- C語言程式設計教程
- C語言 - 首頁
- C語言基礎
- C語言 - 概述
- C語言 - 特性
- C語言 - 歷史
- C語言 - 環境搭建
- C語言 - 程式結構
- C語言 - Hello World
- C語言 - 編譯過程
- C語言 - 註釋
- C語言 - 詞法單元
- C語言 - 關鍵字
- C語言 - 識別符號
- C語言 - 使用者輸入
- C語言 - 基本語法
- C語言 - 資料型別
- C語言 - 變數
- C語言 - 整型提升
- C語言 - 型別轉換
- C語言 - 型別強制轉換
- C語言 - 布林值
- C語言中的常量和字面量
- C語言 - 常量
- C語言 - 字面量
- C語言 - 轉義序列
- C語言 - 格式說明符
- C語言中的運算子
- C語言 - 運算子
- C語言 - 算術運算子
- C語言 - 關係運算符
- C語言 - 邏輯運算子
- C語言 - 位運算子
- C語言 - 賦值運算子
- C語言 - 一元運算子
- C語言 - 自增和自減運算子
- C語言 - 三元運算子
- C語言 - sizeof運算子
- C語言 - 運算子優先順序
- C語言 - 其他運算子
- C語言中的決策語句
- C語言 - 決策語句
- C語言 - if語句
- C語言 - if...else語句
- C語言 - 巢狀if語句
- C語言 - switch語句
- C語言 - 巢狀switch語句
- C語言中的迴圈語句
- C語言 - 迴圈語句
- C語言 - while迴圈
- C語言 - for迴圈
- C語言 - do...while迴圈
- C語言 - 巢狀迴圈
- C語言 - 無限迴圈
- C語言 - break語句
- C語言 - continue語句
- C語言 - goto語句
- C語言中的函式
- C語言 - 函式
- C語言 - 主函式
- C語言 - 按值呼叫函式
- C語言 - 按引用呼叫函式
- C語言 - 巢狀函式
- C語言 - 可變引數函式
- C語言 - 使用者自定義函式
- C語言 - 回撥函式
- C語言 - 返回語句
- C語言 - 遞迴
- C語言中的作用域規則
- C語言 - 作用域規則
- C語言 - 靜態變數
- C語言 - 全域性變數
- C語言中的陣列
- C語言 - 陣列
- C語言 - 陣列的特性
- C語言 - 多維陣列
- C語言 - 向函式傳遞陣列
- C語言 - 從函式返回陣列
- C語言 - 變長陣列
- C語言中的指標
- C語言 - 指標
- C語言 - 指標和陣列
- C語言 - 指標的應用
- C語言 - 指標運算
- C語言 - 指標陣列
- C語言 - 指向指標的指標
- C語言 - 向函式傳遞指標
- C語言 - 從函式返回指標
- C語言 - 函式指標
- C語言 - 指向陣列的指標
- C語言 - 指向結構體的指標
- C語言 - 指標鏈
- C語言 - 指標與陣列的比較
- C語言 - 字元指標和函式
- C語言 - 空指標
- C語言 - void指標
- C語言 - 懸空指標
- C語言 - 指標解引用
- C語言 - 近指標、遠指標和巨大指標
- C語言 - 指標陣列的初始化
- C語言 - 指標與多維陣列的比較
- C語言中的字串
- C語言 - 字串
- C語言 - 字串陣列
- C語言 - 特殊字元
- C語言中的結構體和聯合體
- C語言 - 結構體
- C語言 - 結構體和函式
- C語言 - 結構體陣列
- C語言 - 自引用結構體
- C語言 - 查詢表
- C語言 - 點(.)運算子
- C語言 - 列舉(enum)
- C語言 - 結構體填充和打包
- C語言 - 巢狀結構體
- C語言 - 匿名結構體和聯合體
- C語言 - 聯合體
- C語言 - 位域
- C語言 - typedef
- C語言中的檔案處理
- C語言 - 輸入輸出
- C語言 - 檔案I/O (檔案處理)
- C語言預處理器
- C語言 - 預處理器
- C語言 - 編譯指示
- C語言 - 預處理器運算子
- C語言 - 宏
- C語言 - 標頭檔案
- C語言中的記憶體管理
- C語言 - 記憶體管理
- C語言 - 記憶體地址
- C語言 - 儲存類別
- 其他主題
- C語言 - 錯誤處理
- C語言 - 可變引數
- C語言 - 命令執行
- C語言 - 數學函式
- C語言 - static關鍵字
- C語言 - 隨機數生成
- C語言 - 命令列引數
- C語言程式設計資源
- C語言 - 問答
- C語言快速入門
- C語言 - 速查表
- C語言 - 有用資源
- C語言 - 討論
C語言快速入門
C語言是一種通用的高階語言,最初由Dennis M. Ritchie開發,用於在貝爾實驗室開發UNIX作業系統。C語言最初於1972年在DEC PDP-11計算機上實現。
1978年,Brian Kernighan和Dennis Ritchie製作了第一個公開發布的C語言描述,現在被稱為K&R標準。
UNIX作業系統、C編譯器以及幾乎所有UNIX應用程式都是用C語言編寫的。C語言現在已成為廣泛使用的專業語言,原因如下:
- 易於學習
- 結構化語言
- 生成高效的程式
- 可以處理低階活動
- 可以在各種計算機平臺上編譯
關於C語言的事實
C語言的發明是為了編寫一個名為UNIX的作業系統。
C語言是B語言的繼任者,B語言大約在1970年代初推出。
該語言於1988年由美國國家標準協會(ANSI)正式確定。
UNIX作業系統完全是用C語言編寫的。
如今,C語言是最廣泛使用和最流行的系統程式語言。
大多數最先進的軟體都是使用C語言實現的。
如今最流行的Linux作業系統和RDBMS MySQL都是用C語言編寫的。
為什麼要使用C語言?
C語言最初用於系統開發工作,特別是構成作業系統的程式。C語言被採用作為系統開發語言,因為它生成的程式碼執行速度幾乎與用匯編語言編寫的程式碼一樣快。一些C語言的使用示例可能包括:
- 作業系統
- 語言編譯器
- 彙編器
- 文字編輯器
- 列印後臺程式
- 網路驅動程式
- 現代程式
- 資料庫
- 語言直譯器
- 實用程式
C語言程式
C程式的長度可以從3行到數百萬行不等,它應該被寫入一個或多個副檔名為".c"的文字檔案中;例如,hello.c。您可以使用"vi"、"vim"或任何其他文字編輯器將您的C程式寫入檔案。
本教程假設您知道如何編輯文字檔案以及如何在程式檔案中編寫原始碼。
C語言 - 環境搭建
本地環境搭建
如果您想為C程式語言設定您的環境,您需要在您的計算機上提供以下兩個軟體工具:(a) 文字編輯器和(b) C編譯器。
文字編輯器
這將用於鍵入您的程式。一些編輯器的示例包括Windows記事本、OS Edit命令、Brief、Epsilon、EMACS以及vim或vi。
文字編輯器的名稱和版本在不同的作業系統上可能會有所不同。例如,Notepad將用於Windows,而vim或vi可以在Windows以及Linux或UNIX上使用。
您使用編輯器建立的檔案稱為原始檔,它們包含程式原始碼。C程式的原始檔通常以副檔名".c"命名。
在開始程式設計之前,請確保您已準備好一個文字編輯器,並且您有足夠的經驗來編寫計算機程式,將其儲存在檔案中,編譯它,最後執行它。
C編譯器
寫在原始檔中的原始碼是您的程式的人類可讀原始碼。它需要被“編譯”成機器語言,以便您的CPU可以根據給定的指令實際執行程式。
編譯器將原始碼編譯成最終的可執行程式。最常用且免費提供的編譯器是GNU C/C++編譯器,否則,如果您有相應的作業系統,您可以使用HP或Solaris的編譯器。
以下部分說明如何在各種作業系統上安裝GNU C/C++編譯器。我們一起提到C/C++,因為GNU gcc編譯器適用於C和C++程式語言。
在UNIX/Linux上安裝
如果您使用的是Linux或UNIX,請透過從命令列輸入以下命令來檢查您的系統上是否安裝了GCC:
$ gcc -v
如果您的機器上安裝了GNU編譯器,則它應該列印如下訊息:
Using built-in specs. Target: i386-redhat-linux Configured with: ../configure --prefix=/usr ....... Thread model: posix gcc version 4.1.2 20080704 (Red Hat 4.1.2-46)
如果未安裝GCC,則您需要使用https://gcc.gnu.org/install/中提供的詳細說明自行安裝。
本教程是基於Linux編寫的,所有給出的示例都在Cent OS版本的Linux系統上編譯。
在Mac OS上安裝
如果您使用的是Mac OS X,獲取GCC最簡單的方法是從Apple的網站下載Xcode開發環境,然後按照簡單的安裝說明進行操作。設定好Xcode後,您就可以使用GNU C/C++編譯器了。
Xcode目前可在developer.apple.com/technologies/tools/獲得。
在Windows上安裝
要在Windows上安裝GCC,您需要安裝MinGW。要安裝MinGW,請訪問MinGW主頁www.mingw.org,然後點選連結到MinGW下載頁面。下載最新版本的MinGW安裝程式,其名稱應為MinGW-<version>.exe。
安裝 MinGW 時,至少必須安裝 gcc-core、gcc-g++、binutils 和 MinGW 執行時,但您可能希望安裝更多元件。
將 MinGW 安裝目錄下的 bin 子目錄新增到您的 **PATH** 環境變數中,以便您可以透過簡單的名稱在命令列中指定這些工具。
安裝完成後,您將能夠從 Windows 命令列執行 gcc、g++、ar、ranlib、dlltool 和其他一些 GNU 工具。
C語言 - 程式結構
在我們學習 C 程式語言的基本構建塊之前,讓我們先看一下 C 程式的最小結構,以便在接下來的章節中將其作為參考。
Hello World 示例
C 程式主要由以下部分組成:
- 預處理器命令
- 函式
- 變數
- 語句和表示式
- 註釋
讓我們來看一段簡單的程式碼,它將列印“Hello World”:
#include <stdio.h>
int main() {
/* my first program in C */
printf("Hello, World! \n");
return 0;
}
讓我們看一下上面程式的各個部分:
程式的第一行 #include
是一個預處理器命令,它告訴 C 編譯器在進行實際編譯之前包含 stdio.h 檔案。 下一行 int main() 是主函式,程式執行從此處開始。
下一行 /*...*/ 將被編譯器忽略,它被用來在程式中新增額外的註釋。因此,這樣的行被稱為程式中的註釋。
下一行 printf(...) 是 C 中另一個可用的函式,它會使訊息“Hello, World!”顯示在螢幕上。
下一行 **return 0;** 終止 main() 函式並返回 0 值。
編譯和執行 C 程式
讓我們看看如何將原始碼儲存在檔案中,以及如何編譯和執行它。以下是簡單的步驟:
開啟一個文字編輯器並新增上述程式碼。
將檔案儲存為 hello.c
開啟命令提示符並轉到儲存檔案的目錄。
鍵入 gcc hello.c 並按 Enter 鍵編譯程式碼。
如果程式碼中沒有錯誤,命令提示符將帶您進入下一行並生成 a.out 可執行檔案。
現在,鍵入 a.out 來執行您的程式。
您將看到輸出“Hello World”列印在螢幕上。
$ gcc hello.c $ ./a.out Hello, World!
確保 gcc 編譯器在您的 PATH 中,並且您在包含原始檔 hello.c 的目錄中執行它。
C語言 - 基本語法
您已經看到了 C 程式的基本結構,因此很容易理解 C 程式語言的其他基本構建塊。
C語言中的標記
C 程式由各種標記組成,標記是關鍵字、識別符號、常量、字串文字或符號。例如,以下 C 語句包含五個標記:
printf("Hello, World! \n");
各個標記是:
printf ( "Hello, World! \n" ) ;
分號
在 C 程式中,分號是語句終止符。也就是說,每個語句都必須以分號結尾。它表示一個邏輯實體的結束。
下面給出兩個不同的語句:
printf("Hello, World! \n");
return 0;
註釋
註釋就像 C 程式中的幫助文字,編譯器會忽略它們。它們以 /* 開頭,以 */ 結尾,如下所示:
/* my first program in C */
您不能在註釋中巢狀註釋,並且它們不會出現在字串或字元文字中。
識別符號
C 識別符號是用於標識變數、函式或任何其他使用者定義項的名稱。識別符號以字母 A 到 Z、a 到 z 或下劃線 '_' 開頭,後跟零個或多個字母、下劃線和數字 (0 到 9)。
C 不允許在識別符號中使用 @、$ 和 % 等標點符號。C 是一種 **區分大小寫** 的程式語言。因此,Manpower 和 manpower 在 C 中是兩個不同的識別符號。以下是一些可接受的識別符號示例:
mohd zara abc move_name a_123 myname50 _temp j a23b9 retVal
關鍵字
以下列表顯示了 C 中的保留字。這些保留字不能用作常量或變數或任何其他識別符號名稱。
| auto | else | long | switch |
| break | enum | register | typedef |
| case | extern | return | union |
| char | float | short | unsigned |
| const | for | signed | void |
| continue | goto | sizeof | volatile |
| default | if | static | while |
| do | int | struct | _Packed |
| double |
C語言中的空白字元
僅包含空白字元(可能還有註釋)的行稱為空行,C 編譯器會完全忽略它。
空白字元是 C 中用來描述空格、製表符、換行符和註釋的術語。空白字元將語句的一個部分與另一部分隔開,並使編譯器能夠識別語句中一個元素(例如 int)的結尾和下一個元素的開始。因此,在以下語句中:
int age;
int 和 age 之間必須至少有一個空白字元(通常是空格),以便編譯器能夠區分它們。另一方面,在以下語句中:
fruit = apples + oranges; // get the total fruit
fruit 和 = 之間,或 = 和 apples 之間不需要空白字元,儘管您可以根據需要新增一些以提高可讀性。
C語言 - 資料型別
C語言中的資料型別指的是一個廣泛的系統,用於宣告不同型別的變數或函式。變數的型別決定了它在儲存中佔據的空間大小以及如何解釋儲存的位模式。
C語言中的型別可以分為如下幾類:
| 序號 | 型別和描述 |
|---|---|
| 1 | 基本型別 它們是算術型別,進一步分為:(a)整數型別和(b)浮點型別。 |
| 2 | 列舉型別 它們也是算術型別,用於定義只能在整個程式中賦值某些離散整數值的變數。 |
| 3 | void 型別 型別說明符 void 表示沒有可用值。 |
| 4 | 派生型別 它們包括 (a) 指標型別,(b) 陣列型別,(c) 結構型別,(d) 聯合型別和 (e) 函式型別。 |
陣列型別和結構型別統稱為聚合型別。函式的型別指定函式返回值的型別。我們將在下一節中看到基本型別,而其他型別將在接下來的章節中介紹。
整數型別
下表提供了標準整數型別及其儲存大小和值範圍的詳細資訊:
| 型別 | 儲存大小 | 值範圍 |
|---|---|---|
| char | 1 位元組 | -128 到 127 或 0 到 255 |
| unsigned char | 1 位元組 | 0 到 255 |
| signed char | 1 位元組 | -128 到 127 |
| int | 2 或 4 位元組 | -32,768 到 32,767 或 -2,147,483,648 到 2,147,483,647 |
| unsigned int | 2 或 4 位元組 | 0 到 65,535 或 0 到 4,294,967,295 |
| short | 2 位元組 | -32,768 到 32,767 |
| unsigned short | 2 位元組 | 0 到 65,535 |
| long | 8 位元組 | -9223372036854775808 到 9223372036854775807 |
| unsigned long | 8 位元組 | 0 到 18446744073709551615 |
要獲取特定平臺上某個型別或變數的確切大小,可以使用 **sizeof** 運算子。表示式 sizeof(type) 以位元組為單位給出物件或型別的儲存大小。下面是一個示例,它使用 limits.h 標頭檔案中定義的不同常量來獲取機器上各種型別的 size:
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#include <float.h>
int main(int argc, char** argv) {
printf("CHAR_BIT : %d\n", CHAR_BIT);
printf("CHAR_MAX : %d\n", CHAR_MAX);
printf("CHAR_MIN : %d\n", CHAR_MIN);
printf("INT_MAX : %d\n", INT_MAX);
printf("INT_MIN : %d\n", INT_MIN);
printf("LONG_MAX : %ld\n", (long) LONG_MAX);
printf("LONG_MIN : %ld\n", (long) LONG_MIN);
printf("SCHAR_MAX : %d\n", SCHAR_MAX);
printf("SCHAR_MIN : %d\n", SCHAR_MIN);
printf("SHRT_MAX : %d\n", SHRT_MAX);
printf("SHRT_MIN : %d\n", SHRT_MIN);
printf("UCHAR_MAX : %d\n", UCHAR_MAX);
printf("UINT_MAX : %u\n", (unsigned int) UINT_MAX);
printf("ULONG_MAX : %lu\n", (unsigned long) ULONG_MAX);
printf("USHRT_MAX : %d\n", (unsigned short) USHRT_MAX);
return 0;
}
編譯並執行上述程式時,它在 Linux 上會產生以下結果:
CHAR_BIT : 8 CHAR_MAX : 127 CHAR_MIN : -128 INT_MAX : 2147483647 INT_MIN : -2147483648 LONG_MAX : 9223372036854775807 LONG_MIN : -9223372036854775808 SCHAR_MAX : 127 SCHAR_MIN : -128 SHRT_MAX : 32767 SHRT_MIN : -32768 UCHAR_MAX : 255 UINT_MAX : 4294967295 ULONG_MAX : 18446744073709551615 USHRT_MAX : 65535
浮點型別
下表提供了標準浮點型別及其儲存大小、值範圍和精度的詳細資訊:
| 型別 | 儲存大小 | 值範圍 | 精度 |
|---|---|---|---|
| float | 4 位元組 | 1.2E-38 到 3.4E+38 | 6 位小數 |
| double | 8 位元組 | 2.3E-308 到 1.7E+308 | 15 位小數 |
| long double | 10 位元組 | 3.4E-4932 到 1.1E+4932 | 19 位小數 |
float.h 標頭檔案定義了宏,允許您在程式中使用這些值以及有關實數二進位制表示的其他詳細資訊。以下示例列印 float 型別佔用的儲存空間及其範圍值:
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#include <float.h>
int main(int argc, char** argv) {
printf("Storage size for float : %d \n", sizeof(float));
printf("FLT_MAX : %g\n", (float) FLT_MAX);
printf("FLT_MIN : %g\n", (float) FLT_MIN);
printf("-FLT_MAX : %g\n", (float) -FLT_MAX);
printf("-FLT_MIN : %g\n", (float) -FLT_MIN);
printf("DBL_MAX : %g\n", (double) DBL_MAX);
printf("DBL_MIN : %g\n", (double) DBL_MIN);
printf("-DBL_MAX : %g\n", (double) -DBL_MAX);
printf("Precision value: %d\n", FLT_DIG );
return 0;
}
編譯並執行上述程式時,它在 Linux 上會產生以下結果:
Storage size for float : 4 FLT_MAX : 3.40282e+38 FLT_MIN : 1.17549e-38 -FLT_MAX : -3.40282e+38 -FLT_MIN : -1.17549e-38 DBL_MAX : 1.79769e+308 DBL_MIN : 2.22507e-308 -DBL_MAX : -1.79769e+308 Precision value: 6
void 型別
void 型別指定沒有可用值。它用於三種情況:
| 序號 | 型別和描述 |
|---|---|
| 1 | 函式返回 void C 中有許多函式不返回值,或者可以說它們返回 void。沒有返回值的函式的返回型別為 void。例如,void exit (int status); |
| 2 | 函式引數為 void C 中有許多函式不接受任何引數。不帶引數的函式可以接受 void。例如,int rand(void); |
| 3 | 指向 void 的指標 void * 型別的指標表示物件的地址,但不表示其型別。例如,記憶體分配函式 void *malloc( size_t size ); 返回指向 void 的指標,可以將其強制轉換為任何資料型別。 |
C語言 - 變數
變數只不過是賦予程式可以操作的儲存區域的名稱。C 中的每個變數都有一個特定的型別,該型別決定變數記憶體的大小和佈局;可以儲存在該記憶體中的值的範圍;以及可以應用於該變數的操作集。
變數的名稱可以由字母、數字和下劃線組成。它必須以字母或下劃線開頭。大寫字母和小寫字母是不同的,因為 C 區分大小寫。基於上一章中解釋的基本型別,將有以下基本變數型別:
| 序號 | 型別和描述 |
|---|---|
| 1 | char 通常是一個單位元組(一個位元組)。它是一個整數型別。 |
| 2 | int 機器上最自然的整數大小。 |
| 3 | float 單精度浮點值。 |
| 4 | double 雙精度浮點值。 |
| 5 | void 表示型別不存在。 |
C 程式語言還允許定義各種其他型別的變數,我們將在後續章節中介紹,例如列舉、指標、陣列、結構、聯合等。在本節中,我們只學習基本變數型別。
C語言中的變數定義
變數定義告訴編譯器在哪裡以及為變數建立多少儲存空間。變數定義指定一個數據型別,幷包含一個或多個該型別變數的列表,如下所示:
type variable_list;
這裡,type 必須是有效的 C 資料型別,包括 char、w_char、int、float、double、bool 或任何使用者定義的物件;variable_list 可以包含一個或多個用逗號分隔的識別符號名稱。這裡顯示了一些有效的宣告:
int i, j, k; char c, ch; float f, salary; double d;
語句 int i, j, k; 宣告並定義了變數 i、j 和 k;它指示編譯器建立名為 i、j 和 k 的 int 型別變數。
可以在變數宣告中初始化(賦值初始值)變數。初始化器由等號後跟一個常量表達式組成,如下所示:
type variable_name = value;
一些例子:
extern int d = 3, f = 5; // declaration of d and f. int d = 3, f = 5; // definition and initializing d and f. byte z = 22; // definition and initializes z. char x = 'x'; // the variable x has the value 'x'.
對於沒有初始化器的定義:具有靜態儲存期的變數隱式初始化為 NULL(所有位元組的值均為 0);所有其他變數的初始值未定義。
C 語言中的變數宣告
變數宣告向編譯器保證存在具有給定型別和名稱的變數,以便編譯器可以在不需要關於變數的完整細節的情況下繼續進行編譯。變數定義只在編譯時才有意義,編譯器在連結程式時需要實際的變數定義。
當使用多個檔案並將變數定義在一個檔案中(該檔案將在程式連結時可用)時,變數宣告非常有用。你將使用關鍵字 extern 在任何地方宣告變數。雖然你可以在 C 程式中多次宣告一個變數,但它在一個檔案、一個函式或一個程式碼塊中只能定義一次。
示例
嘗試以下示例,其中變數已在頂部宣告,但已在 main 函式內部定義和初始化:
#include <stdio.h>
// Variable declaration:
extern int a, b;
extern int c;
extern float f;
int main () {
/* variable definition: */
int a, b;
int c;
float f;
/* actual initialization */
a = 10;
b = 20;
c = a + b;
printf("value of c : %d \n", c);
f = 70.0/3.0;
printf("value of f : %f \n", f);
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
value of c : 30 value of f : 23.333334
相同的概念也適用於函式宣告,你可以在函式宣告時提供函式名稱,其實際定義可以在其他任何地方給出。例如:
// function declaration
int func();
int main() {
// function call
int i = func();
}
// function definition
int func() {
return 0;
}
C 語言中的左值和右值
C 語言中有兩種表示式:
左值 (lvalue) - 指向記憶體位置的表示式稱為“左值”表示式。左值可以出現在賦值的左側或右側。
右值 (rvalue) - 右值是指儲存在記憶體某個地址的資料值。右值是一個不能為其賦值的表示式,這意味著右值可以出現在賦值的右側,但不能出現在左側。
變數是左值,因此它們可以出現在賦值的左側。數字字面量是右值,因此它們不能被賦值,也不能出現在左側。請看以下有效和無效的語句:
int g = 20; // valid statement 10 = 20; // invalid statement; would generate compile-time error
C 語言 - 常量和字面量
常量是指程式在其執行期間可能不會更改的固定值。這些固定值也稱為字面量。
常量可以是任何基本資料型別,例如整數常量、浮點常量、字元常量或字串字面量。還有列舉常量。
常量與常規變數一樣,只是它們的定義後不能修改其值。
整數字面量
整數字面量可以是十進位制、八進位制或十六進位制常量。字首指定基數或基:十六進位制為 0x 或 0X,八進位制為 0,十進位制為無。
整數字面量還可以帶字尾,它是 U 和 L 的組合,分別表示無符號和長整型。字尾可以是大寫或小寫,並且可以按任何順序排列。
以下是一些整數字面量的示例:
212 /* Legal */ 215u /* Legal */ 0xFeeL /* Legal */ 078 /* Illegal: 8 is not an octal digit */ 032UU /* Illegal: cannot repeat a suffix */
以下是各種型別整數字面量的其他示例:
85 /* decimal */ 0213 /* octal */ 0x4b /* hexadecimal */ 30 /* int */ 30u /* unsigned int */ 30l /* long */ 30ul /* unsigned long */
浮點字面量
浮點字面量具有整數部分、小數點、小數部分和指數部分。你可以以十進位制形式或指數形式表示浮點字面量。
在表示十進位制形式時,必須包含小數點、指數或兩者;在表示指數形式時,必須包含整數部分、小數部分或兩者。帶符號的指數由 e 或 E 引入。
以下是一些浮點字面量的示例:
3.14159 /* Legal */ 314159E-5L /* Legal */ 510E /* Illegal: incomplete exponent */ 210f /* Illegal: no decimal or exponent */ .e55 /* Illegal: missing integer or fraction */
字元常量
字元字面量用單引號括起來,例如,'x' 可以儲存在 char 型別的簡單變數中。
字元字面量可以是普通字元(例如 'x')、轉義序列(例如 '\t')或通用字元(例如 '\u02C0')。
在 C 語言中,某些字元在以反斜槓開頭時表示特殊含義,例如換行符 (\n) 或製表符 (\t)。
以下示例顯示了一些轉義序列字元:
#include <stdio.h>
int main() {
printf("Hello\tWorld\n\n");
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Hello World
字串字面量
字串字面量或常量用雙引號 "" 括起來。字串包含類似於字元字面量的字元:普通字元、轉義序列和通用字元。
可以使用字串字面量將長行分成多行,並使用空格分隔它們。
以下是一些字串字面量的示例。所有三種形式都是相同的字串。
"hello, dear" "hello, \ dear" "hello, " "d" "ear"
定義常量
在 C 語言中定義常量有兩種簡單的方法:
使用 #define 預處理器。
使用 const 關鍵字。
#define 預處理器
以下是使用 #define 預處理器定義常量的形式:
#define identifier value
以下示例詳細說明了它:
#include <stdio.h>
#define LENGTH 10
#define WIDTH 5
#define NEWLINE '\n'
int main() {
int area;
area = LENGTH * WIDTH;
printf("value of area : %d", area);
printf("%c", NEWLINE);
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
value of area : 50
const 關鍵字
可以使用 const 字首宣告具有特定型別的常量,如下所示:
const type variable = value;
以下示例詳細說明了它:
#include <stdio.h>
int main() {
const int LENGTH = 10;
const int WIDTH = 5;
const char NEWLINE = '\n';
int area;
area = LENGTH * WIDTH;
printf("value of area : %d", area);
printf("%c", NEWLINE);
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
value of area : 50
請注意,良好的程式設計習慣是用大寫字母定義常量。
C語言 - 儲存類別
儲存類定義 C 程式中變數和/或函式的作用域(可見性)和生命週期。它們位於它們修飾的型別之前。C 程式中有四種不同的儲存類:
- auto
- register
- static
- extern
auto 儲存類
auto 儲存類是所有區域性變數的預設儲存類。
{
int mount;
auto int month;
}
上面的示例在同一個儲存類中定義了兩個變數。'auto' 只能在函式中使用,即區域性變數。
register 儲存類
register 儲存類用於定義應儲存在暫存器而不是 RAM 中的區域性變數。這意味著變數的最大大小等於暫存器大小(通常是一個字),並且不能對其應用一元 '&' 運算子(因為它沒有記憶體位置)。
{
register int miles;
}
register 應該只用於需要快速訪問的變數,例如計數器。還應注意,定義 'register' 並不意味著變數將儲存在暫存器中。這意味著它可能會儲存在暫存器中,具體取決於硬體和實現限制。
static 儲存類
static 儲存類指示編譯器在程式的生命週期內保持區域性變數的存在,而不是在每次進入和離開作用域時建立和銷燬它。因此,使區域性變數靜態允許它們在函式呼叫之間保持其值。
static 修飾符也可以應用於全域性變數。當這樣做時,它會導致該變數的作用域限制在宣告它的檔案中。
在 C 程式設計中,當在全域性變數上使用static 時,它會導致其類的所有物件共享該成員的單個副本。
#include <stdio.h>
/* function declaration */
void func(void);
static int count = 5; /* global variable */
main() {
while(count--) {
func();
}
return 0;
}
/* function definition */
void func( void ) {
static int i = 5; /* local static variable */
i++;
printf("i is %d and count is %d\n", i, count);
}
編譯並執行上述程式碼時,會產生以下結果:
i is 6 and count is 4 i is 7 and count is 3 i is 8 and count is 2 i is 9 and count is 1 i is 10 and count is 0
extern 儲存類
extern 儲存類用於引用對所有程式檔案可見的全域性變數。當使用 'extern' 時,變數不能被初始化,但是,它將變數名稱指向先前定義的儲存位置。
當有多個檔案並定義一個全域性變數或函式,並且該變數或函式也將用於其他檔案時,則將在另一個檔案中使用extern 來提供已定義變數或函式的引用。為了便於理解,extern 用於在另一個檔案中宣告全域性變數或函式。
如以下所述,當兩個或多個檔案共享相同的全域性變數或函式時,extern 修飾符最常用。
第一個檔案:main.c
#include <stdio.h>
int count ;
extern void write_extern();
main() {
count = 5;
write_extern();
}
第二個檔案:support.c
#include <stdio.h>
extern int count;
void write_extern(void) {
printf("count is %d\n", count);
}
在這裡,extern 用於在第二個檔案中宣告count,而它在第一個檔案 main.c 中定義。現在,編譯這兩個檔案,如下所示:
$gcc main.c support.c
它將生成可執行程式a.out。執行此程式時,會產生以下結果:
count is 5
C語言 - 運算子
運算子是一個符號,它告訴編譯器執行特定的數學或邏輯函式。C 語言富含內建運算子,並提供以下型別的運算子:
- 算術運算子
- 關係運算符
- 邏輯運算子
- 位運算子
- 賦值運算子
- 其他運算子
本章將探討每個運算子的工作方式。
算術運算子
下表顯示了 C 語言支援的所有算術運算子。假設變數A值為 10,變數B值為 20,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| + | 將兩個運算元相加。 | A + B = 30 |
| - | 從第一個運算元中減去第二個運算元。 | A - B = -10 |
| * | 將兩個運算元相乘。 | A * B = 200 |
| / | 將分子除以分母。 | B / A = 2 |
| % | 取模運算子,整數除法後的餘數。 | B % A = 0 |
| ++ | 遞增運算子使整數的值增加一。 | A++ = 11 |
| -- | 遞減運算子使整數的值減少一。 | A-- = 9 |
關係運算符
下表顯示了 C 語言支援的所有關係運算符。假設變數A值為 10,變數B值為 20,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| == | 檢查兩個運算元的值是否相等。如果相等,則條件為真。 | (A == B) 為假。 |
| != | 檢查兩個運算元的值是否相等。如果不相等,則條件為真。 | (A != B) 為真。 |
| > | 檢查左運算元的值是否大於右運算元的值。如果是,則條件為真。 | (A > B) 為假。 |
| < | 檢查左運算元的值是否小於右運算元的值。如果是,則條件為真。 | (A < B) 為真。 |
| >= | 檢查左運算元的值是否大於或等於右運算元的值。如果是,則條件為真。 | (A >= B) 為假。 |
| <= | 檢查左運算元的值是否小於或等於右運算元的值。如果是,則條件為真。 | (A <= B) 為真。 |
邏輯運算子
下表顯示了C語言支援的所有邏輯運算子。假設變數A的值為1,變數B的值為0,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| && | 稱為邏輯與運算子。如果兩個運算元都非零,則條件為真。 | (A && B) 為假。 |
| || | 稱為邏輯或運算子。如果兩個運算元中任何一個非零,則條件為真。 | (A || B) 為真。 |
| ! | 稱為邏輯非運算子。用於反轉其運算元的邏輯狀態。如果條件為真,則邏輯非運算子將使其為假。 | !(A && B) 為真。 |
位運算子
位運算子作用於位並執行逐位運算。&,| 和 ^ 的真值表如下:
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
假設A = 60,B = 13,其二進位制格式如下:
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A|B = 0011 1101
A^B = 0011 0001
~A = 1100 0011
下表列出了C語言支援的位運算子。假設變數'A'的值為60,變數'B'的值為13,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| & | 二進位制與運算子:如果位同時存在於兩個運算元中,則將其複製到結果中。 | (A & B) = 12,即 0000 1100 |
| | | 二進位制或運算子:如果位存在於任何一個運算元中,則將其複製。 | (A | B) = 61,即 0011 1101 |
| ^ | 二進位制異或運算子:如果位在一個運算元中設定,但在另一個運算元中未設定,則複製該位。 | (A ^ B) = 49,即 0011 0001 |
| ~ | 二進位制反碼運算子:是一元運算子,其作用是“反轉”位。 | (~A ) = ~(60),即 -61 |
| << | 二進位制左移運算子:左運算元的值向左移動右運算元指定的位數。 | A << 2 = 240,即 1111 0000 |
| >> | 二進位制右移運算子:左運算元的值向右移動右運算元指定的位數。 | A >> 2 = 15,即 0000 1111 |
賦值運算子
下表列出了C語言支援的賦值運算子:
| 運算子 | 描述 | 示例 |
|---|---|---|
| = | 簡單賦值運算子:將右側運算元的值賦給左側運算元。 | C = A + B 將 A + B 的值賦給 C |
| += | 加法賦值運算子:將右運算元加到左運算元上,並將結果賦給左運算元。 | C += A 等效於 C = C + A |
| -= | 減法賦值運算子:從左運算元中減去右運算元,並將結果賦給左運算元。 | C -= A 等效於 C = C - A |
| *= | 乘法賦值運算子:將右運算元乘以左運算元,並將結果賦給左運算元。 | C *= A 等效於 C = C * A |
| /= | 除法賦值運算子:將左運算元除以右運算元,並將結果賦給左運算元。 | C /= A 等效於 C = C / A |
| %= | 取模賦值運算子:使用兩個運算元進行取模運算,並將結果賦給左運算元。 | C %= A 等效於 C = C % A |
| <<= | 左移賦值運算子。 | C <<= 2 與 C = C << 2 相同 |
| >>= | 右移賦值運算子。 | C >>= 2 與 C = C >> 2 相同 |
| &= | 按位與賦值運算子。 | C &= 2 與 C = C & 2 相同 |
| ^= | 按位異或賦值運算子。 | C ^= 2 與 C = C ^ 2 相同 |
| |= | 按位或賦值運算子。 | C |= 2 與 C = C | 2 相同 |
其他運算子 ↦ sizeof & 三元運算子
除了上面討論的運算子外,C語言還支援一些其他重要的運算子,包括sizeof和? :。
| 運算子 | 描述 | 示例 |
|---|---|---|
| sizeof() | 返回變數的大小。 | sizeof(a),其中a是整數,將返回4。 |
| & | 返回變數的地址。 | &a; 返回變數的實際地址。 |
| * | 指向變數的指標。 | *a; |
| ? : | 條件表示式。 | 如果條件為真 ? 則值為 X : 否則值為 Y |
C語言中的運算子優先順序
運算子優先順序決定了表示式中項的組合方式以及表示式的計算方式。某些運算子的優先順序高於其他運算子;例如,乘法運算子的優先順序高於加法運算子。
例如,x = 7 + 3 * 2; 這裡,x 的值為 13,而不是 20,因為 * 運算子的優先順序高於 +,所以它先計算 3*2,然後加上 7。
表中,優先順序最高的運算子位於頂部,優先順序最低的運算子位於底部。在一個表示式中,優先順序高的運算子將首先被計算。
| 類別 | 運算子 | 結合性 |
|---|---|---|
| 字尾 | () [] -> . ++ - - | 從左到右 |
| 一元 | + - ! ~ ++ -- (type)* & sizeof | 從右到左 |
| 乘法 | * / % | 從左到右 |
| 加法 | + - | 從左到右 |
| 移位 | << >> | 從左到右 |
| 關係 | < <= > >= | 從左到右 |
| 相等 | == != | 從左到右 |
| 按位與 | & | 從左到右 |
| 按位異或 | ^ | 從左到右 |
| 按位或 | | | 從左到右 |
| 邏輯與 | && | 從左到右 |
| 邏輯或 | || | 從左到右 |
| 條件 | ?: | 從右到左 |
| 賦值 | = += -= *= /= %=>>= <<= &= ^= |= | 從右到左 |
| 逗號 | , | 從左到右 |
C語言 - 決策語句
決策結構要求程式設計師指定一個或多個條件供程式進行評估或測試,以及如果條件確定為真則要執行的語句,以及可選地,如果條件確定為假則要執行的其他語句。
以下是大多數程式語言中典型的決策結構的一般形式:
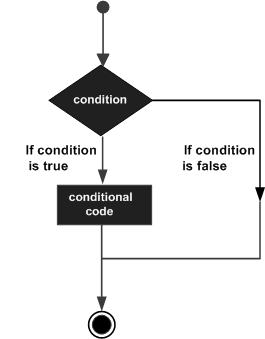
C語言將任何非零和非空值視為真,如果值為零或空,則將其視為假值。
C語言提供以下型別的決策語句。
| 序號 | 語句 & 說明 |
|---|---|
| 1 | if 語句
if 語句由一個布林表示式和一個或多個語句組成。 |
| 2 | if...else 語句
if 語句後面可以跟一個可選的else 語句,當布林表示式為假時執行。 |
| 3 | 巢狀 if 語句
可以在另一個if或else if語句中使用一個if或else if語句。 |
| 4 | switch 語句
switch語句允許測試變數與值的列表是否相等。 |
| 5 | 巢狀 switch 語句
可以在另一個switch語句中使用一個switch語句。 |
? : 運算子
我們在上一章中介紹了條件運算子 ? :,它可以用來替換if...else語句。它具有以下一般形式:
Exp1 ? Exp2 : Exp3;
其中 Exp1、Exp2 和 Exp3 是表示式。注意冒號的使用和位置。
? 表示式的值如下確定:
計算 Exp1。如果為真,則計算 Exp2,並將其作為整個 ? 表示式的值。
如果 Exp1 為假,則計算 Exp3,並將其值作為表示式的值。
C語言 - 迴圈語句
您可能會遇到需要多次執行程式碼塊的情況。通常情況下,語句是按順序執行的:函式中的第一個語句首先執行,然後是第二個語句,依此類推。
程式語言提供各種控制結構,允許更復雜的執行路徑。
迴圈語句允許我們多次執行語句或語句組。以下是大多數程式語言中迴圈語句的一般形式:
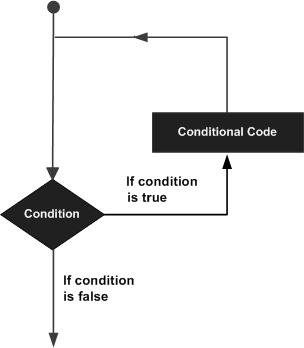
C語言提供以下型別的迴圈來處理迴圈需求。
| 序號 | 迴圈型別 & 說明 |
|---|---|
| 1 | while 迴圈
在給定條件為真時重複執行語句或語句組。它在執行迴圈體之前測試條件。 |
| 2 | for 迴圈
多次執行一系列語句,並縮短管理迴圈變數的程式碼。 |
| 3 | do...while 迴圈
它更像 while 語句,只是它在迴圈體末尾測試條件。 |
| 4 | 巢狀迴圈
您可以在任何其他 while、for 或 do..while 迴圈中使用一個或多個迴圈。 |
迴圈控制語句
迴圈控制語句改變執行的正常順序。當執行離開作用域時,在該作用域中建立的所有自動物件都將被銷燬。
C語言支援以下控制語句。
| 序號 | 控制語句 & 說明 |
|---|---|
| 1 | break 語句
終止迴圈或switch語句,並將執行轉移到迴圈或switch語句後的語句。 |
| 2 | continue 語句
使迴圈跳過其主體其餘部分,並在重複迭代之前立即重新測試其條件。 |
| 3 | goto 語句
將控制轉移到標記的語句。 |
無限迴圈
如果條件永不為假,則迴圈將變成無限迴圈。for迴圈通常用於此目的。由於構成“for”迴圈的三個表示式都不需要,因此您可以透過省略條件表示式來建立一個無限迴圈。
#include <stdio.h>
int main () {
for( ; ; ) {
printf("This loop will run forever.\n");
}
return 0;
}
如果條件表示式不存在,則假定其為真。您可能有一個初始化和增量表達式,但是C程式設計師更常用 for(;;) 結構來表示無限迴圈。
注意 - 可以透過按 Ctrl + C 鍵來終止無限迴圈。
C語言 - 函式
函式是一組共同執行任務的語句。每個C程式至少有一個函式,即main(),並且大多數最簡單的程式都可以定義附加函式。
您可以將程式碼劃分為單獨的函式。如何將程式碼劃分為不同的函式取決於您,但邏輯上劃分方式是每個函式執行特定任務。
函式宣告告訴編譯器函式的名稱、返回型別和引數。函式定義提供了函式的實際主體。
C標準庫提供了許多內建函式,程式可以呼叫這些函式。例如,strcat()用於連線兩個字串,memcpy()用於將一個記憶體位置複製到另一個位置,以及許多其他函式。
函式也可以稱為方法、子例程或過程等。
定義函式
C語言中函式定義的一般形式如下:
return_type function_name( parameter list ) {
body of the function
}
C語言中的函式定義由函式頭和函式體組成。以下是函式的所有部分:
返回型別 - 函式可以返回值。返回型別是函式返回的值的資料型別。有些函式執行所需的運算而不返回值。在這種情況下,返回型別是關鍵字void。
函式名 - 這是函式的實際名稱。函式名和引數列表一起構成函式簽名。
引數 − 引數就像一個佔位符。當呼叫函式時,您將值傳遞給引數。此值稱為實際引數或自變數。引數列表指的是函式引數的型別、順序和數量。引數是可選的;也就是說,函式可能不包含任何引數。
函式體 − 函式體包含定義函式功能的一組語句。
示例
下面是名為max()函式的原始碼。此函式接受兩個引數 num1 和 num2,並返回兩者之間的最大值 −
/* function returning the max between two numbers */
int max(int num1, int num2) {
/* local variable declaration */
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}
函式宣告
函式宣告告訴編譯器函式名稱以及如何呼叫函式。函式的實際主體可以單獨定義。
函式宣告包含以下部分 −
return_type function_name( parameter list );
對於上面定義的函式 max(),函式宣告如下 −
int max(int num1, int num2);
引數名稱在函式宣告中並不重要,只需要它們的型別,因此以下也是有效的宣告 −
int max(int, int);
當您在一個原始檔中定義一個函式並在另一個檔案中呼叫該函式時,需要函式宣告。在這種情況下,應在呼叫函式的檔案頂部宣告該函式。
呼叫函式
建立 C 函式時,您會給出函式必須執行的操作的定義。要使用函式,您必須呼叫該函式來執行定義的任務。
當程式呼叫函式時,程式控制將轉移到被呼叫函式。被呼叫的函式執行定義的任務,當執行其 return 語句或到達其函式結束的閉合大括號時,它將程式控制返回到主程式。
要呼叫函式,您只需將所需的引數與函式名稱一起傳遞,如果函式返回值,則可以儲存返回值。例如 −
#include <stdio.h>
/* function declaration */
int max(int num1, int num2);
int main () {
/* local variable definition */
int a = 100;
int b = 200;
int ret;
/* calling a function to get max value */
ret = max(a, b);
printf( "Max value is : %d\n", ret );
return 0;
}
/* function returning the max between two numbers */
int max(int num1, int num2) {
/* local variable declaration */
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}
我們將 max() 與 main() 保持在一起並編譯了原始碼。執行最終的可執行檔案時,它將產生以下結果 −
Max value is : 200
函式引數
如果函式要使用引數,則必須宣告接受引數值的變數。這些變數稱為函式的形式引數。
形式引數在函式內部的行為類似於其他區域性變數,並在進入函式時建立,並在退出時銷燬。
呼叫函式時,可以透過兩種方式將引數傳遞給函式 −
| 序號 | 呼叫型別和描述 |
|---|---|
| 1 | 按值呼叫
此方法將引數的實際值複製到函式的形式引數中。在這種情況下,對函式內部引數所做的更改不會影響引數。 |
| 2 | 按引用呼叫
此方法將引數的地址複製到形式引數中。在函式內部,該地址用於訪問呼叫中使用的實際引數。這意味著對引數所做的更改會影響引數。 |
預設情況下,C 使用按值呼叫傳遞引數。一般來說,這意味著函式內的程式碼無法更改用於呼叫函式的引數。
C語言 - 作用域規則
任何程式設計中的作用域都是程式的一個區域,在該區域中,已定義的變數可以存在,並且超出該變數範圍就不能訪問它。在 C 程式語言中,可以在三個地方宣告變數 −
在函式或塊內,稱為區域性變數。
在所有函式之外,稱為全域性變數。
在函式引數的定義中,稱為形式引數。
讓我們瞭解一下什麼是區域性變數、全域性變數和形式引數。
區域性變數
在函式或塊內宣告的變數稱為區域性變數。它們只能由函式或程式碼塊內的語句使用。區域性變數對於其自身以外的函式是未知的。以下示例顯示瞭如何使用區域性變數。這裡所有變數 a、b 和 c 對 main() 函式都是區域性的。
#include <stdio.h>
int main () {
/* local variable declaration */
int a, b;
int c;
/* actual initialization */
a = 10;
b = 20;
c = a + b;
printf ("value of a = %d, b = %d and c = %d\n", a, b, c);
return 0;
}
全域性變數
全域性變數在函式外部定義,通常在程式的頂部。全域性變數在程式的整個生命週期中保持其值,並且可以在為程式定義的任何函式內訪問它們。
任何函式都可以訪問全域性變數。也就是說,全域性變數在其聲明後即可在整個程式中使用。以下程式顯示瞭如何在程式中使用全域性變數。
#include <stdio.h>
/* global variable declaration */
int g;
int main () {
/* local variable declaration */
int a, b;
/* actual initialization */
a = 10;
b = 20;
g = a + b;
printf ("value of a = %d, b = %d and g = %d\n", a, b, g);
return 0;
}
程式可以為區域性變數和全域性變數使用相同的名稱,但函式內區域性變數的值將優先。這是一個例子 −
#include <stdio.h>
/* global variable declaration */
int g = 20;
int main () {
/* local variable declaration */
int g = 10;
printf ("value of g = %d\n", g);
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
value of g = 10
形式引數
形式引數在函式內被視為區域性變數,並且它們優先於全域性變數。以下是一個例子 −
#include <stdio.h>
/* global variable declaration */
int a = 20;
int main () {
/* local variable declaration in main function */
int a = 10;
int b = 20;
int c = 0;
printf ("value of a in main() = %d\n", a);
c = sum( a, b);
printf ("value of c in main() = %d\n", c);
return 0;
}
/* function to add two integers */
int sum(int a, int b) {
printf ("value of a in sum() = %d\n", a);
printf ("value of b in sum() = %d\n", b);
return a + b;
}
編譯並執行上述程式碼時,會產生以下結果:
value of a in main() = 10 value of a in sum() = 10 value of b in sum() = 20 value of c in main() = 30
初始化區域性變數和全域性變數
定義區域性變數時,系統不會對其進行初始化,您必須自行初始化它。當您按如下方式定義全域性變數時,系統會自動對其進行初始化 −
| 資料型別 | 初始預設值 |
|---|---|
| int | 0 |
| char | '\0' |
| float | 0 |
| double | 0 |
| 指標 | NULL |
正確初始化變數是一種良好的程式設計習慣,否則您的程式可能會產生意外結果,因為未初始化的變數將採用其記憶體位置中已有的某些垃圾值。
C語言 - 陣列
陣列是一種資料結構,可以儲存相同型別元素的固定大小的順序集合。陣列用於儲存資料集合,但通常將陣列視為相同型別變數的集合更有用。
無需宣告各個變數,例如 number0、number1、... 和 number99,您可以宣告一個數組變數,例如 numbers,並使用 numbers[0]、numbers[1] 和 ...、numbers[99] 來表示各個變數。陣列中的特定元素透過索引訪問。
所有陣列都由連續的記憶體位置組成。最低地址對應於第一個元素,最高地址對應於最後一個元素。

宣告陣列
要在 C 中宣告陣列,程式設計師應指定元素的型別和陣列所需的元素數量,如下所示 −
type arrayName [ arraySize ];
這稱為一維陣列。arraySize必須是一個大於零的整數常量,而type可以是任何有效的 C 資料型別。例如,要宣告一個名為balance的 10 個元素的雙精度型陣列,請使用此語句 −
double balance[10];
這裡balance是一個變數陣列,足以容納多達 10 個雙精度數。
初始化陣列
您可以在 C 中逐個初始化陣列,也可以使用單個語句進行初始化,如下所示 −
double balance[5] = {1000.0, 2.0, 3.4, 7.0, 50.0};
大括號 { } 之間的數值不能大於我們在方括號 [ ] 之間為陣列宣告的元素數量。
如果省略陣列的大小,則會建立一個足夠大的陣列來儲存初始化值。因此,如果您寫 −
double balance[] = {1000.0, 2.0, 3.4, 7.0, 50.0};
您將建立與在前面示例中建立的完全相同的陣列。以下是一個為陣列分配單個元素的示例 −
balance[4] = 50.0;
上述語句將陣列中的第 5個元素賦值為 50.0。所有陣列的第一個元素的索引均為 0,也稱為基索引,陣列的最後一個索引將是陣列的總大小減 1。下面是我們上面討論的陣列的圖形表示 −

訪問陣列元素
透過對陣列名稱進行索引來訪問元素。這是透過在陣列名稱後方括號中放置元素的索引來完成的。例如 −
double salary = balance[9];
上述語句將從陣列中取出第 10個元素並將該值賦給 salary 變數。以下示例顯示瞭如何使用上述所有三個概念,即宣告、賦值和訪問陣列 −
#include <stdio.h>
int main () {
int n[ 10 ]; /* n is an array of 10 integers */
int i,j;
/* initialize elements of array n to 0 */
for ( i = 0; i < 10; i++ ) {
n[ i ] = i + 100; /* set element at location i to i + 100 */
}
/* output each array element's value */
for (j = 0; j < 10; j++ ) {
printf("Element[%d] = %d\n", j, n[j] );
}
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Element[0] = 100 Element[1] = 101 Element[2] = 102 Element[3] = 103 Element[4] = 104 Element[5] = 105 Element[6] = 106 Element[7] = 107 Element[8] = 108 Element[9] = 109
陣列詳解
陣列對 C 非常重要,需要更多關注。C 程式設計師應該清楚以下與陣列相關的重要的概念 −
| 序號 | 概念和描述 |
|---|---|
| 1 | 多維陣列
C 支援多維陣列。多維陣列最簡單的形式是二維陣列。 |
| 2 | 將陣列傳遞給函式
您可以透過指定陣列的名稱(不帶索引)來將指向陣列的指標傳遞給函式。 |
| 3 | 從函式返回陣列
C 允許函式返回陣列。 |
| 4 | 指向陣列的指標
您可以透過簡單地指定陣列名稱(不帶任何索引)來生成指向陣列第一個元素的指標。 |
C語言 - 指標
C 語言中的指標易於學習且趣味性強。有些 C 程式設計任務使用指標更容易完成,而其他任務(例如動態記憶體分配)則無法在不使用指標的情況下完成。因此,學習指標成為一名完美的 C 程式設計師是必要的。讓我們以簡單易懂的步驟開始學習它們。
如您所知,每個變數都是一個記憶體位置,每個記憶體位置都有其定義的地址,可以使用地址符 (&) 運算子訪問,該運算子表示記憶體中的地址。考慮以下示例,它列印已定義變數的地址 −
#include <stdio.h>
int main () {
int var1;
char var2[10];
printf("Address of var1 variable: %x\n", &var1 );
printf("Address of var2 variable: %x\n", &var2 );
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Address of var1 variable: bff5a400 Address of var2 variable: bff5a3f6
什麼是指標?
指標是一個變數,其值是另一個變數的地址,即記憶體位置的直接地址。與任何變數或常量一樣,您必須在使用指標儲存任何變數地址之前宣告它。指標變數宣告的一般形式為 −
type *var-name;
這裡,type是指標的基型別;它必須是有效的 C 資料型別,而var-name是指標變數的名稱。用於宣告指標的星號 * 與用於乘法的星號相同。但是,在此語句中,星號用於將變數指定為指標。讓我們看一些有效的指標宣告 −
int *ip; /* pointer to an integer */ double *dp; /* pointer to a double */ float *fp; /* pointer to a float */ char *ch /* pointer to a character */
所有指標的實際資料型別,無論是整數、浮點數、字元還是其他型別,都是相同的,都是表示記憶體地址的長十六進位制數。不同資料型別指標之間的唯一區別是指標指向的變數或常量的型別。
如何使用指標?
有一些重要的操作,我們將經常藉助指標來完成。(a) 我們定義一個指標變數,(b) 將變數的地址賦給指標,並(c) 最終訪問指標變數中可用地址處的值。這是透過使用一元運算子* 來完成的,該運算子返回其運算元指定的地址處變數的值。以下示例使用了這些操作 −
#include <stdio.h>
int main () {
int var = 20; /* actual variable declaration */
int *ip; /* pointer variable declaration */
ip = &var; /* store address of var in pointer variable*/
printf("Address of var variable: %x\n", &var );
/* address stored in pointer variable */
printf("Address stored in ip variable: %x\n", ip );
/* access the value using the pointer */
printf("Value of *ip variable: %d\n", *ip );
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Address of var variable: bffd8b3c Address stored in ip variable: bffd8b3c Value of *ip variable: 20
空指標
如果您沒有確切要分配的地址,則始終將 NULL 值賦給指標變數是一種良好的做法。這是在變數宣告時完成的。賦予 NULL 值的指標稱為空指標。
NULL 指標是一個值為零的常量,在多個標準庫中定義。考慮以下程式 −
#include <stdio.h>
int main () {
int *ptr = NULL;
printf("The value of ptr is : %x\n", ptr );
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
The value of ptr is 0
在大多數作業系統中,程式不允許訪問地址為 0 的記憶體,因為該記憶體由作業系統保留。然而,記憶體地址 0 具有特殊意義;它表示指標並非指向可訪問的記憶體位置。但按照慣例,如果指標包含空(零)值,則假定它不指向任何內容。
要檢查空指標,可以使用如下所示的 'if' 語句:
if(ptr) /* succeeds if p is not null */ if(!ptr) /* succeeds if p is null */
指標詳解
指標的概念很多,但都很容易理解,它們對 C 程式設計非常重要。任何 C 程式設計師都應該清楚以下重要的指標概念:
| 序號 | 概念和描述 |
|---|---|
| 1 | 指標運算
指標可以使用四種算術運算子:++、--、+、- |
| 2 | 指標陣列
可以定義陣列來儲存多個指標。 |
| 3 | 指向指標的指標
C 允許你擁有指向指標的指標,以此類推。 |
| 4 | 在 C 中將指標傳遞給函式
透過引用或地址傳遞引數使被呼叫函式能夠在呼叫函式中更改傳遞的引數。 |
| 5 | 在 C 中從函式返回指標
C 允許函式返回指向區域性變數、靜態變數和動態分配記憶體的指標。 |
C語言 - 字串
字串實際上是由空字元 '\0' 終止的字元一維陣列。因此,空終止字串包含構成字串的字元,後跟一個空字元。
以下宣告和初始化建立一個包含單詞“Hello”的字串。為了在陣列末尾保留空字元,包含字串的字元陣列的大小比單詞“Hello”中的字元數多一個。
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};
如果你遵循陣列初始化規則,則可以按如下方式編寫上述語句:
char greeting[] = "Hello";
以下是上述在 C/C++ 中定義的字串的記憶體表示:

實際上,你不需要在字串常量的末尾放置空字元。C 編譯器在初始化陣列時會自動在字串末尾放置 '\0'。讓我們嘗試列印上面提到的字串:
#include <stdio.h>
int main () {
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};
printf("Greeting message: %s\n", greeting );
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Greeting message: Hello
C 支援廣泛的操作空終止字串的函式:
| 序號 | 函式及用途 |
|---|---|
| 1 | strcpy(s1, s2); 將字串 s2 複製到字串 s1 中。 |
| 2 | strcat(s1, s2); 將字串 s2 連線到字串 s1 的末尾。 |
| 3 | strlen(s1); 返回字串 s1 的長度。 |
| 4 | strcmp(s1, s2); 如果 s1 和 s2 相同,則返回 0;如果 s1 |
| 5 | strchr(s1, ch); 返回指向字串 s1 中字元 ch 首次出現的指標。 |
| 6 | strstr(s1, s2); 返回指向字串 s1 中字串 s2 首次出現的指標。 |
以下示例使用了一些上述函式:
#include <stdio.h>
#include <string.h>
int main () {
char str1[12] = "Hello";
char str2[12] = "World";
char str3[12];
int len ;
/* copy str1 into str3 */
strcpy(str3, str1);
printf("strcpy( str3, str1) : %s\n", str3 );
/* concatenates str1 and str2 */
strcat( str1, str2);
printf("strcat( str1, str2): %s\n", str1 );
/* total lenghth of str1 after concatenation */
len = strlen(str1);
printf("strlen(str1) : %d\n", len );
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
strcpy( str3, str1) : Hello strcat( str1, str2): HelloWorld strlen(str1) : 10
C語言 - 結構體
陣列允許定義可以儲存多種相同型別資料的變數。類似地,結構體是 C 中另一種使用者定義的資料型別,允許組合不同型別的資料項。
結構體用於表示記錄。假設你想跟蹤圖書館中你的書籍。你可能想要跟蹤每本書的以下屬性:
- 書名
- 作者
- 主題
- 圖書 ID
定義結構體
要定義結構體,必須使用struct語句。struct 語句定義了一種新的資料型別,它具有多個成員。struct 語句的格式如下:
struct [structure tag] {
member definition;
member definition;
...
member definition;
} [one or more structure variables];
結構體標籤是可選的,每個成員定義都是一個普通的變數定義,例如 int i; 或 float f; 或任何其他有效的變數定義。在結構體定義的末尾,在最後一個分號之前,可以指定一個或多個結構體變數,但這是可選的。以下是宣告 Book 結構體的方法:
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
} book;
訪問結構體成員
要訪問結構體的任何成員,我們使用成員訪問運算子 (.)。成員訪問運算子被編碼為結構體變數名和我們想要訪問的結構體成員之間的句點。你會使用關鍵字struct來定義結構體型別的變數。以下示例顯示如何在程式中使用結構體:
#include <stdio.h>
#include <string.h>
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main( ) {
struct Books Book1; /* Declare Book1 of type Book */
struct Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
strcpy( Book1.title, "C Programming");
strcpy( Book1.author, "Nuha Ali");
strcpy( Book1.subject, "C Programming Tutorial");
Book1.book_id = 6495407;
/* book 2 specification */
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Zara Ali");
strcpy( Book2.subject, "Telecom Billing Tutorial");
Book2.book_id = 6495700;
/* print Book1 info */
printf( "Book 1 title : %s\n", Book1.title);
printf( "Book 1 author : %s\n", Book1.author);
printf( "Book 1 subject : %s\n", Book1.subject);
printf( "Book 1 book_id : %d\n", Book1.book_id);
/* print Book2 info */
printf( "Book 2 title : %s\n", Book2.title);
printf( "Book 2 author : %s\n", Book2.author);
printf( "Book 2 subject : %s\n", Book2.subject);
printf( "Book 2 book_id : %d\n", Book2.book_id);
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Book 1 title : C Programming Book 1 author : Nuha Ali Book 1 subject : C Programming Tutorial Book 1 book_id : 6495407 Book 2 title : Telecom Billing Book 2 author : Zara Ali Book 2 subject : Telecom Billing Tutorial Book 2 book_id : 6495700
結構體作為函式引數
你可以像傳遞任何其他變數或指標一樣將結構體作為函式引數傳遞。
#include <stdio.h>
#include <string.h>
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
/* function declaration */
void printBook( struct Books book );
int main( ) {
struct Books Book1; /* Declare Book1 of type Book */
struct Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
strcpy( Book1.title, "C Programming");
strcpy( Book1.author, "Nuha Ali");
strcpy( Book1.subject, "C Programming Tutorial");
Book1.book_id = 6495407;
/* book 2 specification */
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Zara Ali");
strcpy( Book2.subject, "Telecom Billing Tutorial");
Book2.book_id = 6495700;
/* print Book1 info */
printBook( Book1 );
/* Print Book2 info */
printBook( Book2 );
return 0;
}
void printBook( struct Books book ) {
printf( "Book title : %s\n", book.title);
printf( "Book author : %s\n", book.author);
printf( "Book subject : %s\n", book.subject);
printf( "Book book_id : %d\n", book.book_id);
}
編譯並執行上述程式碼時,會產生以下結果:
Book title : C Programming Book author : Nuha Ali Book subject : C Programming Tutorial Book book_id : 6495407 Book title : Telecom Billing Book author : Zara Ali Book subject : Telecom Billing Tutorial Book book_id : 6495700
指向結構體的指標
你可以像定義指向任何其他變數的指標一樣定義指向結構體的指標:
struct Books *struct_pointer;
現在,你可以將結構體變數的地址儲存在上面定義的指標變數中。要查詢結構體變數的地址,請在結構體名稱前加上 '&' 運算子,如下所示:
struct_pointer = &Book1;
要使用指向該結構體的指標訪問結構體的成員,必須使用 → 運算子,如下所示:
struct_pointer->title;
讓我們使用結構體指標重寫上面的示例。
#include <stdio.h>
#include <string.h>
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
/* function declaration */
void printBook( struct Books *book );
int main( ) {
struct Books Book1; /* Declare Book1 of type Book */
struct Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
strcpy( Book1.title, "C Programming");
strcpy( Book1.author, "Nuha Ali");
strcpy( Book1.subject, "C Programming Tutorial");
Book1.book_id = 6495407;
/* book 2 specification */
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Zara Ali");
strcpy( Book2.subject, "Telecom Billing Tutorial");
Book2.book_id = 6495700;
/* print Book1 info by passing address of Book1 */
printBook( &Book1 );
/* print Book2 info by passing address of Book2 */
printBook( &Book2 );
return 0;
}
void printBook( struct Books *book ) {
printf( "Book title : %s\n", book->title);
printf( "Book author : %s\n", book->author);
printf( "Book subject : %s\n", book->subject);
printf( "Book book_id : %d\n", book->book_id);
}
編譯並執行上述程式碼時,會產生以下結果:
Book title : C Programming Book author : Nuha Ali Book subject : C Programming Tutorial Book book_id : 6495407 Book title : Telecom Billing Book author : Zara Ali Book subject : Telecom Billing Tutorial Book book_id : 6495700
位域
位域允許在結構體中打包資料。當記憶體或資料儲存非常寶貴時,這尤其有用。典型的例子包括:
將多個物件打包到一個機器字中。例如,可以壓縮 1 位標誌。
讀取外部檔案格式——可以讀取非標準檔案格式,例如 9 位整數。
C 允許我們在結構體定義中透過在變數後加上 :bit length 來做到這一點。例如:
struct packed_struct {
unsigned int f1:1;
unsigned int f2:1;
unsigned int f3:1;
unsigned int f4:1;
unsigned int type:4;
unsigned int my_int:9;
} pack;
這裡,packed_struct 包含 6 個成員:四個 1 位標誌 f1..f3、一個 4 位型別和一個 9 位 my_int。
C 會自動儘可能緊湊地打包上述位域,前提是欄位的最大長度小於或等於計算機的整數字長。如果不是這種情況,則某些編譯器可能允許欄位的記憶體重疊,而其他編譯器則將下一個欄位儲存在下一個字中。
C語言 - 聯合體
聯合體是 C 中的一種特殊資料型別,允許在同一記憶體位置儲存不同的資料型別。你可以定義一個具有多個成員的聯合體,但在任何給定時間,只有一個成員可以包含值。聯合體提供了一種有效的方式來將同一記憶體位置用於多種用途。
定義聯合體
要定義聯合體,必須像定義結構體一樣使用union語句。union 語句定義了一種新的資料型別,為你的程式提供多個成員。union 語句的格式如下:
union [union tag] {
member definition;
member definition;
...
member definition;
} [one or more union variables];
聯合體標籤是可選的,每個成員定義都是一個普通的變數定義,例如 int i; 或 float f; 或任何其他有效的變數定義。在聯合體定義的末尾,在最後一個分號之前,可以指定一個或多個聯合體變數,但這是可選的。以下是如何定義名為 Data 的聯合體型別,它具有三個成員 i、f 和 str:
union Data {
int i;
float f;
char str[20];
} data;
現在,Data 型別的變數可以儲存整數、浮點數或字串。這意味著單個變數(即相同的記憶體位置)可以用來儲存多種型別的資料。你可以根據需要在聯合體中使用任何內建或使用者定義的資料型別。
聯合體佔用的記憶體將足夠大,足以容納聯合體中最大的成員。例如,在上面的例子中,Data 型別將佔用 20 個位元組的記憶體空間,因為這是字元字串可以佔用的最大空間。以下示例顯示上述聯合體佔用的總記憶體大小:
#include <stdio.h>
#include <string.h>
union Data {
int i;
float f;
char str[20];
};
int main( ) {
union Data data;
printf( "Memory size occupied by data : %d\n", sizeof(data));
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Memory size occupied by data : 20
訪問聯合體成員
要訪問聯合體的任何成員,我們使用成員訪問運算子 (.)。成員訪問運算子被編碼為聯合體變數名和我們想要訪問的聯合體成員之間的句點。你會使用關鍵字union來定義聯合體型別的變數。以下示例顯示如何在程式中使用聯合體:
#include <stdio.h>
#include <string.h>
union Data {
int i;
float f;
char str[20];
};
int main( ) {
union Data data;
data.i = 10;
data.f = 220.5;
strcpy( data.str, "C Programming");
printf( "data.i : %d\n", data.i);
printf( "data.f : %f\n", data.f);
printf( "data.str : %s\n", data.str);
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
data.i : 1917853763 data.f : 4122360580327794860452759994368.000000 data.str : C Programming
在這裡,我們可以看到聯合體的i和f成員的值已損壞,因為分配給變數的最終值已佔用記憶體位置,這就是str成員的值能夠很好地打印出來的原因。
現在讓我們再次檢視同一個示例,在這裡我們將一次只使用一個變數,這是使用聯合體的主要目的:
#include <stdio.h>
#include <string.h>
union Data {
int i;
float f;
char str[20];
};
int main( ) {
union Data data;
data.i = 10;
printf( "data.i : %d\n", data.i);
data.f = 220.5;
printf( "data.f : %f\n", data.f);
strcpy( data.str, "C Programming");
printf( "data.str : %s\n", data.str);
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
data.i : 10 data.f : 220.500000 data.str : C Programming
在這裡,所有成員都能夠很好地打印出來,因為一次只使用一個成員。
C語言 - 位域
假設你的 C 程式包含許多在名為 status 的結構體中分組的 TRUE/FALSE 變數,如下所示:
struct {
unsigned int widthValidated;
unsigned int heightValidated;
} status;
此結構體需要 8 個位元組的記憶體空間,但實際上,我們將在每個變數中儲存 0 或 1。C 程式語言提供了一種更好的方法來利用此類情況下的記憶體空間。
如果在結構體中使用此類變數,則可以定義變數的寬度,這將告訴 C 編譯器你將只使用這些位元組數。例如,上述結構體可以改寫如下:
struct {
unsigned int widthValidated : 1;
unsigned int heightValidated : 1;
} status;
上述結構體需要 4 個位元組的記憶體空間來儲存 status 變數,但只有 2 位將用於儲存值。
如果使用多達 32 個變數,每個變數的寬度為 1 位,則 status 結構體也將使用 4 個位元組。但是,一旦你擁有 33 個變數,它將分配下一個記憶體槽,並將開始使用 8 個位元組。讓我們檢查以下示例以瞭解這個概念:
#include <stdio.h>
#include <string.h>
/* define simple structure */
struct {
unsigned int widthValidated;
unsigned int heightValidated;
} status1;
/* define a structure with bit fields */
struct {
unsigned int widthValidated : 1;
unsigned int heightValidated : 1;
} status2;
int main( ) {
printf( "Memory size occupied by status1 : %d\n", sizeof(status1));
printf( "Memory size occupied by status2 : %d\n", sizeof(status2));
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Memory size occupied by status1 : 8 Memory size occupied by status2 : 4
位域宣告
位域的宣告在結構體內部具有以下形式:
struct {
type [member_name] : width ;
};
下表描述了位域的變數元素:
| 序號 | 元素及描述 |
|---|---|
| 1 | 型別 確定如何解釋位域值的整數型別。型別可以是 int、signed int 或 unsigned int。 |
| 2 | 成員名 位域的名稱。 |
| 3 | 寬度 位域中的位數。寬度必須小於或等於指定型別的位寬度。 |
使用預定義寬度定義的變數稱為位域。位域可以容納多個位;例如,如果你需要一個變數來儲存 0 到 7 的值,則可以定義一個寬度為 3 位的位域,如下所示:
struct {
unsigned int age : 3;
} Age;
上述結構體定義指示 C 編譯器 age 變數將只使用 3 位來儲存值。如果你嘗試使用超過 3 位,則它將不允許你這樣做。讓我們嘗試以下示例:
#include <stdio.h>
#include <string.h>
struct {
unsigned int age : 3;
} Age;
int main( ) {
Age.age = 4;
printf( "Sizeof( Age ) : %d\n", sizeof(Age) );
printf( "Age.age : %d\n", Age.age );
Age.age = 7;
printf( "Age.age : %d\n", Age.age );
Age.age = 8;
printf( "Age.age : %d\n", Age.age );
return 0;
}
編譯上述程式碼時,它將編譯併發出警告,執行時,將產生以下結果:
Sizeof( Age ) : 4 Age.age : 4 Age.age : 7 Age.age : 0
C - typedef
C 程式語言提供了一個名為typedef的關鍵字,你可以用它來為型別賦予一個新名稱。以下是如何為一個位元組的數字定義術語BYTE的示例:
typedef unsigned char BYTE;
在此型別定義之後,識別符號 BYTE 可以用作型別unsigned char 的縮寫,例如。
BYTE b1, b2;
按照慣例,大寫字母用於這些定義,以提醒使用者型別名稱實際上是一個符號縮寫,但你可以使用小寫,如下所示:
typedef unsigned char byte;
你也可以使用typedef為使用者定義的資料型別命名。例如,你可以將 typedef 與結構體一起使用以定義一種新的資料型別,然後直接使用該資料型別來定義結構體變數,如下所示:
#include <stdio.h>
#include <string.h>
typedef struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
} Book;
int main( ) {
Book book;
strcpy( book.title, "C Programming");
strcpy( book.author, "Nuha Ali");
strcpy( book.subject, "C Programming Tutorial");
book.book_id = 6495407;
printf( "Book title : %s\n", book.title);
printf( "Book author : %s\n", book.author);
printf( "Book subject : %s\n", book.subject);
printf( "Book book_id : %d\n", book.book_id);
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Book title : C Programming Book author : Nuha Ali Book subject : C Programming Tutorial Book book_id : 6495407
typedef 與 #define
#define是一個 C 指令,它也用於定義各種資料型別的別名,類似於typedef,但存在以下差異:
typedef僅限於為型別賦予符號名稱,而#define也可用於為值定義別名,例如,你可以將 1 定義為 ONE 等。
typedef的解釋由編譯器執行,而#define語句由預處理器處理。
以下示例顯示如何在程式中使用 #define:
#include <stdio.h>
#define TRUE 1
#define FALSE 0
int main( ) {
printf( "Value of TRUE : %d\n", TRUE);
printf( "Value of FALSE : %d\n", FALSE);
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Value of TRUE : 1 Value of FALSE : 0
C - 輸入和輸出
當我們說輸入時,指的是將一些資料饋送到程式中。輸入可以以檔案的形式給出,也可以從命令列給出。C程式設計提供了一套內建函式來讀取給定的輸入,並根據需要將其饋送到程式。
當我們說輸出時,指的是在螢幕、印表機或任何檔案中顯示一些資料。C程式設計提供了一套內建函式來將資料輸出到計算機螢幕,以及將其儲存到文字檔案或二進位制檔案中。
標準檔案
C程式設計將所有裝置都視為檔案。因此,諸如顯示器之類的裝置的定址方式與檔案相同,並且在程式執行時會自動開啟以下三個檔案,以便訪問鍵盤和螢幕。
| 標準檔案 | 檔案指標 | 裝置 |
|---|---|---|
| 標準輸入 | stdin | 鍵盤 |
| 標準輸出 | stdout | 螢幕 |
| 標準錯誤 | stderr | 您的螢幕 |
檔案指標是訪問檔案以進行讀寫操作的方式。本節說明如何從螢幕讀取值以及如何在螢幕上列印結果。
getchar() 和 putchar() 函式
int getchar(void) 函式從螢幕讀取下一個可用字元,並將其作為整數返回。此函式一次只讀取單個字元。如果您想從螢幕讀取多個字元,可以在迴圈中使用此方法。
int putchar(int c) 函式將傳遞的字元放在螢幕上並返回相同的字元。此函式一次只輸出單個字元。如果您想在螢幕上顯示多個字元,可以在迴圈中使用此方法。請檢視以下示例:
#include <stdio.h>
int main( ) {
int c;
printf( "Enter a value :");
c = getchar( );
printf( "\nYou entered: ");
putchar( c );
return 0;
}
當編譯並執行上述程式碼時,它會等待您輸入一些文字。當您輸入文字並按回車鍵時,程式繼續執行,只讀取單個字元並將其顯示如下:
$./a.out Enter a value : this is test You entered: t
gets() 和 puts() 函式
char *gets(char *s) 函式從stdin讀取一行到s指向的緩衝區,直到遇到終止換行符或 EOF(檔案結束)。
int puts(const char *s) 函式將字串 's' 和一個尾隨換行符寫入stdout。
注意:儘管已棄用使用 gets() 函式,但建議不要使用 gets,而應使用fgets()。
#include <stdio.h>
int main( ) {
char str[100];
printf( "Enter a value :");
gets( str );
printf( "\nYou entered: ");
puts( str );
return 0;
}
當編譯並執行上述程式碼時,它會等待您輸入一些文字。當您輸入文字並按回車鍵時,程式繼續執行,讀取直到行尾的完整行,並將其顯示如下:
$./a.out Enter a value : this is test You entered: this is test
scanf() 和 printf() 函式
int scanf(const char *format, ...) 函式從標準輸入流stdin讀取輸入,並根據提供的format掃描該輸入。
int printf(const char *format, ...) 函式將輸出寫入標準輸出流stdout,並根據提供的格式生成輸出。
format可以是一個簡單的常量字串,但是您可以指定 %s、%d、%c、%f 等來分別列印或讀取字串、整數、字元或浮點數。還有許多其他可根據需要使用的格式選項。讓我們繼續一個簡單的例子來更好地理解這些概念:
#include <stdio.h>
int main( ) {
char str[100];
int i;
printf( "Enter a value :");
scanf("%s %d", str, &i);
printf( "\nYou entered: %s %d ", str, i);
return 0;
}
當編譯並執行上述程式碼時,它會等待您輸入一些文字。當您輸入文字並按回車鍵時,程式繼續執行,讀取輸入並將其顯示如下:
$./a.out Enter a value : seven 7 You entered: seven 7
這裡需要注意的是,scanf() 期望輸入的格式與您提供的 %s 和 %d 相同,這意味著您必須提供有效的輸入,例如“字串 整數”。如果您提供“字串 字串”或“整數 整數”,則會被認為是錯誤的輸入。其次,在讀取字串時,scanf() 一旦遇到空格就會停止讀取,因此“this is test”對於 scanf() 來說是三個字串。
C - 檔案 I/O
上一章解釋了 C 程式語言處理的標準輸入和輸出裝置。本章介紹 C 程式設計師如何建立、開啟、關閉文字檔案或二進位制檔案以進行資料儲存。
檔案表示一系列位元組,無論它是文字檔案還是二進位制檔案。C 程式語言提供高階函式以及低階(作業系統級)呼叫來處理儲存裝置上的檔案。本章將引導您完成檔案管理的重要呼叫。
開啟檔案
您可以使用fopen( )函式建立新檔案或開啟現有檔案。此呼叫將初始化型別為FILE的物件,其中包含控制流所需的所有資訊。此函式呼叫的原型如下:
FILE *fopen( const char * filename, const char * mode );
這裡,filename是一個字串文字,您將使用它來命名您的檔案,並且access mode可以具有以下值之一:
| 序號 | 模式 & 說明 |
|---|---|
| 1 | r 以只讀方式開啟現有文字檔案。 |
| 2 | w 開啟文字檔案以寫入。如果它不存在,則建立一個新檔案。在這裡,您的程式將從檔案的開頭開始寫入內容。 |
| 3 | a 以追加模式開啟文字檔案以寫入。如果它不存在,則建立一個新檔案。在這裡,您的程式將開始將內容追加到現有檔案內容中。 |
| 4 | r+ 開啟文字檔案進行讀寫。 |
| 5 | w+ 開啟文字檔案進行讀寫。如果檔案存在,則首先將其截斷為零長度;如果不存在,則建立檔案。 |
| 6 | a+ 開啟文字檔案進行讀寫。如果檔案不存在,則建立檔案。讀取將從開頭開始,但寫入只能追加。 |
如果您要處理二進位制檔案,則將使用以下訪問模式代替上述模式:
"rb", "wb", "ab", "rb+", "r+b", "wb+", "w+b", "ab+", "a+b"
關閉檔案
要關閉檔案,請使用 fclose( ) 函式。此函式的原型為:
int fclose( FILE *fp );
fclose(-)函式在成功時返回零,如果關閉檔案時出錯則返回EOF。此函式實際上將緩衝區中仍掛起的任何資料重新整理到檔案,關閉檔案並釋放用於檔案的任何記憶體。EOF 是在標頭檔案stdio.h中定義的常量。
C 標準庫提供了各種函式來逐字元或以固定長度字串的形式讀取和寫入檔案。
寫入檔案
以下是將單個字元寫入流的最簡單函式:
int fputc( int c, FILE *fp );
fputc()函式將引數 c 的字元值寫入 fp 引用的輸出流。成功時返回寫入的字元,否則如果出錯則返回EOF。您可以使用以下函式將以 null 結尾的字串寫入流:
int fputs( const char *s, FILE *fp );
fputs()函式將字串s寫入 fp 引用的輸出流。成功時返回非負值,否則在發生任何錯誤時返回EOF。您也可以使用int fprintf(FILE *fp,const char *format, ...)函式將字串寫入檔案。試試下面的例子。
確保您有可用的/tmp目錄。如果沒有,則在繼續之前,必須在您的機器上建立此目錄。
#include <stdio.h>
main() {
FILE *fp;
fp = fopen("/tmp/test.txt", "w+");
fprintf(fp, "This is testing for fprintf...\n");
fputs("This is testing for fputs...\n", fp);
fclose(fp);
}
當編譯並執行上述程式碼時,它會在 /tmp 目錄中建立一個新檔案test.txt,並使用兩個不同的函式寫入兩行。讓我們在下一節中讀取此檔案。
讀取檔案
以下是從檔案中讀取單個字元的最簡單函式:
int fgetc( FILE * fp );
fgetc()函式從 fp 引用的輸入檔案中讀取一個字元。返回值是讀取的字元,或者在發生任何錯誤時返回EOF。以下函式允許從流中讀取字串:
char *fgets( char *buf, int n, FILE *fp );
fgets()函式最多從 fp 引用的輸入流中讀取 n-1 個字元。它將讀取的字串複製到緩衝區buf中,並追加一個null字元以終止字串。
如果此函式在讀取最大字元數之前遇到換行符 '\n' 或檔案結束 EOF,則它只返回讀取到該點的字元,包括換行符。您還可以使用int fscanf(FILE *fp, const char *format, ...)函式從檔案中讀取字串,但它會在遇到第一個空格字元後停止讀取。
#include <stdio.h>
main() {
FILE *fp;
char buff[255];
fp = fopen("/tmp/test.txt", "r");
fscanf(fp, "%s", buff);
printf("1 : %s\n", buff );
fgets(buff, 255, (FILE*)fp);
printf("2: %s\n", buff );
fgets(buff, 255, (FILE*)fp);
printf("3: %s\n", buff );
fclose(fp);
}
當編譯並執行上述程式碼時,它讀取上一節中建立的檔案併產生以下結果:
1 : This 2: is testing for fprintf... 3: This is testing for fputs...
讓我們更詳細地瞭解一下這裡發生了什麼。首先,fscanf()只讀取This,因為之後它遇到一個空格,第二次呼叫是fgets(),它讀取剩餘的行直到遇到行尾。最後,最後一次呼叫fgets()完整地讀取第二行。
二進位制 I/O 函式
有兩個函式可用於二進位制輸入和輸出:
size_t fread(void *ptr, size_t size_of_elements, size_t number_of_elements, FILE *a_file);
size_t fwrite(const void *ptr, size_t size_of_elements, size_t number_of_elements, FILE *a_file);
這兩個函式都應用於讀取或寫入記憶體塊——通常是陣列或結構。
C語言 - 預處理器
C 預處理器不是編譯器的一部分,而是編譯過程中的一個單獨步驟。簡單來說,C 預處理器只是一個文字替換工具,它指示編譯器在實際編譯之前進行必要的預處理。我們將 C 預處理器稱為 CPP。
所有預處理器命令都以井號 (#) 開頭。它必須是第一個非空字元,並且為了可讀性,預處理器指令應該從第一列開始。以下部分列出了所有重要的預處理器指令:
| 序號 | 指令 & 說明 |
|---|---|
| 1 | #define 替換預處理器宏。 |
| 2 | #include 從另一個檔案插入特定的標頭檔案。 |
| 3 | #undef 取消定義預處理器宏。 |
| 4 | #ifdef 如果此宏已定義,則返回 true。 |
| 5 | #ifndef 如果此宏未定義,則返回 true。 |
| 6 | #if 測試編譯時條件是否為 true。 |
| 7 | #else #if 的替代方案。 |
| 8 | #elif #else 和 #if 合併成一個語句。 |
| 9 | #endif 結束預處理器條件。 |
| 10 | #error 在 stderr 上列印錯誤訊息。 |
| 11 | #pragma 使用標準化的方法向編譯器發出特殊命令。 |
預處理器示例
分析以下示例以瞭解各種指令。
#define MAX_ARRAY_LENGTH 20
此指令告訴 CPP 將 MAX_ARRAY_LENGTH 的例項替換為 20。使用#define定義常量以提高可讀性。
#include <stdio.h> #include "myheader.h"
這些指令告訴 CPP 從系統庫獲取 stdio.h 並將文字新增到當前原始檔中。下一行告訴 CPP 從本地目錄獲取myheader.h並將內容新增到當前原始檔中。
#undef FILE_SIZE #define FILE_SIZE 42
它告訴 CPP 取消定義現有的 FILE_SIZE 並將其定義為 42。
#ifndef MESSAGE #define MESSAGE "You wish!" #endif
它告訴 CPP 僅在 MESSAGE 未定義時才定義 MESSAGE。
#ifdef DEBUG /* Your debugging statements here */ #endif
它告訴 CPP 如果定義了 DEBUG,則處理包含的語句。如果您在編譯時向 gcc 編譯器傳遞-DDEBUG標誌,這將非常有用。這將定義 DEBUG,因此您可以在編譯過程中動態地開啟和關閉除錯。
預定義宏
ANSI C 定義了許多宏。儘管每個宏都可以在程式設計中使用,但不應直接修改預定義宏。
| 序號 | 宏 & 描述 |
|---|---|
| 1 | __DATE__ 當前日期,以 "MMM DD YYYY" 格式的字元字面量表示。 |
| 2 | __TIME__ 當前時間,以 "HH:MM:SS" 格式的字元字面量表示。 |
| 3 | __FILE__ 包含當前檔名,作為字串字面量。 |
| 4 | __LINE__ 包含當前行號,作為十進位制常量。 |
| 5 | __STDC__ 當編譯器符合 ANSI 標準時定義為 1。 |
讓我們嘗試以下示例:
#include <stdio.h>
int main() {
printf("File :%s\n", __FILE__ );
printf("Date :%s\n", __DATE__ );
printf("Time :%s\n", __TIME__ );
printf("Line :%d\n", __LINE__ );
printf("ANSI :%d\n", __STDC__ );
}
當以上程式碼在一個名為test.c的檔案中編譯並執行時,會產生以下結果:
File :test.c Date :Jun 2 2012 Time :03:36:24 Line :8 ANSI :1
預處理器運算子
C 預處理器提供以下運算子來幫助建立宏:
宏續行 (\) 運算子
宏通常限制在一行內。宏續行運算子 (\) 用於繼續一個太長而無法在一行內完成的宏。例如:
#define message_for(a, b) \ printf(#a " and " #b ": We love you!\n")
字串化 (#) 運算子
字串化或井號運算子 ('#' ),當在宏定義中使用時,會將宏引數轉換為字串常量。此運算子只能在具有指定引數或引數列表的宏中使用。例如:
#include <stdio.h>
#define message_for(a, b) \
printf(#a " and " #b ": We love you!\n")
int main(void) {
message_for(Carole, Debra);
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Carole and Debra: We love you!
令牌貼上 (##) 運算子
宏定義中的令牌貼上運算子 (##) 將兩個引數組合在一起。它允許將宏定義中的兩個單獨的令牌連線成一個令牌。例如:
#include <stdio.h>
#define tokenpaster(n) printf ("token" #n " = %d", token##n)
int main(void) {
int token34 = 40;
tokenpaster(34);
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
token34 = 40
出現這種情況是因為此示例導致預處理器產生以下實際輸出:
printf ("token34 = %d", token34);
此示例顯示了 token##n 與 token34 的連線,這裡我們同時使用了字串化和令牌貼上。
已定義() 運算子
預處理器defined運算子用於常量表達式中,以確定是否使用 #define 定義了識別符號。如果指定了識別符號,則值為真 (非零)。如果未定義符號,則值為假 (零)。defined 運算子的指定方式如下:
#include <stdio.h>
#if !defined (MESSAGE)
#define MESSAGE "You wish!"
#endif
int main(void) {
printf("Here is the message: %s\n", MESSAGE);
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Here is the message: You wish!
引數化宏
CPP 的強大功能之一是能夠使用引數化宏來模擬函式。例如,我們可能有一些程式碼來計算一個數的平方,如下所示:
int square(int x) {
return x * x;
}
我們可以使用宏重寫以上程式碼,如下所示:
#define square(x) ((x) * (x))
帶有引數的宏必須使用#define指令定義才能使用。引數列表用括號括起來,必須緊跟在宏名稱之後。宏名稱和左括號之間不允許有空格。例如:
#include <stdio.h>
#define MAX(x,y) ((x) > (y) ? (x) : (y))
int main(void) {
printf("Max between 20 and 10 is %d\n", MAX(10, 20));
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Max between 20 and 10 is 20
C語言 - 標頭檔案
標頭檔案是一個副檔名為.h的檔案,其中包含要在多個原始檔中共享的 C 函式宣告和宏定義。標頭檔案有兩種型別:程式設計師編寫的檔案和編譯器自帶的檔案。
您可以透過使用 C 預處理指令#include包含標頭檔案來請求在程式中使用它,就像您已經看到包含編譯器自帶的stdio.h標頭檔案一樣。
包含標頭檔案等同於複製標頭檔案的內容,但我們不這樣做,因為這容易出錯,並且在原始檔中複製標頭檔案的內容不是一個好主意,尤其是在程式中有多個原始檔的情況下。
在 C 或 C++ 程式中,一個簡單的做法是將所有常量、宏、系統範圍的全域性變數和函式原型都放在標頭檔案中,並在需要的地方包含該標頭檔案。
包含語法
使用者和系統標頭檔案都是使用預處理指令#include包含的。它有以下兩種形式:
#include <file>
此形式用於系統標頭檔案。它在一個標準的系統目錄列表中搜索名為“file”的檔案。您可以在編譯原始碼時使用 -I 選項將目錄新增到此列表的前面。
#include "file"
此形式用於您自己程式的標頭檔案。它在包含當前檔案的目錄中搜索名為“file”的檔案。您可以在編譯原始碼時使用 -I 選項將目錄新增到此列表的前面。
包含操作
#include指令的工作原理是指示 C 預處理器在繼續處理當前原始檔的其餘部分之前,先掃描指定的檔案作為輸入。預處理器的輸出包含已生成的輸出,後跟包含檔案生成的輸出,最後是#include指令後面的文字生成的輸出。例如,如果您有一個如下所示的 header.h 標頭檔案:
char *test (void);
以及一個使用該標頭檔案的名為program.c的主程式,如下所示:
int x;
#include "header.h"
int main (void) {
puts (test ());
}
編譯器將看到與program.c讀取相同的令牌流。
int x;
char *test (void);
int main (void) {
puts (test ());
}
一次性標頭檔案
如果一個頭檔案恰好被包含了兩次,編譯器將處理其內容兩次,這將導致錯誤。防止這種情況的標準方法是將檔案的全部實際內容放在一個條件語句中,如下所示:
#ifndef HEADER_FILE #define HEADER_FILE the entire header file file #endif
這種結構通常稱為包裝器#ifndef。當再次包含標頭檔案時,條件將為假,因為 HEADER_FILE 已定義。預處理器將跳過檔案的全部內容,編譯器將不會看到它兩次。
計算包含
有時需要選擇多個不同的標頭檔案中的一種包含到程式中。例如,它們可能會指定要在不同型別的作業系統上使用的配置引數。您可以使用一系列條件語句來做到這一點,如下所示:
#if SYSTEM_1 # include "system_1.h" #elif SYSTEM_2 # include "system_2.h" #elif SYSTEM_3 ... #endif
但是隨著它的增長,它變得很繁瑣,相反,預處理器提供了使用宏作為標頭檔案名的能力。這稱為計算包含。不是將標頭檔案名作為#include的直接引數寫入,而是隻需在那裡放置一個宏名:
#define SYSTEM_H "system_1.h" ... #include SYSTEM_H
SYSTEM_H 將被擴充套件,預處理器將查詢 system_1.h,就好像#include最初是這樣編寫的。SYSTEM_H 可以透過您的 Makefile 使用 -D 選項定義。
C語言 - 型別強制轉換
型別轉換是一種將變數從一種資料型別轉換為另一種資料型別的方法。例如,如果要將“long”值儲存到簡單的整數中,則可以將“long”型別轉換為“int”型別。您可以使用強制轉換運算子顯式地將值從一種型別轉換為另一種型別,如下所示:
(type_name) expression
考慮以下示例,其中強制轉換運算子導致將一個整型變數除以另一個整型變數作為浮點運算執行:
#include <stdio.h>
main() {
int sum = 17, count = 5;
double mean;
mean = (double) sum / count;
printf("Value of mean : %f\n", mean );
}
編譯並執行上述程式碼時,會產生以下結果:
Value of mean : 3.400000
這裡應該注意的是,強制轉換運算子的優先順序高於除法,所以sum的值首先轉換為double型別,最後它被count除,得到一個double值。
型別轉換可以是隱式的,由編譯器自動執行,也可以透過使用強制轉換運算子顯式指定。當需要型別轉換時,使用強制轉換運算子被認為是良好的程式設計習慣。
整數提升
整數提升是一個過程,透過該過程,小於int或unsigned int的整型值被轉換為int或unsigned int。考慮一個將字元與整數相加的例子:
#include <stdio.h>
main() {
int i = 17;
char c = 'c'; /* ascii value is 99 */
int sum;
sum = i + c;
printf("Value of sum : %d\n", sum );
}
編譯並執行上述程式碼時,會產生以下結果:
Value of sum : 116
這裡,sum的值是116,因為編譯器正在進行整數提升並將'c'的值轉換為ASCII碼,然後再執行實際的加法運算。
通常的算術轉換
通常的算術轉換是隱式執行的,以將其值轉換為公共型別。編譯器首先執行整數提升;如果運算元的型別仍然不同,則它們將轉換為以下層次結構中出現的最高型別:
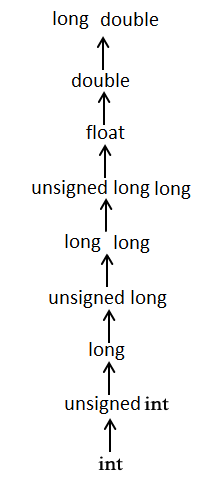
通常的算術轉換不適用於賦值運算子,也不適用於邏輯運算子 && 和 ||。讓我們來看下面的例子來理解這個概念:
#include <stdio.h>
main() {
int i = 17;
char c = 'c'; /* ascii value is 99 */
float sum;
sum = i + c;
printf("Value of sum : %f\n", sum );
}
編譯並執行上述程式碼時,會產生以下結果:
Value of sum : 116.000000
這裡,很容易理解,首先 c 被轉換為整數,但是由於最終值是 double,通常的算術轉換適用,編譯器將 i 和 c 轉換為 'float' 並將它們相加,得到一個 'float' 結果。
C語言 - 錯誤處理
因此,C 程式語言不直接支援錯誤處理,但作為一個系統程式語言,它以返回值的形式提供對底層的訪問。大多數 C 甚至 Unix 函式呼叫在發生任何錯誤時返回 -1 或 NULL,並設定錯誤程式碼errno。它被設定為全域性變數,表示在任何函式呼叫期間發生錯誤。您可以在<error.h>標頭檔案中找到各種錯誤程式碼的定義。
因此,C 程式設計師可以檢查返回值,並根據返回值採取相應的措施。一個好習慣是在程式初始化時將 errno 設定為 0。值為 0 表示程式中沒有錯誤。
errno、perror() 和 strerror()
C 程式語言提供perror()和strerror()函式,可用於顯示與errno關聯的文字訊息。
perror()函式顯示您傳遞給它的字串,後跟一個冒號、一個空格,然後是當前 errno 值的文字表示。
strerror()函式返回指向當前 errno 值的文字表示的指標。
讓我們嘗試模擬一個錯誤條件並嘗試開啟一個不存在的檔案。這裡我同時使用這兩個函式來顯示用法,但是您可以使用一種或多種方法來列印錯誤。第二個需要注意的重要點是,您應該使用stderr檔案流來輸出所有錯誤。
#include <stdio.h>
#include <errno.h>
#include <string.h>
extern int errno ;
int main () {
FILE * pf;
int errnum;
pf = fopen ("unexist.txt", "rb");
if (pf == NULL) {
errnum = errno;
fprintf(stderr, "Value of errno: %d\n", errno);
perror("Error printed by perror");
fprintf(stderr, "Error opening file: %s\n", strerror( errnum ));
} else {
fclose (pf);
}
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Value of errno: 2 Error printed by perror: No such file or directory Error opening file: No such file or directory
除以零錯誤
這是一個常見問題,在除任何數字時,程式設計師不檢查除數是否為零,最終會產生執行時錯誤。
下面的程式碼透過在除法之前檢查除數是否為零來解決這個問題:
#include <stdio.h>
#include <stdlib.h>
main() {
int dividend = 20;
int divisor = 0;
int quotient;
if( divisor == 0){
fprintf(stderr, "Division by zero! Exiting...\n");
exit(-1);
}
quotient = dividend / divisor;
fprintf(stderr, "Value of quotient : %d\n", quotient );
exit(0);
}
編譯並執行上述程式碼時,會產生以下結果:
Division by zero! Exiting...
程式退出狀態
通常的做法是,如果程式在成功操作後退出,則以 EXIT_SUCCESS 的值退出。這裡,EXIT_SUCCESS 是一個宏,定義為 0。
如果程式中存在錯誤條件並且您要退出,則應以 EXIT_FAILURE 狀態退出,它定義為 -1。因此,讓我們將以上程式編寫如下:
#include <stdio.h>
#include <stdlib.h>
main() {
int dividend = 20;
int divisor = 5;
int quotient;
if( divisor == 0) {
fprintf(stderr, "Division by zero! Exiting...\n");
exit(EXIT_FAILURE);
}
quotient = dividend / divisor;
fprintf(stderr, "Value of quotient : %d\n", quotient );
exit(EXIT_SUCCESS);
}
編譯並執行上述程式碼時,會產生以下結果:
Value of quotient : 4
C語言 - 遞迴
遞迴是一個以自相似的方式重複專案的過程。在程式語言中,如果一個程式允許你在同一個函式內部呼叫該函式,那麼這就被稱為函式的遞迴呼叫。
void recursion() {
recursion(); /* function calls itself */
}
int main() {
recursion();
}
C 程式語言支援遞迴,即函式自身呼叫自身。但是,在使用遞迴時,程式設計師需要注意定義函式的退出條件,否則它將進入無限迴圈。
遞迴函式非常有用,可以解決許多數學問題,例如計算數字的階乘、生成斐波那契數列等。
數字階乘
以下示例使用遞迴函式計算給定數字的階乘:
#include <stdio.h>
unsigned long long int factorial(unsigned int i) {
if(i <= 1) {
return 1;
}
return i * factorial(i - 1);
}
int main() {
int i = 12;
printf("Factorial of %d is %d\n", i, factorial(i));
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
Factorial of 12 is 479001600
斐波那契數列
以下示例使用遞迴函式生成給定數字的斐波那契數列:
#include <stdio.h>
int fibonacci(int i) {
if(i == 0) {
return 0;
}
if(i == 1) {
return 1;
}
return fibonacci(i-1) + fibonacci(i-2);
}
int main() {
int i;
for (i = 0; i < 10; i++) {
printf("%d\t\n", fibonacci(i));
}
return 0;
}
編譯並執行上述程式碼時,會產生以下結果:
0 1 1 2 3 5 8 13 21 34
C語言 - 可變引數
有時,你可能會遇到這樣的情況:你想要一個函式,它可以接受可變數量的引數(即引數),而不是預定義數量的引數。C 程式語言為此提供瞭解決方案,你可以定義一個可以根據你的需求接受可變數量引數的函式。以下示例顯示了此類函式的定義。
int func(int, ... ) {
.
.
.
}
int main() {
func(1, 2, 3);
func(1, 2, 3, 4);
}
需要注意的是,函式**func()** 的最後一個引數是省略號,即三個點 (**...**),而省略號之前的引數始終是**int** 型別,它將表示傳遞的可變引數的總數。要使用此功能,你需要使用**stdarg.h** 標頭檔案,該檔案提供實現可變引數功能的函式和宏,並遵循以下步驟:
定義一個函式,其最後一個引數為省略號,而省略號之前的引數始終為**int** 型別,它將表示引數的數量。
在函式定義中建立一個**va_list** 型別的變數。此型別在 stdarg.h 標頭檔案中定義。
使用**int** 引數和**va_start** 宏將**va_list** 變數初始化為引數列表。va_start 宏在 stdarg.h 標頭檔案中定義。
使用**va_arg** 宏和**va_list** 變數訪問引數列表中的每個專案。
使用宏**va_end** 清理分配給**va_list** 變數的記憶體。
現在讓我們遵循上述步驟,編寫一個可以接受可變數量引數並返回其平均值的簡單函式:
#include <stdio.h>
#include <stdarg.h>
double average(int num,...) {
va_list valist;
double sum = 0.0;
int i;
/* initialize valist for num number of arguments */
va_start(valist, num);
/* access all the arguments assigned to valist */
for (i = 0; i < num; i++) {
sum += va_arg(valist, int);
}
/* clean memory reserved for valist */
va_end(valist);
return sum/num;
}
int main() {
printf("Average of 2, 3, 4, 5 = %f\n", average(4, 2,3,4,5));
printf("Average of 5, 10, 15 = %f\n", average(3, 5,10,15));
}
編譯並執行上述程式碼後,將產生以下結果。需要注意的是,函式**average()** 被呼叫了兩次,每次第一個引數都表示傳遞的可變引數的總數。僅使用省略號傳遞可變數量的引數。
Average of 2, 3, 4, 5 = 3.500000 Average of 5, 10, 15 = 10.000000
C語言 - 記憶體管理
本章解釋 C 語言中的動態記憶體管理。C 程式語言提供了一些用於記憶體分配和管理的函式。這些函式可以在**<stdlib.h>** 標頭檔案中找到。
| 序號 | 函式和描述 |
|---|---|
| 1 | void *calloc(int num, int size); 此函式分配一個包含**num** 個元素的陣列,每個元素的大小(以位元組為單位)為**size**。 |
| 2 | void free(void *address); 此函式釋放由 address 指定的記憶體塊。 |
| 3 | void *malloc(size_t size); 此函式分配一個大小為**num** 位元組的陣列,並將其保留為未初始化狀態。 |
| 4 | void *realloc(void *address, int newsize); 此函式重新分配記憶體,將其擴充套件到**newsize**。 |
動態分配記憶體
在程式設計中,如果你知道陣列的大小,那麼它很容易,你可以將其定義為陣列。例如,要儲存任何人的姓名,最多可以儲存 100 個字元,因此你可以定義如下內容:
char name[100];
但是現在讓我們考慮這種情況:你不知道需要儲存文字的長度,例如,你想要儲存有關某個主題的詳細說明。這裡我們需要定義一個指向字元的指標,而無需定義需要多少記憶體,之後,根據需要,我們可以分配記憶體,如下面的示例所示:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
char name[100];
char *description;
strcpy(name, "Zara Ali");
/* allocate memory dynamically */
description = malloc( 200 * sizeof(char) );
if( description == NULL ) {
fprintf(stderr, "Error - unable to allocate required memory\n");
} else {
strcpy( description, "Zara ali a DPS student in class 10th");
}
printf("Name = %s\n", name );
printf("Description: %s\n", description );
}
編譯並執行上述程式碼後,將產生以下結果。
Name = Zara Ali Description: Zara ali a DPS student in class 10th
可以使用**calloc();** 編寫相同的程式,只需將 malloc 替換為 calloc,如下所示:
calloc(200, sizeof(char));
因此,你可以完全控制,並且可以在分配記憶體時傳遞任何大小的值,這與陣列不同,陣列一旦定義了大小,就不能更改它。
調整記憶體大小和釋放記憶體
當你的程式退出時,作業系統會自動釋放你的程式分配的所有記憶體,但作為一個好的習慣,當你不再需要記憶體時,你應該透過呼叫函式**free()** 來釋放該記憶體。
或者,你可以透過呼叫函式**realloc()** 來增加或減少已分配記憶體塊的大小。讓我們再次檢查上述程式,並使用 realloc() 和 free() 函式:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
char name[100];
char *description;
strcpy(name, "Zara Ali");
/* allocate memory dynamically */
description = malloc( 30 * sizeof(char) );
if( description == NULL ) {
fprintf(stderr, "Error - unable to allocate required memory\n");
} else {
strcpy( description, "Zara ali a DPS student.");
}
/* suppose you want to store bigger description */
description = realloc( description, 100 * sizeof(char) );
if( description == NULL ) {
fprintf(stderr, "Error - unable to allocate required memory\n");
} else {
strcat( description, "She is in class 10th");
}
printf("Name = %s\n", name );
printf("Description: %s\n", description );
/* release memory using free() function */
free(description);
}
編譯並執行上述程式碼後,將產生以下結果。
Name = Zara Ali Description: Zara ali a DPS student.She is in class 10th
你可以嘗試在不重新分配額外記憶體的情況下執行上述示例,並且由於 description 中缺少可用記憶體,strcat() 函式將給出錯誤。
C語言 - 命令列引數
可以將一些值從命令列傳遞到 C 程式的執行過程中。這些值稱為**命令列引數**,它們在許多情況下對你的程式非常重要,尤其是在你想要從外部控制程式而不是在程式碼中硬編碼這些值時。
命令列引數使用 main() 函式引數處理,其中**argc** 指的是傳遞的引數數量,**argv[]** 是一個指向傳遞給程式的每個引數的指標陣列。以下是一個簡單的示例,它檢查是否從命令列提供了任何引數並相應地採取行動:
#include <stdio.h>
int main( int argc, char *argv[] ) {
if( argc == 2 ) {
printf("The argument supplied is %s\n", argv[1]);
}
else if( argc > 2 ) {
printf("Too many arguments supplied.\n");
}
else {
printf("One argument expected.\n");
}
}
編譯並執行上述程式碼以及單個引數後,將產生以下結果。
$./a.out testing The argument supplied is testing
編譯並執行上述程式碼以及兩個引數後,將產生以下結果。
$./a.out testing1 testing2 Too many arguments supplied.
編譯並執行上述程式碼而沒有傳遞任何引數時,將產生以下結果。
$./a.out One argument expected
需要注意的是,**argv[0]** 儲存程式本身的名稱,**argv[1]** 是指向提供的第一個命令列引數的指標,而 *argv[n]* 是最後一個引數。如果未提供任何引數,則 argc 為 1,如果傳遞一個引數,則**argc** 設定為 2。
你透過空格分隔所有命令列引數,但是如果引數本身包含空格,則可以透過將其放在雙引號 "" 或單引號 '' 內來傳遞這些引數。讓我們再次重寫上面的示例,我們將列印程式名稱,並且我們還透過將命令列引數放在雙引號內來傳遞它:
#include <stdio.h>
int main( int argc, char *argv[] ) {
printf("Program name %s\n", argv[0]);
if( argc == 2 ) {
printf("The argument supplied is %s\n", argv[1]);
}
else if( argc > 2 ) {
printf("Too many arguments supplied.\n");
}
else {
printf("One argument expected.\n");
}
}
編譯並執行上述程式碼以及用空格分隔但在雙引號內的單個引數後,將產生以下結果。
$./a.out "testing1 testing2" Progranm name ./a.out The argument supplied is testing1 testing2