- Python人工智慧教程
- 首頁
- Python人工智慧 - 基礎概念
- Python人工智慧 - 快速入門
- Python人工智慧 - 機器學習
- Python人工智慧 - 資料準備
- 監督學習:分類
- 監督學習:迴歸
- Python人工智慧 - 邏輯程式設計
- 無監督學習:聚類
- 自然語言處理
- Python人工智慧 - NLTK包
- 時間序列資料分析
- Python人工智慧 - 語音識別
- Python人工智慧 - 啟發式搜尋
- Python人工智慧 - 遊戲
- Python人工智慧 - 神經網路
- 強化學習
- Python人工智慧 - 遺傳演算法
- Python人工智慧 - 計算機視覺
- Python人工智慧 - 深度學習
- Python人工智慧資源
- Python人工智慧 - 快速指南
- Python人工智慧 - 有用資源
- Python人工智慧 - 討論
Python人工智慧 - 機器學習
學習是指透過學習或經驗獲得知識或技能。基於此,我們可以將機器學習 (ML) 定義如下:
它可以定義為計算機科學領域,更具體地說,是人工智慧的一個應用,它使計算機系統能夠透過資料學習並從經驗中改進,而無需顯式程式設計。
基本上,機器學習的主要重點是讓計算機在沒有人為干預的情況下自動學習。現在的問題是,這種學習如何開始和進行?它可以從資料的觀察開始。資料可以是一些例子、指令或一些直接的經驗。然後,根據這個輸入,機器透過尋找資料中的某些模式來做出更好的決策。
機器學習 (ML) 的型別
機器學習演算法幫助計算機系統學習,而無需顯式程式設計。這些演算法分為監督學習或無監督學習。讓我們現在看看一些演算法:
監督機器學習演算法
這是最常用的機器學習演算法。它被稱為監督學習,因為演算法從訓練資料集學習的過程可以被認為是老師在監督學習過程。在這種ML演算法中,可能的結果已經知道,並且訓練資料也用正確的答案標記。它可以理解為:
假設我們有輸入變數x和輸出變數y,並且我們應用演算法來學習從輸入到輸出的對映函式,例如:
Y = f(x)
現在,主要目標是很好地逼近對映函式,以便當我們有新的輸入資料 (x) 時,我們可以預測該資料的輸出變數 (Y)。
主要監督學習問題可以分為以下兩種問題:
分類 - 當我們有分類輸出時,例如“黑色”、“教學”、“非教學”等,問題被稱為分類問題。
迴歸 - 當我們有實數值輸出時,例如“距離”、“公斤”等,問題被稱為迴歸問題。
決策樹、隨機森林、knn、邏輯迴歸是監督機器學習演算法的例子。
無監督機器學習演算法
顧名思義,這些型別的機器學習演算法沒有任何監督者提供任何指導。這就是為什麼無監督機器學習演算法與一些人所說的真正人工智慧密切相關。它可以理解為:
假設我們有輸入變數 x,那麼與監督學習演算法一樣,將沒有相應的輸出變數。
簡單來說,我們可以說在無監督學習中,將沒有正確的答案,也沒有老師來指導。演算法有助於發現數據中有趣的模式。
無監督學習問題可以分為以下兩種問題:
聚類 - 在聚類問題中,我們需要發現數據中固有的分組。例如,按客戶的購買行為對客戶進行分組。
關聯 - 一個問題被稱為關聯問題,因為這種問題需要發現描述我們大部分資料的規則。例如,找到同時購買x和y的客戶。
用於聚類的K均值、用於關聯的Apriori演算法是無監督機器學習演算法的例子。
強化機器學習演算法
這些型別的機器學習演算法使用較少。這些演算法訓練系統做出特定決策。基本上,機器被暴露在一個環境中,它使用反覆試驗的方法不斷地訓練自己。這些演算法從過去的經驗中學習,並試圖捕捉最佳知識以做出準確的決策。馬爾可夫決策過程是強化機器學習演算法的一個例子。
最常見的機器學習演算法
在本節中,我們將學習最常見的機器學習演算法。演算法描述如下:
線性迴歸
它是統計學和機器學習中最著名的演算法之一。
基本概念 - 線性迴歸主要是一種線性模型,它假設輸入變數(例如 x)和單個輸出變數(例如 y)之間存線上性關係。換句話說,我們可以說 y 可以從輸入變數 x 的線性組合計算出來。變數之間的關係可以透過擬合最佳線來建立。
線性迴歸的型別
線性迴歸有以下兩種型別:
簡單線性迴歸 - 如果線性迴歸演算法只有一個自變數,則稱為簡單線性迴歸。
多元線性迴歸 - 如果線性迴歸演算法有多個自變數,則稱為多元線性迴歸。
線性迴歸主要用於根據連續變數估計實數值。例如,可以使用線性迴歸根據實數值估計商店一天的總銷售額。
邏輯迴歸
它是一種分類演算法,也稱為logit迴歸。
邏輯迴歸主要是一種分類演算法,用於根據給定的自變數集估計離散值,如 0 或 1、真或假、是或否。基本上,它預測機率,因此其輸出介於 0 和 1 之間。
決策樹
決策樹是一種監督學習演算法,主要用於分類問題。
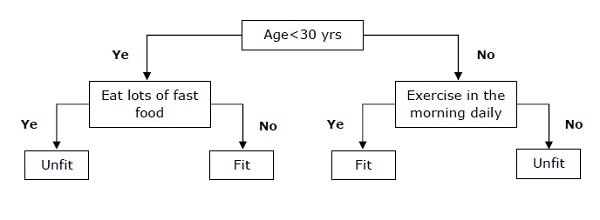
基本上,它是一個分類器,表示為基於自變數的遞迴分割槽。決策樹具有構成有根樹的節點。有根樹是一個有向樹,其中一個節點稱為“根”。根沒有任何傳入邊,所有其他節點都有一個傳入邊。這些節點稱為葉節點或決策節點。例如,考慮以下決策樹來檢視一個人是否健康。
支援向量機 (SVM)
它用於分類和迴歸問題。但主要用於分類問題。SVM 的主要概念是將每個資料項繪製為 n 維空間中的一個點,其中每個特徵的值是特定座標的值。這裡 n 將是我們擁有的特徵。下面是一個簡單的圖形表示,用於理解 SVM 的概念:
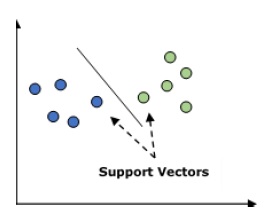
在上圖中,我們有兩個特徵,因此我們首先需要將這兩個變數繪製在二維空間中,其中每個點都有兩個座標,稱為支援向量。這條線將資料分成兩個不同的分類組。這條線將是分類器。
樸素貝葉斯
它也是一種分類技術。這種分類技術的邏輯是使用貝葉斯定理來構建分類器。假設預測器是獨立的。簡單來說,它假設類中特定特徵的存在與任何其他特徵的存在無關。以下是貝葉斯定理的方程式:
$$P\left ( \frac{A}{B} \right ) = \frac{P\left ( \frac{B}{A} \right )P\left ( A \right )}{P\left ( B \right )}$$
樸素貝葉斯模型易於構建,尤其適用於大型資料集。
K 近鄰 (KNN)
它用於問題的分類和迴歸。它廣泛用於解決分類問題。該演算法的主要概念是它用於儲存所有可用案例,並透過其 k 個鄰居的多數投票對新案例進行分類。然後將案例分配給在其 K 個最近鄰居中最常見的類別,透過距離函式測量。距離函式可以是歐幾里德距離、明科夫斯基距離和漢明距離。考慮使用 KNN:
在計算上,KNN 比用於分類問題的其他演算法更昂貴。
如果不進行變數歸一化,則較高範圍的變數可能會對其產生偏差。
在 KNN 中,我們需要處理像噪聲去除這樣的預處理階段。
K 均值聚類
顧名思義,它用於解決聚類問題。它基本上是一種無監督學習。K 均值聚類演算法的主要邏輯是透過多個聚類對資料集進行分類。按照以下步驟透過 K 均值形成聚類:
K 均值選擇每個聚類的 k 個點,稱為質心。
現在每個資料點都與最接近的質心形成一個聚類,即 k 個聚類。
現在,它將根據現有的聚類成員找到每個聚類的質心。
我們需要重複這些步驟直到收斂。
隨機森林
它是一種監督分類演算法。隨機森林演算法的優點是它可以用於分類和迴歸問題。基本上,它是決策樹的集合(即森林),或者可以說,是決策樹的整合。隨機森林的基本概念是每棵樹都給出一個分類,而森林則從其中選擇最佳分類。以下是隨機森林演算法的優點:
隨機森林分類器可用於分類和迴歸任務。
它們可以處理缺失值。
即使森林中樹木的數量更多,它也不會過度擬合模型。