中,指定了 (WHERE f.id = "WakefieldFamily") 條件,它將檢索 id 等於 WakefieldFamily 的文件。
SELECT * FROM f WHERE f.id = "WakefieldFamily"
執行上述查詢時,它將返回 WakefieldFamily 的完整 JSON 文件,如以下輸出所示。
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
}
]
讓我們看另一個示例,其中查詢將檢索成績大於 5 的 children 資料。
SELECT * FROM Families.children[0] c WHERE (c.grade > 5)
執行上述查詢時,它將檢索以下子文件,如輸出所示。
[
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
}
]
DocumentDB SQL - BETWEEN 關鍵字
BETWEEN 關鍵字用於表達針對值範圍的查詢,就像在 SQL 中一樣。BETWEEN 可以用於字串或數字。DocumentDB 中使用 BETWEEN 與 ANSI SQL 的主要區別在於,您可以針對混合型別的屬性表達範圍查詢。
例如,在某些文件中,您可能將“grade”作為數字,而在其他文件中,它可能是字串。在這些情況下,兩種不同型別結果之間的比較是“未定義的”,並且將跳過該文件。
讓我們考慮前面示例中的三個文件。以下是 **AndersenFamily** 文件。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是 SmithFamily 文件。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是 WakefieldFamily 文件。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
讓我們來看一個示例,其中查詢返回所有第一個孩子的年級在 1-5(包括兩者)之間的家庭文件。

以下是使用 BETWEEN 關鍵字然後使用 AND 邏輯運算子的查詢。
SELECT * FROM Families.children[0] c WHERE c.grade BETWEEN 1 AND 5
執行上述查詢時,會產生以下輸出。
[
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
]
要顯示超出前一個示例範圍的年級,請使用 NOT BETWEEN,如下面的查詢所示。
SELECT * FROM Families.children[0] c WHERE c.grade NOT BETWEEN 1 AND 5
執行此查詢時,會產生以下輸出。
[
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
}
]
DocumentDB SQL - IN 關鍵字
IN 關鍵字可用於檢查指定值是否與列表中的任何值匹配。IN 運算子允許您在 WHERE 子句中指定多個值。IN 等效於連結多個 OR 子句。
類似的三個文件被視為在前面的示例中所做的那樣。以下是 **AndersenFamily** 文件。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是 SmithFamily 文件。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是 WakefieldFamily 文件。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
讓我們來看一個簡單的示例。
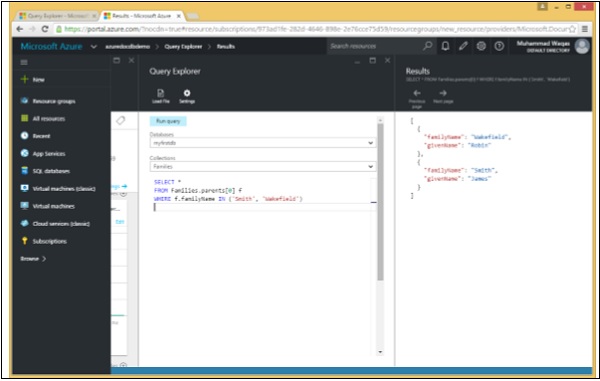
以下是將檢索 familyName 為“Smith”或 Wakefield 的資料的查詢。
SELECT *
FROM Families.parents[0] f
WHERE f.familyName IN ('Smith', 'Wakefield')
執行上述查詢時,會產生以下輸出。
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Smith",
"givenName": "James"
}
]
讓我們考慮另一個簡單的示例,其中將檢索所有 id 為“SmithFamily”或“AndersenFamily”的家庭文件。以下是查詢。
SELECT *
FROM Families
WHERE Families.id IN ('SmithFamily', 'AndersenFamily')
執行上述查詢時,會產生以下輸出。
[
{
"id": "SmithFamily",
"parents": [
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{
"givenName": "Tweetie",
"type": "Bird"
}
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEDAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEDAAAAAAAAAA==/",
"_etag": "\"00000600-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]
DocumentDB SQL - VALUE 關鍵字
當您知道只返回單個值時,VALUE 關鍵字可以透過避免建立完整物件的開銷來幫助生成更精簡的結果集。VALUE 關鍵字提供了一種返回 JSON 值的方法。
讓我們來看一個簡單的示例。

以下是使用 VALUE 關鍵字的查詢。
SELECT VALUE "Hello World, this is DocumentDB SQL Tutorial"
執行此查詢時,它將返回標量“Hello World, this is DocumentDB SQL Tutorial”。
[ "Hello World, this is DocumentDB SQL Tutorial" ]
在另一個示例中,讓我們考慮前面示例中的三個文件。
以下是 AndersenFamily 文件。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是 SmithFamily 文件。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是 WakefieldFamily 文件。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
以下是查詢。
SELECT VALUE f.location FROM Families f
執行此查詢時,它將返回地址,但不帶位置標籤。
[
{
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
{
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
{
"state": "WA",
"county": "King",
"city": "Seattle"
}
]
如果我們現在在沒有 VALUE 關鍵字的情況下指定相同的查詢,則它將返回帶位置標籤的地址。以下是查詢。
SELECT f.location FROM Families f
執行此查詢時,會產生以下輸出。
[
{
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
}
},
{
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
}
},
{
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
}
}
]
DocumentDB SQL - ORDER BY 語句
Microsoft Azure DocumentDB 支援使用 SQL 對 JSON 文件進行文件查詢。您可以使用查詢中的 ORDER BY 子句對集合中的數字和字串進行排序。該子句可以包含一個可選的 ASC/DESC 引數,以指定必須檢索結果的順序。
我們將考慮與前面示例中相同的文件。
以下是 AndersenFamily 文件。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是 SmithFamily 文件。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是 WakefieldFamily 文件。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
讓我們來看一個簡單的示例。
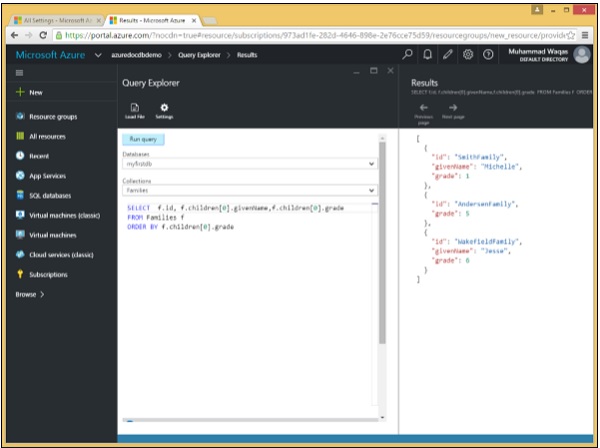
以下是包含 ORDER BY 關鍵字的查詢。
SELECT f.id, f.children[0].givenName,f.children[0].grade FROM Families f ORDER BY f.children[0].grade
執行上述查詢時,會產生以下輸出。
[
{
"id": "SmithFamily",
"givenName": "Michelle",
"grade": 1
},
{
"id": "AndersenFamily",
"grade": 5
},
{
"id": "WakefieldFamily",
"givenName": "Jesse",
"grade": 6
}
]
讓我們考慮另一個簡單的示例。
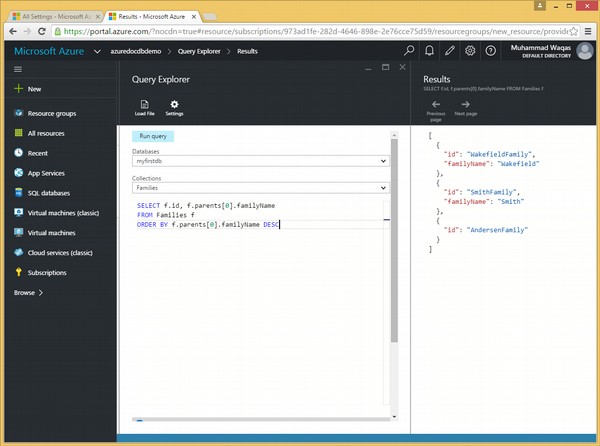
以下是包含 ORDER BY 關鍵字和 DESC 可選關鍵字的查詢。
SELECT f.id, f.parents[0].familyName FROM Families f ORDER BY f.parents[0].familyName DESC
執行上述查詢時,將產生以下輸出。
[
{
"id": "WakefieldFamily",
"familyName": "Wakefield"
},
{
"id": "SmithFamily",
"familyName": "Smith"
},
{
"id": "AndersenFamily"
}
]
DocumentDB SQL - 迭代
在 DocumentDB SQL 中,Microsoft 添加了一個新的構造,它可以與 IN 關鍵字一起使用,以提供對 JSON 陣列進行迭代的支援。在 FROM 子句中提供了迭代支援。
我們將再次考慮前面示例中的三個類似文件。
以下是 AndersenFamily 文件。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是 SmithFamily 文件。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是 WakefieldFamily 文件。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
讓我們來看一個在 FROM 子句中沒有 IN 關鍵字的簡單示例。

以下是將返回 Families 集合中所有父母的查詢。
SELECT * FROM Families.parents
執行上述查詢時,會產生以下輸出。
[
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
[
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
[
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
]
]
如上述輸出所示,每個家庭的父母都顯示在單獨的 JSON 陣列中。
讓我們來看同一個示例,但是這次我們將在 FROM 子句中使用 IN 關鍵字。

以下是包含 IN 關鍵字的查詢。
SELECT * FROM c IN Families.parents
執行上述查詢時,會產生以下輸出。
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
},
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
},
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
{
"id": "WakefieldFamily",
"givenName": "Jesse",
"grade": 6
}
]
在上面的示例中,可以看到,透過迭代,對集合中的父母執行迭代的查詢具有不同的輸出陣列。因此,每個家庭的所有父母都新增到單個數組中。
DocumentDB SQL - 連線
在關係資料庫中,Joins 子句用於組合資料庫中兩個或多個表中的記錄,並且在設計規範化模式時,跨表連線的需求非常重要。由於 DocumentDB 處理無模式文件的非規範化資料模型,因此 DocumentDB SQL 中的 JOIN 等效於“自連線”。
讓我們考慮前面示例中的三個文件。
以下是 AndersenFamily 文件。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是 SmithFamily 文件。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是 WakefieldFamily 文件。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
讓我們來看一個示例,以瞭解 JOIN 子句的工作原理。

以下是將根連線到子文件 children 的查詢。
SELECT f.id FROM Families f JOIN c IN f.children
執行上述查詢時,將產生以下輸出。
[
{
"id": "WakefieldFamily"
},
{
"id": "WakefieldFamily"
},
{
"id": "SmithFamily"
},
{
"id": "SmithFamily"
},
{
"id": "AndersenFamily"
}
]
在上面的示例中,連線在文件根和子根 children 之間,它在兩個 JSON 物件之間進行交叉積。以下是一些需要注意的事項 -
在 FROM 子句中,JOIN 子句是一個迭代器。
前兩個文件 WakefieldFamily 和 SmithFamily 包含兩個孩子,因此結果集也包含產生每個孩子的單獨物件的交叉積。
第三個文件 AndersenFamily 只包含一個孩子,因此此文件只有一個對應的物件。
讓我們來看同一個示例,但是這次我們還檢索子名稱,以便更好地理解 JOIN 子句。

以下是將根連線到子文件 children 的查詢。
SELECT f.id AS familyName, c.givenName AS childGivenName, c.firstName AS childFirstName FROM Families f JOIN c IN f.children
執行上述查詢時,會產生以下輸出。
[
{
"familyName": "WakefieldFamily",
"childGivenName": "Jesse"
},
{
"familyName": "WakefieldFamily",
"childGivenName": "Lisa"
},
{
"familyName": "SmithFamily",
"childGivenName": "Michelle"
},
{
"familyName": "SmithFamily",
"childGivenName": "John"
},
{
"familyName": "AndersenFamily",
"childFirstName": "Henriette Thaulow"
}
]
DocumentDB SQL - 別名
在關係資料庫中,SQL 別名用於臨時重命名錶或列標題。類似地,在 DocumentDB 中,別名用於臨時重新命名 JSON 文件、子文件、物件或任何欄位。
重新命名是一個臨時更改,實際文件不會更改。基本上,建立別名是為了使欄位/文件名稱更易讀。對於別名,使用 AS 關鍵字,該關鍵字是可選的。
讓我們考慮前面示例中使用的三個類似文件。
以下是 AndersenFamily 文件。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是 SmithFamily 文件。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是 WakefieldFamily 文件。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
讓我們來看一個示例來討論別名。

以下是將根連線到子文件 children 的查詢。我們有別名,例如 f.id AS familyName、c.givenName AS childGivenName 和 c.firstName AS childFirstName。
SELECT f.id AS familyName, c.givenName AS childGivenName, c.firstName AS childFirstName FROM Families f JOIN c IN f.children
執行上述查詢時,會產生以下輸出。
[
{
"familyName": "WakefieldFamily",
"childGivenName": "Jesse"
},
{
"familyName": "WakefieldFamily",
"childGivenName": "Lisa"
},
{
"familyName": "SmithFamily",
"childGivenName": "Michelle"
},
{
"familyName": "SmithFamily",
"childGivenName": "John"
},
{
"familyName": "AndersenFamily",
"childFirstName": "Henriette Thaulow"
}
]
上述輸出顯示欄位名稱已更改,但這是一個臨時更改,原始文件未修改。
DocumentDB SQL - 陣列建立
在 DocumentDB SQL 中,Microsoft 添加了一個關鍵功能,藉助該功能,我們可以輕鬆地建立一個數組。這意味著當我們執行查詢時,結果將建立一個類似於 JSON 物件的集合陣列作為查詢的結果。
讓我們考慮與前面示例中相同的文件。
以下是 AndersenFamily 文件。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是 SmithFamily 文件。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是 WakefieldFamily 文件。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
讓我們來看一個示例。

以下是將返回每個家庭的 family name 和 address 的查詢。
SELECT f.id AS FamilyName, [f.location.city, f.location.county, f.location.state] AS Address FROM Families f
如您所見,city、county 和 state 欄位包含在方括號中,這將建立一個數組,並且此陣列命名為 Address。執行上述查詢時,會產生以下輸出。
[
{
"FamilyName": "WakefieldFamily",
"Address": [
"NY",
"Manhattan",
"NY"
]
},
{
"FamilyName": "SmithFamily",
"Address": [
"Forest Hills",
"Queens",
"NY"
]
},
{
"FamilyName": "AndersenFamily",
"Address": [
"Seattle",
"King",
"WA"
]
}
]
在上述輸出中,city、county 和 state 資訊已新增到 Address 陣列中。
DocumentDB SQL - 標量表達式
在 DocumentDB SQL 中,SELECT 子句還支援標量表達式,如常量、算術表示式、邏輯表示式等。通常,很少使用標量查詢,因為它們實際上並不查詢集合中的文件,它們只是計算表示式。但是,使用標量表達式查詢來學習基礎知識、如何使用表示式和在查詢中塑造 JSON 仍然很有幫助,這些概念直接適用於您將在集合中針對文件執行的實際查詢。
讓我們來看一個包含多個標量查詢的示例。

在查詢資源管理器中,僅選擇要執行的文字並單擊“執行”。讓我們先執行第一個。
SELECT "Hello"
執行上述查詢時,會產生以下輸出。
[
{
"$1": "Hello"
}
]
此輸出可能看起來有點令人困惑,所以讓我們分解一下。
首先,正如我們在最後一個演示中看到的,查詢結果始終包含在方括號中,因為它們作為 JSON 陣列返回,即使來自像這樣只返回單個文件的標量表達式查詢的結果也是如此。
我們有一個包含一個文件的陣列,並且該文件在其內有一個屬性,用於 SELECT 語句中的單個表示式。
SELECT 語句沒有為此屬性提供名稱,因此 DocumentDB 使用 $1 自動生成一個。
這通常不是我們想要的,這就是為什麼我們可以使用 AS 為查詢中的表示式設定別名,這會按照您希望的方式設定生成文件中的屬性名稱,在本例中為 word。
SELECT "Hello" AS word
執行上述查詢時,會產生以下輸出。
[
{
"word": "Hello"
}
]
類似地,以下是另一個簡單的查詢。
SELECT ((2 + 11 % 7)-2)/3
查詢檢索以下輸出。
[
{
"$1": 1.3333333333333333
}
]
讓我們來看另一個塑造巢狀陣列和嵌入物件的示例。
SELECT
{
"words1":
["Hello", "World"],
"words2":
["How", "Are", "You?"]
} AS allWords
執行上述查詢時,會產生以下輸出。
[
{
"allWords": {
"words1": [
"Hello",
"World"
],
"words2": [
"How",
"Are",
"You?"
]
}
}
]
DocumentDB SQL - 引數化
在關係資料庫中,引數化查詢是指在其中使用佔位符作為引數並在執行緒執行時提供引數值的查詢。DocumentDB 也支援引數化查詢,並且引數化查詢中的引數可以用熟悉的 @ 符號表示。使用引數化查詢的最重要原因是避免 SQL 注入攻擊。它還可以提供對使用者輸入的強大處理和轉義。
讓我們來看一個我們將使用 .Net SDK 的示例。以下是將刪除集合的程式碼。
private async static Task DeleteCollection(DocumentClient client, string collectionId) {
Console.WriteLine();
Console.WriteLine(">>> Delete Collection {0} in {1} <<<",
collectionId, _database.Id);
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id",
Parameters = new SqlParameterCollection { new SqlParameter { Name =
"@id", Value = collectionId } }
};
DocumentCollection collection = client.CreateDocumentCollectionQuery(database.SelfLink,
query).AsEnumerable().First();
await client.DeleteDocumentCollectionAsync(collection.SelfLink);
Console.WriteLine("Deleted collection {0} from database {1}",
collectionId, _database.Id);
}
引數化查詢的構造如下所示。
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id",
Parameters = new SqlParameterCollection { new SqlParameter { Name =
"@id", Value = collectionId } }
};
我們沒有對 collectionId 進行硬編碼,因此此方法可用於刪除任何集合。我們可以使用“@”符號作為引數名稱的字首,類似於 SQL Server。
在上面的示例中,我們正在按 Id 查詢特定集合,其中 Id 引數在此 SqlParameterCollection 中定義,並分配給此 SqlQuerySpec 的引數屬性。然後,SDK 會完成構建 DocumentDB 的最終查詢字串的工作,並將 collectionId 嵌入到其中。我們執行查詢,然後使用其 SelfLink 刪除集合。
以下是 CreateDocumentClient 任務的實現。
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM
c WHERE c.id = 'earthquake'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'myfirstdb'").AsEnumerable().First();
await DeleteCollection(client, "MyCollection1");
await DeleteCollection(client, "MyCollection2");
}
}
執行程式碼時,會產生以下輸出。
**** Delete Collection MyCollection1 in mydb **** Deleted collection MyCollection1 from database myfirstdb **** Delete Collection MyCollection2 in mydb **** Deleted collection MyCollection2 from database myfirstdb
讓我們來看另一個示例。我們可以編寫一個查詢,將姓氏和地址州作為引數,然後根據使用者輸入針對姓氏和 location.state 的各種值執行它。
SELECT * FROM Families f WHERE f.lastName = @lastName AND f.location.state = @addressState
然後,此請求可以作為引數化的 JSON 查詢傳送到 DocumentDB,如下面的程式碼所示。
{
"query": "SELECT * FROM Families f WHERE f.lastName = @lastName AND
f.location.state = @addressState",
"parameters": [
{"name": "@lastName", "value": "Wakefield"},
{"name": "@addressState", "value": "NY"},
]
}
DocumentDB SQL - 內建函式
DocumentDB 支援大量用於常用操作的內建函式,這些函式可以在查詢內使用。有很多函式用於執行數學計算,以及在處理不同模式時非常有用的型別檢查函式。這些函式可以測試某個屬性是否存在,如果存在,則測試它是否為數字或字串、布林值或物件。
我們還獲得了這些用於解析和操作字串的便捷函式,以及一些用於處理陣列的函式,允許您執行諸如連線陣列和測試陣列是否包含特定元素之類的操作。
以下是不同型別的內建函式 -
| 序號 | 內建函式和說明 |
|---|---|
| 1 | 數學函式
數學函式執行計算,通常基於作為引數提供的輸入值,並返回數值。 |
| 2 | 型別檢查函式
型別檢查函式允許您檢查 SQL 查詢中表達式的型別。 |
| 3 | 字串函式
字串函式對字串輸入值執行操作,並返回字串、數值或布林值。 |
| 4 | 陣列函式
陣列函式對陣列輸入值執行操作,並以數值、布林值或陣列值的格式返回。 |
| 5 | 空間函式
DocumentDB 還支援用於地理空間查詢的開放地理空間聯盟 (OGC) 內建函式。 |
DocumentDB SQL - Linq to SQL 轉換
在 DocumentDB 中,我們實際上使用 SQL 來查詢文件。如果我們正在進行 .NET 開發,還可以使用 LINQ 提供程式,該提供程式可以從 LINQ 查詢生成相應的 SQL。
支援的資料型別
在 DocumentDB 中,LINQ 提供程式(包含在 DocumentDB .NET SDK 中)支援所有 JSON 基本型別,如下所示:
- 數值型
- 布林型
- 字串型
- 空值
支援的表示式
以下標量表達式在 LINQ 提供程式(包含在 DocumentDB .NET SDK 中)中受支援。
常量值 - 包括基本資料型別的常量值。
屬性/陣列索引表示式 - 表示式引用物件的屬性或陣列元素。
算術表示式 - 包括數值和布林值上的常見算術表示式。
字串比較表示式 - 包括將字串值與某個常量字串值進行比較。
物件/陣列建立表示式 - 返回複合值型別或匿名型別或此類物件陣列的物件。這些值可以巢狀。
支援的 LINQ 運算子
以下是 LINQ 提供程式(包含在 DocumentDB .NET SDK 中)中支援的 LINQ 運算子列表。
Select - 投影轉換為 SQL SELECT,包括物件構造。
Where - 篩選器轉換為 SQL WHERE,並支援在 && 、 || 和 ! 與 SQL 運算子之間進行轉換。
SelectMany - 允許將陣列展開到 SQL JOIN 子句。可用於連結/巢狀表示式以篩選陣列元素。
OrderBy 和 OrderByDescending - 轉換為 ORDER BY 升序/降序。
CompareTo - 轉換為範圍比較。通常用於字串,因為它們在 .NET 中不可比較。
Take - 轉換為 SQL TOP 以限制查詢的結果。
數學函式 - 支援從 .NET 的 Abs、Acos、Asin、Atan、Ceiling、Cos、Exp、Floor、Log、Log10、Pow、Round、Sign、Sin、Sqrt、Tan、Truncate 轉換為等效的 SQL 內建函式。
字串函式 - 支援從 .NET 的 Concat、Contains、EndsWith、IndexOf、Count、ToLower、TrimStart、Replace、Reverse、TrimEnd、StartsWith、SubString、ToUpper 轉換為等效的 SQL 內建函式。
陣列函式 - 支援從 .NET 的 Concat、Contains 和 Count 轉換為等效的 SQL 內建函式。
地理空間擴充套件函式 - 支援從存根方法 Distance、Within、IsValid 和 IsValidDetailed 轉換為等效的 SQL 內建函式。
使用者定義擴充套件函式 - 支援從存根方法 UserDefinedFunctionProvider.Invoke 轉換為相應的使用者定義函式。
其他 - 支援合併和條件運算子的轉換。可以根據上下文將 Contains 轉換為 String CONTAINS、ARRAY_CONTAINS 或 SQL IN。
讓我們來看一個使用 .Net SDK 的示例。以下是我們將在此示例中考慮的三個文件。
新客戶 1
{
"name": "New Customer 1",
"address": {
"addressType": "Main Office",
"addressLine1": "123 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
}
新客戶 2
{
"name": "New Customer 2",
"address": {
"addressType": "Main Office",
"addressLine1": "678 Main Street",
"location": {
"city": "London",
"stateProvinceName": " London "
},
"postalCode": "11229",
"countryRegionName": "United Kingdom"
},
}
新客戶 3
{
"name": "New Customer 3",
"address": {
"addressType": "Main Office",
"addressLine1": "12 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
}
以下是我們使用 LINQ 查詢的程式碼。我們在 q 中定義了一個 LINQ 查詢,但只有在我們對其執行 .ToList 時才會執行。
private static void QueryDocumentsWithLinq(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Query Documents (LINQ) ****");
Console.WriteLine();
Console.WriteLine("Quering for US customers (LINQ)");
var q =
from d in client.CreateDocumentQuery<Customer>(collection.DocumentsLink)
where d.Address.CountryRegionName == "United States"
select new {
Id = d.Id,
Name = d.Name,
City = d.Address.Location.City
};
var documents = q.ToList();
Console.WriteLine("Found {0} US customers", documents.Count);
foreach (var document in documents) {
var d = document as dynamic;
Console.WriteLine(" Id: {0}; Name: {1}; City: {2}", d.Id, d.Name, d.City);
}
Console.WriteLine();
}
SDK 會將我們的 LINQ 查詢轉換為 DocumentDB 的 SQL 語法,根據我們的 LINQ 語法生成 SELECT 和 WHERE 子句。
讓我們從 CreateDocumentClient 任務呼叫上述查詢。
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'").AsEnumerable().First();
QueryDocumentsWithLinq(client);
}
}
執行上述程式碼時,會生成以下輸出。
**** Query Documents (LINQ) **** Quering for US customers (LINQ) Found 2 US customers Id: 7e9ad4fa-c432-4d1a-b120-58fd7113609f; Name: New Customer 1; City: Brooklyn Id: 34e9873a-94c8-4720-9146-d63fb7840fad; Name: New Customer 1; City: Brooklyn
DocumentDB SQL - JavaScript 整合
如今,JavaScript 無處不在,不僅在瀏覽器中。DocumentDB 將 JavaScript 視為一種現代的 T-SQL,並支援在資料庫引擎內部原生執行 JavaScript 邏輯的事務。DocumentDB 提供了一個程式設計模型,用於根據儲存過程和觸發器直接在集合上執行基於 JavaScript 的應用程式邏輯。
讓我們來看一個建立簡單儲存過程的示例。步驟如下:
步驟 1 - 建立一個新的控制檯應用程式。
步驟 2 - 從 NuGet 新增 .NET SDK。我們在這裡使用 .NET SDK,這意味著我們將編寫一些 C# 程式碼來建立、執行,然後刪除我們的儲存過程,但儲存過程本身是用 JavaScript 編寫的。
步驟 3 - 在解決方案資源管理器中右鍵單擊專案。
步驟 4 - 為儲存過程新增一個新的 JavaScript 檔案,並將其命名為 HelloWorldStoreProce.js

每個儲存過程都只是一個 JavaScript 函式,因此我們將建立一個新函式,並且自然地,我們也將此函式命名為 HelloWorldStoreProce。我們根本不需要為函式命名。DocumentDB 將僅透過我們在建立時提供的 Id 來引用此儲存過程。
function HelloWorldStoreProce() {
var context = getContext();
var response = context.getResponse();
response.setBody('Hello, and welcome to DocumentDB!');
}
所有儲存過程所做的就是從上下文獲取響應物件並呼叫其 setBody 方法以將字串返回給呼叫方。在 C# 程式碼中,我們將建立儲存過程、執行它,然後刪除它。
儲存過程的作用域為每個集合,因此我們將需要集合的 SelfLink 來建立儲存過程。
步驟 5 - 首先查詢 myfirstdb 資料庫,然後查詢 MyCollection 集合。
建立儲存過程就像在 DocumentDB 中建立任何其他資源一樣。
private async static Task SimpleStoredProcDemo() {
var endpoint = "https://azuredocdbdemo.documents.azure.com:443/";
var masterKey =
"BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
using (var client = new DocumentClient(new Uri(endpoint), masterKey)) {
// Get database
Database database = client
.CreateDatabaseQuery("SELECT * FROM c WHERE c.id = 'myfirstdb'")
.AsEnumerable()
.First();
// Get collection
DocumentCollection collection = client
.CreateDocumentCollectionQuery(database.CollectionsLink, "SELECT * FROM
c WHERE c.id = 'MyCollection'")
.AsEnumerable()
.First();
// Create stored procedure
var sprocBody = File.ReadAllText(@"..\..\HelloWorldStoreProce.js");
var sprocDefinition = new StoredProcedure {
Id = "HelloWorldStoreProce",
Body = sprocBody
};
StoredProcedure sproc = await client.
CreateStoredProcedureAsync(collection.SelfLink, sprocDefinition);
Console.WriteLine("Created stored procedure {0} ({1})",
sproc.Id, sproc.ResourceId);
// Execute stored procedure
var result = await client.ExecuteStoredProcedureAsync(sproc.SelfLink);
Console.WriteLine("Executed stored procedure; response = {0}", result.Response);
// Delete stored procedure
await client.DeleteStoredProcedureAsync(sproc.SelfLink);
Console.WriteLine("Deleted stored procedure {0} ({1})",
sproc.Id, sproc.ResourceId);
}
}
步驟 6 - 首先使用新資源的 Id 建立一個定義物件,然後在 DocumentClient 物件上呼叫其中一個 Create 方法。對於儲存過程,定義包括 Id 和您想要傳送到伺服器的實際 JavaScript 程式碼。
步驟 7 - 呼叫 File.ReadAllText 從 JS 檔案中提取儲存過程程式碼。
步驟 8 - 將儲存過程程式碼分配給定義物件的 body 屬性。
就 DocumentDB 而言,我們在此定義中指定的 Id 是儲存過程的名稱,無論我們實際將 JavaScript 函式命名為何。
但是,在建立儲存過程和其他伺服器端物件時,建議我們命名 JavaScript 函式,並且這些函式名稱與我們在 DocumentDB 的定義中設定的 Id 相匹配。
步驟 9 - 呼叫 CreateStoredProcedureAsync,傳入 MyCollection 集合的 SelfLink 和儲存過程定義。這將建立儲存過程和 DocumentDB 為其分配的 ResourceId。
步驟 10 - 呼叫儲存過程。ExecuteStoredProcedureAsync 獲取一個型別引數,您將其設定為儲存過程返回的值的預期資料型別,如果您希望返回動態物件,則可以簡單地將其指定為物件。也就是說,一個在執行時繫結其屬性的物件。
在此示例中,我們知道我們的儲存過程只是返回一個字串,因此我們呼叫 ExecuteStoredProcedureAsync<string>。
以下是 Program.cs 檔案的完整實現。
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
using Microsoft.Azure.Documents.Linq;
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DocumentDBStoreProce {
class Program {
private static void Main(string[] args) {
Task.Run(async () => {
await SimpleStoredProcDemo();
}).Wait();
}
private async static Task SimpleStoredProcDemo() {
var endpoint = "https://azuredocdbdemo.documents.azure.com:443/";
var masterKey =
"BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
using (var client = new DocumentClient(new Uri(endpoint), masterKey)) {
// Get database
Database database = client
.CreateDatabaseQuery("SELECT * FROM c WHERE c.id = 'myfirstdb'")
.AsEnumerable()
.First();
// Get collection
DocumentCollection collection = client
.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'")
.AsEnumerable()
.First();
// Create stored procedure
var sprocBody = File.ReadAllText(@"..\..\HelloWorldStoreProce.js");
var sprocDefinition = new StoredProcedure {
Id = "HelloWorldStoreProce",
Body = sprocBody
};
StoredProcedure sproc = await client
.CreateStoredProcedureAsync(collection.SelfLink, sprocDefinition);
Console.WriteLine("Created stored procedure {0} ({1})", sproc
.Id, sproc.ResourceId);
// Execute stored procedure
var result = await client
.ExecuteStoredProcedureAsync<string>(sproc.SelfLink);
Console.WriteLine("Executed stored procedure; response = {0}",
result.Response);
// Delete stored procedure
await client.DeleteStoredProcedureAsync(sproc.SelfLink);
Console.WriteLine("Deleted stored procedure {0} ({1})",
sproc.Id, sproc.ResourceId);
}
}
}
}
執行上述程式碼時,會生成以下輸出。
Created stored procedure HelloWorldStoreProce (Ic8LAMEUVgACAAAAAAAAgA==) Executed stored procedure; response = Hello, and welcome to DocumentDB!
如上述輸出所示,response 屬性具有儲存過程返回的“Hello, and welcome to DocumentDB!”。
DocumentDB SQL - 使用者定義函式
DocumentDB SQL 支援使用者定義函式 (UDF)。UDF 只是您可以編寫的另一種 JavaScript 函式,它們的工作方式與您期望的幾乎相同。您可以建立 UDF 來擴充套件查詢語言,並使用您可以在查詢中引用的自定義業務邏輯。
DocumentDB SQL 語法已擴充套件為支援使用這些 UDF 的自定義應用程式邏輯。UDF 可以註冊到 DocumentDB,然後作為 SQL 查詢的一部分進行引用。
讓我們考慮以下三個文件作為此示例。
AndersenFamily 文件如下所示。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
SmithFamily 文件如下所示。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
WakefieldFamily 文件如下所示。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
讓我們來看一個建立一些簡單 UDF 的示例。
以下是 CreateUserDefinedFunctions 的實現。
private async static Task CreateUserDefinedFunctions(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Create User Defined Functions ****");
Console.WriteLine();
await CreateUserDefinedFunction(client, "udfRegEx");
}
我們有一個 udfRegEx,在 CreateUserDefinedFunction 中,我們從本地檔案獲取其 JavaScript 程式碼。我們為新的 UDF 構造定義物件,並使用集合的 SelfLink 和 udfDefinition 物件呼叫 CreateUserDefinedFunctionAsync,如下面的程式碼所示。
private async static Task<UserDefinedFunction>
CreateUserDefinedFunction(DocumentClient client, string udfId) {
var udfBody = File.ReadAllText(@"..\..\Server\" + udfId + ".js");
var udfDefinition = new UserDefinedFunction {
Id = udfId,
Body = udfBody
};
var result = await client
.CreateUserDefinedFunctionAsync(_collection.SelfLink, udfDefinition);
var udf = result.Resource;
Console.WriteLine("Created user defined function {0}; RID: {1}",
udf.Id, udf.ResourceId);
return udf;
}
我們從結果的 resource 屬性中獲取新的 UDF 並將其返回給呼叫方。要顯示現有的 UDF,以下是 ViewUserDefinedFunctions 的實現。我們呼叫 CreateUserDefinedFunctionQuery 並像往常一樣迴圈遍歷它們。
private static void ViewUserDefinedFunctions(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** View UDFs ****");
Console.WriteLine();
var udfs = client
.CreateUserDefinedFunctionQuery(_collection.UserDefinedFunctionsLink)
.ToList();
foreach (var udf in udfs) {
Console.WriteLine("User defined function {0}; RID: {1}", udf.Id, udf.ResourceId);
}
}
DocumentDB SQL 沒有提供用於搜尋子字串或正則表示式的內建函式,因此以下簡短的一行程式碼填補了這一空白,它是一個 JavaScript 函式。
function udfRegEx(input, regex) {
return input.match(regex);
}
給定第一個引數中的輸入字串,使用 JavaScript 的內建正則表示式支援將第二個引數中的模式匹配字串傳遞到 .match 中。我們可以執行子字串查詢以查詢 lastName 屬性中包含 Andersen 字樣的所有儲存。
private static void Execute_udfRegEx(DocumentClient client) {
var sql = "SELECT c.name FROM c WHERE udf.udfRegEx(c.lastName, 'Andersen') != null";
Console.WriteLine();
Console.WriteLine("Querying for Andersen");
var documents = client.CreateDocumentQuery(_collection.SelfLink, sql).ToList();
Console.WriteLine("Found {0} Andersen:", documents.Count);
foreach (var document in documents) {
Console.WriteLine("Id: {0}, Name: {1}", document.id, document.lastName);
}
}
請注意,我們必須使用字首 udf 限定每個 UDF 引用。我們只需將 SQL 傳遞到 CreateDocumentQuery,就像任何普通查詢一樣。最後,讓我們從 CreateDocumentClient 任務呼叫上述查詢
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)){
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE
c.id = 'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'Families'").AsEnumerable().First();
await CreateUserDefinedFunctions(client);
ViewUserDefinedFunctions(client);
Execute_udfRegEx(client);
}
}
執行上述程式碼時,會生成以下輸出。
**** Create User Defined Functions **** Created user defined function udfRegEx; RID: kV5oANVXnwAlAAAAAAAAYA== **** View UDFs **** User defined function udfRegEx; RID: kV5oANVXnwAlAAAAAAAAYA== Querying for Andersen Found 1 Andersen: Id: AndersenFamily, Name: Andersen
DocumentDB SQL - 複合 SQL 查詢
複合查詢 使您能夠組合來自現有查詢的資料,然後在呈現報表結果之前應用篩選器、聚合等,這些結果顯示組合的資料集。複合查詢檢索現有查詢上的多個級別的相關資訊,並將組合資料作為單個且扁平化的查詢結果呈現。
使用複合查詢,您還可以選擇:
選擇 SQL 剪枝選項以根據使用者的屬性選擇刪除不需要的表和欄位。
設定 ORDER BY 和 GROUP BY 子句。
將 WHERE 子句設定為複合查詢結果集的篩選器。
上述運算子可以組合形成更強大的查詢。由於 DocumentDB 支援巢狀集合,因此組合可以連線或巢狀。
讓我們考慮以下文件作為此示例。
AndersenFamily 文件如下所示。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
SmithFamily 文件如下所示。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
WakefieldFamily 文件如下所示。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
讓我們來看一個連線查詢的示例。

以下是將檢索第一個孩子 givenName 為 Michelle 的家庭的 id 和位置的查詢。
SELECT f.id,f.location FROM Families f WHERE f.children[0].givenName = "Michelle"
執行上述查詢時,會產生以下輸出。
[
{
"id": "SmithFamily",
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
}
}
]
讓我們再來看一個連線查詢的示例。

以下是將返回所有第一個孩子年級大於 3 的文件的查詢。
SELECT *
FROM Families f
WHERE ({grade: f.children[0].grade}.grade > 3)
執行上述查詢時,會產生以下輸出。
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]
讓我們來看一個巢狀查詢的示例。

以下是將迭代所有父母,然後返回 familyName 為 Smith 的文件的查詢。
SELECT * FROM p IN Families.parents WHERE p.familyName = "Smith"
執行上述查詢時,會產生以下輸出。
[
{
"familyName": "Smith",
"givenName": "James"
}
]
讓我們再來看一個巢狀查詢的示例。

以下是將返回所有 familyName 的查詢。
SELECT VALUE p.familyName FROM Families f JOIN p IN f.parents
執行上述查詢時,會生成以下輸出。
[ "Wakefield", "Miller", "Smith", "Curtis" ]