- 資料探勘教程
- 資料探勘 - 首頁
- 資料探勘 - 概述
- 資料探勘 - 任務
- 資料探勘 - 問題
- 資料探勘 - 評估
- 資料探勘 - 術語
- 資料探勘 - 知識發現
- 資料探勘 - 系統
- 資料探勘 - 查詢語言
- 分類與預測
- 資料探勘 - 決策樹歸納
- 資料探勘 - 貝葉斯分類
- 基於規則的分類
- 資料探勘 - 分類方法
- 資料探勘 - 聚類分析
- 資料探勘 - 挖掘文字資料
- 資料探勘 - 挖掘WWW
- 資料探勘 - 應用與趨勢
- 資料探勘 - 主題
- 資料探勘有用資源
- 資料探勘 - 快速指南
- 資料探勘 - 有用資源
- 資料探勘 - 討論
資料探勘 - 挖掘全球資訊網
全球資訊網包含大量資訊,為資料探勘提供了豐富的來源。
Web挖掘中的挑戰
基於以下觀察,Web對基於資源和知識的發現提出了巨大挑戰:
Web規模龐大 - Web的規模非常龐大,並且正在迅速增長。這似乎表明Web對於資料倉庫和資料探勘來說過於龐大。
網頁的複雜性 - 網頁沒有統一的結構。與傳統的文字文件相比,它們非常複雜。Web數字圖書館中存在大量文件。這些庫沒有按照任何特定的排序順序排列。
Web是動態資訊源 - Web上的資訊正在快速更新。諸如新聞、股票市場、天氣、體育、購物等資料會定期更新。
使用者社群的多樣性 - Web上的使用者社群正在迅速擴大。這些使用者具有不同的背景、興趣和使用目的。有超過1億個工作站連線到網際網路,並且仍在快速增長。
資訊的關聯性 - 認為特定的人通常只對Web的一小部分感興趣,而Web的其餘部分包含與使用者無關的資訊,可能會淹沒所需的結果。
挖掘網頁佈局結構
網頁的基本結構基於文件物件模型 (DOM)。DOM結構指的是樹狀結構,其中頁面中的HTML標籤對應於DOM樹中的節點。我們可以使用HTML中的預定義標籤來分割網頁。HTML語法靈活,因此網頁不遵循W3C規範。不遵循W3C規範可能會導致DOM樹結構錯誤。
DOM結構最初是為了在瀏覽器中進行呈現而引入的,而不是為了描述網頁的語義結構。DOM結構無法正確識別網頁不同部分之間的語義關係。
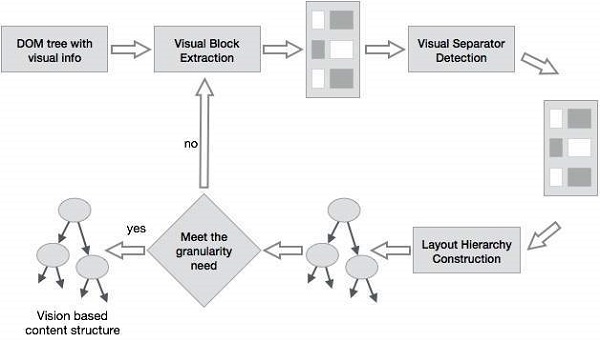
基於視覺的頁面分割 (VIPS)
VIPS的目的是根據其視覺呈現提取網頁的語義結構。
這種語義結構對應於樹狀結構。在這棵樹中,每個節點對應於一個塊。
為每個節點分配一個值。此值稱為連貫度。分配此值是為了根據視覺感知指示塊中連貫的內容。
VIPS演算法首先從HTML DOM樹中提取所有合適的塊。之後,它找到這些塊之間的分隔符。
分隔符指的是網頁中水平或垂直的線條,這些線條在視覺上交叉且沒有塊。
網頁的語義是基於這些塊構建的。
下圖顯示了VIPS演算法的過程: