- Apache Flink 教程
- Apache Flink - 首頁
- Apache Flink - 大資料平臺
- 批處理與即時處理
- Apache Flink - 簡介
- Apache Flink - 架構
- Apache Flink - 系統要求
- Apache Flink - 設定/安裝
- Apache Flink - API 概念
- Apache Flink - Table API 和 SQL
- 建立 Flink 應用程式
- Apache Flink - 執行 Flink 程式
- Apache Flink - 庫
- Apache Flink - 機器學習
- Apache Flink - 使用案例
- Apache Flink - Flink 與 Spark 與 Hadoop 的比較
- Apache Flink - 總結
- Apache Flink 資源
- Apache Flink 快速指南
- Apache Flink - 有用資源
- Apache Flink - 討論
Apache Flink 快速指南
Apache Flink - 大資料平臺
過去十年中,資料的發展速度驚人;這催生了一個術語“大資料”。大資料沒有固定的資料大小,任何傳統系統(RDBMS)無法處理的資料都可以稱為大資料。這些大資料可以是結構化、半結構化或非結構化格式。最初,資料有三個維度:容量、速度、多樣性。現在,維度已經超出了這三個 V。我們現在添加了其他 V - 真實性、有效性、脆弱性、價值、可變性等。
大資料導致了多種工具和框架的出現,這些工具和框架有助於資料的儲存和處理。有一些流行的大資料框架,例如 Hadoop、Spark、Hive、Pig、Storm 和 Zookeeper。它還為在醫療保健、金融、零售、電子商務等多個領域建立下一代產品提供了機會。
無論是跨國公司還是初創企業,每個人都利用大資料來儲存和處理它,並做出更明智的決策。
Apache Flink - 批處理與即時處理
在 Big Data 方面,有兩種型別的處理:
- 批處理
- 即時處理
基於一段時間內收集的資料進行的處理稱為批處理。例如,銀行經理希望處理過去一個月的歷史資料(隨時間推移收集),以瞭解過去一個月內有多少支票被取消。
基於即時資料進行處理以獲得即時結果稱為即時處理。例如,銀行經理在欺詐交易(即時結果)發生後立即收到欺詐警報。
下表列出了批處理和即時處理之間的區別:
| 批處理 | 即時處理 |
|---|---|
靜態檔案 |
事件流 |
以分鐘、小時、天等為週期進行處理 |
立即處理 納秒 |
磁碟儲存上的歷史資料 |
記憶體儲存 |
示例 - 生成賬單 |
示例 - 自動取款機交易警報 |
如今,即時處理在每個組織中都被廣泛使用。諸如欺詐檢測、醫療保健中的即時警報和網路攻擊警報等用例需要對即時資料進行即時處理;即使延遲幾毫秒也會產生巨大的影響。
對於此類即時用例的理想工具應該是可以將資料作為流而不是批處理輸入的工具。Apache Flink 就是這樣的即時處理工具。
Apache Flink - 簡介
Apache Flink 是一個即時處理框架,可以處理流資料。它是一個開源的流處理框架,用於構建高效能、可擴充套件和準確的即時應用程式。它具有真正的流模型,並且不將輸入資料作為批處理或微批處理。
Apache Flink 由 Data Artisans 公司創立,現在由 Apache Flink 社群在 Apache 許可下開發。到目前為止,該社群擁有 479 多位貢獻者和 15500 多次提交。
Apache Flink 生態系統
下圖顯示了 Apache Flink 生態系統的不同層:
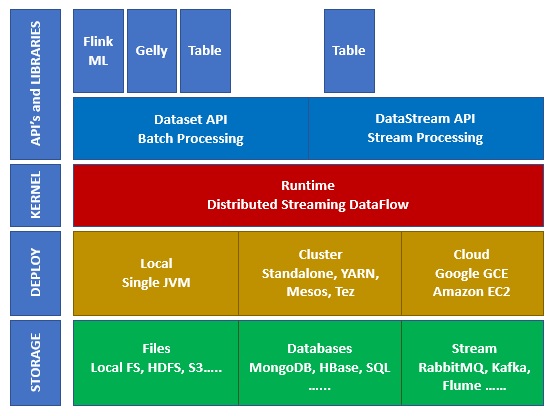
儲存
Apache Flink 可以從多個選項中讀取/寫入資料。下面是一個基本的儲存列表:
- HDFS(Hadoop 分散式檔案系統)
- 本地檔案系統
- S3
- RDBMS(MySQL、Oracle、MS SQL 等)
- MongoDB
- HBase
- Apache Kafka
- Apache Flume
部署
您可以以本地模式、叢集模式或雲模式部署 Apache Fink。叢集模式可以是獨立的、YARN、MESOS。
在雲端,Flink 可以部署在 AWS 或 GCP 上。
核心
這是執行時層,它提供分散式處理、容錯、可靠性、本地迭代處理能力等。
API 和庫
這是 Apache Flink 的頂層也是最重要的一層。它具有 Dataset API,負責批處理,以及 Datastream API,負責流處理。還有其他庫,如 Flink ML(用於機器學習)、Gelly(用於圖處理)、Tables 用於 SQL。此層為 Apache Flink 提供了多種功能。
Apache Flink - 架構
Apache Flink 基於 Kappa 架構。Kappa 架構具有單個處理器 - 流,它將所有輸入視為流,流引擎即時處理資料。Kappa 架構中的批處理是流處理的特例。
下圖顯示了**Apache Flink 架構**。

Kappa 架構的關鍵思想是透過單個流處理引擎處理批處理和即時資料。
大多數大資料框架都基於 Lambda 架構,該架構具有用於批處理和流資料的單獨處理器。在 Lambda 架構中,您為批處理和流檢視具有單獨的程式碼庫。為了查詢和獲取結果,需要合併程式碼庫。不維護單獨的程式碼庫/檢視併合並它們是一件痛苦的事情,但 Kappa 架構解決了這個問題,因為它只有一個檢視 - 即時檢視,因此不需要合併程式碼庫。
這並不意味著 Kappa 架構取代了 Lambda 架構,它完全取決於用例和應用程式,決定哪種架構更可取。
下圖顯示了 Apache Flink 作業執行架構。
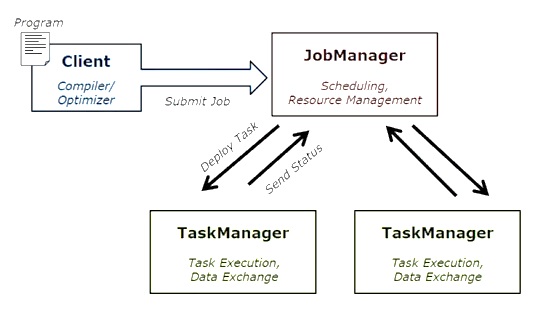
程式
它是您在 Flink 叢集上執行的一段程式碼。
客戶端
它負責獲取程式碼(程式)並構建作業資料流圖,然後將其傳遞給 JobManager。它還檢索作業結果。
JobManager
在從客戶端接收作業資料流圖後,它負責建立執行圖。它將作業分配給叢集中的 TaskManager 並監督作業的執行。
TaskManager
它負責執行 JobManager 分配的所有任務。所有 TaskManager 都以指定的並行度在其單獨的槽中執行任務。它負責將任務狀態傳送到 JobManager。
Apache Flink 的特性
Apache Flink 的特性如下:
它有一個流處理器,可以執行批處理和流程式。
它可以以閃電般的速度處理資料。
提供 Java、Scala 和 Python 的 API。
為所有常見操作提供 API,程式設計師非常容易使用。
以低延遲(納秒)和高吞吐量處理資料。
它具有容錯性。如果節點、應用程式或硬體發生故障,它不會影響叢集。
可以輕鬆與 Apache Hadoop、Apache MapReduce、Apache Spark、HBase 和其他大資料工具整合。
可以自定義記憶體管理以獲得更好的計算效能。
它具有高度可擴充套件性,可以擴充套件到叢集中的數千個節點。
Apache Flink 中的視窗非常靈活。
提供圖處理、機器學習、複雜事件處理庫。
Apache Flink - 系統要求
以下是下載和使用 Apache Flink 的系統要求:
推薦的作業系統
- Microsoft Windows 10
- Ubuntu 16.04 LTS
- Apple macOS 10.13/High Sierra
記憶體要求
- 記憶體 - 最低 4 GB,推薦 8 GB
- 儲存空間 - 30 GB
注意 - 必須安裝 Java 8 並已設定環境變數。
Apache Flink - 設定/安裝
在開始設定/安裝 Apache Flink 之前,讓我們檢查一下我們的系統中是否安裝了 Java 8。
Java - version
現在我們將繼續下載 Apache Flink。
wget http://mirrors.estointernet.in/apache/flink/flink-1.7.1/flink-1.7.1-bin-scala_2.11.tgz

現在,解壓縮 tar 檔案。
tar -xzf flink-1.7.1-bin-scala_2.11.tgz

轉到 Flink 的主目錄。
cd flink-1.7.1/
啟動 Flink 叢集。
./bin/start-cluster.sh
開啟 Mozilla 瀏覽器並訪問以下 URL,它將開啟 Flink Web 儀表板。
https://:8081
這就是 Apache Flink 儀表板的使用者介面。
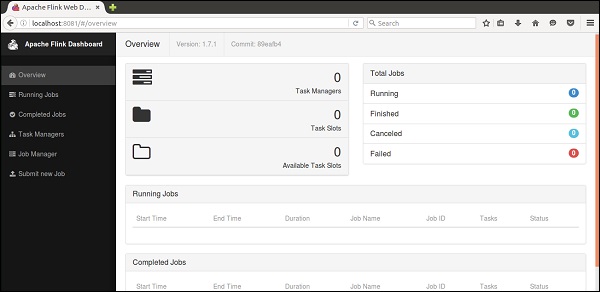
現在 Flink 叢集已啟動並執行。
Apache Flink - API 概念
Flink 有一套豐富的 API,開發人員可以使用這些 API 對批處理和即時資料執行轉換。各種轉換包括對映、過濾、排序、連線、分組和聚合。Apache Flink 的這些轉換是在分散式資料上執行的。讓我們討論一下 Apache Flink 提供的不同 API。
Dataset API
Apache Flink 中的 Dataset API 用於對一段時間內的資料執行批處理操作。此 API 可用於 Java、Scala 和 Python。它可以對資料集應用各種轉換,例如過濾、對映、聚合、連線和分組。
資料集是從諸如本地檔案之類的源建立的,或者透過從特定源讀取檔案來建立,結果資料可以寫入不同的接收器,例如分散式檔案或命令列終端。此 API 受 Java 和 Scala 程式語言的支援。
這是一個 Dataset API 的 Wordcount 程式:
public class WordCountProg {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.fromElements(
"Hello",
"My Dataset API Flink Program");
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
wordCounts.print();
}
public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
DataStream API
此 API 用於處理連續流中的資料。您可以對流資料執行各種操作,例如過濾、對映、視窗化、聚合。此資料流有各種來源,例如訊息佇列、檔案、套接字流,結果資料可以寫入不同的接收器,例如命令列終端。Java 和 Scala 程式語言都支援此 API。
這是一個 DataStream API 的流式 Wordcount 程式,其中您有連續的單詞計數流,並且資料在第二個視窗中進行分組。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WindowWordCountProg {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
dataStream.print();
env.execute("Streaming WordCount Example");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
Apache Flink - Table API 和 SQL
Table API 是一種關係 API,具有類似 SQL 的表示式語言。此 API 可以執行批處理和流處理。它可以嵌入到 Java 和 Scala 的 Dataset 和 Datastream API 中。您可以從現有的 Dataset 和 Datastream 或外部資料來源建立表。透過此關係 API,您可以執行諸如連線、聚合、選擇和過濾等操作。無論輸入是批處理還是流,查詢的語義都保持相同。
這是一個 Table API 程式示例:
// for batch programs use ExecutionEnvironment instead of StreamExecutionEnvironment
val env = StreamExecutionEnvironment.getExecutionEnvironment
// create a TableEnvironment
val tableEnv = TableEnvironment.getTableEnvironment(env)
// register a Table
tableEnv.registerTable("table1", ...) // or
tableEnv.registerTableSource("table2", ...) // or
tableEnv.registerExternalCatalog("extCat", ...)
// register an output Table
tableEnv.registerTableSink("outputTable", ...);
// create a Table from a Table API query
val tapiResult = tableEnv.scan("table1").select(...)
// Create a Table from a SQL query
val sqlResult = tableEnv.sqlQuery("SELECT ... FROM table2 ...")
// emit a Table API result Table to a TableSink, same for SQL result
tapiResult.insertInto("outputTable")
// execute
env.execute()
Apache Flink - 建立 Flink 應用程式
在本章中,我們將學習如何建立 Flink 應用程式。
開啟 Eclipse IDE,單擊“新建專案”,然後選擇“Java 專案”。

輸入專案名稱,然後單擊“完成”。

現在,單擊“完成”,如下圖所示。

現在,右鍵單擊**src**,然後轉到“新建”>“類”。

輸入類名,然後單擊“完成”。

複製並貼上以下程式碼到編輯器中。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.util.Collector;
public class WordCount {
// *************************************************************************
// PROGRAM
// *************************************************************************
public static void main(String[] args) throws Exception {
final ParameterTool params = ParameterTool.fromArgs(args);
// set up the execution environment
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// make parameters available in the web interface
env.getConfig().setGlobalJobParameters(params);
// get input data
DataSet<String> text = env.readTextFile(params.get("input"));
DataSet<Tuple2<String, Integer>> counts =
// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(new Tokenizer())
// group by the tuple field "0" and sum up tuple field "1"
.groupBy(0)
.sum(1);
// emit result
if (params.has("output")) {
counts.writeAsCsv(params.get("output"), "\n", " ");
// execute program
env.execute("WordCount Example");
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
counts.print();
}
}
// *************************************************************************
// USER FUNCTIONS
// *************************************************************************
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}
您將在編輯器中看到許多錯誤,因為需要將 Flink 庫新增到此專案中。

右鍵點選專案 >> 構建路徑 >> 配置構建路徑。

選擇“庫”選項卡,然後點選“新增外部JAR檔案”。

轉到Flink的lib目錄,選擇所有4個庫,然後點選“確定”。

轉到“順序和匯出”選項卡,選擇所有庫,然後點選“確定”。

您會看到錯誤已經消失了。
現在,讓我們匯出此應用程式。右鍵點選專案,然後點選“匯出”。
選擇JAR檔案,然後點選“下一步”。

指定目標路徑,然後點選“下一步”。

點選“下一步”。

點選“瀏覽”,選擇主類(WordCount),然後點選“完成”。

注意 - 如果出現任何警告,請點選“確定”。
執行以下命令。它將進一步執行您剛剛建立的Flink應用程式。
./bin/flink run /home/ubuntu/wordcount.jar --input README.txt --output /home/ubuntu/output

Apache Flink - 執行 Flink 程式
在本章中,我們將學習如何執行Flink程式。
讓我們在Flink叢集上執行Flink單詞計數示例。
轉到Flink的主目錄,並在終端中執行以下命令。
bin/flink run examples/batch/WordCount.jar -input README.txt -output /home/ubuntu/flink-1.7.1/output.txt

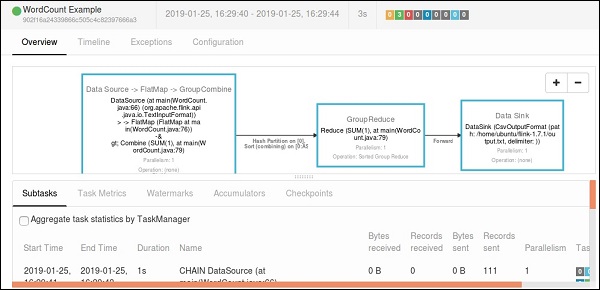
轉到Flink儀表板,您將能夠看到一個已完成的作業及其詳細資訊。

如果您點選“已完成作業”,您將獲得作業的詳細概述。
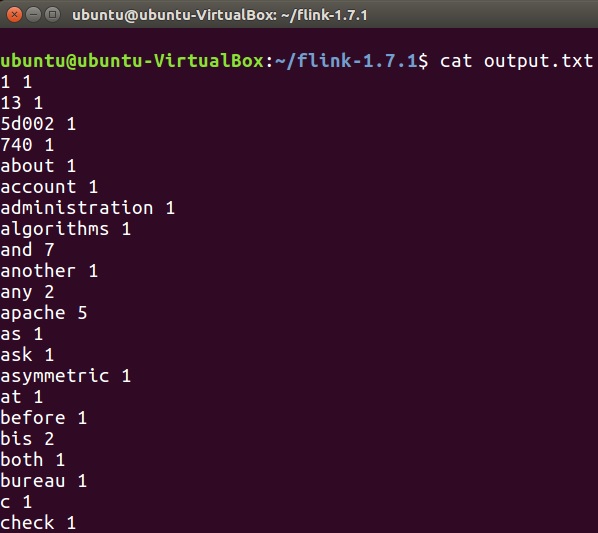
要檢查單詞計數程式的輸出,請在終端中執行以下命令。
cat output.txt
Apache Flink - 庫
在本章中,我們將瞭解Apache Flink的不同庫。
複雜事件處理(CEP)
FlinkCEP是Apache Flink中的一個API,它分析連續流資料上的事件模式。這些事件是近乎即時的,具有高吞吐量和低延遲。此API主要用於感測器資料,這些資料即時傳入,處理起來非常複雜。
CEP分析輸入流的模式並很快給出結果。它能夠在事件模式複雜的情況下提供即時通知和警報。FlinkCEP可以連線到不同型別的輸入源並在其中分析模式。
以下是帶有CEP的示例架構:
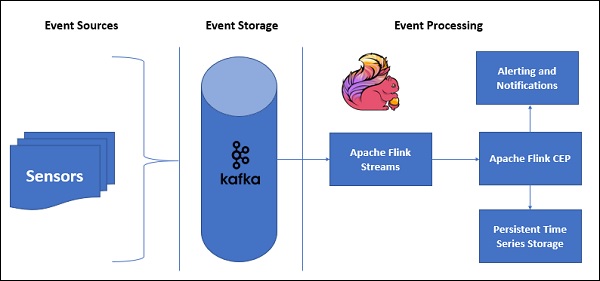
感測器資料將來自不同的來源,Kafka將充當分散式訊息框架,它將流分發到Apache Flink,FlinkCEP將分析複雜的事件模式。
您可以使用Pattern API在Apache Flink中編寫用於複雜事件處理的程式。它允許您確定要從連續流資料中檢測的事件模式。以下是一些最常用的CEP模式:
開始
用於定義起始狀態。以下程式顯示瞭如何在Flink程式中定義它:
Pattern<Event, ?> next = start.next("next");
其中
用於在當前狀態中定義過濾器條件。
patternState.where(new FilterFunction <Event>() {
@Override
public boolean filter(Event value) throws Exception {
}
});
下一頁
用於附加新的模式狀態以及傳遞先前模式所需的匹配事件。
Pattern<Event, ?> next = start.next("next");
後跟
用於附加新的模式狀態,但此處兩個匹配事件之間可能會發生其他事件。
Pattern<Event, ?> followedBy = start.followedBy("next");
Gelly
Apache Flink的圖API是Gelly。Gelly用於使用一組方法和實用程式在Flink應用程式上執行圖分析。您可以使用Apache Flink API以分散式方式使用Gelly分析大型圖。還有其他相簿,例如Apache Giraph,用於相同目的,但由於Gelly是在Apache Flink之上使用的,因此它使用單個API。這在開發和操作方面非常有幫助。
讓我們使用Apache Flink API - Gelly執行一個示例。
首先,您需要將2個Gelly jar檔案從Apache Flink的opt目錄複製到其lib目錄。然後執行flink-gelly-examples jar。
cp opt/flink-gelly* lib/ ./bin/flink run examples/gelly/flink-gelly-examples_*.jar
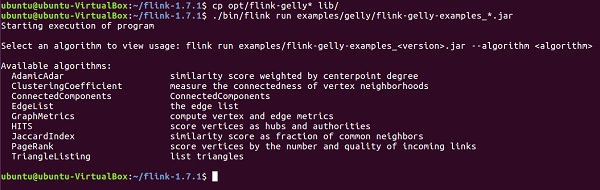
現在讓我們執行PageRank示例。
PageRank計算每個頂點的分數,它是透過入邊傳輸的PageRank分數的總和。每個頂點的分數平均分配到出邊。高分頂點與其他高分頂點連結。
結果包含頂點ID和PageRank分數。
usage: flink run examples/flink-gelly-examples_<version>.jar --algorithm PageRank [algorithm options] --input <input> [input options] --output <output> [output options] ./bin/flink run examples/gelly/flink-gelly-examples_*.jar --algorithm PageRank --input CycleGraph --vertex_count 2 --output Print

Apache Flink - 機器學習
Apache Flink的機器學習庫稱為FlinkML。由於機器學習的使用在過去5年中呈指數級增長,因此Flink社群決定在其生態系統中也新增此機器學習APO。FlinkML中的貢獻者和演算法列表正在增加。此API尚未成為二進位制分發的一部分。
以下是用FlinkML進行線性迴歸的示例:
// LabeledVector is a feature vector with a label (class or real value) val trainingData: DataSet[LabeledVector] = ... val testingData: DataSet[Vector] = ... // Alternatively, a Splitter is used to break up a DataSet into training and testing data. val dataSet: DataSet[LabeledVector] = ... val trainTestData: DataSet[TrainTestDataSet] = Splitter.trainTestSplit(dataSet) val trainingData: DataSet[LabeledVector] = trainTestData.training val testingData: DataSet[Vector] = trainTestData.testing.map(lv => lv.vector) val mlr = MultipleLinearRegression() .setStepsize(1.0) .setIterations(100) .setConvergenceThreshold(0.001) mlr.fit(trainingData) // The fitted model can now be used to make predictions val predictions: DataSet[LabeledVector] = mlr.predict(testingData)
在flink-1.7.1/examples/batch/路徑中,您將找到KMeans.jar檔案。讓我們執行此示例FlinkML示例。
此示例程式使用預設點和質心資料集執行。
./bin/flink run examples/batch/KMeans.jar --output Print

Apache Flink - 使用案例
在本章中,我們將瞭解Apache Flink中的一些測試用例。
Apache Flink - Bouygues Telecom
Bouygues Telecom是法國最大的電信公司之一。它擁有1100多萬移動使用者和250多萬固定使用者。Bouygues在巴黎舉行的Hadoop小組會議上第一次聽說Apache Flink。從那時起,他們一直在將Flink用於多種用例。他們每天透過Apache Flink即時處理數十億條訊息。
以下是Bouygues對Apache Flink的評價:“我們最終選擇了Flink,因為該系統支援真正的流處理 - 同時在API和執行時級別,為我們提供了我們正在尋找的可程式設計性和低延遲。此外,與其他解決方案相比,我們能夠在很短的時間內啟動並執行我們的Flink系統,這使得開發人員能夠有更多資源來擴充套件系統中的業務邏輯。”
在Bouygues,客戶體驗是重中之重。他們即時分析資料,以便能夠向其工程師提供以下見解:
透過其網路的即時客戶體驗
網路上發生的全球事件
網路評估和運營
他們建立了一個名為LUX(Logged User Experience)的系統,該系統處理來自網路裝置的大量日誌資料以及內部資料參考,以提供體驗質量指標,這些指標將記錄其客戶體驗並構建警報功能,以便在60秒內檢測資料使用中的任何故障。
為了實現這一點,他們需要一個能夠即時處理海量資料、易於設定並提供豐富的API來處理流資料的框架。Apache Flink非常適合Bouygues Telecom。
Apache Flink - 阿里巴巴
阿里巴巴是全球最大的電子商務零售公司,2015年收入為3940億美元。阿里巴巴搜尋是所有客戶的入口點,它顯示所有搜尋並相應地推薦。
阿里巴巴在其搜尋引擎中使用Apache Flink,以便為每個使用者以最高的準確性和相關性即時顯示結果。
阿里巴巴正在尋找一個框架,該框架:
在維護整個搜尋基礎設施過程的單個程式碼庫方面非常敏捷。
為網站上產品的可用性變化提供低延遲。
一致且經濟高效。
Apache Flink滿足了上述所有要求。他們需要一個具有單個處理引擎的框架,並且可以使用相同的引擎處理批處理和流資料,而這正是Apache Flink所做的。
他們還使用Blink(Flink的分支版本)來滿足其搜尋的一些獨特要求。他們還在其搜尋中使用Apache Flink的Table API並進行了一些改進。
以下是阿里巴巴對apache Flink的評價:“回顧過去,毫無疑問,Blink和Flink在阿里巴巴取得了巨大進步。沒有人想到我們會在一年內取得如此大的進步,我們非常感謝社群中幫助我們的人。Flink已被證明可以在非常大的規模上工作。我們比以往任何時候都更加致力於繼續與社群合作,推動Flink向前發展!”
Apache Flink - Flink 與 Spark 與 Hadoop 的比較
這是一個綜合表,顯示了三個最流行的大資料框架之間的比較:Apache Flink、Apache Spark和Apache Hadoop。
| Apache Hadoop | Apache Spark | Apache Flink | |
|---|---|---|---|
起源年份 |
2005 | 2009 | 2009 |
起源地 |
MapReduce(谷歌)Hadoop(雅虎) | 加州大學伯克利分校 | 柏林工業大學 |
資料處理引擎 |
批處理 | 批處理 | 流處理 |
處理速度 |
比Spark和Flink慢 | 比Hadoop快100倍 | 比Spark快 |
程式語言 |
Java、C、C++、Ruby、Groovy、Perl、Python | Java、Scala、Python和R | Java和Scala |
程式設計模型 |
MapReduce | 彈性分散式資料集(RDD) | 迴圈資料流 |
資料傳輸 |
批處理 | 批處理 | 流水線和批處理 |
記憶體管理 |
基於磁碟 | JVM管理 | 主動管理 |
延遲 |
低 | 中 | 低 |
吞吐量 |
中 | 高 | 高 |
最佳化 |
手動 | 手動 | 自動 |
API |
低階 | 高階 | 高階 |
流處理支援 |
否 | Spark Streaming | Flink Streaming |
SQL支援 |
Hive、Impala | SparkSQL | Table API和SQL |
圖支援 |
否 | GraphX | Gelly |
機器學習支援 |
否 | SparkML | FlinkML |
Apache Flink - 總結
我們在上一章看到的比較表總結了要點。Apache Flink是最適合即時處理和用例的框架。其單引擎系統是獨一無二的,可以使用不同的API(如Dataset和DataStream)處理批處理和流資料。
但這並不意味著Hadoop和Spark已經過時,選擇最適合的大資料框架始終取決於用例並因用例而異。可能會有幾種用例,其中Hadoop和Flink或Spark和Flink的組合可能更合適。
儘管如此,Flink目前仍然是最佳的即時處理框架。Apache Flink的增長令人驚歎,其社群的貢獻者數量也與日俱增。
Flink快樂!