- Python AI 教程
- 首頁
- Python AI – 基礎概念
- Python AI – 入門
- Python AI – 機器學習
- Python AI – 資料準備
- 監督學習:分類
- 監督學習:迴歸
- Python AI – 邏輯程式設計
- 無監督學習:聚類
- 自然語言處理
- Python AI – NLTK 包
- 分析時間序列資料
- Python AI – 語音識別
- Python AI – 啟發式搜尋
- Python AI – 遊戲
- Python AI – 神經網路
- 強化學習
- Python AI – 遺傳演算法
- Python AI – 計算機視覺
- Python AI – 深度學習
- Python AI 資源
- Python AI – 快速指南
- Python AI – 有用資源
- Python AI – 討論
Python AI – 語音識別
在本章中,我們將學習如何使用 Python AI 進行語音識別。
語音是成年人最基本的交流方式。語音處理的基本目標是在人與機器之間建立互動。
語音處理系統主要有三個任務:
**首先**,語音識別,允許機器捕捉我們所說的單詞、短語和句子
**其次**,自然語言處理,允許機器理解我們所說的內容,以及
**第三**,語音合成,允許機器說話。
本章重點介紹**語音識別**,即理解人類所說的話語的過程。請記住,語音訊號是藉助麥克風捕捉的,然後系統必須理解它。
構建語音識別器
語音識別或自動語音識別 (ASR) 是機器人等 AI 專案關注的焦點。如果沒有 ASR,就無法想象認知機器人與人類互動。然而,構建語音識別器並非易事。
開發語音識別系統的困難
開發高質量的語音識別系統確實是一個難題。語音識別技術的難度可以沿著以下幾個方面進行概括:
**詞彙量大小** – 詞彙量的大小會影響 ASR 的開發難度。考慮以下詞彙量大小,以便更好地理解。
小型詞彙量包含 2-100 個單詞,例如,在語音菜單系統中
中型詞彙量包含幾百到幾千個單詞,例如,在資料庫檢索任務中
大型詞彙量包含幾萬個單詞,例如,在一般聽寫任務中。
**通道特性** – 通道質量也是一個重要的維度。例如,人類語音包含高頻寬和全頻段,而電話語音包含低頻寬和有限頻段。請注意,後者更難。
**說話模式** – ASR 的開發難易程度也取決於說話模式,即語音是孤立詞模式、連線詞模式還是連續語音模式。請注意,連續語音更難識別。
**說話風格** – 閱讀語音可能是正式風格,也可能是自發和對話式的隨意風格。後者更難識別。
**說話人依賴性** – 語音可以是說話人依賴的、說話人自適應的或說話人獨立的。說話人獨立的識別系統最難構建。
**噪聲型別** – 在開發 ASR 時,噪聲也是需要考慮的因素。信噪比可能處於不同的範圍,具體取決於聲學環境觀察到的背景噪聲較少還是較多:
如果信噪比大於 30dB,則認為是高範圍
如果信噪比介於 30dB 到 10db 之間,則認為是中 SNR
如果信噪比小於 10dB,則認為是低範圍
**麥克風特性** – 麥克風的質量可能是好的、平均的或低於平均水平的。此外,嘴巴與麥克風的距離也可能不同。這些因素也應該在識別系統中考慮。
請注意,詞彙量越大,執行識別的難度就越大。
例如,背景噪聲的型別(例如靜止噪聲、非人類噪聲、背景語音和其他說話者的串擾)也會增加問題的難度。
儘管存在這些困難,研究人員還是在語音的各個方面做了大量工作,例如理解語音訊號、說話者以及識別口音。
您需要按照以下步驟構建語音識別器:
視覺化音訊訊號 - 從檔案讀取並處理它
這是構建語音識別系統的第一步,因為它可以幫助理解音訊訊號的結構。一些可以用來處理音訊訊號的常見步驟如下:
錄音
當您需要從檔案中讀取音訊訊號時,首先使用麥克風錄製它。
取樣
使用麥克風錄製時,訊號以數字形式儲存。但要處理它,機器需要以離散數值形式儲存。因此,我們應該以一定的頻率進行取樣,並將訊號轉換為離散數值形式。選擇高取樣頻率意味著當人類收聽訊號時,他們會感覺到它是一個連續的音訊訊號。
示例
以下示例展示了使用 Python 分析儲存在檔案中的音訊訊號的分步方法。此音訊訊號的頻率為 44,100 HZ。
匯入必要的包,如下所示:
import numpy as np import matplotlib.pyplot as plt from scipy.io import wavfile
現在,讀取儲存的音訊檔案。它將返回兩個值:取樣頻率和音訊訊號。提供音訊檔案儲存的路徑,如下所示:
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")
使用顯示的命令顯示取樣頻率、訊號的資料型別及其持續時間等引數:
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')
此步驟涉及對訊號進行歸一化,如下所示:
audio_signal = audio_signal / np.power(2, 15)
在此步驟中,我們從該訊號中提取前 100 個值進行視覺化。為此,請使用以下命令:
audio_signal = audio_signal [:100] time_axis = 1000 * np.arange(0, len(signal), 1) / float(frequency_sampling)
現在,使用以下命令視覺化訊號:
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time (milliseconds)')
plt.ylabel('Amplitude')
plt.title('Input audio signal')
plt.show()
您將能夠看到輸出圖形和上面音訊訊號的提取資料,如這裡所示的影像

Signal shape: (132300,) Signal Datatype: int16 Signal duration: 3.0 seconds
音訊訊號特徵化:轉換為頻域
音訊訊號特徵化涉及將時域訊號轉換為頻域,並瞭解其頻率成分。這是一個重要的步驟,因為它提供了許多關於訊號的資訊。您可以使用傅立葉變換等數學工具來執行此轉換。
示例
以下示例分步展示瞭如何使用 Python 對儲存在檔案中的訊號進行特徵化。請注意,這裡我們使用傅立葉變換數學工具將其轉換為頻域。
匯入必要的包,如下所示:
import numpy as np import matplotlib.pyplot as plt from scipy.io import wavfile
現在,讀取儲存的音訊檔案。它將返回兩個值:取樣頻率和音訊訊號。提供音訊檔案儲存的路徑,如以下命令所示:
frequency_sampling, audio_signal = wavfile.read("/Users/admin/sample.wav")
在此步驟中,我們將使用以下命令顯示音訊訊號的取樣頻率、訊號的資料型別及其持續時間等引數:
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')
在此步驟中,我們需要對訊號進行歸一化,如下面的命令所示:
audio_signal = audio_signal / np.power(2, 15)
此步驟涉及提取訊號的長度和半長。為此,請使用以下命令:
length_signal = len(audio_signal) half_length = np.ceil((length_signal + 1) / 2.0).astype(np.int)
現在,我們需要應用數學工具進行頻域轉換。這裡我們使用傅立葉變換。
signal_frequency = np.fft.fft(audio_signal)
現在,對頻域訊號進行歸一化並對其進行平方:
signal_frequency = abs(signal_frequency[0:half_length]) / length_signal signal_frequency **= 2
接下來,提取頻率變換訊號的長度和半長:
len_fts = len(signal_frequency)
請注意,傅立葉變換訊號必須針對偶數和奇數情況進行調整。
if length_signal % 2: signal_frequency[1:len_fts] *= 2 else: signal_frequency[1:len_fts-1] *= 2
現在,提取以分貝 (dB) 為單位的功率:
signal_power = 10 * np.log10(signal_frequency)
調整 X 軸上的頻率為 kHz:
x_axis = np.arange(0, len_half, 1) * (frequency_sampling / length_signal) / 1000.0
現在,如下所示視覺化訊號的特徵:
plt.figure()
plt.plot(x_axis, signal_power, color='black')
plt.xlabel('Frequency (kHz)')
plt.ylabel('Signal power (dB)')
plt.show()
您可以觀察到上面程式碼的輸出圖形,如下面的影像所示:

生成單調音訊訊號
您到目前為止看到的這兩個步驟對於學習訊號非常重要。現在,如果您想使用一些預定義的引數生成音訊訊號,則此步驟將很有用。請注意,此步驟會將音訊訊號儲存到輸出檔案中。
示例
在以下示例中,我們將使用 Python 生成單調訊號,該訊號將儲存在檔案中。為此,您需要執行以下步驟:
匯入必要的包,如下所示:
import numpy as np import matplotlib.pyplot as plt from scipy.io.wavfile import write
提供應將輸出檔案儲存到的檔案
output_file = 'audio_signal_generated.wav'
現在,指定您選擇的引數,如下所示:
duration = 4 # in seconds frequency_sampling = 44100 # in Hz frequency_tone = 784 min_val = -4 * np.pi max_val = 4 * np.pi
在此步驟中,我們可以生成音訊訊號,如下所示:
t = np.linspace(min_val, max_val, duration * frequency_sampling) audio_signal = np.sin(2 * np.pi * tone_freq * t)
現在,將音訊檔案儲存在輸出檔案中:
write(output_file, frequency_sampling, signal_scaled)
提取我們圖形的前 100 個值,如下所示:
audio_signal = audio_signal[:100] time_axis = 1000 * np.arange(0, len(signal), 1) / float(sampling_freq)
現在,如下所示視覺化生成的音訊訊號:
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time in milliseconds')
plt.ylabel('Amplitude')
plt.title('Generated audio signal')
plt.show()
您可以觀察到此處提供的圖形,如下所示:

從語音中提取特徵
這是構建語音識別器中最重要的步驟,因為在將語音訊號轉換為頻域後,我們必須將其轉換為特徵向量的可用形式。為此,我們可以使用不同的特徵提取技術,例如 MFCC、PLP、PLP-RASTA 等。
示例
在以下示例中,我們將使用 Python 分步從訊號中提取特徵,並使用 MFCC 技術。
匯入必要的包,如下所示:
import numpy as np import matplotlib.pyplot as plt from scipy.io import wavfile from python_speech_features import mfcc, logfbank
現在,讀取儲存的音訊檔案。它將返回兩個值:取樣頻率和音訊訊號。提供音訊檔案儲存的路徑。
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")
請注意,這裡我們採用前 15000 個樣本進行分析。
audio_signal = audio_signal[:15000]
使用 MFCC 技術並執行以下命令以提取 MFCC 特徵:
features_mfcc = mfcc(audio_signal, frequency_sampling)
現在,列印 MFCC 引數,如下所示:
print('\nMFCC:\nNumber of windows =', features_mfcc.shape[0])
print('Length of each feature =', features_mfcc.shape[1])
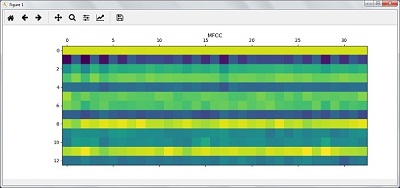
現在,使用以下命令繪製和視覺化 MFCC 特徵:
features_mfcc = features_mfcc.T
plt.matshow(features_mfcc)
plt.title('MFCC')
在此步驟中,我們使用濾波器組特徵,如下所示:
提取濾波器組特徵:
filterbank_features = logfbank(audio_signal, frequency_sampling)
現在,列印濾波器組引數。
print('\nFilter bank:\nNumber of windows =', filterbank_features.shape[0])
print('Length of each feature =', filterbank_features.shape[1])
現在,繪製和視覺化濾波器組特徵。
filterbank_features = filterbank_features.T
plt.matshow(filterbank_features)
plt.title('Filter bank')
plt.show()
作為上述步驟的結果,您可以觀察到以下輸出:圖 1 用於 MFCC,圖 2 用於濾波器組

識別口語
語音識別是指當人類說話時,機器能夠理解它。這裡我們使用 Python 中的 Google 語音 API 來實現它。我們需要為此安裝以下包:
**Pyaudio** – 可以使用命令 **pip install Pyaudio** 進行安裝。
**SpeechRecognition** – 可以使用命令 **pip install SpeechRecognition** 安裝此包。
**Google-Speech-API** – 可以使用命令 **pip install google-api-python-client** 安裝。
示例
觀察以下示例以瞭解有關識別口語的資訊:
匯入必要的包,如下所示:
import speech_recognition as sr
建立如下所示的物件:
recording = sr.Recognizer()
現在,**Microphone()** 模組將語音作為輸入:
with sr.Microphone() as source: recording.adjust_for_ambient_noise(source)
print("Please Say something:")
audio = recording.listen(source)
現在,Google API 將識別語音並給出輸出。
try:
print("You said: \n" + recording.recognize_google(audio))
except Exception as e:
print(e)
您可以看到以下輸出:
Please Say Something: You said:
例如,如果您說 **tutorialspoint.com**,則系統會正確識別如下:
tutorialspoint.com