- Apache Solr 教程
- Apache Solr - 首頁
- Apache Solr - 概述
- Apache Solr - 搜尋引擎基礎
- Apache Solr - Windows環境
- Apache Solr - 在Hadoop上
- Apache Solr - 架構
- Apache Solr - 術語
- Apache Solr - 基本命令
- Apache Solr - Core
- Apache Solr - 索引資料
- Apache Solr - 新增文件 (XML)
- Apache Solr - 更新資料
- Apache Solr - 刪除文件
- Apache Solr - 檢索資料
- Apache Solr - 查詢資料
- Apache Solr - 分面搜尋
- Apache Solr 有用資源
- Apache Solr 快速指南
- Apache Solr - 有用資源
- Apache Solr - 討論
Apache Solr 快速指南
Apache Solr - 概述
Solr是一個開源搜尋平臺,用於構建搜尋應用程式。它構建在Lucene(全文搜尋引擎)之上。Solr 具備企業級功能,快速且高度可擴充套件。使用Solr構建的應用程式功能強大,效能高。
Yonik Seely於2004年建立了Solr,目的是為CNET Networks的公司網站新增搜尋功能。2006年1月,它成為Apache軟體基金會下的一個開源專案。其最新版本Solr 6.0於2016年釋出,支援並行SQL查詢的執行。
Solr可以與Hadoop一起使用。由於Hadoop處理大量資料,Solr幫助我們從如此龐大的資料來源中找到所需的資訊。Solr不僅用於搜尋,還可以用於儲存。像其他NoSQL資料庫一樣,它是一種非關係型資料儲存和處理技術。
簡而言之,Solr是一個可擴充套件、隨時部署的搜尋/儲存引擎,經過最佳化,可以搜尋大量以文字為中心的資料。
Apache Solr 的特性
Solr是對Lucene的Java API的封裝。因此,使用Solr,您可以利用Lucene的所有功能。讓我們來看看Solr的一些最突出的功能:
RESTful API - 與Solr通訊,不需要掌握Java程式設計技能。您可以使用RESTful服務與之通訊。我們以XML、JSON和.CSV等檔案格式將文件輸入Solr,並以相同的格式獲取結果。
全文搜尋 - Solr提供全文搜尋所需的所有功能,例如標記、短語、拼寫檢查、萬用字元和自動完成。
企業級 - 根據組織的需求,Solr可以部署在任何型別的系統(大型或小型)中,例如獨立部署、分散式部署、雲部署等。
靈活且可擴充套件 - 透過擴充套件Java類並進行相應配置,我們可以輕鬆定製Solr的元件。
NoSQL資料庫 - Solr也可以用作大規模NoSQL資料庫,我們可以在叢集中分配搜尋任務。
管理介面 - Solr提供了一個易於使用、使用者友好、功能強大的使用者介面,我們可以使用它來執行所有可能的任務,例如管理日誌、新增、刪除、更新和搜尋文件。
高度可擴充套件 - 將Solr與Hadoop一起使用時,我們可以透過新增副本來擴充套件其容量。
以文字為中心並按相關性排序 - Solr主要用於搜尋文字文件,結果按與使用者查詢的相關性順序交付。
與Lucene不同,在使用Apache Solr時,您不需要具備Java程式設計技能。它提供了一種很棒的隨時可部署的服務來構建具有自動完成功能的搜尋框,而Lucene則不提供此功能。使用Solr,我們可以擴充套件、分發和管理索引,以用於大型(大資料)應用程式。
Lucene 在搜尋應用程式中的應用
Lucene是一個簡單而強大的基於Java的搜尋庫。它可以用於任何應用程式以新增搜尋功能。Lucene是一個可擴充套件且高效能的庫,用於索引和搜尋幾乎任何型別的文字。Lucene庫提供了任何搜尋應用程式所需的核心操作,例如索引和搜尋。
如果我們有一個包含大量資料的資料門戶,那麼我們很可能需要在我們的門戶中使用搜索引擎來從龐大的資料池中提取相關資訊。Lucene作為任何搜尋應用程式的核心,並提供與索引和搜尋相關的關鍵操作。
Apache Solr - 搜尋引擎基礎
搜尋引擎是指網際網路資源(如網頁、新聞組、程式、影像等)的巨大資料庫。它有助於在全球資訊網上查詢資訊。
使用者可以透過以關鍵字或短語的形式將查詢傳遞到搜尋引擎來搜尋資訊。然後,搜尋引擎在其資料庫中搜索並向用戶返回相關連結。

搜尋引擎元件
通常,搜尋引擎有三個基本元件,如下所示:
網路爬蟲 - 網路爬蟲也稱為蜘蛛或機器人。它是一個遍歷網路以收集資訊的軟體元件。
資料庫 - 網路上的所有資訊都儲存在資料庫中。它們包含大量的網路資源。
搜尋介面 - 此元件是使用者和資料庫之間的介面。它幫助使用者搜尋資料庫。
搜尋引擎的工作原理?
任何搜尋應用程式都需要執行以下部分或全部操作。
| 步驟 | 標題 | 描述 |
|---|---|---|
1 |
獲取原始內容 |
任何搜尋應用程式的第一步都是收集要進行搜尋的目標內容。 |
2 |
構建文件 |
下一步是從原始內容構建文件,以便搜尋應用程式可以輕鬆理解和解釋。 |
3 |
分析文件 |
在索引開始之前,需要分析文件。 |
4 |
索引文件 |
一旦文件被構建和分析,下一步就是對其進行索引,以便可以基於某些鍵檢索此文件,而不是文件的全部內容。 索引類似於我們在書末尾的索引,其中顯示了常用詞及其頁碼,以便可以快速跟蹤這些詞,而不是搜尋整本書。 |
5 |
搜尋的使用者介面 |
一旦索引資料庫準備就緒,應用程式就可以執行搜尋操作。為了幫助使用者進行搜尋,應用程式必須提供一個使用者介面,使用者可以在其中輸入文字並啟動搜尋過程。 |
6 |
構建查詢 |
一旦使用者請求搜尋文字,應用程式應該使用該文字準備一個查詢物件,然後可以使用該物件查詢索引資料庫以獲取相關詳細資訊。 |
7 |
搜尋查詢 |
使用查詢物件,檢查索引資料庫以獲取相關詳細資訊和內容文件。 |
8 |
呈現結果 |
一旦收到所需的結果,應用程式應該決定如何使用其使用者介面向用戶顯示結果。 |
請看下圖。它顯示了搜尋引擎功能的整體檢視。

除了這些基本操作外,搜尋應用程式還可以提供管理使用者介面,以幫助管理員根據使用者配置檔案控制搜尋級別。搜尋結果分析是任何搜尋應用程式的另一個重要且高階方面。
Apache Solr - 在 Windows 環境中
本章將討論如何在Windows環境中設定Solr。要在Windows系統上安裝Solr,您需要按照以下步驟操作:
訪問Apache Solr的主頁,然後單擊下載按鈕。
選擇一個映象以獲取Apache Solr的索引。從那裡下載名為Solr-6.2.0.zip的檔案。
將檔案從下載資料夾移動到所需目錄並解壓縮。
假設您下載了Solr檔案並將其解壓縮到C盤。在這種情況下,您可以像以下螢幕截圖所示啟動Solr。

要驗證安裝,請在瀏覽器中使用以下URL。
https://:8983/
如果安裝過程成功,您將看到Apache Solr使用者介面的儀表板,如下所示。

設定Java環境
我們還可以使用Java庫與Apache Solr通訊;但在使用Java API訪問Solr之前,您需要為這些庫設定類路徑。
設定類路徑
在.bashrc檔案中將類路徑設定為Solr庫。在任何編輯器中開啟.bashrc,如下所示。
$ gedit ~/.bashrc
設定Solr庫(HBase中的lib資料夾)的類路徑,如下所示。
export CLASSPATH = $CLASSPATH://home/hadoop/Solr/lib/*
這是為了防止在使用Java API訪問HBase時出現“找不到類”異常。
Apache Solr - 在Hadoop上
Solr可以與Hadoop一起使用。由於Hadoop處理大量資料,Solr幫助我們從如此龐大的資料來源中找到所需的資訊。在本節中,讓我們瞭解如何在您的系統上安裝Hadoop。
下載Hadoop
以下是下載Hadoop到您的系統的步驟。
步驟1 - 轉到Hadoop的主頁。您可以使用連結:www.hadoop.apache.org/。單擊Releases連結,如下面的螢幕截圖中突出顯示的那樣。

它將引導您進入Apache Hadoop Releases頁面,其中包含各種版本的Hadoop的原始檔和二進位制檔案的映象連結,如下所示:

步驟2 - 選擇最新版本的Hadoop(在本教程中為2.6.4),然後單擊其二進位制連結。它將帶您到一個頁面,其中提供Hadoop二進位制檔案的映象。單擊這些映象之一以下載Hadoop。
從命令提示符下載Hadoop
開啟Linux終端並以超級使用者身份登入。
$ su password:
進入需要安裝Hadoop的目錄,使用之前複製的連結將檔案儲存到該目錄,如下面的程式碼塊所示。
# cd /usr/local # wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop- 2.6.4/hadoop-2.6.4.tar.gz
下載Hadoop後,使用以下命令解壓。
# tar zxvf hadoop-2.6.4.tar.gz # mkdir hadoop # mv hadoop-2.6.4/* to hadoop/ # exit
安裝Hadoop
按照以下步驟以偽分散式模式安裝**Hadoop**。
步驟1:設定Hadoop
您可以透過將以下命令新增到**~/.bashrc**檔案中來設定Hadoop環境變數。
export HADOOP_HOME = /usr/local/hadoop export HADOOP_MAPRED_HOME = $HADOOP_HOME export HADOOP_COMMON_HOME = $HADOOP_HOME export HADOOP_HDFS_HOME = $HADOOP_HOME export YARN_HOME = $HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL = $HADOOP_HOME
接下來,將所有更改應用到當前執行的系統中。
$ source ~/.bashrc
步驟2:Hadoop配置
您可以在“$HADOOP_HOME/etc/hadoop”位置找到所有Hadoop配置檔案。需要根據您的Hadoop基礎架構更改這些配置檔案。
$ cd $HADOOP_HOME/etc/hadoop
為了使用Java開發Hadoop程式,您必須透過將**JAVA_HOME**值替換為系統中Java的路徑來重置**hadoop-env.sh**檔案中的Java環境變數。
export JAVA_HOME = /usr/local/jdk1.7.0_71
以下是您必須編輯以配置Hadoop的檔案列表:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
**core-site.xml**檔案包含諸如Hadoop例項使用的埠號、分配給檔案系統的記憶體、儲存資料的記憶體限制以及讀/寫緩衝區大小等資訊。
開啟core-site.xml並在<configuration>,</configuration>標籤內新增以下屬性。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://:9000</value>
</property>
</configuration>
hdfs-site.xml
**hdfs-site.xml**檔案包含諸如複製資料的值、**namenode**路徑和本地檔案系統的**datanode**路徑等資訊。這意味著您要儲存Hadoop基礎架構的位置。
讓我們假設以下資料。
dfs.replication (data replication value) = 1 (In the below given path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
開啟此檔案並在<configuration>,</configuration>標籤內新增以下屬性。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>
**注意** — 在上面的檔案中,所有屬性值都是使用者定義的,您可以根據您的Hadoop基礎架構進行更改。
yarn-site.xml
此檔案用於將yarn配置到Hadoop中。開啟yarn-site.xml檔案,並在該檔案的<configuration>,</configuration>標籤之間新增以下屬性。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
此檔案用於指定我們正在使用哪個MapReduce框架。預設情況下,Hadoop包含yarn-site.xml的模板。首先,需要使用以下命令將檔案從**mapred-site,xml.template**複製到**mapred-site.xml**檔案。
$ cp mapred-site.xml.template mapred-site.xml
開啟**mapred-site.xml**檔案,並在<configuration>,</configuration>標籤內新增以下屬性。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
驗證Hadoop安裝
以下步驟用於驗證Hadoop安裝。
步驟1:Name Node設定
使用命令“hdfs namenode –format”設定namenode,如下所示。
$ cd ~ $ hdfs namenode -format
預期結果如下所示。
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
步驟2:驗證Hadoop dfs
以下命令用於啟動Hadoop dfs。執行此命令將啟動您的Hadoop檔案系統。
$ start-dfs.sh
預期輸出如下:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop- hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop- hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
步驟3:驗證Yarn指令碼
以下命令用於啟動Yarn指令碼。執行此命令將啟動您的Yarn守護程序。
$ start-yarn.sh
預期輸出如下:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn- hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop- 2.6.4/logs/yarn-hadoop-nodemanager-localhost.out
步驟4:在瀏覽器上訪問Hadoop
訪問Hadoop的預設埠號是50070。使用以下URL在瀏覽器上獲取Hadoop服務。
https://:50070/

在Hadoop上安裝Solr
按照以下步驟下載和安裝Solr。
步驟1
單擊以下連結開啟Apache Solr的主頁:https://lucene.apache.org/solr/

步驟2
單擊**下載按鈕**(如上截圖中突出顯示的那樣)。單擊後,您將被重定向到一個頁面,其中包含Apache Solr的各種映象。選擇一個映象並單擊它,這將重定向您到一個頁面,您可以在該頁面下載Apache Solr的原始檔和二進位制檔案,如下面的截圖所示。

步驟3
單擊後,系統下載資料夾中將下載一個名為**Solr-6.2.0.tqz**的資料夾。解壓下載資料夾的內容。
步驟4
在Hadoop主目錄中建立一個名為Solr的資料夾,並將解壓資料夾的內容移動到該資料夾中,如下所示。
$ mkdir Solr $ cd Downloads $ mv Solr-6.2.0 /home/Hadoop/
驗證
瀏覽Solr主目錄的**bin**資料夾,並使用**version**選項驗證安裝,如下面的程式碼塊所示。
$ cd bin/ $ ./Solr version 6.2.0
設定主目錄和路徑
使用以下命令開啟**.bashrc**檔案:
[Hadoop@localhost ~]$ source ~/.bashrc
現在為Apache Solr設定主目錄和路徑目錄,如下所示:
export SOLR_HOME = /home/Hadoop/Solr export PATH = $PATH:/$SOLR_HOME/bin/
開啟終端並執行以下命令:
[Hadoop@localhost Solr]$ source ~/.bashrc
現在,您可以從任何目錄執行Solr命令。
Apache Solr - 架構
在本章中,我們將討論Apache Solr的架構。下圖顯示了Apache Solr架構的框圖。

Solr架構 — 構建塊
以下是Apache Solr的主要構建塊(元件):
**請求處理器** — 我們傳送給Apache Solr的請求由這些請求處理器處理。請求可能是查詢請求或索引更新請求。根據我們的需求,我們需要選擇請求處理器。要將請求傳遞給Solr,我們通常會將處理程式對映到某個URI端點,並由其提供指定的請求服務。
**搜尋元件** — 搜尋元件是Apache Solr中提供的搜尋型別(功能)。它可能是拼寫檢查、查詢、構面、命中高亮顯示等。這些搜尋元件註冊為**搜尋處理程式**。多個元件可以註冊到一個搜尋處理程式。
**查詢解析器** — Apache Solr查詢解析器解析我們傳遞給Solr的查詢,並驗證查詢的語法錯誤。解析查詢後,它會將它們轉換為Lucene可以理解的格式。
**響應編寫器** — Apache Solr中的響應編寫器是為使用者查詢生成格式化輸出的元件。Solr支援XML、JSON、CSV等響應格式。我們為每種型別的響應都有不同的響應編寫器。
**分析器/標記器** — Lucene以標記的形式識別資料。Apache Solr分析內容,將其劃分為標記,並將這些標記傳遞給Lucene。Apache Solr中的分析器檢查欄位的文字並生成標記流。標記器將分析器準備的標記流分解為標記。
**更新請求處理器** — 每當我們向Apache Solr傳送更新請求時,該請求都會透過一組外掛(簽名、日誌記錄、索引)執行,這些外掛統稱為**更新請求處理器**。此處理器負責修改,例如刪除欄位、新增欄位等。
Apache Solr - 術語
在本章中,我們將嘗試理解在使用Solr時經常使用的一些術語的真正含義。
常用術語
以下是所有型別的Solr設定中使用的常用術語列表:
**例項** — 與**tomcat例項**或**jetty例項**一樣,此術語指的是在JVM內執行的應用程式伺服器。Solr的主目錄提供了對每個Solr例項的引用,其中可以在每個例項中配置一個或多個核心來執行。
**核心** — 在應用程式中執行多個索引時,您可以在每個例項中擁有多個核心,而不是每個例項擁有一個核心。
**主目錄** — 術語$SOLR_HOME指的是包含有關核心及其索引、配置和依賴項的所有資訊的根目錄。
**分片** — 在分散式環境中,資料在多個Solr例項之間進行分割槽,其中每個資料塊都可以稱為**分片**。它包含整個索引的子集。
SolrCloud術語
在前面的一章中,我們討論瞭如何在獨立模式下安裝Apache Solr。請注意,我們也可以在分散式模式(雲環境)下安裝Solr,其中Solr以主從模式安裝。在分散式模式下,索引是在主伺服器上建立的,並複製到一個或多個從伺服器。
與Solr Cloud相關的關鍵術語如下:
**節點** — 在Solr Cloud中,Solr的每個單個例項都被視為一個**節點**。
**叢集** — 環境的所有節點組合在一起構成一個**叢集**。
**集合** — 叢集具有一個稱為**集合**的邏輯索引。
**分片** — 分片是集合的一部分,它具有一個或多個索引副本。
**副本** — 在Solr Core中,在節點中執行的分片副本稱為**副本**。
**領導者** — 它也是分片的副本,它將Solr Cloud的請求分發到其餘的副本。
**Zookeeper** — 這是一個Apache專案,Solr Cloud使用它進行集中式配置和協調,以管理叢集並選舉領導者。
配置檔案
Apache Solr中的主要配置檔案如下:
**Solr.xml** — 它是$SOLR_HOME目錄中的檔案,包含Solr Cloud相關資訊。要載入核心,Solr會引用此檔案,這有助於識別它們。
**Solrconfig.xml** — 此檔案包含與請求處理和響應格式相關的定義和特定於核心的配置,以及索引、配置、記憶體管理和提交。
**Schema.xml** — 此檔案包含整個模式以及欄位和欄位型別。
**Core.properties** — 此檔案包含特定於核心的配置。它用於**核心發現**,因為它包含核心的名稱和資料目錄的路徑。它可以用於任何目錄,然後將其視為**核心目錄**。
Apache Solr - 基本命令
啟動Solr
安裝Solr後,瀏覽Solr主目錄中的**bin**資料夾,並使用以下命令啟動Solr。
[Hadoop@localhost ~]$ cd [Hadoop@localhost ~]$ cd Solr/ [Hadoop@localhost Solr]$ cd bin/ [Hadoop@localhost bin]$ ./Solr start
此命令在後臺啟動Solr,偵聽埠8983,並顯示以下訊息。
Waiting up to 30 seconds to see Solr running on port 8983 [\] Started Solr server on port 8983 (pid = 6035). Happy searching!
在前景啟動Solr
如果您使用**start**命令啟動**Solr**,則Solr將在後臺啟動。相反,您可以使用**–f選項**在前景啟動Solr。
[Hadoop@localhost bin]$ ./Solr start –f 5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader Adding 'file:/home/Hadoop/Solr/contrib/extraction/lib/xmlbeans-2.6.0.jar' to classloader 5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader Adding 'file:/home/Hadoop/Solr/dist/Solr-cell-6.2.0.jar' to classloader 5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/carrot2-guava-18.0.jar' to classloader 5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/attributes-binder1.3.1.jar' to classloader 5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/simple-xml-2.7.1.jar' to classloader …………………………………………………………………………………………………………………………………………………………………………………………………………… …………………………………………………………………………………………………………………………………………………………………………………………………. 12901 INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample] o.a.s.u.UpdateLog Took 24.0ms to seed version buckets with highest version 1546058939881226240 12902 INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample] o.a.s.c.CoreContainer registering core: Solr_sample 12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.u.UpdateLog Took 16.0ms to seed version buckets with highest version 1546058939894857728 12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.c.CoreContainer registering core: my_core
在另一個埠上啟動Solr
使用**start**命令的**–p選項**,我們可以在另一個埠啟動Solr,如下面的程式碼塊所示。
[Hadoop@localhost bin]$ ./Solr start -p 8984 Waiting up to 30 seconds to see Solr running on port 8984 [-] Started Solr server on port 8984 (pid = 10137). Happy searching!
停止Solr
您可以使用**stop**命令停止Solr。
$ ./Solr stop
此命令停止Solr,並顯示如下訊息。
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to allow Jetty process 6035 to stop gracefully.
重新啟動Solr
Solr的**restart**命令會停止Solr 5 秒鐘,然後再次啟動它。您可以使用以下命令重新啟動Solr:
./Solr restart
此命令重新啟動Solr,並顯示以下訊息:
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to allow Jetty process 6671 to stop gracefully. Waiting up to 30 seconds to see Solr running on port 8983 [|] [/] Started Solr server on port 8983 (pid = 6906). Happy searching!
Solr — help命令
Solr的**help**命令可用於檢查Solr提示及其選項的使用情況。
[Hadoop@localhost bin]$ ./Solr -help Usage: Solr COMMAND OPTIONS where COMMAND is one of: start, stop, restart, status, healthcheck, create, create_core, create_collection, delete, version, zk Standalone server example (start Solr running in the background on port 8984): ./Solr start -p 8984 SolrCloud example (start Solr running in SolrCloud mode using localhost:2181 to connect to Zookeeper, with 1g max heap size and remote Java debug options enabled): ./Solr start -c -m 1g -z localhost:2181 -a "-Xdebug - Xrunjdwp:transport = dt_socket,server = y,suspend = n,address = 1044" Pass -help after any COMMAND to see command-specific usage information, such as: ./Solr start -help or ./Solr stop -help
Solr — status命令
Solr的**status**命令可用於搜尋和查詢計算機上正在執行的Solr例項。它可以為您提供有關Solr例項的資訊,例如其版本、記憶體使用情況等。
可以使用以下 status 命令檢查 Solr 例項的狀態:
[Hadoop@localhost bin]$ ./Solr status
執行上述命令後,Solr 的狀態將顯示如下:
Found 1 Solr nodes:
Solr process 6906 running on port 8983 {
"Solr_home":"/home/Hadoop/Solr/server/Solr",
"version":"6.2.0 764d0f19151dbff6f5fcd9fc4b2682cf934590c5 -
mike - 2016-08-20 05:41:37",
"startTime":"2016-09-20T06:00:02.877Z",
"uptime":"0 days, 0 hours, 5 minutes, 14 seconds",
"memory":"30.6 MB (%6.2) of 490.7 MB"
}
Solr 管理介面
啟動 Apache Solr 後,您可以使用以下 URL 訪問Solr Web 介面的主頁。
Localhost:8983/Solr/
Solr 管理介面的外觀如下:

Apache Solr - Core
Solr Core 是 Lucene 索引的執行例項,其中包含使用它所需的所有 Solr 配置檔案。我們需要建立一個 Solr Core 來執行索引和分析等操作。
一個 Solr 應用程式可能包含一個或多個 Core。如有必要,Solr 應用程式中的兩個 Core 可以相互通訊。
建立 Core
安裝並啟動 Solr 後,您可以連線到 Solr 的客戶端(Web 介面)。

如下面的螢幕截圖所示,最初 Apache Solr 中沒有 Core。現在,我們將瞭解如何在 Solr 中建立 Core。
使用 create 命令
建立 Core 的一種方法是使用create命令建立一個無模式 Core,如下所示:
[Hadoop@localhost bin]$ ./Solr create -c Solr_sample
在這裡,我們嘗試在 Apache Solr 中建立一個名為Solr_sample 的 Core。此命令將建立一個 Core 並顯示以下訊息。
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/Solr_sample
Creating new core 'Solr_sample' using command:
https://:8983/Solr/admin/cores?action=CREATE&name=Solr_sample&instanceD
ir = Solr_sample {
"responseHeader":{
"status":0,
"QTime":11550
},
"core":"Solr_sample"
}
您可以在 Solr 中建立多個 Core。在 Solr 管理介面的左側,您可以看到一個Core 選擇器,您可以在其中選擇新建立的 Core,如下面的螢幕截圖所示。

使用 create_core 命令
或者,您可以使用create_core命令建立 Core。此命令具有以下選項:
| –c core_name | 要建立的 Core 的名稱 |
| -p port_name | 要建立 Core 的埠 |
| -d conf_dir | 埠的配置目錄 |
讓我們看看如何使用create_core命令。在這裡,我們將嘗試建立一個名為my_core 的 Core。
[Hadoop@localhost bin]$ ./Solr create_core -c my_core
執行上述命令後,將建立一個 Core 並顯示以下訊息:
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/my_core
Creating new core 'my_core' using command:
https://:8983/Solr/admin/cores?action=CREATE&name=my_core&instanceD
ir = my_core {
"responseHeader":{
"status":0,
"QTime":1346
},
"core":"my_core"
}
刪除 Core
您可以使用 Apache Solr 的delete命令刪除 Core。假設我們在 Solr 中有一個名為my_core 的 Core,如下面的螢幕截圖所示。

您可以使用delete命令透過將 Core 的名稱傳遞給此命令來刪除此 Core,如下所示:
[Hadoop@localhost bin]$ ./Solr delete -c my_core
執行上述命令後,將刪除指定的 Core 並顯示以下訊息。
Deleting core 'my_core' using command:
https://:8983/Solr/admin/cores?action=UNLOAD&core = my_core&deleteIndex
= true&deleteDataDir = true&deleteInstanceDir = true {
"responseHeader" :{
"status":0,
"QTime":170
}
}
您可以開啟 Solr 的 Web 介面來驗證 Core 是否已被刪除。

Apache Solr - 索引資料
一般來說,索引是對文件或(其他實體)進行系統化的排列。索引使使用者能夠在文件中查詢資訊。
索引收集、解析和儲存文件。
進行索引是為了提高查詢所需文件時搜尋查詢的速度和效能。
Apache Solr 中的索引
在 Apache Solr 中,我們可以索引(新增、刪除、修改)各種文件格式,例如 xml、csv、pdf 等。我們可以透過多種方式將資料新增到 Solr 索引中。
本章將討論索引:
- 使用 Solr Web 介面。
- 使用任何客戶端 API,例如 Java、Python 等。
- 使用post 工具。
本章將討論如何使用各種介面(命令列、Web 介面和 Java 客戶端 API)將資料新增到 Apache Solr 的索引中。
使用 Post 命令新增文件
Solr 的bin/目錄中有一個post命令。使用此命令,您可以將 JSON、XML、CSV 等各種格式的檔案索引到 Apache Solr 中。
瀏覽 Apache Solr 的bin目錄並執行 post 命令的–h 選項,如下面的程式碼塊所示。
[Hadoop@localhost bin]$ cd $SOLR_HOME [Hadoop@localhost bin]$ ./post -h
執行上述命令後,您將獲得post 命令的選項列表,如下所示。
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post –help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or -port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
Examples:
* JSON file:./post -c wizbang events.json
* XML files: ./post -c records article*.xml
* CSV file: ./post -c signals LATEST-signals.csv
* Directory of files: ./post -c myfiles ~/Documents
* Web crawl: ./post -c gettingstarted http://lucene.apache.org/Solr -recursive 1 -delay 1
* Standard input (stdin): echo '{commit: {}}' | ./post -c my_collection -
type application/json -out yes –d
* Data as string: ./post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'
示例
假設我們有一個名為sample.csv的檔案,其內容如下(在bin目錄中)。
| 學生 ID | 名字 | 姓氏 | 電話 | 城市 |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | 海德拉巴 |
| 002 | Siddharth | Bhattacharya | 9848022338 | 加爾各答 |
| 003 | Rajesh | Khanna | 9848022339 | 德里 |
| 004 | Preethi | Agarwal | 9848022330 | 浦那 |
| 005 | Trupthi | Mohanty | 9848022336 | 布巴內斯瓦爾 |
| 006 | Archana | Mishra | 9848022335 | 欽奈 |
以上資料集包含個人詳細資訊,例如學生 ID、名字、姓氏、電話和城市。資料集的 CSV 檔案如下所示。這裡,您必須注意,您需要提及模式,並記錄其第一行。
id, first_name, last_name, phone_no, location 001, Pruthvi, Reddy, 9848022337, Hyderabad 002, kasyap, Sastry, 9848022338, Vishakapatnam 003, Rajesh, Khanna, 9848022339, Delhi 004, Preethi, Agarwal, 9848022330, Pune 005, Trupthi, Mohanty, 9848022336, Bhubaneshwar 006, Archana, Mishra, 9848022335, Chennai
您可以使用post命令將此資料索引到名為sample_Solr 的 Core 中,如下所示:
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csv
執行上述命令後,給定的文件將被索引到指定的 Core 中,並生成以下輸出。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = Solr_sample -Ddata = files org.apache.Solr.util.SimplePostTool sample.csv SimplePostTool version 5.0.0 Posting files to [base] url https://:8983/Solr/Solr_sample/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf, htm,html,txt,log POSTing file sample.csv (text/csv) to [base] 1 files indexed. COMMITting Solr index changes to https://:8983/Solr/Solr_sample/update... Time spent: 0:00:00.228
使用以下 URL 訪問 Solr Web UI 的主頁:
https://:8983/
選擇 Core Solr_sample。預設情況下,請求處理程式為/select,查詢為“:” 。無需進行任何修改,單擊頁面底部的ExecuteQuery按鈕。
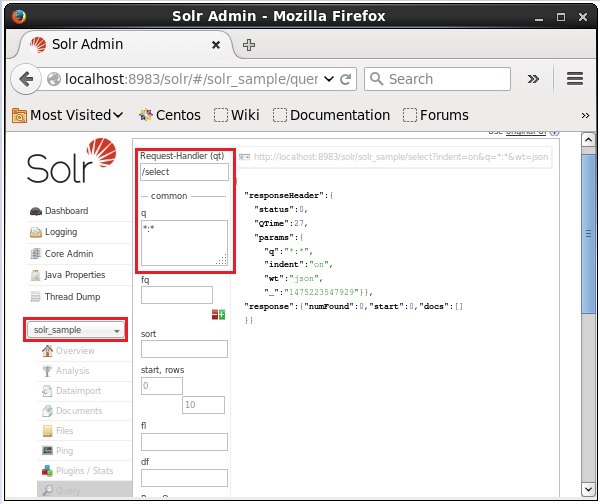
執行查詢後,您可以以 JSON 格式(預設)檢視已索引 CSV 文件的內容,如下面的螢幕截圖所示。
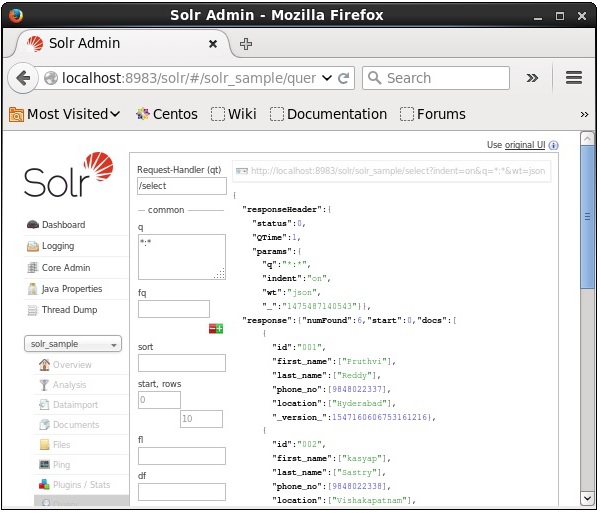
注意 - 同樣,您可以索引其他檔案格式,例如 JSON、XML、CSV 等。
使用 Solr Web 介面新增文件
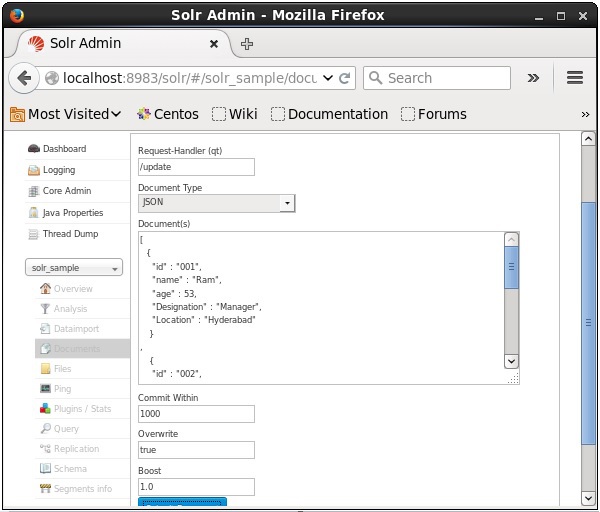
您還可以使用 Solr 提供的 Web 介面索引文件。讓我們看看如何索引以下 JSON 文件。
[
{
"id" : "001",
"name" : "Ram",
"age" : 53,
"Designation" : "Manager",
"Location" : "Hyderabad",
},
{
"id" : "002",
"name" : "Robert",
"age" : 43,
"Designation" : "SR.Programmer",
"Location" : "Chennai",
},
{
"id" : "003",
"name" : "Rahim",
"age" : 25,
"Designation" : "JR.Programmer",
"Location" : "Delhi",
}
]
步驟1
使用以下 URL 開啟 Solr Web 介面:
https://:8983/
步驟2
選擇 Core Solr_sample。預設情況下,請求處理程式、公共範圍、覆蓋和提升欄位的值分別為 /update、1000、true 和 1.0,如下面的螢幕截圖所示。
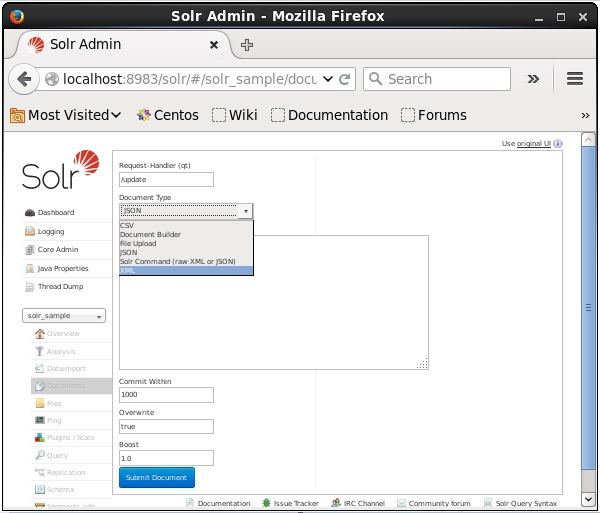
現在,從 JSON、CSV、XML 等中選擇您想要的文件格式。在文字區域中鍵入要索引的文件,然後單擊Submit Document按鈕,如下面的螢幕截圖所示。
使用 Java 客戶端 API 新增文件
以下是將文件新增到 Apache Solr 索引的 Java 程式。將此程式碼儲存到名為AddingDocument.java的檔案中。
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class AddingDocument {
public static void main(String args[]) throws Exception {
//Preparing the Solr client
String urlString = "https://:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Adding fields to the document
doc.addField("id", "003");
doc.addField("name", "Rajaman");
doc.addField("age","34");
doc.addField("addr","vishakapatnam");
//Adding the document to Solr
Solr.add(doc);
//Saving the changes
Solr.commit();
System.out.println("Documents added");
}
}
透過在終端中執行以下命令來編譯上述程式碼:
[Hadoop@localhost bin]$ javac AddingDocument [Hadoop@localhost bin]$ java AddingDocument
執行上述命令後,您將獲得以下輸出。
Documents added
Apache Solr - 新增文件 (XML)
在上一章中,我們解釋瞭如何將 JSON 和 .CSV 檔案格式的資料新增到 Solr 中。在本章中,我們將演示如何使用 XML 文件格式將資料新增到 Apache Solr 索引中。
示例資料
假設我們需要使用 XML 檔案格式將以下資料新增到 Solr 索引中。
| 學生 ID | 名字 | 姓氏 | 電話 | 城市 |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | 海德拉巴 |
| 002 | Siddharth | Bhattacharya | 9848022338 | 加爾各答 |
| 003 | Rajesh | Khanna | 9848022339 | 德里 |
| 004 | Preethi | Agarwal | 9848022330 | 浦那 |
| 005 | Trupthi | Mohanty | 9848022336 | 布巴內斯瓦爾 |
| 006 | Archana | Mishra | 9848022335 | 欽奈 |
使用 XML 新增文件
要將上述資料新增到 Solr 索引中,我們需要準備一個 XML 文件,如下所示。將此文件儲存到名為sample.xml的檔案中。
<add>
<doc>
<field name = "id">001</field>
<field name = "first name">Rajiv</field>
<field name = "last name">Reddy</field>
<field name = "phone">9848022337</field>
<field name = "city">Hyderabad</field>
</doc>
<doc>
<field name = "id">002</field>
<field name = "first name">Siddarth</field>
<field name = "last name">Battacharya</field>
<field name = "phone">9848022338</field>
<field name = "city">Kolkata</field>
</doc>
<doc>
<field name = "id">003</field>
<field name = "first name">Rajesh</field>
<field name = "last name">Khanna</field>
<field name = "phone">9848022339</field>
<field name = "city">Delhi</field>
</doc>
<doc>
<field name = "id">004</field>
<field name = "first name">Preethi</field>
<field name = "last name">Agarwal</field>
<field name = "phone">9848022330</field>
<field name = "city">Pune</field>
</doc>
<doc>
<field name = "id">005</field>
<field name = "first name">Trupthi</field>
<field name = "last name">Mohanthy</field>
<field name = "phone">9848022336</field>
<field name = "city">Bhuwaeshwar</field>
</doc>
<doc>
<field name = "id">006</field>
<field name = "first name">Archana</field>
<field name = "last name">Mishra</field>
<field name = "phone">9848022335</field>
<field name = "city">Chennai</field>
</doc>
</add>
正如您所看到的,寫入以將資料新增到索引的 XML 檔案包含三個重要的標籤,即<add> </add>、<doc></doc>和<field></field>。
add - 這是將文件新增到索引的根標籤。它包含一個或多個要新增的文件。
doc - 我們新增的文件應該用<doc></doc>標籤括起來。此文件包含欄位形式的資料。
field - field 標籤儲存文件欄位的名稱和值。
準備文件後,您可以使用上一章中討論的任何方法將此文件新增到索引中。
假設 XML 檔案存在於 Solr 的bin目錄中,並且它要索引到名為my_core 的 Core 中,那麼您可以使用post工具將其新增到 Solr 索引中,如下所示:
[Hadoop@localhost bin]$ ./post -c my_core sample.xml
執行上述命令後,您將獲得以下輸出。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr- core6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files org.apache.Solr.util.SimplePostTool sample.xml SimplePostTool version 5.0.0 Posting files to [base] url https://:8983/Solr/my_core/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx, xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log POSTing file sample.xml (application/xml) to [base] 1 files indexed. COMMITting Solr index changes to https://:8983/Solr/my_core/update... Time spent: 0:00:00.201
驗證
訪問 Apache Solr Web 介面的主頁並選擇 Core my_core。嘗試透過在文字區域q中傳遞查詢“:”來檢索所有文件,然後執行查詢。執行後,您可以看到所需資料已新增到 Solr 索引中。
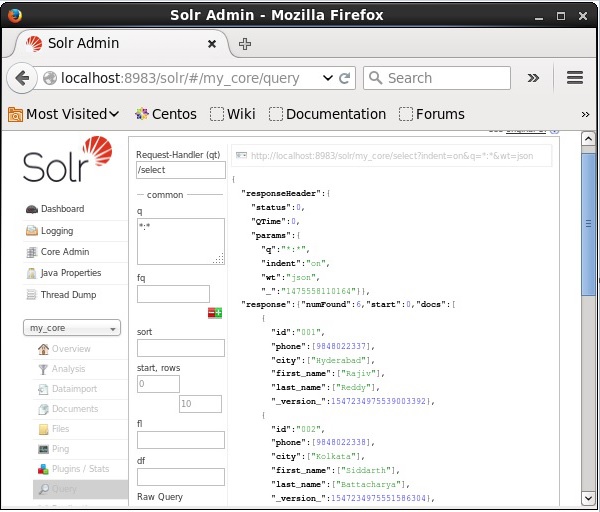
Apache Solr - 更新資料
使用 XML 更新文件
以下是用於更新現有文件中欄位的 XML 檔案。將其儲存到名為update.xml的檔案中。
<add>
<doc>
<field name = "id">001</field>
<field name = "first name" update = "set">Raj</field>
<field name = "last name" update = "add">Malhotra</field>
<field name = "phone" update = "add">9000000000</field>
<field name = "city" update = "add">Delhi</field>
</doc>
</add>
正如您所看到的,用於更新資料的 XML 檔案與我們用於新增文件的 XML 檔案非常相似。但唯一的區別在於我們使用了欄位的update屬性。
在我們的示例中,我們將使用上述文件並嘗試更新 ID 為001的文件的欄位。
假設 XML 文件存在於 Solr 的bin目錄中。由於我們正在更新存在於名為my_core 的 Core 中的索引,因此您可以使用post工具進行更新,如下所示:
[Hadoop@localhost bin]$ ./post -c my_core update.xml
執行上述命令後,您將獲得以下輸出。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files org.apache.Solr.util.SimplePostTool update.xml SimplePostTool version 5.0.0 Posting files to [base] url https://:8983/Solr/my_core/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf, htm,html,txt,log POSTing file update.xml (application/xml) to [base] 1 files indexed. COMMITting Solr index changes to https://:8983/Solr/my_core/update... Time spent: 0:00:00.159
驗證
訪問 Apache Solr Web 介面的主頁並選擇 Core 為my_core。嘗試透過在文字區域q中傳遞查詢“:”來檢索所有文件,然後執行查詢。執行後,您可以看到文件已更新。

使用 Java(客戶端 API)更新文件
以下是將文件新增到 Apache Solr 索引的 Java 程式。將此程式碼儲存到名為UpdatingDocument.java的檔案中。
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.UpdateRequest;
import org.apache.Solr.client.Solrj.response.UpdateResponse;
import org.apache.Solr.common.SolrInputDocument;
public class UpdatingDocument {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "https://:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.setAction( UpdateRequest.ACTION.COMMIT, false, false);
SolrInputDocument myDocumentInstantlycommited = new SolrInputDocument();
myDocumentInstantlycommited.addField("id", "002");
myDocumentInstantlycommited.addField("name", "Rahman");
myDocumentInstantlycommited.addField("age","27");
myDocumentInstantlycommited.addField("addr","hyderabad");
updateRequest.add( myDocumentInstantlycommited);
UpdateResponse rsp = updateRequest.process(Solr);
System.out.println("Documents Updated");
}
}
透過在終端中執行以下命令來編譯上述程式碼:
[Hadoop@localhost bin]$ javac UpdatingDocument [Hadoop@localhost bin]$ java UpdatingDocument
執行上述命令後,您將獲得以下輸出。
Documents updated
Apache Solr - 刪除文件
刪除文件
要從 Apache Solr 的索引中刪除文件,我們需要在<delete></delete>標籤之間指定要刪除的文件的 ID。
<delete> <id>003</id> <id>005</id> <id>004</id> <id>002</id> </delete>
這裡,此 XML 程式碼用於刪除 ID 為003和005的文件。將此程式碼儲存到名為delete.xml的檔案中。
如果您想刪除屬於名為my_core 的 Core 的索引中的文件,那麼您可以使用post工具釋出delete.xml檔案,如下所示。
[Hadoop@localhost bin]$ ./post -c my_core delete.xml
執行上述命令後,您將獲得以下輸出。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files org.apache.Solr.util.SimplePostTool delete.xml SimplePostTool version 5.0.0 Posting files to [base] url https://:8983/Solr/my_core/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots, rtf,htm,html,txt,log POSTing file delete.xml (application/xml) to [base] 1 files indexed. COMMITting Solr index changes to https://:8983/Solr/my_core/update... Time spent: 0:00:00.179
驗證
訪問 Apache Solr Web 介面的主頁並選擇 Core 為my_core。嘗試透過在文字區域q中傳遞查詢“:”來檢索所有文件,然後執行查詢。執行後,您可以看到指定的文件已被刪除。

刪除欄位
有時我們需要根據 ID 以外的欄位刪除文件。例如,我們可能需要刪除城市為欽奈的文件。
在這種情況下,您需要在<query></query>標籤對中指定欄位的名稱和值。
<delete> <query>city:Chennai</query> </delete>
將其另存為delete_field.xml,然後使用 Solr 的post工具對名為my_core 的 Core 執行刪除操作。
[Hadoop@localhost bin]$ ./post -c my_core delete_field.xml
執行上述命令後,它將產生以下輸出。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files org.apache.Solr.util.SimplePostTool delete_field.xml SimplePostTool version 5.0.0 Posting files to [base] url https://:8983/Solr/my_core/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots, rtf,htm,html,txt,log POSTing file delete_field.xml (application/xml) to [base] 1 files indexed. COMMITting Solr index changes to https://:8983/Solr/my_core/update... Time spent: 0:00:00.084
驗證
訪問Apache Solr Web介面的主頁,選擇核心為my_core。嘗試在文字區域q中輸入查詢“:”,然後執行查詢來檢索所有文件。執行後,您可以觀察到包含指定欄位值對的文件已被刪除。

刪除所有文件
就像刪除特定欄位一樣,如果您想從索引中刪除所有文件,只需在<query></query>標籤之間輸入“:”,如下所示。
<delete> <query>*:*</query> </delete>
將其儲存為delete_all.xml,並使用Solr的post工具對名為my_core的核心執行刪除操作。
[Hadoop@localhost bin]$ ./post -c my_core delete_all.xml
執行上述命令後,它將產生以下輸出。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files org.apache.Solr.util.SimplePostTool deleteAll.xml SimplePostTool version 5.0.0 Posting files to [base] url https://:8983/Solr/my_core/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf, htm,html,txt,log POSTing file deleteAll.xml (application/xml) to [base] 1 files indexed. COMMITting Solr index changes to https://:8983/Solr/my_core/update... Time spent: 0:00:00.138
驗證
訪問Apache Solr Web介面的主頁,選擇核心為my_core。嘗試在文字區域q中輸入查詢“:”,然後執行查詢來檢索所有文件。執行後,您可以觀察到包含指定欄位值對的文件已被刪除。

使用Java(客戶端API)刪除所有文件
以下是將文件新增到 Apache Solr 索引的 Java 程式。將此程式碼儲存到名為UpdatingDocument.java的檔案中。
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class DeletingAllDocuments {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "https://:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Deleting the documents from Solr
Solr.deleteByQuery("*");
//Saving the document
Solr.commit();
System.out.println("Documents deleted");
}
}
透過在終端中執行以下命令來編譯上述程式碼:
[Hadoop@localhost bin]$ javac DeletingAllDocuments [Hadoop@localhost bin]$ java DeletingAllDocuments
執行上述命令後,您將獲得以下輸出。
Documents deleted
Apache Solr - 檢索資料
本章將討論如何使用Java客戶端API檢索資料。假設我們有一個名為sample.csv的.csv文件,其內容如下。
001,9848022337,Hyderabad,Rajiv,Reddy 002,9848022338,Kolkata,Siddarth,Battacharya 003,9848022339,Delhi,Rajesh,Khanna
您可以使用post命令將此資料索引到名為sample_Solr的核心下。
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csv
以下是將文件新增到Apache Solr索引的Java程式。將此程式碼儲存到名為RetrievingData.java的檔案中。
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrDocumentList;
public class RetrievingData {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "https://:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing Solr query
SolrQuery query = new SolrQuery();
query.setQuery("*:*");
//Adding the field to be retrieved
query.addField("*");
//Executing the query
QueryResponse queryResponse = Solr.query(query);
//Storing the results of the query
SolrDocumentList docs = queryResponse.getResults();
System.out.println(docs);
System.out.println(docs.get(0));
System.out.println(docs.get(1));
System.out.println(docs.get(2));
//Saving the operations
Solr.commit();
}
}
透過在終端中執行以下命令來編譯上述程式碼:
[Hadoop@localhost bin]$ javac RetrievingData [Hadoop@localhost bin]$ java RetrievingData
執行上述命令後,您將獲得以下輸出。
{numFound = 3,start = 0,docs = [SolrDocument{id=001, phone = [9848022337],
city = [Hyderabad], first_name = [Rajiv], last_name = [Reddy],
_version_ = 1547262806014820352}, SolrDocument{id = 002, phone = [9848022338],
city = [Kolkata], first_name = [Siddarth], last_name = [Battacharya],
_version_ = 1547262806026354688}, SolrDocument{id = 003, phone = [9848022339],
city = [Delhi], first_name = [Rajesh], last_name = [Khanna],
_version_ = 1547262806029500416}]}
SolrDocument{id = 001, phone = [9848022337], city = [Hyderabad], first_name = [Rajiv],
last_name = [Reddy], _version_ = 1547262806014820352}
SolrDocument{id = 002, phone = [9848022338], city = [Kolkata], first_name = [Siddarth],
last_name = [Battacharya], _version_ = 1547262806026354688}
SolrDocument{id = 003, phone = [9848022339], city = [Delhi], first_name = [Rajesh],
last_name = [Khanna], _version_ = 1547262806029500416}
Apache Solr - 查詢資料
除了儲存資料外,Apache Solr還提供按需查詢資料的功能。Solr提供了一些引數,我們可以用這些引數來查詢其中儲存的資料。
下表列出了Apache Solr中可用的各種查詢引數。
| 引數 | 描述 |
|---|---|
| q | 這是Apache Solr的主要查詢引數,文件根據其與該引數中詞語的相似度進行評分。 |
| fq | 此引數表示Apache Solr的過濾器查詢,它將結果集限制為與該過濾器匹配的文件。 |
| start | start引數表示分頁結果的起始偏移量,此引數的預設值為0。 |
| rows | 此引數表示每頁要檢索的文件數量。此引數的預設值為10。 |
| sort | 此引數指定欄位列表(用逗號分隔),根據這些欄位對查詢結果進行排序。 |
| fl | 此引數指定要為結果集中的每個文件返回的欄位列表。 |
| wt | 此引數表示我們想要檢視結果的響應編寫器的型別。 |
您可以將所有這些引數作為查詢Apache Solr的選項。訪問Apache Solr的主頁。在頁面左側,單擊“查詢”選項。在這裡,您可以看到查詢引數的欄位。

檢索記錄
假設我們在名為my_core的核心中有3條記錄。要從選定的核心檢索特定記錄,您需要傳遞特定文件欄位的名稱和值對。例如,如果您想檢索欄位id值為001的記錄,您需要將欄位的名稱值對作為引數q的值傳遞,例如:Id:001,然後執行查詢。

同樣,您可以透過將*:*作為引數q的值來檢索索引中的所有記錄,如下面的螢幕截圖所示。

從第2條記錄開始檢索
我們可以透過將2作為引數start的值來從第二條記錄開始檢索記錄,如下面的螢幕截圖所示。

限制記錄數量
您可以透過在rows引數中指定一個值來限制記錄數量。例如,我們可以透過將值2傳遞給引數rows來將查詢結果中的記錄總數限制為2,如下面的螢幕截圖所示。

響應編寫器型別
您可以透過從引數wt提供的多個值中選擇一個來獲得所需文件型別的響應。

在上例中,我們選擇了.csv格式來獲取響應。
欄位列表
如果我們想要在結果文件中包含特定欄位,我們需要將所需欄位的列表(用逗號分隔)作為屬性fl的值傳遞。
在下面的示例中,我們嘗試檢索欄位:id、phone和first_name。

Apache Solr - 分面搜尋
Apache Solr中的分面是指將搜尋結果分類到各個類別。本章將討論Apache Solr中可用的分面型別:
查詢分面 - 它返回當前搜尋結果中也匹配給定查詢的文件數量。
日期分面 - 它返回屬於特定日期範圍的文件數量。
分面命令新增到任何普通的Solr查詢請求中,分面計數在同一個查詢響應中返回。
分面查詢示例
使用欄位faceting,我們可以檢索所有詞語的計數,或者只是任何給定欄位中的前幾個詞語的計數。
例如,讓我們考慮一下包含各種書籍資料的books.csv檔案。
id,cat,name,price,inStock,author,series_t,sequence_i,genre_s 0553573403,book,A Game of Thrones,5.99,true,George R.R. Martin,"A Song of Ice and Fire",1,fantasy 0553579908,book,A Clash of Kings,10.99,true,George R.R. Martin,"A Song of Ice and Fire",2,fantasy 055357342X,book,A Storm of Swords,7.99,true,George R.R. Martin,"A Song of Ice and Fire",3,fantasy 0553293354,book,Foundation,7.99,true,Isaac Asimov,Foundation Novels,1,scifi 0812521390,book,The Black Company,4.99,false,Glen Cook,The Chronicles of The Black Company,1,fantasy 0812550706,book,Ender's Game,6.99,true,Orson Scott Card,Ender,1,scifi 0441385532,book,Jhereg,7.95,false,Steven Brust,Vlad Taltos,1,fantasy 0380014300,book,Nine Princes In Amber,6.99,true,Roger Zelazny,the Chronicles of Amber,1,fantasy 0805080481,book,The Book of Three,5.99,true,Lloyd Alexander,The Chronicles of Prydain,1,fantasy 080508049X,book,The Black Cauldron,5.99,true,Lloyd Alexander,The Chronicles of Prydain,2,fantasy
讓我們使用post工具將此檔案釋出到Apache Solr。
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csv
執行上述命令後,給定.csv檔案中提到的所有文件都將上傳到Apache Solr。
現在,讓我們在集合/核心my_core上對欄位author執行一個包含0行記錄的分面查詢。
開啟Apache Solr的Web UI,在頁面左側,選中facet複選框,如下面的螢幕截圖所示。
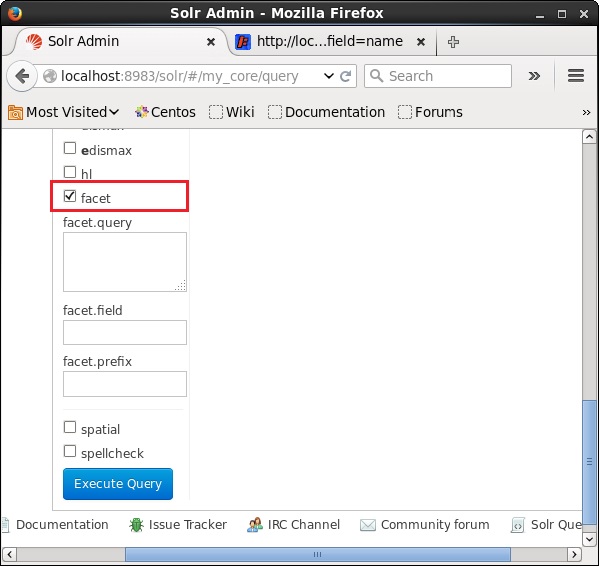
選中複選框後,您將有另外三個文字欄位來傳遞分面搜尋的引數。現在,作為查詢的引數,傳遞以下值。
q = *:*, rows = 0, facet.field = author
最後,點選執行查詢按鈕執行查詢。
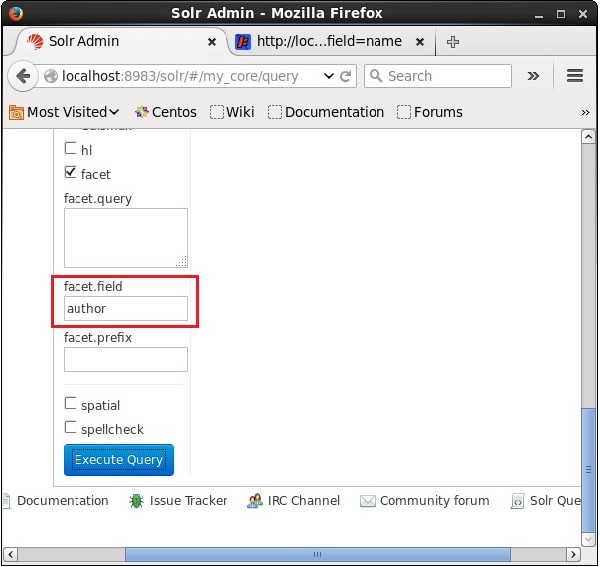
執行後,將生成以下結果。
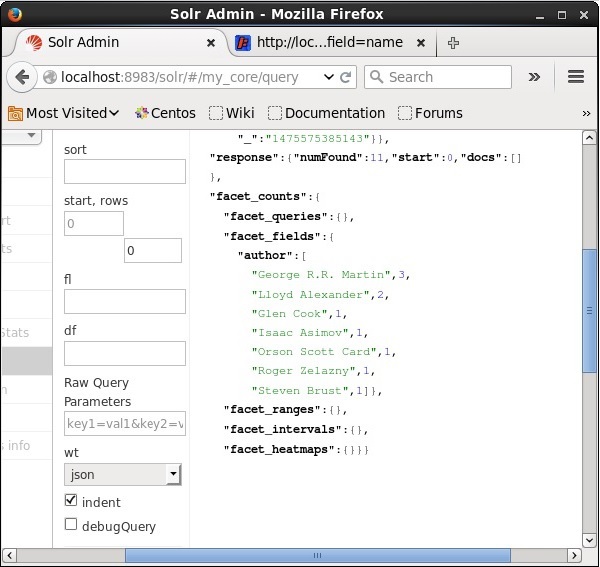
它根據作者對索引中的文件進行分類,並指定每位作者貢獻的書籍數量。
使用Java客戶端API進行分面
以下是將文件新增到Apache Solr索引的Java程式。將此程式碼儲存到名為HitHighlighting.java的檔案中。
import java.io.IOException;
import java.util.List;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.QueryRequest;
import org.apache.Solr.client.Solrj.response.FacetField;
import org.apache.Solr.client.Solrj.response.FacetField.Count;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrInputDocument;
public class HitHighlighting {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "https://:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//String query = request.query;
SolrQuery query = new SolrQuery();
//Setting the query string
query.setQuery("*:*");
//Setting the no.of rows
query.setRows(0);
//Adding the facet field
query.addFacetField("author");
//Creating the query request
QueryRequest qryReq = new QueryRequest(query);
//Creating the query response
QueryResponse resp = qryReq.process(Solr);
//Retrieving the response fields
System.out.println(resp.getFacetFields());
List<FacetField> facetFields = resp.getFacetFields();
for (int i = 0; i > facetFields.size(); i++) {
FacetField facetField = facetFields.get(i);
List<Count> facetInfo = facetField.getValues();
for (FacetField.Count facetInstance : facetInfo) {
System.out.println(facetInstance.getName() + " : " +
facetInstance.getCount() + " [drilldown qry:" +
facetInstance.getAsFilterQuery());
}
System.out.println("Hello");
}
}
}
透過在終端中執行以下命令來編譯上述程式碼:
[Hadoop@localhost bin]$ javac HitHighlighting [Hadoop@localhost bin]$ java HitHighlighting
執行上述命令後,您將獲得以下輸出。
[author:[George R.R. Martin (3), Lloyd Alexander (2), Glen Cook (1), Isaac Asimov (1), Orson Scott Card (1), Roger Zelazny (1), Steven Brust (1)]]