- 資料探勘教程
- 資料探勘 - 首頁
- 資料探勘 - 概述
- 資料探勘 - 任務
- 資料探勘 - 問題
- 資料探勘 - 評估
- 資料探勘 - 術語
- 資料探勘 - 知識發現
- 資料探勘 - 系統
- 資料探勘 - 查詢語言
- 分類與預測
- 資料探勘 - 決策樹歸納
- 資料探勘 - 貝葉斯分類
- 基於規則的分類
- 資料探勘 - 分類方法
- 資料探勘 - 聚類分析
- 資料探勘 - 文字資料探勘
- 資料探勘 - 全球資訊網挖掘
- 資料探勘 - 應用與趨勢
- 資料探勘 - 主題
- 資料探勘有用資源
- 資料探勘 - 快速指南
- 資料探勘 - 有用資源
- 資料探勘 - 討論
資料探勘 - 快速指南
資料探勘 - 概述
資訊產業中存在大量可用資料。在將這些資料轉換為有用的資訊之前,這些資料毫無用處。有必要分析這些海量資料並從中提取有用的資訊。
資訊提取並非我們唯一需要執行的過程;資料探勘還涉及其他過程,例如資料清洗、資料整合、資料轉換、資料探勘、模式評估和資料呈現。一旦所有這些過程完成,我們就可以將這些資訊用於許多應用程式,例如欺詐檢測、市場分析、生產控制、科學探索等。
什麼是資料探勘?
資料探勘被定義為從海量資料集中提取資訊。換句話說,我們可以說資料探勘是從資料中挖掘知識的過程。因此提取的資訊或知識可用於以下任何應用程式:
- 市場分析
- 欺詐檢測
- 客戶留存
- 生產控制
- 科學探索
資料探勘應用
資料探勘在以下領域非常有用:
- 市場分析和管理
- 公司分析與風險管理
- 欺詐檢測
除此之外,資料探勘還可用於生產控制、客戶留存、科學探索、體育、占星術和網際網路網路衝浪援助等領域。
市場分析和管理
以下是資料探勘應用的各個市場領域:
客戶畫像 - 資料探勘有助於確定什麼樣的人購買什麼型別的產品。
識別客戶需求 - 資料探勘有助於識別不同客戶的最佳產品。它利用預測來尋找可能吸引新客戶的因素。
交叉市場分析 - 資料探勘執行產品銷售之間的關聯/相關性。
目標營銷 - 資料探勘有助於找到具有相同特徵(例如興趣、消費習慣、收入等)的模式客戶群。
確定客戶購買模式 - 資料探勘有助於確定客戶購買模式。
提供彙總資訊 - 資料探勘為我們提供了各種多維彙總報告。
公司分析和風險管理
資料探勘應用於公司部門的以下領域:
財務規劃和資產評估 - 它涉及現金流量分析和預測,使用或有債權分析來評估資產。
資源規劃 - 它涉及總結和比較資源和支出。
競爭 - 它涉及監控競爭對手和市場方向。
欺詐檢測
資料探勘也用於信用卡服務和電信領域以檢測欺詐。在欺詐電話呼叫中,它有助於找到呼叫目的地、呼叫時長、一天或一週中的時間等。它還會分析偏離預期規範的模式。
資料探勘 - 任務
資料探勘處理可以挖掘的模式型別。根據要挖掘的資料型別,資料探勘中涉及兩種型別的功能:
- 描述性
- 分類和預測
描述性功能
描述性功能處理資料庫中資料的通用屬性。以下是描述性功能的列表:
- 類/概念描述
- 頻繁模式挖掘
- 關聯挖掘
- 相關性挖掘
- 聚類挖掘
類/概念描述
類/概念是指與類或概念相關聯的資料。例如,在一個公司中,銷售專案的類別包括計算機和印表機,客戶的概念包括大額支出者和預算支出者。這類或概念的描述稱為類/概念描述。這些描述可以透過以下兩種方式得出:
資料特徵化 - 這指的是總結所研究類別的的資料。這個被研究的類別稱為目標類別。
資料區分 - 它指的是將一個類別與一些預定義的組或類別進行對映或分類。
頻繁模式挖掘
頻繁模式是指在事務資料中頻繁出現的模式。以下是頻繁模式型別的列表:
頻繁項集 - 它指的是一組經常一起出現的專案,例如牛奶和麵包。
頻繁子序列 - 經常出現的模式序列,例如購買相機後接著購買儲存卡。
頻繁子結構 - 子結構指的是不同的結構形式,例如圖、樹或格,它們可以與項集或子序列組合。
關聯挖掘
關聯用於零售銷售,以識別經常一起購買的模式。此過程指的是揭示資料之間關係並確定關聯規則的過程。
例如,零售商生成一條關聯規則,表明 70% 的時間牛奶與麵包一起銷售,只有 30% 的時間餅乾與麵包一起銷售。
相關性挖掘
這是一種附加分析,用於揭示關聯屬性值對或兩個專案集之間有趣的統計相關性,以分析它們是否對彼此產生積極、消極或沒有影響。
聚類挖掘
聚類是指一組類似的物件。聚類分析是指形成彼此非常相似但與其他聚類中的物件高度不同的物件組。
分類和預測
分類是尋找描述資料類別或概念的模型的過程。目的是能夠使用此模型來預測類標籤未知的物件的類別。此派生模型基於對訓練資料集的分析。派生模型可以以下列形式呈現:
- 分類(IF-THEN)規則
- 決策樹
- 數學公式
- 神經網路
參與這些過程的功能列表如下:
分類 - 它預測類標籤未知的物件的類別。其目標是找到一個派生模型來描述和區分資料類別或概念。派生模型基於訓練資料集的分析,即類標籤眾所周知的 data 物件。
預測 - 它用於預測缺失或不可用的數值資料值,而不是類標籤。迴歸分析通常用於預測。預測也可用於根據可用資料識別分佈趨勢。
異常值分析 - 異常值可以定義為不符合可用資料的通用行為或模型的資料物件。
演化分析 - 演化分析指的是描述和模擬行為隨時間變化的物件的規律或趨勢。
資料探勘任務基元
- 我們可以以資料探勘查詢的形式指定資料探勘任務。
- 此查詢是輸入到系統的。
- 資料探勘查詢是根據資料探勘任務基元定義的。
注意 - 這些基元允許我們以互動方式與資料探勘系統進行通訊。以下是資料探勘任務基元的列表:
- 要挖掘的任務相關資料集。
- 要挖掘的知識型別。
- 要在發現過程中使用的背景知識。
- 模式評估的有趣性度量和閾值。
- 視覺化發現模式的表示。
要挖掘的任務相關資料集
這是使用者感興趣的資料庫部分。此部分包括以下內容:
- 資料庫屬性
- 感興趣的資料倉庫維度
要挖掘的知識型別
它指的是要執行的功能型別。這些功能是:
- 特徵化
- 區分
- 關聯和相關性分析
- 分類
- 預測
- 聚類
- 異常值分析
- 演化分析
背景知識
背景知識允許在多個抽象級別挖掘資料。例如,概念層次結構是允許在多個抽象級別挖掘資料的背景知識之一。
模式評估的有趣性度量和閾值
這用於評估知識發現過程發現的模式。不同型別的知識有不同的有趣性度量。
視覺化發現模式的表示
這指的是要顯示發現模式的形式。這些表示可能包括以下內容:
- 規則
- 表格
- 圖表
- 圖形
- 決策樹
- 多維資料集
資料探勘 - 問題
資料探勘並非易事,因為所使用的演算法可能非常複雜,而且資料並不總是位於一個地方。它需要從各種異構資料來源整合。這些因素也帶來了一些問題。在本教程中,我們將討論以下主要問題:
- 挖掘方法和使用者互動
- 效能問題
- 各種資料型別問題
下圖描述了主要問題。

挖掘方法和使用者互動問題
它指的是以下幾種問題:
挖掘資料庫中不同型別的知識 - 不同的使用者可能對不同型別的知識感興趣。因此,資料探勘需要涵蓋廣泛的知識發現任務。
在多個抽象級別上互動式挖掘知識 - 資料探勘過程需要是互動式的,因為它允許使用者專注於模式搜尋,根據返回的結果提供和改進資料探勘請求。
結合背景知識 - 為指導發現過程並表達發現的模式,可以使用背景知識。背景知識不僅可以用簡潔的術語表達發現的模式,而且可以在多個抽象級別上表達。
資料探勘查詢語言和 ad hoc 資料探勘 - 允許使用者描述 ad hoc 挖掘任務的資料探勘查詢語言應與資料倉庫查詢語言整合,並針對高效靈活的資料探勘進行最佳化。
資料探勘結果的呈現和視覺化 - 一旦發現模式,就需要用高階語言和視覺化表示來表達。這些表示應該易於理解。
處理噪聲或不完整資料 - 在挖掘資料規律時,需要資料清洗方法來處理噪聲和不完整物件。如果沒有資料清洗方法,則發現模式的準確性會很差。
模式評估 − 發現的模式應該是有趣的,因為它們要麼代表常識,要麼缺乏新穎性。
效能問題
可能存在以下與效能相關的問題:
資料探勘演算法的效率和可擴充套件性 − 為了有效地從資料庫中海量資料中提取資訊,資料探勘演算法必須高效且可擴充套件。
並行、分散式和增量挖掘演算法 − 資料庫規模巨大、資料廣泛分佈以及資料探勘方法複雜等因素推動了並行和分散式資料探勘演算法的發展。這些演算法將資料劃分成多個分割槽,然後並行處理。之後,將各個分割槽的結果合併。增量演算法則更新資料庫,而無需從頭開始重新挖掘資料。
各種資料型別問題
關係型和複雜型別資料的處理 − 資料庫可能包含複雜資料物件、多媒體資料物件、空間資料、時間資料等。一個系統不可能挖掘所有這些型別的資料。
從異構資料庫和全球資訊系統中挖掘資訊 − 資料存在於區域網或廣域網上不同的資料來源中。這些資料來源可能是結構化的、半結構化的或非結構化的。因此,從中挖掘知識給資料探勘帶來了挑戰。
資料探勘 - 評估
資料倉庫
資料倉庫具有以下特性,以支援管理層的決策過程:
面向主題 − 資料倉庫面向主題,因為它提供圍繞某個主題的資訊,而不是組織的日常運營資訊。這些主題可以是產品、客戶、供應商、銷售額、收入等。資料倉庫不關注日常運營,而是關注資料的建模和分析以進行決策。
整合 − 資料倉庫透過整合來自異構資料來源(如關係資料庫、平面檔案等)的資料構建而成。這種整合增強了資料的有效分析。
隨時間變化 − 資料倉庫中收集的資料與特定時間段相關聯。資料倉庫中的資料提供了從歷史角度來看的資訊。
非易失性 − 非易失性意味著在新增新資料時不會刪除以前的資料。資料倉庫與操作資料庫分開,因此操作資料庫中的頻繁更改不會反映在資料倉庫中。
資料倉庫技術
資料倉庫技術是構建和使用資料倉庫的過程。資料倉庫透過整合來自多個異構資料來源的資料構建而成。它支援分析報告、結構化和/或臨時查詢以及決策制定。
資料倉庫技術涉及資料清洗、資料整合和資料整合。為了整合異構資料庫,我們有以下兩種方法:
- 查詢驅動方法
- 更新驅動方法
查詢驅動方法
這是整合異構資料庫的傳統方法。此方法用於在多個異構資料庫之上構建包裝器和整合器。這些整合器也稱為中介器。
查詢驅動方法的過程
當向客戶端發出查詢時,元資料字典會將查詢轉換為適合所涉及各個異構站點的查詢。
現在這些查詢被對映併發送到本地查詢處理器。
來自異構站點的結果被整合到全域性答案集中。
缺點
此方法具有以下缺點:
查詢驅動方法需要複雜的整合和過濾過程。
對於頻繁查詢,它非常低效且非常昂貴。
對於需要聚合的查詢,此方法成本很高。
更新驅動方法
當今的資料倉庫系統遵循更新驅動方法,而不是前面討論的傳統方法。在更新驅動方法中,來自多個異構資料來源的資訊會預先整合並存儲在倉庫中。此資訊可用於直接查詢和分析。
優點
此方法具有以下優點:
此方法提供高效能。
資料可以在語義資料儲存中預先複製、處理、整合、註釋、彙總和重組。
查詢處理不需要與本地源的處理進行互動。
從資料倉庫 (OLAP) 到資料探勘 (OLAM)
聯機分析挖掘 (OLAM) 將聯機分析處理 (OLAP) 與資料探勘和多維資料庫中的知識挖掘相結合。下圖顯示了 OLAP 和 OLAM 的整合:
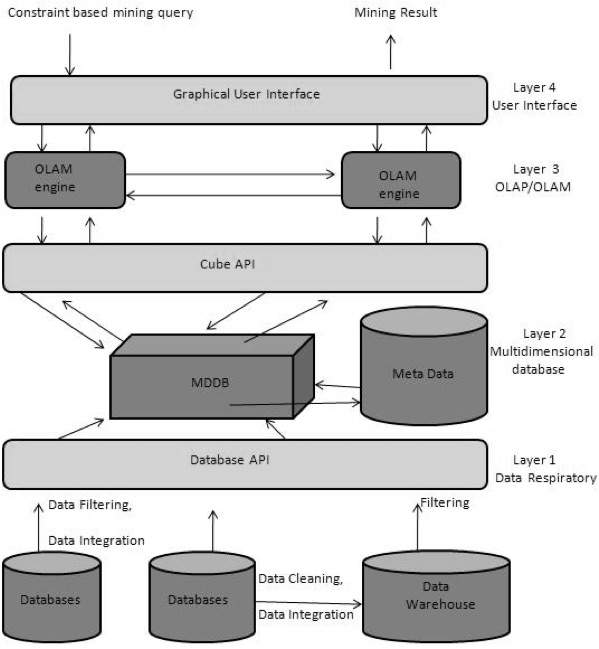
OLAM 的重要性
OLAM 重要的原因如下:
資料倉庫中的高質量資料 − 資料探勘工具需要處理整合、一致和清洗後的資料。這些步驟在資料預處理中非常昂貴。透過這種預處理構建的資料倉庫是 OLAP 和資料探勘的寶貴高質量資料來源。
資料倉庫周圍可用的資訊處理基礎設施 − 資訊處理基礎設施是指訪問、整合、整合和轉換多個異構資料庫、網路訪問和服務設施、報告和 OLAP 分析工具。
基於 OLAP 的探索性資料分析 − 需要進行探索性資料分析才能有效進行資料探勘。OLAM 提供了在不同資料子集和不同抽象級別上進行資料探勘的功能。
資料探勘功能的線上選擇 − 將 OLAP 與多個數據挖掘功能和聯機分析挖掘相結合,使使用者能夠靈活地選擇所需的資料探勘功能並動態地切換資料探勘任務。
資料探勘 - 術語
資料探勘
資料探勘定義為從海量資料集中提取資訊。換句話說,我們可以說資料探勘是從資料中挖掘知識。此資訊可用於以下任何應用程式:
- 市場分析
- 欺詐檢測
- 客戶留存
- 生產控制
- 科學探索
資料探勘引擎
資料探勘引擎對於資料探勘系統至關重要。它包含一組執行以下功能的功能模組:
- 特徵化
- 關聯和相關性分析
- 分類
- 預測
- 聚類分析
- 異常值分析
- 演化分析
知識庫
這是領域知識。此知識用於指導搜尋或評估結果模式的趣味性。
知識發現
有些人將資料探勘與知識發現視為相同,而另一些人則將資料探勘視為知識發現過程中的一個重要步驟。以下是知識發現過程涉及的步驟列表:
- 資料清洗
- 資料整合
- 資料選擇
- 資料轉換
- 資料探勘
- 模式評估
- 知識呈現
使用者介面
使用者介面是資料探勘系統中的模組,它有助於使用者與資料探勘系統之間的通訊。使用者介面允許以下功能:
- 透過指定資料探勘查詢任務來與系統互動。
- 提供資訊以幫助集中搜索。
- 基於中間資料探勘結果進行挖掘。
- 瀏覽資料庫和資料倉庫模式或資料結構。
- 評估挖掘的模式。
- 以不同的形式視覺化模式。
資料整合
資料整合是一種資料預處理技術,它將來自多個異構資料來源的資料合併到一個一致的資料儲存中。資料整合可能涉及不一致的資料,因此需要資料清洗。
資料清洗
資料清洗是一種用於去除噪聲資料和糾正資料中不一致性的技術。資料清洗涉及轉換以糾正錯誤資料。資料清洗是在準備資料倉庫的資料時作為資料預處理步驟執行的。
資料選擇
資料選擇是從資料庫中檢索與分析任務相關的資料的過程。有時在資料選擇過程之前會執行資料轉換和整合。
聚類
聚類是指一組類似的物件。聚類分析是指形成彼此非常相似但與其他聚類中的物件高度不同的物件組。
資料轉換
在此步驟中,透過執行彙總或聚合操作,將資料轉換為或整合為適合挖掘的形式。
資料探勘 - 知識發現
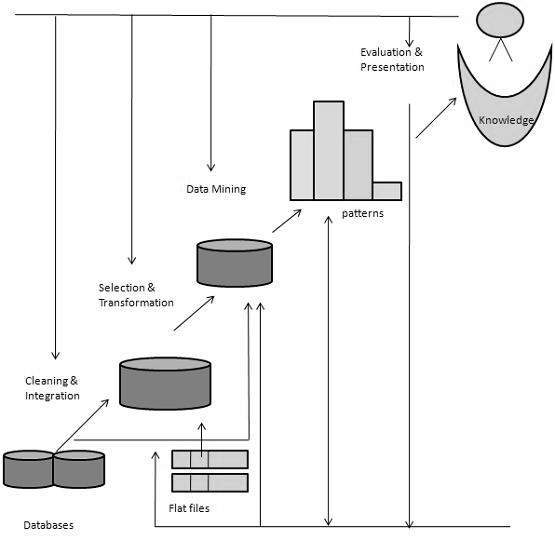
什麼是知識發現?
有些人不會區分資料探勘和知識發現,而另一些人則將資料探勘視為知識發現過程中的一個重要步驟。以下是知識發現過程涉及的步驟列表:
資料清洗 − 在此步驟中,將刪除噪聲和不一致的資料。
資料整合 − 在此步驟中,將組合多個數據源。
資料選擇 − 在此步驟中,將從資料庫中檢索與分析任務相關的資料。
資料轉換 − 在此步驟中,透過執行彙總或聚合操作,將資料轉換為或整合為適合挖掘的形式。
資料探勘 − 在此步驟中,將應用智慧方法以提取資料模式。
模式評估 − 在此步驟中,將評估資料模式。
知識呈現 − 在此步驟中,將表示知識。
下圖顯示了知識發現的過程:
資料探勘 - 系統
有各種各樣的資料探勘系統可用。資料探勘系統可以整合以下技術:
- 空間資料分析
- 資訊檢索
- 模式識別
- 影像分析
- 訊號處理
- 計算機圖形學
- Web 技術
- 商業
- 生物資訊學
資料探勘系統分類
資料探勘系統可以根據以下標準進行分類:
- 資料庫技術
- 統計學
- 機器學習
- 資訊科學
- 視覺化
- 其他學科
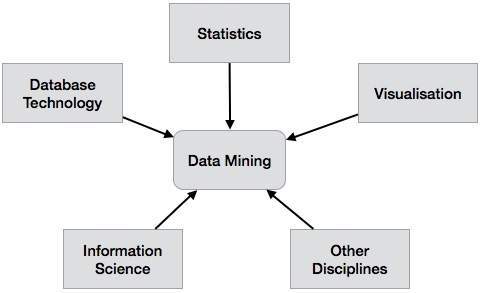
除此之外,資料探勘系統還可以根據(a)挖掘的資料庫型別、(b)挖掘的知識型別、(c)使用的技術以及(d)採用的應用程式進行分類。
基於挖掘的資料庫的分類
我們可以根據挖掘的資料庫型別對資料探勘系統進行分類。資料庫系統可以根據不同的標準進行分類,例如資料模型、資料型別等。資料探勘系統也可以相應地進行分類。
例如,如果我們根據資料模型對資料庫進行分類,那麼我們可能會有關係型、事務型、物件關係型或資料倉庫挖掘系統。
基於挖掘的知識型別的分類
我們可以根據挖掘的知識型別對資料探勘系統進行分類。這意味著資料探勘系統是根據以下功能進行分類的:
- 特徵化
- 區分
- 關聯和相關性分析
- 分類
- 預測
- 異常值分析
- 演化分析
基於所用技術的分類
我們可以根據使用的技術型別對資料探勘系統進行分類。我們可以根據所涉及的使用者互動程度或所採用的分析方法來描述這些技術。
基於所採用應用程式的分類
我們可以根據所採用的應用程式對資料探勘系統進行分類。這些應用程式如下:
- 金融
- 電信
- DNA
- 股票市場
- 電子郵件
將資料探勘系統與資料庫/資料倉庫系統整合
如果資料探勘系統沒有與資料庫或資料倉庫系統整合,那麼將沒有系統可以進行通訊。這種方案被稱為非耦合方案。在這種方案中,主要關注的是資料探勘設計以及為挖掘可用資料集而開發高效且有效的演算法。
整合方案列表如下:
無耦合 - 在此方案中,資料探勘系統不使用任何資料庫或資料倉庫功能。它從特定來源獲取資料,並使用一些資料探勘演算法處理這些資料。資料探勘結果儲存在另一個檔案中。
松耦合 - 在此方案中,資料探勘系統可能會使用資料庫和資料倉庫系統的一些功能。它從這些系統管理的資料儲存庫中獲取資料,並對這些資料執行資料探勘。然後,它將挖掘結果儲存在檔案中,或資料庫或資料倉庫中的指定位置。
半緊耦合 - 在此方案中,資料探勘系統與資料庫或資料倉庫系統連結,此外,可以在資料庫中提供一些資料探勘原語的高效實現。
緊耦合 - 在這種耦合方案中,資料探勘系統被平滑地整合到資料庫或資料倉庫系統中。資料探勘子系統被視為資訊系統的一個功能元件。
資料探勘 - 查詢語言
Han、Fu、Wang 等人針對 DBMiner 資料探勘系統提出了資料探勘查詢語言 (DMQL)。資料探勘查詢語言實際上是基於結構化查詢語言 (SQL) 的。可以設計資料探勘查詢語言來支援臨時和互動式資料探勘。此 DMQL 提供用於指定原語的命令。DMQL 也可以與資料庫和資料倉庫一起使用。DMQL 可用於定義資料探勘任務。我們特別研究瞭如何在 DMQL 中定義資料倉庫和資料倉儲。
任務相關資料規範的語法
以下是用於指定任務相關資料的 DMQL 語法:
use database database_name or use data warehouse data_warehouse_name in relevance to att_or_dim_list from relation(s)/cube(s) [where condition] order by order_list group by grouping_list
指定知識型別的語法
在這裡,我們將討論表徵、區分、關聯、分類和預測的語法。
特徵化
表徵的語法是:
mine characteristics [as pattern_name]
analyze {measure(s) }
analyze 子句指定聚合度量,例如 count、sum 或 count%。
例如:
Description describing customer purchasing habits. mine characteristics as customerPurchasing analyze count%
區分
區分的語法是:
mine comparison [as {pattern_name]}
For {target_class } where {t arget_condition }
{versus {contrast_class_i }
where {contrast_condition_i}}
analyze {measure(s) }
例如,使用者可以將大額消費者定義為平均每次購買商品價格超過 100 美元的顧客;將預算消費者定義為平均每次購買商品價格低於 100 美元的顧客。可以使用 DMQL 指定對來自這些類別中每個類別的客戶的判別性描述的挖掘:
mine comparison as purchaseGroups for bigSpenders where avg(I.price) ≥$100 versus budgetSpenders where avg(I.price)< $100 analyze count
關聯
關聯的語法是:
mine associations [ as {pattern_name} ]
{matching {metapattern} }
例如:
mine associations as buyingHabits matching P(X:customer,W) ^ Q(X,Y) ≥ buys(X,Z)
其中 X 是客戶關係的鍵;P 和 Q 是謂詞變數;W、Y 和 Z 是物件變數。
分類
分類的語法是:
mine classification [as pattern_name] analyze classifying_attribute_or_dimension
例如,要挖掘模式,對客戶信用評級進行分類,其中類別由屬性 credit_rating 確定,並確定挖掘分類為 classifyCustomerCreditRating。
analyze credit_rating
預測
預測的語法是:
mine prediction [as pattern_name]
analyze prediction_attribute_or_dimension
{set {attribute_or_dimension_i= value_i}}
概念層次結構規範的語法
要指定概念層次結構,請使用以下語法:
use hierarchy <hierarchy> for <attribute_or_dimension>
我們使用不同的語法來定義不同型別的層次結構,例如:
-schema hierarchies
define hierarchy time_hierarchy on date as [date,month quarter,year]
-
set-grouping hierarchies
define hierarchy age_hierarchy for age on customer as
level1: {young, middle_aged, senior} < level0: all
level2: {20, ..., 39} < level1: young
level3: {40, ..., 59} < level1: middle_aged
level4: {60, ..., 89} < level1: senior
-operation-derived hierarchies
define hierarchy age_hierarchy for age on customer as
{age_category(1), ..., age_category(5)}
:= cluster(default, age, 5) < all(age)
-rule-based hierarchies
define hierarchy profit_margin_hierarchy on item as
level_1: low_profit_margin < level_0: all
if (price - cost)< $50
level_1: medium-profit_margin < level_0: all
if ((price - cost) > $50) and ((price - cost) ≤ $250))
level_1: high_profit_margin < level_0: all
興趣度量規範的語法
使用者可以使用以下語句指定興趣度量和閾值:
with <interest_measure_name> threshold = threshold_value
例如:
with support threshold = 0.05 with confidence threshold = 0.7
模式呈現和視覺化規範的語法
我們有一種語法,允許使用者指定以一種或多種形式顯示已發現的模式。
display as <result_form>
例如:
display as table
DMQL 的完整規範
作為一家公司的市場經理,您希望根據客戶的年齡、購買的商品型別和購買商品的地點,來描述能夠購買價格不低於 100 美元的商品的客戶的購買習慣。您想知道擁有該特徵的客戶的百分比。特別是,您只對在加拿大購買並使用美國運通訊用卡支付的商品感興趣。您希望以表格形式檢視生成的描述。
use database AllElectronics_db use hierarchy location_hierarchy for B.address mine characteristics as customerPurchasing analyze count% in relevance to C.age,I.type,I.place_made from customer C, item I, purchase P, items_sold S, branch B where I.item_ID = S.item_ID and P.cust_ID = C.cust_ID and P.method_paid = "AmEx" and B.address = "Canada" and I.price ≥ 100 with noise threshold = 5% display as table
資料探勘語言標準化
資料探勘語言的標準化將具有以下目的:
有助於系統地開發資料探勘解決方案。
提高多個數據挖掘系統和功能之間的互操作性。
促進教育和快速學習。
促進資料探勘系統在工業和社會中的應用。
資料探勘 - 分類與預測
有兩種形式的資料分析可用於提取描述重要類別或預測未來資料趨勢的模型。這兩種形式如下:
- 分類
- 預測
分類模型預測類別類別標籤;預測模型預測連續值函式。例如,我們可以構建一個分類模型,將銀行貸款申請分類為安全或有風險,或者構建一個預測模型,根據潛在客戶的收入和職業來預測他們在計算機裝置上的支出(美元)。
什麼是分類?
以下是資料分析任務為分類的情況示例:
銀行貸款經理想要分析資料,以瞭解哪些客戶(貸款申請人)有風險,哪些客戶安全。
公司市場經理需要分析具有給定配置檔案的客戶,哪些客戶會購買新電腦。
在以上兩個示例中,都構建了一個模型或分類器來預測類別標籤。這些標籤對於貸款申請資料來說是風險或安全,對於營銷資料來說是肯定或否定。
什麼是預測?
以下是資料分析任務為預測的情況示例:
假設市場經理需要預測給定客戶在其公司促銷期間將花費多少。在這個例子中,我們關心的是預測一個數值。因此,資料分析任務是數值預測的示例。在這種情況下,將構建一個模型或預測器,該模型或預測器預測一個連續值函式或有序值。
注意 - 迴歸分析是一種統計方法,最常用於數值預測。
分類是如何工作的?
藉助我們上面討論過的銀行貸款申請,讓我們瞭解分類的工作原理。資料分類過程包括兩個步驟:
- 構建分類器或模型
- 使用分類器進行分類
構建分類器或模型
此步驟是學習步驟或學習階段。
在此步驟中,分類演算法構建分類器。
分類器是由訓練集構建的,訓練集由資料庫元組及其相關的類別標籤組成。
構成訓練集的每個元組被稱為類別。這些元組也可以被稱為樣本、物件或資料點。
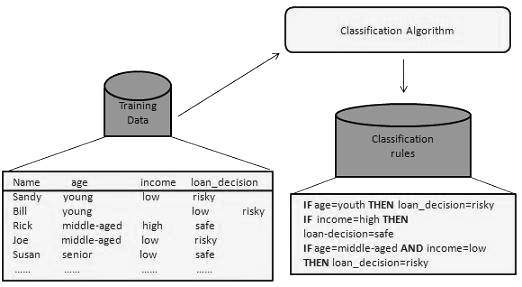
使用分類器進行分類
在此步驟中,分類器用於分類。在這裡,測試資料用於估計分類規則的準確性。如果準確性被認為是可以接受的,則可以將分類規則應用於新的資料元組。

分類和預測問題
主要問題是準備用於分類和預測的資料。準備資料涉及以下活動:
資料清洗 - 資料清洗包括去除噪聲和處理缺失值。透過應用平滑技術去除噪聲,並透過用該屬性中最常出現的值替換缺失值來解決缺失值問題。
相關性分析 - 資料庫也可能包含不相關的屬性。相關性分析用於瞭解任何兩個給定屬性是否相關。
資料轉換和約簡 - 資料可以透過以下任何方法進行轉換。
歸一化 - 使用歸一化轉換資料。歸一化包括縮放給定屬性的所有值,以使它們落在一個小指定的範圍內。當在學習步驟中使用神經網路或涉及測量的方法時,使用歸一化。
泛化 - 資料也可以透過將其泛化到更高的概念來轉換。為此,我們可以使用概念層次結構。
注意 - 資料也可以透過其他一些方法進行約簡,例如小波變換、分箱、直方圖分析和聚類。
分類和預測方法的比較
以下是比較分類和預測方法的標準:
準確性 - 分類器的準確性是指分類器的能力。它可以正確預測類別標籤,預測器的準確性是指給定預測器能夠多好地猜測新資料的預測屬性的值。
速度 - 這指的是生成和使用分類器或預測器的計算成本。
魯棒性 - 它指的是分類器或預測器從給定噪聲資料中進行正確預測的能力。
可擴充套件性 - 可擴充套件性是指有效構建分類器或預測器;給定大量資料。
可解釋性 - 它指的是分類器或預測器理解的程度。
資料探勘 - 決策樹歸納
決策樹是一種包含根節點、分支和葉節點的結構。每個內部節點表示對屬性的測試,每個分支表示測試的結果,每個葉節點都包含一個類別標籤。樹中最頂部的節點是根節點。
以下決策樹用於概念 buy_computer,該概念指示公司客戶是否可能購買電腦。每個內部節點表示對屬性的測試。每個葉節點都表示一個類別。
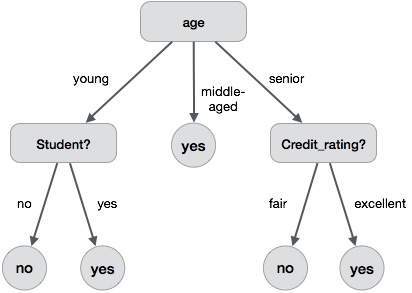
決策樹的優點如下:
- 它不需要任何領域知識。
- 易於理解。
- 決策樹的學習和分類步驟簡單快速。
決策樹歸納演算法
1980年,一位名叫J. Ross Quinlan的機器學習研究人員開發了一種名為ID3(迭代二分器)的決策樹演算法。後來,他提出了C4.5,它是ID3的繼任者。ID3和C4.5採用貪婪演算法。在這個演算法中,沒有回溯;樹木以自頂向下的遞迴分治方式構建。
Generating a decision tree form training tuples of data partition D
Algorithm : Generate_decision_tree
Input:
Data partition, D, which is a set of training tuples
and their associated class labels.
attribute_list, the set of candidate attributes.
Attribute selection method, a procedure to determine the
splitting criterion that best partitions that the data
tuples into individual classes. This criterion includes a
splitting_attribute and either a splitting point or splitting subset.
Output:
A Decision Tree
Method
create a node N;
if tuples in D are all of the same class, C then
return N as leaf node labeled with class C;
if attribute_list is empty then
return N as leaf node with labeled
with majority class in D;|| majority voting
apply attribute_selection_method(D, attribute_list)
to find the best splitting_criterion;
label node N with splitting_criterion;
if splitting_attribute is discrete-valued and
multiway splits allowed then // no restricted to binary trees
attribute_list = splitting attribute; // remove splitting attribute
for each outcome j of splitting criterion
// partition the tuples and grow subtrees for each partition
let Dj be the set of data tuples in D satisfying outcome j; // a partition
if Dj is empty then
attach a leaf labeled with the majority
class in D to node N;
else
attach the node returned by Generate
decision tree(Dj, attribute list) to node N;
end for
return N;
樹剪枝
進行樹剪枝是為了去除訓練資料中由於噪聲或異常值造成的異常。剪枝後的樹更小,更簡單。
樹剪枝方法
有兩種方法可以剪枝一棵樹:
預剪枝 - 透過提前停止樹的構建來剪枝。
後剪枝 - 此方法從完全生長的樹中刪除子樹。
代價複雜度
代價複雜度由以下兩個引數衡量:
- 樹中葉子的數量,以及
- 樹的錯誤率。
資料探勘 - 貝葉斯分類
貝葉斯分類基於貝葉斯定理。貝葉斯分類器是統計分類器。貝葉斯分類器可以預測類成員機率,例如給定元組屬於特定類的機率。
貝葉斯定理
貝葉斯定理以托馬斯·貝葉斯命名。有兩種型別的機率:
- 後驗機率 [P(H/X)]
- 先驗機率 [P(H)]
其中X是資料元組,H是一些假設。
根據貝葉斯定理,
貝葉斯信念網路
貝葉斯信念網路指定聯合條件機率分佈。它們也稱為信念網路、貝葉斯網路或機率網路。
信念網路允許在變數子集之間定義類條件獨立性。
它提供因果關係的圖形模型,可以在其上進行學習。
我們可以使用訓練好的貝葉斯網路進行分類。
定義貝葉斯信念網路的兩個組成部分是:
- 有向無環圖
- 一組條件機率表
有向無環圖
- 有向無環圖中的每個節點代表一個隨機變數。
- 這些變數可能是離散值或連續值。
- 這些變數可能對應於資料中給出的實際屬性。
有向無環圖表示
下圖顯示了六個布林變數的有向無環圖。
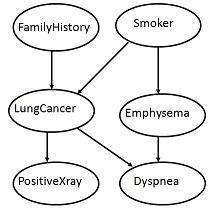
圖中的弧允許表示因果知識。例如,肺癌受人的家族肺癌史以及該人是否吸菸的影響。值得注意的是,鑑於我們知道病人患有肺癌,變數PositiveXray與病人是否有家族肺癌史或病人是否吸菸無關。
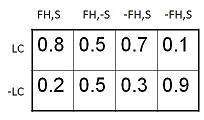
條件機率表
變數LungCancer (LC) 的值的條件機率表顯示其父節點FamilyHistory (FH)和Smoker (S) 的值的每種可能組合,如下所示:
資料探勘 - 基於規則的分類
IF-THEN規則
基於規則的分類器使用一組IF-THEN規則進行分類。我們可以用以下形式表達規則:
讓我們考慮規則R1:
R1: IF age = youth AND student = yes THEN buy_computer = yes
要點:
規則的IF部分稱為規則前件或前提條件。
規則的THEN部分稱為規則後件。
前件部分的條件由一個或多個屬性測試組成,這些測試在邏輯上是與操作。
後件部分包含類預測。
注意 - 我們也可以將規則R1寫成如下形式:
R1: (age = youth) ^ (student = yes))(buys computer = yes)
如果條件對給定元組成立,則前件滿足。
規則提取
在這裡,我們將學習如何透過從決策樹中提取IF-THEN規則來構建基於規則的分類器。
要點:
要從決策樹中提取規則:
為從根節點到葉節點的每條路徑建立一個規則。
為了形成規則前件,每個分裂標準都在邏輯上進行與操作。
葉節點儲存類預測,形成規則後件。
使用順序覆蓋演算法進行規則歸納
順序覆蓋演算法可用於從訓練資料中提取IF-THEN規則。我們不需要先生成決策樹。在這個演算法中,給定類的每個規則都覆蓋該類的許多元組。
一些順序覆蓋演算法包括AQ、CN2和RIPPER。根據一般策略,規則一次學習一個。每次學習規則時,都會刪除該規則覆蓋的元組,並對其餘元組繼續此過程。這是因為決策樹中通向每個葉子的路徑對應於一個規則。
注意 - 決策樹歸納可以被認為是同時學習一組規則。
以下是順序學習演算法,其中規則一次學習一個類。當從類Ci學習規則時,我們希望該規則只覆蓋來自類C的所有元組,而不覆蓋來自任何其他類的任何元組。
Algorithm: Sequential Covering
Input:
D, a data set class-labeled tuples,
Att_vals, the set of all attributes and their possible values.
Output: A Set of IF-THEN rules.
Method:
Rule_set={ }; // initial set of rules learned is empty
for each class c do
repeat
Rule = Learn_One_Rule(D, Att_valls, c);
remove tuples covered by Rule form D;
until termination condition;
Rule_set=Rule_set+Rule; // add a new rule to rule-set
end for
return Rule_Set;
規則剪枝
由於以下原因進行規則剪枝:
在原始訓練資料集上進行質量評估。該規則在訓練資料上可能表現良好,但在後續資料上的表現較差。這就是需要規則剪枝的原因。
透過刪除合取來剪枝規則。如果規則R的剪枝版本比在獨立元組集上評估的質量更高,則剪枝規則R。
FOIL是一種簡單有效的規則剪枝方法。對於給定的規則R,
其中pos和neg分別是R覆蓋的正元組和負元組的數量。
注意 - 此值將隨著R在剪枝集上的準確性提高而增加。因此,如果R的剪枝版本的FOIL_Prune值更高,則我們剪枝R。
其他分類方法
在這裡,我們將討論其他分類方法,例如遺傳演算法、粗糙集方法和模糊集方法。
遺傳演算法
遺傳演算法的思想源於自然進化。在遺傳演算法中,首先建立初始種群。這個初始種群由隨機生成的規則組成。我們可以用位串表示每個規則。
例如,在給定的訓練集中,樣本由兩個布林屬性(例如A1和A2)描述。這個給定的訓練集包含兩個類,例如C1和C2。
我們可以將規則IF A1 AND NOT A2 THEN C2編碼成位串100。在這個位表示中,最左邊的兩位分別表示屬性A1和A2。
同樣,規則IF NOT A1 AND NOT A2 THEN C1可以編碼為001。
注意 - 如果屬性有K個值,其中K>2,那麼我們可以使用K位來編碼屬性值。類也以相同的方式編碼。
要點:
基於適者生存的概念,形成一個新的種群,該種群由當前種群中最適宜的規則及其後代值組成。
規則的適應度透過其在訓練樣本集上的分類準確性來評估。
應用遺傳運算元(如交叉和變異)來建立後代。
在交叉中,交換一對規則的子串以形成一對新的規則。
在變異中,規則字串中隨機選擇的位被反轉。
粗糙集方法
我們可以使用粗糙集方法來發現不精確和噪聲資料中的結構關係。
注意 - 此方法只能應用於離散值屬性。因此,必須在使用前離散化連續值屬性。
粗糙集理論基於在給定的訓練資料中建立等價類。構成等價類的元組是不可區分的。這意味著樣本在描述資料的屬性方面是相同的。
在給定的現實世界資料中,有一些類在可用屬性方面無法區分。我們可以使用粗糙集來粗略地定義這些類。
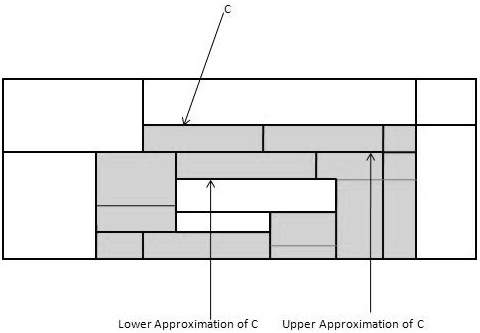
對於給定的類C,粗糙集定義由以下兩個集合近似:
C的下近似 - C的下近似由所有資料元組組成,這些元組根據屬性的知識,肯定屬於類C。
C的上近似 - C的上近似由所有元組組成,這些元組根據屬性的知識,不能描述為不屬於C。
下圖顯示了類C的上近似和下近似:
模糊集方法
模糊集理論也稱為可能性理論。該理論由Lotfi Zadeh於1965年提出,作為二值邏輯和機率論的替代方案。該理論允許我們在較高的抽象級別上工作。它還為我們處理資料的不精確測量提供了方法。
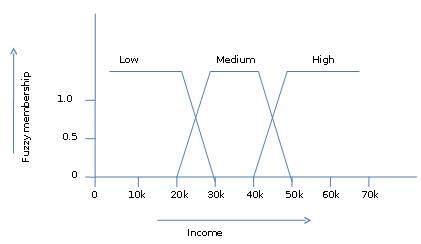
模糊集理論還允許我們處理模糊或不精確的事實。例如,成為高收入者集合的成員是不精確的(例如,如果50,000美元是高的,那麼49,000美元和48,000美元呢)。與傳統CRISP集不同,在傳統CRISP集中,元素要麼屬於S要麼屬於其補集,但在模糊集理論中,元素可以屬於多個模糊集。
例如,收入值49,000美元屬於中等和高模糊集,但程度不同。此收入值的模糊集表示法如下:
mmedium_income($49k)=0.15 and mhigh_income($49k)=0.96
其中“m”是在中等收入和高收入的模糊集上執行的隸屬函式。此表示法可以用圖表表示如下:
資料探勘 - 聚類分析
叢集是一組屬於同一類的物件。換句話說,相似的物件被分組到一個叢集中,不相似的物件被分組到另一個叢集中。
什麼是聚類?
聚類是將一組抽象物件分組到相似物件類別的過程。
要點
資料物件的叢集可以作為一個組對待。
在進行聚類分析時,我們首先根據資料相似性將資料集劃分為組,然後為組分配標籤。
聚類相對於分類的主要優點是它能夠適應變化,並有助於挑選出區分不同組的有用特徵。
聚類分析的應用
聚類分析廣泛應用於許多應用中,例如市場研究、模式識別、資料分析和影像處理。
聚類還可以幫助營銷人員發現其客戶群中的不同群體。他們可以根據購買模式來描述其客戶群體。
在生物學領域,它可以用來推導植物和動物分類法,對具有相似功能的基因進行分類,並深入瞭解群體中固有的結構。
聚類分析也有助於識別地球觀測資料庫中具有相似土地利用的區域。它還有助於根據房屋型別、價值和地理位置識別城市中各組房屋。
聚類分析還有助於對網路上的文件進行分類,以進行資訊發現。
聚類分析也用於異常值檢測應用,例如信用卡欺詐檢測。
作為一種資料探勘功能,聚類分析可作為一種工具來深入瞭解資料的分佈,觀察每個聚類的特徵。
資料探勘中聚類的需求
以下幾點闡明瞭為什麼資料探勘中需要聚類:
可擴充套件性 - 我們需要高度可擴充套件的聚類演算法來處理大型資料庫。
處理不同型別屬性的能力 - 演算法應該能夠應用於任何型別的資料,例如基於區間的(數值)資料、分類資料和二元資料。
發現具有屬性形狀的聚類 - 聚類演算法應該能夠檢測任意形狀的聚類。它們不應僅限於傾向於找到小型球形聚類的距離度量。
高維性 - 聚類演算法不僅能夠處理低維資料,還能夠處理高維空間。
處理噪聲資料的能力 - 資料庫包含噪聲、缺失或錯誤的資料。某些演算法對這種資料很敏感,並可能導致質量差的聚類。
可解釋性 - 聚類結果應具有可解釋性、可理解性和可用性。
聚類方法
聚類方法可以分為以下幾類:
- 劃分方法
- 層次方法
- 基於密度的聚類方法
- 基於網格的方法
- 基於模型的方法
- 基於約束的方法
劃分方法
假設我們得到一個包含“n”個物件的資料庫,劃分方法構造資料的“k”個劃分。每個劃分都代表一個聚類,且k ≤ n。這意味著它會將資料分類為k組,這些組滿足以下要求:
每組至少包含一個物件。
每個物件必須恰好屬於一個組。
要點:
對於給定的分割槽數(例如k),劃分方法將建立一個初始劃分。
然後,它使用迭代重定位技術透過將物件從一個組移動到另一個組來改進劃分。
層次方法
此方法建立給定資料集物件的層次分解。我們可以根據層次分解的形成方式對層次方法進行分類。這裡有兩種方法:
- 凝聚法
- 分裂法
凝聚法
這種方法也稱為自下而上的方法。在這裡,我們從每個物件形成一個單獨的組開始。它不斷合併彼此靠近的物件或組。它會一直這樣做,直到所有組合併成一個組,或者直到滿足終止條件。
分裂法
這種方法也稱為自上而下的方法。在這裡,我們從同一聚類中的所有物件開始。在連續迭代中,一個聚類被分成更小的聚類。它一直向下進行,直到每個物件都在一個聚類中或滿足終止條件。此方法是嚴格的,即一旦合併或拆分完成,就無法撤消。
改進層次聚類質量的方法
以下是用於提高層次聚類質量的兩種方法:
仔細分析每個層次劃分的物件連結。
透過首先使用層次凝聚演算法將物件分組到微聚類,然後對微聚類執行宏聚類來整合層次凝聚。
基於密度的聚類方法
此方法基於密度的概念。其基本思想是,只要鄰域中的密度超過某個閾值,就繼續增長給定的聚類,即對於給定聚類中的每個資料點,給定聚類的半徑必須至少包含最小數量的點。
基於網格的方法
在此方法中,物件一起形成一個網格。物件空間被量化為有限數量的單元格,形成網格結構。
優點
此方法的主要優點是處理速度快。
它僅取決於量化空間中每個維度中的單元格數量。
基於模型的方法
在此方法中,為每個聚類假設一個模型,以找到給定模型資料的最佳擬合。此方法透過聚類密度函式來定位聚類。它反映了資料點的空間分佈。
此方法還提供了一種基於標準統計自動確定聚類數量的方法,同時考慮了異常值或噪聲。因此,它產生了穩健的聚類方法。
基於約束的方法
在此方法中,透過結合使用者或應用程式導向的約束來執行聚類。約束是指使用者期望或所需聚類結果的屬性。約束為我們提供了一種與聚類過程互動式通訊的方法。約束可以由使用者或應用程式需求指定。
資料探勘 - 文字資料探勘
文字資料庫包含大量的文件集合。它們從新聞文章、書籍、數字圖書館、電子郵件、網頁等多個來源收集這些資訊。由於資訊量的增加,文字資料庫正在迅速增長。在許多文字資料庫中,資料是半結構化的。
例如,文件可能包含一些結構化欄位,例如標題、作者、出版日期等。但除了結構化資料外,文件還包含非結構化文字元件,例如摘要和內容。在不知道文件中可能包含什麼內容的情況下,很難制定有效的查詢來分析和提取資料中的有用資訊。使用者需要工具來比較文件並對其重要性和相關性進行排名。因此,文字挖掘已成為流行的主題,也是資料探勘中的一個重要主題。
資訊檢索
資訊檢索處理從大量基於文字的文件中檢索資訊。一些資料庫系統通常不存在於資訊檢索系統中,因為兩者處理不同型別的資料。資訊檢索系統的示例包括:
- 線上圖書館目錄系統
- 線上文件管理系統
- 網路搜尋系統等。
注意 - 資訊檢索系統中的主要問題是根據使用者的查詢在文件集合中找到相關的文件。這種使用者的查詢包含一些描述資訊需求的關鍵詞。
在這種搜尋問題中,使用者主動從集合中提取相關資訊。當用戶有臨時資訊需求(即短期需求)時,這是合適的。但如果使用者有長期資訊需求,則檢索系統也可以主動向使用者推送任何新到的資訊項。
這種訪問資訊的方式稱為資訊過濾。相應的系統被稱為過濾系統或推薦系統。
文字檢索的基本度量
我們需要檢查系統在根據使用者的輸入檢索多個文件時的準確性。將與查詢相關的文件集合表示為{Relevant},將檢索到的文件集合表示為{Retrieved}。相關且已檢索到的文件集合可以表示為{Relevant} ∩ {Retrieved}。這可以用維恩圖表示如下:

評估文字檢索質量有三個基本度量:
- 精確率
- 召回率
- F1值
精確率
精確率是實際與查詢相關的檢索到的文件的百分比。精確率可以定義為:
Precision= |{Relevant} ∩ {Retrieved}| / |{Retrieved}|
召回率
召回率是實際與查詢相關且已檢索到的文件的百分比。召回率定義為:
Recall = |{Relevant} ∩ {Retrieved}| / |{Relevant}|
F1值
F1值是常用的權衡指標。資訊檢索系統通常需要權衡精確率或召回率,反之亦然。F1值定義為召回率或精確率的調和平均數,如下所示:
F-score = recall x precision / (recall + precision) / 2
資料探勘 - 挖掘全球資訊網
全球資訊網包含大量資訊,為資料探勘提供了豐富的資源。
Web挖掘中的挑戰
基於以下觀察結果,Web對基於資源和知識的發現提出了巨大的挑戰:
Web規模龐大 - Web的規模非常龐大,並且正在迅速增長。這似乎表明Web對於資料倉庫和資料探勘來說過於龐大。
網頁的複雜性 - 網頁沒有統一的結構。與傳統的文字文件相比,它們非常複雜。Web數字圖書館中有大量的文件。這些圖書館沒有按照任何特定的排序順序排列。
Web是動態資訊源 - Web上的資訊會迅速更新。新聞、股票市場、天氣、體育、購物等資料會定期更新。
使用者社群的多樣性 - Web上的使用者社群正在迅速擴大。這些使用者具有不同的背景、興趣和使用目的。有超過1億個工作站連線到網際網路,並且仍在迅速增長。
資訊的關聯性 - 人們認為,特定的人通常只對Web的一小部分感興趣,而Web的其餘部分包含與使用者無關的資訊,並可能淹沒所需的結果。
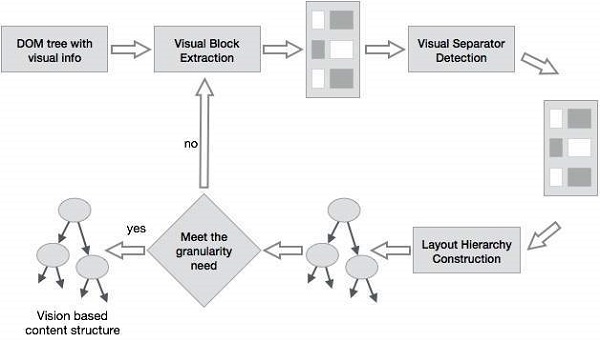
挖掘網頁佈局結構
網頁的基本結構基於文件物件模型 (DOM)。DOM結構指的是樹狀結構,其中頁面中的HTML標籤對應於DOM樹中的節點。我們可以使用HTML中的預定義標籤來分割網頁。HTML語法靈活,因此網頁不遵循W3C規範。不遵循W3C規範可能會導致DOM樹結構出錯。
DOM結構最初是為瀏覽器中的呈現而引入的,而不是為了描述網頁的語義結構。DOM結構無法正確識別網頁不同部分之間的語義關係。
基於視覺的頁面分割 (VIPS)
VIPS的目的是根據網頁的視覺呈現來提取其語義結構。
這種語義結構對應於樹狀結構。在此樹中,每個節點對應於一個塊。
為每個節點分配一個值。此值稱為連貫性度。分配此值是為了根據視覺感知指示塊中連貫的內容。
VIPS演算法首先從HTML DOM樹中提取所有合適的塊。之後,它找到這些塊之間的分隔符。
分隔符指的是網頁中水平或垂直的線條,這些線條在視覺上與任何塊都不相交。
網頁的語義是在這些塊的基礎上構建的。
下圖顯示了VIPS演算法的過程:
資料探勘 - 應用與趨勢
資料探勘廣泛應用於各個領域。目前有很多商業資料探勘系統可用,但該領域仍面臨許多挑戰。在本教程中,我們將討論資料探勘的應用和趨勢。
資料探勘應用
以下是資料探勘廣泛應用的領域:
- 金融資料分析
- 零售業
- 電信行業
- 生物資料分析
- 其他科學應用
- 入侵檢測
金融資料分析
銀行和金融行業中的金融資料通常可靠且高質量,這有利於系統的數 據分析和資料探勘。一些典型的案例如下:
為多維資料分析和資料探勘設計和構建資料倉庫。
貸款還款預測和客戶信用政策分析。
對客戶進行分類和聚類以進行目標營銷。
檢測洗錢和其他金融犯罪。
零售業
資料探勘在零售業有著廣泛的應用,因為它從銷售、客戶購買歷史、商品運輸、消費和服務等方面收集大量資料。由於網路的易用性、可用性和普及性不斷提高,所收集的資料量自然會繼續快速增長。
零售業中的資料探勘有助於識別客戶購買模式和趨勢,從而提高客戶服務質量,提高客戶留存率和滿意度。以下是零售業中資料探勘示例的列表:
基於資料探勘的優勢設計和構建資料倉庫。
對銷售、客戶、產品、時間和區域進行多維分析。
分析銷售活動的效果。
客戶留存。
產品推薦和商品交叉參考。
電信行業
如今,電信行業是發展最快的行業之一,提供傳真、尋呼機、手機、網際網路即時通訊、影像、電子郵件、網路資料傳輸等各種服務。由於新型計算機和通訊技術的進步,電信行業正在快速擴張。這就是為什麼資料探勘對於幫助和理解業務變得非常重要的原因。
電信行業中的資料探勘有助於識別電信模式,發現欺詐活動,更好地利用資源,並提高服務質量。以下是資料探勘改進電信服務的示例列表:
電信資料的多分維分析。
欺詐模式分析。
識別異常模式。
多分維關聯和順序模式分析。
移動電信服務。
在電信資料分析中使用視覺化工具。
生物資料分析
近年來,我們在基因組學、蛋白質組學、功能基因組學和生物醫學研究等生物學領域取得了巨大發展。生物資料探勘是生物資訊學中非常重要的一部分。以下是資料探勘對生物資料分析的貢獻方面:
異構分散式基因組學和蛋白質組學資料庫的語義整合。
比對、索引、相似性搜尋和多個核苷酸序列的比較分析。
發現結構模式和分析基因網路和蛋白質通路。
關聯和路徑分析。
基因資料分析中的視覺化工具。
其他科學應用
上述討論的應用傾向於處理相對較小且同質的資料集,統計技術適合這些資料集。從地球科學、天文學等科學領域收集了大量資料。由於氣候和生態系統建模、化學工程、流體動力學等各個領域的快速數值模擬,正在生成大量資料集。以下是資料探勘在科學應用領域的應用:
- 資料倉庫和資料預處理。
- 基於圖的挖掘。
- 視覺化和領域特定知識。
入侵檢測
入侵是指任何威脅網路資源的完整性、機密性或可用性的行為。在這個互聯互通的世界中,安全已成為主要問題。隨著網際網路使用量的增加以及入侵和攻擊網路的工具和技巧的可用性,入侵檢測已成為網路管理的關鍵組成部分。以下是資料探勘技術可用於入侵檢測的領域:
開發用於入侵檢測的資料探勘演算法。
關聯和相關分析、聚合,有助於選擇和構建區分屬性。
流資料分析。
分散式資料探勘。
視覺化和查詢工具。
資料探勘系統產品
有很多資料探勘系統產品和特定領域的資料探勘應用程式。新的資料探勘系統和應用程式正在新增到以前的系統中。此外,人們還在努力標準化資料探勘語言。
選擇資料探勘系統
資料探勘系統的選擇取決於以下特性:
資料型別 - 資料探勘系統可以處理格式化文字、基於記錄的資料和關係資料。資料也可以是ASCII文字、關係資料庫資料或資料倉庫資料。因此,我們應該檢查資料探勘系統可以處理的確切格式。
系統問題 - 我們必須考慮資料探勘系統與不同作業系統的相容性。一個數據挖掘系統可能只在一個作業系統上執行,也可能在多個作業系統上執行。還有一些資料探勘系統提供基於 Web 的使用者介面,並允許 XML 資料作為輸入。
資料來源 - 資料來源指的是資料探勘系統將執行的資料格式。一些資料探勘系統可能只在 ASCII 文字檔案上工作,而另一些則在多個關係源上工作。資料探勘系統還應該支援 ODBC 連線或用於 ODBC 連線的 OLE DB。
資料探勘功能和方法 - 一些資料探勘系統只提供一種資料探勘功能,例如分類,而另一些則提供多種資料探勘功能,例如概念描述、發現驅動的 OLAP 分析、關聯挖掘、關聯分析、統計分析、分類、預測、聚類、異常值分析、相似性搜尋等。
將資料探勘與資料庫或資料倉庫系統耦合 - 資料探勘系統需要與資料庫或資料倉庫系統耦合。耦合的元件整合到統一的資訊處理環境中。以下是列出的耦合型別:
- 無耦合
- 松耦合
- 半緊耦合
- 緊耦合
可擴充套件性 - 資料探勘中存在兩個可擴充套件性問題:
行(資料庫大小)可擴充套件性 - 當行數擴大 10 倍時,資料探勘系統被認為是行可擴充套件的。執行查詢的時間不超過 10 倍。
列(維度)可擴充套件性 - 如果挖掘查詢執行時間隨列數線性增加,則資料探勘系統被認為是列可擴充套件的。
視覺化工具 - 資料探勘中的視覺化可以分為以下幾類:
- 資料視覺化
- 挖掘結果視覺化
- 挖掘過程視覺化
- 視覺資料探勘
資料探勘查詢語言和圖形使用者介面 - 易於使用的圖形使用者介面對於促進使用者引導的互動式資料探勘非常重要。與關係資料庫系統不同,資料探勘系統不共享底層資料探勘查詢語言。
資料探勘趨勢
資料探勘概念仍在不斷發展,以下是我們在該領域看到的最新趨勢:
應用探索。
可擴充套件且互動式的資料探勘方法。
將資料探勘與資料庫系統、資料倉庫系統和 Web 資料庫系統整合。
資料探勘查詢語言的標準化。
視覺資料探勘。
挖掘複雜型別資料的新方法。
生物資料探勘。
資料探勘和軟體工程。
網路挖掘。
分散式資料探勘。
即時資料探勘。
多資料庫資料探勘。
資料探勘中的隱私保護和資訊安全。
資料探勘 - 主題
資料探勘的理論基礎
資料探勘的理論基礎包括以下概念:
資料約簡 - 該理論的基本思想是減少資料表示,它以精度換取速度,以響應對非常大的資料庫上的查詢快速獲得近似答案的需求。一些資料約簡技術如下:
奇異值分解
小波
迴歸
對數線性模型
直方圖
聚類
抽樣
索引樹的構建
資料壓縮 - 該理論的基本思想是用以下方面進行編碼來壓縮給定的資料:
位
關聯規則
決策樹
聚類
模式發現 - 該理論的基本思想是發現數據庫中發生的模式。以下是為此理論做出貢獻的領域:
機器學習
神經網路
關聯挖掘
順序模式匹配
聚類
機率論 - 該理論基於統計理論。該理論背後的基本思想是發現隨機變數的聯合機率分佈。
機率論 - 根據該理論,資料探勘發現的模式僅在其可用於某個企業的決策過程中才有意義。
微觀經濟學觀點 - 根據該理論,資料庫模式由儲存在資料庫中的資料和模式組成。因此,資料探勘是在資料庫上執行歸納的任務。
歸納資料庫 - 除了面向資料庫的技術外,還有用於資料分析的統計技術。這些技術也可以應用於科學資料以及經濟和社會科學的資料。
統計資料挖掘
一些統計資料挖掘技術如下:
迴歸 - 迴歸方法用於根據一個或多個預測變數預測響應變數的值,其中變數是數值型的。以下是迴歸的形式:
線性
多元
加權
多項式
非引數
穩健的
廣義線性模型 - 廣義線性模型包括:
邏輯迴歸
泊松迴歸
模型的泛化允許以類似於使用線性迴歸對數值響應變數進行建模的方式,將分類響應變數與一組預測變數相關聯。
方差分析 - 此技術分析:
用數值響應變數描述的兩個或多個總體的實驗資料。
一個或多個分類變數(因素)。
混合效應模型 - 這些模型用於分析分組資料。這些模型描述了響應變數與根據一個或多個因素分組的資料中的一些協變數之間的關係。
因子分析 - 因子分析用於預測分類響應變數。此方法假設自變數服從多元正態分佈。
時間序列分析 -以下是分析時間序列資料的方法:
自迴歸方法。
單變數ARIMA(自迴歸積分移動平均)模型。
長記憶時間序列建模。
視覺化資料探勘
視覺化資料探勘利用資料和/或知識視覺化技術,從大型資料集中發現隱含知識。視覺化資料探勘可以看作是以下學科的整合:
資料視覺化
資料探勘
視覺化資料探勘與以下密切相關:
計算機圖形學
多媒體系統
人機互動
模式識別
高效能計算
通常,資料視覺化和資料探勘可以以以下方式整合:
資料視覺化 - 資料庫或資料倉庫中的資料可以以多種視覺化形式檢視,如下所示:
箱線圖
三維立方體
資料分佈圖
曲線
曲面
連結圖等。
資料探勘結果視覺化 - 資料探勘結果視覺化是以視覺化形式呈現資料探勘結果。這些視覺化形式可以是散點圖、箱線圖等。
資料探勘過程視覺化 - 資料探勘過程視覺化呈現資料探勘的多個過程。它允許使用者檢視資料的提取方式。它還允許使用者檢視資料是從哪個資料庫或資料倉庫中清洗、整合、預處理和挖掘的。
音訊資料探勘
音訊資料探勘利用音訊訊號指示資料模式或資料探勘結果的特徵。透過將模式轉換為聲音和音樂,我們可以聆聽音調和旋律,而不是觀看圖片,以便識別任何有趣的內容。
資料探勘和協同過濾
如今,消費者在購物時會遇到各種各樣的商品和服務。在即時客戶交易中,推薦系統透過提供產品推薦來幫助消費者。協同過濾方法通常用於向客戶推薦產品。這些推薦基於其他客戶的意見。